
Abstract
Person names, which hold within them extensive meaning, such as gender and cultural information, play an essential role in our social interaction. The intentional memory advantage of person names has been proved, but whether the automatic memory advantage of them exists remains unclear. In order to explore this question, we used a paradigm called attribute amnesia that allows us to test the automatic memory of person names in a working memory task. In Experiment 1, we adopted a classic attribute amnesia paradigm including 11 pre-surprise trials requiring participants to report the location of the target (person names or animal names) among three distractors and one surprise trial requiring them to unexpectedly report the identity of the target. The results showed that the identity report accuracy of person names in the surprise test was significantly better than that of animal names that served as a control group. Experiment 2 replicated Experiment 1 but increased the number of pre-surprise trials that could reduce the report accuracy of surprise test according to previous studies. The results revealed that the accuracy of the surprise test of person names decreased significantly, and showed no significant difference from that of animal names. These results suggest that there exists an automatic memory advantage of person names in working memory; however, such an automatic memory advantage effect could be reduced after participants learn to stop automatically encoding the attended but no-need-to-report person names through experiencing sufficient trials.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Previous studies have proposed that a person’s name is a linguistic symbol representing the individual identity, a complex and meaningful stimulus with rich social meaning and cultural background information (Berger et al., 2012; Hanks & Parkin, 2016; Mehrabian & Valdez, 1990; Yen, 2006). As a personal identity label, person names have an intentional memory advantage, which has been supported by some empirical studies (Burton et al., 2018; Yarmey, 1970; but see James, 2004). For instance, as Burton et al. (2018) shown in their research, participants were required to remember unfamiliar person names and faces in a learning task, after which they were asked to complete a recognition test, and the results showed that participants had a better recognition accuracy for person names than faces.
It should be noted that in all the above studies, participants were specifically asked to remember the person names in a learning task and their intentional memory was tested. To the best of our knowledge, none of previous studies have tried to explore whether the memory advantage of person names could persist in the context of automatic memory tasks.
Many studies have suggested that automatic memory plays a crucial role in memory processing and involves different mechanisms and behavioral manifestations with intentional memory (Chen et al., 2019; Jacoby, 1991; Jefferies et al., 2004; Jennings & Jacoby, 1993). For instance, Chen et al. (2019) demonstrated that despite the fact that complex and meaningful stimuli had a robust intentional memory advantage in long-term memory, they did not show an automatic memory advantage in working memory. Thus, it is possible that the memory advantage of person names that was well documented in intentional long-term memory tasks may disappear in the context of automatic working memory tasks. However, research into social attention has shown that social information has an automatic attentional advantage over non-social information in working memory (Ji et al., 2020; Kosonogov et al., 2018; Langton & Bruce, 1999; Nie et al., 2018), suggesting that as one type of important social stimuli (Li et al., 2018), person names may have an automatic processing advantage in working memory.
Therefore, it remains unclear whether there is an automatic working memory advantage of person names, and the current study sought to directly address this unsolved issue. Addressing such a critical issue would not only fill in the gap in memory research of person names, but also add to our comprehensive understanding of social working memory.
In order to explore whether there is an automatic memory advantage of person names in working memory, we used a paradigm called attribute amnesia (AA), which probes the automatic memory of stimuli in a surprise working memory test (Chen & Wyble, 2015a, 2016). In the classic AA paradigm, participants were presented with one target stimulus and three distractors simultaneously, and were required to report the location of the target stimuli for multiple trials. Then in a surprise trial, participants were unexpectedly asked to report another attribute (i.e., identity o color) of the target stimulus before the location report task. For instance, the first AA experiment of Chen and Wyble (2015a) presented four stimuli in different colors in each trial, including one target letter and three distractor numbers, and required participants to locate the target letter. After performing several location-report trials (pre-surprise trials), participants were unexpectedly asked to report the identity and color of the target letter that they had just seen in that trial (surprise trial). Surprisingly, most of participants could not correctly report the identity information or the color information of the target letter in the surprise test, even though they had just moments before attended to and used the identity information to locate the target letter. However, the accuracy of identity and color report significantly improved in control trials (which immediately followed the surprise trial) once they expected to have to report them. Chen and Wyble (2015a) termed this counterintuitive phenomenon the AA effect, which refers to the difference in accuracy between the surprise trial and the first control trial. This effect suggested that attended information could not be well encoded into working memory automatically without expectation.
The AA effect has been repeatedly verified in a subsequent series of studies (Born et al., 2020; Born et al., 2019; Chen & Wyble, 2015b, 2016; Chen et al., 2019; Chen & Howe, 2017; Jiang et al., 2016). Furthermore, Chen and Wyble (2016) demonstrated that AA was not driven by forgetting or interferences caused by the surprise tests, but rather occurred due to a lack of consolidating fragilely encoded information into working memory. Thus, this AA paradigm provides a nice tool to investigate whether there is an automatic memory advantage of person names in working memory. If the automatic memory advantage exists, then we would expect to observe that the accuracy of reporting the person names in the surprise test of an AA paradigm is better than other stimuli. In the current study, Experiment 1 was designed to test this possibility, in which person names and animal names were, respectively, used in two groups and their accuracy in the surprise tests was compared.
Additionally, previous studies have found that the AA effect was modulated by the number of pre-surprise trials, which is manifested by the enhancement of the AA effect (a decrease in accuracy in the surprise test) when the number of pre-surprise trials increases (Chen & Wyble, 2018; Chen et al., 2019; Wyble et al., 2018). Thus, in order to explore the potential constraints on the automatic memory advantage of person names, we increased the number of pre-surprise trials from 11 to 155 to test whether the memory advantage effect could be eliminated or at least reduced in this case.
Experiment 1: Is there an automatic memory advantage with person names?
Experiment 1 was designed to test whether there is an automatic memory advantage with person names, by adopting the classic AA design of 16 trials (11 pre-surprise trials, one surprise trial, and four control trials) as in most previous AA studies (Chen & Wyble, 2015a, 2015b, 2016; Chen et al., 2019). The automatic memory advantage effect was probed by directly comparing the memory for person names with that for animal names (which served as a control group) in the surprise test.
Method
Participants
Eighty participants were randomly divided into two groups (each group had 40 participants), a person names group (average age: 20.48 ± 2.15 years) and an animal names group (average age: 20.80 ± 2.01 years). All of them reported normal or corrected-to-normal visual acuity. This study was approved by the local review board for the ethical treatment of human participants. All the participants were to complete a post-experiment questionnaire to check that they had been not previously aware of the purpose of the experiment nor had carried out relevant or similar experiments before.
Apparatus
The stimuli were presented on a 20-in. computer (1,024 × 768 resolution) using MATLAB with the Psychophysics Toolbox (Brainard, 1997; Pelli, 1997). Participants were situated 50 cm away by use of a chin rest and made responses through a computer keyboard.
Stimuli
All the stimuli were two characters in Chinese, including four person names, four animal names, and 12 distractor nouns. To balance the impact of the familiarity of the person names in the experiment, four kinds of person names including self name, friend name, celebrity name, and stranger name were used as target stimuli in the person names group. The gender of each name was the same as that of the participant and without a last name, such as 晓刚 (xiao-gang). Four different kinds of animal names that were familiar to participants, i.e., 骆驼 (camel), 松鼠 (squirrel), 海豹 (seal), and 狐狸 (fox), were included in the animal names group. Twelve distractor nouns were included, i.e., 电脑 (computer), 火焰 (flame), 戒指 (ring), 筷子 (chopsticks), 钥匙 (key), 衬衫 (shirt), 商店 (shop), 公寓 (flat), 茶杯 (teacup), 足球 (football), 青菜 (greens), and轮船 (ship). Animal names and distractor nouns were high-word-frequency items chosen from the Chinese Word Frequency Table (prepared by Professor Cai Qing of East China Normal University in 2010). The word frequency and character strokes of the stimuli were balanced. Each stimulus array contained one target (person name or animal name) and three distractors.
Procedure and design
As shown in Fig. 1, each trial began with the fixation display, which consisted of a black central fixation cross (0.62°of visual angle in size) and four black placeholder circles (0.62° × 0.62°) located in the four corners of an invisible square (6.25° × 6.25°) for a duration that varied between 600 ms and 1,000 ms, followed by a fixation cross for 100 ms. Then, the stimulus array (1.03° × 1.03° of one Chinese character) appeared for 1 s, which was replaced by the masks for 100 ms. A 400-ms blank screen with a fixation cross followed the disappearance of the masks. In the first 11 pre-surprise trials, participants were asked to report the location of the target (person name or animal name in two different groups, respectively) by pressing one of four number keys (1–4) corresponding to the four stimuli. In the 12th trial (i.e., surprise trial), four different targets appeared randomly with the numbers 5–8, and participants were unexpectedly asked to report the identity of the target (person name or animal name) by pressing a corresponding number key (5–8). After reporting the target identity, participants reported the location as former trials. Following the surprise trial, the participants received four more control trials in the same format as the surprise trial.

Example of classic sequences in Experiments 1 and 2. The true scale of the stimuli is smaller than depicted, size only for illustration purpose. The questions for the location task and identity task were, respectively, “Press a corresponding number to indicate the ‘Location’ of the target name” and “This is a surprise memory test! Here we test the ‘Identity’ of the target name. Press a corresponding number to indicate the ‘Identity’ of the target name”
Results
In the location task, 98.64% of responses in the person names group and 99.77% of responses in the animal names group were correct in the pre-surprise trials, respectively.
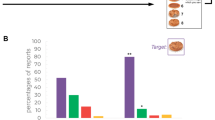
In the person names group, the performance in the surprise test (an identity task in a surprise trial) of person names is depicted in Fig. 2 and Table 1; 33 of 40 (82.5%) participants correctly reported the identity of the person names in the surprise trial, compared with 100% accuracy in the first control trial, 82.5% versus 100%, χ2 (1, N = 80) = 5.64, p = 0.018, φ = 0.31, indicating that the AA effect, despite still persisting, was very small.

In the animal names group, we also combined the results of four kinds of animal names, showing that 24 of 40 (60%) participants correctly reported the identity of animal names in the surprise trial, which was significantly worse than the first control trial (97.5%), 60% versus 97.5%, χ2 (1, N = 80) = 16.81, p < 0.001, φ = 0.46, indicating a strong AA effect for animal names.
More importantly, a comparison between the two groups showed that the performance of the identity report in the surprise test of the person names group was significantly better than that of the animal names group, 82.5% versus 60%, χ2 (1, N = 80) = 4.94, p = 0.026, φ = 0.25, suggesting an automatic memory advantage for person names over animal names.
Experiment 2: Exploring the potential constraints on the automatic memory advantage of person names
Some previous studies have demonstrated that the report accuracy of a surprise test was reduced when increasing the number of pre-surprise trials (Chen & Wyble, 2018; Chen et al., 2019; Wyble et al., 2018). Thus, Experiment 2 sought to test whether the automatic memory advantage of person names can be weakened or even eliminated when increasing the number of pre-surprise trials (increased to 155 pre-surprise trials). This experiment enabled us to explore the potential constraints on the automatic memory advantage of person names shown in Experiment 1.
Method
Eighty new participants were recruited for Experiment 2, who were also divided into two groups (each included 40 participants), a person names group (average age: 21.30 ± 1.99 years) and an animal names group (average age: 20.90 ± 2.30 years). The method of Experiment 2 was identical to Experiment 1, except that the number of pre-surprise trials was increased to 155.
Result
In the location task, 98.87% of responses in the person names group and 99% of responses in the animal names group were correct in the pre-surprise trials, respectively. As shown in Fig. 2 and Table 1, 22 of 40 (55%) participants correctly reported the identity of the person names in the surprise test, and their performance improved significantly in the first control trial (95%), 55% versus 95%, χ2 (1, N = 80) = 17.07, p < 0.001, φ = 0.46. Similarly, the performance of reporting the identity of animal names in the surprise test (16 of 40; 40%) was also significantly worse than the first control trial (97.5%), 40% versus 97.5%, χ2 (1, N = 80) = 30.78, p < 0.001, φ = 0.62.
Comparing these two groups, there was no significant difference between the surprise test results of the person names group (55%) and the animal names group (40%), 55% versus 40%, χ2 (1, N = 80) =1.81, p = 0.179, φ = 0.15, which suggests that the memory advantage of person names observed in Experiment 1 was at least reduced or even disappeared.
Additionally, for the person names groups, a comparison of performance in surprise tests between the two experiments showed that performance in Experiment 2 (55%) was significantly worse than that in Experiment 1 (82.5%), 55% versus 82.5%, χ2 (1, N = 80) = 7.04, p = 0.008, φ = 0.30. For the animal names groups, there was a marginally significant difference between the surprise test results of Experiment 2 (40%) and Experiment 1 (60%), 40% versus 60%, χ2 (1, N = 80) = 3.20, p = 0.074, φ = 0.20.
General discussion
In this study, to explore whether there is an automatic memory advantage of person names, we used the AA paradigm and compared the accuracy of person names with animal names in the surprise test. Experiment 1 adopted the classic design of 11 pre-surprise trials and found that person names had an automatic memory advantage over animal names. Furthermore, in Experiment 2, when the number of pre-surprise trials was increased to 155 trials, the observed automatic memory advantage for person names largely reduced, suggesting that there are some constraints on such a memory advantage effect.
Implications in understanding the memory of person names
The findings of Experiment 1, showing an automatic memory advantage of person names in working memory, extend the current knowledge of person names in two important ways. First, the memory advantage of person names has typically been observed in intentional long-term memory tasks, and it remains unclear whether such a memory advantage effect would persist in the context of automatic working memory tasks. To the best of our knowledge, the current study provided first evidence showing the automatic working memory advantage of person names, which fills the gap of the memory research of person names.
Second, the current study has implications in understanding social working memory. Previous researchers have employed three categories of stimuli in exploring social working memory: person names, human faces, and biological motion (e.g., He et al., 2018; Meyer & Collier, 2020; Meyer et al., 2012). However, with regard to important social information, previous studies of social working memory only set “person name” as a cue associated with other information, but did not test the memory of person names directly (Dumontheil et al., 2020; Meyer et al., 2012; Meyer et al., 2015). In the current study, we specially studied the working memory of the person name itself, which complements the research regarding the social working memory of person names. Moreover, the previous research showed the processing advantage of social information in the intentional working memory tasks (Thornton & Conway, 2013), while the current study proved the processing advantage of social information in the context of automatic working memory tasks, adding to our comprehensive understanding of social working memory.
Implications of understanding the boundary of the attribute amnesia (AA) effect
The results of the current study also have important implications with regard to understanding the boundaries of AA. In previous AA studies using the classic design of 11 pre-surprise trials, which was the same as the design of Experiment 1 in the current study, the AA effect was repeatedly replicated with different types of stimuli. For instance, in the initial study by Chen and Wyble (2015a), AA was observed by using simple letter stimuli, with the accuracy of the target letters’ identity in the surprise test being 35%. Furthermore, Chen et al. (2019) selected multiple types of complex and meaningful stimuli as target stimuli, including picture, Chinese character, and ancient poem, and found that AA persisted in all these types of stimuli, with the accuracy of the surprise test being 50%, 55%, and 45%, respectively.
However, in the current study, the AA effect was largely reduced, with the report accuracy in the surprise test being 82.5%, which was much higher than animal names in Experiment 1 and other stimuli in previous studies (Chen & Wyble, 2015a, 2016; Chen et al., 2019). Thus, the current study suggested that, apart from location (Chen & Wyble, 2015b), person names, under some conditions, were also automatically encoded into working memory, and almost broke through the boundary of the AA effect.
Why do person names show this automatic working memory advantage and almost break through the boundary of the AA effect? From a biological point of view, some researchers have suggested that person names play a role in identifying individuals for human beings, just the same as sound or olfactory signals do for some animals, and are used for mutual recognition between individuals (Müller & Kutas, 1997; Yen, 2006). At the same time, the special status of person names is also supported by physiological evidence and dysphasia patient research (Gainotti, 2007; Ghika-Schmid & Nater, 2003; Marful et al., 2015; Mcneil et al., 1994; Seidenberg et al., 2009; Yen et al., 2015). Additionally, a person’s name is a type of complex and meaningful stimulus, a symbol of individual and important information that we need to acquire in social communication. In terms of social adaptation, the ability to process and recognize person names may reflect a long-term learning ability of people in our society (Dunbar, 2003; Müller & Kutas, 1996; Murphy, 1992; Yen, 2006). In other words, it is also an evolutionary and social advantage to be able to encode person names automatically and efficiently. This is consistent with previous studies showing that social information was not only more likely to be automatically processed as revealed by a larger social-information-related Stroop effect (Beall & Herbert, 2008), but was also more likely to be automatically encoded into memory (Harvey et al., 2007; Harvey & Lepage, 2014).
Some explanations for the reduction of an automatic memory advantage of person names in Experiment 2
Two potential possibilities could explain the reduced memory advantage effect of person names in Experiment 2. Firstly, the decline in memory accuracy in the surprise test might be caused by proactive interference, when the retention of more recently gained information was affected by previously learned information (Keppel & Underwood, 1962; Neath & Surprenant, 2015; Underwood, 1957). When the stimuli in the earlier lists are highly similar to the recent stimuli, proactive interference would become more prominent (Keppel & Underwood, 1962; Underwood, 1957). This is an important characteristic of AA, wherein the same four target stimuli were used repeatedly across the entire trial sequence. Thus, the worse memory for person names in the surprise test of Experiment 2 might result from the stronger proactive interference built up from the increase in the number of pre-surprise trials. However, it should be noted that proactive interference cannot completely explain why such a high performance exists in the control trials (post-surprise trials) in which proactive interference would also affect the performance. Furthermore, Wyble et al. (2018) directly tested the influence of proactive interference on AA by introducing new target stimuli prior to the surprise trial (which should release the proactive interference) and found that such a manipulation did not significantly affect the performance, suggesting that proactive interference is not the primary contribution of AA.
Another more plausible explanation is that participants might learn to stop automatically encoding person names through practice. That is, in the early stage of the experiment, participants encoded the identity of person names automatically. However, with the successive repetition of experimental tasks, participants had repeatedly finished the same location-report tasks for multiple times and had not been asked about the identity of names even once. Therefore, participants would learn to stop automatically encoding the attended to but no-need-to-report information (identity of person names) into working memory through experiencing sufficient trials (Chen & Wyble, 2015a, 2018; Gaspar & McDonald, 2014; Gaspelin et al., 2015, 2017; Sawaki & Luck, 2010, 2011). Consequently, performance in the surprise test of person names decreased with increasing the number of per-surprise trials, consistent with other previous studies (Chen & Wyble, 2018; Wyble et al., 2018).
In conclusion, our results showed that, firstly, person names have an automatic memory advantage over other common nouns (such as animal names) in working memory and almost break through the boundary of the AA effect. Secondly, the automatic memory advantage effect of person names was largely reduced when increasing the number of pre-surprise trials, indicating that there were some constraints on such a memory advantage effect. The current results extend the present knowledge about the memory of person names and the boundaries of the AA phenomenon.
References
Beall, P. M., & Herbert, A. M. (2008). The face wins: Stronger automatic processing of affect in facial expressions than words in a modified Stroop task. Cognition & Emotion, 22(8), 1613-1642. https://doi.org/10.1080/02699930801940370
Berger, J., Bradlow, E. T., Braunstein, A., & Zhang, Y. (2012). From Karen to Katie: using baby names to understand cultural evolution. Psychological Science, 23(10), 1067-1073. https://doi.org/10.1177/0956797612443371
Born, S., Jordan, D., & Kerzel, D. (2020). Attribute amnesia can be modulated by foveal presentation and the pre-allocation of endogenous spatial attention. Attention Perception & Psychophysics, 82(10), 2302-2314. https://doi.org/10.3758/s13414-020-01983-7
Born, S., Puntiroli, M., Jordan, D., & Kerzel, D. (2019). Saccadic Selection Does Not Eliminate Attribute Amnesia. Journal of Experimental Psychology Learning Memory and Cognition, 45(12), 2165-2173. https://doi.org/10.1037/xlm0000703
Brainard, D. H. (1997). The Psychophysics Toolbox. Spatial Vision, 10(4), 433–436.
Burton, M., Jenkins, R., & Robertson, D. J. (2018). I recognise your name but I can't remember your face: An advantage for names in recognition memory. The Quarterly Journal of Experimental Psychology, 72(7), 1847-1854. https://doi.org/10.1177/1747021818813081
Chen, H., & Wyble, B. (2015a). Amnesia for Object Attributes: Failure to Report Attended Information That Had Just Reached Conscious Awareness. Psychological Science, 26(2), 203-210. https://doi.org/10.1177/0956797614560648
Chen, H., & Wyble, B. (2015b). The location but not the attributes of visual cues are automatically encoded into working memory. Vision Research, 107, 76-85. https://doi.org/10.1016/j.visres.2014.11.010
Chen, H., & Wyble, B. (2016). Attribute amnesia reflects a lack of memory consolidation for attended information. Journal of Experimental Psychology Human Perception & Performance, 42(2), 225-234. https://doi.org/10.1037/xhp0000133
Chen, H., & Wyble, B. (2018). The Neglected Contribution of Memory Encoding in Spatial Cueing effects: A New Theory of Costs and Benefits. Journal of Vision, 125(6), 936-968. https://doi.org/10.1037/rev0000116
Chen, H., Yu, J., Fu, Y., Zhu, P., Li, W., Zhou, J., & Shen, M. (2019). Does attribute amnesia occur with the presentation of complex, meaningful stimuli? The answer is, "it depends". Memory & Cognition, 47(6), 1133-1144. https://doi.org/10.3758/s13421-019-00923-7
Chen, W., & Howe, P. D. L. (2017). Attribute amnesia is greatly reduced with novel stimuli. PeerJ, 5, e4016. https://doi.org/10.7717/peerj.4016
Dumontheil, I., Kilford, E. J., & Blakemore, S. J. (2020). Development of dopaminergic genetic associations with visuospatial, verbal and social working memory. Developmental Science, 23(2), e12889. https://doi.org/10.1111/desc.12889
Dunbar, R. I. M. (2003). The Social Brain: Mind, Language, and Society in Evolutionary Perspective. Annual Review of Anthropology, 32(1), 163-181. https://doi.org/10.1146/annurev.anthro.32.061002.093158
Gainotti, G. (2007). Different patterns of famous people recognition disorders in patients with right and left anterior temporal lesions: A systematic review. Neuropsychologia, 45(8), 1591-1607. https://doi.org/10.1016/j.neuropsychologia.2006.12.013
Gaspar, J. M., & McDonald, J. J. (2014). Suppression of salient objects prevents distraction in visual search. Journal of Neuroscience the Official Journal of the Society for Neuroscience, 34(16), 5658 –5666. https://doi.org/10.1523/JNEUROSCI.4161-13.2014
Gaspelin, N., Leonard, C. J., & Luck, S. J. (2015). Direct Evidence for Active Suppression of Salient-but-Irrelevant Sensory Inputs. Psychological Science, 26(11), 1740-1750. https://doi.org/10.1177/0956797615597913
Gaspelin, N., Leonard, C. J., & Luck, S. J. (2017). Suppression of overt attentional capture by salient-but-irrelevant color singletons .Attention, Perception, & Psychophysics, 79(1), 45-62. https://doi.org/10.3758/s13414-016-1209-1
Ghika-Schmid, F., & Nater, B. (2003). Anomia for people's names, a restricted form of transient epileptic amnesia. European Journal of Neurology, 10(6), 651-654. https://doi.org/10.1046/j.1468-1331.2003.00685.x
Hanks, P., & Parkin, H. (2016). The Oxford handbook of names and naming. Oxford University Press, 214–236.
Harvey, P.-O., Fossati, P., & Lepage, M. (2007). Modulation of Memory Formation by Stimulus Content: Specific Role of the Medial Prefrontal Cortex in the Successful Encoding of Social Pictures. Journal of Cognitive Neuroscience, 19(2), 351-362. https://doi.org/10.1162/jocn.2007.19.2.351
Harvey, P.-O., & Lepage, M. (2014). Neural correlates of recognition memory of social information in people with schizophrenia. Journal of Psychiatry & Neuroscience, 39(2), 97-109. https://doi.org/10.1503/jpn.130007
He, J., Guo, D., Zhai, S., Shen, M., & Gao, Z. (2018). Development of Social Working Memory in Preschoolers and Its Relation to Theory of Mind. Child Development, 1-14. https://doi.org/10.1111/cdev.13025
Jacoby, L. L. (1991). A process dissociation framework: Separating automatic from intentional uses of memory. Journal of Memory Language, 30(5), 513–541. https://doi.org/10.1016/0749-596x(91)90025-f
James, L. E. (2004). Meeting Mr. Farmer versus meeting a farmer: specific effects of aging on learning proper names. Psychology & Aging, 19(3), 515-522. https://doi.org/10.1037/0882-7974.19.3.515
Jefferies, E., Ralph, M. A. L., & Baddeley, A. D. (2004). Automatic and controlled processing in sentence recall: The role of long-term and working memory. Journal of Memory and Language, 51(4), 623-643. https://doi.org/10.1016/j.jml.2004.07.005
Jennings, J. M., & Jacoby, L. L. (1993). Automatic versus intentional uses of memory: aging, attention, and control. Psychology and Aging, 8(2), 283-293. https://doi.org/10.1037/0882-7974.8.2.283
Ji, H., Wang, L., & Jiang, Y. (2020). Cross-category adaptation of reflexive social attention. Journal of Experimental Psychology: General, 149(11), 2145-2153. https://doi.org/10.1037/xge0000766
Jiang, Y. V., Shupe, J. M., Swallow, K. M., & Tan, D. H. (2016). Memory for Recently Accessed Visual Attributes. Journal of Experimental Psychology: Learning, Memory, and Cognition, 42(8), 1331–1337. https://doi.org/10.1037/xlm000023110.1037/xlm0000231
Keppel, G., & Underwood, B. J. (1962). Proactive inhibition in short-term retention of single items. Journal of Verbal Learning and Verbal Behavior, 1(3), 153-161. https://doi.org/10.1016/S0022-5371(62)80023-1
Kosonogov, V., Martinez-Selva, J. M., Carrillo-Verdejo, E., Torrente, G., Carretié, L., & Sanchez-Navarro, J. P. (2018). Effects of social and affective content on exogenous attention as revealed by event-related potentials. Cognition and Emotion, 33(4), 689-695. https://doi.org/10.1080/02699931.2018.1486287
Langton, S. R. H., & Bruce, V. (1999). Reflexive Visual Orienting in Response to the Social Attention of Others. Visual Cognition, 6(5), 541-567. https://doi.org/10.1080/135062899394939
Li, L., Xu, Q., Gan, T., Tan, C., & Lim, J.-H. (2018). A Probabilistic Model of Social Working Memory for Information Retrieval in Social Interactions. IEEE Transactions On Cybernetics, 48(5), 1540-1552. https://doi.org/10.1109/TCYB.2017.2706027
Marful, A., Gómez Amado, J. C., Ferreira, C. S., & Bajo, M. T. (2015). Face naming and retrieval inhibition in old and very old age. Experimental Aging Research, 41(1), 39-56. https://doi.org/10.1080/0361073X.2015.978205
Mcneil, J. E., Cipolotti, L., & Warrington, E. K. (1994). The accessibility of proper names. Neuropsychologia, 32(2), 193-208. https://doi.org/10.1016/0028-3932(94)90005-1
Mehrabian, A., & Valdez, P. (1990). Basic name connotations and related sex stereoty**. Psychological Reports, 66(3), 1309-1310. https://doi.org/10.2466/pr0.1990.66.3c.1309
Meyer, M. L., & Collier, E. (2020). Theory of minds: managing mental state inferences in working memory is associated with the dorsomedial subsystem of the default network and social integration. Social Cognitive and Affective Neuroscience, 15(1), 63-73. https://doi.org/10.1093/scan/nsaa022
Meyer, M. L., Spunt, R. P., Berkman, E. T., Taylor, S. E., & Lieberman, M. D. (2012). Evidence for social working memory from a parametric functional MRI study. Proc Natl Acad Sci USA, 109(6), 1883-1888. https://doi.org/10.1073/pnas.1121077109
Meyer, M. L., Taylor, S. E., & Lieberman, M. D. (2015). Social working memory and its distinctive link to social cognitive ability: an fMRI study. Social Cognitive and Affective Neuroscience, 10(10), 1338-1347. https://doi.org/10.1093/scan/nsv065
Müller, H. M., & Kutas, M. (1996). Whatʼs in a name? Electrophysiological differences between spoken nouns, proper names and oneʼs own name. NeuroReport, 8(1), 221–225. https://doi.org/10.1097/00001756-199612200-00045
Müller, H. M., & Kutas, M. (1997). Die Verarbeitung von Eigennamen und Gattungsbezeichnungen. Eine elektrophysiologische Studie. In G. Rickheit (Ed.), Studien zur klinischen Linguistik. Modelle, Methoden, Intervention (pp. 147-169). Opladen: Westdeutscher Verlag. https://doi.org/10.1007/978-3-322-90938-1_7
Murphy, G. L. (1992). Comprehension and memory of personal reference: The use of social information in language processing. Discourse Processes, 15(3), 337-356. https://doi.org/10.1080/01638539209544816
Neath, I., & Surprenant, A. M. (2015). Proactive Interference. International Encyclopedia of the Social & Behavioral Sciences, 19, 1-8. https://doi.org/10.1016/B978-0-08-097086-8.51054-X
Nie, Q.-Y., Ding, X., Chen, J., & Conci, M. (2018). Social attention directs working memory maintenance. Cognition, 171, 85-94. https://doi.org/10.1016/j.cognition.2017.10.025
Pelli, D. G. (1997). The VideoToolbox software for visual psychophysics: Transforming numbers into movies. Spatial Vision, 10(4), 437–442. https://doi.org/10.1163/156856897x00366
Sawaki, R., & J.Luck, S. (2010). Capture versus suppression of attention by salient singletons: electrophysiological evidence for an automatic attend-to-me signal. Attention Perception Psychophysics, 72(6), 1455-1470. https://doi.org/10.3758/APP.72.6.1455
Sawaki, R., & J.Luck, S. (2011). Active suppression of distractors that match the contents of visual working memory. Visual Cognition, 19(7), 956-972. https://doi.org/10.1080/13506285.2011.603709
Seidenberg, M., Guidotti, L., Nielson, K. A., Woodard, J. L., Durgerian, S., Zhang, Q., .… Rao, S. M. (2009). Semantic knowledge for famous names in mild cognitive impairment. Journal of the International Neuropsychological Society, 15(1), 9-18. https://doi.org/10.1017/S1355617708090103
Thornton, M. A., & Conway, A. R. A. (2013). Working memory for social information: chunking or domain-specific buffer? Neuroimage, 70, 233-239. https://doi.org/10.1016/j.neuroimage.2012.12.063
Underwood, B. J. (1957). Interference and forgetting. Psychological Review, 64(1), 49-60. https://doi.org/10.1037/h0044616
Wyble, B., Hess, M., O’Donnell, R. E., Chen, H., & Eitam, B. (2018). Learning how to exploit sources of information. Memory & Cognition, 47(4), 696-705. https://doi.org/10.3758/s13421-018-0881-x
Yarmey, A. D. (1970). The effect of mnemonic instructions on paired-associate recognition memory for faces or names. Canadian Journal of Behavioural Science, 2(3), 181-190. https://doi.org/10.1037/h0082723
Yen, H.-L. (2006). Processing of Proper Names in Mandarin Chinese: A Behavioral and Neuroimaging Study. (Ph.D. Dissertation), University of Bielefeld,
Yen, H.-L., Liu, H.-L., Lee, C.-Y., & Müller, H. (2015). Are proper names really different from common nouns? – A view of brain processing. Paper presented at the Proceedings of the 11th annual Meeting of the Organization for of Hunamn Brain Map**, Toronto, Canada.
Acknowledgements
This work was supported by the National Natural Science Foundation of China (Nos. 31771249, 31971032, 31771201), Major Program of National Social Science Foundation of China (No. 18ZDA293), Guangdong-Hong Kong-Macao Greater Bay Area Center for Brain Science and Brain-Inspired Intelligence Fund (No. 2019023), Key Realm R&D Program of Guangzhou (No. 202007030005), Key Realm R&D Program of Guangdong Province (No. 2019B030335001), Guangdong Basic and Applied Basic Research Foundation (No. 2020A1515011250), National Science Foundation for Distinguished Young Scholars of Zhejiang Province, China (No. LR19C090002), and Humanities and Social Sciences Foundation of the Ministry of Education of China (No. 17YJA190001).
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
We are not aware of any real or potential conflicts of interest associated with this research.
Additional information
Open practices statement
The data for this study are available at https://osf.io/at6xh/. This study was not preregistered.
Supplementary Information
In order to make the results of Experiment 2 more convincing and reliable, Experiment 2 was repeated and the new data from repeated Experiment 2 are available at https://osf.io/at6xh/. Comparing the person names group (21/40) with the animal names group (18/40), there was no significant difference, 52.5% versus 45%, χ2 (1, N = 80) =0.45, p = 0.50, φ = 0.08. Therefore, the results of the repeated Experiment 2 essentially replicated the original Experiment 2, indicating that the results of Experiment 2 are reliable.
Additionally, we used different kinds of person names to balance the familiarity effect. Here we listed the results of four subgroups of person names. In Experiment 1, the performance in the surprise test of self name, friend name, celebrity name, and stranger name was 9, 7, 8, and 9 of every 10 participants, respectively. In Experiment 2, the performance in the surprise test of self name, friend name, celebrity name, and stranger name was 7, 5, 4, and 6 of every 10 participants, respectively. Indeed, we did not analyze whether there was a significant difference among four different types of person names in either Experiment 1 or Experiment 2 because there were only 10 participants in each subgroup, which did not provide sufficient data to do this analysis.
We tried to do this analysis by combining the data of the original and repeated Experiment 2 (there were 20 participants in each subgroup after combining the data: self name, friend name, celebrity name, and stranger name were 12, 12, 9, and 10 of every 20 participants respectively). The results showed that there was no significant difference between these four kinds of person names (all p ≥ 0.34). These results demonstrated that the familiarity did not impact on the memory of person names in this AA paradigm.
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Liu, Y., Huang, C., Huang, X. et al. Using the attribute amnesia paradigm to test the automatic memory advantage of person names. Psychon Bull Rev 28, 2019–2026 (2021). https://doi.org/10.3758/s13423-021-01975-0
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-021-01975-0