
Abstract
Well-known continuous distributions such as Beta and Kumaraswamy distribution are useful for modeling the datasets which are based on unit interval [0,1]. But every distribution is not always useful for all types of data sets, rather it depends on the shapes of data as well. In this research, a three-parameter new distribution named bounded exponentiated Weibull (BEW) distribution is defined to model the data set with the support of unit interval [0,1]. Some fundamental distributional properties for the BEW distribution have been investigated. For modeling dependence between measures in a dataset, a bivariate extension of the BEW distribution is developed, and graphical shapes for the bivariate BEW distribution have been shown. Several estimation methods have been discussed to estimate the parameters of the BEW distribution and to check the performance of the estimator, a Monte Carlo simulation study has been done. Afterward, the applications of the BEW distribution are illustrated using COVID-19 data sets. The proposed distribution shows a better fit than many well-known distributions. Lastly, a quantile regression model from bounded exponentiated Weibull distribution is developed, and its graphical shapes for the probability density function (PDF) and hazard function have been shown.
Similar content being viewed by others


Introduction
The need to develop the unit interval distributions due to their applications in engineering, economics, psychology, and biology are quickly increasing. The unit interval or distribution bounded with the interval [0,1] are significant for modeling data given in the intervals between zero and one, such as ratios, rates, and percentages. For example, in psychology the percentages and proportions are useful to judgement possibilities, the percentage of mind section captured by a specific region. In economics, under study variable or data is generally limited to unit intervals e.g., market share, capital structure, and percentage of income spent on non-permanent utilizations. It is also observed that unit distributions have attractive hazard rate shapes like a bathtub. A well-known distribution named two parameter beta distribution is bounded with data between zero and one but due its intractable cumulative distribution function (CDF) and quantile function (QF), beta distribution has some limitations. The procedure of generating random observations from the beta distribution is difficult due to the complexity of the expressions of its QF and CDF. Therefore, researchers were inspired to develop such type of unit interval distributions having attractive expressions for CDF, QF and variety of shapes for the hazard functions.
Several noteworthy contributions can be found in the literature, such as the unit inverse Gaussian distribution (UIGD) introduced by1 and the unit Lindley distribution (ULD) proposed by2. Additionally, a multivariate quasi-beta regression model for bounded data developed by3, while the unit generalized half normal distribution generated by4. The unit gamma/Gompertz distribution introduced by5, and a quantile regression model based on the unit Birnbaum-Saunders distribution have produced by6, demonstrating its applications in medicine and politics. Furthermore, the transmuted unit Rayleigh quantile regression model developed by7, adding to the repertoire of methodologies available for analyzing unit interval datasets. The continuous distribution with support on the unit interval continues to advance as researchers strive to address the challenges associated with modeling and analyzing such data. By develo** new bounded distributions and innovative regression models, scholars are expanding the toolkit available for studying unit interval datasets across various disciplines. These advancements are expected to have a profound impact on the fields of engineering, economics, psychology, and biology, enabling more accurate and effective analysis of data involving ratios, rates, and percentages within the unit interval [0, 1]. Nasiru et al.8 introduced a new lifetime distribution named as bounded truncated Cauchy power exponential distribution to model the unit data, Almazah et al.9 executed various distribution methods to find five new different forms of the inverse Weibull model and the resultant models applied on the mortality rate of COVID-19. Moraes-Rego10 introduced a unit interval distribution named a truncated exponentiated exponential distribution. Afify et al.11 developed and applied discrete exponential distribution to COVID-19 data. Maya et al.12 introduced bounded probability distribution and named it unit distribution, they derived its various properties and finally applied to the real data sets. Mustafa & Zehra13 developed the unit log–log distribution, with quantile regression modelling and applied to educational measurements. Hannan et al.14 introduced unit exponential Pareto distribution with properties and modeled it on the recovery rate of COVID-19. Ayuyuen & Bodhisuwan15 developed the unit Garima distribution with properties. Sangsanit & Bodhisuwan16 introduced Topp-Leone generator of distributions.
This study addresses the limitations of existing unit interval distributions by proposing a novel solution, the bounded exponentiated Weibull (BEW) distribution. The proposed BEW distribution fills a crucial gap in the existing literature by providing a dedicated distribution specifically designed for unit interval data. This fills an important need in fields such as reliability analysis, survival analysis, and time-to-event modeling, where unit interval data frequently arise. By addressing this gap, the paper contributes to the advancement of mathematical methodologies in these areas. Therefore, unlike other distributions, the BEW distribution offers an attractive cumulative distribution function and quantile function, making it better suited for describing various types of datasets within unit intervals. The paper also explores the influence of the widely used Weibull distribution in inspiring the development of the BEW distribution. Additionally, the paper introduces a bivariate extension of the BEW distribution to model the independence among random data over unit intervals. Lastly, the paper presents a novel quantile regression model based on the BEW distribution, enabling the investigation of the relationship between a given covariate and a response variable. By employing BEW distribution-based quantile regression, researchers can enhance their mathematical modeling techniques and broaden their applications across domains such as economics, social sciences, and finance. This novel approach has the potential to accelerate research in these areas by providing new insights into the relationships between variables.
Methods
This section presents a methodology for develo** a bounded exponentiated Weibull (BEW) distribution along with its properties.
New proposed BEW distribution
Consider, a CDF and a probability density function (PDF) of an exponentiated Weibull distribution respectively are given by,
Now, a distribution termed as the BEWD is developed following the conversion of \(e^{ - X} = {\text{Y}} \to - {\text{ln}}\left( {\text{Y}} \right) = {\text{X}}\). The CDF of the BEWD is as follows,
or
Now, the following is a CDF of the BEW distribution,
where \({\varvec{y}}^{{{\varvec{\uplambda}}}} = {{\varvec{\Upsilon}}},\) \({{\varvec{\uplambda}}}\) is a location parameter, while \({\varvec{\alpha}}\) & \({{\varvec{\upbeta}}}\) are respectively shape and scale parameters.
Hence, the PDF of the BEWD is given by
Reliability measures of BEW distribution
In this section a few reliability measures such as survival function, hazard function, reversed hazard function, cumulative hazard function, odd function, elasticity, and mills ratio for the BEW distribution have been discussed.
The survival function represents the probability that an individual will survive beyond a certain time, denoted as y. In the case of the BEW distribution, the survival function can be expressed as,
On the other hand, the hazard function characterizes the death rate of an individual at a specific age, denoted as y For the BEW distribution, the hazard function can be calculated as,
Additionally, the reverse hazard function determines the fraction of the life probability density to its distribution function. In the case of the BEW distribution, the reverse hazard function can be defined as, \({\varvec{r}}_{{\varvec{h}}} \left( {\varvec{y}} \right) = \frac{{\user2{F^{\prime}}\left( {\varvec{y}} \right)}}{{{\varvec{F}}\left( {\varvec{y}} \right)}}\) = \(\frac{{{\varvec{f}}\left( {\varvec{y}} \right)}}{{{\varvec{F}}\left( {\varvec{y}} \right)}},\)
The cumulative hazard function for the BEW distribution is
The odd function for the BEW distribution is
The elasticity for the BEW distribution is
Mills ratio for the BEW distribution is
By utilizing the mathematical expressions stated above, researchers can analyze or model the data using the survival, hazard, and reverse hazard characteristics associated with the BEW distribution.
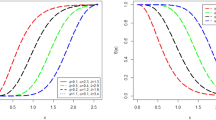
From Fig. 1, the PDF graphs of BEW distribution show a variety of shapes, positively/negatively skewed, symmetrical, U shapes, reverse J shape. The hazard function of the BEW distribution shows bathtub shape.

PDF (left) and HRF (right) of the BEWD.
Some distributional properties of BEW distribution
In this section some fundamental distributional properties such as quantile function, median, inter quartile range, moments, moment generating function (mgf), mean, variance and standard deviation for the BEW distribution have been presented.
The quantile function (QF) is the inverse of the CDF of any PDF. The QF of the BEW distribution is as follow:
The median and Inter quartile range (IQR) for the BEW distribution are calculated as Median = \(y_{0.5}\) and IQR = \(y_{0.75} - { }y_{0.25}\) in (12).
The \(r{\text{th}}\) moments for the BEW distribution are defined as
The mean of the BEW distribution is
The variance of the BEW distribution is
The MGF for the BEW distribution is given below
Numerical description of the standard deviation (SD), coefficient of Skewness (CV), and coefficient of Kurtosis (CK), coefficient of skewness (CS) for the BEW distribution for some parametric values are given in Table 1.
Inequality measures
The Lorenz and Bonferroni curves are used in several fields of study, such as economics, demography, reliability, medicine, and insurance. They are commonly used to analyze the poverty and income values of imbalance. To find these inequalities we first need to derive incomplete moments.
Theorem 1.
An \(r{\text{th}}\) incomplete central moment of BEW distribution is given below.
where B \(\left( {u;\alpha ,{ }\beta } \right)\) = \(\mathop \smallint \limits_{0}^{u} y^{\alpha - 1} \left( {1 - y} \right)^{\beta - 1}\) dy, it is known as the incomplete beta function.
Proof.
Let the random variable Y follow the PDF given in Eq. (4), then the incomplete moments are.
Let \({\text{z}} = {\Upsilon }^{\beta } ,\) and simplifying it we get.
So, the above expression becomes the expression given in Eq. (17).
Theorem 2.
The Lorenz curve \(L_{F} \left( y \right)\) for the BEW distribution is defined as
where \({\text{B}}\left( {z;\alpha ,{ }\beta } \right) = \mathop \smallint \limits_{0}^{z} y^{\alpha - 1} \left( {1 - y} \right)^{\beta - 1}\) dy, it is known as the incomplete beta function.
Proof.
Let \(r = 1\) in the incomplete moments of BEW distribution derived in Theorem 1, and the Lorenz curve is defined as
By simplifying it we get the expression given in (18).
Theorem 3.
Bonferroni curve \({\text{B}}_{F} \left( y \right)\) for the BEW distribution is defined as
Proof:
let Lorenz curve derived in Theorem 2, and the CDF of the BEW distribution given in Eq. (3), in the following expression
By simplifying this we get the results given in Eq. (19).
Generalization of proposed methodology: a bivariate version of a BEW distribution
Many researchers are making prognostications regarding the relationship between the two numerical variables in a dataset, such as the correlation between an individual's age and BMI. Bivariate distributions serve as a valuable tool to observe the independence between variables and evaluate the dependability of products, particularly in insurance risk analysis, economics, and waiting time analysis. Within this section, an extended form of the BEW distribution known as the bivariate bounded exponentiated Weibull distribution (B-BEWD), is presented. We provide a illustration of CDF and PDF of the B-BEWD below.
where \(\lambda ,{ }\alpha ,\beta > 0\), \({ } - 1 < \delta_{{3{ }}} + \delta_{1} < 1\), \(- 1 < \delta_{3} + \delta_{2} < 1\), \(0 < {\text{y}} < 1\), \(0 < {\text{ x}} < 1{ }\) and \({\varvec{\eta}}{ } = { }\left( {\lambda ,\delta_{1} ,\delta_{2} ,\delta_{3} ,\alpha ,\beta ,{ }} \right)^{{\varvec{T}}}\). The constraints \(\delta_{1} ,\delta_{2,}\) and \(\delta_{3}\) estimate the dependency or independency between a B-BWD random variables.
Figure 2 shows the CDF graphs for the given parameter values.
-
(i)
λ = 6.0, \(\alpha\) = 4.5, \(\beta\) = 1.3, \(\delta_{1}\) = 0.5, \(\delta_{2}\) = 0.2, \(\delta_{3}\) = 0.4;
-
(ii)
λ = 10.5, \(\alpha\) = 9.5, \(\beta\) = 1.3, \(\delta_{1}\) = 0.2, \(\delta_{2}\) = 0.9, \(\delta_{3}\) = 0.4 and
-
(iii)
λ = 4.8, \(\alpha\) = 0.5, \(\beta\) = 2.1, \(\delta_{1}\) = − 0.3, \(\delta_{2}\) = − 0.7, \(\delta_{3}\) = − 0.1.

CDF plots of the B-BEW distribution.
Figure 3 shows the PDF plots for the given parameter values.
-
(i)
λ = 1.0, \(\delta_{1}\) = 0.5, \(\delta_{2}\) = 0.2, \(\delta_{3}\) = 0.4, \(\alpha\) = 2.5, \(\beta\) = 1.3;
-
(ii)
λ = 0.5, \(\delta_{1}\) = 0.2, \(\delta_{2}\) = 0.9, \(\delta_{3}\) = 0.4, \(\alpha\) = 2.5, \(\beta\) = 1.3 and
-
(iii)
λ = 5.8, \(\delta_{1}\) = − 0.3, \(\delta_{2}\) = − 0.7, \(\delta_{3}\) = − 0.1, \(\alpha\) = 4.5, \(\beta\) = 4.1,

PDF plots of the B-BEW distribution.
Parameter estimation methods
Six different methods for the estimation of the parameters have been covered in this section. These methods include maximum likelihood estimation (MLE) Cramér-von Mises estimation (CVME), ordinary least squares estimation (OLSE), weighted least squares estimation (WLSE), Percentile estimation (PC), and Anderson-Darling estimation (ADE) methods.
Maximum Likelihood Estimation
In this section the parameters of the BEW distribution are estimated by the MLE. Let \(Y_{1} ,Y_{2} , \ldots , Y_{n}\) be a random sample of size n and let \(y_{1} ,y_{2} , \ldots , y_{n}\) be a random sample values from the BEW distribution the likelihood function (L) is:
we have
Then applying the log-likelihood function \(l = l\left( \vartheta \right),{\text{ where }}\vartheta = \alpha ,\beta , {\text{and}} \lambda .\)
To estimate the values of the parameters of BEW, taking derivative of Eq. (22) with respect to \(\alpha ,\beta { }and{ }\lambda\) respectively, and we obtain
Because the above equations do not have a closed form, the non-linear system of equations \(\left( {\frac{{d\ell_{n}^{*} }}{d\alpha },\frac{{d\ell_{n}^{*} }}{d\lambda }} \right){ }^{T} = \left( {0,0} \right)^{T}\) therefore these equations can be numerically solved to find the parameter estimates.
Ordinary and Weighted Least Squares Estimation Methods
Let \(Y_{1} ,Y_{2} , \ldots ,Y_{n}\) be the ordered values from the BEW distribution with distribution function F(Y). For a sample of size n, we have \({\text{E}}\left[ {F\left( {Y_{\left( i \right)} } \right)} \right]{ } = { }\frac{i}{{\left( {n + 1} \right)}}\). The least-square estimator parameters \(\alpha\), \(\beta\) and \(\lambda\) for the BEW distribution are estimated by minimizing.
In the case of BEW distribution, Eq. (23) becomes.
Take the partial derivative of (24) with respect to the parameters to determine the estimates for \(\alpha ,\) \(\beta ,\) and \(\lambda .\) The following equations are,
where
and
By simplifying Eq. (25) the WLS estimates \(\hat{\alpha }_{WLS}\), \(\hat{\beta }_{WLS}\) and \(\hat{\lambda }_{WLS}\), can obtain by minimizing.
Take the partial derivative of Eq. (27) with respect to the parameters \(\hat{\user2{\alpha }}\),\(\user2{ \hat{\beta }}\) and \(\hat{\user2{\lambda }}\). The following equations are:
where, \(\Delta_{s} \left( {y_{\left( i \right)} |\alpha ,{\upbeta },\lambda } \right) = { }0,{\text{ s }} = { }1,{ }2,{ }3\) is defined above.
Cramér–Von Mises estimation
Let \(Y_{1} ,Y_{2} , \ldots ,Y_{n}\) be the ordered values arise from the BEW distribution. The Cramér–Von Mises is used to find the parameters \(\hat{\alpha }_{CVM}\), \(\hat{\beta }_{CVM}\), and \(\hat{\lambda }_{CVM}\) that are find out by minimizing the function that is given below.
Differentiate the Eq. (30) with respect to \(\alpha\), \(\beta\) and \(\lambda\), the estimates of the parameters can be determined numerically by the equations given below.
where, \(\Delta_{s} \left( {y_{\left( i \right)} |\alpha ,\beta ,\lambda } \right)\) are defined in the section “Ordinary and Weighted Least Squares estimation methods”.
Anderson–Darling estimation
Let \(Y_{1} ,Y_{2} , \ldots ,Y_{n}\) be ordered observations arise from BEW distribution. The Anderson–Darling is determined by minimizing the function that are given below to find the parameters \(\hat{\alpha }_{AD}\) and \(\hat{\lambda }_{AD}\).
These estimators can be derived by solving the non-linear equations that are given below.
Percentile estimation
Let \(Y_{1} ,Y_{2} , \ldots ,Y_{n}\) be ordered observations came from BEW distribution and \(u_{i}\) = \(\frac{i}{n + 1}\) is an unbiased estimate of \(F_{Y} \left( {y_{\left( i \right)} ;\alpha ,\beta ,\lambda } \right)\). The PC estimates for the BEW distribution parameters are derived by minimizing the following function:
Simulation study
In this section a simulation study is represented by using the BEW distribution to assess the performance of the estimators discussed in the previous section and numerical results are obtained. We generate N = 10,000 samples of the size n = (20, 40, 100, 300) from BEW distribution with parameter settings \(\left( {\alpha = 1,{ }\beta = 2,{ }\lambda = 3{\text{ and }}\alpha = 1.7,{ }\beta = 0.5,{ }\lambda = 2.8} \right)\). The random numbers generation is obtained by quantile function of BEW distribution. In this simulation study, we calculate the empirical mean, bias, and mean square errors (MSE’s) of all estimators to compare in the terms of their biases and MSE’s with varying sample size.
and
In Tables 2 and 3 the simulations study with the help of bias, average bias, MSE and mean relative error (MRE) are shown for small, medium, and large ample sizes. The proposed estimation methods are used such as maximum likelihood estimator (MLE), Anderson Darling (AD), Cramer-von Mises (CVM), ordinary least square (OLS) and weighted least square (WLS). It is observed that for large (n = 300) and for medium (n = 100) sample sizes MLE is performing better as compared to AD, CVM, OLS and WLS. For small (n = 20) and (n = 50) AD is better than MLE, CVM, OLS and WLS and MLE is better than CVM, OLS and WLS.
For the numerical solutions, simulations of the estimation methods including MLE, AD, CVM, OLS, WLS, further analysis and applications, R studio17, and Wolfram MATHEMATICA 13.3 software are used.
Applications
This section determines the significance of the BEW distribution and compares its performance with the other competing unit interval distributions. The databases belong to the unit interval observations as the mortality rate of COVID-19 patient (1) in Canada and (2) in the UK, and recovery rate (3) in Spain.
Table 4 explains some descriptive measures for the mortality and recovery rate of COVID-19 data in three countries. The UK data is positive skewed, and Canada and Spain are negatively skewed similar trend is shown by the box plot in Fig. 4.

Box Plot of Covid-19 datasets.
Tables 5, 6 and 7 contain the fitted distributions' along with values of test statistics with p-values and also the estimated values of the parameters by MLE of the parameters along with their standard errors. Figures 5, 6 and 7 show the comparison of empirical and fitted PDFs and CDFs for the three data sets.

Fitted and empirical PDFs and CDFs of the UK dataset.

Empirical and fitted PDFs and CDFs of Canada dataset.

Fitted and empirical PDFs and CDFs of Spain dataset.
Mortality rate of COVID-19 in UK
The BEW distribution offers the best fit to the data due to the smallest AIC, BIC, CAID, AD, and highest log-likelihood value and p-value of the KS test.
COVID-19 mortality rate in Canada
The BEW distribution offers the best fit to the data due to the smallest AIC, BIC, CAID, AD, and highest log-likelihood value and p-value of the KS test.
COVID-19 recovery rate in Spain
The BEW distribution offers the best fit to the data due to the smallest AIC, BIC, CAID, AD, and highest log-likelihood value and p-value of the KS test.
BEW quantile regression model
In this section BEW quantile regression model is developed using the quantile of the BEW distribution. When the response variables are bounded in the unit interval, then beta regression models indicating conditional mean responses becomes difficult to apply there. In this study, quantiles of responses are modeled using quantile regression models. Considering the quantile function of the BEW distribution, we developed the PDF for the BEW distribution.
Suppose \(\omega = {\text{Q}}\left( {y;{ }\alpha ,\lambda } \right)\) then \({\uplambda } = \frac{{log\left[ {1{ } - { }\left( {1 - q} \right)^{{{\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 \alpha }}\right.\kern-0pt} \!\lower0.7ex\hbox{$\alpha $}}}} } \right]}}{{{{\beta {\text log}}}\left( \omega \right)}}\), So, the PDF and CDF of newly developed distribution respectively, are given below.
and
here \(\omega\) is the parameter of quantile. The BEW quantile is expressed as
where \(z_{i}{\prime} = { }\left( {1,{ }z_{i1} ,{ }z_{i2} , \ldots ,z_{ip} { }} \right)\) are the ith covariate vectors, \(\theta { } = \left( {\theta_{o} ,\theta_{1} ,{ } \ldots ,{ }\theta_{p} } \right){\prime}\) is the vectors of unknown parameters. The quantile \(\in { }\left[ {0,1} \right]\) is linked to the covariates using the logit link function. So, we have
Substitute the \(\omega_{i}\) in Eq. (36) and we get
where \(z_{i} = y_{i}^{{\left[ {\frac{{log\left\{ {1{ } - { }\left( {1 - q} \right)^{{{\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 \alpha }}\right.\kern-0pt} \!\lower0.7ex\hbox{$\alpha $}}}} } \right\}}}{{{{\beta {\text log}}}\left( \omega \right)}}} \right]}}\).
The log-likelihood for estimating the parameters bounded exponentiated Weibull quantile regression (BEWQRM) model is provided by
where \(z_{i}\) is defined above.
The regression equations parameters are estimated by maximizing the log-likelihood (LL) function. The parameters will be written as \(\hat{\user2{\alpha }}\) and \(\hat{\user2{\theta }}\) of \(\alpha\) and \(\theta\) respectively.
The survival function and the hazard function of BEWQRM are given as
and
Figure 8 represents the density plot for the BEWQRM for various values of parameters. It can be seen that the PDF shows a variety of shapes such as slightly and extremely positively skewed, negatively skewed, and symmetric. Figure 9 shows the hazard rate shapes for the BEWQRM and it exhibits j shapes and reverse j shape.

PDF plot of BEWQRM for some parametric and quantile values.

Hazard function plot of BEWQRM.
Conclusion
In various real-life situations, the random variable supports the bounded data with support [0,1] and moreover the data set shows a variety of shapes. While we model any data sets the selection of probability distribution is always a complex matter. Here in this article a new unit interval distribution is proposed named as bounded exponentiated Weibull (BEW) distribution to model data sets with support [0,1]. Although various unit interval distributions have been developed recently but firstly, every distribution is not suitable for all types of data sets, secondly, Weibull distribution has always attracted researchers due to its wide range of applications. The proposed distribution has a variety of shapes positively/negatively skewed, symmetrical, U shapes and reversed J shape. The hazard rate plot of the BEW distribution shows a bathtub shape. Various characteristics for the BEW distribution including the CDF, QF, median, moments, inequality measures, reliability measures, have been derived. Six different techniques have been investigated for estimating the parameters of the BEW distribution. A simulation has been conducted to show the performance of estimators. BEW distribution has been applied to three datasets, the data sets are COVID-19 death and recovery rates from the UK, Canada, and Spain. The proposed distribution outperforms as compared to the other competing unit interval distributions. A bivariate extension for the BEW distribution has been developed and its graphical shapes have also been shown. A BEW quantile regression model is also developed to examine the association between covariates and the conditional quantiles of unit interval response variable.
Data availability
The data set used and/or analyzed during the current study is available from the corresponding author on reasonable request.
References
Ghitany, M. E., Mazucheli, J., Menezes, A. F. & Alqallaf, F. The unit-inverse Gaussian distribution: A new alternative to two parameter distributions on the unit interval. Commun. Stat. Theory Methods 48(14), 3423–3438 (2019).
Mazucheli, J., Menezes, A. F. B. & Chakraborty, S. On the one parameter unit-Lindley distribution and its associated regression model for proportion data. J. Appl. Stat. 46(4), 700–714. https://doi.org/10.1080/02664763.2018.1511774 (2019).
Petterle, R. R., Bonat, W. H., Scarpin, C. T., Jonasson, T. & Borba, V. Z. C. Multivariate quasi-beta regression models for continuous bounded data. Int. J. Biostat. 17(1), 39–53 (2020).
Korkmaz, M. Ç. The unit generalized half normal distribution: A new bounded distribution with inference and application. UPB Sci. Bull. Ser. A: Appl. Math. Phys. 82(2), 133–140 (2020).
Bantan, R., Jamal, F., Chesneau, C. & Elgarhy, M. Theory and applications of the Unit Gamma/Gompertz Distribution. Mathematics 9(16), 1850 (2021).
Mazucheli, J., Leiva, V., Alves, B. & Menezes, A. F. B. A new quantile regression for modeling bounded data under a unit Birnbaum-Saunders distribution with applications in medicine and politics. Symmetry 13, 682. https://doi.org/10.3390/sym13040682 (2021).
Korkmaz, M. Ç., Chesneau, C. & Korkmaz, Z. S. Transmuted unit Rayleigh quantile regression model: Alternative to beta and Kumaraswamy quantile regression models. UPB Sci. Bull. Ser. A: Appl. Math. Phys. 83(3), 149–158 (2021).
Nasiru, S., Abubakari, A. G. & Chesneau, C. New lifetime distribution for modeling data on the Unit Interval: Properties, Applications and Quantile Regression. Math. Comput. Appl. 27, 105. https://doi.org/10.3390/mca27060105 (2022).
Almazah, M. M. A. et al. New statistical approaches for modeling the COVID-19 Data Set: A case study in the medical sector. Complexity 2022, 1325825 (2022).
Moraes-Rego, L. D. Truncated exponentiated-exponential distribution: A distribution for unit interval. J. Stat. Manage. Syst. 25(8), 2061–2072 (2022).
Afify, A. Z. et al. A new one-parameter discrete exponential distribution: Properties, inference, and applications to COVID-19 data. J. King Saud Univ. Sci. 34, 102199 (2022).
Maya, R., Jodrá, P., Irshad, M. R. & Krishna, A. The unit Muth distribution: Statistical properties and applications. Ricerche Mate. https://doi.org/10.1007/s11587-022-00703-7 (2022).
Mustafa, C. K. & Zehra, S. K. The unit log–log distribution: A new unit distribution with alternative quantile regression modeling and educational measurements applications. J. Appl. Stat. 50(4), 889–908. https://doi.org/10.1080/02664763.2021.2001442 (2023).
Hannan, H. A., Ehab, M. A., Mohammed, E. & Dina, A. R. On unit exponential Pareto Distribution for modeling the recovery rate of COVID-19. Processes 11(1), 232. https://doi.org/10.3390/pr11010232 (2023).
Ayuyuen, S. & Bodhisuwan, W. A generating family of unit-Garima distribution: Properties, likelihood inference, and application. Pak. J. Stat. Oper. Res. 20(1), 69–84 (2024).
Sangsanit, Y. & Bodhisuwan, W. The Topp-Leone generator of distributions: Properties and inferences. Songklanakarin J. Sci. Technol. 38(5), 537–548 (2016).
R Core Team R. A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna. https://www.r-project.org/ (2020).
Acknowledgements
Princess Nourah bint Abdulrahman University Researchers Supporting Project Number (PNURSP), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Author information
Authors and Affiliations
Contributions
S.B. & B.M.: conceptualization, theoretical and mathematical framework; software handling, data visualization, and analysis; writing the first draft writing. S.B.; A.S. & I.S.: Concept, supervision, data visualization analysis, editing and reviewing the final draft. A.S. & L.A.A.-E.: Edited, reviewed and proofread the final draft, Project management, resources and funding. S.B.: editing, formatting, and reviewing the final draft of the manuscript. All authors reviewed the final draft of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bashir, S., Masood, B., Al-Essa, L.A. et al. Properties, quantile regression, and application of bounded exponentiated Weibull distribution to COVID-19 data of mortality and survival rates. Sci Rep 14, 14353 (2024). https://doi.org/10.1038/s41598-024-65057-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-65057-6
- Springer Nature Limited