
Abstract
Background
The progression rates of Alzheimer’s disease (AD) are variable and dynamic, yet the mechanisms that contribute to heterogeneity in progression rates remain ill-understood. Particularly, the role of synergies in pathological processes reflected by biomarkers for amyloid-beta (‘A’), tau (‘T’), and neurodegeneration (‘N’) in progression along the AD continuum is not fully understood.
Methods
Here, we used a combination of model and data-driven approaches to address this question. Working with a large dataset (N = 321 across the training and testing cohorts), we first applied unsupervised clustering on longitudinal cognitive assessments to divide individuals on the AD continuum into those showing fast vs. moderate decline. Next, we developed a deep learning model that differentiated fast vs. moderate decline using baseline AT(N) biomarkers.
Results
Training the model with AT(N) biomarker combination revealed more prognostic utility than any individual biomarkers alone. We additionally found little overlap between the model-driven progression phenotypes and established atrophy-based AD subtypes. Our model showed that the combination of all AT(N) biomarkers had the most prognostic utility in predicting progression along the AD continuum. A comprehensive AT(N) model showed better predictive performance than biomarker pairs (A(N) and T(N)) and individual biomarkers (A, T, or N).
Conclusions
This study combined data and model-driven methods to uncover the role of AT(N) biomarker synergies in the progression of cognitive decline along the AD continuum. The results suggest a synergistic relationship between AT(N) biomarkers in determining this progression, extending previous evidence of A-T synergistic mechanisms.
Similar content being viewed by others

Background
Alzheimer’s disease (AD) is a progressive neurodegenerative disorder which gradually impairs memory, cognition, and other vital functions [1]. Individuals along the AD continuum exhibit markedly heterogeneous progression rates as the disease advances [2, 3]. Both linear and non-linear progression of cognitive decline has been documented in AD [4, 5], with distinct progression profiles found among individuals [2, 3]. Still, the mechanisms that underlie the heterogeneity in AD progression rates remain incompletely understood.
The neuropathological hallmarks of AD are centered around the presence of amyloid-beta (Aβ) plaques and neurofibrillary tangles of hyperphosphorylated tau, which are believed to precede structural neurodegenerative changes in the brain [6, 7]. Links between cognitive decline in AD and biomarker levels for Aβ [8], tau [9], and atrophy/neurodegeneration [10] have been reported in the literature. However, with little exception, studies have focused on individual biomarkers rather than examining their synergies and combined contribution to progressive cognitive decline along the AD continuum. An accurate characterization of the mechanisms leading to heterogeneity in progression rates would nevertheless benefit from considering biomarkers for Aβ (‘A’), tau (‘T’), and neurodegeneration (‘N’) together, consistent with the recently proposed AT(N) framework [11, 12]. Yet, combining AT(N) biomarkers in a single model is not trivial, given their complex, non-linear relationships with one another and/or their relationship with cognitive decline [13, 14]. A modeling approach based on deep learning arises as a natural solution to this problem, given its ability to model complex and non-linear map**s [15, 16]. Deep learning models have emerged as a powerful tool recently in relevant tasks, such as differentiating between individuals with dementia and controls [17, 18], and classifying stable vs. progressive mild cognitive impairment (MCI) [15, 19,20,21].
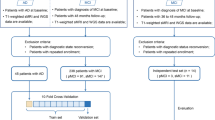
In the current study, we propose a model-driven approach, based on AT(N) biomarkers, for stratifying progression rates along the AD continuum and delineating their underlying mechanisms. Notably, this work focuses on heterogeneity of cognitive decline along the AD continuum unlike previous studies where MCI progression was examined [22, 23]. We first employ data-driven clustering of cognitive assessments to define individuals with prodromal or clinical AD as either Fast Decliners (FD) or Moderate Decliners (MD) (Fig. 1A). These progression phenotypes are then used to train, validate, and test a deep learning model using baseline biomarkers for A (CSF Aβ 1–42), T (CSF p-tau 181), and N (MRI images and FDG-PET) (Fig. 1B). The model was trained with and without Aβ, tau, and neurodegeneration biomarkers, allowing us to compare the relative contribution of biomarker synergies, particularly amyloid-, and tau-mediated neurodegeneration to progression rates along the AD continuum. We additionally examined the extent to which the cognitive progression phenotypes predicted by our model reflected variation in regional atrophy characteristics (Fig. 1C), commonly used for subty** AD [24,25,26,27]. This allowed us to examine if our model-based framework reflected patterns of neurodegeneration captured by other commonly used approaches.

Study setup. A Clustering of MMSE scores to classify subjects as Fast and Moderate Decliners (FD and MD, respectively). B Baseline AT(N) biomarkers including CSF Aβ (A), CSF p-tau (T), and FDG-PET along with T1-weighted images (N), from a cohort of subjects with prodromal and clinical AD (n = 321, augmented to 1104) were used to train the deep learning models for FD/MD prediction. C The predicted cognitive progression phenotypes in the test set (ntest = 97) were also examined for overlap with putative atrophy-based AD subtypes
Methods
time points during 24 months following baseline, (3) had T1-weighted MRI images takenParticipants and data acquisition
Data used in this study were obtained from the Alzheimer’s Disease Neuroimaging Initiative (ADNI) database (adni.loni.usc.edu; clinical trial registration: NCT00106899). The ADNI was launched in 2003 as a public-private partnership, led by the Principal Investigator Michael W. Weiner, M.D. The primary goal of the ADNI has been to test whether serial MRI, positron emission tomography (PET), other biological markers, and clinical and neuropsychological assessments can be combined to measure the progression of MCI and early AD. In the current study, participants from the ADNI-1, ADNI-2/Go, and ADNI-3 cohorts were included if they were (1) diagnosed with AD at baseline or within 1 year of their first diagnosis (i.e., MCI subjects were included if they were later diagnosed as AD), (2) had valid cognitive evaluations (Mini-Mental State Examination (MMSE) scores) performed at a minimum of t = 4 time points during 24 months following baseline, (3) had T1-weighted MRI images taken using 3T scanners based on either an inversion recovery-fast spoiled gradient recalled (IR-SPGR) or a magnetization-prepared rapid gradient-echo (MP-RAGE) sequences, and (4) were determined to be amyloid-positive within the study’s timeline according to published criteria (CSF Aβ < 976.6 pg/mL or 18F-florbetapir-PET uptake ratio > 1.11). The 18F-florbetapir-PET uptake ratios, provided in ADNI as a derived variable, were calculated by extracting weighted cortical retention means from frontal, cingulate, parietal, and temporal regions, after co-registering the PET and MRI scans. These data were used to calculate standardized uptake value ratios (SUVRs), normalized by a whole cerebellum reference region. SUVRs with a positivity threshold of 1.11 were then identified [28, 29].
In total, 321 unique subjects were identified using these criteria. Out of these, 310 subjects were determined to be amyloid-positive using CSF Aβ cutoff while 11 subjects satisfied the PET uptake ratio criterion. All subjects provided written informed consent, and the procedures were approved by the Institutional Review Boards of participating centers.
MRI images and their processing
T1-weighted SPGR or MPRAGE images were acquired using 3T scanners (full details of the image acquisition protocols can be found online (http://adni.loni.usc.edu/methods/documents/mri-protocols/). T1-weighted images were used for training of the deep learning models. The cohort with valid MRI and cognitive assessments were split between the training (n train = 224) and testing (n test = 97) datasets.
CSF Aβ 1-42 (amyloid-beta) and p-tau181 (tau) biomarkers along with MRI + fluorodeoxyglucose (FDG)-PET data (neurodegeneration) were used as the A, T, and N biomarkers respectively in our AT(N)-centered analytical framework. CSF samples used in this study were collected and processed previously (see, [30]; http://adni.loni.usc.edu/methods). CSF Aβ and p-tau were measured with the fully automated Elecsys immunoassay (Roche Diagnostics, Basel, Switzerland) by the ADNI biomarker core (University of Pennsylvania, Philadelphia, PA). Processed (see, http://adni.loni.usc.edu/methods) FDG PET images were averaged, with uptake values from angular, temporal, and posterior cingulate cortices serving as one of our two biomarkers for neurodegeneration (along with MRI) [31]. This average FDG PET was previously obtained using a series of steps to mitigate inter-scanner variability and normalized in spatial resolution and intensity range for further analysis [32]. Each MRI image was standardized to 0 mean and unit standard deviation. Similarly, other AT(N) biomarkers were standardized before being used as input in the deep learning model.
Unsupervised clustering of cognitive measurements
To characterize longitudinal change in cognition, we used 2-year follow-up MMSE scores. In addition, other cognitive assessments over the same duration were used for validation purposes, including the Alzheimer’s Disease Assessment Scale, 13-Item Subscale (ADASCog13), Clinical Dementia Rating Sum of Boxes (CDR-SB), and Functional Assessment Questionnaire (FAQ). These tests were administered as described online (http://www.adni-info.org).
We used time-series clustering based on the dynamic time-war** (DTW) method [33] to identify cognitive phenotypes in a data-driven manner. Clustering is typically applied in order to partition a heterogeneous set of samples into more homogeneous clusters based on some similarity measure. When it comes to clustering of time-series data, a DTW-based similarity measure is more widely applicable than the conventional Euclidean distance or spatial distance based measures [34, 35]. DTW is able to find optimal global alignment between sequences of different shapes. The shape-based DTW method is particularly well-suited to dynamic time-series data with potential temporal drift, showing better accuracy than linear models [34, 36]. We used the DTW to cluster the MMSE scores of our cohort using t = 4 time points, collected over 2 years from baseline, using Hierarchical Agglomerative Clustering with Ward’s linkage [37]. Clustering was repeated with other linkage methods such as Ward1 and the unweighted pair-group method using arithmetic averages (UPGMA) to examine the similarity of cluster labels [38, 39]. Other cognitive assessments such as ADASCog13, CDR-SB, and FAQ were used for validation purposes, testing if the phenotypes based on MMSE scores also differ in other measures of cognition in AD. Further, to determine the optimal number of cognitive decline clusters in our cohort, we used silhouette analysis to compare average silhouette width for k = 2, 3, and 4 clusters.
Deep learning model architecture and training
Deep learning models have been extensively used for AD classification [17, 18] and predicting progression of MCI [15, 21, 40]. Deep learning models are typically compared against linear or non-linear Support-Vector Machine (SVM), logistic regression, or random forest classifiers, where SVM has been shown to outperform the latter two [41]. We first calibrated our deep learning model’s performance using a similar comparison with SVM. Our deep learning model used a parameter-efficient architecture similar to that previously proposed for classification of MCI [42]. The Parameter-Efficient Network model, designated as PENet, takes a combination of baseline AT(N) biomarkers including MRI images and FDG-PET (N), CSF p-tau (T), and CSF Aβ (A) and learns to predict the subject’s cognitive decline status (FD vs MD) using these baseline measurements only. The multi-modal feature extractor implemented in the model uses a series of convolutional blocks, or conv blocks, to process MRI tensors. These conv blocks are composed of a convolutional layer followed by batch normalization and exponential linear unit (ELU) transformation. The model also makes use of separable convolution blocks, or sep-conv blocks, which perform the operation of a convolution block but with far fewer parameters, hence reducing the risk of over-fitting. PENet uses 2 conv blocks followed by 3 sep-conv blocks with increasing number of filters (Fig. 3A). It processes non-imaging biomarkers by dense or FC (fully connected) blocks.
Implementation
Experiments were conducted using python version 3.6. The implementation was developed using the Keras deep learning library with Tensorflow backend. The model was trained on Ubuntu 18.04 on a single Nvidia Tesla V100 GPU with 16G memory, using a batch size of 25 and trained for 50 epochs after which the model showed stable dynamics (Fig. S2). This training was performed using the Stochastic Gradient Descent algorithm with an initial learning rate = 8 × 10-4 and exponential decay with a drop rate = 0.5. The FC layers used in the model were regularized using L2 regularization with penalty coefficient = 5 × 10-4.
Data augmentation and validation framework
The implemented model was trained and validated using 5-fold cross-validation stratified by class phenotypes. All qualifying subjects from ADNI-1, ADNI-2/Go, and ADNI-3 were used in our experiments, yielding a total of n = 321 subjects (n train = 224, MD = 136, FD = 88; n test = 97, MD = 58, FD = 39). To improve model generalizability, we augmented the training dataset through a combination of image rotation (random angle in [−90°, 90°], translation (random shift in [0, 0.5]), and flip** operations, resulting in 1104 training images. Special care was taken to use the test dataset only after all steps of augmentation, model selection, and hyperparameter tuning were completed, ensuring no data leakage.
Analysis of atrophy-based AD subtypes
MRI images for the test dataset were processed (http://adni.loni.usc.edu/) using Freesurfer (http://surfer.nmr.mgh.harvard.edu/) to extract region of interest (ROI)-based gray matter (GM) volume. The following processing steps were performed: (1) motion-correction and skull-strip** based on a watershed deformation method [43], (2) image registration to the Talairach brain template, (3) estimation and labeling of gray matter-white matter (GM-WM) boundary using a tessellation step, and (4) registration of volume to an atlas to acquire volume and surface statistics for each ROI. Using these extracted volumes, we investigated the potential association between the model-based cognitive progression phenotypes and atrophy-based AD subtypes, as previously identified [24]. Subtypes were identified using the ratio of hippocampal volume (HV) to cortical total volume (CTV). Following the same procedure as described previously [24], subjects in the test dataset with an HV:CTV ratio above the 75th percentile were identified as belonging to the Hippocampal-Sparing AD (HpSp) subtype, those with HV:CTV ratio below the 25th percentile as belonging to the Limbic-Predominant subtype (LP) and the rest were designated as typical-AD (tAD).
To visualize the spatial extent of atrophy, the subtypes HpSp, LP, and tAD were also contrasted against age-matched controls (n = 30) to extract voxel-wise contrast maps using FSL's optimized voxel-based morphometry (VBM) (http://www.fmrib.ox.ac.uk/fsl/) [44]. The FSL VBM processing pipeline involved brain extraction of T1-weighted images followed by segmentation into WM, GM, and CSF volume probability maps. Next, a random subset of each compared cohort was used to create the average study-specific GM template by registration to MNI152 space using the FSL FLIRT tool. This was followed by non-linear registration of all GM images in the native image space to the average GM template. Subsequently, these registered images were smoothed using a full-width half-maximum (FWHM) of 6mm and their voxel-wise GM volumes were contrasted using a general linear model (GLM) formulation. To identify significant differences between the compared groups, non-parametric statistics were performed using the ‘randomise’ FSL function (5000 permutations) with FWE correction set at p < 0.05, based on threshold-free cluster enhancement (TFCE).
Statistical analysis
For comparisons between two groups, unpaired two-sided t tests or Wilcoxon rank-sum test were used. For testing significant differences in MMSE scores of the MD and FD phenotypes, we used the selective inference method [33, 37], suitable for shape-based clustering of dynamic time-varying observations [34, 35]. The longitudinal MMSE scores of the entire cohort were clustered to reveal 2 different progression phenotypes identified as moderate (MD: n = 194; ages 73.8 ± 7.28; Supplementary Table 1) and fast (FD: n = 127; ages 73.2 ± 8.02) decline (Fig. 2A and B). Other linkage methods such as Ward1 [38] and UPGMA resulted in very similar clustering solutions [38, 39]. The 2 clusters did not exhibit any significant differences in age, education, gender, total cortical volume, and APOE e4 status (all p > 0.05; Supplementary Table 1 and Fig. S3). Silhouette analysis, used to determine the optimal number of clusters, resulted in maximal silhouette width for k = 2 clusters (Supplementary Table 2). The MD and FD phenotypes showed, as expected, significant differences in MMSE profiles (p = 6.73 × 10-3), revealed using a method developed for post-clustering comparisons [24] based solely of patterns of neurodegeneration. We found no significant differences in the distribution of AD subtypes among the two cognitive progression phenotypes. Thus, the model-based phenotypes identified here, may not be readily detectable using atrophy-based methods. Data-driven studies on AD subty** revealed neurodegeneration patterns similar to those found here [24,25,26], but atrophy-based methods do not always result in distinct cognitive progression phenotypes [27]. Additional work is needed to better reconcile atrophy and cognitive-based subty** of AD and its progression.
Limitations
Several limitations should be noted. First, we acknowledge that any study investigating the effects of AT(N) biomarkers in AD should ideally test longitudinal changes in these biomarkers in the same cohort. However, this was not applicable in the current study due to missing data in several of the biomarkers. Second, while being beyond the scope of the current study, an examination of the spatiotemporal characteristics of amyloid and tau deposition using PET-based markers can provide useful information about the progression of cognitive decline along the AD continuum. Future work focusing on spatiotemporal changes in the synergy between biomarkers for Aβ, tau, and neurodegeneration as it relates to progression rates is thus warranted.
Conclusions
To conclude, our study combined data and model-driven methods to uncover the role of AT(N) biomarkers in the progression of cognitive decline along the AD continuum. The results converge to support a more complex, synergistic relationship between AT(N) biomarkers in determining this progression. Our findings further demonstrate the utility of using modeling approaches to study the complex multifaceted mechanisms that underlie disease progression in AD.
Availability of data and materials
Data used in this study were obtained from the ADNI database (adni.loni.usc.edu), excluded in specific cases according to pre-established exclusion criterion determined by study design constraints such as MRI image resolution, availability of longitudinal data, subject’s amyloid-beta levels, etc.
References
Sloane PD, Zimmerman S, Suchindran C, Reed P, Wang L, Boustani M, et al. The public health impact of Alzheimer’s disease, 2000–2050: potential implication of treatment advances. Annu. Rev. Public Health. 2002:213–31 [cited 2021 Feb 10] Available from: https://pubmed.ncbi.nlm.nih.gov/11910061/.
Eldholm RS, Barca ML, Persson K, Knapskog AB, Kersten H, Engedal K, et al. Progression of Alzheimer’s disease: a longitudinal study in Norwegian memory clinics. J Alzheimer’s Dis. 2018;61:1221–32 [cited 2021 Feb 9] Available from: https://pubmed.ncbi.nlm.nih.gov/29254085/.
Scheltens NME, Tijms BM, Koene T, Barkhof F, Teunissen CE, Wolfsgruber S, et al. Cognitive subtypes of probable Alzheimer’s disease robustly identified in four cohorts. Alzheimer’s Dement. 2017;13:1226–36 [cited 2021 Feb 9] Available from: /pmc/articles/PMC5857387/?report=abstract.
Stern Y, Liu X, Albert M, Brandt J, Jacobs DM, Castillo-Castaneda CD, et al. Application of a growth curve approach to modeling the progression of Alzheimer’s disease. Journals Gerontol Ser A Biol Sci Med Sci. 1996;51A:M179–84. [cited 2021 Feb 9] Available from: https://academic.oup.com/biomedgerontology/article-lookup/doi/10.1093/gerona/51A.4.M179
Doody RS, Pavlik V, Massman P, Rountree S, Darby E, Chan W. Predicting progression of Alzheimer’s disease. Alzheimer’s Res Ther. 2010;2:2. [cited 2021 Mar 31] Available from: http://alzres.biomedcentral.com/articles/10.1186/alzrt25
Meyer PF, Pichet Binette A, Gonneaud J, Breitner JCS, Villeneuve S. Characterization of Alzheimer disease biomarker discrepancies using cerebrospinal fluid phosphorylated tau and AV1451 positron emission tomography. JAMA Neurol. 2020;77:508–16 [cited 2021 Apr 26] Available from: http://adni.loni.usc.edu.
Deture MA, Dickson DW. The neuropathological diagnosis of Alzheimer’s disease. Mol. Neurodegener. 2019:1–18 [cited 2021 Mar 31] Available from: https://doi.org/10.1186/s13024-019-0333-5.
Haass C, Selkoe DJ. Soluble protein oligomers in neurodegeneration: lessons from the Alzheimer’s amyloid β-peptide. Nat. Rev. Mol. Cell Biol. 2007:101–12 [cited 2021 Feb 11] Available from: www.nature.com/reviews/molcellbio.
Ballatore C, Lee VMY, Trojanowski JQ. Tau-mediated neurodegeneration in Alzheimer’s disease and related disorders. Nat. Rev. Neurosci. 2007:663–72 [cited 2021 Feb 11] Available from: www.nature.com/reviews/neuro.
Fox NC, Warrington EK, Freeborough PA, Hartikainen P, Kennedy AM, Stevens JM, et al. Presymptomatic hippocampal atrophy in Alzheimer’s disease. Brain. 1996;119:2001–7. [cited 2021 Feb 11] Available from: https://academic.oup.com/brain/article-lookup/doi/10.1093/brain/119.6.2001
Jack CR, Bennett DA, Blennow K, Carrillo MC, Feldman HH, Frisoni GB, et al. A/T/N: an unbiased descriptive classification scheme for Alzheimer disease biomarkers. Neurology. 2016:539–47 [cited 2021 Mar 2] Available from: /pmc/articles/PMC4970664/.
Jack CR, Bennett DA, Blennow K, Carrillo MC, Dunn B, Haeberlein SB, et al. NIA-AA Research Framework: toward a biological definition of Alzheimer’s disease. Alzheimer’s Dement. 2018:535–62 [cited 2021 Apr 28] Available from: https://pubmed.ncbi.nlm.nih.gov/29653606/.
Williams JH, Wilcock GK, Seeburger J, Dallob A, Laterza O, Potter W, et al. Non-linear relationships of cerebrospinal fluid biomarker levels with cognitive function: an observational study. Alzheimer’s Res Ther. 2011;3:5. [cited 2021 Mar 31] Available from: http://alzres.biomedcentral.com/articles/10.1186/alzrt64
Popescu SG, Whittington A, Gunn RN, Matthews PM, Glocker B, Sharp DJ, et al. Nonlinear biomarker interactions in conversion from mild cognitive impairment to Alzheimer’s disease. Hum Brain Mapp. 2020;41:4406–18 [cited 2021 Mar 31] Available from: https://onlinelibrary.wiley.com/doi/10.1002/hbm.25133.
Shen D, Wu G, Suk H-I. Deep learning in medical image analysis. Annu Rev Biomed Eng. 2017;19:221–48 [cited 2021 Mar 31] Available from: http://www.annualreviews.org/doi/10.1146/annurev-bioeng-071516-044442.
Litjens G, Kooi T, Bejnordi BE, Setio AAA, Ciompi F, Ghafoorian M, et al. A survey on deep learning in medical image analysis. Med. Image Anal. 2017:60–88.
Islam J, Zhang Y. Brain MRI analysis for Alzheimer’s disease diagnosis using an ensemble system of deep convolutional neural networks. Brain Informatics. 2018;5 [cited 2021 Feb 9] Available from: /pmc/articles/PMC6170939/.
Lu D, Popuri K, Ding GW, Balachandar R, Beg MF, Weiner M, et al. Multimodal and multiscale deep neural networks for the early diagnosis of Alzheimer’s disease using structural MR and FDG-PET images. Sci Rep. 2018;8 [cited 2021 Feb 9] Available from: https://pubmed.ncbi.nlm.nih.gov/29632364/.
Zhang D, Wang Y, Zhou L, Yuan H, Shen D. Multimodal classification of Alzheimer’s disease and mild cognitive impairment. Neuroimage. 2011;55:856–67.
Kwak K, Niethammer M, Giovanello KS, Styner M, Dayan E. Differential Role for hippocampal subfields in Alzheimer’s disease progression revealed with deep learning. Cereb Cortex. 2021; [cited 2021 Aug 15] Available from: https://pubmed.ncbi.nlm.nih.gov/34322704/.
Jo T, Nho K, Saykin AJ. Deep learning in Alzheimer’s disease: diagnostic classification and prognostic prediction using neuroimaging data. Front Aging Neurosci. 2019; 11:220.[cited 2021 Feb 9] Available from: https://www.frontiersin.org/article/10.3389/fnagi.2019.00220/full.
Mitchell AJ, Shiri-Feshki M. Rate of progression of mild cognitive impairment to dementia - meta-analysis of 41 robust inception cohort studies. Acta Psychiatr Scand. 2009;119:252–65.[cited 2021 Feb 10] Available from: http://doi.wiley.com/10.1111/j.1600-0447.2008.01326.x
Duara R, Loewenstein DA, Greig MT, Potter E, Barker W, Raj A, et al. Pre-MCI and MCI: Neuropsychological, clinical, and imaging features and progression rates. Am J Geriatr Psychiatry. 2011;19:951–60 [cited 2021 Feb 10] Available from: /pmc/articles/PMC3175279/.
Risacher SL, Anderson WH, Charil A, Castelluccio PF, Shcherbinin S, Saykin AJ, et al. Alzheimer disease brain atrophy subtypes are associated with cognition and rate of decline. Neurology. 2017;89:2176–86 [cited 2021 Feb 6] Available from: /pmc/articles/PMC5696639/?report=abstract.
Ferreira D, Shams S, Cavallin L, Viitanen M, Martola J, Granberg T, et al. The contribution of small vessel disease to subtypes of Alzheimer’s disease: a study on cerebrospinal fluid and imaging biomarkers. Neurobiol Aging. 2018;70:18–29 [cited 2021 Feb 8] Available from: https://pubmed.ncbi.nlm.nih.gov/29935417/.
Park JY, Na HK, Kim S, Kim H, Kim HJ, Seo SW, et al. Robust identification of Alzheimer’s disease subtypes based on cortical atrophy patterns. Sci Rep. 2017;7 [cited 2021 Feb 9] Available from: /pmc/articles/PMC5343676/.
Poulakis K, Pereira JB, Mecocci P, Vellas B, Tsolaki M, Kłoszewska I, et al. Heterogeneous patterns of brain atrophy in Alzheimer’s disease. Neurobiol Aging. 2018;65:98–108 [cited 2021 Feb 9] Available from: https://pubmed.ncbi.nlm.nih.gov/29455029/.
Landau SM, Marks SM, Mormino EC, Rabinovici GD, Oh H, O’Neil JP, et al. Association of lifetime cognitive engagement and low β-amyloid deposition. Arch Neurol. 2012 ;69:623–9. [cited 2021 Oct 23] Available from: https://pubmed.ncbi.nlm.nih.gov/22271235/
Landau SM, Breault C, Joshi AD, Pontecorvo M, Mathis CA, Jagust WJ, et al. Amyloid-β imaging with Pittsburgh compound B and florbetapir: comparing radiotracers and quantification methods. J Nucl Med. 2013;54:70–7 [cited 2021 Feb 2] Available from: https://pubmed.ncbi.nlm.nih.gov/23166389/.
Shaw LM, Vanderstichele H, Knapik-Czajka M, Clark CM, Aisen PS, Petersen RC, et al. Cerebrospinal fluid biomarker signature in alzheimer’s disease neuroimaging initiative subjects. Ann Neurol. 2009;65:403–13 [cited 2021 Feb 2] Available from: /pmc/articles/PMC2696350/?report=abstract.
Toussaint PJ, Perlbarg V, Bellec P, Desarnaud S, Lacomblez L, Doyon J, et al. Resting state FDG-PET functional connectivity as an early biomarker of Alzheimer’s disease using conjoint univariate and independent component analyses. Neuroimage. 2012;63:936–46.
WJ J, SM L, LM S, JQ T, RA K, EM R, et al. Relationships between biomarkers in aging and dementia. Neurology. 2009;73:1193–1199. [cited 2021 Oct 22] Available from: https://pubmed.ncbi.nlm.nih.gov/19822868/
Petitjean F, Ketterlin A, Gançarski P. A global averaging method for dynamic time war**, with applications to clustering. Pattern Recognit. 2011;44:678–93.
Aach J, Church GM. Aligning gene expression time series with time war** algorithms. Bioinformatics. 2001;17:495–508. [cited 2021 Feb 3] Available from: https://academic.oup.com/bioinformatics/article-lookup/doi/10.1093/bioinformatics/17.6.495
Kruskal JB. An overview of sequence comparison: time warps, string edits, and macromolecules*. 1983. Available from: https://epubs.siam.org/page/terms
Aghabozorgi S, Shirkhorshidi AS, Wah Y. Time-series clustering – a decade review. 2015 [cited 2021 Feb 9]; Available from: http://dx.doi.org/https://doi.org/10.1016/j.is.2015.04.007
Ward JH. Hierarchical grou** to optimize an objective function. J Am Stat Assoc. 1963;58:236–44.
Murtagh F, Legendre P. Ward’s Hierarchical agglomerative clustering method: which algorithms implement ward’s criterion? J Classif. 2014;31:274–95 [cited 2021 Jul 14] Available from: www.clustan.com.
Montero P, Vilar JA. TSclust: an R package for time series clustering. J Stat Softw. 2014;62:1–43.
Il SH, Lee SW, Shen D. Hierarchical feature representation and multimodal fusion with deep learning for AD/MCI diagnosis. Neuroimage. 2014;101:569–82.
Wen J, Thibeau-Sutre E, Diaz-Melo M, Samper-González J, Routier A, Bottani S, et al. Convolutional neural networks for classification of Alzheimer’s disease: overview and reproducible evaluation. Med Image Anal2020;63:101694.
Spasov S, Passamonti L, Duggento A, Liò P, Toschi N. A parameter-efficient deep learning approach to predict conversion from mild cognitive impairment to Alzheimer’s disease. Neuroimage. 2019;189:276–87.
Fischl B, Salat DH, Busa E, Albert M, Dieterich M, Haselgrove C, et al. Whole brain segmentation: automated labeling of neuroanatomical structures in the human brain. Neuron. 2002;33:341–55.
Good CD, Johnsrude IS, Ashburner J, Henson RNA, Friston KJ, Frackowiak RSJ. A voxel-based morphometric study of ageing in 465 normal adult human brains. Neuroimage. 2001;14:21–36 [cited 2021 Feb 3] Available from: https://pubmed.ncbi.nlm.nih.gov/11525331/.
Gao LL, Bien J, Witten D. Selective inference for hierarchical clustering. ar**v. 2020 [cited 2021 Apr 1]; Available from: http://arxiv.org/abs/2012.02936
Jack CR, Bernstein MA, Fox NC, Thompson P, Alexander G, Harvey D, et al. The Alzheimer’s disease neuroimaging initiative (ADNI): MRI methods. J. Magn. Reson. Imaging. 2008:685–91.
Folstein MF, Robins LN, Helzer JE. The Mini-Mental State Examination. Arch. Gen. Psychiatry. 1983:812 [cited 2021 Mar 31] Available from: https://jamanetwork.com/journals/jamapsychiatry/fullarticle/493108.
DeLong ER, DeLong DM, Clarke-Pearson DL. Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach. Biometrics. 1988;44:837.
Gispert JD, Rami L, Sánchez-Benavides G, Falcon C, Tucholka A, Rojas S, et al. Nonlinear cerebral atrophy patterns across the Alzheimer’s disease continuum: impact of APOE4 genotype. Neurobiol Aging. 2015;36:2687–701.
Groot C, van Loenhoud AC, Barkhof F, van Berckel BNM, Koene T, Teunissen CC, et al. Differential effects of cognitive reserve and brain reserve on cognition in Alzheimer disease. Neurology. 2008;90(2):e149-56. https://doi.org/10.1212/WNL.0000000000004802.
Ossenkoppele R, Lyoo CH, Sudre CH, Westen D, Cho H, Ryu YH, et al. Distinct tau PET patterns in atrophy-defined subtypes of Alzheimer’s disease. Alzheimer’s dement. 2020;16:335–44 [cited 2021 Apr 5] Available from: https://onlinelibrary.wiley.com/doi/abs/10.1016/j.jalz.2019.08.201.
Hall CB, Lipton RB, Sliwinski M, Stewart WF. A change point model for estimating the onset of cognitive decline in preclinical Alzheimer’s disease. Stat Med. 2000;19:1555–1566. [cited 2021 Apr 28] Available from: https://onlinelibrary.wiley.com/doi/10.1002/(SICI)1097-0258(20000615/30)19:11/12%3C1555::AID-SIM445%3E3.0.CO;2-3
Schmidt C, Wolff M, Weitz M, Bartlau T, Korth C, Zerr I. Rapidly progressive alzheimer disease. Arch. Neurol. 2011:1124–30 [cited 2021 Feb 9] Available from: https://jamanetwork.com/.
Haaksma ML, Calderón-Larrañaga A, Olde Rikkert MGM, Melis RJF, Leoutsakos J-MS. Cognitive and functional progression in Alzheimer disease: a prediction model of latent classes. Int J Geriatr Psychiatry. 2018;33:1057–64 [cited 2021 Feb 9] Available from: http://doi.wiley.com/10.1002/gps.4893.
Bernick C, Cummings J, Raman R, Sun X, Aisen P. Age and rate of cognitive decline in Alzheimer disease: implications for clinical trials. Arch Neurol. 2012;69:901–5 [cited 2021 Feb 9] Available from: http://www.r-project.
Crane PK, Trittschuh E, Mukherjee S, Saykin AJ, Sanders RE, Larson EB, et al. Incidence of cognitively defined late-onset Alzheimer’s dementia subgroups from a prospective cohort study. Alzheimer’s Dement. 2017;13:1307–16 [cited 2021 Feb 9] Available from: https://pubmed.ncbi.nlm.nih.gov/28623677/.
Habes M, Grothe MJ, Tunc B, McMillan C, Wolk DA, Davatzikos C. Disentangling heterogeneity in Alzheimer’s disease and related dementias using data-driven methods. Biol. Psychiatry. 2020. 70–82. [cited 2021 Feb 9] Available from: https://doi.org/https://doi.org/10.1016/j.biopsych.2020.01.016
Thalhauser CJ, Komarova NL. Alzheimer’s disease: rapid and slow progression. J R Soc Interface. 2012;9:119–26 [cited 2021 Feb 9] Available from: /pmc/articles/PMC3223623/.
Liu S, Liu S, Cai W, Pujol S, Kikinis R, Feng D. Early diagnosis of Alzheimer’s disease with deep learning. 2014 IEEE 11th Int Symp Biomed Imaging, ISBI 2014. Institute of Electrical and Electronics Engineers Inc.; 2014. p. 1015–1018.
Busche MA, Hyman BT. Synergy between amyloid-β and tau in Alzheimer’s disease. Nat. Neurosci. 2020:1183–93 [cited 2021 May 26] Available from: https://pubmed.ncbi.nlm.nih.gov/32778792/.
Bennett RE, DeVos SL, Dujardin S, Corjuc B, Gor R, Gonzalez J, et al. Enhanced tau aggregation in the presence of amyloid β. Am J Pathol. 2017;187:1601–12. [cited 2021 Jul 21] Available from: https://pubmed.ncbi.nlm.nih.gov/28500862/
Götz J, Chen F, van Dorpe J, Nitsch RM. Formation of Neurofibrillary Tangles in P301L Tau Transgenic Mice Induced by Aβ42 Fibrils. Science. 2001;293(5534):1491-5. https://doi.org/10.1126/science.1062097.
Hanseeuw BJ, Betensky RA, Jacobs HIL, Schultz AP, Sepulcre J, Becker JA, et al. Association of Amyloid and Tau With Cognition in Preclinical Alzheimer Disease. JAMA Neurol. 2019;76(8):915. https://doi.org/10.1001/jamaneurol.2019.1424.
Sperling RA, Mormino EC, Schultz AP, Betensky RA, Papp K V., Amariglio RE, et al. The impact of amyloid-beta and tau on prospective cognitive decline in older individuals. Ann Neurol. 2019;85:181–93. [cited 2021 Jul 21] Available from: https://pubmed.ncbi.nlm.nih.gov/30549303/
Adams JN, Maass A, Harrison TM, Baker SL, Jagust WJ. Cortical tau deposition follows patterns of entorhinal functional connectivity in aging. Elife. 2019;8 [cited 2021 Nov 5] Available from: https://pubmed.ncbi.nlm.nih.gov/31475904/.
Fortea J, Vilaplana E, Alcolea D, Carmona-Iragui M, Sánchez-Saudinos MB, Sala I, et al. Cerebrospinal fluid β-amyloid and phospho-tau biomarker interactions affecting brain structure in preclinical Alzheimer disease. Ann Neurol. 2014;76:223–30 [cited 2021 Nov 5] Available from: https://pubmed.ncbi.nlm.nih.gov/24852682/.
Jacobs HIL, Hedden T, Schultz AP, Sepulcre J, Perea RD, Amariglio RE, et al. Structural tract alterations predict downstream tau accumulation in amyloid-positive older individuals. Nat Neurosci. 2018;21:424–31. [cited 2021 Jul 21] Available from: https://pubmed.ncbi.nlm.nih.gov/29403032/
Huang Y, Xu J, Zhou Y, Tong T, Zhuang X. Diagnosis of Alzheimer’s disease via multi-modality 3D convolutional neural network. Front Neurosci. Frontiers; 2019;13:509.
Qiu S, Joshi PS, Miller MI, Xue C, Zhou X, Karjadi C, et al. Development and validation of an interpretable deep learning framework for Alzheimer’s disease classification. Brain. 2020;143:1920–33. [cited 2021 Jul 21] Available from: https://academic.oup.com/brain/article/143/6/1920/5827821
Dujardin S, Commins C, Lathuiliere A, Beerepoot P, Fernandes AR, Kamath TV, et al. Tau molecular diversity contributes to clinical heterogeneity in Alzheimer’s disease. Nat Med. 2020;26:1256–63 [cited 2021 Mar 17] Available from: https://doi.org/10.1038/s41591-020-0938-9.
Blom ES, Giedraitis V, Zetterberg H, Fukumoto H, Blennow K, Hyman BT, et al. Rapid progression from mild cognitive impairment to alzheimer’s disease in subjects with elevated levels of tau in cerebrospinal fluid and the Apoe ε4/ε4 genotype. Dement Geriatr Cogn Disord. Dement Geriatr Cogn Disord; 2009;27:458–64. [cited 2021 Mar 17] Available from: https://pubmed.ncbi.nlm.nih.gov/19420940/
Buchhave P, Minthon L, Zetterberg H, Wallin ÅK, Blennow K, Hansson O. Cerebrospinal fluid levels of β-amyloid 1-42, but not of tau, are fully changed already 5 to 10 years before the onset of Alzheimer dementia. Arch Gen Psychiatry. 2012;69:98–106. [cited 2021 Jul 15] Available from: https://jamanetwork.com/journals/jamapsychiatry/fullarticle/1107443
Li R, Zhang W, Il SH, Wang L, Li J, Shen D, et al. Deep learning based imaging data completion for improved brain disease diagnosis. Lect Notes Comput Sci (including Subser Lect Notes Artif Intell Lect Notes Bioinformatics). Springer Verlag. 2014:305–12 [cited 2021 Apr 5] Available from: https://pubmed.ncbi.nlm.nih.gov/25320813/.
Li H, Habes M, Wolk DA, Fan Y. A deep learning model for early prediction of Alzheimer’s disease dementia based on hippocampal magnetic resonance imaging data. Alzheimer’s Dement. 2019;15:1059–70 [cited 2021 Feb 9] Available from: https://pubmed.ncbi.nlm.nih.gov/31201098/.
Acknowledgments
We would like to thank William Stanford for helpful comments on the manuscript.
Funding
This work was supported by the National Institute On Aging of the National Institutes of Health under Award Number R01AG062590. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Data collection and sharing for this project was funded by the Alzheimer’s Disease Neuroimaging Initiative (ADNI) (National Institutes of Health Grant U01 AG024904) and DOD ADNI (Department of Defense award number W81XWH-12-2-0012). ADNI is funded by the National Institute on Aging, the National Institute of Biomedical Imaging and Bioengineering, and through generous contributions from the following: AbbVie, Alzheimer’s Association; Alzheimer’s Drug Discovery Foundation; Araclon Biotech; BioClinica, Inc.; Biogen; Bristol-Myers Squibb Company; CereSpir, Inc.; Cogstate; Eisai Inc.; Elan Pharmaceuticals, Inc.; Eli Lilly and Company; EuroImmun; F. Hoffmann-La Roche Ltd. and its affiliated company Genentech, Inc.; Fujirebio; GE Healthcare; IXICO Ltd.; Janssen Alzheimer Immunotherapy Research & Development, LLC.; Johnson & Johnson Pharmaceutical Research & Development LLC.; Lumosity; Lundbeck; Merck & Co., Inc.; Meso Scale Diagnostics, LLC.; NeuroRx Research; Neurotrack Technologies; Novartis Pharmaceuticals Corporation; Pfizer Inc.; Piramal Imaging; Servier; Takeda Pharmaceutical Company; and Transition Therapeutics. The Canadian Institutes of Health Research is providing funds to support ADNI clinical sites in Canada. Private sector contributions are facilitated by the Foundation for the National Institutes of Health (www.fnih.org). The grantee organization is the Northern California Institute for Research and Education, and the study is coordinated by the Alzheimer’s Therapeutic Research Institute at the University of Southern California. ADNI data are disseminated by the Laboratory for Neuro Imaging at the University of Southern California.
Author information
Authors and Affiliations
Consortia
Contributions
M.S. and E.D. conceived the study. M.S. implemented the model-based approach and statistical analysis. K. K implemented the SVM model. All authors contributed to revision and editing of the manuscript. The authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
ADNI investigators obtained ethics approval from the local ethical committees of all involved sites. Access to all ADNI data was granted to us after registration to ADNI (https://adni.loni.usc.edu) and compliance with the data usage agreement. All work complied with ethical regulations for work with human participants.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Data used in the preparation of this article were obtained from the Alzheimer’s Disease Neuroimaging Initiative (ADNI) database (adni.loni.usc.edu). As such, the investigators within the ADNI contributed to the design and implementation of ADNI and/or provided data but did not participate in the analysis or writing of this report. A complete listing of ADNI investigators can be found at: http://adni.loni.usc.edu/wp-content/uploads/how_to_apply/ADNI_Acknowledgement_List.pdf
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Sadiq, M.U., Kwak, K., Dayan, E. et al. Model-based stratification of progression along the Alzheimer disease continuum highlights the centrality of biomarker synergies. Alz Res Therapy 14, 16 (2022). https://doi.org/10.1186/s13195-021-00941-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13195-021-00941-1