
Abstract
In 1998, the paper Sergeyev (Math Program 81(1):127–146, 1998) has been published where a smooth piece-wise quadratic minorant has been proposed for multiextremal functions f(x) with the first derivative \(f'(x)\) satisfying the Lipschitz condition with a constant L, i.e., \(f'(x)\) cannot increase with the slope higher than L and decrease with the slope smaller than \(-L\). This minorant has been successfully applied in several efficient global optimization algorithms and used in engineering applications. In the present paper, it is supposed that the first derivative \(f'(x)\) cannot increase with the slope higher than a constant \(\beta \) and decrease with the slope smaller than \(\alpha \). The interval \([\alpha ,\beta ]\) is called the Lipschitz interval (clearly, in this case the Lipschitz constant \(L = \max \{|\alpha |, |\beta | \}\)). For this class of functions, smooth piece-wise estimators (minorants and majorants) have been proposed and applied in global optimization. Both theoretically and experimentally (on 200 randomly generated test problems) it has been shown that in cases where \( |\alpha | \ne |\beta |\) the new estimators can give a significant improvement w.r.t. those proposed in Sergeyev (Math Program 81(1):127–146, 1998), for example, in the framework of branch-and-bound global optimization methods.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Global optimization is one of the thriving fields of mathematical programming. As it can be seen from numerous applications in electronics, machine learning, engineering, optimal decision making, finance, etc. (see, e.g., [1, 2, 7,8,9,10, 20,21,22, 24, 28, 39, 40, 49,50,51] and references given therein), problems of this kind are often characterized by the presence of numerous local minima and maxima and the necessity to find among them the absolutely best, in other words global, solution. In local optimization, univariate problems have lost their importance decades ago and nowadays can be considered only as illustrative examples in university optimization courses. In contrast, in global optimization, where the objective functions can be strongly multiextremal making so local optimization methods inapplicable, univariate problems are still a very active research area. This happens due to at least the following three reasons. First, global optimization is significantly younger w.r.t. local optimization and there still exists a lot of room for improvement and new ideas. Second, global optimization problems are extremely difficult even in the one-dimensional case and there exists a huge number of applications (it is sufficient to mention elaboration of signals) where problems of this kind arise (see, e.g.,[4, 5, 8, 15, 30, 31, 34, 36, 39, 40, 42,43,44,45,46]). The third reason is that one-dimensional schemes are broadly used for constructing multi-dimensional global optimization methods for a single objective (see, e.g., [20, 22, 26, 28, 36, 42, 43, 48]) and in the multiobjective case (see, e.g. [25]). Therefore, univariate global optimization can be viewed as a good training ground for a subsequent development of multi-dimensional algorithms.
The univariate global optimization problem can be stated as follows
where the objective function f(x) can have a high number of local minima and maxima and evaluation of f(x) at each point is a time consuming operation. The goal is to find a global minimizer \(x^* \in [a,b]\) and the value \(f(x^*)\) such that
Hereinafter we assume that f(x) is a continuous function over [a, b]. Thus, the point \(x^*\) in (2) always exists.
In many cases, finding the exact solution \(f(x^*)\) either analytically or by numerical algorithms is impractical (see, e.g., [7, 8, 20, 26, 28, 42, 43, 48]). Thus, numerical methods are often aimed at finding approximate solutions. In this paper, there are considered algorithms that guarantee to find an \(\varepsilon \)-optimal solution \(x^{(\varepsilon )}\) satisfying the following condition
One of the key methodologies developed to deal with global optimization problems is Lipschitz global optimization (see, e.g., [12,13,14, 16,17,18, 20, 27,28,29, 47, 48]). It uses a natural assumption that the function f(x) from (1) has bounded slopes. In other words, it satisfies the Lipschitz condition (it will be introduced formally shortly). An important subclass in Lipschitz global optimization consists of functions with the first derivative satisfying the Lipschitz condition (see [3, 5, 8, 11, 18, 19, 23, 35, 48], etc.). The importance of methods using derivatives has increased significantly after the introduction of the Infinity Computer (see [38]) allowing one to compute numerically (i.e., neither analytically nor symbolically) exact derivatives and to use them in global optimization algorithms (see [37, 41, 46]).
Since the nineties of the XXth century people started to propose algorithms for solving this problem using piece-wise quadratic minorants. Breiman and Cutler (see [3]) and Gergel (see [11]) have introduced methods constructing non-smooth minorants that were adaptively improved during optimization. Then, since the objective function f(x) is differentiable over the search region, in [23, 35, 46] there have been introduced methods constructing smooth minorants that are closer to the objective function f(x) with respect to non-smooth ones providing so a significant acceleration in comparison with the algorithms [3, 11].
In the present paper, a further substantial improvement is proposed. In order to explain its essence we need the following two definitions.
Definition 1
A function \(h(x), x \in [a,b],\) is called Lipschitz continuous on the interval [a, b] if there is a non-negative finite real constant L such that the property
holds for any \(x_1,x_2 \in [a,b]\). Any such L is called a Lipschitz constant.
The property (4) bounds the absolute value of the function variation. In the present paper, we use a more accurate notion of interval Lipschitz continuity that provides both lower and upper bounds for slopes of h(x).
Definition 2
A function \(h(x), x \in [a,b],\) is called interval Lipschitz continuous over the interval [a, b] if there exist real numbers \(\alpha , \beta \), \(\alpha \le \beta \), such that
for any \(x_1,x_2 \in [a,b]\), \(x_1 \le x_2\). Any interval \([\alpha , \beta ]\) satisfying (5) is called a Lipschitz interval.
Obviously, a Lipschitz continuous function with a constant L is interval Lipschitz continuous with the interval \([-L,L]\). Vice-versa, an interval Lipschitz continuous function with a Lipschitz interval \([\alpha ,\beta ]\) is Lipschitz continous with the Lipschitz constant \(L = \max \{|\alpha |, |\beta | \}\). It is easy to show that if a function is differentiable and its derivative values belong to an interval \([\alpha , \beta ]\) then it is interval Lipschitz continuous with this interval. In what follows we suppose that constants \(\alpha \) and \(\beta \) are known. It should be stressed that in this we follow the tradition existing in Lipschitz global optimization w.r.t. the knowledge of L (see, e.g., [3, 11, 16, 20, 27,28,29, 35]). In practice, both L and \(\alpha \) and \(\beta \) can be estimated using, for example, the interval analysis (see, e.g., [6, 32]). There exist also techniques allowing one to accelerate the search by using adaptive estimates of L (see, e.g., [18, 19, 23, 35, 46] and references therein). These aspects are beyond the interest of the present paper and will be considered in further investigations.
In this paper, we focus on a problem of constructing smooth estimators (minorants and majorants) for a differentiable univariate function f(x) assuming that its first derivative is interval Lipschitz continuous over [a, b] with the Lipschitz interval \([\alpha , \beta ]\). Formally, this can be written as follows:
Clearly, construction of such estimators has its own intrinsic importance since they can be applied in different contexts. Hereinafter, it will be shown how such estimators can be constructed and used to solve global optimization problems.
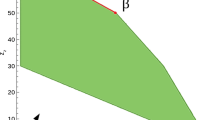
In order to illustrate the interval Lipschitz continuity property, let us consider Fig. 1a that presents an example of a piecewise linear function h(x) which is interval Lipschitz continuous with the Lipschitz interval \([-3, 1]\). Figure 1b shows a function f(x) such that \(f'(x) = h(x)\). The function in Fig. 1b satisfies the property (6) with \(\alpha = -3, \beta = 1\). In this figure, the roots of h(x) are points of extrema of f(x). These points are marked with blue on both plots.

An interval Lipschitz continuous function (a) and a function with an interval Lipschitz derivative (b)
As was already mentioned, in [35], a smooth piece-wise quadratic minorant for functions with Lipschitzian first derivatives has been proposed. In the present paper, we show that this minorant can be improved significantly if the Lipschitz property for the first derivative is replaced with the interval Lipschitz property (6).
To illustrate this fact that will be proved hereinafter, let us consider a function \(f(x) = 3 \, sin(x) + x^2\), \(x \in [-4,4]\). The Lipschitz interval computed by interval arithmetics (see [32]) as the interval bounds for its second derivative is \([-1, 5]\). Thus, the respective Lipschitz constant is \(L = 5\). Figure 2a shows the lower and upper estimators obtained with the techniques from [35] that relies solely on a Lipschitz constant. Figure 2b depicts the estimators constructed by the method presented in the rest of the paper that uses the Lipschitz interval. As one can see, considering the Lipschitz interval entails tighter estimators w.r.t. the Lipschitz constant.

Lower (blue) and upper (green) estimators obtained using Lipschitz (a) and interval Lipschitz (b) properties of the first derivative of the function shown in red. (Color figure online)
2 Preliminary notions and facts
Lemma 1
Let h(x) be an interval Lipschitz continuous function defined on an interval [a, b] with a Lipschitz interval \([\alpha , \beta ]\), see (5). If
then h(x) is the interval Lipschitz continuous function with the Lipschitz interval \([\alpha , \alpha ]\) and \(h(x) = h(a) + \alpha (x - a)\). Similarly if
then h(x) is the interval Lipschitz continuous function with the Lipschitz interval \([\beta , \beta ]\) and \(h(x) = h(a) + \beta (x - a)\).
Proof
Notice that according to (5), we have
Due to this fact and (7), it follows that
On the other hand, according to (5), we get
As a result, we obtain that,
Since h(x) in (9) is linear with the slope \(\alpha \), h(x) is interval Lipschitz continuous with Lipschitz interval \([\alpha , \alpha ]\). The case (8) is considered by a complete analogy. \(\square \)
Lemma 2
Let h(x) be an interval Lipschitz continuous function defined on an interval [a, b] with a Lipschitz interval \([\alpha , \beta ]\), see (5). Then the following inequalities hold
where
i.e., \(\underline{h}(x)\) and \(\overline{h}(x)\) are an underestimator and an overestimator for h(x).
Proof
From (5) we get
Rewriting these inequalities we obtain
In the same way we obtain
and
The inequality (10) is a direct consequence of (11), (12). \(\square \)
Let us introduce more compact representation of functions \(\underline{h}(x)\), \(\overline{h}(x)\), provided by the following Lemma.
Lemma 3
The underestimator \(\underline{h}(x)\) can be rewritten in the following equivalent form
where
The overestimator \(\overline{h}(x)\) can be rewritten in this equivalent form
where
Proof
The value s is the abscissa of the intersection of lines \(h(a) + \alpha (x - a)\) and \(h(b) + \beta (x - b)\). Therefore it is a root of the algebraic equation
This root is computed explicitly as follows
Thus, the formula (13) has been proven. The formula (15) can be proven in a similar way. \(\square \)
Lemmas 2 and 3 are illustrated in Fig. 3 for the function \(h(x) = \sin (x) + 0.5, x \in [-\pi , \pi ]\). Observe that \(h'(x) = \cos (x) + 0.5\). Since the range of \(\cos (x)\) for \(x \in [-\pi , \pi ]\) is \([-1, 1]\), then the range of \(h'(x)\) is \([-0.5, 1.5]\), i.e., \(\alpha = -0.5, \beta = 1.5\). In Fig. 3, points s and t are also shown.

Lower (blue) and upper (green) estimators according to Lemma 2. (Color figure online)
3 The second order estimators
In what follows we construct a piecewise quadratic underestimator for a function f(x) satisfying (6) starting from a step function \(\phi (x,c,d)\) depending on an argument x and parameters c, d. A function \(\psi (x,c,d)\) of the argument x is then defined as a definite integral of \(\phi (x,c,d)\) with a variable upper limit and, in its turn, a function \(\chi (x,c,d)\) of the argument x is defined as a definite integral with a variable upper limit of \(\psi (x,c,d)\).
Below we introduce the mentioned functions formally, study their properties and show that it is always possible to choose parameters c, d in such a way that \(\chi (x, c, d)\) becomes a differentiable piecewise quadratic underestimator for f(x).
We start by considering the following step function \(\phi (x, c, d)\) of the variable x:
where c, d are two real numbers such that \(a \le c \le d \le b\) (the proper choice of these parameters is discussed later). Let us now define functions \(\psi (x, c, d)\) and \(\chi (x, c, d)\) as follows
In what follows we study the properties of these functions and start by considering the following two possible cases for \(\alpha \) and \(\beta \): (i) \(\alpha = \beta \), (ii) \(\alpha < \beta \).
Lemma 4
Let \(\alpha = \beta \). Then f(x) is a quadratic function and for any \(c,d \in [a,b]\), \(c \le d\), it follows
Proof
Since \(\alpha = \beta \), \(\phi (x,c,d) = \alpha \), \(x \in [a,b]\), regardless of the choice of c and d. Therefore, it follows from (18) that
On the other hand, from (6) it follows that
Thus, \(f'(x) = \psi (x, c, d)\), \(x \in [a,b]\), and by definition (19) we get
We conclude that in the case \(\alpha = \beta \) the choice of c, d is irrelevant and the underestimator coincides with f(x), i.e., the first equality in (20) is true. After substitution of (21)–(22) and integration we obtain the second equality in (20). This observation concludes the proof. \(\square \)
From Lemma 4 it follows that for arbitrary c and d in [a, b] the function \(\chi (x, c, d)\) coincides with f(x) and thus is a trivial underestimator. The situation is different if \(\alpha < \beta \). In what follows we show how to choose c and d within [a, b] to ensure that \(\chi (x, c, d)\) bounds f(x) from below.
Let us assume now that \(\alpha < \beta \). Let \(\delta \) be a real number defined as follows
Notice that due to (6), the inequalities
are valid. Moreover, according to Lemma 1, if at least one of the inequalities (24) degenerates to equality then \(f'(x)\) is interval Lipschitz continuos with an interval with equal ends. This case (\(\alpha = \beta \)) was considered above. Thus both inequalities in (24) can be assumed strict and therefore
Let c be an arbitrary number in \([a, b - \delta ]\). In the rest of the paper we assume that the parameter d used in (17)—(19) has the form
From (25) it immediately follows that \(d \in [a, b]\). For \(c \in [a, b - \delta ]\) we denote \(\hat{\psi }(x,c) = \psi (x, c, c + \delta )\) hereinafter.
After substituting the value (26) for d to (18) and expanding integrals we obtain
Then, from (23) it follows that the third line in (27) can be reformulated as follows:
Thus, (27) can be rewritten in a more compact form
Lemma 5
The function \(\hat{\psi }(x, c)\) is a continuous piecewise linear in x and the following equality holds
Proof
From (27) it follows that the function \(\hat{\psi }(x, c)\) is piecewise linear by definition. Thus, to prove the continuity, it is necessary to study values of the function \( \hat{\psi }(x, c)\) at points c and d. After substituting \(x = c\), the 1st and 2nd expressions in (27) take the same value \(f'(a) + \alpha (c - a)\) which means continuity at that point.
After assuming \(x = d\) and substituting (26), the 2nd expression in (27) becomes
Then, after substituting \(x = d\) to the 3rd expression in (27) we obtain
The rightmost parts of (30) and (31) coincide, which means the continuity at the point d.
Finally, equality (29) becomes evident after a direct substitution \(x=b\) to the last equation in (28). \(\square \)
The following Lemma provides concise representations for some specific choices of the second arguments of \(\hat{\psi }(x, c)\) function. These properties are used later in the rest of the paper.
Lemma 6
The following two expressions are valid for \(x \in [a,b]\)
Proof
Let us prove the formula (32). After substituting \(c = b-\delta \) to (26) we get \(d = b\). Thus, the substitution \(c = b-\delta \) to (28) yields
By substituting expression (23) for \(\delta \) the second case in (34) can be simplified
Thus, (34) can be rewritten in a more compact form (32).
Now, let us prove (33). After substituting \(c = a\) and \(d = c + \delta \) to (28) the half interval [a, c) becomes empty and therefore we get
This completes the proof. \(\square \)
The following two Lemmas 7 and 8 establish some properties of the function \(\hat{\psi }(x,c)\) that will be used later to prove the proposition 1. Let start with the first Lemma illustrated in Fig. 4.
Lemma 7
Inequalities
are valid for \(x \in [a,b]\).
Proof
Let us prove the first inequality in (35). Notice that
We need to recall Lemma 3 and compare (13) with (32). Observe that s in (14) is equal to \(b - \delta \) under assumption \(h(x) = f'(x)\). Thus \(\underline{h}(x)\) coincides with \(\hat{\psi }(x, b-\delta )\). As a result, according to Lemmas 2 and 3, \(\hat{\psi }(x, b-\delta )\) is an underestimator for \(f'(x)\), i.e.,
The first of inequalities (35) has been proven.
Now, let us prove the second inequality in (35). Observe that
Thus, due to (15) and (16) the point \(a+\delta \) is equal to t and \(\overline{h}(x)\) coincides with \(\hat{\psi }(x, a)\) under assumption \(h(x) = f'(x)\). As a result, due to Lemmas 2 and 3, \(\hat{\psi }(x,a)\) is an overestimator for \(f'(x)\):
This completes the proof. \(\square \)

Functions \(\hat{\psi }(x,a)\) and \(\hat{\psi }(x, b - \delta )\) are lower and upper estimators for \(f'(x)\), respectively
Lemma 8
The function \(\hat{\psi }(x, c)\) is monotonically non-increasing and Lipschitz continuous for its second argument over the interval [a, b] with the Lipschitz constant equal to \(\beta - \alpha \), i.e.,
where \(\alpha , \beta \) are from (17).
Proof
This Lemma is proved in “Appendix A”. \(\square \)
Let us introduce the notation \(\hat{\chi }(x, c) = \chi (x, c, d)\), where d is computed according to (26). Then, it follows from (19) that
Let us now define the function
and prove the following corollary.
Corollary 1
Function \(\xi (c)\) is a Lipschitz continuous non-increasing function of c, \(c \in [a, b - \delta ]\), with the Lipschitz constant equal to \((b - a)(\beta - \alpha )\).
Proof
Let \(c_1\), \(c_2\) be two reals such that \(a \le c_1 < c_2 \le b - \delta \). Due to (37), (38), and (36) we have
Thus, the monotonicity has been proven. The Lipschitz continuity follows from (36) and the following inequalities:
\(\square \)
In what follows we derive a useful explicit formula for \(\hat{\chi }(x,c)\) obtained in the following Lemma.
Lemma 9
For the function \(\hat{\chi }(x,c)\) computed accordingly to (37) the following expression holds
Proof
The proof is given in “Appendix B”. \(\square \)
The following proposition shows that we can choose a point \(c^*\) in the interval \([a, b-\delta ]\) in such a way, that \(\xi (c^*) = f(b)\). Later this property will be used to prove that the function \(\hat{\chi }(x, c^*)\) is an underestimator for f(x), coinciding with it at the ends of the interval [a, b]. The fact that \(c^*\) satisfies the inequalities \(a \le c^* \le b - \delta \) is essential to ensure that both \(c^*\) and \(d^* = c^* + \delta \) belong to [a, b].
Proposition 1
There exists a unique point \(c^* \in [a, b - \delta ]\) such that \(\xi (c^*) = f(b)\), where
Proof
The proof is given in “Appendix C”. \(\square \)
Now we can define
The following Corollary gives an explicit formula for \(d^*\).
Corollary 2
The value of \(d^*\) can be calculated as follows
Proof
By substituting the expression (23) for \(\delta \) to the right part of (41), and recalling (40), we obtain
\(\square \)
Notice, that if the derivative of f(x) satisfies the Lipschitzian property with the constant L then we can safely assume \(\alpha = -L\) and \(\beta = L\). The following Corollary establishes the formulae for \(c^*\) and \(d^*\) in this case.
Corollary 3
If \(\alpha = -L\) and \(\beta = L\) then
and
Proof
Formulae (43), (44) can be obtained by a direct substitution of values \(-L\), L instead of \(\alpha \), \(\beta \) in (40) and (42) respectively. \(\square \)
As expected, formulae (43), (44) coincide with the formulae (13), (12) from [35], respectively, that provide gluing points of three quadratic pieces of the smooth piece-wise quadratic support function for the function f(x) constructed for the case where \(f'(x)\) satisfies the Lipschitzian property with the constant L.
Let us introduce now the following two functions
From (37), (38), and the equality \(\xi (c^*) = b\), proved in Proposition 1 it follows that
Thus, \(\nu (x)\) is the first derivative for \(\mu (x)\). Recall, that by construction, \(\nu (x)\) is piece-wise linear and \(\mu (x)\) is piece-wise quadratic.
Hereinafter we show that the function \(\mu (x)\) is an underestimator for the function f(x) and illustrate this fact by the following example, where Fig. 5 shows the function \(f(x) = 5 \, sin(x - 2) + x\), its derivative \(f'(x) = 5 \, cos (x - 2) + 1\), and functions \(\nu (x), \mu (x)\) defined on the interval [0, 5].

A function f(x), its derivative \(f'(x)\), the underestimator \(\mu (x)\) of f(x), and the derivative \(\nu (x)\) of \(\mu (x)\)
Theorem 1
For any differentiable function f(x) obeying (6) the function \(\mu (x)\) defined according to (46) is an underestimator for f(x) over the interval [a, b], i.e.,
Proof
Since \(f'(x)\) is interval Lipschitz continuous on [a, b], the following two inequalities follow from (6)
for all \(x \in [a,b]\). Recalling (28) and (45), from (48) we get
Thus, for the points \(c^*\), \(d^*\) we have \(f'(c^*) - \nu (c^*) \ge 0\) and \(f'(d^*) - \nu (d^*) \le 0\). Due to continuity of the function \(f'(x) - \nu (x)\) there exists a point \(s \in [c^*, d^*]\) such that \(f'(s) - \nu (s) = 0\), i.e., \(f'(s) = \nu (s)\), see Fig. 5 for illustration.
From (28) and (45) it directly follows that
Due to the fact that \(s \in [c^*, d^*]\), we get
from where we obtain
Since \(f'(s) = \nu (s)\), we have
Thus, the expression (49) can be rewritten as
Observe that \(f'(a) + \alpha (x-a)\) and \(f'(s) + \beta (x - s)\) are two linear functions intersecting at the point \(x = c^*\). Thus, since \(\beta > \alpha \), we have
In a similar way we can prove that
Thus, the function \(\nu (x)\) can be rewritten as follows
By applying Lemma 2 to (50) we get
Then, the Newton-Leibniz formula and (51) allow us to write
for \(x \in [a,s]\) and
for \(x \in [s,b]\). On the other hand, by taking into account (46) we get
for \(x \in [s,b]\).
Finally, the inequality (47) is a direct consequence of (52) and (53). \(\square \)
4 Computational formulae for estimators and the objective ranges
The cumbersome formula (39) can be used to evaluate \(\mu (x) = \hat{\chi }(x, c^*)\) at a given point \(x \in [a,b]\). The following proposition shows that \(\mu (x)\) can be written in a more compact way.
Proposition 2
The function \(\mu (x)\) defined according to (46) can be expressed as follows
and, in its turn, the piecewise linear derivative \(\nu (x)\) of \(\mu (x)\) can be computed as follows
where \(c^*\) is calculated accordingly to (40) and \(d^* = c^* + \delta \).
Proof
Let us prove expression (55) first. According to (45), \(\nu (x) = \hat{\psi }(x, c^*)\). Then expression (55) is obtained from (28) by replacing c with \(c^*\).
Let us now prove (54). Since cases \(x \in [a,c^*)\) and \(x \in [c^*, d^*)\) in (54) coincide with respective equations in (39), it is necessary to consider only the remaining case \(x \in [d^*, b]\). According to (39) and (45) we get
Due to (46) we have \(\mu (b) = f(b)\). Thus, it follows
By subtracting (57) from (56) we obtain
The proposition has been proven. \(\square \)
The formula (54) provides a lower estimator for the function f(x). In many applications, e.g., global optimization or solving non-linear equations, one needs an estimation interval [m, M] of a function’s range over [a, b], where
Let us denote by Z a set of all zeros of the function \(\nu (x)\). Since \(\mu (x)\) is differentiable in [a, b] and \(\mu '(x) = \nu (x), x \in [a,b]\), we get
Thus, the minimum m of \(\mu (x)\) can be found by the following sequence of steps:
-
1.
Find a set Z of all roots of \(\nu (x) = 0\), \(x \in [a,b]\).
-
2.
Compute m according to (59).
The first step requires some explanation. Since \(\nu (x)\) is a piecewise linear function, finding its root is reduced to finding intersections of its segments with the horizontal line \(y = 0\) (see Fig. 5 for illustration). In the general case \(\alpha \ne 0, \, \beta \ne 0\), the set Z consists of no more then three points since the number of line segments comprising \(\nu (x)\) is three.
The situation becomes a bit more complex when \(\alpha = 0\) or \(\beta = 0\). Then some of line segments comprising \(\nu (x)\) are parallel to \(y = 0\). The intersection is either an empty set or a horizontal line segment. Within such segment \(\nu (x) = 0\) and, therefore, \(\mu (x)\) is constant. Thus it is sufficient to add one of the ends of this segment to the set Z.
In order to obtain the upper bound M from (58), observe that
where \(\hat{m}\) is a lower bound for the function \(\hat{f}(x) = -f(x)\) on interval [a, b]. Thus, M can be easily computed by applying the procedure described above to the function \(\hat{f}(x)\) and reversing the sign of the found value.
5 The accuracy of the proposed estimators
In this section, we study the accuracy of the proposed estimators. First of all, it should be mentioned that the accuracy depends largely on the tightness of the Lipschitzian interval \([\alpha , \beta ]\). We leave without proof the following obvious fact meaning that the tighter \([\alpha , \beta ]\), the better the lower estimator.
Proposition 3
Let \(\mu (x)\) and \(\tilde{\mu }(x)\) be two lower bounds constructed accordingly to (54) for Lipschitzian intervals \([\alpha , \beta ]\) and \([\tilde{\alpha }, \tilde{\beta }]\), respectively. If \([\alpha ,\beta ] \subseteq [\tilde{\alpha }, \tilde{\beta }]\) then
Let us now perform a comparison of the proposed estimator \(\mu (x)\) with the estimator defined in [35], where a second-order smooth estimator \(\mu _L(x)\) for a univariate function f(x) whose first derivative satisfies the Lipschitz condition
was proposed.
From (6) and (60) it follows that \([-L,L]\) is a Lipschitzian interval for \(f'(x)\) over [a, b]. Vice-versa, if \([\alpha , \beta ]\) is a Lipschitzian interval for \(f'(x)\) over [a, b], then \(L = \max \{|\alpha |, |\beta | \}\) satisfies (60). Thus, without loss of generality we assume the following inclusion
As was already mentioned above, the lower estimator proposed in [35] coincides with the lower estimator \(\mu (x)\) defined in (45) when \(\alpha = -L, \beta = L\). In the general case, \([\alpha , \beta ]\) can be significantly narrower than \([-L, L]\) which entails a more tight lower bound. Below we show that in some cases this difference can be arbitrary large.
Let \(\mu _L(x)\) be an estimator for f(x) constructed according to (45) with the Lipschitzian interval for the first derivative set to \([-L, L]\), where \(L = \max \{|\alpha |, |\beta | \}\). Denote the minimum of f(x), lower bounds for estimators \(\mu (x)\) and \(\mu _L(x)\) as z, m, and \(m_L\) respectively
It follows from Proposition 3 that \(m \ge m_L\). Below we construct a parametric series of examples where \(m = z\) and the ratio \(|m_L| / |m|\) can be arbitrary large. To do this consider a function defined over the interval \([-1, 1]\) as follows
where
Here r, \(\alpha \), and \(\beta \) are real numbers satisfying the following properties
Notice that from (61) it follows that \(\alpha< 0 < \beta \). Observe that
By substituting \(a = -1, b = 1\) and values (62) to (23) we get
Thus, the expression (40) can be written as follows
Due to the obvious symmetry, the minimum of \(\mu (x)\) is achieved at the point \(x = 0\). Then, from (63), (64), and (54) we get
After substituting the value of \(c^*\) to this formula we obtain
By construction the underestimator \(\mu (x)\) coincides with f(x) and thus
By substituting values of \(\alpha \) and \(\beta \) from (61) we obtain

Function f(x) coinciding with the underestimator \(\mu (x)\) (red) and underestimator \(\mu _L(x)\) (blue) for \(r = 0.45\) (left), 0.25 (center), 0.1 (right). (Color figure online)
Recall that the underestimator \(\mu _L(x)\) is obtained in the same way as \(\mu (x)\) by assuming \(\alpha = -L, \beta = L\). For this example we have \(L = \max \{|\alpha |, |\beta | \} = \beta \). Thus
Due to (65), ratio \((z - m_L) / (z - m)\) is undefined, since the bound m is exact. In order to perform a meaningful comparison, let us consider the ratio \(|m_L|/|m|\). From (66) and (67) it follows that
This value tends to \(+ \infty \) when \(r \rightarrow 0\), i.e., the bound \(m_L\) can be arbitrary worse with respect to m which is precise for this example. To illustrate this tendency underestimators \(\mu (x)\), \(\mu _L(x)\) for different values of r are shown in Fig. 6.
6 Experimental evaluation on two series of global optimization test problems
6.1 A global optimization algorithm using the new estimator
To evaluate the efficiency of the proposed estimator we have implemented a classical branch-and-bound procedure for solving the problem (1). The algorithm finds an approximate \(\varepsilon \)-solution \(x^{(\varepsilon )}\) (see (3)) in a finite number of steps (see the rest of the section for the explanation).
This branch-and-bound method (Algorithm 1) uses an auxiliary procedure get_bound (Algorithm 2) that for a given interval \([\hat{a},\hat{b}]\) constructs an underestimator g(x) (line 2), finds a point of its minimum \(\hat{c}\) (line 3), computes the objective’s value at this point and updates the record point \(x^r\) if necessary (lines 4–6).Footnote 1 Notice that different underestimators g(x) can be employed. The procedure returns a pair consisting of a minimizer \(\hat{c}\) and the corresponding lower bound \(g(\hat{c})\).

Experiments were performed for four different underestimators g(x). The first one is the classical Pijavskij piece-wise linear underestimator (see [29]) defined as follows
where l is the Lipschitz constant for the function f(x) on the interval \([\hat{a},\hat{b}]\).

The second underestimator was proposed in [6] and has the following form
where \([\gamma , \lambda ]\) is a Lipschitz interval for the function f(x) over \([\hat{a},\hat{b}]\).Footnote 2 Notice, that \([\gamma , \lambda ] \subseteq [-l, l]\). Thus, the underestimator (69) is always not worse than (68).
The third underestimator is the smooth supporting function \(\mu _L(x)\), introduced in [35] and considered in detail earlier in Sect. 5. The fourth one is the underestimator \(\mu (x)\) proposed in the present paper, see (54).
The Branch-and-Bound algorithm (Algorithm 1) takes the feasible interval [a, b] and the tolerance \(\varepsilon \) as parameters. It maintains the list of tuples \(\mathcal {L}\), initialized with a tuple (a, b, c, lb) corresponding to the the initial problem (line 2). Each tuple stores the interval ends \(\hat{a}\), \(\hat{b}\), the split point \(\hat{c}\) and the lower bound \(\hat{lb}\) for the objective function on this interval. The point \(\hat{c}\) is used to separate the interval into two smaller intervals \([\hat{a},\hat{c}]\), \([\hat{c},\hat{b}]\). The value lb is used in lower bound tests in lines 6, 8 and 12 of Algorithm 1.
The point \(\hat{c}\) is usually taken as the global minimizer of the underestimator g(x) (line 3 in Algorithm 2). Notice that \(\tilde{c}\) computed at the line 7 of Algorithm 1 may coincide with one of the interval ends. For the underestimators under consideration, in this case \(g(\tilde{c}) = f(\tilde{c})\). In all four underestimators under consideration the values of the function f(x) is obligatory computed at the interval ends and the record \(x^r\) is updated if necessary. Therefore, we get
Thus, the tuple \((\hat{a},\hat{c},\tilde{c},\tilde{lb})\) (or \((\hat{c},\hat{b},\tilde{c},\tilde{lb})\)) will not be placed to the list \(\mathcal {L}\) as failed the lower bound test at lines 9 or 13 of Algorithm 1.
The tuples are stored in the increasing order of their lower bounds. At each iteration of the main while loop (lines 3-15 of Algorithm 1) the tuple S is taken from the head of this list, i.e., the tuple with the least lower bound is selected for processing.
Featured with the considered underestimators the algorithm 1 always terminates in a finite number of steps (iterations of the while loop in lines 3–16). The proof of this fact follows easily from the general finite convergence conditions of the Branch-and-Bound scheme (see [33]) and the properties of the underestimators under consideration.
6.2 Experimental setup and numerical results
For experimental evaluation of the proposed underestimators two sets of benchmarks described in [48] have been applied. The first set, A, contains 100 Shekel test problems defined as follows
where parameters
were randomly generated within the specified intervals. The set B contains 100 reverse Shekel test problems obtained from (70) by reversing the sign of the objective function f(x). The example functions from these test sets are presented in Figs. 7 and 8.

The Shekel test function and trial points for \(\mu _P(x)\) (1), \(\mu _C(x)\) (2), \(\mu _P(x)\) (3) and \(\mu (x)\) (4) underestimators

The reverse Shekel test function and trial points for \(\mu _P(x)\) (1), \(\mu _C(x)\) (2), \(\mu _P(x)\) (3) and \(\mu (x)\) (4) underestimators
It should be mentioned that for reverse Shekel functions the global minimizer can occur at the margins of the search interval [0, 1]. These cases have been excluded from the experiments. Thus, all functions included in the set B have global minimizers being internal points of the search interval.
The Lipschitzian interval \([\gamma , \lambda ]\) used in the \(\mu _C(x)\) underestimator was computed at the beginning of a global optimization problem solution as the natural interval extension (see [32]) of the first derivative \(f'(x)\) of the objective function on the entire interval [a, b]. The value of the Lipschitz constant l used in \(\mu _P(x)\) underestimator for the objective function was assumed equal to \(\max \{|\gamma |, |\lambda | \}\).
The Lipschitzian interval \([\alpha , \beta ]\) for the derivative \(f'(x)\) was also computed once at the beginning of the benchmark problem processing as the natural interval extension of the second derivative \(f''(x)\) of the objective function on the interval [a, b]. The Lipschitz constant L for the first derivative was assumed equal to \(\max \{|\alpha |, |\beta | \}\).
The experimental results are presented in Tables 1 and 2. Table 1 contains the average number of steps (iterations of the main loop of Algorithm 1) for four underestimators \(\mu _P(x)\), \(\mu _C(x)\), \(\mu _L(x)\), and \(\mu (x)\). Figures 7 and 8 depict the trial points for two arbitrary selected functions from test sets A and B, respectively. To obtain a meaningful visualization, only each 1000th trial point is depicted, others are skipped (otherwise points become indistinguishable due to a huge number of them).
As we can see from Table 1, the average number of steps performed by the Algorithm 1 equipped with the quadratic underestimators (\(\mu _L(x)\) and \(\mu (x)\)) is in an order of magnitude less than the linear ones (\(\mu _P(x)\) and \(\mu _C(x)\)). However, it should be taken into account that iterations of methods using derivatives are heavier w.r.t. \(\mu _P(x)\) and \(\mu _C(x)\) since to compute \(\mu _L(x)\) and \(\mu (x)\) not only values of f(x) but values of \(f'(x)\) are required. It can be seen that, as expected, using the \(\mu (x)\) underestimator in average yields less number of steps w.r.t. the \(\mu _L(x)\) underestimator. However, the ratio of steps performed for these two cases differs for different benchmarks. The minimal, average, and maximal values of this ratio are given in Table 2.
Let us note, that the large number of trials is caused by a global estimation of a Lipschitz interval. If we used the local estimation instead the number of trial points would be dramatically less. The second observation is that for all the algorithms tested the reverse Shekel functions appear much more complex w.r.t. the original ones. This can be explained by the fact that a reverse Shekel function assumes values close to the global minimum for large portions of the feasible region (see Fig. 8) where the lower bound tests perform poorly.
In conclusion, experimental results confirm that: (i) smooth piece-wise quadratic estimators work better than piece-wise linear ones; (ii) the smooth piece-wise quadratic underestimator \(\mu (x)\) proposed in this paper gives a significant improvement over \(\mu _L(x)\) introduced in [35].
Data availability
Data sharing is not applicable to this article as no datasets were generated or analysed during the current study.
References
Ahmed, M.O., Vaswani, S., Schmidt, M.: Combining Bayesian optimization and Lipschitz optimization. Mach. Learn. 109, 79–102 (2020)
Archetti, F., Candelieri, A.: Bayesian Optimization and Data Science. Springer, New York (2019)
Breiman, L., Cutler, A.: A deterministic algorithm for global optimization. Math. Program. 58(1–3), 179–199 (1993)
Calvin, J.M., Chen, Y., Z̆ilinskas, A.: An adaptive univariate global optimization algorithm and its convergence rate for twice continuously differentiable functions. J. Optim. Theory Appl. 155(2), 628–636 (2012)
Calvin, J.M., Z̆ilinskas, A.: One-dimensional P-algorithm with convergence rate O(n-3+delta) for smooth functions. J. Optim. Theory Appl. 106(2), 297–307 (2000)
Casado, L.G., Martínez, J.A., García, I., Sergeyev, Ya.D.: New interval analysis support functions using gradient information in a global minimization algorithm. J. Glob. Optim. 25(4), 345–362 (2003)
Cavoretto, R., De Rossi, A., Mukhametzhanov, M.S., Sergeyev, Ya.D.: On the search of the shape parameter in radial basis functions using univariate global optimization methods. J. Glob. Optim. 79, 305–327 (2021)
Daponte, P., Grimaldi, D., Molinaro, A., Sergeyev, Ya.D.: An algorithm for finding the zero-crossing of time signals with Lipschitzean derivatives. Measurement 16(1), 37–49 (1995)
De Santis, A., Dellepiane, U., Lucidi, S., Renzi, S.: A derivative-free optimization approach for the autotuning of a forex trading strategy. Optim. Lett. 15(5), 1649–1664 (2021)
Floudas, C.A., Pardalos, P.M.: State of the Art in Global Optimization. Kluwer, Dordrecht (1996)
Gergel, V.P.: A global search algorithm using derivatives. In: Neymark, Yu.I. (Ed.) Systems Dynamics and Optimization, pp. 161–178. N. Novgorod University Press (1992)
Gergel, V.P., Barkalov, K.A., Sysoyev, A.V.: Globalizer: a novel supercomputer software system for solving time-consuming global optimization problem. Numer. Algebra Control Optim. 8(1), 47–62 (2018)
Gergel, V.P., Grishagin, V.A., Israfilov, R.A.: Local tuning in nested scheme of global optimization. Procedia Comput. Sci. 51, 865–874 (2015)
Grishagin, V.A., Israfilov, R.A., Sergeyev, Ya.D.: Convergence conditions and numerical comparison of global optimization methods based on dimensionality reduction schemes. Appl. Math. Comput. 318, 270–280 (2018)
Hamacher, K.: On stochastic global optimization of one-dimensional functions. Phys. A Stat. Mech. Appl. 354(15 August 2005), 547–557 (2005)
Hansen, P., Jaumard, B., Lu, H.: Global optimization of univariate Lipschitz functions: 1–2. Math. Program. 55, 251–293 (1992)
Jones, D.R., Perttunen, C.D., Stuckman, B.E.: Lipschitzian optimization without the Lipschitz constant. J. Optim. Theory Appl. 79, 157–181 (1993)
Kvasov, D.E., Sergeyev, Ya.D.: A univariate global search working with a set of Lipschitz constants for the first derivative. Optim. Lett. 3(2), 303–318 (2009)
Kvasov, D.E., Sergeyev, Ya.D.: Univariate geometric Lipschitz global optimization algorithms. Numer. Algebra Control Optim. 2, 113134 (2012)
Kvasov, D.E., Sergeyev, Ya.D.: Lipschitz global optimization methods in control problems. Autom. Remote Control 74(9), 1435–1448 (2013)
Kvasov, D.E., Sergeyev, Ya.D.: Deterministic approaches for solving practical black-box global optimization problems. Adv. Eng. Softw. 80, 58–66 (2015)
Lera, D., Posypkin, M., Sergeyev, Ya.D.: Space-filling curves for numerical approximation and visualization of solutions to systems of nonlinear inequalities with applications in robotics. Appl. Math. Comput. 390, 66 (2021)
Lera, D., Sergeyev, Ya.D.: Acceleration of univariate global optimization algorithms working with Lipschitz functions and Lipschitz first derivatives. SIAM J. Optim. 23(1), 508–529 (2013)
Modorskii, V.Y., Gaynutdinova, D.F., Gergel, V.P., Barkalov, K.A.: Optimization in design of scientific products for purposes of cavitation problems. In: Simos, T., Tsitouras, C. (Eds.) Proceedings of the International Conference of Numerical Analysis and Applied Mathematics (ICNAAM 2015), vol. 1738, p. 400013. AIP Publishing, NY (2016). https://doi.org/10.1063/1.4952201
Pardalos, P.M., Žilinskas, A., Žilinskas, J.: Non-convex Multi-objective Optimization. Springer (2018)
Paulavičius, R., Sergeyev, Ya.D., Kvasov, D.E., Žilinskas, J.: Globally-biased BIRECT algorithm with local accelerators for expensive global optimization. Expert Syst. Appl. 144, 113052 (2020)
Paulavičius, R., Žilinskas, J.: Simplicial Global Optimization. Springer, New York (2014)
Pintér, J.D.: Global Optimization in Action (Continuous and Lipschitz Optimization: Algorithms, Implementations and Applications). Kluwer, Dordrecht (1996)
Piyavskii, S.A.: An algorithm for finding the absolute extremum of a function. USSR Comput. Math. Math. Phys. 12(4), 57–67 (1972)
Posypkin, M., Khamisov, O.: Automatic convexity deduction for efficient function’s range bounding. Mathematics 9(2), 134 (2021)
Posypkin, M., Usov, A., Khamisov, O.: Piecewise linear bounding functions in univariate global optimization. Soft Comput. 24(23), 17631–17647 (2020)
Ratschek, H., Rokne, J.: Computer Methods for the Range of Functions. Horwood (1984)
Ratschek, H., Rokne, J.: New Computer Methods for Global Optimization. Halsted Press (1988)
Sergeyev, Ya.D.: A one-dimensional deterministic global minimization algorithm. Comput. Math. Math. Phys. 35(5), 705–717 (1995)
Sergeyev, Ya.D.: Global one-dimensional optimization using smooth auxiliary functions. Math. Program. 81(1), 127–146 (1998)
Sergeyev, Ya.D.: Univariate global optimization with multiextremal non-differentiable constraints without penalty functions. Comput. Optim. Appl. 34(2), 229–248 (2006)
Sergeyev, Ya.D.: Higher order numerical differentiation on the infinity computer. Optim. Lett. 5(4), 575–585 (2011)
Sergeyev, Ya.D.: Numerical infinities and infinitesimals: methodology, applications, and repercussions on two Hilbert problems. EMS Surv. Math. Sci. 4, 219–320 (2017)
Sergeyev, Ya.D., Candelieri, A., Kvasov, D.E., Perego, R.: Safe global optimization of expensive noisy black-box functions in the \(\delta \)-Lipschitz framework. Soft Comput. 24(23), 17715–17735 (2020)
Sergeyev, Ya.D., Daponte, P., Grimaldi, D., Molinaro, A.: Two methods for solving optimization problems arising in electronic measurements and electrical engineering. SIAM J. Optim. 10(1), 1–21 (1999)
Sergeyev, Ya.D., De Leone, R. (eds.): Numerical Infinities and Infinitesimals in Optimization. Springer, Cham (2022)
Sergeyev, Ya.D., Famularo, D., Pugliese, P.: Index branch-and-bound algorithm for Lipschitz univariate global optimization with multiextremal constraints. J. Glob. Optim. 21(3), 317–341 (2001)
Sergeyev, Ya.D., Grishagin, V.A.: A parallel algorithm for finding the global minimum of univariate functions. J. Optim. Theory Appl. 80(3), 513–536 (1994)
Sergeyev, Ya.D., Kvasov, D.E., Mukhametzhanov, M.S.: Operational zones for comparing metaheuristic and deterministic one-dimensional global optimization algorithms. Math. Comput. Simul. 141, 96–109 (2017)
Sergeyev, Ya.D., Kvasov, D.E., Mukhametzhanov, M.S.: On strong homogeneity of a class of global optimization algorithms working with infinite and infinitesimal scales. Commun. Nonlinear Sci. Numer. Simul. 59, 319–330 (2018)
Sergeyev, Ya.D., Nasso, M.C., Mukhametzhanov, M.S., Kvasov, D.E.: Novel local tuning techniques for speeding up one-dimensional algorithms in expensive global optimization using Lipschitz derivatives. J. Comput. Appl. Math. 383, 113134 (2021)
Strongin, R.G.: On the convergence of an algorithm for finding a global extremum. Eng. Cybernet. 11, 549–555 (1973)
Strongin, R.G., Sergeyev, Ya.D.: Global Optimization with Non-convex Constraints: Sequential and Parallel Algorithms. Kluwer, Dordrecht (2000)
Zhigljavsky, A., Žilinskas, A.: Stochastic Global Optimization. Springer, New York (2008)
Zhigljavsky, A., Žilinskas, A.: Bayesian and High-Dimensional Global Optimization. Springer, New York (2021)
Ziadi, R., Bencherif-Madani, A., Ellaia, R.: A deterministic method for continuous global optimization using a dense curve. Math. Comput. Simul. 178, 62–91 (2020)
Funding
Open access funding provided by Università della Calabria within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors state that there is no conflict of interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Proof of Lemma 8
Proof
Let \(c_1, c_2\) be arbitrary points in [a, b], \(c_1 < c_2\). To shorten the formulae in the rest of the proof we designate the difference between \(\hat{\psi }(x, c_1)\) and \(\hat{\psi }(x, c_2)\) as \(\Delta (x)\), i.e., \(\Delta (x) = \hat{\psi }(x, c_1) - \hat{\psi }(x, c_2)\). To prove the Lemma we need to show that
According to (26) define the respective values of d for points \(c_1, c_2\) as follows
Recall, that due to (23) \(\delta \) does not depend on \(c_1, c_2\). The point \(c_2\) may locate before or after \(d_1\) thereby producing two possible orders (see Fig. 9) of points \(c_1, d_1, c_2, d_2\): \(a \le c_1 \le c_2 \le d_1 \le d_2 \le b\) and \(a \le c_1 \le d_1 < c_2 \le d_2 \le b\), cases A and B, respectively. In both of them the interval [a, b] is composed of five adjacent sub-intervals such that both \(\hat{\psi }(x, c_1)\) and \(\hat{\psi }(x, c_2)\) are linear in x within each of these sub-intervals. Below we consider all of them separately and for each sub-interval the inequality (71) is proven for all x within it.

Two possible orders of the points \(c_1, c_2, d_1, d_2\): \(c_2 \le d_1\) (case A, left), \(c_2 > d_1\) (case B, right)
Case A. Let \(a \le c_1 \le c_2 \le d_1 \le d_2 \le b\). In this case, the interval [a, b] is a union of five adjacent intervals \([a, c_1]\), \([c_1, c_2]\), \([c_2, d_1]\), \([d_1, d_2]\), and \([d_2, b]\). Let us consider them separately.
A.1. \(x \in [a, c_1]\). In this case, according to (27), we have
A.2. \(x \in [c_1, c_2]\). In this case, it follows from (27) that
Thus, we obtain
Since \(c_1 \le x \le c_2\), we get \(0 \le \Delta (x) \le (\beta - \alpha )(c_2 - c_1)\).
A.3. \(x \in [c_2, d_1]\). In this case, it follows from (27) that
Therefore, we get
A.4. \(x \in [d_1, d_2]\). In this case, from (27) we get
Thus, we obtain
Recalling that \(\delta = d_1 - c_1\), we get
Then, from \(d_1 \le x \le d_2\) and \(c_2 - c_1 = d_2 - d_1\) it follows that \(0 \le x - d_1 \le c_2 - c_1\). We obtain that in this case (71) is also true.
A.5. \(x \in [d_2, b]\). In this case, by applying (28), we get \(\hat{\psi }(x, c_1) = \hat{\psi }(x, c_2) = f'(b) + \alpha (x - b)\) and \(\Delta (x) = 0\).
Case B. \(a \le c_1 \le d_1 < c_2 \le d_2 \le b\). In this case, the interval [a, b] is a union of five adjacent intervals \([a, c_1]\), \([c_1, d_1]\), \([d_1, c_2]\), \([c_2, d_2]\), and \([d_2, b]\). Let us consider them separately.
B.1. \(x \in [a, c_1]\). Similar to A.1, in this case \(\Delta (x) = 0\).
B.2. \(x \in [c_1, d_1]\). Similar to A.2 we can show that (71) holds in this case.
B.3. \(x \in [d_1, c_2]\). In this case
Thus \(\Delta (x) = (\beta - \alpha ) \delta \). Due to (25), \(0 < \delta \). According to the case B’s assumptions, \(d = d_1 - c_1 \le c_2 - c_1\). Thus, we obtain that in this case (71) is also true.
B.4. \(x \in [c_2, d_2]\). This case is similar to A.4. Thus, it follows again that (71) is valid.
B.5. \(x \in [d_2, b]\). Similar to A.5, \(\Delta (x) = 0\).
We have proven the inequality (71) for each of adjacent intervals comprising [a, b]. Thus, (71) holds for the whole interval [a, b], i.e., the inequality (71) is valid. This observation concludes the proof. \(\square \)
Appendix B: Proof of Lemma 9
Proof
Let us consider the following three cases \(a \le x < c\), \(c \le x < d\), and \(d \le x \le b\) separately.
Let \(a \le x < c\). Accordingly to (37) and (28) we get
Let \(c \le x < d\). In accordance with (37) and (28) we get
Let \(d \le x \le b\). According to (37) and (28) we get
This completes the proof. \(\square \)
Appendix C: Proof of Proposition 1
Proof
According to the Newton-Leibniz formula, we can write
From this equation and (35) it follows that
Notice, that from (37), since \(a\le c \le b - \delta \), we have
and recalling (38) we finally obtain
Due to Corollary 1, \(\xi (c)\) is a continuous monotonic non-increasing function of c. Thus, it follows from (74) that there is a point \(c^* \in [a, b - \delta ]\) such that \(\xi (c^*) = f(b)\).
The value \(c^*\) can be found analytically as a solution of the equation
as follows. By recalling (38) and substituting \(x = b\) to (39) we obtain
From (26), we have
By using (26) again, from (76) and (77) we get
This formula can be simplified by recalling (23) as follows
By using this result we can rewrite formula (75) as follows
Leaving in the left part of the equation only terms depending on c we obtain the following equation
Recall that \(\alpha < \beta \) and, due to (25), \(\delta > 0\). Thus \(\delta (\alpha - \beta ) \ne 0\) and we can safely divide both sides of (78) by this value and obtain
To obtain (40) we transform equation (79) as follows
After regrou** terms in the equation above we get
Now observe that due to (23)
By substituting (81) to (80) we obtain
Thus, formula (40) has been proven. The uniqueness of \(c^*\) is obvious from the proof. \(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Posypkin, M.A., Sergeyev, Y.D. Efficient smooth minorants for global optimization of univariate functions with the first derivative satisfying the interval Lipschitz condition. J Glob Optim (2022). https://doi.org/10.1007/s10898-022-01251-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10898-022-01251-y