
Abstract
Background
The human microbiota are complex systems with important roles in our physiological activities and diseases. Sequencing the microbial genomes in the microbiota can help in our interpretation of their activities. The vast majority of the microbes in the microbiota cannot be isolated for individual sequencing. Current metagenomics practices use short-read sequencing to simultaneously sequence a mixture of microbial genomes. However, these results are in ambiguity during genome assembly, leading to unsatisfactory microbial genome completeness and contig continuity. Linked-read sequencing is able to remove some of these ambiguities by attaching the same barcode to the reads from a long DNA fragment (10–100 kb), thus improving metagenome assembly. However, it is not clear how the choices for several parameters in the use of linked-read sequencing affect the assembly quality.
Results
We first examined the effects of read depth (C) on metagenome assembly from linked-reads in simulated data and a mock community. The results showed that C positively correlated with the length of assembled sequences but had little effect on their qualities. The latter observation was corroborated by tests using real data from the human gut microbiome, where C demonstrated minor impact on the sequence quality as well as on the proportion of bins annotated as draft genomes. On the other hand, metagenome assembly quality was susceptible to read depth per fragment (CR) and DNA fragment physical depth (CF). For the same C, deeper CR resulted in more draft genomes while deeper CF improved the quality of the draft genomes. We also found that average fragment length (μFL) had marginal effect on assemblies, while fragments per partition (NF/P) impacted the off-target reads involved in local assembly, namely, lower NF/P values would lead to better assemblies by reducing the ambiguities of the off-target reads. In general, the use of linked-reads improved the assembly for contig N50 when compared to Illumina short-reads, but not when compared to PacBio CCS (circular consensus sequencing) long-reads.
Conclusions
We investigated the influence of linked-read sequencing parameters on metagenome assembly comprehensively. While the quality of genome assembly from linked-reads cannot rival that from PacBio CCS long-reads, the case for using linked-read sequencing remains persuasive due to its low cost and high base-quality. Our study revealed that the probable best practice in using linked-reads for metagenome assembly was to merge the linked-reads from multiple libraries, where each had sufficient CR but a smaller amount of input DNA.
Video Abstract
Similar content being viewed by others


Background
The human microbiota are complex systems that contribute to a large part of human physiological activities and diseases. Knowing the genomic sequences of the microbiota content allows us to study its functions. However, microbial genome sequences are difficult to obtain. While a few microbes can survive isolation and be cultured in vitro for sequencing, the remaining microbial content remains as “microbial dark matter”. Alternatively, there have been attempts to use computational means to reconstruct the microbial genomes from a mixture of short-reads sequenced from them. However, such metagenome assembly faces the difficulties of having repetitive sequences of both intra- and inter-species origin, horizontal gene transfers, and mobilization events [1], complicated by uneven abundance of microbes in the sample.
Current algorithms such as IDBA-UD [2], MEGAHIT [3], and MetaSPAdes [4] make use of read depth and fragment insert size constraint to unravel the repetitive sequences and estimate microbial abundance. However, their reliability is affected by the low continuity of short-read assembly. Long-read sequencing has been used to attempt to mitigate these problems, e.g., Nicholls et al. [5] and Sevim et al. [6]. In particular, Moss et al. [7] optimized the long-read library preparation protocol of nanopore sequencing and produced more complete bacterial genomes. However, the application of long-read sequencing in practical application remains costly (the “Discussion” section).
Alternative sequencing platforms that provide long-range sequence information for metagenomics are available in the form of Illumina Truseq Synthetic Long Reads (SLR) and linked-reads. SLR arranges long DNA fragments into 384 well plates, which are further amplified and pooled sequenced with sufficiently deep sequencing depth (~ 50X per fragment), thus allowing long fragments to be assembled individually [8, 9]. Linked-reads are short-reads where reads from the same fragment are marked with the same barcode. The 10x linked-read microfluidic system assigns long DNA fragments into around 1 million partitions, where each fragment is sequenced with a shallow depth (0.1X–0.4X). A method for linked-read metagenome assembly, Athena-meta [10], bridges the gaps between contigs by local assembly on co-barcoded reads and outperformed the methods for short-reads and SLR in assembling human gut and environmental microbiome.
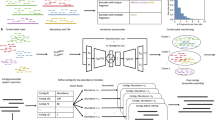
There are four key parameters in linked-read sequencing which may impact metagenome assembly [11] (Fig. 1): (i) CR, average depth of short-reads per fragment; (ii) CF: average physical depth of the genome by long DNA fragments; (iii) NF/P, number of fragments per partition; (iv) Fragment length distribution, which is specified using two parameters, namely, μFL—average unweighted DNA fragment length and WμFL—length-weighted average of DNA fragment length. Several of these parameters are interdependent. For example, a greater amount of input DNA increases both CF and NF/P and decrease CR; and the absolute values of CF and CR are set by how much total read coverage (C) is generated because CR × CF = C. In a previous study, we investigated the effects of these parameters on human diploid assembly [11].

Parameters of linked-read sequencing to be investigated
The present study evaluates these parameters with respect to their impact on metagenome assembly. We used three sets of linked-reads, one from simulation, one from a mock community, and another from a real human gut microbiome sample. The simulated data consists of twenty datasets (Table S1) generated by an improved LRTK-SIM [11] that enables to deal with microbial samples with uneven abundance for this study (the “Methods” section). The mock community (ATCC MSA-1003) is a pool of 20 strains with staggered abundance, while the human gut microbiome is from a healthy Chinese stool sample. Because of an absence of ground truth to evaluate human gut microbiome, we annotated contig bins as draft genomes and assigned them to the corresponding taxonomic classification (the “Methods” section).
Our results show that deeper C resulted in more assembled sequences and enabled better genomic coverage, but it was irrelevant to the assembly quality. C was not a dominating factor for contig continuity, which could be influenced more by genome characteristics. We further found CR to affect the number of draft genomes and that CF was associated with assembly quality. The μFL had marginal effect on assemblies, and lower NF/P values would lead to better assemblies by reducing the ambiguities of off-target reads. Compared to Illumina short-reads, 10x linked-reads significantly improved the metagenome assembly in both contig continuity and genome completeness.
Results
Three sets of linked-reads are used. The first is simulated from the MBARC-26 [6] community (Table S1 and S2), and the twenty simulated datasets are annotated as \( {C}_F^{-} \), \( {C}_R^{-} \),\( {\mu}_{FL}^{-} \), and \( {N}_{F/P}^{-} \)(where superscript “-” represents the actual values of corresponding parameters, Table S1). The second and third sets are sequenced from a mock community of 20 strains (one lane reads from Illumina XTen, 108.7 GB, Table S3) and a human gut microbiome (two lane reads from Illumina XTen, 208.97 GB; the “Methods” section and Supplementary Note) followed by reads subsampling to match the expected parameter values. The microbial complexity in the human gut microbiome was evaluated by aligning linked-reads to the reference sequences from human microbiome project [12] (Supplementary Note). To obtain the datasets of different CR and CF, we subsampled short-reads (MSCR-) and long DNA fragments (MSCF-) of the mock community (the “Methods” section), where value of subscript “-” represents the reciprocal of sequenced lanes—for example, MSCR4/MSCF4 means quarter lane reads were subsampled. Since the composition of the human gut microbiome is unknown, SCR- and SCF- (where subscript “-” represents the reciprocal of sequenced lanes) were generated by subsampling short-reads and barcodes instead. To avoid confusion, we used MSC1 and SCall to denote total one lane and two lanes linked-reads from the mock community and human gut microbiome, respectively.
According to microbial relative abundance, the microbes were classified into low- (Lsim), medium- (Msim), and high-abundance (Hsim) in the simulated data (Table S2); and classified into low- (Lmock), medium- (Mmock), high- (Hmock), and ultrahigh-abundance (UHmock) in the mock community (Table S3). The contigs from the simulation and mock community were evaluated using two reference-based metrics (total aligned length and genomic coverage) and two measures for contig continuity (contig NG50 and NGA50). For human gut microbiome data, we annotated the contig bins as draft genomes and classified them into high-, medium-, and low-quality [13] (the “Methods” section). The number and quality of annotated draft genomes and contig N50 were used to evaluate the assemblies.
The influence of total read depth C
C has little effect on both total aligned length and genomic coverage for Lsim and Hsim microbes in the simulated data. For Msim microbes, their abundance correlates positively with total aligned length and genomic coverage, indicating that a low abundance could reduce assembly completeness even when C is high (Fig. 2a, b, e, and f).

Trends of total assembly length, genomic coverage, contig NG50, and NGA50 by subsampling CR (a–d), CF (e–h), μFL (i–l), and NF/P (m–p) in simulated data. Microbes in cyan, blue, and red represent Lsim, Msim, and Hsim species, respectively
Similarly, we fail to observe any clear trend between NG50 (or NGA50) and C. Two microbes with the deepest C, NC_014212 and NC_017095 (with the highest abundance), were assembled into fragmented contigs (Fig. 2c and g), suggesting that C was not a dominating factor for contig continuity; which is also seen in \( {C}_F^{333} \) and \( {C}_R^{0.77} \), which have deeper C (C = 120X) than the other configurations. They achieved the largest total aligned length and genomic coverage, but their contig NG50 and NGA50 fluctuated and were not always the best. For example, NC_019904 and NC_002737, which have the lowest abundance among Msim microbes, yielded the largest total aligned length in \( {C}_F^{333} \) (NC_019904, 1.29 Mb; NC_002737, 1.42 Mb; Fig. 2a) and \( {C}_R^{0.77} \) (NC_019904, 1.77 Mb, NC_002737, 1.49 Mb; Fig. 2e). \( {C}_R^{0.77} \) assembled fragmented contigs for both of the microbes on NG50 (NC_019904 < 500 bp, NC_002737 = 64.14 kb; Fig. 2g) and NGA50 (NC_019904 < 500 bp, NC_002737 = 62.47 kb; Fig. 2h). Although \( {C}_F^{333} \) produced better NG50 on NC_002737 (NG50, 2.04 Mb, Fig. 2c), misassemblies were dispersed in its contigs (NGA50, 109.43 kb; Fig. 2d).
The results for the mock community are consistent with those from the simulated data. The total aligned length and genomic coverage were fairly stable for Lmock, Hmock, and UHmock microbes regardless of the value of C (Fig. 3a, b, e, and f). For Mmock microbes, the contigs from MSCF8/MSCR8 covered the reference genomes poorly due to the insufficient read depth. A quarter lane reads (MSCF4/MSCR4) appeared to suffice for the read depth, achieving around full genomic coverage for all Mmock microbes, except for ATCC_33323, which required a quarter lane reads more. No consistent trend could be observed for NG50 and NGA50; a quarter lane reads was necessary to generate contigs with non-zero NGA50 for Mmock microbes.

Trends of total assembly length, genomic coverage, contig NG50, and NGA50 by subsampling CR (a–d) and CF (e–h) for the mock community. Microbes in cyan, blue, red, and black represent Lmock, Mmock and Hmock, and UHmock species, respectively
In the results with human gut microbiome, deeper C extends the assembly length but has no impact on the assembly quality. After binning contigs and classifying the bins into draft genomes (the “Methods” section), SCall produced the largest number of bins (148) and the longest assembly length (399.41 Mb). These statistics were reduced along subsampling reads progressively (Table 1). The proportions of bins annotated as draft genomes were reduced by increasing C (SCR8 77.78%, SCR4 69.39%, SCR2 63.75%, SCR1 65.38%, SCall 54.05%; SCF8 68.75%, SCF4 60.94%, SCF2 59.55%, SCF1 58.16%, SCall 54.05%). C negatively correlates with bin average contamination (SCall 14.40%, SCR2 10.46%, SCR4 9.08%, SCR8 8.94%; Table S4 and Figure S1). We annotated the draft genomes as genus or species (> 60% confidence) based on their k-mer similarities with known microbial genomes (the “Methods” section). Most of the taxonomical classifications were observed by at least two parameter configurations, although some were unique to only one (Figure S2). Considering the qualities of annotated draft genomes, C demonstrated a positive correlation with the number of medium- and low-quality bins (Table 1); SCR4 has the most high-quality bins and the largest average bin completeness (73.3%) compared to the other configurations (Table 1 and Table S4). The N50s of high-quality bins are significantly greater than medium- (p value = 0.01) and low-quality (p value = 5.3E−9) bins, suggesting that bin quality (determined by completeness and contamination) is highly correlated with contig continuities (Fig. 4a–c). Interestingly, high-quality bins required read coverage of at least 50X (SCall = 85.81X; SCF1 = 132.71X; SCF2 = 111.11X; SCF4 = 96.43X; SCF8 = 64.67X; SCR1 = 75.66X; SCR2 = 151.55X; SCR4 = 63.42X; SCR8 = 53.08X), suggesting that the low abundance microbes were not assembled into high-quality genomes. Nevertheless, the contigs with extremely high depth may come from repetitive sequences and reduce the qualities of bins they belong to (Fig. 4d–f; C (high) = 81.4X; C (medium) = 140.1X; C (low) = 1636.5X).

Contig N50 and read depth for high-, medium-, and low-quality bins
The tradeoffs between CR and CF
There are tradeoffs between CR and CF in maintaining the same C. Because the product of PCR amplification per partition can generate around 500 Mb short-reads, loading DNA with greater density (deeper CF) results in more fragments per partition and fewer reads sequenced for each fragment (shallower CR). For Msim and Hsim species in the simulated data, we found that increasing CR is more effective than increasing CF when C is around 10X, and they are comparably effective when C is beyond 30X (Fig. 2a, b, e, and f). As a rule, deep CR is more pressing to reconstruct DNA fragment if C is low. For the examples of \( {C}_F^{28} \) and \( {C}_R^{0.064} \) (C = 10x), \( {C}_F^{28} \) (CR = 0.36X) was significantly better than \( {C}_R^{0.064} \) (CR = 0.064X) in total aligned length (\( {C}_F^{28}:{C}_R^{0.064} \) = 2.17 Mb: < 500 bp) and genomic coverage (\( {C}_F^{28}:{C}_R^{0.064} \) = 62.93%: < 1%) for NC_012982. \( {C}_F^{28} \) generated more continuous contigs than \( {C}_R^{0.064} \) for the five Hsim species, NC_018068, NC_014364, NC_017033, NC021184, and NC_019792, (Fig. 2 c, d, g and h). In the mock community, MSCF- and MSCR- produced comparable assemblies when C was kept constant.
In human gut microbiome, SCF- generated more assembled sequences than SCR-(SCF1:SCR1 = 305.24 Mb:290.49 MB; SCF2:SCR2 = 244.55 Mb:225.73 Mb; SCF4:SCR4 = 188.90 Mb:159.40 Mb; SCF8:SCR8 = 152.65 Mb:115.96 Mb, Table 1), but had higher average bin contamination (SCF1:SCR1 = 14.04%:12.10%; SCF2:SCR2 = 14.80%:10.46%; SCF4:SCR4 = 12.66%:9.08%; SCF8:SCR8 = 12.17%:8.95%) and worse contig N50 (SCF1:SCR1 = 137.66 kb:168.67 kb; SCF2:SCR2 = 127.58 kb:151.49 kb; SCF4:SCR4 = 136.40 kb:181.46 kb; SCF8:SCR8 = 115.29 kb:118.0 kb). These observations suggest that deeper CR would result in more assembled sequences, while deeper CF would help in improving assembly quality.
DNA fragment length and metagenome assembly
DNA long fragment information is critical for linked-read assembly, as it can help in spanning the gaps between contig breaks that are due to genome variations and repetitive sequences. On the other hand, it may lead to the loss of barcode specificity in disentangling short tandem repeats if the fragments are exceedingly long.
In practice, it is difficult to extract very long DNA fragments from metagenomic sample; even on the gentlest DNA extractions, the mean fragment length (μFL) is usually at most 10 to 20 kb. Our simulated data of μFL from 5 to 100 kb showed that the assembly was not sensitive to μFL. In some special cases, extremely long DNA fragments could improve the assemblies of Msim microbes with high repeat rates. For example, \( {\mu}_{FL}^{100} \) (μFL = 100 kb) improved the contigs NG50 (3.17 Mb, Fig. 2k) and NGA50 (2.71 Mb, Fig. 2l) of NC_018014, which was the one with the highest repeat rate (18.3%).
Barcode specificity is important in microbial deconvolution
For human genome sequencing, each partition contains ten fragments (NF/P = 10) on average [14]. NF/P is supposed to be larger (NF/P = 40) for metagenomic sequencing due to the limited fragment size (WμFL = 11.15 kb) and relatively small microbial genome size (Table S5). Large NF/P also increases the difficulties in recognizing the fragments that short-reads belong to. The assembly on NF/P1, the smallest NF/P (NF/P = 10) in simulation, had much better NG50 and NGA50 for most of the Hsim and Msim microbes (14 out of 18, the remaining 4 microbes are comparable, Fig. 2 o and p). Small NF/P also failed to assemble Lsim microbes (Fig. 2 m and n).
Assembly on Illumina short-reads and PacBio CCS long-reads
Illumina short-read sequencing is a mainstream technology for metagenomic sequencing, but its quality for metagenome assembly is unsatisfactory due to the lack of long-range connectivity. We downloaded the short-read data of the mock community from the Sequence Read Archive [15] (the “Methods” section) and performed an assembly. The assembly on linked-reads (total aligned length 52.04 Mb; genomic coverage 77.20%) is much better than that on short-reads (total aligned length 38.13 Mb; genomic coverage 56.69%, NG50 and NGA50, see Figure S3). For human gut microbiome, the assembly from 8.8 Gb short-reads showed a comparable number of bins (53) and total assembly length (145.50 Mb vs. 159.40 Mb for SCR4, Table 1). However, the short-read assembly generated no bins with high-quality because it had known issue to detect rRNAs and tRNAs [16, 17] (Table 1). SCF8, with the worst N50 in linked-read assembly, was also 4.49 times (115.29 kb vs. 25.69 kb) greater than Illumina short-reads. The average bin contamination rate of 17.39% for the assembly from short-reads was also much worse than linked-reads (Table S6).
In mock community, we further compared linked-reads to PacBio CCS, which have both extreme long (N50 = 9.08Kb) and highly accurate (> 99% base accuracy) reads. The total aligned length and genomic coverage were comparable between CCS reads (54.04 Mb and 78.68%) and MSC1 (52.02 Mb and 77.18%), but CCS reads improved the contig continuity substantially (Figure S4).
Comparison to human genome parameter statistics
10x linked-read sequencing was originally developed for human genome assembly, so we compared the parameter distributions between human genome and human gut microbiome. Because no reference genome was available for human gut microbiome, we collected the sequences of all the non-redundant high-quality bins from SCF- and SCR- datasets as “pseudo” reference genomes and reconstructed 15,994,284 long fragments (> 2 kb). For human gut microbiome, CR was comparable (CR 0.30X vs. 0.32X, Table S5), and CF was 6.26 times larger than human genome (NA24385, CF 595.85X vs. 95.20X, Table S5); also, the DNA fragments were obviously much shorter (μFL 7.91 kb vs. 28.06 kb; WμFL 11.15 kb vs. 44.53 kb, Table S5, Figure S5 and S6).
Discussion
Human microbiota provide rich information to understand microbial activities impacting human health and disease. Projects such as HMP (Human Microbiome Project) [12] and MetaHIT (Metagenomics of the Human Intestinal Tract) [18] have been proposed to collect microbiomes from diverse places of human body and aimed to understand their compositions and functions. De novo metagenome assembly on short-reads is commonly used to assemble microbial genomes from a mixture of culture-free microbes. Although it has been widely applied to assemble thousands of bacterial genomes [19, 20], there are four difficulties that remain: (1) assembly for low-abundance microbes; (2) repetitive sequences assembly such as 16S, 23S rRNA; (3) assembly of regions with genetic variation; (4) strain level assembly based on haplotype phasing. Besides metaSPAdes used in the current study, IDBA-UD [2] and MEGAHIT [3] were also tested and achieved comparable results with metaSPAdes. They all showed much worse assembly than linked-reads (Table S6).
Long-read sequencing has the potential to assemble more complete genomes and is believed to dominate the field in the future. However, linked-reads are still worth to be considered as a transitional technology. First, both PacBio and Oxford Nanopore are several times more costly than 10x linked-reads (especially for library preparation). Second, high base error rate of long-reads lacks strength for haplotype phasing and strain level assembly. Third, clinical samples benefit from the small amount of input DNA required by linked-read sequencing. A previous study also observed some high-quality bins generated by linked-reads missed in long-reads assembly [7].
In this study, we comprehensively investigated the four parameters of linked-read sequencing on metagenome assembly, which could be fine-tuned in either library preparation or short-read sequencing. Read depth C and microbial abundance are the two most important parameters to determine genome coverage and the number of bins annotated as draft genomes. Low-abundance microbes were almost impossible to be assembled by any of the technologies; the assemblies of medium-abundance microbes were substantially improved by deep C, and they were fairly stable for high-abundance ones.
According to our observation, C should be chosen from 120X to 400X to optimize the assembly quality. There is a tradeoff between CF and CR, where deep CF can generate more high-quality bins and CR controls total assembly length. Large μFL enables DNA fragments spanning distant contigs, but it is unnecessary to produce extremely long fragments for microbial genomes. The repetitive sequences spread in microbial genomes are usually short (e.g.,16S: ~ 1.5 kb, 23S: ~ 2.9 kb), which could be resolved by assembling the co-barcoded reads with small NF/P.
Athena-meta includes four steps: (1) generate “seed” contigs using short-reads without barcodes; (2) link contigs into scaffold graph using aligned paired-end reads; (3) local assembly by recruiting co-barcoded reads that spanning both “seed” contigs; (4) pool and assemble the locally assembled sequences and “seed” contigs. We can link and interpret our observations with the corresponding strategies in Athena-meta. C is critical to construct “seed” contigs, as high-quality seed contigs are the prerequisite for local assembly using co-barcoded reads. CR and CF impact reconstruction of long DNA fragments, and the probability of two distant contigs spanned by the same fragment, respectively. Small NF/P can reduce off-target reads and make local-assembly more efficiently. Our study revealed that the probable best practice in using linked-reads for metagenome assembly is to merge the linked-reads from multiple libraries, where each has sufficient CR but a smaller amount of input DNA.
Methods
Simulate linked-reads for microbes with uneven abundance
LRTK-SIM [11] was initially built for human diploid assembly by simulating 10x linked-reads. In this study, we extended it to allow genomes with uneven depth to reflect different microbial abundance (Figure S7). We downloaded the reference genomes (denoted as M) of 23 bacterial and 3 archaeal strains from MBARC-26 [21] and categorized them into Lsim (Molarity < 10−15), Msim (10−15 < Molarity < 10−14) and Hsim (Molarity > 10−14) (Table S1). The molarity was normalized to sum to 1 as microbial relative abundance (\( {\sum}_{i=1}^{26}{A}_i=1 \)), and CF for microbe i (CFi) was calculated as CFi = CF × Ai × 26 (CF was predefined). The total fragment length for microbe i (Mi) was CFi× Li, where Li was genome size of Mi. The estimated input nucleotides were calculated as \( {\sum}_{i=1}^M{A}_i\times {L}_i\times 26 \). We simulated a wide range of CF (from 28X to 333X), CR (from 0.064X to 0.77X), μFL (from 5 to 100 kb), and NF/P (from 10 to 160) to investigate their impact on metagenome assembly (Table S1).
DNA extraction, library preparation, and sequencing
For mock community, DNA from ATCC 20 strain staggered mix genomic material (ATCC-MSA1003) was extracted without size-selection. For human gut microbiome from stool sample, we extracted the DNA using Qiagen QiAaMP Stool Mini Kit and removed the DNA fragments below 5 kb. After that, the molecular weight of isolated DNA was assayed by pulsed-field electrophoresis. For 10x Chromium library preparation, 1 ng of isolated high molecular weight DNA was denatured according to the manufacturer recommendations, added to the reaction master mix and mixed with gel bead and emulsification oil to generate droplets within a Chromium Genome chip. The rest part of library preparation was done following the manufacturer protocol (Chromium Genome v1, PN-120229).
The two libraries were sequenced by Illumina XTen with 2 × 150 bps paired-end reads, respectively. The DNA of human gut microbiome was also prepared for standard Illumina XTen short-read sequencing.
DNA long fragment reconstruction and linked-read subsampling
Long Ranger v2.2.1 [22] was used to correct barcode base errors, calculate PCR duplication rate, and perform barcode-aware linked-read alignment. BWA-MEM v0.7.17 [Metagenome assembly For linked-read assembly, the linked-reads without barcodes were first assembled into seed contigs by metaSPAdes v3.11.1 [4] with default parameters and aligned to contigs by BWA-MEM v0.7.17. Athena-meta v1.3 was applied for local assembly by collecting co-barcoded reads shared by two “seed” contigs in scaffold graph (Figure S8). For mock community, the Illumina short-reads (SRR8359173) and PacBio CCS reads (SRR9202034 and SRR9328980) were assembled by metaSPAdes v3.12.0 and Canu v2.0 [24], respectively. The command lines were included in the Supplementary Note. We implemented a pipeline (Figure S9) to compare different metagenome assemblies by integrating off-the-shelf software and in-house scripts. First, MaxBin v2.2.4 [25] grouped contigs (longer than 1 kb) into bins, and their completeness and contaminations were assessed by CheckM v1.0.12 [26]. Quast v5.0.0 [27] calculated basic statistics such as contig N50, NG50, NGA50, total aligned length, and genomic coverage; Aragorn v1.2.38 [28] and Barrnap (https://github.com/tseemann/barrnap) were used to infer tRNA and rRNA (5S, 16S, and 23S), respectively; Kraken v0.10.6 [29] annotated taxonomic classification of bins based on its built-in database MiniKrakenDB. The bin abundance was calculated by \( \frac{\mathrm{size}\left(\mathrm{bin}\right)\mathrm{dp}\left(\mathrm{bin}\right)}{\mathrm{len}\left(\mathrm{read}\right)\mathrm{sum}\left(\mathrm{read}\right)} \). For each bin, size(bin) is its total nucleotides, dp(bin) denotes its read depth, len(read) is short-read length, and sum(read) is total number of aligned short-reads. Bins were recognized as draft genomes if they were classified as high-quality (completeness > 90%, contamination < 5%, presence of the 5S, 16S, 23S rRNAs, and at least 18 tRNA), medium-quality (completeness ≥ 50% and contamination < 10%), and low-quality (completeness < 50% and contamination < 10%). The command lines were included in the Supplementary Note.Assembly evaluation
Conclusion
In this study, we comprehensively investigated four parameters of linked-read sequencing on metagenome assembly and compared with Illumina short-reads and PacBio CCS reads. Our study revealed that the probable best practice in using linked-reads for metagenome assembly is to merge the linked-reads from multiple libraries, where each has sufficient CR but a smaller amount of input DNA.
Availability of data and materials
The source codes of LRTK-SIM and analysis pipeline are publicly available at https://github.com/zhanglu295/LRTK-SIM and https://github.com/liaoherui/MetaComp, respectively. The raw sequencing data are deposited in the Sequence Read Archive and the corresponding BioProject accession number is PRJNA573416 and PRJNA647353. For mock community, the Illumina short-reads and PacBio CCS reads are available in Sequence Read Archive; the accession numbers are SRR8359173, SRR9202034, and SRR9328980. All the command lines were included in the Supplementary Note.
Abbreviations
- C R :
-
Average depth of short reads per fragment
- C F :
-
Average physical depth of the genome by long DNA fragments
- N F/P :
-
Number of fragments per partition
- μ FL :
-
Average unweighted DNA fragment length
- WμFL :
-
Length-weighted average of DNA fragment length
- C :
-
Total sequencing depth, CR x CF = C
- MSCR- and MSCF- :
-
Subsampling short-reads and reconstructed long DNA fragment from mock community linked-read data (“-” represents the reciprocal of sequenced lanes)
- SCR- and SCF- :
-
Subsampling short-reads and barcodes from human gut microbiome linked-read data (“-” represents the reciprocal of sequenced lanes)
- Lsim/Msim/Hsim :
-
Low-/medium-/high-abundance microbes in the simulated data
- Lmock/Mmock/Hmock/UHmock :
-
Low-/medium-/high-/ultrahigh-abundance microbes in the mock community
References
He S, Chandler M, Varani AM, Hickman AB, Dekker JP, Dyda F: Mechanisms of evolution in high-consequence drug resistance plasmids. MBio 2016;7(6):e01987–16.
Peng Y, Leung HC, Yiu SM, Chin FY. IDBA-UD: a de novo assembler for single-cell and metagenomic sequencing data with highly uneven depth. Bioinformatics. 2012;28(11):1420–8.
Li D, Liu CM, Luo R, Sadakane K, Lam TW. MEGAHIT: an ultra-fast single-node solution for large and complex metagenomics assembly via succinct de Bruijn graph. Bioinformatics. 2015;31(10):1674–6.
Nurk S, Meleshko D, Korobeynikov A. Pevzner PA: metaSPAdes: a new versatile metagenomic assembler. Genome Res. 2017;27(5):824–34.
Nicholls SM, Quick JC, Tang S, Loman NJ. Ultra-deep, long-read nanopore sequencing of mock microbial community standards. Gigascience. 2019;8(5):1–9.
Sevim V, Lee J, Egan R, Clum A, Hundley H, Lee J, Everroad RC, Detweiler AM, Bebout BM, Pett-Ridge J, et al. Shotgun metagenome data of a defined mock community using Oxford Nanopore, PacBio and Illumina technologies. Sci Data. 2019;6(1):285.
Moss EL, Maghini DG, Bhatt AS. Complete, closed bacterial genomes from microbiomes using nanopore sequencing. Nat Biotechnol. 2020;38:701–7.
Li R, Hsieh CL, Young A, Zhang Z, Ren X, Zhao Z. Illumina synthetic long read sequencing allows recovery of missing sequences even in the “Finished” C. elegans genome. Sci Rep. 2015;5:10814.
McCoy RC, Taylor RW, Blauwkamp TA, Kelley JL, Kertesz M, Pushkarev D, Petrov DA, Fiston-Lavier AS. Illumina TruSeq synthetic long-reads empower de novo assembly and resolve complex, highly-repetitive transposable elements. PLoS One. 2014;9(9):e106689.
Bishara A, Moss EL, Kolmogorov M, Parada AE, Weng Z, Sidow A, Dekas AE, Batzoglou S, Bhatt AS. High-quality genome sequences of uncultured microbes by assembly of read clouds. Nat Biotechnol. 2018;36:1067–75.
Zhang L, Zhou X, Weng Z, Sidow A. Assessment of human diploid genome assembly with 10x linked-reads data. Gigascience. 2019;8(11):1–11.
Human Microbiome Project C. Structure, function and diversity of the healthy human microbiome. Nature. 2012;486(7402):207–14.
Bowers RM, Kyrpides NC, Stepanauskas R, Harmon-Smith M, Doud D, Reddy TBK, Schulz F, Jarett J, Rivers AR, Eloe-Fadrosh EA, et al. Minimum information about a single amplified genome (MISAG) and a metagenome-assembled genome (MIMAG) of bacteria and archaea. Nat Biotechnol. 2017;35(8):725–31.
Weisenfeld NI, Kumar V, Shah P, Church DM, Jaffe DB. Direct determination of diploid genome sequences. Genome Res. 2017;27(5):757–67.
Leinonen R, Sugawara H, Shumway M. International Nucleotide Sequence Database C: The sequence read archive. Nucleic Acids Res. 2011;39(Database issue):D19–21.
Parks DH, Rinke C, Chuvochina M, Chaumeil PA, Woodcroft BJ, Evans PN, Hugenholtz P, Tyson GW. Author correction: Recovery of nearly 8,000 metagenome-assembled genomes substantially expands the tree of life. Nat Microbiol. 2018;3(2):253.
Yuan C, Lei J, Cole J, Sun Y. Reconstructing 16S rRNA genes in metagenomic data. Bioinformatics. 2015;31(12):i35–43.
Qin J, Li R, Raes J, Arumugam M, Burgdorf KS, Manichanh C, Nielsen T, Pons N, Levenez F, Yamada T, et al. A human gut microbial gene catalogue established by metagenomic sequencing. Nature. 2010;464(7285):59–65.
Almeida A, Mitchell AL, Boland M, Forster SC, Gloor GB, Tarkowska A, Lawley TD, Finn RD. A new genomic blueprint of the human gut microbiota. Nature. 2019;568(7753):499–504.
Nayfach S, Shi ZJ, Seshadri R, Pollard KS, Kyrpides NC. New insights from uncultivated genomes of the global human gut microbiome. Nature. 2019;568(7753):505–10.
Singer E, Andreopoulos B, Bowers RM, Lee J, Deshpande S, Chiniquy J, Ciobanu D, Klenk HP, Zane M, Daum C, et al. Next generation sequencing data of a defined microbial mock community. Sci Data. 2016;3:160081.
Zheng GX, Lau BT, Schnall-Levin M, Jarosz M, Bell JM, Hindson CM, Kyriazopoulou-Panagiotopoulou S, Masquelier DA, Merrill L, Terry JM, et al. Haploty** germline and cancer genomes with high-throughput linked-read sequencing. Nat Biotechnol. 2016;34(3):303–11.
Li H. Aligning sequence reads, clone sequences and assembly contigs with BWA-MEM. ar**v e-prints. 2013;ar**v:1303.3997.
Koren S, Walenz BP, Berlin K, Miller JR, Bergman NH, Phillippy AM. Canu: scalable and accurate long-read assembly via adaptive k-mer weighting and repeat separation. Genome Res. 2017;27(5):722–36.
Wu YW, Simmons BA, Singer SW. MaxBin 2.0: an automated binning algorithm to recover genomes from multiple metagenomic datasets. Bioinformatics. 2016;32(4):605–7.
Parks DH, Imelfort M, Skennerton CT, Hugenholtz P, Tyson GW. CheckM: assessing the quality of microbial genomes recovered from isolates, single cells, and metagenomes. Genome Res. 2015;25(7):1043–55.
Mikheenko A, Prjibelski A, Saveliev V, Antipov D, Gurevich A. Versatile genome assembly evaluation with QUAST-LG. Bioinformatics. 2018;34(13):i142–50.
Laslett D, Canback B. ARAGORN, a program to detect tRNA genes and tmRNA genes in nucleotide sequences. Nucleic Acids Res. 2004;32(1):11–6.
Wood DE, Salzberg SL. Kraken: ultrafast metagenomic sequence classification using exact alignments. Genome Biol. 2014;15(3):R46.
Acknowledgements
We would first thank Arend Sidow for his informative comments and revision for the paper. We also thank Research Committee of Hong Kong Baptist University and Interdisciplinary Research Clusters Matching Scheme for their kind support this project.
Funding
LZ is supported by General Research Fund No. 22201419 HKSRA, IRCMS No. IRCMS/19-20/D02 HKBU, Guangdong Basic and Applied Basic Research Foundation, No. 2019A1515011046.
Author information
Authors and Affiliations
Contributions
LZ and SCL conceived the study. LZ implemented LRTK-SIM and performed the assembly. HRL implemented contig analysis pipeline and performed assembly comparison. XDF, LJH, YC, and QWQ prepared the genomic DNA and 10x libraries. LZ, XDF, HRL, ZMZ, YCS, and SCL analyzed the results. LZ and SCL wrote the paper. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors have no conflicts of interest to declare.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Additional file 1: Table S1
. Parameter configurations of the simulated data sets. Table S2. Summary of the microbes in MBARC-26. Microbes were classified as High- (Hsim, Molarity > 10−14), Medium- (Msim,10−15 < Molarity < 10−14) and Low- (Lsim, Molarity < 10−15) abundance based on their molarities. Table S3. Summary of 20 microbes in ATCC MSA-1003. Microbes were classified as UltraHigh- (UHmock, percentage = 18%), High- (Hmock, percentage = 1.8%), Medium- (Mmock, percentage = 0.18%) and Low- (Lmock, percentage = 0.02%) abundance according to their mixture amount. Table S5. The key parameters of 10x linked-read sequencing for human gut metagenome and human genome. Table S6. The performance of metaSPAdes, MEGAHIT and IDBA-UD on short-read sequencing from human gut microbiome.
Additional file 2: Table S4
. Annotations of assemblies for the subsampled linked-reads from human gut microbiome.
Additional file 3: Table S7
A summary of 65,535 microbes in human microbiome project covered by 10x linked-reads from human gut microbiome. Table S8. A summary of 1,285 microbes in human microbiome project covered by 10x linked-reads of human gut microbiome with genomic coverage>90% and sequencing depth > 20X.
Additional file 4: Figure S1
. Distributions of bin completeness and contamination of SCF- and SCR- of human gut microbiome data. Figure S2. Upset plots for the shared genus (A: SCF-, C: SCR-) and species (B: SCF-, D: SCR-) of different subsampling datasets. Figure S3. Comparison of the contig NG50 and NGA50 between Illumina short-reads (Illumina) and 10x linked-reads (MSC1) from the mock community. Figure S4. Comparison of the contig NG50 and NGA50 between PacBio CCS reads (CCS) and 10x linked-reads (MSC1) from the mock community. Figure S5. Parameter distributions of linked-read sequencing from human gut microbiome. PDF: probability density function; CDF: cumulative density function. Figure S6. Parameter distributions of linked-read sequencing from human genome (NA24385). PDF: probability density function; CDF: cumulative density function. Figure S7. Workflow of LRTK-SIM to simulate linked-reads for microbial genomes with uneven depth. Figure S8. Workflow of linked-reads metagenome assembly on simulated 10x linked-reads. Figure S9. Workflow for evaluating and comparing different metagenome assemblies. Figure S10. The distributions of genomic coverage and read depth for the microbes in human microbiome project according to the alignment of the linked-reads from human gut microbiome. CDF: cumulative density function. Supplementary Note: 1. Complexity and statistics for linked-reads from human gut microbiome. 2. Command lines adopted for the analysis.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Zhang, L., Fang, X., Liao, H. et al. A comprehensive investigation of metagenome assembly by linked-read sequencing. Microbiome 8, 156 (2020). https://doi.org/10.1186/s40168-020-00929-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40168-020-00929-3