
Abstract
Despite the wide effects of cardiorespiratory fitness (CRF) on metabolic, cardiovascular, pulmonary and neurological health, challenges in the feasibility and reproducibility of CRF measurements have impeded its use for clinical decision-making. Here we link proteomic profiles to CRF in 14,145 individuals across four international cohorts with diverse CRF ascertainment methods to establish, validate and characterize a proteomic CRF score. In a cohort of around 22,000 individuals in the UK Biobank, a proteomic CRF score was associated with a reduced risk of all-cause mortality (unadjusted hazard ratio 0.50 (95% confidence interval 0.48–0.52) per 1 s.d. increase). The proteomic CRF score was also associated with multisystem disease risk and provided risk reclassification and discrimination beyond clinical risk factors, as well as modulating high polygenic risk of certain diseases. Finally, we observed dynamicity of the proteomic CRF score in individuals who undertook a 20-week exercise training program and an association of the score with the degree of the effect of training on CRF, suggesting potential use of the score for personalization of exercise recommendations. These results indicate that population-based proteomics provides biologically relevant molecular readouts of CRF that are additive to genetic risk, potentially modifiable and clinically translatable.
Similar content being viewed by others

Main
CRF is a powerful prognostic marker linked to greater health, quality of life and longevity across the life course1,2,3,4,5,6. Measuring CRF is an important component of clinical care in several disease conditions3,7 and is often considered an essential health metric on par with clinical vital signs6. Nevertheless, widespread clinical assessment of CRF for risk stratification and health promotion has been limited by test availability, cost and factors (for example, musculoskeletal) that may limit the ability to perform maximum effort exercise. An alternative approach—easily accessible, training-responsive biomarkers of CRF—may address these limitations and enable discovery of pharmacological targets that mimic effects of exercise. Exercise is accompanied by widespread changes in the human metabolic state, spanning pathways of tissue regeneration and fibrosis, muscle structure, mitochondrial dysfunction, insulin resistance and inflammation8,9,10,11,12. While molecular surrogates of CRF and training responses are associated with clinical prognosis8,10,13, most studies have been across a single population with limited follow-up and outcomes and have demonstrated effect sizes that are not significantly additive over standard risk factors.
Here, we performed an international population-based study of 14,145 individuals with CRF measures spanning four different population-based observational cohorts (the Coronary Artery Risk Development in Young Adults (CARDIA) study; the Fenland Study; the Baltimore Longitudinal Study of Aging (BLSA); and the Health, Risk Factors, Exercise Training and Genetics (HERITAGE) family sutdy) with diverse modes of CRF assessment to define and validate a proteomic signature of CRF. Leveraging data from around 22,000 participants from the UK Biobank (UKB), we tested the association of a proteomic signature of CRF with a broad array of clinical outcomes (death, cardiovascular, metabolic, malignancy, neurological) and examined the interaction with polygenic risk. In HERITAGE, we evaluated whether a 20-week exercise training program modified a proteomic signature of CRF. To our knowledge, this study provides the largest, most comprehensive human population-based proteomic study of CRF, demonstrating its broad functional and clinical relevance to human disease with a path for clinical translation.
Results
Characteristics of study samples
Our initial sample to establish relations of the circulating proteome with CRF included participants from CARDIA. The CARDIA sample consisted of 2,238 individuals with a median age 51 years (56% female, 43% Black; Table 1). CARDIA participants were generally overweight (median body mass index (BMI) 29 kg m−2) with a modest prevalence of diabetes (14%) and treated hypertension (26%). We did not observe any important differences between our CARDIA derivation (70%) and validation (30%) subsets (split randomly, balanced on exercise treadmill test (ETT) time). We validated our findings in three external cohorts: Fenland14; BLSA15; and HERITAGE10. These cohorts spanned early to older adulthood with a wide range of BMI and comorbidity (Supplementary Table 1a). A subsample of the UKB (N = 21,988; median age 58 years, 54% female, 93% white; Supplementary Table 1b) with available proteomics was used to test the association of the CRF proteome with a broad array of outcomes. The method of CRF assessment differed across cohorts (Methods), which—in conjunction with cohort-specific differences (for example, age)—contributed to differences in CRF distributions.
Development of a proteomic CRF score
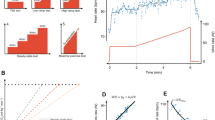
We sought to develop an integrative score of CRF to leverage the multiorgan and diverse drivers of CRF. Using penalized regression (least absolute shrinkage and selection operator (LASSO)) across the assayed proteome, we developed a proteomic CRF score in the CARDIA derivation subset, using ETT time as the CRF measure, and validated it across approximately 12,500 participants across four samples (Fig. 1). We achieved a >95% reduction in proteomic space (272 aptamers selected from 7,230 candidates) with good calibration in both the CARDIA derivation (Spearmanʼs ρ = 0.79) and validation subsets (Spearmanʼs ρ = 0.67; Fig. 2), comparable with previously published metabolomic13 or proteomic instruments16. We observed mechanistically plausible directionality for many of the proteins of the highest effect sizes (Table 2), including proteins implicated in innate immunity and inflammation (C5a17,18), atherosclerosis (AGER19, RGMB19), neuronal survival and growth (CDNF20, LSAMP21), cell physiology (TNR—migration, adhesion, differentiation; DUSP13—differentiation, proliferation), oxidative stress (MRM122), energy expenditure and substrate fuel utilization (OLFM223, FABP424, FABP325, HNF4A26, GLYATL2), adiposity (LEP, CA627), peripheral muscle responses to exercise (MB28, ATF629) and autophagy (GLIPR230).

We developed and validated a circulating proteomic signature of CRF across four cohorts and various exercise modalities. In the UKB, we examined the relationship a proteomic CRF signature with a broad range of clinical endpoints and examined its interaction with polygenic risk. In HERITAGE, we examined the association of the proteomic CRF signature with response to exercise training and correlated changes in signature with changes in CRF. NAFLD, nonalcoholic fatty liver disease.

a, Correlations between the proteomic CRF score and CRF (defined by ETT time) in CARDIA across derivation (left) and validation (right) samples. b–d, Correlations of the proteomic CRF score with age (b), sex and race (c) and BMI (d). Colors on scatter plots represent density of overlap** observations, with red being the most dense and blue the least dense. P values in a, b and d are from Spearman rank correlation tests. P values in c are from linear regression modeling of the proteomic CRF score as a function of sex and race. All P values are from two-sided tests.
After recalibration to shared proteins across each of our validation samples (Fenland, HERITAGE, BLSA; Supplementary Tables 3–5 and Methods), we observed differences in fit against measured CRF, most likely owing to heterogeneity in methods for assessment of CRF (Extended Data Fig. 1). The best validation fits were observed in HERITAGE (ρ = 0.71) and BLSA (ρ = 0.68), where CRF was assessed by symptom-limited peak exercise testing with directly measured gas exchange (peak VO2). The weakest validation fit was observed in Fenland (ρ = 0.35), where CRF was estimated from heartrate response to submaximal exercise with extrapolation to age-predicted maximal heartrate. We observed consistent differences in the proteomic CRF score by sex (men higher) and inverse associations with age and BMI (Extended Data Figs. 1 and 2), consistent with the general epidemiology of CRF14.
Relations of a proteomic CRF score with clinical outcomes
Given the multicohort replication of the proteomic CRF score and its biological plausibility, we next sought to test its clinical relevance. We identified a sample of 21,988 UKB participants with proteomic data (Olink Explore 1536) and with survival data for a wide array of outcomes (Supplementary Table 1b). Over a median follow-up of 13.7 years (25th–75th percentile, 13.0–14.5 years), 2,394 deaths occurred (other outcomes reported in Supplementary Table 7). Per each 1 s.d. higher CRF proteome score, we observed a near 50% lower hazard of all-cause mortality (hazard ratio (HR) = 0.53, 95% confidence interval (CI) 0.50–0.56; P < 0.0001) and cause-specific mortality (Fig. 3a; all HRs and 95% CIs in Supplementary Table 7), robust to adjustment for standard clinical risk factors and bioimpedance-based measured fat mass. In addition to censoring at other causes of death for models for cause-specific mortality, we observed similar results using Fine–Gray competing risk models (Supplementary Table 8). Strikingly, we observed a consistent and strong protective association of a greater proteomic CRF score for cardiovascular, metabolic and neurological outcomes (but not with most cancers). Moreover, the proteomic CRF score improved risk prediction beyond standard risk factors, with improved discrimination and reclassification across nearly every endpoint (for example, all-cause mortality: C-index 0.75 to 0.77, P < 0.001; cardiovascular mortality: C-index 0.79 to 0.82, P < 0.001; Fig. 3a). Reclassification was substantial, with a near 30–40% net reclassification beyond clinical risk factors for most conditions across several systems.

a, Forest plot of Cox model results with proteomic score as the main predictor, grouped by outcome category. The ‘full’ adjustment model includes adjustment for age, sex, race, BMI, systolic blood pressure, diabetes, Townsend deprivation index, smoking, alcohol and LDL. Error bars, 95% CI. The adjoining table reports the C-index for Cox models without proteomic score (Base) and with the score (Score). Base models include age, sex, race, BMI, systolic blood pressure, diabetes, Townsend deprivation index, smoking, alcohol and LDL. Reported P value is from comparison testing of C-indices by z distribution (two-sided) without correct for multiple comparison. b, Cox beta coefficients from models including an interaction between the protein score of CRF and PRSs of the indicated conditions or diseases. Error bars, 95% CI. c, Contour map of the model predicted HR across the range of protein score of fitness and PRSs. The referent hazard was set at the median of the protein score and median of the PRS. Values reported and visualized are from point estimates and 95% CI. d, Comparison of Cox model coefficients from a parsimonious 21-protein panel and the full 307-protein panel. The halo represents the 95% CI around the model coefficient. P value is from two-sided Spearman rank correlation test. For visualization, we reversed the sign of the beta coefficients. Full data on sample sizes, model estimates and results of statistical testing may be found in Supplementary Tables 7 and 13.
To evaluate whether the strong associations with clinical outcomes were confounded by proteomic markers of disease in the CARDIA cohort from which the proteomic CRF score was derived, we conducted a sensitivity analysis by deriving the proteomic CRF from a subset of the CARDIA study cohort that excluded participants with a history of cardiovascular disease (CVD—myocardial infarction, stroke, heart failure, carotid artery disease, peripheral artery disease), diabetes and hypertension. This proteomic CRF score was then translated for use in the UKB in the same manner, and we observed directionally consistent results as our primary analysis with slightly decreased effect sizes (Supplementary Tables 9–12).
Integration of a proteomic CRF score and polygenic risk
Previous reports have highlighted the complementary impact of polygenic risk and lifestyle in human disease31,32,33,34. Given the centrality of CRF as an integrative measure of human health, we next explored interaction between the proteomic CRF score and polygenic risk of common diseases (Fig. 3b and Supplementary Table 13). We constructed models for six conditions with established polygenic risk scores (PRS) within the UKB, as a function of the proteomic CRF score, a corresponding PRS and their multiplicative interaction with adjustments for age, sex, race and four principal components of genetic ancestry. While several PRS-by-proteomic CRF score interactions reached weak statistical significance (including CVD and type 2 diabetes), the effect sizes were marginal. Overall, we observed a substantial and additive effect between the proteomic CRF score and each PRS on the corresponding disease outcome, with highest hazards of disease observed among those participants with the lowest proteomic CRF score (corresponding to poor CRF) and high genetic risk (Fig. 3c). For most conditions, the standardized estimates for the proteomic CRF score were on the order of (or higher than) those for PRS (for example, diabetes: HRproteome = 0.37, 95% CI 0.35–0.40; HRPRS = 1.97, 95% CI 1.83–2.12).
Association of a parsimonious proteomic CRF score with clinical risk
Even with regularization in regression, one main limitation in most multivariable proteomic approaches is the lack of sufficient reduction in molecular dimension to permit clinical translation16 (for example, 307 proteins in our recalibrated proteomic CRF score used in UKB). To address the feasibility of clinical translation, we constructed an ‘abbreviated’ score including coefficients from the top 21 most important proteins (ranked by absolute value of the LASSO beta coefficient). We selected 21 proteins since Olink currently offers 21-plex absolute quantification panels. In CARDIA, this abbreviated 21-protein score was correlated with CRF (ρ = 0.71). In UKB, we observed consistent effect sizes for nearly all outcomes between the recalibrated proteomic CRF score (307 proteins) and the abbreviated 21-protein score, albeit with generally slightly lower effect sizes for the abbreviated CRF score (Fig. 3d and Supplementary Table 7). These results support plausibility of translation of these results as a biomarker panel of CRF that can be measured at the scale necessary to offer clinical utility.
Dynamicity of the proteomic CRF score with training
To leverage the human proteome for CRF assessment, it is critical to evaluate its potential for modification through intervention. After a 20-week exercise training program in HERITAGE35, we observed an increase in the recalibrated (nonabbreviated) proteomic CRF score (paired t-test, 0.14; 95% CI, 0.11–0.18; P = 2.5 × 10−15), which was correlated with a change in peak VO2 (Extended Data Fig. 3). In regression modeling, we found that a change in the recalibrated proteomic CRF score was associated with a change in peak VO2 (1 s.d. increase in recalibrated proteomic CRF score ≈ 0.84 ± 0.25 ml kg−1 min−1 increase in peak VO2; P = 8.5 × 10−4), independent of age, sex, race, BMI, pretraining peak VO2 and pretraining recalibrated proteomic CRF score. There were no differences in the response to changes in the proteomic CRF score with training by sex (P = 0.62). Additionally, we examined whether the pretraining proteomic CRF score was associated with the VO2 response to training, and observed that a higher recalibrated proteomic CRF score was associated with a greater increase in peak VO2 with training, independent of age, sex and race (0.59 ± 0.17 ml kg−1 min−1 increase per 1 s.d. increase in recalibrated proteomic CRF score; P = 6.4 × 10−4), with mitigation of the association when further adjusted for BMI (0.30 ± 0.17 ml kg−1 min−1 increase per 1 s.d. increase in recalibrated proteomic CRF score; P = 0.08). Constituents of the proteomic CRF score that exhibited significant changes with 20-week training in HERITAGE36 were correlated with an array of metabolic, vascular and myocardial phenotypes in CARDIA (Fig. 4 and Supplementary Table 14). Several of these proteins exhibit clinical and molecular plausibility, with reduction in adiposity (LEP), lipid metabolism (RARRES2), regulation of bone morphogenic protein pathways (RGMB) and mitigation of ischemia-reperfusion injury (CDNF37) among others. Many were not related to cardiometabolic phenotypes in CARDIA, suggesting potential new mechanisms of benefit.

Heatmap of Pearson correlations between individual proteins and cardiometabolic risk factors and disease in CARDIA using the CARDIA validation sample (N = 589–669). Proteins visualized are included in the proteomic CRF score and change after a 20-week exercise intervention in HERITAGE (false discovery rate < 5%). Proteins marked with an asterisk are included in the abbreviated 21-protein score. Cells marked with an asterisk indicate Pearson correlations with false discovery rate < 5%. AAC, abdominal aorta calcification; AHA LS7, American Heart Association Life Simple 7; CAC, coronary artery calcification; DBP, diastolic blood pressure; eGFR, estimated glomerular filtration rate; FC, fold change; GLS, global longitudinal strain; HbA1c, hemoglobin A1c; HDL, high density lipoprotein; LV, left ventricular; PA, physical activity; SAT, subcutaneous adipose tissue; SBP, systolic blood pressure; VAT, visceral adipose tissue.
Discussion
The notion that tissue-specific, exercise-responsive biomolecules (‘exerkines’35,38) mirror the metabolic benefits of physical exercise has prompted various efforts to catalog these biomolecular changes8,10,11,13,16,39. Several studies have highlighted acute metabolic changes during physical exercise that are linked to important physiological processes such as insulin resistance, inflammation and metabolic health across a wide array of mediators (for example, metabolites8,11,39,40, proteins10,16 and transcripts11,41), some of which overlap in association with total habitual physical activity12. While all biomolecule types offer relevant insights as functional biomarkers of CRF, the proteome can rapidly capture functional information (a ‘cause’ and ‘effect’ of CRF), broad cellular processes (with direct pathway implication) and application to a clinical setting as a quantifiable blood-based surrogate of CRF.
Here, we studied a diverse group of 14,145 individuals with varied modes of CRF assessment to characterize the circulating proteomic architecture of CRF. Beginning in a sample of 2,238 middle-aged Black and white adults in the CARDIA study, we successfully developed and validated a broad-based proteomic signature of CRF (‘proteomic CRF score’) using symptom-limited treadmill exercise test that displayed a consistent relation across submaximal treadmill exams in 10,320 individuals in the UK (Fenland, estimated maximal VO2) and maximal cardiopulmonary exercise tests (CPETs) in 1,587 individuals in the USA (BLSA, treadmill VO2; HERITAGE, cycle VO2). Proteins included in the proteomic CRF score specified pathways canonically implicated in CRF biology across several systems, including inflammation and hemostasis, muscle and adipose physiology, pathways of energy and fuel metabolism, oxidative stress and neuronal survival, among others. In 21,988 UKB participants, we observed two key findings of clinical relevance. First, the proteomic CRF score was strongly, independently associated with a range of metabolic, cardiovascular and neurological clinical outcomes, many displaying significant prognostic improvement over standard risk factors (via reclassification and discrimination metrics). Second, these associations appeared to be additive to polygenic risk, suggesting a role for multiomic evaluation in clinical risk assessment. These prognostic relations were maintained using an abbreviated 21-protein panel (the largest currently available for direct absolute protein quantification with Olink). The proteomic CRF score was also dynamic with a 20-week exercise training program, and was associated with response to training. To our knowledge, these data provide the largest report to date establishing a biologically plausible, population-based proteomic biomarker of CRF across a diverse setting, linking these measures to phenotypes and precision medicine risk assessment approaches (including human genetics) longitudinally.
Although other studies have demonstrated the ability of broad circulating proteomics to predict diverse health outcomes16, the highest priority protein targets are likely to differ for each outcome, presenting challenges for develo** unifying lifestyle or pharmacological approaches for broad risk modification or health promotion. In line with established relations of greater CRF itself with protection from a wide array of adverse cardiovascular2,42, respiratory43, oncological44 and neurocognitive outcomes45, we observed a proteomic signature trained on CRF (‘proteomic CRF score’) was associated with diverse clinical outcomes in a large sample of around 22,000 UKB participants (an order of magnitude larger than previous studies16). Beyond merely establishing a statistical association, the proteomic CRF score offered significant improvement in risk reclassification and discrimination across several conditions (for example, all-cause death, cardiovascular death, diabetes), suggesting its potential to augment clinical risk prediction. Moreover, in line with previous work demonstrating lack of strong interaction between genetics and lifestyle31, proteomic and genetic risk were complementary, with the highest clinical risks observed for those individuals with both high proteomic and genomic risk and a lowered risk for those individuals with high proteomic CRF across genetic risk. A critical finding was that these associations were robust to increased parsimony via an abbreviated 21-protein proteomic CRF score, laying groundwork for future studies of clinical translation. In this context, a proteomic CRF score may have clinical utility as a surrogate of CRF to extend its applicability to resource-limited settings, older adults or individuals with contraindications to exercise or musculoskeletal disabilities (with impaired achievement of peak exercise) in whom direct CRF assessment is challenging.
Given modifiability of CRF with lifestyle interventions (for example, physical activity46)—a critical test for any precision biomarker of CRF lies in modifiability with training. After a 20-week exercise training program within HERITAGE, we observed a modest but significant relation between changes in the proteomic CRF score with training and the peak VO2, with a 1 s.d. increase in proteomic score corresponding to an increase in peak VO2 of nearly 1 ml kg−1 min−1 (approximately 20% of the mean effect of training in HERITAGE). While HERITAGE is a healthy group (and effect sizes in a clinical population probably vary), 1 ml kg−1 min−1 is considered a ‘clinically actionable’ effect size in CVD47: in the HF-ACTION trial, an increase in peak VO2 of approximately 0.9 ml kg−1 min−1 was associated with a ~5% lower risk of mortality48. This effect size is greater than the median 3-month increase in peak VO2 observed among HF-ACTION participants randomized to exercise intervention (0.6 ml kg−1 min−1), but is on par with effects of diet and exercise within a trial of participants with HFpEF49. Moreover, we observed an association between pretraining proteomic score and changes in peak VO2 with training. These findings contribute new contributory evidence on the plasticity of the proteomic CRF biomarker, supporting broad, ongoing efforts to develop multiomic biomarkers of CRF with divergent exercise and training regimens toward personalization of exercise training responses50.
The innovation of our approach is contextualized by a rich history of approaches targeting CRF prediction to ease clinical translation. Indeed, previous work to develop nonexercise prediction models of CRF has spanned physical activity questionnaires51,52,53,54,55,56,57,58,59,60, resting heartrate53,58,60, BMI/body composition51,52,53,54,55,56,57,58,59,60,61,62,63, genetics64, proteomics16, metabolomics13 and activity monitor data61,62,63,65. However, most previous studies have been conducted in healthy or trained individuals and lack a demonstration of strong relations with to multisystem clinical outcomes. The current approach represents a notable advance, merging populations at higher metabolic risk (mirroring the advancing prevalence of cardiometabolic diseases worldwide), modes of exercise, a broad proteomic space, with several validation samples incorporating human genetics (UKB), subclinical phenotypes (CARDIA) and exercise training response (HERITAGE). As precision medicine approaches advance, incorporation of several methods (for example, wearable activity monitor plus ‘omics’) to refine clinically translatable estimates of CRF are likely to improve on any single method.
While biological plausibility and reproducibility of previous smaller studies suggest external validity, several important limitations of this work merit discussions. CRF assessments were not standardized across cohorts, which were themselves variable by age, geography, race and time epoch, although this heterogeneity may also be viewed as a strength since it highlights the robustness of our approach through successful crossvalidation. In addition, there was an interval of around 5 years between the proteomic and CRF assessment in CARDIA, which may have introduced additional variability in our estimates. However, replication of our multivariable proteomic CRF score across three additional studies (Fenland, HERITAGE and BLSA), and demonstration of its modifiability with exercise training (HERITAGE) testifies to the transportability of this approach. Although our study was limited in representation of older adults, the prognostic utility of proteomics independent of age, sex and race are a testament to potential clinical relevance. The proteomic platform utilized in the derivation samples was aptamer-based (SomaScan), which has some limitations in terms of specificity on per-protein level66. Nonetheless, we validated the clinical associations of these signatures in a different platform (Olink) in a broader set of individuals (UKB). The assessment of outcomes in UKB was administrative, with potential attendant misclassification and ascertainment biases, which we would anticipate leading to a bias toward null association. Additional forthcoming consortium-level studies across a wider range of exercise types will be important tools to study for potential sex-specific differences and may help clarify proteomic effects from changes in metabolic or lifestyle factors and CRF50.
In summary, we define, characterize, and validate a CRF-related proteome across four studies including approximately 14,000 individuals, spanning age, sex, race, geography and type of CRF assessment. CRF-related proteins demonstrated biological plausibility (including consistency with previous studies) and identified individuals with high risk of adverse clinical events across a wide array of organ systems in around 22,000 individuals. Proteomic risk appeared additive to polygenic risk and was maintained down to a clinically actionable proteomic panel. These results suggest the potential for population-based proteomics to provide a biologically relevant, clinically actionable molecular barometer of CRF with clinical potential.
Methods
Population-based cohorts
Coronary Artery Risk Development in Young Adults
The CARDIA study is a prospective, population-based, cohort study designed to study risk factors for cardiovascular disease development through the lifecourse. The original study commenced in 1985–1986 across four US field centers (Birmingham, AL; Chicago, IL; Minneapolis, MN and Oakland, CA) to study risk factor development throughout young adulthood to midlife, as previously described72,73,74,75. For this study, we included 2,238 individuals with circulating proteomics (SomaScan) at Year 25 (2010–2011) and ETT time for CRF at year 20 (2005–2006). We intentionally did not refine the CARDIA study population based on reason for stop** ETT or thresholds signifying maximal effort (for example, 85% maximum predicted heartrate) to preserve a maximal sample size and include participants who stopped early for several reasons that may reflect heightened clinical risk. Characterization of demographic, clinical and exercise test data were used as previously published76,77. Specifically, CVD was defined as a history of myocardial infarction, heart failure, stroke, carotid artery disease and peripheral artery disease. Participants provided written informed consent and approval to use deidentified data from CARDIA for this study was provided by the Institutional Review Board (IRB) at Vanderbilt University Medical Center (IRB no. 211402).
Fenland
The Fenland Study is a population-based cohort study of 12,435 participants (born between 1950 and 1975) recruited from general practices in Cambridgeshire, UK, from January 2005 to April 201578. Exclusion criteria were known diabetes, pregnancy or lactation, inability to walk unaided for a minimum of 10 min, psychosis or terminal illness. Our analytic sample included 5,473 women and 4,847 men with available CRF testing, proteomic and clinical data who attended one of three study sites (Cambridge, Ely or Wisbech). The study was approved by the Cambridge Local Research Ethics Committee (NRES Committee, East of England Cambridge Central, reference no. 04/Q0108/19). All participants provided written informed consent for blood sample measurements, exercise testing and other assessments beyond the baseline examination.
Baltimore Longitudinal Study of Aging
The BLSA is a prospective, longitudinal cohort study commenced in 1958 to study age-related conditions15,79. Our analytic sample included 845 participants who had undergone CPETs and had circulating plasma proteins quantified at the same time. Demographic and exercise data were defined as previously published80. The BLSA study protocol was approved by the Internal Review Board of the Intramural Research Program of the National Institutes of Health (protocol no. 03AG0325) and all participants provided written informed consent at each visit.
Health, Risk Factors, Exercise Training and Genetics study
HERITAGE is a study of the genetic and nongenetic contributors to biological responses to aerobic exercise training81. Participants were recruited as family units with African or European descent at five centers in the USA and Canada between 1992 and 1997, as described81. Participants had to be healthy without cardiometabolic disease but with a sedentary lifestyle for the 3 months preceding enrollment. We included published association data from 742 participants with directly measured maximal aerobic capacity (peak VO2) before exercise training and circulating proteomics10. Proteomic changes after a 20-week training period were also included36. All participants provided written informed consent. The IRB at Beth Israel Deaconess Medical Center approved this study (IRB no. 2016P000186).
UK Biobank
The UKB is a population-based study of >500,000 participants aged 40–69 years when recruited between 2006 and 2010 across the UK. UKB was constructed to enable large-scale scientific discoveries of human health82. Recently, the study coordinators released proteomics data using the Olink Explore 1536 panel on approximately 52,000 UKB participants. Our analytic sample included 21,988 participants without missing values for the proteins used to calculate a proteomic score of CRF. Approval for UKB access is under proposal no. 57492.
To maximize external validity and generalizability across broad populations, we selected CARDIA as the discovery cohort to develop a proteomic score of CRF, despite 5-year differences between proteomic and CRF assessments. Unlike Fenland and HERITAGE, which excluded participants with prevalent cardiometabolic disease, CARDIA is a population-based study inclusive of prevalent conditions. While BLSA and UKB included participants with prevalent cardiometabolic disease, the number of participants with both CRF and proteomic data is less than half of that in CARDIA. Additional considerations that guided our selection of CARDIA include its broad proteomic coverage (7k SomaScan versus 5k SomaScan in HERITAGE, Fenland and Olink Explore 1536 in UKB), and use of a symptom-limited maximal stress test (Fenland and UKB impute peak VO2 data from submaximal tests).
CRF assessment
CRF was assessed in CARDIA, BLSA, Fenland and HERITAGE according to cohort-specific protocols. In CARDIA, a symptom-limited ETT (modified Balke protocol) was performed as previously described76,83,84. Each test consisted of a maximum 18 min, with changes in treadmill speed or grade every 2 min with a maximum workload of 19 metabolic equivalents of task (METs) (for example, 5.6 miles per hour and 25% incline). Participants were excluded from ETT if they had cardiovascular or pulmonary diseases, musculoskeletal diseases worsened by exercise, uncontrolled metabolic or infectious disease, severe rest hypertension (systolic over 200 mmHg or diastolic over 110 mmHg), electrocardiographic features of ischemic heart disease or arrhythmia, pregnancy or at the discretion of exercise personnel. CRF was estimated as the duration of time a participant was able to walk/run on the treadmill. We did not exclude participants based on submaximal or early test conclusion in CARDIA.
In Fenland, CRF was assessed using a submaximal treadmill test (with imputation to maximal effort as described, methods taken from ref.14 with attribution provided by this statement) to generate estimated maximal oxygen consumption (peak VO2) per kilogram of total body mass. Participants exercised for up to 21 min while treadmill speed and incline increased across four stages. Exercise heartrate response was recorded using a combined heartrate and movement sensor (Actiheart; CamNtech)85. The test ended if one of the following criteria were satisfied: (1) levelling-off of heartrate (<3 beats per min (bpm)) despite an increase in workrate; (2) reaching 90% of the participant’s age-predicted maximal heartrate86; (3) exercising above 80% of age-predicted maximal heartrate for over 2 min; (4) reaching a respiratory exchange ratio (RER) of 1.1; (5) participant desire to stop; (6) participant indication of angina, light-headedness or nausea; or (7) failure of the testing equipment. Gas exchange measurements were sometimes unavailable for various reasons (for example, participants declining to wear a gas analysis mask, mask fit issues during exercise, system errors) that could be correlated with health-related factors. To mitigate biases that would emerge from the exclusion of participants lacking gas exchange data, and to maintain a standardized approach in estimating peak VO2 across the study, we opted to extrapolate the workrate-to-heartrate relationship to age-predicted maximal heartrate. Peak VO2 was estimated by extrapolating the linear relationship between heartrate and treadmill workrate87 to age-predicted maximal heartrate86, adding an estimate of resting energy expenditure, and then converting the resultant workrate value to VO2 (ml O2 min−1 kg−1) using a caloric equivalent for oxygen of 20.35 J ml O2−1.
In HERITAGE, CRF was measured using a cycle ergometer with metabolic cart gas exchange measures with VO2 averaged over 20 s intervals, as described10. CRF was defined as the peak VO2 and exercise peak was determined from at least one of the following: RER >1.1, a plateau in VO2 (<100 ml min−1 change in the last three measures), or a maximal heartrate within 10 bpm of the age-predicted maximum. After baseline CRF assessment, HERITAGE participants underwent supervised exercise training three times per week for 20 weeks10. CRF assessment was then repeated after completion of the training protocol.
In BLSA, CRF was measured using a symptom-limited treadmill exercise test with metabolic cart gas exchange measures using a modified Balke protocol with VO2 averaged over 30 s intervals80. Exercise testing ended after self-reported exhaustion or health- and/or safety-related stop** criteria occurred. To ensure that the maximal VO2 was achieved, the analysis was limited to participants with an RER ≥ 1. Of the 845 participants included in our study, 133 (15%) had RER between 1 and 1.1. Of these participants, 119 (89%) either reached >85% of their age-predicted maximum heartrate (calculated as 220 − age) or rated their exertion during the treadmill test as 17 or great on a 20-point Borg perceived exertion scale.
Proteomics
Proteomic quantification in CARDIA was performed using aptamer-based technology (Somalogic). Overall, 7,524 circulating aptamers were quantified. A total of 68 participants had more than one measurement of plasma proteins (at the same visit), and their protein data was averaged. We excluded nonhuman proteins (N = 233) and proteins with a coefficient of variation >20% (N = 61). Using principal component analysis on a matrix of the log-transformed, and scaled proteomic data, we checked visually for batch effects and participant outliers by plotting the first two principal components against each other. No batch effects were detected, and no participant outliers were identified (Supplementary Fig. 1). Fenland (5k aptamer platform), HERITAGE (5k aptamer platform) and BLSA (7k aptamer platform) also used SomaScan proteomics technology with methods described previously10,16,88,89. The UKB quantified circulating proteins using the Olink Explore 1536 panel90, and we excluded proteins where >40% of measurements were below the limit of detection (N = 130) or were missing in >20% of participants (N = 3). Of note, as noted above, HERITAGE data was used as published; the remainder of cohorts were analyzed as part of this work.
Statistical methods
Construction and validation of a proteomic score of CRF (‘CRF proteome’)
To explore the multidimensionality of the CRF proteome, we used LASSO regression within a linear modeling framework to develop a multivariable signature of CRF. For the purposes of analysis, the CARDIA cohort was split into a 70% derivation and 30% validation sample balanced on ETT time. The LASSO model was constructed in the CARDIA derivation sample with CRF (ETT time) as the outcome. Adjustments for age, sex, race and BMI were included as unpenalized factors (forced in regression models) with the entire proteome included as penalized factors for selection. Proteins were log-transformed, and proteins and CRF were standardized (mean 0, variance 1) for modeling. Crossvalidation was used for model hyperparameter optimization. Each CARDIA participant’s proteomic CRF score was defined as a linear combination of each protein concentration by the respective model coefficient. We excluded age, sex, race, BMI and intercept coefficients in the score calculation, such that each protein coefficient was conditioned on these covariates (to reduce dependence of the final score on these covariates). Protein scores were standardized (mean 0, variance 1) for downstream analyses.
External cohort validation of the CRF proteome
To test the external validity of the CRF proteome across additional cohorts with different proteomic coverages, we employed a recalibration approach. Our recalibration effort used a LASSO model in CARDIA, where the original score (as above) was the dependent variable and all overlap** proteins were included as independent variables. This approach generated coefficients in CARDIA that could be applied to Fenland, HERITAGE and UKB. It was not needed in BLSA, where the platform was the same as CARDIA. Recalibration accuracy (based on correlation between the original score and the recalibrated scores in CARDIA) was excellent (HERITAGE score, Pearson r = 0.98; Fenland score, Pearson r = 0.99; UKB score, Pearson r = 0.93).
Relation of the CRF proteome with clinical outcomes and its interaction with polygenic risk
Finally, we performed survival analysis in UKB to estimate the prospective association of the CRF proteome with a broad array of outcomes. Death and death category (cardiovascular death, cancer death, respiratory death) were defined by using death registry data (UKB Data Field 40000) and the International Classification of Disease tenth revision (ICD10) code provided for primary cause of death (UKB Data Field 40001). Map**s for ICD10 data to death category were informed by previous work91. The censor dates for death data (and other outcome data) were determined for each participant using the location of initial assessment (UKB Data Field 54) and the region-specific censor dates provided by the UKB. Survival analysis with death outcomes were censored on 30 November 2022 for all alive participants. Survival analysis with incident disease outcomes (for example, chronic obstructive pulmonary disease) were censored on 31 October 2022 for participants in England (N = 19,768), 31 July 2021 for participants in Scotland (N = 1,356), and 28 February 2018 for participants in Wales (N = 864) without events or the death date. Other outcomes in UKB were defined by ICD10 diagnosis codes. To group the ICD10 codes into relevant phenotypes, we used the PheWAS package to generate Phecodes, which represent a composite phenotypes comprised of several related ICD10 codes92. For each Phecode, we generated a case, control and excluded status for each participant. Participants with an ‘excluded’ status for a given Phecode were those who had a confounding ICD10 code. This confounding code would not qualify the participant as a case but would disqualify them as being a control. To determine the date of onset for each phenotype, source ICD10 codes were mapped individually to Phecodes, and the date of the earliest qualifying ICD10 code was selected. Prevalent cases were excluded from incident disease models, with prevalent cases being defined as those with a Phecode before their assessment visit, a self-reported diagnosis (UKB Data Field 20002), or a physician diagnosis (UKB Data Fields 2453, 2443, 6150). Details for model phecodes and the corresponding exclusion criteria are listed in the Supplementary Table 7.
Models were constructed using standard Cox regression with the proteomic CRF score as the predictor and the following nested adjustments: (1) unadjusted; (2) age, sex, race; (3) age, sex, race, Townsend deprivation index, body mass index, diabetes, smoking status, alcohol use, systolic blood pressure, low-density lipoprotein (LDL); (4) age, sex, race, Townsend deprivation index, body mass index, diabetes, smoking status, alcohol use, systolic blood pressure, LDL, fat mass as measured by bioimpedance (UKB Data Field 23101). We compared survival models using the maximal set of adjustments with and without the proteomic CRF score to examine differences in C-statistics and net reclassification index (NRI; calculated at the 75th percentile for NRI for events). Our primary analysis for cause-specific death used a ‘cause-specific’ approach where participants without the event of interest (for example, CVD death) are censored at the time of last known vital status or time of death from another cause (for example, cancer death). This approach was complemented using a competing risk framework with a Fine–Gray model with separate models for each of the three modes of death analyzed (for example, CVD, cancer, respiratory). For incident disease models, participants who did not experience the event were censored at the region-specific censor date or the date of death.
To examine potential complementarity of the CRF proteome with polygenic risk of diseases associated with CRF, we used Cox regression models with proteomic CRF score and standard polygenic risk score (UKB Fields 26206, 26212, 26223, 26244, 26248, 26285 (ref. 93)) as independent variables (with an interaction term between the two) with adjustments for age, sex, race and four principal components of genetic ancestry (UKB Field 26201).
To examine the potential for clinical translation, we examined performance of a 21-protein score (the maximum number of proteins in an absolute quantification Olink panel currently available) with the recalibrated protein score (307 proteins) in standard Cox models in UKB and compared beta coefficients on the two versions of the CRF proteome. The 21 proteins selected were the top 21 proteins from the recalibrated 307-protein score LASSO model, ranked by the absolute value of the beta coefficients.
Dynamicity of CRF proteome with exercise training
Finally, to examine the modifiability of the proteomic CRF score with exercise training and how it tracks with changes in peak VO2, in HERITAGE we used paired t-tests and regression models for change in peak VO2 as a function of change in proteomic CRF score with adjustments for age, sex, race, BMI, pretraining peak VO2 and pretraining proteomic CRF score. To test whether the proteomic CRF score was associated with the response to exercise training, we used a model of posttraining peak VO2 as a function of pretraining proteomic CRF score adjusted for baseline peak VO2, age, sex, race and BMI.
Analyses were conducted with R v.4 or later. All P values reported are from two-sided tests.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
Data for this study are publicly available via the CARDIA coordinating center (www.cardia.dopm.uab.edu), the Fenland Study coordinating center (https://www.mrc-epid.cam.ac.uk/research/data-sharing/), published data from HERITAGE10,35 and the UKB (https://www.ukbiobank.ac.uk). Participants did not consent to unrestricted data sharing at the time of study conduct for BLSA. Data from BLSA may be obtained via application to the BLSA coordinating center (https://www.blsa.nih.gov).
Code availability
Statistical code for the analyses can be found at https://github.com/asperry125/CRF-Proteomics.
References
Shah, R. V. et al. Association of fitness in young adulthood with survival and cardiovascular risk: the Coronary Artery Risk Development in Young Adults (CARDIA) study. JAMA Intern. Med. 176, 87–95 (2016).
Kodama, S. et al. Cardiorespiratory fitness as a quantitative predictor of all-cause mortality and cardiovascular events in healthy men and women: a meta-analysis. JAMA 301, 2024–2035 (2009).
Mancini, D. M. et al. Value of peak exercise oxygen consumption for optimal timing of cardiac transplantation in ambulatory patients with heart failure. Circulation 83, 778–786 (1991).
Sandvik, L. et al. Physical fitness as a predictor of mortality among healthy, middle-aged Norwegian men. N. Engl. J. Med. 328, 533–537 (1993).
Wei, M. et al. Relationship between low cardiorespiratory fitness and mortality in normal-weight, overweight, and obese men. JAMA 282, 1547–1553 (1999).
Ross, R. et al. Importance of assessing cardiorespiratory fitness in clinical practice: a case for fitness as a clinical vital sign. A scientific statement from the American Heart Association. Circulation 134, e653–e699 (2016).
Balady, G. J. et al. Clinician’s guide to cardiopulmonary exercise testing in adults: a scientific statement from the American Heart Association. Circulation 122, 191–225 (2010).
Nayor, M. et al. Metabolic architecture of acute exercise response in middle-aged adults in the community. Circulation 142, 1905–1924 (2020).
Robbins, J. M. et al. Association of dimethylguanidino valeric acid with partial resistance to metabolic health benefits of regular exercise. JAMA Cardiol. 4, 636–643 (2019).
Robbins, J. M. et al. Human plasma proteomic profiles indicative of cardiorespiratory fitness. Nat. Metab. 3, 786–797 (2021).
Contrepois, K. et al. Molecular choreography of acute exercise. Cell 181, 1112–1130.e1116 (2020).
Nayor, M. et al. Integrative analysis of circulating metabolite levels that correlate with physical activity and cardiorespiratory fitness. Circ. Genom. Precis Med 15, e003592 (2022).
Shah, R. V. et al. Blood-based fingerprint of cardiorespiratory fitness and long-term health outcomes in young adulthood. J. Am. Heart Assoc. 11, e026670 (2022).
Gonzales, T. I. et al. Descriptive epidemiology of cardiorespiratory fitness in UK adults: the Fenland Study. Med. Sci. Sports Exerc. 55, 507–516 (2023).
Shock, N. W. et al. Normal Human Aging: The Baltimore Longitudinal Study of Aging NIH publication 84-2450 (National Institutes of Health, 1984).
Williams, S. A. et al. Plasma protein patterns as comprehensive indicators of health. Nat. Med. 25, 1851–1857 (2019).
Klos, A. et al. The role of the anaphylatoxins in health and disease. Mol. Immunol. 46, 2753–2766 (2009).
Camus, G. et al. Anaphylatoxin C5a production during short-term submaximal dynamic exercise in man. Int. J. Sports Med. 15, 32–35 (1994).
Yang, F. et al. Proteomic insights into the associations between obesity, lifestyle factors, and coronary artery disease. BMC Med 21, 485 (2023).
Huttunen, H. J. & Saarma, M. CDNF protein therapy in Parkinson’s disease. Cell Transplant. 28, 349–366 (2019).
Pimenta, A. F. et al. The limbic system-associated membrane protein is an Ig superfamily member that mediates selective neuronal growth and axon targeting. Neuron 15, 287–297 (1995).
Knupp, J., Arvan, P. & Chang, A. Increased mitochondrial respiration promotes survival from endoplasmic reticulum stress. Cell Death Differ. 26, 487–501 (2019).
Gonzalez-Garcia, I. et al. Olfactomedin 2 deficiency protects against diet-induced obesity. Metabolism 129, 155122 (2022).
Numao, S., Uchida, R., Kurosaki, T. & Nakagaichi, M. Differences in circulating fatty acid-binding protein 4 concentration in the venous and capillary blood immediately after acute exercise. J. Physiol. Anthropol. 40, 5 (2021).
Li, B., Syed, M. H., Khan, H., Singh, K. K. & Qadura, M. The role of fatty acid binding protein 3 in cardiovascular diseases. Biomedicines 10, 2283 (2022).
Huck, I., Morris, E. M., Thyfault, J. & Apte, U. Hepatocyte-specific hepatocyte nuclear factor 4 alpha (HNF4) deletion decreases resting energy expenditure by disrupting lipid and carbohydrate homeostasis. Gene Expr. 20, 157–168 (2021).
Carayol, J. et al. Protein quantitative trait locus study in obesity during weight-loss identifies a leptin regulator. Nat. Commun. 8, 2084 (2017).
Roxin, L. E., Hedin, G. & Venge, P. Muscle cell leakage of myoglobin after long-term exercise and relation to the individual performances. Int. J. Sports Med. 7, 259–263 (1986).
Wu, J. et al. The unfolded protein response mediates adaptation to exercise in skeletal muscle through a PGC-1alpha/ATF6alpha complex. Cell Metab. 13, 160–169 (2011).
Zhao, Y. et al. GLIPR2 is a negative regulator of autophagy and the BECN1-ATG14-containing phosphatidylinositol 3-kinase complex. Autophagy 17, 2891–2904 (2021).
Khera, A. V. et al. Genetic risk, adherence to a healthy lifestyle, and coronary disease. N. Engl. J. Med. 375, 2349–2358 (2016).
Rutten-Jacobs, L. C. et al. Genetic risk, incident stroke, and the benefits of adhering to a healthy lifestyle: cohort study of 306 473 UK Biobank participants. Br. Med. J. 363, k4168 (2018).
Al Ajmi, K., Lophatananon, A., Mekli, K., Ollier, W. & Muir, K. R. Association of nongenetic factors with breast cancer risk in genetically predisposed groups of women in the UK Biobank cohort. JAMA Netw. Open 3, e203760 (2020).
Lourida, I. et al. Association of lifestyle and genetic risk with incidence of dementia. JAMA 322, 430–437 (2019).
Robbins, J. M. & Gerszten, R. E. Exercise, exerkines, and cardiometabolic health: from individual players to a team sport. J. Clin. Invest. 133, e168121 (2023).
Robbins, J. M. et al. Plasma proteomic changes in response to exercise training are associated with cardiorespiratory fitness adaptations. JCI Insight 8, e165867 (2023).
Maciel, L. et al. New cardiomyokine reduces myocardial ischemia/reperfusion injury by PI3K-AKT pathway via a putative KDEL-receptor binding. J. Am. Heart Assoc. 10, e019685 (2021).
Chow, L. S. et al. Exerkines in health, resilience and disease. Nat. Rev. Endocrinol. 18, 273–289 (2022).
Lewis, G. D. et al. Metabolic signatures of exercise in human plasma. Sci. Transl. Med. 2, 33ra37 (2010).
Stanford, K. I. et al. 12,13-diHOME: an exercise-induced lipokine that increases skeletal muscle fatty acid uptake. Cell Metab. 27, 1111–1120.e1113 (2018).
Shah, R. et al. Small RNA-seq during acute maximal exercise reveal RNAs involved in vascular inflammation and cardiometabolic health. Am. J. Physiol. Heart Circ. Physiol. 13, H1162–H1167 (2017).
Clausen, J. S. R., Marott, J. L., Holtermann, A., Gyntelberg, F. & Jensen, M. T. Midlife cardiorespiratory fitness and the long-term risk of mortality: 46 years of follow-up. J. Am. Coll. Cardiol. 72, 987–995 (2018).
Hansen, G. M. et al. Midlife cardiorespiratory fitness and the long-term risk of chronic obstructive pulmonary disease. Thorax 74, 843–848 (2019).
Ekblom-Bak, E. et al. Association between cardiorespiratory fitness and cancer incidence and cancer-specific mortality of colon, lung, and prostate cancer among Swedish men. JAMA Netw. Open 6, e2321102 (2023).
Wu, C. H. et al. Cardiorespiratory fitness is associated with sustained neurocognitive function during a prolonged inhibitory control task in young adults: an ERP study. Psychophysiology 59, e14086 (2022).
Nayor, M. et al. Physical activity and fitness in the community: the Framingham Heart Study. Eur. Heart J. 42, 4565–4575 (2021).
Lewis, G. D. et al. Developments in exercise capacity assessment in heart failure clinical trials and the rationale for the design of METEORIC-HF. Circ. Heart Fail. 15, e008970 (2022).
Swank, A. M. et al. Modest increase in peak VO2 is related to better clinical outcomes in chronic heart failure patients: results from heart failure and a controlled trial to investigate outcomes of exercise training. Circ. Heart Fail. 5, 579–585 (2012).
Kitzman, D. W. et al. Effect of caloric restriction or aerobic exercise training on peak oxygen consumption and quality of life in obese older patients with heart failure with preserved ejection fraction: a randomized clinical trial. JAMA 315, 36–46 (2016).
Sanford, J. A. et al. Molecular transducers of physical activity consortium (MoTrPAC): map** the dynamic responses to exercise. Cell 181, 1464–1474 (2020).
Jackson, A. S. et al. Prediction of functional aerobic capacity without exercise testing. Med. Sci. Sports Exerc. 22, 863–870 (1990).
Heil, D. P., Freedson, P. S., Ahlquist, L. E., Price, J. & Rippe, J. M. Nonexercise regression models to estimate peak oxygen consumption. Med. Sci. Sports Exerc. 27, 599–606 (1995).
Whaley, M. H., Kaminsky, L. A., Dwyer, G. B. & Getchell, L. H. Failure of predicted VO2peak to discriminate physical fitness in epidemiological studies. Med. Sci. Sports Exerc. 27, 85–91 (1995).
George, J. D., Stone, W. J. & Burkett, L. N. Non-exercise VO2max estimation for physically active college students. Med. Sci. Sports Exerc. 29, 415–423 (1997).
Matthews, C. E., Heil, D. P., Freedson, P. S. & Pastides, H. Classification of cardiorespiratory fitness without exercise testing. Med. Sci. Sports Exerc. 31, 486–493 (1999).
Malek, M. H., Housh, T. J., Berger, D. E., Coburn, J. W. & Beck, T. W. A new nonexercise-based VO2max equation for aerobically trained females. Med. Sci. Sports Exerc. 36, 1804–1810 (2004).
Malek, M. H., Housh, T. J., Berger, D. E., Coburn, J. W. & Beck, T. W. A new non-exercise-based Vo2max prediction equation for aerobically trained men. J. Strength Cond. Res. 19, 559–565 (2005).
Jurca, R. et al. Assessing cardiorespiratory fitness without performing exercise testing. Am. J. Prev. Med. 29, 185–193 (2005).
Bradshaw, D. I. et al. An accurate VO2max nonexercise regression model for 18-65-year-old adults. Res. Q. Exerc. Sport 76, 426–432 (2005).
Nes, B. M. et al. Estimating V·O 2peak from a nonexercise prediction model: the HUNT Study, Norway. Med. Sci. Sports Exerc. 43, 2024–2030 (2011).
Cao, Z. B. et al. Prediction of VO2max with daily step counts for Japanese adult women. Eur. J. Appl. Physiol. 105, 289–296 (2009).
Cao, Z. B. et al. Predicting VO2max with an objectively measured physical activity in Japanese women. Med. Sci. Sports Exerc. 42, 179–186 (2010).
Cao, Z. B., Miyatake, N., Higuchi, M., Miyachi, M. & Tabata, I. Predicting VO2max with an objectively measured physical activity in Japanese men. Eur. J. Appl. Physiol. 109, 465–472 (2010).
Cai, L. et al. Causal associations between cardiorespiratory fitness and type 2 diabetes. Nat. Commun. 14, 3904 (2023).
Spathis, D. et al. Longitudinal cardio-respiratory fitness prediction through wearables in free-living environments. NPJ Digit. Med. 5, 176 (2022).
Katz, D. H. et al. Proteomic profiling platforms head to head: leveraging genetics and clinical traits to compare aptamer- and antibody-based methods. Sci. Adv. 8, eabm5164 (2022).
da Silva, W. A. B. et al. Physical exercise increases the production of tyrosine hydroxylase and CDNF in the spinal cord of a Parkinson’s disease mouse model. Neurosci. Lett. 760, 136089 (2021).
Graham, J. R. et al. Serine protease HTRA1 antagonizes transforming growth factor-beta signaling by cleaving its receptors and loss of HTRA1 in vivo enhances bone formation. PLoS ONE 8, e74094 (2013).
Lee, J. et al. EWSR1, a multifunctional protein, regulates cellular function and aging via genetic and epigenetic pathways. Biochim. Biophys. Acta, Mol. Basis Dis. 1865, 1938–1945 (2019).
Jung, I. H. et al. SVEP1 is a human coronary artery disease locus that promotes atherosclerosis. Sci. Transl. Med. 13, eabe0357 (2021).
Nakamura, R. et al. Serum fatty acid-binding protein 4 (FABP4) concentration is associated with insulin resistance in peripheral tissues, a clinical study. PLoS ONE 12, e0179737 (2017).
Wagenknecht, L. E. et al. Cigarette smoking behavior is strongly related to educational status: the CARDIA study. Prev. Med. 19, 158–169 (1990).
Dyer, A. R. et al. Alcohol intake and blood pressure in young adults: the CARDIA Study. J. Clin. Epidemiol. 43, 1–13 (1990).
Bild, D. E. et al. Physical activity in young black and white women. The CARDIA Study. Ann. Epidemiol. 3, 636–644 (1993).
Sidney, S. et al. Comparison of two methods of assessing physical activity in the Coronary Artery Risk Development in Young Adults (CARDIA) Study. Am. J. Epidemiol. 133, 1231–1245 (1991).
Sidney, S. et al. Symptom-limited graded treadmill exercise testing in young adults in the CARDIA study. Med. Sci. Sports Exerc. 24, 177–183 (1992).
Pettee Gabriel, K. et al. Factors associated with age-related declines in cardiorespiratory fitness from early adulthood through midlife: CARDIA. Med. Sci. Sports Exerc. 54, 1147–1154 (2022).
Lindsay, T. et al. Descriptive epidemiology of physical activity energy expenditure in UK adults (the Fenland study). Int J. Behav. Nutr. Phys. Act. 16, 126 (2019).
Ferrucci, L. The Baltimore Longitudinal Study of Aging (BLSA): a 50-year-long journey and plans for the future. J. Gerontol. A Biol. Sci. Med. Sci. 63, 1416–1419 (2008).
Simonsick, E. M., Fan, E. & Fleg, J. L. Estimating cardiorespiratory fitness in well-functioning older adults: treadmill validation of the long distance corridor walk. J. Am. Geriatr. Soc. 54, 127–132 (2006).
Bouchard, C. et al. The HERITAGE family study. Aims, design, and measurement protocol. Med. Sci. Sports Exerc. 27, 721–729 (1995).
Protocol for a Large-Scale Prospective Epidemiological Resource (UK Biobank, 2006); www.ukbiobank.ac.uk/media/gnkeyh2q/study-rationale.pdf
Carnethon, M. R. et al. Association of 20-year changes in cardiorespiratory fitness with incident type 2 diabetes: the coronary artery risk development in young adults (CARDIA) fitness study. Diabetes Care 32, 1284–1288 (2009).
Balke, B. & Ware, R. W. An experimental study of physical fitness of Air Force personnel. US Armed Forces Med. J. 10, 675–688 (1959).
Brage, S., Brage, N., Franks, P. W., Ekelund, U. & Wareham, N. J. Reliability and validity of the combined heart rate and movement sensor Actiheart. Eur. J. Clin. Nutr. 59, 561–570 (2005).
Tanaka, H., Monahan, K. D. & Seals, D. R. Age-predicted maximal heart rate revisited. J. Am. Coll. Cardiol. 37, 153–156 (2001).
Brage, S. et al. Hierarchy of individual calibration levels for heart rate and accelerometry to measure physical activity. J. Appl. Physiol. (1985) 103, 682–692 (2007).
Pietzner, M. et al. Synergistic insights into human health from aptamer- and antibody-based proteomic profiling. Nat. Commun. 12, 6822 (2021).
Candia, J., Daya, G. N., Tanaka, T., Ferrucci, L. & Walker, K. A. Assessment of variability in the plasma 7k SomaScan proteomics assay. Sci. Rep. 12, 17147 (2022).
Sun, B. B. et al. Plasma proteomic associations with genetics and health in the UK Biobank. Nature 622, 329–338 (2023).
Gonzales, T. I. et al. Cardiorespiratory fitness assessment using risk-stratified exercise testing and dose-response relationships with disease outcomes. Sci. Rep. 11, 15315 (2021).
Wu, P. et al. Map** ICD-10 and ICD-10-CM codes to phecodes: workflow development and initial evaluation. JMIR Med. Inf. 7, e14325 (2019).
Thompson, D. J. et al. UK Biobank release and systematic evaluation of optimised polygenic risk scores for 53 diseases and quantitative traits. Preprint at medRxiv https://doi.org/10.1101/2022.06.16.22276246 (2022).
Acknowledgements
A.S.P. is supported by the AHA (20SFRN35120123). J.M.R. is supported by the National Institutes of Health (NIH) (K23HL150327). R.V.S. is supported by grants from the American Heart Association (AHA) and NIH. M.N. is supported by NIH (R01HL156975, R01HL131029) and by a Career Investment Award from the Department of Medicine, Boston University School of Medicine. R.E.G. and M.A.S. were funded by R01NR019628. T.T., K.A.W., and L.F. are supported by the National Institute on Aging’s Intramural Research Program. P.R. is supported by the John S. LaDue Memorial Fellowship at Harvard Medical School. Q.S.W. is supported by the NIH (R01HL140074). M.Y.M. was supported by the NIH (K23HL171855). B.C. is supported by an Early Career Investigator Grant from the American Lung Association. The BLSA study was funded by the National Institute on Aging’s Intramural Research Program. Proteomics in CARDIA were funded by a grant to R.K. (R01HL122477). CARDIA is conducted and supported by the National Heart, Lung, and Blood Institute (NHLBI) in collaboration with the University of Alabama at Birmingham (75N92023D00002 and 75N92023D00005), Northwestern University (75N92023D00004), University of Minnesota (75N92023D00006) and Kaiser Foundation Research Institute (75N92023D00003). This manuscript has been reviewed by CARDIA for scientific content. Exercise testing in CARDIA was funded by a grant to S.S. and B. Sternfeld (R01HL078972). The Fenland Study is funded by the UK Medical Research Council, with proteomic assessment funded by Somalogic; Investigators T.G., N.J.W. and S.B. received support from the UK Medical Research Council (MC_UU_00006/1, MC_UU_00006/4) as well as the National Institute for Health and Care Research Cambridge Biomedical Research Centre (IS-BRC-1215-20014). The HERITAGE study was supported by several grants from the NHLBI (R01HL45670, R01HL47317, R01HL47321, R01HL47323 and R01HL47327).
Author information
Authors and Affiliations
Contributions
A.S.P., T.G., S.B., M.N. and R.V.S. contributed to the conceptualization. Analyses in CARDIA were performed by A.S.P., L.A.C. and R.V.S. Analyses in Fenland were performed by T.G. and S.B. Analyses in BLSA were performed by T.T. and K.A.W. Analyses in UKB were performed by A.S.P., E.F.-E., S.H., Q.S.W. and R.V.S. Analyses in HERITAGE were performed by J.M.R., S.D. and R.E.G. A.S.P., T.G., E.F.-E., T.T., J.M.R., V.L.M., L.K.S., S.Z., S.H., L.A.C., S.D., L.H., D.M.L.-J., K.A.W., L.F., E.L.W., J.L.B., P.R., M.Y.M., K.P.G., B.H., S.S., N.H., G.D.L., G.Y.L., B.T., S.S.K., G.W., B.C., R.K., N.W., C.B., M.A.S., R.E.G., S.B., Q.S.W., M.N. and R.V.S., contributed to data acquisition, data analysis or interpretation of data. A.S.P. and R.V.S. drafted the initial manuscript. All authors contributed to critical revisions and approval of the final manuscript.
Corresponding author
Ethics declarations
Competing interests
R.V.S. and A.S.P. have applied for a patent related to the findings in this manuscript. R.V.S. is supported in part by grants from the National Institutes of Health and the American Heart Association. In the past 12 months, R.V.S. has served for a consultant for Amgen and Cytokinetics. R.V.S. is a co-inventor on a patent for ex-RNAs signatures of cardiac remodeling and a pending patent on proteomic signatures of fitness and lung and liver diseases. V.L.M. has received grant support from Siemens Healthineers, NIDDK, NIA, NHLBI and AHA. V.L.M. has received other research support from NIVA Medical Imaging Solutions. V.L.M. owns stock in Eli Lilly, Johnson & Johnson, Merck, Bristo-Myers Squibb, Pfizer and stock options in Ionetix. V.L.M. has received research grants and speaking honoraria from Quart Medical. G.D.L. has hospital-based research agreements with from National Institutes of Health R01-HL 151841, R01-HL131029, R01-HL159514, U01HL160278, American Heart Association 15GPSGC-24800006 and SFRN for research involving exercise omics, and has received consulting fees from American Regent, Amgen, Cytokinetics, Boehringer Ingelheim, and Edwards and has received royalties from UpToDate for scientific content authorship related to exercise physiology. M.N. has received speaking honoraria from Cytokinetics. The remaining authors declare no competing interests.
Peer review
Peer review information
Nature Medicine thanks Jonatan Ruiz, Jason Gill and Lili Niu for their contribution to the peer review of this work. Primary Handling Editor: Michael Basson, in collaboration with the Nature Medicine team.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data
Extended Data Fig. 1 Relationship of a protein score of fitness with VO2 max, age, sex, race and BMI in 3 validation cohorts.
The proteomic CRF score was scaled (mean 0, variance 1) in BLSA and HERITAGE cohorts. Colors on scatter plots represent density of overlap** observations with red being the most dense and blue the least dense. P values on panels showing the relationship of the proteomic CRF score with sex and race are from linear regression models of the proteomic CRF score as a function of sex and race. All other panels report P values from Spearman rank correlation tests. P values below 2.2 × 10–16 are reported as p < 2.2e-16.
Extended Data Fig. 2 Relations of a protein score of fitness with age, sex, race and BMI in UK Biobank.
Colors on scatter plots represent density of overlap** observations with red being the most dense and blue the least dense. P values on panels showing the relationship of the proteomic CRF score with sex and race are from linear regression models of the proteomic CRF score as a function of sex and race. All other panels report P values from Spearman rank correlation tests. P values below 2.2 × 10–16 are reported as p < 2.2e-16.
Extended Data Fig. 3 Correlation of change in proteomic CRF score with change in peak VO2 with exercise training in HERITAGE.
After a 20-week exercise training program in HERITAGE, we observed correlation between changes in the proteomic CRF score with changes in peak VO2, which were replicated in regression models. P value is from two sided Spearman rank correlation test.
Supplementary information
Supplementary Information
Supplemental Fig. 1.
Supplemental Tables 1–14
Supplemental Tables 1–14.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Perry, A.S., Farber-Eger, E., Gonzales, T. et al. Proteomic analysis of cardiorespiratory fitness for prediction of mortality and multisystem disease risks. Nat Med 30, 1711–1721 (2024). https://doi.org/10.1038/s41591-024-03039-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41591-024-03039-x
- Springer Nature America, Inc.