

Abstract
Reservoir computing originates in the early 2000s, the core idea being to utilize dynamical systems as reservoirs (nonlinear generalizations of standard bases) to adaptively learn spatiotemporal features and hidden patterns in complex time series. Shown to have the potential of achieving higher-precision prediction in chaotic systems, those pioneering works led to a great amount of interest and follow-ups in the community of nonlinear dynamics and complex systems. To unlock the full capabilities of reservoir computing towards a fast, lightweight, and significantly more interpretable learning framework for temporal dynamical systems, substantially more research is needed. This Perspective intends to elucidate the parallel progress of mathematical theory, algorithm design and experimental realizations of reservoir computing, and identify emerging opportunities as well as existing challenges for large-scale industrial adoption of reservoir computing, together with a few ideas and viewpoints on how some of those challenges might be resolved with joint efforts by academic and industrial researchers across multiple disciplines.
Similar content being viewed by others
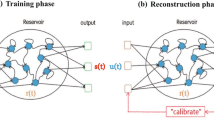

Introduction
At the core of today’s technological challenges is the ability to process information at massively superior speed and accuracy. Despite large-scale success of deep learning approaches in producing exciting new possibilities1,2,3,4,5,6,7, such methods generally rely on training big models of neural networks posing severe limitations on their deployment in the most common applications8. In fact, there is a growing demand for develo** small, lightweight models that are capable of fast inference and also fast adaptation - inspired by the fact that biological systems such as human brains are able to accomplish highly accurate and reliable information processing across different scenarios while costing only a tiny fraction of the energy that would have been needed using big neural networks.
As an alternative direction to the current deep learning paradigm, research into the so-called neuromorphic computing has been attracting significant interest9. Neuromorphic computing generally focuses on develo** novel types of computing systems that operate at a fraction of the energy comparing against current transistor-based computers, often deviating from the von-Neumann architecture and drawing inspirations from biological and physical principles10. Within the broader field of neuromorphic computing, an important family of models known as reservoir computing (RC) has progressed significantly over the past two decades11,12. RC conceptualizes how a brain-like system operates, with a core three-layer architecture (see Box 1 and Box 2): An input (sensing) layer which receives information and performs some pre-processing, a middle (processing) layer typically defined by some nonlinear recurrent network dynamics with input signals acting as stimulus and an output (control) layer that recombines signals from the processing layer to produce the final output. Reminiscent of many biological neuronal systems, the front end of an RC network, including its input and processing layers, is fixed and non-adaptive, which transforms input signals before reaching the output layer; in the last, output part of an RC the signals are combined in some optimized way to achieve the desired task. An important aspect of the output layer is its simplicity, where typically a weighted sum is sufficient, reminding a great deal of how common mechanical and electrical systems operate - with a complicated core that operates internally and a control layer that enables simple adaptation according to the specific application scenario.
Can such an architecture work? This inquiry was attempted in the early 2000s by Jaeger (echo state networks (ESNs)11) and Maass (liquid state machines (LSMs),12), achieving surprisingly high level of prediction accuracy in systems that exhibit strong nonlinearity and chaotic behavior. These two initially distinct lines of work were later reconciled into a unified, reservoir computing framework by Schrauwen and Verstraeten13, explicitly defining a new area of research that touches upon nonlinear dynamics, complex networks and machine learning. Research in RC over the past twenty years has produced significant results in the mathematical theory, computational methods as well as experimental prototypes and realizations, summarized in Fig. 1. Despite successes in those respective directions, large-scale industry-wide adoption of RC or broadly convincing “killer-applications” beyond synthetic and lab experiments are still not available. This is not due to the lack of potential applications. In fact, thanks to its compact design and fast training, RC has long been sought as an ideal solution in many industry-level signal processing and learning tasks including nonlinear distortion compensation in optical communications, real-time speech recognition, active noise control, among others. For practical applications, an integrated RC approach is much needed and can hardly be derived from existing work that focuses on either the algorithm or the experiment alone. This perspective offers a unified overview of the current status in theoretical, algorithmic and experimental RCs, to identify critical gaps that prevents industry adoption of RC and to discuss remedies.

For each category a selection of the representative publications were highlighted.


Theory and algorithm design of RC systems
The core idea of RC is to design and use a dynamical system as reservoir that adaptively generates signal basis according to the input data and combines them in some optimal way to mimic the dynamic behavior of a desired process. Under this angle, we review and discuss important results on representing, designing and analyzing RC systems.
Mathematical representation of an RC system
The mathematical abstraction of an RC can generally be described in the language of dynamical systems, as follows. Consider a coupled system of equations
Here the operator Δ acting on x becomes \(\frac{{{{{{{{\rm{d}}}}}}}}x}{{{{{{{{\rm{d}}}}}}}}t}\) for a continuous-time system, x(t + 1) − x(t) for a discrete-time system, and a compound of these two operations for a hybrid system. Additionally, \({{{{{{ u}}}}}}\in {{\mathbb{R}}}^{d}\), \({{{{{{ x}}}}}}\in {{\mathbb{R}}}^{n}\), and \({{{{{{ y}}}}}}\in {{\mathbb{R}}}^{m}\) are generally referred to as the input, internal state and output of the system, respectively, with vector field F, output function G and parameters p (fixed) and q (learnable) representing their functional couplings. Once set up by fixing the vector field F and the output function G and the parameters p, one can utilize the RC system to perform learning tasks, typically in time-series data. Given a time series \({\{{{{{{{ z}}}}}}(t)\in {{\mathbb{R}}}^{m}\}}_{t\in {\mathbb{N}}}\), an optimization problem is usually formulated to determine the best q:
where R(q) is a regularization term.
Also, when z(t) is seen as a driving signal, the optimization problem can be regarded as a driving-response synchronization problem finding appropriate parameters q14. Since RC is often simulated on classical computers, most commonly used RC takes discrete time steps:
which is a special form of (1), but now with time steps and network parameters more explicitly expressed. In this form, f is usually a component-wise nonlinear activation function (e.g., \(\tanh\)), the input-to-internal and internal-to-output map**s are encoded by the matrices W(in) and W(out), whereas the internal network is represented by the matrix W. The additional parameters b and γ are used to ensure that the dynamics of x is bounded, non-diminishing and (ideally) exhibits rich patterns that enable later extraction. Given some training time series data {z(t)} (assumed to be scalar for notational convenience), once the RC system is set up by fixing the choice of f, γ, b, W(in) and W, the output weight matrix W(out) can be obtained by attempting to minimize a loss function. A commonly used loss function is
where \(X={({{{{{{ x}}}}}}{(1)}^{\top },\,{{{{{{ x}}}}}}{(2)}^{\top },\ldots,\,{{{{{{ x}}}}}}{(T)}^{\top })}^{\top }\), z = (z(1), z(2), …, z(T))⊤ and β ∈ [0, 1] is a prescribed parameter. This problem is in a special form of Tikhonov regularization and yields an explicit solution \({W}^{(out)\top }={\left({X}^{\top }X+{\beta }^{2}I\right)}^{-1}{X}^{\top }{{{{{{ z}}}}}}\).
Common RC designs
Designing is a crucial step for acquiring a powerful RC network. There are still no complete instructions on how to design optimal RC networks based on various necessities. With the unified forms Eqs. (1) and (2) in mind, a standard RC system as initially proposed contains everything random and fixed including the input and internal matrices W(in) and W, leaving the choice of parameters γ and β according to some heuristic rules. Based on this default setting, we show how different RC designs can generally be interpreted as optimizing in one and/or multiple parts along the following directions. Firstly, in RC coupling parameter search, with the goal of selecting a good and potentially optimal coupling parameter γ to maintain the RC dynamics bounded and produces rich pattern that allow for the internal states to form a signal bases that can later be combined to approximate the desired series {z(t)}. Empirical studies have shown that γ chosen so that the system is around the edge of chaos15 typically produces the best outcome, which is supported by a necessary but not sufficient condition - imposed on the largest singular value of the effective stability matrix Wγ = (1 − γ) + γW. Then, in RC output training, whose design commonly amounts to two aspects. One is to determine the right optimization objective, for instance the one in Eq. (4) with common generalizations include to change the norms used in the objective in particular the term ∥w∥ to enforce sparsity or to impose additional prior information by changing β∥w∥ into ∥Lw∥ with some matrix L encoding the prior information. On the other hand, (upon choice of the objective) to further determine the parameter, e.g., β as in Eq. (4). Although there is no general theoretically guaranteed optimal choice, several common methods can be utilized, e.g., cross-validation techniques that had been well-developed in the literature of computational inverse problems. RC network design is crucial to determine the dynamic characteristics. With the goal of determining a good internal coupling network W. This has received much attention and has attracted many novel proposals, which include structured graphs with random as well as non-random weights16,17, and networks that are layered and deep or hierarchically coupled18,19,20. Furthermore, sometimes those designs are themselves coupled with the way the input and output parts of the system are used, for example in solving partial differential equations (PDEs)21,22 or representing the dynamics of multivariate time series23. Finally, as for RC input design, although received relatively little attention until recently, it turns out that the input part of an RC can play very important roles in the system’s performance. Here input design is generally interpreted to include not only the design of the input coupling matrix W(in) but also potentially some (non)linear transformation on the input u(t) and/or target variable z(t) prior to setting up the rest of the RC system. The so-called next-generation RC (NG-RC) is one such example24, showing great potential of input design in improving the data efficiency (less data required to train) of an RC.
In addition to the separate designs of the individual parts of an RC, the novel concept of neural architecture search (NAS) has motivated the research of hyperparmeter optimization11. Ref. 11 considers RC network with sigmoid nonlinearity and unit output function and showed that if the largest singular value of the weight matrix W is less than one then the system has ESP, and if the spectral radius of W is larger than one then the system is asymptotically unstable and thus cannot has ESP. Tighter bounds were subsequently derived in41. In particular, the spectral radius condition provides a practical way of ruling out bad RCs and can be seen a necessary condition for RC to properly function.
The second category is about memory capacity. Defined by the summation of delay linear correlations of the input sequence and output states, was shown to not exceed N for under iid input stream42, can be approached with arbitrary precision using simple linear cyclic reservoirs16, and can be improved using the time delays in the reservoir neurons43.
Universal approximation theorems can be regarded as a single category. Prior to the research of RC, universal representation theorems by Boyd and Chua showed that any time-invariant continuous nonlinear operator can be approximated either by a Volterra series or alternatively by a linear dynamical system with nonlinear readout44. RC’s representation power has attracted significant recent interest: ESNs are shown to be universally approximating for discrete-time fading memory processes that are uniformly bounded45 and further that the approximating family can be associated with networks with ESP and fading memory46. For discrete-time stochastic inputs, linear reservoir systems with either polynomial or neural network readout maps are universal and so are ESNs with linear outputs under further exponential moment constraints imposed on the input process47. For structurally stable systems, they can be approximated (upon topological conjugacy) by a sufficiently large ESN48. In particular, ESNs whose output states are trained with Tikhonov regularization are shown to approximate ergodic dynamical systems49. Also rigorously, the dynamics of RC is validated as a higher-dimensional embedding of the input nonlinear dynamics43. In addition, explicit error bounds are derived for ESNs and general RCs with ESP and fading memory properties under input sequences with given dependency structures50. Finally, according to conventional and generalized embedding theories, the RCs with time delays are established with significantly-reduced network sizes, and sometimes can achieve dynamics reconstruction even in the reservoir with a single neuron43.
The last category includes research about linear versus nonlinear transformations and next-generation RC. Focusing on linear reservoirs (possibly upon pre-transformations of the input states), recent work showed that the output states of an RC can be expressed in terms of a controllability matrix together with the network encoded inputs17. Moreover, a simplified class of RCs are shown to be equivalent to general vector autoregressive (VAR) processes51 - with possible nonlinear basis expansions it forms theoretical foundations for the recently coined concept of next-generation RC24.
Research of how to design RC architectures, how to train them and why they work have, over the past two decades following the pioneering works of Jaeger and Maass, led to much evolved view of the capabilities as well as limitations of the RC framework for learning. On the one hand, simulation and numerical research has produced many new network architectures improving the performance of RC beyond purely random connections; future works can either adopt a one-fits-all approach to investigate very large random RCs or perhaps more likely to follow the concept of domain-specific architecture (DSA)52 to explore structured classes of RCs that achieve optimal performance for particular types of applications, with Bayesian optimization26,

Application benchmarks of RC
Applications of RC are quite diverse and can be mainly divided into several categories: signal classification (e.g., spoken digit recognition), time series prediction (e.g., chaos prediction such as in the Mackey-Glass dynamics), control of system dynamics (e.g., learning to control robots in real-time) and PDE computations (e.g., fast simulation of Kuramoto-Sivashinsky equations), which we discuss below respectively.
In signal classification tasks, the input of RC are usually broadly-interpreted (physical) signals such as audio, image or temporal waves. The target output are the corresponding labels which can be spoken digits16,28,29,34,35,65,68,82,83,84, image labels33,35,85,86,87, bit-symbols16,29,68,88,89,90,91,92,93 and so on. The effectiveness of traditional neural networks in classification tasks has been verified in lots of work. However, dealing with temporal input signal is still a challenge. Compared with traditional neural networks, RC can map temporal signals with multiple timescales to high dimension, encoding these signals with its various internal states. Furthermore, RC network has much less parameters thus requiring less training resources. Therefore, RC can be a good candidate to be utilized in temporal signal classification tasks. The signals are in various types (audio, image or temporal waves), and usually require some preprocessing before injecting to RC network. For example, in the spoken-digit recognition task, the raw signal is first transformed to frequency domain in terms of multiple frequency channels via Lyon’s passive ear model, as shown in Fig. 2a. Then the 2-D signals can be directly mapped to the RC network as input u(t) via input mask, or can be transformed to 1-D input sequence u(t) by connecting each row successively. The targets are a vector of size ten corresponding to digit number from 0 to 9. The state-of-the-art of RC currently can reach a word error rate (WER) of 0.4% from memristor chip RC35, and 0.2% from electronic RC94.

Flow diagrams showing how RC is applied in different types of applications, here referring to as signal classification, nonlinear time series prediction, dynamical control and PDE computing, respectively. a RC for spoken-digit recognition16,28,29,34,35,65,68,82,83,84, when the targets are a vector of digit numbers corresponding to 0–9. b RC for time series prediction with Mackey-Glass equations11,31,34,51,95 as an example. In method 1 with off-line training, the training sequence starts with the first point (black point), while the target sequence starts with the second one (orange point). In method 2 with on-line retraining, the training and testing are alternately presented. c RC acts as the prediction optimizer in the general model predictive control (MPC)104,105,106,107,108,11,31,34,51,95, Lorenz system22,26,49,51,95,96,97, Santa Fe Chaotic time series16,86,89,95, Ikeda system95, auto-regressive moving average (NARMA) sequence16,28,29,93,94,97 and wind power103. Given a training time series \({\{{{{{{{ z}}}}}}(t)\}}_{t\in {\mathbb{Z}}}\) and prescribed prediction horizon τ, the input sequence of RC can be defined as u(t) = z(t) while the target output as y(t) = z(t + τ). (For one-step prediction we use τ = 1.) Once the parameters of RC is learned, it can be used as a predictive model, taking a temporal input and predicts its next steps. In particular, RC trained with one-step prediction can nevertheless be used to make multi-step predictions, in the following way. Suppose that a finite-length time series {u(t)}t=1,…,T is provided, we feed it into RC to compute a state y(t + 1) as a one-step prediction. We then append this state to the end of the input effectively defining u(t + 1) = y(t + 1) and through RC to compute a next state y(t + 2), and so on and so forth to obtain a series of next steps y(t + 1, t + 2, …, t + h). A schematic example of nonlinear time series prediction task is shown in Fig. 2b. In order to realize long-term prediction, there is another training scheme in which the target sequence is inserted periodically. In particular, the input to the RC now comes from its feedback or target sequence alternately, as shown in Fig. 2b (method 2). Compared with the previous case which can be regarded as an offline training scheme, here RC can acquire target data periodically, then retraining and updating the output weights regularly. This is an online training scheme. Since RC has access to target data during its evolution, it can adjust the output weights to prevent the predictive output data from diverging. Therefore, the online training typically yields longer prediction period and better prediction performances.
RC can play important roles in the control of nonlinear dynamical systems104,105,106,107,108,Intelligent robots Opportunities. Robots are becoming increasingly important in today’s information society due to their ability to take many forms, including intelligent physical manifestations. One example of this is large-scale commercial swee** robots used in smart homes115, which have replaced traditional manual operations in various scenarios, improving both production efficiency and living standards. With advances in technology, more types of intelligent robots are expected to emerge over the next decade, capable of completing complicated tasks through autonomous perception, calculation, optimization, and control in complex environments like failure detection, medical diagnosis, and search-and-rescue operations. Biological intelligence serves as inspiration for achieving robot intelligence, which relies on three key elements: real-time intensive information collection and perception capabilities (made possible by technologies such as flexible sensing, electronic skin, and multi-dimensional environment modeling), fast information processing capabilities (enabled by technologies like decision-making optimization and dynamic control), and physical control capabilities (facilitated by nonlinear modeling and electromechanical control). Challenges. Due to physical constraints such as battery capacity and deployment environment uncertainty, the core modules supporting robot intelligence are expected to be embedded in the physical entity of the robot in an offline manner rather than relying on cloud and network capabilities to provide potential large model capabilities. Similar to the IoT scenario, machine learning that is widely relied on in robot intelligence must have the characteristics of miniaturization, low energy consumption, and easy deployment, while requiring the ability to recognize, predict, calculate, and control dynamic processes. This presents an excellent application field for RC systems to play a role. In MPC, since the role of RC merely replaces a linear predictor the overall controller architecture remains transparent and intact. In principle, it is possible to adopt RC for general controller design beyond usage in the MPC framework, e.g., directly learning control rules from data together with (some) prior model knowledge. However, the main challenge would be to pose theoretical guarantees on error and convergence neither of which have been resolved by existing works of RC. Opportunities. To fully realize the ongoing information revolution, it is essential to rethink and reshape crucial aspects of industrial manufacturing through the innovative framework of AI for science and digital twins. This involves achieving full perception and precise control of physical systems through interactions and iterative feedback between digital models and entities in the physical world. Essentially, digital twins establish a synchronous relationship between physical systems and their digital representations. Using this synchronous function, simulations can be run in the digital world, and optimized designs can repeatedly and iteratively be imported into the physical system, ultimately leading to optimization and control. For systems with clear and complete physical mechanisms, synchronization models that digital twins rely on are usually sets of ODEs/PDEs. For example, simulating full three-dimensional turbulence, weather forecasting, laser dynamics, etc. Preliminary studies suggest that reservoir computing can be used to reduce the computational resources required for these expensive simulations. Arcomano et al.111 developed a low-resolution global prediction model based on reservoir computing and investigated the applicability of RC in weather forecasting. They demonstrated that a parallel ML model based on RC can predict the global atmospheric state in the same grid format as the numerical (physics-based) global weather forecast model. They also found that the current version of the ML model has potential in short-term weather forecasting. They further discovered that when full-state dynamics are available for training, RC outperforms the time-based backpropagation through time (BPTT) method in terms of prediction performance and capturing long-term statistical data while requiring less training time. Challenges. Calculations of these physics-inferred equations can be challenging. In more complex industrial applications, multiple coupling modules are often present, and interactions between the system and the open environment cannot be fully described by physical mechanisms or mathematical functions. Therefore, it is necessary to consider fast calculation techniques, but also find ways to build synchronization models for non-white-box complex dynamic systems. Mathematical modeling of fusion between physical mechanisms and data-driven techniques has been significantly developed in the past decade. For instance, Physics-inspired Neural Networks (PINN) embed the structure and form of physical equations into neural network loss functions, which guides the neural network to approximate provided physics equations during parameter training124. Another type of physics-inspired computing system, RC, inherently provides an embedding method of the mechanism model, which is expected to provide a powerful supplement to the solver for basic physical models of industrial simulation, focusing on offering a dynamic modeling framework for the fusion of mechanisms and data. However, for reduced-order data, large-scale RC models may be unstable and more likely to exhibit bias than the BPTT algorithm. In another example of research on nonlinear laser dynamics, the authors found that RC methods have simpler training mechanisms and can reduce training time compared to deep neural networks125. For practical problems involving complex nonlinear physical processes, we have reason to believe that RC methods may provide us with solutions for computational acceleration.AI for science and digital twins
Outlook
In summary, although RC has the potential for large-scale application in terms of functions, in order to truly solve the technical problems in the above-mentioned various major applications, there are still many key challenges in the existing RC system in various aspects. For example, in theoretical research, although the universal approximation theory of RC has advanced significantly in recent years, most of the theoretical results focus on existence proofs and lack structural design. Hence, the current approximation theory has not yet played an important guiding role in RC network architecture design, training methods, etc., nor can it quantitatively evaluate the approximation potential of a specific RC scheme for dynamic systems or time series. An important reason to further advance the mathematical theory of RC is for data-driven control applications. In most of those applications, rigorous theory on control error and convergence are necessary for the corresponding controller to be considered usable in an industrial setting. However, so far very little work has been done to address these important problems. As for algorithmic challenges, most industrial applications do not require a universal approximator, but in the same field, the approximation model needs to be generalizable. Existing RC research has very little exploration in domain-specific architecture optimization. Problems in the industrial field are divided into scenarios and categories. Therefore, it is important to construct general-purpose RC models possibly by means of architecture search. In addition, leaving aside the practicality of RC for the time being, past research has turned its advantages into constraints, such as small size, simple training, and so on. However, how strong is RC’s learning ability (whether there is an RC architecture that can compare with GPT’s ability), it is still unknown.
At the experimental level, there are still some gaps when map** RC models to physical systems. The first is timescale problem of physical substrate RC: Matching the timescales between the computational challenge and the internal dynamics of the physical RC substrate is a key issue in reservoir computing. If the timescale of the problem is much faster than the response time of the physical system, the response of the reservoir will be too small or the fading memory of the reservoir will not be properly utilized, rendering the physical reservoir computing system ineffective. One intuitive solution is to adjust the physical parameters of the reservoir to match the timescale of the computational problem. This poses high requirements for the design of RC network structures and training algorithms. Using other technologies such as super-resolution and compressive sensing to overcome the resolution problem of single-point measurement and processing in RC systems may be a viable solution. The second is the real-time data processing problem: One of the significant advantages of reservoir computing is lightweight and fast computation. However, in practical physical systems, it is often unrealistic to sample and store a large number of node responses to a certain input due to limitations such as sampling bandwidth, storage depth and bandwidth, or their combinations. It is simply not feasible in many cases to probe a system with a large number of probes (10s–1000s) interfaced with AD converters. In addition to these practical challenges, hardware drift often requires regular repetition of calibration procedures, hence it cannot be a one-of optimization. Furthermore, data preprocessing and postprocessing also limit the overall computational speed of the physical RC system. One approach to address this issue is to use hardware-based readout instead of software-based readout126,127,128,129.
Moving forward, it is crucial that we thoroughly explore the potential of intelligent learning machines based on dynamical systems. In the realm of theoretical and algorithmic research, it is necessary to continuously push the boundaries of performance and offer guidance for experimental design. Reservoir computing (RC) research can take root in theory and algorithms, with experiments serving as approximations to theoretical and algorithmic results. However, one disadvantage of this approach is that it can be challenging to identify equivalent devices in experiments that can achieve the nonlinear properties of RC in theory, which can lead to reduced accuracy. Alternatively, researchers can focus on building physical RC system as the ultimate goal, which requires close collaboration between theoretical and experimental teams to optimize the system jointly. This approach has the advantage of considering physical constraints and application characteristics when designing algorithms, making it more likely to achieve better solutions at the implementation level. This also raises the bar for interdisciplinary research, as participants will need to possess cross-disciplinary communication skills and knowledge, along with an openness towards multi-module complex coupling optimization.
Looking ahead, unlocking the full potential of RC and neuromorphic computing in general is critical yet challenging. In fact, this goes beyond just putting out open-source codes or solve a few specific problems. Innovative ideas and interdisciplinary research formats are much needed. As concrete suggestions, researchers of the applied mathematics and nonlinear dynamics communities who have been the main players in RC will need to get close(r) to the mainstream AI applications and try to develop next-generation RC systems to compete in these scenarios where the value of application has been established and recognized by the industry. A good starting point can be open-source tasks and datasets such as Kaggle, and more generally to directly partner with industrial research labs to put RC into real applications. On the other hand, raising awareness of the (potential) utility of RC requires attracting interest from researchers and decision-makers who are traditionally outside of the field. For instance, themed conferences and workshops may be organized to foster such discussions among scientists and researchers from diverse fields across academia and industry. Despite the many challenges, with persistence and innovations a new and future paradigm of intelligent learning and computing may possibly emerge from the works of RC and neuromorphic computing.
References
Graves, A., Mohamed, A. R. & Hinton, G. Speech recognition with deep recurrent neural networks. In IEEE International Conference on Acoustics, Speech and Signal Processing, 6645–6649 (IEEE, 2013).
LeCun, Y., Bengio, Y. & Hinton, G. E. Deep learning. Nature 521, 436–444 (2015).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770–778 (IEEE, 2016).
Silver, D. et al. Mastering the game of go with deep neural networks and tree search. Nature 529, 484–489 (2016).
Krizhevsky, A., Sutskever, I. & Hinton, G. E. Imagenet classification with deep convolutional neural networks. Commun. ACM 60, 84–90 (2017).
Jumper, J. et al. Highly accurate protein structure prediction with alphafold. Nature 596, 583–589 (2021).
Brown, T. et al. Language models are few-shot learners. NeurIPS 33, 1877–1901 (2020).
Khan, A., Sohail, A., Zahoora, U. & Qureshi, A. S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 53, 5455–5516 (2020).
Schuman, C. D. et al. Opportunities for neuromorphic computing algorithms and applications. Nat. Comput. Sci 2, 10–19 (2022).
Christensen, D. V. et al. 2022 roadmap on neuromorphic computing and engineering. Neuromorph. Comput. Eng. 2, 022501 (2022).
Jaeger, H. The “echo state” approach to analysing and training recurrent neural networks-with an erratum note. Bonn, Germany: German Nat. Res. Center for Inf. Technol. GMD Tech. Rep. 148, 13 (2001). The first paper develo** the concept and framework of echo state networks, e.g. reservoir computing. The paper provides propositions on how to construct ESNs and how to train them. The paper also shows that the ESN is able to learn and predict chaotic time series (Mackey-Glass equations).
Maass, W., Natschläger, T. & Markram, H. Real-time computing without stable states: A new framework for neural computation based on perturbations. Neural Comput. 14, 2531–2560 (2002). The first paper proposing the idea of liquid state machines. The model is able to learn from abundant perturbed states so as to learn various sequences, and can also fulfill real-time signal processing for time-varying inputs. This paper demonstrates that LSMs can be used for learning tasks such as spoken-digit recognition.
Verstraeten, D., Schrauwen, B., D’Haene, M. & Stroobandt, D. The unified reservoir computing concept and its digital hardware implementations. In Proceedings of the 2006 EPFL LATSIS Symposium, 139–140 (EPFL, Lausanne, 2006).
Zhu, Q., Ma, H. & Lin, W. Detecting unstable periodic orbits based only on time series: When adaptive delayed feedback control meets reservoir computing. Chaos 29, 093125 (2019).
Bertschinger, N. & Natschläger, T. Real-time computation at the edge of chaos in recurrent neural networks. Neural Comput. 16, 1413–1436 (2004).
Rodan, A. & Tino, P. Minimum complexity echo state network. IEEE Trans. Neural Netw. 22, 131–144 (2010).
Verzelli, P., Alippi, C., Livi, L. & Tino, P. Input-to-state representation in linear reservoirs dynamics. IEEE Trans. Neural Netw. Learn. Syst. 33, 4598–4609 (2021).
Gallicchio, C., Micheli, A. & Pedrelli, L. Deep reservoir computing: A critical experimental analysis. Neurocomputing 268, 87–99 (2017).
Gallicchio, C., Micheli, A. & Pedrelli, L. Design of deep echo state networks. Neural Netw. 108, 33–47 (2018).
Gallicchio, C. & Scardapane, S. Deep randomized neural networks. In Recent Trends in Learning From Data: Tutorials from the INNS Big Data and Deep Learning Conference, 43–68 (Springer Cham, Switzerland, 2020).
Pathak, J., Hunt, B., Girvan, M., Lu, Z. & Ott, E. Model-free prediction of large spatiotemporally chaotic systems from data: A reservoir computing approach. Phys. Rev. Lett. 120, 024102 (2018). This paper proposes a parallel RC architecture to learn the behavior of Kuramoto-Sivashinsky (KS) equations. The work shows the exciting potential of RC in learning the computational behavior and state evolution of PDEs.
Vlachas, P. R. et al. Backpropagation algorithms and reservoir computing in recurrent neural networks for the forecasting of complex spatiotemporal dynamics. Neural Netw. 126, 191–217 (2020).
Bianchi, F. M., Scardapane, S., Løkse, S. & Jenssen, R. Reservoir computing approaches for representation and classification of multivariate time series. IEEE Trans. Neural Netw. Learn. Syst. 32, 2169–2179 (2020).
Gauthier, D. J., Bollt, E., Griffith, A. & Barbosa, W. A. Next generation reservoir computing. Nat. Commun. 12, 1–8 (2021). This work reveals an intriguing link between traditional RC and regression methods and in particular shows that nonlinear vector autoregression (NVAR) can equivalently represent RC while requiring fewer parameters to tune, leading to the development of so-called next-generation RC, shown to outperform traditional RC with less data and higher efficiency, pushing forward a significant step for constructing an interpretable machine learning.
Joy, H., Mattheakis, M. & Protopapas, P. Rctorch: a pytorch reservoir computing package with automated hyper-parameter optimization. Preprint at https://doi.org/10.48550/ar**v.2207.05870 (2022).
Griffith, A., Pomerance, A. & Gauthier, D. J. Forecasting chaotic systems with very low connectivity reservoir computers. Chaos 29, 123108 (2019).
Yperman, J. & Becker, T. Bayesian optimization of hyper-parameters in reservoir computing. Preprint at https://doi.org/10.48550/ar**v.1611.05193 (2016).
Appeltant, L. et al. Information processing using a single dynamical node as complex system. Nat. Commun. 2, 1–6 (2011).
Paquot, Y. et al. Optoelectronic reservoir computing. Sci. Rep. 2, 1–6 (2012).
Larger, L. et al. High-speed photonic reservoir computing using a time-delay-based architecture: Million words per second classification. Phys. Rev. X 7, 011015 (2017).
Dong, J., Rafayelyan, M., Krzakala, F. & Gigan, S. Optical reservoir computing using multiple light scattering for chaotic systems prediction. IEEE J. Sel. Top. Quantum Electron. 26, 1–12 (2019).
Rafayelyan, M., Dong, J., Tan, Y., Krzakala, F. & Gigan, S. Large-scale optical reservoir computing for spatiotemporal chaotic systems prediction. Phys. Rev. X 10, 041037 (2020).
Du, C. et al. Reservoir computing using dynamic memristors for temporal information processing. Nat. Commun. 8, 1–10 (2017). The work develops a physical RC system based on memristor arrays, finding that such a system is able to perform well in realizing handwritten digit recognition and solving a second-order nonlinear dynamic tasks with less than 100 reservoir nodes.
Moon, J. et al. Temporal data classification and forecasting using a memristor-based reservoir computing system. Nat. Electron. 2, 480–487 (2019).
Zhong, Y. et al. Dynamic memristor-based reservoir computing for high-efficiency temporal signal processing. Nat. Commun. 12, 1–9 (2021).
Sun, L. et al. In-sensor reservoir computing for language learning via two-dimensional memristors. Sci. Adv. 7, eabg1455 (2021).
Lin, W. & Chen, G. Large memory capacity in chaotic artificial neural networks: A view of the anti-integrable limit. IEEE Trans. Neural Netw. 20, 1340–1351 (2009).
Silva, N. A., Ferreira, T. D. & Guerreiro, A. Reservoir computing with solitons. New J. Phys. 23, 023013 (2021).
Ghosh, S., Opala, A., Matuszewski, M., Paterek, T. & Liew, T. C. Quantum reservoir processing. npj Quantum Inf. 5, 1–6 (2019). Proposed a platform for quantum information processing developed on the principle of reservoir computing.
Govia, L. C. G., Ribeill, G. J., Rowlands, G. E., Krovi, H. K. & Ohki, T. A. Quantum reservoir computing with a single nonlinear oscillator. Phys. Rev. Res. 3, 013077 (2021).
Buehner, M. & Young, P. A tighter bound for the echo state property. IEEE Trans. Neural Netw. 17, 820–824 (2006).
Jaeger, H. Short Term Memory in Echo State Networks. Technical Report 152 (GMD, Berlin, 2001).
Duan, X. Y. et al. Embedding theory of reservoir computing and reducing reservoir network using time delays. Phys. Rev. Res. 5, L022041 (2023).
Boyd, S. & Chua, L. Fading memory and the problem of approximating nonlinear operators with volterra series. IEEE Trans. Circuits Syst. 32, 1150–1161 (1985).
Grigoryeva, L. & Ortega, J. P. Echo state networks are universal. Neural Netw. 108, 495–508 (2018).
Gonon, L. & Ortega, J. P. Fading memory echo state networks are universal. Neural Netw. 138, 10–13 (2021).
Gonon, L. & Ortega, J. P. Reservoir computing universality with stochastic inputs. IEEE Trans. Neural Netw. Learn. Syst. 31, 100–112 (2019).
Hart, A., Hook, J. & Dawes, J. Embedding and approximation theorems for echo state networks. Neural Netw. 128, 234–247 (2020).
Hart, A. G., Hook, J. L. & Dawes, J. H. Echo state networks trained by tikhonov least squares are l2 (μ) approximators of ergodic dynamical systems. Physica D Nonlinear Phenomena 421, 132882 (2021).
Gonon, L., Grigoryeva, L. & Ortega, J. P. Risk bounds for reservoir computing. J. Mach. Learn. Res. 21, 9684–9744 (2020).
Bollt, E. On explaining the surprising success of reservoir computing forecaster of chaos? the universal machine learning dynamical system with contrast to var and dmd. Chaos 31, 013108 (2021).
Krishnakumar, A., Ogras, U., Marculescu, R., Kishinevsky, M. & Mudge, T. Domain-specific architectures: Research problems and promising approaches. ACM Trans. Embed. Comput. Syst. 22, 1–26 (2023).
Subramoney, A., Scherr, F. & Maass, W. Reservoirs learn to learn. Reservoir Computing: Theory, Physical Implementations, and Applications, 59–76 (Springer Singapore, 2021).
Tanaka, G. et al. Recent advances in physical reservoir computing: A review. Neural Netw. 115, 100–123 (2019).
Jiang, W. et al. Physical reservoir computing using magnetic skyrmion memristor and spin torque nano-oscillator. Appl. Phys. Lett. 115, 192403 (2019).
Coulombe, J. C., York, M. C. & Sylvestre, J. Computing with networks of nonlinear mechanical oscillators. PLOS ONE 12, e0178663 (2017).
Larger, L., Goedgebuer, J. P. & Udaltsov, V. Ikeda-based nonlinear delayed dynamics for application to secure optical transmission systems using chaos. C. R. Phys. 5, 669–681 (2004).
Brunner, D., Soriano, M. C., Mirasso, C. R. & Fischer, I. Parallel photonic information processing at gigabyte per second data rates using transient states. Nat. Commun. 4, 1364 (2013).
Katayama, Y., Yamane, T., Nakano, D., Nakane, R. & Tanaka, G. Wave-based neuromorphic computing framework for brain-like energy efficiency and integration. IEEE Trans. Nanotechnol. 15, 762–769 (2016).
Dion, G., Mejaouri, S. & Sylvestre, J. Reservoir computing with a single delay-coupled non-linear mechanical oscillator. J. Appl. Phys. 124, 152132 (2018).
Cucchi, M. et al. Reservoir computing with biocompatible organic electrochemical networks for brain-inspired biosignal classification. Sci. Adv. 7, eabh0693 (2021).
Rowlands, G. E. et al. Reservoir computing with superconducting electronics. Preprint at https://doi.org/10.48550/ar**v.2103.02522 (2021).
Verstraeten, D., Schrauwen, B. & Stroobandt, D. Reservoir computing with stochastic bitstream neurons. In Proceedings of the 16th Annual Prorisc Workshop, 454–459 (2005). https://doi.org/https://biblio.ugent.be/publication/336133.
Schürmann, F., Meier, K. & Schemmel, J. Edge of chaos computation in mixed-mode vlsi-a hard liquid. NeurIPS, 17, (NIPS, 2004).
Torrejon, J. et al. Neuromorphic computing with nanoscale spintronic oscillators. Nature 547, 428–431 (2017). First demonstration of RC implementation using a spintronic oscillator, opens up a route to realizing large-scale neural networks using magnetization dynamics.
Vandoorne, K. et al. Experimental demonstration of reservoir computing on a silicon photonics chip. Nat. Commun. 5, 1–6 (2014). First demonstration of on-chip integrated photonic reservoir neural network, paves the way for the high density and high speeds photonic RC architecture.
Larger, L. et al. Photonic information processing beyond turing: an optoelectronic implementation of reservoir computing. Opt. Express 20, 3241–3249 (2012). This paper proposed optical-based time-delay feedback RC architecture with a single nonlinear optoelectronic hardware. The experiment shows that the RC performs well in spoken-digit recognition and one-time-step prediction tasks.
Duport, F., Schneider, B., Smerieri, A., Haelterman, M. & Massar, S. All-optical reservoir computing. Opt. Express 20, 22783–22795 (2012). The first paper to develop RC system with a fiber-based all-optical architecture. The experiments show that the RC can be utilized in channel equalization and radar signal prediction tasks.
Brunner, D. & Fischer, I. Reconfigurable semiconductor laser networks based on diffractive coupling. Opt. Lett. 40, 3854–3857 (2015).
Gan, V. M., Liang, Y., Li, L., Liu, L. & Yi, Y. A cost-efficient digital esn architecture on fpga for ofdm symbol detection. ACM J. Emerg. Technol. Comput. Syst. 17, 1–15 (2021).
Elbedwehy, A. N., El-Mohandes, A. M., Elnakib, A. & Abou-Elsoud, M. E. Fpga-based reservoir computing system for ecg denoising. Microprocess. Microsyst. 91, 104549 (2022).
Lin, C., Liang, Y. & Yi, Y. Fpga-based reservoir computing with optimized reservoir node architecture. In 23rd International Symposium on Quality Electronic Design (ISQED), 1–6 (IEEE, 2022).
Bai, K. & Yi, Y. Dfr: An energy-efficient analog delay feedback reservoir computing system for brain-inspired computing. ACM J. Emerg. Technol. Comput. Syst. 14, 1–22 (2018).
Petre, P. & Cruz-Albrecht, J. Neuromorphic mixed-signal circuitry for asynchronous pulse processing. In IEEE International Conference on Rebooting Computer, 1–4 (IEEE, 2016).
Nowshin, F., Zhang, Y., Liu, L. & Yi, Y. Recent advances in reservoir computing with a focus on electronic reservoirs. In International Green and Sustainable Computing Workshops, 1–8 (IEEE, 2020).
Soriano, M. C. et al. Delay-based reservoir computing: noise effects in a combined analog and digital implementation. IEEE Trans. Neural Netw. Learn. Syst. 26, 388–393 (2014).
Marinella, M. J. & Agarwal, S. Efficient reservoir computing with memristors. Nat. Electron. 2, 437–438 (2019).
Sun, W. et al. 3d reservoir computing with high area efficiency (5.12 tops/mm 2) implemented by 3d dynamic memristor array for temporal signal processing. In IEEE Symposium on VLSI Technology and Circuits (VLSI Technology and Circuits), 222–223 (IEEE, 2022).
Allwood, D. A. et al. A perspective on physical reservoir computing with nanomagnetic devices. Appl. Phys. Lett. 122, 040501 (2023).
Shen, Y. et al. Deep learning with coherent nanophotonic circuits. Nat. Photonics 11, 441–446 (2017).
Van der Sande, G., Brunner, D. & Soriano, M. C. Advances in photonic reservoir computing. Nanophotonics 6, 561–576 (2017).
Maass, W., Natschläger, T. & Markram, H. A model for real-time computation in generic neural microcircuits. NeurIPS 15 (NIPS, 2002).
Verstraeten, D., Schrauwen, B., Stroobandt, D. & Van Campenhout, J. Isolated word recognition with the liquid state machine: a case study. Inf. Process. Lett. 95, 521–528 (2005).
Verstraeten, D., Schrauwen, B. & Stroobandt, D. Reservoir-based techniques for speech recognition. In IEEE International Joint Conference on Neural Network Proceedings, 1050–1053 (IEEE, 2006).
Jalalvand, A., Van Wallendael, G. & Van de Walle, R. Real-time reservoir computing network-based systems for detection tasks on visual contents. In 7th International Conference on Computational Intelligence, Communication Systems and Networks, 146–151 (IEEE, 2015).
Nakajima, M., Tanaka, K. & Hashimoto, T. Scalable reservoir computing on coherent linear photonic processor. Commun. Phys. 4, 20 (2021).
Cao, J. et al. Emerging dynamic memristors for neuromorphic reservoir computing. Nanoscale 14, 289–298 (2022).
Jaeger, H. & Haas, H. Harnessing nonlinearity: Predicting chaotic systems and saving energy in wireless communication. Science 304, 78–80 (2004).
Nguimdo, R. M. & Erneux, T. Enhanced performances of a photonic reservoir computer based on a single delayed quantum cascade laser. Opt. Lett. 44, 49–52 (2019).
Argyris, A., Bueno, J. & Fischer, I. Photonic machine learning implementation for signal recovery in optical communications. Sci. Rep. 8, 1–13 (2018).
Argyris, A. et al. Comparison of photonic reservoir computing systems for fiber transmission equalization. IEEE J. Sel. Top. Quantum Electron. 26, 1–9 (2019).
Sackesyn, S., Ma, C., Dambre, J. & Bienstman, P. Experimental realization of integrated photonic reservoir computing for nonlinear fiber distortion compensation. Opt. Express 29, 30991–30997 (2021).
Sozos, K. et al. High-speed photonic neuromorphic computing using recurrent optical spectrum slicing neural networks. Comms. Eng. 1, 24 (2022).
Jaeger, H. Adaptive nonlinear system identification with echo state networks. In NeurIPS, 15 (NIPS, 2002).
Soh, H. & Demiris, Y. Iterative temporal learning and prediction with the sparse online echo state gaussian process. In International Joint Conference on Neural Networks (IJCNN), 1–8 (IEEE, 2012).
Kim, J. Z., Lu, Z., Nozari, E., Pappas, G. J. & Bassett, D. S. Teaching recurrent neural networks to infer global temporal structure from local examples. Nat. Mach. Intell. 3, 316–323 (2021).
Li, X. et al. Tip** point detection using reservoir computing. Research 6, 0174 (2023).
Goudarzi, A., Banda, P., Lakin, M. R., Teuscher, C. & Stefanovic, D. A comparative study of reservoir computing for temporal signal processing. Preprint at https://doi.org/10.48550/ar**v.1401.2224 (2014).
Walleshauser, B. & Bollt, E. Predicting sea surface temperatures with coupled reservoir computers. Nonlinear Process. Geophys. 29, 255–264 (2022).
Okamoto, T. et al. Predicting traffic breakdown in urban expressways based on simplified reservoir computing. In Proceedings of AAAI 21 Workshop: AI for Urban Mobility, (2021). https://aaai.org/conference/aaai/aaai-21/ws21workshops/.
Yamane, T. et al. Application identification of network traffic by reservoir computing. In International Conference on Neural Information Processing, 389–396 (Springer Cham, 2019).
Ando, H. & Chang, H. Road traffic reservoir computing. Preprint at https://doi.org/10.48550/ar**v.1912.00554 (2019).
Wang, J., Niu, T., Lu, H., Yang, W. & Du, P. A novel framework of reservoir computing for deterministic and probabilistic wind power forecasting. IEEE Trans. Sustain. Energy 11, 337–349 (2019).
Joshi, P. & Maass, W. Movement generation and control with generic neural microcircuits. In International Workshop on Biologically Inspired Approaches to Advanced Information Technology, 258–273 (Springer, 2004).
Burgsteiner, H. Training networks of biological realistic spiking neurons for real-time robot control. In Proceedings of the 9th international conference on engineering applications of neural networks, 129–136 (2005). https://users.abo.fi/abulsari/EANN.html.
Burgsteiner, H., Kröll, M., Leopold, A. & Steinbauer, G. Movement prediction from real-world images using a liquid state machine. In Innovations in Applied Artificial Intelligence: 18th International Conference on Industrial and Engineering Applications of Artificial Intelligence and Expert Systems, 121–130 (Springer, 2005).
Schwedersky, B. B., Flesch, R. C. C., Dangui, H. A. S. & Iervolino, L. A. Practical nonlinear model predictive control using an echo state network model. In IEEE International Joint Conference on Neural Networks (IJCNN), 1–8 (IEEE, 2018).
Canaday, D., Pomerance, A. & Gauthier, D. J. Model-free control of dynamical systems with deep reservoir computing. J. Phys. Complexity 2, 035025 (2021).
Baldini, P. Reservoir computing in robotics: a review. Preprint at https://doi.org/10.48550/ar**v.2206.11222 (2022).
Arcomano, T., Szunyogh, I., Wikner, A., Hunt, B. R. & Ott, E. A hybrid atmospheric model incorporating machine learning can capture dynamical processes not captured by its physics-based component. Geophys. Res. Lett. 50, e2022GL102649 (2023).
Arcomano, T. et al. A machine learning-based global atmospheric forecast model. Geophys. Res. Lett. 47, e2020GL087776 (2020). This work extends the “parallel RC” framework in the application of weather forecasting, suggesting great potential of RC in challenging real-world scenarios at a fraction of the cost of deep neural networks.
Latva-Aho, M. & Leppänen, K. Key drivers and research challenges for 6g ubiquitous wireless intelligence. https://urn.fi/URN:ISBN:9789526223544 (2019).
Rong, B. 6G: The Next Horizon: From Connected People and Things to Connected Intelligence. IEEE Wirel. Commun. 28, 8–8 (2021).
Mytton, D. & Ashtine, M. Sources of data center energy estimates: A comprehensive review. Joule 6, 2032–2056 (2022).
Jung, J. H. & Lim, D. G. Industrial robots, employment growth, and labor cost: A simultaneous equation analysis. Technol. Forecast. Soc. Change 159, 120202 (2020).
Boschert, S. & Rosen, R. Digital twin-the simulation aspect. In Mechatronic Futures: Challenges and Solutions for Mechatronic Systems and Their Designers Page 59–74 (Springer Cham, Switzerland, 2016).
Kao, C. K. Nobel lecture: Sand from centuries past: Send future voices fast. Rev. Mod. Phys. 82, 2299 (2010).
Hillerkuss, D., Brunner, M., Jun, Z. & Zhicheng, Y. A vision towards f5g advanced and f6g. In 13th International Symposium on Communication Systems, Networks and Digital Signal Processing (CSNDSP) 483–487 (IEEE, 2022).
Liu, X. Optical Communications in the 5G Era (Academic Press, Cambridge, 2021).
Liu, Q., Ma, Y., Alhussein, M., Zhang, Y. & Peng, L. Green data center with iot sensing and cloud-assisted smart temperature control system. Comput. Netw. 101, 104–112 (2016).
Magno, M., Polonelli, T., Benini, L. & Popovici, E. A low cost, highly scalable wireless sensor network solution to achieve smart led light control for green buildings. IEEE Sens. J. 15, 2963–2973 (2014).
Shen, S., Roy, N., Guan, J., Hassanieh, H. & Choudhury, R. R. Mute: bringing iot to noise cancellation. In Proceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication, 282–296 (ACM, 2018).
Mokrani, H., Lounas, R., Bennai, M. T., Salhi, D. E. & Djerbi, R. Air quality monitoring using iot: A survey. In IEEE International Conference on Smart Internet of Things (SmartIoT), 127–134 (IEEE, 2019).
Raissi, M., Perdikaris, P. & Karniadakis, G. E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 378, 686–707 (2019).
Amil, P., Soriano, M. C. & Masoller, C. Machine learning algorithms for predicting the amplitude of chaotic laser pulses. Chaos 29, 113111 (2019).
Antonik, P. et al. Online training of an opto-electronic reservoir computer applied to real-time channel equalization. IEEE Trans. Neural Netw. Learn. Syst. 28, 2686–2698 (2016).
Porte, X. et al. A complete, parallel and autonomous photonic neural network in a semiconductor multimode laser. J. Phys. Photon. 3, 024017 (2021).
Gholami, A., Yao, Z., Kim, S., Mahoney, M. W., and Keutzer, K. Ai and memory wall. RiseLab Medium Post, University of Califonia Berkeley. https://medium.com/riselab/ai-and-memory-wall-2cb4265cb0b8 (2021).
Dai, Y., Yamamoto, H., Sakuraba, M. & Sato, S. Computational efficiency of a modular reservoir network for image recognition. Front. Comput. Neurosci. 15, 594337 (2021).
Komkov, H. B. Reservoir Computing with Boolean Logic Network Circuits. Doctoral dissertation, (University of Maryland, College Park, 2021).
Zhang, Y., Li, P., **, Y. & Choe, Y. A digital liquid state machine with biologically inspired learning and its application to speech recognition. IEEE Trans. Neural Netw. Learn. Syst. 26, 2635–2649 (2015).
Dai, Z. et al. A scalable small-footprint time-space-pipelined architecture for reservoir computing. IEEE Trans. Circuits Syst. II: Express Briefs 70, 3069–3073 (2023).
Bai, K., Liu, L. & Yi, Y. Spatial-temporal hybrid neural network with computing-in-memory architecture. IEEE Trans. Circuits Syst. I: Regul. Pap. 68, 2850–2862 (2021).
Watt, S., Kostylev, M., Ustinov, A. B. & Kalinikos, B. A. Implementing a magnonic reservoir computer model based on time-delay multiplexing. Phys. Rev. Appl. 15, 064060 (2021).
Qin, J., Zhao, Q., Yin, H., **, Y. & Liu, C. Numerical simulation and experiment on optical packet header recognition utilizing reservoir computing based on optoelectronic feedback. IEEE Photonics J. 9, 1–11 (2017).
Susandhika, M. A comprehensive review and comparative analysis of 5g and 6g based mimo channel estimation techniques. In International Conference on Recent Trends in Electronics and Communication (ICRTEC), 1–8 (IEEE, 2023).
Chang, H. H., Liu, L. & Yi, Y. Deep echo state q-network (deqn) and its application in dynamic spectrum sharing for 5g and beyond. IEEE Trans. Neural Netw. Learn. Syst. 33, 929–939 (2020).
Zhou, Z., Liu, L., Chandrasekhar, V., Zhang, J. & Yi, Y. Deep reservoir computing meets 5g mimo-ofdm systems in symbol detection. In Proceedings of the AAAI Conference on Artificial Intelligence 34, 1266–1273 (AAAI, 2020).
Zhou, Z., Liu, L. & Xu, J. Harnessing tensor structures-multi-mode reservoir computing and its application in massive mimo. IEEE Trans. Wirel. Commun. 21, 8120–8133 (2022).
Wanshi, C. et al. 5g-advanced towards 6g: Past, present, and future. IEEE J. Sel. Areas Commun. 41, 1592–1619 (2023).
Möller, T. et al. Distributed fibre optic sensing for sinkhole early warning: experimental study. Géotechniqu 73, 701–715 (2023).
Liu, X. et al. Ai-based modeling and monitoring techniques for future intelligent elastic optical networks. Appl. Sci. 10, 363 (2020).
Saif, W. S., Esmail, M. A., Ragheb, A. M., Alshawi, T. A. & Alshebeili, S. A. Machine learning techniques for optical performance monitoring and modulation format identification: A survey. IEEE Commun. Surv. Tutor. 22, 2839–2882 (2020).
Song, H., Bai, J., Yi, Y., Wu, J. & Liu, L. Artificial intelligence enabled internet of things: Network architecture and spectrum access. IEEE Comput. Intell. Mag. 15, 44–51 (2020).
Nyman, J., Caluwaerts, K., Waegeman, T. & Schrauwen, B. System modeling for active noise control with reservoir computing. In 9th IASTED International Conference on Signal Processing, Pattern Recognition, and Applications, 162–167 (IASTED, 2012).
Hamedani, K. et al. Detecting dynamic attacks in smart grids using reservoir computing: A spiking delayed feedback reservoir based approach. IEEE Trans. Emerg. Top. Comput. Intell. 4, 253–264 (2019).
Patel, Y. S., Jaiswal, R. & Misra, R. Deep learning-based multivariate resource utilization prediction for hotspots and coldspots mitigation in green cloud data centers. J. Supercomput. 78, 5806–5855 (2022).
Antonelo, E. A. & Schrauwen, B. On learning navigation behaviors for small mobile robots with reservoir computing architectures. IEEE Trans. Neural Netw. Learn. Syst. 26, 763–780 (2014).
Dragone, M., Gallicchio, C., Guzman, R. & Micheli, A. RSS-based robot localization in critical environments using reservoir computing. In The 24th European Symposium on Artificial Neural Networks (ESANN, 2016).
Sumioka, H., Nakajima, K., Sakai, K., Minato, T. & Shiomi, M. Wearable tactile sensor suit for natural body dynamics extraction: case study on posture prediction based on physical reservoir computing. In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 9504–9511 (IEEE, 2021).
Wang, K. et al. A review of microsoft academic services for science of science studies. Front. Big Data 2, 45 (2019).
Smolensky, P., McCoy, R., Fernandez, R., Goldrick, M. & Gao, J. Neurocompositional computing: From the central paradox of cognition to a new generation of ai systems. AI Mag. 43, 308–322 (2022).
Callaway, E. ‘it will change everything’: Deepmind’s ai makes gigantic leap in solving protein structures. Nature 588, 203–205 (2020).
Callaway, E. The entire protein universe’: Ai predicts shape of nearly every known protein. Nature 608, 15–16 (2022).
Lee, P., Bubeck, S. & Petro, J. Benefits, limits, and risks of gpt-4 as an ai chatbot for medicine. N. Engl. J. Med. 388, 1233–1239 (2023).
Hu, Z., Jagtap, A. D., Karniadakis, G. E. & Kawaguchi, K. Augmented physics-informed neural networks (apinns): A gating network-based soft domain decomposition methodology. Eng. Appl. Artif. Intell. 126, 107183 (2023).
Kashinath, K. et al. Physics-informed machine learning: case studies for weather and climate modelling. Philos. Trans. R. Soc. A 379, 20200093 (2021).
Min, Q., Lu, Y., Liu, Z., Su, C. & Wang, B. Machine learning based digital twin framework for production optimization in petrochemical industry. Int. J. Inf. Manag. 49, 502–519 (2019).
Kamble, S. S. et al. Digital twin for sustainable manufacturing supply chains: Current trends, future perspectives, and an implementation framework. Technol. Forecast. Soc. Change 176, 121448 (2022).
Röhm, A. et al. Reconstructing seen and unseen attractors from data via autonomous-mode reservoir computing. In AI and Optical Data Sciences IV Page PC124380E (SPIE, Bellingham, 2023).
Kong, L. W., Weng, Y., Glaz, B., Haile, M. & Lai, Y. C. Reservoir computing as digital twins for nonlinear dynamical systems. Chaos 33, 033111 (2023).
Acknowledgements
W.L. is supported by the National Natural Science Foundation of China (No. 11925103) and by the STCSM (Nos. 22JC1402500, 22JC1401402, and 2021SHZDZX0103). P.B. is supported by the EU H2020 program under grant agreements 871330 (NEoteRIC), 101017237 (PHOENICS), 101098717 (Respite), 101046329 (NEHO), 101070238 (Neuropuls), 101070195 (Prometheus); the Flemish FWO project G006020N and the Belgian EOS project G0H1422N.
Author information
Authors and Affiliations
Contributions
J.S., C.H. and M.Y. initiated the paper and developed its outline. J.S., C.H. and M.Y. wrote the first draft. P.B., P.T. and W.L. contributed substantially during the preparation of the manuscript. All authors approved the submission.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Sylvain Gigan, and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yan, M., Huang, C., Bienstman, P. et al. Emerging opportunities and challenges for the future of reservoir computing. Nat Commun 15, 2056 (2024). https://doi.org/10.1038/s41467-024-45187-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-024-45187-1
- Springer Nature Limited
This article is cited by
-
Reservoir-computing based associative memory and itinerancy for complex dynamical attractors
Nature Communications (2024)