
Abstract
Background and Objective
In context of the End TB goal of zero tuberculosis (TB)-affected households encountering catastrophic costs due to TB by 2020, the estimation of national prevalence of catastrophic costs due to TB is a priority to inform programme design. We explore approaches to estimate the national prevalence of catastrophic costs due to TB from existing datasets as an alternative to nationally representative surveys.
Methods
We obtained, standardized and merged three patient-level datasets from existing studies on patient-incurred costs due to TB in South Africa. A deterministic cohort model was developed with the aim of estimating the national prevalence of catastrophic costs, using national data on the prevalence of TB and likelihood of loss to follow-up by income quintile and HIV status. Two approaches were tested to parameterize the model with existing cost data. First, a meta-analysis summarized study-level data by HIV status and income quintile. Second, a regression analysis of patient-level data also included employment status, education level and urbanicity. We summarized findings by type of cost and examined uncertainty around resulting estimates.
Results
Overall, the median prevalence of catastrophic costs for the meta-analysis and regression approaches were 11% (interquartile range [IQR] 9–13%) and 6% (IQR 5–8%), respectively. Both approaches indicated that the main burden of catastrophic costs falls on the poorest households. An individual-level regression analysis produced lower uncertainty around estimates than a study-level meta-analysis.
Conclusions
This paper presents a novel application of existing data to estimate the national prevalence of catastrophic costs due to TB. This type of model could be useful for researchers and policy makers looking to inform certain policy decisions; however, some uncertainties remain due to limitations in data availability. There is an urgent need for standardized reporting of cost data and improved guidance on methods to collect income data to improve these estimates going forward.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
The presented cohort model approach to estimate the national prevalence of catastrophic costs due to tuberculosis (TB), adjusting for variability across studies to reflect national demographics and loss to follow-up along the patient pathway of care, allows for the costs of those in care to be captured more accurately. |
This approach facilitates estimation of the prevalence of catastrophic costs due to TB and the uncertainty of these estimates, and can identify the comparative impact of TB-related costs on different sections of the population. |
Depending on the policy application, this approach could serve as a feasible alternative to country-wide national surveys to estimate catastrophic costs due to TB, where there are sufficient existing data available. |
1 Introduction
Tuberculosis (TB) remains the leading cause of death from a single infectious agent worldwide, with 10 million people falling ill and 1.2 million people dying from TB in 2018 [1]. Often those who are most affected by TB are the most vulnerable in society, and affected households can face substantial costs associated with the disease [2]. Globally, costs associated with TB represent an average of 58% and 39% of individual and household income, respectively [3].
In recognition of the impact of the costs of illness on households, the World Health Organization (WHO) has highlighted reduction of catastrophic costs due to TB as one of three priority targets for 2020 [1]. Costs due to TB are defined as ‘catastrophic’ by the WHO Global TB Programme where they exceed 20% of a household’s annual pre-TB income [4]. The focus of this metric is on economic hardship associated with seeking TB care, including direct out-of-pocket medical costs (such as money paid for medicines, diagnostics, consultation fees or informal payments made to health workers), direct non-medical costs (transport and accommodation costs, costs of any special food or supplements taken because of illness) as well as indirect (opportunity) costs of time spent seeking care by people with TB and guardians or household members accompanying them [5,6,7,8].
To help track country progress against this goal and inform programme planning, the Global TB Programme has developed guidelines for the conduct of nationally representative cross-sectional surveys to estimate the prevalence of catastrophic costs [4]. However, these surveys require ample resources and time to complete and will not be feasible for all 130 WHO member states to carry out repeatedly, leaving countries searching for another source of estimates.
In many settings, data on patient costs of TB have been collected as part of trials or other smaller-scale projects; however, recent systematic reviews of patient-incurred costs due to TB observed large heterogeneity in the quality of reporting as well as the methods used to collect cost data and measure income loss [3, 10, 11]. Given this variation, it is currently unclear to what extent this existing data can be used to inform national estimates of catastrophic costs due to TB. We hypothesize that with the use of a cohort model these data could still be a useful resource for countries looking for decision-making support, in the absence of a national survey. We aim to investigate approaches to model the national prevalence of catastrophic costs due to TB using the case study of South Africa, which has one of the world’s highest TB incidence rates, with an estimated incidence of 520 per 100,000 people in 2018 [12].
2 Methods
2.1 Parameterizing the Cohort Model: Population Characteristics
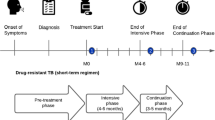
We created an individual-level deterministic cohort model that simulated progression through the TB care cascade in order to estimate the prevalence of catastrophic costs in South Africa (Fig. 1). The model contained a hypothetical cohort of 1000 South Africans with drug-susceptible (DS) TB, with population characteristics mirroring those of the national population of people with DS-TB. Individuals in the cohort were first distributed across national income quintiles 1–4 using data on the national income distribution and distribution of TB across income quintiles [13,14,15]. We then sampled employment status by income quintile, and household size reflecting national distributions of each [16]. Individual income was estimated by dividing household income by household size; individual income took a value of zero if unemployed or otherwise not income-earning. HIV sero-status was modelled for each individual in the cohort based on the national HIV prevalence among individuals with DS-TB [17]. We then estimated the likelihood of loss to follow-up before treatment start based on HIV status, following evidence from Naidoo et al. [17].

Analysis structure. DS drug-susceptible, TB tuberculosis
2.2 Parameterizing the Cohort Model: Cost Data
2.2.1 Identifying and Reconciling Primary Data
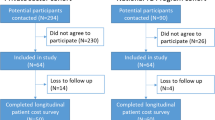
We collated all research articles reporting any estimates of patient-incurred costs due to TB in South Africa from the Unit Cost Study Repository (UCSR) of the Global Health Cost Consortium [18]. Patient-incurred costs included any costs paid out-of-pocket by TB patients and their households, and any lost income or productivity due to TB. Eleven studies presenting patient cost data in South Africa were identified [19,20,21,22,23,24,25,26,27,28,29]. Of these, four were excluded due to outdated models of care and one was excluded as a duplicate of previously published data. Corresponding authors of seven eligible studies were invited to participate, and a protocol identifying variables to be included in the pooled dataset was provided. Collaborators from three of the seven eligible studies agreed to participate in the analysis. Due to data availability, the scope of this analysis was restricted to costs whilst on treatment for DS-TB; we did not consider costs for drug-resistant (DR) TB, nor did we consider costs during the diagnostic process [10]. All datasets had obtained ethical approval for their original study. Ethical approval for the pooled analysis was granted by the London School of Hygiene and Tropical Medicine (reference 14486).
We reconciled timeframes for cost data by identifying the treatment start date, interview date and recall period for each participant. Direct out-of-pocket costs incurred in each treatment phase (intensive and continuation phase) were categorized as direct medical costs (consultation fees, medicines, diagnostics), direct non-medical costs (transportation, accommodation) and food costs (food supplements, special foods). Cost estimates were distinguished by treatment phase (intensive and continuation phase) and by type of healthcare provider, including public healthcare (PHC) facility (study site), another PHC facility (non-study site), private general practitioner, pharmacy, hospital inpatient service, hospital outpatient service, and traditional healer.
All data in different studies were collected using adaptations of the Tool to Estimate Patient Costs [30], and thus definitions for out-of-pocket cost variables were homogeneous; however, the Researching Equity in ACcess to Healthcare (REACH) dataset did not contain information on direct non-medical costs or time spent accessing providers other than the main study clinic. As this was omitted entirely from data collection, we assumed these values to be missing at random and used imputation to complete these costs (imputation methods described in Sect. 2.2.2). In contrast, methods for collecting data on income and estimating indirect costs varied widely across datasets and were not reconcilable. To complete the datasets, we took a statistical approach to predict income quintile for households in the dataset. Assuming income distribution to be the same as the national distribution of income amongst people with TB, we used regression coefficients from an analysis run on the most recent (2015) South African National Income Dynamics Survey (NIDS) for variables including asset holdings, housing quality indicators and basic demographics to predict income. Full methods to predict household income quintiles are described in Electronic Supplementary Material (ESM) Appendix 2.
All costs are reported in 2017 US dollars. Data collected before 2017 were inflated using the US consumer price index [31]. Prior to generating model parameters using the standardized data, we conducted a descriptive analysis of sociodemographic and cost variables within and across datasets. Variables were summarized using the mean and standard deviation for each individual dataset and across the pooled dataset. We tested for significant differences in categorical variables using a chi-squared test, and tested for significant differences in continuous variables using a one-way analysis of variance (ANOVA) within and between studies.
2.2.2 Generating Model Parameters
We tested two approaches to estimate mean and standard error values for direct costs and hours lost due to treatment by household income quintile, HIV status and treatment phase: (1) meta-analysis of summary statistics from the standardized datasets; and (2) regression analysis of the pooled standardized dataset.
Our first approach was meta-analysis to calculate pooled estimates of available (study-level) mean values for the above-described cost categories for each treatment phase, by HIV status and household income quintile [32]. Given that patient demographics varied significantly across datasets, and assuming that patient costs vary according to demographics, we used a random effects meta-analysis approach, which does not assume that all studies investigate the same population [32]. Data on direct costs, travel time and consultation time were log-transformed for the meta-analysis as they were highly skewed, and results were exponentiated following meta-analysis.
Our second approach was to identify a regression model to predict the above-described cost categories for each treatment phase, by HIV status and household income quintile. Firstly, we imputed missing values in the pooled dataset. Where total consultation hours were missing, we used multivariate imputation with chained equations (MICE) to impute these values based on the number of visits by phase and provider type. Total travel hours and total direct non-medical costs were imputed based on number of visits and transport method, as well as demographic variables included in the regression analysis. All imputations used predictive mean matching (PMM), as a non-parametric alternative for imputing skewed data. Imputations generated 20 plausible datasets, which were then used for analysis. The number of missing observations by dataset are listed in ESM Table 3 [33].
Following imputation, we conducted a series of regression analyses to predict the cost of each cost category for each treatment phase. The regression analyses used a generalized linear model (GLM) approach assuming a gamma distribution and a log link to accommodate skewed data [34]. The specification of each regression was held constant across analyses and included independent variables identified following theory, as well as previous published evidence [35,36,37,18], the wide variance in methods used to collect cost data remains a persistent limitation in the feasibility of pooling data. There are several areas where further data collection or better guidance on data collection methods would improve these estimates substantially. Firstly, methods for estimation and reporting of income data in patient-incurred cost surveys are currently inconsistent, with limited guidance on methods [41]. Going forward, better guidance on methods to estimate household and individual income is critical for any future attempts to pool data for drawing national estimates as well as more generally informing policy. Guidance on the appropriate measures of indirect costs in the numerator, and ability to pay in the denominator (e.g. household income vs. household expenditures), would also improve the theoretical validity of the metric [41].
Despite the above-discussed uncertainties, this type of model could be useful for researchers and policy makers. A cohort model such as the one presented in this paper can estimate the national prevalence of catastrophic costs due to TB and the uncertainty around these estimates, and can identify the comparative impact of TB-related costs on different sections of the population. It also has potential to inform certain policy decisions; for example, Verguet et al. [40] use a similar approach to illustrate the potential number of catastrophic costs averted from a range of TB interventions. The approach presented in this paper improves estimates by using a systematic approach to pool data from multiple studies, and allowing for adjustment of demographics and by treatment phase.
The usefulness of the type of analysis presented in this paper depends on the objectives of the analysis. This analysis may be sensitive enough to capture major movement towards the End TB goal of zero catastrophic costs due to TB; however, it is likely not sensitive enough to capture small changes from year to year—especially in settings where the cost function is still unknown or differs substantially in different settings. Ongoing primary data collection through national surveys is likely still necessary to facilitate annual reporting and programme management until the availability of cost and epidemiological data improves, and the cost function is better identified. However, while probably not providing quite as robust an estimate of catastrophic costs as a national survey, this type of analysis can complement, enrich and add depth to findings from the national surveys, especially for certain groups.
5 Conclusions
This paper presents a novel use of existing data to estimate the prevalence of catastrophic costs due to TB [4]. We find that in the absence of nationally representative surveys, a deterministic model can provide an alternative for estimating catastrophic cost prevalence and the uncertainty around those estimates, with uncertainty slightly reduced using a regression approach as compared with a meta-analysis approach. A repeat of this analysis with additional primary data from South Africa added would test the validity of the main finding. Analyses testing the results of a cohort model against national estimates of catastrophic costs of other conditions would also help researchers to understand the validity of these models and the value of information added as compared with primary data collection through national surveys. Ultimately, to improve estimates from such cost-saving approaches, there is an urgent need for standardized methods to collect income data and standardized reporting of cost estimates.
Data availability statement
The dataset generated during the MERGE study is available in the LSHTM Data Compass repository at https://doi.org/10.17037/DATA.00001593. The dataset generated during the XTEND study is available in the LSHTM Data Compass repository at https://datacompass.lshtm.ac.uk/791/. The datasets generated during the REACH study are available from the corresponding author (NC) on reasonable request.
References
Global tuberculosis report 2019. Geneva: World Health Organization; 2019. https://www.who.int/tb/publications/global_report/en/. Accessed 17 Jan 2020.
Lönnroth K, Jaramillo E, Williams BG, Dye C, Raviglione M. Drivers of tuberculosis epidemics: the role of risk factors and social determinants. Soc Sci Med. 2009;68(12):2240–6.
Tanimura T, Jaramillo E, Weil D, Raviglione M, Lönnroth K. Financial burden for tuberculosis patients in low-and middle-income countries: a systematic review. Eur Respir J. 2014;43(6):1763–75.
World Health Organization. Tuberculosis patient cost surveys: a handbook. 2017. https://www.who.int/tb/publications/patient_cost_surveys/en/. Accessed 17 Jan 2020.
Cooper BS, Rice DP. The economic cost of illness revisited. Soc Secur Bull. 1976;39:21–36.
Rice DP. Estimating the cost of illness. Am J Public Health Nations Health. 1967;57(3):424–40.
McIntyre D, Thiede M, Dahlgren G, Whitehead M. What are the economic consequences for households of illness and of paying for health care in low-and middle-income country contexts? Soc Sci Med. 2006;62(4):858–65.
Posnett J, Jan S. Indirect cost in economic evaluation: the opportunity cost of unpaid inputs. Health Econ. 1996;5(1):13–23.
Sculpher M, Drummond MF. The role and estimation of productivity costs in economic evaluation. In: Sculpher MJ, Drummond M, McGuire A, editors. Economic evaluation in health care: merging theory with practice. Oxford: Oxford University Press; 2001. p. 94–112.
Laurence YV, Griffiths UK, Vassall A. Costs to health services and the patient of treating tuberculosis: a systematic literature review. Pharmacoeconomics. 2015;33(9):939–55.
de Siqueira-Filha NT, Legood R, Cavalcanti A, Santos AC. Cost of tuberculosis diagnosis and treatment in patients with HIV: a systematic literature review. Value Health. 2018;21(4):482–90.
WHO in consultation with South Africa. South Africa tuberculosis profile 2019. https://extranet.who.int/sree/Reports?op=Replet&name=/WHO_HQ_Reports/G2/PROD/EXT/TBCountryProfile&ISO2=ZA&outtype=PDF. Accessed 17 Jan 2020.
Ataguba JE, Akazili J, McIntyre D. Socioeconomic-related health inequality in South Africa: evidence from General Household Surveys. Int J Equity Health. 2011;10(1):48.
Harttgen K, Vollmer S. Inequality decomposition without income or expenditure data: using an asset index to simulate household income. UNDP; 2011. http://hdr.undp.org/en/content/inequality-decomposition-without-income-or-expenditure-data. Accessed 20 Mar 2020.
Statistics South Africa. Living conditions of households in South Africa: an analysis of household expenditure and income date using the LCS 2014/2015. Statistics South Africa; 2015. https://www.statssa.gov.za/publications/P0310/P03102014.pdf. Accessed 17 Jan 2020.
Southern Africa Labour and Development Research Unit. National Income Dynamics Study 2014–2015, Wave 4. Version 2.0.0. 2018. https://microdata.worldbank.org/index.php/catalog/2595. Accessed 17 Jan 2020.
Naidoo P, Theron G, Rangaka MX, Chihota VN, Vaughan L, Brey ZO, et al. The South African tuberculosis care cascade: estimated losses and methodological challenges. J Infect Dis. 2017;216(suppl_7):S702–13.
DeCormier PW, Bollinger LA, Alexander L, Cameron DB, Carroll LN, Cunnama L, et al. Develo** the Global Health Cost Consortium unit cost study repository for HIV and TB: methodology and lessons learned. Afr J AIDS Res. 2019;18(4):263–76.
Wilkinson D, Floyd K, Gilks CF. Costs and cost-effectiveness of alternative tuberculosis management strategies in South Africa-implications for policy. S Afr Med J. 1997;87(4):451–5.
Sinanovic E, Floyd K, Dudley L, Azevedo V, Grant R, Maher D. Cost and cost-effectiveness of community-based care for tuberculosis in Cape Town, South Africa. Int J Tuberc Lung Dis. 2003;7(9):S56–62.
Mandalakas AM, Hesseling AC, Gie RP, Schaaf HS, Marais BJ, Sinanovic E. Modelling the cost-effectiveness of strategies to prevent tuberculosis in child contacts in a high-burden setting. Thorax. 2013;68(3):247–55.
Sinanovic E, Kumaranayake L. Financing and cost-effectiveness analysis of public-private partnerships: provision of tuberculosis treatment in South Africa. Cost Eff Resour Alloc. 2006;4(1):11.
Fairall L, Bachmann MO, Zwarenstein M, Bateman ED, Niessen LW, Lombard C, et al. Cost-effectiveness of educational outreach to primary care nurses to increase tuberculosis case detection and improve respiratory care: economic evaluation alongside a randomised trial. Trop Med Int Health. 2010;15(3):277–86.
Van Rie A, Page-Shipp L, Hanrahan CF, Schnippel K, Dansey H, Bassett J, et al. Point-of-care Xpert® MTB/RIF for smear-negative tuberculosis suspects at a primary care clinic in South Africa. Int J Tuberc Lung Dis. 2013;17(3):368–72.
Du Toit E, Squire SB, Dunbar R, Machekano R, Madan J, Beyers N, et al. Comparing multidrug-resistant tuberculosis patient costs under molecular diagnostic algorithms in South Africa. Int J Tuberc Lung Dis. 2015;19(8):960–8.
Ramma L, Cox H, Wilkinson L, Foster N, Cunnama L, Vassall A, et al. Patients’ costs associated with seeking and accessing treatment for drug-resistant tuberculosis in South Africa. Int J Tuberc Lung Dis. 2015;19(12):1513–9.
Chimbindi N, Bor J, Newell ML, Tanser F, Baltusen R, Hontelez J, et al. Time and money: the true costs of health care utilization for patients receiving “free” HIV/tuberculosis care and treatment in rural KwaZulu-Natal. J Acquir Immune Defic Syndr. 2015;70(2):e52–60.
Foster N, Vassall A, Cleary S, Cunnama L, Churchyard G, Sinanovic E. The economic burden of TB diagnosis and treatment in South Africa. Soc Sci Med. 2015;1(130):42–50.
Mudzengi D, Sweeney S, Hippner P, Kufa T, Fielding K, Grant AD, et al. The patient costs of care for those with TB and HIV: a cross-sectional study from South Africa. Health Policy Plan. 2017;32(suppl_4):iv48–56.
USAID, KNCV, TBCTA. The tool to estimate patients’ costs. 2008. pp. 1–83. https://www.stoptb.org/wg/dots_expansion/tbandpoverty/assets/documents/Tool%20to%20estimate%20Patients'%20Costs.pdf. Accessed 17 Jan 2020.
US Bureau of Labor Statistics. Consumer Price Index (CPI) databases. https://www.bls.gov/cpi/data.htm. Accessed 27 Nov 2018.
Borenstein M, Hedges LV, Higgins JP, Rothstein HR. A basic introduction to fixed-effect and random-effects models for meta-analysis. Res Synth Methods. 2010;1(2):97–111.
Horton NJ, Lipsitz SR. Multiple imputation in practice: comparison of software packages for regression models with missing variables. Am Stat. 2001;55(3):244–54.
Barber J, Thompson S. Multiple regression of cost data: use of generalised linear models. J Health Serv Res Policy. 2004;9(4):197–204.
Wingfield T, Boccia D, Tovar M, Gavino A, Zevallos K, Montoya R, et al. Defining catastrophic costs and comparing their importance for adverse tuberculosis outcome with multi-drug resistance: a prospective cohort study, Peru. PLoS Med. 2014;11(7):e1001675.
Ukwaja KN, Alobu I, Abimbola S, Hopewell PC. Household catastrophic payments for tuberculosis care in Nigeria: incidence, determinants, and policy implications for universal health coverage. Infect Dis Poverty. 2013;2(1):21.
Laokri S, Dramaix-Wilmet M, Kassa F, Anagonou S, Dujardin B. Assessing the economic burden of illness for tuberculosis patients in Benin: determinants and consequences of catastrophic health expenditures and inequities. Trop Med Int Health. 2014;19(10):1249–58.
Zhou C, Long Q, Chen J, **ang L, Li Q, Tang S, et al. Factors that determine catastrophic expenditure for tuberculosis care: a patient survey in China. Infect Dis Poverty. 2016;5(1):6.
Kufa T, Fielding KL, Hippner P, Kielmann K, Vassall A, Churchyard GJ, et al. An intervention to optimise the delivery of integrated tuberculosis and HIV services at primary care clinics: results of the MERGE cluster randomised trial. Contemp Clin Trials. 2018;1(72):43–52.
Verguet S, Riumallo-Herl C, Gomez GB, Menzies NA, Houben RM, Sumner T, et al. Catastrophic costs potentially averted by tuberculosis control in India and South Africa: a modelling study. Lancet Glob Health. 2017;5(11):e1123–e1132132.
Sweeney S, Mukora R, Candfield S, Guinness L, Grant AD, Vassall A. Measuring income for catastrophic cost estimates: limitations and policy implications of current approaches. Soc Sci Med. 2018;1(215):7–15.
World Bank, Development Research Group. GINI index (World Bank estimate)—South Africa. https://data.worldbank.org/indicator/SI.POV.GINI?locations=ZA. Accessed 27 Jan 2020.
Bloom T, Ganley E, Winker M. Data access for the open access literature: PLOS's data policy. PLoS Med. 2014;11(2):e1001607.
Butler D. Gates Foundation announces open-access publishing venture. Nature. 2017;543(7647):599.
Acknowledgements
The authors are grateful to the study teams for the MERGE, XTEND and REACH studies for use of their data. The authors are also grateful to Nicola Foster (collected original data for the XTEND project), Carol Levin (provided feedback on an earlier draft) and Carlos Jesus Pineda Antunez (developed a STATA® program to facilitate data pooling, and advised on the analysis).
Author information
Authors and Affiliations
Contributions
SS designed and conducted the analysis and wrote the initial and subsequent drafts of the paper. NC and DM collected the original data used in this pooled analysis. MS and GBG constructed the original database of papers with patient cost estimates for the Global Health Cost Consortium and provided input on regression methods. LG, AV and GBG supported the design of the study and data analysis. All co-authors contributed comments and approved the final version of the paper. SS is the overall guarantor for this study.
Corresponding author
Ethics declarations
Funding
This analysis was funded by the Bill and Melinda Gates Foundation, as part of the Global Health Cost Consortium (Grant reference number: OPP1109722).
Conflict of interest
GBG is currently employed by Sanofi Pasteur as Regional Lead for vaccine epidemiology and modelling on Europe and does not work in any project related to TB. Sanofi Pasteur has not provided any funding for this work. GBG’s contribution to this work pertains to activities during LSHTM employment. SS, AV, LG, MS, NC and DM have no conflicts of interest to declare.
Ethical approval
All datasets had obtained ethical approval for their original study. Ethical approval for the pooled analysis was granted by the London School of Hygiene and Tropical Medicine (reference 14486).
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sweeney, S., Vassall, A., Guinness, L. et al. Examining Approaches to Estimate the Prevalence of Catastrophic Costs Due to Tuberculosis from Small-Scale Studies in South Africa. PharmacoEconomics 38, 619–631 (2020). https://doi.org/10.1007/s40273-020-00898-3
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40273-020-00898-3