
Abstract
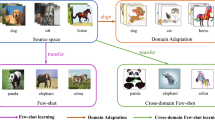
Cross-Domain Few-Shot Learning (CD-FSL) aims at recognizing unseen classes from target domains that vastly differ from training classes from source domains, utilizing only a few labeled samples. However, the substantial domain disparities between target and source domains pose huge challenges to few-shot generalization. To resolve domain disparities, we propose HybridPrompt, a novel architecture for Domain-Aware Prompting that integrates a variety of cross-domain learned prompts as knowledge experts for CD-FSL. The proposed method enjoys several merits. First, to encode knowledge from diverse source domains, several Domain Prompts are introduced to capture domain-specific knowledge. Subsequently, to facilitate the cross-domain transfer of valuable knowledge, a Transferred Prompt is specifically tailored for each target task by retrieving highly relevant Domain Prompts based on domain properties. Finally, to complement insufficient transferred information, an Adaptive Prompt is learned to incorporate additional target characteristics for model adaptation. Consequently, the collaboration of these three types of prompts contributes to a hybridly prompted model that achieves domain-aware encoding, transfer, and adaptation, thereby enhancing adaptability on unseen domains. Extensive experimental results on the Meta-Dataset benchmark demonstrate that our method achieves superior performance against state-of-the-art methods. The source code is available at https://github.com/Jamine-W/HybridPrompt.






Similar content being viewed by others


Data Availability
The datasets generated during and/or analyzed during the current study are available in the original references, i.e., Meta-Dataset (Triantafillou et al., 2019) https://github.com/google-research/meta-dataset.
References
Antoniou, A., Edwards, H., & Storkey, A. (2018). How to train your MAML. In International conference on learning representations
Bateni, P., Goyal, R., Masrani, V., Wood, F., & Sigal, L. (2020) Improved few-shot visual classification. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 14493–14502).
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I., & Amodei, D. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems, 33, 1877–1901.
Bulat, A., Guerrero, R., Martinez, B., & Tzimiropoulos, G. (2023) FS-DETR: Few-shot detection transformer with prompting and without re-training. In Proceedings of the IEEE/CVF international conference on computer vision. (pp. 11793–11802).
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., & Zagoruyko, S. (2020) End-to-end object detection with transformers. In European conference on computer vision (pp. 213–229).
Caron, M., Misra, I., Mairal, J., Goyal, P., Bojanowski, P., & Joulin, A. (2020). Unsupervised learning of visual features by contrasting cluster assignments. Advances in Neural Information Processing Systems, 33, 9912–9924.
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., & Joulin, A. (2021). Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE international conference on computer vision (pp. 9650–9660).
Cheng, G., Lang, C., & Han, J. (2022). Holistic prototype activation for few-shot segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(4), 4650–4666.
Cimpoi, M., Maji, S., Kokkinos, I., Mohamed, S., & Vedaldi, A. (2014). Describing textures in the wild. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3606–3613).
Cui, Y., Song, Y., Sun, C., Howard, A., & Belongie, S. (2018). Large scale fine-grained categorization and domain-specific transfer learning. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4109–4118).
Cuturi, M. (2013). Sinkhorn distances: Lightspeed computation of optimal transport. Advances in Neural Information Processing Systems, 26, 2292–2300.
Deng, J., Dong, W., Socher, R., Li, L. J., Li, K., & Fei-Fei, L. (2009). ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE international conference on computer vision (pp. 248–255). IEEE.
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., & Houlsby, N. (2021). An image is worth 16 x 16 words: Transformers for image recognition at scale. In International conference on learning representations.
Dvornik, N., Schmid, C., & Mairal, J. (2020). Selecting relevant features from a multi-domain representation for few-shot classification. In European conference on computer vision (pp. 769–786).
Fei-Fei, L., Fergus, R., & Perona, P. (2006). One-shot learning of object categories. IEEE Transactions on Pattern Analysis and Machine Intelligence, 28(4), 594–611.
Finn, C., Abbeel, P., & Levine, S. (2017). Model-agnostic meta-learning for fast adaptation of deep networks. In International conference on machine learning (pp. 1126–1135).
Guo, Y., Codella, N. C., Karlinsky, L., Codella, J. V., Smith, J. R., Saenko, K., Rosing, T., & Feris, R. (2020). A broader study of cross-domain few-shot learning. In European conference on computer vision (pp. 124–141).
Hou, R., Chang, H., Ma, B., Shan, S., & Chen, X. (2019). Cross attention network for few-shot classification. In Advances in neural information processing systems (pp. 4003–4014).
Houben, S., Stallkamp, J., Salmen, J., Schlipsing, M., & Igel, C. (2013). Detection of traffic signs in real-world images: The German traffic sign detection benchmark. In International joint conference on neural networks (pp. 1–8). IEEE
Hu, S. X., Li, D., Stühmer, J., Kim, M., & Hospedales, T. M. (2022). Pushing the limits of simple pipelines for few-shot learning: External data and fine-tuning make a difference. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 9068–9077).
Jia, M., Tang, L., Chen, B. C., Cardie, C., Belongie, S., Hariharan, B., & Lim, S. N. (2022). Visual prompt tuning. In European conference on computer vision (pp. 709–727).
Jongejan, J., Rowley, H., Kawashima, T., Kim, J., & Fox-Gieg, N. (2016). The quick, draw!-ai experiment. http://quickdraw.withgoogle.com
Krizhevsky, A., & Hinton, G. (2009). Learning multiple layers of features from tiny images. Technical report, Citeseer.
Kumar Dwivedi, S., Gupta, V., Mitra, R., Ahmed, S., & Jain, A. (2019). Protogan: Towards few shot learning for action recognition. In Proceedings of the IEEE/CVF international conference on computer vision workshops (pp. 0–0).
Lake, B. M., Salakhutdinov, R., & Tenenbaum, J. B. (2015). Human-level concept learning through probabilistic program induction. Science, 350(6266), 1332–1338.
Lang, C., Cheng, G., Tu, B., & Han, J. (2023a). Few-shot segmentation via divide-and-conquer proxies. International Journal of Computer Vision, 132, 1–23.
Lang, C., Cheng, G., Tu, B., Li, C., & Han, J. (2023b). Base and meta: A new perspective on few-shot segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence. https://doi.org/10.1109/TPAMI.2023.3265865
Lang, C., Cheng, G., Tu, B., Li, C., & Han, J. (2023c). Retain and recover: Delving into information loss for few-shot segmentation. IEEE Transactions on Image Processing. https://doi.org/10.1109/TIP.2023.3315555
LeCun, Y., & Cortes, C. (2010). MNIST handwritten digit database. http://yann.lecun.com/exdb/mnist
Lee, K., Maji, S., Ravichandran, A., & Soatto, S. (2019). Meta-learning with differentiable convex optimization. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 10657–10665).
Lester, B., Al-Rfou, R., & Constant, N. (2021). The power of scale for parameter-efficient prompt tuning. In Proceedings of the conference on empirical methods in natural language processing (pp. 3045–3059).
Li, W., Liu, X., & Bilen, H. (2022). Cross-domain few-shot learning with task-specific adapters. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7161–7170).
Li, W. H., Liu, X., & Bilen, H. (2021). Universal representation learning from multiple domains for few-shot classification. In Proceedings of the IEEE international conference on computer vision (pp. 9526–9535).
Li, X. L., & Liang, P. (2021). Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (pp. 4582–4597).
Lin, T. Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., & Zitnick, C. L. (2014). Microsoft coco: Common objects in context. In European conference on computer vision (pp. 740–755). Springer.
Liu, B., Cao, Y., Lin, Y., Li, Q., Zhang, Z., Long, M., & Hu, H. (2020). Negative margin matters: Understanding margin in few-shot classification. In European conference on computer vision (pp. 438–455).
Liu, L., Hamilton, W., Long, G., Jiang, J., & Larochelle, H. (2021a). A universal representation transformer layer for few-shot image classification. In International conference on learning representations.
Liu, P., Yuan, W., Fu, J., Jiang, Z., Hayashi, H., & Neubig, G. (2023). Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Computing Surveys, 55(9), 1–35.
Liu, Y., Lee, J., Zhu, L., Chen, L., Shi, H., & Yang, Y. (2021b). A multi-mode modulator for multi-domain few-shot classification. In Proceedings of the IEEE international conference on computer vision (pp. 8453–8462).
Ma, T., Sun, Y., Yang, Z., & Yang, Y. (2023). Prod: Prompting-to-disentangle domain knowledge for cross-domain few-shot image classification. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 19754–19763).
Maji, S., Rahtu, E., Kannala, J., Blaschko, M., & Vedaldi, A. (2013). Fine-grained visual classification of aircraft. ar**v preprint ar**v:1306.5151
Nilsback, M. E., & Zisserman, A. (2008). Automated flower classification over a large number of classes. In Indian Conference on Computer Vision (pp. 722–729). IEEE: Graphics & Image Processing.
Oreshkin, B., Rodríguez López, P., & Lacoste, A. (2018). TADAM: Task dependent adaptive metric for improved few-shot learning. In Advances in neural information processing systems (pp. 721–731).
Perrett, T., Masullo, A., Burghardt, T., Mirmehdi, M., & Damen, D. (2021). Temporal-relational crosstransformers for few-shot action recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 475–484).
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., & Sutskever, I. (2021). Learning transferable visual models from natural language supervision. In International conference on machine learning (pp. 8748–8763). PMLR.
Raghu, M., Unterthiner, T., Kornblith, S., Zhang, C., & Dosovitskiy, A. (2021). Do vision transformers see like convolutional neural networks?. In Advances in neural information processing systems (pp. 12116–12128).
Ravi, S., & Larochelle, H. (2017). Optimization as a model for few-shot learning. In International conference on learning representations.
Requeima, J., Gordon, J., Bronskill, J., Nowozin, S., & Turner, R. E. (2019). Fast and flexible multi-task classification using conditional neural adaptive processes. In Advances in neural information processing systems (pp. 7959–7970).
Rubner, Y., Tomasi, C., & Guibas, L. J. (1998). A metric for distributions with applications to image databases. In Sixth international conference on computer vision (IEEE Cat. No. 98CH36271) (pp. 59–66). IEEE.
Schroeder, B., & Cui, Y. (2018). FGVCx fungi classification challenge 2018. https://github.com/visipedia/fgvcx_fungi_comp
Shin, T., Razeghi, Y., Logan IV, R. L., Wallace, E., & Singh, S. (2020). Autoprompt: Eliciting knowledge from language models with automatically generated prompts. In EMNLP (pp. 4222–4235).
Simon, C., Koniusz, P., Nock, R., & Harandi, M. (2020). Adaptive subspaces for few-shot learning. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4136–4145).
Snell, J., Swersky, K., & Zemel, R. (2017). Prototypical networks for few-shot learning. In Advances in neural information processing systems (pp. 4077–4087).
Sun, B., Li, B., Cai, S., Yuan, Y., & Zhang, C. (2021). FSCE: Few-shot object detection via contrastive proposal encoding. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 7352–7362).
Sun, Q., Liu, Y., Chua, T. S., & Schiele, B. (2019). Meta-transfer learning for few-shot learning. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 403–412).
Sung, F., Yang, Y., Zhang, L., **ang, T., Torr, P. H., & Hospedales, T. M. (2018). Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE conference on computer vision and pattern recognition.
Tian, Y., Wang, Y., Krishnan, D., Tenenbaum, J. B., & Isola, P. (2020). Rethinking few-shot image classification: A good embedding is all you need? In European conference on computer vision (pp. 266–282).
Triantafillou, E., Zhu, T., Dumoulin, V., Lamblin, P., Evci, U., Xu, K., Goroshin, R., Gelada, C., Swersky, K., Manzagol, P. A., & Larochelle, H. (2019). Meta-dataset: A dataset of datasets for learning to learn from few examples. ar**v preprint ar**v:1903.03096
Triantafillou, E., Larochelle, H., Zemel, R., & Dumoulin, V. (2021). Learning a universal template for few-shot dataset generalization. In International conference on machine learning (pp. 10424–10433).
Vinyals, O., Blundell, C., Lillicrap, T., & Wierstra, D. (2016). Matching networks for one shot learning. In Advances in neural information processing systems (pp. 3630–3638).
Wah, C., Branson, S., Welinder, P., Perona, P., & Belongie, S. (2011). The Caltech-UCSD birds-200-2011 dataset. Technical report.
Wang, Z., Zhang, Z., Ebrahimi, S., Sun, R., Zhang, H., Lee, C. Y., Ren, X., Su, G., Perot, V., Dy, J. & Pfister, T. (2022). Dualprompt: Complementary prompting for rehearsal-free continual learning. In European conference on computer vision (pp. 631–648).
Wu, J., Zhang, T., Zhang, Y., & Wu, F. (2021). Task-aware part mining network for few-shot learning. In Proceedings of the IEEE international conference on computer vision (pp. 8433–8442).
Wu, J., Zhang, T., Zhang, Z., Wu, F., & Zhang, Y. (2022). Motion-modulated temporal fragment alignment network for few-shot action recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 9151–9160).
**e, E., Wang, W., Yu, Z., Anandkumar, A., Alvarez, J. M., & Luo, P. (2021). SegFormer: Simple and efficient design for semantic segmentation with transformers. Advances in Neural Information Processing Systems, 34, 12077–12090.
Ye, H. J., Hu, H., Zhan, D. C., & Sha, F. (2020). Few-shot learning via embedding adaptation with set-to-set functions. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 8808–8817).
Zeiler, M. D. (2012). Adadelta: An adaptive learning rate method. ar**v preprint ar**v:1212.5701
Zeiler, M. D., & Fergus, R. (2014). Visualizing and understanding convolutional networks. In European conference on computer vision (pp. 818–833). Springer.
Zhang, C., Cai, Y., Lin, G., & Shen, C. (2020). DeepEMD: Few-shot image classification with differentiable earth mover’s distance and structured classifiers. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 12203–12213).
Zhang, R., Hu, X., Li, B., Huang, S., Deng, H., Qiao, Y., Gao, P., & Li, H. (2023) Prompt, generate, then cache: Cascade of foundation models makes strong few-shot learners. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 15211–15222).
Zhou, K., Yang, J., Loy, C. C., & Liu, Z. (2022a). Learning to prompt for vision-language models. International Journal of Computer Vision, 130(9), 2337–2348.
Zhou, K., Yang, J., Loy, C. C., & Liu, Z. (2022b) Conditional prompt learning for vision-language models. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 16816–16825).
Zhu, C., Chen, F., Ahmed, U., Shen, Z., & Savvides, M. (2021). Semantic relation reasoning for shot-stable few-shot object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 8782–8791).
Acknowledgements
This work was supported by the Excellent Young Scientists Fund (Grant 62022078).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevant financial or non-financial interests to disclose.
Additional information
Communicated by Zhun Zhong.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Wu, J., Zhang, T. & Zhang, Y. HybridPrompt: Domain-Aware Prompting for Cross-Domain Few-Shot Learning. Int J Comput Vis (2024). https://doi.org/10.1007/s11263-024-02086-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11263-024-02086-8