
Abstract
The stationary point of optimization problems can be obtained via conjugate gradient (CG) methods without the second derivative. Many researchers have used this method to solve applications in various fields, such as neural networks and image restoration. In this study, we construct a three-term CG method that fulfills convergence analysis and a descent property. Next, in the second term, we employ a Hestenses-Stiefel CG formula with some restrictions to be positive. The third term includes a negative gradient used as a search direction multiplied by an accelerating expression. We also provide some numerical results collected using a strong Wolfe line search with different sigma values over 166 optimization functions from the CUTEr library. The result shows the proposed approach is far more efficient than alternative prevalent CG methods regarding central processing unit (CPU) time, number of iterations, number of function evaluations, and gradient evaluations. Moreover, we present some applications for the proposed three-term search direction in image restoration, and we compare the results with well-known CG methods with respect to the number of iterations, CPU time, as well as root-mean-square error (RMSE). Finally, we present three applications in regression analysis, image restoration, and electrical engineering.
Similar content being viewed by others


1 Introduction
In order to determine the stationary point of optimization problems, the nonlinear conjugate gradient (CG) method does not necessitate the second derivative or its approximation. Here, the form we consider in the present investigation is as follows:
where \(f:R^{n} \to R\) as well as the gradient \(g(x) = \nabla f(x)\) is available. The following is how iterative approaches are usually applied to solve (1).
where \(\alpha _{k}\) is obtained by an exact or inexact line search. Moreover, an inexact line search, for instance, a strong Wolfe–Powell (SWP) line [1, 2], is commonly used and may be expressed as the following:
and
A weak Wolfe-Powell (WWP) line search is as given by Equation (3) and
with \(0 < \delta < \sigma < 1\).
The following expresses the search direction, \(d_{k}\) pertaining to two terms
where \(g_{k} = g(x_{k})\), while \(\beta _{k}\) resembles the CG parameter. Here, the most well-known CG parameters are divided into two groups, the first of which is an efficient group defined as follows, which includes the Hestenses–Stiefel (HS) [3], Polak–Ribière–Polyak (PRP) [4], as well as Liu and Storey (LS) [5] methods.
where \(y_{k - 1} = g_{k} - g_{k - 1}\). However, this group encounters a convergence problem if their values become negative [6]. In contrast, the second group is inefficient and exhibits strong global convergence. This category includes the Fletcher–Reeves (FR) [7], Fletcher (CD) [8], and Dai and Yuan (DY) [9] approaches, as defined by the following equations.
The subsequent conjugacy condition was put forth by Dai and Liao [10].
where \(s_{k - 1} = x_{k} - x_{k - 1}\) and \(t \ge 0\). Pertaining to \(t = 0\), the classical conjugacy condition is then expressed as Equation (8) becomes the classical conjugacy condition. They also presented the CG formula below [10], utilizing (6) and (7).
Nonetheless, \(\beta _{k}^{DL}\) carries over the same issue as \(\beta _{k}^{PRP}\) and \(\beta _{k}^{\mathrm{HS}}\), e.g., \(\beta _{k}^{DL}\) is generally not nonnegative. Equation (8) was then replaced [10]:
Hager and Zhang [11, 12] provided the CG formula below, predicated in Eq. (8).
where \(\beta _{k}^{N} = \frac{1}{d_{k}^{T}y_{k}} (y_{k} - 2d_{k}\frac{ \Vert y_{k} \Vert ^{2}}{d_{k}^{T}y_{k}} )^{T}g_{k}, \eta _{k} = - \frac{1}{ \Vert d_{k} \Vert \min \{ \eta , \Vert g_{k} \Vert \}}\), while \(\eta > 0\) is a constant. Note that \(t = 2\frac{ \Vert y_{k} \Vert ^{2}}{s_{k}^{T}y_{k}}\) when \(\beta _{k}^{N} = \beta _{k}^{DY}\).
Based on Equation (8), many researchers have suggested the three-term CG methods given below. Let the following equation represent the general form with regard to the three-term CG method:
where \(\theta _{k} = \frac{g_{k}^{T}y_{k - 1} - tg_{k}^{T}s_{k - 1}}{y_{k - 1}^{T}d_{k - 1}}\) and \(\eta _{k} = \frac{g_{k}^{T}d_{k - 1}}{y_{k - 1}^{T}d_{k - 1}}\). We then obtain a wide variety of choices by replacing t in Eq. (10) with an appropriate term, as shown in Table 1.
By replacing \(y_{k - 1}\) with \(g_{k - 1}\), Liu et al. [17] proposed the following three-term CG method:
with the following assumption
Liu et al. [17] demonstrated how nonconvex functions may address nonlinear monotone equations if the sufficient descent condition is met. Meanwhile, Liu et al. [18] created the three-term CG methods given below and solved Equation (1) by utilizing it in order to avoid using the condition \(( \frac{g_{k}^{T}d_{k - 1}}{d_{k - 1}^{T}g_{k - 1}} ) > \nu \in (0,1)\).
Yao et al. [19] suggested a three-term CG with the following new choice of t given by
\(t_{k}\) was also chosen to meet the descent condition like the one below as per the SWP line search.
Another theorem put forth by Yao et al. [19] states that if \(t_{k}\) is close to \(\frac{ \Vert y_{k} \Vert ^{2}}{y_{k}^{T}s_{k}}\), then the search direction produces a zigzag search path. Thus, they decided on the option \(t_{k}\) given below.
At the beginning of the CG method, a nonnegative CG formula with a new restart property was presented by Alhawarat et al. [20].
where \(\Vert \cdot \Vert \) denotes the Euclidean norm, while \(\mu _{k}\) can be represented as
Similarly, Jiang et al. [21] suggested the CG method given by:
To improve the efficiency of prior methods, they constructed a restart criterion given as follows:
where \(0 < \xi < 1\).
Recently, a convex combination between two distinct search directions is presented by Alhawarat et al. [22] as follows:
where
and
The authors selected \(\beta _{k}^{(}(1))\) and \(\beta _{k}^{(}(2))\) given below:
and
The descent condition, also known as the downhill condition, given by
helps research CG methods and is crucial to the validation of global convergence analysis. Al-Baali [23] also utilized the subsequent version of (13) to demonstrate the FR method.
where \(c \in (0, 1)\). Next, the sufficient descent condition is given by Eq. (14) below. Moreover, it performs better than (13) because the quantity of \(g_{k}^{T}d_{k}\) can be controlled using \(\Vert g_{k} \Vert ^{2}\).
2 Proposed modified search direction (3TCGHS) and motivation
The main motivation for researchers in CG methods is to propose a positive CG method with an efficiency similar to that of PRP or HS, with a global convergence. In the following modification, we utilize the new search direction \(g_{k - 1}\) proposed by [17] with \(\beta _{k}^{\mathrm{HS}}\) restricted to be nonnegative, as given below:
where \(\mu _{k} = \frac{ \Vert x_{k} - x_{k - 1} \Vert }{ \Vert g_{k} - g_{k - 1} \Vert }\).
The procedures acquired to determine the optimization function’s stationary point are outlined in the following Algorithm 1.
3 Global convergence properties
The assumption that follows is considered as a condition for the objective function.
Assumption 1
I. The level set \(\Psi = \{ x \in R^{n}:f(x) \le f(x_{1})\}\) is bounded. Here, a positive constant ρ exists; in this case
II. f is a continuous and differentiable function in some neighborhood W of Ψ, and its gradient is Lipchitz continuous, meaning that, for every \(x,y \in W\), a constant \(L > 0\) exists, in which case
As per this assumption, there must be a positive constant η; in this case
The CG method’s convergence properties are typically established using the following lemma proposed by Zoutendijk [24]. The method involves multiple line searches, including SWP and WWP line searches.
Lemma 3.1
Let Assumption 1hold. If \(\alpha _{k}\) satisfies the WWP line search with the descent condition (9), then take any form of (2) and (3). Then, the inequality that follows holds.
As can be seen from the following theorem, the new formula fulfills the descent condition (9).
Theorem 3.1
Let the sequences \(\{ x_{k}\}\) and \(\{ d_{k}^{\mathrm{Jiang}}\}\) be developed by Equations (2) and (12), and consider the line search method obtained using Equations (3) and (4). The sufficient descent condition (11) is then satisfied.
Proof
Multiply (12) by \(g_{k}^{T}\) to obtain
Using a SWP line search, we obtain
If \(\sigma \le \frac{1}{2}\),
The proof is now complete. □
Theorem 3.2
Let sequence \(\{ x_{k}\}\) be generated by Equation (2), where \(d_{k} = - \mu _{k}\frac{g_{k}^{T}s_{k - 1}}{d_{{k - 1}}^{T}(g_{k} - g_{k - 1})} \) is the step length obtained by SWP line search. Afterwards, condition (11) for a sufficient descent holds.
Proof
After multiplying (2) by \(g_{k}^{T}\) and substituting \(d_{k} = - \mu _{k}\frac{g_{k}^{T}s_{k - 1}}{d_{{k - 1}}^{T}(g_{k} - g_{k - 1})} \), we acquire
This completes the proof. □
Gilbert and Nocedal [25] outlined a property known as Property* to perform a specialized role in studies on CG formulas related to the PRP method. The property is described below.
Property*
Consider a method of the form (2) and (6), and let
We claim that the method contains Property (*) provided that constants \(b > 1\) and \(\lambda > 0\) exist, where for every \(k \ge 1\), we acquire \(\vert \beta _{k} \vert \le b\). Meanwhile, if \(\Vert x_{k} - x_{k - 1} \Vert \le \lambda \), then
The lemma below illustrates that \(\beta _{k}^{\mathrm{HS}}\) inherits Property*. The proof is similar to that given by Gilbert and Nocedal [25].
Lemma 3.2
Let Assumption 1hold and consider any form of Equations (2) and (3). Consequently, \(\beta _{k}^{\mathrm{HS}}\) fulfills Property*.
Proof
Let \(b = \frac{2\bar{\gamma}}{(1 - \sigma )c\gamma ^{2}} > 1\), and \(\lambda = \frac{(1 - \sigma )c\gamma ^{4}}{2L\bar{\gamma} b}\). Then, using (14) and SWP line search, we obtain
If \(\Vert x_{k + 1} - x_{k} \Vert \le \lambda \) holds with Assumption 1, then
□
Lemma 3.3
Via Algorithm 1, let Assumption 1hold while the sequences \(\{ g_{k} \}\) and \(\{ d_{k}^{\mathrm{Jiang}} \}\) are developed. The step size \(\alpha _{k}\) is determined by utilizing the SWP line search to ensure that the sufficient descent condition is met. Provided that \(\beta _{k} \ge 0\), then a constant \(\gamma > 0\) exists, where \(\Vert g_{k} \Vert > \gamma \) for every \(k \ge 1\). Afterwards, \(d_{k} \ne 0\) and
where \(u_{k} = \frac{d_{k}}{ \Vert d_{k} \Vert }\).
Proof
First, given that \(d_{k} = 0\), we can acquire \(g_{k} = 0\) from the sufficient descent condition. Hence, we can assume that \(d_{k} \ne 0\) and
We provide definitions as below:
where
Since \(u_{k}\) denotes a unit vector, we have
By the triangular inequality and \(\delta _{k} \ge 0\), we obtain
We now define
Utilizing the triangular inequality, we establish
Using the SWP Equations (4) and (5), we can obtain the following two inequalities.
Hence, the inequality in Eq. (18) can be expressed in the following way:
Let
Then, \(\Vert \nu \Vert \le T\). From Eq. (17), we have \(\Vert u_{k} - u_{k - 1} \Vert \le 2w\).
By Eqs. (16) and (15), we acquire what is presented below
This completes the proof. □
By Lemmas 4.1 and 4.2 in [10], we are able to obtain the following outcome:
Theorem 3.3
Using the CG method in Eq. (12), let (2) and (3) generate the sequences \(\{ x_{k} \}\) and \(\{ d_{k}^{\mathrm{Jiang}} \}\), and let the step size satisfy (4) and (5). Utilizing Lemmas 3.2, 3.3, and Lemmas 4.1 and 4.2 in [10], we acquire such findings of \(\lim \ \inf_{ k \to \infty} \Vert g_{k} \Vert = 0\).
4 Numerical results and discussions
In this section, we provide some numerical findings to validate the efficiency for the proposed search direction. Details are provided in the Appendix. We used 166 test functions from the CUTEr library [26]. The functions can be downloaded in .SIF file format from the URL below.
https://www.cuter.rl.ac.uk/Problems/mastsif.shtml
We modified the code from CG-Descent 6.8 to implement the proposed search direction and DL+ method. The following website has the code available for download.
https://people.clas.ufl.edu/hager/software/
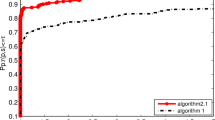
With an AMD A4-7210 CPU and 4 GB of RAM, the host computer was running Ubuntu 20.04 to carry out the necessary computations. We compared the modified search direction \(d_{k}^{\mathrm{Jiang}}\) with DL+ methods, and we used a SWP line search to acquire the step length with \(\sigma = 0.1\) and \(\delta = 0.01\) for 3TCGHS and DL+ and the previously mentioned approximate Wolfe-Powell line search for CG-Descent. Figures 1–4 present all outcomes via a performance measure first used by Dolan and More [27]. We utilize an SWP line search together with \(\sigma = 0.1\) and \(\delta = 0.01\) for \(d_{k}^{\mathrm{Jiang}}\) method and DL+. From Figs. 1–4, it may be observed that the new search direction strongly outperformed DL+ in terms of the number of iterations, function evaluation, CPU time, and a number of gradient evaluations. The subsequent big notations are used in the Appendix:

Algorithm 1

Graph of the number of iterations

Graph of the number of function evaluations

Graph of CPU time

Graph of the number of number of gradient evaluations
No. iter: Number of iterations.
No. function: Number of function evaluations
No. gradient: Number of gradient evaluations
4.1 Application to image restoration
To the original images, we applied Gaussian noise with a standard deviation of 25%. Next, we used 3TCGHS as well as the \(\beta _{k}^{DL +} \) (Dai–Liao) CG algorithm to restore these images. Take note that we made use of the (Dai–Liao) CG algorithm and 3TCGHS.
If the descent condition was met; if not, we employed the steepest-descent approach to restart the algorithm. We utilized the root-mean-square error (RMSE) between the restored image and the original true image to assess the quality of the restored image.
The restored image is denoted by \(\varsigma _{k}\) and the true image by ς. The RMSE determines the quality of the restored image, in which lower values correspond to higher quality. The criteria for stop** is
In this context, \(\omega = 10^{ - 3}\). Note that if \(\omega = 10^{ - 4}\) or \(\omega = 10^{ - 6}\), then RMSE remains constant, meaning that a fixed RMSE can vary in the number of iterations.
Table 2 compares 3TCGHS with the Dai-Liao CG algorithm through a series of numerical experiments. The RMSE, CPU time, and the number of iterations are all compared. It may be observed that the 3TCGHS method performed better than Dai–Liao with respect to CPU time, RMSE, and the number of iterations for most experimental tests.
Table 3 shows the outcomes of restoring destroyed images using Algorithm 1, indicating that it can be considered an efficient approach.
4.2 Application to a regression problem
Table 4 shows data on the prices and demand for some commodities over several years. The data is similar to that used by [28].
The relation between x and y is parabolic; thus, the regression function can be defined as follows:
where \(w_{0}\), \(w_{1}\), and \(w_{2}\) are the regression parameters. We aim to solve the equation given below using the least square method.
This equation is able to be modified to the following unconstrained optimization problem.
Next, we can use Algorithm 1 to get the subsequent outcomes. \(w_{2} = 0.1345,w_{1} = - 2.1925,w_{0} = 7.0762\).
4.3 Solving system of linear equations in electrical engineering
The main challenge is solving complex systems of linear equations generated from linear circuits with many components. The first CG formula was suggested by Hestenes and Steifel [3] in 1952 to solve the linear equation systems. The linear equation system is presented in the format
In the case where the matrix Q is symmetric and positive definite, it may be regarded as a method for resolving a corresponding quadratic function.
To see the similarities between the above equations, differentiate \(f(x)\) in relation to x and make the gradient zero. In other words,
The following example illustrates using the CG method to solve a linear equation system generated from the circuit.
Example 1
[29, 30]. Consider the circuit shown in Fig. 6. To create the loop equations, use loop analysis. Then, Algorithm 1 is applied to find the solution for the unknown currents.

The circuit of Example 1
Kirchhoff’s Current Law (often abbreviated as KCL) asserts that all currents entering and leaving a node must sum up to zero algebraically. This law describes the flow of charge into and out of a wire junction point or node. The circuit in Fig. 6 has four loops; thus, Kirchhoff’s Loop Equations can be written as follows:
where the following is one way to write the system of equations:
Thus, we can write the system \(Qx = b\) as follows:
where Q denotes positive definite and symmetric matrix. Thus, we have the following form:
i.e.,
After simple calculations, we compute the following function:
Using Algorithm 1, we can find the following solution for Eq. (20)
and the function value is
5 Conclusion
We have outlined a three-term CG method in the present research that satisfies both the convergence analysis and the descent condition via an SWP line search. Moreover, we have presented numerical results with different values of sigma, showing that the new search direction strongly outperformed alternative approaches with regard to the number of iterations as well as was very competitive when it came to the number of functions, gradients, and CPU time evaluated. Additionally, we have offered an application of the new search direction of image restoration, regression analysis, and solving linear systems in electrical engineering. Algorithm 1 demonstrates its efficiency in restoring destroyed images from degraded pixel data. In addition, using Algorithm 1 to solve a system of linear equations is easier than other traditional methods. In regression analysis, we found Algorithm 1 useful for obtaining the value of regression parameters. In future research, we intend to utilize CG methods in machine learning, mathematical problems in engineering, and neural networks.
Data Availability
No datasets were generated or analysed during the current study.
References
Wolfe, P.: Convergence conditions for ascent methods. SIAM Rev. 11, 226–235 (1969)
Wolfe, P.: Convergence conditions for ascent methods. II: some corrections. SIAM Rev. 13, 185–188 (1971)
Hestenes, M.R., Stiefel, E.: Methods of conjugate gradients for solving linear systems. J. Res. Natl. Bur. Stand. 49, 409–436 (1952)
Polak, E., Ribiere, G.: Note sur la convergence de méthodes de directions conjuguées. Rev. Fr. Inform. Rech. Opér. Sér. Rouge 3, 35–43 (1969)
Liu, Y., Storey, C.: Efficient generalized conjugate gradient algorithms, part 1: theory. J. Optim. Theory Appl. 69, 129–137 (1991)
Powell, M.J.D.: Nonconvex minimization calculations and the conjugate gradient method. In: Numerical Analysis: Proceedings of the 10th Biennial Conference, pp. 122–141. Springer, Berlin (1984)
Fletcher, R.: Function minimization by conjugate gradients. Comput. J. 7, 149–154 (1964)
Fletcher, R.: Practical Methods of Optimization. Wiley, New York (2000)
Dai, Y.H., Yuan, Y.: A nonlinear conjugate gradient method with a strong global convergence property. SIAM J. Optim. 10, 177–182 (1999)
Dai, Y.H., Liao, L.Z.: New conjugacy conditions and related nonlinear conjugate gradient methods. Appl. Math. Optim. 43, 87–101 (2001)
Hager, W.W., Zhang, H.: A new conjugate gradient method with guaranteed descent and an efficient line search. SIAM J. Optim. 16, 170–192 (2006)
Hager, W.W., Zhang, H.: The limited memory conjugate gradient method. SIAM J. Optim. 23, 2150–2168 (2013)
Andrei, N.: A simple three-term conjugate gradient algorithm for unconstrained optimization. J. Comput. Appl. Math. 241, 19–29 (2013)
Andrei, N.: On three-term conjugate gradient algorithms for unconstrained optimization. Appl. Math. Comput. 219, 6316–6327 (2013)
Babaie-Kafaki, S., Ghanbari, R.: Two modified three-term conjugate gradient methods with sufficient descent property. Optim. Lett. 8, 2285–2297 (2014)
Deng, S., Wan, Z.: A three-term conjugate gradient algorithm for large-scale unconstrained optimization problems. Appl. Numer. Math. 92, 70–81 (2015)
Liu, J.K., Xu, J.Ł., Zhang, L.Q.: Partially symmetrical derivative-free Liu–Storey projection method for convex constrained equations. Int. J. Comput. Math. 96, 1787–1798 (2019)
Liu, J.K., Zhao, Y.X., Wu, X.L.: Some three-term conjugate gradient methods with the new direction structure. Appl. Numer. Math. 150, 433–443 (2020)
Yao, S., Ning, L., Tu, H., Xu, J.: A one-parameter class of three-term conjugate gradient methods with an adaptive parameter choice. Optim. Methods Softw. 35, 1051–1064 (2020)
Alhawarat, A., Salleh, Z., Mamat, M., Rivaie, M.: An efficient modified Polak–Ribière–Polyak conjugate gradient method with global convergence properties. Optim. Methods Softw. 32, 1299–1312 (2017)
Jiang, X., Jian, J., Song, D., Liu, P.: An improved Polak–Ribière–Polyak conjugate gradient method with an efficient restart direction. Comput. Appl. Math. 40, 1–24 (2021)
Alhawarat, A., Salleh, Z., Masmali, I.A.: A convex combination between two different search directions of conjugate gradient method and application in image restoration. Math. Probl. Eng. 2021, 1–15 (2021)
Al-Baali, M.: Descent property and global convergence of the Fletcher—Reeves method with inexact line search. IMA J. Numer. Anal. 5, 121–124 (1985)
Zoutendijk, G.: Some algorithms based on the principle of feasible directions. In: Nonlinear Programming, pp. 93–121. Elsevier, Amsterdam (1970)
Gilbert, J.C., Nocedal, J.: Global convergence properties of conjugate gradient methods for optimization. SIAM J. Optim. 2, 21–42 (1992)
Bongartz, I., Conn, A.R., Gould, N., Toint, P.L.: CUTE: constrained and unconstrained testing environment. ACM Trans. Math. Softw. 21, 123–160 (1995)
Dolan, E.D., Moré, J.J.: Benchmarking optimization software with performance profiles. Math. Program. 91, 201–213 (2002)
Yuan, G., Wei, Z.: Non monotone backtracking inexact BFGS method for regression analysis. Commun. Stat. Methods 42, 214–238 (2013)
Bakr, M.: Nonlinear optimization in electrical engineering with applications in Matlab. The Institution of Engineering and Technology (2013)
Mishra, S.K., Ram, B.: Introduction to Unconstrained Optimization with R. Springer, Berlin (2019)
Acknowledgements
This project is supported by the Researchers Supporting Project number (RSP2024R317), King Saud University, Riyadh, Saudi Arabia. The authors greatly appreciate the editors and reviewers for any advice and insights that could help enhance this work. We express our gratitude to Dr. William Hager for sharing his CG method code.
Funding
The third author would like to thank King Saud University for its partial support in this paper. The corresponding author would like to express here sincere gratitude to Universiti Sains Islam Malaysia (USIM) for the financial support it has given us in this research.
Author information
Authors and Affiliations
Contributions
Ahmad Alhawarat wrote the main text with proofs. Zabidin Salleh review the proofs. Hanan Alolaiyan prepared the figures and computer software. Hamid El hor and Shahrina Ismail did the application part.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
Function | Dim | No. iter 3TCGHS | No. function 3TCGHS | No. gradient 3TCGHS | CPU time 3TCGHS | No. iter DL+ | NO. function DL+ | No. gradient DL+ | CPU time DL+ |
|---|---|---|---|---|---|---|---|---|---|
AKIVA | 2 | 9 | 21 | 13 | 00.03 | 8 | 20 | 15 | 00.03 |
ALLINITU | 4 | 11 | 25 | 15 | 00.03 | 9 | 25 | 18 | 0.03 |
ARGLINB | 200 | 2 | 105 | 104 | 0.06 | 5 | 73 | 72 | 0.09 |
ARGLINC | 200 | 2 | 106 | 104 | 00.03 | 5 | 79 | 78 | 0.06 |
ARWHEAD | 5000 | 8 | 16 | 10 | 0.03 | 6 | 16 | 12 | 00.03 |
BARD | 3 | 16 | 33 | 17 | 00.03 | 12 | 32 | 22 | 00.03 |
BDEXP | 5000 | 4 | 9 | 4 | 00.03 | 2 | 7 | 7 | 00.03 |
BDQRTIC | 5000 | 141 | 299 | 278 | 0.55 | 168 | 363 | 359 | 0.63 |
BEALE | 2 | 13 | 30 | 18 | 00.03 | 11 | 33 | 26 | 00.03 |
BIGGS3 | 6 | 78 | 172 | 100 | 00.03 | 79 | 207 | 144 | 00.03 |
BIGGS5 | 6 | 78 | 172 | 100 | 00.03 | 79 | 207 | 144 | 00.03 |
BIGGS6 | 6 | 26 | 58 | 33 | 00.03 | 24 | 64 | 44 | 00.03 |
BIGGSB1 | 5000 | 2500 | 2507 | 4995 | 2.4 | 8328 | 8335 | 16651 | 10.86 |
BOX2 | 3 | 10 | 22 | 12 | 00.03 | 10 | 23 | 14 | 00.03 |
BOX3 | 3 | 10 | 22 | 12 | 00.03 | 10 | 23 | 14 | 00.03 |
BOX | 10000 | 7 | 23 | 18 | 0.11 | 7 | 25 | 21 | 0.09 |
BRKMCC | 2 | 5 | 11 | 6 | 00.03 | 5 | 11 | 6 | 00.03 |
BROYDNBDLS | 10 | 26 | 54 | 28 | 00.03 | 25 | 57 | 34 | 00.03 |
BROWNAL | 200 | 2 | 106 | 104 | 0.05 | 10 | 29 | 21 | 00.03 |
BROWNBS | 2 | 12 | 26 | 17 | 00.03 | 10 | 24 | 18 | 00.03 |
BROWNDEN | 4 | 15 | 31 | 19 | 00.03 | 16 | 38 | 31 | 00.03 |
BRYBND | 5000 | 48 | 103 | 58 | 0.17 | 149 | 317 | 174 | 0.55 |
CAMEL6 | 2 | 11 | 36 | 28 | 00.03 | 6 | 22 | 18 | 00.03 |
CHNROSNB | 50 | 281 | 556 | 295 | 00.03 | 1009 | 1998 | 1180 | 0.01 |
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Alhawarat, A., Salleh, Z., Alolaiyan, H. et al. A three-term conjugate gradient descent method with some applications. J Inequal Appl 2024, 73 (2024). https://doi.org/10.1186/s13660-024-03142-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13660-024-03142-0