
Abstract
Hydropower plants are known as major renewable energy sources, usually used to meet energy demand during peak periods. The performance of hydropower reservoir systems is mainly affected by their operating rules, thus, optimizing these rules results in higher and/or more reliable energy production. Due to the complex nonlinear, nonconvex, and multivariable characteristics of the hydropower system equations, deriving the operating rules of these systems remains a challenging issue in multi-reservoir systems optimization. This study develops a self-adaptive teaching learning-based algorithm with differential evolution (SATLDE) to derive reliable and precise operating rules for multi-reservoir hydropower systems. The main novelty of SATLDE is its enhanced teaching and learning mechanism with three significant improvements: (i) a ranking probability mechanism is introduced to select the learner or teacher stage adaptively; (ii) at the teacher stage, the teaching mechanism is redefined based on learners’ performance/level; and (iii) at the learner stage, an effective mutation operator with adaptive control parameters is proposed to boost exploration ability. The proposed SATLDE algorithm is applied to the ten-reservoir benchmark systems and a real-world hydropower system in Iran. The results illustrate that the SATLDE achieves superior precision and reliability to other methods. Moreover, results show that SATLDE can increase the total power generation by up to 23.70% compared to other advanced optimization methods. Therefore, this study develops an efficient tool to extract optimal operating rules for the mentioned systems.
Similar content being viewed by others


Introduction
Hydropower is one of the most common sources of renewable energy, which is highly flexible to generate and has low environmental contamination compared with the fossil1,2,3,4. Most hydroelectricity is generated at large dams in the world, and several of the largest hydropower dams are located in the southern Iran. A dam reservoir maintains water to different target elevations such as flood control, hydropower production, and supplying irrigation demands2,5,6. A multi-reservoir system is a set of reservoirs placed in the same river basin. Optimizing the systems in terms of operation is useful for the comprehensive development of the river basin7,8. Extracting optimal operating rules for multi-reservoir hydropower systems is considered an arduous engineering problem because of the following reasons: (1) its optimization problem is commonly large-scale with a lot of constraints and unknown variables9; (2) due to different operational and physical constraints and opposite objectives10, it is not simple to achieve a suitable solution that meets all constraints11 and (3) the hydropower systems are nonconvex, nonlinear and non-differentiable12.
To optimize the problems related to the hydropower reservoir operation systems different types of optimization methods have been developed. In general, the optimization methods can be classified into three categories: (1) classical (traditional) techniques, (2) metaheuristic algorithms, and (3) hybrid algorithms. Traditional methods include linear programming (LP), nonlinear programming (NLP), and dynamic programming (DP). A metaheuristic optimization algorithm is a contemporary approach for guiding the search toward the optimal sections of the decision space in a given situation. A lot of various metaheuristic algorithms have been developed, comprising genetic algorithm (GA)13, differential evolution (DE)14, particle swarm optimization (PSO)15, gravitational search algorithm (GSA)16, cuckoo search (CS)17, artificial bee colony (ABC)18, gradient-based optimizer (GBO)19, Runge–Kutta optimization (RUN)20, and weighted mean of vectors (INFO)21.
Metaheuristic techniques are substantially flexible beyond the classical optimization ones because they do not need the constraints and fitness functions to be differentiable, convex, and linear, and therefore the methods can be taken on for solving a mixed variety of optimization problems. In this regard, these techniques are not able to ensure the global optimum, but they globally search for it and therefore are expected to find a near-optimum solution. Also, these approaches can readily be coupled with simulation models without the requirement for making any simplifying assumption22,23,24,25,26. Hybrid optimization algorithms use the strengths of various algorithms to achieve a more powerful optimization algorithm. For instance, Ahmadianfar et al. developed a hybrid optimization algorithm called A-DEPSO (i.e., Adaptive Differential Evolution with Particle Swarm Optimization) by combining the DE algorithm with PSO to optimize nonlinear and nonconvex hydropower systems27.
By 2021, a wide range of optimization procedures have been proposed to solve hydropower systems. Zhang et al. developed a multi-elite guide PSO (MGPSO) approach to maximize the energy provided by a multi-reservoir system consisting of ten cascaded hydroelectric units28. Asadzadeh et al. applied the Pareto Archived Dynamically Dimensioned Search heuristic multi-objective optimization algorithm to design the operation of the Great Lakes of the North America8. Taghian et al. used the GA algorithm to extract optimal hedging rule curves for a set of reservoirs built in a river in Iran29. Ahmadianfar et al. improved the bat algorithm (BA) utilizing the DE algorithm and used to find better solutions for sophisticated multi-reservoir systems30. Bozorg-Haddad et al. applied the biogeography-based optimization (BBO) to solve a single- and multi-reservoir system in Iran31. Their results confirmed the ability of the BBO algorithm to optimize the systems. Moravej and Hosseini-Moghari assessed the interior search algorithm (ISA) to solve problems in water resource management, and demonstrated that the ISA has an efficient performance to optimize complicated multi-reservoir problems32. Ehteram et al. optimized operation of the single- and multi-reservoir systems using shark algorithm (SA)32. They showed that the SA has the better efficiency to solve reservoir operation problems than the PSO and GA methods. Ahmadianfar et al. applied a powerful optimization technique namely hybrid of differential evolution (DE) and particle swarm optimization (PSO) with multi-strategy (MS-DEPSO) to solve multi-reservoir systems, which have purpose of hydropower generation and irrigation supply23. The outcomes indicated that the proposed optimizer can effectively extract operating rules for multi-reservoir systems. Liu et al. evaluated the ability of lion swarm optimization (LSO) algorithm to optimize the dispatch of cascade hydropower stations located in China33. They demonstrated that the LSO algorithm has a better efficiency than the GA, PSO, and improved cuckoo search (CS) algorithms in terms of reliability and accuracy. Feng et al. developed a modified version of sine cosine algorithm (SCA) called quasi-opposition SCA (QSCA) to precision optimization of multiple hydropower reservoir systems4. Their findings demonstrated that the suggested QSCA approach, which is based on the convergence rate and the quality of the solution, is a dependable and resilient method. It should be noted that all the studies mentioned above were single-objective. In applying optimization methods in the multi-objective water resources problems, many studies, such as Ahmadianfar et al., introduced a novel multi-objective PSO with DE algorithm (MOPSO-DE) to optimize a multi-reservoir and multi-objective system in Iran34. They showed that the proposed method could significantly mitigate severe drought periods. Hatamkhani and Moridi applied the MOPSO algorithm and linked it to the water evaluation and planning system (WEAP) model to optimize long-term planning at a basin in Iran35. The findings proved that the simulation–optimization model performed its duties correctly in the context of the best distribution and planning of water resources within the basin. Fang and Popole developed an efficient multi-objective PSO (MOPSO) improved by adopting self-organizing map** (SOM) method36. They applied the proposed algorithm on a hydropower system in China. The findings demonstrate that the model can obtain the best schedule by considering the environmental advantages and the benefits of power production. Despite the considerable success that has been obtained in practice, the utilization of the above optimizers is still confined by some drawbacks, such as parameter tuning, dimensionality course, and premature convergence4,21,23,37,38,39,40.
Teaching–learning-based optimization (TLBO) introduced by Ref.41 emulates the teaching–learning procedure in a class. TLBO is an effective and simple optimizer with only one parameter tuning (i.e., the size of population). Several variants of TLBO have been recently developed, e.g. generalized oppositional TLBO (GOTLBO)42, self-adaptive TLBO (SATLBO)43, and improved TLBO (ITLBO)44. However, these variants of the TLBO algorithm suffer from low reliability, insufficient precision, especially for complex and high dimensional problems38.
SATLDE is developed in this study to derive reliable and precise operating rules of hydropower reservoir operation systems. SATLDE uses a ranking mechanism to adaptively select a learner or teacher stage, instead of selecting both stages, to reduce the computing cost significantly, in each iteration. At the teacher stage, the teaching mechanism is enhanced to teach learners based on the level (performance) of each learner, aiming to assist all learners to achieve promising levels. Also, at the learner stage, an effective mutation operator is introduced based on the DE algorithm with self-adaptive control parameters to promote population diversity and boost wider global search ability, avoiding TLBO from being trapped into local optimal solutions. This paper evaluates the performance of SATLDE in the context of addressing benchmark and real-world multi-reservoir hydropower system problems.
The structure of paper can be arranged as follows. “Methodology” section expresses the TLBO and SATLDE algorithms. The performance criteria of optimization method are described in “Teaching learning-based optimization” section. The mathematical formulation and outcomes of ten-reservoir ordeals is illustrated in “Performance assessment of the optimizers” section. “Results and discussion” section formulates a real-world case study with four reservoirs, stating the experimental outcomes. In the last Section, results and complementary information are given.
Methodology
Multi-reservoir system modeling
Defining the operating rules of hydropower reservoir systems has the most significant impact on the performance of these systems; improving these rules could lead to an increased energy output that is either more dependable or more consistent. Specifying operating rules for these systems continues to be a challenging topic in multi-reservoir system optimization because of the complicated nonlinear and multivariable properties of the equations that make up the hydropower system. Therefore, providing an efficient optimization algorithm to solve these systems is an inevitable task. In this section, a benchmark multi-reservoir system with ten reservoir is modeled and the performance of proposed optimization method is assessed on this problem. Finally, optimal operating rules are extracted using the proposed optimization method for a real-world multi-reservoir system in Iran.
Ten-reservoir system
A well-known hypothetical multi-reservoir system namely the ten-reservoir system introduced by Ref.45 is solved by all optimization algorithms introduced in the previous section. The problem is substantially more complex that the four-reservoir problem due to the large number of constraints and decision variables. Figure 1 displays the schematic of this system. As it can be seen from this figure, the system has 10 reservoirs with the purpose of hydropower generation at 12-time steps. Detail of this system were provided in Ref.45. The fitness function of the problem is defined by Eq. (1),
where \(F\) denotes the fitness function, \(l\) denotes reservoir number, \(L\) is known as the total number of reservoirs, \(T\) denotes the total number of simulation periods, \({C}_{t}^{l}\) is stated as the benefit of lth reservoir at period t, \({R}_{t}^{l}\) is the lth reservoir release amount at period t.

Schematic of ten-reservoir problem.
The main constraints of this system are described by Eqs. (2)–(5),
where \({V}_{t+1}^{l}\) and \({V}_{t}^{l}\) are the volume of lth reservoir storage at period t + 1 and t respectively, \({In}_{t}^{l}\) denotes the amount of inflow into lth storage at period t, \({R}_{min}^{l}\) and \({R}_{max}^{l}\) denote the minimum and maximum volume of release form lth reservoir storage at period t, \({V}_{min}^{l}\) and \({V}_{max}^{l}\) denote the lowest and highest volume of storage of lth reservoir storage at period span t. In this problem, the main decision variables are considered the amount of reservoir release (\({R}_{t}^{l}\)) and the state variables are the volume of reservoir storage (\({V}_{t}^{l}\)). Therefore, the constraints related to releases are directly handled by the proposed optimizer, while the constraints applied to the reservoir storage volumes are embedded as the penalty functions (PFs). In this regard, the fitness function defined in Eq. (1) can be redefined by embedding the following PFs,
where \({d}_{1}\), \({d}_{2}\), and \({d}_{3}\) are the PF coefficients and are equal to 6022,30. Accordingly, the fitness function can be expressed as,
Real-world multi-reservoir system
In the current section, a real-world multi-reservoir system with the hydropower generation purpose is considered for examining the performance of SATLDE. This multi-reservoir system is situated in the Karoon–Dez (KD) basin, the southwest of Iran. In the KD basin, there are four reservoirs including Karoon3, Karoon1, Godar, and Dez. The map of study area is depicted in Fig. 2. This system was optimized during a 55-year operational time period (monthly time step). The diagram of this four-reservoir system is displayed in Fig. 3. In addition, the monthly inflow into the system is depicted in Fig. 4.

Location of Karoon–Dez basin.

Diagram of the real-world multi-reservoir system.

Monthly inflow into the multi-reservoir system.
Mathematical model of a multi-reservoir system
The mathematical formulation of the multi-reservoir system operation is explained in this section. It should be noted that the proposed problem was simplified and turned into a single objective problem. Therefore, the fitness function and constraints are formulated based on this simplification. It is worth noting that the main goal of the proposed four-reservoir system is power production, so we formulated the problem based on maximizing power generated at each time step (monthly). The fitness (objective) function, limitations, and the proposed operating rule are all specified in great details.
Fitness function
The fitness function of the multi-reservoir hydropower system utilized here is to maximize the total power generated of the mentioned system, subject to different physical and technical constraints. In this research, the fitness function is to reach the lowest disparity between the maximum power produced by power plants and power generated by each of them over the operation periods, which is defined below,
where \(Z\) denotes the fitness function, \({Power}_{t}^{l}\) is the energy yield of the lth reservoir over the tth time period, \({Power}_{max}^{l}\) denotes the maximum power produced by the lth power plant over the tth time period. \(g\) is deemed 9.81, \({e}^{l}\) is the efficiency of lth power plant at the tth period, \({havg}_{t}^{l}\) denotes the water head of the lth power plant at the tth period, \({f}^{l}\) denotes the plant factor of the lth power plant, \({h}_{t}^{l}\) denotes the water level of lth reservoir during the tth time period, \({htail}^{l}\) is the downstream water level of lth reservoir.
Constraints
In this subsection, the main constraints of this problem are expressed as,
where \({Sp}_{t}^{l}\) denotes the spill form the lth reservoir at the tth time period, \({Evp}_{t}^{l}\) denotes the evaporation volumes from the lth reservoir at the tth time period, \({Area}_{t}^{l}\) denotes the lth reservoir at the tth time period, \({hevp}_{t}^{l}\) denotes the evaporation level of the lth reservoir at the tth time period.
Nonlinear operating rule
For the multi-reservoir system, this section introduces a nonlinear operating rule. The rule is implemented by conditioning reservoir release on reservoir storage and inflow into each reservoir at each time step46. Based on this rule, a suitable regression analysis is used to fit a nonlinear relationship to the data, which is formulated as,
where \({\alpha }^{l}\) and \({u}^{l}\) are the main parameters of this rule for the lth reservoir, which are determined by the optimizer.
Simulation–optimization process
The main steps for extracting the optimal operating rules for the hydropower multi-reservoir system are described as,
-
(a)
Generate a set of random values (96 decision variables: 24 variables for each reservoir) using the optimization method within a feasible range (feasible ranges for \(\alpha\) and \(u\) are (0, 1] and [− 400, 400], respectively) and calculating the reservoir release for each reservoir using Eq. (16).
-
(b)
Enter the releases as the input to the reservoir simulation model to calculate the volume of storage at period t + 1 utilizing Eq. (10).
-
(c)
Evaluate the storage volumes to be in the range of the allowable range.
-
(d)
Save the values of each created releases if they are in the range of search space.
-
(e)
Repeat steps (b)–(d) for calculating the volumes of releases and computing the fitness function for all time steps using Eq. (9). Next, the stop** criteria in the optimization process is evaluated, if it is met, then the simulation–optimization process is finished, else go to Step (b).
Teaching learning-based optimization
TLBO is known as an effective optimization algorithm41. This algorithm mimics the teaching process in a class and is deemed a population-based optimizer. The optimization process in TLBO includes two main stages: the teacher stage (TS) and learner stage (LS). In the first stage (i.e., TS), teacher tries share its data with the existing learners and in the LS, learners teach each other41.
Teacher stage
There is a teacher and Np − 1 learners in the TLBO algorithm, where Np is the number of members in a population. In TS, the teacher shares its information with learners to promote the mean score of the class. In this algorithm, the teaching action can be formulated as,
where \({x}_{TS,k}\) denotes the kth position calculated in TS, \({r}_{1}\) denotes a random number in the interval of [0, 1]. \({x}_{T}\) is the position of teacher (i.e., best-so-far position), \(TF\) is the factor of teaching and is equal to \(round(1+rand)\). \(rand\) denotes a random number in the interval of [0, 1]. \({x}_{M}\) denotes the mean value of class, which is defined in Eq. (18).
After the position of all learners was updated in TS, they are assessed by the fitness function \(f(x)\). If \(f({x}_{TS,k})\) is better than \(f({x}_{k})\), then \({x}_{k}\) is substituted with \({x}_{TS,k}\); otherwise, \({x}_{k}\) is maintained.
Learner stage
In LS, a learner boosts itself by choosing another random learner from the population, which is formulated in Eq. (19).
where \({x}_{l}\) is the lth learner and \(l\ne k\). After creating the \({x}_{LS,k}\), if \(f\left({x}_{LS,k}\right)\) is superior than \(f\left({x}_{k}\right)\), then accept \({x}_{LS,k}\).
Proposed self-adaptive teaching learning-based with differential evolution
The TLBO method is a simple and effective optimization algorithm that solves the problem by mimicking the teaching–learning process in a classroom. In the TLBO, the optimization process is implemented by the teacher and learner stages, bring along a lot of computational time (2Np) compared with other optimization algorithms43. In the TS, whereas the learner’s score is likely to be promoted, the enhancement of each learner’s score depends to some extent on their capability. In addition, in LS, a learner (\({x}_{l}\)) is randomly selected to share information, which may lead to confined learning capability and ultimately a weak global searchability (exploration)42,43,44. Accordingly, implementing a strategy that adaptively selects LT or LS based on the performance of learners can significantly decrease the computational time. Hence, TLBO is enhanced to the self-adaptive teaching learning-based with differential evolution (SATLDE) in this study, which is described in the subsequent sections.
Ranking probability strategy
Ranking probability strategy (RPS) proposed by Ref.43 is used in SATLDE in order to better identify the degrees of various learners. According to RPS, the whole of the learners is sorted from the best to the worst based on their objective function value as in Eq. (20),
where \(Ind\) denotes the index of learners after sorting. \(f\) denotes the objective function values.
Next, the ranking of all learners is calculated as in Eq. (21).
Finally, the ranking probability of each learner (\(Rankp\)) is formulated as Eq. (22).
According to Eq. (22), the better learners have the larger \(Rankp\) while the worst learners have lower \(Rankp\).
Teacher stage of SATLDE
The original TLBO uses the teacher (\({x}_{T}\)) and the mean level of learners (\({x}_{M}\)) for guiding all learners in the teacher stage (see Eq. (1)). Generally, learning levels of various learners is different from each other. Therefore, this study suggests employing an effective technique to assist diverse learners in achieving a better score. Accordingly, learners in a class can be divided into two groups. To specify these groups, \({x}_{M}\) has a key role. With this consideration, learners are located with the better learning level in the first group with condition \(f\left({x}_{k}\right)<f({x}_{M})\), while the second group (\(f\left({x}_{k}\right)\ge f({x}_{M})\)) belongs to the worse learners. In the proposed strategy, better ones are guided by \({x}_{T}\), the teacher, and \({x}_{k}\), the current learner. Additionally, in order to stay away from local solutions, two learners are picked at random and utilized to conduct the better learners. The proposed teacher stage procedure in SATLDE is presented by script (S1).

where \(i1\) and \(i2\) are two random integer number in the interval of [1, Np] and \(i1\ne i2\ne k\). It is noteworthy that \(i2\) is randomly selected from the union \(P\cup Ar\), where \(P\) is the current population and \(Ar\) is a set of inferior solutions at each iteration47. \({\alpha }_{k}\) denotes the scale factor, which is calculated as follows,
where \(randn\) denotes a random number with a normal distribution. \({\upsilon }_{\alpha }\) is equal to 0.5 in the first iteration and updated by utilizing Eq. (24),
where \({S}_{\alpha }\) is the set of all successful learner factors \({\alpha }_{k}\) at each iteration. \(M\) is the size of \({S}_{\alpha }\). \(df\) is the difference between the kth learner and successful learner and it can be defined according to the following script (S2).

Learner stage of SATLDE
As stated in “Real-world multi-reservoir system” section, TLBO uses a random learner to find a better region in the search space, leading to confined learning capability and weak global search. Hence, it is critical for the TLBO to improve the efficiency of the learning stage. In this research, an efficient mutant vector is utilized to create the new learner \({x}_{new,k}\), which is expressed as,
According to Eq. (25), the knowledge of learners (\({x}_{i1}\), \({x}_{i2}\), and \({x}_{k}\)) can be fully used and an exploration capability can be guaranteed. The proposed algorithm uses random vectors (\({x}_{i1}-{x}_{i2}\)) to search globally in the solution space at each iteration. This mechanism is used to have a chance to explore most regions of the search space to find better solutions.
Crossover
In order to improve the population variety, crossover is one of the most often used operators48. This operator combines the new learner created by the TS or LS with the current learner at each iteration and generates a new learner, which is given as,
in which
where \(jr\) denotes an inter random number choosen from the interval of [1, D], \(NFE\) is the number of function evaluations, \(MaxNFE\) is maximum number of function evaluations, \({xp}_{k}\) is a learner which is specified from between \({x}_{k}\) and \({x}_{lb}\) based on the condition \(rand<(1-\frac{NFE}{MaxNFE})\). Accordign to Eq. (14), in the first iteration the learner \({xp}_{k}\) is most probably equal to \({x}_{k}\) and in the last iteration it is most probably equal to \({x}_{lb}\). \({Cr}_{k}\) is the kth crossover rate, which is determined based on Eq. (28),
where \({\upsilon }_{Cr}\) is equal to 0.5 in the first iteration and updated by using Eqs. (29) and (29-1),
in which
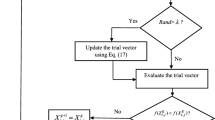
where \({S}_{Cr}\) denotes the set of all successful learner crossover rate (\({Cr}_{k}\)) at each iteration. Algorithm 1 gives the pseudo code of SATLDE algorithm. Also, the SATLDE flowchart is displayed in Fig. 5.

Flowchart of SATLDE.

Performance assessment of the optimizers
The correlation coefficient (R), root mean square error (RMSE), mean absolute error (MAE), mean absolute percentage error (MAPE), Willmott’s agreement Index (IA), the Legate and McCabe’s index (\(\text{E}\)), and centered root mean square error (cRMSE) are taken on to evaluate the efficiency of optimization methods, which are defined here.
where N is number of dataset (for four- and ten-reservoir problems is equal to 48 and 120, respectively), \({R}_{LP,i}\) denotes the reservoir release obtained by LP model, \({R}_{OM,i}\) denotes the reservoir release achieved by optimization methods, \(\overline{{R }_{LP}}\) and \(\overline{{R }_{OM}}\) denote the mean values of reservoir releases optimized by LP and optimization methods, respectively. Decisions based on these criteria are difficult, and for easier decision-making in order to select the best method, they can be turned into a single criterion. In this paper, a multi-index metric was applied to assess the performance of optimization methods, which is called the performance index (PI) and defined as,
where \({R}_{min}\), \({E}_{min}\), and \({IA}_{min}\) are the minimum value of \(R\), \(E\), and \(IA\) calculated by all optimizers. Also, \({RMSE}_{max}\), \({MAE}_{max}\), and \({MAEP}_{max}\) are the maximum value of \(RMSE\), \(MAE\), and \(MAEP\) computed by seven optimizers.
In this study an effective graphical method called Taylor diagram49 is used to better show the efficiency of proposed method compared with the other methods. To implement this graph, it is used three performance indices, including standard deviation (SD), correlation coefficient (R), and centered root mean square error (\(cRMSE\)). This graph is plotted in a polar space in which its geometrical distance to the target point indicates the efficiency of each method49. The \(cRMSE\) can be formulated as,
where \({SD}_{LP}\) and \({SD}_{Alg}\) refers the standard deviation of the optimal values of releases caluclated by the LP and optimization algorithms, respectively.
Results and discussion
Results of ten-reservoir problem
Optimal results of ten-reservoir problem calculated by all certain optimization techniques are pointed out in this section. The problem was solved by using LINGO 8.0 software and the global solution was 1194.4430,50. The control parameter amounts of all optimizers for the problem are illustrated in Table 1. Also, the population size and \(MaxNFE\) for this problem are equal to100 and 600,000, respectively. Table 2 shows the outcomes achieved by the seven competitors, including the best, worst, mean, and SD for this problem in 30 different experiments. For ten-reservoir problem, only SATLDE can achieve the best values on four metrics (i.e., the best (1196.98), worst (1194.00), mean (1195.85), and SD (0.84)). A polar space is used to produce this graph, and the geometrical distance between the target point and the graph’s origin represents the effectiveness of each approach. From the results, it can powerfully certificate the importance of the proposed SATLDE in optimizing complicated multi-reservoir optimization problem. It should be noted that for this problem the value of global optimum is 1194.44, while the best value obtained by the SATLDE is 1196.98. Therefore, there are a difference between the optimum value achieved by the LP and SATLDE. This difference is due to the PF coefficients considered for this problem30,50,51. In fact, the PF in Eq. (23) is not equal to zero, because the PF coefficient is small for this problem. Similar to the previous problem, the value of PF coefficient is not changed in this study, because this problem is a benchmark problem.
Table 3 presents the performance of seven optimization algorithms in this study, which are comprehensively evaluated by six performance metrics (i.e., R, RMSE, MAE, MAPE, E, and IA). The obtained results reported in Table 5 indicated that the SATLDE algorithm has the highest correlation and lowest error (R = 0.995, RMSE = 0.276, MAE = 0.061, MAPE = 4.809, E = 0.989, IA = 0.997) compared with the optimal value calculated by the other optimization algorithms.
According to Fig. 6, SATLDE has a superior performance compared to its competitors MS-DEPSO (0.52), MLBSA (0.64), HSLSO (0.77), jDE (0.81), SATLBO (0.85), and ITLBO (1.00). Consequently, it can be concluded based on this index that, the optimal results calculated by SATLDE have a significant compliance with the global optimal solution computed by the LP. The boxplot of all optimizers in Fig. 7 shows that SATLDE illustrates a superior performance compared with other optimizers with regard to the solution distribution.

Comparing PI metric for SATLDE and other optimizers for four-reservoir problem.

Boxplots of all optimizers for ten-reservoir problem.
The convergence graphs in Fig. 8 show that SATLDE has the fastest convergence speed compared with the other competitors for the ten-reservoir problem. Accordingly, it can be inferred SATLDE can achieve precise and reliable reservoir releases compared to the others. Figure 9 shows the monthly volume of reservoir releases and storage optimized by SATLDE and top two other optimization algorithms (i.e., SATLBO, MS-DEPSO, and MLBSA). Visually, the optimal release and storage achieved by SATLD have the significant correspondence with the global optimal values calculated by LP.

Convergence curves of all optimization techniques for ten-reservoir problem.

Reservoir volumes for ten-reservoir problem at two modes: (a) storage, (b) release.
The Taylor diagram of all optimization algorithms is depicted in Fig. 10, showing that, the proposed algorithm is closer to the global optimal solution (target point) compared to the other algorithms. This graph highlights once again the capacity of SATLDE to handle complex multi-reservoir systems.

Taylor diagram of all optimizers for ten-reservoir problem.
Ranking analysis
In this section, two non-parametric statistical tests namely the Friedman52 and Wilcoxon Signed Rank (WSR)52 tests are used to show the best method for optimizing multi-reservoir systems. Table 4 gives the results of Friedman test for two multi-reservoir problems. According to this test, SATLD has the best rank (1) compared with the six other optimizers.
Based on the WSR, R+ illustrates the sum of ranks over all different runs in which SATLDE outperformed the contestant optimizer, while R− represents the sum of ranks over all runs where the contestant optimizer outperformed the SATLDE. In addition, in a statistical hypothesis test (\(\alpha\) = 0.05), the p-value detects the importance of the outcomes. The results showed that the values of R+ and R− obtained by WSR for the proposed method compared to other optimization methods are the same and equal 465 and 0, respectively. Accordingly, it can be said that SATLDE performs significantly better than the other optimizers.
Results of real-world multi-reservoir system
Results of the multi-reservoir system as a real-world case study are provided in this section in detail. As stated in “Real-world multi-reservoir system” section, this system consists of four reservoirs and its main purpose is hydropower generation.
Statistical criteria comparison
To indicate the robustness of the SATLDE, the statistical results of seven optimizers (i.e., HSLSO, MS-DEPSO, jDE, MLBSA, ITLBO, SATLBO) are reported in Table 5, comprising the best, mean, worst, and SD of the fitness function values. Seven optimization algorithms are independently run 30 times, while the \(Np\) and \(MaxNFE\) are set to 100 and 1000, respectively. The problem was optimized over a 55-year operational time step.
As demonstrated in Table 5, it can be obviously found that the best (207.63), mean (223.63), and worst (255.08) of the fitness function values obtained by SATLDE are obviously better than the control optimizers. In addition, SATLDE makes about 49%, 32%, 83%, 29%, 32%, and 65% improvements in the SD values compared with HSLSO, ITLBO, jDE, MS-DEPSO, SATLBO, and MLBSA, respectively. Besides, from Table 6 also finds that the SATLDE is more reliable and accurate than other optimizers according to the performance.
Box plot analysis
Box plot graph is used to illustrate the variation rate of the fitness function calculated by the proposed SATLDE and other optimization methods during 30 different runs. Figure 11 depicts the Box plot of 7 optimizers for the multi-reservoir system. The figure indicates the seven optimization algorithms’ maximum, minimum, and average fitness functions. In addition, the Box plot shows the density range of fitness function over 30 runs. It can be seen that compared with six other optimization algorithms, the location of SATLDE is clearly lower, and the range of distribution is smaller, indicating the priority of the optimization technique. Therefore, SATLDE can be utilized as an efficient tool for optimizing multi-reservoir problems.

Boxplots of all optimizers for real world multi-reservoir problem.
Convergence trajectory analysis
Figure 12 illustrates the convergence graphs of seven methods for the multi-reservoir problem. The figure displays the average values of the fitness function for all optimizers, obtained in 30 different runs. It has been discovered that the SATLDE has a faster convergence speed than the other approaches after 12,500 NFE. In fact, the proposed method can quickly explore feasible solutions by increasing the NFE. The high accuracy and speed up of the SATLDE convergence are due to the adaptive parameters and different strategies added to the proposed algorithm.

Convergence graphs of all optimizers for the multi-reservoir system.
Detailed hydropower production analysis
Table 6 gives the total power generated by all optimization methods for each reservoir of the multi-reservoir system. It can be found from the table that the power generated by SATLDE for Karoun3 (6.35E+05 MW), Karoun1 (8.46E+05 MW), Godar (8.51E+05 MW), and Dez (2.78E+05 MW) are more than those produced by the other methods. In addition, the total power generated by SATLDE (2.61E+06 MW) is more than the MLBSA (2.46E+06), HSLSO (2.55E+06), ITLBO (2.11E+06 MW), jDE (2.39E+06 MW), MS-DEPSO (2.53E+06 MW), and SATLBO (2.47 + 06 MW), respectively. Based on the results, the best optimization method to produce power is the SATLDE, followed by the HSLSO, MS-DEPSO, SATLBO, MLBSA, jDE, and ITLBO, respectively.
Figure 13 displays the monthly distribution of power generated by all optimizers in the form of a heat map plot. It can be observed that the proposed SATLDE can produce more monthly power than those generated by the six other optimizers. It is worth noting that in the SATLDE, most of the power generated occurs in months 1 to 9 (January to September).

Monthly average of hydropower energy generated by all optimizers.
Figure 14 depicts the distribution of monthly power generated by SATLDE in the form of a Box plot. Based on the figure, the maximum and minimum energy produced belong to the 6th and 10th, respectively. Moreover, the monthly maximum, minimum, and average volumes of reservoir storage achieved by the proposed method are shown in Fig. 15. According to the findings of this study, SATLDE outperforms the MS-DEPSO, HSLSO, MLBSA, jDE, and ITLBO in determining the optimal power generated from the multi-reservoir system. This is the case, although all six optimizers can be used effectively to reach optimal operating rules for the multi-reservoir system successfully.

Monthly generated power gained by SATLDE.

Monthly maximum, minimum, and average of reservoir storage gained by SATLDE.
Conclusion
A self-adaptive teaching learning-based with differential evolution (SATLDE) is developed for optimizing hydropower multi-reservoir systems. SATLDE uses a ranking probability mechanism to select the teacher or learner stage; then a boosted teacher stage utilizing various teaching ways is applied to move the learners to enhance themselves based on their levels. Finally, an efficient mutation operator is employed to the learner stage for improving global search capability. In addition, an adaptive method is used for parameter settings. SATLDE applies a learner factor according to the adaptive approach to store the optimal control parameter values at each iteration.
The efficiency of SATLDE has been evaluated by optimizing a well-known benchmark multi-reservoir system, i.e., the ten-reservoir problem. For the ten-reservoir problem, SATLDE shows superior results, with the best fitness function value equal to 1196.98, while MLBSA, HSLSO, ITLBO, jDE, MS-DEPSO, and SATLBO can converge to 1168.20, 1142.39, 1091.07, 1133.47, 1187.02, and 1138.69, respectively. SATLDE demonstrates significant efficiency in reliability, precision, and robustness. Therefore, the proposed algorithm can be employed in other multi-reservoir systems in order to quickly extract the optimal operating rules for multi-reservoir systems, thus improving energy efficiency.
To exhibit the ability of SATLDE in optimizing real-world problems, a multi-reservoir system consists of four reservoirs located in Iran was used as a case study. In this research, a nonlinear operating rule is developed to maximize the energy produced from the multi-reservoir system. In fact, SATLDE and six other optimizers are applied to derive the optimal operating rules. It statistical analysis of results shows that, SATLDE can present the superior ability in obtaining more promising solutions as compared with the six optimization methods. In addition, SATLDE could produce remarkably more power (2610 GW) than the MLBSA (2460 GW), HSLSO (2550 GW), ITLBO (2110 GW), jDE (2390 GW), MS-DEPSO (2530 GW), and SATLBO (2470 GW). Consequently, results show that SATLDE is able to present more reliable and accurate operating rules for the multi-reservoir system. Accordingly, it can be considered an effectual alternative for optimizing operating rules of other complex hydropower multi-reservoir systems.
For future study, the proposed SATLDE can be ensembled with other optimization methods such as the GBO algorithm. Moreover, we will investigate the ability of proposed method to derive optimal parameters of photovoltaic models. In addition, although the data in the present study shows both wet and dry periods, we recommend that future work focus on including climate change scenarios to ensure that the operating rules can respond to a broader range of climate conditions. Finally, SATLDE can be used for solving machine learning problems.
Data availability
All data used in the study are available from the corresponding author by request.
Code availability
The source codes of the paper and online web service for any question and Supplementary Material including all equations of the algorithms will be publicly available at http://imanahmadianfar.com.
References
Abdollahi, A. & Ahmadianfar, I. Multi-mechanism ensemble interior search algorithm to derive optimal hedging rule curves in multi-reservoir systems. J. Hydrol. 598, 126211 (2021).
Ahmadianfar, I., Noshadian, S., Elagib, N. A. & Salarijazi, M. Robust diversity-based sine-cosine algorithm for optimizing hydropower multi-reservoir systems. Water Resour. Manag. 35, 3513–3538 (2021).
Feng, Z. et al. A modified sine cosine algorithm for accurate global optimization of numerical functions and multiple hydropower reservoirs operation. Knowl.-Based Syst. 208, 106461 (2020).
Feng, Z. et al. Multiple hydropower reservoirs operation optimization by adaptive mutation sine cosine algorithm based on neighborhood search and simplex search strategies. J. Hydrol. 590, 125223 (2020).
Ivetić, D. et al. Framework for dynamic modelling of the dam and reservoir system reduced functionality in adverse operating conditions. Water 14, 1549 (2022).
Oliveira, R. & Loucks, D. P. Operating rules for multireservoir systems. Water Resour. Res. 33, 839–852 (1997).
Razavi, S. et al. Evaluation of new control structures for regulating the Great Lakes system: Multiscenario, multireservoir optimization approach. Water Resour. Plan. Manag. 140, 10–1061 (2013).
Asadzadeh, M., Razavi, S., Tolson, B. A. & Fay, D. Pre-emption strategies for efficient multi-objective optimization: Application to the development of Lake Superior regulation plan. Environ. Model. Softw. 54, 128–141 (2014).
Labadie, J. W. Optimal operation of multireservoir systems: State-of-the-art review. J. water Resour. Plan. Manag. 130, 93–111 (2004).
Haimes, Y. Y. & Hall, W. A. Multiobjectives in water resource systems analysis: The surrogate worth trade off method. Water Resour. Res. 10, 615–624 (1974).
Simonovic, S. The implicit stochastic model for reservoir yield optimization. Water Resour. Res. 23, 2159–2165 (1987).
Lyra, C. & Ferreira, L. R. M. A multiobjective approach to the short-term scheduling of a hydroelectric power system. IEEE Trans. Power Syst. 10, 1750–1755 (1995).
Holland, J. H. Genetic algorithms. Sci. Am. 267, 66–73 (1992).
Storn, R. & Price, K. Differential evolution—A simple and efficient heuristic for global optimization over continuous spaces. J. Glob. Optim. 11, 341–359 (1997).
Eberhart, R. & Kennedy, J. A new optimizer using particle swarm theory. In MHS’95. Proceedings of the Sixth International Symposium on Micro Machine and Human Science, 39–43 (IEEE, 1995).
Rashedi, E., Nezamabadi-Pour, H. & Saryazdi, S. GSA: A gravitational search algorithm. Inf. Sci. (N.Y.) 179, 2232–2248 (2009).
Gandomi, A. H., Yang, X.-S. & Alavi, A. H. Cuckoo search algorithm: A metaheuristic approach to solve structural optimization problems. Eng. Comput. 29, 17–35 (2013).
Karaboga, D. & Basturk, B. A powerful and efficient algorithm for numerical function optimization: Artificial bee colony (ABC) algorithm. J. Glob. Optim. 39, 459–471 (2007).
Ahmadianfar, I., Bozorg-Haddad, O. & Chu, X. Gradient-based optimizer: A new metaheuristic optimization algorithm. Inf. Sci. (N.Y.) 540, 131–159 (2020).
Ahmadianfar, I., Heidari, A. A., Gandomi, A. H., Chu, X. & Chen, H. RUN beyond the metaphor: An efficient optimization algorithm based on Runge Kutta method. Expert Syst. Appl. 181, 115079 (2021).
Ahmadianfar, I., Heidari, A. A., Noshadian, S., Chen, H. & Gandomi, A. H. INFO: An efficient optimization algorithm based on weighted mean of vectors. Expert Syst. Appl. 195, 116516 (2022).
Ahmadianfar, I., Samadi-Koucheksaraee, A. & Bozorg-Haddad, O. Extracting optimal policies of hydropower multi-reservoir systems utilizing enhanced differential evolution algorithm. Water Resour. Manag. 31, 4375 (2017).
Ahmadianfar, I., Khajeh, Z., Asghari-Pari, S.-A. & Chu, X. Develo** optimal policies for reservoir systems using a multi-strategy optimization algorithm. Appl. Soft Comput. 80, 888–903 (2019).
Cheng, C.-T., Wang, W.-C., Xu, D.-M. & Chau, K. W. Optimizing hydropower reservoir operation using hybrid genetic algorithm and chaos. Water Resour. Manag. 22, 895–909 (2008).
Mohammadi, M., Farzin, S., Mousavi, S.-F. & Karami, H. Investigation of a new hybrid optimization algorithm performance in the optimal operation of multi-reservoir benchmark systems. Water Resour. Manag. 33, 4767–4782 (2019).
Niu, W. et al. Multireservoir system operation optimization by hybrid quantum-behaved particle swarm optimization and heuristic constraint handling technique. J. Hydrol. 590, 125477 (2020).
Ahmadianfar, I., Kheyrandish, A., Jamei, M. & Gharabaghi, B. Optimizing operating rules for multi-reservoir hydropower generation systems: An adaptive hybrid differential evolution algorithm. Renew. Energy 167, 774–790 (2021).
Zhang, R., Zhou, J., Ouyang, S., Wang, X. & Zhang, H. Optimal operation of multi-reservoir system by multi-elite guide particle swarm optimization. Int. J. Electr. Power Energy Syst. 48, 58–68 (2013).
Taghian, M., Rosbjerg, D., Haghighi, A. & Madsen, H. Optimization of conventional rule curves coupled with hedging rules for reservoir operation. J. Water Resour. Plan. Manag. 140, 693–698 (2014).
Ahmadianfar, I., Adib, A. & Salarijazi, M. Optimizing multireservoir operation: Hybrid of bat algorithm and differential evolution. J. Water Resour. Plan. Manag. 142, 606 (2016).
Haddad, O. B., Hosseini-Moghari, S.-M. & Loáiciga, H. A. Biogeography-based optimization algorithm for optimal operation of reservoir systems. J. Water Resour. Plan. Manag. 142, 4015034 (2016).
Moravej, M. & Hosseini-Moghari, S.-M. Large scale reservoirs system operation optimization: The interior search algorithm (ISA) approach. Water Resour. Manag. 30, 3389–3407 (2016).
Liu, J., Li, D., Wu, Y. & Liu, D. Lion swarm optimization algorithm for comparative study with application to optimal dispatch of cascade hydropower stations. Appl. Soft Comput. 87, 105974 (2020).
Ahmadianfar, I., Adib, A. & Taghian, M. Optimization of fuzzified hedging rules for multipurpose and multireservoir systems. J. Hydrol. Eng. 21, 5016003 (2016).
Hatamkhani, A. & Moridi, A. Multi-objective optimization of hydropower and agricultural development at river basin scale. Water Resour. Manag. 33, 4431–4450 (2019).
Fang, R. & Popole, Z. Multi-objective optimized scheduling model for hydropower reservoir based on improved particle swarm optimization algorithm. Environ. Sci. Pollut. Res. 27, 12842–12850 (2020).
Wang, Y., Cai, Z. & Zhang, Q. Differential evolution with composite trial vector generation strategies and control parameters. IEEE Trans. Evol. Comput. 15, 55–66 (2011).
Li, S., Gong, W., Wang, L., Yan, X. & Hu, C. A hybrid adaptive teaching–learning-based optimization and differential evolution for parameter identification of photovoltaic models. Energy Convers. Manag. 225, 113474 (2020).
Luo, J. et al. Multi-strategy boosted mutative whale-inspired optimization approaches. Appl. Math. Model. 73, 109–123 (2019).
Ghasemi, M., Aghaei, J., Akbari, E., Ghavidel, S. & Li, L. A differential evolution particle swarm optimizer for various types of multi-area economic dispatch problems. Energy 107, 182–195 (2016).
Rao, R. V., Savsani, V. J. & Vakharia, D. P. Teaching–learning-based optimization: A novel method for constrained mechanical design optimization problems. Comput. Des. 43, 303–315 (2011).
Chen, X., Yu, K., Du, W., Zhao, W. & Liu, G. Parameters identification of solar cell models using generalized oppositional teaching learning based optimization. Energy 99, 170–180 (2016).
Yu, K., Chen, X., Wang, X. & Wang, Z. Parameters identification of photovoltaic models using self-adaptive teaching-learning-based optimization. Energy Convers. Manag. 145, 233–246 (2017).
Li, S. et al. Parameter extraction of photovoltaic models using an improved teaching–learning-based optimization. Energy Convers. Manag. 186, 293–305 (2019).
Murray, D. M. & Yakowitz, S. J. Constrained differential dynamic programming and its application to multireservoir control. Water Resour. Res. 15, 1017–1027 (1979).
Celeste, A. B. & Billib, M. Evaluation of stochastic reservoir operation optimization models. Adv. Water Resour. 32, 1429–1443 (2009).
Li, S., Gu, Q., Gong, W. & Ning, B. An enhanced adaptive differential evolution algorithm for parameter extraction of photovoltaic models. Energy Convers. Manag. 205, 112443 (2020).
Zhao, D. et al. Ant colony optimization with horizontal and vertical crossover search: Fundamental visions for multi-threshold image segmentation. Expert Syst. Appl. 167, 114122 (2021).
Taylor, K. E. Summarizing multiple aspects of model performance in a single diagram. J. Geophys. Res. Atmos. 106, 7183–7192 (2001).
Haddad, O. B., Afshar, A. & Mariño, M. A. Multireservoir optimisation in discrete and continuous domains. Proc. Inst. Civil Eng. Water Manag. 164, 57–72 (2011).
Jalali, M. R., Afshar, A. & Marino, M. A. Multi-colony ant algorithm for continuous multi-reservoir operation optimization problem. Water Resour. Manag. 21, 1429–1447 (2007).
Derrac, J., García, S., Molina, D. & Herrera, F. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evol. Comput. 1, 3–18 (2011).
Acknowledgements
This study was funded by Vice-Chancellor for Research and Technology, Behbahan Khatam Alanbia University of Technology, (project code. 1401- 17-G).
Author information
Authors and Affiliations
Contributions
I.A.: Conceptualization, Methodology, Software, Writing—Original draft preparation, Visualization, Investi- gation, A.S.-K.: Writing—Original draft preparation, Visualization, Investigation, M.A.: Supervision, Reviewing and Editing, Visualization, Investigation.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ahmadianfar, I., Samadi-Koucheksaraee, A. & Asadzadeh, M. Extract nonlinear operating rules of multi-reservoir systems using an efficient optimization method. Sci Rep 12, 18880 (2022). https://doi.org/10.1038/s41598-022-21635-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-21635-0
- Springer Nature Limited
This article is cited by
-
Applying the new multi-objective algorithms for the operation of a multi-reservoir system in hydropower plants
Scientific Reports (2024)
-
Development of the FA-KNN hybrid algorithm and its application to reservoir operation
Theoretical and Applied Climatology (2024)
-
Multi-objective optimal allocation of water resources based on improved marine predator algorithm and entropy weighting method
Earth Science Informatics (2024)