
Abstract
The proliferation of the Internet of Things (IoT) paradigm has ushered in a new era of connectivity and convenience. Consequently, rapid IoT expansion has introduced unprecedented security challenges , among which source code vulnerabilities present a significant risk. Recently, machine learning (ML) has been increasingly used to detect source code vulnerabilities. However, there has been a lack of attention to IoT-specific frameworks regarding both tools and datasets. This paper addresses potential source code vulnerabilities in some of the most commonly used IoT frameworks. Hence, we introduce IoTvulCode - a novel framework consisting of a dataset-generating tool and ML-enabled methods for detecting source code vulnerabilities and weaknesses as well as the initial release of an IoT vulnerability dataset. Our framework contributes to improving the existing coding practices, leading to a more secure IoT infrastructure. Additionally, IoTvulCode provides a solid basis for the IoT research community to further explore the topic.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Internet of Things (IoT) refers to the interconnected physical objects connected to the internet or each other, relying primarily on Wireless Sensor Networks (WSN) to exchange information without human intervention [29]. These devices are widely used in both consumer and industrial applications due to the benefits of the automation they bring. IoT use cases range from smart homes, vehicular technology, and healthcare to transport, power, and agriculture. In recent years, we have witnessed a rapid increase in the number and complexity of IoT infrastructure. However, IoT devices have posed security threats and vulnerabilities over the years, primarily due to the programming languages used and programmers’ disregard for secure coding practices [20]. The IoT Operating Systems(OS) and applications are vulnerable to security breaches, and the existing higher-level security measures may not help [2].
Open Web Application Security Project (OWASP) [30], Common Vulnerability and Enumerations (CVE) [26], and Common Weakness Enumeration (CWE) [13], and Common Vulnerability Scoring System (CVSS) [12] are major resources for understanding, categorizing and addressing vulnerabilities, including those in IoT systems. These resources can be used to understand the common vulnerabilities affecting IoT systems. OWASP mainly publishes standard awareness documents for developers and web application security, representing the most critical security risks to various systems as reported IoT top 10 list [30]. The IoT developers can consider the information for more secure coding. There is also a push to incorporate security into DevOps by develo** DevSecOps (Development, Security, and Operations) [1]. DevSecOps concentrates on integrating security controls and practices into the DevOps cycle, offering substantial potential for develo** secure IoT software.
Furthermore, in real-world software systems, many types of IoT data, including network traffic, sensor readings, metrics, logs, alerts, and traces, play an essential role in cybersecurity engineering. In particular, network traffic has been widely exploited for malware and attack detection [4, 16, 31]. Similarly, sensor data is used for anomaly detection and environment-control measures. However, the methods mentioned above are incapable of detecting threats in advance because they are not designed for such purposes. Regarding threat detection, most of the existing security threats originate from the vulnerabilities in the code [6, 25, 37].
The attackers can exploit security vulnerabilities to compromise the affected system’s data and functionality and possibly use them for further malicious activities. Therefore, static application security testing (SAST) is an essential process of the DevSecOps pipeline, during which source code is automatically analyzed to identify security vulnerabilities in the early development stages [1].
In this study, we present IoTvulCode - a comprehensive framework consisting of a data extraction tool for C/C++ source code vulnerabilities and ML and natural language processing (NLP) methods to detect them. We also provide an initial release of an IoT vulnerability dataset. We collected the source code of the most commonly used IoT projects to create a labeled dataset of both vulnerable and benign samples. To create a generic dataset, we only included projects containing CVE-recorded vulnerable entries. The types of vulnerabilities in the extracted dataset are labeled according to CWE categorization. The main contributions of this study are the following:
-
An open-source tool for vulnerability dataset extraction relying on static security analyzers for source code, and we provide an initial IoT vulnerability dataset,
-
A novel IoT-specific method for source code vulnerability detection using ML and NLP, and
-
We show that our model can accurately classify vulnerabilities as we discover a considerable number of weaknesses in the most prevalent IoT-specific open-source projects.
The remainder of the paper is organized as follows. Section 2 discusses the existing datasets for identifying IoT vulnerable codes and existing AI-based approaches to vulnerability classification of IoT projects. Section 3 represents the details of the proposed IoTvulCode methodology. Section 4 elaborates on the initial release of the IoTvulCode dataset by the proposed tool and its statistics. Similarly, Sect. 5 presents the experimental results and comparative performance measures of the ML modules on the extracted dataset. The section also discusses the observations and challenges in AI-based models for vulnerability detection on the source code of IoT projects. Finally, Sect. 6 concludes the paper.
2 Related work
Together with the challenges confronted by the Internet, IoT faces substantial challenges (including scalability, mobility, and resource limitations) due to a massive number of interconnected devices and heterogeneity of exchanged data [36]. Researchers and practitioners have delved into various OSI layers to scrutinize security concerns within the IoT software development process, a crucial aspect of the DevSecOps pipeline. In this section, we present an overview of code vulnerability detection and describe prior work most related to our study, construction of the IoT vulnerability dataset, and detection of vulnerability in IoT smart environments.
2.1 Overview of code vulnerability detection
The rising number of security vulnerabilities in software highlights the need for improved detection methods. Literature shows that there is a practice of using automated source code scanning tools, specifically static code analysis, for early detection of vulnerabilities in classic software development. For example, a survey conducted in [2] have created a tool called iDetect for detecting vulnerabilities in the C/C++ source code of IoT operating systems (IoT OSs). The labeling of the dataset was done using static code analyzing tools (SATs) - Cppcheck version 2.1 [11], Flawfinder version 2.0.11 [14], and Rough Auditing Tool for Security (emphRATS) [32]. Alnaeli et al. [3] conducted an empirical study involving 18 open-source systems encompassing millions of lines of C/C++ code utilized in IoT devices. Static code analysis methods were employed for each source code project to identify unsafe commands, such as strcpy, strcmp, and strlen, which pose potential risks to the system. Celik et al.[7] introduced an IoT-specific test suite, IoTBench, an open-source repository for evaluating information leakage in IoT apps. The IoTBench includes 19 hand-crafted malicious SmartThings apps that contain 27 data leaks via either Internet or messaging service sinks.
Some of the generic datasets for vulnerability detection that are publicly available are summarized in Table 1. The iDetect dataset is the only IoT code-specific dataset. However, after removing the duplicates and ambiguous samples, the dataset included 6,245 samples (3082 vulnerable and 3163 non-vulnerable). In comparison with iDetect, our IoTvulCode dataset is 162.4 times bigger than iDetect, covering 1,014,548 statements (948,996 benign and 65,052 vulnerable samples).
The IoTvulCode dataset and the extraction tool are unique to existing studies in several ways as follows-
-
The size of the dataset is bigger in terms of the sample size than the existing IoT-specific source-code dataset.
-
The open-source extraction tool makes adding new projects to the list easy to crawl more data.
-
The incremental service of the tool facilitates the stop and resume feature to the projects in case the system hangs in the intermediate state.
-
The dataset includes binary and multi-class vulnerability types which enable the classification of binary as well as multi-class.
-
Specially, existing commit-based datasets may suffer accuracy because they assume all the changes made in the commit were vulnerable code; however, our tool picks the exact occurrences of the vulnerable code rather than the assumption-based vulnerable code.
2.3 ML models for IoT code vulnerability detection
Most existing studies on IoT security systems have concentrated on pinpointing security issues associated with IoT communication processes, data privacy, and authentication methods. Naeem and Alalfi [27] have presented deep learning-based vulnerability identification of IoT system applications. The method categorizes the vulnerabilities that lead to sensitive information leakage that can be identified using taint flow analysis on synthesized test-suite dataset [7]. The source code is converted into a list of tokens and then transformed into vectors (token2vec). Additionally, the identified tainted flows are also transformed into vectors (flow2vec). Similarly, Nazzal and Alalfi have proposed a tainted flow static analysis approach for identifying and reporting information leakage in the Smarthings IoT app.
Gao et al. [17] have presented IoTSeeker a function semantic learning-based vulnerability search approach for cross-platform IoT binary. The IoTSeeker aims to design a vulnerability search approach using semantic feature extraction and a neural network that can automatically inform whether a given binary program from IoT devices contains clone vulnerabilities or not.
3 Methodology
This section presents the methodology employed in the proposed framework, which encompasses a data extraction method for C/C++ source code vulnerabilities and implementation of the ML and NLP techniques for their detection. The dataset is curated by gathering the source code from prevalent IoT projects, creating a labeled dataset comprising vulnerable and benign code segments. To ensure the comprehensiveness of the dataset, only projects with documented vulnerabilities recorded in the CVE database were considered for inclusion. Moreover, the vulnerabilities within the dataset are categorized based on CWE standards.
The CVE provides vulnerability records of all the software and hardware systems and releases them publicly with their references. There are more than 122,000 vulnerability entries in the CVE database. Some vulnerabilities occur within the C/C++ source-code function and provide corresponding source-code references. We analyze the CVE references to check whether the IoT-related project is available in the CVE records. The intuition behind this is that IoT-related code vulnerability follows similar characteristics on different systems. The NLP or ML-based approach will be helpful in detecting such patterns.
3.1 Static security analyzers and supplementary tools
Some static analyzers use similar techniques to detect security bugs and abnormal behavior of the codes, and some use unique techniques. Using multiple analyzers covers multiple weaknesses of the source code compared to a single analyzer. Therefore, in this study, we have used three static analysis tools; FlawFinder, CppCheck, and Rats.
FlawFinder: This static analyzer is licensed under GNU GPLv2. For the data extraction, we used FlawFinder [14] version 2.0.19 (\(\star \) 376), which was released on Aug 29, 2021. The tool implements a syntactic analysis technique to scan C/C++ source code for potentially vulnerable code patterns stored in a local database. It identifies the susceptible vulnerabilities at the function level from the integrated rules in the past. It also assesses their risk of triggering a security bug by analyzing the arguments in the code, ranking them as likely severity.
CppCheck: It is a static security analysis tool for C/C++ code [11]. The tool is released under GPL3.0 and has obtained 4.9k GitHub \(\star \)stars. The tool detects bugs and focuses on detecting undefined behavior and dangerous coding constructs. It uses unsound flow-sensitive analysis, unlike other analyzers that use path-sensitive analysis.
Rats: The rough auditing tool for security (Rats) [32] is an open-source tool licensed under GPL\(-\)2.0 developed by Secure Software Inc. The tool scans code of multiple programming languages; C, C++, Perl, PHP, Python, and Ruby. Unlike other tools, Rats performs only a rough analysis of source code flagging common security-related errors such as buffer overflows and TOCTOU (Time Of Check, Time Of Use) race conditions.
In addition to the above static security analysis tools, we have used the following libraries and tools for the construction of the IoTvulCode dataset-
srcML: this is a software tool for the exploration, analysis, and manipulation of source code [10]. The tool is mainly used to convert source code into abstract syntax tree (AST) and back into source code, which allows converting source code into language-independent format (XML) and translating code of one programming to another. In this study, we have used srcML tool to retrieve source code into function blocks and perform srcML transformation in the following order: code \(\rightarrow \) AST \(\rightarrow \) function blocks \(\rightarrow \) function code.
Guesslang: this is an open-source tool used to recognize the programming language of the source code file [35]. The tool is trained using deep learning methods with over a million source-code files and supports 54 programming languages. The Guesslang tool is precise to guess the language with guessing accuracy higher than 90%; however, it takes considerable time to guess.

The proposed framework for vulnerability data collection

3.2 The IoTvulCode dataset extraction method
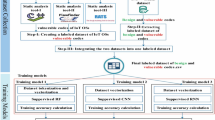
The referred IoT software are crawled and analyzed for security vulnerabilities and flaws using static code analysis tools, FlawFinder, CppCheck, and Rats. Once the contexts of the security flaws were extracted from the tools, the corresponding file of the project was analyzed to extract the statement-level and function-level metrics to provide additional code information in the dataset. The extracted metrics include the actual vulnerable code statements, corresponding function blocks, function metrics, file names, project names, vulnerability labels, and additional information. Algorithm 1 summarizes all the major steps of the data extraction pipeline. Additionally, Fig. 1 also shows the proposed extraction framework for the collection of vulnerability data which is also briefly as follows:
3.2.1 Vulnerable samples extraction
The vulnerable sample extraction mainly involves scanning the projects and composing the collected vulnerable data into an SQLite2 database file. It resembles from step 1 to step 4 as shown in Fig. 1.
-
1.
To extract the vulnerable sample, at first, the source code of the projects should be crawled locally, and their directories listed in the configuration file (ext_projects.yaml). The user can provide the initial input parameters, i.e., database name and other settings. The iteration of the extraction process goes into each project on an incremental basis. If the status of any of the projects is ’Not Started’ or ’In Progress’, then the extraction continues for the remaining files for each incomplete project.
-
2.
This step (optional) checks whether the project is registered to CVE vulnerability records. This process mainly involves picking only the benchmarked IoT software. The notion is that the project registered in the CVE records follows standard coding practices.
-
3.
This step scans project files and applies the static security analysis tools. Only the remaining files will be extracted for the projects that were incomplete in scanning their vulnerable data, ignoring the already stored files in the database. The user can select either guesslang or file extension-based method options to classify the programming language of the file because the file-extension-based method is very fast compared to the Guesslang. If a file extension is not in the given programming language list, it is set to ’unknown’. On each file, the static analyzers run to detect vulnerability and weakness. The analyzers retrieve the composed results of the statement-level vulnerability data of the file.
-
4.
The next step is to compose the generated vulnerable statements and populate the function-level data from the statements. In this study, we have fetched the function-level data using srcML [10].
3.2.2 Benign sample extraction
To apply machine learning techniques to vulnerability assessment, we require both vulnerable and benign (non-vulnerable) samples. The given static analyzers only provide the context or line of the vulnerable code in the file and its line number. We have conducted several steps to collect benign samples for statement- and function-level data.
-
5.
The function is labeled as vulnerable if it contains any of the vulnerable statements resulting from static analyzers on the file. The rest of the functions of the file are labeled as benign samples.
-
6.
For gathering the benign statements, we took randomly sampled non-vulnerable statements from the function bodies of the file.

3.3 Vulnerability detection framework
Creating an ML model for vulnerability detection involves several steps of MLOps. The high-level overview of the steps is presented in Fig. 2 and Algorithm 2 also explained as follows-
-
1.
Data collection: The above data extraction process gives us a dataset of IoT software that is both vulnerable and non-vulnerable. This could be from open-source projects, vulnerability databases, and other sources.
-
2.
Preprocessing: Perform several preprocessing steps to convert the code into a format suitable for ML models. In code analysis, this could involve parsing raw code, tokenization, and vectorization to represent code into an encoded sequence as shown in step-1 in Fig. 2.
-
3.
Model training: Train an ML model on the preprocessed data to detect vulnerabilities involved as a next step (step 2 of Fig. 2). The training process implements sequence models like RNNs or LSTMs to capture the code’s sequential nature.
-
4.
Evaluation: This process involves cross-checking the trained model on separate data not used for the training. Evaluate the model’s performance and calculate metrics such as accuracy, precision, recall, and loss (step 3 of Fig. 2).
-
5.
Deployment: If the model’s performance is satisfactory with training and testing, deploy it to a production environment where it can analyze new IoT code for vulnerabilities. The model can be deployed as a plugin in any integrated development environment (IDE) to detect vulnerabilities automatically.

The proposed method for vulnerability detection in IoT OSs and applications
3.4 Experimental setup
The resource-intensive operations, i.e., training of the machine learning models were carried out on NVIDIA DGX (DualProcessor Intel Xeon Scalable Platinum 8176 w/ 16 qty Nvidia Volta V100) and NVIDIA HGX (DualProcessor AMD EPYC Milan 7763 64-core w/ 8 qty Nvidia Volta A100/80GB). Both high-performance infrastructures (HCI) have GPU power for parallel executions which is suitable for neural network matrix multiplications. Both the infrastructures are hosted in the eX3 cluster at Simula Research Laboratory (https://www.ex3.simula.no/). To extract the dataset, we used a general-purpose PC - Lenovo Legion 7 powered by AMD Ryzen 7 5800 H/3.2 GHz, 16GB RAM, 1TB SSD, and RTX 3080 16GB GPU. After downloading all the projects to our local machine, it took 23 h to extract the vulnerability data from the 11 downloaded projects.
3.5 Hyperparameter settings
RNN and LSTM models training and testing were carried out, with different setup hyperparameters for the experiment as presented in Table 2. Additionally, we have used categorical_crossentropy for multiclass and binary_crossentropy for binary classification on both statement and function level data.

The sunburst chart showing the frequency of vulnerability categories, names, and CWEs
4 The IoTvulCode dataset
The IoTvulCode dataset is constructed from the source code of the IoT projects, which are listed in Table 3, along with their versions and links to the open-source repositories. The projects are selected based on the following criteria: (1) the project is an IoT project (OS or software), (2) the project is open-source, (3) the project is written in C/C++, (4) the project is actively maintained, and (5) the project is popular (checking CVE records).
4.1 Dataset overview
In the current version of the extracted dataset, there are 1,014,548 statements (948,996 benign and 65,052 vulnerable samples) and 548,089 functions (481,390 benign and 66,699 vulnerable samples). Among all extracted projects, linux-rpi has the most recorded entries with 816,672 total statements and 456,380 functions, followed by ARMmbed with 43,782 statements and 26,095 functions. Of course, the severity of the project can be seen in the size of the vulnerability and weakness samples present. However, linux-rpi being the biggest project in the list, can tend to hold more vulnerable samples. Table 4 shows further detailed information on the frequency of the vulnerable and benign samples in both the statement- and function of all the extracted projects.
4.2 Major vulnerabilities and weaknesses
The majority of the static analyzers categorize the vulnerabilities and weaknesses based on CWE type, which is used as a labeling technique for multiclass vulnerability identification. The Fig. 3 sunburst plot (or multi-level pie chart) visualizes the hierarchical data structures of the vulnerability and weakness type, i.e., frequency of the CWE category, name, and types. In the figure, the majority of classes- memcpy of CWE-120 type (#21153 samples) and char of CWE-119/-120 type (#16396 samples) covered more than half of the vulnerability samples.
More specifically, the top 10 CWEs in the statement- and function-level data are shown in Table 5. At the statement level, CWE-120 (Buffer Copy without Checking Size of Input) is the most frequent CWE with 30,953 samples, followed by CWE-119!/CWE-120 (Improper Restriction of Operations within the Bounds of a Memory Buffer) with 16408 samples. In function-level, again, CWE-120 is the most frequent CWE with 28,119 samples, followed by CWE-119!/CWE-120 with 12,014 samples.
4.3 Sequences sizes of the source-code
Sequence models, such as RNN, LSTM, and transformers, are the most popular models for the NLP-based classification and translation of the code. To plan for the correct sequence size of the NLP-based models for predicting vulnerabilities and weaknesses, observation of the common distribution of the token sizes is essential. Therefore, Figs. 4 and 5 show the distribution of the number of tokens in the statement and function-level source code, respectively. Each sequence of the input data can be padded to the vocabulary size. The vocabulary size of the NLP-based models is the number of unique words in the dataset.

The frequency of #tokens in the statement-level data

The frequency of #tokens in the function-level data

The frequency of #chars in the statement-level data
Similarly, Fig. 6 shows the frequency of the number of characters in the statement-level data. The majority of the statements have 10 to 80 characters, and the average number of characters in a statement is 38. The number of characters in a statement is a good indicator of the vocabulary size of the NLP-based models.
5 Experimental results
The dataset needs benchmarking to check whether ML models, especially NLP-based approaches to the data, perform well in predicting vulnerabilities and weaknesses at both the statement and function levels. The experimental dataset consists of the data from all the mentioned projects. We randomly split (seeding) the obtained dataset into training (70%) and validation (30%) sets. The training and validation sets are disjoint and do not contain duplicate samples.

Training and validation loss on the IoTvulCode dataset with different ML models

Training and validation accuracy on the IoTvulCode dataset with different ML models
Sequence models, such as recurrent neural networks (RNN) and long-short-term memory networks (LSTM), are well-suited for classification problems and detecting vulnerability in code because they are designed to work with sequential data. RNN model processes sequences of code by maintaining a hidden state that captures information about the tokens. However, it has a vanishing gradient problem capturing long-term dependencies. LSTM overcomes this using an explicit memory cell that allows them to capture long-term dependencies and makes them more effective for tasks like vulnerability detection, where context from earlier in the code can be important for identifying vulnerabilities. For vulnerability detection, these ML models should be trained on both vulnerable and benign samples for binary classification. They should be labeled as vulnerability types (i.e., CWE types) for multiclass classification.

Training and validation precision on IoTvulCode dataset using different ML models

Training and validation recall on IoTvulCode dataset using different ML models
5.1 Performance of the models
The performance scores of the ML models provide insights into how well each model performs in classifying statements in the IoTvulCode dataset, focusing on detecting vulnerabilities. The performance metrics help assess the model’s overall accuracy and ability to correctly identify positive instances while minimizing false positives and false negatives.
The loss in training and validation on the dataset over time with multiple ML models are given in Fig. 7. The loss curve (also known as the learning curve) shows the loss function value as a function of the number of training epochs. The loss is typically high at the beginning of training, meaning the model has not learned anything yet. As iteration increases, the loss should decrease to indicate the model is learning the data to predict the target variable more accurately. In our experiment, in both training and testing causes, the decreasing loss curve tends to 0.01, showing that the model is learning well enough to predict vulnerabilities accurately.
Similarly, the training and validation accuracy scores on our IoTvulCode dataset using multiple ML models are projected in Fig. 8. An accuracy curve visualizes the accuracy of a model over training epochs. The increasing accuracy over time indicates the model is learning to predict the target label more accurately. Being that both training and validation accuracy are almost similar in the plot indicates there is no overfitting, i.e., it can generalize the data.
Along with accuracy, precision and recall are also two fundamental metrics used to evaluate the performance of ML models, especially in classification problems such as vulnerability detection in source code. Precision is the ratio of correctly predicted positive observations (vulnerable samples) to the total predicted positive observations. On the other hand, recall is the ratio of correctly classified positive observations to all observations in the actual class. Figures 9 and 10 show the training and validation precision and recall, trained on our statement-level data using different ML models.
Table 6 summarizes performance scores of different ML models on the IoTvulCode dataset at the statement level for both training and validation sets. The table scores loss, accuracy, precision, and recall scores of both binary classifications(IoTvulCode -RNN, CNN, and \(iDetect-RNN, -CNN\)) and multiclass classification (IoTvulCode -RNNmul, -CNNmul, -LSTMmul).
For binary classification, the calculated scores indicate that the IoTvulCode -RNN model achieves superior results in both the training and validation sets of the IoTvulCode dataset, boasting an accuracy score of 0.99 and a precision score of 0.99. Specifically, the training recall stands at 0.97, while the validation recall reaches an even higher value of 0.99. Our ML models do better than the iDetect classifiers, having a lower loss score (0.044) as compared to iDetect (lowest loss 0.196 training and 0.236 validation in RNN) and better performance in most measures except recall. Our IoTvulCode dataset is much larger than iDetect, being 162.4 times bigger and including 1,014,548 unique statements (948,996 benign and 65,052 vulnerable samples). Even though the iDetect has a higher recall, the dataset may lack performance in the general scenarios of IoT software.
For multiclass classification, the calculated scores indicate that the IoTvulCode -RNN model achieves superior results in both the training and validation sets of the IoTvulCode dataset, boasting an accuracy, precision, and recall score of 0.99, among all three multiclass classifiers (IoTvulCode -RNNmul, -CNNmul, LSTMmul). Comparing the loss score, IoTvulCode -RNNmul performs better in the training set and IoTvulCode -LSTMmul performs better in the validation set. In the case of multi-classification, pinpointing the precise multiple labels in the iDetect dataset proved challenging. Additionally, their dataset contains numerous duplicate and ambiguous samples, necessitating additional preprocessing.
5.2 Discussion on the proposed IoTvulCode method
For application-level software testing, bad coding practices leave the code vague and difficult to understand and leave loopholes and weaknesses in the code. Identifying the vulnerabilities in the early stages of the software development life cycle helps reduce the maintenance cost and ensures the program is more secure and robust. The proposed IoTvulCode extraction tool and the initial version of the dataset can be utilized in multiple applications for the assessment of IoT vulnerabilities in source code-
-
The IoTvulCode extraction tool can easily be extended for other applications not only limited to the IoT software but also to the generic software.
-
The initial release of the IoTvulCode dataset can be utilized to detect a vulnerability to check its presence in the source code of the IoT software.
-
Similarly, the labeling of the dataset is based on CWE weakness types, which supports the multi-class prediction of the vulnerability, not only the presence but also the category of vulnerability that appeared in the code.
-
The extracted dataset by the IoTvulCode tool also has multiple granular levels of source code snippets; statement-level and function-level. Therefore the dataset enables vulnerability assessment at a multi-granular level.
-
The dataset and its extraction tool are open-source licensed, enabling the interested user to replicate, extend, and redistribute the tool and the extracted dataset.
The extraction tool, the initial release of the dataset, and the ML models will open up the research in implementing NLP and ML models to detect vulnerabilities and security flaws in IoT source code at both statement-, and function-levels.
6 Conclusion
Detecting vulnerabilities and weaknesses in IoT operating systems and applications is critical to ensuring the security and reliability of interconnected devices in the smart world. As a component of the DevSecOps pipeline for vulnerability detection, our proposed tool scans the source code of the IoT software and identifies possible loopholes in the source code. In this study, we created a dataset named IoTvulCode , labeled as binary and multiclass, based on CWE’s most common IoT code vulnerabilities. The dataset contains around a million statements (6.5% vulnerable) and around half a million functions (12% vulnerable).
Additionally, we applied several ML methods and trained the models to detect vulnerabilities in the C/C++ source code of IoT software and compare and validate the models. Our experiment shows that the RNN model achieved a binary accuracy of 99%, precision of 97%, recall of 88%, and a multiclass accuracy, precision, and recall of 99% on the labeled IoTvulCode dataset. In future work, we will extend the labeled dataset to cover other generic software projects and identify security issues. We will exploit more sequence models and transformers to fine-tune the existing models like VulBERTa [19], which better understand the semantics of the code hence improving the performance.
Data availibility
The experimented models, including the source code of the study, are publicly available at GitHub repository-https://github.com/SmartSecLab/IoTvulCode. The initial version of the extracted IoTvulCode dataset is available at https://zenodo.org/records/10573928. The plots and figures presented in the paper can be reproduced running notebooks/statistics.ipynb jupyter notebook at the GitHub repository. We welcome the IoT software security community to reproduce our results and further enhance the detection methods of vulnerabilities and weaknesses of IoT open-source software.
References
Akula, B.S.: Vulnerability Management in DevSecOps.(2023) https://dzone.com/articles/vulnerability-management-in-devsecops
Al-Boghdady, A., El-Ramly, M., Wassif, K.: iDetect for vulnerability detection in internet of things operating systems using machine learning. Sci. Rep. 12(1), 17086 (2022). https://doi.org/10.1038/s41598-022-21325-x
Alnaeli, S.M., Sarnowski, M., Aman, M.S., Abdelgawad, A., Yelamarthi, K.: Source code vulnerabilities in IoT software systems. Adv. Sci. Technol. Eng. Syst. J. 2(3), 1502–1507 (2017). https://doi.org/10.25046/aj0203188
Bhandari, G., Lyth, A., Shalaginov, A., Grønli, T.M.: Distributed deep neural-network-based middleware for cyber-attacks detection in smart IoT Ecosystem: a novel framework and performance evaluation approach. Electronics 12(2), 298 (2023). https://doi.org/10.3390/electronics12020298
Bhandari, G., Naseer, A., Moonen, L.: CVEfixes: automated collection of vulnerabilities and their fixes from open-source software. In: Proceedings of the 17th international conference on predictive models and data analytics in software engineering, PROMISE 2021, pp. 30–39. Association for Computing Machinery, New York, NY, USA (2021). https://doi.org/10.1145/3475960.3475985
Blinowski, G.J., Piotrowski, P.: CVE Based Classification of Vulnerable IoT Systems. In: W. Zamojski, J. Mazurkiewicz, J. Sugier, T. Walkowiak, J. Kacprzyk (eds.) Theory and applications of dependable computer systems, advances in intelligent systems and computing, pp. 82–93. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-48256-5_9
Celik, Z.B., Babun, L., Sikder, A.K., Aksu, H., Tan, G., McDaniel, P., Uluagac, A.S.: Sensitive Information Tracking in Commodity IoT. 27th USENIX Security Symposium (2018)
Chakraborty, S., Krishna, R., Ding, Y., Ray, B.: Deep learning based vulnerability detection: are we there yet? IEEE Trans. Softw. Eng. 48(9), 3280–3296 (2021)
Chen, Y., Ding, Z., Chen, X., Wagner, D.: DiverseVul: a new vulnerable source code dataset for deep learning based vulnerability detection (2023). https://doi.org/10.48550/ar**v.2304.00409
Collard, M.L., Decker, M.J., Maletic, J.I.: srcML: an infrastructure for the exploration, analysis, and manipulation of source code: a tool demonstration. In: 2013 IEEE International conference on software maintenance, pp. 516–519 (2013). https://doi.org/10.1109/ICSM.2013.85
Cppcheck2.1: a tool for static C/C++ code analysis. (2021) https://cppcheck.sourceforge.io/
CVSS: NVD - Vulnerability Metrics. (2022) https://nvd.nist.gov/vuln-metrics/cvss
CWE: CWE - Common weakness enumeration. (2023) https://cwe.mitre.org/index.html
dwheeler: Flawfinder v. 2.0.11. (2021) https://dwheeler.com/flawfinder/
Fan, J., Li, L., Wang, S., Nguyen, T.N.: A C/C++ Code vulnerability dataset with code changes and CVE Summaries. In: International conference on mining software repositories (MSR), p. 5 (2020)
Ferrag, M.A., Friha, O., Hamouda, D., Maglaras, L., Janicke, H.: Edge-IIoTset: a new comprehensive realistic cyber security dataset of IoT and IIoT applications for centralized and federated learning. IEEE Access 10 (2022)
Gao, J., Yang, X., Jiang, Y., Song, H., Choo, K.K.R., Sun, J.: Semantic learning based cross-platform binary vulnerability search For IoT devices. IEEE Trans. Industr. Inf. 17(2), 971–979 (2021). https://doi.org/10.1109/TII.2019.2947432
GitHub: code security documentation. (2023) https://docs.github.com/code-security
Hanif, H., Maffeis, S.: VulBERTa: Simplified source code pre-training for vulnerability detection. In: 2022 International joint conference on neural networks (IJCNN), pp. 1–8 (2022). https://doi.org/10.1109/IJCNN55064.2022.9892280
Ibrahim, A., El-Ramly, M., Badr, A.: Beware of the vulnerability! How vulnerable are GitHub’s Most Popular PHP Applications? In: 2019 IEEE/ACS 16th international conference on computer systems and applications (AICCSA), pp. 1–7 (2019). https://doi.org/10.1109/AICCSA47632.2019.9035265
Kaur, A., Nayyar, R.: A comparative study of static code analysis tools for vulnerability detection in C/C++ and JAVA source code. Procedia Comput. Sci. 171, 2023–2029 (2020). https://doi.org/10.1016/j.procs.2020.04.217
Li, Z., Zou, D., Xu, S., Ou, X., **, H., Wang, S., Deng, Z., Zhong, Y.: VulDeePecker: a deep learning-based system for vulnerability detection. In: Network and distributed system security symposium (2018)
Lin, G., Wen, S., Han, Q.L., Zhang, J., **ang, Y.: Software vulnerability detection using deep neural networks: a survey. Proc. IEEE 108(10), 1825–1848 (2020). https://doi.org/10.1109/JPROC.2020.2993293
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., Stoyanov, V.: RoBERTa: a robustly optimized bert pretraining approach (2019). https://doi.org/10.48550/ar**v.1907.11692
McLean, R.K.: Comparing static security analysis tools using open source software | IEEE Conference Publication | IEEE Xplore. In: 2012 IEEE Sixth international conference on software security and reliability companion. IEEE, Gaithersburg, MD, USA (2012). https://doi.org/10.1109/SERE-C.2012.16
MITRE: Common Vulnerability and Enumerations (CVE). (2023) https://cve.mitre.org/index.html
Naeem, H., Alalfi, M.H.: Identifying vulnerable IoT applications using deep learning. In: 2020 IEEE 27th International conference on software analysis, evolution and reengineering (SANER), pp. 582–586. IEEE, London, ON, Canada (2020). https://doi.org/10.1109/SANER48275.2020.9054817
Nikitopoulos, G., Dritsa, K., Louridas, P., Mitropoulos, D.: CrossVul: a cross-language vulnerability dataset with commit data. In: Joint meeting on european software engineering conference and symposium on the foundations of software engineering, pp. 1565–1569. ACM, New York, NY, USA (2021). DOIurl:10/gmvfdq
Oracle: what is the internet of things (IoT)? (2023) https://www.oracle.com/internet-of-things/what-is-iot/
OWASP: OWASP internet of things | OWASP Foundation. (2023) https://owasp.org/www-project-internet-of-things/
Popoola, S.I., Ande, R., Adebisi, B., Gui, G., Hammoudeh, M., Jogunola, O.: Federated Deep Learning for Zero-Day Botnet Attack Detection in IoT-Edge Devices. IEEE Internet Things J. 9(5), 3930–3944 (2022). https://doi.org/10.1109/JIOT.2021.3100755
RATS: rough auditing tool for security. (2021) https://security.web.cern.ch/recommendations/en/ codetools/rats.shtml
Russell, R., Kim, L., Hamilton, L., Lazovich, T., Harer, J., Ozdemir, O., Ellingwood, P., McConley, M.: Automated vulnerability detection in source code using deep representation learning. In: International conference on machine learning and applications (ICMLA), pp. 757–762. IEEE, Orlando, FL (2018). DOIurl:10/ggssk7
Russell, R.L., Kim, L., Hamilton, L.H., Lazovich, T., Harer, J.A., Ozdemir, O., Ellingwood, P.M., McConley, M.W.: Automated vulnerability detection in source code using deep representation learning (2018). https://doi.org/10.48550/ar**v.1807.04320
Somda, Y.: Guesslang - Detect the programming language of a source code (2021)
Swessi, D., Idoudi, H.: A Survey on Internet-of-Things Security: Threats and Emerging Countermeasures. Wireless Pers. Commun. 124(2), 1557–1592 (2022). https://doi.org/10.1007/s11277-021-09420-0
Viega, J., Bloch, J., Kohno, Y., McGraw, G.: ITS4: a static vulnerability scanner for C and C++ code. In: Proceedings 16th annual computer security applications conference (ACSAC’00), pp. 257–267 (2000). https://doi.org/10.1109/ACSAC.2000.898880
Wang, H., Ye, G., Tang, Z., Tan, S.H., Huang, S., Fang, D., Feng, Y., Bian, L., Wang, Z.: Combining graph-based learning with automated data collection for code vulnerability detection. IEEE Trans. Inf. Forensics Secur. 16, 1943–1958 (2021). https://doi.org/10.1109/TIFS.2020.3044773
Zhou, Y., Liu, S., Siow, J., Du, X., Liu, Y.: Devign: effective vulnerability identification by learning comprehensive program semantics via graph neural networks. In: International Conference on Neural Information Processing Systems (NeurIPS), p. 11. Curran Associates, Inc., Vancouver, Canada. (2018)
Acknowledgements
The machine learning experimentation in this research study benefited from the Experimental Infrastructure for Exploration of Exascale Computing (eX3), financially supported by the Research Council of Norway under contract 270053. Data extraction part received significant support from the Kristiania-HPC infrastructure, financially sponsored by Kristiania University College.
Funding
Open access funding provided by Kristiania University College.
Author information
Authors and Affiliations
Contributions
GPB, GA, and NG wrote the main manuscript text. GPB, AS, and TG designed the concept and methodology of the study. All authors reviewed the manuscript. Guru developed source code and constructed the IoT vulnerability dataset. GA, AS and TMG pre-reviewed the study before submission.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bhandari, G.P., Assres, G., Gavric, N. et al. IoTvulCode: AI-enabled vulnerability detection in software products designed for IoT applications. Int. J. Inf. Secur. (2024). https://doi.org/10.1007/s10207-024-00848-6
Published:
DOI: https://doi.org/10.1007/s10207-024-00848-6