
Abstract
We consider an investor who is dynamically informed about the future evolution of one of the independent Brownian motions driving a stock’s price fluctuations. With linear temporary price impact the resulting optimal investment problem with exponential utility turns out to be not only well posed, but it even allows for a closed-form solution. We describe this solution and the resulting problem value for this stochastic control problem with partial observation by solving its convex-analytic dual problem.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Information is arguably a key driver in stochastic optimal control problems as policy choice strongly depends on assessments of the future evolution of a controlled system and on how these can be expected to change over time. This is particularly obvious in Finance where information drives price fluctuations and where the question how it affects investment decisions is still a topic of great interest for financial economics and mathematics alike.
In part this may be due to the many ways information can be modeled and due to the various difficulties that come with each such model choice. If, as we are setting out to do in this paper, one seeks to understand how imperfect signals on future stock price evolution can be factored into present investment decisions, one needs to specify how the signal and the stock price are connected and work out the trading opportunities afforded by the signal. For a dynamic specification of the signal and its noise such as ours, this often leads to challenging combinations of filtering and optimal control and we refer to [2, 7, 8, 12, 20] for classical and more recent work in this direction.
The present paper contributes to this literature with a simple Bachelier stock price model driven by two independent Brownian motions. The investor dynamically gets advanced knowledge about the evolution of one of these over some time period, but the noise arising from the other Brownian motion makes perfect prediction of stock price fluctuations impossible. Accounting in addition for temporary price impact from finite market depth (cf. [16]) as suggested in the Almgren–Chriss model [1], we arrive at a viable expected utility maximization problem. In fact, for exponential utility we follow an approach similar to the one of [4], where the case of perfect stock price predictions is considered, and we work out explicitly the optimal investment strategy and maximum expected utility in this case. We can even allow for dynamically varying horizons over which peeks ahead are possible, thus extending beyond the fixed horizon setting of [4] (which is still included as a special case).
Our model also complements the literature on optimal order execution where different forms of market signals have been studied. For instance, [9] add a Markovian drift to the stock price evolution to model market trends as perceived by the agent; latent factors are added in [10]. With transient price impact rather than temporary one as in our setting, [17] and [19] study such signals and [6] adds a version with non-Markovian finite variation signals. Yet another version of market signals is considered in [5] who use Meyer \(\sigma \)-fields to model ultra short-term signals on the jumps in the order flow.
Describing how signals are specifically processed into strategies is a challenge for each of these models. In our setting, we find that the investor should optimally weigh her noisy signals of future stock price evolution and aggregate these weights into a projection of its fluctuations. The difference of this projection with the present stock price determines the signal-based part of her investment strategy. The relevant projection weights are computed explicitly and we analyze how they depend on the signal to noise ratio. On top of that, the investor also is interested in chasing the risk premium afforded by the stock and thus aims to take her portfolio to the Merton ratio, well-known from standard expected utility maximization. In addition, we investigate the value of reductions in noise and show that it is convex in signal quality. In other words, incentives for signal improvement turn out to be skewed in favor of investors who are already good at sniffing out the market’s evolution. Finally, we also use the flexibility in the signal horizon of our model to investigate when our investor would most like to be peek ahead if she can do so only once and how much of an advantage a continually probing investor has over her more relaxed counterpart who does so only periodically.
Mathematically, our method is based on the general duality result given in [4]. Here, however, we need to understand how changes of measures can be optimized when two Brownian motions are affected. Fortunately, we again find the problem to reduce to deterministic variational problems, which, albeit more involved, remain quadratic and thus can still be solved explicitly. The time-dependent knowledge horizon adds further challenges, but also affords us the opportunity to show that the problem is continuous with respect to perturbations in signal reach.
The present paper generalizes [4] and, while similar in its line of attack, the method of solution here differs in essential ways. Indeed, both papers apply the dual approach and do not deal with the primal infinite dimensional stochastic control problem directly. But the current paper decomposes the information flow into independent parts and passes to a conditional model driven by independent Brownian motions in the ‘usual’ way. This approach does not require applying the results from the theory of Gaussian Volterra integral equations [14, 15] and readily accommodates time-dependent signal specifications and noise.
Section 2 of the paper formalizes the optimal investment problem with dynamic noisy signals mathematically. Section 3 states the main results on optimal investment strategy and utility and comments on some financial-economic implications. Section 4 is devoted to the proof of the main results.
2 Problem Formulation
Consider an investor who can invest over some time horizon [0, T] both in the money market at zero interest (for simplicity) and in stock. The price of the stock follows Bachelier dynamics
where \(S_0 \in {\mathbb {R}}\) denotes the initial stock price, \(\mu \in {\mathbb {R}}\) describes the stock’s risk premium and \(\sigma \in (0,\infty )\) its volatility; \(\gamma \in [-1,1]\) and \({\bar{\gamma }}:=\sqrt{1-\gamma ^2}\) parameterize the correlation between the stock price process S and its drivers W, \(W'\), two independent Brownian motions specified on a complete probability space \((\Omega ,{\mathscr {F}},{\mathbb {P}})\). On top of the information flow from present and past stock prices as captured by the augmented filtration \(({\mathscr {F}}^S_t)_{t \in [0,T]}\) generated by S, the investor is assumed to have access to a signal which at any time \(t \in [0,T]\) allows her to deduce the future evolution of \(W'\) (but not of W) over a time window \([t,\tau (t)]\) where \(\tau :[0,T] \rightarrow [0,T]\) is a right-continuous, nondecreasing time shift satisfying \(\tau (t) \ge t\) throughout. In other words, the investor is able to partially predict the evolution of future stock prices, albeit with some uncertainty. The uncertainty is described by a noise whose variance accrues over \([t,\tau (t)]\) solely from W at the rate \(\sigma ^2(1-\gamma ^2)\) and accrues from both W and \(W'\) at the joint rate \(\sigma ^2\) afterwards. As a result, the investor can draw on the information flow given by the filtration
when making her investment decisions.
In case \(\gamma =\pm 1\) all noise is wiped out from the stock price signal and so the investor gets perfect knowledge of some future prices, affording her obvious arbitrage opportunities. But even for the complementary case \(\gamma \in (-1,1)\) it is easy to check that S is not a semimartingale and, by the Fundamental Theorem of Asset Pricing of [11], there is a free lunch with vanishing risk (and in fact even a strong arbitrage as can be shown by a Borel–Cantelli argument similar to the one in [18]). As a consequence, we need to curb the investor’s trading capabilities in order to maintain a viable financial model. In line with the economic view of the role and effect of arbitrageurs, we choose to accomplish this by taking into account the market impact from the investor’s trades. These cause execution prices for absolutely continuous changes \(d\Phi _t = \phi _t dt\) in the investor’s position to be given by
So, when marking to market her position \(\Phi _t = \Phi _0 + \int _0^t \phi _s ds\) in the stock accrued by time \(t \in [0,T]\), the investor will consider her net profit to be
As a consequence, the investor will have to choose her turnover rates from the class of admissible strategies
Assuming for convenience constant absolute risk aversion \(\alpha \in (0,\infty )\), the investor would then seek to
Remark 2.1
The special case of no signal noise (\(\gamma =1\)) and constant peek ahead period (i.e., \(\tau (t) = (t+\Delta ) \wedge T\), \(t \in [0,T]\), for some \(\Delta >0\)) was solved in [4].
3 Main Results and Their Financial-Economic Discussion
The paper’s main results are collected in the following theorem.
Theorem 3.1
The investor’s unique optimal strategy is to average out the risk-premium adjusted stock price estimates
to obtain the risk- and liquidity-weighted projection of prices
where
with \(\rho :=\alpha \sigma ^2/\Lambda \). With the projection \({\bar{S}}_t\) at hand, the investor should then take at time \(t \in [0,T]\) into view her present stock holdings \({\hat{\Phi }}_t=\Phi _0+\int _0^t {\hat{\phi }}_sds\) and choose to turn her position over at the rate
Finally, the maximum utility the investor can expect is
where \(\tau ^{-1}(t):=\inf \{s \in [0,T]:\tau (s)> t\}\), \(t\in [0,T]\), denotes the right-continuous inverse of \(\tau \).
Let us briefly collect some financial-economic observations from this result. First, similar to the case without signal noise discussed in [4], an average of future price proxies \({\hat{S}}_{t,h}\) is formed, but here weights are time-inhomogenous. In fact, the weights used in this averaging are determined in terms of the function \(\Upsilon \) and interestingly depend on the peek-ahead horizon \(\tau \) only through its present value \(\tau (t)\). As a consequence, when deciding about the time t turnover rate \({\hat{\phi }}_t\), the investor does not care if her information horizon \(\tau \) is going to stall or to jump all the way to T soon. The reason for this is the investor’s exponential utility which makes investment decisions insensitive to present wealth and thus does not require planning ahead. It would be interesting to see how this changes with different utility functions. Unfortunately, our method to obtain an explicit solution to the optimal investment problem strongly depends on our choice of exponential utility, leaving this a challenge for future research.
Second, it is interesting to assess the impact of signal noise on investment decisions. Here, we observe that the emphasis \(\Upsilon _t(0)/\Upsilon _t(\tau (t)-t)\) that the projection \({\bar{S}}_t\) puts on the last learned signal \({\hat{S}}_{t,\tau (t)-t}\) decreases when noise gets stronger due to an increase in \({\overline{\gamma }}\). This reflects the investor’s reduced trust in this most noisy of her signals when noise becomes more prominent.
Third, we can assess how the presence of noise affects the value of the signal \(W'\). To this end, let us consider the certainty equivalent
that an agent, who can eliminate a fraction \(\gamma ^2\) from the variance in stock price noise \(\gamma W'+\sqrt{1-\gamma ^2}W\) by observing part of \(W'\), gains compared to her peer without that privilege (whence her terminal wealth \({\tilde{V}}_T\) is determined by \({\tilde{S}}_t=S_0+\mu t + \sigma W_t\), \(t\in [0,T]\), instead of S). Contributions to this quantity from times long before the investment horizon (\(T-t\) large) when the signal \(W'_t\) has been received for a long time (\(t-\tau ^{-1}(t))\) large), depend on \(\gamma \) by a factor of about \(\gamma ^2/(\sqrt{1-\gamma ^2}+1)\). This factor increases from 0 to 1 as \(\gamma \) increases from 0 (no signal) to 1 (noiseless signal), with the steepest increase at \(\gamma =1\), indicating limited, but ever higher returns from noise reductions. Conversely, an increase in noise is making itself felt the most when the signal is already quite reliable.
Finally, the flexibility concerning the form of the peek-ahead length given by \(\tau :[0,T] \rightarrow [0,T]\) affords one to account for periods when predictions are harder to make over periods where they are easier. Moreover, this flexibility also allows us to shed light on some natural questions such as the following ones:
-
(i)
When best to peek ahead? Suppose that the investor has an opportunity to choose a (deterministic) moment in time \({\mathbb {T}}\in [0,T]\) when, for one time only, she can peek ahead over some period \(\Delta >0\) into the future. What time \({\mathbb {T}}\) should she choose? We can formalize this as an optimization problem over the family of time changes
$$\begin{aligned} \tau _{{\mathbb {T}}}(t) = \left. {\left\{ \begin{array}{ll} t, &{} \text {for } t \le {\mathbb {T}} \\ (t\vee ( {\mathbb {T}}+ \Delta )) \wedge T, &{} \text {otherwise}\\ \end{array}\right. } \right\} ,\ \ \ {\mathbb {T}}\in [0,T]. \end{aligned}$$Clearly, the corresponding inverse function is given by
$$\begin{aligned} \tau ^{-1}_{{\mathbb {T}}}(t) = \left. {\left\{ \begin{array}{ll} {\mathbb {T}}, &{} \text {for } {\mathbb {T}}\le t<{\mathbb {T}}+\Delta \\ t, &{} \text {otherwise}\\ \end{array}\right. } \right\} . \end{aligned}$$Hence, in view of (3.3) we need to maximize over \(\mathbb T\in [0,T]\) the value of
$$\begin{aligned} \int _{{\mathbb {T}}}^{({\mathbb {T}}+\Delta )\wedge T} \frac{dt}{{\overline{\gamma }}\coth \left( {\overline{\gamma }}\sqrt{\rho }\left( t-\mathbb T\right) \right) + \tanh \left( \sqrt{\rho }\left( T-t\right) \right) }\rightarrow \max . \end{aligned}$$Observe that
$$\begin{aligned}&\int _{{\mathbb {T}}}^{({\mathbb {T}}+\Delta )\wedge T} \frac{dt}{{\overline{\gamma }}\coth \left( {\overline{\gamma }}\sqrt{\rho }\left( t-\mathbb T\right) \right) + \tanh \left( \sqrt{\rho }\left( T-t\right) \right) }\\&\quad =\int _{0}^{(T-{\mathbb {T}})\wedge \Delta } \frac{dt}{{\overline{\gamma }}\coth \left( {\overline{\gamma }}\sqrt{\rho }t\right) + \tanh \left( \sqrt{\rho }\left( T-{\mathbb {T}}-t\right) \right) }\\&\quad \le \int _{0}^{T\wedge \Delta } \frac{dt}{{\overline{\gamma }}\coth \left( {\overline{\gamma }}\sqrt{\rho }t\right) + \tanh \left( \sqrt{\rho }\left( T-t\right) \right) } \end{aligned}$$We conclude that the optimal time is \({\mathbb {T}}=0\) and so one should peek ahead immediately.
-
(ii)
How much of an advantage does continual probing have over periodic probing? For this we can compare the continual probing where we keep predicting what is going to happen over the next \(\Delta \) time units with its discrete counter part where we only peek ahead every \(\Delta \) units:
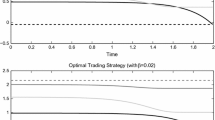
$$\begin{aligned} \tau ^c(t)=(t+\Delta ) \wedge T \quad \text {vs.} \quad \tau ^p(t)=\left( (\lfloor \frac{t}{\Delta } \rfloor +1)\Delta \right) \wedge T, \end{aligned}$$where \(\lfloor 2.8 \rfloor =2\) denotes the floor function. Clearly, the continual probing is superior to periodic probing, but its advantage depends on the probing period length \(\Delta \). Indeed, Fig. 1 below shows the difference in certainty equivalents for the choices \(\Delta =T/n\) corresponding to \(n=1,2,\dots \) updates in the periodic case. We see that, for the considered parameters, the periodically updating investor will be at the greatest disadvantage compared to her more diligent, continually probing counterpart when updating about 80 times for periods of length \(\Delta =T/80\).

Continual vs. periodic probing: Difference of certainty equivalents for \(\Delta =T/n\), \(n=1,2,\dots ,500\), when \(\gamma =0.7\), \(\rho =0.49\), \(\alpha =0.01\), \(T=100\)
4 Proof
We start this section by outlining the main steps of the proof. The first step in Sect. 4.1 deals with simplifying the general setup to obtain a notationally and computationally more convenient special case of our problem. The second step (Sect. 4.2) consists of the main idea which is to apply duality theory. We show that the dual problem can be reduced to the solution of three separate deterministic variational problems. The third step (Sect. 4.3) is to solve these deterministic problems, which are quite involved and for which we therefore compute only their values and the essential properties of the corresponding optimal control. The fourth step (Sect. 4.4) combines the second and the third step to solve the dual problem. The last step (Sect. 4.5) uses duality and the Markovian structure of our problem to finally construct the solution to the primal problem from the dual solution.
4.1 Simplification of Our Setting
Parameter reduction Let us first note that it suffices to treat the special case where \(S_0=0\), \(\sigma =1\), \(\mu =0\), \(\alpha =1\):
Lemma 4.1
If \({\hat{\phi }}^0 \in {\mathscr {A}}\) is optimal when starting with the initial position \(\Phi ^0_0:=\alpha \sigma \Phi _0-\mu /\sigma \) in the baseline model with parameters \(S^0_0:=0\), \(\sigma ^0:=1\), \(\mu ^0:=0\), \(\alpha ^0:=1\) and \(\Lambda ^0:=\Lambda /(\alpha \sigma ^2)\), then the optimal strategy in the model with general parameters \(\Phi _0\), \(S_0\), \(\sigma \), \(\mu \), \(\alpha \) and \(\Lambda \) is given by
where \({\hat{\varphi }}\) is the measurable functional on \(C[0,T]\times C[0,T]\) for which \({\hat{\phi }}^0={\hat{\varphi }}(W',W)\). Moreover, the maximum expected utility is \(\exp \left( -\frac{1}{2}\frac{\mu ^2}{\sigma ^2}T\right) \) times as high as the maximum utility in the baseline model.
Proof
Let \(\phi =\varphi (W,W') \in {\mathscr {A}}\) be the representation of an arbitrary admissible strategy as a functional of the underlying Brownian motions W and \(W'\). Then \(({\tilde{W}},{\tilde{W}}'):=\left( W_s(\omega )+\frac{\mu }{\sigma }\gamma s,W'_s(\omega ) +\frac{\mu }{\sigma }{\overline{\gamma }} s\right) _{s \in [0,T]}\), is a standard two-dimensional Brownian motion under \({\tilde{{\mathbb {P}}}}\approx {\mathbb {P}}\) with \(d{\tilde{{\mathbb {P}}}}/d{\mathbb {P}}={\mathscr {E}}(-\frac{\mu }{\sigma }(\gamma W'+{\overline{\gamma }}W))_T\), \(({\tilde{W}},{\tilde{W}}')\) and we can write the expected utility from \(\phi \) as
where \({\tilde{V}}_T^{\Phi ^0_0,{\tilde{\phi }}}\) is the terminal wealth generated in the baseline model from the initial position \(\Phi ^0_0\) by the strategy given by
In the baseline model, \({\hat{\phi }}^0={\hat{\varphi }}({\tilde{W}},{\tilde{W}}')\) is optimal by assumption and we obtain an upper bound for the maximum utility in the general model. This bound is sharp since it is attained by \({\hat{\phi }}\) as in the formulation of the lemma. \(\square \)
Reduction to differentiable, increasing time changes Let us argue next why we can assume without loss of generality that
and that it suffices to do the computation of the value of the problem (3.2) for \(\tau \) satisfying, in addition, \(\tau (0)=0\).
In fact, using that the description of optimal policies from Theorem 3.1 holds for \(\tau \) satisfying (4.1) and that (3.2) holds when, in addition, \(\tau (0)=0\) (which we will prove independently below), we can even prove that the optimization problem depends continuously on \(\tau \) and thus it suffices to consider smooth \(\tau \) with (4.1):
Lemma 4.2
If \(\tau _n(t)\rightarrow \tau _\infty (t)\) for \(t=T\) and for every continuity point t of \(\tau _\infty \) (i.e., if \(d\tau _n \rightarrow d\tau _\infty \) weakly as Borel measures on [0, T]), then the optimal terminal wealth associated with \(\tau _n\) converges almost surely to the one associated with \(\tau _\infty \) and the problem value for \(\tau _n\) converges to the one of \(\tau _\infty \).
Proof
Let us denote by \(v(\tau )\) the value of our problem in dependence on \(\tau \) and by \({\tilde{v}}(\tau )\) its claimed value from the right-hand side of (3.2). Similarly, denote by \(V(\tau )\) the optimal terminal wealth (if it exists) for \(\tau \) and by \({\tilde{V}}(\tau )\) our candidate described in Theorem 3.1. Let us furthermore denote by \({\mathscr {T}}\) the class of all \(\tau \) satisfying (4.1) and by \({\mathscr {T}}_0 \subset {\mathscr {T}}\) those \(\tau \) which in addition satisfy \(\tau (0)=0\). We will assume that \(V(\tau )={\tilde{V}}(\tau )\) for \(\tau \in {\mathscr {T}}\) and \(v(\tau )={\tilde{v}}(\tau )\) for \(\tau \in {\mathscr {T}}_0\) as these statements will be derived below independently from this lemma.
Let us observe first that both \({\tilde{V}}(\tau )\) and \({\tilde{v}}(\tau )\) continuously depend on \(\tau \). For \({\tilde{v}}\) this readily follows from (3.2) by dominated convergence; for \({\tilde{V}}\) this is due to the stability of the linear ODE (3.1) and the continuous dependence of its coefficients on \(\tau \).
Let us next argue why an optimal control for general \(\tau \) exists and its terminal wealth is \(V(\tau )={\tilde{V}}(\tau )\). For this take \(\tau _n \in {\mathscr {T}}\) converging to \(\tau \) from above and observe that \(V(\tau _n)={\tilde{V}}(\tau _n) \rightarrow {\tilde{V}}(\tau )\). By Fatou’s lemma we conclude that \(\limsup _n {\mathbb {E}}[-\exp (-\alpha V(\tau _n))] \le {\mathbb {E}}[-\exp (-\alpha {\tilde{V}}(\tau ))] \le v(\tau )\). Because \(\tau _n \ge \tau \), any competitor \(\phi \in {\mathscr {A}}(\tau )\) is also in \({\mathscr {A}}(\tau _n)\) and thus \(v(\tau _n)={\mathbb {E}}[-\exp (-\alpha V(\tau _n))] \ge {\mathbb {E}}[-\exp (-\alpha V_T^{\phi ,\Phi _0})] \). In conjunction with the preceding estimate, this shows that the candidate for general \(\tau \) is indeed optimal with value \(v(\tau )={\tilde{v}}(\tau )=\lim _n v(\tau _n)\).
Let us conclude by arguing why it suffices to compute the problem value for \(\tau \in {\mathscr {T}}_0\). For this choose \(\tau _n \in {\mathscr {T}}_0\) to converge to a general \(\tau \) from below. From the above, we know that \(v(\tau ) \ge {\tilde{v}}(\tau )=\lim _n v(\tau _n)\). To see that conversely \({\tilde{v}}(\tau ) \ge {v}(\tau )\) (and conclude), take a risk-aversion \(\alpha '<\alpha \) and observe that the corresponding (candidate) problem values \(v_{\alpha '}(\cdot )\) and \({\tilde{v}}_{\alpha '}(\cdot )\) satisfy
Indeed, the first identity is due to the stability of the right-hand side of (3.2) in \(\tau \); the estimate holds because the optimal strategy for risk-aversion \(\alpha \) is also admissible for risk-aversion \(\alpha '\); the final identity holds because of uniform integrability which in turn follows from boundedness in \(L^p({\mathbb {P}})\) with \(p=\alpha /\alpha '>1\):
Letting \(\alpha ' \uparrow \alpha \) in (4.2), its left-hand side converges to \({\tilde{v}}(\tau )\) by continuous dependence on \(\alpha \) of the right-side of (3.2); the right-hand side in (4.2) converges by monotone convergence to \({\mathbb {E}}[-\exp (-\alpha V(\tau ))]=v(\tau )\) and we are done. \(\square \)
Decomposing the filtration into independent Brownian parts and passage to a conditional model For time changes \(\tau \) satisfying (4.1), we can introduce
and readily check that it is a Brownian motion stopped at time \(\tau ^{-1}(T)\le T\) which is independent of both W and \((W'_s)_{s \in [0,\tau (0)]}\). Moreover, using that \(\tau ^{-1}(t)=0\) for \(t \in [0,\tau (0)]\), we can write the stock price dynamics as
and view the insider’s filtration as generated by the following independent components:
for \(t \in [0,T]\) and with \({\mathscr {N}}\) denoting the collection of \({\mathbb {P}}\)-nullsets. So, maximizing expected utility conditional on \({\mathscr {G}}_0=\sigma (W'_s, \; s \in [0,\tau (0)]) \vee {\mathscr {N}}\) amounts to maximizing an unconditional expected utility in a model with probability \({\mathbb {P}}_0\) where, by a slight abuse of notation, asset prices evolve according to
for some deterministic path segment \(w \in C([0,\tau (0)])\), a \({\mathbb {P}}_0\)-Brownian motion B stopped at time \(\tau ^{-1}(T)\) and a standard \({\mathbb {P}}_0\)-Brownian motion W which generate the filtration
specifying the information flow for admissible strategies.
4.2 Duality
For the unconditional expected utility maximization under the measure \({\mathbb {P}}_0\) identified above, we can apply Proposition A.2 in [4] to deduce that we can proceed by solving the dual problem with value
where \(\rho :=1/\Lambda \) and \({\mathscr {Q}}\) is the set of all probability measures \({\mathbb {Q}}\approx {\mathbb {P}}_0\) with finite relative entropy \({\mathbb {E}}_{{\mathbb {Q}}}\left[ \log \frac{d\mathbb Q}{d{\mathbb {P}}_0} \right] <\infty \). Said proposition also yields that the unique solution \({\hat{{\mathbb {Q}}}}\) to the dual problem allows us to construct the solution \({\hat{\phi }}\) to the primal problem considered under \({\mathbb {P}}_0\) as
Following the path outlined in the special case treated in [4], we need to rewrite the dual target functional (4.4). For this it will be convenient to introduce the functionals \(\Psi _1:(L^2[0,\tau ^{-1}(T)],dt)\times (L^2[0,T],dt)\rightarrow {\mathbb {R}}\) and \(\Psi _2,\Psi _3:L^2\left( [0,\tau ^{-1}(T)]^2, dt\otimes ds\right) \times L^2\left( [0,T]^2, dt\otimes ds\right) \rightarrow {\mathbb {R}}\) given by
and
Lemma 4.3
The dual infimum in (4.4) coincides with the one taken over all \({\mathbb {Q}} \in {\mathscr {Q}}\) whose densities take the form
for some bounded, \(({\mathscr {G}}^\tau _t)\)-adapted \(\theta \) and \({{\tilde{\theta }}}\) changing values only at finitely many deterministic times. For such \({\mathbb {Q}}\), we have the Girsanov \(({\mathscr {G}}^\tau ,{\mathbb {Q}})\)-Brownian motions
which allow for Ito representations
for suitable \(a_t, {\tilde{a}}_t \in {\mathbb {R}}\) and suitable \(\mathscr {G}^{\tau }\)-predictable processes \(l_{t,.}\), \(m_{t,.}\), \(\tilde{l}_{t,.}\), \({{\tilde{m}}}_{t,.}\). In terms of these, the dual target value associated with \({\mathbb {Q}}\) is
Proof
For any \({\mathbb {Q}} \in {\mathscr {Q}}\) the martingale representation property of Brownian motion gives us a predictable \(\theta ,{{\tilde{\theta }}}\) with
such that (4.9) holds. Using this density to rewrite the dual target functional as an expectation under \(\mathbb P\), we can use standard density arguments to see that the infimum over \({\mathbb {Q}} \in {\mathscr {Q}}\) can be realized by considering the \({\mathbb {Q}}\) induced by simple \(\theta ,{{\hat{\theta }}}\) as described in the lemma’s formulation via (4.9). As a consequence, the Itô representations of \(\theta _t,{\hat{\theta }}_t\) can be chosen in such a way that the resulting \(a_t,{{\tilde{a}}}_t, l_{t,.}{{\tilde{l}}}_{t,.},m_{t,.},{{\tilde{m}}}_{t,.}\) are also measurable in t; in fact they only change when \(\theta ,{{\hat{\theta }}}\) change their values, i.e., at finitely many deterministic times. This measurability property will be used below for applying Fubini’s theorem.
Next, we compute the value of the dual problem in terms of \(a,\tilde{a},l,{{\tilde{l}}},m,{{\tilde{m}}}\). Recalling the dynamics for S in (4.3), we get
From Itô’s isometry and Fubini’s theorem we obtain
Next, from the Fubini Theorem
This together with the Itô’s isometry and (4.12)–(4.13) gives (4.11). \(\square \)
4.3 Solving the Deterministic Variational Problems
Lemma 4.3 above suggests to consider the minimization of the functionals \(\Psi _1\), \(\Psi _2\), and \(\Psi _3\) specified there. This amounts to solving deterministic variational problems and the following lemmas sum up the main findings.
Lemma 4.4
The functional \(\Psi _2=\Psi _2(l,{\tilde{l}})\) defined for square-integrable l, \({\tilde{l}}\) by (4.7) has the minimum value
for some \(({\underline{l}},\underline{{\tilde{l}}})\).
Proof
For a given \((l,{{\tilde{l}}})\in L^2\left( [0,\tau ^{-1}(T)]^2, dt\otimes ds\right) \times L^2\left( [0,T]^2, dt\otimes ds\right) \) and \(s<\tau ^{-1}(T)\) introduce the functions
Clearly, almost surely the functions \(g_s,{{\tilde{g}}}_s\) are absolutely continuous in t for almost every \(s \in [0,\tau ^{-1}(T)]\) with boundary values
Changing variables we note
where \({\dot{g}}_s\) denotes the derivative with respect to t and so
for
Minimization of \(\Psi _2\) can thus be carried out separately for each \(s \in [0,\tau ^{-1}(T)]\). So we fix such an s and seek to determine the absolutely continuous \(({\underline{g}}_s,\underline{{\tilde{g}}}_s)\) which minimizes \(\psi _s\) under the boundary condition (4.15). To this end, observe fist that the functional \(\psi _s\) is strictly convex and so existence of a minimizer follows by a standard Komlos-argument.
In the computation of the minimum value, let us, for ease of notation, put \(g:=g_s\), \({\tilde{g}}:={\tilde{g}}_s\). We first focus on the contributions to \(\psi _s(g,{\tilde{g}})\) from its integrals over the interval \([\tau (s),T]\), assuming \(\tau (s)<T\) of course; for \(\tau (s)=T\) we can directly proceed with the minimization over \([s,\tau (s)]\) as carried out below with \(z_s:=0\). Clearly if \(\gamma x+{\overline{\gamma }} y\) is given then the minimum of \(x^2+y^2\) is obtained for x, y which satisfy \(\frac{y}{x}=\frac{{\overline{\gamma }}}{\gamma }\). Hence, the optimal solution will satisfy
for some function \(f_s\) which satisfies \(f_s(T)=0\). Hence the functional to be minimized is really
Its Euler–Lagrange reads \(\ddot{f_s}=\rho f_s\); c.f., e.g., Sect. 1 in [13]. Since \(f_s(T)=0\), we conclude that
for some \(z_s \in {\mathbb {R}}\) which is yet to be determined optimally.
Next, we treat the interval \([s,\tau (s)]\). The Euler–Lagrange equation for minimizing the functional
subject to the boundary condition \({{\tilde{g}}}_s(\tau (s))={\overline{\gamma }} z_s\) (which we infer from (4.18)) is
Hence,
for some \(u_s \in {\mathbb {R}}\) which we still need to choose optimally.
We plug (4.17)–(4.19) into (4.16) to obtain
Simple computations show that, for \(\tau (s)<T\), the minimal value of the above positive definite quadratic pattern in \((u_s,z_s) \in {\mathbb {R}}^2\) is equal to
and is attained for some constants \(z_s\) and \(u_s\) which depend continuously on s. For \(\tau (s)=T\), we have \(z_s=0\) and the minimization over \(u_s\in {\mathbb {R}}\) leads again to this last expression which thus holds for any s. Upon integration over s, we thus find
and (4.14) follows by the substitution \(t=\tau (s)\). \(\square \)
Lemma 4.5
The functional \(\Psi _1=\Psi _1(a,{\tilde{a}})\) given for square-integrable \((a,{\tilde{a}})\) by (4.6) is minimized by \(({\underline{a}},\tilde{{\underline{a}}}) :=\Psi \left( \Phi _0,(w(t)-w(0))_{t \in [0,\tau (0)]}\right) \) for some continuous functional \(\Psi : {\mathbb {R}}\times C([0,\tau (0)])\rightarrow L^2\left( [0,\tau ^{-1}(T)], dt\right) \times L^2\left( [0,T], dt\right) \). This minimizer \(({\underline{a}},\tilde{{\underline{a}}})\) satisfies
where \({{\bar{S}}}\) and \(\Upsilon \) are given in Theorem 3.1.
Moreover, in the special case \(\tau (0)=0\) the minimum value is
Proof
Similar arguments as in Lemma 4.4 give the uniqueness of the minimizer.
For a given \(a,{{\tilde{a}}}\in L^2\left( [0,\tau ^{-1}(T)], dt\right) \times L^2\left( [0,T], dt\right) \) introduce the functions
Clearly, \(h,{{\tilde{h}}}\) are absolutely continuous and satisfy
From a change of variables we obtain
and so \(\Psi _1(a,{{\tilde{a}}})=\psi _1(h,{{\tilde{h}}})\) for
We aim to find absolutely continuous functions \(h,{{\tilde{h}}}\) which minimize the right hand side of (4.25) under the boundary condition (4.24).
Using the same arguments as in Lemma 4.4, we obtain that a unique minimizer \((h,{{\tilde{h}}})\) exists. Focusing first on minimizing the contributions to \(\gamma \) collected over \([\tau (0),T]\) (if \(\tau (0)<T\)), we moreover find that it satisfies
for some \(v=h(\tau (0))/\gamma ={\tilde{h}}(\tau (0))/{\overline{\gamma }}\) which we still need to optimize over.
For the contributions to \(\psi _1(h,{\tilde{h}})\) over the interval \([0,\tau (0)]\), i.e., for the minimization of
over \({\tilde{h}}\) subject to the yet to be optimally chosen starting value \({\tilde{h}}(0)=u\) and the terminal value \({\tilde{h}}(\tau (0))={\overline{\gamma }}v\) fixed above, we apply Theorem 3.2 in [3] for our present deterministic setup. This result shows that
allows us to describe the minimizer \(\underline{{\tilde{h}}}\) as the solution to the linear ODE
and the minimum value is
for
Minimizing over u in (4.30) we obtain
and we find the corresponding minimum value to be
Next, we plugin (4.26)–(4.27) and (4.33) into (4.25). The result is
and from (4.28) (for \(t=0\)) it follows that the minimum over v is achieved for
The minimizer \(({\underline{a}},\underline{{\tilde{a}}})\) can now be recovered from (4.22)–(4.23), (4.26)–(4.29), (4.31) and (4.35) and turns out to be a continuous functional of \((\Phi _0, (w(t)-w(0))_{t \in [0,\tau (0)]})\). From (4.26), (4.28), (4.32)
where the last equality follows from (4.31), (4.35) and the Fubini theorem. This together with (4.22)–(4.23) gives (4.20). Finally, (4.21) follows from (4.34)–(4.35). \(\square \)
Lemma 4.6
The functional \(\Psi _3=\Psi _s(m,{\tilde{m}})\) given by (4.8) is minimized by \(({\underline{m}},\underline{{\tilde{m}}})=(0,0)\) which yields the minimum value \(\Psi _3({\underline{m}},\underline{{\tilde{m}}})= 0\).
Proof
The statement is obvious since \(\Psi _3\ge 0\) and \(\Psi _3(m,\tilde{m})=0\) if and only if \((m,{{\tilde{m}}})=(0,0)\). \(\square \)
4.4 Construction of the Solution to the Dual Problem
Having found the minimum values for the functionals \(\Psi _1\), \(\Psi _2\), and \(\Psi _3\) from Lemma 4.3, we conclude that their sum yields a lower bound for the value of the dual problem (4.4). In fact, this lower bound is sharp since we can construct a measure \({\underline{{\mathbb {Q}}}} \in {\mathscr {Q}}\) whose dual target value coincides with it. For this consider the resolvent kernel \({\underline{k}}\) associated with \({\underline{l}}\) via
This kernel allows us to construct the solution
to the Volterra equation
Now, the probability \({\mathbb {Q}}={\underline{{\mathbb {Q}}}}\) given by (4.9) with \(\theta ={\underline{\theta }}\) of (4.36) and
induces the Girsanov \({\underline{{\mathbb {Q}}}}\)-Brownian motion \(B^{{\underline{{\mathbb {Q}}}}}\) of (4.10) and, using that \({\underline{\theta }}\) solves the Volterra equation (4.37), we find the Ito representations
As a consequence, \({\underline{\theta }}\), \(\underline{{\tilde{\theta }}}\), \({\underline{a}}\), \(\underline{{\tilde{a}}}\), \({\underline{l}}\), \(\underline{{\tilde{l}}}\) and \({\underline{m}}=0\), \(\underline{{\tilde{m}}}=0\) are related exactly in the same way as the corresponding quantities in Lemma 4.3. By the same calculation as in the proof of this lemma, the dual target value thus turns out to be
where in the last line we are allowed to drop the expectation \({\mathbb {E}}_{{\underline{{\mathbb {Q}}}}}\) because the quantity there is deterministic anyway. It follows that \({\underline{{\mathbb {Q}}}}\) indeed attains the lower bound for the dual problem.
Moreover, we learn from Lemmas 4.5, 4.4, and 4.6, that the dual problem’s value is given by
where the last identity holds in case \(\tau (0)=0\).
4.5 Construction of the Solution to the Primal Problem
Having constructed the dual optimizer \({\hat{{\mathbb {Q}}}}:={\underline{{\mathbb {Q}}}}\), we now can use (4.5) to compute the optimal primal solution \({\hat{\phi }}\). For \(t=0\), we use the representation of \(S_T\) from (4.3) and the fact that B and W have, respectively, drift \({\underline{\theta }}\) and \(\underline{{\tilde{\theta }}}\) under \({\underline{{\mathbb {Q}}}}\). Hence, upon taking expectation with respect to \({\underline{{\mathbb {Q}}}}\), we find
where the last identity is just (4.20). It follows that the optimal initial turnover rate is
Invoking the same dynamic programming argument as in Lemma 3.5 of [4], we conclude that the analogous formula holds for arbitrary t. This establishes optimality of the strategy described in Theorem 3.1.
References
Almgren, R., Chriss, N.: Optimal execution of portfolio transactions. J. Risk 3, 5–39 (2001)
Bandini, E., Cosso, A., Fuhrman, M., Pham, H.: Randomized filtering and Bellman equation in Wasserstein space for partial observation control problem. Stoch. Process. Appl. 129, 674–711 (2019)
Bank, P., Soner, H.M., Voß, M.: Hedging with temporary price impact. Math. Financ. Econ. 11, 215–239 (2017)
Bank, P., Dolinsky, Y., Rásonyi, M.: What if we knew what the future brings? Optimal investment for a frontrunner with price impact. Appl. Math. Optim. 86, article 25 (2022)
Bank, P., Cartea, Á., Körber, L.: Optimal execution and speculation with trade signals (2023). https://doi.org/10.48550/ar**v.2306.00621
Belak, C., Muhle-Karbe, J., Ou, K.: Optimal trading with general signals and liquidation in target zone models (2018). https://doi.org/10.48550/ar**v.1808.00515
Bensoussan, A.: Stochastic Control of Partially Observable Systems. Cambridge University Press, Cambridge (1992)
Bismut, J.-M.: Partially observed diffusions and their control. SIAM J. Control Optim. 20, 302–309 (1982)
Cartea, Á., Jaimungal, S.: Incorporating order-flow into optimal execution. Math. Financ. Econ. 10(3), 339–364 (2016)
Casgrain, P., Jaimungal, S.: Trading algorithms with learning in latent alpha models. Math. Finan. 29(3), 735–772 (2019). https://doi.org/10.1111/mafi.12194. https://ideas.repec.org/a/bla/mathfi/v29y2019i3p735-772.html
Delaben, F., Schachermayer, W.: A general version of the fundamental theorem of asset pricing. Math. Ann. 300, 463–520 (1994)
Fleming, W., Pardoux, E.: Optimal control for partially observed diffusions. SIAM J. Control Optim. 20, 261–285 (1982)
Gelfand, I.M., Fomin, S.V.: Calculus of Variations. Prentice Hall, Englewood Cliffs (1963)
Hida, T., Hitsuda, M.: Gaussian Processes. American Mathematical Society, Providence (1993)
Hitsuda, M.: Representation of Gaussian processes equivalent to wiener process. Osaka J. Math. 5, 299–312 (1968)
Kyle, A.S.: Continuous auctions and insider trading. Econometrica 53, 1315–1335 (1985)
Lehalle, C.A., Neuman, E.: Incorporating signals into optimal trading. Finan. Stochast. 23(1), 275–311 (2019)
Levental, S., Skorohod, A.V.: A necessary and sufficient condition for absence of arbitrage with tame portfolios. Ann. Appl. Probab. 5, 463–520 (1995)
Neuman, E., Voß, M.: Optimal signal-adaptive trading with temporary and transient price impact. SIAM J. Financ. Math. 13(2), 551–575 (2022). https://doi.org/10.1137/20M1375486
Tang, S.: The maximum principle for partially observed optimal control of stochastic differential equations. SIAM J. Control Optim. 36, 1596–1617 (1998)
Acknowledgements
P. Bank is supported in part by the GIF Grant 1489-304.6/2019. Y. Dolinsky is supported in part by the GIF Grant 1489-304.6/2019 and the ISF grant 230/21.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bank, P., Dolinsky, Y. Optimal Investment with a Noisy Signal of Future Stock Prices. Appl Math Optim 89, 35 (2024). https://doi.org/10.1007/s00245-023-10099-x
Accepted:
Published:
DOI: https://doi.org/10.1007/s00245-023-10099-x
Keywords
- Optimal control with partial observation
- Exponential utility maximization
- Noisy price signals
- Duality
- Temporary price impact