
Abstract
Following cerebellar tumour surgery, children may suffer impairments of spontaneous language. Yet, the language processing deficits underlying these impairments are poorly understood. This study is the first to try to identify these deficits for four levels of language processing in cerebellar tumour survivors. The spontaneous language of twelve patients who underwent cerebellar tumour surgery (age range 3–24 years) was compared against his or her controls using individual case statistics. A distinction was made between patients who experienced postoperative cerebellar mutism syndrome (pCMS) and those who did not. Time since surgery ranged between 11 months and 12;3 years. In order to identify the impaired language processing levels at each processing level (i.e., lexical, semantic, phonological and/or morphosyntactic) nouns and verbs produced in the spontaneous language samples were rated for psycholinguistic variables (e.g., concreteness). Standard spontaneous language measures (e.g., type-token ratio) were calculated as well. First, inter-individual heterogeneity was observed in the spontaneous language outcomes in both groups. Nine out of twelve patients showed language processing deficits three of whom were diagnosed with pCMS. Results implied impairments across all levels of language processing. In the pCMS-group, the impairments observed were predominantly morphosyntactic and semantic, but the variability in nature of the spontaneous language impairments was larger in the non-pCMS-group. Patients treated with cerebellar tumour surgery may show long-term spontaneous language impairments irrespective of a previous pCMS diagnosis. Individualised and comprehensive postoperative language assessments seem necessary, given the inter-individual heterogeneity in the language outcomes.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Cerebellar tumours are the most common paediatric brain tumours [1, 2]. The five-year survival rate of patients treated for a cerebellar tumour steadily increases [2, 3], probably due to treatment improvements [4, 5]. This increased survival rate draws attention to the wide range of acute and long-term sequelae observed in survivors, which are partly attributable to the tumours, and partly to the necessary surgical and post-surgical treatments provided. Understanding the exact nature of possible detrimental late effects of such treatments is essential in providing long-term support for this group, including language rehabilitation [6].
Following cerebellar tumour resection, impairments have been observed across all language processing levels (i.e., semantic, lexical, phonological, morphosyntactic, pragmatic), including word-finding difficulties [7,8,9], pragmatic deficits [10] and agrammatism [8, 11, 12]. When these language impairments are preceded by mutism (i.e., a temporary absence of speech commonly accompanied by severe emotional lability and neurological deficits), this cluster of symptoms is referred to as postoperative cerebellar mutism syndrome (pCMS) [13]. This syndrome occurs in approximately 25 to 35% of children who have cerebellar tumour surgery [14, 15]. Postoperative language impairments may also occur without being preceded by pCMS and the comparison between children who did and did not suffer from pCMS has yielded inconsistent results in the patterns of impairment and their severity [7, 16, 17]. To the best of our knowledge, no study has tried to identify impairments across all language processing levels. Results of this type of assessment would help guide language rehabilitation on an individual level and could shed further light into the nature of the language impairments in children who had cerebellar tumour surgery. It should be noted, however, that this population is already burdened with many other medical/psychological assessments after neurosurgery, highlighting the need for an ecologically valid assessment that gives an overview of the performance on multiple language areas while reducing testing time. To this end, the present study evaluates language impairments using spontaneous language.
Most of the data that currently exist on postoperative language outcomes in cerebellar tumour patients come from formal tests. Yet, spontaneous language analysis has been reported to be more ecologically valid than formal tests [18]. In addition, by examining multiple levels of language processing simultaneously, spontaneous language tasks can be used as a quick assessment when the patient is too tired for a comprehensive formal assessment. The assessment of spontaneous language is considered relevant in linguistic studies to differentiate between children with a developmental language disorder and typically develo** peers [19, 20] and can classify different types of post-stroke aphasia [21, 22].
Reports on the spontaneous language outcomes in children treated with cerebellar tumour surgery are scarce, but have aided in documenting morphosyntactic (e.g., the omission of grammatical elements) [11, 12, 16], lexical-semantic (e.g., a reduced lexical diversity) [16] and/or pragmatic impairments [22]. The benefits for our understanding of language difficulties in cerebellar tumour survivors notwithstanding, studies that addressed spontaneous language generally looked at quantitative measures, such as lexical diversity (e.g., type-token ratio) which reflects vocabulary size [10, 11] and syntactic complexity [11, 16, 23]. However, these standard measures are too coarse to provide a deeper understanding of the nature of the language deficits in children after treatment for cerebellar tumours. Given that such measures have provided inconsistent results in previous research with children with cerebellar tumours [10, 11, 16], it is unclear if these standard measures alone are successful in differentiating patients with language problems from their controls. Also, none of these spontaneous language measures or previously used formal tests in this clinical population assess more than three aspects of language processing.
In this work, we introduce a novel and comprehensive approach to detect spontaneous language deficits. We conduct a detailed examination of psycholinguistic properties reflecting four linguistic levels, namely, phonological, lexical, semantic and morphosyntactic processing alongside standard spontaneous language measures (e.g., type-token ratio). We include a wide range of spontaneous language variables to determine which variables may be successful in differentiating patients from their controls. Also, we use these variables to characterise the nature of the deficits in our patient group. The rationale for adopting this method to cerebellar tumour survivors is based on previous work with similar populations.
Word Properties: a Window Into the Processing Nature of Language Impairments
According to Shallice’s (1988) critical variable approach, word properties or psycholinguistic variables (e.g., imageability, word frequency) can influence both language comprehension [24,25,26] and production [27,28,29]. Furthermore, certain word properties can influence processing at specific linguistic levels [24, 28, 30]. When adopting the critical variable approach to spontaneous language analysis, the psycholinguistic variables extracted from the produced words may unravel the nature of observed language impairments [31, 32]. In this study, nine word properties that are extensively described in adults with post-stroke aphasia [25, 28, 31, 33] and children with a developmental language disorder [32, 34, 35] were extracted from the produced nouns and verbs in spontaneous language. This approach has already been used in studies with verbal fluency, for example in adults with primary progressive aphasia [30], and post-stroke aphasia [36] and in one spontaneous language study in bilingual children with developmental language disorder [32]. In what follows, the included psycholinguistic variables are outlined per level of language processing. These were selected to rate every patient’s ability to produce spontaneous language.
Semantic Variables
We selected three variables to assess participants’ ability to produce semantic properties of spoken language: imageability, concreteness, and verb instrumentality. Imageability represents the degree to which a concept gives rise to a mental image or sensory experience [30]. For example, “cat” has a high imageability rating, while “thought” has a low imageability rating. Concreteness, on the other hand, reflects the degree to which a concept is perceptible (e.g., “car” is more concrete than “happiness”) [30]. Verb instrumentality indicates if an action requires an instrument (not a body part). For example, the verb “to cut” requires scissors for the action to be completed, while the verb “to throw” does not require a tool or instrument. Effects of these word properties may reflect impairments of semantic processing (i.e., the activation of meanings in response to concepts or ideas), for example reduced stored knowledge within semantic representations [28, 30, 31]. Words of a higher imageability or concreteness have been reported to be easier to process than words of low imageability or concreteness in both people with post-stroke aphasia [28, 31] and in some children with a developmental language disorder [37]. Verb instrumentality has been reported to have both a facilitating and inhibitory effect on verb retrieval in people with post-stroke aphasia [33, 38]. In children with a developmental language disorder, non-instrumental verbs have been shown to be easier to name than instrumental verbs [35]. In spontaneous language, individuals with a semantic processing impairment may thus produce more imageable and/or concrete and more instrumental or non-instrumental verbs compared to their controls.
Lexical Variables
Three psycholinguistic variables were selected to investigate the lexical properties of spontaneous language, more specifically word frequency, age of acquisition (AoA) and phonological neighbourhood. Word frequency is obtained by counting the number of times a word appears in a corpusFootnote 1 (e.g., “home” occurs many times in a corpus while “forklift” occurs much less) [39]. AoA is the age at which a word is learned in the written or spoken form. For example, “cookie” is learned at a young age, while “globe” is acquired later [40]. Word frequency and AoA have been reported to be negatively correlated (e.g., “to eat” has a low AoA but a high frequency). Phonological neighbourhood, finally, refers to the number of phonologically similar words created by substituting one phoneme of a target word [41]. For example, “book” has a high number of phonological neighbours (e.g., “look”, “bock”, “bush”) while “helicopter” has no phonological neighbours [42]. These three psycholinguistic variables have been consistently reported and can be indicative of deficiencies of the phonological output lexicon (i.e., the storage of spoken word forms) or lexical retrieval from the semantic system [24, 25, 28]. It has been proposed that high-frequency words with a lower AoA are easier to retrieve from the phonological lexicon and evoke fewer errors [27, 28]. However, AoA has also been argued to reflect language processing at the semantic level, considering that later acquired words have less dense semantic representations and are thus more vulnerable to impairment [24, 31]. A higher number of phonological neighbours has been reported to be a possible marker of developmental language disorders [32] and the number of phonological neighbours can hinder spoken word production [41].
Phonological Variables
One psycholinguistic variable was chosen to assess participants’ ability to process phonological properties of spoken language. Word length in phonemes (e.g., “cook” has three phonemes /c-oo-k/) was selected since this is the only property that could be extracted from the spontaneous language samples and of which effects were consistently reported in the literature. Word length effects can indicate deficiencies of phonological encoding. This is the assembly of phoneme strings before articulation [43]. For example, children with a developmental language disorder have been reported to have more difficulties with repeating non-words of an increasing length than typically develo** children [34]. The predominance of shorter words can also reflect deficits in phonological short-term memory (i.e., the temporary storage of speech sounds).
Morphological and Syntactic Variables
Finally, two psycholinguistic variables were selected to investigate the syntactic (i.e., verb transitivity) and morphological (i.e., verb regularity) properties of spontaneous language. Transitive verbs are verbs that require a direct object. For example, in the sentence “the girl carries the bag” the verb “to carry” takes the direct object “the bag”. In contrast, intransitive verbs do not require an object. For example, in the sentence “the girl swims” the verb “to swim” does not take a direct object [38, 44]. Regularity is determined based on the patterns of inflection of a verb, related to, for example, tense and aspect. In English, for example, regular verbs retain the verb stem with the addition of the suffixes -d or -ed in the past tense (e.g., “jump-jumped”). Irregular verbs, on the other hand, do not follow this typical inflection as the vowel of the verb stem changes in the past tense (e.g., “drink-drank”). We selected these variables because they reflect morphological and syntactic processing on a word level. Effects of these variables have been reported to be indicative of a morphosyntactic impairment [38, 44,45,46,47]. For example, in adults with post-stroke aphasia and children with a developmental language disorder, transitive verbs have been reported to be more difficult to produce than intransitive verbs [38, 44, 45], but the opposite pattern has been found as well [46]. Although few studies have addressed the influence of verb regularity on language production, irregular verbs have been reported to be more prone to errors in children with a developmental language disorder [47] and children have been shown to be sensitive to verb regularity during language acquisition [48, 49]. Further, the cerebellar involvement in noun regularity has recently been described [50].
These psycholinguistic variables can help us thus understand the nature of the spontaneous language impairments in children with cerebellar tumours. For example, while previous studies reported lexical and morphosyntactic difficulties in children with posterior fossa tumours, semantic processing was never investigated in children after cerebellar tumour surgery [51, 52]. It was, however, associated with cerebellar functioning in individuals without neural damage and thus research is also warranted in case of cerebellar lesion. Also, psycholinguistic variables could provide us more insights into the differences in the nature of the spontaneous language impairments in children with and without pCMS. The few studies that compare postoperative spontaneous language outcomes in children with and without pCMS, generally report language impairment in both groups [11, 53]. Further, a preoperative reduction of the mean length of utterance (MLU; a measure of syntactic complexity) has been indicated as a possible prognostic factor for the development of pCMS, with morphosyntactic impairments persisting in the postoperative phase [11, 23, 54].
In summary, spontaneous language analysis is a powerful way to analyse language skills. Yet, to the best of our knowledge, spontaneous language has been underutilised in the study of postoperative language impairments after cerebellar tumour resection. The aim of the present study is twofold (1) to determine which spontaneous language variables can differentiate between ‘patients after cerebellar tumour surgery’ and ‘control speakers’ and (2) to characterise the nature of the deficits in our patient group across four linguistic levels. For the first aim, we conducted a principal component analysis (PCA) to select the relevant variables in our data and then conducted an individual patient analysis, comparing scores on these variables between patients and controls. For the second aim, we also differentiated between patients who experienced pCMS and patients who did not. This is the first study to evaluate four linguistic levels and is the most comprehensive study of spontaneous language in this clinical population.
Methods
Participants
Patient group
The data for this study were collected as part of a larger project that also investigated cerebellar-induced motor speech impairments [53, 55]. The patient group was recruited initially through a review of the neuropsychological and neurolinguistic records of children who underwent cerebellar tumour surgery at the Erasmus Medical Centre/Sophia Children’s hospital in Rotterdam between 1995 and 2007. The inclusion criteria were (1) surgical resection of a cerebellar tumour before the age of eighteen; (2) no reported history of preoperative developmental, neuropsychiatric, learning or language deficits; (3) no history of neurological or motor impairments before tumour diagnosis; (4) the presurgical presence of a cerebellar tumour as confirmed by Magnetic Resonance Imaging (MRI) and (5) availability of premorbid developmental data and a recorded speech sample of at least three hundred words which is the minimum for a reliable analysis [19, 22, 56]. Patients who experienced pCMS and patients who did not were included in this study. MRI scans were conducted pre- and postoperatively (within three months of assessment) to determine tumour characteristics (i.e., location, type, and size), the surgical incision site and the degree of tumour removal. The presence of pre- or postoperative hydrocephalus was determined with the bicaudate index (BI) for ventricle dilatation [57]. We distinguished between no (BI < 0.19), mild (BI = 0.19–0.26) and severe hydrocephalus (BI > 0.26) [58].
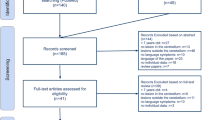
Thirty-two children and young adults treated with cerebellar tumour surgery were identified. Of this group, fourteen patients were excluded because their files were incomplete. More specifically, language data were absent for thirteen patients and medical information was incomplete for one patient. One other patient was excluded because of a premorbid developmental delay and one because no surgical resection was done. Four patients were excluded because the recorded speech sample contained less than three hundred words. The mean age at assessment of the final group of twelve participants was 11;3 years (SD = 6;3 years; range = 3–24;2 years) and consisted of five females and seven males. Mean age at surgery was 7;2 years (SD = 4;7 years; range = 2;1–17;9 years), meaning that patients were on average at 4;8 years (SD = 3;8 years; range = 0;11–12;3 years) post-surgery. Most patients were operated for a medulloblastoma (5/12) or pilocytic astrocytoma (5/12). Five patients suffered from pCMS. The individual demographic, tumour and tumour treatment characteristics of the patient group are provided in Table 1.
Control group
The control group consisted of thirty-nine individuals with no history of language impairment (24 males, 15 females) who were matched for age and gender with each patient. Mean age of the control group was 11;1 years (SD = 5;11 years; range = 3;0 – 24;3 years) at the time of assessment. The controls were recruited via primary schools and a speech and language therapy practice in the north of the Netherlands. The latter included siblings of children treated at the practice but without any speech and language impairments. The recruitment target was five control participants per patient with a cerebellar tumour, to allow statistical comparisons between an individual’s result and a matched control group [59]. Inclusion criteria were: (1) no history of neurological impairments and; (2) no history of developmental, neuropsychiatric, learning and/or language deficits. All participants who were twelve years of age or older gave written informed consent. Also, all parents of participants less than eighteen years of age gave consent. Ethical approval for the collection of control data was obtained from the Research Ethics Committee (CETO) from the faculty of arts of the University of Groningen (review number 76303408).
To ensure that none of the controls had a language impairment or delay, language was assessed using formal tests according to age in addition to the spontaneous language assessment. For children of five years or younger, the Core Language Score of the Dutch version of the Clinical Evaluation of Language Fundamentals Preschool (CELF-Preschool-2-NL) [60] was determined. For children between six and sixteen years of age, the Core Language Score of the Dutch version of the CELF (CELF-4-NL) [61] was calculated if a child was recruited via the speech therapy practice. A standard score between 85 and 115 was deemed within the normal range. If a child was enrolled in the study through contact with a primary school, the scores of the language subtests of the Cito tests were examined. These are tests routinely administered to children in the Netherlands to predict future learning success [62]. Children receive a score of A to E (A = highest 25% of achieving pupils; B = 25% at to above the national average; C = 25% at the national average to well below; D = 15% well below to far below national average; E = 10% lowest performing pupils) based on standardised assessments of reading comprehension, reading fluency, spelling and mathematics. Children with a score ranging from A to D on the subtests ‘technical reading’, ‘spelling’, ‘vocabulary’ and ‘reading comprehension’ were included. Parents of children between the ages of six and sixteen years of age also completed the Children’s Communication Checklist (CCC-2-NL) to exclude the presence of language impairments [63]. To ensure that a control had no history of any other deficits, the participant and/or his/her parents filled in a questionnaire considering their demographic information, language development and history of language and neurodevelopmental impairments. This questionnaire was designed by the authors for the purpose of this study.
Procedure
The linguistic data were collected during systematic clinical neuropsychological assessments which are offered to children who have been treated for a central nervous system tumour. According to the Dutch Child Oncology Group follow-up protocol (SKION), these assessments take place during a follow-up period of one to three years, and after that, every three years after tumour resection. The speech samples were either recorded or videotaped for future intra-subject comparison.
Spontaneous language was collected through an open-ended conversation about daily activities (i.e., school, family, hobbies, pets) and by describing three pictures [64,65,66]. Spontaneous language was video recorded or audiotaped and transcribed by four independent researchers following a detailed transcription protocol. This protocol was largely based on the Spontaneous Language Analysis Procedure (STAP) [67] and Analysis of Spontaneous Language in Aphasia (ASTA) [56]. Some changes were made, however, to fit the clinical group and goals of the analysis. Thirty percent of the samples were transcribed by the first and fourth authors (both native speakers of Dutch) to calculate inter-rater reliability.
Participants had to produce at least three hundred words (all words starting from the beginning of the sample, including repetitions, content words and function words) to be included in the study. This sample length has been reported to provide reliable measures in samples of children with a developmental language disorder and adults with post-stroke aphasia [19, 22]. If the beginning of the speech sample was not representative of the communicative abilities of the participant (e.g., the participant was very shy at the beginning of testing), the word count started after the first fifty words were produced. Part of the data of the children who underwent cerebellar tumour surgery were gathered in 2007. An auditory-perceptual speech analysis of the sample was published previously [55]. Additional control data were collected in 2020–2021. The procedure was different for controls, for whom language assessment consisted of two sessions instead of one.
Data coding
Data coding was done separately for the conversation and picture description data since these are two different methods of spontaneous language elicitation. This distinction resulted in shorter samples (10–50 utterances) than the three hundred word minimum, but this has been reported to be sufficient to obtain reliable results for the included measures [68, 69]. The length of the samples of the conversational data was based on the total number of utterances produced by every patient (excluding minimal responses), to which the samples of the controls were matched. For the picture analysis, the complete descriptions of the three pictures were analysed.
A total of twenty-one standard (i.e., lexical diversity, syntactic complexity and accuracy) and psycholinguistic spontaneous language variables were included. In Table 2, an overview of the variables per level of language processing is provided. We included five semantic, nine lexical, two phonological and five morphosyntactic variables.
Five standard language measures were included, reflecting lexical and morphosyntactic processing. Lexical diversity was measured by type-token ratio, which was calculated by dividing the total number of produced nouns/verbs by the number of tokens (i.e., the number of different nouns/verbs). Syntactic complexity was measured using MLU or the average number of produced words per utterance. To evaluate lexical/grammatical accuracy or the correctness of the produced utterances, the proportion of lexically (e.g., no neologisms, word choice errors) and grammatically (e.g., no errors on sentence structure, verb conjugation) correct utterances was calculated. Finally, finiteness index (i.e., the proportion of correctly inflected finite verbs) evaluated finite-verb-conjugation.
All nouns and verbs were extracted from the spontaneous language samples to obtain the values for the psycholinguistic variables. Ratings for imageability, concreteness and AoA were based on self-ratings by speakers, while phonological neighbourhood and word frequency were objectively quantified. Values for imageability were acquired from the database of Van Loon-Vervoorn [70]. Values for concreteness and AoA were obtained from the databases by Brysbaert et al. [40]. The number of phonological neighbours and the word length of each noun or verb was retrieved from the Dutch interface of the Cross-Linguistic Easy-Access Resource for Phonological and Orthographic Neighbourhood Densities (DutchPOND) [42]. Finally, lexeme frequency ratings were obtained from the SUBTLEX-NL database [39] that is also embedded in DutchPOND. More specifically, the SUBTLEXWF value was extracted for every noun or verb. This value represents the frequency of occurrence of a word per million words and is independent of corpus size [39]. Verbs were coded for instrumentality, transitivity and regularity based on the linguists’ experience (first to third and seventh to ninth authors) and previous literature [33]. For every participant, the mean and standard deviation for the ratings of every psycholinguistic variable were calculated (see Supplementary materials). Data coding was performed by two experienced researchers and 30% of samples were coded by both researchers. Inter-rater reliability was calculated for the data coding of these samples using Cohen’s Kappa. Disagreement in data coding was resolved by discussion between raters.
Statistical analyses
Statistical analyses encompassed a PCA and individual comparisons using Crawford’s modified t-tests [59]. A separate analysis was conducted for the conversation and picture data. First, a PCAFootnote 2 was carried out for each level of language processing to reduce the number of variables into overlap** components. Second, comparisons between each patient’s data and the average of his or her corresponding matched control group were performed separately for each of the components identified with PCA. In what follows, the statistical analyses are explained in further detail.
The suitability of the data for the PCA was examined with the Kaiser–Meyer–Olkin Measure of Sampling Adequacy (KMO) and Barlett’s test of sphericity. For the data to be suitable, a KMO statistic of at least 0.50 was required for every variable along with a significant Bartlett’s test [71]. Variables scoring below the 0.50 KMO criterion were removed from the PCA. An orthogonal Varimax rotation was employed to increase the interpretability of the data. The number of principal components for every subset of variables was determined based on their eigenvalues (i.e., > 1.0), the proportion of explained data variance (i.e., at least 70%) and the interpretability of the components (e.g., variable loadings > 0.45; previous literature e.g. [24, 28],).
Heterogeneity was expected in the language outcomes of the patient group [72]. Therefore, each score of every patient was compared to scores of five age- and gender-matched control speakers. Modified t-tests were already employed in this clinical population [73]. All analyses were performed in Rstudio v1.4.
Results
Below, we will detail the PCA (aim 1) and then the individual comparisons per patient (aim 1 and 2). The language evaluations are described separately for the five patients who suffered from pCMS and the seven patients who did not receive this diagnosis. P6 was excluded from the conversation data and P2 from the picture description data. These patients produced less than five utterances on the respective spontaneous language tasks, rendering their outcomes unreliable for that task. Cohen’s Kappa indicated a moderate to substantial agreement (range = 0.58–0.73) between researchers based on 30% of the spontaneous language samples that were coded by two researchers. The main sources of disagreement were determining if a sentence was lexically correct (0.58) and the calculation of the finiteness index (0.59).
Principal Component Analysis
A PCA was performed for every subset of variables (i.e., semantic, lexical and morphosyntactic) to make the analysis more manageable in relation to the number of variables while maintaining most (> 70%) of the data variance. Since only two phonological variables were included in the analysis, this subset of variables was not suitable for the PCA. Even though the literature is divided on this issue, AoA was included as a lexical variable for the PCA [24, 28]. Several variables were excluded to fulfil the KMO criterion. For the conversation data, the lexical variables ‘phonological neighbourhood nouns’ and ‘lexical accuracy’ and the morphosyntactic variable ‘finiteness index’ were removed. For the picture data, the lexical variables ‘phonological neighbourhood nouns’ and ‘word frequency nouns’ and the morphosyntactic variable ‘verb regularity’ were removed. Overall KMO statistics ranged from average (0.50 – 0.69) to good (> 0.70). All Bartlett’s tests of sphericity were significant (p < 0.001). This means that the correlation matrix of the variables was not an identity matrix. The data were thus suitable for PCA.
Conversation Data
Several principal components were extracted from the conversation data. Two principal components were extracted from the semantic variables, explaining 82% of the variance in the original semantic subset. These components are independent and should be compared between patients treated with cerebellar tumour surgery and their control speakers. The first component (C1; 42% of variance explained) included all semantic psycholinguistic variables for nouns. The second component (C2; 41% of the variance explained) consisted of all semantic psycholinguistic variables for verbs.
Three principal components were extracted from the lexical subset of variables, explaining 73% of the variance in the original dataset. The first principal component (C1; 29% of variance explained) included the psycholinguistic variables age of acquisition (nouns and verbs) and phonological neighbourhood (verbs). The second component (C2; 24% of variance explained) consisted of lexical diversity (nouns and verbs) and word frequency (nouns). The third component (C3) included the psycholinguistic variable word frequency (nouns and verbs). This component explained 20% of the data variance.
Three principal components were identified for the subset of morphosyntactic variables, explaining 83% of the variance in the original data. The first component (C1; 31% of variance explained) consisted of the variable grammatical accuracy and the proportion of regular verbs. The second component (C2; 27% of variance explained) and third component (C3; 25% of variance explained) each only consisted of one variable, respectively, mean length of utterance and the proportion of transitive verbs. The different components per level of language processing and the loadings of the variables per subset can be found in Table 3.
Picture Descriptions
Several components were extracted from the picture descriptions in sentences. Two principal components were extracted from the semantic subset of variables, explaining 85% of the variance in the original semantic variables subset. The first component (C1; 48% of data variance explained) consisted of all semantic psycholinguistic variables for verbs. The second component (C2; 37% of variance explained) included all semantic psycholinguistic variables for nouns.
From the lexical subset of variables, three principal components were extracted, explaining 75% of the data variance. The first principal component (C1) explained 34% of the data and included lexical accuracy and the lexical psycholinguistic variables for verbs (i.e., word frequency, age of acquisition and phonological neighbourhood). The second component (C2; 23% of variance explained) consisted of lexical diversity for nouns and verbs. The third component (C3; 17% of variance explained) included the psycholinguistic variable age of acquisition (nouns).
Two principal components were identified for the subset of morphosyntactic variables, explaining 78% of the data variance. The first component (C1; 42% of variance explained) included grammatical accuracy and finiteness index. The second component (C2; 35% of variance explained) consisted of mean length of utterance and the proportion of transitive verbs. The different components and the individual loadings per subset of variables can be found in Table 4.
Individual Case Statistics
The scores on the variables previously identified as principal components were compared for every patient who had cerebellar tumour surgery to five age- and gender-matched controls using Crawford’s modified t-tests. When describing the results, in addition to characterising the sample as a whole, a distinction was made between the patients who were diagnosed with pCMS (n = 5) and those who were not (n = 7). In total, nine out of twelve (75%) patients presented with an atypical spontaneous language profile in the conversational data and/or picture descriptions, suggesting a language impairment. Overall, three out of five patients in the pCMS-group had an atypical spontaneous language profile. More specifically, two patients (40%) showed evidence of a semantic deficit, one (20%) of lexical, three (60%) of morphosyntactic and one (20%) of phonological deficit. Six out of seven patients without pCMS had an atypical spontaneous language profile. Three (42.86%) presented evidence of semantic, two (28.57%) of lexical, three (42.86%) of morphosyntactic and four (57.14%) of phonological impairments. The raw scores (z values) for every patient and his/her controls and the results of the individual comparisons (p values) can be found in Tables 5, 6, 7, 8.
Conversation
Of the pCMS-group, two (i.e., P7 and P16) out of four presented with a possible semantic deficit. P16 also presented evidence of a lexical impairment, as indicated by atypical scores on the lexical properties. Other patients in the pCMS-group did not have a lexical deficit. Two patients (i.e., P8 and P16) had a deviant score for one or more of the morphosyntactic components. Finally, one patient (i.e., P7) showed evidence of a phonological deficit. P8, on the other hand, scored better on the phonological variables compared to her controls. Other statistical comparisons between conversation data of patients who suffered from pCMS and corresponding controls did not yield significant differences. P2 scored within the average range for all measures. Two patients (i.e., P7 and P16) presented with multi-level impairments. In Fig. 1, the individual z scores of every patient for the conversation data can be found for every component. See Table 5 for results of individual comparisons.

z scores of the patients who suffered from pCMS (n = 4) for the conversation
Of the seven patients who did not experience pCMS, three (i.e., P17, P20 and P23) showed evidence of a semantic processing impairment (nouns or verbs). P17 had deviant scores for the semantic verb component but scored better than his controls for noun semantic processing. Two patients (i.e., P20 and P22) had deviant scores for one or more of the included lexical components. Another two patients (i.e., P22 and P25) showed evidence of a morphosyntactic deficit. P17 and P26, on the other hand, scored better compared to their controls for one or more of the morphosyntactic variables. Finally, P26 and P20 scored below average for word length, indicating a phonological deficit. P24 scored within the normal range for all measures. Other statistical comparisons between conversation data of patients who did not experience pCMS and corresponding controls did not yield significant differences. Two participants (i.e., P20, P22) presented with multi-level impairments. See Fig. 2 for the individual z scores for every component and Table 6 for individual p values.

z scores of the patients who did not experience pCMS (n = 7) for the conversation data
Picture descriptions
For the picture descriptions in sentences, patients who experienced pCMS did not score significantly different compared to controls on semantic components. P16 performed better than his controls for lexical diversity. Three (i.e., P7, P8, P16) out of four patients had a possible morphosyntactic impairment. None of the patients had deviant scores on the phonological components. P6 scored within the average range for all measures. Other statistical comparisons between picture description data of the pCMS-group and corresponding controls did not yield significant differences. None of the patients presented with multi-level impairments. The individual z scores for every principal component can be found in Fig. 3 (p values in Table 7).

z scores of the participants who were diagnosed with pCMS (n = 4) for the picture description data
Of the seven patients in the non-pCMS-group, only P17 had scores indicative of a semantic impairment, while P20 scored better for semantic processing compared to his controls. P20 also had a lower score on one of the lexical components. One out of seven patients (i.e., P23) had a possible morphosyntactic deficit. Finally, three patients (i.e., P17, P20 and P22) scored lower compared to their controls for word length, indicating a phonological deficit. P24, P25 and P26 showed no significant differences compared to their controls (see Fig. 4). Other statistical comparisons between picture description data of patients who did not experience pCMS and corresponding controls did not yield significant differences. Two patients (i.e., P17 and P20) presented with multi-level impairments. The individual z scores for every principal component can be found in Fig. 4. Results of the individual comparisons between patients and their controls can be found in Table 8.

z scores of the patients who did not experience pCMS (n = 7) for the picture description data
Discussion
In the present study, we aimed to (1) identify variables extracted from spontaneous language which differentiate between patients treated with cerebellar tumour surgery and healthy controls and (2) characterise the spontaneous language outcomes of twelve patients treated with cerebellar tumour surgery. This is the most comprehensive spontaneous language analysis in this population up to date by including four levels of language processing. Nine out of twelve patients showed evidence of a language impairment as reflected by an atypical spontaneous language profile (i.e., the patient scored significantly different compared to his or her controls for one or more of the included variables). These were persistent impairments, affecting language in the long-term, as patients were on average four years after surgery at the time of language assessment.
Principal Components and the Potential to Differentiate Groups Based On a Psycholinguistic Approach to Spontaneous Language Analysis
Results from the PCA indicate that the variables used in individual case–control comparisons do have the potential to differentiate these groups, as each component explained a substantial amount of variance. Within each level of processing and separately for the conversation and picture data, the PCA produced independent components which clearly reflect different aspects of processing within a level. For example, in the picture data the PCA divided the semantic psycholinguistic variables into a noun and verb component, possibly indicating that these should be considered separately in our population. This is in line with previous research in a variety of clinical populations indicating that nouns and verbs can be selectively impaired [74, 75]. Nouns were also separated in the identified morphosyntactic components, but the majority of the morphosyntactic variables were verb specific. This differentiation in the PCA between noun- and verb-related variables cannot be studied in a controlled manner within our spontaneous language data; however, the results indicate that this should be explored in future research aiming to test dissociations between nouns and verbs in children treated with cerebellar tumour surgery.
Another clinically relevant observation from the PCA data is that psycholinguistic spontaneous language variables were often clustered together in the PCA and cannot be seen as independent from each other. Likewise, the PCA clustered some psycholinguistic variables together with standard language measures in a component (e.g., lexical accuracy with frequency, AoA, and phonological neighbourhood for verbs in the picture data). Such results have methodological implications for studies in which each variable is compared independently between groups.
Several psycholinguistic variables, such as phonological neighbourhood (nouns) and verb regularity (in picture data) were removed from the PCA as they did not contribute to the data variance. Such variables were not included in further case–control comparisons, thus taking advantage of PCA’s potential to aid in dimensionality reduction [76]. This way, PCA worked as a preparatory step for individual case–control comparisons, which are discussed next.
Characterising Language Impairments at the Individual Level
The results of this study showed spontaneous language impairments across all levels. Comparisons involving semantic variables detected impairments in five out of twelve patients. These were identified with the psycholinguistic noun and verb component. This is a unique contribution of the present study, as semantic processing has not been distinguished from lexical processing in previous studies, even though cerebellar involvement in semantic processing has been reported in non-neurological-impaired individuals [51, 52]. At the lexical level, three out of twelve patients showed impairments which were detected across all included lexical variables (e.g., lexical correctness, AoA, word frequency). Comparisons involving morphosyntactic variables detected impairments in six out of twelve patients. Again, impairments were reported across all morphosyntactic variables. Five out of twelve patients had a possible phonological impairment which was detected by the psycholinguistic variable word length (nouns and verbs). Previous studies also reported lexical-semantic, phonological and morphosyntactic impairments in a comparable clinical population [7, 11, 12, 16].
The present study also investigated the differential spontaneous language outcomes in patients who were diagnosed with pCMS and those who were not. Similar to previous studies [11, 16] most patients in our study presented with long-term atypical spontaneous language profiles irrespective of a previous pCMS diagnosis. Even though the sample size was small, the nature of the suggested impairments appears to differ somewhat between groups. Three out of five patients who suffered from pCMS had a deviant score on predominantly semantic (i.e., ‘semantic psycholinguistic variables nouns’) and morphosyntactic (i.e., ‘grammatical accuracy’ and ‘mean length of utterance’) components. Other language processing impairments were also observed for the conversation data, but only morphosyntactic impairments were present in the picture descriptions. Furthermore, two patients (P2 and P6) had a severe reduction of self-generated language, limiting spontaneous language analysis as reported in a previous study by Riva and Giorgi [11]. These deficits could be a possible long-term adverse effect of pCMS.
Semantic and morphosyntactic impairments were also observed in the non-pCMS-group, but the language impairments seemed to encompass different language processing levels more broadly than in the pCMS-group (where morphosyntactic deficits were more frequent than other deficits). Furthermore, this group also had a similar incidence of lexical and phonological deficits in both the conversation and picture description data. The two previous studies comparing patients with and without pCMS did not report differences in the nature of the observed spontaneous language deficits [11, 16]. However, in Cámara et al. [7] worse verbal memory outcomes were found during formal testing in children who suffered from pCMS. Furthermore, children in the pCMS-group had additional lexical-semantic impairments that were not observed in the non-pCMS group [7]. Differently, in the present study, the tendency to produce shorter words (which can be indicative of worse verbal memory) was identified in patients of both groups as were lexical-semantic impairments. This highlights the importance of reporting individual case–control comparisons, in addition to group comparisons, to document deficits that were not identified on a group level.
While we discussed possible differences between groups, these results need to be interpreted with caution given the small and unequal sample sizes. Although there were tendencies towards differences in the nature of the deficits, the same impairments or the same severity of impairments were not observed in all patients belonging to a group. Replications in bigger and equal patient groups will be better placed to answer questions of prevalence.
In the pCMS-group a high incidence of morphosyntactic deficits in conversation and picture descriptions was observed. Studies by, for example, Di Rocco et al. [23] suggested preoperative lexical-semantic and/or morphosyntactic impairments to be a possible risk factor for pCMS. In our study, language impairments and a reduced spontaneous language output were still observable after the mutism resolved and were not found in patients who did not experience pCMS. This is in line with earlier studies [23, 54]. It should be further investigated if morphosyntactic impairments in pCMS-patients indeed originate pre-operatively as a result of tumour growth or presence. Differently, the linguistic deficits in the non-pCMS group might be more intrinsically linked to cerebellar lesions which occur during tumour surgery.
While morphosyntactic impairments have often been reported as part of the cerebellar cognitive-affective syndrome (CCAS), they have scarcely been reported in relation to pCMS [7, 16, 77]. Our results might suggest that pCMS should be regarded as a hyper-acute severe form of CCAS, rather than a separate clinical syndrome [78, 79]. It is also possible that the physiopathological mechanisms underlying the atypical spontaneous language profiles differ between groups. Yet, no preoperative language assessment was conducted and no diffusion tensor imaging data were available for our patient group. In order to test these hypotheses, future research would need to compare the pre- and postoperative spontaneous language outcomes in patients with and without pCMS, and relate these outcomes to the integrity of the cerebello-cerebral circuitry by means of MRI studies [80,81,82].
Even though our results suggest differential patterns of spontaneous language outcomes in the pCMS- and non-pCMS-group, interindividual heterogeneity was still observed both in the nature and the severity of the deficits, as reported in earlier research [72]. This finding might be explained by several variables related to the cerebellar tumour survivor (e.g., age at surgery [83]), the tumour (e.g., location or presence of a hydrocephalus [7]) or treatment (e.g., neurotoxicity caused by radiotherapy [11]). In our patient group, however, no obvious relation was found between these variables and the spontaneous language outcomes. This might be attributed to the limited size and large diversity of our clinical sample.
On the other hand, the severity of the language deficits (i.e., the number of impaired variables and/or the degree to which individual variables were impaired) in patients who experienced pCMS has also been related to the length of the mute phase [6]. This also seemed to be the case in our pCMS-group, with patients who were mute for several months following surgery (i.e., P7 and P16) presenting with severe multi-level impairments as opposed to other patients (e.g., P2) who were mute for a shorter period. It is possible that these more severe language impairments are caused by a reduced language experience or the influence of dysarthria during language acquisition. Nonetheless, P7 and P16 were already teenagers at the time of surgery, when language acquisition is near-complete.
Finally, even though the present study was limited to a linguistic analysis, the possible influence of cognitive impairment on the language outcomes cannot be ignored. For example, working memory has been reported to influence word learning and sentence processing which are important for language development [84, 85]. Cerebellar tumour survivors can present with a variety of postoperative cognitive impairments (e.g., working memory problems, attentional deficits; see Wolfe et al. for a review [86]) and these might have contributed to the observed heterogeneity. Unfortunately, it was not possible to investigate the influence of cognitive impairment in the current sample because of the inconsistent (in time and targeted functions) neuropsychological assessments across individuals, but this should be explored in future studies. The present results do confirm that cerebellar tumour survivors have a broad spectrum of long-term language impairments, as was reported in previous studies [7, 16]. These may significantly hinder daily communication years after surgery and should be assessed comprehensively in clinical practice [18].
Methodological Considerations
Since this study introduced a novel method of spontaneous language analysis, some methodological remarks can be made. The present study showed that PCA can be a promising aid when interpreting patterns of impairment in a heterogeneous clinical population. Future studies should explore if the same principal components are identified in a similar patient group. It should be mentioned that, even though we counted the included spontaneous language variables separately and attributed them to separate language processing levels, these variables, levels, and impairments at a given level interact during language production [87]. For example, when producing a sentence, a semantic processing deficit might induce a highly concrete (i.e., less semantically rich) verb, but also an intransitive (i.e., less syntactically complex) verb due to higher processing demands. The interactions could provide (at least in part) an explanation for the observed heterogeneity in our sample.
Overall, both standard variables (e.g., grammatical accuracy, MLU) and psycholinguistic variables (e.g., imageability, word length) could differentiate individual patients from their controls. Several standard variables identified lexical-semantic, phonological and morphosyntactic impairments in our patient group, in accordance with previous studies [7, 11, 12, 16]. Nonetheless, analysing the psycholinguistic variables allowed us to characterise the nature of the observed deficits in more detail than possible via standard spontaneous language measures and structured tasks used in earlier studies [30]. Our results suggest that semantic and phonological psycholinguistic variables can identify language processing problems that are not found with standard spontaneous language measures (e.g., lexical diversity). However, not all psycholinguistic variables could be used to identify spontaneous language deficits. For example, scores on standard morphosyntactic measures (e.g., grammatical accuracy) suggested language impairments that were not identified with morphological and syntactic properties (e.g., verb transitivity and regularity). In P25, on the other hand, a morphosyntactic impairment was evident with the word property ‘transitivity’ that was not identified with standard morphosyntactic measures. Regarding verb regularity, the generalisability of our findings might be limited to languages that share linguistic properties with Dutch (e.g., English, German [88, 89]).
Interestingly, fewer atypical spontaneous language profiles were found for the picture descriptions than for the conversation. Although both elicitation methods require the integration of different levels of linguistic processing, the visual representation of objects or actions in pictures limits the number of possible verbal responses and the possible variety in several psycholinguistic properties [21]. For example, all presented nouns in the pictures were highly concrete. This might explain why lexical-semantic processing deficits were only identified in spontaneous conversation. Finally, two of the three administered pictures were meant for language assessment in children, while several patients were adults at follow-up [65]. Therefore, picture description tasks might have been easier than spontaneous conversation.
In what concerns the feasibility of using this approach in clinical practice it should also be noted that, while gathering a spontaneous language sample with the patient may not take long, and our results suggest that this method is able to uncover difficulties, extracting psycholinguistic properties from the produced nouns and verbs in spontaneous language is time consuming. Ratings for different psycholinguistic variables are spread out across databases and some values need to be calculated manually. Therefore, after careful validation of our method, the development of a user-friendly clinical tool is warranted.
Finally, it is important to note some limitations of the present study. Although the results suggest long-term spontaneous language impairments in our patient group, these should be interpreted with caution. The large diversity (e.g., regarding age range) and small sample size of our patient group make it difficult to draw definite conclusions regarding the long-term language outcomes in cerebellar tumour survivors. Therefore, future studies should replicate our methods and results in larger patient groups. These studies should also include more homogeneous subgroups of patients, regarding, for example, age and tumour type to further evaluate the possible influence of risk factors on language in this clinical population.
Conclusions
In the present study, the long-term spontaneous language outcomes in participants who underwent cerebellar tumour surgery during childhood were investigated. Results show that many cerebellar tumour survivors have atypical spontaneous language profiles, suggesting language impairments. This was the first study to use psycholinguistic variables for a comprehensive spontaneous language assessment, showing promising results in terms of this tool being able to identify difficulties. For example, our method allowed us to identify isolated semantic and phonological impairments in spontaneous language that were not reported in previous studies. Possible differential patterns in the language outcomes in patients who were and were not diagnosed with pCMS were identified, implying different mechanisms underlying these impairments. Results show that spontaneous language might be a useful clinical assessment tool, allowing a short assessment time which is advantageous for patients who can become easily tired. Further research is necessary, however, to confirm these results and validate this novel method of spontaneous language analysis. A comprehensive postoperative language assessment in this clinical population is necessary irrespective of pCMS diagnosis, given the need for early intervention and the identification of language impairments across all levels of language processing.
Data Availability
The patient data analysed during the current study were shared with us and requests for data sharing should go to Prof Philippe Paquier. Control data are available from the corresponding author on reasonable request and can be shared via DataverseNL.
Notes
A corpus or text corpus is a large collection of written or spoken texts that are stored electronically. For example, the iWeb corpus contains fourteen billion English words extracted from twenty-two million web pages [90].
PCA is a data-driven approach. It generates a single multi-dimensional model based on the patterns of a group while capturing individual differences between participants [76, 91]. In other words, a large number of variables are summarized in a smaller number of inter-correlated quantitative variables or ‘emergent principal components’ that explain most of the data variance. Among others, PCA can be employed as a dimensionality reduction technique [76]. The variables that explain the least of the data variance (i.e., the noise in the data) are removed from the data. PCA has been employed in studies with adults with post-stroke aphasia [92, 93], but also in one study investigating the neuropsychological outcomes in children with a medulloblastoma [94].
Abbreviations
- AoA:
-
Age of acquisition
- ASTA:
-
Analysis of Spontaneous Language in Aphasia
- BI:
-
Bicaudate index
- CCAS:
-
Cerebellar cognitive-affective syndrome
- CCC:
-
Children’s Communication Checklist
- CELF:
-
Clinical Evaluation of Language Fundamentals
- CETO:
-
Research Ethics Committee, Faculty of Arts University of Groningen
- DutchPOND:
-
Dutch interface of the Cross-Linguistic Easy-Access Resource for Phonological and Orthographic Neighbourhood Densities
- KMO:
-
Kaiser-Meyer-Olkin Measure of Sampling Adequacy
- MLU:
-
Mean length of utterance
- MRI:
-
Magnetic Resonance Imaging
- PCA:
-
Principal component analysis
- pCMS:
-
Postoperative cerebellar mutism syndrome
- STAP:
-
Spontaneous Language Analysis Procedure
References
Bauchet L, Rigau V, Mathieu-Daudé H, Fabbro-Peray P, Palenzuela G, Figarella-Branger D, et al. Clinical epidemiology for childhood primary central nervous system tumors. J Neurooncol. 2009;92:87–98.
Rickert CH, Paulus W. Epidemiology of central nervous system tumors in childhood and adolescence based on the new WHO classification. Child’s Nerv Syst. 2001;17:503–11.
Ramaswamy V, Remke M, Adamski J, Bartels U, Tabori U, Wang X, et al. Medulloblastoma subgroup-specific outcomes in irradiated children: Who are the true high-risk patients? Neuro Oncol. 2016;18:291–7.
Ojemann JG, Partridge SC, Poliakov AV, Niazi TN, Shaw DW, Ishak GE, et al. Diffusion tensor imaging of the superior cerebellar peduncle identifies patients with posterior fossa syndrome. Child’s Nerv Syst. 2013;29:2071–7.
Palmer SL, Glass JO, Li Y, Ogg R, Qaddoumi I, Armstrong GT, et al. White matter integrity is associated with cognitive processing in patients treated for a posterior fossa brain tumor. Neuro Oncol. 2012;14:1185–93.
Paquier PF, Walsh KS, Docking KM, Hartley H, Kumar R, Catsman-Berrevoets CE. Post-operative cerebellar mutism syndrome: rehabilitation issues. Child’s Nerv Syst. 2020;36:1215–22.
Cámara S, Fournier C, Cordero P, Melero J, Robles F, Esteso B, et al. Neuropsychological profile in children with posterior fossa tumors with or without postoperative cerebellar mutism syndrome (CMS). Cerebellum. 2020;19:78–88.
Hudson LI, Murdoch BE, Ozanne AE. Posterior fossa tumours in childhood: Associated speech and language disorders post-surgery. Aphasiology. 1989;3:1–18.
Levisohn L, Cronin-Golomb A, Schmahmann JD. Neuropsychological consequences of cerebellar tumour resection in children: Cerebellar cognitive affective syndrome in a paediatric population. Brain. 2000;123:1041–50.
Docking K, Munro N, Marshall T, Togher L. Narrative skills of children treated for brain tumours: The impact of tumour and treatment related variables on microstructure and macrostructure. Brain Inj England. 2016;30:1005–18.
Riva D, Giorgi C. The cerebellum contributes to higher functions during development. Evidence from a series of children surgically treated for posterior fossa tumours. Brain. 2000;123:1051–61.
Frank B, Schoch B, Hein-Kropp C, Hövel M, Gizewski ER, Karnath H-O, et al. Aphasia, neglect and extinction are no prominent clinical signs in children and adolescents with acute surgical cerebellar lesions. Exp Brain Res Germany. 2008;184:511–9.
Gudrunardottir T, Morgan AT, Lux AL, Walker DA, Walsh KS, Wells EM, et al. Consensus paper on post-operative pediatric cerebellar mutism syndrome: the Iceland Delphi results. Child’s Nerv Syst. 2016;32:1195–203.
Wells EM, Khademian ZP, Walsh KS, Vezina G, Sposto R, Keating RF, et al. Postoperative cerebellar mutism syndrome following treatment of medulloblastoma: neuroradiographic features and origin. J Neurosurg Pediatr. 2010;5:329–34.
Robertson PL, Muraszko KM, Holmes EJ, Sposto R, Packer RJ, Gajjar A, et al. Incidence and severity of postoperative cerebellar mutism syndrome in children with medulloblastoma: A prospective study by the Children’s Oncology Group. J Neurosurg. 2006;105:444–51.
De Smet HJ. Neurolinguistics and the cerebellum: An analysis of speech and language disturbances resulting from acquired cerebellar lesions. PhD Dissertation, Vrije Universiteit Brussel; 2009.
Grieco JA, Abrams AN, Evans CL, Yock TI, Pulsifer MB. A comparison study assessing neuropsychological outcome of patients with post-operative pediatric cerebellar mutism syndrome and matched controls after proton radiation therapy. Child’s Nerv Syst. 2020;36:305–13.
Rofes A, Talacchi A, Santini B, Pinna G, Nickels L, Bastiaanse R, et al. Language in individuals with left hemisphere tumors: Is spontaneous speech analysis comparable to formal testing? J Clin Exp Neuropsychol. 2018;40:722–32.
Bastiaanse R, Bol G. Verb inflection and verb diversity in three populations: Agrammatic speakers, normally develo** children, and children with specific language impairment (SLI). Brain Lang. 2001;77:274–82.
Kambanaros M, Grohmann KK. More general all-purpose verbs in children with specific language impairment? Evidence from Greek for not fully lexical verbs in language development. Appl Psycholinguist. 2014;36:1029–57.
Prins RS, Bastiaanse R. Spontane-taalanalyse bij afasie [Spontaneous language analysis in aphasia]. Stem-, Spraak- en Taalpathologie. 2001;10:003–23.
Vermeulen J, Bastiaanse R, Van Wageningen B. Spontaneous speech in aphasia: A correlational study. Brain Lang. 1989;36:252–74.
Di Rocco C, Chieffo D, Frassanito P, Caldarelli M, Massimi L, Tamburrini G. Heralding Cerebellar Mutism: Evidence for Pre-surgical Language Impairment as Primary Risk Factor in Posterior Fossa Surgery. Cerebellum United States. 2011;10:551–62.
Brysbaert M, Van Wijnendaele I, De Deyne S. Age-of-acquisition effects in semantic processing tasks. Acta Psychol (Amst). 2000;104:215–26.
Dede G. Effects of word frequency and modality on sentence comprehension impairments in people with aphasia. Am J Speech-Language Pathol. 2012;21:S103–14.
Shallice T. Specialisation within the semantic system. Cogn Neuropsychol. 1988;5:133–42.
Meschyan G, Hernandez A. Age of acquisition and word frequency: Determinants of object-naming speed and accuracy. Mem Cogn. 2002;30:262–9.
Nickels L, Howard D. Aphasic naming: What matters? Neuropsychologia. 1995;33:1281–303.
Nickels LA, Howard D. Dissociating effects of number of phonemes, number of syllables, and syllabic complexity on word production in aphasia: It’s the number of phonemes that counts. Cogn Neuropsychol. 2004;21:57–78.
Rofes A, de Aguiar V, Ficek B, Wendt H, Webster K, Tsapkini K. The Role of Word Properties in Performance on Fluency Tasks in People with Primary Progressive Aphasia. J Alzheimer’s Dis. 2019;68:1521–34.
Howard D, Gatehouse C. Distinguishing semantic and lexical word retrieval deficits in people with aphasia. Aphasiology. 2006;20:921–50.
Ní Chéileachair F, Chondrogianni V, Sorace A, Paradis J, De Aguiar V. Developmental language disorder in sequential bilinguals: Characterising word properties in spontaneous speech. J Child Lang. 2022; 1–27.
Jonkers R, Bastiaanse R. Action naming in anomic aphasic speakers: Effects of instrumentality and name relation. Brain Lang. 2007;102:262–72.
Boerma T, Chiat S, Leseman P, Timmermeister M, Wijnen F, Blom E. A Quasi-Universal Nonword Repetition Task as a Diagnostic Tool for Bilingual Children Learning Dutch as a Second Language. J Speech, Lang Hear Res. 2015;58:1747–60.
Kambanaros M. Does verb type affect action naming in specific language impairment (SLI)? Evidence from instrumentality and name relation. J Neurolinguistics. 2013;26:160–77.
de Aguiar V, Rofes A, Wendt H, Ficek BN, Webster K, Tsapkini K. Treating lexical retrieval using letter fluency and tDCS in primary progressive aphasia: a single-case study. Aphasiology. 2021; 1–27.
Kambanaros M, Grohmann KK. Patterns of Object and Action Naming in Cypriot Greek Children with SLI and WFDs Maria. Sawston, United Kingdom: Woodhead Publishing; 2010. p. 1–12.
Bastiaanse R, Jonkers R. Verb retrieval in action naming and spontaneous speech in agrammatic and anomic aphasia. Aphasiology. 1998;12:951–69.
Keuleers E, Brysbaert M, New B. SUBTLEX-NL: A new measure for Dutch word frequency based on film subtitles. Behav Res Methods. 2010;42:643–50.
Brysbaert M, Stevens M, De Deyne S, Voorspoels W, Storms G. Norms of age of acquisition and concreteness for 30,000 Dutch words. Acta Psychol (Amst). 2014;150:80–4.
Hameau S, Biedermann B, Nickels L. Lexical activation in late bilinguals: effects of phonological neighbourhood on spoken word production. Lang Cogn Neurosci. 2020; 0:1–18.
Marian V, Bartolotti J, Chabal S, Shook A. Clearpond: Cross-linguistic easy-access resource for phonological and orthographic neighborhood densities. PLoS One. 2012; 7.
Martin AD, Wasserman NH, Gilden L, Gerstman L, West JA. A process model of repetition in aphasia: An investigation of phonological and morphological interactions in aphasic error performance. Brain Lang. 1975;2:434–50.
Thompson CK, Lange KL, Schneider SL, Shapiro LP. Agrammatic and non-brain-damaged subjects’ verb and verb argument structure production. Aphasiology. 1997;11:473–90.
Andreu L, Sanz-Torrent M, Legaz LB, MacWhinney B. Effect of verb argument structure on picture naming in children with and without specific language impairment (SLI). Int J Lang Commun Disord. 2012;47:637–53.
Bastiaanse R, van Zonneveld R. Sentence production with verbs of alternating transitivity in agrammatic Broca’s aphasia. J Neurolinguistics. 2005;18:57–66.
Redmond SM, Rice ML. Detection of Irregular Verb Violations by Children with and Without SLI. J Speech, Lang Hear Res. 2001;44:655–69.
Colombo L, Laudanna A, De Martino M, Brivio C. Regularity and/or consistency in the production of the past participle? Brain Lang. 2004;90:128–42.
Say T, Clahsen H. Words, Rules and Stems in the Italian Mental Lexicon. Storage Comput Lang Fac. Springer Netherlands; 2020; 93–129.
Russo AG, Esposito F, Laudanna A, Mancuso A, Di Salle F, Elia A, et al. The neural substrate of noun morphological inflection: A rapid event-related fMRI study in Italian. Neuropsychologia Elsevier Ltd. 2021;151:107699.
Nakatani H, Nakamura Y, Okanoya K. Respective Involvement of the Right Cerebellar Crus I and II in Syntactic and Semantic Processing for Comprehension of Language. Cerebellum. 2022; 1–17.
Moberget T, Gullesen EH, Andersson S, Ivry RB, Endestad T. Generalized role for the cerebellum in encoding internal models: Evidence from semantic processing. J Neurosci. 2014;34:2871–8.
De Smet HJ, Baillieux H, Wackenier P, De Praeter M, Engelborghs S, Paquier PF, et al. Long-Term Cognitive Deficits Following Posterior Fossa Tumor Resection: A Neuropsychological and Functional Neuroimaging Follow-Up Study. Neuropsychology. 2009;23:694–704.
Bianchi F, Chieffo DPR, Frassanito P, Di Rocco C, Tamburrini G. Cerebellar mutism: the predictive role of preoperative language evaluation. Child’s Nerv Syst Germany. 2020;36:1153–7.
De Smet HJ. Catsman-Berrevoets C, Aarsen F, Verhoeven J, Mariën P, Paquier PF. Auditory-perceptual speech analysis in children with cerebellar tumours: a long-term follow-up study. Eur J Paediatr Neurol EJPN Off J Eur Paediatr Neurol Soc. England. 2012;16:434–42.
Boxum E, van der Scheer F, Zwaga M. ASTA: Analyse voor Spontane Taal bij Afasie. Standaard [Analysis of Spontaneous Speech in Aphasia]. Vereniging voor Klinische Linguïstiek; 2013. 2–23.
Catsman-Berrevoets CE, Van Dongen HR, Mulder PGH, Geuze Paz Y, D, Paquier PF, Lequin MH. Tumour type and size are high risk factors for the syndrome of “cerebellar” mutism and subsequent dysarthria. J Neurol Neurosurg Psychiatry. 1999;67:755–7.
Aarsen FK, Paquier PF, Arts W-F, Van Veelen M-L, Michiels E, Lequin M, et al. Cognitive Deficits and Predictors 3 Years After Diagnosis of a Pilocytic Astrocytoma in Childhood. J Clin Oncol. 2009;27:3526–32.
Crawford JR, Garthwaite PH. Investigation of the single case in neuropsychology: confidence limits on the abnormality of test scores and test score differences. Neuropsychologia. 2002;40:1196–208.
Wiig EH, Secord WA, Semel E, De Jong J. Clinical Evaluation of Language Fundamentals: preschool-2 Dutch version. Amsterdam, the Netherlands: Pearson Assessment & Information B.V.; 2012.
Kort W, Schittekatte M, Compaan E. Clinical Evaluation of Language Fundamentals-4 Dutch version (CELF-4-NL). Amsterdam, the Netherlands: Pearson Assessment & Information B.V.; 2010.
Hollenberg J, van der Lubbe M. Toetsen op School Primair onderwijs. Sander P, editor. Arnhem: Stichting Cito Instituut voor Toetsontwikkeling; 2017.
Geurts HM. CCC-2-NL: Children’s Communication Checklist-2 Dutch version. Amsterdam, the Netherlands: Harcourt Assessment B.V.; 2007.
Goodglass H, Kaplan E, Weintraub S. BDAE: The Boston Diagnostic Aphasia Examination. Philadelphia, the United States: Lippincott Williams and Wilkins; 2001.
Van der Zee-Zetstra J, Nales B, Smit J. Praatboeken voor speciaal onderwijs [Talking books for special education]. Doetichem, the Netherlands: Edudesk; 1989.
Watamori TS, Sasanuma S, Ueda S. Recovery and plasticity in child-onset aphasics: Ultimate outcome at adulthood. Aphasiology. 2007;4:9–30.
van Ierland M, Verbeek J, van den Dungen L. Spontane Taal Analyse Procedure (STAP) Handleiding [Spontaneous Speech Analysis Procedure (STAP) manual]. Amsterdam, the Netherlands: University of Amsterdam; 2008. p. 83.
Casby MW. An examination of the relationship of sample size and mean length of utterance for children with developmental language impairment. Child Lang Teach Ther. 2011;27:286–93.
Heilmann J, Nockerts A, Miller JF. Language sampling: Does the length of the transcript matter? Lang Speech Hear Serv Sch. 2010;41:393–404.
Loon-Vervoorn V. Voorstelbaarheidswaarden van Nederlandse woorden : 4600 substantieven, 1000 verba en 500 adjectieven [Imageability ratings of Dutch words: 4600 nouns, 1000 verbs and 500 adjectives]. Lisse: Swets en Zeitlinger; 1985.
Watkins MW. Exploratory Factor Analysis: A Guide to Best Practice. J Black Psychol. 2018;44:219–46.
Murdoch BE, Hudson LJ. Variability in Patterns of Language Impairment in Children Following Treatment for Posterior Fossa Tumour. Commun Disord Child Cancer. 2008. 89–125.
Benavides-Varela S, Lorusso R, Baro V, Denaro L, Estévez-Pérez N, Lucangeli D, et al. Mathematical skills in children with pilocytic astrocytoma. Acta Neurochir (Wien). 2019;161:161–9.
Black M, Chiat S. Noun-verb dissociations: a multi-faceted phenomenon. J Neurolinguistics [Internet]. 2003;16:231–50. Available from: papers://81d652f4-a340–49dc-a15a-bca505f8366e/Paper/p408
Bak TH, O’Donovan DG, Xuereb JH, Boniface S, Hodges JR. Selective impairment of verb processing associated with pathological changes in Brodmann areas 44 and 45 in the motor neurone disease-dementia-aphasia syndrome. Brain. 2001;124:103–20.
Wold S, Esbensen K, Geladi P. Principal Component Analysis. Chemom Intell Lab Syst. 1987; 37–52.
Schmahmann JD, Sherman JC. The cerebellar cognitive affective syndrome. Brain. 1998;121:561–79.
Schmahmann JD. Pediatric post-operative cerebellar mutism syndrome, cerebellar cognitive affective syndrome, and posterior fossa syndrome: historical review and proposed resolution to guide future study. Child’s Nerv Syst. 2020;36:1205–14.
Mariën P, De Smet HJ, Wijgerde E, Verhoeven J, Crols R, De Deyn PP, et al. Posterior fossa syndrome in adults: A new case and comprehensive survey of the literature. Cortex Italy. 2013;49:284–300.
Miller NG, Reddick WE, Kocak M, Glass JO, Löbel U, Morris B, et al. Cerebellocerebral diaschisis is the likely mechanism of postsurgical posterior fossa syndrome in pediatric patients with midline cerebellar tumors. Am J Neuroradiol. 2010;31:288–94.
van Baarsen KM, Grotenhuis JA. The anatomical substrate of cerebellar mutism. Med Hypotheses United States. 2014;82:774–80.
Di Rocco C, Chieffo D, Pettorini BL, Massimi L, Caldarelli M, Tamburrini G. Preoperative and postoperative neurological, neuropsychological and behavioral impairment in children with posterior cranial fossa astrocytomas and medulloblastomas: The role of the tumor and the impact of the surgical treatment. Child’s Nerv Syst Germany. 2010;26:1173–88.
Murdoch BE, Hudson-Tennent LJ. Differential language outcomes in children following treatment for posterior fossa tumours. Aphasiology. 1994;8:507–34.
Lewis RL, Vasishth S, Van Dyke JA. Computational principles of working memory in sentence comprehension. Trends Cogn Sci. 2006;10:447–54.
Gathercole SE, Baddeley AD. Working memory and language. Psychology Press; 2014.
Wolfe KR, Madan-Swain A, Kana RK. Executive dysfunction in pediatric posterior fossa tumor survivors: a systematic literature review of neurocognitive deficits and interventions. Dev Neuropsychol. 2012;37:153–75.
Crystal D. Towards a “bucket” theory of language disability: Taking account of interaction between linguistic levels. Clin Linguist Phonetics. 1987;1:7–22.
Baayen RH, Martín FMDP. Semantic density and past-tense formation in three germanic languages. Language (Baltim). 2005;81:666–98.
Krok W, Leonard L. Past Tense Production in Children With and Without Specific Language Impairment Across Germanic Languages: A Meta-Analysis. J Speech, Lang Hear Res. 2015;58:132.
Davies M, Kim JB. The advantages and challenges of “big data”: Insights from the 14 billion word iWeb corpus. Linguist Res. 2019;36:1–34.
Pearson KLIII. On lines and planes of closest fit to systems of points in space. London, Edinburgh, Dublin Philos Mag J Sci. 1901;2:559–72.
Halai AD, Woollams AM, Ralph MAL. Using principal component analysis to capture individual differences within a unified neuropsychological model of chronic post-stroke aphasia : Revealing the unique neural correlates of speech fluency, phonology and semantics. Cortex. 2016;86:275–89.
Ramanan S, Roquet D, Goldberg Z, Hodges JR, Piguet O, Irish M, et al. Establishing two principal dimensions of cognitive variation in logopenic progressive aphasia. Brain Commun. 2020;1–17.
Law N, Smith M Lou, Greenberg M, Bouffet E, Taylor MD, Laughlin S, et al. Executive function in paediatric medulloblastoma: The role of cerebrocerebellar connections. J Neuropsychol. 2017;11:174–200.
Acknowledgements
We thank all the children and their parents for participating in this study, and acknowledge the contribution of Hyo Jung De Smet, PhD, in an early phase of this study [16]. We would also like to thank Dr Serje Robidoux for his help with the statistical analyses.
Funding
This study is part of a doctoral research funded by the International Doctorate in Experimental Approaches to Language and Brain (IDEALAB) via the University of Groningen and Macquarie University.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material provision, data collection and analysis were performed by Cheyenne Svaldi, Coriene Catsman-Berrevoets, Philippe Paquier and Henrieke Van Elp. The first draft of the manuscript was written by Cheyenne Svaldi and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing Interests
The authors declare no competing interests.
Ethics Approval
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and national research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards. According to Dutch law, no approval of a Medical Ethical Committee is needed when patient data are studied that are obtained as part of routine patient care. Ethical approval for the collection of data from participants without neurological or language impairments was obtained from the Research Ethics Committee (CETO) from the faculty of arts of the University of Groningen (review number 76303408).
Informed Consent
As is required by Dutch law, parents and patients over 12 years old signed a consent form before neuropsychological assessment in which they allowed the data to be used for research.
Conflict of Interest
The authors have no competing interests to declare that are relevant to the content of this article.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Svaldi, C., Paquier, P., Keulen, S. et al. Characterising the Long-Term Language Impairments of Children Following Cerebellar Tumour Surgery by Extracting Psycholinguistic Properties from Spontaneous Language. Cerebellum 23, 523–544 (2024). https://doi.org/10.1007/s12311-023-01563-z
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12311-023-01563-z