
Abstract
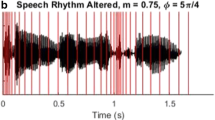
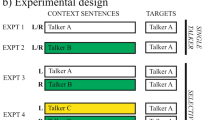
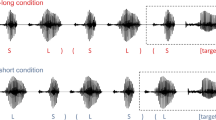
Previous work by McAuley et al. Attention, Perception, & Psychophysics, 82, 3222–3233, (2020), Attention, Perception & Psychophysics, 83, 2229–2240, (2021) showed that disruption of the natural rhythm of target (attended) speech worsens speech recognition in the presence of competing background speech or noise (a target-rhythm effect), while disruption of background speech rhythm improves target recognition (a background-rhythm effect). While these results were interpreted as support for the role of rhythmic regularities in facilitating target-speech recognition amidst competing backgrounds (in line with a selective entrainment hypothesis), questions remain about the factors that contribute to the target-rhythm effect. Experiment 1 ruled out the possibility that the target-rhythm effect relies on a decrease in intelligibility of the rhythm-altered keywords. Sentences from the Coordinate Response Measure (CRM) paradigm were presented with a background of speech-shaped noise, and the rhythm of the initial portion of these target sentences (the target rhythmic context) was altered while critically leaving the target Color and Number keywords intact. Results showed a target-rhythm effect, evidenced by poorer keyword recognition when the target rhythmic context was altered, despite the absence of rhythmic manipulation of the keywords. Experiment 2 examined the influence of the relative onset asynchrony between target and background keywords. Results showed a significant target-rhythm effect that was independent of the effect of target-background keyword onset asynchrony. Experiment 3 provided additional support for the selective entrainment hypothesis by replicating the target-rhythm effect with a set of speech materials that were less rhythmically constrained than the CRM sentences.






Similar content being viewed by others
Data availability
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
Code availability
Not applicable.
References
Allen, K., Carlile, S., & Alais, D. (2008). Contributions of talker characteristics and spatial location to auditory streaming. The Journal of the Acoustical Society of America, 123(3), 1562–1570.
Assmann, P. F., & Summerfield, Q. (1989). Modeling the perception of concurrent vowels: Vowels with the same fundamental frequency. The Journal of the Acoustical Society of America, 85(1), 327–338.
Assmann, P. F., & Summerfield, Q. (1990). Modeling the perception of concurrent vowels: Vowels with different fundamental frequencies. The Journal of the Acoustical Society of America, 88(2), 680–697.
Aubanel, V., Davis, C., & Kim, J. (2016). Exploring the role of brain oscillations in speech perception in noise: intelligibility of isochronously retimed speech. Frontiers in Human Neuroscience, 10, 430.
Auditech. (2015). Multitalker Noise—20 Talkers (Frank Version) [Audio recording]. https://auditec.com/2015/08/04/multitalker-noise-20-talkers-frank-version/
Baese-Berk, M. M., Dilley, L. C., Henry, M. J., Vinke, L., & Banzina, E. (2019). Not just a function of function words: Distal speech rate influences perception of prosodically weak syllables. Attention, Perception, & Psychophysics, 81(2), 571–589.
Barnes, R., & Jones, M. R. (2000). Expectancy, attention, and time. Cognitive Psychology, 41, 254–311.
Bolia, R. S., Nelson, W. T., Ericson, M. A., & Simpson, B. D. (2000). A speech corpus for multitalker communications research. Journal of the Acoustical Society of America, 107, 1065–1066.
Bregman, A. S. (1990). Auditory scene analysis. MIT Press.
Brokx, J. P. L., & Nooteboom, S. G. (1982). Intonation and the perceptual separation of simultaneous voices. Journal of Phonetics, 10(1), 23–36.
Darwin, C. J. (1981). Perceptual grou** of speech components differing in fundamental frequency and onset-time. The Quarterly Journal of Experimental Psychology Section A, 33(2), 185–207.
Darwin, C. J., & Ciocca, V. (1992). Grou** in pitch perception: Effects of onset asynchrony and ear of presentation of a mistuned component. The Journal of the Acoustical Society of America, 91(6), 3381–3390.
Dauer, R. M. (1983). Stress-timing and syllable-timing reanalyzed. Journal of Phonetics, 11, 51–62.
Desjardins, J. L., & Doherty, K. A. (2013). Age-related changes in listening effort for various types of masker noises. Ear and Hearing, 34(3), 261–272.
Dilley, L. C., & McAuley, J. D. (2008). Distal prosodic context affects word segmentation and lexical processing. Journal of Memory and Language, 59, 294–311.
Ding, N., Melloni, L., Zhang, H., Tian, X., & Poeppel, D. (2016). Cortical tracking of hierarchical linguistic structures in connected speech. Nature Neuroscience, 19, 158.
Ding, N., & Simon, J. Z. (2012). Emergence of neural encoding of auditory objects while listening to competing speakers. Proceedings of the National Academy of Sciences, 109(29), 11854–11859.
Ding, N., & Simon, J. Z. (2014). Cortical entrainment to continuous speech: functional roles and interpretations. Frontiers in Human Neuroscience, 8, 311.
Friston, K. (2005). A theory of cortical responses. Philosophical transactions of the Royal Society B: Biological sciences, 360(1456), 815–836.
Friston, K. (2018). Does predictive coding have a future? Nature neuroscience, 21(8), 1019–1021.
Ghitza, O. (2011). Linking speech perception and neurophysiology: Speech decoding guided by cascaded oscillators locked to the input rhythm. Frontiers in Psychology, 2, 130.
Giraud, A. L., & Poeppel, D. (2012). Cortical oscillations and speech processing: Emerging computational principles and operations. Nature Neuroscience, 15, 511.
Golumbic, E. M. Z., Ding, N., Bickel, S., Lakatos, P., Schevon, C. A., McKhann, G. M., Simon, J. Z., Poeppel, D., & Schroeder, C. (2013). Mechanisms underlying selective neuronal tracking of attended speech at a “cocktail party.” Neuron, 77, 980–991.
Goswami, U. (2019). Speech rhythm and language acquisition: An amplitude modulation phase hierarchy perspective. Annals of the New York Academy of Sciences, 1453(1), 67–8.
Henry, M. J., & Herrmann, B. (2014). Low-frequency neural oscillations support dynamic attending in temporal context. Timing & Time Perception, 2(1), 62–86.
Humes, L. E., Kidd, G. R., & Fogerty, D. (2017). Exploring use of the coordinate response measure in a multitalker babble paradigm. Journal of Speech, Language, and Hearing Research, 60(3), 741–754.
Johnson, T. A., Cooper, S., Stamper, G. C., & Chertoff, M. (2017). Noise exposure questionnaire: A tool for quantifying annual noise exposure. Journal of the American Academy of Audiology, 28(1), 14–35.
Jones, M. R. (1976). Time, our lost dimension: Toward a new theory of perception, attention, and memory. Psychological Review, 83, 323–355.
Jones, M. R., & Boltz, M. (1989). Dynamic attending and responses to time. Psychological Review, 96, 459–491.
Jones, M. R., Moynihan, H., MacKenzie, N., & Puente, J. (2002). Temporal aspects of stimulus-driven attending in dynamic arrays. Psychological Science, 13, 313–319.
Kollmeier, B., Warzybok, A., Hochmuth, S., Zokoll, M. A., Uslar, V., Brand, T., & Wagener, K. C. (2015). The multilingual matrix test: Principles, applications, and comparison across languages: A review. International Journal of Audiology, 54(Suppl. 2), 3–16.
Large, E. W., & Jones, M. R. (1999). The dynamics of attending: How people track time-varying events. Psychological Review, 106, 119–159.
Lehiste, I. (1977). Isochrony reconsidered. Journal of phonetics, 5(3), 253–263.
McAuley, J. D., & Jones, M. R. (2003). Modeling effects of rhythmic context on perceived duration: A comparison of interval and entrainment approaches to short-interval timing. Journal of Experimental Psychology: Human Perception and Performance, 29, 1102–1125.
McAuley, J. D., Jones, M. R., Holub, S., Johnston, H. M., & Miller, N. S. (2006). The time of our lives: Life span development of timing and event tracking. Journal of Experimental Psychology: General, 135, 348–367.
McAuley, J. D., Shen, Y., Dec, S., & Kidd, G. (2020). Altering the rhythm of target and background talkers differentially affects speech understanding: Support for a selective-entrainment hypothesis. Attention, Perception, & Psychophysics, 82, 3222–3233.
McAuley, J. D., Shen, Y., Smith, T., & Kidd, G. R. (2021). Effects of speech-rhythm disruption on selective listening with a single background talker. Attention, Perception & Psychophysics, 83(5), 2229–2240. https://doi.org/10.3758/s13414-021-02298-x
Miller, J. E., Carlson, L. A., & McAuley, J. D. (2013). When what you hear influences when you see: Listening to an auditory rhythm influences the temporal allocation of visual attention. Psychological Science, 24(1), 11–18.
Milne, A. E., Bianco, R., Poole, K. C., Zhao, S., Oxenham, A. J., Billig, A. J., & Chait, M. (2021). An online headphone screening test based on dichotic pitch. Behavior Research Methods, 53(4), 1551–1562.
Morrill, T. H., Dilley, L. C., McAuley, J. D., & Pitt, M. A. (2014). Distal rhythm influences whether or not listeners hear a word in continuous speech: Support for a perceptual grou** hypothesis. Cognition, 131, 69–74.
Noble, W., Jensen, N. S., Naylor, G., Bhullar, N., & Akeroyd, M. A. (2013). A short form of the Speech, Spatial and Qualities of Hearing scale suitable for clinical use: The SSQ12. International Journal of Audiology, 52(6), 409–412.
Peng, Z. E., Waz, S., Buss, E., Shen, Y., Richards, V., Bharadwaj, H.,..., Venezia, J. H. (2022). Remote testing for psychological and physiological acoustics. The Journal of the Acoustical Society of America, 151(5), 3116–3128.
Rao, R. P., & Ballard, D. H. (1999). Predictive coding in the visual cortex: A functional interpretation of some extra-classical receptive-field effects. Nature Neuroscience, 2(1), 79–87.
Reips, U. D. (2002). Standards for Internet-based experimenting. Experimental Psychology, 49(4), 243.
Riecke, L., Formisano, E., Sorger, B., Baskent, D., & Gaudrain, E. (2018). Neural entrainment to speech modulates speech intelligibility. Current Biology, 28, 161–169.
Rosen, S., Souza, P., Ekelund, C., & Majeed, A. A. (2013). Listening to speech in a background of other talkers: Effects of talker number and noise vocoding. The Journal of the Acoustical Society of America, 133(4), 2431–2443.
Schütt, H. H., Harmeling, S., Macke, J. H., & Wichmann, F. A. (2016). Painfree and accurate Bayesian estimation of psychometric functions for (potentially) overdispersed data. Vision Research, 122, 105–123.
Shen, Y., & Richards, V. M. (2012). A maximum-likelihood procedure for estimating psychometric functions: Thresholds, slopes, and lapses of attention. The Journal of the Acoustical Society of America, 132(2), 957–967.
Tilsen, S., & Arvaniti, A. (2013). Speech rhythm analysis with decomposition of the amplitude envelope: characterizing rhythmic patterns within and across languages. The Journal of the Acoustical Society of America, 134(1), 628–639.
Turgeon, M., Bregman, A. S., & Roberts, B. (2005). Rhythmic masking release: Effects of asynchrony, temporal overlap, harmonic relations, and source separation on cross-spectral grou**. Journal of Experimental Psychology: Human Perception and Performance, 31(5), 939.
Vuust, P., & Witek, M. A. (2014). Rhythmic complexity and predictive coding: A novel approach to modeling rhythm and meter perception in music. Frontiers in Psychology, 5, 1111.
Wang, M., Kong, L., Zhang, C., Wu, X., & Li, L. (2018). Speaking rhythmically improves speech recognition under “cocktail-party” conditions. The Journal of the Acoustical Society of America, 143, EL255–EL259.
Acknowledgments
The authors thank Frank Dolecki and Kyle Oliver for their assistance with data collection and helpful insights, Dylan V. Pearson at Indiana University for assistance with stimulus generation, and members of the Timing, Attention and Perception Lab at Michigan State University for their helpful suggestions and comments at various stages of this project. NIH Grant R01DC013538 (PIs: Gary R. Kidd and J. Devin McAuley), NIH Grant R01017988 (PI: Yi Shen), and the University of Washington Mary Gates Undergraduate Research Scholarship (Awardee: Christina N. Williams; Mentor: Yi Shen) supported this research.
Funding
This work was supported by NIH Grant R01DC013538 (PIs: Gary R. Kidd and J. Devin McAuley), NIH Grant R01017988 (PI: Yi Shen), and the University of Washington Mary Gates Undergraduate Research Scholarship (Awardee: Christina N. Williams; Mentor: Yi Shen)
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest
The authors have no relevant financial or nonfinancial interests to disclose
Ethics approval
This study was approved by the institutional review boards at Michigan State University and the University of Washington. The procedures of this study adhere to the principles of the Declaration of Helsinki.
Consent to participate
Informed consent was obtained from all individual participants included in the study.
Consent for publication
Not applicable.
Additional information
Open practices statement
The data and materials for all experiments are available upon request. None of the experiments was preregistered.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1
Experiment 1: Supplementary results
Learning analysis
At the suggestion of a reviewer, we investigated whether there were any learning effects on performance. Since intact and rhythm-altered conditions were alternated from one block to the next and there was no interaction between rhythm condition and block, F(7, 98) = 1.88, p = .082, η2 = 0.118, we averaged proportion correct data over pairs of blocks. There was a small but significant learning effect, F(7, 98) = 2.86, p = .009, η2 = 0.170. Follow-up Bonferroni-corrected paired t tests showed that the only comparison that approached significance was between the first (M = 0.39, SD = 0.09) and last (M = 0.49, SD = 0.12) blocks, t(14) = −3.62, p = .077, 95% CI [−0.22, 0.01]. No other differences approached significance (all p > .10).
NEQ and SSQ
Supplementary analyses considered the possible relation between individual scores on the NEQ and SSQ and overall speech-in-noise performance (as well as any relation to the magnitude of the target-rhythm effect) in Experiment 1. Estimates of annual noise exposure (ANE) were calculated for each participant from their NEQ responses, based on the procedure outlined in Johnson et al. (2017). The overall SSQ score was calculated by averaging responses across all items. Separate scores were also calculated for the speech, spatial, and qualities subscales of the SSQ by averaging individual responses across only items within one of the given subscales. The correlation between ANE and SSQ was significantly positive, r(13) = 0.56, p = .029. We found no relationship between estimates of ANE and overall speech-in-noise performance (averaged across target rhythm intact and target rhythm altered conditions), r(13) = −0.22, p = 0.44, nor between overall speech-in-noise performance and overall SSQ scores, r(13) = 0.33, p = 0.24. There also was no reliable correlation between overall speech-in-noise performance and any of the SSQ subscales—speech: r(13) = 0.33, p = .24; spatial: r(13) = 0.16, p = .58; qualities: r(13) = 0.30, p = .28.
In terms of the magnitude of the target-rhythm effect (the performance in the rhythm intact condition minus performance in the rhythm altered condition), there was similarly no relationship between ANE and the magnitude of the target-rhythm effect, r(13) = −0.08, p = .77, nor between SSQ scores and the magnitude of the target-rhythm effect, r(13) = 0.28, p = .31. There was also no correlation between the magnitude of the rhythm effect and any of the three SSQ subscales—speech: r(13) = 0.26, p = .35; spatial: r(13) = 0.27, p = .33; qualities: r(13) = 0.18, p = .53.
Finally, there was no evidence of a relationship between formal music training and speech-in-noise performance when overall performance was compared between participants who did not report having any formal music training (M = 0.45, SD = 0.08) and those who did (M = 0.46, SD = 0.08), t(13) = −0.42, p = .68, Cohen’s d = −0.22, 95% CI [−0.11, 0.07]. Similarly, the magnitude of the target-rhythm effect was not significantly different for participants with formal music training (M = 0.11, SD = 0.06) and without formal music training (M = 0.06, SD = 0.04), t(13) = −1.86, p = .09, Cohen’s d = −0.96, 95% CI [−0.10, 0.01].
Experiment 2: Supplementary results
Supplementary analyses considered the potential relations between estimated ANE from the NEQ, SSQ scores, formal music training and overall speech-in-noise performance. To create a composite speech-in-noise score, proportion correct data was averaged for each participant across OA and rhythm intact/altered conditions. Since there were different SNR groups, we conducted partial correlations between ANE, overall SSQ score, years of formal music training, and speech-in-noise performance, controlling for SNR. Three participants were excluded from these analyses due to data quality issues with their survey responses (e.g., responding “10” to all SSQ items, or having multiple inconsistent responses on the NEQ that may have led to underestimates of ANE). There was no correlation between overall performance and ANE, r(33) = 0.244, p = .16, between overall performance and overall SSQ score, r(33) = -0.116, p = .51, or between overall performance and years of formal music training, r(33) = −0.04, p = .80. When SSQ responses were broken down into three subscales, there was still no correlation with overall proportion correct scores—speech: r(33) = 0.038, p = .83; spatial: r(33) = −0.08, p = .67; qualities: r(33) = −0.193, p = .27.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Smith, T.M., Shen, Y., Williams, C.N. et al. Contribution of speech rhythm to understanding speech in noisy conditions: Further test of a selective entrainment hypothesis. Atten Percept Psychophys 86, 627–642 (2024). https://doi.org/10.3758/s13414-023-02815-0
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-023-02815-0