
Abstract
Although the value of adding AI as a surrogate second reader in various scenarios has been investigated, it is unknown whether implementing an AI tool within double reading practice would capture additional subtle cancers missed by both radiologists who independently assessed the mammograms. This paper assesses the effectiveness of two state-of-the-art Artificial Intelligence (AI) models in detecting retrospectively-identified missed cancers within a screening program employing double reading practices. The study also explores the agreement between AI and radiologists in locating the lesions, considering various levels of concordance among the radiologists in locating the lesions. The Globally-aware Multiple Instance Classifier (GMIC) and Global–Local Activation Maps (GLAM) models were fine-tuned for our dataset. We evaluated the sensitivity of both models on missed cancers retrospectively identified by a panel of three radiologists who reviewed prior examinations of 729 cancer cases detected in a screening program with double reading practice. Two of these experts annotated the lesions, and based on their concordance levels, cases were categorized as 'almost perfect,' 'substantial,' 'moderate,' and 'poor.' We employed Similarity or Histogram Intersection (SIM) and Kullback–Leibler Divergence (KLD) metrics to compare saliency maps of malignant cases from the AI model with annotations from radiologists in each category. In total, 24.82% of cancers were labeled as “missed.” The performance of GMIC and GLAM on the missed cancer cases was 82.98% and 79.79%, respectively, while for the true screen-detected cancers, the performances were 89.54% and 87.25%, respectively (p-values for the difference in sensitivity < 0.05). As anticipated, SIM and KLD from saliency maps were best in ‘almost perfect,’ followed by ‘substantial,’ ‘moderate,’ and ‘poor.’ Both GMIC and GLAM (p-values < 0.05) exhibited greater sensitivity at higher concordance. Even in a screening program with independent double reading, adding AI could potentially identify missed cancers. However, the challenging-to-locate lesions for radiologists impose a similar challenge for AI.
Similar content being viewed by others


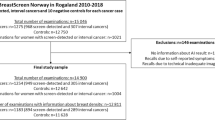
Introduction
Breast cancer is the most common cancer among women, with approximately 2.3 million new cases diagnosed worldwide in 2020, and one of the leading causes of cancer deaths, with an estimated 685,000 deaths per year1. The early detection of breast cancer can help to improve survival rates and treatment choices, with the five-year survival rate ranging from 90% survival for breast cancer diagnosed at Stage 1, to 35% for Stage 42. Mammography is a mainstream breast screening imaging technique for cancer diagnosis worldwide. A screening mammogram generally consists of x-ray imaging with 2 standard views of each breast: a mediolateral oblique (MLO) view taken with compression from the lateral side of the breast with an angled tube and a craniocaudal (CC) view taken with compression from superior to inferior with a straight tube. In the screening scenario through the national program BreastScreen Australia (BSA), there are two possible pathways. Women may be recalled for further imaging or examinations if there is suspicion of a cancer. For cases where the radiological interpretation is that no cancer is present, women will generally receive a recommendation to ‘return to screening’ at a defined interval, usually every two years. For women who are recalled, additional tests such as further X-ray imaging, ultrasound and biopsy may be required through an assessment clinic. A doctor will explain the examination results and follow-up procedures for positive results.
Interpretation of the screening mammography is a challenging task. A recent large-scale study, which included 418,041 women and 110 radiologists, showed that overall sensitivity of radiologists was 73% which means about 27% of cancers were missed or not acted on3. Although these radiologists interpreted more than 5000 annual screening mammograms and were considered high-volume screen readers, they still exhibited relatively low sensitivity. When double reading and consensus discussion is practiced, the overall sensitivity of the entire process reaches 85%3. Although some diagnostic errors are inevitable when perceptual tasks are practised, the error rates remain unacceptably high. As a technique to mitigate these errors, various computerized tools have been developed over the past decades to assist radiologists with mixed results and clinical uptake.
Artificial Intelligence (AI) has been widely used in visual object detection and/or recognition, providing promising results in the last decade4,5,6,7,8,9. The application of AI with deep learning in medical imaging analysis for cancer diagnosis has attracted strong interest from researchers, and practitioners in radiology. High quality medical images with accurate annotations are required to train a reliable and effective AI model for cancer diagnosis. Training AI models for clinical use also requires large datasets. Once trained, these models can potentially alleviate workload pressures on radiologists/physicians and improve cancer diagnosis efficiency. AI has been deployed for medical image analysis in abnormal lesion detection in the lung10, liver11, brain12, and breast13,14. A recent meta-analysis15 concluded that standalone AI performed as well as or better than radiologists in screening digital mammography.
Retrospective studies have suggested that AI tools can assist radiologists in reducing the number of missed cancers16. In cases where mammographic examinations undergo double reading practices, with two readers independently interpreting the images, such as with BSA, the incidence of missed cancers substantially decreases. However, based on these studies, it remains unknown whether AI can help identify subtle cancers beyond what is detected by two radiologists. There is only a single prospective study17 that explored triple reading by two radiologists plus AI in the context of Swedish breast cancer screening. Based on the cancer detection rate, the study concluded that triple reading was deemed superior to double reading with two radiologists. However, no previous study has compared AI's sensitivity on a cohort of missed cancers from a double reading scenario against its performance for true screen-detected cancers. It is unknown whether these cases pose more significant challenges for AI and if AI tools’ sensitivity values are significantly for these missed cases. Further investigation is needed to fully understand the capabilities of AI tools in the double reading setting and their potential to enhance program’s sensitivity. Particularly, if AI tools are intended to be used as part of the current practice without major changes (i.e., replacing one of the readers with AI), the added benefit of AI tools in double reading practice should be thoroughly investigated.
In addition to providing a diagnosis for a mammographic examination at the case level, many AI tools offer a saliency map or annotated image that aids radiologists in identifying and localizing suspicious areas or lesions detected by the AI tools. These annotated images or maps can also assist radiologists in reporting important characteristics of the lesion, such as shape, margin, and tumor size on mammograms18. However, even experienced radiologists may differ in their interpretation of lesion locations. It remains unclear whether lesions that are challenging to annotate for human observers are also difficult for AI tools to localize and detect. Addressing this question would provide a better understanding of the potential applications of AI in this context to reduce inter-reader variability.
This paper investigates the performance of two state-of-the-art AI models, Globally-aware Multiple Instance Classifier (GMIC)13 and Global–Local Activation Maps (GLAM)14. The main objectives of this study are as follows: (1) to assess whether these AI tools can identify retrospectively-identified missed cancers in a screening with double-reader practice and determine if these missed cancers pose a greater challenge for the AI tools in terms of detection; (2) to explore the concordance between radiologists in annotating lesion locations and the agreement between radiologists' annotations and the saliency maps generated by AI; and (3) to investigate whether lesions that are challenging to annotate are also difficult for the AI to detect. We compared the saliency maps from GLAM and GMIC with annotations from two radiologists in four concordance levels using two most common metrics: similarity or histogram intersection (SIM) and Kullback–Leibler divergence (KLD)19.
Transfer learning of the two AI models was conducted on 1712 mammographic cases (856 proven cancer and 856 normal or benign cases) derived from an Australian clinical research database linked to BreastScreen Australia. The cases were collected from multiple screening centers, from diverse cultural and ethnic populations and with different imaging vendors. The application of transfer learning of these two AI models on our image sets was also tested and an optimal protocol was developed. Transfer learning29 with a learning rate of 10−5. The loss function used the binary cross-entropy30. Both the width and the height of the global saliency map were set as 256. Setting the number K of patches from the global saliency map for local module was relatively complex because the classification performance improved with an increase in K but fluctuated when K > 3. Thus, K was set as 3 in this study.
For the transfer learning of GLAM model, the processes of resizing, crop** and flip** images were similar to GMIC model. The transfer learning model of GLAM also used Adam optimization algorithm30 with a learning rate of 10−5 and the binary cross-entropy loss function30. Both the width and the height of the global saliency map were set as 512. The model fed mammographic images into a ResNet-22 network and returned 256 intermediate feature maps with 46 × 30 size. The larger number of patches selected for the local module improve the classification performance for GLAM model. Therefore, to balance the computational time, the number of patches was set as 6.
Evaluation metrics
Specificity and sensitivity metric
Specificity and sensitivity metrics were used to evaluate the performance of the AI models with and without transfer learning (the pre-trained vs transfer learning modes). We also evaluated the sensitivity of the two AI models on ‘missed’ cancers, ‘prior-vis’ and ‘prior-invis’ cancers among four concordance levels. Two common metrics (SIM and KLD) were used to compare the saliency maps of the two AI methods and the two radiologists’ annotations.
Similarity or histogram intersection metric
Similarity or Histogram Intersection (SIM)7a,c) encompassed more of the overlap** area and thus lead to more accurate results. For the GLAM with transfer learning in Fig. 7a, the AI was able to detect the same lesion area as seen within the green rectangle (i.e., annotation from Radiologist B), which was missed by GLAM only without transfer learning.
The lesion sensitivity of GLAM without and with transfer learning on the Dataset 2 was 71.2% and 86.5%, respectively. The lesion sensitivity of GMIC without and with transfer learning on the Dataset 2 was 72.3% and 89.7%, respectively. Both the GLAM and GMIC with transfer learning outperformed the AI models without transfer learning in correctly identifying the location of lesions.
Sensitivity of GLAM and GMIC models on missed cases
For “missed” cases, the GMIC model after transfer learning had a sensitivity of 82.98% while its sensitivity for the other two categories was 89.54% (p-value for the difference in sensitivity among three categories: 0.017). The GLAM model, transferred to our dataset, exhibited a sensitivity of 79.79% on “Missed” cases and a sensitivity of 87.25% on the remaining cases (p-value for the difference in among three categories: 0.006). After applying post-hoc pairwise comparison tests, we found significant differences in sensitivity between 'missed' and 'prior-vis' cancers, 'missed' and 'prior-invis' cancers, as well as 'prior-vis' and 'prior-invis' cancers for both the GLAM model with transfer learning (p-values < 0.01) and the GMIC model with transfer learning, with and without transfer learning (p-values < 0.01). The performance of the AI models was also evaluated in terms of sensitivity on mammograms with different groups of cancer sizes. The ANOVA test was conducted for statistical analysis of the AI models across different size groups of “prio-vis” and “prior-invis” groups. The sensitivity of GMIC models on Groups T1, T2 and T3 was 0.882, 0.928, and 0.947, respectively. The GMIC model (p-values < 0.05) demonstrated significant difference in sensitivity between each group of cancer sizes. The sensitivity of GLAM models on Groups T1, T2 and T3 was 0.851, 0.894, and 0.923, respectively. Similarly, GLAM (p-values < 0.05) demonstrated significant difference in sensitivity between each group. However, the sensitivity values of Group T1 were still higher than the sensitivity values observed for the “missed” category.
As stated, all cases in Dataset 1 were also included in Dataset 2 for concordance analysis. Table 1 shows the sensitivity of GMIC models with and without transfer learning for three categories of cancers: ‘missed’ cancers, ‘prior-vis’ cancers and ‘prior-invis’ cancers across four concordance levels in the dataset. As anticipated, the GMIC model with transfer learning provided the highest sensitivity of 94.1% in the ‘prior-vis’ group in the ‘almost perfect’ concordance level. Similarly, the sensitivity for the GLAM model with and without transfer learning was also shown in Table 1. The GMIC model outperformed the GLAM model in terms of the sensitivity in each of three categories of cancers. There were significant differences (p-values < 0.01) among four concordance levels in each cancer categories between the pre-trained and transfer learning modes of the two AI models.
Comparison on concordance classifications
As shown in Table 2, we compared the SIM and KLD between each saliency map of GLAM and GMIC with pre-trained mode in four interpretation levels of radiologists’ agreement on 856 abnormal mammograms, respectively. SIM between saliency maps of GLAM and GMIC was highest in ‘almost perfect’ (0.932), followed by ‘substantial’ (0.927), ‘moderate’ (0.912) and ‘poor’ (0.899). KLD between saliency maps of GLAM and GMIC was lowest in ‘almost perfect’ (0.153), followed by ‘substantial’ (0.166), ‘moderate’ (0.177) and ‘poor’ (0.190).
As shown in Table 2, we also compared the SIM and KLD between the saliency maps of two AI methods with transfer learning mode on our dataset. The SIM between the saliency maps of the two models increased from 0.932 to 0.961 with transfer learning in the almost perfect category. The SIM values for two models with transfer learning also increased for all other concordance categories. KLD between saliency maps of two models decreased from 0.153 to 0.097 for two models with transfer learning in the ‘almost perfect’ category, with a similar trend in other categories.
Specificity and sensitivity of GLAM and GMIC models on dataset 2
Table 3 shows the sensitivity of GLAM and GMIC models with and without transfer learning on four concordance levels in the image dataset. The pre-trained GLAM and GMIC models had the highest sensitivity of 82.4% and 83.7% in the ‘almost perfect’ cases, followed by the ‘substantial’, ‘moderate’, and ‘poor’ levels. Similarly, the transfer learning GLAM and GMIC models had the highest sensitivity of 93.2% and 95.5% in the ‘almost perfect’, followed by the ‘substantial’, ‘moderate’, and ‘poor’ levels. The GLAM and GMIC models had a specificity of 84.78% and 86.50%, which increased to 94.43% and 96.50% after transfer learning process. Applying an ANOVA test, both the pre-trained GLAM (p-value = 0.029) and GMIC (p-value = 0.014) models had statistically significant difference of sensitivity among four concordance levels. Similarly, both the transfer learning of GLAM (p-value = 0.021) and GMIC (p-value = 0.038) models showed statistically significant difference of sensitivity among four concordance levels. The GLAM and GMIC models with transfer learning demonstrated statistically significant improvement compared with pre-trained mode with an average sensitivity of 11.03% (p-value = 0.014) and 12.55% (p-value = 0.009) respectively among four concordance levels.
Discussion
This study assessed the potential of AI tools to identify missed cancers retrospectively found in a dataset from a screening program with a double-reading practice, where each examination was independently interpreted by two readers. Our findings suggest that triple reading, involving two radiologists plus AI, could enhance the sensitivity of screening programs with two independent double readings. However, the results supported the need for further fine-tuning of the model when translating it from one setting with certain mammography machines and populations to another. Transfer learning resulted in significant improvements in both sensitivity and specificity values.
We also evaluated and compared the diagnostic accuracy of two AI breast cancer detection models developed for a mammogram database with different agreement levels of radiologists’ annotations (i.e., concordance). These four concordance levels also served as a metric indicating the difficulty of the cases. As anticipated, the results indicated that the stronger concordance between radiologists’ annotations, the higher the performance of GLAM and GMIC models. The SIM values from transfer learning models were greater than those from the pre-trained models in each concordance classification. In contrast, the KLD values obtained from the transfer learning models were less than those from the pre-trained models, considering that greater SIM values and lower KLD values reflect higher performance of the AI models. The “almost perfect” category had the highest SIM and lowest KLD values between saliency maps of the two transfer learning models, followed by “substantial”, “moderate”, and “poor” categories. Despite the differences in performance, for the best-performing model (i.e., the GMIC model) in all four concordance categories, the sensitivity values were above 90%. Therefore, even in the most challenging categories (i.e., poor and moderate), which are more demanding for radiologists and where the two AI tools agree with each other less, AI still exhibits a reasonable performance level.
The “missed” cancers refers to cases incorrectly classified as normal by two original radiologists during screening examinations. In a preliminary study33, the global radiomic signature features were extracted from “missed” cancers, “identified” cancers and “normal” cases. This global radiomic signature describes the overall appearance, texture, and density of mammographic examinations. In earlier studies, such a global signature was used to classify images into various breast density categories, estimating difficulty of case34 or to stratify the risk of breast cancer35. It was also associated with radiologists' initial impressions of the abnormality of a case36. The “identified” cancers were detected and biopsy-proven cancers and the immediate prior examination of the “missed” cancers were collected from the same database. AUCs of a random forest classifier on “missed” vs “identified” cancers, “identified” cancers vs “normal” cases, and “missed” cancers vs “normal” cases were 0.66, 0.65, and 0.53. The signatures were significantly different for “missed” vs “identified” cancers, “identified” cancers vs “normal” cases, but not for “missed” cancers vs “normal” cases. Hence, it is reasonable to assume these “missed” cases are among the most challenging cases as their overall mammographic texture resembles that of the “normal” cases. Upon evaluating the pre-trained GMIC, it was observed that the average sensitivity of “missed” cancers (68.5%) was notably lower than that of “prior-vis” (82.1%) and “prior-invis” cancers (78.2%). However, when employing GMIC with transfer learning, the average sensitivity of “missed” cancers significantly increased to 82.8%, closing the gap with “prior-vis” (90.1%) and “prior-invis” cancers (88.8%). Similar trends were observed with GLAM in both pre-trained and transfer learning modes, yielding significant results for the difference in sensitivity in two modes (p-values < 0.05). The performance of the AI models across the three categories—“prior-vis,” “prior-invis,” and “missed” cancers—suggests that, overall, the difficulty of cases when using AI models is comparable to the interpretation by radiologists. This implies that both AI models and breast radiologists may encounter challenges in interpreting particularly difficult mammograms, as seen in the “missed” category. However, the results also indicate that triple reading, involving the GMIC model and two radiologists, can significantly improve the detection of cancers currently missed in standard double reading practices. This approach may lead to the identification of over 82% of the cancers that would otherwise be overlooked. The findings underscore the potential of integrating AI models into the breast cancer screening process with double reading to enhance sensitivity and reduce the likelihood of missed diagnoses.
Cancer size could be considered as another surrogate variable for case difficulty. As anticipated, the diagnostic accuracy of AI systems is affected by the sizes of cancers in mammograms, with larger cancer sizes yielding more accurate cancer detection. However, the sensitivity values of AI tools for the smallest group were still higher than the sensitivity values observed for the 'missed' category. Therefore, being of a smaller size is not the only contributing factor that results in lower sensitivity for AI tools in the “missed” category. In a previous study33, global radiomic signature features were extracted from "missed" cancers, detected cancers, and normal cases. The findings revealed that the global radiomic signature of “missed” cancer cases closely resembled that of normal cases. This similarity suggests that interpreting “missed” cancer cases would be exceptionally challenging due to the overall global appearance of the images with radiomic signature features, potentially leading to false-negative diagnoses. The implication of this observation is significant and the reliance on the overall global image appearance might create a bias and contribute to radiologists mistakenly categorizing “missed” cancer cases as normal. To address this challenge, AI tools such as GMIC and GLAM, which excel in meticulous local image inspection, could potentially assist radiologists. These AI tools have the capacity to discern subtle local features that might be indicative of cancer even when the global radiomic signature suggests normalcy33. By leveraging the capabilities of AI models like GMIC and GLAM, radiologists could potentially overcome the limitations associated with global image interpretation. This, in turn, might enhance the accuracy of cancer detection by providing a more comprehensive and nuanced analysis that goes beyond the global radiomic signature.
In the current study, the normal cases were randomly selected from a pool of BSA archive, collected from multiple screening services across various jurisdictions within BreastScreen Australia. While our dataset inherently encompasses elements of benign disease and normal variants within the "normal cases" category, we recognize the importance of further enriching the dataset with a larger representation of benign cases from multicenter sources. It is expected that the false positive rate of GMIC and GLAM would be increased if the current study had specifically inserted benign cases. One of the main limitations of our study was the absence of cases that were specifically labelled as such, but rather, benign cases were included under a normal classification as BSA uses a recall/return to screening pathway. For transfer learning of the GLAM and GMIC models, we have only investigated the performance of the AI models from the point of view of malignancy detection and normal cases, which might include some benign mammographic features and normal variants. The Australian Screening dataset for this study did not have any labelled benign cases, so the results cannot comment on the GLAM and GMIC’s ability to identify discrete benign pathology that may require clinical action. Future research endeavors will focus on conducting larger multicenter studies to gather a more comprehensive dataset that includes a diverse range of benign conditions, thus enhancing the robustness and generalizability of AI models in mammography interpretation. Another limitation identified for the GLAM model was incorrectly localizing ‘false positive’ regions for cancers that were not present. As shown in Fig. 1b,d, the case was cancer free, yet the GLAM model returned malignancy features on mammographic images of LCC and LMLO. Similarly, the right breast was cancer free for Fig. 3a,c, but the GLAM model returned malignancy features on mammographic images of RCC and RMLO. One of the reasons for these incorrect decisions is that GLAM needs to use a larger number of patches selected from global saliency map for the local module, compared with the number of patches selected for GMIC model. Therefore, GLAM returned more obvious saliency maps of incorrect cancer locations than GMIC, as shown in Figs. 3a and 4a, and Figs. 1b and 2b.
In the clinical scenario of breast cancer detection via double-blinded reading in breast screening programs such as those in Australian37, two independent radiologists may sometimes provide different reading outcomes on the same images. Two methods can be used to address discordant reads. One is to use a third radiologist who is a highly experienced breast reader to arbitrate but this can be time consuming and expensive. The other method arranges the two original radiologists to discuss the two differing interpretation and agree on the outcome as a single recommendation. Our research shows promise for the use of GLAM and GMIC models to provide cancer detection results in situations of discordant outcomes, for example in the blue saliency maps in Figs. 5c and 6c, where the only Radiologist A and the AI models identified a cancer. Triple reading, including GMIC and two independent radiologists, might provide an effective way to improve the detection rate of cancers in the standard double reading breast screening program because the model successfully identified > 80% of previously missed cancer cases.
The GMIC and the GLAM models performed well on all four interpretation levels of concordance in our dataset which consists of mammography exams from different manufacturers such as Sectra, Fuji, Siemens, Hologic, GE Healthcare and Philips Healthcare. While many existing AI modes demonstrate good performance on mammographic images from a sole manufacturer (e.g., Ribli et al.’s38 paper with Hologic, Dhungel et al.’s paper39 with Siemens, and Yang et al.’s paper40 with Siemens), our study applied the GLAM and GMIC to a range of vendor images and found high SIM values (> 0.91) between the saliency maps of the AI models and radiologists’ annotations regardless of the image source. The results showed that the GMIC model was successful in finding mammographic cases at specificity and sensitivity of > 90% for cases with different manufacturers.
Conclusions
In this paper, we presented diagnostic accuracy of the two AI models in interpreting mammographic images based on the strength of concordance between radiologists in breast cancer detection. The study also supports the potential of AI tools to identify missing cancers within a double-reading practice, where each examination was independently interpreted by two readers. The results showed that AI systems testing on mammographic images with stronger concordance data from radiologists outperformed that with weaker concordance levels. Transfer learning for the pre-trained AI models can also improve the performance, which suggests that AI models can be used as an effective method for decision making when radiologists do not agree with each other in the annotations of suspicious lesions. The average sensitivity of AI models across different groups of cancer sizes outperformed that of the “missed” cancers, indicating that cancer sizes is not the only factor affecting the AI performance on screening mammograms.
For future work, we will conduct eye tracking experiments with radiologists and breast physicians on of the “missed” cancers, “prior-vis” cancers and “prior-invis” cancers. We intend to compare heat maps of radiologists with the saliency maps of AI models on these three categories.
Data availability
The data supporting this study’s findings are available on request from the corresponding authors.
References
Sung, H. et al. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 71(3), 209–249. https://doi.org/10.3322/caac.21660 (2021).
Fiorica, J. Breast cancer screening, mammography, and other modalities. Clin. Obstet. Gynecol. 59(4), 688–709. https://doi.org/10.1097/GRF.0000000000000246 (2016).
Salim, M., Dembrower, K., Eklund, M., Lindholm, P. & Strand, F. Range of radiologist performance in a population-based screening cohort of 1 million digital mammography examinations. Radiology 297(1), 33–39. https://doi.org/10.1148/radiol.2020192212 (2020).
Wu, N. et al. Deep neural networks improve radiologists’ performance in breast cancer screening. IEEE Trans. Med. Imaging 39(4), 1184–1194. https://doi.org/10.1109/TMI.2019.2945514 (2020).
McKinney, S. M. et al. International evaluation of an AI system for breast cancer screening. Nature 577, 89–94. https://doi.org/10.1038/s41586-019-1799-6 (2020).
Shen, L. et al. Deep learning to improve breast cancer detection on screening mammography. Sci. Rep. 9, 12495. https://doi.org/10.1038/s41598-019-48995-4 (2019).
Al-Masni, M. et al. Simultaneous detection and classification of breast masses in digital mammograms via a deep learning YOLO-based CAD system. Comput. Methods Progr. Biomed. 157, 85–94. https://doi.org/10.1016/j.cmpb.2018.01.017 (2018).
Jung, H. et al. Detection of masses in mammograms using a one-stage object detector based on a deep convolutional neural network. PLOS One 13(9), e0203355. https://doi.org/10.1371/journal.pone.0203355 (2018).
Li, Y., Zhang, L., Chen, H. & Cheng, L. Mass detection in mammograms by bilateral analysis using convolution neural network. Comput. Methods Progr. Biomed. 195, 105518. https://doi.org/10.1016/j.cmpb.2020.105518 (2020).
Chiu, H. Y., Chao, H. S. & Chen, Y. M. Application of artificial intelligence in lung cancer. Cancers (Basel) 14(6), 1370. https://doi.org/10.3390/cancers14061370 (2022).
Othman, E. et al. Automatic detection of liver cancer using hybrid pre-trained models. Sensors 22(14), 5429. https://doi.org/10.3390/s22145429 (2022).
Akinyelu, A. A., Zaccagna, F., Grist, J. T., Castelli, M. & Rundo, L. Brain tumor diagnosis using machine learning, convolutional neural networks, capsule neural networks and vision transformers, applied to MRI: A survey. J. Imaging 8(8), 205. https://doi.org/10.3390/jimaging8080205 (2022).
Shen, Y. et al. An interpretable classifier for high-resolution breast cancer screening images utilizing weakly supervised localization. Med. Image Anal. https://doi.org/10.1016/j.media.2020.101908 (2021).
Liu, K. et al. Weakly-supervised high-resolution segmentation of mammography images for breast cancer diagnosis. Proc. Mach. Learn. Res. 143, 268–285 (2021).
Yoon, J. H. et al. Standalone AI for breast cancer detection at screening digital mammography and digital breast tomosynthesis: A systematic review and meta-analysis. Radiology 23, 222639. https://doi.org/10.1148/radiol.222639 (2023).
Leibig, C. et al. Combining the strengths of radiologists and AI for breast cancer screening: A retrospective analysis. Lancet Digit. Health 4(7), e507-19. https://doi.org/10.1016/S2589-7500(22)00070-X (2022).
Dembrower, K., Crippa, A., Colón, E., Eklund, M. & Strand, F. Artificial intelligence for breast cancer detection in screening mammography in Sweden: A prospective, population-based, paired-reader, non-inferiority study. Lancet Digit. Health 5(10), e703–e711 (2023).
Sechopoulos, I., Teuwen, J. & Mann, R. Artificial intelligence for breast cancer detection in mammography and digital breast tomosynthesis: State of the art. Semin. Cancer Biol. 72, 214–225. https://doi.org/10.1016/j.semcancer.2020.06.002 (2021).
Bylinskii, Z., Judd, T., Oliva, A., Torralba, A. & Durand, F. What do different evaluation metrics tell us about saliency models?. IEEE Trans. Pattern Anal. Mach. Intell. 41(3), 740–757. https://doi.org/10.1109/TPAMI.2018.2815601 (2019).
Zhuang, F., Qi, Z., Duan, K., **, D., Zhu, Y., Zhu, H., **ong, H., & He, Q. A Comprehensive survey on transfer learning, ar**v, https://doi.org/10.48550/ar**v.1911.02685 (2019)
Yap, M. H. et al. Automated breast ultrasound lesions detection using convolutional neural networks. IEEE J. Biomed. Health Inform. 22, 1218–1226. https://doi.org/10.1109/JBHI.2017.2731873 (2018).
Byra, M. et al. Impact of ultrasound image reconstruction method on breast lesion classification with deep learning. In Pattern Recognition and Image Analysis: 9th Iberian Conference, IbPRIA 2019, Madrid, Spain, July 1–4, 2019, Proceedings, Part I (eds Morales, A. et al.) 41–52 (Springer International Publishing, 2019). https://doi.org/10.1007/978-3-030-31332-6_4.
Rezatofighi, S., Tsoi, N., Gwak, J., Sadeghian, A., Reid, I., & Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression, Ar**v, ar**v:1902.09630 (2019).
Lin, L.I.-K. A concordance correlation coefficient to evaluate reproducibility. Biometrics 45, 255–268 (1989).
McBride, G.B. A proposal for strength of agreement criteria for lin’s concordance correlation coefficient, NIWA Client Report HAM2005–062. Hamilton, New Zealand: National Institute of Water & Atmospheric Research Ltd (2005).
He, K., Zhang, X., Ren, S., & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, DOI: https://doi.org/10.1109/CVPR.2016.90, (2016).
Mastyło, M. Bilinear interpolation theorems and applications. J. Funct. Anal. 265, 185–207 (2013).
Wu, N., Phang, J., Park, J., Shen, Y., Kim, S. G., Heacock, L., Moy, L., Cho, K., & Geras, K. J. The NYU Breast Cancer Screening Dataset v1.0. Technical Report, (2019)
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. In International Conference on Learning Representations, pp. 1–15, (2015).
Zadeh, S. G. & Schmid, M. Bias in cross-entropy-based training of deep survival networks. IEEE Trans. Pattern Anal. Mach. Intell. 43(9), 3126–3137 (2020).
Li, J., **a, C., Song, Y., Fang, S. & Chen, X. A data-driven metric for comprehensive evaluation of saliency models. In International Conference on Computer Vision, pp. 190–198, (2015).
Emami, M. & Hoberock, L. L. Selection of a best metric and evaluation of bottom-up visual saliency models. Image Vis. Comput. 31(10), 796–808. https://doi.org/10.1016/j.imavis.2013.08.004 (2013).
Gandomkar, Z., Lewis, S. J., Siviengphanom, S., Wong, D., Ekpo, E. U., Suleiman, M. E., Tao, X., Reed, W., & Brennan, P. C. False-negative diagnosis might occur due to absence of the global radiomic signature of malignancy on screening mammograms, Proc. SPIE Medical Imaging: Image Perception, Observer Performance, and Technology Assessment, 124670A, DOI: https://doi.org/10.1117/12.2655154, (2023).
Tao, X., Gandomkar, Z., Li, T., Brennan, P. C. & Reed, W. Using radiomics-based machine learning to create targeted test sets to improve specific mammography reader cohort performance: A feasibility study. J. Personaliz. Med. 13(6), 888 (2023).
Gandomkar, Z. et al. Global processing provides malignancy evidence complementary to the information captured by humans or machines following detailed mammogram inspection. Sci. Rep. 11(1), 20122 (2021).
Siviengphanom, S., Lewis, S. J., Brennan, P. C. & Gandomkar, Z. Computer-extracted global radiomic features can predict the radiologists’ first impression about the abnormality of a screening mammogram. Br. J. Radiol. 97(1153), 168–179 (2024).
BreastScreen Australia National Accreditation Standards (NAS) Information for Clinical Staff, https://www.breastscreen.nsw.gov.au/, March, (2022).
Ribli, D., Horváth, A., Unger, Z., Pollner, P. & Csabai, I. Detecting and classifying lesions in mammograms with Deep Learning. Sci. Rep. 8(1), 4165. https://doi.org/10.1038/s41598-018-22437-z (2018).
Dhungel, N., Carneiro, G. & Bradley, A. P. A deep learning approach for the analysis of masses in mammograms with minimal user intervention. Med. Image Anal. 37, 114–128. https://doi.org/10.1016/j.media.2017.01.009 (2017).
Yang, Z. et al. MommiNet-v2: Mammographic multi-view mass identification networks. Med. Image Anal. 73, 102204. https://doi.org/10.1016/j.media.2021.102204 (2021).
Acknowledgement
We would like to acknowledge the support for this project by the National Breast Cancer Foundation (NBCF) Australia, funding grant: IIRS-22-087.
Author information
Authors and Affiliations
Contributions
Conceptualization, Z.J., Z.G., P.T., S.T., and S.L.; methodology, Z.J., Z.G., P.T., S.T., and S.L.; software, Z.J., formal analysis, Z.J., Z.G., P.T., S.T., and S.L.; data curation, Z.J., Z.G. and S.L.; writing—original draft preparation, Z.J.; writing—review and editing, all coauthors; visualization, Z.J.; supervision, S.L.; project administration, M.B., S.L.; funding acquisition, Z.G., P.T., S.T., and S.L.; All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Jiang, Z., Gandomkar, Z., Trieu, P.D. et al. AI for interpreting screening mammograms: implications for missed cancer in double reading practices and challenging-to-locate lesions. Sci Rep 14, 11893 (2024). https://doi.org/10.1038/s41598-024-62324-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-62324-4
- Springer Nature Limited