
Abstract
Nursery rhymes provide insights into the traditions, beliefs, and values of a culture, thereby making it an integral part of a community’s heritage. As representative linguistic resources within the intangible cultural heritage of the Hoklo people, Minnan nursery rhymes (MNRs) play a crucial role in connecting the Chinese mainland, Taiwan Strait, and overseas Chinese communities. This study delves into features of 617 traditional and 289 modern pieces through text mining techniques, including text segmentation, the TF-IDF (term frequency-inverse document frequency) method, and the complex network analysis. We examine the frequency and emotional purity of lyrics at a larger scale than previous studies using a small set of manually annotated samples. Furthermore, we analyze the patterns of MNRs by assessing the overall, individual, core-periphery structures of the constructed MNR networks, considering key terms as nodes and co-occurrence relationships between nodes as links. Our investigation reveals the heterogeneous nature of terms in both traditional and modern MNR networks. Moreover, through the community detection method, we identify five primary imagery features presented in MNRs. Traditional MNRs place emphasis on family relationships, folk culture, and food culture, reflecting enduring aspects of Minnan cultural heritage. In contrast, modern MNRs pivot towards themes of children’s emotions and natural scenery, indicative of evolving societal values. This study represents the first large-scale complex network analysis of MNRs, providing valuable insights into the embedded Minnan culture and serving as a foundation for further research into the societal dynamics reflected in these cherished MNRs resources.
Similar content being viewed by others
Introduction
Intangible cultural heritage (ICH) is a crucial component of human culture, representing the accumulation of human civilization and wisdom. In 2003, UNESCO adopted the Convention for the Safeguarding of the ICH, which greatly contributed to the protection and record of ICH in the world [1]. After two decades of continuous exploration and efforts, ICH protection work has achieved fruitful results, including a series of word-level protection items, such as Chinese Kunqu, Spanish Flamenco, and Indian Kutiyattam. As of December 2023, the UNESCO Representative List of the ICH of Humanity included 730 heritage projects from 145 different countries [2]. Minnan nursery rhymes (MNRs), created as songs for children, are recognized as an artistic form within the “oral traditions and expressions” domain of UNESCO’s 2003 Convention for the Safeguarding of the ICH [1]. MNRs are categorized into this domain as they are traditional forms of oral literature, usually specific to a culture, region, or language group. As a crucial part of cultural traditions, MNRs are transmitted from generation to generation, typically through informal ways such as family members, educational settings, community events, or various media platforms.
MNRs encompass a rich and enduring legacy that spans from the Tang Dynasty to the contemporary era. Local historical classics from the Tang Dynasty (618–907) documented a nursery rhyme called “Yue guang guang,” which celebrated the beauty of moonlight [3, 40,41,42], as well as internet sources. The MNRs edited by experts in the field of Minnan culture ensure the accuracy and reliability of the data. Moreover, internet sources can provide access to a broader range of MNRs, which helps explore variations, interpretations, and even uncover lesser-known MNRs that might not be included in edited collections. After manually selecting and removing duplicates, we have obtained a total of 617 traditional MNRs and 289 modern MNRs. The MNRs are categorize into different content types by domain experts, and Table 1 shows five of them.
Methodology
Overall framework
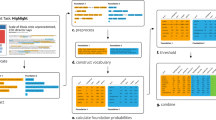
As shown in Fig. 1, our approach comprises three main parts: data pre-processing, lyrical term analysis, and complex network analysis. In the data pre-processing step, we sequentially process the lyrics of MNRs through text segmentation and the TF-IDF (term frequency-inverse document frequenc) method. Subsequently, we utilize techniques such as word cloud generation and information entropy to analyze the characteristics of lyrical terms. Finally, in the complex network analysis phase, we define various measures, including network characteristic indicators, degree distribution, core-periphery analysis, and community detection.

Research framework
Data pre-processing
We outline tailored processing steps for the lyrics of MNRs, as specific characteristics exist in the lyrical texts, including a mixture of written Chinese (both simplified and traditional) and written Hokkien (a written form of the Minnan language).
-
(1)
Language Standardization: This step standardizes the MNRs dataset by converting all lyric texts into simplified Chinese, which ensures consistency and ease of processing.
-
(2)
Removing Irrelevant Characters: By removing irrelevant characters such as special characters and punctuation, the lyrical text is streamlined, and further steps can focus solely on elements contributing to understanding the lyrics.
-
(3)
Custom Dictionary: Traditional text segmentation methods might not accurately handle non-Chinese texts, particularly those in the Minnan language. Therefore, we create an integrated Chinese-Minnan dictionary to allow for more accurate tokenization.
-
(4)
Lyrics Segmentation and Post-processing: The LTP (Language Technology Platform) is employed to segment the lyrics into meaningful units. To enhance the accuracy of the segmented lyrical terms, the post-processing, like filtering out noise, irrelevant tokens, and correcting segmentation errors, is applied to refine the segmented tokenization.
-
(5)
Keyword Extraction: By calculating the TF-IDF values, the critical terms of lyrics are identified based on the obtained TF-IDF values.
Lyrical term analysis method
Word clouds
After the pre-processing algorithm TF-IDF on assessing the significance of terms in section 4.2, the word cloud technology is applied to discern main themes or trends of the MNRs’ lyrics based on the obtained TF-IDF values. Subsequently, these lyrical terms are visually represented in a cloud diagram, with their sizes adjusted proportionally to their significance.
Emotion entropy
A song typically conveys either positive or negative emotions. Instead of discussing the emotional tendency of a rhyme, we delve into the emotional preference of words extracted in 4.2. The emotion category of a word is usually context-dependent, and it may have the opposite emotion category in different contexts [43, 44]. Furthermore, in the MNRs, many lyrical words are not included in traditional categories of emotions, and they do not express direct positive or negative feelings, like the negative word “anger” and the positive word “amusement”. In this study, the emotions of lyrical words are determined by deep-learning technology and experts. Specifically, a supervised-learning based skip-gram model is employed to train word vectors based on large-scale text. Triples (a word/phrase, sentence in which word/phrase is located, sentiment category of the word/phrase) are used as the training samples of the model. The training set is obtained by integrating the NTUSD,Footnote 1 HowNetFootnote 2 dictionaries, and experts-designed dictionaries. The emotion category of lyrical words are automatically predicted by the trained skip-gram model. Crucially, the predicted sentiment categories are then verified by domain experts, ensuring the credibility of the predictions.
To tackle the issue of a lyrical word potentially having contrasting emotional classes in different lyrical sentences, we define the concept of “emotion entropy” to describe the emotional preference of a word. Specifically, emotion entropy quantifies the degree to which a word is associated with a specific (pure) emotion-positive or negative-instead of an ambiguous emotional connotation [45]. We define two possible emotional states of a word \((x)\) as positive (\(x_{1}\)) and negative (\(x_{2}\)), and \(p(x_1)\) is the probability that the word \(x\) conveys a positive emotion. In contrast, \(p(x_2)\) is the probability that the word conveys a negative emotion. Therefore, the emotion entropy \(H(x)\) of the word \((x)\) could be defined as formula 1 by using the Shannon entropy formula [46]. It is noticeable that the emotions (positive or negative) of some words are labeled by a deep neural network model (Long short-term memory neural network) and validated by experts.
As shown in formula 1, a higher value of emotion entropy indicates that the emotional connotation of a word is more uncertain or unpredictable, suggesting it is less emotionally pure. Conversely, a word with a lower value indicates a more precise emotional connotation or higher “emotion purity,” so the probability of this word conveying either positive or negative emotion is more heavily inclined toward one particular emotion.
Complex network analysis method
We introduce the construction of MNR networks in section 4.4.1 and provide measures of complex networks in section 4.4.2.
The construction of MNR networks
In this section, we construct a Minnan nursery rhyme network (abbreviated as MNR network) by representing lyrical keywords as network nodes and capturing the co-occurrence relationships between nodes as edges. The processes involved in constructing and analyzing the MNR networks are listed as follows: (1) Building the Vocabulary: A vocabulary is created, comprising all unique terms extracted in section 4.2. This step aims to eliminate duplicates and organize the vocabulary in a structured manner for constructing a co-occurrence matrix.
(2) Co-occurrence matrix generation: The co-occurrence matrix is constructed based on the frequency of occurrence of each keyword pair within the lyrics. Each row and column of the matrix corresponds to a unique keyword from the vocabulary. The value at the intersection of a row and column represents the frequency with which the corresponding keywords co-occur within the nursery rhymes.
(3) MNR network construction: Each unique keyword is assigned as a node, and the co-occurrence relationships between keywords are depicted as edges. Whenever two keywords appear together in a nursery rhyme, they are regarded as having a co-occurring relation. The weight of an edge is determined by the frequency of their co-occurrence.
The definition of network measures
Overall network characteristic indicators
We explore the overall network characteristics of the MNR networks by indicators: network density, average clustering coefficient, and average path length. Analyzing these indicators allows us to discern patterns, trends, and emergent properties within the network, enriching our understanding of linguistic and cultural contexts within MNRs. We assume \(N\) and \(E\) denote the number of nodes and edges for simplifying the following definitions.
A. Network density Network density is to measure the level of connection density among nodes, with higher values indicating denser connections [47]. It can be quantified by the equation 2, where \(\rho\) represents the network density.
B. Average clustering coefficient The average clustering coefficient quantifies the tendency of nodes to form clusters or groups within a network, with values ranging from 0 to 1 [48]. A higher coefficient signifies closer connections between nodes and a more clustered network. This indicator is commonly used to analyze network community structure, evolution processes, and randomness. The definition of the average clustering coefficient \(C\) is provided in the formula 3, where the \(c_i\) represents the clustering coefficient of node \(i\).
C. Average path length The average path length of networks is employed to estimate the average efficiency of information delivery in a network [49]. As defined in the formula 4, the average path length \(L\) is calculated as the average number of shortest path lengths along the shortest paths for all possible pairs of network nodes. The symbol \(d_{ij}\) in the formula 4 denotes the shortest path length between node \(i\) and node \(j\).
Individual network characteristic indicators
In network theory, individual network characteristic indicators provide valuable information about individual nodes and their roles within a network [50], allowing for a better understanding of the behavior and functionality of nodes. In the following measures, we denote the adjacency matrix and the weight matrix of a network as \(\textbf{A}\) and \(\textbf{W}\).
A. Degree centrality The degree of a node refers to the number of connections that a node has in a network, where a higher value indicates its prominence and influence within the network [51,52,53]. The node degree is defined as the formula 5. The element \(A_{ij}\) of the adjacency matrix \(\textbf{A}\) is defined as 0 if there is no link between node \(i\) and node \(j\), and \(A_{ij} = 1\) if a link exists between them.
B. Weighted degree centrality The weighted degree is a variant of the degree centrality [51,52,53], as defined in formula 6. It takes into account the weights associated with the edges between nodes, which \(W_{i}\) is the weighted degree of the node \(i\), and \(\omega _{ij}\) represents the weight of the node between \(i\) and \(j\).
C. Betweenness centrality The betweenness centrality measures the extent to which a node lies on paths between other nodes in a network. Nodes with high betweenness centrality act as crucial bridges or connectors, facilitating the flow of information and resources between different parts of the network [51,52,53]. The formula 7 shows how to calculate betweenness centrality, where \(N_{st}\) represents the number of shortest paths from node \(s\) to \(t\), and \(N_{st}(i)\) denotes the number of shortest paths passing through node \(i\).
D. Closeness centrality Closeness centrality detects how close a node is to all other nodes in the network [51,52,53]. The closeness centrality of a node in formula 8 is quantified as the average of the shortest path length from the node to other nodes in the network. Nodes with high closeness centrality tend to have shorter average path lengths to other nodes, allowing for efficient information dissemination and quick access to resources. The variable \(B_{i}\) represents closeness centrality, where \(N\) is the total number of nodes and \(\sum _{j=1}^N d_{ij}\) represents the distance from node \(i\) to all other nodes.
E. Eigenvector centrality Eigenvector centrality assesses a node’s importance within a network not solely by its direct connections but also by the importance of its neighboring nodes [54, 55]. Consequently, nodes with high eigenvector centrality are usually linked to other important and influential nodes. This measure is especially useful for identifying influential nodes that are influential in the network, even if they do not have many direct connections. We assume that \(M_{i}\) represents the eigenvector centrality of node \(i\), and it is defined as follows,
where \(\lambda\) is the eigenvalue eigenvector associated with \(M_{i}\).
Degree distribution
In complex networks, degree distribution is viewed as a critical metric for characterizing network structure. It is the probability distribution of node degrees over the entire network. The power-law characteristic of degree distribution has attracted significant academic interest due to its prevalence across a wide array of natural and artificial systems, such as urban traffic [56], earthquake magnitudes [57], and power outage extents [58]. When the degree distribution of a network follows a power-law relationship, the probability P(k) of nodes with degree k is characterized by \(P(k) \propto k^{-\gamma }\) as defined in formula 10, where the \({\gamma }\) is the power-law exponent [59]. As shown in formula 10, the inverse relationship indicated by the negative exponent \({(-\gamma )}\) implies that there are many nodes with a small number of connections and only a few nodes with a large number of connections.
By taking the logarithm of both sides of the formula 10, we derive the relationship as \(\log (P(k)) = -\gamma \log (k) + r\) presented in formula 11. Here, the constant \(r\) represents any multiplicative factors that might have been present in the original equation before taking the logarithmic transformation.
Core-periphery structure
The core-periphery structure of complex networks typically consists of a densely connected core and a sparsely connected periphery [60]. The “core” consists of a highly interconnected group of nodes, which often play crucial roles in the network’s function and dynamics. The “periphery” contains nodes with fewer connections, typically connected to the rest of the network through the core nodes. Other nodes within the network belong to the set of “semi-periphery”. This core-periphery structure can influence the robustness of a network, the efficiency of information or resource transfer, and the overall behavior of the network.
In a network, it is assumed that the coreness value of node \(i\) is \(C_{i}\). The overall average coreness of the network is represented by \(C_{mean}\), and the standard deviation of the network coreness is denoted as \(C_{sd}\). As shown in formula 12, a node \(i\) belonging to one of the three types “core”, “periphery,” or “semi-periphery” is defined as its coreness value \(C_i\) relative to the network’s average coreness \(C_{mean}\) and standard deviation \(C_{sd}\).
Community structure
Community structure in complex networks is characterized by organizing nodes into clusters. The connections within each cluster are dense, while connections are sparser between clusters. The Louvain algorithm [61], as one of the most popular community detection algorithms, is to find communities in a network by optimizing the modularity score, which quantifies the strength of the division of a network into communities. Higher modularity values indicate a more robust partitioning of the network into communities. The modularity of the given partition of a network is defined as formula 13, where \(\gamma\) is the resolution parameter, and the \(\sigma (c_i,c_j)\) is 1 if nodes i and j are in the same community else 0 [62].
Results
Basic information statistics
Analysis of word cloud
The word cloud diagram is a visualization technique that summarizes the textual content by presenting high-frequency words prominently [Folk culture As shown in Fig. 5, the community, characterized by red-colored nodes, encapsulates the distinctive imagery of traditional folk culture in the Minnan region using terms such as “Goddess Mazu (妈祖),” “Buddha (佛祖),” “Guanyin (观音),” “dragon boat (龙船),” “the 7th day of the lunar month, often associated with particular festivals (初七),” “matchmaking (做媒),” and “lighting lamps (点灯).” Traditional nursery rhythms related to these terms usually convey the praying and blessing emotions and describe the related elements of the local culture. For example, the lyrics of a notable traditional nursery rhyme “Swallows Fly (燕仔飞)” go as follows: “swallows fly (燕仔飞), has the dragon boat come yet (龙船遘抑未)?... a wooden comb combs the bride’s hair (岭兜一支柴梳好梳头), both the comb and hair are shiny (梳也光,篦也光)....” This nursery rhyme is widespread in the Minnan region, particularly in the Hua’an county of Zhangzhou, and it vividly portrays scenes to reflect the marriage customs involving the terms “dragon boat” and “combing the bride’s hair.” Another famous rhyme “** (去逛街)” and “Singing cat (猫咪唱歌), the lyrics are respectively go as follows: “Going shop** is so fun, buying shirts, trousers, and bowls and chopsticks (去逛街,真有趣,买衫买裤买碗筷)...” and “the cat is so amusing, wanting to learn to sing do re mi, singing many times, but it always comes out as mi mi mi (猫咪猫咪真有趣,想要学唱 do re mi,唱来唱去,怎么都是 mi mi mi)...” Overall, the traditional MNRs incorporate diverse emotions of Minnan generations, and mainly describe the negative sentiments in the years of hardship. With China’s economic growth and modernization, the modern MNRs reflect societal changes and often aim to capture the joyful aspects of children’s lives. As shown in Fig. 5b, the yellow-color community and dark blue-color community symbolize the daily life of children and the natural scenes in children’s experiences, respectively, in the modern MNR network. The genres of many word nodes overlap in the two communities, i.e., a variety of words can be relevant to both daily life and natural environments. Such an overlap is caused by an interconnection between children’s everyday experiences and their perception or interaction with nature. Words like “singing (唱歌),” hide-and-seek (捉迷藏),” ” drawing (画画),” “body (身体)” and “washed up bright and clean (白白)” in the daily-life community reflect everyday activities and concepts in children’s routines, possibly instilling values of personal hygiene, politeness, respect for others, and appreciation of the natural world. Within the dark blue-colored community of the modern MNR network, terms such as “garden (花园),” “beach (海边),” “sea waves (海浪),” ”landscape (风景),” and “rural (田园)” represent the theme of natural scenes. For example, the modern nursery rhyme “** on the beautiful bed. (月娘月光光,起厝田**。爱食三色糖,爱睏水眠床。)” The second version contains similar thematic content: “Bright moonlight, rising up in the center of the fields. River snails transform into water jars, and paper boxes transform into beds (月娘月光光, 起厝田**,田螺做水缸,纸盒做眠床。)” In contrast, the lyrics of another variant differ considerably from the above two nursery rhymes. This version portrays the “Bright Moon (月娘月光光)” as follows: “Bright moonlight, an old man in the garden plans to cultivate new crops. Yet, his efforts are met with frustration. The onions fail to sprout, the tea plants remain flowerless, and the melons develop without seeds. This series of agricultural endeavors leaves the old man exasperated to the point of despair (月娘月光光,老公仔伫菜园,菜园掘松松,老公仔欲种葱,葱无芽。欲种茶,茶无花。欲种瓜,瓜无子。老公仔气甲欲死).” The MNRs encompass a wide range of topics, including societal issues, historical figures and events, local folklore, and natural elements, reflecting various aspects of life and culture of the Minnan region. These MNRs will foster children’s social interaction, cooperation, and teamwork by participating in group recitations or singing sessions. The rhythmic patterns, repetition, and melodic tones of MNRs contribute to the language development of children. Therefore, MNRs serve as a significant education value for children’s education from an early age. In addition, by incorporating elements of local dialects, societal norms, folklore, and historical events, MNRs serve as a living repository of cultural knowledge. As children learn and pass on these rhymes, they create connections with their cultural knowledge. So, MNRs also serve as an invaluable tool for the preservation of Minnan cultural heritage because cultural knowledge is reinforced and inherited through these interactions. The popularity of MNRs is not only within the Minnan and Taiwanese regions but also extends to Chaoshan and Leizhou in Guangdong province, Hainan Island, **yang and Yuhuan in Zhejiang province. Moreover, the dissemination of MNRs transcends geographical boundaries into Southeast Asian regions owing to people’s migration. The shared elements, such as proverbs, stories, and values, that are found within the MNRs create a sense of belonging among Minnan-speaking communities. For communities dispersed across various regions, these shared cultural practices serve as an essential link connecting the Minnan people at home and abroad, significantly contributing to the cultural identity and cohesion among its members. Given the long history of Minnan nursery rhymes, the data gathered in this study remains relatively sparse. It is necessary to conduct more comprehensive and in-depth fieldwork to collect MNRs. As the lyrics of MNRs comprise numerous non-Mandarin characters and Minnan proverbs, the traditional word segmentation method employed in this study may still result in inaccurate outcomes. It is noticeable that the obtained segmentation may potentially influence the structure of MNR networks. Consequently, it is essential to design a more sophisticated approach for extracting and analyzing the semantic meaning of lyrics while also considering rhyme patterns. The tailored segmentation approach would align with the unique characteristics of the Minnan language, ensuring further precise analysis and interpretation. In this study, we employ the conventional approach of community detection to analyze the MNR network. It is worth highlighting that the integration of advanced techniques for community detection, such as machine learning and graph neural network-driven methods, may potentially unveil novel insights and provide a deeper understanding of the symbolic imagery embedded within MNRs.Daily life and natural scenery
Values of MNRs
Limitation
Conclusion and future research
This study aims to examine the unique characteristics and patterns of Minnan nursery rhymes through text mining methods, including text segmentation, TF-IDF, and complex network theory. Specifically, we first collected traditional MNRs edited by experts and modern MNRs sourced from the internet. Subsequently, we preprocessed and segmented the lyrics using our designed Chinese-Minnan dictionary. We further extracted vital terms using the TF-IDF method and constructed separate networks for traditional and modern MNRs, with the terms serving as nodes and the co-occurrence relationships forming the links.
The analysis of lyrical terms revealed that a limited number of key terms had a high frequency of occurrence and conveyed specific emotions in both traditional and modern MNRs. Additionally, we employed network indicators to evaluate the structure of the constructed MNR networks. The findings demonstrated that both the traditional and modern MNR networks exhibited overall sparsity, internal cohesion, and strong community characteristics. When examining node centrality, the highly central nodes in the traditional MNR network reflected unique elements associated with idyllic depictions of life, folks, values, and distinctive cultural themes in the Minnan region. Conversely, important nodes in the modern MNR network are primarily related to positive emotional words. Our further investigation included analyzing the degree distribution of the traditional and modern MNR networks, and both of them followed a power-law distribution. We also explored the core-periphery structure of the MNR networks. The core terms within the traditional MNR network represent folkloric and food culture, as well as emotional expressions specific to the Minnan region. In contrast, the core of the modern MNR network did not relate to Minnan culture and was primarily focused on conveying joyful emotions among children. Lastly, we conducted community detection on both the traditional and modern MNR networks, resulting in five communities for each. In the traditional MNR network, these communities represent family relationships, folk culture, food culture, animal imagery, and emotional expressions, aligning with the values and beliefs of the Minnan people in historical periods. Conversely, the modern MNR network is also comprised of five communities, but with differing imagery symbols, including family relationships, animal imagery, emotional expressions, daily life, and natural scenery. These changes could be attributed to shifts in people’s lifestyles, economic development, and the impact of cultural globalization.
The exploration of Minnan nursery rhymes through the complex network analysis unveiled intriguing research directions for future work. We plan to compare the characteristics of Minnan nursery rhymes with nursery rhymes from other regions in our future research. Such a comparative study can help deepen our understanding of the diversity and uniqueness of nursery rhymes across different regions, contributing to the preservation of cultural heritage. Moreover, constructing a large-scale and comprehensive multimodal knowledge graph to encompass MNRs will be a promising direction for future research. This research has the potential to address hidden knowledge embedded in MNRs and promote interdisciplinary research and cross-cultural understanding in the fields of linguistics, cultural studies, and digital humanities. Another interesting direction for future research is the impact of Minnan nursery rhymes on children’s development and language acquisition. This study may involve empirical research, such as conducting experiments or surveys, to examine how exposure to Minnan nursery rhymes influences aspects such as language proficiency, cognitive development, and cultural awareness of children.
Availability of data and materials
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Notes
http://nlg.csie.ntu.edu.tw/nlpresource/NTUSD-Fin/
https://www.heywhale.com/mw/dataset/6113895baca2460017a475be/file.
People will eat seven types of vegetables (brassica juncea, chard, celery, garlic, lactuca sativa, garlic chives, and Chinese broccoli) on the 7th day of the Lunar New Year, which is traditionally recognized as “Renri” - the human’s birthday. It is a tradition to make a type of pancake with these seven vegetables. This practice embodies the wish for prosperity and good fortune.
In order to pray for peace, auspiciousness, and welfare, people will invite monks to conduct blessing ceremonies.
The ninth day of the Lunar New Year is the birthday of the Jade Emperor, a significant deity in Chinese tradition. On this day, families prepare elaborate banquets as offerings to honor the Jade Emperor, which serve as a means for the community to beseech blessings for the nation’s tranquility and affluence, agricultural abundance, and overall harmony.
On the tenth day of the first lunar month, the young people usually form percussion ensembles, performing a variety of rhythmic music. These performances are imbued with the intent to enhance the festive atmosphere, to pray for auspiciousness, and to ward off evil and avoid calamities.
On the eleventh day of the first lunar month, it is a custom for eleven members of a family to light eleven lamps together. This tradition is to pay people’s respect to their ancestors, and hope their forebears will provide their blessings and protection to the family. Such traditional practices are deeply rooted in the culture of honoring and remembering ancestors. Lighting lamps is a symbolic meant to guide the ancestors’ spirits and to bring light and wisdom to the family.
References
Blake J. Unesco’s 2003 convention on intangible cultural heritage: the implications of community involvement. Milton Park: Routledge; 2008. p. 45–50.
United Nations Educational S., Organization C. human intangible cultural heritage representative list. 2023. https://whc.unesco.org/zh/list/. Accessed 11 Oct 2023.
Wang M. A new perspective on the inheritance of minnan nursery rhymes from the perspective of intangible cultural heritage. Conten Lit Art. 2015;6:204–6.
**amen.chinadaily.com.cn: Minnan nursery rhymes. 2019. https://xiamen.chinadaily.com.cn/2019-05/06/c_346992.html. Accessed 11 Oct 2023.
White C. Waves of influence across the south seas: mutual support between protestants in minnan and southeast asia. Ching Feng. 2012;11(1):29–54.
Hui L. The multicultural value of minnan nursery rhymes and their contemporary inheritance. Fujian Tribune (Human Soc Sci). 2012;12:125–8.
Yaling L. A brief discussion on the application of minnan nursery rhymes in kindergarten games. Asia-Pacific Educ. 2019;4(4):48–9.
Zhenwen L. Inheritance and protection strategies of minnan language- taking quanzhou primary school as a sample. North Lit. 2019;1(17):250–2.
Fang C. The distinction among tongyao, erge and chenyao and the characteristics of minnan tongyao. J Jimei Univ (Philos Soc Sci). 2022;25(1):6.
Huan L. Investigation and research on the status quo of campus inheritance of minnan nursery rhymes– taking three primary schools in quanzhou city as examples. Master’s thesis, Quanzhou Normal University; 2023.
Network CICH. List of representative items of national intangible cultural heritage. 2008. https://www.ihchina.cn/project.html. Accessed 20 Dec 2023
Zhang Y, Han M, Chen W. The strategy of digital scenic area planning from the perspective of intangible cultural heritage protection. Eurasip J Image Video Process. 2018;2018(1):1–11.
Lv L, Wu J, Lv H. A community discovery algorithm for complex networks. J Phys: Conf Seri. 2020;1533:032076.
Ebrahimi AS, Yavari E, Khatibi T. Novel methods for creating an earthquake complex network using a declustered catalog. Chaos, Solitons Fract. 2021;147: 110945.
Li Y, Guo J, Zhao L, Chen Y, Wang C, Wang C, Li J. Spatial evolution path of gulangyu island historical international community: from the perspective of actor-network theory. Herit Sci. 2021;9:1–17.
Liu J, Fang Y, Chi Y. Evolution of innovation networks in industrial clusters and multidimensional proximity: a case of chinese cultural clusters. Heliyon. 2022;8(10):e10805.
Li J, Zhang C, Tan H, Li C. Complex networks of characters in fictional novels. In: 2019 IEEE/ACIS 18th international conference on computer and information science (ICIS), IEEE 2019. pp. 417–420.
Li Z, Ma L, He J. Study on character relationship modeling based on complex network –take a dream of red mansions as an example. Mod Inf Technol. 2021;5(3):5.
Boccaletti S, Latora V, Moreno Y, Chavez M, Hwang D-U. Complex networks: structure and dynamics. Phys Rep. 2006;424(4–5):175–308.
Barabási A-L, Loscalzo J, Silverman EK. Network medicine: complex systems in human disease and therapeutics. Harvard University Press; 2017.
Sporns O. Networks of the brain. Cambridge: MIT press; 2016.
Labatut V. Complex network analysis of a graphic novel: the case of the bande dessinée thorgal. Adv Complex Syst. 2022;25(05n06):2240003.
Bost X, Gueye S, Labatut V, Larson M, Linarès G, Malinas D, Roth R. Remembering winter was coming: character-oriented video summaries of tv series. Multimed Tools Appl. 2019;78:35373–99.
Weng C-Y, Chu W-T, Wu J-L. Rolenet: movie analysis from the perspective of social networks. IEEE Trans Multimed. 2009;11(2):256–71.
Buk S, Rovenchak A. Stanza-based networks for poetic texts: a pilot study. Glottotheory. 2023;14(1):11–32.
Roxas-Villanueva RM, Nambatac MK, Tapang G. Characterizing english poetic style using complex networks. Int J Mod Phys C. 2012;23(02):1250009.
Smolla M, Akçay E. Cultural selection shapes network structure. Sci Adv. 2019;5(8):0609.
Xu Y. Entering into minnan nursery rhymes and feeling the charm of art. Contemp Fam Educ. 2020;26:55–6.
Huang X. Research on the design of conceptual picture books for minnan nursery rhymes - starting from “roasted meat dumplings’’. J Kaifeng Vocat Coll Cult. 2022;42:121–5.
Wang M. An analysis of the contemporary cultural and educational value of minnan nursery rhymes. Conten Lit Art. 2017;11:205–8.
Chen F. The protection and inheritance of minnan nursery rhymes from the perspective of chen fang’s same origin in fujian and taiwan. J Jimei Univ (Philos Soc Sci). 2016;19:9–13.
Wang L. On the inheritance and development of minnan nursery rhymes. Olk Art Lit. 2011;04:98–9.
Shunmei L, Zahari ZA. The design and development of cultural and creative products from the perspective of digital media-taking intangible cultural heritage of nursery rhymes in minnan dialect as an example. J Posit Sch Psychol. 2022;6(8):287–98.
Zhang J. Exploring the integration of minnan nursery rhymes into low stage music classes in primary schools. J North Music. 2020;08:157–8.
**e J. Singing local sounds to evoke local sentiment - on the practice and reflection of integrating minnan nursery rhymes into primary school music teaching. J North Music. 2017;37:105.
Lin X. The application and innovative strategies of minnan nursery rhymes in kindergarten teaching activities. Theory Pract Innov Entrep. 2019;2:41–2.
Wang L, Zhang X. The lively inheritance and media enhancement of minnan nursery rhymes from the perspective of sociocultural psychology. J Fuzhou Univ (Philos Soc Sci). 2021;35(04):107–12.
Chen C. Research on the design of children’s picture books based on mobile augmented reality technology - taking minnan nursery rhyme picture books as an example. View on Publishing. 2021;83–85. https://doi.org/10.16491/j.cnki.cn45-1216/g2.2021.04.025.
Danhong Z. Music teaching practice based on the five characteristics of minnan nursery rhymes. J Fujian Inst Educ. 2020;21:104–5.
Zhou C. 500 nursery rhymes from Southern Fujian. Fuzhou: Strait Publishing and Distribution Group; 2003.
Jiang Y. Zhangtai Minnan dialect nursery rhymes. **amen: **amen University Press; 2011.
Zhou C, Zhou Q. Selections of Singaporean Hokkien folk songs. **amen: **amen University Press; 2003.
Hoemann K, Xu F, Barrett LF. Emotion words, emotion concepts, and emotional development in children: a constructionist hypothesis. Dev Psychol. 2019;55(9):1830–49.
Gennari SP, MacDonald MC, Postle BR, Seidenberg MS. Context-dependent interpretation of words: evidence for interactive neural processes. Neuroimage. 2007;35(3):1278–86.
Yu Y, Zhou B, Chen L, Gao T, Liu J. Identifying important nodes in complex networks based on node propagation entropy. Entropy. 2022;24(2):275.
Shannon CE. A mathematical theory of communication. Bell Syst Tech J. 1948;27(3):379–423.
Qiu H, Zheng Q, Msahli M, Memmi G, Qiu M, Lu J. Topological graph convolutional network-based urban traffic flow and density prediction. IEEE Trans Intell Transp Syst. 2020;22(7):4560–9.
You J, Gomes-Selman JM, Ying R, Leskovec J. Identity-aware graph neural networks. Proc AAAI Conf Artif Intell. 2021;35:10737–45.
You J, Ying Z, Leskovec J. Design space for graph neural networks. Adv Neural Inf Process Syst. 2020;33:17009–21.
Yu Z, Chen L, Tong H, Chen L, Zhang T, Li L, Yuan L, **ao J, Wu R, Bai L, et al. Spatial correlations of land-use carbon emissions in the yangtze river delta region: a perspective from social network analysis. Ecol Ind. 2022;142: 109147.
Zhang Q, Shuai B, Lü M. A novel method to identify influential nodes in complex networks based on gravity centrality. Inf Sci. 2022;618:98–117.
Rodrigues FA. Network centrality: an introduction. A mathematical modeling approach from nonlinear dynamics to complex systems. Berlin: Springer; 2019. p. 177–96.
Zhong S, Zhang H, Deng Y. Identification of influential nodes in complex networks: a local degree dimension approach. Inf Sci. 2022;610:994–1009.
Wikipedia: Eigenvector centrality. 2024. https://en.wikipedia.org/wiki/Eigenvector_centrality. Accessed 2 Jan 2024.
Ma H, Liu J, Zhao X, Zhang B. A study of highway logistics transportation network structure in China: from the perspective of complex network. J Data, Inf Manag. 2022;4(2):89–105.
Ding R, Ujang N, Hamid HB, Manan MSA, Li R, Albadareen SSM, Nochian A, Wu J. Application of complex networks theory in urban traffic network researches. Netw Spat Econ. 2019;19:1281–317.
Pastén D, Czechowski Z, Toledo B. Time series analysis in earthquake complex networks. Chaos: Interdiscip J Nonlinear Sci. 2018. https://doi.org/10.1063/1.5023923.
Furse CM, Kafal M, Razzaghi R, Shin Y-J. Fault diagnosis for electrical systems and power networks: a review. IEEE Sens J. 2020;21(2):888–906.
Bonfanti A, Kaplan JL, Charras G, Kabla A. Fractional viscoelastic models for power-law materials. Soft Matter. 2020;16(26):6002–20.
Borgatti SP, Everett MG. Models of core/periphery structures. Soc Netw. 2000;21(4):375–95.
Que X, Checconi F, Petrini F, Gunnels JA. Scalable community detection with the louvain algorithm. In: 2015 IEEE international parallel and distributed processing symposium, IEEE. 2015;28–37.
Newman M. Networks: an introduction. Oxford: Oxford University Press; 2010.
Ma Y, **e Z, Li G, Ma K, Huang Z, Qiu Q, Liu H. Text visualization for geological hazard documents via text mining and natural language processing. Earth Science Informatics, 2022;1–16.
Clauset A, Shalizi CR, Newman ME. Power-law distributions in empirical data. SIAM Rev. 2009;51(4):661–703.
Virkar Y, Clauset A. Power-law distributions in binned empirical data. Dissertations and Theses Gradworks, 2012.
Maydeu-Olivares A. Maximum likelihood estimation of structural equation models for continuous data: standard errors and goodness of fit. Struct Equ Modeling. 2017;24(3):383–94.
Blondel VD, Guillaume J-L, Lambiotte R, Lefebvre E. Fast unfolding of communities in large networks. J Stat Mech Theory Exp. 2008;2008(10):10008.
Tang Z. Changes with Chinese characteristics: rural clan culture, clan communities, and Kinship relations during urbanization. Singapore: Springer; 2017. p. 161–98. https://doi.org/10.1007/978-981-10-4831-9_10.
Yang X. Ritual and gender role in a sanyang village patriarchal clan, fujian. Praxis, Folks’ Beliefs, Rit Explor Anthropol Relig. 2022. https://doi.org/10.9734/bpi/mono/978-93-5547-925-9/CH6.
Mullen G. More than words: using nursery rhymes and songs to support domains of child development. J Child Stud. 2017;42:42–53.
Ayres B. Animals and Their Children in Victorian Culture. Milton Park: Routledge; 2019. p. 12–30.
Pullinger D. Nursery rhymes: poetry, language, and the body. Milton Park: Routledge; 2017. p. 156–73.
Newman J. Food culture in China. London: Bloomsbury Publishing; 2004.
Montanari M. Food is culture. Columbia: Columbia University Press; 2006.
Tomlinson J. Globalization and culture. Chicago: University of Chicago Press; 1999.
Lum C-H. Home musical environment of children in singapore: on globalization, technology, and media. J Res Music Educ. 2008;56(2):101–17.
Zhuang X. “Reciting four sentences’’ in fujian and taiwan wedding customs and its cultural implications. Root Explor. 2014;5:57–61.
Zhu J, Xu P. The Chinese zodiac. Child Music. 2004;12:9–9.
Acknowledgements
We gratefully thank Yuena Wang and Deyi Yu for their valuable suggestions on understanding the proverbs of the Minnan language.
Funding
This study was supported by the National Natural Science Foundation of China (No. 62106092), the Natural Science Foundation of Fujian Province (No. 2022J01916), the National Social Sciences and Arts Project (No. 15CH165), the Graduate Education Reform Project of Minnan Normal University (No. YJG202305), the Department of Education, Fujian Province (No. JSZM2021047), and the Department of Education, Fujian Province (No. JSZM2021045)
Author information
Authors and Affiliations
Contributions
Conceptualization: WH and LS; Methodology: WH and ZL; Validation: HZ, CZ, YW, SY and TX; Result analysis: WH, ZL, YW and TX; Investigation: HZ, CZ, TX and SY; Data collection and labeling: HZ and CZ; Data curation: HZ, CZ, ZL and TX; Writing-original draft preparation: WH and ZL; Writing-review and editing: YW, LB and TX; Visualization: ZL and TX; Reviewing, language and editing: YW, LB and SY Project administration: Shunxing Li; Funding acquisition: WH and SY. All authors have read and agreed to the published version of the manuscript.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
The authors approved the manuscript and the submission to this journal.
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Wu, H., Zhang, L., Huang, Z. et al. Unraveling minnan imagery: a comprehensive analysis of traditional and modern minnan nursery rhymes through complex networks. Herit Sci 12, 180 (2024). https://doi.org/10.1186/s40494-024-01300-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40494-024-01300-7