
Abstract
The fuzzy support vector machine (FSVM) assigns each sample a fuzzy membership value based on its relevance, making it less sensitive to noise or outliers in the data. Although FSVM has had some success in avoiding the negative effects of noise, it uses hinge loss, which maximizes the shortest distance between two classes and is ineffective in dealing with feature noise near the decision boundary. Furthermore, whereas FSVM concentrates on misclassification errors, it neglects to consider the critical within-class scatter minimization. We present a Fuzzy support vector machine with pinball loss (FPin-SVM), which is a fuzzy extension of a reformulation of a recently proposed support vector machine with pinball loss (Pin-SVM) with several significant improvements, to improve the performance of FSVM. First, because we used the squared L2- norm of errors variables instead of the L1 norm, our FPin-SVM is a strongly convex minimization problem; second, to speed up the training procedure, solutions of the proposed FPin-SVM, as an unconstrained minimization problem, are obtained using the functional iterative and Newton methods. Third, it is proposed to solve the minimization problem directly in primal. Unlike FSVM and Pin-SVM, our FPin-SVM does not require a toolbox for optimization. We dig deeper into the features of FPin-SVM, such as noise insensitivity and within-class scatter minimization. We conducted experiments on synthetic and real-world datasets with various sounds to validate the usefulness of the suggested approach. Compared to the SVM, FSVM, and Pin-SVM, the presented approaches demonstrate equivalent or superior generalization performance in less training time.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Because of its theoretical base and high generalization capability, a support vector machine (SVM) is an innovative and successful solution for data categorization and regression issues in the field of machine learning. SVM's main notion for binary classification problems is to find a hyperplane that can separate two classes with the greatest possible margin [5]. SVM [6, 33] is a convex quadratic programming problem that optimizes the margin between the nearest points of various classes while minimizing misclassification errors. In most cases, SVM is solved in dual space, resulting in a sparse and global solution [1]. Furthermore, SVM outperforms other machine learning algorithms such as artificial neural networks in terms of generalization instead of artificial neural networks, which suffer from overfitting and local minima. In a wide range of applications, such as human face detection, feature extraction, gene prediction, and several other classification issues, SVM beats most other learning techniques [12, 16, 23].
The hinge loss is used in SVM to maximize the shortest distance between classes; therefore, the final decision hyperplane is decided by the training points that are near to the decision boundary and are referred to as support vectors [29]. Normally, feature noise creates turbulence near the class boundaries [28]. As a result, feature noise may have a role in selecting the decision hyperplane as support vectors in SVM with hinge loss. Various approaches have been made to cope with feature noise ([4, 19, 30, 36, 37]; etc.). Huang et al. [14] presented the Pin-SVM (support vector machine with pinball loss), similar to SVM but using pinball loss rather than hinge loss. Unlike SVM, Pin-SVM applies penalties to correctly and incorrectly classified samples and learns the decision hyperplane by maximizing the quantile distance between classes resulting in noise insensitivity and resampling stability [14]. By incorporating the aggregation operators in hinge loss function and via Fuzzy logic, [20] proposed models that deal with the dataset shift. Xu et al. [34] presented a twin parametric SVM with pinball loss (Pin-TSVM) model that works faster than Pin-SVM and reduces noise sensitivity. Large-scale pinball twin SVM (TWSVM) provides the greater stability under sampling and tunable insensitivity to feature noise in comparison to TWSVM [32]. A novel twin bounded support vector machine classifier with squared pinball loss and its solution by functional iterative and Newton methods are proposed in [26].
For the regression problem, Asymmetric ν-twin support vector regression (Asy-v-TSVR) not only works faster than Asy-v-SVR but also employs the pinball loss to effectively reduce the disturbance of the noise and improve the generalization performance [35]. An improved regularization based Lagrangian asymmetric ν-TSVR using pinball loss function are proposed in [10]. An unconstrained variant of Asy-v-TWSVR, called robust asymmetric Lagrangian ν-TSVR using pinball loss function, that avoids the need to solve a pair of quadratic optimization problem thereby resulting in unique global solution [11].
Important data points can be fully allocated to one class in many real-world classification situations. In contrast, less meaningful data points, such as noise-corrupted data, cannot be assigned to any class. As a result, each data point should be treated differently depending on its significance; however, SVM doesn't have this capability. Lin and Wang [18] proposed the Fuzzy support vector machine (FSVM) to reduce the impact of noise and outliers in data. FSVM finds the ideal separation hyperplane by maximizing the margin between classes after assigning each sample a fuzzy membership value based on its relevance. Although FSVM has successfully avoided the negative impact of noise, it relies on the hinge loss and is ineffective in dealing with feature noise near the decision boundary.
Motivated by the works on Pin-SVM [14], FSVM [18], Functional and Newton method of solutions [2, 39], we propose a new fuzzy support vector machine with pinball loss (FPin-SVM whose solutions are obtained by two approaches: (i) obtaining its critical point by functional iterative algorithm, (ii) since it is not twice differentiable, either considering its generalized Hessian [8, 13] or introducing a smooth function [17] in place of the 'plus' function and applying Newton–Armijo algorithm. The effectiveness of the proposed FPin-SVM problem is demonstrated by performing experiments on a number of interesting synthetics and real-world datasets with different noises and comparing their results with SVM, FSVM, Pin-SVM, k-NN and OWAWA-FSVM.
In this work, all vectors are considered column vectors. For a vector \(x=({x}_{1},\text{...},{x}_{n}{)}^{t}\in {R}^{n}\), its transpose and 2-norm will be denoted by \({x}^{t}\) and \(||x||\) respectively. We define the plus function \({x}_{+}\) by \(({x}_{+}{)}_{i}={\text{max}}\left\{0,{x}_{i}\right\}\) where \(i=1,\text{...},n\). The \(m\) dimensional column vector of zeros and similarly the vector of ones will be denoted by 0 and \(e\) respectively and denote the identity matrix of appropriate size by .
The paper is organized as follows. Section 2 provides a brief review of the formulations of SVM, SVM with pinball loss (Pin-SVM), and fuzzy SVM (FSVM). Section 3 presents a new fuzzy SVM with pinball loss (FPin-SVM) in primal, whose solutions are obtained by functional and Newton-Armijo iterative methods. In Sect. 4, we investigate FPin-SVM properties. For comparison purposes, numerical tests on synthetic and benchmark datasets with different noises are performed in Sect. 5, while Sect. 6 concludes the paper.
2 Related work
In this section, we briefly describe the formulations of SVM, SVM with pinball loss, and Fuzzy support vector machine. For the binary classification problem, let the training set \({\left\{{x}_{i},{y}_{i}\right\}}_{i=1}^{m}\) be given where \({x}_{i}\in {R}^{n},{y}_{i}\in \left\{1,-1\right\}\).Let \(A\in {R}^{m\times n}\) represents the input matrix where the input example \({x}_{i}^{t}\) is its \({i}^{\text{th}}\) row and \(y=({y}_{1},\dots ,{y}_{m}{)}^{t}.\) Where \({x}_{i}^{t}\) the transpose of vector \({x}_{i}.\)
2.1 Support vector machine with hinge loss (SVM)
The linear SVM classifier attempts to find an optimal hyperplane \({w}^{t}x+b=0,w\in {R}^{n},b\in R;\) to maximize the margin and minimize the training error where wt is the transpose of vector w. The training error is measured by the hinge loss function defined as follows
By taking \(C>0\) as a trade-off parameter, \(\xi =({\xi }_{1},\dots ,{\xi }_{m}{)}^{t}\) as a vector of slack variables and \(e\) as a vector of ones of dimension m, the SVM model is obtained as
Usually, dual of a problem (2) is solved and is obtained as
where \(\alpha =({\alpha }_{1},\dots ,{\alpha }_{m}{)}^{t}\) is the vector of Lagrangian multipliers. The linear SVM decision function is given by
where \(b\) can be determined by Karush–Kuhn–Tucker (K.K.T.) conditions.
A nonlinear map** is introduced in SVM to map the input example into a high dimensional feature space for the nonlinear case. Then SVM attempts to find the optimal separating hyperplane \({w}^{t}\phi ({x}_{i})+b=0\) in that feature space. By applying the kernel trick [6, 33] in (3), the minimization problem in dual for nonlinear SVM is obtained as
where \(\alpha =({\alpha }_{1},\dots ,{\alpha }_{m}{)}^{t}\) is the vector of Lagrangian multipliers,\(k({x}_{i},{x}_{j})=\phi ({x}_{i}{)}^{t}\phi ({x}_{j})\) and \(k(.,.)\) is a kernel function. The nonlinear SVM decision function is given by
2.2 Support vector machine with pinball loss (Pin-SVM)
Since SVM with hinge loss is susceptible to noise and unstable with respect to resampling, Huang et al. [14] suggested using the pinball loss instead of hinge loss applied in SVM. The pinball loss function is defined as follows
where \(0\le \tau \le 1\) is a user-defined parameter. The hinge loss and absolute \({L}_{1}\)-loss are the particular cases of pinball loss with \(\tau =0\) and \(\tau =1\), respectively. The support vector machine with pinball loss (Pin-SVM) model proposed by Huang et al. [14] is the following QPP,
The dual of problem (8) is derived as the following minimization problem
where \(\alpha =({\alpha }_{1},\dots ,{\alpha }_{m}{)}^{t}\) and \(\beta =({\alpha }_{1},\dots ,{\alpha }_{m}{)}^{t}\) are the vectors of Lagrangian multipliers, respectively. The linear Pin-SVM decision function is given by
where \(b\) can be determined by K.K.T. conditions.
For the nonlinear case, the minimization problem in dual for nonlinear Pin-SVM can be obtained as
where \(k({x}_{i},{x}_{j})=\phi ({x}_{i}{)}^{t}\phi ({x}_{j})\) and \(k(.,.)\) is a kernel function. Finally, the nonlinear Pin-SVM decision function is given by
As the parameter \(\tau \) increases, the weights on the correctly classified points become great, so the margin width becomes large. Thus, the points near the boundaries of classes become less important in deciding the optimal decision hyperplane. The Effects of the feature noise are weakened, which leads to noise insensitivity.
2.3 Fuzzy support vector machine with hinge loss (FSVM)
In SVM, each data point is treated equally, but some data points can be more important than others for many real-world classification problems. Lin and Wang [18] proposed a fuzzy extension of SVM called fuzzy support vector machine (FSVM) to solve this problem. In FSVM, the fuzzy membership function assigns the fuzzy membership values to each data point based on its importance. We will use the class center method to generate the fuzzy membership [18].We denote \({x}_{+}\) and \({r}_{+}\) as the mean and radius of class + 1 and \({x}_{-}\) and \({r}_{-}\) as the mean and radius of class -1, respectively. The radius of each class is the farthest distance between its training points and its class center, namely \({r}_{+}=\underset{\left\{{x}_{i},{y}_{i}\text{=+}1\right\}}{\text{max}}\Vert {x}_{+}-{x}_{i}\Vert \) and \({r}_{-}=\underset{\left\{{x}_{i},{y}_{i}=-1\right\}}{\text{max}}\Vert {x}_{-}-{x}_{i}\Vert \). For any training point,\({x}_{i},\) its fuzzy membership \({s}_{i}\) is defined as follows:
where \(d>0\) is used to avoid the case \({s}_{i}=0\text{.}\)
For the nonlinear classification problem, we will employ an improved fuzzy membership function studied (used) in [3, 15] and is defined as
where
m+ and m- are the number of samples in positive and negative classes, respectively.
The formulation of FSVM in primal is written as:
For a detailed discussion on the problem formulation of FSVM, its solution method, and its advantages, see [18].
3 Proposed Fuzzy support vector machine with pinball loss (FPin-SVM)
Following the work of Pin-SVM [14] and FSVM [18], a Fuzzy support vector machine with pinball loss (FPin-SVM) is proposed in this section to enhance the performance of FSVM with the attractive features of pinball loss including noise insensitivity and within-class scatter minimization. It is proposed to compute the solution of Pin–FSVM by iterative-based schemes [2, 39], which leads to lower training time.
Introducing the pinball loss function into the FSVM (13) with squared L2- norm of slack variables and adding the term \(({b}^{2}/2)\) into its objective function, we formulate the FPin-SVM for the linear case as the following QPP:
where \(C>0\) and \(0\le \tau \le 1\) are the user-defined parameters;\({s}_{i}\) and \({\xi }_{i}\) are the fuzzy membership and slack variable corresponding to \({i}^{\text{th}}\) input example \({x}_{i}\), respectively.
Remark 1
Since \({y}_{i}({{\varvec{w}}}^{t}{{\varvec{x}}}_{i}+b)\ge 1-{{\xi }_{i}}_{\hspace{1em}}\Rightarrow \hspace{1em}{\xi }_{i}\ge 1-{y}_{i}({{\varvec{w}}}^{t}{{\varvec{x}}}_{i}+b)\) or \({\xi }_{i}=\mathit{max}(\mathrm{0,1}-{y}_{i}({{\varvec{w}}}^{t}{{\varvec{x}}}_{i}+b))\)
Therefore, the empirical risk term with given constraints in optimization problem (14) can be equivalently written as a minimization problem of the form
where \(u=[{w}^{t}b{]}^{t}\in {R}^{n+1},D={\text{diag}}({y}_{1},\dots ,{y}_{m}),S={\text{diag}}({s}_{1},\dots ,{s}_{m})\) and \(G=[Ae]\text{.}\)
Problem (14) can be written as an unconstrained minimization problem as follows
Remark 2
The unconstrained formulation (15) of the problem (14) is a strongly convex minimization problem because we considered the squared \(L2\) norm of slack variables instead of \(L1\) norm in (14). Further adding the \(({b}^{2}/2)\) term in the objective function of (14), effects in maximization of margin with respect to both orientation vector \(w\) and location parameter b of the separating decision hyperplane [22].
Once the solution vector \(u\) of the problem (15) is known, then given any input,\(x\) the linear decision function determines its class \(f(x)={\text{sign}}([{x}^{t}1]u)\text{.}\)
For the nonlinear extension of linear FPin-SVM to nonlinear FPin-SVM, we consider the kernel matrix \(K=K(A,{A}^{t})\) of order m having \(K(A,{A}^{t}{)}_{\text{ij}}=k({x}_{i},{x}_{j})\in R\) as its \((i,j{)}^{\text{th}}\) element. Further, for a given vector \(x\in {R}^{n}\), let \(K({x}^{t},{A}^{t})=(k(x,{x}_{1}),\dots ,k(x,{x}_{m}))\) be a row vector in \({R}^{m}\).Following the work of [22], we formulate the nonlinear Pin-SVM as the following QPP:
where \(C>0\) and \(0\le \tau \le 1\) are the user-defined parameters;\(D={\text{diag}}({y}_{1},\dots ,{y}_{m}),S={\text{diag}}({s}_{1},\dots ,{s}_{m})\) and \(\xi =({\xi }_{1},\dots ,{\xi }_{m}{)}^{t}\text{.}\)
Problem (16) can be written as an unconstrained minimization problem as follows
where \(u=[{w}^{t}b{]}^{t}\in {R}^{m+1}\),\(G=[K(A,{A}^{t})e]\).
We propose to solve the primal problem (17) by obtaining its critical point through a functional iterative algorithm and the Newton method. Once the solution vector \(u\) of the problem (17) is known, then given any input \(x\), its class is determined by the nonlinear decision function:
3.1 Functional iterative method of solving FPin-SVM (FFPin-SVM)
Solving the unconstrained nonlinear FPin-SVM problem (17) in this subsection is proposed by computing its critical point, which becomes a root-finding problem by setting its gradient to zero.
The gradient vector of (17) can be obtained as
Using the inequality \({u}_{+}=\frac{u+\left|u\right|}{2},\nabla L(u)\) becomes
Now, computing \(\nabla L(u)=0,\) we get
This leads to the following functional iterative scheme (FFPin-SVM), for \(i=\mathrm{0,1},\dots \)
where \(Q=\left(\frac{2I}{C}+(1+{\tau }^{2}){G}^{t}{\text{DSDG}}\right)\)
Since one can write the matrix product \({G}^{t}{\text{DSDG}}={G}^{t}{\text{DS}}^{1/2}{S}^{1/2}{\text{DG}}\) and it is of the form \({P}^{t}P\) where \(P={S}^{1/2}{\text{DG}}\) implies the matrix \({G}^{t}{\text{DSDG}}\) is positive semi-definite. Therefore, for the given parameters C > 0 and \(0\le \tau \le 1\), the matrix \(Q\) which is the sum of a positive definite matrix, and a positive semi-definite matrix is also a positive definite matrix.
Remark 3
The proposed iterative scheme (20) needs the inverse of a positive definite matrix Q having an order that equals to a number of input examples, but it is computed only once before the first iterative step begins the execution.
Remark 4
In FFPin-SVM (20), the time complexities for the matrix multiplications DG, SDG, GtDSDG, Q−1 GtDS and the matrix inversion Q−1 are m(m + 1), m(m + 1), m(m + 1)2 and (m + 1)3 respectively. Thus, the cumulative complexity of FFPin-SVM is O(2 m(m + 1) + m(m + 1)2 + (m + 1)3).
3.2 Newton method of solving FPin-SVM
In this subsection, we apply Newton iterative method with Armijo stepsize for solving the unconstrained nonlinear FPin-SVM problem (17), and it is defined as:
Newton method with Armijo stepsize [8, 21].
For solving (17), start with an initial guess \({u}^{0}\in {R}^{m+1}\)
-
(i)
Stop the iteration if \(g({u}^{i})=0\)
Else
Determine the direction vector \({d}^{i}\in {R}^{m}\) as the solution of the following linear system of equations in \(m\) variables:
-
(ii)
Armijo stepsize. Define:where the stepsize \({\lambda }_{i}={\text{max}}\left\{1,\frac{1}{2},\frac{1}{4},\text{...}\right\}\) is such that:\(L({u}^{i})-L({u}^{i}+{\lambda }_{i}{d}^{i})\ge -\delta {\lambda }_{i}g({u}^{i}{)}^{t}{d}^{i}\) and \(\delta \in (0,\frac{1}{2})\text{.}\)
$${u}^{i+1}={u}^{i}+{\lambda }_{i}{d}^{i},$$
Applying the Newton-Armijo algorithm to the problem (17) requires both gradient vector and Hessian matrix to be computed. For this purpose, the absolute value Eq. (19) is considered in the form
Then, we compute a generalized Hessian [13] of \({g}_{1}(u)\) as.
where \({E}_{1}(u)=I+{\text{diag}}({\text{sign}}(e-{\text{DG}}u)),{E}_{2}(u)=I+{\text{diag}}({\text{sign}}({\text{DG}}u-e))\)
Remark 5
One can observe the matrices \({E}_{1}(u)\) and \({E}_{2}(u)\) with their diagonal values 0 or 1 or 2. By defining matrices \({P}_{1}={E}_{1}(u{)}^{1/2}{S}^{1/2}{\text{DG}}\) and \({P}_{2}={E}_{2}(u{)}^{1/2}{S}^{1/2}{\text{DG}}\), the matrices.
\({G}^{t}{\text{DSE}}_{1}(u){\text{DG}}\) and \({G}^{t}{\text{DSE}}_{2}(u){\text{DG}}\) can be written in the form \({P}_{1}^{t}{P}_{1}\) and \({P}_{2}^{t}{P}_{2}\) respectively. Therefore, for the given parameters C > 0 and \(0\le \tau \le 1\), the generalized Hessian matrix (22) which is the sum of a positive definite matrix, and two positive semi-definite matrices is also a positive definite matrix.
Since the gradient and generalized hessian defined by (21) and (22) of the proposed problem (17) are given, one can perform the Newton method with Armijo stepsize to obtain its solution. We call this generalized derivative approach of solution as NFPin-SVM1. It can be shown that [17] for any starting vector \({u}^{0}\) in \({R}^{m+1}\); the sequence \(\left\{{u}^{i}\right\}\) obtained using the Newton–Armijo algorithm described above converges globally and terminates at the global minimum in a finite number of iterations.
One can employ a popular smoothing technique as another approach for solving the proposed unconstrained nonlinear FPin-SVM. A smooth approximation function for the plus function introduced by Lee and Mangasarian [17] is defined as
where \(x\in R\) and \(\alpha >0\) is a smoothing parameter.
Now substituting \(p(x,\alpha )\) for \((x{)}_{+}\) in (18), its smooth reformulation is obtained as
The Hessian matrix corresponding to smooth approximation problem (24) can be obtained as
Since the Hessian matrix (25) is positive definite, the Newton method with Armijo stepsize can be used to find the solution. We call this smooth approach to solution as NFPin-SVM2.Following the proof of [17], it can be shown that for any starting vector \({u}^{0}\) in \({R}^{m+1}\); the sequence \(\left\{{u}^{i}\right\}\) obtained using the Newton–Armijo algorithm described above converges globally and quadratically. Further, when the smoothing parameter \(\alpha >0\) converges to infinity, the unique solution converges to the unique solution of the original minimization problem (17) [17].
Remark 6
The key advantage in considering either the generalized Hessian or smooth approach for solving (17) is that a system of linear equations is solved instead of a QPP as in the case of SVM, FSVM, and Pin-SVM.
Remark 7
In NFPin-SVM1, for the evaluation of gradient (21) and generalized Hessian (22), compute the matrix multiplications DG, SDG, GtDSDG, E1(u)DG, GtDSE1(u)DG, E2(u)DG and GtDS E2(u)DG with complexities of m(m + 1), m(m + 1), m(m + 1)2, m(m + 1), m(m + 1)2, m(m + 1) and m(m + 1)2 respectively. Also, the system of linear equation i.e., \(\partial g({u}^{i}){d}^{i}=-g({u}^{i})\) (see step (i) of Newton iterative method) can be solved in (m + 1)3. In case of simple Newton algorithm terminates at p (< = itmax) iteration, its total complexity is: O(2 m(m + 1) + m(m + 1)2 + p[( 2 m(m + 1) + 2 m(m + 1)2,]. One can also compute the total complexity of NFPin-SVM2 algorithm as O(2 m(m + 1) + p[( 2 m(m + 1) + 2 m(m + 1)2).
4 Analysis of FPin-SVM
4.1 Noise insensitivity of FPin-SVM
We focus on the unconstrained FPin-SVM for the linear case for easy comprehension. Differentiating (15) with respect to variables \(u\) leads to the following K.K.T. condition
Since \(u=[{w}^{t}b{]}^{t}\in {R}^{n+1},D={\text{diag}}({y}_{1},\dots ,{y}_{m}),S={\text{diag}}({s}_{1},\dots ,{s}_{m})\) and \(G=[Ae],\) the above optimality condition can be expressed as
Defining the index sets \({T}_{1}^{+}=\left\{i:1-{y}_{i}({w}^{t}{x}_{i}+b)>0\right\}\) and \({T}_{2}^{-}=\left\{i:1-{y}_{i}({w}^{t}{x}_{i}+b)<0\right\}\) the Eq. (26) can be written as
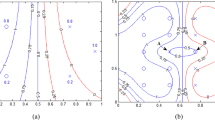
The parameter \(\tau \) in condition (27) controls the number of points in \({T}_{1}^{+}\) and \({T}_{2}^{-}\). When \(\tau \) is small, there are a lot of points in \({T}_{2}^{-}\) compared to \({T}_{1}^{+}\), and the result is sensitive. Both sets contain many points when \(\tau \) becomes large, and the result is less sensitive. This is also illustrated in Fig. 1. It is observed in Fig. 1a that the SVM is sensitive to the feature noise around the decision boundary, which results in an SVM classifier having a smaller margin. The linear decision boundaries obtained by the proposed FPin-SVM are shown in Fig. 1b, c. Here sets \({T}_{1}^{+}\) and \({T}_{2}^{-}\) contains the points within and outside the region defined by the positive and negative supporting hyperplanes, respectively. In Fig. 1b, FPin-SVM obtains a classifier with a margin slightly better and larger than SVM but still sensitive to feature noise because \({T}_{2}^{-}\) contains many points for smaller values \(0\text{.}1\) for \(\tau \).It can be seen that in Fig. 1c, for larger value 1 for \(\tau \) both sets contains many points, and the result is less sensitive to feature noise with larger margin width.

Illustrations of a SVM, b FPin-SVM with τ = 0.1, and c FPin-SVM with τ = 1 on a 2-D synthetic dataset
4.2 Within-class scatter minimization
The proposed FPin-SVM formulation (14) can be equivalently transformed into \(\underset{w,b,\xi }{\text{min}}\frac{1}{2}({w}^{t}w+{b}^{2})+\frac{C}{2}{\sum }_{i=1}^{m}{s}_{i}\left[{\text{max}}{\left\{0,{e}_{i}\right\}}^{2}+{\tau }^{2}{\text{max}}{\left\{0,-{e}_{i}\right\}}^{2}\right]\)
Note that when \(\tau =0,\) Eq. (28) reduces to the following L2 norm-Fuzzy support vector machine (L2-FSVM) [38]
and when \(\tau =1,\) Eq. (28) becomes Least square Fuzzy support vector machine (LS-FSVM) below
Thus, FPin-SVM acts as a trade-off between the L2-FSVM and LS-FSVM:
Note that we obtain the FPin-SVM (28) with \(C={C}_{1}+{C}_{2}\) and \({\tau }^{2}=\frac{{C}_{2}}{C}\text{.}\) This observation also interprets the reasonable range of \(\tau \) is \(0\le \tau \le 1\text{.}\)
Remark 8
When membership values of all input points are equal, say 1, then Eq. (31) becomes.
.
and the FPin-SVM also becomes the trade-off between L2-SVM and LS-SVM [31]. L2-SVM focuses on the misclassification error because it maximizes the distance between positive and negative supporting hyperplanes \({w}^{t}{x}_{i}+b=\pm 1,\) and pushes the points to \({y}_{i}({w}^{t}{x}_{i}+b)\ge 1\text{.}\) LS-SVM also seeks the maximum margin hyperplane but pushes the positive and negative samples to be located around their respective supporting hyperplane, which results in small within-class scatter minimization and is related to Fisher discriminant Analysis [9, 31].
In Eq. (31), first-term maximizes the margin between the two supporting hyperplanes \({w}^{t}{x}_{i}+b=\pm 1,\) with respect to both orientation parameter \(w\) and location variable b; the second term minimizes the sum of squared misclassified sample's errors weighted by the corresponding sample's fuzzy membership value, and the third term minimizes the fuzzy membership weighted scatter of positive and negative samples from their respective supporting hyperplanes. Thus, FPin-SVM emphasizes misclassification error and focuses on within-class scatter minimization together, and incorporating the fuzzy membership of input points further improves its classification accuracy.
4.3 Comparison with other related methods
Both FSVM and FPin-SVM consider the importance of training data points in finding the optimal separating hyperplane between two classes but the loss function they employ are significantly different. FSVM employs the hinge loss function, while our proposed FPin-SVM uses the pinball loss function. Huang et al. [14] proposed the Pin-SVM that enjoys noise robustness but does not consider the importance of training samples, further improving its classification accuracy. Like Pin-SVM, our proposed FPin-SVM also adopts the pinball loss function, but we have made certain modifications to its objective function,first, we added b2/2 in the regularization term; second, in the empirical risk term, we considered the squared L2 norm of error variables and fuzzy membership function used to give different weightings to slack error variables. Unlike Pin-SVM, solutions of the FPin-SVM are obtained by functional and Newton-Armijo iterative algorithms, and it is proposed to solve the FPin-SVM directly in primal.
5 Experiments and results
To analyze the generalization performance and the computational efficiency of our proposed FPin-SVM formulation solved by functional iterative method (FFPin-SVM) and Newton method by considering generalized derivative approach (NFPin-SVM1) or Smooth approach (NFPin-SVM2), we compare the FFPin-SVM, NFPin-SVM1, and NFPin-SVM2 with SVM, FSVM, and Pin-SVM on well-known synthetic and benchmark datasets. All the classifiers are implemented on a P.C. running on Windows XP O.S. with a 64-bit, 3.20 GHz, Intel®core™2 Duo processor, having 8 G.B. of RAM under MATLAB R2015a environment. The MOSEK optimization toolbox solves the compared algorithms SVM, FSVM, and Pin-SVM for MATLAB, available at http://www.mosek.com; however, no external optimizer was used for solving FFPin-SVM, NFPin-SVM1, and NFPin-SVM2.
In implementing FFPin-SVM, NFPin-SVM1, and NFPin-SVM2, the values of the termination criteria tol and itmax were set to 0.001 and 10, respectively. Since smooth function approximation with parameter α = 5 has shown successful results [17]., we assumed α = 5 in implementingNFPin-SVM2.
Experiments are performed by choosing the popular Gaussian kernel function of the form: \(k(x,z)={\text{exp}}(-||x-z|{|}^{2}/2{\sigma }^{2})\) where \(x,z\in {R}^{n}\) and \(\sigma 0\) is the parameter. All the parameters are selected by employing the grid search using a ten-fold cross-validation methodology. The optimal regularization parameters \(C,{C}_{1}={C}_{2},{C}_{3}={C}_{4}\) and the kernel parameter \(\sigma \) are chosen from the set \(\left\{{2}^{i}|i=-9,-8,-7,\dots ,9\right\}\text{.}\) The optimal \(\tau \) is selected from the range{0.1, 0.2, 0.5, 1}. For optimal parameter values of k-NN and OWAWA-FSVM, we have taken parameter from the set as given in [20].
5.1 Performance on synthetic datasets
First, we consider a two-dimensional example used in [14]: positive and negative samples come from the Gaussian distributions: \({x}_{i},i\in I\text{ }N({\mu }_{1},\sum ),\) and \({x}_{j},j\in \text{II }N({\mu }_{2},\sum ),\) where \({\mu }_{1}=[0\text{.}\mathrm{5,3}],{\mu }_{2}=[0\text{.}5,-3]\) and \(\Sigma_{1} = \Sigma_{2} = diag(0.2,3).\) respectively. We also introduce the noise data points in the training set. The labels of noise points are selected from \(\left\{\mathrm{0,1}\right\}\) with equal probability, and the positions of the noise points follow the Gaussian distribution.
\(N({\mu }_{n},\sum )\) with \({\mu }_{n}=[\mathrm{0,0}{]}^{t}\text{.}\) We generate six different synthetic datasets with \((m={100},r=0),(m={100},r=0\text{.05}),(m={100},r=0\text{.}1),(m={200},r=0),(m={200},r=0\text{.05})(m={200},r=0\text{.}1)\text{.}\) where \(m\) the number of samples and \(r\) is the ratio of the noise data in the training set. To illustrate the performances of proposed algorithms, we repeat the resampling and training process 100 times, then report the average accuracy and training time in Table 1. One can observe that in all cases, the performance of SVM and FSVM are worse than all remaining algorithms, namely: Pin-SVM, FFPin-SVM, NFPin-SVM1, and NFPin-SVM2. In case of noisy data, our proposed algorithms FFPin-SVM, NFPin-SVM1, and NFPin-SVM2obtain the higher accuracies than compared algorithms SVM, FSVM, and Pin-SVM. Again, it is obvious from Table 1 that our proposed algorithms learning times are faster than compared algorithms which also validates the effectiveness of the proposed algorithms.
As our second example, we consider the Ripley's Synthetic dataset [27], containing 250 training points and 1000 test points. Figure 2 shows the nonlinear decision boundaries obtained by all the algorithms on Ripley's dataset, where red and blue colors show positive and negative class points. The decision boundaries learned on a training set by proposed algorithms FFPin-SVM, NFPin-SVM1, and NFPin-SVM2 are similar but better than the compared algorithms SVM, FSVM, and Pin-SVM. The prediction accuracies and learning time of all the algorithms are listed in Table 2. It is evident from Table 2 that proposed algorithms obtained higher testing accuracies compared to SVM, FSVM, and Pin-SVM. Furthermore, the proposed algorithms are more computationally efficient than the compared algorithms, as shown in Table 2.

Classification results of the out proposed methods FFPin-SVM, NFPin-SVM1, and NFPin-SVM2 with nonlinear Pin-SVM, FSVM, and SVM on Example 2 (Ripley's dataset)
The third example is a two-dimensional synthetic checkerboard dataset consisting of a series of uniform points taken from 16 black and white squares of a checkerboard [25]. To test the learning ability of all algorithms on the checkerboard dataset, we consider the checkerboard dataset with 800 uniform points,each of the 16 squares consists of 50 points. Figure 2 shows the classification results of all the algorithms. It is observed in Fig. 3 that Pin-SVM, FFPin-SVM, NFPin-SVM1, and NFPin-SVM2 obtained the best separating decision hyperplane than SVM and FSVM because they simultaneously handle the within-class scatter minimization and misclassification error. To avoid the biased comparison, we make 10 independent runs on the checkerboard problem with 6400 uniform test sets, then report the average accuracies and training time of all the algorithms in Table 3. The results show that FFPin-SVM, NFPin-SVM1, and NFPin-SVM2 obtain the best test accuracies than Pin-SVM, FSVM, and SVM.

Classification results of our proposed methods FFPin-SVM, NFPin-SVM1, and NFPin-SVM2 with Pin-SVM, FSVM, and SVM on Examlpe3 (synthetic Checkerboard dataset)
5.2 Performance on U.C.I. datasets
To further test the performance of the proposed methods, we perform experiments on several benchmark datasets, which are commonly used for testing the machine learning algorithms. These datasets are publically available at the U.C.I. repository of Machine Learning Datasets [24]. All the datasets are normalized so that features are located in [0, 1] before the training. We discussed the first example with labeled noise in the synthetic case, but classification problems may also have feature noise(Bi and Zhang, 2004). For this purpose, features of each dataset are corrupted by zero-mean Gaussian noise. For each feature, the ratio of the variance of noise to that of feature, denoted by \(r\), is set to be 0 (i.e., noise-free), 0.05, and 0.1. The same noise corrupted the training and testing datasets [14]. In order to compare the performance of the proposed algorithms (FF-PinSVM, NFPin-SVM1, NFPin-SVM2) with other algorithms (FSVM, Pin-SVM, k-NN, OWAWA-FSVM), we obtain their results on U.C.I. datasets where Gaussian kernel are employed in all the algorithms. We repeat the experiments ten times for each dataset and report the average test accuracies, standard deviation, and average learning time in Table 4.
Further, they are ranked according to the accuracy obtained for every dataset, and their average ranks are also reported in Table 4. Note that the average ranks of proposed algorithms are better than compared algorithms. To avoid any biasedness in comparison of the effectiveness with the compared algorithms, we statistically analyze the results of Table 4 by performing the popular Friedman test with the corresponding Nemenyi test recommended [7]. To validate that all the algorithms are significantly different against the null hypothesis, which states that all the algorithms are equivalent, we have
where \({F}_{F}\) is distributed according to \(F-\) distribution with \((\mathrm{7,7}\times {32})=(\mathrm{7,224})\) degree of freedom. Since the \({F}_{F}\) value is greater than the critical value of \(F(7,{224})=2\text{.}{0506}\) for the level of significance \(\alpha =0\text{.05}\), we reject the null hypothesis. We apply the Nemenyi post-hoc test to find the pair-wise comparison of algorithms. From [7], the critical value \({q}_{\alpha }\) for \(\alpha =0\text{.10}\) is 2.780, and the value of CD is \(2\text{.780}\sqrt{\frac{8\times 9}{6\times {33}}}\simeq 1\text{.6764}\text{.}\) Again, from Table 4, in terms of average ranks, the difference between (i). the best of SVM, FSVM, Pin-SVM, k-NN, OWAWA-FSVM and worst NFPin-SVM1, NFPin-SVM2 is: \(4.3182-2\text{.}\text{5303 = 1.7879}>1\text{.}{6764},\) the performance of NFPin-SVM1 and NFPin-SVM2 is better than SVM, FSVM, Pin-SVM, k-NN and OWAWA-FSVM; (ii). The best of SVM, FSVM, k-NN, OWAWA-FSVM and the value of FFPin-SVM are: \(4\text{.}\text{9091 - 3.0303}=1\text{.}{8788}>1\text{.6764,}\) the performance of FFPin-SVM is better than SVM, FSVM, k-NN, OWAWA-FSVM; (iii). The best and worst of FFPin-SVM, Pin-SVM is: \(4\text{.}{3182}-3\text{.}{0303}=1\text{.}{2879}<1\text{.}{6764},\) we conclude that the posthoc test is not powerful enough to detect any significant differences between these algorithms; (iv). The best and worst of SVM, Pin-SVM is: \(6\text{.3}{030}-4\text{.}{3182}=1.{9848}>1\text{.}{6764},\) the performance of Pin-SVM is better than SVM; (v).the best and worst of FSVM, Pin-SVM, OWAWA-FSVM is: \(\text{5.5152}-4.3182=1\text{.}{1970}<1\text{.}{6764},\) we conclude that the post hoc test could not find any significant differences between these algorithms.
The average AUC (area under curve) metric computed for real-world datasets on 10 different sets, and average rank is listed in Table 5. One can observe that our proposed methods have obtained largest AUC value for most of the datasets. Least average ranks of the proposed method show their effectiveness and applicability in comparison to SVM, FSVM, Pin-SVM, k-NN, OWAWA-FSVM.
With the above study of statistical comparison of all algorithms and their results reported in Table 4, it is evident that proposed algorithms result in superior classification performance on most of the datasets with the noise of different variances and obtain a lower learning time than those compared algorithms SVM, FSVM, Pin-SVM, k-NN and OWAWA-FSVM. Furthermore, the average rank for all datasets listed in the last row of the Table 4 shows that FFPin-SVM, NFPin-SVM1, and NFPin-SVM2 are ranked; third, first, and second, respectively, which also validates the effectiveness of the proposed algorithms.
6 Conclusions and future work
This paper proposes a Fuzzy support vector machine with pinball loss (Fpin-SVM) to enhance the generalization performance. The advantage of Fpin-SVM is that it is a strongly convex minimization problem whose solutions are obtained in primal by iterative based algorithms rather than solving QPP as is the case with the compared algorithms SVM, FSVM, Pin-SVM, k-NN and OWAWA-FSVM. We investigated Fpin-SVM properties, including noise insensitivity and within-class scatter minimization. In addition, we also compared Fpin-SVM with two related algorithms, FSVM and Pin-SVM. The numerical experiments conducted on several synthetic and benchmark datasets with different noises validate that the proposed algorithms are feasible and effective on both classification performance and computational speed. The main limitation of proposed method is that it is suitable for medium sized data because it requires inverse of positive definite matrix and due to use of pinball loss function it. Another issue is the sparsity because pinball loss function is not as sparse as hinge loss.
In addition to deal with limitation of proposed methods, our future work includes studying how to apply the pinball loss to other variants of SVM and develop faster algorithms to improve their computational speed. There is also room for the study of \(\varepsilon \)-insensitive pinball loss function to handle the unbalanced problem by weighting different sparseness parameters \(\varepsilon \) for each class.
Data availability
Datasets are publically available at the U.C.I. repository of Machine Learning Datasets [24].
References
Abe S. Support vector machines for pattern classification. Berlin: Springer-Verlag; 2005.
Balasundaram S, Gupta D, Prasad SC. A new approach for training lagrangian twin support vector machine via unconstrained convex minimization. Appl Intell. 2017;46:124–34.
Balasundaram S, Tanveer M. On proximal bilateral-weighted fuzzy support vector machine classifiers. IJAIP. 2013;4:199–210.
Bi J, Zhang T. Support vector classification with input data uncertainty. Adv Neural Inf Process Syst. 2005;17:161–8.
Cortes C, Vapnik V. Support vector networks. Mach Learn. 1995;20(3):273–97.
Cristianini N, Shawe-Taylor J. An introduction to support vector machines and other kernel-based learning method. Cambridge: Cambridge University Press; 2000.
Demsar J. Statistical comparisons of classifiers over multiple data sets. J Mach Learn Res. 2006;7:1–30.
Fung G, Mangasarian OL. Finite newton method for lagrangian support vector machine. Neurocomputing. 2003;55:39–55.
Gestel TV, Suykens JAK, Lanckriet G, Lambrechts A, Moor BDe and Vanderwalle J. Bayesian framework for least squares support vector machine classifiers, gaussian processes and kernel fisher discriminant analysis. Neural Comput. 2002;15(5):1115–48.
Gupta U, Gupta D. An improved regularization based lagrangian asymmetric ν-twin support vector regression using pinball loss function. Appl Intell. 2019;49(10):3606–27.
Gupta D, Gupta U. On robust asymmetric lagrangian ν-twin support vector regression using pinball loss function. Appl Soft Comput. 2021;102: 107099.
Guyon I, Weston J, Barnhill S, Vapnik V. Gene selection for cancer classification using support vector machine. Mach Learn. 2002;46:389–422.
Hiriart-Urruty J-B, Strodiot JJ, Nguyen VH. Generalized hessian matrix and second-order optimality conditions for problems with CL1 data. Appl Math Optim. 1984;11:43–56.
Huang X, Shi L, Suykens JAK. Support vector machine classifier with pinball loss. IEEE Trans Pattern Anal Mach Intell. 2014;5:984–97.
Jiang X, Yi Z, Lv JC. Fuzzy SVM with a new fuzzy membership function. Neural Comput Appl. 2006;15(3–4):268–76.
Kim SK, Park YJ, Toh KA, Lee S. SVM-based feature extraction for face recognition. Pattern Recogn. 2010;43(8):2871–81.
Lee YJ, Mangasarian OL. SSVM: a smooth support vector machine for classification. Comput Optim Appl. 2001;20(1):5–22.
Lin CF, Wang SD. Fuzzy support vector machines. IEEE Trans Neural Networks. 2002;13(5):464–71.
Ma Y. Robust support vector machine using least median loss penalty. IFAC Proc. 2011;41(1):11208–13.
Maldonado S, López J, Vairetti C. Time-weighted fuzzy support vector machines for classification in changing environments. Inf Sci. 2021;559:97–110.
Mangasarian OL. A finite newton method for classification. Optim Methods Softw. 2002;17:913–29.
Mangasarian OL, Musicant DR. Lagrangian support vector machines. J Mach Learn Res. 2001;1:161–77.
Osuna F, Freund R, Girosi F.T raining support vector machines: an application to face detection, In: Proceed. Computer Vision and Pattern Recognition, 1997. https://doi.org/10.1109/CVPR.1997.609310
Murphy PM, Aha DW. UCI Repository of machine learning databases. Irvine: University of California; 1992.
Peng XJ, Xu D. Robust minimum class variance twin support vector machine classifier. Neural Comput Appl. 2013;22:999–10111.
Prasad SC, Balasundaram S. On lagrangian L2-norm pinball twin bounded support vector machine via unconstrained convex minimization. Inf Sci. 2021;571:279–302.
Ripley BD. Pattern recognition and neural networks. Cambridge: Cambridge University Press; 1996. p. 1996.
Shen X, Niu L, Qi Z, Tian Y. Support vector machine classifier with truncated pinball loss. Pattern Recogn. 2017;68:199–210.
Steinwart I. Sparseness of support vector machines. J Mach Learn Res. 2003;4:1071–105.
Steinwart I, Christmann A. Estimating conditional quantiles with the help of the pinball loss. Bernoulli. 2011;17:211–25.
Suykens JAK, Gestel V, De Brabanter J, De Moor B, Vandewalle J. Least squares support vector machines. Singapore: World Scientific; 2002.
Tanveer M, Tiwari A, Choudhary R, Ganaie MA. Large-scale pinball twin support vector machines. Mach Learn. 2021. https://doi.org/10.1007/s10994-021-06061-z.
Vapnik VN. The nature of statistical learning theory. 2nd ed. New York: Springer; 2000.
Xu Y, Yang Z, Pan X. A novel twin support vector machine with pinball loss. IEEE Trans Neural Netw Learn Syst. 2016;28(2):359–70.
Xu Y, Li X, Pan X, Yang Z. Asymmetric ν-twin support vector regression. Neural Comput Appl. 2018;30:3799–814.
Yang X, Song Q, Wang Y. A weighted support vector machine for data classification. Int J Pattern Recognit Artifi Intell. 2007;21(5):961–76.
Zhang X. Using class-center vectors to build support vector machines, in: Proceedings of the 1999 IEEE Signal Processing Society Workshopon Neural Networks for Signal Processing IX, IEEE, 1999, pp. 3–11
Zhang R, Liu T, Zheng M. A new fuzzy support vector machine for binary classification. Adv Mater Res. 2012;433–440:2856–61.
Zhou S, Liu H, Zhou L, Ye F. Semismooth newton support vector machine, Pattern Recogn. Lett. 2007;28:2054–62.
Acknowledgements
R.N.V. is financially supported by the University Grants Commission (U.G.C.) No.F.40-2/2019(N.E.T./Fellowship) UGC-Ref.No.210510614476, New Delhi, India. G.P.S. acknowledges the Support from the Department of Science and Technology (DST)-Science and Engineering Research Board (SERB) project (Id: File No- E.C.R./2017/003480/P.M.S.) and the Department of Biotechnology, Ministry of Science & Technology, Govt. of India (Project id BT/PR40251/BITS/137/11/2021).
Author information
Authors and Affiliations
Contributions
RNV conceptualized the work and did mathematical formulations. RNV and RD, RS conducted experiments, analyzed the results, and prepared the figures. GPS and NS supervised the work. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Verma, R.N., Deo, R., Srivastava, R. et al. A new fuzzy support vector machine with pinball loss. Discov Artif Intell 3, 14 (2023). https://doi.org/10.1007/s44163-023-00057-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44163-023-00057-5