
Abstract
In vivo cardiac diffusion tensor imaging (cDTI) is a promising Magnetic Resonance Imaging (MRI) technique for evaluating the microstructure of myocardial tissue in living hearts, providing insights into cardiac function and enabling the development of innovative therapeutic strategies. However, the integration of cDTI into routine clinical practice poses challenging due to the technical obstacles involved in the acquisition, such as low signal-to-noise ratio and prolonged scanning times. In this study, we investigated and implemented three different types of deep learning-based MRI reconstruction models for cDTI reconstruction. We evaluated the performance of these models based on the reconstruction quality assessment, the diffusion tensor parameter assessment as well as the computational cost assessment. Our results indicate that the models discussed in this study can be applied for clinical use at an acceleration factor (AF) of \(\times 2\) and \(\times 4\), with the D5C5 model showing superior fidelity for reconstruction and the SwinMR model providing higher perceptual scores. There is no statistical difference from the reference for all diffusion tensor parameters at AF \(\times 2\) or most DT parameters at AF \(\times 4\), and the quality of most diffusion tensor parameter maps is visually acceptable. SwinMR is recommended as the optimal approach for reconstruction at AF \(\times 2\) and AF \(\times 4\). However, we believe that the models discussed in this study are not yet ready for clinical use at a higher AF. At AF \(\times 8\), the performance of all models discussed remains limited, with only half of the diffusion tensor parameters being recovered to a level with no statistical difference from the reference. Some diffusion tensor parameter maps even provide wrong and misleading information.
Similar content being viewed by others

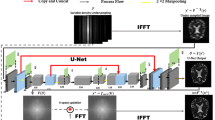

Introduction
In vivo cardiac diffusion tensor (DT) imaging (cDTI) is an emerging Magnetic Resonance Imaging (MRI) technique that has the potential to describe the microstructure of myocardial tissue in living hearts. The diffusion of water molecules occurs anisotropically due to the microstructure of the myocardium, which can be approximated by fitting three-dimensional (3D) tensors with a specific shape and orientation in cDTI. Various parameters can be derived from the DT, including mean diffusivity (MD) and fractional anisotropy (FA), which are crucial indices that can indicate the structural integrity of myocardial tissues. The helix angle (HA) signifies local cell orientations, while the second eigenvector (E2A) represents the average sheetlet orientation1. The development of cDTI provides insights into the myocardial microstructure and offers new perspectives on the elusive connection between cellular contraction and macroscopic cardiac function1,2. Furthermore, it presents opportunities for novel assessments of the myocardial microstructure and cardiac function, as well as the development and evaluation of innovative therapeutic strategies3. Early exploratory clinical studies, e.g., cardiomyopathy1,2,4, myocardial infarction5,6, have been reported, and shown very promising results and high potential for cDTI to contribute to the clinic.
Despite the numerous advantages, there are still significant technical obstacles that must be overcome to integrate cDTI into routine clinical practice. For the calculation of the DT, diffusion-weighted images (DWIs) with diffusion encoding in at least six distinct directions need to be collected. Due to the movement derived from heart beats and human breath, in vivo cDTI exploits single-shot encoding acquisition for repetitive fast scanning, e.g., single-shot echo planar imaging (SS-EPI) or spiral diffusion-weighted imaging7. The utilisation of these single-shot encoding acquisitions, leading to low signal-to-noise ratio (SNR) images, typically requires multiple repetitions to enhance the accuracy of the DT estimation8,9. Each repetition necessitates an additional breath-hold for the patient when using breath-hold acquisitions, which significantly increases the total scanning time and leads to uncomfortable patient experience.
Numerous studies have been proposed to accelerate cDTI technique, which can be mainly categorised as (1) reducing the total amount of DWIs used for the calculation of the DT; (2) general fast DWI by k-space undersampling and reconstruction using compressed sensing (CS) or deep learning techniques. It is noted that this study focuses on the second strategy.
Deep learning has emerged as a powerful technique for image analysis, capitalising on the non-linear and complex nature of networks through supervised or unsupervised learning, and has found widespread applications in medical image research10. Deep learning-based MRI reconstruction11,12 has gained significant attention, leveraging its capability of learning complex and hierarchical representations from large MRI datasets13.
In this work, we investigated the application of deep learning-based methods for cDTI reconstruction. We explored and implemented three representative deep learning-based models from algorithm unrolling models14,15,16, enhancement-based models17,18,19,20 to emerging generative models21,22,23, on the cDTI dataset with acceleration factor (AF) of \(\times 2\), \(\times 4\) and \(\times 8\), including a Convolutional Neural Network (CNN)-based algorithm unrolling method, i.e., D5C515, a CNN-based and conditional Generative Adversarial Network (GAN)-based method, i.e., DAGAN21, and a Transformer-based and enhancement-based method, i.e., SwinMR19. The performance of these models was evaluated by the reconstruction quality assessment and the DT parameters assessment.
To the best of our knowledge, this work is the first comparison study that focuses on evaluating various deep learning-based models on in vivo cDTI, encompassing algorithm unrolling models, enhancement-based models, and generative models. The purpose of this work is not to propose a new reconstruction model for cDTI. Instead, it aims to validate the performance of existing MRI reconstruction models on the DWI reconstruction and to provide a general framework for a fair comparison.
Our experiments demonstrate that the models discussed in this paper can be applied for clinical use at AF \(\times 2\) and AF \(\times 4\), since both the reconstruction of DWIs and DT parameters reach satisfactory levels. Among these models, D5C5 shows superior fidelity for the reconstruction, while SwinMR provides results with higher perceptual scores. There is no statistical difference from the reference for all the DT parameters at AF \(\times 2\) or most of the DT parameters at AF \(\times 4\). The quality of most the DT parameter maps we considered are visually acceptable. Considering various factors, SwinMR is recommended as the optimal approach for the reconstruction with AF \(\times 2\) and AF \(\times 4\).
However at AF \(\times 8\), the performance of these three models, including the best-performing SwinMR, is still limited. The reconstruction quality is unsatisfactory due to the artefact remaining and the noisy (DAGAN) or hallucinated (SwinMR) estimation. Only half of the DT parameters can be recovered to a level that is no statistical difference from the reference. Some DT parameter maps even provide wrong and misleading information, which is unacceptable and dangerous for clinical use.
Related works
Diffusion tensor MRI acceleration
A major drawback of DTI is its extended scanning time, as it requires multiple DWIs with varying b-value and diffusion gradient directions to calculate the DT. In theory, the estimation of the DT requires only six DWIs with different diffusion gradient directions and one reference image. However, in practical for cDTI, a considerable number of cardiac DWIs and multiple averages are typically required to enhance the accuracy of DT estimation, due to the inherently low SNR of single-shot acquisitions.
Strategies to accelerate the DTI technique have been explored. One technical route aims to reduce the number of DWIs required for the DT estimation24,25,26,27,28,29,30, which can be further categorised into three sub-class.
-
(1)
Learn a direct map** from DWIs with reduced number of repetitions (or gradient directions), to the DT or DT parameter maps. Ferreira et al.24 proposed a U-Net31-based model for cDTI acceleration, which directly estimated the DT, using DWIs collected within one breath-hold, instead of solving a conventional linear-least-square (LLS) tensor fitting. Karimi et al.25 introduced a Transformer-based model with coarse-and-fine strategy to provide accuracy estimation of the DT, using only six diffusion-weighted measurements. Aliotta et al.32 proposed a neural network for brain DTI, namely DiffNet, which estimated MD and FA maps directly from diffusion-weighted acquisitions with as few as three diffusion-encoding directions. They further improved their method by combining a parallel U-Net for slice-to-slice map** and a multi-layer perceptron for pixel-to-pixel map**26. Li et al.27 developed a CNN-based model for brain DTI, i.e., SuperDTI, to generate FA, MD and directionally encoded color maps with as few as six diffusion-weighted acquisitions.
-
(2)
Enhance DWIs (denoising). This kind of methods usually apply only a small amount of enhanced images to achieve comparable estimation results with the results reconstructed using a standard protocol. Tian et al.28 developed a novel DTI processing framework, entitled DeepDTI, which minimised the required data for DTI to six diffusion-weighted images. The core idea of this framework was to use a CNN that took a stack of non-diffusion-weighted (b0) image, six DWIs as well as a anatomical (T1- or T2-weighted) image as input, to produce high-quality b0 images and six DWIs. Phipps et al.29 applied a denoising CNN to enhance the quality of b0 images and corresponding DWIs for cDTI.
-
(3)
Refine the DT quality. Tänzer et al.30 proposed a GAN-based Transformer, aiming to directly enhance the quality of the DT that was calculated with a reduce number of DWIs in an end-to-end manner.
Another technical route follows the general DWIs acceleration by k-space undersampling and reconstruction33,34,35,36. Zhu et al.33 directly estimated the DT from highly undersampled k-space data. Chen et al.34 incorporated a joint sparsity prior of different DWIs with the L1-L2 norm and the DT’s smoothness with the total variational (TV) semi-norm to efficiently expedite DWI reconstruction. Huang et al.35 utilised a local low-rank model and 3D TV constraints to reconstruct the DWIs from undersampled k-space measurements. Teh et al.36 introduced a directed TV-based method for DWI images reconstruction, applying the information on the position and orientation of edges in the reference image.
In addition to these major technical routes, Liu et al.37 explored deep learning-based image synthetics for inter-directional DWIs generation. The true b0 and 6 DWIs were concatenated with the generated data and passed to the CNN-based tensor fitting network.
Deep learning-based reconstruction
The aim of MRI reconstruction is to recover the image of interest \({\textbf{x}} \in {\mathbb {C}}^n\) from the undersampled k-space measurement \({\textbf{y}} \in {\mathbb {C}}^m\), which is mathematically described as an inverse problem:
in which the degradation matrix \({\textbf{A}} \in {\mathbb {C}}^{m \times n}\) can be further presented as the combination of the undersampling trajectory \({\textbf{M}} \in {\mathbb {C}}^{m \times n}\), discrete Fourier transform matrix \(\boldsymbol{\mathcal{F}}\in {\mathbb {C}}^{n \times n}\) and a diagonal matrix that denotes coil sensitivity maps \({\textbf{S}} \in {\mathbb {C}}^{n \times n}\). \(\lambda\) is the coefficient that balances regularisation term \({\mathcal {R}}({\textbf{x}})\).
Deep learning technique has been widely used for MRI reconstruction, among which the three most representative methods are (1) algorithm unrolling models14,15,16, (2) enhancement-based models17,18,19,20, and the emerging (3) generative models21,22,23.
Algorithm unrolling models typically integrate neural networks with traditional CS algorithms, simulating the iterative reconstruction algorithms through learnable iterative blocks12. Yang et al.14 reformulated an Alternating Direction Method of Multipliers (ADMM) algorithm to a multi-stage deep architecture, namely Deep-ADMM-Net, for MRI reconstruction, of which each stage corresponds to an iteration in traditional ADMM algorithm. Some algorithm unrolling-based models defined the regulariser with the denoising residual of a deep denoiser15,16, where Eq. (1) can be reformulated as:
in which \({\textbf{f}}_{\theta }(\cdot )\) is a deep neural network and \({\textbf{x}}_u\) is the undersampled zero-filled images (ZF). Schlemper et al.15 designed a deep cascade of CNNs for cardiac cine reconstruction, in which a spatio-temporal correlations can be also efficiently learned via the data sharing approach. Aggarwal et al.16 proposed a model-based deep learning method, namely MoDL, which exploited a CNN-based regularisation prior with a conjugate gradient-based data consistency (DC) for MRI reconstruction.
Enhancement-based models typically train a deep neural network \({\textbf{f}}_{\theta }(\cdot )\) that directly maps the undersampled k-space measurement \({\textbf{y}}\) or zero-filled images \({\textbf{x}}_u\), to fully-sampled images \({\hat{\textbf{x}}}\) or its residual in an end-to-end manner, which can be formulated as \({\hat{\textbf{x}}} = {\textbf{f}}_{\theta }({\textbf{x}}_u)\) or \({\hat{\textbf{x}}} = {\textbf{f}}_{\theta }({\textbf{x}}_u) + {\textbf{x}}_u\). Hyun et al.17 introduced a CNN-based U-Net for MRI reconstruction. Feng et al.18 exploited the task-specific novel cross-attention and designed an end-to-end Transformer-based model for jointly MRI reconstruction and super-resolution. Huang et al.20 explored the graph representation and the non-Euclidean relationship for MR images, and designed a Vision Graph Neural Network-based U-Net for fast MRI.
Generative models for solving inverse problems represent an emerging and rapidly evolving field of data-driven models. In the area of MRI reconstruction, various models and techniques have been found and achieved promising performance21,22,23,38. Generative models usually focus on learning the true data distribution, instead of heavily replying upon the regularisation term or directly learning an inverse map**39. For example, Variational AutoencodersFull size image
Data acquisition
All data used in this study were approved by the National Research Ethics committee, Bloomsbury with reference number 13/LO/1830, REC reference 10/H0701/112, and IRAS reference number 33773. The study adheres to the principles of the Declaration of Helsinki and the UK Research Governance Framework version 2. All participants provided informed written consent.
Retrospectively acquired cDTI data were acquired using Siemens Skyra 3T MRI scanner and Siemens Vida 3T MRI scanner (Siemens AG, Erlangen, Germany). A diffusion-weighted stimulated echo acquisition mode (STEAM) SS-EPI sequence with reduced phase field-of-view and fat saturation was used. Some MR sequence parameters are listed: \(\text {TR} = 2 \ \text {RR intervals}\); \(\text {TE} = 23 \ \text {ms}\); mSENSE or GRAPPA with \(\text {AF} = 2\); echo train duration \(= 13 \ \text {ms}\); spatial resolution \(= 2.8 \times 2.8 \times 8.0 \ \text {mm}^\text {3}\). Diffusion-weighted images were encoded in six directions with diffusion-weighted of \(\text {b} = 150 \ \text {and} \ 600 \ \text {sec/mm}^\text {2}\) (namely b150 and b600) in a short-axis mid-ventricular slice. Reference images, namely b0, were also acquired with a minor diffusion weighting.
We used 481 cDTI cases including 2 cardiac phases, i.e., diastole (\(n = 232\)) and systole (\(n = 249\)), for the experiments section. The dataset contains 241 healthy cases, 31 amyloidosis (AMYLOID) cases, 47 dilated cardiomyopathy (DCM) cases, 35 in-recovery DCM (rDCM) cases, 39 hypertrophic cardiomyopathy (HCM) cases, 48 HCM genotype-positive-phenotype-negative (HCM G+P-) cases, and 40 acute myocardial infarction (MI) cases. The overall data distribution of our dataset is shown in Table 1. The detailed data distribution per cohort and cardiac phase can be found in Supplementary (Supp.) Table S4.
This work separately discussed the reconstruction of systole and diastole cases. For each deep learning-based methods, two network weights were trained for either systole or diastole reconstruction. In the training stage, we applied a 5-fold-cross-validation strategy, using 169 diastole cases (TrainVal-D) or 183 systole cases (TrainVal-S). In the testing stage, four testing sets were utilised, including a mixed ordinary testing set with diastole cases (Test-D) or systole cases (Test-S) and an out-of-distribution MI testing set with diastole cases (Test-MI-D) or systole cases (Test-MI-S). According to Supp. Table S4, Test-D and Test-S include the data of Health, AMYLOID, rDCM, DCM, HCM and HCM G+P-, which are also included in the TrainVal. For further examining the model robustness and ability to handle out-of-the-distribution data, Test-MI dataset includes only MI cases, which were ‘invisible’ for models during the training stage.
Data pre-processing
In the data pre-processing stage, all DWIs (b0, b150 and b600) were processed following the same protocol.
The pixel intensity ranges of DWIs vary considerably across different b-values. To address this, We normalised all DWIs in the dataset to a pixel intensity range of \(0 \sim 1\) using the max-min method, while the maximum and minimum pixel values of all DWIs were recorded for the pixel intensity range recovery at the beginning of the data post-processing stage.
In our dataset, the majority of DWIs have a resolution of \(256 \times 96\), while a small subset of 2D slices exhibit a resolution of \(256 \times 88\). red In order to standardise the resolution, zero-padding was conducted, turning the images with a resolution of \(256 \times 88\) to a resolution of \(256 \times 96\).
GRAPPA-like Cartesian k-space undersampling masks with AF \(\times 2\), \(\times 4\) and \(\times 8\), generated by the official protocol of fastMRI dataset56. For example, blurred images generally exhibit better pixel-wise fidelity, while the images with clear but ‘fake’ details tend to have better perceptual-similarity38. This trade-off is observable in the visualised examples provided in Supp. Figure S11.
From another perspective, such ‘fake’ details with high perceptual score but low fidelity can be viewed as hallucinations, which are harmful for clinical use54. Consequently, for further studies, more efforts should be made to consider how to improve the pixel-wise fidelity rather than the perceptual-similarity, or how to prevent the appearance of the ‘fake’ information. We have found more and more researchers in the computer vision community tended to exploit larger and deeper network backbones and leverage emerging generative models for solving inverse problem including MRI reconstruction22. Concurrently, it is becoming essential and urgent to mitigate the incidence of hallucinations, potentially through updating the network structure, incorporating new restrictions, or adopting novel training strategies.
There is a gap between current DT evaluation methods and the true quality of cDTI reconstruction. This study has revealed that the global mean value of diffusion parameters is not always accurate or sensitive enough to evaluate the diffusion tensor quality. For example, Table 3 indicates no statistically significant difference in MD between reconstruction results (even including ZF) and the reference on Test-S, whereas the Fig. 8 shows that the MD maps are entirely unacceptable. This discrepancy arises because the MD value increases and decreases in different parts of the MD map, while the global mean value maintains relative consistency, rendering the global mean MD ineffective in reflecting the quality of the final DT estimation. For future work, in addition to the visualised assessment, we will applied the down-stream task assessment, e.g., utilising a pre-trained pathology classification or detection model to evaluate the reconstruction quality. Theoretically, better classification or detection accuracy corresponds to improved reconstruction results.
There are still limitations for this study. (1) The size of the testing sets is not sufficiently large. The relatively small testing sets enlarge the randomness of experimental results and reduce the reliability of statistical tests. In future studies, we will expand our dataset, especially for the patient data. According to Supp. Table S4, compared to the healthy volunteers, samples from patients in our dataset are insufficient and unbalanced. The lack of patient samples leads to the model’s inability to correctly recover the pathology information, which also results in errors in subsequent DT estimation. With sufficient patient samples, we will consider incorporating pathology information into the reconstruction model, allowing accurate DWI reconstruction and further DT estimation for different types of cardiac diseases. (2) Our simulation experiment is based on the retrospective k-space undersampling on single-channel magnitude DWIs that have been reconstructed by the MR scanner software. However, the raw data acquired from the scanner, prior to reconstruction, is typically multi-channel complex-value data in k-space. The retrospective undersampling step itself removed a large amount of high-frequency noise, leading to unrealistic post-processing results. Additionally, our experiment involves retrospective undersampling using simulation-based GRAPPA-like Cartesian k-space undersampling masks (Supp. Figure S1), which are inconsistent with the equal-spaced readout used in the scanner. In future studies, we aim to conduct our experiment on prospectively acquired multi-channel k-space raw data.
