
Abstract
Purpose
Ensuring equivalence of examiners’ judgements within distributed objective structured clinical exams (OSCEs) is key to both fairness and validity but is hampered by lack of cross-over in the performances which different groups of examiners observe. This study develops a novel method called Video-based Examiner Score Comparison and Adjustment (VESCA) using it to compare examiners scoring from different OSCE sites for the first time.
Materials/ methods
Within a summative 16 station OSCE, volunteer students were videoed on each station and all examiners invited to score station-specific comparator videos in addition to usual student scoring. Linkage provided through the video-scores enabled use of Many Facet Rasch Modelling (MFRM) to compare 1/ examiner-cohort and 2/ site effects on students’ scores.
Results
Examiner-cohorts varied by 6.9% in the overall score allocated to students of the same ability. Whilst only a tiny difference was apparent between sites, examiner-cohort variability was greater in one site than the other. Adjusting student scores produced a median change in rank position of 6 places (0.48 deciles), however 26.9% of students changed their rank position by at least 1 decile. By contrast, only 1 student’s pass/fail classification was altered by score adjustment.
Conclusions
Whilst comparatively limited examiner participation rates may limit interpretation of score adjustment in this instance, this study demonstrates the feasibility of using VESCA for quality assurance purposes in large scale distributed OSCEs.
Similar content being viewed by others

Background
Although contemporary views of assessment have evolved considerably over the last decade [1], Objective Structured Clinical Exams [2] remain a cornerstone of many programs of assessment programs because of their ability to assess students’ performances on a structured range of blueprinted tasks under formally observed conditions [3] and because they aim to ensure equivalence of standards [4] for all students who are assessed. The latter is important as it is critical to both the ability to reassure patients that consistent standards have been met and to ensure that students are judged according to a comparable, and therefore fair, standard.
Being able to demonstrate equivalence of OSCE exams is, consequently, a key component of the chain of validity [5] on which resulting assessment decisions are based. In contrast to the original conception of OSCEs [6], candidate numbers in most institutions require the use of multiple parallel versions of (ostensibly) the same OSCE ‘diet’, with different groups of examiners and students in each parallel form of the test. As a result, it becomes necessary for each separate group of examiners to collectively judge to the same standard in order to ensure equivalence across these multiple parallel forms of the same test, otherwise whether or not a student passes or fails may depend on the parallel form of the test to which they were allocated, rather than solely on their ability per se. Whilst the meaning of fairness can be debated [7], few educators would find it reasonable that a students’ outcome could be determined by their allocation to a circuit or location within the exam.
Ensuring the equivalence of different groups of examiners (or “examiner-cohorts” [8]) is difficult; conventional psychometric analyses of reliability do not readily provide parameters which describe examiner-cohorts effects. One limitation in determining equivalence across different examiner-cohorts is that students and examiners are typically “fully-nested”, that is, there is no overlap between the students examined by different groups of examiners, so there is no means to directly compare scoring without making strong assumptions about equivalence of students’ performance in each parallel form of the test.
Owing to these methodological difficulties, research on the influence of different examiner-cohorts has been limited, but a few studies are informative. Floreck et al. [9] found up to 0.0-15.7% of score variance in an OSCE could be attributed to different sites. Consistently Sebok et al. [10] found raters at different sites contribute 2.0–17% of variance. In each instance we can see that whilst variations between groups of examiners was not ubiquitous, it occurred in some instances and had the potential importantly influence outcomes (e.g., graduation or progression) for some candidates.
More recently, Yeates et al. have developed a method called “Video-based Examiner Score Comparison and Adjustment” (VESCA) [11, 11] and 7.1% [13], an increase in the number of videos examiners were asked to score, and variations in the method of video scoring, including trialing an approach to internet-based video scoring by examiners [
How does the stringency / leniency of different examiner cohorts compare within a multi-site OSCE? How does the stringency / leniency of examiners compare between different OSCE sites within a multi-site OSCE? What are the relative magnitudes of any within vs. between site differences in examiners stringency / leniency? What is the (theoretical) impact of adjusting students’ scores for any observed differences in examiner-cohort stringency/leniency on their overall score, pass/fail outcome and rank position within the OSCE?
Methods
Overview
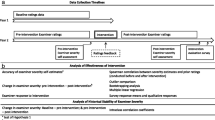
We employed the VESCA methodology as described by Yeates et al. [13]. Audio was recorded using boundary microphones. Participating students were filmed on all 16 stations within the OSCE. Examiners were not deliberately filmed but sometimes featured in the background of videos. Video footage was processed by an audio-visual technician to provide a blend of wide-angle and close-up views of students’ performances, resulting in 8 videos of each station. Where detailed views of physical items were required (for example to show students’ labelling of specimen tubes / details of an ECG), these were collected between students by researchers, numbered and either photographed or scanned. The first 4 videos of each station which showed unobstructed pictures and adequate sound were selected for use in subsequent video scoring. Videos were available 24 h after the OSCE was completed.
Video scoring: The 4 selected videos for each station were uploaded to a secure web-survey system (Keele’s Faculty of Medicine and Health Survey System) which is built on the open-source websurvey system Lime Survey (LimeSurvey GmbH) [17]. Once videos were available and uploaded, all examiners who participated in the OSCE (all examiner-cohorts at both sites) were invited via email to score videos from their station as part of a research project. Examiners had received email advertisements for the study in the weeks running up to the OSCE so were aware that these invitations would be sent. The web-based survey system presented examiners with a participant information sheet, obtained consent and played a test video to ensure their audio and picture were adequate. Next examiners were streamed into a portion of the survey which was specific to the station they had examined. There they were presented with the same examiner information they had been given during the exam (including marking criteria), before being presented with four videos of students performing on the station they had examined. They were asked to observe, score and provide written feedback to each performance sequentially. The web-survey system collected scores according to the specific scoring domains for each station. Following completion of video scoring examiners were provided brief de-briefing information.
For each station, all participating examiners scored the same video performances. Examiners who had scored the videoed performances live were also invited to score videos so that live and video scoring could be compared. Examiners who examined different stations (for example on different days) were invited to score each of the stations they had examined. Reminder emails were sent via the survey system to examiners who had not yet participated. All invitations included an option to decline to participate and opt out of future invitations.
Analysis: Scores which examiners allocated to video performances were aligned with the score data from the OSCE to create one dataset. To address the study research questions, data were analysed with Many Facet Rash Measurement (MFRM), using FACETS v3.83.6 [18]. We performed a number of analyses to determine the suitability of the data for MFRM. Firstly, we examined examiner participation rates, comparing these across different examiner-cohorts. Secondly, we compared the distribution of scores within video performances with the distribution of overall performances. Next we used a Bland-Altmann plot [19], using the package ‘BlandAltmanLeh’ [20] in R to compare scores given to the same performances by the subset of examiners who examined them under both “live” and “video” condition, to determine whether there were any differences in scores added to video and live performances. Following this, we examined Mean Square Infit and Outfit parameters provided by FACETS software to determine whether data fit the Rasch model, using the fit parameters suggested by Linacre [21], i.e. that Mean Square values between 0.5 and 1.5 indicate productive fit for measurement. Finally, as MFRM makes strong assumptions of unidimensionality, we performed Principal Components Analysis (PCA) of model residuals to seek any evidence of additional (and therefore distorting) dimensions within the data, using base R [22].
To address our principal research question, we used a four facet Rasch model in FACETs, with a dependent variable of score (out of 27 scale points), with facets of: Student (ability), station (difficulty), site (site effect), and examiner-cohort (stringency). We used output of this analysis to compare examiner-cohort effects, site effects, and examiner-cohort effects within sites. We calculated students score adjustments by subtracting the observed from the adjusted score for each student and calculating descriptive data.
To determine the influence of score adjustment on pass/fail categorization, we obtained the cut score using the institution’s standard approach of borderline regression [23] + 1 additional SEM. We then compared student observed (unadjusted scores) and adjusted scores with the cut score to determine which students passed and failed in each condition. We did not consider impact on conjunctive passing rules as the MFRM only adjusts overall (rather than station level) scores.
To determine influence of score adjustment on rank, we firstly order students by unadjusted score and noted their rank position, then ordered by adjusted scores and noted their rank position, and then computed the change in rank by subtracting the unadjusted rank from the adjusted rank for each student and calculating descriptive statistics.
Results
Descriptive data and participation rates
Data were available for all 126 students who were assessed within the OSCE. Students unadjusted average scores (i.e. their average across all 16 stations) ranged from 15.5 out of 27 (57.4%) to 24.1 out of 27 (89.3%), and were normally distributed with a mean of 20.9 and SD of 1.6. Mean scores varied by station, from 18.7 (69.2%, the hardest stationi) to 22.5 (83.5%, the easiest station), thereby showing the anticipated range of station difficulty. The Cronbach alpha for the data overall was 0.76, with Corresponding Cronbach’s alpha of 0.73 for site 1 and 0.79 for site 2.
Students who volunteered to be filmed had unadjusted average scores ranging from 17.0 (62.9%) to 22.3 (82.6%) with a median of 20.6. Consequently, videoed students’ average ability range constituted 61% of the range of total student ability. Scores allocated to individual video performances by examiners ranged from 9 (33.3%) to 27 (100.0%) with a median of 20 (74.1%), thereby covering a wider range of levels of performance.
Examiners scored comparison videos on 242 out of 512 available opportunities, giving an overall examiner participation rate of 47.3%. Video scoring rates varied by station, ranging from scoring completed on 0 out of 32 (0.0%) eligible occasions for station 16, to scores provided on 28 out of 32 (87.5%) eligible occasions for station 10. Examiner participation rates also varied by site, with videos scored on 80 out of 256 (31.2%) eligible occasions by examiners from site 1, whilst videos were scored on 162 out of 256 (63.3%) eligible occasions by examiners from site 2.
Given these examiners participation rates, we further examined the degree of score linkage which the video scores had achieved between the 2 OSCE sites. Forty-six out of sixty-four comparison videos (71.9%) were scored by at least one examiner from each site. Whilst no formal method exists to determine linkage adequacy, this is expected to be sufficient for the analyses we performed. See Table 1 for demonstration of the linkage pattern produced by video scores. Score allocated to videos comprised 11% of the total dataset.
Adequacy of data for many facet rasch models
The Bland-Altman plot which compared the scores given by the same examiners to the same performances in both “live” and video formats had a mean and 95%Cis of -0.28 (-6.24–5.67), indicating that there was no significant difference between live and video scoring (see Fig. 1).

Bland Altman Plot comparing live and video scores
The PCA of models residuals, used to examine dimensionality of the data, showed that all eigenvalues were > -2, a commonly used cut-off for indicating that variance is at a random level [24], As a result, there was no indication that data breached unidimensional assumptions.
Data generally showed good fit to the Many Facet Rasch Model. Mean Square Init and Outfit values were 0.5–1.5 for all 16 stations, all 8 examiner-cohorts and for both sites. Four out of the 126 students (3.2%) showed overfit to the Many Facet Rasch Model (MnSq < 0.5). Eleven students showed underfit to the model (MnSq > 1.5). Of these, 9 showed mild underfit (MnSq 1.5–1.7, Z std < 2.0). Two students showed greater underfit (MnSq 2.0-2.3, Z std > 2.0). As these students’ data had the potential to distort the model, we removed them and recalculated the model. This resulted in a median alteration of students’ score adjustments of 0.05% of the assessment scale. On this basis we determined that these data were not distorting the model and proceeded with the full dataset.
Main research question
-
1.
How does the stringency / leniency of different examiner cohorts compare within a multi-site OSCE?
Observed (unadjusted) average values for the 8 examiner-cohorts ranged from 20.23 (74.9%) for examiner cohort 5 to 21.39 (79.2%) for examiner cohort 2. Model-derived parameters (which make use of the linkage provided by scores given to the comparison videos to compare the effects of these examiner cohorts) produced a different rank ordering of examiner-cohorts, with the lowest adjusted score of 20.28 (75.1%) for examiner cohort 3, and the highest adjusted score of 22.13 (82.0%) for examiner cohort 2, giving a difference of 1.85 (6.9%). Notably, these scores are the model estimates of the score that a student of the same ability would have received from these different examiner cohorts. These data are illustrated in Fig. 2.

Wright Map showing relative influence of items within all four facets: students, stations, examiner-cohorts, and site
Whilst FACETs output does not provide a formal test of statistical significance, considering these data on the logit measurement scale enables them to be appreciated relative to the model standard error. Examiner-cohort 3 had a logit measure value of 0.28 logits and examiner-cohort 2 had a logit measure value of 0.47. The model standard error was 0.02, therefore the difference between the highest and lowest examiner-cohort (0.47 − 0.28 = 0.19 represents 9.5 multiples of the model standard error making the differences very unlikely to be due to measurement error.
As well as demonstrating these differences, model-adjusted parameters changed the rank order of examiner-cohorts, with unadjusted scores suggesting an order from most stringent to most lenient of examiner cohorts: 5, 7,4, 3, 6, 8, 1, 2; whereas the model-adjusted scores suggested an order from most stringent to most lenient of examiner cohorts: 3, 1, 8, 6, 7, 4, 5,2.
-
2.
How does the stringency / leniency of examiners compare between different OSCE sites within a multi-site OSCE?
Observed (unadjusted) average values for the 2 OSCE sites were 20.97 (77.7%) for site 1 and 20.73 (76.8%) for site 2, a difference of 0.24 (0.9%). Model derived estimates for site differences suggested a minimally larger difference between the OSCE sites, with parameters of 21.28 (78.8%) for site 1 and 20.92 (77.5%) for site 2, giving a difference of 0.36 (1.3%). Corresponding logit measure values for OSCE site 1 was 0.02 logits and for OSCE site 2 was − 0.02 logits with a model standard error of 0.01. Consequently, the difference between these parameters of 0.04 logits is 4 times the model standard error (0.04/0.01 = 4) and therefore this very small difference may still be considered statistically significant.
-
3.
What are the relative magnitudes of any within vs. between site differences in examiners stringency / leniency?
Organising examiners-cohorts by sites showed that within site variation was greater at both sites then between site variation. Moreover, the magnitude of variation between examiner cohorts varied between sites. For site one, model-adjusted score parameters ranged from 20.28 (75.1%) for examiner-cohort 3 to 22.13 (82.0%) for examiner-cohort 2, a difference of 1.85 score points (6.9%). These were the most stringent and the most lenient examiner cohorts in the OSCE, and as explained earlier, are arguably statistically significantly different based on comparison of logit measure values in comparison to the model standard error. By contrast, for site two, model-adjusted score parameters ranged from 20.77 (77.0%) for examiner cohort 8 to 21.39 (79.2%) for examiner-cohort 5, a difference of 0.62 score points (2.3%). Moreover, examination of the same logit-scale measure values relative to the model standard error suggests that these differences were not statistically significant (examiner cohort 8 = 0.33 logits; examiner cohort 5 = 0.39 logits, difference 0.06 logits, model SE 0.02 logits, therefore difference = 3x model standard error). These parameters are displayed graphically in Fig. 3.

Examiner-Cohort Parameters by Site
-
4.
How does adjusting students’ scores for any observed differences alter their score, pass/fail categorization or rank position within the OSCE?
Although video scores only compare examiners scoring directly for a limited subset of students, the linkage that this creates enables the Many Facet Rasch Model to estimate adjusted scores for all students (including those who weren’t videoed). Model-based ‘fair scores’ for students’ average overall performance differed from the corresponding observed scores and would result in adjustment to students’ scores if these were adopted. Notably, the model-derived scores aim to correct for differences in the stringency of the examiner cohort which each student met. Students’ score adjustments (fair average score – observed average score) ranged from − 1.66 scale points (-7.9%) to + 0.80 scale points (3.8%). Fourteen students’ scores (11.1%) were adjusted downward by at least 5% of the scale (in response to lenient examiners) whilst twelve students’ scores (9.5%) were adjusted upwards by at least 3% (in response to stringent examiners. Sixty-six students (52%) received score adjustments (either up or down) of < ± 1.5%. The median score adjustment (regardless of whether up or down) was 0.31 scale points (1.1%). The distribution of score adjustments suggested by the model are shown in Fig. 4.

Plot of Students’ score adjustments
The cut score for the test was 16.38 out of 27. Score adjustments had a minimal impact on students’ pass/fail categorization. In the observed (unadjusted) scores, 124 students (98.4%) passed the OSCE; in the adjusted scores 123 students (97.6%) of students passed. 1 student (0.8%) changed from pass to fail whilst no students changed classification from fail to pass.
Scores adjustments influenced students’ rank position within the OSCE. The largest increase in rank was 20 rank places (1.6 deciles), whilst the largest decrease in rank was − 44 rank positions (-3.5 deciles). Four students (3.2%) changed rank position by more than 3 deciles. Nineteen students (15.0%) increased their rank by at least 1 decile (i.e. > 12.6 rank places), whilst a further 15 students (11.9%) decreased their rank position by at least 1 decile. The median change in rank (regardless of whether rank increased or decreased) was 6 rank positions (0.48 deciles).
Discussion
Summary of findings
In this study we have again shown that VESCA procedures can be used to provide estimates of examiner-cohort effects in a distributed OSCE, this time comparing across different geographical locations for the first time. Examiner participation rates were lower than in previous studies, ranging from 31 to 62% by site. Results showed that examiner cohorts varied in their stringency / leniency with a 6.9% difference between estimates of the scores the highest and lowest examiner-cohorts would give to a student of the same ability. There was minimal overall difference between the stringency / leniency of examiners in each site (1.3%) but the apparent variation in stringency between groups of examiners was much greater in site 1 than in site 2. Adjusting students’ scores for these differences produced a substantial alteration for a subset of students, resulting in greater than 1 decile change in rank for 26.9% of students and a 3 decile change in rank position for 3.2% of students. By contrast, only 1 student (0.8%) changed their pass/fail categorization as a result of score adjustment.
Theoretical considerations
Taken at face value, the differing estimates of leniency / stringency shown by different-examiner cohorts in this study offer some challenge to the equivalence of the OSCE for students in different examiner-cohorts. Whilst the validity argument for an OSCE relies on an evidentiary chain which includes its blueprint, content, station design, scoring approach and faculty and simulated patient development efforts [25], few would argue that the group of examiners to which a student is allocated should influence their score. Moreover, the size of change in score and the change in rank position for some students would raise questions about the degree to which observed scores reflect their performance if, indeed, the score adjustments suggested by these data can be validated.
Notably, score adjustment produced very different impacts on students pass/fail categorization and on their rank. This is likely to be attributable to two factors: firstly, in this instance very few students were near to the pass/fail boundary, so despite many students receiving notable adjustments to their scores this did not influence their classification because their observed scores were sufficiently far from the cut score. Secondly, students’ scores were relatively tightly distributed, so these adjustments were sufficient to produce changes in rank which were sometimes substantial. Two points are theoretically important in relation to this. Firstly, whilst the impact on pass/fail categorization was limited in this instance, the same score adjustments would have had a substantial impact on pass/fail categorization in an OSCE with a higher observed (unadjusted) failure rate, such as was demonstrated in Yeates et al’ 2021 paper [11] and 76.0% [13], whilst examiners were aware that their scoring behaviour was not being directly scrutinized. Moreover, videoed students broadly represented the range of performances in the student cohort. Consequently, the impact of these limitations is expected to be small. Analysis relied on the equivalence of scores given to video and live performance. Our data and a range of prior findings support the equivalence of these scores.
Suggestions for future research
Future research, using simulation, should seek to determine to what extent score adjustments produced by VESCA more accurately represent students’ performances, and how a range of operational parameters (number of linking videos, examiner participation rates, range of students’ abilities) influence these estimates. Further research should explore more about how, when and why examiners will score videos in order to maximise engagement with the intervention.
Conclusions
This study has, for the first time, used VESCA to compare the influence of fully nested groups of examiners across different sites in a distributed OSCE. Whilst the findings suggest potentially substantial differences in stringency of different groups of examiners, more work is needed to determine the influence of examiner participation and other parameters on the estimates provided. VESCA appears to offer a feasible means to determine the stringency of examiners across different sites in distributed OSCEs which could importantly aid demonstration of equivalence as part of quality assurance work.
Data availability
The datasets generated and/or analysed during the current study are not publicly available due the limitations of the study’s ethical approvals but are available from the corresponding author on reasonable request.
References
Ginsburg S, Watling CJ, Schumacher DJ, Gingerich A, Hatala R, Numbers Encapsulate. Words elaborate: toward the best use of comments for Assessment and Feedback on Entrustment ratings. Acad Med. 2021;96(7S):81–6.
Newble D. Techniques for measuring clinical competence: objective structured clinical examinations. Med Educ. 2004;38:199–203.
Boursicot K, Kemp S, Wilkinson T, Findyartini A, Canning C, Cilliers F et al. Performance assessment: Consensus statement and recommendations from the 2020 Ottawa Conference. Med Teach [Internet]. 2021;43(1):58–67. https://doi.org/10.1080/0142159X.2020.1830052.
Norcini J, Anderson MB, Bollela V, Burch V, Costa MJ, Duvivier R et al. 2018 Consensus framework for good assessment. Med Teach [Internet]. 2018;0(0):1–8. Available from: https://www.tandfonline.com/doi/full/https://doi.org/10.1080/0142159X.2018.1500016.
Kane MT. Validating the interpretations and uses of Test scores. J Educ Meas. 2013;50(1):1–73.
Harden RM, Stevenson M, Downie WW, Wilson GM. Medical Education Assessment of Clinical competence using objective structured examination. Br Med J. 1975;1(February):447–51.
Valentine N, Durning S, Shanahan EM, Schuwirth L. Fairness in human judgement in assessment: a hermeneutic literature review and conceptual framework. Advances in Health Sciences Education [Internet]. 2020;26(2):713–38. https://doi.org/10.1007/s10459-020-10002-1.
Yeates P, Sebok-Syer SS, Hawks. Doves and Rasch decisions: Understanding the influence of different cycles of an OSCE on students’ scores using Many Facet Rasch Modeling. Med Teach [Internet]. 2017;39(1):92–9. Available from: https://www.tandfonline.com/doi/full/https://doi.org/10.1080/0142159X.2017.1248916.
Floreck LM, de Champlain AF. Assessing sources of score variability in a Multi-site Medical Performance Assessment: an application of hierarchical Linear modeling. Acad Med. 2001;76(10):93–5.
Sebok SS, Roy M, Klinger Da, de Champlain AF. Examiners and content and site: Oh My! A national organization’s investigation of score variation in large-scale performance assessments. Adv Health Sci Educ Theory Pract [Internet]. 2015 Aug 28 [cited 2014 Sep 16];20(3):581–94. Available from: http://www.ncbi.nlm.nih.gov/pubmed/25164266.
Yeates P, Cope N, Hawarden A, Bradshaw H, McCray G, Homer M. Develo** a video-based method to compare and adjust examiner effects in fully nested OSCEs. Med Educ [Internet]. 2019;53(3):250–63. https://doi.org/10.1111/medu.13783.
Yeates P, Moult A, Cope N, McCray G, ** procedures for video-based assessment in medical education. Med Teach [Internet]. 2020;42(11):1250–60. https://doi.org/10.1080/0142159X.2020.1801997.
Yeates P, Moult A, Cope N, McCray G, Fuller R, McKinley R. Determining influence, interaction and causality of contrast and sequence effects in objective structured clinical exams. Med Educ. 2022;56(3):292–302.
Yeates P, McCray G, Moult A, Cope N, Fuller R, McKinley R. Determining the influence of different linking patterns on the stability of students’ score adjustments produced using Video-based Examiner Score Comparison and Adjustment (VESCA). BMC Med Educ [Internet]. 2022;22(1):1–9. https://doi.org/10.1186/s12909-022-03115-1.
Lefroy J, Gay SP, Gibson S, Williams S, McKinley RK. Development and face validation of an instrument to assess and improve clinical consultation skills. Int J Clin Skills. 2011;5(2):115–25.
Limesurvey GmbH [Internet]. [cited 2022 Mar 1]. LimeSurvey: An Open Source survey tool. Available from: http://www.limesurvey.org.
Linacre JM. Facets computer program for many-facet Rasch measurement. Beaverton, Oregon: Winsteps.com; 2019.
Bland J, Altman D. Statistics notes: calculating correlation coefficients with repeated observations: part 1 - correlation within subjects. BMJ. 1995;310(6977):446.
Lehnert B, BlandAltmanLeh. Plots (Slightly Extended) Bland-Altman Plots. 2015.
Linacre JM, Rasch.Org website. 2002 [cited 2018 Jun 12]. p. 16:2, p878 What do Infit and Outfit, Mean-square and Standardized mean? Available from: https://www.rasch.org/rmt/rmt162f.htm.
R Core Team. R: A language and environment for statistical computing [Internet]. Vienna, Austria: R Foundation for Statistical Computing. 2021. Available from: https://www.r-project.org/.
Downing SM, Tekian A, Yudkowsky R. Procedures for establishing defensible Absolute passing scores on Performance examinations in Health professions Education procedures for establishing defensible Absolute passing scores on Performan. Teach Learn Med. 2006;18(1):50–7.
Raîche G. Critical eigenvalue sizes in standardized residual principal components analysis. Rasch Meas Trans. 2005;19(1):1012.
Downing SM. Validity: on meaningful interpretation of assessment data. Med Educ [Internet]. 2003;37(9):830–7. Available from: http://www.ncbi.nlm.nih.gov/pubmed/14506816.
Homer M. Pass/fail decisions and standards: the impact of differential examiner stringency on OSCE outcomes. Adv Health Sci Educ. 2022;457–73.
Bond T, Fox C. Applying the Rasch Model Fundamental Measurement in the Human Sciences. 2nd Editio. New York & London: Routledge; 2012.
Myford CM, Wolfe EW. Strengthening the ties that bind: improving the linking Network in sparsely connected rating designs. ETS Res Rep Ser. 2000;2000(1):i–34.
Wind SA, Engelhard G, Wesolowski B. Exploring the effects of Rater linking designs and Rater Fit on Achievement estimates within the Context of Music Performance assessments. Educational Assess. 2016;21(4):278–99.
Makrides A, Yeates P. Memory, credibility and insight: how video-based feedback promotes deeper reflection and learning in objective structured clinical exams. Med Teach. 2022;0(0):1–8.
Chen TC, Lin MC, Chiang YC, Monrouxe L, Chien SJ. Remote and onsite scoring of OSCEs using generalisability theory: a three-year cohort study. Med Teach. 2019;41(5):578–83.
Gormley GJ, Hodges BD, McNaughton N, Johnston JL. The show must go on? Patients, props and pedagogy in the theatre of the OSCE. Med Educ. 2016;50(12):1237–40.
Taylor CA, Gurnell M, Melville CR, Kluth DC, Johnson N, Wass V. Variation in passing standards for graduation-level knowledge items at UK medical schools. Med Educ [Internet]. 2017;51(6):612–20. https://doi.org/10.1111/medu.13240.
n der Vleuten CPM. The assessment of professional competence: Developments, research and practical implications. Advances in Health Sciences Education [Internet]. 1996;1(1):41–67. Available from: http://www.springerlink.com/index/10.1007/BF00596229.
Acknowledgements
We would like to thank the assessment team, clinical skills team and IT/AV teams at Keele University Faculty of Health and Medical Sciences for their help with conducting the study, in particular Kirsty Hartley, Sharon Simpson, Ang Coles, Jemma Stevenson-Tellwright, Dan Harvey and Steve Holt. We would like to thank all of the students, examiners and simulated patients who took part.
Funding
The study is funded through a National Institute for Health Research (NIHR) Clinician Scientist award held by the Principal Investigator, Peter Yeates. The study constitutes independent research and does not represent the views of the NIHR, the NHS or the department of health and social care.
Author information
Authors and Affiliations
Contributions
PY: substantial contribution to study conception, data collection, analysis.AM: substantial contribution to data collection, analysis.NC: substantial contribution to study conception, data collection.GM: substantial contribution to data analysis.SB: substantial contribution to study conception, data collection.DB: substantial contribution to study conception, data collection.RF: substantial contribution to study conception, analysis.RMcK: substantial contribution to study conception, analysis.All authors aided in critical revision of the manuscript and approved the final text.
Corresponding author
Ethics declarations
Ethical approval and consent to participate
This study received ethical approval from Keele University Research Ethics Committee, reference: MH-1901. All participants provided informed consent.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Yeates, P., Maluf, A., Cope, N. et al. Using video-based examiner score comparison and adjustment (VESCA) to compare the influence of examiners at different sites in a distributed objective structured clinical exam (OSCE). BMC Med Educ 23, 803 (2023). https://doi.org/10.1186/s12909-023-04774-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12909-023-04774-4