
Abstract
In this work, we tackle the problem of estimating the density \( f_X \) of a random variable \( X \) by successive smoothing, such that the smoothed random variable \( Y \) fulfills the diffusion partial differential equation \( (\partial _t - \Delta _1)f_Y(\,\cdot \,, t) = 0 \) with initial condition \( f_Y(\,\cdot \,, 0) = f_X \). We propose a product-of-experts-type model utilizing Gaussian mixture experts and study configurations that admit an analytic expression for \( f_Y (\,\cdot \,, t) \). In particular, with a focus on image processing, we derive conditions for models acting on filter, wavelet, and shearlet responses. Our construction naturally allows the model to be trained simultaneously over the entire diffusion horizon using empirical Bayes. We show numerical results for image denoising where our models are competitive while being tractable, interpretable, and having only a small number of learnable parameters. As a by-product, our models can be used for reliable noise level estimation, allowing blind denoising of images corrupted by heteroscedastic noise.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The problem of estimating the probability density \( f_X: \mathcal {X} \rightarrow \mathbb {R}\) of a random variable \( X \) in \( \mathcal {X} \), given a set of data samples \( \{ x_i \}_{i=1}^N \) drawn from \( f_X \) has received significant attention in the recent years [1,2,3,4,5]. The applications range from purely generative purposes [5, 6], over classical image restoration problems [7,8,9] to medical image reconstruction [10,11,12]. This is a challenging problem in high dimension (e.g., for images of size \( M \times N \), i.e., \( \mathcal {X} = \mathbb {R}^{M \times N} \)), due to extremely sparsely populated regions [13]. A fruitful approach is to estimate the density at different times when undergoing a diffusion process [3, 5]. Intuitively, the diffusion equilibrates high- and low-density regions over time, thus easing the estimation problem.
Let \( Y_t \) (carelessly) denote the random variable whose distribution is defined by diffusing \( f_X \) for some time \( t \). We denote the density of \( Y_t \) by \( f_Y(\,\cdot \,, t) \), which fulfills the diffusion partial differential equation (PDE) \( (\partial _t - \Delta _1)f_Y(\,\cdot \,, t) = 0 \) with initial condition \( f_Y(\,\cdot \,, 0) = f_X \). The empirical Bayes theory [14] provides a machinery for reversing the diffusion PDE: Given an instantiation of the random variable \( Y_t \), the Bayesian least squares estimate of \( X \) can be expressed solely using \( f_Y(\,\cdot \,, t) \). Importantly, this holds for all positive \( t \), as long as \( f_Y \) is properly constructed.
In practice, we wish to have a parametrized, trainable model of \( f_Y \), say \( f_\theta \) where \( \theta \) is a parameter vector, such that \( f_Y(x, t) \approx f_\theta (x, t) \) for all \( x \in \mathcal {X} \) and all \( t \in [0, \infty ) \). Recent choices [3, 15] for the family of functions \( f_\theta (\,\cdot \,, t) \) were of practical nature: Instead of an analytic expression for \( f_\theta \) at any time \( t \), authors proposed a time-conditioned network in the hope that it can learn to behave as if it had undergone the diffusion PDE. Further, instead of worrying about the normalization \( \int _\mathcal {X} f_Y(\,\cdot \,, t) = 1 \) for all \( t \in [0, \infty ) \), usually they directly estimate the score \( -\nabla _{\hspace{-2.22214pt}1} \log f_Y(\,\cdot \,, t): \mathcal {X} \rightarrow \mathcal {X} \) with some network \( s_\theta (\,\cdot \,, t): \mathcal {X} \rightarrow \mathcal {X} \). This has the advantage that normalization constants vanish, but usually the constraint \( \partial _j (s_\theta (\,\cdot \,, t))_i = \partial _i (s_\theta (\,\cdot \,, t))_j \) is not enforced in the architecture of \( s_\theta \). Thus, \( s_\theta (\,\cdot \,, t) \) is in general not the gradient of a scalar function (the negative-log-density it claims to model).
In contrast to this line of works, in this paper we pursue a more principled approach. Specifically, we leverage products of Gaussian mixure model (GMM) experts to model the distribution of responses of transformations acting on natural images. Here, an expert is a one-dimensional distribution modeling certain characteristics of the random variable \( Y_t \) (the terminology is borrowed from [1]). In particular, we derive conditions under which \( f_Y(\,\cdot \,, t) \) can be expressed analytically from \( f_Y(\,\cdot \,, 0 ) \). We call our model product of Gaussian mixture diffusion model (PoGMDM) to reflect the building blocks: products of GMM experts and diffusion. The conditions arising for a model acting on filter responses naturally lead to the consideration of the wavelet transformation. Analyzing the conditions for a convolutional model naturally leads to the shearlet transformation. Thus, we present three models that utilize transformations that are extremely popular in image processing: linear filters, the wavelet transformation and the shearlet transformation. To the best of our knowledge, this paper is the first in proposing strategies to learn patch-based and convolutional priors in a unified framework.
1.1 Contributions
This paper constitutes an extension to our previous conference publication [7], in which we introduced the idea of explicit diffusion models and showed preliminary numerical results. In this work, we present two additional explicit diffusion models and derive conditions under which they fulfill the diffusion PDE. In particular, the derived conditions naturally lead to models that can leverage transformations that are well known and popular in image processing: wavelets and shearlets. For all models, we show how the associated transformation, along with the diffusion model for the density, can be learned. We provide numerical results for denoising and extend our analysis regarding noise level estimation and blind heteroscedastic denoising. Our contributions can be summarized as follows:
-
We derive conditions under which products of GMM experts acting on filter, wavelet, and shearlet responses obey the diffusion PDE.
-
We show how the GMM experts, along with the corresponding transformations, can be learned and provide algorithms to solve the arising sub-problems.
-
We evaluate the learned models on the prototypical image restoration problem: denoising.
Code for training, validation, and visualization, along with pre-trained models is available at https://github.com/VLOGroup/PoGMDM.
This paper is organized as follows: In Sect. 2, we give background information on diffusion and how it can be used for parameter estimation of learned densities. This section also encompasses an overview of related work. In Sect. 3, we introduce the backbone of our models and derive conditions under which they obey the diffusion PDE. We demonstrate the practical applicability of our models in Sect. 4 with numerical experiments. We explore alternative parametrizations and possible extensions of our models in Sect. 5 and finally conclude the paper, providing future research directions, in Sect. 6.
1.2 Notation and Preliminaries
For the sake of simplicity, throughout this article, we assume that all distributions admit a density with respect to the Lebesgue measure, although the numerical experiments only assume access to an empirical distribution. Thus, we use the terms distribution and density interchangeably. In Sect. 3, we define normal distributions that are supported on a subspace (e.g., the zero-mean subspace \(\{ x \in \mathbb {R}^n: \langle \mathbbm {1}_{\mathbb {R}^n}, x \rangle _{\mathbb {R}^n} = 0 \}\)). In this case, we restrict our analysis to the support, which is theoretically supported by the disintegration theorem [16]. We use the symbols \( \mathbb {R}_{+} \) and \( \mathbb {R}_{++} \) to denote the non-negative real numbers \( \{ x \in \mathbb {R}: x \ge 0 \} \) and positive reals numbers \( \{ x \in \mathbb {R}: x > 0 \} \), respectively. We denote with \( \langle \,\cdot \,, \,\cdot \,\rangle _{\mathbb {R}^n} {: \mathbb {R}^n \times \mathbb {R}^n \rightarrow \mathbb {R}: (x, y) \mapsto \sum _{i=1}^n x_i y_i} \) the standard inner product in the Euclidean space \( \mathbb {R}^n \), and with \( \Vert \,\cdot \,\Vert ^2: \mathbb {R}^n \rightarrow \mathbb {R}_+ \) the map \( x \mapsto \langle x, x\rangle _{\mathbb {R}^n}\). In addition, \( (\,\cdot \,\otimes \,\cdot \,): \mathbb {R}^n \times \mathbb {R}^n \rightarrow \mathbb {R}^{n \times n} \) is the standard outer product in \( \mathbb {R}^n \): \( (x \otimes y)_{ij} = x_i y_j \). \({\text {conj}}\) denotes element-wise complex conjugation. Let \( \mathcal {Q} \subset \mathcal {H} \) be a (not necessarily convex) subset of a Hilbert space \( \mathcal {H} \). We define by \( {{\,\textrm{proj}\,}}_\mathcal {Q}: \mathcal {H} \rightarrow {\mathcal {H}} \) the orthogonal projection onto the set \( \mathcal {Q} \). With slight abuse of notation, we ignore that this is a multivalued map in general. \( L^2(\Omega ) \) denotes the standard Lebesgue space on a domain \( \Omega \subset \mathbb {R}^n \). Lastly, \( \textrm{Id}_{\mathcal {H}} \) and \( \mathbbm {1}_\mathcal {H} \) denote the identity map and the one-vector in \( \mathcal {H} \), respectively.
2 Background
In this section, we first emphasize the importance of diffusion in density estimation (and sampling) in high dimensions. Then, we detail the relationship between diffusing the density function, empirical Bayes, and denoising score matching [17].
2.1 Diffusion Eases Density Estimation and Sampling
Let \( f_X \) be a density on \( \mathcal {X} \subset \mathbb {R}^d\). A major difficulty in estimating \( f_X \) with parametric models is that \( f_X \) is extremely sparsely populated in high dimensional spaces,Footnote 1 i.e., \( d\gg 1 \). This phenomenon has many names, e.g., the curse of dimensionality or the manifold hypothesis [13]. Thus, the learning problem is difficult, since meaningful gradients are rare. Conversely, let us for the moment assume access to a model \( \tilde{f}_X \) that approximates \( f_X \) well. In general, it is still very challenging to generate a set of points \( \{ x_i \}_{i=1}^I \) such that we can confidently say that the associated empirical density \( \frac{1}{I} \sum _{i=1}^I \delta _{x_i} \) approximates \( \tilde{f}_X \) (let alone \(f_X\)) well. This is because, in general, there does not exist a procedure to directly draw samples from \( \tilde{f}_X \), and Markov chain Monte Carlo methods are prohibitively slow in practice, especially for multimodal distributions in high dimensions [3].
The diffusion PDE or heat equation
equilibrates the density \( f_X \), thus mitigating the challenges outlined above. Here, \( \partial _t \) denotes the standard partial derivative with respect to time \( \frac{\partial }{\partial t} \) and \( \Delta _1 = {{\,\mathrm{\textrm{Tr}}\,}}\circ \nabla _{\hspace{-2.22214pt}1}^2 \) is the Laplace operator, where the \( 1 \) indicates its application to the first argument. We detail the evolution of \( f_X \) under this diffusion PDE and relations to empirical Bayes in Sect. 2.2.
Learning \( f(\,\cdot \,, t) \) for \( t \ge 0 \) is more stable since the diffusion “fills the space” with meaningful gradients [3]. Of course, this assumes that for different times \( t_1 \) and \( t_2 \), the models of \( f(\,\cdot \,, t_1) \) and \( f(\,\cdot \,, t_2) \) are somehow related to each other. As an example of this relation, the recently popularized noise-conditional score-network [3] shares convolution filters over time, but their input is transformed through a time-conditional instance normalization. In this work, we make this relation explicit by considering a family of functions \( f(\,\cdot \,, 0) \) for which \( f(\,\cdot \,, t) \) can be expressed analytically.
For sampling, \( f(\,\cdot \,, t) \) for \( t > 0 \) can help by gradually moving samples toward high-density regions of \( f_X \), regardless of initialization. To utilize this, a very simple idea with relations to simulated annealing [18] is to have a pre-defined time schedule \( t_T> t_{T-1}> \cdots> t_{{0}} > 0 \) and sample \( f(\,\cdot \,, t_i) \), \( i = T, \dotsc , 0 \) (e.g. with Langevin Monte Carlo [19]) successively [3]. In [15], instead of considering discrete time steps, the authors propose to model the sampling procedure as a continuous-time stochastic differential equation. We note that the diffusion PDE (1) on the densities corresponds to the stochastic differential equation
on the random variables, where \( W \) is the standard Wiener process. This is known as the variance exploding stochastic differential equation in the literature.
2.2 Diffusion, Empirical Bayes, and Denoising Score Matching
In this section, similar to the introduction, we again adopt the interpretation that the evolution in (1) defines the density of a random variable \( Y_t \). That is, \( Y_t \) is a random variable with probability density \( f_Y(\,\cdot \,, t) \), which fulfills \( (\partial _t - \Delta _1) f_Y(\,\cdot \,, t) = 0 \) and \( f_Y(\,\cdot \,, 0) = f_X \). It is well known that Green’s function of (1) is a Gaussian (see, e.g., [20]) with zero mean and covariance \( 2t\textrm{Id}\). In other words, for \( t > 0 \) we can write \( f_Y(\,\cdot \,, t) = G_{0,2t\textrm{Id}_{{\mathcal {X}}}} * f_X \), where
Thus, the diffusion PDE constructs a (linear) scale space in the space of probability densities and we refer to \( Y_t \) (respectively, \( f_{Y_t} \)) as the smoothed random variable (respectively, density). Equivalently, in terms of the random variables, we can write \( Y_t = X + \sqrt{2t}N \) where \( N \) is a random variable with normal distribution \( \mathcal {N}(0, \textrm{Id}_{\mathcal {X}}) \). Next, we show how to estimate the corresponding instantiation of \( X \) which has “most likely” spawned an instantiation of \( Y_t \) using empirical Bayes.
In the school of empirical Bayes [14], we try to estimate a clean random variable given a corrupted instantiation, using only knowledge about the density of the random variable corresponding to the corrupted instance. In particular, for our setup we have a corruption model
with \( x \sim f_X \) and \( \eta \sim \mathcal {N}(0, \textrm{Id}_{\mathcal {X}})\). It is well known that the Bayesian minimum mean-squared-error (MMSE) estimate is the conditional mean, i.e., the map \( y_t \mapsto \int x f_{X \mid Y_t}(x \mid y_t)\,\textrm{d}x \). In classical Bayes theory, such a map would be constructed by utilizing Bayes theorem, i.e., writing \( f_{X \mid Y_t} = \frac{f_{Y_t\mid X}f_{X}}{f_{Y_t}} \) and choosing an appropriate prior \( f_{X} \). However, a classical result from empirical Bayes estimation reveals that a map \( y_t \mapsto \int x f_{X \mid Y_t}(x \mid y_t)\,\textrm{d}x \) can be constructed only assuming access to the smoothed density \( f_{Y_t} \) without any reference to the prior \( f_X \). This result is known as the Miyasawa estimate [21] or Tweedie’s formula [22, 23] and we derive it here for completeness.
First, by the corruption model (4) we can write
where we use the relation \( \sigma = \sqrt{2t} \), and thus by Bayes theorem it follows that
Taking the gradient w.r.t. \( y \) and multiplying by \( \sigma ^2 \) yields
and after dividing by \( f_{Y_t} \) it follows that
where we used the definition of conditional densities, i.e., that \( f_{X \mid Y_t} = \frac{f_{X, Y_t}}{f_{Y_t}} \). Finally, by noting that \( \frac{\nabla f_{Y_t}}{f_{Y_t}} = \nabla \log f_{Y_t} \), the above can be rewritten as
We refer to the work of Raphan and Simoncelli [23] for an empirical Bayes theory encompassing a more general family of corruptions. They refer to this type of estimator more generally as nonparametric empirical Bayes least squares (NEBLS).
We illustrate the idea of empirical MMSE estimation on a toy example in Fig. 1, where the data distribution consists of Dirac measures \( f_X = \sum _{i=1}^6 w_i \delta _{x_i} \) with
The figure illustrates that that \( f_{Y_t} \) approaches a simple form as \( t \) approaches infinity. Indeed, it has been shown [24] that \( f_{Y_t} \) is log-concave for large enough \( t \), and \(-\log f_{Y_t}\) approaches a quadratic function.

Diffusion of an empirical density consisting of the weighted Dirac measures \( \sum _{i=1}^6 w_i \delta _{x_i} \) specified in (10) at times \( t \in \{ {0.008}, {0.078}, {0.3} \} \). The arrows show the empirical Bayes estimate \( y \mapsto y + 2t \nabla \log {f}_{Y_t}(y) \). As \( t \) approaches infinity, \( {f}_{Y_t} \) becomes log-concave and \(-\log f_{Y_t}\) approaches a quadratic function
Recently, (9) has been used for parameter estimation [15, 17]: Let \( \{ x_i \}_{i=1}^I \) be a dataset of \( I \) samples drawn from \( f_X \) and let \( Y_t \) be governed by diffusion. Additionally, let \( f_\theta : \mathcal {X} \times [0, \infty ) \rightarrow \mathbb {R}_+ \) denote a parametrized model for which we wish that \( f_\theta (\,\cdot \,, t) \approx f_{Y_t} \), for all \( t > 0 \). Then, both the left- and right-hand side of (9) are known—in expectation. This naturally leads to the loss function
for estimating \( \theta \) such that \( f_\theta (\,\cdot \,, t) \approx f_{Y_t} \) for all \( t > 0 \). Here, \( f_{X, Y_t} \) denotes the joint distribution of the clean and smoothed random variables and \( \Theta \) describes the set of feasible parameters. This learning problem is known as denoising score matching [15, 17, 25].
3 Methods
In this section, we first introduce one-dimensional GMMs as the backbone of our model and recall some properties that are needed for the analysis in the following subsections. Then, we detail how we can utilize PoGMDMs based on filter, wavelet, and shearlet responses to model the distribution of natural images. For all models, we present assumptions under which they obey the diffusion PDE.
The backbone of our models is the one-dimensional GMM expert \( \psi _j: \mathbb {R}\times \triangle ^L \times [0, \infty ) \rightarrow \mathbb {R}_+ \) with \( L \) components of the form
The weights of each expert \( w_j = (w_{j1}, \dotsc , w_{jL})^\top \) must satisfy the unit simplex constraint, i.e., \( w_j \in \triangle ^L \), \( \triangle ^L = \{ x \in \mathbb {R}^L: x \ge 0, \langle \mathbbm {1}_{\mathbb {R}^L}, x \rangle _{\mathbb {R}^L} = 1 \} \). Although not necessary, we assume for simplicity that all experts \( \psi _j \) have the same number of components and the discretization of their means \( \mu _l \) over the real line is shared and fixed a priori (for details see Sect. 4.1).
The main contribution of our work is to show that, under certain assumptions, it suffices to adapt the variances of the individual experts to implement the diffusion of a model built through multiplying experts of the form (12). In detail, we show that the variance \( \sigma _j^2: [0, \infty ) \rightarrow \mathbb {R}_+ \) of the \( j \)-th expert can be modeled as
where \( \sigma _0 {> 0} \) is chosen a priori to support the uniform discretization of the means \( \mu _l \) and \( c_j \in \mathbb {R}_{++} \) are derived from properties of the product model such that it obeys the diffusion PDE (1).
In the following subsections we exploit two well-known properties of GMMs to derive how to adapt the variance \( \sigma _j^2(t) \) of each expert with diffusion time \( t \), such that the product model obeys the diffusion PDE: First, up to normalization, the product of GMMs is again a GMM (see, e.g., [26]). This allows us to work on highly expressive models that enable efficient evaluations due to factorization. Second, we use the fact that there exists an analytical solution to the diffusion PDE if \( f_X \) is a GMM: Green’s function associated with the linear isotropic diffusion PDE (1) is a Gaussian with isotropic covariance \( 2t \textrm{Id} \). Due to the linearity of the convolution, it suffices to analyze the convolution of individual components of the product model, which is just the convolution of two Gaussians. Using previous notation, if \( X \) is a random variable with normal distribution \( \mathcal {N}(\mu _X, \Sigma _X) \), then \( Y_t \) follows the distribution \( \mathcal {N}(\mu _X, \Sigma _X + 2t\textrm{Id}) \). In particular, the mean remains unchanged and it suffices to adapt the covariance matrix with the diffusion time.
In what follows, we discuss three product models whose one-dimensional GMM experts act on filter, wavelet, and shearlet responses. In particular, we present conditions under which the diffusion of the product model can be implemented by adapting the variances of the one-dimensional GMM experts. For all three models, we give an analytic expression for the constants \( c_j \) in (13).
3.1 Patch Model
In this section, we approximate the distribution of image patches \( p \in \mathbb {R}^a \) of size \( a = b\times b \) by a product of \( J \in \mathbb {N} \) GMM experts acting on filter responses. In detail, the model is of the form
Each GMM expert \( \psi _j: \mathbb {R}\times \triangle ^L \times [0, \infty ) \rightarrow \mathbb {R}_+ \) for \( j=1,\ldots ,J \) models the distribution of filter responses \( \mathbb {E}_{p_t\sim f_{Y_t}} {\bigl [} \delta (\,\cdot \,- \langle k_j, p_t \rangle _{\mathbb {R}^a}) {\bigr ]} \) of the associated filters \( k_j \in \mathbb {R}^a \) for all \( t > 0 \). We denote with \( Z(\{ k_j \}_{j=1}^J{,\sigma _0, t}) \) the partition function such that \( f^{\textrm{filt}}_\theta \) is properly normalized. In this model, we can summarize the learnable parameters \(\theta = \{ (k_j, w_j) \}_{j=1}^J \).
First, the following theorem establishes the exact form of (12) as a GMM on \( \mathbb {R}^a \). The covariance matrix and the means are endowed with the subscript \( \mathbb {R}^a \) to emphasize that the resulting GMM models patches of this size; The models based on wavelet and shearlet responses discussed later (Sects. 3.2 and 3.3, respectively) can be applied to images of arbitrary size, which we emphasize by using the subscript \( \mathbb {R}^n \). We denote with \( \hat{l}: \{ 1, \dotsc , J \} \rightarrow \{ 1, \dotsc , L \} \) a fixed but arbitrary selection from the index set \( \{ 1, \dotsc , L \} \).
Theorem 1
\( f^{\textrm{filt}}_\theta (\,\cdot \,, 0) \) is a homoscedastic GMM on \( \mathbb {R}^a \) with \( L^J \) components and precision matrix
The mean of the component identified by the choice of the index map \( \hat{l} \) has the form
Proof
By definition,
The general component of the above is uniquely identified by the choice of the map \( \hat{l} \) as
To find \( (\Sigma _{\mathbb {R}^a})^{-1} \), we match the gradient of the familiar quadratic form: Motivated by \( \nabla _{\hspace{-2.22214pt}p} \Vert p - \mu _{\mathbb {R}^a,\hat{j}}\Vert ^2_{\Sigma _{\mathbb {R}^a}^{-1}} / 2 = \Sigma _{\mathbb {R}^a}^{-1} (p - \mu _{\mathbb {R}^a,\hat{l}}) \) we find that \( \nabla _{\hspace{-2.22214pt}p} \bigl ( \frac{1}{2\sigma _0^2} \sum _{j=1}^J (\langle k_j, p \rangle _{\mathbb {R}^a} - \mu _{\hat{l}(j)})^2 \bigr ) = \frac{1}{\sigma _0^2} \sum _{j=1}^J \bigl ( (k_j \otimes k_j) p - k_j \mu _{\hat{l}(j)}\bigr ) \). From the first term, we immediately identify \( (\Sigma _{\mathbb {R}^a})^{-1} = \frac{1}{\sigma _0^2} \sum _{j=1}^J (k_j \otimes k_j) \), and we find \( \mu _{\mathbb {R}^a, \hat{l}} \) by left-multiplying \( \Sigma _{\mathbb {R}^a} \) onto \( \sum _{j=1}^J k_j \mu _{\hat{l}(j)} \). \(\square \)
The next theorem establishes a tractable analytical expression for the diffusion process under the assumption of pair-wise orthogonal filters, that is
Theorem 2
(Patch diffusion) Under assumption (19), \( f^{\textrm{filt}}_\theta (\,\cdot \,, t) \) satisfies the diffusion PDE \( (\partial _t - \Delta _1) f^{\textrm{filt}}_\theta (\,\cdot \,, t) = 0 \) if \( \sigma _j^2(t) = \sigma _0^2 + \Vert k_j\Vert ^2 2t \).
Proof
Assuming (19), the Eigendecomposition of the precision matrix can be trivially constructed. In particular, \( (\Sigma _{\mathbb {R}^a})^{-1} = \sum _{j=1}^J \frac{\Vert k_j\Vert ^{2}}{\sigma _0^2} (\frac{k_j}{\Vert k_j\Vert } \otimes \frac{k_j}{\Vert k_j\Vert }) \), hence \( \Sigma _{\mathbb {R}^a} = \sum _{j=1}^J \frac{\sigma _0^2}{\Vert k_j\Vert ^{2}} (\frac{k_j}{\Vert k_j\Vert } \otimes \frac{k_j}{\Vert k_j\Vert }) \). As discussed in Sect. 2.2, \( \Sigma _{\mathbb {R}^a} \) evolves as \( \Sigma _{\mathbb {R}^a} \mapsto \Sigma _{\mathbb {R}^a} + 2t\textrm{Id}_{\mathbb {R}^a} \) under diffusion. Equivalently, on the level of Eigenvalues, \( \frac{\sigma _0^2}{\Vert k_j\Vert ^{2}} \mapsto \frac{\sigma _0^2 + 2t\Vert k_j\Vert ^{2}}{\Vert k_j\Vert ^{2}} \) for all \( j = 1, \ldots , J \). Recall that \( \sigma _0^2 \) is just \( \sigma _j^2(0) \). Thus, \( f^{\textrm{filt}}_\theta (\,\cdot \,,t) \) satisfies the diffusion PDE if \( \sigma _j^2(t) = \sigma _0^2 + \Vert k_j\Vert ^2 2t \). \(\square \)
Corollary 1
With assumption (19), the experts \( \psi _j(\,\cdot \,, w_j, t) \) in (14) model the marginal distribution of the random variable \( U_{j, t} = \langle k_j, Y_t \rangle \). In addition, \({f^{\text {filt}}_{\theta }} \) is normalized when \( Z(\{ k_j \}_{j=1}^J{, \sigma _0, t}) = \Bigl ((2\pi )^a \prod _{j=1}^J \frac{\sigma _0^2 + 2t\Vert k_j\Vert ^2}{\Vert k_j\Vert ^2}\Bigr )^{\frac{1}{2}} \).
Proof
We first show that \( \psi _j(\,\cdot \,, w_j, t) \) model the marginal distribution of the random variable \( U_{j, t} = \langle k_j, Y_t \rangle \). Consider one component of the resulting homoscedastic GMM: \( \hat{Y}_t \sim \mathcal {N}(\mu _{\mathbb {R}^a,\hat{l}}, \Sigma _{\mathbb {R}^a} + 2t\textrm{Id}_{\mathbb {R}^a}) \). The distribution of \( \hat{U}_{j, t} = \langle k_j, \hat{Y}_t \rangle \) is \( \hat{U}_{j, t} \sim \mathcal {N}(k_j^\top \mu _{\mathbb {R}^a,\hat{l}}, k_j^\top (\Sigma _a + 2t\textrm{Id}_a) k_j) \) (see e.g. [27] for a proof). Under our orthogonality assumptions, this simplifies to \( \mathcal {N}(\mu _{\hat{l}(j)}, \sigma _0^2 + 2t\Vert k_j\Vert ^2) \). The claim follows from the linear combination of the different components.
The normalization constant is the classical normalization of a Gaussian, which requires the pseudo-determinant of \( \Sigma _{\mathbb {R}^a} \) [16]. The pseudo-determinant is easily calculated by the product of the Eigenvalues outlined in Theorem 2. \(\square \)
3.2 Wavelet Model
The key ingredient in the previous section was the orthogonality of the filters. In other words, the filter bank \( \{ k_j \}_{j=1}^J \) forms an orthogonal (not necessarily orthonormal) basis for (a subspace of) \( \mathbb {R}^a \). In this section, we discuss the application of explicit diffusion models in another well-known orthogonal basis: Wavelets. In what follows, we briefly discuss the main concepts of the discrete wavelet transformation needed for our purposes. For the sake of simplicity, we stick to the one-dimensional case but note that the extension to two dimensions is straight forward, see e.g. [28, Chapter 4.4]. The following is largely adapted from [28], we refer the reader to this and [29, 30] for information on the extension to two-dimensional signals as well as efficient implementations using the fast wavelet transformation.
3.2.1 The Discrete Wavelet Transformation
Let \( \omega \in L^2(\mathbb {R}) \) be a wavelet satisfying the admissibility condition
The set of functions
forms an orthonormal basis of \( L^2(\mathbb {R}) \) under certain conditions that we now recall. Let \( (V_j)_{j\in \mathbb {Z}} \) be a multiscale analysis with generator or scaling function \( \phi \in V_0 \), i.e., \( \{ T_k \phi : k \in \mathbb {Z} \} \) form an orthonormal basis of \( V_0 \) (\( T_k \) is a translation operator \( (T_k \phi )(x) = \phi (x + k) \)). The scaling property
of the multiscale analysis \( (V_j)_{j\in \mathbb {Z}} \) implies that the functions \( \phi _{{j}, k} = 2^{-j/2}\phi (2^{-j}\,\cdot \,- k) \), \( k \in \mathbb {Z} \) form an orthonormal basis of \( V_j \). Further, the scaling property implies that \( \phi \in V_{-1} \) and since \( \phi _{-1, k} \) form an orthonormal basis of \( V_{-1} \), we have that
with \( h_k = \langle \phi , \phi _{-1, k} \rangle _{L^2(\mathbb {R})} \). We define the detail or wavelet spaces \( W_j \) as the orthogonal complements of the approximation spaces \( V_j \) in \( V_{j-1} \), i.e.,
From this follows that \( V_j = \bigoplus \limits _{m\ge j+1} W_m \) and due to the completeness of \( V_j \), that \( \bigoplus \limits _{m \in \mathbb {Z}} W_m = L^2(\mathbb {R}) \). By the orthogonality, we have that \( {{\,\textrm{proj}\,}}_{V_{j-1}} = {{\,\textrm{proj}\,}}_{V_j} + {{\,\textrm{proj}\,}}_{W_j} \) and hence \( {{\,\textrm{proj}\,}}_{W_j} = {{\,\textrm{proj}\,}}_{V_{j-1}} - {{\,\textrm{proj}\,}}_{V_j} \). Thus, any \( u \in L^2(\mathbb {R}) \) can be represented as
justifying the name multiscale analysis. Then (see [28, Theorem 4.67] for details) \( \omega \in V_{-1} \) defined by
is a wavelet, \( \{ \omega _{j,k}: k \in \mathbb {Z} \} \) is an orthonormal basis of \( W_j \) and in particular the construction (21) is an orthonormal basis of \( L^2(\mathbb {R}) \).
3.2.2 Modeling Wavelet Coefficients
In this section, we describe how we can utilize a product of GMM experts to model the distribution of wavelet responses. For the subsequent analysis, first observe that by (24) the detail spaces (and the approximation spaces) are orthogonal. Utilizing the shorthand notation
since \( \mathcal {W}_j \) is an orthogonal projection, it satisfies the properties
where \( \mathcal {W}_j|_{W_j} \) denotes the restriction of \( \mathcal {W}_j \) to \( W_j \).
As in the previous section, we model the wavelet responses with Gaussian mixture experts. In detail, let \( x \) be a signal in \( \mathbb {R}^n \) and thus, \( \mathcal {W}_j: \mathbb {R}^n \rightarrow \mathbb {R}^n \). Then, the model readsFootnote 2
Following the approach utilized in Theorem 2, we first describe the exact form of (29) as a GMM on \( \mathbb {R}^n \). We denote with \( \hat{l}: \{1, \dotsc , n \} \rightarrow \{ 1, \dotsc , L \} \) a fixed but arbitrary selection from the index set \( \{ 1, \dotsc , L \} \). In addition, the notation \( \sum _{\hat{l} = 1}^{L^n} \) indicates the summation over all \( L^n \) possible selections and for the following proof we define \( \mu _{\mathbb {R}^n}(\hat{l})\, {{:}{=}}\, (\mu _{\hat{l}(1)}, \mu _{\hat{l}(2)},\dotsc ,\mu _{\hat{l}(n)})^\top \in \mathbb {R}^n \).
Theorem 3
\( f^{\textrm{wave}}_\theta (\,\cdot \,, t) \) is a homoscedastic GMM on \( \mathbb {R}^n \) with precision matrix
Proof
By definition for \( t = 0\), we have
First, we expand the product over the pixels
using the index map \( \hat{l} \) and \(\overline{w}_{j\hat{l}} = \prod _{i=1}^I w_{j\hat{l}(i)} \). Further, expanding over the features results in
where \( \overline{\overline{w}}_{\hat{\imath }(i,j)}=\prod _{j=1}^{J}\prod _{i=1}^{I} w_{\hat{\imath }(i,j)} \). Notice that (33) describes a homoscedastic GMM on \( \mathbb {R}^n \) with precision matrix
Using the properties of a projection (28) and the orthogonality property \( W_i \perp W_j \) for \( i \ne j \), this simplifies to
\(\square \)
Theorem 4
(Wavelet diffusion) \( f^{\textrm{wave}}_\theta (\,\cdot \,, t) \) satisfies the diffusion PDE \( (\partial _t - \Delta _1) f^{\textrm{wave}}_\theta (\,\cdot \,, t) = 0 \) if \( \sigma _j^2(t) = \sigma _0^2 + 2t \).
Proof
Notice that, using the properties of a projection (28), \( (\Sigma _{\mathbb {R}^n})^{-1}|_{\oplus _{j=1}^J W_j} = \frac{1}{\sigma ^2}\textrm{Id}_{\oplus _{j=1}^J W_j} \). Thus, on \( \bigoplus \limits _{j=1}^J W_j \), in analogy to the model based on filter responses, it suffices to adapt the variance of the one-dimensional GMMs \( \psi _j \) with \( \sigma _0^2 \mapsto \sigma _0^2 + 2t \). \(\square \)
We can endow the different sub-bands of the wavelet transformation with scalars to weight their influence as follows: Replacing \( \mathcal {W}_j \) with \( \lambda _j \mathcal {W}_j \) in (34) (the derivation does not change up to this point), we find that \( (\Sigma _{\mathbb {R}^n})^{-1} = \sum _{j=1}^J \frac{\lambda _j^2}{\sigma _0^2} \mathcal {W}_j \). Then, the diffusion PDE is satisfied when \( \sigma _j^2(t) = \sigma _0^2 + 2t \lambda _j^2 \). Thus, the scaling parameters \( \lambda _{{j}} \) are analogous to the filter-norm \( \Vert k_j\Vert \) in Theorem 2.
We briefly discuss the extension to two-dimensional signals: Let \( x \in \mathbb {R}^{n \times n} \) be a two-dimensional signal. \( \mathcal {W}_j^{d}: \mathbb {R}^{n \times n} \rightarrow \mathbb {R}^{n \times n} \) is a linear operator corresponding to the \( j \)-th detail level (\( j \in \{ 1, \dotsc , J \} \) where \( J \in \mathbb {N} \) is the coarsest scale in the decomposition) in the wavelet decomposition in direction \( d \). We denote the (now three) detail spaces at scale \( j \) as \( W_{j}^{d} \), where \( d \in \{ \textbf{v}, \textbf{h}, \textbf{d} \} \) indexes the direction (vertical, horizontal, and diagonal.). Our model accounts for the directional sub-bands with individual GMM experts, i.e., every \( \psi _j \) is replaced by a triplet \( \psi _j^{d} \) endowed with weights \( w_j^d \in \triangle ^{n_w} \) for \( d \in \{ \textbf{v}, \textbf{h}, \textbf{d} \} \). Then, the entire previous discussion holds, where in particular \( W_i^{d} \perp W_j^{\tilde{d}} \) for all \( d, \tilde{d} \in \{ \textbf{v}, \textbf{h}, \textbf{d} \} \) and all \( i \ne j \). Since the operators \( \mathcal {W}_j^d \) are derived from generating sequence \( h \in \mathbb {R}^k \) (see Sect. 4.1.2), the learnable parameters are summarized as \( \theta = \{ h, \{\lambda _j^d\}_{j,d}, \{ w_j^d \}_{j,d} \} \).
3.2.3 Interpretation as Diffusion Wavelet Shrinkage
Wavelet shrinkage is a popular class of denoising algorithms. Starting from the seminal work of [31,32,33], a vast literature is dedicated to finding optimal shrinkage parameters for wavelet-based denoising (see, e.g.
[34,35,36,37,38,39] and the references therein). In what follows, we briefly describe historical approaches to estimating shrinkage parameters.
The key motivation behind wavelet shrinkage denoising algorithms is the observation that wavelet coefficients of natural images are sparse, wheres the wavelet coefficients of noisy images are densely filled with “small” values. Thus, a straight forward denoising algorithm might be to calculate the wavelet coefficients, “shrink” small coefficients toward zero, and calculate the inverse wavelet transform of the shrank coefficients. Popular shrinkage operators include the soft-shrinkage \( x \mapsto {\text {sgn}}(x) \max \{ |x| - \tau , 0 \} \) and the hard-shrinkage \( x \mapsto x {\chi }_{\{|x| > \tau \}} \). It is easy to see that these operators promote sparsity in the wavelet coefficients, as they correspond to the proximal maps w.r.t. \( \tau \Vert \,\cdot \,\Vert _1 \) and \( \tau \Vert \,\cdot \,\Vert _{0} \), respectively. Here, \( \tau > 0 \) is a thresholding parameter that has to be chosen depending on the noise level.
Historically, research for wavelet shrinkage models has focused on finding the optimal shrinkage parameter \( \tau \) (w.r.t. some risk, e.g. the squared error), assuming a particular choice of the shrinkage operator (e.g. the soft-shrinkage). Popular selection methods include VisuShrink [31] and SureShrink [32]. The former is signal independent and the threshold is essentially determined by the dimensionality of the signal as well as the (assumed known) noise level. In contrast, the latter chooses the thresholding parameter depending on the energy in a particular sub-band and does not depend on the dimensionality of the signal explicitly. The BayesShrink [40] method is also sub-band adaptive, and the authors provide expressions (or at least good approximations) for the optimal thresholding parameter under a generalized Gaussian prior on the wavelet coefficients. In particular, they rely on classical noise level estimation techniques to fit the generalized Gaussian to the wavelet coefficients (of the noisy image) and arrive at a simple expression for a sub-band dependent threshold.
The general methodology outlined in the previous section allows us to take a different approach: Instead of fixing the thresholding function and estimating the threshold solely on the corrupted image, we instead propose to learn the distribution of wavelet coefficients in different sub-bands for all noise levels \( \sigma > 0 \). Notice that an empirical Bayes step on the wavelet coefficients under our model corresponds to applying a point-wise nonlinearity.
In contrast to the traditional wavelet shrinkage, our model does not prescribe a shrinkage function for which an optimal parameter has to be estimated for different noise levels. Rather, by learning the distribution of the wavelet coefficients at “all” noise levels, we have access to an MMSE optimal “shrinkage” function view of the empirical Bayes step on the experts. In addition, our wavelet prior can be used in more general inverse problems whereas classical shrinkage methods are only applicable to denoising (although the denoising engine could be used in regularization by denoising [41] or plug-and-play [42] approaches).
3.3 Convolutional Model
The model based on filter responses discussed in Sect. 3.1 cannot account for the correlation of overlap** patches when used for whole image restoration [43, 44]. Similarly, the model based on wavelet responses is limited in expressiveness since it only models the distribution of a scalar random variable per sub-band. In what follows, we describe a convolutional PoGMDM that avoids the extraction and combination of patches in patch-based image priors and can account for the local nature of low-level image features. The following analysis assumes vectorized images \( x \in \mathbb {R}^n \) with \( n \) pixels; the generalization to higher dimensions is straight forward.
In analogy to the product-of-experts-type model acting on filter responses, here we extend the fields-of-experts model [44] to our considered diffusion setting by accounting for the diffusion time \( t \) and obtain
Here, each expert \( \psi _j \) models the density of convolution features extracted by convolution kernels \( {\{ k_j \}}_{j=1}^J \) of size \( a = b \times b \), where \( {\{ K_j \}}_{j=1}^J \subset \mathbb {R}^{n \times n}\) are the corresponding matrix representations. Further, \( w_j \in \triangle ^L \) are the weights of the components of the \( j \)-th expert \( \psi _j \) [see (12)]. As with the models based on filter and wavelet responses, it is sufficient to adapt the variances \(\sigma _j^2(t)\) by the diffusion time as the following analysis shows.
Equation (36) again describes a homoscedastic GMM on \( \mathbb {R}^n \) with precision \( (\Sigma _{\mathbb {R}^n})^{-1} = \frac{1}{\sigma _0^2} \sum _{j=1}^J K_j^\top K_j \). This can be seen by essentially following the derivation of (34) in Theorem 4, at which point we did not yet exploit the special structure of \( \mathcal {W}_j: \mathbb {R}^n \rightarrow \mathbb {R}^n \) (i.e., it may be an arbitrary linear operator).
In order to derive conditions under which (36) fulfills the diffusion PDE, we begin by fixing the convolutions as cyclic, i.e., \( K_j x \equiv k_j *_n x \), where \( *_n \) denotes a 2-dimensional convolution with cyclic boundary conditions. Due to the assumed boundary conditions, the Fourier transformation \( \mathcal {F} \) diagonalizes the convolution matrices: \( K_j = \mathcal {F}^* {{\,\textrm{diag}\,}}(\mathcal {F}k_j) \mathcal {F} \). Thus, the precision matrix can be expressed as
where we used the fact that \( \mathcal {F}\mathcal {F}^* = \textrm{Id}_{\mathbb {R}^n} \) and \( {{\text {conj}}(z)}z = |z|^2 \) (here \( |\,\cdot \,| \) denotes the complex modulus acting element-wise on its argument). To get a tractable analytic expression for the variances \( \sigma _j^2(t) \), we further assume that the spectra of \( k_j \) have disjoint support, i.e.,
where \( \Gamma _j = {\text {supp}} \mathcal {F}k_j \). In addition, we assume that the magnitude is constant over the support, i.e.,
where \(\xi _j \in \mathbb {R}\) is the magnitude and \( {\chi _A} \) is the characteristic function of the set \( A \)
Theorem 5
(Convolutional Diffusion) Under assumptions (38) and (39), \( f^{\textrm{conv}}_\theta (\,\cdot \,, t) \) satisfies the diffusion PDE \( (\partial _t - \Delta _1) f^{\textrm{conv}}_\theta (\,\cdot \,, t) = 0 \) if \( \bar{\sigma }_j^2(t) = \sigma _0^2 + \xi _j^2 2t \).
Proof
In analogy to Theorem 2, with (37) \( \mathcal {F}^*{{\,\textrm{diag}\,}}\bigg (\sum _{j=1}^J \frac{\sigma ^2}{|\mathcal {F}k_j|^2} \bigg ) \mathcal {F} \mapsto \mathcal {F}^*{{\,\textrm{diag}\,}}\left( \frac{\sigma ^2 + 2t\sum _{j=1}^J|\mathcal {F}k_j|^2 }{\sum _{j=1}^J |\mathcal {F}k_j|^2}\right) \mathcal {F} \) under diffusion. The inner sum decomposes as
using (38), and with (39) the numerator reduces to \( \sigma _0^2 + 2t\xi _j^2 \). \(\square \)
We emphasize that the convolutional model (36) is distinctly different from the model based on filter responses discussed in Sect. 3.1. In particular, the one-dimensional GMM experts \( \psi _j(\,\cdot \,, w_j, t) \) do not model the distribution of the filter responses of their corresponding filter kernels \( k_j \), but account for the non-trivial correlation of overlap** patches. We discuss this in more detail in Sect. 5.3.
3.3.1 Shearlets
In the previous section, we derived abstract conditions under which a product of one-dimensional GMM experts, with each expert modeling the distribution of convolutional features, can obey the diffusion PDE. In particular, we derived that the spectra of the corresponding convolution filters must be non-overlap** and constant on their support. Naturally, the question arises how such a filter bank can be constructed. Luckily, the shearlet transformation [45] (and in particular the non-separable version of [46]) fulfills these conditions. As an extension to the wavelet transformation, the shearlet transformation [45] can represent directional information in multidimensional signals via shearing. Here, we consider the non-separable digital shearlet transformation [46], whose induced frequency tiling is shown schematically in Fig. 2. In particular, the frequency plane is partitioned into non-overlap** cones indexed by the scaling and shearing parameters described in the next paragraph.

Schematic illustration of the cone-like frequency tiling of the non-separable shearlet transformation [46]. The shearlets are constructed such that their spectra are non-overlap**
We briefly describe our setup but refer the interested reader to [46, 47] for more details. We construct a digital shearlet system, specified by the positive scaling integer \( j = 0,\dotsc ,J \) the translations \( m \in \mathbb {Z}^2 \) and shearing \( |k| \le \lceil 2^{\lfloor \frac{j}{2} \rfloor }\rceil \). The system is constructed by a one-dimensional low-pass filter \( h_1 \) and a two-dimensional directional filter \( P \). Given one-dimensional filters \( h_{J-j/2} \) and \( g_{J-j} \) derived from \( h_1 \) in a wavelet multiresolution analysis, let \( W_j = g_{J-j} \otimes h_{J-j/2} \) and let \( p_j \) be the Fourier coefficients of \( P \) at scaling level \( j \). Then, the system is constructed by
Here, \( \uparrow _{a} \) and \( \downarrow _{a} \) are \( a \)-fold up- and down-sampling operators, and \( {\overleftarrow{(\cdot )}} \) indicates sequence reversal \( {\overleftarrow{(\cdot )}}(n) = (\cdot )(-n) \), and \( S_k \) is a shearing operator. The digital shearlet transformation of an image \( x \in \mathbb {R}^{n \times n} \) is then given by
where \( \lambda _{j,k} > 0 \) are learnable weights that reflect the importance of the respective scale and shear level. The learnable weights \( \lambda _{j,k} > 0 \) are easily accounted for in the diffusion models by adapting \( \xi _{j, k} \) in (39) (where we have swapped the index \( j \) for a two-index \( j, k \) to account for the scales and shearing levels). Thus, we can summarize the learnable parameters for the model based on shearlet responses as \( \theta = \{ h_1, P, \{\lambda _{j,k}\}_{j,k}, \{w_{j,k}\}_{j,k} \} \).
4 Numerical Results
In this section, we first detail the setup for numerical optimization. In particular, we discuss how we can learn the one-dimensional GMM experts along with the corresponding transformation (filters, wavelets, and shearlets) jointly. Then, we show results for denoising utilizing a simple one-step empirical Bayes scheme as well as denoising algorithms derived for classical diffusion models. In addition, we show that we can use our models for noise level estimation and blind heteroscedastic denoising, and exploit Corollary 1 to derive a direct sampling scheme.
4.1 Numerical Optimization
For the numerical experiments, \( f_X \) reflects the distribution of rotated and flipped \( b \times b \) patches from the 400 gray-scale images in the BSDS 500 [48] training and test set, with each pixel value in the interval \( [0, 1] \). We optimize the score matching objective function (11) using projected AdaBelief [49] for \( {100\,000} \) steps. We approximate the infinite-time diffusion PDE by uniformly drawing \( \sqrt{2t} \) from the interval \( [{0}, {0.4}] \). For the denoising experiments, we utilize the validation images from [44] (also known as “Set68”). Due to computational constraints, we utilize only the first 15 images of the dataset according to a lexicographic ordering of the filenames. In addition, our wavelet and shearlet toolboxes only allow the processing of square images. To avoid boundary artifacts arising through padding images to a square, we only utilize the central region of size \( {320} \times {320} \).
For all experiments, \( \psi _j \) is a \( L = {125} \) component GMM, with equidistant means \( \mu _l\) in the interval \( [-\eta _j, \eta _j] \) (we discuss the choice of \( \eta _j \) for the different models in their respective sections). To support the uniform discretization of the means, the standard deviation of the \( j \)-th experts is \( \sigma _{0} = \frac{2\eta _j}{L - 1} \). In the one-dimensional GMM backbone of all models, we have to project a weight vector \( w \in \mathbb {R}^L \) onto the unit simplex \( \triangle ^L \). We realize the projection \( {{\,\textrm{proj}\,}}_{\triangle ^{L}}: \mathbb {R}^L \rightarrow \mathbb {R}^L \) with the sorting-based method proposed by [50], which is summarized in Algorithm 2. In addition, we further assume that the one-dimensional GMM experts are symmetric around \( 0 \), i.e., that the weights \( w_j \) are in the set \( \{ x \in \mathbb {R}^L: (x \in \triangle ^L) \wedge (x = {\overleftarrow{x}}) \} \). We implement by storing only \( \lceil L / 2 \rceil \) weights, and mirroring the tail of \( \lceil L / 2 \rceil - 1 \) elements prior to the projection algorithm and function evaluations. To ensure that the one-dimensional GMM experts are sufficiently peaky around zero, we always choose \( L \) to be odd.
In the next sections, we detail the constraints the building blocks of the learned transformations have to fulfill and how to satisfy them in practice.
4.1.1 Learning Orthogonal Filters
Let \( K = [k_1, k_2, \dotsc , k_J] \in \mathbb {R}^{a \times J} \) denote the matrix obtained by horizontally stacking the filters. We are interested in finding
where \( \mathcal {O} = \{ X \in \mathbb {R}^{a \times J}: X^\top X = D^2 \} \), \( D = {{\,\textrm{diag}\,}}(\lambda _1,\lambda _2,\dotsc ,\lambda _J) \) is diagonal, and \( \Vert \,\cdot \,\Vert _F \) is the Frobenius norm. Since \( {\text {proj}}_{\mathcal {O}}(K)^\top {\text {proj}}_{\mathcal {O}}(K) = D^2 \) we can represent it as \( {\text {proj}}_{\mathcal {O}}(K) = OD \) with \( O \) semi-unitary (\( O^\top O = \textrm{Id}_{\mathbb {R}^J} \)). Other than positivity, we do not place any restrictions on \( \lambda _1, \dotsc , \lambda _J \), as these are related to the precision in our model. Thus, we rewrite the objective
where
with \( \langle \,\cdot \,, \,\cdot \,\rangle _F \) denoting the Frobenius inner product.
We propose the following alternating minimization scheme for finding \( O \) and \( D \). The solution for the reduced sub-problem in \( O \) can be computed by setting \( O = U \), using the polar decomposition of \( DK^\top = UP \), where \( U \in \mathbb {R}^{J \times a}\) is semi-unitary (\( U^\top U = \textrm{Id}_{\mathbb {R}^a} \)) and \( P = P^\top \succeq 0 \). The sub-problem in \( D \) is solved by setting \( D_{i,i} = \bigl ((O^\top K)_{i,i}\bigr )_{+} \). The algorithm is summarized in Algorithm 1, where we have empirically observed fast convergence; \( B = 3 \) steps already yielded satisfactory results. A preliminary theoretical analysis of the algorithm is presented in the supplementary material of our conference paper [7].

Algorithm for orthogonalizing a set of filters \( K \).
Assuming a patch size of \( a = b \times b \) we use \( J = b^2 - 1 \) filters spanning the space of zero-mean patches \( \mathfrak {Z} = \{ x \in \mathbb {R}^a: \langle \mathbbm {1}_{\mathbb {R}^a}, x \rangle _{\mathbb {R}^a} = 0 \} \). We found that implementing \( {{\,\textrm{proj}\,}}_{\mathcal {O} \cap \mathfrak {Z}} \) as \( {{\,\textrm{proj}\,}}_{\mathfrak {Z}} \circ {{\,\textrm{proj}\,}}_{\mathcal {O}} \), both constraints were always almost exactly fulfilled. To ensure the correct projection, an alternative would be to utilize Dykstra’s projection algorithm [51]. The filters are initialized by independently drawing their entries from a zero-mean Gaussian distribution with standard deviation \( b^{-1} \). Since the filters can be freely scaled, we simply choose \( \eta _j = 1 \) for all \( j = 1, \dotsc , J \).
To visually evaluate whether our learned model matches the empirical marginal densities for any diffusion time \( t \), we plot them in Fig. 3. At the top, the learned \( 7 \times 7 \) orthogonal filters \( k_j \) are depicted. The filters bare striking similarity to the Eigenimages of the covariance matrices of [43, Fig. 6], who learn a GMM directly on the space of image patches (i.e., without any factorizing structure). This comes as no surprise, since the construction of the patch model (14) can be interpreted as “learning the Eigendecomposition” (see Theorem 1 and the proof of Theorem 2). The learned potential functions \( -\log \psi _j(\,\cdot \,, w_j, t) \) and activation functions \( -\nabla \log \psi _j(\,\cdot \,, w_j, t) \)Footnote 3 associated with the \( j \)-th filter are shown below the filters in Fig. 3. Indeed, the learned potential functions match the negative-log empirical marginal response histograms
visualized at the bottom almost perfectly even at extremely low-density tails. This supports the theoretical argument that diffusion eases the problem of density estimation outlined in the introductory sections.

Learned filters \( k_j \) (top, the intervals show the values of black and white, respectively, amplified by a factor of 10), potential functions \( -\log \psi _j(\,\cdot \,, w_j, t) \) and activation functions \( -\nabla \log \psi _j(\,\cdot \,, w_j, t) \). On the bottom, the negative-log empirical marginal response histograms are drawn
4.1.2 Learning Wavelets
The discrete wavelet transformation is characterized by the sequence \( h \in \mathbb {R}^K \). In addition to learning the parameters of the one-dimensional GMM, we follow [52] and also learn \( h \). From the sequence \( h \), the scaling function \( \phi \) and wavelet function \( \omega \) are defined by
and
where \( {\bigl (g(h)\bigr )_k} = (-1)^kh_{K - k - 1} \). For \( \omega \) to be a wavelet, it must follow the admissibility criterion
cf [29], from which it immediately follows that \( (\mathcal {F}\omega )(0) = \int _\mathbb {R}\omega = 0 \). For the transformation to be unitary, we need that \( \int _\mathbb {R}\phi = 1 \), and
From these constraints, the feasible set of wavelet-generating sequences is described by
Here \( \circlearrowleft _{n}: \mathbb {R}^K \rightarrow \mathbb {R}^K \) rolls its argument by \( n \) entries, i.e., \( \circlearrowleft _{n} x = (x_{K-n+1}, x_{K-n+2},\dotsc ,x_{K},x_1,x_2,\dotsc ,x_{K-n})^\top \). Observe that the orthogonality condition encodes \( K / 2 \) constraints (we assume that \( K \) is even), since \( \circlearrowleft _{0} = \circlearrowleft _{K} = \textrm{Id}_{\mathbb {R}^K} \). To project onto \( \Omega \), we write the projection problem
in its Lagragian form using \( \mathcal {L}: \mathbb {R}^K \times \mathbb {R}\times \mathbb {R}\times \mathbb {R}^{K/2} \rightarrow \mathbb {R}: \)
and find stationary points by solving the associated nonlinear least-squares problem
using 10 iterations of Gauss-Newton. To facilitate convergence, we warm start the Lagrange multipliers \( \Lambda _{\textrm{scal}}, \Lambda _{\textrm{adm}}, \Lambda \) with the solution from the previous outer iteration. We initialize the sequence \( h \) with the generating sequences of the db2- (\( K = 4 \)) and db4-wavelet (\( K = 8 \)). For both, we utilize \( J = 2 \) levels. We use the pytorch_wavelets [53] implementation of the discrete wavelet transformation.
In contrast to the model based on filter responses, the model based on wavelet responses does not have the freedom to adapt the scaling of filters. To overcome this, we discretize the means over the real line individually for each sub-band. In detail, for the \( j \)-th level and \( d \)-th direction, \( d \in \{ \textbf{h}, \textbf{v}, \textbf{d} \} \), we choose \( \eta ^d_j = 1.1 q^{d}_j \), where \( q^d_j \) is the \(.999 \)-quantile of corresponding responses.
The initial and learned generating sequences, their corresponding scaling and wavelet functions, along with the learned potential functions and MMSE-shrinkage are shown in Fig. 4. In these figures, it is apparent that our chosen parametrization is sub-optimal. In particular, in order to represent the heavy tails (especially for level \( j = 1\)), many intermediate weights are set to \( 0 \). This leads to the MMSE shrinkage functions becoming step-like. We emphasize that this is a practical problem of choosing the appropriate parametrization; we discuss alternatives to our equispaced GMM in Sect. 5.

Left: db2 initial generating sequence (\( K = 4\)). Right: db4 initial generating sequence (\( K = 8\)). From top to bottom: Initial generating sequence \( h \) along with the corresponding scaling and wavelet functions \( \phi \) and \( {\omega } \), learned generating sequence \( h \) along with the corresponding scaling and wavelet functions \( \phi \) and \( {\omega } \), learned potential functions \( -\log \psi (\,\cdot \,, w, t) \) and the learned MMSE shrinkage functions \( y_t \mapsto y_t {+} 2t \nabla \log \psi (y_t, w, t) \)
4.1.3 Learning Shearlets
We initialize the one-dimensional low-pass filter \( h_1 \) and the two-dimensional directional filter \( P \) with the standard choices from [47]: \( h_1 \) is initialized as maximally flat 9-tap symmetric low-pass filterFootnote 4, \( P \) is initialized as the maximally flat fan filterFootnote 5 described in [54]. Furthermore, \( \lambda _{j,k} \) is initialized as \( 1 \) for all scale levels \( j \) and shearings \( k \), and we set \( \eta _{j, k} = 0.5 \).
We enforce the following constraints on the parameter blocks: The weighting parameters \( \lambda _{j,k} \) must satisfy non-negativity \( \lambda _{j, k} \in \mathbb {R}_{\ge 0} \). The parameters \( h_1 \) and \( P \) specifying the shearlet system must satisfy \( h_1 \in \mathcal {H} {:}{=}\{ x \in \mathbb {R}^9: \langle \mathbbm {1}_{{\mathbb {R}^9}}, x \rangle _{\mathbb {R}^9} = 1 \} \) and \( P \in \mathcal {P} {:}{=}\{ x \in \mathbb {R}^{17 \times 17}: \Vert x\Vert _1 = 1 \}\).
The projection operators can be realized as follows: The projection onto the non-negative real line is just \( {{\,\textrm{proj}\,}}_{\mathbb {R}_{\ge 0}}(x) = \max \{ x, 0 \} \). The map \( {{\,\textrm{proj}\,}}_{\mathcal {H}}(x) = x - \frac{\langle \mathbbm {1}_{{\mathbb {R}^9}}, x \rangle _{\mathbb {R}^9} - 1}{9} \) realizes the projection onto the linear constrain encoded in \( \mathcal {H} \). The projection onto the unit-one-norm-sphere is \( {{\,\textrm{proj}\,}}_{\mathcal {P}}(x) = {\text {sgn}}(x) \odot {{\,\textrm{proj}\,}}_{\triangle ^m}(|x|) \) (see e.g. [55, 56]), where we ignore the degenerate case of projecting the origin where \( {{\,\textrm{proj}\,}}_{\mathcal {P}} \) is not well defined. Our implementation of the shearlet transformation is based on the ShearLab 3D [47] toolboxFootnote 6.

Simplex projection from [50].
For the numerical experiments, we chose \( J = 2 \) scales and \( 5 \) shearings (\( k \in \{ -2, \dotsc , 2 \} \)). We show the initial and learned filter weights \( \lambda _{j,k} \), the one-dimensional low-pass filter \( h_1 \), and the two-dimensional directional filter \( P \) in Fig. 5. The resulting shearlet system in the frequency- and time-domain, along with the learned potential functions, is shown in Fig. 6. We again emphasize that the learned one-dimensional potential functions \( \psi _{j,k}(\,\cdot \,, w_{j,k}, t) \) are distinctly different from the other models. In particular, they exhibit multiple local minima, sometimes different from \( 0 \), such that certain image structures can be enhanced under this prior. This is in stark contrast to the learned filter and wavelet responses, which show a single minimum at \( 0 \) and the classical heavy-tailed shape.

Initial (a) and learned (b) building blocks for the shearlet system: One-dimensional low-pass filter \( h_1 \) and the two-dimensional directional filter \( P \). The corresponding shearlet filters along with their frequency response, learned weights and learned potential functions are shown in Fig. 6

The five left columns show the frequency response, time-domain filters and corresponding potential functions of the first cone of the learned shearlet system. The inset numbers show the values of the corresponding weighting factor \( \lambda _{j, k} \). The five unlabeled right columns show the second cone
Figure 6 also shows that the shearlet system only approximately fulfills the assumption (38) and (39). We analyze the shearlet system with respect to the assumption of disjoint support (38) by visualizing the pair-wise cosine similarity of the magnitude of the spectra in Fig. 7. In detail, the figure shows \( \langle \frac{|\gamma _{\tilde{\jmath },\tilde{k}}|}{\Vert |\gamma _{\tilde{\jmath },\tilde{k}}|\Vert }, \frac{|\gamma _{j,k}|}{\Vert |\gamma _{j,k}|\Vert } \rangle _{\mathbb {R}^{n}} \), for \( \tilde{\jmath }, j \in \{ 1, 2 \} \) and \( \tilde{k}, k \in \{ -2,\dotsc , 2 \} \) and both cones. Although less for the learned shearlet system, the plot is dominated by the main diagonal, indicating that the corresponding spectra are almost non-overlap**. To meet the theoretical assumptions, it would be possible to penalize \( \langle \frac{|\gamma _{\tilde{\jmath },\tilde{k}}|}{\Vert |\gamma _{\tilde{\jmath },\tilde{k}}|\Vert }, \frac{|\gamma _{j,k}|}{\Vert |\gamma _{j,k}|\Vert } \rangle _{\mathbb {R}^n} \) for \( \tilde{\jmath }\ne j \) and \( \tilde{k} \ne k \) during training.
The fact that the spectra are not constant over their support raises the question of how to choose \( \xi _a \) that best approximates (39). During training and evaluation, we simply chose \( \xi _a = \Vert |\gamma _a|\Vert _\infty \), where \( a \) is a two-index ranging over the chosen scale-shearing grid. It remains an open question how the violation of the constraints (38) and (39) influences the diffusion, and if there exists a better choice for \( \xi _a \).

Cosine similarity between the magnitude the spectra of different levels, shearings and cones of the initial (a) and learned (b) shearlet system. A system exactly fulfilling the assumption (38) would be unpopulated off the main diagonal
4.2 Image Denoising
To exploit our patch-based prior for whole-image denoising, following [43], we define the expected patch log-likelihood of a noisy image \( y \in \mathbb {R}^n \) with variance \( \sigma ^2(t) = 2t \) as
Here, \( \tilde{n} \) denotes the total number of overlap** patches (e.g. for \( n = 4 \times 4 \) and \( a = 3 \times 3 \), \( \tilde{n} = 4 \), ), \( P_i: \mathbb {R}^n \rightarrow \mathbb {R}^a \) denotes the patch-extraction matrix for the \( i \)-th patch and \( p_i = \bigl ( \sum _{j=1}^{\tilde{n}} P_j^\top P_j \bigr )_{i, i} \) counts the number of overlap** patches to compensate for boundary effects (see [57, Appendix B] for a more rigorous discussion). The wavelet- and shearlet-based priors can act on images of arbitrary size.
Let \( \log f_\theta \) be either \( {\text {epll}}_\theta ^{\textrm{filt}}, \log f_\theta ^{\textrm{wave}}\), or \( \log f_\theta ^{\textrm{conv}} \). We consider two inference methods: The one-step empirical Bayes estimate
corresponds to the Bayesian MMSE estimator. Notice that, in the case of \( \log f_\theta = {\text {epll}}_\theta ^{\textrm{filt}} \) the estimator
computes patch-wise MMSE estimates and combines them by averaging. This is known to be a sub-optimal inference strategy, since the averaged patches are not necessarily likely under the model [43]. The discussion of algorithm utilizing patch-based priors for whole-image restoration is beyond the scope of this article. We refer the interested reader to the works of [43, 57] for a detailed discussion on this topic. In addition, we refer to our previous conference publication [7], in which we present a proximal gradient continuation scheme that slightly improves over the empirical Bayes estimate by allowing patch-crosstalk.
The second inference method we consider is the stochastic denoising algorithm proposed by [58] and summarized in Algorithm 3. In detail, this algorithm proposes a sampling scheme to approximately sample from the posterior of a denoising problem when utilizing diffusion priors. This is achieved by properly weighting the score \( \nabla \log f_\theta \) with the gradient of the data term while annealing the noise level. Sampling from the posterior, as opposed to directly computing MMSE estimates with an empirical Bayes step, is known to produce sharper results when utilizing modern highly expressive diffusion models [58, 59]. We chose \( \epsilon = 5 \times 10^{-6} \), \( \sigma _{{C}} = 0.01 \) and the exponential schedule \( \sigma _i = \sqrt{2t} \bigl (\frac{\sigma _{{C}}}{\sqrt{2t}}\bigr )^{i/{C}} \), using \( B = 3 \) inner loops and \( C = {100} \) diffusion steps.

Stochastic image denoising algorithm from [58].
Let \( x \in \mathbb {R}^n \) denote a test sample from the distribution \( f_X \), and let \( \hat{x} \) denote the estimation of \( x \) given \( y_t = x + \sqrt{2t} \eta \) where \( \eta \sim \mathcal {N}(0, \textrm{Id}_{\mathbb {R}^n}) \), through either of the discussed inference methods. In Table 1, we show a quantitative evaluation utilizing the standard metrics peak signal-to-noise ratio (PSNR) \( 10\log _{10}\frac{n}{\Vert \hat{x} - x\Vert _2^2} \) and structural similarity (SSIM) [60] with a window size of 7 and the standard parameters \( K_1 = {0.01} \) and \( K_2 = {0.03} \). The column with the heading “Patch-GSM” utilized the Gaussian scale mixture parametrization discussed in Sect. 5.1. The results are obtained for one run of the algorithms, i.e., we did not compute the expectation over the noise (neither in the construction of \( y_t \) nor during the iterations of the stochastic denoising algorithm). However, we did not observe any noteworthy deviation when performing different runs of the experiments.
The quantitative evaluation shows impressive results of the model based on shearlet responses, despite having very little trainable parameters. In particular, it performs best across all noise levels and inference methods, with the exception of the one-step empirical Bayes denoising at \( \sigma = 0.2 \). There, the patch-based model with \( a = 15 \times 15 \) performs best, but notably has about 50 times the number of trainable parameters. By leveraging symmetries between the cones in the shearlet system, the number of trainable parameters could even be approximately halved. These symmetries are strongly apparent in Fig. 6, where the potential functions of the second cone (rightmost 5 potentials) are almost a perfect mirror image of the potential functions of the first cone (leftmost 5 potential functions).
Additionally, the table reveals that the empirical Bayes estimator beats the stochastic denoising in every quality metric. This is not surprising, as—in expectation—it is the optimal estimator in the MMSE sense, which directly corresponds to PSNR. Comparing the qualitative evaluation in Fig. 8 (empirical Bayes) to Fig. 9 (stochastic denoising) we do not observe that sharper images using the stochastic denoising algorithm; we are unsure why.

Qualitative denoising results for one-step empirical Bayes denoising. In the rows, the noise standard deviation ranges in \( \sigma \in \{ 0.025, 0.05, 0.1, 0.2 \} \). The inlays show a zoomed region (magnifying factor 3), and the absolute difference of the reconstruction to the ground truth image (0  \(\frac{1}{3}\)). The accompanying quantitative results are shown in Table 1
\(\frac{1}{3}\)). The accompanying quantitative results are shown in Table 1

Qualitative denoising results using the stochastic denoising algorithm from [58]. In the rows, the noise standard deviation ranges in \( \sigma \in \{ 0.025, 0.05, 0.1, 0.2 \} \). The inlays show a zoomed region (magnifying factor 3), and the absolute difference of the reconstruction to the reference image (0  \(\frac{1}{3}\)). The accompanying quantitative results are shown in Table 1
\(\frac{1}{3}\)). The accompanying quantitative results are shown in Table 1
The analysis of posterior variance is out of the scope of this paper. However, techniques for analyzing the posterior induced by diffusion models are also readily applicable to our models. In particular, we refer to [58] or related papers such as [61] for an in-depth discussion of these techniques.
4.3 Noise Estimation and Blind Image Denoising
Within this and the following subsection, we describe two applications that arise as a by-product of our principled approach: Noise estimation (and, consequently, blind denoising) and analytic sampling. For both, we utilize the model based on filter responses as a stand-in but emphasize that similar results hold also for the models based on wavelet and shearlet responses.
The construction of our model allows us to interpret \( f^{\textrm{filt}}_\theta (\,\cdot \,, t) \) as a time-conditional likelihood density. Thus, it can naturally be used for noise level estimation: We assume a noisy patch \( y \) constructed by \( y = x + \sigma \eta \), where \( x \sim f_X \), \( \eta \sim \mathcal {N}(0, \textrm{Id}_{\mathbb {R}^n}) \) and \( \sigma \) is unknown. We can estimate the noise level \( \sigma \) by maximizing the likelihood of \( y \) w.r.t. to the diffusion time \( t \)—\(\hat{t} = \mathop {\mathrm {arg\,max}}\limits _t f^{\text {filt}}_\theta (y, t) \)—and recover the noise level via \( \sigma = \sqrt{2\hat{t}} \).
To demonstrate the feasibility of this approach, Fig. 10 shows the expected negative-log densityFootnote 7\( \mathbb {E}_{p \sim f_X, \eta \sim \mathcal {N}(0, \textrm{Id})} {\bigl [} l_\theta (p+\sigma \eta , t) {\bigr ]} \) over a range of \( \sigma \) and \( t \). The noise level estimate \( \sigma \mapsto \mathop {\mathrm {arg\,min}}\limits _t \mathbb {E}_{p \sim f_X, \eta \sim \mathcal {N}(0, \textrm{Id})} {\bigl [} l_\theta (p + \sigma \eta , t) {\bigr ]} \) perfectly matches the identity map \( \sigma \mapsto \sqrt{2t} \).
In addition, we can leverage this noise level estimation procedure to perform blind heteroscedastic denoising with the same model as follows: First, for all \( \tilde{n} \) overlap** patches \( P_j y \) in the corrupted image, we estimate the noise level through \( \hat{t}_j = \mathop {\mathrm {arg\,max}}\limits _t f^{\textrm{filt}}_\theta (P_j y, t) \). Given the noise levels \( \hat{t}_{{j}} \), we can estimate the clean image with an empirical Bayes step of the form
where for each patch \( P_j y \) we utilize the estimated noise level \( \hat{t}_j \).
In Fig. 11, the original image is corrupted by heteroscedastic Gaussian noise with standard deviation 0.1 and 0.2 in a checkerboard pattern, which is clearly visible in the noise level map. In the restored image and the absolute difference to the reference, the checkerboard pattern is hardly visible, indicating that the noise level estimation is robust also when confronted with little data.

Expected normalized negative-log density along with the noise estimate  \( \sigma \mapsto \mathop {\mathrm {arg\,min}}\limits _t \mathbb {E}_{p \sim f_X, \eta \sim \mathcal {N}(0, \textrm{Id})}{\bigl [}l_\theta (p+\sigma \eta , t) {\bigr ]} \),
\( \sigma \mapsto \mathop {\mathrm {arg\,min}}\limits _t \mathbb {E}_{p \sim f_X, \eta \sim \mathcal {N}(0, \textrm{Id})}{\bigl [}l_\theta (p+\sigma \eta , t) {\bigr ]} \),  \( \sigma \mapsto \sqrt{2t} \); (left) and the slices at \( \sigma \in \{ 0.1, 0.2, 0.3, 0.4 \} \) (right)
\( \sigma \mapsto \sqrt{2t} \); (left) and the slices at \( \sigma \in \{ 0.1, 0.2, 0.3, 0.4 \} \) (right)

Noise estimation and blind denoising. Top left: Image \( y \) corrupted with heteroscedastic Gaussian noise in a checkerboard pattern with standard deviation 0.1 and 0.2. Top right: Noise level map (0  0.5). Bottom left: One-step empirical Bayes denoising result using (59). Bottom right: Absolute difference to the reference image (0
0.5). Bottom left: One-step empirical Bayes denoising result using (59). Bottom right: Absolute difference to the reference image (0  \(\frac{1}{3}\))
\(\frac{1}{3}\))
4.4 Sampling
A direct consequence of Corollary 1 is that our models admit a simple sampling procedure: The statistical independence of the components allows drawing random patches by
where \( U_{j, t} \) is a random variable on \( \mathbb {R}\) sampled from the one-dimensional GMM \( \psi _j(\,\cdot \,, w_j, t) \). The samples in Fig. 12 indicate a good match over a wide range of \( t \). However, for small \( t \) the generated patches appear slightly noisy, which is due to an over-smooth approximation of the sharply peaked marginals around \( 0 \). This indicates that the (easily adapted) discretization of \( \mu _l \) equidistant over the real line is not optimal. We discuss alternative parametrizations in Sect. 5.

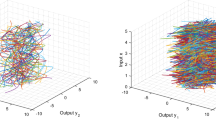
Ground-truth samples from the random variable \( Y_t \) (top) and samples generated by the analytic sampling procedure (60) (bottom)
5 Discussion
5.1 Alternative Parametrizations
The potential functions of the models based on filter- and wavelet responses shown in Figs. 3 and 4 exhibit leptokurtic behavior, which has been noticed quite early in the literature [44, 62,63,64,65,66]. To model these leptokurtic potential functions, our parametrization relies on one-dimensional GMMS with a priori chosen equidistant means on the real line. The GMM is a very natural choice in our framework, as the Gaussian family is the only function family closed under diffusion (i.e., convolution with a Gaussian, cf. the central limit theorem). However, as a consequence, the discretization of the means over the real line has to be fine enough to allow proper modeling of the leptokurtic marginals. Thus, the majority of the learnable parameters are actually the weights of the one dimensional Gaussian mixtures. This motivates the consideration of other expert functions \( \psi \).
An extremely popular choice for modeling the distribution of filter responses on natural images is the Student-t expert [44, 63]
As outlined above, the convolution of this function with a Gaussian cannot be expressed in closed form. However, there exist approximations, such as the ones shown in [67] or [68, Theorem 1], which we recall here for completeness: Let \( X \) be a random variable on \( \mathbb {R}\) with density
where \( \Gamma (z) = \int _0^\infty t^{z-1}\exp (-t)\,\textrm{d}t \) is the Gamma function, and let \( Y_t \) be a random variable defined as previously. Then, \( f_{Y_t} = \lim _{N\rightarrow \infty } f_{Y_t}^{(N)} \) where
with the confluent hypergeometric function of the second kind (also known as Tricomi’s function, or the hypergeometric \( U \) function) [69] \( \Psi \).
We show \( - \log f_{Y_t}^{(N)} \) for different \( N \) and \( t > 0 \) in Fig. 13, along with \( - \log f_{Y_t} \) which we computed numerically. Notice that (63) is composed of two terms: A Gaussian with variance \( 2t \) and an infinite polynomial in the even powers, filling up the tails of the distribution. Thus, it is not surprising that the approximation fails to model the tails of the distribution when \( t \) is small, and becomes better as \( t \) increases and the distribution approaches a Gaussian.

Another popular expert function is the Gaussian scale mixture (GSM)
which has been used in the context of modeling both the distributions of filter [70, 71] as well as wavelet responses [72, 73]. Here, \( f_Z \) is the mixing density of the multiplier \( Z \). Thus, GSMs can represent densities of random variables that follow
where \( Z \) is a scalar random variable and \( U \) is a zero mean Gaussian (see [74] for conditions under which a random variable can be represented with a GSM). In practice, for our purposes we model the mixing density as a Dirac mixture \( f_Z = \sum _{i=1}^I w_i \delta _{z_i} \) with \( (w_1,\dotsc ,w_I)^\top \in \triangle ^I \) and \( z_i \) a priori fixed. Then, the GSM expert reads
where without loss of generality we set \( \sigma = 1 \).
To show the practical merit of this parametrization in our context, we train a patch model using \( b = 7 \) with the following choice of \( z_i \): As the GMM experiments indicated that the discretization of the means was a bit too coarse, we chose \( z_i = 0.01 \times 1.4^{i - 1} \), such that \( z_1 = 0.01 < 0.016 = \sigma _0 \). The idea outlined in Sect. 3.1 naturally extends to such models: Diffusion (for the \( j \)-th feature channel) amounts to rescaling \( z_i^2 \mapsto z_i^2 + 2t\Vert k_j\Vert ^2 \).
We show learned filters and their corresponding potential functions and activation functions when utilizing a GSM in Fig. 14, where we used \( I = {20} \) scales. The number of learnable parameters is \( (a - 1)(a + I) \), which is 3312 when modeling \( a = 7 \times 7 \) patches with our choice of \( I \). This is considerably less than the 5376 parameters for the GMM, which, as discussed in Sect. 4.4, seems to still be discretized too coarsely. This might indicate that a GSM parametrization is more fit for this purpose. Indeed, the quantitative analysis presented in Table 1 shows superiority of the patch-based GSM model over the patch-based GMM. However, note that the GMM parametrization is strictly more versatile as it does not assume a maximum at 0. For instance, GSMs cannot model the potential functions of the model based on shearlet responses (Fig. 6).

Learned filters \( k_j \) (top, the intervals show the values of black and white, respectively, amplified by a factor of 10), potential functions \( -\log \psi _j^{\textrm{GSM}}(\,\cdot \,, w_j, t) \) and activation functions \( -\nabla \log \psi _j^{\textrm{GSM}}(\,\cdot \,, w_j, t) \)
5.2 Designing More Expressive Models
All architectures discussed until now are shallow in the sense that they model the distribution of filter responses (either directly, or through wavelets or shearlets). A possible extension of our work would be to consider deep networks, i.e., networks with more than one layer. Indeed, many popular image restoration frameworks, such as trainable nonlinear reaction diffusion [75] or the cascade of shrinkage fields [76] employ trainable Gaussian mixture potential functions (often referred to more generally as radial basis splines). However, they are typically trained as point estimators in a classic discriminative (task-specific) framework, and have not been studied in the context of diffusion priors. We quickly note that the diffusion in the trainable nonlinear reaction diffusion is a diffusion in image space, whereas our framework considers diffusion in probability space. Extending the idea of diffusion in probability space to deep networks is non-trivial. We believe that such models can only be tackled by approximating the diffusion PDE.
5.2.1 Wavelets: Modeling Neighborhoods
In essence, the model based on wavelet responses described in Sect. 3.2 models the histogram of wavelet coefficients in different sub-bands. However, it does not take the spatial neighborhood (neither in its own sub-band nor of siblings or parents) into account. There have been many attempts at making these types of models more powerful: Guerrero-Colon et al. [77] introduce mixtures of GSMs to model the spatial distribution of wavelet coefficients in and across sub-bands. The authors of [78] extend this idea to mixtures of generalized Gaussian scale model mixtures. We believe that these extensions can be used also in our work. In particular, modeling disjoint neighborhoods leads to a block diagonal structure in the product GMM, which can be efficiently inverted. However, modeling disjoint neighborhoods is known to introduce artifacts [73]. Still, such models can be globalized, e.g. by utilizing ideas similar to the expected patch log-likelihood [43], which amounts to applying a local model to overlap** local neighborhoods individually and averaging the results.
Another interesting research direction with applications to generative modeling would be to condition the distribution of the wavelet coefficients on their parent sub-bands. Notice that when utilizing conditioning and modeling local neighborhoods, we essentially recover the wavelet score-based generative model of Guth et al. [79]. Their model uses the score network architecture proposed in [80], but we believe that modeling local neighborhoods could yield results that are close to theirs.
5.3 Patch Versus Convolutional Model
One of the major open questions in this work is the relationship between the models based on filter responses and shearlet responses.
We again want to emphasize that they are distinctly different: The former “only” models the distribution of filter responses, essentially forming a histogram. In particular, the distribution of filter responses of natural images on arbitrary filters will always exhibit leptokurtic behavior [62, 65], with sharp peaks at \( 0 \) (see our learned potential functions of the model based on filter responses in Fig. 3). The experts in the model based on shearlet responses do not model the marginal distribution of filter responses, but takes into account the non-trivial correlation of overlap** patches This leads to significantly more complex expert functions with multiple minima, sometimes different from zero (see our learned potential functions of the model based on shearlet responses in Fig. 6). Although quite well known in the literature [43, 57, 75, 81], this distinction is sometimes overlooked (e.g. when [44] chose the restrictive Student-t potential functions in their convolutional fields-of-experts model). To the best of our knowledge, this paper is the first in proposing strategies to learn patch-based and convolutional priors in a unified framework.
The assumption of non-overlap** spectra of the filters in the convolutional model (38) is in analogy to the assumption of pair-wise orthogonality of the filters in the patch model (19): From (38) immediately follows that \( \langle \mathcal {F}k_j, \mathcal {F}k_i \rangle _{\mathbb {C}^n} = 0 \) when \( i \ne j \). Thus, in some sense, the convolutional model becomes a patch-based model in Fourier space. However, the relationship remains unclear and deserves being investigated further.
The second assumption—that the spectra are constant over their support (39)—restricts the space of admissible filters quite heavily. Unfortunately, we did not find a way to relax this constraint and we believe that it cannot be relaxed without losing exact diffusion. However, we think that the constraint can be relaxed such that the diffusion PDE is fulfilled within some error bounds.
6 Conclusion
In this paper, we introduced PoGMDMs as products of Gaussian mixture experts that allow for an explicit solution of the diffusion PDE of the associated density. For models acting on filter, wavelet, and shearlet responses, we derive conditions for the associated filters and potential functions such that the diffusion PDE is exactly fulfilled. Our explicit formulation enables learning of image priors simultaneously for all diffusion times using denoising score matching. Numerical results demonstrated that PoGMDMs capture the statistics of the underlying distribution well for any diffusion time. As a by-product, our models can naturally be used for noise estimation and blind heteroscedastic denoising.
Future work will include the design of multi-layer architectures for which the diffusion can be expressed analytically, or approximated within some error bounds. In addition, the learned models could be evaluated on more involved inverse problems such a deblurring or even medical imaging. Further, the extensive evaluation of the model based on filter responses in terms of sampling the distribution and performing heteroscedastic blind denoising can also be applied to the models based on wavelet and shearlet responses. Finally, the connection between the models based on filter and shearlet responses deserves being investigated further.
Notes
Without any reference to samples \( x_i \sim f_X \), an equivalent statement may be that \( f_X \) is (close to) zero almost everywhere (in the layman—not measure-theoretic—sense).
For simplicity, we discard the partition function \( Z \).
We refer to the (gradient of the) negative-log experts as “potential functions” (“activation functions”). This nomenclature is often used in the neural network literature, but clashes with what is typically used in the context of graphical models and Markov random fields.
The matlab command design(fdesign.lowpass(‘N,F3dB’, 8, 0.5), ‘maxflat’) generates the filter.
The filter can be obtained in matlab using the Nonsubsampled Contourlet Toolbox by fftshift(fft2(modulate2(dfilters(‘dmaxflat4’, ‘d’)./ sqrt(2), ‘c’))).
For visualization purposes, we normalized the negative-log density to have a minimum of zero over \( t \): \( l_\theta (x, t) = -\log f^{\textrm{filt}}_\theta (x, t) - (\max _t \log f^{\textrm{filt}}_\theta (x, t)) \).
References
Hinton, G.E.: Training products of experts by minimizing contrastive divergence. Neural Comput. 14(8), 1771–1800 (2002)
Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., Ganguli, S.: Deep unsupervised learning using nonequilibrium thermodynamics. In: Proc. of the International Conference on Machine Learning, vol. 37, pp. 2256–2265. PMLR, Lille, France (2015)
Song, Y., Ermon, S.: Generative modeling by estimating gradients of the data distribution. In: Proceedings of the Conference on Neural Information Processing Systems, vol. 32. Curran Associates Inc., Red Hook, NY, USA (2019)
Du, Y., Mordatch, I.: Implicit generation and modeling with energy based models. In: Proceedings of the Conference on Neural Information Processing Systems, vol. 32. Curran Associates, Inc., Red Hook, NY, USA (2019)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: Proceedings of the Conference on Neural Information Processing Systems. Curran Associates, Inc., Red Hook, NY, USA (2020)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10674–10685 (2022)
Zach, M., Pock, T., Kobler, E., Chambolle, A.: Explicit diffusion of Gaussian mixture model based image priors. In: Calatroni, L., Donatelli, M., Morigi, S., Prato, M., Santacesaria, M. (eds.) Scale Space and Variational Methods in Computer Vision, pp. 3–15. Springer, Cham (2023)
Özdenizci, O., Legenstein, R.: Restoring vision in adverse weather conditions with patch-based denoising diffusion models. IEEE Trans. Pattern Anal. Mach. Intell. 45(8), 10346–10357 (2023)
Lugmayr, A., Danelljan, M., Romero, A., Yu, F., Timofte, R., Gool, L.V.: Repaint: Inpainting using denoising diffusion probabilistic models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11451–11461. IEEE Computer Society, Los Alamitos, CA, USA (2022)
Zach, M., Knoll, F., Pock, T.: Stable deep MRI reconstruction using generative priors. IEEE Trans. Med. Imaging 42(12), 3817–3832 (2023)
Chung, H., Ye, J.C.: Score-based diffusion models for accelerated MRI. Med. Image Anal. 80, 102479 (2022)
Zach, M., Kobler, E., Pock, T.: Computed tomography reconstruction using generative energy-based priors. In: Proceedings of the OAGM Workshop 2021, pp. 52–58. Verlag der Technischen Universität Graz, Graz (2021)
Bengio, Y., Courville, A., Vincent, P.: Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 35(8), 1798–1828 (2013)
Robbins, H.: An empirical Bayes approach to statistics. In: Proceedings of the Berkeley Symposium on Mathematical Statistics and Probability, pp. 157–163 (1956)
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score-based generative modeling through stochastic differential equations. In: Proceedings of the International Conference on Learning Representations (2021)
Rao, C.R.: Linear Statistical Inference and Its Applications. Wiley, Hoboken, NJ, USA (1973)
Vincent, P.: A connection between score matching and denoising autoencoders. Neural Comput. 23(7), 1661–1674 (2011)
Kirkpatrick, S., Gelatt, C.D., Vecchi, M.P.: Optimization by simulated annealing. Science 220(4598), 671–680 (1983)
Roberts, G.O., Tweedie, R.L.: Exponential convergence of Langevin distributions and their discrete approximations. Bernoulli 2(4), 341–363 (1996)
Cole, K., Beck, J., Haji-Sheikh, A., Litkouhi, B.: Heat Conduction Using Greens Functions. CRC Press, Boca Raton, FL (2010)
Miyasawa, K.: An empirical Bayes estimator of the mean of a normal population. Bull. Int. Stat. Inst. 38, 181–188 (1961)
Efron, B.: Tweedie’s formula and selection bias. J. Am. Stat. Assoc. 106(496), 1602–1614 (2011)
Raphan, M., Simoncelli, E.P.: Least squares estimation without priors or supervision. Neural Comput. 23(2), 374–420 (2011)
Kobler, E., Pock, T.: Learning Gradually Non-convex Image Priors Using Score Matching (2023). https://arxiv.org/abs/2302.10502
Hyvärinen, A.: Estimation of non-normalized statistical models by score matching. J. Mach. Learn. Res. 6(24), 695–709 (2005)
Schrempf, O.C., Feiermann, O., Hanebeck, U.D.: Optimal mixture approximation of the product of mixtures. In: Proceedings of the International Conference on Information Fusion, vol. 1, pp. 85–92 (2005)
Gut, A.: An Intermediate Course in Probability. Springer, New York (2009)
Bredies, K., Lorenz, D.: Mathematical Image Processing. Birkhäuser, Cham (2018)
Mallat, S.G.: A theory for multiresolution signal decomposition: The Wavelet representation. IEEE Trans. Pattern Anal. Mach. Intell. 11(7), 674–693 (1989)
Vetterli, M., Kovačevic, J.: Wavelets and Subband Coding. Prentice-Hall Inc, USA (1995)
Donoho, D.L., Johnstone, I.M.: Ideal spatial adaptation by Wavelet shrinkage. Biometrika 81(3), 425–455 (1994)
Donoho, D.L., Johnstone, I.M.: Adapting to unknown smoothness via Wavelet shrinkage. J. Am. Stat. Assoc. 90(432), 1200–1224 (1995)
Donoho, D.L.: De-noising by soft-thresholding. IEEE Trans. Inf. Theory 41(3), 613–627 (1995)
Simoncelli, E.P., Adelson, E.H.: Noise removal via Bayesian wavelet coring. In: Proceedings of 3rd IEEE International Conference on Image Processing, vol. 1, pp. 379–3821 (1996)
Chambolle, A., De Vore, R.A., Lee, N.-Y., Lucier, B.J.: Nonlinear Wavelet image processing: Variational problems, compression, and noise removal through Wavelet shrinkage. IEEE Trans. Image Process. 7(3), 319–335 (1998)
Chipman, H.A., Kolaczyk, E.D., McCulloch, R.E.: Adaptive Bayesian Wavelet shrinkage. J. Am. Stat. Assoc. 92(440), 1413–1421 (1997)
Clyde, M., Parmigiani, G., Vidakovic, B.: Multiple shrinkage and subset selection in Wavelets. Biometrika 85(2), 391–401 (1998)
Crouse, M.S., Nowak, R.D., Baraniuk, R.G.: Wavelet-based statistical signal processing using hidden Markov models. IEEE Trans. Signal Process. 46(4), 886–902 (1998)
Jansen, M., Malfait, M., Bultheel, A.: Generalized cross validation for Wavelet thresholding. Signal Process. 56(1), 33–44 (1997)
Chang, S.G., Yu, B., Vetterli, M.: Adaptive Wavelet thresholding for image denoising and compression. IEEE Trans. Image Process. 9(9), 1532–1546 (2000)
Romano, Y., Elad, M., Milanfar, P.: The little engine that could: Regularization by denoising (RED). SIAM J. Imag. Sci. 10(4), 1804–1844 (2017)
Venkatakrishnan, S.V., Bouman, C.A., Wohlberg, B.: Plug-and-play priors for model based reconstruction. In: 2013 IEEE Global Conference on Signal and Information Processing, pp. 945–948 (2013)
Zoran, D., Weiss, Y.: From learning models of natural image patches to whole image restoration. In: Proceedings of the International Conference on Computer Vision, pp. 479–486 (2011)
Roth, S., Black, M.J.: Fields of Experts. Int. J. Comput. Vision 82(2), 205–229 (2009)
Kutyniok, G., Labate, D. (eds.): Shearlets. Birkhäuser, Boston (2012)
Lim, W.-Q.: Nonseparable Shearlet transform. IEEE Trans. Image Process. 22(5), 2056–2065 (2013)
Kutyniok, G., Lim, W.-Q., Reisenhofer, R.: ShearLab 3D: Faithful digital Shearlet transforms based on compactly supported Shearlets. ACM Trans. Math. Softw. 42(1), 1–42 (2016)
Martin, D., Fowlkes, C., Tal, D., Malik, J.: A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In: Proceedings of the Internation Conference on Computer Vision, vol. 2, pp. 416–423 (2001)
Zhuang, J., Tang, T., Ding, Y., Tatikonda, S.C., Dvornek, N., Papademetris, X., Duncan, J.: AdaBelief optimizer: Adapting stepsizes by the belief in observed gradients. In: Proceedings of the Conferene on Neural Information Processing Systems Vol. 33 (2020)
Held, M., Wolfe, P., Crowder, H.P.: Validation of subgradient optimization. Math. Program. 6(1), 62–88 (1974)
Boyle, J.P., Dykstra, R.L.: A method for finding projections onto the intersection of convex sets in Hilbert spaces. In: Dykstra, R., Robertson, T., Wright, F.T. (eds.) Advances in Order Restricted Statistical Inference, pp. 28–47. Springer, New York (1986)
Grandits, T., Pock, T.: Optimizing Wavelet bases for sparser representations. In: Pelillo, M., Hancock, E. (eds.) Energy Minimization Methods in Computer Vision and Pattern Recognition, pp. 249–262. Springer, Cham (2018)
Cotter, F.: Uses of complex Wavelets in deep convolutional neural networks. PhD Thesis, University of Cambridge (2020)
Da Cunha, A.L., Zhou, J., Do, M.N.: The nonsubsampled Contourlet transform: Theory, design, and applications. IEEE Trans. Image Process. 15(10), 3089–3101 (2006)
Duchi, J., Shalev-Shwartz, S., Singer, Y., Chandra, T.: Efficient projections onto the \( \ell _1 \)-ball for learning in high dimensions. In: Proceedings of the International Conference on Machine Learning, pp. 272–279. Association for Computing Machinery, New York, NY, USA (2008)
Condat, L.: Fast projection onto the simplex and the \( \ell _1 \) ball. Math. Program. 158(1–2), 575–585 (2015)
Romano, Y., Elad, M.: Boosting of image denoising algorithms. SIAM J. Imag. Sci. 8(2), 1187–1219 (2015)
Kawar, B., Vaksman, G., Elad, M.: Stochastic image denoising by sampling from the posterior distribution. In: Proceedings of the IEEE International Conference on Computer Vision Workshops, pp. 1866–1875. IEEE Computer Society, Los Alamitos, CA, USA (2021)
Karras, T., Aittala, M., Aila, T., Laine, S.: Elucidating the design space of diffusion-based generative models. In: Proceedings of the Conference on Neural Information Processing Systems. Curran Associates, Inc., Red Hook, NY, USA (2022)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 13(4), 600–612 (2004)
Chung, H., Kim, J., Mccann, M.T., Klasky, M.L., Ye, J.C.: Diffusion posterior sampling for general noisy inverse problems. In: The Eleventh International Conference on Learning Representations (2023)
Huang, J., Mumford, D.: Statistics of natural images and models. In: Proceedings of the 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (Cat. No PR00149), vol. 1, pp. 541–5471 (1999)
Hinton, G.E., Teh, Y.-W.: Discovering multiple constraints that are frequently approximately satisfied. In: Proceedings of the Seventeenth Conference on Uncertainty in Artificial Intelligence, pp. 227–234. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA (2001)
Teh, Y.W., Welling, M., Osindero, S., Hinton, G.E.: Energy-based models for sparse overcomplete representations. J. Mach. Learn. Res. 4, 1235–1260 (2003)
Freeman, W.T., Weiss, Y.: What makes a good model of natural images? In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1–8. IEEE Computer Society, Los Alamitos, CA, USA (2007)
Hyvärinen, A., Hurri, J., Hoyer, P.O.: Natural Image Statistics. Springer, London (2009)
Forchini, G.: The distribution of the sum of a normal and a t random variable with arbitrary degrees of freedom. Metron - Int. J. Stat. 66(2), 205–208 (2008)
Berg, C., Vignat, C.: On the density of the sum of two independent Student t-random vectors. Statistics & Probability Letters 80(13), 1043–1055 (2010)
Tricomi, F.: Sulle funzioni ipergeometriche confluenti. Annali di Matematica 26(1), 141–175 (1947)
Schmidt, U., Gao, Q., Roth, S.: A generative perspective on MRFs in low-level vision. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1751–1758 (2010)
Gao, Q., Roth, S.: How well do filter-based MRFs model natural images? In: Pattern Recognition, pp. 62–72. Springer, Berlin, Heidelberg (2012)
Wainwright, M.J., Simoncelli, E.: Scale mixtures of Gaussians and the statistics of natural images. In: Proceedings of the Conferene on Neural Information Processing Systems, vol. 12, pp. 855–861. MIT Press, Cambridge, MA, USA (1999)
Portilla, J., Strela, V., Wainwright, M.J., Simoncelli, E.P.: Image denoising using scale mixtures of Gaussians in the Wavelet domain. IEEE Trans. Image Process. 12(11), 1338–1351 (2003)
Andrews, D.F., Mallows, C.L.: Scale mixtures of normal distributions. J. Royal Stat. Soc. Ser. B (Methodological) 36(1), 99–102 (1974)
Chen, Y., Pock, T.: Trainable nonlinear reaction diffusion: A flexible framework for fast and effective image restoration. IEEE Trans. Pattern Anal. Mach. Intell. 39(6), 1256–1272 (2017)
Schmidt, U., Roth, S.: Shrinkage fields for effective image restoration. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2774–2781. IEEE, Columbus, OH, USA (2014)
Guerrero-Colon, J.A., Simoncelli, E.P., Portilla, J.: Image denoising using mixtures of Gaussian scale mixtures. In: 2008 15th IEEE International Conference on Image Processing, pp. 565–568 (2008)
Gupta, P., Moorthy, A.K., Soundararajan, R., Bovik, A.C.: Generalized Gaussian scale mixtures: A model for Wavelet coefficients of natural images. Signal Processing: Image Communication 66, 87–94 (2018)
Guth, F., Coste, S., Bortoli, V.D., Mallat, S.: Wavelet score-based generative modeling. In: Proceedings of the Conference on Neural Information Processing Systems (2022)
Nichol, A.Q., Dhariwal, P.: Improved denoising diffusion probabilistic models. In: Proceedings of the International Conference on Machine Learning, pp. 8162–8171 (2021). PMLR
Zhu, S.C., Wu, Y., Mumford, D.: Filters, random fields and maximum entropy (FRAME): Towards a unified theory for texture modeling. Int. J. Comput. Vision 27(2), 107–126 (1998)
Funding
Open access funding provided by Graz University of Technology.
Author information
Authors and Affiliations
Contributions
M.Z., E.K, and T.P. contributed to conceptualization. A.C. was involved in designing numerical algorithms. Data analysis and the first draft of the manuscript was done by M.Z. All authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zach, M., Kobler, E., Chambolle, A. et al. Product of Gaussian Mixture Diffusion Models. J Math Imaging Vis (2024). https://doi.org/10.1007/s10851-024-01180-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10851-024-01180-3