
Abstract
Passionfruit (Passiflora edulis) is a significant fruit crop in the commercial sector, owing to its high nutritional and medicinal value. The advent of high-throughput genomics sequencing technology has led to the publication of a vast amount of passionfruit omics data, encompassing complete genome sequences and transcriptome data under diverse stress conditions. To facilitate the efficient integration, storage, and analysis of these large-scale datasets, and to enable researchers to effectively utilize these omics data, we developed the first passionfruit genome database (PGD). The PGD platform comprises a diverse range of functional modules, including a genome browser, search function, heatmap, gene expression patterns, various tools, sequence alignment, and batch download, thereby providing a user-friendly interface. Additionally, supplementary practical tools have been developed for the PGD, such as gene family analysis tools, gene ontology (GO) terms, a pathway enrichment analysis, and other data analysis and mining tools, which enhance the data’s utilization value. By leveraging the database’s robust scalability, the intention is to continue to collect and integrate passionfruit omics data in the PGD, providing comprehensive and in-depth support for passionfruit research. The PGD is freely accessible via http://passionfruit.com.cn.
Similar content being viewed by others


Background
Passiflora is the largest and most widely distributed genus in the Passifloraceae family, comprising about 500 species [1]. The genus contains many species with edible fruits, but only a few have commercial value. Passionfruit, a native plant of South America, is widely cultivated around the world because of its economic value [2]. The fruit is round or oval, with a tough outer rind and juicy, aromatic pulp inside. It is commonly used in juices, desserts, and as a flavoring for other foods [3,4,5]. In addition to their edible fruits, some species of Passiflora have medicinal properties and are used in traditional herbal medicine [6, 7]. Many region-specific traditional cultivars are widely promoted and cultivated [4, 8] but only a few varieties are recognized in the market, including the purple Passiflora edulis Sims (purple passionfruit) and the yellow form Passiflora edulis f. flavicarpa Degener (yellow passionfruit) [3]. Although these two passionfruit cultivars have notably market value and a remarkable survival capacity, like other passionfruit cultivars, their yield and quality are easily affected by biotic and abiotic factors in the growing environment, resulting in a significant decline in planting benefits. Therefore, it is necessary to conduct further research on this species, master the basic knowledge needed to improve yields and stress resistance, and ensure its safe agricultural production.
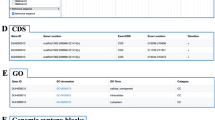
The lack of publicly available tools to support fundamental research in Passiflora species can be attributed to factors such as their large, complex genomes. Despite these challenges, multiple data sets covering various aspects of Passiflora genetics and genomics have been published over the last decade. Santos et al. [8] have constructed and characterized the first large-insert bacterial artificial chromosome (BAC) library of Passiflora edulis. In 2021, two high-quality purple Passiflora edulis genome sequences were reported, with assembled sequences of 1.28 Gb [ We downloaded the genome sequence of purple passionfruit (Passiflora edulis Sims) (PRJCA004251) from the China National Center for Bioinformation (CNCB) (https://www.cncb.ac.cn/). For yellow passionfruit (Passiflora edulis f. flavicarpa Degener.), we performed whole genome sequencing and obtained a high-quality genome assembly sequence at the chromosome level (CNCB, PRJCA020234 or http://passionfruit.com.cn/downloads_data.html). After obtaining the whole genome sequence of passionfruit, we used a custom program for genome (re)annotation. RepeatModeler2 [11] (v2.0.1) was used for ab initio prediction and homology-based annotation of transposable elements (TEs) in both passionfruit genomes, and a TEs library for this species was also established. To predict protein-coding genes, three complementary strategies were employed, including ab initio prediction (Augustus [12] (v3.1.0), SNAP [13] (v4.0)), homology-based prediction (GeMoMa [14] (v1.7)), and transcriptome-based prediction (Trinity [15] (v2.11) and PASA [16] (v2.4.1)), which were integrated using PASA and EVM [17] (v1.1.1) software. Additionally, the protein domain and motif annotation were performed using the InterProScan [18] (v5.39–77.0) software to search multiple databases such as SMART [19], InterPro [20], PROSITE [21]. Finally, the HMMER [22] software was used to identify gene families. The Kyoto Encyclopedia of Genes and Genomes (KEGG) Mapper [23,24,25,26], BlastKOALA (https://www.kegg.jp/blastkoala/), and Blast2GO [27] (v2.7.2) were used for KEGG pathway and gene ontology (GO) annotation, respectively. All annotation results were stored in a specific format in databases for easy accessibility (Fig. 1A). Constructing PGD via prior pipeline. A Genome data sources and annotation. B Transcriptome data analysis (C) Data integration and website construction. D Main function module To obtain a better understanding of the gene expression patterns, we obtained 96 RNA-Seq transcriptome datasets from seven different treatment conditions, including 24 tissues, six heat-treated samples, six cold-treated samples, six salt-treated samples, six drought-treated samples, 30 hormone-treated samples, and 18 virus-treated samples. After filtering the raw data with fastqc, high-quality sequencing data were obtained (CNCB,PRJCA020235). We used Hisat2 [28] (v2.0.4) software to map clean RNA-seq data to the corresponding reference genome, and conducted a transcriptome assembly and quantification using StringTie [29] (v1.3.3) software and the fragments per kilobase of gene/transcript model per Million mapped fragments (FPKM) method. Finally, we reconstructed a single expression matrix file based on the common gene ID of the 96 transcriptome expression datasets for further analysis (Fig. 1B). The PGD consists of a front-end web interface, a back-end application server, and a suite of Perl, R, and Python scripts for data processing, analysis, and visualization. The web server runs on a Linux server based on CentOS (v7) and Apache (v2.4). To improve the user experience, the PGD uses technologies such as JavaScript and CSS libraries, JQuery, and Bootstrap to enhance the website interface. The PGD also uses custom Perl scripts to process user interaction data and extract feature data. Additionally, the PGD integrates several open-source plugins such as ECharts (http://echarts.baidu.com/) and SVGweb (https://code.google.com/p/svgweb/) to dynamically display data. Furthermore, the PGD includes JBrowse, an open-source and full-featured genome browser based on JavaScript and HTML5. The BLAST online search tool was built using SequenceServer (v2.0) software (http://www.sequenceserver.com/).Finally, we have uploaded the web code for develo** PGD to GitHub. (https://github.com/yuchaowei2023/Passionfruit_Genomic_Database). In order to enrich the usability of the database, we developed an online toolkit for researchers to perform a customized gene family analysis (Fig. 1C, D). The PGD database consists of seven main functional modules: Search, Browse, Heatmap, Enrichment Analysis, Tools, Download, and User Guide. These functional modules can be used separately or work collaboratively as a whole. The PGD interface is divided into several sections: quick data search, navigation bar, PGD introduction, and a column for commonly used gene family analysis tools. The quick data search module is located at the top of the page. Underneath it there is a navigation bar comprising five tabs: Home, Search, Genome Browser, Gene Expression Analysis, Analysis Tools, User Guide, and Data Download. In the middle of the page there is a PGD summary and seven frequently used tools. At the bottom of the homepage, there are four user-friendly links that lead to corresponding frequently used functional modules. The PGD search module provides two search category options, “Quick Search” and “Annotation Search.” Users can quickly search the database by clicking the “Search” button at the top of the page (Fig. 2A). The search information includes species selection, locus ID, keywords, or other annotation IDs (such as KEGG pathway, GO terms, and Pfam ID) (Fig. 2A). The locus ID search results include detailed basic gene information (Fig. 2B), such as chromosome location, protein physicochemical properties, characteristic structural domains or motifs, homologous genes, coding sequence (CDS), and peptide sequence. Expression data from different tissues and biotic/abiotic stresses can be displayed as plant sketch heatmaps or boxplots (Fig. 2C). To facilitate the display of gene location and gene structure information in the genome, a small genome browser JBrowse2 is embedded into the gene information introduction page (Fig. 2D). The KEGG pathway and GO functional annotation results are presented as a table (Fig. 2E). Links are provided in the corresponding entries to the source pages of the original annotation databases, such as KEGG, GO, or InterPro ID, to obtain more comprehensive information (Fig. 2F). The page of gene detailed information introduction. A “Quick search” using keywords or annotation information. B Gene basic information. C Gene expression pattern diagram. D Gene information in JBrowse. E, F KEGG pathway and GO functional annotation of gene The drop-down menu of “Annotation Search” provides a list of annotation dataset search links: Gene Locus, Motif/Domain, KEGG, GO, SSR (Simple Sequence Repeat) markers and non-coding RNA annotation data. Each search page can filter data by the two reference species (yellow passionfruit and purple passionfruit), annotation classification, annotation name, and list the gene symbols and total number that meet the criteria in tabular form. To enable users to view detailed gene information, users can click on the gene symbol hyperlink to jump to the gene information interface. Similarly, other result entries can also hyperlink to the original annotation database source page. JBrowse is a widely used interactive genome visualization browser for displaying genome data resources, including genome sequences, gene structures, protein-coding gene annotations, single nucleotide polymorphisms (SNPs) site information, and expression profiles. We integrated the JBrowse2 tool into the PGD and imported all publicly available passionfruit RNA-Seq, genome data, and annotation data (General feature format files) into JBrowse2 (Fig. 3A). To improve Jbrowse’s query function, we added an ElasticSearch module. Users can not only query by region range but also use keywords to accurately search for genes of interest. In addition, users can upload and analyze their own omics data through tracks and download the corresponding reports. The “Genome Browser,” “Heatmap,” and “KEGG and GO Enrichment” modules of PGD. A The “Genome Browser” module provides genomic data, including gene structure and location, genome and transcript sequence, and SNPs loci. B, C A dynamic, editable heatmap retrieved by the user. D The “KEGG and GO Enrichment” shows enriched KEGG and GO terms within a query gene list We developed a visualization interface for a gene expression heatmap, providing two search methods: searching by gene family or keyword (Fig. 3B), or by a list of gene IDs (Fig. 3C). Next-generation sequencing (NGS) is one of the most effective methods for studying biological functions. The NGS method can generate and fully analyze many differentially expressed genes (DEGs), which is a prerequisite for studying the potential mechanisms of biological processes. A functional enrichment analysis (e.g., GO terms and KEGG pathways) is a commonly used method to identify major biological functions from DEG datasets. Therefore, we developed two functional modules based on Perl and R scripts to perform a GO functional enrichment analysis and KEGG pathway enrichment analysis on DEG datasets provided by users (Fig. 3D). These modules can effectively identify significantly enriched GO terms and KEGG pathways from DEGs, providing important information for further research on biological processes. The PGD offers a very useful suite of analysis and visualization bioinformatics tools to explore and analyze genomic data. The “BLAST” tool permits the user to paste queries relating to one or more sequences in the input box, drag and drop FASTA format files, and then select BLAST parameters, including preformatted database, programs (blastn, blastp, blastx, tblastn, and tblstx), and an E-value cutoff (Figure S1A). In the “Gene Family Search” tool, users can search by Pfam ID and set filtering parameters such as genome database, control report type, and threshold screening. On the output page, users can not only download the filtered gene family list, but also truncate domain sequences based on the threshold and draw sequence polymorphism diagrams (Figure S1B). The gene structure analysis tool can not only obtain gene structure information in batches based on the user-input gene list, but also draw gene structure maps online (Figure S1C). To support the batch prediction of protein physicochemical properties, we developed an online tool for predicting protein physicochemical properties. The prediction results are presented in table form, including various properties related to protein properties, such as protein length (AA), molecular weight (MW), theoretical isoelectric point (Pi), and protein hydrophilicity grand average (GRAVY) (Figure S1D). To facilitate the calculation of the Ka/Ks ratio for homologous genes, we integrated a Ka/Ks calculator into the PGD. Users only need to provide a list of homologous genes for a Ka/Ks calculation, and the results are provided in table and Ka/Ks scale distribution formats (Figure S1E). The lipoxygenase (LOX) protein gene family of passionfruit was analyzed using the PGD platform (Figure S2). LOX is a multifunctional enzyme in plants, characterized by its non-heme iron-containing dioxygenases. Its functions include participation in seed development, tissue development, and fruit flavor formation, as well as playing a crucial role in the plant response to stressors such as pathogen infection, drought, and salt stress. Previous studies have demonstrated the significance of LOX in the synthesis of volatile compounds in fruits, making the analysis of the LOX gene family essential for understanding the rich and unique aroma of passionfruit. The “Protein family prediction” module was employed to search for candidate genes in the genome libraries of purple and yellow passionfruit using the “lipoxigenase” domain “PF00305” in Pfam as an input and a full-length alignment threshold E-value of 1e-5. Subsequently, the results were subjected to the “Physicochemical properties of protein analysis tool” and “Gene structure analysis tool” to filter and screen them (Figure S2B), resulting in the identification of 17 and 12 LOX genes in yellow and purple passionfruit, respectively. The Ka/Ks analysis of homologous LOX genes in both passionfruit varieties revealed a Ka/Ks ratio that was predominantly concentrated between 0 and 0.15 (Figure S2C), it was observed that the LOX genes underwent gene purification selection in both varieties. To conduct a phylogenetic tree analysis of the passionfruit LOX gene, we employed the same methodology on the PGD platform to identify LOX in the complete genome of Arabidopsis thaliana. Subsequently, utilizing the LOX protein sequences of passionfruit and A. thaliana, we utilized the mega software to construct a maximum likelihood phylogenetic tree (Figure S2A). The findings of the analysis revealed that the LOX protein was classified into two subfamilies, namely 9-LOXs and 13-LOXs. Furthermore, we also analyzed the expression pattern of the LOX gene in yellow passion fruit (Figure S2D). The PGD platform's forecast of LOX in purple passionfruit was aligned with the findings of the LOX gene family identification in purple passionfruit by Huang et al. [30,31,32,33,34,35]. Additionally, some growth and development regulation gene families have been found to be closely related to the fruit growth and ripening process of passionfruit [30, 35]. These research findings contribute to a better understanding of the biological characteristics of passionfruit and provide a theoretical basis for further genetic improvement and cultivation. Although passionfruit genomics research is still in its early stages, encouraging progress has already been made. To enhance the accessibility, analysis, and visualization of passionfruit genomics data, the PGD web portal was developed. As a sustainable solution, the PGD constructed a comprehensive central portal for passionfruit genomics, which will amalgamate diverse omics data and create a suite of omics data mining tools. To date, the PGD has amassed a range of passionfruit omics data, comprising genome assembly sequences, protein-coding gene structural and functional annotation, non-coding gene annotation, homologous gene pair data, and gene expression profiles. Furthermore, the PGD website offers a plethora of interactive analysis tools, enabling basic and batch queries, download options, BLAST, use of a genome browser, screening and analysis of gene families, determination of the physicochemical properties of proteins, gene structure analysis, conserved protein motif analysis, KEGG pathway and GO term enrichment analysis, and calculations of the substitution ratios (Ka/Ks) of orthologous gene-pairs. In conclusion, the PGD offers a diverse range of tools to facilitate the querying, analysis, and visualization of molecular interactions. As a new genomic dataset, with the potential to include genomes and transcriptomes that become publicly accessible for passionfruit species, the PGD will be regularly updated. It is envisaged that the PGD will serve as a valuable platform for conducting functional genomics research and molecular breeding endeavors in passionfruit.Construction and content
Genome data sources and annotation

Transcriptome data analysis
Data integration and website construction
Utility and discussion
Essential modules and interface of PGD
Search module of PGD

Jbrowse module of PGD

Heatmap and enrichment analysis modules of PGD
Analysis tools modules of PGD
BLAST
Gene family search
Gene structure analysis
Protein physicochemical properties online analysis
The Ka/Ks calculation for homologous genes
A case study for the application of the PGD
Availability of data and materials
Data generated or analysed during this study are already publicly available, The purple passionfruit (Passiflora edulis Sims) genome data can be found at the following website: https://ngdc.cncb.ac.cn/search/?dbId=&q=PRJCA004251. In addition, other data can be downloaded from the PGD: http://passionfruit.com.cn/Downloads.html.
References
Dhawan K, Dhawan S, Sharma A. Passiflora: a review update. J Ethnopharmacol. 2004;94(1):1–23.
He X, Luan F, Yang Y, Wang Z, Zhao Z, Fang J, Wang M, Zuo M, Li Y. Passiflora edulis: an insight into current researches on phytochemistry and pharmacology. Front Pharmacol. 2020;11:617.
Simirgiotis MJ, Schmeda-Hirschmann G, Bórquez J, Kennelly EJ. The Passiflora tripartita (Banana Passion) fruit: a source of bioactive flavonoid C-glycosides isolated by HSCCC and characterized by HPLC–DAD–ESI/MS/MS. Molecules (Basel, Switzerland). 2013;18(2):1672–92.
Nóbrega D, Peixoto JR, Vilela MS, Gomes K, Nogueira I. Agronomic descriptors and ornamental potential of passion fruit species. Ornamental Horticulture. 2017;23(3):357.
Yang K, Yan H, Song L, ** P, Miao W, Cui H. Analysis of the complete genome sequence of a potyvirus from passion fruit suggests its taxonomic classification as a member of a new species (vol 163, pg 2583, 2018). Adv Virol. 2021;1:166.
Matsumoto Y, Katano Y. Cardiovascular protective effects of polyphenols contained in passion fruit seeds namely piceatannol and scirpusin b: a review. Tokai J Exp Clin Med. 2021;46(3):151–61.
Viera W, Shinohara T, Samaniego I, Sanada A, Terada N, Ron L, Suárez-Tapia A, Koshio K: Phytochemical Composition and Antioxidant Activity of Passiflora spp. Germplasm Grown in Ecuador. Plants (Basel, Switzerland). 2022;11(3).
Santos AA, Penha HA, Bellec A, MunhozCde F, Pedrosa-Harand A, Bergès H, Vieira ML. Begin at the beginning: a BAC-end view of the passion fruit (Passiflora) genome. BMC Genomics. 2014;15(1):816.
**a Z, Huang D, Zhang S, Wang W, Ma F, Wu B, Xu Y, Xu B, Chen D, Zou M, et al. Chromosome-scale genome assembly provides insights into the evolution and flavor synthesis of passion fruit (Passiflora edulis Sims). Horticulture Research. 2021;8(1):14.
Ma D, Dong S, Zhang S, Wei X, **e Q, Ding Q, **a R, Zhang X. Chromosome-level reference genome assembly provides insights into aroma biosynthesis in passion fruit (Passiflora edulis). Mol Ecol Resour. 2021;21(3):955–68.
Flynn JM, Hubley R, Goubert C, Rosen J, Clark AG, Feschotte C, Smit AF. RepeatModeler2 for automated genomic discovery of transposable element families. Proc Natl Acad Sci U S A. 2020;117(17):9451–7.
Stanke M, Waack S. Gene prediction with a hidden Markov model and a new intron submodel. Bioinformatics (Oxford, England). 2003;19(19 Suppl 2):ii215-225.
Korf I. Gene finding in novel genomes. BMC Bioinformatics. 2004;5:59.
Keilwagen J, Wenk M, Erickson JL, Schattat MH, Grau J, Hartung F. Using intron position conservation for homology-based gene prediction. Nucleic Acids Res. 2016;44(9):e89.
Grabherr MG, Haas BJ, Yassour M, Levin JZ, Thompson DA, Amit I, Adiconis X, Fan L, Raychowdhury R, Zeng Q, et al. Full-length transcriptome assembly from RNA-Seq data without a reference genome. Nat Biotechnol. 2011;29(7):644–52.
Haas BJ, Delcher AL, Mount SM, Wortman JR, Smith RK Jr, Hannick LI, Maiti R, Ronning CM, Rusch DB, Town CD, et al. Improving the Arabidopsis genome annotation using maximal transcript alignment assemblies. Nucleic Acids Res. 2003;31(19):5654–66.
Haas BJ, Salzberg SL, Zhu W, Pertea M, Allen JE, Orvis J, White O, Buell CR, Wortman JR. Automated eukaryotic gene structure annotation using EVidenceModeler and the Program to Assemble Spliced Alignments. Genome Biol. 2008;9(1):R7.
Jones P, Binns D, Chang HY, Fraser M, Li W, McAnulla C, McWilliam H, Maslen J, Mitchell A, Nuka G, et al. InterProScan 5: genome-scale protein function classification. Bioinformatics (Oxford, England). 2014;30(9):1236–40.
Letunic I, Doerks T, Bork P. SMART 7: recent updates to the protein domain annotation resource. Nucleic Acids Res. 2012;40(Database issue):D302-305.
Mitchell AL, Attwood TK, Babbitt PC, Blum M, Bork P, Bridge A, Brown SD, Chang HY, El-Gebali S, Fraser MI, et al. InterPro in 2019: improving coverage, classification and access to protein sequence annotations. Nucleic Acids Res. 2019;47(D1):D351-d360.
Sigrist C, Cerutti L, de Castro E, Langendijk-Genevaux P, Bulliard V, Bairoch A, Hulo N. PROSITE, a protein domain database for functional characterization and annotation. Nucleic Acids Res. 2010;38:D161-166.
Potter SC, Luciani A, Eddy SR, Park Y, Lopez R, Finn RD. HMMER web server: 2018 update. Nucleic Acids Res. 2018;46(W1):W200-w204.
Kanehisa M, Sato Y. KEGG Mapper for inferring cellular functions from protein sequences. Protein Sci. 2020;29(1):28–35.
Kanehisa M, Furumichi M, Sato Y, Kawashima M, Ishiguro-Watanabe M. KEGG for taxonomy-based analysis of pathways and genomes. Nucleic Acids Res. 2023;51(D1):D587-d592.
Kanehisa M. Toward understanding the origin and evolution of cellular organisms. Protein Sci. 2019;28(11):1947–51.
Kanehisa M, Goto S. KEGG: kyoto encyclopedia of genes and genomes. Nucleic Acids Res. 2000;28(1):27–30.
Götz S, García-Gómez JM, Terol J, Williams TD, Nagaraj SH, Nueda MJ, Robles M, Talón M, Dopazo J, Conesa A. High-throughput functional annotation and data mining with the Blast2GO suite. Nucleic Acids Res. 2008;36(10):3420–35.
Kim D, Paggi JM, Park C, Bennett C, Salzberg SL. Graph-based genome alignment and genoty** with HISAT2 and HISAT-genotype. Nat Biotechnol. 2019;37(8):907–15.
Pertea M, Pertea GM, Antonescu CM, Chang TC, Mendell JT, Salzberg SL. StringTie enables improved reconstruction of a transcriptome from RNA-seq reads. Nat Biotechnol. 2015;33(3):290–5.
Huang D, Ma F, Wu B, Lv W, Xu Y, **ng W, Chen D, Xu B, Song S: Genome-Wide Association and Expression Analysis of the Lipoxygenase Gene Family in Passiflora edulis Revealing PeLOX4 Might Be Involved in Fruit Ripeness and Ester Formation. Int J Mol Sci. 2022;23(20).
Rizwan HM, Waheed A, Ma S, Li J, Arshad MB, Irshad M, Li B, Yang X, Ali A, Ahmed MAA, et al. Comprehensive Genome-Wide Identification and Expression Profiling of Eceriferum (CER) Gene Family in Passion Fruit (Passiflora edulis) Under Fusarium kyushuense and Drought Stress Conditions. Front Plant Sci. 2022;13:898307.
Zhang YS, Xu Y, **ng WT, Wu B, Huang DM, Ma FN, Zhan RL, Sun PG, Xu YY, Song S. Identification of the passion fruit (Passiflora edulis Sims) MYB family in fruit development and abiotic stress, and functional analysis of PeMYB87 in abiotic stresses. Front Plant Sci. 2023;14:1124351.
Ma F, Zhou H, Xu Y, Huang D, Wu B, **ng W, Chen D, Xu B, Song S. Comprehensive analysis of bZIP transcription factors in passion fruit. iScience. 2023;26(4):106556.
Wang L, Liu Y, Chai G, Zhang D, Fang Y, Deng K, Aslam M, Niu X, Zhang W, Qin Y, et al. Identification of passion fruit HSF gene family and the functional analysis of PeHSF-C1a in response to heat and osmotic stress. Plant Physiol Biochem. 2023;200:107800.
Liang J, Fang Y, An C, Yao Y, Wang X, Zhang W, Liu R, Wang L, Aslam M, Cheng Y, et al. Genome-wide identification and expression analysis of the bHLH gene family in passion fruit (Passiflora edulis) and its response to abiotic stress. Int J Biol Macromol. 2023;225:389–403.
Acknowledgements
Not applicable.
Funding
This work was supported by grants from the Fujian Provincial Finance Department Fund (KLE21004A),the key discipline construction project of the Plant Protection College of Fujian Agriculture and Forestry University, the National Natural Science Foundation of China (No. 31972243).
Author information
Authors and Affiliations
Contributions
SZ: Conceptualization, Supervision. CY: Data curation, Writing-Original draft preparation, Software and Database construction. PW: Software, Validation. SZ: Formal analysis. JL: Visualization. YC: Data Curation. Z W: Methodology, Funding acquisition. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Yu, C., Wang, P., Zhang, S. et al. Passionfruit Genomic Database (PGD): a comprehensive resource for passionfruit genomics. BMC Genomics 25, 157 (2024). https://doi.org/10.1186/s12864-024-10069-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12864-024-10069-9