
Abstract
Recent years have witnessed a mushrooming of reading corpora that have been built by means of eye tracking. This article showcases the Hong Kong Corpus of Chinese Sentence and Passage Reading (HKC for brevity), featured by a natural reading of logographic scripts and unspaced words. It releases 28 eye-movement measures of 98 native speakers reading simplified Chinese in two scenarios: 300 one-line single sentences and 7 multiline passages of 5,250 and 4,967 word tokens, respectively. To verify its validity and reusability, we carried out (generalised) linear mixed-effects modelling on the capacity of visual complexity, word frequency, and reading scenario to predict eye-movement measures. The outcomes manifest significant impacts of these typical (sub)lexical factors on eye movements, replicating previous findings and giving novel ones. The HKC provides a valuable resource for exploring eye movement control; the study contrasts the different scenarios of single-sentence and passage reading in hopes of shedding new light on both the universal nature of reading and the unique characteristics of Chinese reading.
Similar content being viewed by others


Background & Summary
Over the past two decades, researchers have given increasing attention to reading behaviours and conducted in-depth investigations into when and where the underlying cognitive mechanisms of reading concurrently function by using recordings of physiological signals from human organs (e.g., lung, heart, eye, and brain)1. As one of the most prominent types of empirical data, eye movements possess unique advantages in representing accurately sliced time segments (e.g., first fixation duration, second go-past duration, and total reading time), flexibly segmented interest areas (e.g., local words and phrases or global sentences and paragraphs), and high ecological validity that allows for previewing and reviewing texts. Along with this direction, a growing number of eye-tracking datasets have been developed in recent years2,3,4,5,6,7,8,9,10,11,12,13,14,15 (see details in Table 1). However, it is noteworthy that the few Chinese reading corpora, such as GECO-CN12, BSC13 and CEMD14, were not published until last year.
The rapid growth of eye-movement corpora has boosted a variety of empirical studies that address new challenges arising from reading. In reading research with alphabetic languages, the Dundee Corpus promotes the discussion on word processing in parafoveal and foveal vision2,16, while the PSC is employed to examine word surprisal effects3,17, the Provo Corpus to investigate undersweep fixations in multiline contexts8,18, the GECO to explore the age-of-acquisition effect on fixations regardless of word length and frequency6,19 and the ZuCo to train machine learning models to predict human reading behaviours7,20, Schematic overview of HKC development.
Methods
Participants
This study was approved in advance of implementation by the Human Subjects Ethics Subcommittee of the corresponding college. We recruited 98 university students (89 females, age = 26 ± 3.64) as our test-takers, who are native speakers of Mandarin, skilled in reading simplified Chinese with normal (or corrected-to-normal) eyesight and no illness that impacts cognitive abilities. They each signed a consent form before the experiment and received monetary remuneration upon completion. Due to privacy protection, other information is not disclosed.
Apparatus
Two experiments take advantage of the following hardware: (1) tower-mounted EyeLink 1000 series (SR Research, Canada) with a sampling rate up to 1000 Hz and a spatial resolution of 0.01° of visual angle; (2) an 18-inch ViewSonic CRT monitor (resolution rate, 1024 × 768 pixels; and refresh rate, 85 Hz); and (3) an adjustable chin rest.
Materials
The top 300 sentences that were 30 characters long (including punctuation marks) were selected from the XIN subcorpus of the Chinese Gigaword Corpus27,28 by first sorting sentences in ascending order of average entropy per character (i.e., the overall information per language signal29). Entropy is estimated by a simple unigram model using character frequencies in the corpus, followed by filtering out those entries suspected of any lexical, syntactic or semantic inclinations (e.g., long numbers of many digits and repeated expressions) or other bias (e.g., religion, racism, sexuality, and violence). We opted to choose the most likely unbiased sentences in this way in hopes of smoothing the natural reading process to the greatest extent possible. The sentence length was chosen to allow a full utility of the screen width, except for a necessary margin on four sides (left and right, 110 pixels; top and bottom, 180 pixels).
Following a similar procedure with the same criteria except for text length, 7 passages were selected from the same corpus with no overlap with any selected single-lined sentences (see Table 2 for sample materials). Totalling a text length of 8742 characters, these passages cover a variety of topics, including 1 on celebrity news, 1 on city development, 2 on education, 1 on employment, and 2 on sports. A small number of uncommon words, such as technical terms and long numbers, were pruned out or replaced with easier or shorter ones without altering the meanings of original sentences. For the best fit to the monitor, we divided each passage into a title page and several content pages (individually: 6, 4, 5, 6, 5, 10, and 5 for the seven passages, in a total of 41) according to the text length (in number of characters), and configured each page with 9 lines (unless the last page of a passage) and each line with 38 characters (unless the last line of a paragraph). There are 1078 ± 275 characters per passage, 36 ± 21 sentences per passage, and 40 ± 21 characters per sentence.
Given the convention of no interword spacing in Chinese texts, we performed word segmentation following the national standard GB/T 13715-92 (1992) and inserted delimiters (*) between words in the materials for the purpose of facilitating word-based analyses after data collection (see Fig. 2). We manually checked the results of the segmentation word by word and resolved ambiguous and controversial cases according to our best understanding of the standard. Experiment Builder software (SR Research, Canada) automatically specifies an interest area (IA) between two delimiters and keeps all delimiters invisible to participants during reading. Each punctuation mark was also taken as an IA.

Procedure of word segmentation and sample of segmentation results in materials. Note. Pinyin: Zài ** in natural reading). There were pilot runs for the latter, which was intended to record all real-time happenings on the participant computer, including those that indicate the time points of page flip** at the end/beginning of reading the current/next page. Such data were used later for delimiting reading period (see details in the Data preprocessing).
Experimental procedure
The experimental procedure involves three reading tasks for subjects (Ss) to perform: warm-up reading (T1), formal reading (T2), and post-reading comprehension (T3), for the purpose of collecting both behavioural and eye-movement data. The former type of data is collected from Ss pressing buttons to flip pages during T2 and to answer questions for T3, and the latter type from Ss’ dextral eyes during their reading in T2. All Ss successively completed all T1, T2, and T3 of both Exp I and Exp II in a windowless silent booth under identical conditions. Half of the Ss first performed Exp I followed by Exp II, while the other half followed a similar procedure to perform Exp II ahead of Exp I. It took approximately one hour to finish the two experiments with a rest of 5–10 minutes in between. All Ss successfully completed two experiments.
The optimal typography was piloted in advance. We configured single sentences in 18-pt Simsun font, horizontally left-aligned and vertically centred-aligned, with a monitor-to-subject distance of 64 cm; passages were in 16-pt Simsun font, horizontally justified alignment, and double-line spacing, with a monitor-to-subject distance of 55 cm. Notwithstanding the two typography settings, we formatted each Chinese character to extend at 0.85° of visual angle uniformly for both reading scenarios. According to our test runs on typographic settings, passage texts in the smaller font and double spacing could lead to fewer return sweeps, fewer fixations close to screen corners, and less undesired crossline interference.
Warm-up reading (T1)
Before formal reading, we instructed the participants to read silently at their own pace and familiarise themselves with the experimental procedure through two practice sessions, as shown in the Implementation in Fig. 1. The length and content of the practice sentences differ from those in formal reading to prevent develo** a practice effect.
Formal reading (T2)
The procedure of formal reading is similar to that of warm-up reading. Figure 3 exhibits a sample procedure of a subject reading sentences in Exp I and passages in Exp II. In Exp I, Ss had a 3-point calibration and drift correction before one-line sentence reading. Ss had a five-minute break after reading every 60 sentences to prevent a fatigue effect. In Exp II, Ss first had a 9-point calibration and drift correction before beginning multipage passage reading. To sustain their regular reading performance, Ss could rest after reading an entire passage. Additionally, we randomised the order (i.e., trial index) of materials presented to readers to prevent an order effect.

Reading procedure for 300 sentences and 7 passages.
Post-reading comprehension task (T3)
The post-reading tasks required the Ss to provide a Yes/No answer (by pressing the left/right button of the response handle) to whether the meaning of a post-reading sentence (referred to as a comprehension question in order to avoid confusion with text sentences for formal reading) matched the content of formal reading, for evaluating their grasp of the overall message and reminding them to concentrate on reading. In Exp I, we manually formulated 75 comprehension questions for 75 designated sentences, so Ss should answer one of them after reading four sentences on average. The probability of 25% (75 out of 300 sentences) is to ensure a reading task without too much comprehension load31 because our goal is to capture natural reading, rather than hard-working reading that happens only in labs but not in real life. For Exp II, we formulated 25 comprehension questions and assigned them to passages in a way that longer ones are assigned more, in the range of 2 to 5 questions per passage (individually: 4, 2, 3, 4, 4, 5, and 3, in a total of 25).
Data preprocessing
Using Eyelink Data Viewer (DV, SR Research, Canada), we first screened the behavioural data, which show that Ss pressed buttons as required without exception. Then, we calculated the accuracy rates of subjects’ button responses (1: correct; 0: incorrect; −1: no response required) for both experiments. Average rates of 85% and 88% accuracy were obtained for sentence and passage reading, respectively, indicating an overall quality level of reading between those of the RSC (80%)9 and BSC (90%)13. Regardless of accuracy rates, all subject eye-movement data are included in HKC because our main task is to collect real data from natural reading that is supposed to allow for various levels of reading comprehension.
Using DV, data retrieval for Exp I is straightforward, given the setting of one single-line sentence per full-screen page. However, a technical problem arises from data retrieval for Exp II: eye-tracking data for reading content pages were overlaid densely on the title page. To resolve this problem, we used the messages of subjects’ button pressing for page flip** to delimit the entire reading period of a passage into subordinate interest periods (IPs) that identified their page numbers. This method facilitates our data analysis despite missing eye-movement data for the time lags between button pressing and page flip**; these periods were too short (less than 10 milliseconds) to indicate any significant language processing and hence can be disregarded with no harm. Subsequently, we excluded the data from title pages, which reflect the reading performance of single sentences rather than paragraphs. Finally, the data resulting from Exp I and Exp II are stored in two files (UTF-8 encoded): a sentence subcorpus and a passage subcorpus, which jointly form the current version of HKC32.
The eye-tracking data collected with a 1000 Hz sampling rate was aggregated per IA. We excluded the eye-tracking data related to punctuation and blinks (when no pupils were detected), marked the data without fixations as NA, and filtered out single fixations shorter than 80 ms or longer than 1000 ms (for the reason of not revealing linguistic processing14,33). As a result, 3.1% of the total eye movement data was excluded. A total of 980,326 out of 1,149,411 data points are valid, and the number shows that HKC is a sizeable reading corpus among the existing representative ones (see Table 1 for a comparison), although not the largest.
Data Records
HKC is released on the Open Science Framework (OSF) repository32 under the licence of CC BY 4.0 for free access via the identifier doi 10.17605/OSF.IO/Z465B. A set of files are presented in this repository, including (1) datasets (“sentence subcorpus.rda”, “passage subcorpus.rda”, and “HKC.rda”), (2) materials (“materials.xlsx” and “punctuation_distribution.xlsx “), (3) variable definitions (“definitions.csv”), and (4) accuracy information (“accuracy sentence.xlsx” and “accuracy passage.xlsx”).
The files “sentence subcorpus.rda” and “passage subcorpus.rda” store eye-movement measures of reading unrelated and contextually coherent sentences, respectively, and the file “HKC.rda” provides a unified eye-movement dataset of the two, which is fit for direct data loading in an R language environment. Users can transfer it to any other format of their interest by converting it to a data frame and then writing it to other formats. In this released version of HKC, each IA is in a row consisting of a list of eye-movement measures whose definitions are presented in Table 4. The file “materials.xlsx” contains two sheets of the materials, consisting of 300 sentences and 7 passages, with words segmented by delimiters “*” and answers to decision tasks attached. The file “punctuation distribution.xlsx” summarises the distribution of 11 punctuation marks across the two types of materials, and the file “definitions.csv” summarises the variables used in HKC. Two more sheets, “accuracy sentence.xlsx” and “accuracy passage.xlsx”, provide participants’ actual button response (6: left and 7: right) and the corresponding accuracy (1: correct, 0: incorrect, and −1: no button response required) in Exp I and II, respectively.
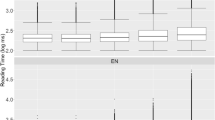
Table 5 exhibits an array of unique descriptive characteristics of HKC in terms of a series of key measures which provide prominent contrasts between the two reading scenarios (S: single-sentence reading and P: passage reading). Specifically, P has higher skip** rates (as reflected in probabilities of the PS1 and PS), lower regression rates (in the probabilities of RI and RO), and shorter FFD, GD, and TRT (despite their large SDs) than S. All of these agree nicely with native speakers’ language intuition about the contrast of the two scenarios. In particular, it is hypothesized that richer contextual information establishes better coherence and continuity of reading and gives a strong account for the better reading performance in the passage reading scenario.
Technical Validation
In addition to the above manifestation of contrastive characteristics of sentence and passage reading, the effects of word frequency, visual complexity, and reading scenario on eye-movement measures in HKC provide further validation, into which we delved by (generalised) linear mixed-effects models ((G)LMMs) and the Wilcoxon signed-rank test. Since HKC does not include any annotation of lexical properties (e.g., length, stroke, and frequency) and is inherently a collection of eye-movement measures for individual word tokens, we resorted to CLD29 for a wide range of (sub)lexical properties (e.g., frequency, complexity, phoneme, and entropy, etc.). CLD offers high explanatory power in that the average deviance explained (ADE) tests indicate a higher value of CLD than those of other datasets (e.g., Chinese Gigaword34, SUBTLEX-CH35, and Leiden Weibo Corpus36). By Java programming, we annotated each word token of HKC with its complete list of lexical properties from CLD by using word matching to align corresponding records of the two datasets. The resulting dataset is then leveraged for our data validation using R language37,38.
(G)LMMs and Wilcoxon signed-rank test
To validate the HKC, we separately constructed four (G)LMMs for four dependent variables, namely, PS, FFD, GD, and TRT (see Table 4 for definitions). The scenario is an independent variable and lexical properties below (with respective abbreviations in parentheses) covariates in our study. We treated all of them as fixed effects in the (G)LMMs:
-
Frequency: frequencies of word (Frequency), 1st character (C1Frequency), 2nd character (C2Frequency), 3rd character (C3Frequency), and 4th character (C4Frequency).
-
Complexity: word length (Length); number of strokes per word (Strokes), 1st character (C1Strokes), 2nd character (C2Strokes), 3rd character (C3Strokes), and 4th character (C4Strokes); and number of pixels per word (Pixels), 1st character (C1Pixels), 2nd character (C2Pixels), 3rd character (C3Pixels), and 4th character (C4Pixels).
-
Scenario
Considering the repeated measures design of our experiment with Ss reading identical materials, we included random error terms as (1) an intercept for the subjects, (2) an intercept for the items, (3) a slope for scenarios across subjects, and (4) a slope for scenarios across items as four random effects in the (G)LMMs. As preliminary processing prior to fitting the (G)LMMs, all complexity measures were scaled by centring, and frequencies were converted to their logarithmic values using base 10 for the correction of the original Zipfian distributions39. To address the data noted as NA, the maximum likelihood estimation approach was applied, and parameters in the (G)LMMs were updated based on the imputed values by the expectation-maximisation algorithm. Regarding the model construction, we first fit each (G)LMM by including all the random effects (without any fixed effects). Second, we deducted the random effects one by one each time and weighed the entropy-based Akaike information criterion (manifested as AIC in R) of the updated model in the hope of settling the model with the lowest AIC. Due to the problematic convergence of random slopes, we used fixed slopes with random intercepts across items and subjects. In this way, a random-effects-ready model was selected. Third, we expanded the random-effects-ready model by adding all fixed effects at once. A backwards stepwise selection was then carried out, and we detected the noncontributive fixed effects or those with unacceptable variance inflation factors (≥5) in case of the presence of collinearity. Due to data sparsity (3.3% of the total), we deleted the sublexical properties of the third and fourth characters (C3Strokes, C4Strokes, C3Pixels, C4Pixels, C3Frequency, C4Frequency) because these properties explain very few data points and the deletion makes little difference. Finally, we built the fittest model for each (G)LMM.
The results from the final (G)LMMs are summarised in Table 6 and visualised in Fig. 4, suggesting that many established lexical effects in controlled experiments can also be revealed in natural reading and that sublexical factors also modulate natural reading. Three main effects on reading stand out from others, namely, word frequency, word length, and scenario. These are visualised in Fig. 5, which illustrates the effects on PS (Fig. 5a–c) and on FFD, GD, and TRT (Fig. 5d–f).

Estimates (odds ratios) of the effects given by the final (G)LMMs.

Main effects of word length, word frequency and scenario on PS, FFD, GD, and TRT. Note. Panels (a–c) present skip** probability in percentage, while panels (d–f) present reading time in milliseconds. Panels (e,f) show the mean FFD, GD, and TRT (with error bars) across word length and scenarios. *p < 0.05, **p < 0.01, ***p < 0.001.
Following the practice of ZuCo7, we conducted a paired one-tailed Wilcoxon signed-rank test to compare the average reading speeds of each participant (across all trials) under two reading scenarios by the unit of words per minute (WPM).
Effects of word frequency
Word frequency plays a crucial role in the validation of eye-movement corpora, as shown in the studies by Laurinavichyute et al.9 and by Zhang et al.14 The effects of word frequency revealed by HKC data are presented in Fig. 5a,d, revealing that high-frequency words tend to be more efficiently processed, according to their greater skip** rates and shorter fixations, than low-frequency words. These results are evidently consistent with the results in the literature.
Effects of visual complexity
We present the effects of visual complexity from two perspectives: word length and spatial density. Regarding the effects of word length, we found its impact on eye-tracking measures of PS, FFD (marginally significant), GD, and TRT (see Fig. 5b,e). The effect of word length on PS reveals such a trend that longer words are less likely to be skipped, which is consistent with native speakers’ intuition. Its impacts on GD and TRT show that dwell times are longer for 2-character words than for 1-character words. The rise of the reading times from 1- to 2-character words is particularly worth noting, given that the latter account for 96.7% of all words. Surprisingly, 3- and 4-character words do not necessarily demand greater cognitive effort than shorter words do, in the sense that shorter FFD, GD, and TRT characterise their reading. Intuitively, one may attribute this to the relatively efficient processing of fixed expressions and strong collocations such as idioms (e.g., Multi-Constituent Unit Hypothesis40). However, further effort is still needed to examine whether eye-movement data on such a small proportion of 3- and 4-character words (approximately 3% of the total in our data) would lend any convincing support to a conclusion such as ours.
Regarding the effects of spatial density, we uncover the lexical modulation of word strokes on TRT, that of word pixels on TRT and GD, and the sublexical effect of 1st-character pixels on FFD. Strokes play a crucial role in measuring the visual complexity of written words in logographic languages such as Chinese, Japanese, and Korean (CJK family), unlike alphabetic languages in which written words are measured by length in number of letters. This difference can be illustrated by contrasting two one-character words in Chinese, e.g., 水 (shui3, “water”) and 美 (mei3, “beauty”), which are of 4 and 9 strokes, respectively, giving a sharp contrast in visual complexity despite the same word length. Compared with strokes, pixels manifest visual complexity in a more delicate (or sensitive) way in that words in HKC contain greater variability in pixels (5212 ± 2148) than in strokes (11 ± 6). This can account for our findings on the sublexical effect of pixels but not strokes.
Generally, word length maintains its significant modulation across all these eye-movement measures in (G)LMMs, i.e., PS, FFD (marginally significant), GD, and TRT, suggesting that Chinese reading performance is affected more significantly by horizontal complexity than by spatial density, clearly in line with the reading of alphabetic scripts. All the above together manifest that complexity factors at both lexical and sublexical levels influence eye movements in the natural reading of Chinese texts, although more details about how they work have yet to be further explored using the available HKC data. Our results replicated the key effects of visual complexity on eye movements in reading. A longer length and a greater stroke count or pixel count tend to give rise to lower likelihoods of skip** and longer fixation durations9,5c) and on the measures of FFD, GD, and TRT (Fig. 5f). Specifically, P manifests shorter duration and greater skip** rates than single-sentence reading in S. This contrast provides evidence for an intuitive observation that among the two scenarios, the one (P) that provides richer contextual information allows more efficient reading performance than the other (S). Our findings on the scenario effect clearly justify the need for further research in this direction.
The Wilcoxon rank-sum test we conducted on HKC revealed that our participants’ reading of the passages was significantly faster than that of the single sentences (Z = 1.88, p < 0.001). Their average reading speeds show that Chinese readers are currently capable of reading 304 ± 182 words per minute (WPM) in S and 527 ± 277 WPM in P (with punctuation and other outliers excluded). The latter appears to have been sped up by approximately 36% from an average of 386 WPM43 when measured twenty-some years ago, suggesting that this generation of readers may read faster on a computer screen.
Taken together, the results we obtained from HKC about the impacts of word frequency, visual complexity of words, and reading scenarios offer dependable justification for its validity and reliability. These results not only echo the previous findings but also provide strong evidence for the usability of HKC as a large-scale dataset to facilitate exploratory linguistic and cognitive studies of Chinese reading, especially those involving multidimensional analysis (of a large number of correlated variables).
Usage Notes
HKC is distinguished as the first Chinese reading corpus that records natural reading data in the two contrastive scenarios for sentence and passage reading. Its within-subject design, as another distinctive feature, may help bypass the data variability issue in between-subject designs for comparative research. It boosts the salience of studies of peculiar issues in Chinese passage reading, such as return-sweeps18 and wrap-up effects44, which play a significant role in the reading process but have remained severely understudied. From a broader perspective, HKC, as a valuable empirical dataset, can be used to facilitate a variety of research on Chinese reading that can deepen our understanding of eye-movement controls in logographic language reading, especially how reading scenarios and contextual factors affect where readers move their eyes next (fixation location) and when (fixation duration)45. It can also be leveraged as training data for machine learning to predict reading behaviours, such as how readers select a saccade landing site, how they perform word segmentation, and where they encounter reading difficulties.
The HKC is now open to the public for academic, pedagogical, or any noncommercial use. Additional measures, not released in this version, are also available upon request. Users may integrate HKC with other linguistic data in a similar fashion as we used CLD, as long as the two sets of data can be properly aligned, especially by word matching. In the R language environment, users may consider subsetting HKC data in a way that best fits their interests with the aid of the filter function if the large size of the original data is their concern. In addition, a number of main packages, such as dplyr46, ggplot247, gtsummary48, lm449,50, performance51, sjplot52, and tidyverse53, are recommended for summarising and normalising data and for fitting (G)LMMs.
Code availability
Two R scripts (“preprocessing.R” and “lmeModelling.R”), resulting from the step-by-step coding for our data preprocessing and technical validation, respectively, are released in the repository of OSF32. Also released is the source code file (mergeChineseInfo.java) of a Java program for integrating lexical property information of CLD for the words in HKC by means of word matching, on the premise of a standardised format (word-based and UTF-8 comma-delimited data format).
References
Ayres, P., Lee, J. Y., Paas, F. & van Merriënboer, J. J. G. The validity of physiological measures to identify differences in intrinsic cognitive load. Front. Psychol. 12, 702538 (2021).
Kennedy, A. The Dundee Corpus (University of Dundee, 2003).
Kliegl, R., Grabner, E., Rolfs, M. & Engbert, R. Length, frequency, and predictability effects of words on eye movements in reading. Eur. J. Cogn. Psychol. 16, 262–284 (2004).
Kuperman, V., Dambacher, M., Nuthmann, A. & Kliegl, R. The effect of word position on eye-movements in sentence and paragraph reading. Q. J. Exp. Psychol. 63, 1838–1857 (2010).
Asahara, M., Ono, H. & Tadashi, M. E. BCCWJ-EyeTrack: Reading time annotation on the 'Balanced Corpus of Contemporary Written Japanese’. IEICE Tech. Rep. 116, 7–12 (2016).
Cop, U., Dirix, N., Drieghe, D. & Duyck, W. Presenting GECO: An eyetracking corpus of monolingual and bilingual sentence reading. Behav. Res. Methods 49, 602–615 (2016).
Hollenstein, N. et al. ZuCo, a simultaneous EEG and eye-tracking resource for natural sentence reading. Sci. Data 5, 180291 (2018).
Luke, S. G. & Christianson, K. The Provo Corpus: A large eye-tracking corpus with predictability norms. Behav. Res. Methods 50, 826–833 (2017).
Laurinavichyute, A. K., Sekerina, I. A., Alexeeva, S., Bagdasaryan, K. & Kliegl, R. Russian Sentence Corpus: Benchmark measures of eye movements in reading in Russian. Behav. Res. Methods 51, 1161–1178 (2018).
Hollenstein, N., Barrett, M. & Björnsdóttir, M. The Copenhagen Corpus of eye tracking recordings from natural reading of Danish texts. In Proceedings of the Thirteenth Language Resources and Evaluation Conference 1712–1720 (2022).
Siegelman, N. et al. Expanding horizons of cross-linguistic research on reading: The Multilingual Eye-movement Corpus (MECO). Behav. Res. Methods 54, 2843–2863 (2022).
Sui, L., Dirix, N., Woumans, E. & Duyck, W. GECO-CN: Ghent eye-tracking corpus of sentence reading for Chinese-English bilinguals. Behav. Res. Methods 1–21, https://doi.org/10.3758/s13428-022-01931-3 (2022).
Pan, J., Yan, M., Richter, E. M., Shu, H. & Kliegl, R. The Bei**g Sentence Corpus: A Chinese sentence corpus with eye movement data and predictability norms. Behav. Res. Methods 1–12, https://doi.org/10.3758/s13428-021-01730-2 (2021).
Zhang, G. et al. The database of eye-movement measures on words in Chinese reading. Sci. Data 9, 411 (2022).
Acartürk, C., Özkan, A., Pekçetin, T. N., Ormanoğlu, Z. & Kırkıcı, B. TURead: An eye movement dataset of Turkish reading. Behav. Res. Methods 1–24, https://doi.org/10.3758/s13428-023-02120-6 (2023).
Kennedy, A., Pynte, J., Murray, W. S. & Paul, S.-A. Frequency and predictability effects in the Dundee Corpus: An eye movement analysis. Q. J. Exp. Psychol. 66, 601–618 (2013).
Boston, M. F., Hale, J., Kliegl, R., Patil, U. & Vasishth, S. Parsing costs as predictors of reading difficulty: An evaluation using the Potsdam Sentence Corpus. J. Eye Mov. Res. 2, 1–36 (2008).
Slattery, T. J. & Parker, A. J. Return sweeps in reading: Processing implications of undersweep-fixations. Psychon. Bull. Rev. 26, 1948–1957 (2019).
Dirix, N. & Duyck, W. An eye movement corpus study of the age-of-acquisition effect. Psychon. Bull. Rev. 24, 1915–1921 (2017).
Hollenstein, N. & Zhang, C. Entity recognition at first sight: Improving NER with eye movement information. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies 1-10 (2019).
Hollenstein, N., Troendle, M., Zhang, C. & Langer, N. ZuCo 2.0: A dataset of physiological recordings during natural reading and annotation. Preprint at ar**v:1912.00903 (2019).
Hollenstein, N., Pirovano, F., Zhang, C., Jäger, L. & Beinborn, L. Multilingual language models predict human reading behavior. Preprint at ar**v:2104.05433 (2019).
Just, M. A. & Carpenter, P. A. A theory of reading: From eye fixations to comprehension. Psychol. Rev. 87, 329–354 (1980).
Asahara, M. Between reading time and clause boundaries in Japanese-wrap-up effect in a head-final language. In Proceedings of the 32nd Pacific Asia Conference on Language, Information and Computation (PACLIC 32) 19–27.
Rayner, K. Eye guidance in reading: Fixation locations within words. Perception 8, 21–30 (1979).
Yang, H.-M. & McConkie, G. W. Reading Chinese: Some basic eye-movement characteristics. In Reading Chinese Script: A Cognitive Analysis (eds. Wang, J. Inhoff, A. W. & Chen, H.-C.) 207–222 (Erlbaum, 1999).
Ma, W.-Y. & Chen, K.-J. Design of CKIP Chinese word segmentation system. Chin. Orient. Lang. Inf. Process. Soc. 14, 235–249 (2005).
Ma, W. Y. & Huang, C. R. Uniform and effective tagging of a heterogeneous giga-word corpus. In Proceedings of the Fifth International Conference on Language Resources and Evaluation (LREC’06). L06–1163 (European Language Resources Association (ELRA), 2006).
Sun, C. C., Hendrix, P., Ma, J. & Baayen, R. H. Chinese lexical database (CLD). Behav. Res. Methods 50, 2606–2629 (2018).
Sun, F., Morita, M. & Stark, L. W. Comparative patterns of reading eye movement in Chinese and English. Percept. Psychophys. 37, 502–506 (1985).
Andrews, S. & Veldre, A. Wrap** up sentence comprehension: The role of task demands and individual differences. Sci. Stud. Read. 25, 123–140 (2020).
Wu, Y. & Kit, C. Hong Kong Corpus of Chinese Sentence and Passage Reading. OSF https://doi.org/10.17605/OSF.IO/7UQ3J (2022).
Sereno, S. Measuring word recognition in reading: Eye movements and event-related potentials. Trends Cogn. Sci. 7, 489–493 (2003).
Graff, D. & Chen, K. Chinese Gigaword LDC2003T09 (Linguistic Data Consortium, 2003).
Cai, Q. & Brysbaert, M. SUBTLEX-CH: Chinese word and character frequencies based on film subtitles. PLoS One 5, e10729 (2010).
Van Esch, D. Leiden Weibo Corpus (Leiden University, 2012).
R Core Team. R: A language and environment for statistical computing (R Foundation for Statistical Computing, 2020).
RStudio Team. RStudio: Integrated development environment for R (RStudio, Inc., 2019).
Tullo, C. & Hurford, J. Modelling Zipfian distributions in language. In Proceedings of Language Evolution and Computation Workshop/Course 62–75 (ESSLLI, 2003).
Zang, C. New perspectives on serialism and parallelism in oculomotor control during reading: The multi-constituent unit hypothesis. Vision 3, 50 (2019).
Just, M. A. & Carpenter, P. A. The Psychology of Reading and Language Comprehension (Allyn & Bacon, 1987).
Zang, C., Liversedge, S. P., Bai, X. & Yan, G. Eye Movements during Chinese Reading (Oxford University Press, 2011).
Sun, F. & Feng, D. Eye movements in reading Chinese and English text. In Reading Chinese Script: A cognitive analysis (eds. Wang, J., Inhoff, A. W. & Chen, H.-C.) 201–218 (Psychology Press, 1999).
Warren, T., White, S. J. & Reichle, E. D. Investigating the causes of wrap-up effects: Evidence from eye movements and E-Z Reader. Cognition 111, 132–137 (2009).
Rayner, K., Sereno, S. C. & Raney, G. E. Eye movement control in reading: A comparison of two types of models. J. Exp. Psychol. Hum. Percept. Perform. 22, 1188–1200 (1996).
Wickham, H., François, R., Henry, L. & Müller, K. dplyr: A grammar of data manipulation. R package version 0.7.6. (2018).
Wickham, H. ggplot2: Elegant graphics for data analysis (Springer-Verlag, 2016).
Sjoberg, D. D., Whiting, K., Curry, M., Lavery, J. A. & Larmarange, J. Reproducible summary tables with the gtsummary package. R J. 13, 570 (2021).
Baayen, R. H., Davidson, D. J. & Bates, D. M. Mixed-effects modeling with crossed random effects for subjects and items. J. Mem. Lang. 59, 390–412 (2008).
Bates, D. M. lme4: Mixed-effects modeling with R (Springer, 2010).
Lüdecke, D., Ben-Shachar, M., Patil, I., Waggoner, P. & Makowski, D. performance: An R package for assessment, comparison and testing of statistical models. J. Open Source Softw. 6, 3139 (2021).
Lüdecke, D. sjPlot: Data visualization for statistics in social science.R package version 2.8.11 (2022).
Wickham, H. et al. Welcome to the tidyverse. J. Open Source Softw. 4, 1686 (2019).
Acknowledgements
This study was supported by grants from the RGC General Research Fund (GRF) 9042276 and CityU Strategic Research Grant (SRG-Fd) 7005411 and 7005708. Thanks go to all our participants and a group of PhD students and assistants (Yanmengnan Cui, Dandan Huang, **anhe Li, Di **ong, Bo Zhang, and Nannan Zhou) who helped with this project.
Author information
Authors and Affiliations
Author notes
Co-first author: Chunyu Kit.
- Chunyu Kit
Contributions
C. Kit conceived the experimental design and supervised material selection and data collection; Y. Wu conducted data retrieval and analysis and drafted the manuscript; C. Kit revised and finalised the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wu, Y., Kit, C. Hong Kong Corpus of Chinese Sentence and Passage Reading. Sci Data 10, 899 (2023). https://doi.org/10.1038/s41597-023-02813-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-023-02813-9
- Springer Nature Limited