
Abstract
Aiming at the problem that the layered water injection cannot be accurately obtained in the process of oilfield development, this paper proposes an optical fiber vibration signal recognition and classification algorithm based on XGBoost integrated learning. Firstly, the optical fiber vibration signal collected by the optical fiber vibration sensor is denoised by variational mode decomposition and reconstruction. Then generate spectrograms corresponding to different water absorption layers at different times. A dataset containing 3000 spectral images is obtained. The data sets are imported into support vector machine, random forest classifier and XGBoost integrated classifier based on decision tree for recognition and classification. The parameters of the obtained model are optimized and the model is evaluated by cross validation. Finally, the obtained models are compared and tested. The experimental results show that the XGBoost ensemble learning algorithm with decision tree as the base classifier can effectively identify different vibration signals. This method has a certain significance for the identification of layered relative water absorption of water injection profile.
Article Highlights
-
The paper presents a machine learning study using fiber-optic sensing data to evaluate the water absorption profile for oilfield water-injection purpose.
-
The correlation model of distributed optical fiber vibration signal and water absorption profile type is obtained by XGBoost algorithm training.
-
The VDM method is introduced to denoise the distributed fiber optic vibration signals to improve the classification effect of XGBoost algorithm recognition.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
After an oilfield is put into development, a reasonable allocation of water injection policy is usually formulated, which requires some understanding of the water absorption profile of the water injection formation to determine the water absorption distribution relationship between layers. Conventional methods for obtaining water absorption profiles, such as isotope water absorption profile method and hierarchical quantitative calculation, cannot be generalized due to a series of problems such as radioactive contamination, expensive testing costs, and complicated formula establishment and derivation process [1]. A lot of research work has been carried out by international scholars on the prediction model methods and applications of absorption profiles. In 2016, Junkey Li et al. [2] established a support vector machine suction profile prediction method based on the optimization of algorithms such as particle swarm and intelligent swarm. The method used particle swarm optimization support vector machine method based on historical suction profile information, and established a suction profile prediction model by fitting historical suction profile information through regression to achieve the prediction of suction profile of injection wells at the time point of no suction profile, so as to achieve the purpose of accurate splitting of water injection. In 2021, Zhao Xu [3] pre-processed the parameters by interpolation through inverse distance weighted interpolation method. Then the main factors of the suction profile prediction model were selected by DTW optimization means, substituted into RNN neural network for modeling, obtained the model and performed suction splitting for each sub-layer of the injection wells, and established an implicit nonlinear relationship between geology, development parameters and relative suction. Yaxuan Wang et al. [4] used gray correlation analysis to screen key indicators affecting relative water absorption, extracted the characteristic values of the suction profile Lorenz curve by the pinch chain code method, built a suction profile learning model using the XGBoost algorithm to predict the suction profile Lorenz curve for each injection well at the specified moment, and used curve inversion to reduce the proportion of water absorption in each layer of each injection well. However, these methods establish the correlation model between the water absorption profile and the injection-production system by studying the hidden laws and relationships in the existing water absorption profile data, and then implement the inversion and prediction of the water absorption profile, which requires the water absorption profile data, reservoir geological data, injection-production well production data, and the other data support. With the rapid development of production profile testing technology using distributed optical fiber vibration sensing system, it provides not only real-time and continuous production profile information for well logging, but also static testing, with little interference to well production, easy access to wells, and small size. At the same time, its cost is also lower than that of traditional logging methods. These provides a new idea for analyzing the downhole water absorption profile [5,6,7].
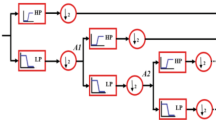
In this paper, we propose a method to identify and classify suction profiles by processing distributed fiber optic vibration signals of injection wells. Compared with previous studies, the method of identifying and classifying suction profiles by distributed fiber-optic vibration signals can reflect the dynamic changes of suction profiles with high accuracy. It is no longer dependent on a large amount of data such as suction profile information, reservoir geological information, and production information of injection and extraction wells, and is more inclined to research on injection wells with little suction profile information [2,3,4,5,6,7]. In this paper, the distributed fiber optic data are firstly preprocessed to remove noise by variational mode decomposition (VMD) method, and then the preprocessed vibration signals are transformed into spectrograms. Then convert the preprocessed vibration signal into a spectrogram. Since the flow rate of the fluid in the wellbore will affect the energy distribution of the optical fiber vibration signal, the water absorption layers with different water absorption capacities can be identified and classified according to the frequency spectrum of the optical fiber vibration signal. The correlation model between the frequency spectrum of the distributed optical fiber vibration signal and the type of water absorption profile is obtained through the training of the XGBoost algorithm. It can simply realize the identification of the relative water absorption of the water absorption profile of the water injection well. The specific workflow is shown in Fig. 1.

Distributed fiber optic vibration signal identification classification absorption profile flow chart
In the next section, the paper introduces the measurement principle of the distributed optical fiber vibration sensing system and illustrates the factors that affect the energy distribution of the optical fiber vibration signal. This explains why the fiber vibration signal can analyze the water absorption profile. Section 3 introduces the basic principles of the VMD method and the XGBoost algorithm. Section 4 shows the criteria for evaluating the applicability of classification models. Then, the fiber data analysis process and specific algorithm are described. The article compares the classification results of different classification algorithms, which shows that XGBoost has good applicability in the solution of this problem. The fifth section is the conclusion.
2 Principle of distributed optical fiber vibration sensing system
The distributed optical fiber vibration sensing system is an optical instrument that uses optical fiber as a sensor to sense vibration. The system uses a single optical fiber to simultaneously monitor vibration and transmit signals. It can continuously measure the vibration occurrence along the optical fiber, and realize the accurate demodulation of the intrusion vibration signal. The system has comprehensive advantages such as long detection distance, high positioning accuracy, wide signal response frequency band, and the ability to perform intelligent signal mode analysis. It is especially suitable for real-time measurement of vibration-related events such as long-distance, omnidirectional, and multi-point illegal intrusion, illegal destruction, and structural damage [8].
The optical fiber sensor is mainly composed of six parts: the light source, the incident fiber, the output fiber, the optical modulator, the photodetector and the demodulator. Optical fiber is a medium-type optical waveguide, mainly composed of two parts: core and cladding. The distributed optical fiber vibration monitoring system is based on optical time domain reflectometry (OTDR) [9]. The principle of the distributed optical fiber vibration monitoring system is shown in Fig. 2. The narrow linewidth pulse light is injected from one end of the fiber, and the disturbance is judged by detecting the interference result of backscattered Rayleigh light within the pulse width range, and then the position of the disturbance point is judged by measuring the time delay between the input pulse and the received signal. When there is external interference on the optical fiber line, the refractive index of the optical fiber at the corresponding position will change, which will lead to the change of the optical phase at that position. The change in the optical phase will in turn cause the interference of back Rayleigh scattering. Therefore, the final interference result will directly reflect the location of the disturbance, so that the specific location of the external disturbance can be determined.

Schematic diagram of distributed optical fiber vibration signal monitoring technology
Under a certain pressure gradient, a vibration signal is generated when the liquid/gas moves through the medium. Turbulent vibration signals are generated when fluid flows in a narrow channel, such as the sound of water flowing in a water pipe. This vibrational signal comes from the vibrations of the fluid itself and surrounding elements as the fluid flows. Distributed fiber optic sensors can capture the sound produced by the flow of gas or liquid downhole, and actually record the amplitude and frequency of the sound wave, and study the frequency characteristics and amplitude characteristics of the vibration signal [10, 11].
The frequency and amplitude of the vibration signal can determine the flow position, flow rate and type of the fluid outside the pipe [12]. The strength of the vibration signal generated by turbulent flow is proportional to the kinetic energy loss of the fluid, that is, proportional to the flow rate and the pressure difference at the position where the fluid passes, so the magnitude of the vibration signal amplitude can be used to qualitatively determine the flow rate. The type of fluid flow can be determined from the frequency of the vibration signal [13]. Linear low frequency vibration signal is the result of fluid flow along the tubing and casing. When the fluid flows through the blasthole of the perforation section, the damaged part of the casing and the fracture channel in the cementing cement, there will generally be a medium frequency vibration signal. The frequency of vibration signal of reservoir flow belongs to high frequency band.
3 Methods and principles
3.1 Variational mode decomposition (VMD)
The VMD method is to introduce the decomposition of the signal into the variational model, find the constrained variational model by the process of optimal solution, and iteratively update the center frequency and bandwidth of each modal component by continuously alternating with each other, and finally decompose the frequency band of the signal adaptively to obtain the modal components of K narrow bands at a given scale. The constrained variational problem of estimating the modal bandwidth in the VMD method can be expressed as the following [14]:
In the above formula, \(u_{k}\) is the K modal components obtained by decomposition. \(\omega_{k}\) is the central frequency of each modal component. \(f(t)\) is the original signal. \(\xi (t)\) is the pulse unit function. The constrained optimization problem of the objective function can be converted to an unconstrained optimization problem by means of the quadratic penalty factor α and the Lagrange multiplier λ(t), where the quadratic penalty factor α is an important parameter to ensure the reconstruction accuracy of the signal in the presence of Gaussian noise [14, 15]. The complete VMD decomposition flow is shown in Fig. 3.

VMD flow chart
3.2 Objective function of XGBoost
Boosting is an ensemble learning algorithm. Its main idea is to gather many weak classifiers together to form a powerful combined classifier to improve the classification accuracy. The main algorithms include adaptive boosting (Adaboost) and gradient boosting tree (gradient boosting decision tree, GBDT). XGBoost is an optimization algorithm of GBDT, which combines many CART (Classification and Regression Trees, CART) regression tree models together to form a strong classifier [16]. The final objective function of XGBoost is
The working steps are shown in the Fig. 4 below:

XGBoost workflow
4 Optical fiber vibration signal data processing and interpretation
4.1 Evaluation criteria for machine learning algorithms
To address the shortcomings of classification accuracy metrics, this paper uses the metrics that most scholars usually use when studying data classification problems: Precision, Recall, \(F_{\beta }\) Value. Precision refers to the percentage of the predicted less class samples that are actually less class samples, also called the accuracy rate of less class samples. Recall refers to the proportion of correct predictions in the true is less class sample, also called the accuracy of the less class sample [17]. Define the minority class sample as the positive class, denoted by P. Multi-class samples are negative classes, denoted by N. The classification prediction results are shown in Table 1.
It can be obtained from Table 1:
-
1.
Recall rate (accuracy rate of positive samples): \({\text{Recall}}\;{\text{(Sensitivity)}} = \frac{{{\text{TP}}}}{{{\text{TP}} + {\text{FN}}}}\quad (3)\)
-
2.
Precision (precision of positive samples): \({\text{Specificity}} = \frac{{{\text{TP}}}}{{ {\text{TP}} + {\text{FP}}}}\quad (4)\)
-
3.
\(F_{\beta }\) Value: \(F_{\beta } = \frac{{\left( {1 + \beta^{2} } \right)*{\text{Recall}}*{\text{Precision}}}}{{\beta^{2} *{\text{Precision}} + {\text{ReCaLl}}}}\quad (5)\)
Since in practical applications, the positive class (minor class) is the class we pay more attention to, the classification effect of positive class samples is more important. Therefore, the value \(F_{\beta }\) is usually used to measure the classification effect of positive samples. This indicator comprehensively considers Precision and Recall. The higher the two, the larger the \(F_{\beta }\) value, and the better the prediction performance. When β > 1 recall is more important than precision; when β = 1, both are equally important; when β < 1, precision is more important than recall. Therefore, in practical applications, adjust the value of β as needed.
4.2 Data preprocessing
In this experiment, the distributed optical fiber vibration signal data of the water injection well A, which is extracted by the optical fiber sensor, is selected for processing. The measurement interval of Well A is 0–2932.61 m. The measurement time is selected from 21:23:15 on October 10, 2021 to 20:51:55 on October 11, 2021. In the later process of data conversion into spectrograms, the distributed fiber optic vibration signal data will be converted into instantaneous spectrograms according to the splitting time duration. Due to the inefficiency of storing massive data, the fiber optic vibration signal acquisition time should not be too long, which determines that this experiment can only constitute a small sample data set. Traditional machine learning has good solution effect on small sample data set. Therefore, in this paper, support vector machine (SVM), random forest classifier (RF) and XGBoost integrated classifier with decision tree as the base classifier are considered to identify the classification. The water absorption profile is divided into three layers. The water absorption profiles are shown in Table 2.
Since the optical fiber signal is a nonlinear and non-stationary signal, and the sensitivity of the optical fiber signal makes it easy to react to external vibration, the vibration signal is often complex and contains interference of various similar information components. Preprocessing cannot simply denoise directly [10, 11]. In this paper, the model of VMD (Variational Mode Decomposition, VMD) decomposition + reconstruction is used instead of direct denoising. The VMD method is to perform Wiener filter iterations on K IMF (Intrinsic Mode Function, IMF) components at the same time to find the optimal solution. In this paper, the method of permutation entropy is used to determine the number of VMD decomposition modes.
The specific denoising steps are as follows:
-
1.
Input a noisy signal, K takes the initial value of 1.
-
2.
Calculate the permutation entropy value of IMF1 after VMD decomposition under the current K value, and compare it with the permutation entropy threshold. If it is greater than the permutation entropy threshold, then K = K − 1, at this time K is the number of VMD decomposition modes. If it is less than the permutation entropy threshold, then K = K + 1, and continue to perform this step.
-
3.
Determine the K value through step (2), execute the VMD program, and obtain the IMFs of useful signals and add them to achieve signal denoising.
The denoised signal can be obtained by reconstructing the IMF component, as shown in Fig. 5, the IMF component decomposed by VMD accurately restores the useful signal without the occurrence of spurious components and modal aliasing.

VMD decomposition reconstruction denoising
4.3 Data conversion
The measured distributed fiber optic vibration signals were converted into instantaneous spectrograms according to the random splitting time duration. The horizontal axis of the spectrogram indicates the frequency, the vertical axis indicates the depth, and the different color scale indicates the different amplitude of the vibration signal. For each of the three different absorption levels, 1000 spectral maps were generated according to different time series, as shown in Fig. 6. It can be seen from the figure that the first line is the spectrogram before denoising of No. I, II and III water absorption horizons at a certain instant, and the second line is the denoising spectrum obtained after VMD decomposition and reconstruction of different water absorption horizons at the corresponding moment. As can be seen from Fig. 6, the energy of the spectrum diagram of the absorbing layer of I, II and III is distributed in the low frequency region. If the low frequency region (0–2300 HZ) is divided into three parts of 0–500 HZ, 500–1350 HZ and 1350–2300 HZ according to the frequency, it is obvious that the energy of the absorbing layer of I is concentrated in the frequency band of 0–500 HZ, and the energy is evenly distributed in the depth. The energy of No. II absorption level is distributed at 0–2300 HZ, and the energy is weaker at 0–500 HZ. The energy distribution in the 500–1350 HZ part of the spectrum is roughly divided into four layers in the depth, showing a low–high–low–high trend from top to bottom in turn. The energy distribution at 1350–2300 HZ is mainly concentrated in the lower part, and the energy of vibration signal in the lower layer is obviously larger than that in the upper layer. The energy of absorption layer III is also concentrated in the 0–500 HZ band, and the energy is mainly distributed in the middle at the depth, and the energy distribution is weaker at 500–2300 HZ.

Spectrogram of different water absorption layers
Only the low frequency region of the spectrogram is focused on, as shown in Fig. 7. The color features and texture features of the spectrograms of different absorption layers are significantly different. After the VMD decomposition and reconstruction process, the spectrogram has no change in shape and texture compared with the original spectrogram, while the color is brighter at the high amplitude, highlighting the features at the higher energy of the vibration signal. To a certain extent, it plays the role of image enhancement.

Spectrum of low frequency region of different absorbent layers
4.4 Model building
From the analysis of Fig. 3, it can be seen that the color features and texture features of the spectrogram can be used to distinguish the water absorption layers with different water absorption capacity. So this paper extracts the image color features and texture features to train the classification model [18, 19]. All the spectrograms were randomly divided into training set, validation set and test set in the ratio of 8:1:1, and the final spectrogram data set was produced (Table 3).
XGBoost mainly uses a decision tree as the base classifier. Although it is a tandem algorithm, it uses a parallel structure in finding the optimal split nodes of the tree, traversing features, and it performs a second-order Taylor expansion of the loss function, which substantially improves the solution efficiency [16]. Therefore, from the practical production focusing on cost and efficiency, this paper uses the XGBoost model for classification. The XGBoost model needs to set three types of hyperparameters when working. They are general parameters, Booster parameters, and learning target parameters, respectively. Common parameters include basic model settings and multi-thread control; The Booster parameter is the parameter for setting the basic model, taking the tree structure as an example, including the learning rate, the maximum depth of the tree, the maximum number of leaves, etc.; Learning the objective parameters includes defining the objective loss function, the complexity of the tree, and the seed of the random number. In this study, the basic model selected a tree structure, the target loss function was a negative log-likelihood function (Mlogloss), and the adjustment of the Booster parameters was determined by the training set validation. In order to compare the model performance, the XGBoost algorithm was compared with Random Forest (RF) and Support Vector Machine (SVM) algorithms. RF mainly uses the bagging algorithm in ensemble learning, which integrates multiple trees to classify together. The relationship between trees is parallel and does not affect each other [20]. As a supervised classification method of machine learning, SVM is based on the VC dimension theory of statistical learning theory and the principle of structural risk minimization. It seeks the best balance between the complexity of the model and the learning ability according to limited sample information. It shows many advantages in solving small sample, nonlinear and high-dimensional pattern recognition [21]. The modeling process of these comparison algorithms has the same parts as XGBoost in form. The difference is that there are four kernel functions in SVM, and the number of features in this experiment is much smaller than the number of samples. Therefore, the radial basis kernel function (RBF kernel) is selected; The performance function of RF to measure the splitting quality is selected as entropy, which is the entropy of information gain; Other parameters In this paper, in order to compare the fairness of the algorithm, they are uniformly set to the same parameter combination. The parameter settings of each classifier are shown in Table 4.
In the training phase of the fivefold cross-validation experimental model, the grid search method is used to search all possible parameter combinations of each algorithm. For each parameter combination, a fivefold cross-validation experiment is used to determine the optimal parameters of each algorithm according to the cross-validation results.
4.5 Experimental results
Spectrograms of different water absorption horizon sample sets are shown in Fig. 8. The vertical axis represents depth and the horizontal axis represents frequency. The larger the value of the color scale, the brighter the color indicates that the vibration signal amplitude is higher and the energy is greater. From the analysis of Fig. 6 in the previous section, it can be seen that the difference between the spectrograms of different absorption layers is mainly concentrated in the low frequency region of 0–2300 HZ. Therefore, only the color features and texture features of the sample set 0–2300 HZ region need to be concerned in this analysis. All sample spectrogram frequencies in Fig. 8 demonstrate the 0–2300 HZ region. (a1) (a2) (a3) are the samples of spectrum maps classified as absorbent layer I in the classification results. (b1) (b2) (b3) are the samples of the spectra classified as absorption layer II in the classification results. (c1) (c2) (c3) are the samples of spectrum maps classified as absorption layer III in the classification results. From the experimental classification and identification results, it can be seen that the spectrogram energy of the absorbing layers of I, II and III have large differences in color and texture characteristics in the region of 0–2300 HZ, however, the biggest difference is at 0–500 HZ. This is in accordance with the principle that the frequency of the fiber optic vibration signal is related to the type of fluid flow. It is therefore inferred that the vibration signal in the 0–500 HZ interval is the result of fluid flow along the oil pipe and casing. At the same time, the spectrogram of the I absorption level has the brightest color in the 0–500 HZ interval, and the area of the brightly colored area is the largest. The spectrogram of absorbing layer II is the darkest in the 0–500 HZ region compared with the spectrogram of other layers, and the area of the brightly colored region is the smallest. The brightly colored area in the 0–500 HZ interval of the spectrum diagram of the III absorption layer is mainly concentrated in the middle part, and the bright area is smaller than that of the I absorption layer but larger than that of the II absorption layer, and the brightness of the color in the place of high energy is not higher than that of the I absorption layer. In the actual water absorption profile data, we can know that the strongest water absorption capacity of the I water absorption layer, the relative water absorption can reach 62.96%; the second strongest water absorption capacity of the III water absorption layer, the relative water absorption reaches 26.11%; the weakest water absorption capacity of the II water absorption layer, the relative water absorption is only 10.93%. This verifies, on the one hand, that the vibration signal in the 0–500 HZ interval of the spectrogram can indeed reflect the water absorption capacity of different water absorption layers. On the other hand, since the brightness of the color in the spectrogram is related to the amplitude magnitude, this further verifies that the magnitude of the vibration signal amplitude is proportional to the fluid flow. In addition, the area of the brightly colored region in the spectrogram, i.e., the size of the region with high values of amplitude, also reflects the water absorption capacity of the absorbing layer.

Comparison of the identification results of different water absorption layer spectrograms
The precision, recall, and \(F_{\beta }\) value indicators of the test results of the three network models are shown in Table 5. By analyzing the performance evaluation indicators of different models, it is found that the performance indicators of all models are above 75%. This indicates that the classification model used in this experiment has good performance, and this paper is feasible to identify the relative water absorption of the water absorption profile of the water injection well.
As can be seen from Table 5, the test recall rate and \(F_{\beta }\) score of the three classification algorithms including XGBoost are over 0.75. The lowest \(F_{\beta }\) score is 0.759 and the highest is 0.859; The lowest recall score is 0.873 and the highest is 0.926. The \(F_{\beta }\) score obtained by the SVM classification algorithm is lower than 0.80, indicating that this algorithm has poor ability to solve this classification problem; The \(F_{\beta }\) scores of both RF and XGBoost are over 0.80, and the performance is better. Compared with RF, XGBoost obtained the highest \(F_{\beta }\) score of 0.859, while the recall rate was 0.926, and the precision rate was also the highest at 0.802.
In order to better compare the performance of the three classification algorithms, this paper draws the ROC curves of the three classification algorithms in the testing process and combines them. A picture is reached, as shown in Fig. 9. The different colors represent the ROC curves of different classification algorithms, the blue line is XGBoost, the red line is RFs, and the yellow line is SVM. It can be seen from the figure that the ROC curve of XGBoost is closer to the (0,1) point, and the classification effect is the best, while the ROC curve of SVM is farthest from the (0,1) point, and the classification effect is the worst. Therefore, based on the above indicators, it can be concluded that XGBoost is the best model for identifying the relative water absorption of the water absorption profile of the classification water injection well.

ROC curves of three classification algorithms
4.6 Discussion
This paper investigates a method to identify and classify suction profiles by processing and analyzing distributed fiber optic vibration signals from injection wells. Firstly, the optical fiber vibration signal collected by the optical fiber vibration sensor is denoised by VMD decomposition. Then, the spectrograms corresponding to different water absorption layers are generated at different times, and a data set containing 2997 spectral images is obtained. Import the dataset into support vector machine (SVM), random forest classifier (RF) and XGBoost ensemble classifier based on decision tree to identify and classify. And use various model indicators such as precision rate and recall rate to evaluate the classifier reasonably. Finally, use the remaining 20% as the test set to test the three models. The experimental results show that, compared with RF and SVM, XGBoost can realize the effective identification of water absorption profiles of water injection wells, with a recall rate of 92.6% and a precision rate of 80.2%. This verifies the feasibility of the proposed XGBoost algorithm to identify and classify the absorption profiles of fiber optic vibration signals. Compared with the previous work of Dapeng Gao et al. [22] based on the Lorenz curve model to evaluate the effect of fine layered water injection, this paper can reflect the dynamic changes of the suction profile and identify and classify the suction profile with higher accuracy through the distributed fiber optic vibration signal identification classification method. Compared with Zhao Xu [3], who modeled the implicit nonlinear relationship between geology, development parameters and relative water absorption through RNN neural networks, this paper no longer relies on a large amount of data such as absorption profile information, reservoir geological information, and production information of injection and extraction wells. Compared with Yaxuan Wang et al. [4], who used XGBoost algorithm to build a suction profile to learn to predict the suction profile Lorenz curve, this paper greatly reduces the workload and improves the efficiency by introducing the processing of distributed fiber optic vibration signals.
5 Conclusion
The main contributions of this work are as follows:
-
1.
In production logging, it is a mature technology to judge downhole fluid type and flow characteristics by measuring the frequency and amplitude of sound produced by downhole fluid flow. Therefore, it is entirely scientific to identify and classify different types of water absorption horizons through the spectrogram generated by the optical fiber vibration signal. The classification is based precisely because in production logging the amplitude of the fiber optic vibration signal depends on the differential pressure, flow rate and fluid type. Frequency depends on channel aperture. Small aperture channels will generate medium and high frequency vibration signals, while large aperture channels will generate low frequency vibration signals. This paper explores the relationship between distributed fiber-optic vibration signals and injection well water absorption capacity. In this paper, the relationship between the optical fiber vibration signal and the water absorption capacity of the water injection well is established through the spectrogram.
-
2.
For the first time, Variational Mode Decomposition (VMD) denoising is combined with XGBoost algorithm to process distributed fiber optic vibration signals with good recognition and classification results. VMD is a new adaptive signal processing method with obvious advantages for nonlinear and non-stationary signal processing. Denoising by VMD can effectively filter the noise in the distributed fiber optic vibration signal to ensure the integrity of the signal, and the combination with XGBoost algorithm improves the recognition and classification accuracy.
-
3.
The instantaneous frequency spectrum of the optical fiber vibration signal is generated according to the method of randomly dividing the three types of water-absorbing layers. Each water-absorbing layer segment is divided into 1000 instantaneous units, with time as the label. For different water absorption layers, the depth is used as the label. Through experiments to compare support vector machine (SVM), random forest classifier (RF) and XGBoost ensemble classifier to identify the classification effect. The experimental results show that the XGBoost algorithm achieves a better recognition and classification effect on the spectrogram.
The main research work in this paper focuses on the qualitative identification and classification of water absorption layers with different water absorption capacities from the spectrogram of the optical fiber vibration signal. It realizes the identification of the relative water absorption of the water absorption profile of the water injection well by only relying on the current distributed optical fiber vibration signal output profile data, and provides a new idea for analyzing the water absorption profile of the well. However, this study also has certain limitations. One of the limitations is that we can currently only achieve qualitative classification and identification of water absorption horizons through classification algorithms. More theoretical research is needed for the quantitative interpretation of the water absorption horizon, and we will try to expand it in the follow-up experimental research.
References
Yiyong S, Zhi** L, Jiqiang W, Yinzhu Y, Yanlai L (2010) Prediction of water absorption profile of water injection well with implicit nonlinear method. J China Univ Pet (Nat Sci Ed) 06:95–98
Junjian L et al (2016) Prediction of water absorption profile of water injection well based on particle swarm optimization support vector machine. China Offshore Oil Gas 05:66–70
Zhao X (2021) DTW-RNN neural network water absorption profile prediction model based on inverse distance weighting method. J Jianghan Pet Univ 03:16–18
W Yaxuan, G Jianwei, W Zhiyong, L Hongbo (2021) Research on water absorption profile prediction method based on XGBoost algorithm. In: Proceedings of the 2021 IPPTC international petroleum and petrochemical technology conference, pp 682–693
Titov A, Fan Y, ** G et al (2020) Experimental investigation of distributed acoustic fiber-optic sensing in production logging: thermal slug tracking and multiphase flow characterization. SPE Annu Tech Conf Exhib. https://doi.org/10.2118/201534-MS
Hveding F, Guraini W, Mahue V et al (2020) Production flow comparison between distributed fiber-optic sensing and conventional PLT in a cased hole horizontal wellbore with ICD. Abu Dhabi Int Pet Exhib Conf. https://doi.org/10.2118/203267-MS
Chen D, Huang K, Meng X et al (2021) Real-time down-hole monitoring of gas injection profile using fibre-optic distribute temperature and acoustic sensing in tarim. Int Pet Technol Conf. https://doi.org/10.2523/IPTC-21177-MS
Spirin VV et al (2020) Using a semiconductor laser with frequency capture as an operating optical generator of a coherent reflectometer for distributed vibration frequency measurements. Instrum Exp Tech 63(4):476–480. https://doi.org/10.1134/S002044122005005X
Yuying S et al (2019) Distributed vibration sensor with laser phase-noise immunity by phase-extraction φ-OTDR. Photonic Sens 9(003):223–229. https://doi.org/10.1007/s13320-019-0540-2
Mullens S, Lees G, Duvivier G (2010) Fiber-optic distributed vibration sensing provides technique for detecting sand production. https://doi.org/10.4043/20429-MS
Ellmauthaler A et al (2019) Vertical seismic profiling via coiled tubing-conveyed distributed acoustic sensing. SPE/ICoTA Well Interv Conf Exhib. https://doi.org/10.2118/194244-MS
Yanni T, Jiacai D, Meng C et al (2020) Spectral noise logging technology and application. Pet Pipes Instrum 02:64–68
Yonggui Ma (2020) Application of noise spectrum logging technology in production wells. Logging Technol 03:229–232
Abufana SA et al (2020) Variational mode decomposition-based threat classification for fiber optic distributed acoustic sensing. IEEE Access, p 99
Miao Y, Yaolu Z, Yutong H, Mingyang S, Qian K, Zhifeng Z (2022) Variational mode decomposition and permutation entropy method for denoising of distributed optical fiber vibration sensing system. Acta Opt Sin 42(07):62–73
Chen T, Guestrin C (2016) Xgboost: a scalable tree boosting system. ACM, pp 785–794
Davis J (2006) The relationship between precision-recall and ROC curves. In: Proceedings of the 23th international conference on machine learning
Miao Y, Yaolu Z, Yutong H (2021) Signal feature extraction method for distributed optical fiber vibration sensing system based on MEEMD-HHT. Infrared Laser Eng 07:207–218
Wang Z (2021) Research on pattern recognition of disturbance events in Φ-OTDR distributed optical fiber sensing system. Dissertation, Bei**g Jiaotong University
Biau G, Scornet E, Welbl J (2019) Neural random forests. Sankhya A 81:347–386. https://doi.org/10.1007/s13171-018-0133-y
Cortes CVV et al (1995) Support-vector networks
Dapeng G, Jigen Y, Yunpeng H et al (2015) Evaluation of fine layered water injection effect based on Lorentz curve model. Pet Explor Dev 42(6):7
Acknowledgements
This word was supported by Key Project of Science and Technology Research Program of Hubei Provincial Department of Education, Grant No. D20191302.
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Cconflict of interest
The authors declare that there are no conflicts of interest regarding the publication of this paper. The authors have no relevant financial or nonfinancial interests to disclose.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors. The submitted work is original. We confirm that neither the manuscript nor any parts of its content are currently under consideration or published in another journal.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wang, Y., Li, M., Li, X. et al. Identification and classification of water absorption profile of distributed optical fiber vibration signal based on XGBoost algorithm. SN Appl. Sci. 4, 289 (2022). https://doi.org/10.1007/s42452-022-05172-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42452-022-05172-z