
Abstract
We study market-to-book ratios of stocks in the context of stochastic portfolio theory. Functionally generated portfolios that depend on auxiliary economic variables other than relative capitalisations (“sizes”) are developed in two ways, together with their relative returns with respect to the market. This enables us to identify the value factor (i.e., market-to-book ratio) in returns of such generated portfolios when the auxiliary variables are stocks’ book values. Examples of portfolios, as well as their empirical results, are given, with the evidence that in addition to size, the value factor does affect the performance of the portfolio.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In the three-factor model of Fama and French [6], the traditional asset pricing model formally known as capital asset pricing model (CAPM) was expanded by including two additional risk factors, size and value, in addition to market risk. The resulting three-factor regression model explains over 90% of the diversified portfolio returns, versus 70% given by the CAPM. It also highlights the historic excess returns of small-cap stocks over big-cap stocks, and of value stocks (with high book-to-market ratios) over growth stocks (with low book-to-market ratios).
Following the work on the three-factor model, there has been additional research by the same authors regarding the value factor, i.e., the book-to-market ratio, in the direction of explaining the expected returns of stocks. The evolution of book-to-market ratio in terms of past changes in book equity and price is shown to contain independent information about expected cashflows that can enhance estimates of expected returns; see Fama and French [8]. The authors also show evidence that a higher book-to-market ratio implies a higher expected stock return, along with two additional variables – expected profitability and expected investment – which are added to obtain a five-factor model; see Fama and French [7,9]. Similar evidence can be found in related works by other authors, for example Rosenberg et al. [18], Chan et al. [4], Capaul et al. [3], Lakonishok et al. [17] and Cohen et al. [5].
Along a parallel development, the size factor of a portfolio’s return has been studied theoretically within a mathematical framework called stochastic portfolio theory (SPT), introduced by Fernholz [10]. SPT models the equity market using random processes, provides a method called functional generation of portfolios to construct a variety of portfolios from a function depending on individual companies’ capitalisations, and analyses portfolio behaviour in a model-free, robust manner. SPT also explains under what structural conditions it becomes possible to outperform a capitalisation-weighted benchmark index, and casts these conditions in very precise mathematical terms.
For example, the equal-weighted portfolio and so-called diversity-weighted portfolio, which favour smaller firms by according them the same (equal-weighted) or more (diversity-weighted) importance compared to large-cap companies are generated from concave functions and are shown to outperform the capitalisation-weighted index under suitable conditions. Then the excess return rate of these portfolios over the benchmark index can be explicitly calculated by exploiting the concavity of portfolio-generating functions. Moreover, SPT also handles rank-based portfolios and enables comparisons of two capitalisation-weighted portfolios, one consisting of a fixed number of big-cap stocks and the other composed of small-cap stocks. By computing the relative return of the large-stock index with respect to the small-cap index, a term called leakage is observed, which measures the loss in relative return due to stocks that decline and are subsequently dropped from the ‘upper capitalisation league’ and replaced by others.
Though there is considerable evidence that the size of stocks does affect the portfolio return (see Fernholz [10, Chap. 6.4], Banner et al. [1] and Fernholz and Karatzas [12]), SPT has not dealt with the value factor so far. We adopt in this paper the methodologies of SPT in order to incorporate market-to-book ratios of stocks in the study of portfolio returns. More specifically, we first present a way of generating portfolios which depend on additional economic variables having paths of finite variation, besides each company’s capitalisation; we compute their relative returns with respect to the market (capitalisation-weighted index), and we provide conditions under which such portfolios can outperform the market.
The additional variables can be any finite-variation stochastic processes investors observe from the stock market; we even allow them to have discontinuous (but right-continuous) paths. In this case, we can construct portfolios in a similar manner under a mild condition on the generating functions. Both the portfolio weights and the relative returns with respect to the market are then stochastic processes with left-continuous paths. To the author’s knowledge, functionally generated portfolios involving such discontinuities are new in the context of SPT.
If we choose relative book values (defined in (5.1)) as auxiliary processes, then we can construct portfolios that depend on the market-to-book ratios of stocks. The relative wealth processes of such portfolios contain a nondecreasing component, again by exploiting the concavity of generating functions. Many examples of such portfolios will be introduced, including those that depend on the ranks of market-to-book ratios. We also provide empirical results that identify the value factor in portfolio returns.
The paper is structured as follows. Section 2 introduces a mathematical setup for a stock market and defines trading strategies and portfolios. Section 3 discusses how to generate portfolios depending on stocks’ capitalisations and an additional process in two ways, additive and multiplicative, along with rank-based portfolios. Section 4 considers the case when the additional process is not necessarily continuous. Section 5 provides several examples of such portfolios depending on the book values or the market-to-book ratios, and Sect. 6 introduces a way to measure the market-to-book ratio component from portfolio returns of general portfolios. Section 7 contains empirical results regarding the portfolios discussed in earlier sections.
2 Setup
2.1 The stock market
Let us suppose that a stock market is composed of \(d\) stocks. We assume that trading is continuous in time, with no transaction costs or taxes, and that shares are infinitely divisible. We consider a vector \(S = (S_{1}, \dots , S_{d})'\) of \(d\) positive continuous semimartingales on a filtered probability space , which represent the prices of \(d\) stocks in this market. We also posit that each stock has always a single share outstanding, so that the price \(S_{i}(t)\) of the \(i\)th stock is equal to its capitalisation at any time \(t \ge 0\) for \(i = 1, \dots , d\).
From the capitalisation vector \(S\), we define the vector process \(\mu = (\mu _{1}, \dots , \mu _{d})\) with components
These are the individual companies’ market weights and satisfy
Note that each \(\mu _{i}\) is also a positive continuous semimartingale and represents the relative capitalisation of the \(i\)th stock with respect to the total capitalisation of the market.
2.2 Trading strategies and portfolios
We introduce the following notion of trading strategy.
Definition 2.1
A \(d\)-dimensional predictable process \(\vartheta = (\vartheta _{1}, \dots , \vartheta _{d})\) is called trading strategy if it is integrable with respect to the market weight vector \(\mu \) and if the corresponding relative wealth process
satisfies the ‘self-financing’ condition
The \(i\)th component \(\vartheta _{i}(t)\) of the trading strategy \(\vartheta \) represents the number of shares held in the \(i\)th stock at time \(t \ge 0\), whereas the product \(\vartheta _{i}(t)S_{i}(t)\) represents the amount of wealth invested in the \(i\)th stock at time \(t\). The last equality in (2.2) follows from (2.1), and \(V^{\vartheta}(t)\) represents the ratio of the total wealth generated by the trading strategy \(\vartheta \) to the total market capitalisation at time \(t \ge 0\). This interpretation justifies its name ‘relative wealth’ with respect to the market, and the quantity \(V^{\vartheta}(t)\) measures the extent to which the trading strategy \(\vartheta \) outperforms (or underperforms) the market over time \(t \ge 0\).
Definition 2.2
For a trading strategy \(\vartheta \), we call the vector \(\pi ^{\vartheta} = (\pi ^{\vartheta}_{1}, \dots , \pi ^{\vartheta}_{d})\) with components
the portfolio corresponding to the trading strategy \(\vartheta \).
The component \(\pi ^{\vartheta}_{i}(t)\) of the portfolio \(\pi ^{\vartheta}\) represents the proportion of wealth invested in the \(i\)th stock at time \(t \ge 0\). We also denote by \(V^{\pi} := V^{\vartheta}\) the relative wealth process generated by the portfolio \(\pi \) that corresponds to the trading strategy \(\vartheta \).
An important example of portfolio is that consisting of the market weights \(\mu = (\mu _{1}, \dots , \mu _{d})\), defined in (2.1), which we also call market portfolio. This is accomplished by setting \(\vartheta _{i}\) in (2.3) to a fixed constant, the same for every \(i\), i.e., by buying a fixed number of shares in each stock and holding on to these shares at all times. Then the value of the market portfolio is proportional to the total capitalisation of the entire stock market. In this sense, the relative wealth process \(V^{\vartheta}\) in (2.2) just represents the ratio of the value of \(\vartheta \) with respect to the value of the market portfolio \(\mu \).
3 Functional generation of portfolios
Functional portfolio generation, introduced by Fernholz [11] more than 20 years ago, is a method of constructing trading strategies using a generating function that acts solely on the market weight vector \(\mu \) of (2.1). Karatzas and Ruf [15] developed another approach for constructing trading strategies which they call ‘additive generation’ of portfolios, as opposed to Fernholz’s ‘multiplicative generation’. The construction of these two types of trading strategies can be generalised by allowing generating functions to depend on an additional argument of finite variation other than the market weights; see Strong [21], Schied et al. [20], Ruf and **e [19] and Karatzas and Kim [13]. In this section, we summarise the ideas of constructing portfolios in terms of the market weight vector \(\mu \) along with an additional auxiliary argument.
3.1 Generating function and its gamma process
Let us consider a function which takes the vector process \(\mu \) of market weights and an additional \(m\)-dimensional vector process \(\Lambda = (\Lambda _{1}, \dots , \Lambda _{m})\) of finite variation as its arguments. When \(d = m\), each component \(\Lambda _{i}\) of \(\Lambda \) can be interpreted to model an observable quantity related to the \(i\)th company, other than its relative capitalization \(\mu _{i}\), for instance (though not exclusively) its book value. We assume in this section that each \(\Lambda _{i}\) is a stochastic process with continuous paths. Furthermore, we assume throughout this paper that the dimension of \(\Lambda \) coincides with that of \(\mu \); the same theory can be developed without much effort for \(d \neq m\).
Assuming \(G\) to be twice continuously differentiable with respect to the components of \(\mu \) and continuously differentiable with respect to the components of \(\Lambda \), we define a continuous adapted process \(\Gamma ^{G}(\,\cdot \,)\), called the gamma process corresponding to the function \(G\), as
An application of Itô’s rule yields the alternative representation
which shows that the process \(\Gamma ^{G}(\,\cdot \,)\) is of finite variation on compact time-intervals.
We show in the next subsection that the relative wealth process \(V^{\vartheta}\) in (2.2) of a trading strategy \(\vartheta \), generated either additively or multiplicatively by a function \(G\), can be expressed in terms of \(G\) and of the gamma process \(\Gamma ^{G}\), and that this finite-variation process \(\Gamma ^{G}\) is responsible for the long-run performance of the trading strategy relative to the market.
3.2 Refined functional generation of portfolios
In order to construct trading strategies which outperform the market, we may want to choose \(G\) such that \(\Gamma ^{G}(\,\cdot \,)\) is nondecreasing. The first integral on the right-hand side of (3.2) will be nondecreasing in \(t\) if \(G\) is concave in \(\mu \). However, it is quite hard to make the second integral nondecreasing, as the integrators \(\Lambda _{i}\) are not generally monotone.
To help deal with this issue, we consider decompositions
for the auxiliary processes \(\Lambda _{i}(\,\cdot \,)\), where \(\gamma _{i}(\,\cdot \,)\) and \(\xi _{i}(\,\cdot \,)\) are the smallest nondecreasing adapted processes with \(\gamma _{i}(0) = \Lambda _{i}(0)\) for which (3.3) holds. We note that every \(\xi _{i}\) is nonnegative with \(\xi _{i}(0) = 0\). We let the function depend on all three arguments \(\mu , \gamma , \xi \); then we have the new definition of (3.1) and the representation of (3.2) as
We are assuming tacitly that the function \(G\) and all its indicated derivatives are continuous. It is now clear that the gamma process \(\Gamma ^{G}(\,\cdot \,)\) is nondecreasing if \(G\) is concave with respect to \(\mu \) and if
Examples of portfolios satisfying the condition (3.5) are given in Sect. 5.2.
For a given function \(G\), we construct now two different (additively and multiplicatively generated) types of trading strategies as well as their corresponding portfolios under appropriate conditions, using the vector of market weights \(\mu \) and two vectors \(\gamma \), \(\xi \) composed of nondecreasing components.
In the following, we denote by \(\mathrm {supp}(X)\) the support of a \(d\)-dimensional stochastic process \(X\), i.e., the smallest closed set with . We denote by \(C^{2, 1, 1}\) (resp. \(C^{2, 1}\)) the collection of functions (resp. ) such that \(G\) is twice continuously differentiable with respect to the first \(d\) components and continuously differentiable with respect to the last \(2d\) (resp. \(d\)) components.
For the proofs of Propositions 3.1 and 3.2 below, we refer to Theorems 4.1 and 4.2 or to Karatzas and Ruf [15, Propositions 4.3, 4.8] or Karatzas and Kim [13, Propositions 3.6, 3.9].
Proposition 3.1
For a given function in \(C^{2, 1, 1}\), we define two vector processes \(\vartheta = (\vartheta _{1}, \dots , \vartheta _{d})\) and \(\varphi = (\varphi _{1}, \dots , \varphi _{d})\) with components
for \(i = 1, \dots , d\) and \(t \ge 0\). Here, the process
is called the ‘defect of self-financibility’, and the real constant \(C^{G}(0)\) is the value at time \(t=0\) of the ‘defect of balance’ process
Then the vector process \(\varphi \) of (3.7) is a trading strategy; it can be represented equivalently as
for \(i=1, \dots , d\), and it generates the relative wealth process \(V^{\varphi}\) given as
Proposition 3.2
For a given function \(G:\mathrm {supp}(\mu ) \times \mathrm {supp}(\gamma ) \times \mathrm {supp}(\xi ) \rightarrow (0, \infty )\) in \(C^{2, 1, 1}\) such that the process \(1/G(\mu , \gamma , \xi )\) is locally bounded, we recall the vector process \(\vartheta = (\vartheta _{1}, \dots , \vartheta _{d})\) of (3.6) and define two vector processes \(\eta = (\eta _{1}, \dots , \eta _{d})\) and \(\psi = (\psi _{1}, \dots , \psi _{d})\) with components
for \(i = 1, \dots , d\) and \(t \ge 0\), where \(Q^{\eta , \mu}\) and \(C^{G}(0)\) are defined as in (3.8) and (3.9). Then \(\psi \) is a trading strategy and can be represented in the form
for \(i=1, \dots , d\). The relative wealth process \(V^{\psi}\) it generates is given as
Definition 3.3
The trading strategies \(\varphi \) of Proposition 3.1 and \(\psi \) of Proposition 3.2 are called additively generated trading strategy and multiplicatively generated trading strategy from \(G\), respectively. This terminology is justified by the expressions in (3.11), (3.14).
When the generating function \(G\) satisfies the identity
we say that it is balanced. If \(G\) is continuously differentiable in the first argument \(\mu \), this condition is equivalent to saying that \(G\) is homogeneous of degree 1 in the variable \(\mu \). We see that for balanced generating functions \(G\), the “defect-of-balance” process \(C^{G}(\,\cdot \,)\) is identically equal to zero in (3.9), and the representations of the trading strategies \(\varphi \) in (3.10) and \(\psi \) in (3.13) are significantly simplified to
in the notation of (3.4), (3.6) and (3.12). We see later in Sect. 4 that this balance condition plays an important role in the construction of trading strategies when the components of the auxiliary process \(\Lambda \) are discontinuous.
3.3 Strong relative arbitrage
A judicious choice of generating function produces a trading strategy with the potential of outperforming the market portfolio \(\mu \) of (2.1) under appropriate conditions. We recall in this subsection the notion of strong relative arbitrage and sufficient conditions leading to it.
Definition 3.4
We say that a given trading strategy \(\vartheta \) is a strong relative arbitrage with respect to the market over the time horizon \([0, T]\) if we have
Since additively generated trading strategies lead to simpler sufficient conditions for strong relative arbitrage than multiplicatively generated ones, we present here only sufficient condition for additive portfolio generation, based on Karatzas and Ruf [15, Theorem 5.1]. We refer interested readers to [15, Theorem 5.2] and Karatzas and Kim [13, Sect. 4.2] for sufficient conditions for multiplicatively generated trading strategies leading to relative arbitrage.
Proposition 3.5
Fix a function \(G : \mathrm {supp}(\mu ) \times \mathrm {supp}(\gamma ) \times \mathrm {supp}(\xi ) \rightarrow [0, \infty )\) in \(C^{2, 1, 1}\) such that the gamma process \(\Gamma ^{G}(\,\cdot \,)\) is nondecreasing. For some real number \(T_{*} > 0\), suppose that we have
Then the trading strategy \(\varphi \) additively generated from \(G\) is a strong relative arbitrage with respect to the market portfolio \(\mu \) over every time interval \([0, t]\) with \(t \ge T_{*}\).
Remark 3.6
In order to obtain relative wealth processes starting from 1 at the initial time, i.e., \(V^{\varphi}(0) = V^{\psi}(0) = 1\) in (3.11) and (3.14), we often normalise the generating function \(G\) to satisfy \(G(\mu , \gamma , \xi )(0) = 1\) by replacing \(G(\mu , \gamma , \xi )(t)\) by
3.4 Rank-based generation of portfolios
Recall the market weight vector \(\mu \) in (2.1) and the auxiliary vector \(\Lambda \) of finite variation. We construct trading strategies depending on the ranks of the components of the vector process \(f(\mu , \Lambda )\), where is a sufficiently smooth function. In order to simplify notation, we do not consider the decomposition of \(\Lambda \) as in (3.3) and let \(f\) have two arguments \(\mu \) and \(\Lambda \).
We introduce the \(k\)th rank process of any given \(d\)-dimensional vector process \(\nu = (\nu _{1}, \dots , \nu _{d})\) via
for \(k = 1, \dots , d\). More specifically, we rank the components of the vector \(\nu \) in descending order
with the lexicographic rule for breaking ties that always assigns a higher rank (a smaller \([k]\)) to the smaller index \(i\). We also consider the random permutation process \(r_{t}\) of \(\{1, \dots , d\}\) such that
hold for every \(t \ge 0\) and \(k = 1, \dots , d\).
We use the notation  for the vector arranged in order of descending rank. In particular, when \(\nu = f(\mu , \Lambda )\), that is, \(\nu _{i}(\,\cdot \,) = f_{i}(\mu (\,\cdot \,), \Lambda (\,\cdot \,))\) for \(i = 1, \dots , d\), we have
for the vector arranged in order of descending rank. In particular, when \(\nu = f(\mu , \Lambda )\), that is, \(\nu _{i}(\,\cdot \,) = f_{i}(\mu (\,\cdot \,), \Lambda (\,\cdot \,))\) for \(i = 1, \dots , d\), we have  , which satisfies \(f_{[1]}(\mu , \Lambda ) \ge \cdots \ge f_{[d]}(\mu , \Lambda )\).
, which satisfies \(f_{[1]}(\mu , \Lambda ) \ge \cdots \ge f_{[d]}(\mu , \Lambda )\).
Example 3.7
Each component \(\nu _{i}\) is equal to the market-to-book ratio \(\rho _{i}\), defined later in (5.2), if \(\Lambda \) is the relative book value vector \(\beta \) of (5.1) and \(f_{i}(\mu , \Lambda ) = \mu _{i}/\Lambda _{i} = \rho _{i}\) for \(i = 1, \dots , d\). In this case, \(r_{t}(k)\) is the index, or name, of the stock whose market-to-book ratio occupies the \(k\)th rank at time \(t\).
We next denote by \(L^{Y}\) the local time at 0 for a continuous semimartingale \(Y\), given by
where \(\mathrm{sgn}(x) := 2 I_{(0, \infty )}(x)-1\). To simplify computations involving local-time terms, we need the following definition. We impose Assumption 3.9throughout this paper.
Definition 3.8
A vector process \(X=(X_{1}, \dots , X_{d})\) is pathwise mutually nondegenerate if
-
1.
for all \(i \ne j\), \(\{t: X_{i}(t) = X_{j}(t)\}\) has Lebesgue measure zero, a.s.;
-
2.
for all \(i < j < k\), \(\{t: X_{i}(t) = X_{j}(t) = X_{k}(t)\} = \emptyset \), a.s.
Assumption 3.9
For a given function , the vector process \(f(\mu , \Lambda )\) is pathwise mutually nondegenerate.
Consider a twice continuously differentiable function \(G\) which takes the ranked vector process  as an argument. In order to simplify the notation, we write
as an argument. In order to simplify the notation, we write  and apply Itô’s rule to obtain
and apply Itô’s rule to obtain

Banner and Ghomrasni [2, Corollary 2.6] along with Assumption 3.9 gives the dynamics of ranked components as
for \(k = 1, \dots , d\), with the convention \(f_{[0]}(\mu , \Lambda ) = f_{[d+1]}(\mu , \Lambda ) = 0\). Another application of Itô’s rule yields
provided that \(f_{j} \in C^{2, 1}\) for \(j = 1, \dots , d\).
We consider in analogy to (3.6) and (3.4) the new definitions
Then the gamma function \(\Gamma ^{G}\) can also be cast with the help of (3.17)–(3.20) as
This shows that the gamma process of (3.20) is again of finite variation.
Without Assumption 3.9, we obtain a similar but more complicated expression of the gamma process, where the last two terms of (3.18) and (3.21) then involve higher orders of collision local time terms \(L^{f_{[k]}(\mu , \Lambda )-f_{[\ell ]}(\mu , \Lambda )}\) for \(|k-\ell | \ge 2\).
We now construct two types of trading strategies from the given ranked vector process  in the same manner as in Propositions 3.1 and 3.2.
in the same manner as in Propositions 3.1 and 3.2.
Proposition 3.10
For a twice continuously differentiable function , we define two vector processes \(\vartheta = (\vartheta _{1}, \dots , \vartheta _{d})\) as in (3.19) and \(\varphi = (\varphi _{1}, \dots , \varphi _{d})\) with components
for \(i = 1, \dots , d\). Here, we recall the defect of self-financibility \(Q^{\vartheta , \mu}\) in (3.8) and the defect of balance
Then \(\varphi \) is a trading strategy and can be represented in the form
for \(i=1, \dots , d\), with \(\Gamma ^{G}\) as in (3.20). Its relative wealth process \(V^{\varphi}\) is given as
Proposition 3.11
For a function \(G : \mathrm {supp}(\nu ) \rightarrow (0, \infty )\) which is twice continuously differentiable and such that the process \(1/G(\nu )\) is locally bounded, recall the vector process \(\vartheta = (\vartheta _{1}, \dots , \vartheta _{d})\) from (3.19). Define two vector processes \(\eta = (\eta _{1}, \dots , \eta _{d})\) and \(\psi = (\psi _{1}, \dots , \psi _{d})\) with components
Here \(Q^{\eta , \mu}\) and \(C^{\eta}(0)\) are given as in (3.8), (3.22), and we recall the process \(\Gamma ^{G}(\,\cdot \,)\) from (3.20). Then \(\psi \) is a trading strategy and can be represented in the form
for \(i=1, \dots , d\). Its relative wealth process \(V^{\psi}\) is given as
4 Discontinuous auxiliary process
If some accounting information that affects companies’ stock prices is updated periodically, say annually or quarterly, then it is more natural to model the components of the auxiliary process \(\Lambda _{1}, \dots , \Lambda _{d}\) as discontinuous processes. In this section, we allow each \(\Lambda _{i}\) to be discontinuous, but assume it to be an RCLL process. This accommodates jumps that occur whenever new accounting information is available.
Each company’s relative capitalisation \(\mu _{i}\) of (2.1) remains a continuous process, whereas \(\Lambda _{i}\) and thus \(\gamma _{i}\) and \(\xi _{i}\) in the decomposition (3.3) are RCLL for \(i = 1, \dots , d\). Here and in what follows, \(\alpha ^{c}(\,\cdot \,)\) and \(\Delta \alpha (t) := \alpha (t+)-\alpha (t-)\) denote the continuous part and a jump at time \(t\) of a stochastic process \(\alpha \), respectively. In particular, \(\Delta \alpha (t) = \alpha (t)-\alpha (t-)\) if \(\alpha \) is RCLL (càdlàg), whereas \(\Delta \alpha (t) = \alpha (t+)-\alpha (t)\) if \(\alpha \) is LCRL (càglàd). At \(t = 0\), we set \(\alpha (0-) := \alpha (0)\).
In order to handle jumps, we slightly modify the definition of a trading strategy \(\vartheta \) in Definition 2.1. We now want it to be a \(d\)-dimensional LCRL \(\mu \)-integrable process which satisfies the new self-financing identity
Here, the relative wealth process \(V^{\vartheta}(t) := \sum _{i=1}^{d} \vartheta _{i}(t)\mu _{i}(t)\) encompasses now possible jumps of the trading strategy \(\vartheta \) up to time \(t\); gains (or losses) from jumps of \(\vartheta \) are reinvested (or absorbed, respectively) to \(V^{\vartheta}\). We then define the portfolio \(\pi ^{\vartheta}\) corresponding to \(\vartheta \) as before in Definition 2.2.
In order to construct functionally generated portfolios, we apply Itô’s rule for jump processes to a function \(G\) in \(C^{2, 1, 1}\) to obtain
where \(\Delta G(\mu , \gamma , \xi )(s) := G(\mu , \gamma , \xi )(s)-G(\mu , \gamma , \xi )(s-)\). We define the gamma process corresponding to the function \(G\) in a similar manner by
along with the alternative representation
where
This shows that \(\Gamma ^{G}(\,\cdot \,)\) is of finite variation.
We show in the following that the balance condition (3.15) is essential for handling the jumps when generating trading strategies.
Theorem 4.1
For a function in \(C^{2, 1, 1}\) satisfying the balance condition (3.15), we introduce two vector processes \(\vartheta = (\vartheta _{1}, \dots , \vartheta _{d})\) and \(\varphi = (\varphi _{1}, \dots , \varphi _{d})\) with components
for \(i = 1, \dots , d\). Here, the defect of self-financibility is defined as
Then \(\varphi \) in (4.4) is a trading strategy and can be represented in the form
for \(i=1, \dots , d\), whereas the relative wealth process \(V^{\varphi}\) it generates is given as
Proof
First, \(\vartheta _{i}\) defined in (4.3) is left-continuous with \(\vartheta _{i}(t+) = D_{\mu _{i}}G(\mu , \gamma , \xi )(t)\). The assertion that \(\varphi \) is a trading strategy follows from Karatzas and Ruf [15, Proposition 4.3]. Thanks to the balance condition, we have the identities
as well as
Substituting the definition (4.5) into (4.4), along with (4.8) and (4.9), we obtain
which is (4.6). Here, the last identity follows from (4.1) and (4.2). The equality \(\sum _{j} \mu _{j} \equiv 1\) with (4.6) and (4.8) now establishes that
□
Theorem 4.2
For a function in \(C^{2, 1, 1}\) such that the process \(1/G(\mu , \gamma , \xi )\) is locally bounded and \(G\) satisfies the balance condition (3.15), we recall the vector process \(\vartheta = (\vartheta _{1}, \dots , \vartheta _{d})\) of (4.3) and define two vector processes \(\eta = (\eta _{1}, \dots , \eta _{d})\) and \(\psi = (\psi _{1}, \dots , \psi _{d})\) with components
where \(Q^{\eta , \mu}\) is defined by (4.5). Then \(Q^{\eta , \mu}(\,\cdot \,) \equiv 0\) in (4.5), the trading strategy \(\psi \) in (4.11) is represented for \(i=1, \dots , d\), as
and it generates the relative wealth process
Proof
First, we argue as in the proof of Theorem 4.1 that \(\psi \) is a trading strategy. We introduce the continuous process
and apply the product rule for jump processes along with (4.1)–(4.3) and (4.10) to get
The last equality uses (4.11) with the identity \(\sum _{j} d\mu _{j} (t) \equiv 0\). At \(t=0\), we have
where the second to last equality follows from (4.8). Moreover, the trivial identity \(\Delta Q^{\eta , \mu}(\,\cdot \,) \equiv 0\) with (4.9) yields for every \(t \ge 0\) that
Therefore we arrive at (4.13) from (4.14)–(4.16). Finally, again from (4.8) and (4.9) along with (4.14), we deduce
and (4.12) follows. □
We conclude with a note that it is hard to apply the method used in this section to rank-based portfolios studied in Sect. 3.4. When the components of \(\Lambda \) are discontinuous, the dynamics of the ranked functions \(f_{[k]}(\mu , \Lambda )\) cannot be obtained in the form (3.18) in terms of the original functions \(f_{j}(\mu , \Lambda )\) and the collision local time terms; jumps of the components of \(\Lambda \) may change the ranks between the components of \(f(\mu , \Lambda )\) without accumulating collision local times. Thus for the examples of rank-based portfolios given in Sect. 5.3, we assume that the components of \(\Lambda \) have continuous paths.
5 Portfolios depending on market-to-book ratios
There is no restriction for investors on how to choose the auxiliary finite-variation process \(\Lambda \) in the functional generation of trading strategies. Thus any observable variables from the financial market which they believe to be relevant in their portfolios can be used as the components of \(\Lambda \), as long as they are continuous for general generating functions as in Sect. 3, or RCLL for balanced generating functions as in Sect. 4. Some examples of such auxiliary variables are the company’s expected profitability and expected investment, which are included in the five-factor asset pricing models of Fama and French [7,9].
In this section, we adopt individual companies’ book values as a primary example of the auxiliary process \(\Lambda \) and construct portfolios which depend on the market-to-book ratios of the stocks. We write \(b = (b_{1}, \dots , b_{d})\) for the vector representing companies’ book values, with each component \(b_{i}\), \(i = 1, \dots , d\), an adapted, positive RCLL process of finite variation on compact time-intervals. The components of the relative book value vector process \(\beta = (\beta _{1}, \dots , \beta _{d})\) are then defined as
We shall see in Sect. 7.2 that the distribution of the components of \(\beta \) has been stable over the recent 20 years.
We next introduce the vector process \(\rho = (\rho _{1}, \dots , \rho _{d})\) of market-to-book ratios with components
which represent the market-to-book ratios of the various stocks in the market. Note that each \(\rho _{i}\) is a ratio between two relative quantities. Here, we use market-to-book ratios, instead of “book-to-market ratios”, to exploit the concavity of portfolio-generating functions in the following; if a function \(G\) is concave in \(\rho \), it is also concave in \(\mu \). Moreover, since the \(\beta _{i}\) sum to 1 at all times, the vector \(\beta \) is itself a portfolio, which appears in the following Example 5.1. We note from the product rule for jump processes the dynamics
Finally, we consider decompositions
where \(g_{i}(\,\cdot \,)\) and \(h_{i}(\,\cdot \,)\) are the smallest nondecreasing adapted processes satisfying \(g_{i}(0) = \beta _{i}(0)\) for which (5.3) holds. We note that all processes \(\mu _{i}, \beta _{i}, \rho _{i}, g_{i}\) are positive, and \(h_{i}\) are nonnegative with \(h_{i}(0) = 0\) for \(i = 1, \dots , d\). We then let the generating function \(G\) in \(C^{2, 1, 1}\) depend on three processes \(\rho , g, h\) by taking \(\mu \), \(\gamma = g\), \(\xi = h\) as its arguments.
All examples in this section, except Example 5.5, have balanced generating functions. Therefore, we assume that the book value processes \(b_{i}\), thus also \(\beta _{i}\), \(\rho _{i}\), \(g_{i}\) and \(h_{i}\), have RCLL paths for \(i = 1, \dots , d\), except in Example 5.5 and in the examples in Sect. 5.3 (due to the difficulty mentioned at the end of Sect. 4).
5.1 Multiplicatively generated portfolios
We introduce in this subsection two important multiplicatively generated portfolios.
Example 5.1
The process \(\mu \) of market weights in (2.1) is itself a long-only portfolio, which invests the proportion \(\mu _{i}(t)\) of current wealth in the \(i\)th stock at all times. It is generated multiplicatively by the constant function, as seen in [10, Example 3.1.6]. In the same manner, we consider a long-only portfolio \(\beta \) which invests the proportion \(\beta _{i}(t-)\) of current wealth in the \(i\)th stock at any time \(t\). We call the latter book value portfolio and show in what follows that it can also be generated multiplicatively.
We consider the generating function
and assume that the market-to-book ratios in (5.2) satisfy
for some positive constants \(m < M\). Then the process \(1/G(\rho (\,\cdot \,))\) is locally bounded. This assumption excludes the possibilities of overpricing by more than the factor \(M\), and of underpricing by more than the factor \(m\), for any stock in the market at any time. We then have
and deduce that \(G\) is balanced as in (3.15) thanks to the property \(\sum _{i=1}^{d} \beta _{i} \equiv 1\). Moreover, we have from (4.10), (4.12) the quantities
and the portfolio \(\pi ^{\psi}\) corresponding to the multiplicatively generated strategy \(\psi = \eta \) is
This indeed invests in the various assets in proportion to their relative book values.
We denote by \(V^{\beta}(\,\cdot \,) := V^{\psi}(\,\cdot \,)\) the relative wealth process this portfolio generates. The log of this process can be computed from (4.13), (4.2) in a manner devoid of stochastic integration as
Empirical evolutions of the log relative wealth process \(\log V^{\beta}\) and the terms on the right-hand side are given in Sect. 7.
If an investor wants to use as a benchmark the book value portfolio \(\beta \) instead of the market portfolio \(\mu \) of (2.1), she can compute the relative value of the functionally generated trading strategies \(\varphi \) and \(\psi \) in Theorems 4.1, 4.2 with respect to \(\beta \) by dividing \(V^{\varphi}\), \(V^{\psi}\) of (4.7), (4.13) by \(V^{\beta}\), respectively.
Example 5.2
It is well known that the so-called “diversity-weighted” portfolio denoted by \(\pi ^{(p)} = (\pi ^{(p)}_{1}, \dots , \pi ^{(p)}_{d})\) with components
and \(0 < p < 1\) is a strong arbitrage relative to the market under mild conditions. See for example Fernholz [10, Sect. 6.2] or Fernholz and Karatzas [12, Sect. 7]. Thanks to the concavity in \(\mu \) of the generating function
the relative value process of the portfolio in (5.11) contains the nondecreasing drift component, which yields a long-term outperformance relative to the market. Note that this portfolio underweights larger and overweights smaller stocks. Similar results can be found in Karatzas and Vervuurt [16] for negative exponents \(p < 0\).
In a similar vein, we call the portfolio \(\Pi ^{(p)} = (\Pi ^{(p)}_{1}, \dots , \Pi ^{(p)}_{d})\) market-to-book ratio weighted portfolio with components
It is straightforward from (4.12) and (2.3) that \(\Pi ^{(p)}\) is multiplicatively generated from the balanced function
which is also concave in \(\mu \) for \(p < 1\). For these values of \(p\), the portfolio tends to invest higher proportions of capital in the stocks with smaller market-to-book ratios. This tilt toward the stocks with small market-to-book ratios becomes more severe as \(p\) gets smaller. Moreover, again from the concavity of \(G\), the relative value process of (4.13) contains a nondecreasing component, namely the first integral on the right-hand side of (4.2). Empirical results for both \(\Pi ^{(p)}\) and \(\pi ^{(p)}\) with different values of \(p\) are given in Sect. 7.3.
5.2 Additively generated portfolios
We now introduce additive analogues of the portfolios in Examples 5.1 and 5.2. Our primary purpose here is to make the gamma process nondecreasing, in order to find the smallest time-interval \([0, T_{*}]\) as in (3.16) over which the generated portfolio outperforms the market with probability 1.
Example 5.3
The integral in (5.10) involves the non-monotone integrator \(d\beta _{i}^{c}\), which makes finding strong relative arbitrage hard. In this endeavour, we consider the slight modification without normalisation
of the function in (5.4), with the bounds for \(\rho \) in (5.5) and \(g_{i} > h_{i} \ge 0\). For this function, we have again the properties (5.6) and (3.15), as well as
In particular, this function satisfies the requirements (3.5). The expression of (4.2) becomes now
and is clearly nondecreasing since the function \(G(\cdot , g, h)\) is concave.
The processes \(\vartheta _{i}(\,\cdot \,)\) of (4.3) are
and thus the additively generated trading strategy \(\varphi \) is obtained from (4.6) as
This strategy holds positive positions in all assets at all times. It invests the baseline amount \(\Gamma ^{G, c}(t)\) across all stocks, and the quantity \(G(t-)\) discounted by the reciprocal \(1/\rho _{i}(t-)\) of the market-to-book ratio for the \(i\)th stock. Thus \(\varphi \) invests less capital in the stocks of companies with higher market-to-book ratios, and generates wealth given by (4.7).
Proposition 3.5 shows that the strategy \(\varphi \) is a strong relative arbitrage with respect to the market over every time-interval \([0, t]\) with \(t \ge T_{*}\), for any \(T_{*}\) satisfying
The portfolio \(\pi ^{\varphi}\) corresponding to the strategy \(\varphi \) is computed from (2.3) as
At any time \(t \ge 0\), this portfolio interpolates linearly between the market portfolio \(\mu (t)\) of (2.1) (with weight \(\Gamma ^{G, c}(t)/(G(\mu , g, h)(t-)+\Gamma ^{G, c}(t))\)) and the book-value portfolio \(\beta (t-)\) of (5.1) (with weight \(G(\mu , g, h)(t-)/(G(\mu , g, h)(t-)+\Gamma ^{G, c}(t))\)).
We note that the portfolio weights multiplicatively generated by the function (5.15) coincide with the book-value portfolio (5.7), from (4.12), (4.10), (5.16) and (2.3).
We assume in the following examples that the relative book values \(\beta _{i}\) admit a universal lower bound \(\delta > 0\), i.e.,
Example 5.4
In order to achieve a nondecreasing gamma process, we consider for any \(p \neq 0\) the generating function
a modification of (5.14). It is easily checked that the function \(G\) satisfies the condition (3.5) and that the gamma process of (4.2) is nondecreasing and computed as
for \(t \ge 0\). Thus the condition (3.16) of Proposition 3.5, with \(\Gamma ^{G}(T_{*})\) replaced by \(\Gamma ^{G, c}(T_{*})\), leads to strong relative arbitrage. From (4.6) and (2.3), the portfolio \(\pi ^{\varphi}\) corresponding to the additively generated strategy \(\varphi \) is computed as
This is again a linear interpolation between the market portfolio \(\mu \) and the portfolio \(\widehat{\pi}\) with components
When \(p = 1\), the function \(G\) of (5.18) is linear in \(\mu \) and the first integral on the right-hand side of (5.19) vanishes; thus the growth of the gamma process depends only on the growth of \(g_{i}\) and \(h_{i}\).
We continue with one more example of additively generated strong arbitrage relative to the market portfolio \(\mu \) of (2.1).
Example 5.5
In this example, the generating function does not satisfy the balance condition; so we assume the relative book values \(\beta _{i}(\,\cdot \,)\) to be continuous. We assume further the lower bound \(\delta \) for \(\beta _{i}(\,\cdot \,)\) in (5.17) as well as the bounds \(m\), \(M\) for the market-to-book ratios \(\rho _{i}(\,\cdot \,)\) in (5.5). We then consider the generating function
which is concave in the argument \(\mu \), for the positive constant
Since the function \(f(x) := \frac{1+x}{x}\log (1+x) \) is nondecreasing, we have \(\kappa \le f(\rho _{i}(t))\) for \(i=1, \dots , d\) and \(t \ge 0\). Computations show that \(G\) satisfies the inequalities (3.5) and admits the nondecreasing gamma process
from (3.4). In Proposition 3.5, the trading strategy \(\varphi \) additively generated from \(G\) is a strong relative arbitrage with respect to the market over any time-interval \([0, t]\) with \(t \ge T_{*}\), with \(T_{*}\) satisfying
5.3 Constant rebalanced portfolio by ranks of market-to-book ratios
We present in this subsection a class of portfolios depending on the ranks of market-to-book ratios. In the setting of Example 3.7, we write  for the ranked market-to-book ratio vector with components \(\nu = (\rho _{[1]}, \rho _{[2]}, \dots , \rho _{[d]})\) in descending ranks. Then the vector \(\vartheta \) of (3.19) and the gamma process of (3.21) take the simplified forms
for the ranked market-to-book ratio vector with components \(\nu = (\rho _{[1]}, \rho _{[2]}, \dots , \rho _{[d]})\) in descending ranks. Then the vector \(\vartheta \) of (3.19) and the gamma process of (3.21) take the simplified forms
and
Fix a vector \(c = (c_{1}, \dots , c_{d})\) in with \(\sum _{k=1}^{d} c_{k} = 1\) and consider the function
Basic computations show that the process \(\vartheta \) in (5.20), the multiplicatively generated trading strategy \(\psi \) of (3.23) and its corresponding portfolio of (2.3) are obtained respectively as
for \(i=1, \dots ,d\). Thus this portfolio \(\pi ^{\psi}\) rebalances at all times to maintain a constant proportion \(c_{k}\) of current wealth invested in the stock having \(k\)th ranked market-to-book ratio, for \(k \le n\). By choosing the exponent vector \(c\) in (5.21), we can construct several portfolios as the following.
Example 5.6
We assume in this example that the number \(d\) of stocks in the market is bigger than a fixed number and consider the vector \(c\) with components
The portfolio \(\tilde{\pi}^{\psi}\) of (5.22) is then
This portfolio invests equal weights at all times in the top \(\ell \) ‘value stocks’, i.e., the \(\ell \) stocks with the highest market-to-book ratios. On the other hand, if we set the last \(\ell \) components of \(c\) to be \(1/\ell \), i.e.,
the corresponding portfolio

distributes equal weights to the top \(\ell \) ‘growth stocks’, i.e., those with the lowest market-to-book ratios, at all times.
Example 5.7
We start with the extreme case where the vector \(c\) in Example 5.6 is given as the unit vector and consider the generating function
Basic computations show that the multiplicatively generated trading strategy \(\psi \) of (3.23) and its corresponding portfolio of (2.3) are obtained respectively as
for \(i=1, \dots , d\). Thus this portfolio invests only in the stock with the biggest market-to-book ratio at all times. Its log relative wealth process from (3.24) is then
The last nonincreasing term involving the local time captures the “leakage effect” caused by crossover from the stock with the biggest market-to-book ratio to the rest of the market. The middle term, however, is not monotone and its direction coincides with that of the book value of the stock with the largest market-to-book ratio. The existence of such a non-monotone term in the drift part of the log relative wealth is a crucial difference to the case of the stock with the biggest size (capitalisation) in Fernholz [10, Example 4.3.1].
In a similar manner, the unit vector with
generates multiplicatively the trading strategy \(\psi \) with components
as well as the corresponding portfolio \(\pi ^{\psi}\) with components
for \(i=1, \dots , d\). This portfolio invests only in the stock with the smallest market-to-book ratio at all times, and its log relative wealth process is given as
The drift part again contains the non-monotone integral with the integrators \(\beta _{i}\) and the nondecreasing integral which represents crossover from the stock with the smallest market-to-book ratio to the rest of the market.
6 Market-to-book ratio component of portfolio returns
In this section, we discuss the market-to-book ratio component of portfolio returns which was introduced in Fernholz [10, Sect. 7.4]. First, we present the method of measuring the component of relative portfolio returns due to changes in the capital distribution.
We recall the notation for the rank process from Sect. 3.4 and consider the ranked market weight vector \(\rho := (\mu _{[1]}, \dots , \mu _{[d]})\). We also consider the random permutation process \(p_{t}\) of \(\{1, \dots , d\}\) such that for \(k = 1, \dots , d\) and every \(t \ge 0\),
Thus \(p_{t}(k)\) indicates the index of the \(k\)th ranked market weight \(\mu _{[k]}\) at time \(t\).
For a given portfolio \(\pi =(\pi _{1}, \dots , \pi _{d})\), we define the process \(w = (w_{1}, \dots , w_{d})\) with components
and call it the vector of weight ratios for \(\pi \). The quantity \(w_{k}(t)\) represents the (fractional) number of shares of the \(k\)th ranked stock held by the portfolio \(\pi \) at time \(t\). For a fixed time \(t_{0} \ge 0\), we consider the weight ratios \(w_{1}(t_{0}), \dots , w_{d}(t_{0})\) of \(\pi \) at \(t_{0}\) and the function
From [10, Theorem 4.2.1], this function \(G\) generates (multiplicatively) a new portfolio \(\nu \) with components
for \(k=1, \dots , d\), whose log relative wealth is given as
for \(t \ge t_{0}\). The weight ratios for \(\nu \) are proportional to the constants \(w_{k}(t_{0})\) because
for \(k=1, \dots , d\). In other words, the new portfolio \(\nu \) keeps the number of shares of the \(k\)th ranked stocks proportional to the constant \(w_{k}(t_{0})\) for \(k = 1, \dots , d\). Note that \(G(\rho (t_{0})) = \sum _{k=1}^{d} \pi _{p_{t}(k)}(t_{0}) = 1\), and thus \(\nu \) and \(\pi \) coincide at time \(t_{0}\).
Over a short period of time from \(t_{0}\) to \(t_{1}>t_{0}\), we estimate the first term on the right-hand side of (6.3) at \(t_{0}\) as
We call this last term the distributional component of the relative return over the period from \(t_{0}\) to \(t_{1}\). Since \(\nu (t_{0}) = \pi (t_{0})\), this component measures the effect on the relative return of both portfolios \(\nu \) and \(\pi \) caused by a change in the capital distribution at time \(t_{0}\). From a practical point of view, investors rebalance portfolios in discrete time so that the above approximation is justified when we pick \(t_{1}\) smaller than the next time of rebalancing after \(t_{0}\).
We now adopt the same methodology to measure the component of relative portfolio returns due to changes in the market-to-book ratios. Let us recall the random permutation process \((r_{t})\) in Example 3.7 and consider the vector \((\mu _{r_{t}(1)}, \dots , \mu _{r_{t}(d)})\) of market weights arranged in descending order of market-to-book ratios. For any portfolio \(\pi =(\pi _{1}, \dots , \pi _{d})\), we consider the vector of weight ratios \(v = (v_{1}, \dots , v_{d})\) with components
The quantity \(v_{k}(t)\) represents the (fractional) number of shares of the stock with the \(k\)th highest market-to-book ratio held in \(\pi \) at time \(t\). We then define the market-to-book ratio component of the relative return of \(\pi \) over the period from \(t_{0}\) to \(t_{1} > t_{0}\) as
Therefore, if a portfolio \(\pi \) is rebalanced at discrete time points \(t_{0}, t_{1}, t_{2}, \dots \), we can compute two different vectors \(w\) and \(v\) of weight ratios in (6.2) and (6.5) which are arranged according to size and according to market-to-book ratio, respectively, at each time \(t_{0}, t_{1}, \dots \) Then the quantities \(DC_{\pi}(t_{0}:t_{1}), DC_{\pi}(t_{1}:t_{2}), \dots \) in (6.4) measure the effect on the relative return of \(\pi \) due to a change in size over time, whereas \(MBRC_{\pi}(t_{0}:t_{1}), MBRC_{\pi}(t_{1}:t_{2}), \dots \) represent the effect due to a change in market-to-book ratio over time.
7 Empirical results
We present in this section some empirical results for the portfolios depending on the relative book values or the market-to-book ratios introduced in Sect. 5. For some of the examples of portfolios \(\pi \) studied in earlier sections, we provide their relative values \(V^{ \pi}\) with respect to the market. By examining these values, we show how the book values (or market-to-book ratios) affect the growth of portfolios.
7.1 Data description
We used daily closing stock prices, year-end annual book values and the number of outstanding shares for 20 years (5032 consecutive trading days, between 2001 January 1st and 2020 December 31st). These data were obtained from the Compustat North America database, accessed via the Wharton research data services: https://wrds-www.wharton.upenn.edu/pages/get-data/compustat-capital-iq-standard-poors.
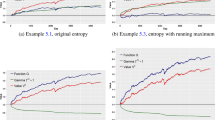
As the number of companies in our dataset varies each day, we consider two different models for simulating the portfolios. For model 1, we selected the \(d = 500\) largest stocks in capitalisation on the first trading day (2001 January 1st) to construct daily rebalancing portfolios without transaction costs. Because such a selection on the first day to make a ‘closed market’ over 20 years is subject to survivorship bias and rebalancing a portfolio without transaction costs is unrealistic, we apply model 1 only for Fig. 2 to examine the decomposition (5.8)–(5.10) of the log relative value process of the book-value portfolio in Example 5.1.
For the rest of the simulations, model 2 is used; we consider an open market, studied in Karatzas and Kim [14], to handle the survivorship bias; we select the \(d=500\) largest stocks in capitalisation every day as an investable universe. Since 500 constituents of the universe change over time according to their size, an extra term involving a local-time process, which is accumulated whenever the 500th and 501st stocks collide, appears when generating portfolios. In this top 500 open market, we construct portfolios imposing a uniform transaction cost rate of \(0.5\%\) on both buying and selling the stocks. In order to lessen the effect of the local-time term and transaction costs, rebalancing of the portfolios and renewal of the constituent list occur every month (21 trading days).
We note that no empirical results of the additively generated portfolios, which appeared in Sect. 5.2, are given because their growth (of the gamma process) depends on the growth of \(g\) and \(h\) in the decomposition (5.3) of the relative book values \(\beta \). However, they remain constant most of the time in our dataset since the book values are only updated annually. The empirical analysis of such portfolios is only meaningful if we have a dataset in which book values are updated more frequently.
For \(N=5032\) trading days, we discretised time as \(0=t_{0} < t_{1} < \cdots < t_{N-1} = T\) and computed the following lists of values for each stock \(i = 1, \dots , 500\) for each day \(\ell = 0, 1, \dots , N-1\);
-
1)
\(S_{i}(t_{\ell})\): the capitalisation (daily closing price multiplied by total number of outstanding shares) of \(i\)th stock at the end of day \(t_{\ell}\).
-
2)
\(\Sigma (t_{\ell}) := \sum _{i=1}^{d} S_{i}(t_{\ell})\): the total capitalisation of \(d=500\) stocks at the end of day \(t_{\ell}\). This quantity represents the dollar value of the market portfolio at the end of day \(t_{\ell}\). In the case of model 2, it is equal to the total capitalisation of the top 500 stocks (which were chosen on the last renewal day).
-
3)
\(\mu _{i}(t_{\ell}) := \frac{S_{i}(t_{\ell})}{\Sigma (t_{\ell})} \): the \(i\)th market weight at the end of day \(t_{\ell}\), as defined in (2.1).
-
4)
\(\beta _{i}(t_{\ell})\): the relative book value of the \(i\)th stock, defined in (5.1), on day \(t_{\ell}\). These values are updated annually, so they remain constant within every calendar year.
-
5)
\(\rho _{i}(t_{\ell})\): the market-to-book ratio of the \(i\)th stock at the end of day \(t_{\ell}\) from (5.2).
-
6)
\(\pi _{i}(t_{\ell})\): the portfolio weight of the \(i\)th stock at the end of day \(t_{\ell}\). We can compute these portfolio weights directly from the quantities in 3)–5), using the formulas given in the examples, e.g. (5.7).
-
7)
\(W(t_{\ell})\): the total value of the portfolio at the end of day \(t_{\ell}\). The transaction or rebalancing of our portfolio is made at the beginning of each (rebalancing) day so that the monetary value of the portfolio for model 1 at the end of day \(t_{\ell}\) can be calculated as
$$ W(t_{\ell}) = \sum _{i=1}^{d} W(t_{\ell -1})\pi _{i}(t_{\ell -1}) \frac{S_{i}(t_{\ell})}{S_{i}(t_{\ell -1})}. $$For model 2, if \(t_{\ell}\) is not a day of rebalancing, then \(W(t_{\ell})\) is computed as
$$ W(t_{\ell}) = \sum _{i=1}^{d} W(t_{\hat{\ell}})\pi _{i}(t_{\hat{\ell}}) \frac{S_{i}(t_{\ell})}{S_{i}(t_{\hat{\ell}})}, $$where \(t_{\hat{\ell}}\) denotes the last rebalancing day before \(t_{\ell}\); if the portfolio is rebalanced at (the beginning of) day \(t_{\ell}\), we have
$$ W(t_{\ell}) = \sum _{i=1}^{d} W(t_{\ell -1})\pi _{i}(t_{\ell -1}) \frac{S_{i}(t_{\ell})}{S_{i}(t_{\ell -1})} - TC(t_{\ell}), $$(7.1)where \(TC(t_{\ell})\) is the transaction cost incurred due to trading at day \(t_{\ell}\), given by
$$ TC(t_{\ell}) = \sum _{i=1}^{d} \bigg\vert \frac{W(t_{\hat{\ell}}) \pi _{i}(t_{\hat{\ell}})}{S_{i}(t_{\hat{\ell}})} - \frac{W(t_{\ell -1})\pi _{i}(t_{\ell -1})}{S_{i}(t_{\ell -1})} \bigg\vert \times S_{i}(t_{\ell -1}) \times 0.005. $$(7.2)If a stock \(j_{1}\) is replaced by another stock \(j_{2}\) during the days \(t_{\hat{\ell}}\) and \(t_{\ell -1}\) (stock \(j_{1}\) exits and stock \(j_{2}\) enters the top 500 open market), the identities (7.1), (7.2) should be slightly modified; the number of summands \(d=500\) should be replaced by some bigger number \(\tilde{d}\), the number of all existing stocks during the days \(t_{\hat{\ell}}\) and \(t_{\ell -1}\), with the setting \(\pi _{j_{1}}(t_{\ell -1}) = 0\) and \(\pi _{j_{2}}(t_{\hat{\ell}}) = 0\).
Finally, in order to compare the performance of our portfolios to the market portfolio, we normalise our initial wealth as \(W(0) = \Sigma (0)\). When writing the trading strategy corresponding to the portfolio \(\pi \) by \(\varphi \), the relative value of (2.2) represents the ratio between the monetary value of our portfolio and the total market capitalisation, i.e.,
7.2 Book value portfolio
Before we give the empirical simulation of the book value portfolio of Example 5.1, we first present the distributions of relative capitalisation \(\mu \) and relative book value \(\beta \) of the \(d=500\) stocks at the beginning of the years 2001, 2011 and 2020 in Fig. 1. Table 1 shows the three largest components of \(\mu \) and \(\beta \) in each of the three years, expressed as percentages. As can be seen from the graph and table, the three companies with the largest capitalisation occupied about \(18\%\) of the total capital of the 500 stocks in 2001; this concentration of capital in the largest stocks has been mitigated over 20 years. On the other hand, the distribution of relative book values has been quite stable over the same period of time, compared to the capital distribution.

Distribution of \(\mu \) and \(\beta \) for the largest 500 stocks in capitalisation
In what follows, we give a detailed empirical analysis of the book value portfolio of Example 5.1. The red graph in Fig. 2 (a) shows the log relative wealth \(\log V^{\beta}\) in model 1 on the left-hand side of (5.8). The green and blue graphs represent the log of the generating function \(G\) on the right-hand side of (5.8) and the drift process in (5.9), respectively, in the decomposition of \(\log V^{\beta}\). We note that the integral in (5.10) vanishes in our dataset as each integrator \(\beta ^{c}_{i}\) is a constant function. Since the drift process (5.9) is derived from the quadratic variation term
and \(G\) of (5.4) is concave in \(\mu \), the blue graph has been increasing over 20 years as expected. Moreover, since the market-to-book ratios appear in the denominator of the integrands of the drift process (5.9), the stocks with smaller market-to-book ratios have more influence on the growth of the drift process. On the other hand, the log of the generating function in (5.8) in the green graph appears to be mean-reverting around its mean 0.0799. Thus the book value portfolio could have outperformed the market over the 20-year period thanks to the increasing drift process.

Log relative values of the book value portfolio
Figure 2 (b) shows a more realistic simulation of the same portfolio in model 2. Because of transaction costs and monthly rebalancing, the performance is not satisfactory compared to Fig. 2 (a); however, the final value is \(\log V^{\beta}(5031) = 0.3359\), or \(V^{\beta}(5031) = 1.399\), i.e., the book value portfolio has outperformed the market by \(40\%\) over 20 years (excess return of \(1.69\%\) a year). Note that there was a huge economic downturn due to the bursting of the U.S. housing bubble lasting from December 2007 to June 2009. We had another stock market crash starting in February 2020 due to the COVID-19 pandemic. We can notice quite abrupt fluctuations in the graphs of both (a) and (b) during those dates (around the days 1730–2150 and 4800–5031).
7.3 Market-to-book ratio weighted portfolios
We present the empirical results of the market-to-book ratio weighted portfolio \(\Pi ^{(p)}\) of (5.13) along with the diversity weighted portfolio \(\pi ^{(p)}\) of (5.11) in Example 5.2. The solid lines in Fig. 3 (a) show the log relative value processes of the market-to-book ratio weighted portfolios \(\Pi ^{(p)}\) with different values of \(p\) in model 2. The portfolio with a smaller value of \(p\) tends to perform better. This clearly shows the “value factor”: overweighting stocks with small market-to-book ratios (and underweighting stocks with big market-to-book ratios) is preferable for the given data over 20 years.

Market-to-book ratio and diversity weighted portfolios with different values of \(p\) in model 2
In order to compare this value factor with the “size factor”, the log relative values of the diversity-weighted portfolios \(\pi ^{(p)}\) with the same values of \(p\) are given as the solid lines in Fig. 3 (b). We note that both \(\Pi ^{(p)}\) and \(\pi ^{(p)}\) approach the equal-weighted portfolio as \(p \downarrow 0\), and \(\pi ^{(1)}\) is just the market portfolio when \(p = 1\).
The dotted lines in Figs. 3 (a) and (b) illustrate the log of the generating functions \(G\) in (5.12) and (5.14), respectively, for \(p = 0.5\). Both dotted lines exhibited upward movement over 20 years, perhaps because of the increase in market diversity as shown in Fig. 1 (a). These uptrends contribute to the growth of log relative values of the portfolios to a certain extent, whereas the increasing drift components, namely \(\int _{0}^{\cdot} \frac{d\Gamma ^{G, c}(s)}{G(s-)}\) in (4.13), account for the rest of the growth.
7.4 Portfolios depending on ranks of market-to-book ratios
In this subsection, we compare the performances of the portfolios described in Example 5.6. We divide the total of \(d = 500\) stocks every trading (rebalancing) day into two groups of 250 stocks, according to the ranks of market-to-book ratios. The relative values of two equally-weighted portfolios generated from these groups are shown as the solid lines (blue and red) in Fig. 4 (a). The dotted lines in Fig. 4 (a) show the relative values of two equally-weighted portfolios constructed from smaller groups of 100 stocks having the largest (orange) and smallest (cyan) market-to-book ratios.

Relative values of equally-weighted portfolios composed of the top and bottom groups by ranks of market-to-book ratios and sizes in model 2
Being equally-weighted portfolios, all of them have outperformed the market, but the return was higher for investment in the stocks with lower market-to-book ratios. The difference in performance between the top and bottom groups tends to be bigger when choosing the stocks from the smaller, extreme groups. This shows another piece of evidence in favour of the value factor in portfolio returns.
In order to compare this “market-to-book ratio effect” with the “size effect”, we construct four more portfolios, equally-weighted for the top group and the bottom group, respectively, composed of 100 and 250 stocks but ranked by size. Recall the notation (6.1) regarding the ranked relative capitalisations. Then the graphs in Fig. 4 (b) describe the relative values of the portfolios

for \(\ell = 100\) (dotted lines) and 250 (solid lines), respectively.
The graphs in (a) and (b) of Fig. 4 behave similarly, but the gaps between the performances of the two portfolios generated from the top and bottom groups are a bit smaller when the ranks of the market-to-book ratios are used to separate the groups. This shows that the value factor has a milder effect than the size factor. The last relative values of these portfolios are summarised in Table 2.
The above empirical results provide evidence of the value factor in portfolio returns as well as of the stability of (relative) book values for U.S. stock market over the last 20 years. Nonetheless, it would be meaningful to conduct similar empirical studies under different settings, e.g. for other stock markets, over a longer period of time, with different sizes of \(d\), transaction costs and rebalancing frequency, etc. It would also be interesting to find economic variables other than the book values, such as the two additional variables included in the Fama–French five-factor model (profitability and investment), which affect the portfolio return in the context of this paper.
References
Banner, A.D., Fernholz, E.R., Papathanakos, V., Ruf, J., Schofield, D.: Diversification, volatility, and surprising alpha. J. Invest. Consult. 19, 23–30 (2019)
Banner, A.D., Ghomrasni, R.: Local times of ranked continuous semimartingales. Stoch. Process. Appl. 118, 1244–1253 (2008)
Capaul, C., Rowley, I., Sharpe, W.F.: International value and growth stock returns. Financ. Anal. J. 49, 27–36 (1993)
Chan, L.K.C., Hamao, Y., Lakonishok, J.: Fundamentals and stock returns in Japan. J. Finance 46, 1739–1764 (1991)
Cohen, R.B., Polk, C., Vuolteenaho, T.: The value spread. J. Finance 58, 609–641 (2003)
Fama, E.F., French, K.R.: Common risk factors in the returns on stocks and bonds. J. Financ. Econ. 33, 3–56 (1993)
Fama, E.F., French, K.R.: Profitability, investment and average returns. J. Financ. Econ. 82, 491–518 (2006)
Fama, E.F., French, K.R.: Average returns, B/M, and share issues. J. Finance 63, 2971–2995 (2008)
Fama, E.F., French, K.R.: A five-factor asset pricing model. J. Financ. Econ. 116, 1–22 (2015)
Fernholz, E.R.: Stochastic Portfolio Theory. Springer, New York (2002)
Fernholz, E.R.: Portfolio generating functions. In: Avellaneda, M. (ed.) Quantitative Analysis in Financial Markets, pp. 344–367. World Scientific, Singapore (1999)
Fernholz, E.R., Karatzas, I.: Stochastic portfolio theory: an overview. In: Bensoussan, A., Zhang, Q. (eds.) Handbook of Numerical Analysis. Mathematical Modeling and Numerical Methods in Finance, pp. 89–167. Elsevier, Amsterdam (2009)
Karatzas, I., Kim, D.: Trading strategies generated pathwise by functions of market weights. Finance Stoch. 24, 423–463 (2020)
Karatzas, I., Kim, D.: Open markets. Math. Finance 31, 1111–1161 (2021)
Karatzas, I., Ruf, J.: Trading strategies generated by Lyapunov functions. Finance Stoch. 21, 753–787 (2017)
Karatzas, I., Vervuurt, A.: Diversity-weighted portfolios with negative parameter. Ann. Finance 11, 411–432 (2015)
Lakonishok, J., Shleifer, A., Vishny, R.W.: Contrarian investment, extrapolation, and risk. J. Finance 49, 1541–1578 (1994)
Rosenberg, B., Reid, K., Lanstein, R.: Persuasive evidence of market inefficiency. J. Portf. Manag. 11, 9–16 (1985)
Ruf, J., **e, K.: Generalised Lyapunov functions and functionally generated trading strategies. Appl. Math. Finance 26, 293–327 (2019)
Schied, A., Speiser, L., Voloshchenko, I.: Model-free portfolio theory and its functional master formula. SIAM J. Financ. Math. 9, 1074–1101 (2018)
Strong, W.: Generalizations of functionally generated portfolios with applications to statistical arbitrage. SIAM J. Financ. Math. 5, 472–492 (2014)
Acknowledgements
The author is deeply grateful to Ioannis Karatzas and Nicola Doninelli for suggesting this topic and for numerous discussions regarding the material in this paper. The author is indebted to Adrian Banner and Robert Fernholz for helpful comments, Johannes Ruf for detailed reading and suggestions which improved this paper. The author is also grateful to two anonymous referees and the Associate Editor for their careful reading of this paper and insightful comments and suggestions.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing Interests
The author declares no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Kim, D. Market-to-book ratio in stochastic portfolio theory. Finance Stoch 27, 401–434 (2023). https://doi.org/10.1007/s00780-023-00501-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00780-023-00501-5