
Abstract
Background
Left ventricular enlargement (LVE) is a common manifestation of cardiac remodeling that is closely associated with cardiac dysfunction, heart failure (HF), and arrhythmias. This study aimed to propose a machine learning (ML)-based strategy to identify LVE in HF patients by means of pulse wave signals.
Method
We constructed two high-quality pulse wave datasets comprising a non-LVE group and an LVE group based on the 264 HF patients. Fourier series calculations were employed to determine if significant frequency differences existed between the two datasets, thereby ensuring their validity. Then, the ML-based identification was undertaken by means of classification and regression models: a weighted random forest model was employed for binary classification of the datasets, and a densely connected convolutional network was utilized to directly estimate the left ventricular diastolic diameter index (LVDdI) through regression. Finally, the accuracy of the two models was validated by comparing their results with clinical measurements, using accuracy and the area under the receiver operating characteristic curve (AUC-ROC) to assess their capability for identifying LVE patients.
Results
The classification model exhibited superior performance with an accuracy of 0.91 and an AUC-ROC of 0.93. The regression model achieved an accuracy of 0.88 and an AUC-ROC of 0.89, indicating that both models can quickly and accurately identify LVE in HF patients.
Conclusion
The proposed ML methods are verified to achieve effective classification and regression with good performance for identifying LVE in HF patients based on pulse wave signals. This study thus demonstrates the feasibility and potential of the ML-based strategy for clinical practice while offering an effective and robust tool for diagnosing and intervening ventricular remodeling.
Similar content being viewed by others

Introduction
In recent years, heart failure (HF) has become an increasingly significant burden on public health [1,2,3], while ventricular structure remodeling has been recognized as a pivotal process in the development of cardiovascular diseases, particularly the progression of HF [4, 5]. The determinants affecting the left ventricular remodeling: (I) the intensity, longevity, and quickness of elevation in pressure burden; (II) the volume load; (III) factors like age, racial/ethnic background, and gender; (IV) accompanying conditions including coronary artery disease, diabetes, obesity, and valve-related heart issues; (V) the hormonal environment within the nervous system; (VI) changes in the extracellular matrix; and (VII) hereditary influences [6]. Left ventricular enlargement (LVE), as a common manifestation of ventricular remodeling, is closely associated with symptoms such as cardiac dysfunction, HF, and arrhythmias [7]. The increase in left ventricular size due to LVE exerts a severe impact on the clinical prognosis of patients with mild with or without severe HF [8]. Recent studies have identified LVE as a precursor to left ventricular dysfunction and clinical HF in asymptomatic individuals [9, 10]. LVE is recognized as a risk factor for both the occurrence and mortality rates associated with cardiovascular diseases (CVDs) [11], serving as a critical indicator of cardiac events, closely associated with deteriorating cardiac function and unfavorable prognosis [12].
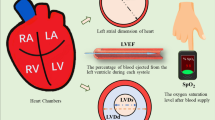
LVE provides a crucial marker in cardiac pathology, and accurate evaluation of LVE facilitates the diagnosis and assessment of heart diseases and enables the prediction of cardiac events and prognosis, providing valuable guidance for medical treatments and management strategies. Thus, as illustrated in Fig. 1a, the monitoring and evaluation of LVE are particularly important from a clinical perspective. Detection of LVE primarily relies on the patient's medical history and imaging tests, with cardiac magnetic resonance (CMR) often being the most precise method due to its ability to accurately assess the heart's morphology, size, and position [13,14,15]. CMR is not routinely available due to its high cost, time-consuming, and magnetic field limitations for patients with metal implants [16, 17]. Consequently, transthoracic echocardiography (TTE), known for its noninvasive and real-time imaging, is widely regarded as an effective, patient-friendly method for evaluating and diagnosing cardiac functions [18]. However, the accessibility and convenience of TTE are limited due to the requirement for specialized equipment and skilled operators. This research leverages pulse waves as a key informational conduit within the cardiovascular system (CVS) to address these limitations and offer a noninvasive, cost-effective solution. Building on our previous study, we demonstrate that pulse waves can effectively infer CVS conditions and aid in diagnosing CVDs [19]. By exploring the use of pulse waveforms, this research identifies them as a promising tool for rapidly identifying and evaluating LVE (Fig. 1b).

Illustration of a LVE and representative symptoms in CVDs, data-driven LVE detection, and b machine learning-based strategy for predicting LVE using pulse wave signals
The physiological signal of pulse waves has been widely utilized for health monitoring and CVD prediction [20,21,22,23]. Pulse waves contain valuable information on both physiological and pathological states of the human CVS while providing crucial physiological information associated with blood supply capacity and transportation efficiency [19, 24, 25]. Noninvasive measurements of pulse wave signals can now be easily implemented using various low-cost home electronic devices, providing helpful information for the low-cost and patient-friendly diagnosis of CVDs and relevant complications [26]. Recently, machine learning (ML) and deep learning (DL) methodologies have been employed for the analysis of pulse wave signals, demonstrating high potential and feasibility in terms of pulse wave pattern classification and cardiac function prediction [22, 27,28,29,31]. Xu et al. classified 320 datasets of pulse waveforms into 16 patterns using a fuzzy neural network to extract the differences in pulse shape, width, position, and specific local parameters, enabling a classification success rate of 90% [32]. Li et al. proposed a CNN model to classify the pulse waveforms associated with five diseases of hypertension, atherosclerosis, hyperlipidemia, type 2 diabetes, and hypertension with concurrent atherosclerosis with a success rate of 95% [33]. More recently, in our previous study [19], Wang et al. established an optimized ML strategy that enables fast and accurate predictions of three cardiovascular functional parameters based on a pulse wave database of 412 patients, demonstrating the feasibility and potential of ML-driven, pulse wave-based predictions of cardiac function. In this study, we aim to propose and establish a pulse wave signal-driven ML-based strategy for identifying and evaluating LVE in HF patients and to provide a clinically effective, patient-friendly, low-cost, and noninvasive tool for early diagnosis and monitoring of CVDs.
Results
Fourier series calculation
Through data screening and pre-processing, we successfully generated two high-quality pulse wave data sets specifically tailored to LVE and non-LVE patients. As shown in Fig. 2a, the representative waveforms of the two groups obtained based on K-means clustering show noticeable differences. Harmonic power decomposition (Fig. 2b) was performed using the 1st to 3rd order Fourier coefficients to examine how the harmonics contribute differently to the waveforms of the two groups. The pulse waveform in LVE is mainly dominated by the 1st order Fourier coefficient, but less by the 2nd order: the LVE group has a significantly higher power, but a slightly lower power than the non-LVE group, and there is rarely a discrepancy in the 3rd order. This implies that the LVE-induced irregular movement of the LV exerts an essential impact by the 1st order on dominating the feature of the pulse waves.

Comparison of representative pulse waveforms associated with LVE and non-LVE patients. a Normalized amplitudes vs. normalized sample points. b Harmonic powers vs. harmonic order
We further analyzed the harmonic frequency dependency of the two pulse wave datasets through independent sample t-tests, summarized in Table 1. In the frequency domain, we observed a significant difference between the 1st− and 2nd-order harmonics (p < 0.05), while the influence of the 3rd-order harmonic was a margin (p > 0.05). This indicates that the datasets of the LVE and non-LVE groups are primarily affected by the 1st- and 2nd-order harmonics, while there is a notable frequency domain distinction between them. This provides further evidence of the validity associated with the dataset creation and an available guideline for data selection in subsequent classification and regression tasks, substantially enhancing the accuracy of pulse wave-driven identification of LVE.
Classification model
For a classification model performance test, the accuracy results of three models (WRF, SVM, and FCNN) are compared in Table 2. The WRF model shows the best classification performance with an accuracy of 91%: its specific classification metrics, as summarized in Table 3, for the LVE and non-LVE groups achieve an overall accuracy of 0.91, which is a remarkably high-accuracy classification, while the non-LVE group presents a slightly better performance (accuracy 0 = 0.93, recall H1 = 0.93, F1-score = 0.93) compared to the LVE group (accuracy 1 = 0.89, recall H2 = 0.89, F1-score = 0.89). This indicates that the current WRF classification model can achieve high prediction precisions with high recalls and F1 scores in identifying and predicting the most positive samples.
The classification performance was further visualized using the confusion matrix, which, as shown in Fig. 3a, was employed to illustrate the classification outcomes of the LVE and non-LVE groups. While 2 out of 17 in the LVE group and 2 out of 29 in the non-LVE group were misclassified, the classification model overall demonstrated a capability to achieve the high-accuracy prediction of 93% for the non-LVE group and 88% for 5 LVE patients, even for the limited number of patients. To quantify the sensitivity and specificity of the classification model, we plotted the ROC curves in Fig. 3b, where a scalar metric of the AUC was employed at an AUC of 0.93 for the WRF model. The results indicate that the current classification model enables excellent differentiation between the LVE and non-LVE groups in up to 93% of cases compared to the perfect case of AUC = 1.

Confusion matrices and receiver operating characteristic (ROC) curves. a Confusion matrix of classification model. b Confusion matrix of regression model. c ROC curve of classification model, AUC = 0.93. d ROC curve of regression model, AUC = 0.89 (AUC: area under the curve)
Regression model
A Dense Net was utilized to predict the left ventricular diastolic diameter index (LVDdI) to optimize the ML network during the training process. The mean squared error (MSE), adopted as a loss function, displays a rapid and monotonic decline during the first several epochs (Fig. 4), converging quickly to a stable and minimum level after 100 training epochs. The relevant parameters and weights gained for the optimized model were then employed for the testing and machine learning-based predictions. As a result, the optimized regression model can achieve a prediction accuracy of 0.88.

Learning the MSE curve of the DenseNet model
To evaluate the consistency between the Dense Net predictions and clinical measurements, we applied the Bland‒Altman method to examine the mean values and differences, illustrated in Fig. 5, with an interval of 95% confidence. The Dense Net predictions are in good agreement with the clinical measurements, with most of the predicted LVDdI plots scattered within the 95% confidence interval. We presented the confusion matrix of the regression model based on the predicted LVDdI for a clearer comparison with the classification model, as shown in Fig. 3c. In this model, 3 cases from the LVE group and 3 cases from the non-LVE group were misclassified, which is slightly higher than the classification model. However, the regression model still demonstrated a high overall prediction accuracy of 88%. In addition, as shown in Fig. 3d, the ROC curve of the regression model, which estimates the LVDdI as a binary classification of the LVE and non-LVE groups, presents an AUC-ROC of 0.89, slightly lower than that of the classification model.

Comparison between Dense Net predictions and clinical measurements based on Bland–Altman analyses for LVDdI
Discussion
Left ventricular enlargement (LVE) plays a pivotal role in the clinical evaluation of HF. In this study, we demonstrate that employing pulse wave signals combined with advanced machine learning (ML) techniques can provide a promising avenue for quantitative identification with LVE and non-LVE in heart failure (HF) patients.
With two high-quality pulse wave datasets of 264 patients for the LVE and non-LVE groups, the ML-based prediction strategy was implemented using classification and regression models, which were validated through comparison with clinical measurements capable of achieving fast and accurate LVE identification in HF patients. Of the three established classification models, weighted random forest (WRF) model can achieve a remarkable differentiation between the LVE and non-LVE groups with a significantly high accuracy of 93%. In contrast, the dense net regression model enables an accuracy of 88% in directly predicting the left ventricular diastolic diameter index (LVDdI). The results demonstrate that the proposed methods and ML-driven methodology have high potential and feasibility to accomplish both LVE classification and LVE identification in HF patients based on pulse wave signals.
From a clinical perspective, the current pulse wave-driven, ML-based identification methodology can provide a noninvasive and low-cost tool for evaluating and diagnosing LVE in HF patients. As a noninvasive, real-time cardiac imaging technique to detect LVE, transthoracic echocardiography (TTE) is widely utilized. However, it has certain limitations regarding accessibility and convenience, which may lead to delayed medical treatments. This issue becomes even more crucial with expensive, high-sensitivity medical equipment such as nonenhanced multilayer spiral CT [34]. Recently, some attempts to utilize artificial intelligence methods have been conducted. Nam et al. [35] developed a way to detect left atrial enlargement (LAE) and LVE on chest X-rays using deep learning algorithms, but the results for LVE detection were all p > 0.05 compared to those for LAE, suggesting a need for inclusion of more images. The current ML-based methods demonstrate a patient-friendly and feasible tool for the first time to effectively differentiate LVE patients from the LVE and non-LVE groups using pulse wave signals. With the rapid advances in portable electronics and wearable devices such as smartphones and smartwatches, the noninvasive measurement of such physiological data has become more convenient and cost-effective. Pulse waves can thus be utilized for LVE detection, holding immense potential in assisting clinical management and treatment.
There are limitations in this study in terms of the relatively small sample size of data, the limited data scope, the singular data source, and a lack of pertinent clinical information. While we employed stringent methods in data selection and successfully created two high-quality datasets for classification and regression models, validation based on preliminary experiments remains open for further improvement; the data source from only one institution may not represent the diverse HF patient population. Additionally, the lack of healthy subjects and patients with other cardiovascular diseases may bring a potential bias, as it fails to encompass the entire HF demographic. To augment the generalizability of the ML models, there is an urgent need to expand the dataset by including a more diverse patient cohort. Further improvements in predictive accuracy and robust feasibility of the ML-based methodology to meet practical clinical applications may be accomplished by integrating multiple data sources, such as TTE and clinical biochemical markers, which will be our future endeavors. More efforts will improve the precision and reliability in training and testing with larger datasets, amalgamating relevant clinical information, and attempting patient classification based on LVE severity.
Conclusion
In this study, the ML-based strategy successfully identified the patients with LVE in HF from those without LVE in HF. The proposed ML methods are verified to achieve effective classification and regression with excellent performance for identifying LVE in HF patients. This points to the potential and superiority of identifying patients with LVE based on pulse waves. Our study thus underscores the significance of the ML-based methodology for clinical practice, offering a robust tool for diagnosing and intervening in cardiac remodeling.
Methods
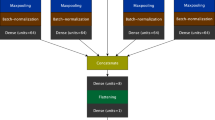
Our machine learning framework consists of four parts: data processing, data screening, Fourier series calculation, and machine learning model analysis, as shown in Fig. 6:

Framework of the machine learning process. a Data processing. b Data screening. c Fourier series calculation. d Machine learning models
Ethics approval
This research received ethical approval from the Ethics Review Board of Chiba University Graduate School of Medicine in 2021 (Approval Number: M10089). The clinical data collection and analysis adhered to the applicable guidelines and regulations.
Clinical data
All data were collected from 264 patients with HF, consisting of raw extremity pulse wave data and relevant clinical, physiological, and pathological information. HF was diagnosed based on the Framingham HF diagnostic criteria [36]. All patients were admitted to Chiba University Hospital between January 2019 and December 2022. After the acute HF condition stabilized, blood pressure/pulse wave detection equipment (Omron 203RPEIII) was used to measure and record the pulse waves and blood pressure. All patients underwent TTE (Vivid E9; GE Healthcare, Horten, Norway) within one week before or after the pulse wave tests. The measured parameters of relevant clinical information (e.g., age and body mass index) were also collected. None of the patients were confirmed to consume spicy food or alcoholic drinks during hospitalization.
Pulse waves
Pulse wave signals were collected from the left upper arms of HF patients, followed by applying denoising and normalization techniques grounded in methodologies from previous studies [37, 38]. First, we utilized wavelet transform decomposition to remove noise from the signals [39]. Then, to prevent distortion of the pulse wave signals, we set the number of sampling points for each pulse wave cycle to 100, considering the Nyquist theorem and the actual sampling frequency [32, 40]. Since our study focused on variations in the pulse wave model, we normalized the pulse wave amplitude within each cycle to a range of 0 to 100.
Datasets
Rigorous data screening was undertaken to ensure data quality. The 264 patients with HF were confirmed to satisfy the following screening criteria: (1) pulse wave data were collected from the left upper arms of the patients; (2) for each patient, five or more valid pulse wave cycles were recorded; and (3) LV size, including LV diastolic diameter (LVDd) and LV systolic diameter (LVSd), was measured by transthoracic echocardiography. Our clinical data were used to evaluate the LVE of each patient based on the guidelines provided by the American Society of Echocardiography (ASE) [36]. LVE was defined as LVDd with an index, namely, LVDdI > 36 mm/m2 for males and > 37 mm/m2 for females [12].
The clinical data for 264 patients underwent classification, as depicted in Fig. 7. This dataset excluded 37 patients because of incomplete records. Among the remaining 227 qualified patients, 137 were identified as non-LVE patients, while 90 were diagnosed with LVE. The K-means clustering algorithm derived characteristic waveforms from these two datasets. These waveforms were then decomposed into 3rd-order Fourier series to explore the variances between the datasets, detailed as follows:
where A0 is the period-average value, A1-A3 and B1-B3 are the 1st-order to 3rd-order Fourier series coefficients, respectively, t is time, and \(\omega\) is the angular frequency. Independent sample t-tests were then conducted to statistically analyze the difference between the patient datasets with LVE and non-LVE.

Flowchart of patient screening under screening criteria a, b, c, and d: (1) exclusion of 22 subjects with incomplete informationa, (2) exclusion of 97 patients with other cardiac remodelingb, (3) creation of a non-LVE patient group of 137 Subjectsc, and (4) creation of an LVE patient group of 90 Subjectsd
Machine learning models
Two ML models were developed and validated for classification and regression tasks. The classification model is a binary classifier that analyzes the pulse waveforms to examine whether the HF patients suffered from LVE; the regression model is employed to estimate the LVDdI based on the pulse waveforms.
Classification
In this study, our objective was to address the classification problem between patients with LVE and non-LVE. We constructed a pulse wave dataset using data from 227 HF patients. The dataset was divided into two subsets, with approximately 80% allocated to the training dataset and the remaining 20% to the testing dataset. To select an appropriate ML model, we conducted numerous preliminary experiments to test and compare the predictive performance among different models, such as the weighted random forest (WRF) model, support vector machine (SVM) model, and fully convolutional neural network (FCNN) method. Due to the imbalance in the data from the two groups of patients, we employed the WRF method, where different weights were assigned to the two groups during the training process. We utilized the class weight parameter of the random forest classifier from the scikit-learn library to adjust the weights based on the class distribution, aiming to improve the performance of the minority class. We extensively investigated various weight settings and substantially determined weight parameters of 1 and 4 for non-LVE and LVE patients, respectively. To mitigate the risk of overfitting, we used fivefold cross-validation and recorded the average scores to evaluate the model's performance more accurately.
Regression
The densely connected convolutional network (Dense Net) was employed for regression prediction of LVDdI, a recently established, innovative network architecture capable of excelling in efficient feature extraction and regression prediction tasks [41]. In the context of our limited dataset, the dense net is verified, enabling the effective employment of data features, and achieving high performance while mitigating overfitting. The relationship between the input and output of the (n + 1)th layer (feature map) associated with the dense block module is given as:
G denotes multiple operations, including the rectified linear unit (ReLU), batch normalization, and convolution.
The specific network architecture, as shown in Fig. 8, consists of a dense net with two hidden layers: the 1st and 2nd hidden layers, which comprised 128 neurons and 32 neurons, respectively. The output layer has a single neuron dedicated to regression prediction. The ReLU is used as the activation function in the two hidden layers. Additionally, dropout layers are inserted between the 1st and 2nd hidden layers to mitigate overfitting.

Schematics of densely connected convolutional networks (Dense Nets) for regression modeling
The model was trained using the Adam optimizer under the following conditions: learning rate = 0.001, ε = 0.001, ρ1 = 0.9, ρ2 = 0.999, and δ = 1E − 8 [42] while using the MSE as the loss function. The ML networks were trained with TensorFlow (v2.0.0rc, Python 3.7) on an NVIDIA Quadro K4000 GPU, encompassing 100 epochs, with each batch having 128 samples. The model performance was evaluated for validation based on 10% of the training dataset.
Performance evaluation
The performance of the weighted RF-based classification model was evaluated with standard classification metrics of accuracy, recall, F1 score, and AUC-ROC, as defined below:
Here, TP and TN represent the total count of correctly detected positive and negative events, while FP and FN denote the total count of erroneously detected positive and negative events.
To evaluate the model's discrimination capability for the two datasets, we employed ROC analysis to derive the AUC. From the plots of the false-positive rate (FPR) on the x-axis and the true positive rate (TPR) on the y-axis, the ROC curve was obtained to calculate the AUC. TPR and FPR are given as follows:
The confusion matrix was further visualized to assess the model performance regarding the training and testing datasets.
For the regression model, we used the metrics of accuracy and AUC-ROC to evaluate the performance. Given that the mean absolute percentage error (MAPE) is defined as an error function:
where y and ŷ denote the clinically measured value and the ML-predicted value of the cardiac function parameters, respectively; n is the quantity of the test dataset; thus, the accuracy is given as:
Moreover, we conducted consistency analysis between clinical measurements and ML-based predictions using the Bland‒Altman method. The Bland–Altman analysis reveals the trends, clustering patterns, and correlations of parameters between the clinical measurement datasets and ML-based prediction datasets. When the parameters fall within an acceptable range, good agreement is obtained between the two datasets, and then both methods can be used interchangeably [43].
Availability of data and materials
Not applicable.
Abbreviations
- LVE:
-
Left ventricular enlargement
- HF:
-
Heart failure
- ML:
-
Machine learning
- WRF:
-
Weighted random forest
- LVDdI:
-
Left ventricular diastolic diameter index
- AUC-ROC:
-
Area under the receiver operating characteristic curve
- CVD:
-
Cardiovascular disease
- CMR:
-
Cardiac magnetic resonance
- TTE:
-
Transthoracic echocardiography
- CVS:
-
Cardiovascular system
- MSE:
-
Mean squared error
- LAE:
-
Left atrial enlargement
- ASE:
-
American Society of Echocardiography
- SVM:
-
Support vector machine model
- FCNN:
-
Fully convolutional neural network
- Dense Net:
-
Densely connected convolutional networks
- FPR:
-
False positive rate
- TPR:
-
True positive rate
- MAPE:
-
Mean absolute percentage error
References
Savarese G, Becher PM, Lund LH, Seferovic P, Rosano GMC, Coats AJS. Global burden of heart failure: a comprehensive and updated review of epidemiology. Cardiovasc Res. 2022;118:3272–87.
Clark KAA, Reinhardt SW, Chouairi F, Miller PE, Kay B, Fuery M, et al. Trends in heart failure hospitalizations in the US from 2008 to 2018. J Card Fail. 2022;28:171–80.
Wei S, Le N, Zhu JW, Breathett K, Greene SJ, Mamas MA, et al. Factors associated with racial and ethnic diversity among heart failure trial participants: a systematic bibliometric review. Circ Heart Fail. 2022;15:e008685.
Cohn JN, Ferrari R, Sharpe N. Cardiac remodeling—concepts and clinical implications: a consensus paper from an international forum on cardiac remodeling. J Am Coll Cardiol. 2000;35:569–82.
Zile MR, Gaasch WH, Patel K, Aban IB, Ahmed A. Adverse left ventricular remodeling in community-dwelling older adults predicts incident heart failure and mortality. JACC Heart Fail. 2014;2:512–22.
Drazner MH. The progression of hypertensive heart disease. Circulation. 2011;123:327–34.
Chen Y, Hua W, Yang W, Shi Z, Fang Y. Reliability and feasibility of automated function imaging for quantification in patients with left ventricular dilation: comparison with cardiac magnetic resonance. Int J Cardiovasc Imaging. 2022;38:1267–76.
Vasan RS, Larson MG, Benjamin EJ, Evans JC, Levy D. Left ventricular dilatation and the risk of congestive heart failure in people without myocardial infarction. N Engl J Med. 1997;336:1350–5. https://doi.org/10.1056/NEJM199705083361903.
Gaudron P, Eilles C, Kugler I, Ertl G. Progressive left ventricular dysfunction and remodeling after myocardial infarction. Potential mechanisms and early predictors. Circulation. 1993;87:755–63.
Yeboah J, Bluemke DA, Hundley WG, Rodriguez CJ, Lima JAC, Herrington DM. Left ventricular dilation and incident congestive heart failure in asymptomatic adults without cardiovascular disease: multi-ethnic study of atherosclerosis (MESA). J Card Fail. 2014;20:905–11.
Levy D, Anderson KM, Savage DD, Balkus SA, Kannel WB, Castelli WP. Risk of ventricular arrhythmias in left ventricular hypertrophy: the Framingham heart study. Am J Cardiol. 1987;60:560–5.
Yamanaka S, Sakata Y, Nochioka K, Miura M, Kasahara S, Sato M, et al. Prognostic impacts of dynamic cardiac structural changes in heart failure patients with preserved left ventricular ejection fraction. Eur J Heart Fail. 2020;22:2258–68.
Salerno M, Kramer CM. Advances in parametric map** with CMR imaging. JACC Cardiovasc Imaging. 2013;6:806–22.
Pennell DJ. Ventricular volume and mass by CMR. J Cardiovasc Magn Reson. 2002;4:507–13.
Vincenti G, Monney P, Chaptinel J, Rutz T, Coppo S, Zenge MO, et al. Compressed sensing single-breath-hold CMR for fast quantification of LV function, volumes, and mass. JACC Cardiovasc Imaging. 2014;7:882–92.
Ibrahim E-SH, Frank L, Baruah D, Arpinar VE, Nencka AS, Koch KM, et al. Value CMR: towards a comprehensive, rapid, cost-effective cardiovascular magnetic resonance imaging. Int J Biomed Imaging. 2021;2021:1–12.
Kramer CM. Potential for rapid and cost-effective cardiac magnetic resonance in the develo** (and Developed) World. J Am Heart Assoc. 2018. https://doi.org/10.1161/JAHA.118.010435.
Pastore MC, Mandoli GE, Aboumarie HS, Santoro C, Bandera F, D’Andrea A, et al. Basic and advanced echocardiography in advanced heart failure: an overview. Heart Fail Rev. 2020;25:937–48.
Wang S, Wu D, Li G, Song X, Qiao A, Li R, et al. A machine learning strategy for fast prediction of cardiac function based on peripheral pulse wave. Comput Methods Programs Biomed. 2022;216:106664.
Guk K, Han G, Lim J, Jeong K, Kang T, Lim E-K, et al. Evolution of wearable devices with real-time disease monitoring for personalized healthcare. Nanomaterials. 2019;9:813.
Sughimoto K, Okauchi K, Zannino D, Brizard CP, Liang F, Sugawara M, et al. Total cavopulmonary connection is superior to atriopulmonary connection Fontan in preventing thrombus formation: computer simulation of flow-related blood coagulation. Pediatr Cardiol. 2015;36:1436–41.
Sughimoto K, Levman J, Baig F, Berger D, Oshima Y, Kurosawa H, et al. Machine learning predicts blood lactate levels in children after cardiac surgery in paediatric ICU. Cardiol Young. 2023;33:388–95.
Song X, Liu Y, Wang S, Zhang H, Qiao A, Wang X. Non-invasive hemodynamic diagnosis based on non-linear pulse wave theory applied to four limbs. Front Bioeng Biotechnol. 2023;11:1081447.
Wilkinson IB, Hall IR, MacCallum H, Mackenzie IS, McEniery CM, Van der Arend BJ, et al. Pulse-wave analysis: clinical evaluation of a noninvasive, widely applicable method for assessing endothelial function. Arterioscler Thromb Vasc Biol. 2002;22:147–52.
Townsend RR, Black HR, Chirinos JA, Feig PU, Ferdinand KC, Germain M, et al. Clinical use of pulse wave analysis: proceedings from a symposium sponsored by North American Artery. J Clin Hypertens. 2015;17:503–13.
Inan OT, Migeotte PF, Kwang-Suk P, Etemadi M, Tavakolian K, Casanella R, et al. seismocardiography: a review of recent advances. Biomedical and health informatics. IEEE J. 2015;19:1414–27.
Li R, Sughimoto K, Zhang X, Wang S, Hiraki Y, Liu H. Impact of respiratory fluctuation on hemodynamics in human cardiovascular system: a 0–1D multiscale model. Fluids. 2022;7:28.
Li R, Sughimoto K, Zhang X, Wang S, Liu H. Impacts of respiratory fluctuations on cerebral circulation: a machine-learning-integrated 0–1D multiscale hemodynamic model. Physiol Meas. 2023;44:035013.
Mathur P, Srivastava S, Xu X, Mehta JL. Artificial intelligence, machine learning, and cardiovascular disease. Clin Med Insights Cardiol. 2020;14:1179546820927404.
Wang S, Wu D, Li G, Zhang Z, **ao W, Li R, et al. Deep learning-based hemodynamic prediction of carotid artery stenosis before and after surgical treatments. Front Physiol. 2023;13:2674.
Wang H, Cheng Y. A quantitative system for pulse diagnosis in traditional Chinese medicine. 2005 IEEE Engineering in Medicine and Biology 27th Annual Conference. IEEE. 2006; 5676–9.
Xu L, Meng MQ-H, Wang K, Lu W, Li N. Pulse images recognition using fuzzy neural network. Expert Syst Appl. 2009;36:3805–11.
Li G, Watanabe K, Anzai H, Song X, Qiao A, Ohta M. Pulse-wave-pattern classification with a convolutional neural network. Sci Rep. 2019;9:14930.
Kathiria NN, Devcic Z, Chen JS, Naeger DM, Hope MD, Higgins CB, et al. Assessment of left ventricular enlargement at multidetector computed tomography. J Comput Assist Tomogr. 2015;39:794–6.
Nam JG, Kim J, Noh K, Choi H, Kim DS, Yoo S-J, et al. Automatic prediction of left cardiac chamber enlargement from chest radiographs using convolutional neural network. Eur Radiol. 2021;31:8130–40.
McKee PA, Castelli WP, McNamara PM, Kannel WB. The natural history of congestive heart failure: the Framingham study. N Engl J Med. 1971;285:1441–6.
Zhang X, Shang Y, Guo D, Zhao T, Li Q, Wang X. A more effective method of extracting the characteristic value of pulse wave signal based on wavelet transform. J Biomed Sci Eng. 2016;9:9–19.
Wu H-T, Lee C-H, Chen C-E, Liu A-B. Predicting arterial stiffness with the aid of ensemble empirical mode decomposition (EEMD) algorithm. 2010 IEEE International Conference on Wireless Communications, Networking and Information Security. IEEE; 2010. p. 179–82.
Chang F, Hong W, Zhang T, **g J, Liu X. Research on wavelet denoising for pulse signal based on improved wavelet thresholding. 2010 First International Conference on Pervasive Computing, Signal Processing and Applications. IEEE. 2010; 564–7.
Hu X, Zhu H, Xu J, Xu D, Dong J. Wrist pulse signals analysis based on deep convolutional neural networks. 2014 IEEE conference on computational intelligence in bioinformatics and computational biology. IEEE. 2014; 1–7.
Huang G, Liu Z, Van Der Maaten L, Weinberger KQ. Densely connected convolutional networks. Proceedings of the IEEE conference on computer vision and pattern recognition. 2017; 4700–8.
Kingma DP, Ba J. Adam: A method for stochastic optimization. ar**v preprint ar**v:14126980. 2014.
Zou GY. Confidence interval estimation for the Bland-Altman limits of agreement with multiple observations per individual. Stat Methods Med Res. 2013;22:630–42.
Acknowledgements
Not applicable.
Funding
This work was partly supported by a Research Fellowship for Informatics-based Medical Engineering and Fujii Sechiro Memorial Osaka Basic Medical Research Foundation in 2020.
Author information
Authors and Affiliations
Contributions
D.W. contributed to clinical data processing and machine learning analysis and played a significant role in drafting the manuscript. R.Y. was responsible for certain aspects of clinical data collection, data processing, and manuscript drafting. S.W. was involved in data processing and machine learning analysis. Y.K. was engaged as a supervisor for clinical data collection and data processing. K.S. was engaged as a supervisor in drafting the manuscript. H.L. played a pivotal role in the conceptualization and design of the study. All authors actively participated in revising the manuscript and have read and approved the final version submitted.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
This study was approved by the Ethics Review Board of Chiba University Graduate School of Medicine in 2021, with an approval number M10089. This study was conducted retrospectively, and the requirement to obtain informed consent was waived. The measurements of clinical data complied with relevant guidelines and regulations.
Competing interests
The authors report no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Wu, D., Ono, R., Wang, S. et al. Pulse wave signal-driven machine learning for identifying left ventricular enlargement in heart failure patients. BioMed Eng OnLine 23, 60 (2024). https://doi.org/10.1186/s12938-024-01257-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12938-024-01257-5