
Abstract
Traditional decomposition integration models decompose the original sequence into subsequences, which are then proportionally divided into training and testing periods for modeling. Decomposition may cause data aliasing, then the decomposed training period may contain part of the test period data. A more effective method of sample construction is sought in order to accurately validate the model prediction accuracy. Semi-stepwise decomposition (SSD), full stepwise decomposition (FSD), single model semi-stepwise decomposition (SMSSD), and single model full stepwise decomposition (SMFSD) techniques were used to create the samples. This study integrates Variational Mode Decomposition (VMD), African Vulture Optimization Algorithm (AVOA), and Least Squares Support Vector Machine (LSSVM) to construct a coupled rainfall prediction model. The influence of different VMD parameters α is examined, and the most suitable stepwise decomposition machine learning coupled model algorithm for various stations in the North China Plain is selected. The results reveal that SMFSD is relatively the most suitable tool for monthly precipitation forecasting in the North China Plain. Among the predictions for the five stations, the best overall performance is observed at Huairou Station (RMSE of 18.37 mm, NSE of 0.86, MRE of 107.2%) and **gxian Station (RMSE of 24.74 mm, NSE of 0.86, MRE of 51.71%), while Hekou Station exhibits the poorest performance (RMSE of 25.11 mm, NSE of 0.75, MRE of 173.75%).
Similar content being viewed by others
Introduction
Strong and frequent rainstorms have put human security and socioeconomic well-being in grave danger in recent times. Reliable rainfall process modeling is critical to water resource management. However, a multitude of intricate and unpredictable mechanisms impact the development of precipitation1. Process-driven and data-driven methodologies can be used to broadly classify the models of precipitation prediction now in use. Unlike process-driven models, data-driven models are exempt from taking into account the physical mechanisms underlying runoff generation2,3. Rather, they only use mathematical analysis of time-series data to determine the functional relationships between the variables that are input and output, which increases tractability4.
With the development of artificial intelligence, especially the application of machine learning techniques, new opportunities are provided to improve rainfall prediction methods5,6. Because it avoids quadratic programming problems, the SVM-based LSSVM model improves computational efficiency7,8. But because the parameters of an LSSVM greatly affect its predictive accuracy, some researchers have added optimization methods to LSSVM in order to find the best model parameters9,10. ** strategy to enhance population diversity, i.e., the two vultures with the first (optimal) and second (suboptimal) fitness values are grouped together, and the remaining (N-2) vultures begin to search for food around the top two24. The following is the iterative process of the AVOA algorithm:
Stage 1: Randomly initialise the population, and then select the best or second best individual for the next stage of optimisation according to the "roulette" rule. For the ith vulture in the population, its learning object is selected according to Eq. (1):
where \(L\) is a user-defined parameter located between (0, 1), which contributes to the increase of population diversity when \(L\) tends to 0; conversely, it accelerates population aggregation; and rand is a [0, 1] uniformly distributed random number.
Phase 2: Define the starvation rate to enable the transition between the algorithm development and exploration process. The starvation rate \(F\) increases as the iterative process advances to more likely facilitate the development process.
where, \(h\), \(z\) are uniformly distributed random numbers in [− 2, 2] and [− 1, 1], respectively; \(w\) is a user-defined parameter that controls the probability that the algorithm enters the exploration mode in the final stage; and \(iter\) is the current number of iterations as the algorithm proceeds.
Phase 3: Spatial exploration. The AVOA uses a user-defined parameter P1 to determine which exploration mode to enter, taking values between (0, 1).
where \(P(i + 1)\) is the updated position of the vulture; \(X\) is a [0, 2] uniformly distributed random number.
Phase 4: Local exploitation. The AVOA initiates the exploitation phase when the absolute value of the starvation rate \(\left| F \right| < 1\). Unlike the exploration phase this phase contains two types of subphases, and the initiation of the two subphases is demarcated by \(\left| F \right| = 0.5\)|.
Subphase 1 judgement condition: \(\left| F \right| \ge 0.5\). In this phase, the position updating method mimics the characteristics of the vulture's spiral flight and is executed according to Eqs. (6) to (9):
where the parameter \(P_{2}\) takes a value between (0, 1).
Sub-stage 2 judgement condition: \(\left| F \right| < 0.5\). This stage is executed according to Eqs. (10)–(12):
Similarly, the parameter \(P_{3}\) takes values between (0, 1).
Variational mode decomposition (VMD)
VMD is a commonly used adaptive and fully recursive signal sequence processing method25, which firstly requires the number of decompositions, K, and the quadratic penalty factor, α, and then iteratively searches for the optimal centre frequency and finite bandwidth corresponding to the optimal solution of the model, which is able to adaptively match the respective intrinsic mode function (IMF) and achieve effective separation of the IMF. IMF, then iteratively search for the optimal centre frequency and finite bandwidth corresponding to the optimal solution of the model that can adaptively match each IMF and achieve effective separation of IMFs26.
where \(A_{K} (t)\) is the instantaneous amplitude function; \(\varphi_{K} (t)\) is the non-decreasing instantaneous phase function. Then \(\omega_{K} (t)\) = \(\varphi^{\prime}_{K} (t) \ge 0\), defining \(\omega_{K} (t)\) as the instantaneous frequency of \(u_{K} (t)\).
Least squares support vector machine (LSSVM)
LSSVM is an improved algorithm based on SVM27. The classical SVM is based on the need to minimise the structural risk minimisation principle by introducing the associated loss function and relaxation variables, and the fitting problem is transformed into solving a quadratic optimisation problem. The improvement made by the LSSVM is that the inequality constraints in this optimisation problem are converted into equality constraints, and the following optimal objective function is constructed:
where \(C\) is the regularisation parameter and \(\delta_{i}\) is the ith relaxation variable. By introducing the Lagrange factor \(\alpha_{i}\), the Lagrange function \(L\) can be written as:
can be obtained by partial differentiation for \(w\), \(b\), \(\delta\) and \(\alpha\), respectively:
where \(E = (1,1, \cdots ,1)^{T}\),\(Z = \left[ {\phi (X_{1} ),\phi (X_{2} ), \cdots ,\phi (X_{n} )} \right]^{T}\), \(A = (\alpha_{1} ,\alpha_{2} , \cdots \alpha_{n} )^{T}\),\(Y = (y_{1} ,y_{2} , \cdots y_{n} )^{T}\), and \(I\) is the unit matrix. The kernel function \(K(x,x_{i} ) \le \phi (x)\), \(\phi (x_{i} ) >\) is chosen to reduce the computational effort, then the regression equation of the LSSVM model is finally determined as:
Monthly precipitation prediction model
Prediction steps
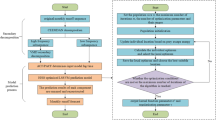
The construction steps of the monthly precipitation prediction model based on the AVOA and VMD are outlined as follows:
Step 1: Utilize the VMD algorithm to decompose the precipitation sequence based on different stepwise decomposition sample construction methods, resulting in K modal components.
Step 2: To precisely describe the preceding influencing factors for each component, determine the corresponding lag months (lagk) for the kth modal component based on AutoCorrelation Function and Partial AutoCorrelation Function. Taking Huairou Station as an example, six modal components are obtained with lag values of [2, 7, 4, 6, 6, 3] for each component.
Step 3: Generate training and testing samples based on different stepwise decomposition sample construction methods, with a training sample ratio of 0.8 and the remaining as testing samples. Normalize the samples according to the training set.
Step 4: The training samples are fed into the prediction model for training.
Step 5: The accuracy and performance of the model is evaluated through evaluation metrics. The flowchart of the monthly precipitation prediction model is shown in Fig. 1.

Construction steps of the monthly precipitation prediction model based on AVOA algorithm and VMD stepwise decomposition.
Evaluation metrics
Model error evaluation indexes include the root mean square error (RMSE), Nash efficiency coefficient (NSE), and mean relative error (MRE). The lower the error, the higher the prediction accuracy; the consistency index (IA), which ranges from 0 to 1, reflects the generalization ability; the closer it is to 1, the better the model prediction performance; and the U-statistic (U1), which evaluates the prediction ability, the closer it is to 0. The model's predictive power increases with the value's proximity to zero. The following is the calculating formula:
In these formulas, P represents the actual values, P* denotes the model-predicted values, and \(\overline{P}\) is the mean of the actual value sequence.
Case analysis
Data source
The North China Plain covers a total area of 300,000 km2, belonging to the continental monsoon climate zone, with obvious changes in the four seasons and an average annual precipitation of 500–900 mm. Alluvial plains are characterized by comparatively flat topography, with the majority of elevations being below 50 m28. One of China's most significant bases for grain production, the North China Plain is crucial to the country's food security. Making timely and efficient judgments about agricultural productivity and water resource management can be aided by predictive rainfall simulation in this area29.
Given the climatic variations across the North China Plain, the study focuses on five meteorological stations as research objects: Huairou (116°38′E, 40°22′N), Zhengding (114°34′E, 38°9′N), **gxian (116°17′E, 37°42′N), Hekou (118°32′E, 37°53′N), and Jiaozuo (113°16′E, 35°14′N). The distribution of these locations is illustrated in Fig. 2. The map in Fig. 2 was created using the ArcGIS software version10.8, available at http://www.esri.com/software/arcgis.

Distribution map of the study sites.
The North China Plain's national meteorological stations provided the precipitation data used in the meteorological analysis (https://data.cma.cn/). For the estuary stations, precipitation data spanning January 1993 to December 2018 is available. Precipitation data from January 1973 to December 2018 are available for the remaining locations.
Sample construction
The ratio of training and testing samples for the model was taken as 4:1. The training period was from August 1972 to July 2009 and the testing period was from August 2009 to December 2018, except for the estuary station (training period: July 1992 to July 2013; testing period: August 2013 to December 2018).
Constructing correct and effective training and test samples is the focus of accurate prediction of precipitation. Commonly employed sample construction methods conducive to practical application include the "Semi-stepwise Decomposition (SSD)" sample technique30, the "Fully Stepwise Decomposition (FSD)" sample technique31, the "Single-model Semi-stepwise Decomposition (SMSSD)" sample technique32, and the "Single-model Fully Stepwise Decomposition (SMFSD)" sample technique20. The first two methods require the simultaneous construction of K (where K represents the number of modal components) models. In contrast, the latter two methods only necessitate a single model to obtain the final prediction result, thereby offering a higher operational speed.
Using VMD and the four sampling strategies, the rainfall data were broken down into subsequences, which were then fed into the LSSVM model to be simulated. Based on rainfall data from five locations in the North China Plain, a comparative analysis was carried out. As seen in Fig. 3, the radial line depicts the correlation coefficient, the horizontal and vertical axes reflect the standard deviation, and the scattered spots in the picture represent various sampling techniques. It is evident that the five stations perform better when using the stepwise decomposition approaches (SMFSD and SMSSD), and the predicted outcomes of these sampling strategies are most similar to the observed values with the least amount of standard deviation. Among the four sample approaches, the majority of correlation coefficients fall between 0.8 and 0.95.

Taylor distribution for different sampling methods.
Suitability of parameter α
The penalty factor α, as a crucial parameter for precipitation sequence denoising, plays an equally significant role in forecasting accuracy. Three scenarios with penalty factor α set to 100, 1000, and 2000 were considered. Since only the testing period results can reflect actual predictive capabilities, Friedman tests were conducted for a total of 12 composite models, encompassing the three α values. The results, as presented in Table 1, indicate that the average ranks for the models corresponding to α values 100, 1000, and 2000 are 13.83, 12.70, and 11.55, respectively. Larger α values within the 2000 range are more conducive to precipitation forecasting.
The composite model based on SMFSD technique consistently maintains its top two positions, continuing to uphold its superiority over other decomposition techniques. In contrast, the AVOA-LSSVM model ranks third. Therefore, the utilization of inappropriate decomposition techniques in monthly precipitation forecasting may result in decreased accuracy. The SMFSD technique emerges as a more suitable sample construction method for predicting monthly precipitation in the North China Plain.
Suitability across different stations
The above study focuses on the overall evaluation of the performance of stepwise decomposition techniques in the North China Plain. However, due to the vast geographical range leading to differences in geographical and climatic conditions, the adaptability of each model may vary across different stations. The average predictive success rate of each model is used to determine the optimal applicable model for each station. According to the Hydrological Information Forecast Specification (GB/T 22482-2008), the permissible error is determined based on a 20% range of the measured values during the same period over multiple years.
According to this requirement, the average success rate of each model at each station is calculated for each month. Similarly, Friedman tests are used to rank the models. Table 2 records the optimal models for each station, along with their success rates in each month and the p-values from the Friedman test. Based on a confidence level of 0.05 and the p-values, the model ranking results are only significantly different for Huairou and Zhengding stations. The optimal monthly precipitation prediction model for Zhengding station is SMFSD-AVOA-LSSVM with α = 100, while for Huairou station, it is SMFSD-AVOA-LSSVM with α = 1000. Using an 80% threshold as the preferred criterion to determine the advantageous months for each station in prediction work, the results are as follows: June for Huairou station (87.8%), February (90.0%) and October (86.7%) for Hekou station, July for Jiaozuo station (88.9%), May (88.9%) and August (90.0%) for Zhengding station. At the **gxian station, the months of May (76.7%) and September (79.0%) are closer to the preferred threshold. In terms of the average success rate, only Zhengding station exceeds 60%. The average success rate at Hekou station is the lowest, only 48.8%, possibly due to insufficient learning caused by limited historical data. Table 2 provides the test results for the optimal models at each station, and Fig. 4 illustrates the training and prediction effects at each station. The best predictive performance in this study is observed at Huairou and **gxian stations, while Hekou station exhibits the poorest predictive performance. Additionally, the prediction of precipitation sequences at each station performs well in the low-value range, while the predictive ability near extreme values requires further.

Optimal prediction results for each station in the North China Plain.
Comparison of simulation results
While Fig. 4 shows the comparison between the prediction effect and the actual rainfall during the test period at each site, Table 3 provides the findings of the evaluation indexes of the ideal models at each site. Based on the error indicator results used to assess the model's prediction accuracy, the NSE ranges from 0.73 to 0.86, with Huairou and **gxian having the best NSE; the RMSE of SMFSD-AVOA-LSSVM is less than 25 mm, with the lowest value being 11.62 mm in Jiaozuo. The IA results show that generalization ability is a key metric for assessing model prediction accuracy; the closer the generalization ability is to 1, the better. All five of the North China Plain stations have IAs better than 0.96, demonstrating the good prediction performance and good generalization capacity of SMFSD-AVOA-LSSVM. U1 is used to measure the prediction abilities of the model; the closer the model is to 0, the better. The three with the finest prediction skill and the least U1 scores are Huairou, **gxian, and Zhengding. In this study, Huairou and **gxian stations have the best prediction performance when combining the least error, optimal generalization ability, and prediction ability.
As shown in Fig. 4, the predicted precipitation series curves for each station are better predicted in the low value range, while the prediction ability near the extremes needs to be strengthened.
Conclusion
The ability of SSD, FSD, SMSSD, and SMFSD to provide support for actual monthly precipitation forecasts was further examined through the combined AVOA-LSSVM model.
-
1.
Considering the differences in sample construction techniques and the impact of different VMD parameters α, the optimal model identified is the SMFSD-AVOA-LSSVM with α = 1000, suitable for Huairou and **gxian stations, with an average success rate of 59.8% and 56.7%, respectively. The model suitable for the monthly precipitation forecast at the Zengding station is the SMFSD-AVOA-LSSVM with α = 100, achieving an average success rate of 61.2%. For the Hekou station, the model best suited is the SMFSD-AVOA-LSSVM with α = 1000, yielding an average success rate of 48.8%. The model suitable for the monthly precipitation forecast at the Jiaozuo station is the SMFSD-AVOA-LSSVM with α = 2000, resulting in an average success rate of 52.1%.
-
2.
The SMFSD sample technique stands out as the most suitable tool for monthly precipitation forecasting in the North China Plain. Combining error and validation assessment results, the overall best predictive performance is observed at Huairou station (RMSE of 18.37mm, NSE of 0.86, MRE of 107.2%, IA = 0.97, U1 = 0.11) and **gxian station (RMSE of 24.74mm, NSE of 0.86, MRE of 51.71%, IA = 0.98, U1 = 0.11), while Hekou station exhibits the poorest overall performance (RMSE of 25.11mm, NSE of 0.75, MRE of 173.75%, IA = 0.96, U1 = 0.15).
-
3.
SMFSD uses a single model in each step of the decomposition for a comprehensive decomposition. This approach ensures that global information is preserved at each step, allowing consistency and completeness of data features across all steps. This avoids loss of information and improves the overall performance of the forecasting model. SMFSD combines the African Vulture Optimisation Algorithm (AVOA) and Least Squares Support Vector Machines (LSSVM) to optimise the model parameters at each decomposition step, allowing the model to better fit the time series data.
The focus of this study is on rainfall prediction in the North China Plain, which may limit the applicability of the results to other regions with different climatic characteristics. Although the study evaluated model performance using metrics such as RMSE, NSE, IA and U1, it may lack a comprehensive assessment of forecast uncertainty, robustness under extreme conditions or comparison with other modelling approaches. This paper only compares the variability of one decomposition model, VMD, across different sampling approaches, and does not compare other decomposition models, which is methodologically deficient, and should be further explored in the future for the differences between different decomposition models in terms of stepwise decomposition sampling approaches.
Data availability
Data and materials are available from the corresponding author upon request.
References
Devia, G. K., Ganasri, B. P. & Dwarakish, G. S. A review on hydrological models. Aquat. Procedia. 4, 1001–1007. https://doi.org/10.1016/j.aqpro.2015.02.126 (2015).
Pérez-Alarcón, A., Garcia-Cortes, D., Fernández-Alvarez, J. C. & Martínez-González, Y. Improving monthly rainfall forecast in a watershed by combining neural networks and autoregressive models. Environ. Process. 9, 53. https://doi.org/10.1007/s40710-022-00602-x (2022).
Salaeh, N. et al. Long-short term memory technique for monthly rainfall prediction in Thale sap Songkhla river basin, Thailand. Symmetry. 14, 1599. https://doi.org/10.3390/sym14081599 (2022).
Tao, L. Z., He, X. G. & Yang, D. R. A multiscale long short-term memory model with attention mechanism for improving monthly precipitation prediction. J. Hydrol. 602, 126815. https://doi.org/10.1016/j.jhydrol.2021.126815 (2021).
Wei, M. & You, X. Y. Monthly rainfall forecasting by a hybrid neural network of discrete wavelet transformation and deep learning. Water Resour. Manag. 36(11), 4003–4018 (2022).
Zhao, J. W., Nie, G. Z. & Wen, Y. H. Monthly precipitation prediction in Luoyang city based on EEMD-LSTM-ARIMA model. Water Sci. Technol. 87(1), 318–335 (2022).
Li, G., Chang, W. & Yang, H. A novel combined prediction model for monthly mean precipitation with error correction strategy. IEEE Access. 81(1), 141445 (2020).
Nourani, V. & Farboudfam, N. Rainfall time series disaggregation in mountainous regions using hybrid wavelet-artificial intelligence methods. Environ. Res. 168, 306–318 (2019).
Zhao, F. Z. et al. Short-term load forecasting for distribution transformer based on VMD-BA-LSSVM algorithm. Trans. Chin. Soc. Agric. Eng. 35(14), 190–197 (2019).
Meng, J. G. Model of medium-long-term precipitation forecasting in arid areas based on PSO and LSSVM methods. J. Yangtze River Sci. Res. Inst. 33(10), 36–40 (2016).
**ang, L., Deng, Z. & Hu, A. Forecasting short-term wind speed based on IEWT-LSSVM model optimized by bird swarm algorithm. IEEE Access. 7, 59333–59345 (2019).
Tripathy, N. S., Kundu, S. & Pradhan, A. Optimal design of a BLDC motor using African vulture optimization algorithm. Adv. Electr. Eng. Electron. Energy 2024, 7100499 (2024).
Mishra, S. & Shaik, G. A. Solving bi-objective economic-emission load dispatch of diesel-wind-solar microgrid using African vulture optimization algorithm. Heliyon 10(3), e24993–e24993 (2024).
Zhang, X. Q., Zheng, Z. W., Li, H. Y., Liu, F. & Yin, Q. W. Deep learning precipitation prediction models combined with feature analysis. Environ. Sci. Pollut. R. 11, 14. https://doi.org/10.1007/s11356-023-30833-w (2023).
Tosunoğlu, F. & Kaplan, N. H. Determination of trends and dominant modes in 7-day annual minimum flows: Additive wavelet transform-based approach. J. Hydrol. Eng. 23(12), 05018022. https://doi.org/10.1061/(ASCE)HE.1943-5584.0001710 (2018).
Liu, Z., Zhou, P., Chen, G. & Guo, L. Evaluating a coupled discrete wavelet transform and support vector regression for daily and monthly streamflow forecasting. J. Hydrol. 519, 2822–2831. https://doi.org/10.1016/j.jhydrol.2014.06.050 (2014).
Fan, M., Xu, J., Chen, Y. & Li, W. Modeling streamflow driven by climate change in data-scarce mountainous basins. Sci. Total Environ. 790, 1.48256. https://doi.org/10.1016/j.scitotenv.2021.148256 (2021).
Rezaie-Balf, M., Naganna, S. R., Kisi, O. & El-Shafie, A. Enhancing streamflow forecasting using the augmenting ensemble procedure coupled machine learning models: Case study of Aswan High Dam. Hydrol. Sci. J. 64(13), 1629–1646. https://doi.org/10.1080/02626667.2019.1661417 (2019).
Li, B. J., Sun, G. L., Liu, Y., Wang, W. C. & Huang, X. D. Monthly runoff forecasting using variational mode decomposition coupled with gray wolf optimizer-based long short-term memory neural networks. Water Resour. Manag. 36(6), 2095–2115 (2022).
He, M. et al. Can sampling techniques improve the performance of decomposition-based hydrological prediction models? Exploration of some comparative experiments. Appl. Water Sci. 12(8), 175 (2022).
Du, K., Zhao, Y. & Lei, J. The incorrect usage of singular spectral analysis and discrete wavelet transform in hybrid models to predict hydrological time series. J. Hydrol. 552(9), 44–51 (2017).
Seo, Y., Kim, S. & Singh, V. P. Machine learning models coupled with variational mode decomposition: A new approach for modeling daily rainfall-runoff. Atmosphere. 9(7), 251 (2018).
Zhang, X., Peng, Y., Zhang, C. & Wang, B. Are hybrid models integrated with data preprocessing techniques suitable for monthly streamflow forecasting? Some experiment evidences. J. Hydrol. 530(11), 137–152 (2015).
Benyamin, A., Soleimanian, F. G. & Seyedali, M. African vultures optimization algorithm: A new nature-inspired metaheuristic algorithm for global optimization problems. Comput. Ind. Eng. 158, 107408. https://doi.org/10.1016/j.cie.2021.107408 (2021).
Slingo, J. & Palmer, T. Uncertainty in weather and climate prediction. Philos. Trans. R. Soc. A. 369(19), 4751–4767. https://doi.org/10.1098/rsta.2011.0161 (2011).
Dragomiretskiy, K. & Zosso, D. Variational mode decomposition. IEEE Trans. Signal Proces. 62(3), 531–544. https://doi.org/10.1109/TSP.2013.2288675 (2014).
Suykens, J. & Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 9(3), 293–300. https://doi.org/10.1023/A:1018628609742 (1999).
Xu, P., Yang, Y. & Gao, W. Comprehensive the seasonal characterization of atmospheric submicron particles at urban sites in the North China Plain. Atmos. Res. 2024(304), 107388 (2024).
Liang, J., Zhao, Y. & Chen, L. Soil inorganic carbon storage and spatial distribution in irrigated farmland on the North China Plain. Geoderma. 445, 116887 (2024).
Karthikeyan, L. & Kumar, N. D. Predictability of nonstationary time series using wavelet and EMD based ARMA models. J. Hydrol. 502(10), 103–119 (2013).
Fang, W. et al. Examining the applicability of different sampling techniques in the development of decomposition-based streamflow forecasting models. J. Hydrol. 568, 534–550 (2018).
Zuo, G. G., Luo, J. G., Wang, N., Lian, Y. & He, X. X. Two-stage variational mode decomposition and support vector regression for streamflow forecasting. Hydrol. Earth Syst. Sci. 24(11), 5491–5518 (2020).
Acknowledgements
This manuscript was supported by the Innovation Fund for Doctoral Students of North China University of Water Resources and Electric Power. The grant number is NCWUBC202303.
Author information
Authors and Affiliations
Contributions
Zhiwen Zheng: Methodology, Visualization, Writing-Original draft; **anqi Zhang: Supervision, Writing-Reviewing and Editing; Qiuwen Yin: Data curation, Investigation; Fang Liu: Methodology, Software; He Ren: Validation, Visualization; Ruichao Zhao: Conceptualization, Data Curation, Supervision.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zheng, Z., Zhang, X., Yin, Q. et al. A novel optimization rainfall coupling model based on stepwise decomposition technique. Sci Rep 14, 15617 (2024). https://doi.org/10.1038/s41598-024-66663-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-66663-0
- Springer Nature Limited