
Abstract
We present a non-anticipative learning- and scenario-based prediction-optimization (ScenPredOpt) framework that combines deep learning, heuristics, and mathematical solvers for solving combinatorial problems under uncertainty. Specifically, we transform neural machine translation frameworks to predict the optimal solutions of scenario-based multi-stage stochastic programs. The learning models are trained efficiently using the input and solution data of the multi-stage single-scenario deterministic problems. Then our ScenPredOpt framework creates a map** from the inputs used in training into an output of predictions that are close to optimal solutions. We present a Non-anticipative Encoder-Decoder with Attention (NEDA) approach, which ensures the non-anticipativity property of multi-stage stochastic programs and, thus, time consistency by calibrating the learned information based on the problem’s scenario tree and adjusting the hidden states of the neural network. In our ScenPredOpt framework, the percent predicted variables used for the solution are iteratively reduced through a relaxation of the problem to eliminate infeasibility. Then, a linear relaxation-based heuristic is performed to further reduce the solution time. Finally, a mathematical solver is used to generate the complete solution. We present the results on two NP-Hard sequential optimization problems under uncertainty: stochastic multi-item capacitated lot-sizing and stochastic multistage multidimensional knapsack. The results show that the solution time can be reduced by a factor of 599 with an optimality gap of only 0.08%. We compare the results of the ScenPredOpt framework with cutting-edge exact and heuristic solution algorithms for the problems studied and find that our framework is more effective. Additionally, the computational results demonstrate that ScenPredOpt can solve instances with a larger number of items and scenarios than the trained ones. Our non-anticipative learning-optimization approach can be beneficial for stochastic programming problems involving binary variables that are solved repeatedly with various types of dimensions and similar decisions at each period.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In this paper, we present a study at the intersection of machine learning (ML) and operations research (OR). In recent years, significant effort and interest have been put into the flourishing area of using ML to solve OR problems. Although significant results have been achieved, there is still a need for frameworks that can handle the special requirements of various OR problems. Here, we focus on this direction and address OR problems involving uncertainty. We present a framework for solving scenario-based multi-stage stochastic programs by combining learning, heuristics, and mathematical solvers.
The uncertainty is crucial in many OR problems and must be addressed for accurate and realistic representations of systems of interest. Although modeling uncertainty can take many forms, we focus on scenario-based problems, which can be formulated in two or more stages. In general, scenario-based programs are complex to solve. Multi-stage stochastic optimization models are considered to be much harder than two-stage stochastic models. The sequence \(\xi _{t},\) \(t=2,\dots ,T\) is the stochastic process, and the decision made at period t is \(x_{t},\) \(t=1,\dots ,T\). In a multi-stage stochastic program, a decision \(x_{1}\) is taken before the observation of an uncertainty \(\xi _{2}\), but then the decision process repeats itself:
decide(\(x_{1}\)) \(\rightarrow \) observe(\(\xi _{2}\)) \(\rightarrow \) decide(\(x_{2}\)) \(\rightarrow \)... \(\rightarrow \) decide(\(x_{T}\)) \(\rightarrow \) observe(\(\xi _{T}\))
The decision \(x_{t}\) is made in period t and may depend on the data of the process up to and including period t, but not on the future due to the non-anticipativity of the unrealized future uncertainty outcomes. Then the T-stage multi-stage stochastic programs can be expressed as:
where \(x_{t} \in \{0,1\}^{n_t}\). The first-stage matrices \(c_{1}\), \(A_{1}\), and \(b_{1}\) are known with sizes of \({n_1} \times 1\), \({m_1} \times {n_1}\), and \({m_1} \times 1\), respectively. For the other stages, \(t=2,\dots ,T\), matrices \(c_{t}\), \(B_{t}\), \(A_{t}\), and \(b_{t}\) have sizes of \({n_t} \times 1\), \({m_t} \times {n_{t-1}}\), \({m_t} \times {n_t}\) and \({m_t} \times 1\), respectively. At stage t, the number of variables is \({n_t} \in \mathbb {Z}^+\), and the number of constraints is \({m_t} \in \mathbb {Z}^+\) for all \(t=1,\dots ,T\). Some or all of these matrices can contain uncertainty.
Multi-stage stochastic programs are very practical in modeling various applications, including airline revenue management (Möller et al., 2008), capacity planning (Huang & Ahmed, 2009), epidemic control planning (Yin & Büyüktahtakın, 2021; Yin et al., 2023b; Yin & Büyüktahtakın, 2022; Yin et al., 2023a), invasive species control and surveillance (Kıbış et al., 2021; Chen et al., 2023), and risk-averse optimization (Homem-de Mello andPagnoncelli, 2016; Bushaj et al., 2022). Despite their modeling power, they pose a computational challenge and usually require specially designed algorithms and heuristics. Exact solution approaches include Lagrangian relaxation (Chen et al., 2002), Dantzig-Wolfe decomposition (Singh et al., 2009), and branch-and-price (Lulli & Sen, 2004).
Most solution algorithms for multi-stage stochastic mixed-integer programs include some form of decomposition or cutting-plane approach, including include Lagrangian relaxation (Chen et al., 2002), Dantzig-Wolfe decomposition (Singh et al., 2009), branch-and-price (Lulli & Sen, 2004), and scenario dominance cuts (Büyüktahtakın, 2022, 2023), and decomposition-based heuristics, such as progressive hedging (Watson & Woodruff, 2011).
In this study, we propose a learning strategy and a testing framework to solve multi-stage stochastic programming problems with binary and continuous variables in a fast setting. Optimization problems are solved repeatedly on a daily basis or more frequently in various areas, including but not limited to logistics (Schmidt & Wilhelm, 2000), energy (Vespucci et al., 2012), healthcare (Guerriero & Guido, 2011), and the air transport industries (Barnhart et al., 2003). Stochastic programs can be used to generate realistic pictures of systems and provide benefits over deterministic problems (Zakaria et al., 2020). However, their size and solution time can limit their benefit. Therefore, problem-specific methods are often required for applications that are frequently solved. This process requires an expert and can be time-consuming. We address this issue and provide a general learning framework for solving scenario-based multi-stage stochastic programs, particularly those that entail making similar decisions over a specified time horizon.
Furthermore, multi-stage stochastic problems require the property of non-anticipativity. Simply put, it ensures that we cannot use information from future periods and the implementability of solutions. The non-anticipativity constraints are fundamental for multi-stage stochastic problems, and they can grow rapidly with the number of scenarios. The underlying stochastic process can be represented with scenarios with a finite number of realizations. The framework that we are proposing is specifically designed to handle scenario-based multi-stage problems and non-anticipativity requirements. We propose a new type of neural network: Non-anticipative Encoder-Decoder with Attention or NEDA, where the Encoder-Decoder with Attention part of the algorithm is based on the neural translation architecture of Luong et al. (2022) and cutting-edge solution algorithms such as stochastic dual dynamic integer programming and progressive hedging and heuristics such as relax-and-fix and adaptive fixing. The details of these baselines used to compare our approach are described in Sect. 5.2.
As an innovative feature of this study, we address the challenge of non-anticipativity with a new neural architecture called NEDA that is specifically designed to solve scenario-based multi-stage stochastic programs. A training mechanism based on deterministic instances, rather than stochastic programs, is presented to significantly reduce training data generation time. Additionally, a novel framework, ScenPredOpt, is presented to utilize predictions from the proposed NEDA neural network. ScenPredOpt integrates a heuristic based on LP relaxation to further improve solution time reductions. Moreover, we propose a variance-based item-wise generalization algorithm that considers the variability of the predictions and extends the predictions to instances with a larger number of items. Our goal is to reduce the solution times of multi-stage stochastic programming problems where they are solved repeatedly, such as vehicle routing, electric power systems, and airline crew planning. Our motivation is to develop a general framework that can solve those problems without a problem-specific design and generate fast and close-to-optimal solutions to multi-stage stochastic programs with many scenarios, periods, and varying dimensions.
2 Literature review
In recent years, the field of machine learning (ML) for solving OR has drawn significant attention. For an excellent review on this subject, we refer to Bengio et al. (2021). Specifically, using ML for solving scenario-based two-stage stochastic programs has gained traction. The closest study to ours is presented by Fre**ger and Larsen (2019). They utilize a learning framework based on a neural translation architecture to solve two-stage stochastic programs. Even though they share the same motivation as ours, i.e., reducing the solution times of stochastic programs, their methodology is significantly different. While we present a new neural architecture that can handle non-anticipativity for multi-stage problems, Fre**ger and Larsen (2019) do not consider the non-anticipativity aspect of the two-stage problem. Fre**ger and Larsen (2019) present a training paradigm based on fully solved stochastic problems, while we present a training strategy based on deterministic and easy-to-solve instances. In addition, Fre**ger and Larsen (2019) ensure the feasibility of predictions using a probability mask, but we present an iterative methodology to select a prediction level that eliminates infeasibility. Additionally, while they predict an averaged solution description for the recourse decision, we output the fully detailed solution for all stages and scenarios of the problem. In a similar vein, Larsen et al. (2022b) present a framework to solve two-stage stochastic programs. The authors work on a problem in which the solution for the second stage is computationally demanding. Therefore, they predict a higher-level and less detailed solution description instead of predicting fully detailed second-stage decisions using multilayer perceptrons.
Abbasi et al. (2020) present a methodology to solve stochastic optimization problems in two stages using well-known machine learning algorithms and a case study on blood transshipment problems with uncertain demand. Abbasi et al. (2020) train their models on the solutions of fully solved stochastic problems and predict only the first-stage decision variables. The first-stage variables are directly actionable; the second-stage variables appear to handle uncertainty and are not actionable. They use classical ML algorithms such as classification and regression trees, k-nearest neighbors, random forest, and neural networks. In practice, the solution framework outperforms the existing policy, but has an optimality gap of 14%. Wu et al. (2021) utilize a conditional variational auto-encoder to solve graph-based two-stage stochastic optimization problems. An encoder is used to generate low-dimensional representations of scenarios, which can be used through a decoder for tasks like scenario reduction and objective prediction. The presented methodology can be used for larger problems and more scenarios than the ones they are trained with. In Crespo-Vazquez et al. (2018), a methodology based on ML is presented to solve the participation problem of wind and storage power plants defined as a two-stage stochastic programming model. They utilize multivariate clustering to generate a set of scenarios from historical data, and the probabilities of scenarios are calculated by a trained Long-Short-Term Memory (LSTM) model. Bengio et al. (2020) present a framework to solve two-stage stochastic programs by predicting a representative scenario of all uncertainty. Therefore, the problem can be solved with a representative scenario deterministically instead of all scenarios and achieve the same solution faster than the Gurobi solver. Also, by only generating a surrogate problem, first-stage feasibility is ensured since the surrogate problem is solved with Gurobi in their framework.
Zheng et al. (2021) propose an encoder-decoder-based framework to solve the online route planning problem that is formulated as a two-stage stochastic program. For supervised learning, the labels are generated by a heuristic algorithm, and probability masking is applied to ensure feasibility. Dumouchelle et al. (2022) utilize neural networks to solve two-stage problems by estimating the expected second-stage cost, which can be done in two ways. In the single-cut version, the expected cost is predicted for a set of scenarios, and in the multi-cut version, the expected cost is predicted for a single scenario. Then, those estimations from the neural network are used in an approximate formulation containing the first-stage decisions. The resulting framework can be used to solve large problems in seconds. Larsen et al. (2022a) present a study to solve two-stage programs using ML to speed up difficult-to-solve second-stage problems. They propose to use multilayer perceptrons and predict the value of the target function when performing the well-known L-shaped method.
In a recent study, Nair et al. (2020) present a learning framework to enhance mixed-integer programming (MIP) solvers using two neural networks. One network is trained to perform multiple partial assignments for its integer variables, which generates smaller sub-problems that can be paralleled. The model is trained using feasible solutions instead of optimal solutions. Another network is trained for variable selection during the branch-and-bound algorithm to generate a bound for the objective function value with a smaller tree. Shen et al. (2021) present a new methodology to enhance branch-and-bound algorithms using ML. In the first step, a graph convolutional network is trained using optimal solutions to problems that can be expressed as graphs. Then, for testing, the trained model outputs a value for each decision variable that represents the probability of being in the optimal solution. In the next step, a probabilistic branching technique with a guided depth-first search is proposed to utilize the optimal solutions predicted. Liu et al. (2022) propose a learning framework by predicting the size of the local branching neighborhood. In the first step, the size of the branching is predicted as a regression task using graph neural networks. In the second stage, the predicted size is dynamically adapted within the local branching algorithms using a trained reinforcement learning model. The results show that the size parameter can be learned, resulting in significant performance gains.
Yilmaz and Büyüktahtakın (2023a) present a deep-reinforcement learning framework to solve stochastic programs based on a two-stage scenario. The authors utilize two different agents for each stage of the problem and can generate solutions for hard problems in a fraction of a second. Bushaj and Büyüktahtakın (2024) present a novel 2-D Deep Reinforcement Learning (DRL) framework that is supported by K-means where the agent, mimicking robot movements, assigns a value of 1 or 0 to each of the variables for the multi-dimensional knapsack problem. Bushaj et al. (2023) integrate an agent-based simulation with a DRL framework for epidemic intervention planning where a governor DRL agent can enforce interventions in the agent-based simulation environment.
Ding et al. (2020) present a study at the intersection of ML and OR. In their framework, a graph convolutional network is trained to predict values of binary decision variables. Then those predictions can either be used to generate a heuristic prediction with a local branching type cut or result in an exact solution with a root branching rule. In a recent study, Jiménez-Cordero et al. (2022) present a methodology for constraint generation that is used to warm-start the solution process. They train an ML model to predict invariant constraints, which is the set of constraints that cannot be removed from the integer programs without changing the feasible region. Shen et al. (2022) aim to improve the solution time of large-scale optimization problems by presenting an ML-based pricing heuristic for the column generation algorithm. The ML model is trained using optimal solutions to the pricing problem in the column generation algorithm, which is the bottleneck of the algorithm. When you have an ML model that predicts the optimal solution to the pricing problem, the efficiency of the branch-and-price increases significantly, which is an exact method.
In Kotary et al. (2021), the authors are interested in learning the OR solution using ML when there are multiple optimal solutions. Additionally, as a result of randomization within combinatorial optimization techniques, the learning task may face a challenge. To overcome this, the problem of optimal dataset design is introduced with a heuristic to find solutions with the smallest total variation. Paulus et al. (2021) present a framework in which integer programming solvers are integrated into neural network architectures as layers that can be learned. The main idea is to provide gradients for both the cost terms and the constraints of an integer program. Therefore, the proposed model can learn the cost and constraints of the problem without explicitly specifying it. Huang et al. (2022) suggest a methodology to rank cuts in a cutting plane algorithm since a good set of cuts can significantly reduce the solution time. The main idea is to learn a scoring function that can measure the efficiency of the cuts and that can be generalized to other instances. The proposed framework can be used during branch-and-cut algorithms with a solver.
Recently, Dai et al. (2021) have introduced Neural Stochastic Dual Dynamic Programming (v-SDDP) to combat high-dimensional and long-horizon stochastic dynamic programs that can be hard to solve with Stochastic Dual Dynamic Programming (SDDP). They utilize a neural network to predict a high-quality value function to increase the efficiency of the SDDP solution. Their study has a similar flavor to ours in terms of its high-level objective, i.e. using ML to help solve sequential stochastic optimization problems. However, they focus on stochastic dynamic programs rather than multi-stage stochastic programs and their solution methodology is entirely different from ours.
2.1 Key contributions of the study
An extensive amount of interest has recently been put toward learning to solve optimization problems; however, there is still a lack of research for solving scenario-based multi-stage stochastic programs. Specifically, deep learning-based supervised methodologies can be considered to solve challenges of training, feasibility, and non-anticipativity in multi-stage stochastic programs. Our motivation is two-fold. First, recent advances at the intersection of machine learning and mathematical optimization programs show a promising direction in solving combinatorial optimization problems (Liu et al., 2022; Larsen et al., 2022b). Second, the vast-applicability and computational difficulties of scenario-based multi-stage stochastic programs inspire us to tackle the computational complexity of the problem. Our goal is to significantly enhance learning-optimization solution algorithms for scenario-based multi-stage stochastic programs by presenting a general framework. Our contributions are summarized below.
To the best of our knowledge, this is the first study that utilizes an encoder-decoder model to learn the solutions of multi-stage stochastic programs. We present an innovative attention-based encoder-decoder model called NEDA, in which the hidden states of the models are adjusted based on the scenario tree to ensure the non-anticipativity of the predicted decision variables. We propose a novel training paradigm for NEDA based on deterministic instances and scenario sampling. This strategy prevents solving stochastic optimization problems to generate training labels, which is computationally intractable.
We introduce the ScenPredOpt framework to handle multi-stage programs by utilizing a general LP-based heuristic to speed up the solution. The ScenPredOpt framework is designed to handle general scenario-based multi-stage programs with binary variables by integrating decisions made by learning models, heuristics, and commercial solvers. Moreover, we improve the item-wise generalization algorithm to account for the variability of the prediction in predicting problems with a large number of items. We test the success of the ScenPredOpt algorithm with a varying number of periods, items, and scenarios. The results show that it outperforms heuristics and that the solution time can be improved by a factor of 599 with a gap of only 0.08%.
Our ScenPredOpt framework provides significant novelty over the PredOpt presented in Yilmaz and Büyüktahtakın (2024) including but not limited to LP relaxation. ScenPredOpt outlines a general methodology to solve scenario-based multi-stage stochastic MIPs, where PredOpt focuses on multi-period deterministic MIP problems. Multi-stage stochastic programming presents quite different challenges and, therefore, requires novel methodologies. First, the ScenPredOpt framework involves a novel ML framework, namely the NEDA network, which generates predictions that meet the non-anticipativity requirement of the multi-stage stochastic programs while PredOpt fails to satisfy this property. Furthermore, we extend the item-wise generalization algorithm with a variance-based strategy and compare it with PredOpt.
Section 3 presents the formulation of SMCLSP and SMSMK and a brief review discussion of the traditional solution approaches. Section 4 outlines the details of NEDA, scenario sampling-based training, ScenPredOpt framework, and item-wise generalization algorithm. Then in Sect. 5, implementation details, including instance generation, training, and evaluation, are presented. Section 6 demonstrates the computational results along with generalization experiments. Finally, Sect. 7 concludes the study with suggestions for future directions.
3 Problems
3.1 Stochastic multi-item capacitated lot-sizing problem
Lot-sizing applications have been central for many industries, including but not limited to glass, chemical, pharmaceutical, steel, paper, and manufacturing. The lot size problem has many variations, including setup times, multiple machines, cyclical schedules, and perishable inventories (Jans & Degraeve, 2008). In this study, we present a scenario-based version of the classical MCLSP. Here, some or all parameters of the problem can be uncertain and can be represented with scenarios. The objective is to minimize the total cost of production, setup, and inventory costs while satisfying the demand for each item under all scenarios. Therefore, MCLSP and SMCLSP are NP-Hard (Bitran & Yanasse, 1982).
SMCLSP can be expressed as an MIP, with the number of periods T, items I, and scenarios S. The parameters of the problems are assumed to be non-negative and are as follows: production cost \(p_{it}^{s}\), setup cost \(f_{it}^{s}\), inventory cost per unit \(h_{it}^{s}\), demand \(d_{it}^{s}\), and capacity \(c_{t}^{s}\) \(\forall i\in \left\{ 1,\ldots ,I\right\} ,\hspace{5.0pt}\forall t\in \left\{ 1,\ldots ,T\right\} ,\hspace{5.0pt}\forall s\in \left\{ 1,\ldots ,S\right\} \). The probability of each scenario is represented by \(\omega ^{s}\). The set of scenarios that share the same scenario path with scenario s up to and including period t for item i is represented by \(\Psi _{it}^{s}\). Non-negative continuous variables \(x_{it}^{s}\) and \(v_{it}^{s}\) represent the units produced and inventory at the end of each period, respectively. The binary variable \(y_{it}^{s}\) takes the value 1 if the item i is produced in period t for scenario s, and 0 if not. The SMCLSP formulation:
The objective function (2a) minimizes the expected cost of production, setup, and inventory in all scenarios, items, and periods. Constraints (2b) assure the flux of inventory in a periodic setting, while demand is satisfied for each item i. Constraints (2c) limit the amount produced for each item by a shared capacity for all items, and constraints (2d) administer the setup cost for the item i produced in period t. Constraints (2e), (2f), and (2g) are non-anticipativity constraints for \(x_{it}^{s}\), \(y_{it}^{s}\), and \(v_{it}^{s}\), respectively. Then constraints (2h) establish the nonnegativity of \(x_{it}^{s}\) and \(v_{it}^{s}\). Finally, the constraints (2i) put binary restrictions on \(y_{it}^{s}\).
The variants of the lot-sizing problem include uncertain demand (Brandimarte, 2006), biofuel production (Kantas et al., 2015), and carbon emissions (Benjaafar et al., 2012). Lot-sizing solution approaches have been studied extensively in the literature. Notably, an exact solution framework was presented by Florian et al. (1980). Furthermore, another important exact approach with valid (\(\ell \),S) inequalities and a separation algorithm was introduced by Barany et al. (1984). More recently, Büyüktahtakın et al. (2018) present dynamic programming-based inequalities to improve the solution of the multi-item capacitated lot-sizing problem. Büyüktahtakın and Liu (2016) present a study on solving single-item capacitated lot-sizing problem by combining dynamic programming with data fitting and approximation. We refer to Pochet and Wolsey (2006) for a review of algorithms on lot-sizing. For general information on stochastic lot-sizing problems, we refer to the review by Tempelmeier (2013). Stochastic lot-sizing problems can be much more challenging, and thus solution approaches such as dynamic programming (Huang & Küçükyavuz, 2008) and progressive hedging (Haugen et al., 2001) are used. Also, more general approaches that are specifically developed to solve multi-stage scenario-based programs can be utilized to solve SMCLSP. One of the most recent and highly successful approaches has been developed by Zou et al. (2019). Their developed stochastic dual dynamic integer programming (SDDiP) framework utilizes different types of cutting planes and achieves a state-of-the-art solution framework for solving multi-stage stochastic programs in different settings (Lara et al., 2020; Yu & Shen, 2020). In another recent study, Büyüktahtakın (2023) proposes scenario dominance cutting planes to solve SMCLSP quickly and with high quality. Heuristic approaches based on the relax-and-fix approach are highly used to solve both deterministic and stochastic versions of the MCLSP (Helber & Sahling, 2010; Toledo et al., 2015; Absi & van den Heuvel, 2019; Beraldi et al., 2006).
3.2 Stochastic multi-stage multi-dimensional knapsack problem
The stochastic multi-stage multi-dimensional knapsack problem is a periodical version of the well-known knapsack problem that also includes uncertainty. In this setting, the aim is to maintain a stable solution over time by maximizing the profit and the stabilization bonus while ensuring that capacity constraints are not violated. Even in a single-dimensional setting, the problem is NP-Hard (Bampis et al., 2022). The consideration of stability over time plays a vital role in applications such as periodically changing prices, energy, raw materials, and resources.
SMSMK is formulated as a binary integer program for a number of periods T, items I, and scenarios S. The binary variable \(x_{it}^{s}\) denotes the decision to insert the item \(i \in \left\{ 1,\ldots ,I\right\} \), in period \(t \in \left\{ 1,\ldots ,T \right\} \), in scenario \(s \in \left\{ 1,\ldots ,S \right\} \) by taking a value of 1, and 0 otherwise. The binary variable \(y_{it}^{s}\) is introduced as the stabilization bonus and assigned a value of 1 if the decision in period t and \(t+1\) is identical, that is, \(x_{it}^{s}, x_{i,t+1}^{s}=0\), or \(x_{it}^{s}, x_{i,t+1}^{s}=1\). Otherwise, \(y_{it}^{s}\) takes the value 0. For item i, period t and scenario s the profit is denoted by \(p_{it}^{s}\), and the bonus is denoted by \(b_{it}^{s}\) except for \(t \ne T\) since \(T-1\) is the last period the stability bonus is added. The problem considers J different knapsack constraints, and the weights are denoted by \(w_{ijt}^{s}\) for each item \(i \in \left\{ 1,\ldots ,I\right\} \), knapsack constraint \(j \in \left\{ 1,\ldots ,J \right\} \), period \(t \in \left\{ 1,\ldots ,T \right\} \), and scenario \(s \in \left\{ 1,\ldots ,S \right\} \). For each resource constraint, the capacity of the knapsack is indicated by \(c_{jt}^{s}\). \(\Psi _{it}^{s}\) is the set of scenario indexes that share the same path with scenario s up to and including period t for item i. In addition, \(\omega ^{s} \) is the probability of each scenario. We modify the formulation in Bampis et al. (2022) to include scenarios and present the problem as:
The objective function (3a) maximizes the expected profit and stability bonus over all scenarios. Constraints (3b) are knapsack constraints that limit the weights of selected items by capacity. The following constraints (3c) and (3d) secure the enforcement of the bonus if \(x_{it}=x_{i,t+1}\). Precisely, they represent the linear equivalent of \(y_{it}^{s} =1- |x_{i,t+1}^{s} - x_{it}^{s}|\). Constraints (3e) and (3f) ensure the non-anticipativity for \(x_{it}^{s}\) and \(y_{it}^{s}\), respectively. Finally, binary restrictions for \(x_{it}^{s}\) and \(y_{it}^{s}\) are given in constraints (3g) and (3h).
The knapsack problem has been studied extensively in the OR literature in various forms. The knapsack problem has a wide range of applications, and many types of complex OR problems can be expressed as knapsack-type sub-problems (Varnamkhasti, 2012). Examples include multiple objectives (Ishibuchi et al., 2014), online knapsack (Cygan et al., 2016), stochastic knapsack (Kosuch & Lisser, 2011), and probabilistic constraints (Gaivoronski et al., 2011). Numerous exact and heuristic approaches have been developed to solve different versions of the knapsack problem. We refer to Cacchiani et al. (2022) for a discussion of recent advances in knapsack problems. As there are not many solution approaches specially developed for SMSMK (3a)-(3h), we utilize a well-known solution framework, namely progressive hedging (PH), for scenario-based multi-stage problems. Introduced by Rockafellar and Wets (1991), PH uses the idea of relaxing non-anticipativity constraints and solves sub-problems independently. Later, a punishment for violating non-anticipativity is added to the objective for each sub-problem. PH performs well in various stochastic integer problems (Gul et al., 2015; Veliz et al., 2015). Büyüktahtakın (2022) presents the scenario dominance concept and a new scenario sub-problem that respects the non-anticipativity constraints to derive bounding relations between scenario couples and solve the multi-stage stochastic knapsack problem.
4 Methodology
Our methodology innovatively integrates deep learning with heuristics and optimization solvers to find efficient solutions to multi-stage stochastic optimization problems. The deep learning aspect of our methodology utilizes neural machine translation frameworks to predict solutions that are close to optimal. This is achieved by learning a map** from input defined by the problem parameters to an output defined by solver-generated optimal solutions. The details of the neural machine translation for the multi-stage stochastic programs and non-anticipative encoder-decoder with attention (NEDA) are given in Sect. 4.1. Then, in Sect. 4.2, we introduce the ScenPredOpt framework that combines learning-based decision making, heuristics, and mathematical optimization solvers, achieving remarkable reductions in solution time, as demonstrated in Sect. 6.
4.1 Non-anticipative encoder-decoder with attention
4.1.1 Neural machine translation and the requirements for multi-stage non-anticipativity
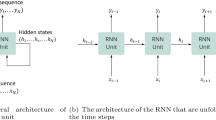
A machine translation system is used to translate from one language to another. In recent years, neural network-based translation systems have gained significant attention and achieved remarkable results (Stahlberg, 2020). In such systems, the sequence \(x_{1},x_{2}, \ldots ,x_{m}\) is the input of the source language and is translated into the target language by generating the output sequence \(y_{1},y_{2}, \ldots ,y_{n}\). The neural machine translation model is trained using pairs of input and output sequence pairs by maximizing the conditional probability: \(P (y \mid x) = \prod _{t=1}^{n} P (y_{t} \mid y_{i \mid i < t},x)\). The readers can refer to Stahlberg (2020) for a detailed review of neural machine translation systems. We develop our NEDA based on the architecture presented by Luong et al. (1b. The decision variables should take the same value if they share the same realizations of the scenarios up to the node’s stage, which is also known as time consistency. For example, all decisions for scenario one should be identical; therefore, there is only one scenario group. In stage two, there are two scenario groups: The upper group for scenarios one to four and the lower group for scenarios five to eight.
The learning network can generate predictions using the data in tabular and extended formats, as presented in Fig. 1b. However, this raises a critical complication for the problem of interest with non-anticipativity. This is because the attention-based neural network uses the processed input information from the preceding and subsequent periods. The former case is harmless since the information from the preceding periods is the same for all scenarios that have the same parent node. However, for the succeeding periods, the child nodes will have different parameters to represent changing scenario data. In effect, the original input data and, therefore, the processed input data are likely to be different for each distinct child node. Since those generated hidden states will be used within the attention mechanism, the predictions can end up being different for each scenario group that requires non-anticipativity. This would lead to a violation of the non-anticipative structure of the problem and would result in an unimplementable decision. For example, we can consider predicting the first scenario group consisting of scenarios one to four in the second stage. The parameters and, therefore, the input data for the first stage would be the same for scenarios one to four. On the other hand, when we are at stage three, only scenarios one and two are identical.
Similarly, scenarios three and four are identical, considering only stage three. Assuming that the attention-based learning model decides by only considering the preceding and succeeding periods, i.e., the attention window of size one, the predictions made would be the same for scenarios one and two and the same for scenarios three and four at stage three. These two sets of predictions would probably be different from each other at stage three, since the encoder uses fourth-stage data when predicting. This would violate the fundamental non-anticipativity requirement. In this small example, if the size of the attention window is two, then four different predictions can be made for the first scenario group, that is, scenarios one to four of the second stage. The learner network makes use of input data for the fourth period and the third period, which would have different parameters for child nodes. Having this violating condition makes the predictions for the scenario-based multi-stage stochastic program infeasible and inexecutable. In order to eliminate this violation, we propose a novel neural network architecture called Non-anticipative Encoder-Decoder with Attention or NEDA.
4.1.2 NEDA framework
The proposed NEDA model is based on the network presented by Luong et al. (2015) and modified to handle the non-anticipative nature of the issue of interest. The main idea is to generate the same encoder hidden state information for all succeeding periods that share the same parent node. Building on previous example, in Fig. 1b, we can consider generating a second-stage prediction for the first scenario group consisting of scenarios 1 to 4. To generate a prediction that ensures non-anticipativity, the hidden states on the next periods within the attention windows should be the same. This is accomplished by averaging the encoder hidden states of child nodes. Here, the hidden states of scenarios 1 to 8 of the first stage and the scenarios 1 to 4 of the third stage have been averaged separately to generate predictions using an attention window of one. The alignment for averaging operations depends on the structure of the scenario tree and is performed separately for each stage and scenario group when generating predictions. When generating the second stage prediction for the second scenario group consisting of scenarios five to eight, the hidden states of scenarios 1 to 8 of the first stage and those of 5 to 8 of the third stage have been averaged separately. The encoder processes all input sequences at once and generates the hidden states, which ideally capture the characteristics and features of the problem parameters. The forward encoder layer \(LSTM^{e}_{f}\) generates the hidden state \(\overrightarrow{h}^{e}_{t,s}\) and the backward encoder layer \(LSTM^{e}_{b}\) generates the hidden state \(\overleftarrow{h}^{e}_{t,s}\). Given the current period t and the length of the attention window D, we can represent the hidden state generated for each scenario \(s\in \left\{ 1,\ldots , S\right\} \) as:
The hidden states of the forward and backward LSTM layers within the attention window are concatenated and represented as a single encoder hidden state \(h^{e}_{t,s}=[\overrightarrow{h}^{e}_{t,s},\overleftarrow{h}^{e}_{t,s}] \hspace{5.0pt}\forall t \in \) \(\left\{ t-D,\ldots ,t,\ldots , t+D\right\} \hspace{5.0pt}\forall s \in \) \(\left\{ 1,\ldots ,S\right\} \). Let \(\Omega _{t,s}\) denote the indices of scenarios that share the same scenario realization up to the current period t with scenarios s. Therefore, for each scenario s in the problem, averaged hidden states \(h^{e}_{t,s} \) can be calculated as:
The explanation behind the the averaging step is to determine all groups of scenarios that have a hidden state similar to the current prediction period t. If those hidden states are close to each other, then the averages of the hidden states would be close to each other. In the end, the model would make a similar prediction of binary variables. However, if the hidden states vary from each other, the trained NEDA model would get varying hidden states throughout the periods. Therefore, the attention scores and context calculated in succeeding steps would lead to differently predicted binary variables for the same scenario clusters violating non-anticipativity. To prevent that, the NEDA model would make an unsure prediction using the averaged hidden states, and the determination of those decision variables would be left to the ScenPredOpt framework, therefore, to the commercial solver to find the best obtainable values.
The decoder cell state is initialized as the scenario average and produces the output sequence. The decoder \(LSTM^{d}\) also generates the decoder hidden state \(h^{d}_{t,s}\) for the current period t using the decision made in the previous period:
Then the attention module is used to further incorporate averaged encoder hidden state \(h^{e}_{i,s}\) by making a comparison with the current decoder hidden state \(h^{d}_{t,s}\). The attention score \(a_{i,s}\) is calculated as:
and the score is calculated by the following formula:
Using the attention scores, a weighted average of encoder hidden states is taken to calculate the context:
Finally, context \(cn_{t,s}\) is concatenated with the decoder hidden state and passed through a linear layer to generate a prediction for scenario s in period t. Note that for all scenarios that share the same scenario realization up to period t, the predicted values would be the same since the predictions are calculated from the same averaged hidden states calculated with Eq. (5).
4.2 The ScenPredOpt framework
4.2.1 Training and scenario sampling
In the ScenPredOpt framework, the learner is responsible for decisions in all periods over all scenario paths that are linked with non-anticipativity constraints, as ensured by the NEDA framework.
One major challenge for solving scenario-based multi-stage stochastic programs is the generation of training instances. The encoder-decoder models require a significant amount of training data generated by a commercial solver in the order of millions to learn the optimal solutions. Therefore, this instance generation approach would be unsuitable for scenario-based multi-stage stochastic programs, even for short-period instances, as they are much more complex and significantly harder to solve than deterministic multi-stage problems. To overcome this computation challenge, we propose a training strategy based on scenario sampling. In this strategy, at each training epoch, we sample a single scenario for each instance and perform a training step using that scenario data and its optimal solution.
Our proposed training based on scenario sampling achieves a few computational advantages. First, considering that the model is trained by the optimal solutions of 3,500,000 instances, it can be computationally infeasible to solve many multi-stage stochastic problems with multiple scenarios. However, solving the problem with only a single scenario, i.e., a single scenario path in Fig. 1b, only takes a few seconds with the Gurobi solver. In this setting, the non-anticipativity constraints in the formulation are removed, and therefore, each subproblem of scenarios can be solved independently in a fast manner. Second, by sampling a problem with a single scenario path, we increase the learning efficiency in a manner similar to experience replay (Mnih et al., 1a, all parameters of the fourth stage scenario would be the same if the cap** period is set to three. Otherwise, the parameters for scenarios 1,3,5, and 7 would be identical and the parameters for scenarios 2,4,6, and 8 would be identical. In Appendix A, we present further details of the generated test instances.
SMCLSP Instances: Instance generation for SMCLSP is implemented according to the approach given in Büyüktahtakın et al. (2018). The hardness of the SMCLSP is controlled by two main factors: capacity-to-demand ratios \(c \in \left\{ 10,14\right\} \) and setup-to-holding cost ratio \(r=1,000\). The production cost \(p_{it}^s\) is drawn from \(U\left[ 1,200\right] \), the inventory cost \(h_{it}^s\) is sampled from \(U\left[ 1,100\right] \), and the demand \(d_{it}^s\) is drawn from \(U\left[ 500,1500\right] \). The overall means of d and h are represented by \(\bar{d}\) and \(\bar{h}\), respectively. Capacity \(c_{t}\) is drawn from \(U\left[ 0.8c\bar{d},1.2c\bar{d}\right] \) and setup cost \(f_{it}^s\) is drawn from \(U\left[ 0.9r\bar{h},1.1r\bar{h}\right] \). Two different models are trained for SMCLSP: The first model is trained with \(T=40\) periods and \(I=8\) items. The second model is trained with \(T=30\) periods and \(I=12\) items. For both models, data sets with some combinations of \(T \in \left\{ 10,15\right\} \) and \(S \in \left\{ 32,64,81,125,243,512\right\} \), where S is the number of scenarios, are used for testing. For item-wise expansion, we used \(T \in \left\{ 15,10\right\} \), \(S \in \left\{ 32,64,81\right\} \), and \(I \in \left\{ 24,32,16\right\} \) for the first model with \(I=8\) and \(T \in \left\{ 15,10\right\} \), \(S \in \left\{ 32,64,81\right\} \), and \(I \in \left\{ 36,48,24\right\} \) for the second model with \(I=12\). For SMCLSP, 18 test sets are generated, each including 20 test instances.
SMSMK Instances: Instances are generated similar to Angulo et al. (2016). Profit \(p_{it}^s\) is drawn from \(U\left[ 1,1000\right] \), stability bonus \(b_{it}^s\) is drawn from \(U\left[ 1,1000\right] \), weights of the elements \(w_{ijt}\) are drawn from \(U\left[ 1,1000\right] \), and capacity \(c_{jt}^s\) is drawn from \(U\left[ 0.5\sum _{i=1}^{I}w_{ijt},0.8\sum _{i=1}^{I}w_{ijt}\right] \). Two models are trained for SMSMK: The one with \(T=30\) periods with \(I=8\) items and the second with \(T=30\) periods with \(I=10\) items. The test set for both models has some combination of \(T \in \left\{ 10,15\right\} \) and \(S \in \left\{ 32,64,81,125,243,512\right\} \). For the first model trained with \(I=8\), instances with \(T \in \left\{ 15,10\right\} \), \(S \in \left\{ 32,64,81\right\} \), and \(I \in \left\{ 24,32,16\right\} \) are used to test item-wise expansion. For the second model trained with \(I=10\), the test set with \(T \in \left\{ 15,10\right\} \), \(S \in \left\{ 32,64,81\right\} \), and \(I \in \left\{ 30,40,20\right\} \) are generated with item-wise expansion. A total of 30 test sets, each with 20 instances, have been generated.
5.2 Implementation Specifications
For SMCLSP, we implement SDDiP based on Ding et al. (2019) with a default setting and a time limit of 7200 s until 20 stable iterations are achieved. Additionally, we implement a heuristic based on Absi and van den Heuvel (2019) to generate a baseline for comparison. Within the heuristic, the number of fixed periods is assigned as \(T \over 20\), and the periods with binary variables are assigned as \(T \over 10\). For SMSMK, we utilize the PH approach presented by Watson and Woodruff (2011) to compare the quality of our solution. Their PH algorithm is an enhanced version of the classical PH algorithms that address convergence issues. SDDiP is not applicable for SMSMK, since SDDiP requires the complete or relatively complete recourse condition, and SMSMK is not completely recourse. Additionally, we utilize the heuristic solution presented in Bertsimas and Demir (2002) for the benchmark, as there is no existing heuristic approach specifically developed for SMSMK given by Eq. (3). Their heuristic solves an LP relaxation of the problem at each iteration. Due to the computational challenge of this heuristic, we set 0.1% of binary variables to 0 instead of a single variable at each step of the iteration. This modification results in a much faster heuristic solution at the cost of a slightly increased optimality gap for instances with a very large number of variables. Our objective with this modification is to present a more fair time comparison between ScenPredOpt and the heuristic of Bertsimas and Demir (2002).
We set the initial level for model-predicted binary variables \(\theta _{M}=50\%\) for SMCLSP and \(\theta _{M}=40\%\) for SMSMK. For both problem types, we assign the initial level for the LP relaxation-assigned binary variables \(\theta _{LP}=5\%\). Also, the reduction in the level for the model-predicted binary variables \(\lambda _{M}=10\%\) and the reduction in the level for the LP relaxation-assigned binary variables \(\lambda _{LP}=1\%\). The time to generate predictions is less than one second for all instances and is included in timeScenPredOpt. For all tables, we present the number of stages T and the total number of scenarios sc.
5.3 Model training
The NEDA models are trained with longer period problems than the instances in the test set to capture and learn more sequential decision structures with the attention structure. The instances used in the training set are deterministic and solved in 1.7 s on average. The SMCLSP models in Tables 1 and 2 have 128 and 64 hidden units in the decoder for both the forward and backward layers, respectively. The former SMCLSP model is trained for 18 h using a training set with \(T=40\). The latter SMCLSP model is trained using \(T=30\) problems in 30 h. The SMSMK models with the results presented in Tables 4 and 5 are trained using instances with \(T=30\) and contain 256 and 128 hidden units in both forward and backward layers, respectively. The encoders contain two bidirectional LSTM layers, while the decoder contains a unidirectional 2-layer LSTM. We have utilized a standard learning schema by applying training, validation, and test sets that contain 3,500,000, 10,000, and 20 instances, respectively (Alpaydin, 2020). Furthermore, a dropout schema (Srivastava et al., 2014) is used to regularize learning with a random rate of \(\left\{ 0.25,0.30,0.35\right\} \), which is known to limit overfitting. We use the popular Adam optimizer with an initial learning rate of 0.01 for SMCLSP and 0.001 for SMSMK (Kingma & Ba, 2014).
5.4 Evaluation methodology
We have utilized the following metrics to measure the success of ScenPredOpt solution time and its quality compared to exact and heuristic approaches.
-
timeGRB: Average solution time in CPU seconds for SMCLSP or SMSMK with Gurobi 9.5 in its default settings.
-
timeScenPredOpt: Average solution time in CPU seconds for SMCLSP or SMSMK with the ScenPredOpt framework.
-
timeHeur: Average solution time in CPU seconds for the heuristic of Absi and van den Heuvel (2019) for SMCLSP and the heuristic of Bertsimas and Demir (2002) for SMSMK.
-
timeSDDiP: Average solution time in CPU seconds for SMCLSP with SDDiP.
-
timePH: Average solution time in CPU seconds for SMSMK with the PH algorithm.
-
accScenPredOpt(%): Percentage of correct binary variables predicted and fixed by ScenPredOpt (or accScenPredOptWoLP for ScenPredOpt without LP relaxation) with respect to the Gurobi solution.
In addition, we define the following metrics:
Definition 1
The optimality gap between the ScenPredOpt solution \(\hat{x}^*\) (heuristic solution for optGapHeur, SDDiP solution for optGapSDDiP, and PH solution for optGapPH) and Gurobi solution \(x^*\). Let \({Z}(\bullet )\) be the corresponding operator to calculate the value of the function given any solution. Then the optimality gap is:
Definition 2
The solution time improvement factor achieved by employing the ScenPredOpt framework (heuristic time improvement for timeImpHeur, SDDiP time improvement for timeImpSDDiP, and PH time improvement for timeImpPH) compared to Gurobi solution time is:
Definition 3
The one-sided Wilcoxon signed rank test is used to measure if both samples are from the same population. It is a nonparametric alternative to the t test and appropriate for statistically comparing solution times of ML-based OR approaches (Accorsi et al., 2022). We conclude that ScenPredOpt is statistically faster than the heuristic if the p-value is smaller than 0.01. The hypotheses are as follows:
6 Results
This section provides a discussion of computational experiments. We compare the ScenPredOpt framework with the optimization solver, exact, and heuristic approaches. The test set for each specified characteristic of an instance includes 20 test instances, and all the results presented in the tables are average values for those 20 instances. All instances are solved using Gurobi 9.5 with a 2 h time limit (Gurobi Optimization, LLC, 2022).
6.1 Quality of predictions for SMCLSP
Table 1 presents the detailed computational results for the first set of SMCLSP instances. The 8-item model is trained using deterministic instances sampled by scenarios with \(T=40\) periods and 8 items. The local attention structure helps the model to generalize instances with a varying number of periods. In the first set of Table 1, the test has 32 scenarios and \(T=10\) stages. Gurobi achieves an average solution time of more than 3000 s, while SDDiP reduces the solution time to nearly 450 s with a gap of 0.03% to the Gurobi value. The heuristic significantly reduces the solution time to almost 8 s, with a relatively high optimality gap of 2.13%. ScenPredOpt remedies the trade-off between solution time and quality and achieves a 3.6-second solution with only a 0.16% optimality gap. Here, the solution time is reduced by a factor of 600, when compared to Gurobi. For the third set of instances with 81 scenarios, ScenPredOpt achieves a similar solution time improvement with a gap of only 0.08%. The Gurobi solution time of the instances is not necessarily proportional to the number of scenarios or stages; rather, it is likely related to the structure of scenario trees. However, ScenPredOpt can solve the 8-item SMCLSP for all cases much faster than Gurobi, SDDiP, and heuristic. Also, compared to the heuristic, the optimality gaps are much smaller. The p-values for the Wilcoxon signed rank test are all below 0.01, ensuring that ScenPredOpt is faster than the heuristic. The time improvement factor values for ScenPredOpt decrease as problems become more difficult because the solution time is set to a 2-hour time limit. Gurobi would require a much longer solution time than two hours for harder instances, as proved by the increasing optimality gap. Since ScenPredOpt has no solution time set, the solution with ScenPredOpt starts to take a long time, and the time improvement values appear to shrink. The time improvement values would be much higher if the Gurobi benchmark instances did not terminate early on.
Table 2 shows the computational results with 12-item SMCLSP. Here, the model is trained using \(T=30\)-period instances with 12 items. The results show a similar trend to that of Table 1, favoring ScenPredOpt over the heuristic. Gurobi solves the first three sets of instances in Table 2 on an average of more than 6000 s. ScenPredOpt solves all three of those instances in less than a minute, achieving a small optimality gap of less than 0.41%. The SDDiP halves solution time with a small optimality gap, but still does not reach a fast solution like ScenPredOpt. The last three sets of instances are significantly challenging since none of the individual instances can be solved to optimality in the set 2-hour time limit using Gurobi, hence the average Gurobi solution time of approximately 7200 s. For such instances, the heuristic time is close to or more than 1000 s, whereas the ScenPredOpt time is closer to 100 s with a significantly lower optimality gap compared to the heuristic. Also, LP-relaxation provides an accuracy improvement in the ScenPredOpt.
All p-values of the Wilcoxon test are smaller than 0.01, suggesting that ScenPredOpt is faster with a much smaller optimality gap than the heuristic. Therefore, ScenPredOpt achieves a notable computational advance by generating fast, high-quality solutions to challenging scenario-based multi-stage stochastic programs. Also, for Tables 1 and 2, the overall average and median solution time with the ScenPredOpt is smaller than the heuristic solution time with a lower standard deviation. Therefore, we can highlight that ScenPredOpt outperforms the heuristic in the solution.
6.1.1 Comparison of ScenPredOpt and Gurobi in the first few seconds
Figure 3 presents the progress of the normalized objective function values during the first seconds of the solution for ScenPredOpt and Gurobi. Specifically, Fig. 3a and b show the progress of the solution for the third and fifth sets of instances in Table 1, with 81 and 243 scenarios, respectively. Figures 3c and d show the progress of the solution for the third and fifth sets of instances in Table 2, having 81 and 243 scenarios, respectively. All four figures highlight that ScenPredOpt reduces the objective function value at a faster rate compared to Gurobi. In addition, the progress of the objective value stabilizes earlier, underlining the success of ScenPredOpt.

Progress of Gurobi and ScenPredOpt objective values during the first few seconds of the solution process. All solution times are given in CPU seconds
6.1.2 Instance-by-Instance results and comparison with PredOpt
In Table 3, we present the instance-by-instance results for 10 SMCLSP instances with larger scenarios than the previously-presented ones. The problem contains 8 items, 13 periods, and 2 scenarios per stage without scenario-cap**. Therefore, each instance contains 4096 scenarios. The results are generated using the 8-item model in Table 1. The Gurobi does not reach an optimal solution for any problem within the given 2-hour solution time limit. In addition, SDDiP cannot reach a better solution than Gurobi in a given 20-stable iteration limit. The solution time of ScenPredOpt changes between 80 and 882 s. The heuristic has a higher solution time than ScenPredOpt for all 10 instances within the range of 1222 to 2086 s. This translates to a higher time-improvement factor of ScenPredOpt compared to the heuristic for all instances. Also, the optimality gaps between ScenPredOpt and heuristic differ considerably in favor of the ScenPredOpt. Table 3 demonstrates that ScenPredOpt is not only dominant in averages but also superior in instance-by-instance cases compared to the heuristic solution times and the optimality gap and solution time of exact approaches. Furthermore, Table 3 presents a comparison between ScenPredOpt and the PredOpt introduced in Yilmaz and Büyüktahtakın (2024). The solution time of PredOpt is denoted by timePredOpt, the time improvement factor achieved by PredOpt is denoted by timeImpPredOpt, and the resulting optimality gap is denoted by optGapPredOpt. In 8 over 10 instances, ScenPredOpt outperforms PredOpt in terms of both the solution time and the optimality gap. In instance 2, ScenPredOpt has a better optimality gap than PredOpt, but with a slightly higher solution time. The third instance presents the opposite case, where ScenPredOpt has a better solution time with a larger optimality gap compared to PredOpt. The averages highlight the superiority of ScenPredOpt over PredOpt, with the former having a lower average solution time, a higher time improvement, and a lower optimality gap.
To summarize the results presented in Tables 1, 2, and 3 and Fig. 3, ScenPredOpt achieves a better solution than the heuristic and PredOpt in a statistically faster process. The optimality gap of state-of-the-art SDDiP is lower than that of ScenPredOpt at the cost of significantly increased solution time. Therefore, ScenPredOpt can be a favorable alternative to Gurobi and SDDiP by providing a fast and high-quality solution at a fraction of the computational cost without requiring expert knowledge about the problem solved.
6.2 Quality of predictions for SMSMK
Table 4 presents the first set of results for SMSMK. The model is trained with \(T=30\)-period instances. For the first set with 32 scenarios, the solution time is reduced from more than 1000 s with Gurobi to only one second with ScenPredOpt. This is much faster compared to the heuristic with a better optimality gap, i.e., a 2.73% gap with the heuristic compared to 1.09% with ScenPredOpt. The PH improves the Gurobi solution time for most cases with a slight optimality gap, but it is much slower compared to the heuristic or ScenPredOpt. For example, PH reduces the solution time more than half with only a 0.02% optimality gap in almost 2000 s in the fourth test set of Table 4. The ScenPredOpt can provide a solution in less than 5 s with only a 0.82% optimality gap. While the heuristic outperforms PH in solution time, ScenPredOpt outperforms the heuristic in terms of both solution time and optimality gap. Also, all p-values of the Wilcoxon signed-rank are smaller than 0.01 highlighting the success of the ScenPredOpt over the heuristic.
Table 5 presents another set of instances for SMSMK with 10 items. The results highlight the quality of the ScenPredOpt solution over the heuristic and the time improvement over Gurobi and PH, similar to Table 4. For example, in the last data set with 512 scenarios, the solution time is reduced to almost a minute from two hours. This significant time improvement factor of 150 is achieved with an optimality gap of only 0.77%. Similarly to the tables presented previously with SMCLSP and SMSMK, all p-values for the Wilcoxon test are less than 0.01. Also, the optimality gaps of the heuristic are much larger than those of the ScenPredOpt for all instances. Furthermore, LP-relaxation enhances ScenPredOpt accuracy.
To sum up Tables 4 and 5, ScenPredOpt achieves a significant reduction in solution time compared to Gurobi and PH at the cost of a small optimality gap. Also, it outperforms the heuristic in terms of solution quality and time for all cases. Thus, ScenPredOpt is a promising alternative to other exact and heuristic algorithms for generating fast but high-quality solutions to complex problems that need to be solved repeatedly and quickly. Furthermore, both models are tested with the parameters given for the two-stage problem and the results are presented in Appendix B.
6.3 Generalization: quality of predictions for item-wise expansion algorithm
In this section, we present the computational results for test sets with a larger number of items than the models are trained with. In the previous section, the results showed that the models can maintain high-quality solutions with the increasing number of periods and scenarios. The expansion in the period dimension is organic since encoder-decoder models can handle variable-length input and output structures. Also, the presented NEDA model can handle a varying number of scenarios by averaging different groups of scenarios based on the scenario tree of the problem using Eq. (5). This provides substantial flexibility to solve instances with a changing number of scenarios and periods. However, predicting a problem with a different number of items is not straightforward with the NEDA, since the predictions are made using a fixed-length output. Algorithm 2 presents an item-wise expansion algorithm that can generate predictions for a problem with a large number of items using a model trained with a small number of items. The main idea is to generate predictions for a subset of items multiple times with the trained model of a fixed number of items and combine them to generate a final prediction for all items considered in the test instance. This algorithm provides significant benefits, as a trained model has the potential to make predictions for a problem with any number of periods, scenarios, and items for a certain distribution of input data. Therefore, the ScenPredOpt framework can provide high levels of flexibility without generating training instances and performing training for the new set of instances with a larger number of items. Furthermore, we compare this with the item-wise expansion strategy presented in Yilmaz and Büyüktahtakın (2024) and show that the deviation-based item-wise expansion method is a further improvement over the former one. For these results, we use metrics timePredOpt, timeImpPredOpt, optGapPredOpt, and optGapPredOpt.
Table 6 presents the results of the item-wise expansion for the SMCLSP. The first three sets of results are generated using the model trained with 8 items in Table 1, and the last three sets of results are generated using the model trained with 12 items in Table 2. The results demonstrate that the ScenPredOpt used within the item-wise expansion algorithm can provide high-quality solutions. For example, in the third set of instances with 16 items, predictions from the 8-item model yield a time improvement of 300, which is significantly more than the heuristic time improvement of 65. In addition, the optimality gap of ScenPredOpt is 0. 09%, which is 20 times lower than the heuristic optimality gap of 1.84%. Also, in the first, second, fourth, and fifth datasets, ScenPredOpt outperforms SDDiP in terms of optimality gap and solution time. For all the test sets in Table 6, ScenPredOpt outperforms the heuristic in terms of solution time and optimality gap. Also, all p-values for the Wilcoxon signed-rank test are all lower than 0.01, confirming that ScenPredOpt is statistically faster than the relax-and-fix heuristic. Moreover, ScenPredOpt outperforms PredOpt in terms of optimality gap in 3 out of 6 test sets and has the same average optimality gap for the remaining 3 instances at the cost of reduced time improvement. Therefore, the variance-based item-wise algorithm achieves a better optimality gap compared to Yilmaz and Büyüktahtakın (2024).
Table 7 presents the item-wise expansion results for SMSMK, similar to Table 6. The first three results are produced with the 8-item model in Table 4, and the remaining three sets of results are produced using the 10-item model in Table 5. The results highlight that the models can be used to predict instances with a varying number of items coming from the same distribution using Algorithm 2. The instances presented in Table 7 do not terminate within a set solution time limit of 7200 s and achieve significant optimality gaps with Gurobi. For example, Gurobi achieves an optimality gap of 0.67% for the second dataset. The ScenPredOpt terminates in only 13 s on average and achieves a 0.70% optimality gap compared to the best solution found by Gurobi. For the same test set, the heuristic terminates in 27 s with a larger gap of 1.07%. On average, ScenPredOpt reduces the solution time by more than 700, with an optimality gap below 1%. The heuristic has an average time improvement factor of 377 with a larger gap. We also conclude that the ScenPredOpt is faster than the heuristic since p-values for the Wilcoxon signed rank test are below 0.01 except for the fourth test set. Additionally, the variance-based item-wise strategy given in Algorithm 2 outperforms the strategy given by Yilmaz and Büyüktahtakın (2024) in terms of the optimality gap for all test sets in Table 7. On average, the reduction of the optimality gap with Algorithm 2 is greater than 0. 2% with an increased average solution time of 6 s. In addition, the accuracy of the fixed binary variables is increased by more than 2% as a result of the LP-relaxation in the ScenPredOpt framework.
In summary, the ScenPredOpt framework with the variance-based item-wise expansion algorithm can be used to predict instances with a varying number of items. This provides significant flexibility for model training, since training can be performed using problems with a small number of items, which is easier to solve. Also, trained models do not need to retrain with changing number of items. Tables 6 and 7 provide the generalization results, in which ScenPredOpt outperforms the heuristics in terms of solution time and quality in 11 of 12 instances. Furthermore, Algorithm 2 reaches a better or the same optimality gap as Yilmaz and Büyüktahtakın (2024) at the cost of an increased solution time.
7 Conclusions and future work
In this study, we presented a learning-enabled framework for solving scenario-based multi-stage stochastic programs. We address the non-anticipativity of predicted variables by develo** the NEDA based on attentional encoder-decoder models. Additionally, generating labels for training instances can be untraceable when considering significant training data requirements. We overcome this issue by sampling a scenario and solving this deterministic problem to optimality, which is used for training. Furthermore, we present the ScenPredOpt algorithm to utilize the predictions without causing any infeasibility. We integrate an LP-based heuristic to further reduce the solution time and to integrate heuristic solution capabilities that might not be captured with a learning methodology. We present the results of our framework by generating benchmark instances with a commercial solver, exact approaches, and heuristics. The results show that the solution time can be reduced by three orders of magnitude by achieving a small optimality gap of less than 1%. Additionally, we present a variance-based item-wise expansion algorithm and test if the models can be used to predict instances with a larger number of items than they are trained with. The results show that the trained models and ScenPredOpt provide a high amount of flexibility and can be utilized to solve instances with varying stages, scenarios, and items. Our framework is general and can be utilized to solve scenario-based multi-stage stochastic programs with binary variables where such problems need to be solved repeatedly quickly, such as resource allocation, price optimization, and scheduling.
We have demonstrated the applicability of our methodology in the context of two prominent multi-stage stochastic programs: multi-item lot-sizing and dynamic knapsack. The multi-item lot-sizing problem can be relaxed to the multi-item knapsack problem (Pochet & Wolsey, 2006). The multi-item knapsack problem resembles the broader class of general multi-stage stochastic MIPs. By considering diverse dimensions, such as items, locations, products, processes, and more, our approach accommodates a flexible framework. Consequently, our item-wise expansion method can be employed to enhance the scalability of predictions to larger instances, applying to a variety of dimension types.
Our study shows a way to successfully integrate learning models, heuristics, and existing mathematical solvers to achieve significant reductions in solution time. In this way, the best of each approach can be used. The scenario-based multi-stage stochastic programs have a wide range of applications in which learning-based frameworks can be exploited. Further studies can focus on solving multi-stage stochastic programs by integrating scenario-generation mechanisms into the framework. Further studies can focus on advancing the scalability of the proposed ScenPredOpt framework for larger dimensional instances. Also, risk-averse stochastic programs can be tackled by adjusting the NEDA model, the probability of scenarios and the distribution of uncertain elements. Another direction relates to the integration of heuristics. Instead of general LP-based heuristics, problem-specific heuristics can be integrated into the ScenPredOpt solution framework to achieve better solutions faster.
References
Abbasi, B., Babaei, T., Hosseinifard, Z., Smith-Miles, K., & Dehghani, M. (2020). Predicting solutions of large-scale optimization problems via machine learning: A case study in blood supply chain management. Computers & Operations Research, 119, 104941.
Absi, N., & van den Heuvel, W. (2019). Worst-case analysis of relax and fix heuristics for lot-sizing problems. European Journal of Operational Research, 279(2), 449–458.
Accorsi, L., Lodi, A., & Vigo, D. (2022). Guidelines for the computational testing of machine learning approaches to vehicle routing problems. Operations Research Letters, 50(2), 229–234.
Alpaydin, E. (2020). Introduction to machine learning. Cambridge, MA: MIT Press.
Angulo, G., Ahmed, S., & Dey, S. S. (2016). Improving the integer l-shaped method. INFORMS Journal on Computing, 28(3), 483–499.
Bampis, E., Escoffier, B., & Teiller, A. (2022). Multistage knapsack. Journal of Computer and System Sciences, 126, 106–118.
Barany, I., Van Roy, T. J., & Wolsey, L. A. (1984). Strong formulations for multi-item capacitated lot sizing. Management Science, 30(10), 1255–1261.
Barnhart, C., Belobaba, P., & Odoni, A. R. (2003). Applications of operations research in the air transport industry. Transportation Science, 37(4), 368–391.
Bengio, Y., Fre**ger, E., Lodi, A., Patel, R., & Sankaranarayanan, S. (2020). A learning-based algorithm to quickly compute good primal solutions for stochastic integer programs. In International Conference on Integration of Constraint Programming, Artificial Intelligence, and Operations Research, pp. 99–111. Cham, Switzerland: Springer.
Bengio, Y., Lodi, A., & Prouvost, A. (2021). Machine learning for combinatorial optimization: a methodological tour d’horizon. European Journal of Operational Research, 290(2), 405–421.
Benjaafar, S., Li, Y., & Daskin, M. (2012). Carbon footprint and the management of supply chains: Insights from simple models. IEEE Transactions on Automation Science and Engineering, 10(1), 99–116.
Beraldi, P., Ghiani, G., Grieco, A., & Guerriero, E. (2006). Fix and relax heuristic for a stochastic lot-sizing problem. Computational Optimization and Applications, 33(2), 303–318.
Bertsimas, D., & Demir, R. (2002). An approximate dynamic programming approach to multidimensional knapsack problems. Management Science, 48(4), 550–565.
Bitran, G. R., & Yanasse, H. H. (1982). Computational complexity of the capacitated lot size problem. Management Science, 28(10), 1174–1186.
Brandimarte, P. (2006). Multi-item capacitated lot-sizing with demand uncertainty. International Journal of Production Research, 44(15), 2997–3022.
Bushaj, S. & Büyüktahtakın, İ. E. (2024). A K-means supported reinforcement learning framework to multi-dimensional knapsack. Forthcoming in Journal of Global Optimization.
Bushaj, S., Büyüktahtakın, İE., & Haight, R. G. (2022). Risk-averse multi-stage stochastic optimization for surveillance and operations planning of a forest insect infestation. European Journal of Operational Research, 299(3), 1094–1110.
Bushaj, S., Yin, X., Beqiri, A., Andrews, D., & Büyüktahtakın, I. E. (2023). A simulation-deep reinforcement learning (SiRL) approach for epidemic control optimization. Annals of Operations Research, 328(1), 245–277.
Büyüktahtakın, İE. (2022). Stage-t scenario dominance for risk-averse multi-stage stochastic mixed-integer programs. Annals of Operations Research, 309(1), 1–35.
Büyüktahtakın, İE. (2023). Scenario-dominance to multi-stage stochastic lot-sizing and knapsack problems. Computers & Operations Research, 153, 106149.
Büyüktahtakın, İE., & Liu, N. (2016). Dynamic programming approximation algorithms for the capacitated lot-sizing problem. Journal of Global Optimization, 65(2), 231–259.
Büyüktahtakın, İE., Smith, J. C., & Hartman, J. C. (2018). Partial objective inequalities for the multi-item capacitated lot-sizing problem. Computers & Operations Research, 91, 132–144.
Cacchiani, V., Hemmelmayr, V. C., & Tricoire, F. (2014). A set-covering based heuristic algorithm for the periodic vehicle routing problem. Discrete Applied Mathematics, 163, 53–64.
Cacchiani, V., Iori, M., Locatelli, A., & Martello, S. (2022). Knapsack problems-an overview of recent advances. Part II: Multiple, multidimensional, and quadratic knapsack problems. Computers & Operations Research, 143, 105693.
Chen, C., Cai, W., Büyüktahtakın, İ. E., & Haight, R. G. (2023). A game-theoretic approach to incentivize landowners to mitigate an emerald ash borer outbreak. IISE Transactions, pp. 1–15.
Chen, Y., & Hao, J.-K. (2014). A “reduce and solve’’ approach for the multiple-choice multidimensional knapsack problem. European Journal of Operational Research, 239(2), 313–322.
Chen, Z.-L., Li, S., & Tirupati, D. (2002). A scenario-based stochastic programming approach for technology and capacity planning. Computers & Operations Research, 29(7), 781–806.
Cohen, E., Cormode, G., Duffield, N., & Lund, C. (2016). On the tradeoff between stability and fit. ACM Transactions on Algorithms, 13(1), 1–24.
Crespo-Vazquez, J. L., Carrillo, C., Diaz-Dorado, E., Martinez-Lorenzo, J. A., & Noor-E-Alam, M. (2018). A machine learning based stochastic optimization framework for a wind and storage power plant participating in energy pool market. Applied Energy, 232, 341–357.
Cygan, M., Jeż, Ł, & Sgall, J. (2016). Online knapsack revisited. Theory of Computing Systems, 58(1), 153–190.
Dai, H., Xue, Y., Syed, Z., Schuurmans, D., & Dai, B. (2021). Neural stochastic dual dynamic programming. In International Conference on Learning Representations. https://openreview.net/forum?id=aisKPsMM3fg
Denizel, M., & Süral, H. (2006). On alternative mixed integer programming formulations and LP-based heuristics for lot-sizing with setup times. Journal of the Operational Research Society, 57(4), 389–399.
Ding, J.-Y., Zhang, C., Shen, L., Li, S., Wang, B., Xu, Y., & Song, L. (2020). Accelerating primal solution findings for mixed integer programs based on solution prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, pp. 1452–1459. Palo Alto, CA: Association for the Advancement of Artificial Intelligence.
Ding, L., Ahmed, S., & Shapiro, A. (2019). A python package for multi-stage stochastic programming. Optimization Online, 1–41.
Dumouchelle, J., Patel, R., Khalil, E. B., & Bodur, M. (2022). Neur2sp: Neural two-stage stochastic programming. ar**v preprint ar**v:2205.12006.
Florian, M., Lenstra, J. K., & Rinnooy Kan, A. (1980). Deterministic production planning: Algorithms and complexity. Management Science, 26(7), 669–679.
Fre**ger, E. & Larsen, E. (2019). A language processing algorithm for predicting tactical solutions to an operational planning problem under uncertainty. ar**v preprint ar**v:1910.08216.
Gaivoronski, A. A., Lisser, A., Lopez, R., & Xu, H. (2011). Knapsack problem with probability constraints. Journal of Global Optimization, 49(3), 397–413.
Guan, Y., Ahmed, S., & Nemhauser, G. L. (2009). Cutting planes for multistage stochastic integer programs. Operations Research, 57(2), 287–298.
Guastaroba, G., & Speranza, M. G. (2014). A heuristic for BILP problems: The single source capacitated facility location problem. European Journal of Operational Research, 238(2), 438–450.
Guerriero, F., & Guido, R. (2011). Operational research in the management of the operating theatre: a survey. Health Care Management Science, 14(1), 89–114.
Gul, S., Denton, B. T., & Fowler, J. W. (2015). A progressive hedging approach for surgery planning under uncertainty. INFORMS Journal on Computing, 27(4), 755–772.
Gurobi Optimization, LLC (2022). Gurobi Optimizer Reference Manual, version 9.5. https://www.gurobi.com
Haugen, K. K., Løkketangen, A., & Woodruff, D. L. (2001). Progressive hedging as a meta-heuristic applied to stochastic lot-sizing. European Journal of Operational Research, 132(1), 116–122.
Helber, S., & Sahling, F. (2010). A fix-and-optimize approach for the multi-level capacitated lot sizing problem. International Journal of Production Economics, 123(2), 247–256.
Homem-de Mello, T., & Pagnoncelli, B. K. (2016). Risk aversion in multistage stochastic programming: A modeling and algorithmic perspective. European Journal of Operational Research, 249(1), 188–199.
Huang, K., & Ahmed, S. (2009). The value of multistage stochastic programming in capacity planning under uncertainty. Operations Research, 57(4), 893–904.
Huang, K., & Küçükyavuz, S. (2008). On stochastic lot-sizing problems with random lead times. Operations Research Letters, 36(3), 303–308.
Huang, Z., Wang, K., Liu, F., Zhen, H.-L., Zhang, W., Yuan, M., Hao, J., Yu, Y., & Wang, J. (2022). Learning to select cuts for efficient mixed-integer programming. Pattern Recognition, 123, 108353.
Ishibuchi, H., Akedo, N., & Nojima, Y. (2014). Behavior of multiobjective evolutionary algorithms on many-objective knapsack problems. IEEE Transactions on Evolutionary Computation, 19(2), 264–283.
Jans, R., & Degraeve, Z. (2008). Modeling industrial lot sizing problems: A review. International Journal of Production Research, 46(6), 1619–1643.
Jiménez-Cordero, A., Morales, J. M., & Pineda, S. (2022). Warm-starting constraint generation for mixed-integer optimization: A machine learning approach. Knowledge-Based Systems, 253, 109570. https://doi.org/10.1016/j.knosys.2022.109570
Kantas, A. B., Cobuloglu, H. I., & Büyüktahtakın, İE. (2015). Multi-source capacitated lot-sizing for economically viable and clean biofuel production. Journal of Cleaner Production, 94, 116–129.
Kıbış, E. Y., Büyüktahtakın, İE., Haight, R. G., Akhundov, N., Knight, K., & Flower, C. E. (2021). A multistage stochastic programming approach to the optimal surveillance and control of the emerald ash borer in cities. INFORMS Journal on Computing, 33(2), 808–834.
Kingma, D. P. & Ba, J. (2014). Adam: A method for stochastic optimization. ar**v preprint ar**v:1412.6980.
Kosuch, S., & Lisser, A. (2011). On two-stage stochastic knapsack problems. Discrete Applied Mathematics, 159(16), 1827–1841.
Kotary, J., Fioretto, F., & Van Hentenryck, P. (2021). Learning hard optimization problems: A data generation perspective. Advances in Neural Information Processing Systems, 34, 24981–24992.
Lara, C. L., Siirola, J. D., & Grossmann, I. E. (2020). Electric power infrastructure planning under uncertainty: Stochastic dual dynamic integer programming (SDDiP) and parallelization scheme. Optimization and Engineering, 21(4), 1243–1281.
Larsen, E., Fre**ger, E., Gendron, B., & Lodi, A. (2022a). Fast continuous and integer l-shaped heuristics through supervised learning. ar**v preprint ar**v:2205.00897.
Larsen, E., Lachapelle, S., Bengio, Y., Fre**ger, E., Lacoste-Julien, S., & Lodi, A. (2022). Predicting tactical solutions to operational planning problems under imperfect information. INFORMS Journal on Computing, 34(1), 227–242.
Liu, D., Fischetti, M., & Lodi, A. (2022). Learning to search in local branching. In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, pp. 3796–3803. Palo Alto, CA: Association for the Advancement of Artificial Intelligence.
Lulli, G., & Sen, S. (2004). A branch-and-price algorithm for multistage stochastic integer programming with application to stochastic batch-sizing problems. Management Science, 50(6), 786–796.
Luong, M.-T., Pham, H., & Manning, C. D. (2015). Effective approaches to attention-based neural machine translation. ar**v preprint ar**v:1508.04025.
Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., & Riedmiller, M. (2013). Playing atari with deep reinforcement learning. ar**v preprint ar**v:1312.5602.
Möller, A., Römisch, W., & Weber, K. (2008). Airline network revenue management by multistage stochastic programming. Computational Management Science, 5(4), 355–377.
Nair, V., Bartunov, S., Gimeno, F., von Glehn, I., Lichocki, P., Lobov, I., O’Donoghue, B., Sonnerat, N., Tjandraatmadja, C., Wang, P., Addanki, R., Hapuarachchi, T., Keck, T., Keeling, J., Kohli, P., Ktena, I., Li, Y., Vinyals, O., & Zwols, Y. (2020). Solving mixed integer programs using neural networks. ar**v preprint ar**v:2012.13349.
Paulus, A., Rolínek, M., Musil, V., Amos, B., and Martius, G. (2021). Comboptnet: Fit the right np-hard problem by learning integer programming constraints. In International Conference on Machine Learning, pp. 8443–8453. Cambridge, MA: Proceedings of Machine Learning Research.
Pochet, Y., & Wolsey, L. A. (2006). Production planning by mixed integer programming. New York, NY: Springer.
Rockafellar, R. T., & Wets, R.J.-B. (1991). Scenarios and policy aggregation in optimization under uncertainty. Mathematics of Operations Research, 16(1), 119–147.
Schmidt, G., & Wilhelm, W. E. (2000). Strategic, tactical and operational decisions in multi-national logistics networks: A review and discussion of modelling issues. International Journal of Production Research, 38(7), 1501–1523.
Shen, Y., Sun, Y., Eberhard, A., & Li, X. (2021). Learning primal heuristics for mixed integer programs. In 2021 International Joint Conference on Neural Networks (IJCNN), pp. 1–8. Piscataway, NJ: Institute of Electrical and Electronics Engineers.
Shen, Y., Sun, Y., Li, X., Eberhard, A., & Ernst, A. (2022). Enhancing column generation by a machine-learning-based pricing heuristic for graph coloring. In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, pp. 9926–9934. Palo Alto, CA: Association for the Advancement of Artificial Intelligence.
Singh, K. J., Philpott, A. B., & Wood, R. K. (2009). Dantzig-Wolfe decomposition for solving multistage stochastic capacity-planning problems. Operations Research, 57(5), 1271–1286.
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: A simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research, 15(1), 1929–1958.
Stahlberg, F. (2020). Neural machine translation: A review. Journal of Artificial Intelligence Research, 69, 343–418.
Tempelmeier, H. (2013). Stochastic lot sizing problems. Handbook of Stochastic Models and Analysis of Manufacturing System Operations (pp. 313–344). New York, NY: Springer.
Toledo, C. F. M., da Silva Arantes, M., Hossomi, M. Y. B., França, P. M., & Akartunalı, K. (2015). A relax-and-fix with fix-and-optimize heuristic applied to multi-level lot-sizing problems. Journal of Heuristics, 21(5), 687–717.
Varnamkhasti, M. J. (2012). Overview of the algorithms for solving the multidimensional knapsack problems. Advanced Studies in Biology, 4(1), 37–47.
Veliz, F. B., Watson, J.-P., Weintraub, A., Wets, R.J.-B., & Woodruff, D. L. (2015). Stochastic optimization models in forest planning: A progressive hedging solution approach. Annals of Operations Research, 232(1), 259–274.
Vespucci, M. T., Maggioni, F., Bertocchi, M. I., & Innorta, M. (2012). A stochastic model for the daily coordination of pumped storage hydro plants and wind power plants. Annals of Operations Research, 193(1), 91–105.
Watson, J.-P., & Woodruff, D. L. (2011). Progressive hedging innovations for a class of stochastic mixed-integer resource allocation problems. Computational Management Science, 8(4), 355–370.
Wu, Y., Song, W., Cao, Z., & Zhang, J. (2021). Learning scenario representation for solving two-stage stochastic integer programs. In International Conference on Learning Representations. https://openreview.net/forum?id=06Wy2BtxXrz
Yilmaz, D. & Büyüktahtakın, İ. E. (2023a). A deep reinforcement learning framework for solving two-stage stochastic programs. Optimization Letters, pp. 1–28.
Yilmaz, D., & Büyüktahtakın, İE. (2023). Learning optimal solutions via an LSTM-optimization framework. Operations Research Forum, 4(2), 48.
Yilmaz, D., & Büyüktahtakın, İE. (2024). An expandable machine learning-optimization framework to sequential decision-making. European Journal of Operational Research, 314(1), 280–296.
Yin, X., Bushaj, S., Yuan, Y., & Büyüktahtakın, İ. E. (2023a). Covid-19: Agent-based simulation-optimization to vaccine center location vaccine allocation problem. IISE Transactions, 1–16.
Yin, X., & Büyüktahtakın, İE. (2021). A multi-stage stochastic programming approach to epidemic resource allocation with equity considerations. Health Care Management Science, 24(3), 597–622.
Yin, X., & Büyüktahtakın, İE. (2022). Risk-averse multi-stage stochastic programming to optimizing vaccine allocation and treatment logistics for effective epidemic response. IISE Transactions on Healthcare Systems Engineering, 12(1), 52–74.
Yin, X., Büyüktahtakın, İE., & Patel, B. P. (2023). Covid-19: Data-driven optimal allocation of ventilator supply under uncertainty and risk. European Journal of Operational Research, 304(1), 255–275.
Yu, X., & Shen, S. (2020). Multistage distributionally robust mixed-integer programming with decision-dependent moment-based ambiguity sets. Mathematical Programming, 196, 1025–64.
Zakaria, A., Ismail, F. B., Lipu, M. H., & Hannan, M. A. (2020). Uncertainty models for stochastic optimization in renewable energy applications. Renewable Energy, 145, 1543–1571.
Zha, D., Lai, K.-H., Zhou, K., & Hu, X. (2019). Experience replay optimization. ar**v preprint ar**v:1906.08387.
Zheng, J., Wang, L., Wang, S., Liang, Y., & Pan, J. (2021). Solving two-stage stochastic route-planning problem in milliseconds via end-to-end deep learning. Complex & Intelligent Systems, 7(3), 1207–1222.
Zou, J., Ahmed, S., & Sun, X. A. (2019). Stochastic dual dynamic integer programming. Mathematical Programming, 175(1), 461–502.
Acknowledgements
We gratefully acknowledge the support of the National Science Foundation CAREER Award, cofunded by the CBET / ENG Environmental Sustainability program, and the Division of Mathematical Sciences in MPS/NSF under Grant No. CBET-1554018. We would like to thank the anonymous referee and the guest editor for their helpful and constructive comments that have significantly improved our paper’s quality and presentation of the results. Furthermore, we acknowledge the support of New Jersey Institute of Technology Academic & Research Computing (ARC )Systems for High Performance Computing resources. The authors also thank Dr. Selina Cai for her help in accessing ARC resources.
Funding
This study was funded by the National Science Foundation CAREER Award (grant number CBET-1554018).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
Author DY declares that he has no Conflict of interest. Author EB declares that she has no Conflict of interest.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
The details of the test instances
Here, we present the details of our testing instances for each table in Sect. 6. Table 8 gives the details of SMCLSP instances presented in Tables 1, 2, and 6. Table 9 gives the details of SMSMK instances presented in Tables 4, 5, and 7. We denote the number of scenarios sc, the number of scenarios per period scPer, and the period in which no further scenarios are generated for the problem as capPer. These three variables are interconnected as: \(sc=scPer^{capPer-1}\). We have utilized a scenario-cap** strategy to combat the exponentially growing number of scenarios. Additionally, the number of binary variables is denoted by binVar, and the number of continuous variables is denoted by contVar. Note that SMSMK does not contain any continuous variables. We also present the total number of constraints excluding variable restrictions as const and the number of non-anticipativity constraints as NAC, and the number of items in the test set as testItems.
Quality of predictions for 2SMK
In this section, we present the results for a two-stage multi-dimensional knapsack problem (2SMK). The traditional solution methodologies for two-stage problems can be notably separated from the multi-stage problem. While the latter is usually considered more complex with growing scenario trees and non-anticipativity constraints, two-stage problems are highly utilized for various applications. Our aim here is to show that our trained model can still be used as an out-of-the-box solution approach if a model has already been trained for a multi-stage problem.
Table 10 presents the results for the two-stage problem with 8 items, similar to Table 4, and Table 11 demonstrates the results for 2SMK with 10 items, as in Table 5. For both Tables 10 and 11, the first three sets of instances are solved in a second with Gurobi, since the number of scenarios and, therefore, the size of the problem is small. Even in these cases, the solution time of ScenPredOpt is shorter than that of all other approaches. As instances become harder and larger, the benefits of ScenPredOpt become clearer. For example, the last data set from Table 10 is solved in more than 5 min on average. ScenPredOpt reduces the average solution time below 30 s, achieving a faster solution than Gurobi, heuristic, and PH. For all the cases in Tables 10 and 11, the p-values for the Wilcoxon test are smaller than 0.01, confirming that the ScenPredOpt outperforms the heuristic solution time. Additionally, the average optimality gap of ScenPredOpt is better than the heuristic for all cases in Tables 10 and 11, making it a superior solution approach. However, the optimality gaps for two-stage problems in Tables 10 and 11 seem to be higher than those in the multi-stage problems in Tables 4 and 5. This is because of the lack of periods required for attention structure in NEDA to capture problem characteristics, which can likely be remedied by training the model using the solutions of two-stage problems. Also, the solution characteristics might be different for a two-stage problem than a multi-stage problem since, in a long-enough multi-stage problem, decisions tend to be cyclical. Nevertheless, ScenPredOpt outperforms the heuristic for solving two-stage problems in terms of solution time and quality. It can be used to achieve significant solution time benefits for large-scale problems when a trained multi-stage model is available.

Results on the tightness parameter
In this section, we present the results for changing the tightness coefficients \(\eta \) presented in Sect. 4.2.2. Here, our objective is to test the stability and solution performance of the ScenPredOpt with varying tightness coefficients \(\eta \). Figure 4 provides the results for SMCLSP and SMSMK containing \(\eta \) \(\in \) \(\left\{ 0.1,0.2,\ldots ,0.9\right\} \). Figure 4a and b provide the optimality gap and time improvement for the 6 sets of SMCLSP instances presented in Table 1, respectively. Figure 4c and d provide the optimality gap and the time improvement for the 6 sets of SMSMK instances presented in Table 4, respectively.
The results highlight that ScenPredOpt provides highly stable solutions in various \(\eta \) values. The prediction of tight constraints are only used within the first loop in Algorithm 1 within a feasibility checker to find the first feasible solution. Later in the algorithm, this information is used to generate an optimal solution. Since this former operation is much less computationally challenging compared to the latter, the variation \(\eta \) has a minimal impact on the time improvement. In addition, the optimality gap is stable across instances, since it is determined by the latter process of solving the problem to optimality with all constraints. As discussed in Sect. 4.2.2, the value of \(\eta \) has a crucial impact on successful model training.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yilmaz, D., Büyüktahtakın, İ.E. A non-anticipative learning-optimization framework for solving multi-stage stochastic programs. Ann Oper Res (2024). https://doi.org/10.1007/s10479-024-06100-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10479-024-06100-7