
Abstract
Age-related Macular Degeneration (AMD), a retinal disease that affects the macula, can be caused by aging abnormalities in number of different cells and tissues in the retina, retinal pigment epithelium, and choroid, leading to vision loss. An advanced form of AMD, called exudative or wet AMD, is characterized by the ingrowth of abnormal blood vessels beneath or into the macula itself. The diagnosis is confirmed by either fundus auto-fluorescence imaging or optical coherence tomography (OCT) supplemented by fluorescein angiography or OCT angiography without dye. Fluorescein angiography, the gold standard diagnostic procedure for AMD, involves invasive injections of fluorescent dye to highlight retinal vasculature. Meanwhile, patients can be exposed to life-threatening allergic reactions and other risks. This study proposes a scale-adaptive auto-encoder-based model integrated with a deep learning model that can detect AMD early by automatically analyzing the texture patterns in color fundus imaging and correlating them to the vasculature activity in the retina. Moreover, the proposed model can automatically distinguish between AMD grades assisting in early diagnosis and thus allowing for earlier treatment of the patient’s condition, slowing the disease and minimizing its severity. Our model features two main blocks, the first is an auto-encoder-based network for scale adaption, and the second is a convolutional neural network (CNN) classification network. Based on a conducted set of experiments, the proposed model achieves higher diagnostic accuracy compared to other models with accuracy, sensitivity, and specificity that reach 96.2%, 96.2%, and 99%, respectively.
Similar content being viewed by others
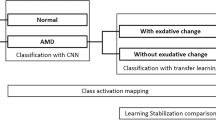

Introduction
Age-related macular degeneration (AMD) is a retina disease that affects the retina’s macular region, a part of the retina that controls sharp straight-ahead vision1, causing progressive loss of central vision2, and may lead to complete visual disability3. AMD happens when aging causes damage to the macula. Dry AMD and Wet AMD are the two primary forms of AMD; each has different grading. Dry AMD also called Atrophic AMD or non-neovascular AMD, has three grades: early, intermediate, and late, also called geographic atrophy (GA) or advanced non-neovascular AMD. Wet AMD, also called exudative4 or neovascular AMD, is always late stage and has two grades: inactive and active5. Moreover, wet AMD can be further classified into classic, occult or mixed6. Neovascular and late dry are considered advanced AMD7. The hallmark of AMD is the drusen formation that is an accumulation of retinal deposits, pigmentary changes at the macula that serves as a predictor of more advanced AMD development4,8 and mild to moderate vision loss7. Change in size and number of drusen indicates AMD progression risk8 and grading characteristics9. Dry AMD is the most common form, although wet AMD is less frequent but is responsible for 90% of blindness due to AMD7.
AMD is the cause of 87% of blindness cases worldwide10,11, where Europeans recorded the highest prevalence over Asians in early and late AMD over Africans in any AMD. Statistically, in 201410 anticipated that new cases of AMD would reach 196 million in 2020 and by 2040 this number will reach 288 million globally, while12 predicted that in 2050, the number of early AMD cases would be 39.05 million and late AMD will be 6.41 million. AMD is a chronic disease and neither of its forms can be cured13. However, treatment for wet AMD can help maintain and even improve vision, or halt the disease’s development14. Early detection can help prevent disease progression; however, any dry AMD stages can turn into wet AMD. Traditionally the clinical diagnosis of the disease requires examination and assessment of either fundus autofluorescence imaging or optical coherence tomography (OCT) supplemented by fluorescein angiography or OCT angiography without dye3,6 or Spectral Domain Optical Coherence Tomography (SD-OCT).
During the past few years, much deep learning (DL) approaches have been applied in computer vision (CV) tasks including medical imaging classification, due to its robust architecture and better performance. DL models record good results in retinal image analysis for detecting and diagnosing retinal diseases like AMD, glaucoma, choroidal neovascularization (CNV), and diabetic macular edema (DME) based on different imaging modalities such as retinal fundus images, OCT, SD-OCT. In the literature, several studies have tried to classify and discriminate between AMD’s different grades and normal retinas. Rivu Chakraborty and Ankita Pramanik proposed a novel deep convolutional neural network (DCNN) architecture with 13-layers to classify non-AMD and AMD based on fundus images15. The model is composed of five convolutional layers (CL), five max-pooling layers (MPL), and three fully connected layers (FCL) training on the iChallenge-AMD dataset. The model recorded 89.75% accuracy without data augmentation, while applying 4-time and 16-time data augmentation versions, the model recorded 91.69%, and 99.45% accuracy respectively. They also trained their model on the ARIA dataset and recorded accuracy of 90%, 93.03%, and 99.55% for original, 4-time data augmentation, and 16-time data augmentation respectively. In Ref.16 the authors proposed a multiscale CNN with 7 CL for binary classification of AMD and standard images using OCT images. The generated model is trained on the Mendeley dataset and achieved high accuracy between 99.73 and 96.66% when tested on different datasets like Mendeley OCTID, SD-OCT Noor dataset, and Duke. Several authors17,18,19 reported high accuracy and good performance on AMD classification based on OCT images. References20,21,22,23 are some of the state-of-the-art deep learning architectures for AMD classification where Refs.20,21 used transfer learning to apply different classification problems for AMD grades while Tan et al.22 used 14-layer DCNN with data augmentation to increase the size of the iChallenge-AMD training dataset to perform binary classification between AMD and normal retina recording accuracy of 89.69%.
Based on OCT imaging datasets24,25,26,27,28,29 applied transfer learning using different pre-trained models to detect and classify AMD. Xu et al.24 used the ResNet5030 model recording an accuracy 83.2%. Hwang et al.25 used different pre-trained models such as VGG16 The proposed model was trained on Colab-Pro GPU. We developed, trained, validated, tested our model, and calculated its performance metrics in python using TensorFlow43, Keras44, and scikit-learn45, the later along with matplotlib46 and seaborn47 were used for plotting all of the shown figures and graphs such as performance metrics, confusion matrix, feature extraction, and activation map. We applied k-fold cross-validation technique to validate the best model performance and propose our model that is composed of our SA model integrated with ResNet50 model. The hyperparameters have been set for each model separately where the scale adaptive auto-encoder-based model hyperparameters were set as follows: batch size is 1, Adam optimizer with a fixed 0.001 learning rate, and tanh as the activation function while the ResNet50 pre-trained model hyperparameters were set as: batch size 64, SGD optimizer with automatic adaptive learning rate starting with 0.001 and reduced whenever the accuracy evaluation metric stops improving. Distinguishing between the normal healthy retina and AMD different grades recorded the best performance when using our proposed integrated model compared to the other models. This is shown in Table 5 and Figs. 3, 6, 7, 8 and 9 plots the loss and accuracy recorded for the experimental models being integrated with SA and standalone respectively. Figures 6a,c,e and 7a,c,e shows the loss and accuracy for ResNet50, InceptionV3, VGG16, ResNet101, VGG19, and ResNet18 integrated with SA model using SGD optimizer respectively, while Figs. 6b,d,f, 7b and 9d,f shows the loss and accuracy for ResNet50, InceptionV3, VGG16, ResNet101, VGG19, and ResNet18 integrated with SA model using Adam optimizer respectively. Figures 8a,c,e and 9a,c,e shows the loss and accuracy for ResNet50, InceptionV3, VGG16, ResNet101, VGG19, and ResNet18 standalone pre-trained models using SGD optimizer respectively, while Figs. 8b,d,f and 9b,d,f shows the loss and accuracy for ResNet50, InceptionV3, VGG16 ResNet101, VGG19, and ResNet18 standalone pre-trained model using Adam optimizer respectively (Figs. 4, 5, 6). Comparison of models’ accuracy for using SGD optimizer and Adam optimizer. Feature Map visualization of first and last convolution layer of ResNet50, InceptionV3, and VGG16 pre-trained model after being integrated with SA model. Feature Map visualization of first and last convolution layer of ResNet101, VGG19, and ResNet18 pre-trained model after being integrated with SA model. Plot diagrams of loss and accuracy records over 300 epochs for SA model integrated with InceptionV3, ResNet50, and VGG16 models using SGD and Adam optimizer. SGD48 and Adam49 are significant optimization techniques used in machine learning for updating the weights of a neural network during training where the latter is considered as a hybrid combination of RMSProp and SGD with momentum49. SGD is a straightforward optimization approach that updates the neural network weights in the direction of the loss function’s negative gradient with respect to the weights. It randomly chooses a subset of the training data for every update, reducing the optimization’s computational cost. The choice of optimization algorithm depends on the problem being solved as well as the computing resources available. SGD is simple and computationally efficient, whereas Adam is more complex, but can achieve faster convergence on larger datasets and more complex studies50. According to the outcomes of applying the Bayesian optimization approach to detect the optimal hyperparameter tuning, the top nominated optimizers for tackling our problem were SGD and Adam optimizers with a batch size of 64 and 32 respectively as shown in Table 6 (Figs. 7, 8, 9).
Plot diagrams of loss and accuracy records over 300 epochs for SA model integrated with ResNet101, VGG19, and ResNet18 models using SGD and Adam optimizer. Plot diagrams of loss and accuracy records over 300 epochs for InceptionV3, ResNet50, and VGG16 standalone models using SGD and Adam optimizer. Plot diagrams of loss and accuracy records over 300 epochs for ResNet101, VGG19, and ResNet18 standalone models using SGD and Adam optimizer. Based on our study, SGD proved to be a better optimization technique compared with Adam optimizer, the results are shown in Table 5 and Fig. 3. For every experiment, we started the learning rate value by 0.001 that adapted and reduced its value automatically, while to ensure fair experimental results we fixed any other hyper-parameter and set it to default except for batch size set to 64 over 300 epochs. Performance metrics of the trained models are shown in Tables 1 and 2 for SGD and Adam optimizers respectively, were computed based on the overall true-positives (TP), true-negatives (TN), false-positives (FP) and false-negatives (FN). The overall performance metrics and parameters are shown in Table 8 for using SGD optimizer and Table 9 for using the Adam optimizer. The confusion matrices is shown in Figs. 10 and 11 for the experimental models being integrated with SA, where Figs. 10a,c,e and 11a,c,e shows the confusion matrix for ResNet50, InceptionV3, VGG16, ResNet101, VGG19, and ResNet18 integrated with SA model using SGD optimizer respectively, while Figs. 10b,d,f and 13b,d,f shows the confusion matrix for ResNet50, InceptionV3, VGG16, ResNet101, VGG19, and ResNet18 integrated with SA model using Adam optimizer respectively. Figures 12 and 13 shows the confusion matrices for the standalone pre-trained models, where Figs. 12a,c,e and 13a,c,e shows the confusion matrix for ResNet50, InceptionV3, VGG16, ResNet101, VGG19, and ResNet18 standalone pre-trained models using SGD optimizer respectively, while Figs. 12b,d,f and 13b,d,f shows the confusion matrix for ResNet50, InceptionV3, VGG16, ResNet101, VGG19, and ResNet18 standalone pre-trained model using Adam optimizer respectively. The receiver operating characteristic (ROC) curves for all of the trained models are plotted in Figs. 14, 15, 16 and 17 for the experimental models being integrated with SA and standalone respectively. Figures 14a,c,e and 17a,c,e shows the ROC for ResNet50, InceptionV3, VGG16, ResNet101, VGG19, and ResNet18 integrated with SA model using SGD optimizer respectively, while Figs. 14b,d,f and 17b,d,f shows the ROC for ResNet50, InceptionV3, VGG16, ResNet101, VGG19, and ResNet18 integrated with SA model using Adam optimizer respectively. Figures 16a,c and 16e, 17a,c,e shows the ROC for ResNet50, InceptionV3, VGG16, ResNet101, VGG19, and ResNet18 standalone pre-trained models using SGD optimizer respectively, while Figs. 16b,d,f and 17b,d,f shows the ROC for ResNet50, InceptionV3, VGG16, ResNet101, VGG19, and ResNet18 standalone pre-trained model using Adam optimizer respectively. From the recorded results shown in Tables 1, 2, 8 and 9, it was clear that ResNet50 recorded the most promising performance metrics during training and testing phases by either using SGD or Adam optimizers concerning precision or positive predictive value (PPV), sensitivity or recall or true positive rate (TPR), and specificity or true negative rate (TNR) results. We applied 10-fold, 5-fold, and 3-fold cross-validation techniques for the pre-trained models integrated with SA using SGD optimizer or Adam optimizer to find the optimized performance as shown in Tables 3 and 4, comparing the results recorded for accuracy by training models in each k-fold. We also examined the proposed model with batch sizes 16, 32, and 128 as shown in Table 7 where it was observed that using the SGD optimizer recorded the highest accuracy value of 96.2% with batch size 64 although using the Adam optimizer with the same experimental environment recorded higher accuracy the cross-validation results promotes to using of SGD as shown in Table 3. Confusion matrices of SA model integrated with InceptionV3 model, ResNet50 model, and VGG16 model using SGD and Adam optimizer. Confusion matrices of SA model integrated with ResNet101, VGG19, and ResNet18 models using SGD and Adam optimizer. Confusion matrices of InceptionV3, ResNet50, and VGG16 standalone models using SGD and Adam optimizer. Confusion matrices of ResNet101, VGG19, and ResNet18 standalone models using SGD and Adam optimizer. ROC of SA model integrated with InceptionV3, ResNet50, and VGG16 models using SGD and Adam optimizer. ROC of SA model integrated with ResNet101, VGG19, and ResNet18 models using SGD and Adam optimizer. ROC of InceptionV3, ResNet50, and VGG16 standalone model using SGD and Adam optimizer. ROC of ResNet101, VGG19, and ResNet18 standalone models using SGD and Adam optimizer. We used a feature map to ensure the availability of information and visualize feature propagation among convolution layers till the last layer. Figure 4 shows feature maps visualization of the first and last convolution layer of the proposed model and SA integrated with other pre-trained models, where Fig. 4a shows the output of its 64 filters first convolution layer of ResNet50 pre-trained model integrated with SA while its last convolution layer shown in Fig. 4b displays the output of 64 filters. Similarly, for SA integrated with InceptionV3 pre-trained model, we displayed its 25 filters of first convolution layers as shown in Fig. 4c while its output is shown in Fig. 4d where we display the output of 64 kernels out of 192 filters. For the VGG16 pre-trained model being integrated with SA, Fig. 4e,f show the output of the top 64 filters for the first and last convolution layers, respectively. Figure 5a,c,e show the output of the top 64 filters for the first convolution layer of ResNet101, VGG19, and ResNet18 pre-trained models being integrated with SA respectively, while Fig. 5b,d,f show the output of top 64 filters for the last convolution layer of ResNet101, VGG19, and ResNet18 pre-trained models being integrated with SA respectively. The predicted output using the proposed model is shown in Fig. 18, where it successfully discriminates between AMD different grading.
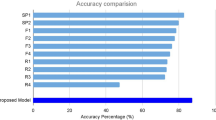
Sample prediction outputs of SA + ResNet50 model using SGD optimizer successfully detected AMD different grads. In this study, we propose an integrated deep learning model capable of recognizing and differentiating between the normal retina and various clinical grades of AMD (intermediate, GA, or Wet AMD) successfully with high accuracy using retinal fundus images. We faced limitations to optimize the performance and build high accuracy model because of a limited number and variety of fundus dataset image samples; we applied transfer learning approach and compared the results between training standalone ResNet50, VGG16, InceptionV3, ResNet101, VGG19, ResNet18 pre-trained models and integrating each of these models with SA model, where SA is the model trained for accepting fundus images of different sizes and dimensions and producing scaled output image of \(224 \times 224\) px size. Many public datasets contain medical fundus images covering various retinal diseases such as AMD, diabetic retinopathy, glaucoma, and cataracts. Most of the datasets for AMD such as iChallenge-AMD51, ODIR-201952, Automated Retinal Image Analysis ARIA53, and STARE54 classify images into AMD and normal retina. Hence, it was hard to use any of these datasets in either training, testing, or evaluating the proposed model (Tables 5, 6, 7). Despite these limitations, our model classified the AMD grades successfully and recorded an accuracy of 96.2% for integrating the SA model with the ResNet50 model using SGD optimizer although using Adam optimizer recorded an accuracy of 97.7%. The best model was determined based on the results from Tables 1, 2, 8 and 9 and applying several deep learning methodologies such as k-fold cross validation recorded in Table 3 to ensure high model performance and by evaluating the model using 3-folds, 5-folds and 10-folds to determine optimal performance and decide the best model. By applying data augmentation, the dataset was sufficient to demonstrate the feasibility of our proposed deep learning model to distinguish AMD grades using fundus images. We examined the integrated model and tried different optimization like Adam and SGD which proved to be the best optimization technique in our case study. The pre-trained model represented in ResNet50 proved to be more efficient either integrated with the SA model or standalone whether using SGD or Adam optimizer. It recorded the best-fit model to our study according to cross-validation technique results recorded in Table 3. During the training phase it recorded accuracy that is comparatively 3% accuracy higher than using VGG16 and InceptionV3 models when being integrated with SA model. Compared with ResNet101, VGG19, and ResNet18; the proposed model recorded higher accuracy by more than 6%, 10%, and 15% respectively. It recorded 91.7% accuracy when trained as a standalone model. Although VGG16 pre-trained model recorded performance metrics like InceptionV3 pre-trained model using SGD, and VGG19 pre-trained model recorded acceptable results using SGD both VGG16 and VGG19 recorded the lowest results using Adam optimizer either as a standalone model or integrated with the SA model. InceptionV3 recorded good performance metrics during the training phase. However, it was excluded due to cross-validation technique results similar, to ResNet101 and ResNet18. In this study, we have proposed an integrated model for scaling input images and distinguishing between normal retinas and AMD grades using color fundus images. Our approach involves two stages. The first stage is a custom auto-encoder-based model that aims to resize the input images to \(224 \times 224 \times 3\) dimensions, then considers any needed data preprocessing, and then feeds its output to the second stage that aims to classify its input into normal retinas, intermediate AMD, GA and wet AMD grades using ResNet50 pre-trained model. The proposed model is trained on the color fundus images dataset provided by the CATT Study Group. We compared our proposed model performance against different pre-trained models either standalone or integrated with our SA model. We validate our approach using a cross-validation technique that proves our proposed model is the best model performance. For future work, we plan to integrate the scale adapting network with other systems that diagnose other retinal disease, such as diabetic retinopathy, and with other networks that work on different imaging modalities. Also, we plan to expand the study by collecting data from additional cohorts that include subjects from a wider range of institutions and geographic areas globally.
Experiments and results
Accurate detection and grading compared to other models















Explainable retina maps

Discussion
Conclusion and future work
Data availibility
The datasets used and analysed during the current study will be available from the corresponding author on reasonable request.
References
Klein, R., Peto, T., Bird, A. & Vannewkirk, M. R. The epidemiology of age-related macular degeneration. Am. J. Ophthalmol. 137, 486–495 (2004).
Mitchell, P., Liew, G., Gopinath, B. & Wong, T. Y. Age-related macular degeneration. Lancet 392, 1147–1159 (2018).
Lim, L. S., Mitchell, P., Seddon, J. M., Holz, F. G. & Wong, T. Y. Age-related macular degeneration. Lancet 379, 1728–1738 (2012).
Klein, R., Klein, B. E., Tomany, S. C., Meuer, S. M. & Huang, G.-H. Ten-year incidence and progression of age-related maculopathy: The beaver dam eye study. Ophthalmology 109, 1767–1779 (2002).
Elsharkawy, M. et al. Role of optical coherence tomography imaging in predicting progression of age-related macular disease: A survey. Diagnostics 11, 2313 (2021).
Mitchell, P., Liew, G., Gopinath, B. & Wong, T. Y. Age-related macular degeneration. Lancet 392, 1147–1159 (2018).
Hernández-Zimbrón, L. F. et al. Age-related macular degeneration: New paradigms for treatment and management of AMD. Oxidat. Med. Cell. Longevity. 2018, 1–14 (2018).
Thomas, C. J., Mirza, R. G. & Gill, M. K. Age-related macular degeneration. Med. Clin. 105, 473–491 (2021).
Ferris, F. L. et al. A simplified severity scale for age-related macular degeneration: AREDS report no. 18. Arch. Ophthalmol. (Chicago, Ill.: 1960) 123, 1570–1574 (2005).
Wong, W. L. et al. Global prevalence of age-related macular degeneration and disease burden projection for 2020 and 2040: A systematic review and meta-analysis. Lancet Glob. Health 2, e106–e116 (2014).
Jonas, J. B., Cheung, C. M. G. & Panda-Jonas, S. Updates on the epidemiology of age-related macular degeneration. Asia-Pacific J. Ophthalmol. 6, 493–497 (2017).
Wang, Y. et al, Global incidence, progression, and risk factors of age-related macular degeneration and projection of disease statistics in 30 years: a modeling study. Gerontology. 68(7), 721–735 (2021).
Gehrs, K. M., Anderson, D. H., Johnson, L. V. & Hageman, G. S. Age-related macular degeneration-emerging pathogenetic and therapeutic concepts. Ann. Med. 38, 450–471 (2006).
InformedHealth.org. Age-related macular degeneration (AMD): Overview. https://www.ncbi.nlm.nih.gov/books/NBK315804/ (2006). Accessed 2018 May 3.
Chakraborty, R. & Pramanik, A. DCNN-based prediction model for detection of age-related macular degeneration from color fundus images. Med. Biol. Eng. Comput. 60, 1431–1448 (2022).
Thomas, A., Harikrishnan, P., Krishna, A. K., Palanisamy, P. & Gopi, V. P. A novel multiscale convolutional neural network based age-related macular degeneration detection using OCT images. Biomed. Signal Process. Control 67, 102538 (2021).
Farsiu, S. et al. Quantitative classification of eyes with and without intermediate age-related macular degeneration using optical coherence tomography. Ophthalmology 121, 162–172 (2014).
Apostolopoulos, S., Ciller, C., De Zanet, S., Wolf, S. & Sznitman, R. RetiNet: Automatic AMD identification in OCT volumetric data. Investig. Ophthalmol. Visual Sci. 58, 387–387 (2017).
Lee, C. S., Baughman, D. M. & Lee, A. Y. Deep learning is effective for classifying normal versus age-related macular degeneration OCT images. Ophthalmol. Retina 1, 322–327 (2017).
Burlina, P., Pacheco, K. D., Joshi, N., Freund, D. E. & Bressler, N. M. Comparing humans and deep learning performance for grading AMD: A study in using universal deep features and transfer learning for automated AMD analysis. Comput. Biol. Med. 82, 80–86 (2017).
Burlina, P. M. et al. Automated grading of age-related macular degeneration from color fundus images using deep convolutional neural networks. JAMA Ophthalmol. 135, 1170–1176 (2017).
Tan, J. H. et al. Age-related macular degeneration detection using deep convolutional neural network. Future Generat. Comput. Syst. 87, 127–135 (2018).
Grassmann, F. et al. A deep learning algorithm for prediction of age-related eye disease study severity scale for age-related macular degeneration from color fundus photography. Ophthalmology 125, 1410–1420 (2018).
Xu, Z. et al. Automated diagnoses of age-related macular degeneration and polypoidal choroidal vasculopathy using bi-modal deep convolutional neural networks. Br. J. Ophthalmol. 105, 561–566 (2021).
Hwang, D.-K. et al. Artificial intelligence-based decision-making for age-related macular degeneration. Theranostics 9, 232 (2019).
Yoo, T. K. et al. The possibility of the combination of oct and fundus images for improving the diagnostic accuracy of deep learning for age-related macular degeneration: A preliminary experiment. Med. Biol. Eng. Comput. 57, 677–687 (2019).
Chen, Y.-M., Huang, W.-T., Ho, W.-H. & Tsai, J.-T. Classification of age-related macular degeneration using convolutional-neural-network-based transfer learning. BMC Bioinform. 22, 1–16 (2021).
Wang, Y., Lucas, M., Furst, J., Fawzi, A. A. & Raicu, D. Explainable deep learning for biomarker classification of oct images. in 2020 IEEE 20th International Conference on Bioinformatics and Bioengineering (BIBE), 204–210 (IEEE, 2020).
Serener, A. & Serte, S. Dry and wet age-related macular degeneration classification using oct images and deep learning. in 2019 Scientific Meeting on Electrical-Electronics & Biomedical Engineering and Computer Science (EBBT), 1–4 (IEEE, 2019).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 770–778 (2016).
Simonyan, K. & Zisserman, A. Very deep convolutional networks for large-scale image recognition. ar**v preprintar**v:1409.1556 (2014).
Szegedy, C. et al. Going deeper with convolutions. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1–9 (2015).
Bank, D., Koenigstein, N. & Giryes, R. Autoencoders. ar**v preprintar**v:2003.05991 (2020).
Baldi, P. Autoencoders, unsupervised learning, and deep architectures. in Proceedings of ICML Workshop on Unsupervised and Transfer Learning, 37–49 (JMLR Workshop and Conference Proceedings, 2012).
Choi, Y., El-Khamy, M. & Lee, J. Variable rate deep image compression with a conditional autoencoder. in Proceedings of the IEEE/CVF International Conference on Computer Vision, 3146–3154 (2019).
Yoo, J., Eom, H. & Choi, Y. S. Image-to-image translation using a cross-domain auto-encoder and decoder. Appl. Sci. 9, 4780 (2019).
Wang, Y., Yao, H. & Zhao, S. Auto-encoder based dimensionality reduction. Neurocomputing 184, 232–242 (2016).
Sakurada, M. & Yairi, T. Anomaly detection using autoencoders with nonlinear dimensionality reduction. in Proceedings of the MLSDA 2014 2nd Workshop on Machine Learning for Sensory Data Analysis, 4–11 (2014).
Steudel, A., Ortmann, S. & Glesner, M. Medical image compression with neural nets. in Proceedings of 3rd International Symposium on Uncertainty Modeling and Analysis and Annual Conference of the North American Fuzzy Information Processing Society, 571–576 (IEEE, 1995).
Ramamurthy, M., Robinson, Y. H., Vimal, S. & Suresh, A. Auto encoder based dimensionality reduction and classification using convolutional neural networks for hyperspectral images. Microprocess. Microsyst. 79, 103280 (2020).
Kingma, D. P. et al. An introduction to variational autoencoders. Foundations Trends Mach. Learn. 12, 307–392 (2019).
The Comparisons of Age-Related Macular Degeneration Treatments Trials (CATT). https://www.med.upenn.edu/cpob/catt.html Accessed 2022 May 8.
Create production-grade machine learning models with tensorflow. https://www.tensorflow.org/. Accessed 15 March 2022.
Keras: Deep learning for humans. https://keras.io/. Accessed 15 March 2022.
scikit-learn: Machine learning in python. https://scikit-learn.org/stable/. Accessed 10 March 2022.
Matplotlib—Visualization with python. https://matplotlib.org/. Accessed 20 March 2022.
seaborn: Statistical data visualization. https://seaborn.pydata.org/. Accessed 20 March 2022.
Ketkar, N. & Ketkar, N. Stochastic gradient descent. Deep learning with Python: A hands-on introduction, 113–132 (2017).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. ar**v preprintar**v:1412.6980 Accessed 12 April 2022 (2014).
Zhou, P. et al. Towards theoretically understanding why sgd generalizes better than adam in deep learning. Adv. Neural Inform. Process. Syst. 33, 21285–21296 (2020).
Amd public dataset: ichallenge-amd. http://ai.baidu.com/broad/introduction Accessed 15 June 2022.
Amd public dataset: Odir-2019. https://odir2019.grand-challenge.org/dataset/. Accessed 15 June 2022.
Amd public dataset: Aria. http://www.eyecharity.com/aria_online Accessed 20 June 2022.
Amd public dataset: Stare. https://cecas.clemson.edu/~ahoover/stare/. Accessed 20 June 2022.
Acknowledgements
This research is supported by ASPIRE, the technology program management pillar of Abu Dhabi’s Advanced Technology Research Council (ATRC), via the ASPIRE Award for Research Excellence program (AARE) 2019. Also, this research work is partially funded by Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2023R40), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Author information
Authors and Affiliations
Contributions
N.N.E.-D.: computational model development, conducting experiments, and manuscript writing. A.N.: computational model development, technical advising and manuscript preparation. M.E.: data preparation, and manuscript preparation. H.S.: medical advising. N.S.A., M.G., H.M., and A.E.-B.: engineering advising. N.S.A.: conducting experiments in the revised version, and aiding in the writing of the revised statement within the manuscript.
Corresponding author
Ethics declarations
Competing interest
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
El-Den, N.N., Naglah, A., Elsharkawy, M. et al. Scale-adaptive model for detection and grading of age-related macular degeneration from color retinal fundus images. Sci Rep 13, 9590 (2023). https://doi.org/10.1038/s41598-023-35197-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-35197-2
- Springer Nature Limited