
Abstract
Risk genes for Mendelian (single-gene) disorders (SGDs) are consistent across populations, but pathogenic risk variants that cause SGDs are typically population-private. The goal was to develop “QChip1,” an inexpensive genoty** microarray to comprehensively screen newborns, couples, and patients for SGD risk variants in Qatar, a small nation on the Arabian Peninsula with a high degree of consanguinity. Over 108 variants in 8445 Qatari were identified for inclusion in a genoty** array containing 165,695 probes for 83,542 known and potentially pathogenic variants in 3438 SGDs. QChip1 had a concordance with whole-genome sequencing of 99.1%. Testing of QChip1 with 2707 Qatari genomes identified 32,674 risk variants, an average of 134 pathogenic alleles per Qatari genome. The most common pathogenic variants were those causing homocystinuria (1.12% risk allele frequency), and Stargardt disease (2.07%). The majority (85%) of Qatari SGD pathogenic variants were not present in Western populations such as European American, South Asian American, and African American in New York City and European and Afro-Caribbean in Puerto Rico; and only 50% were observed in a broad collection of data across the Greater Middle East including Kuwait, Iran, and United Arab Emirates. This study demonstrates the feasibility of develo** accurate screening tools to identify SGD risk variants in understudied populations, and the need for ancestry-specific SGD screening tools.
Similar content being viewed by others


Introduction
A major goal of precision medicine is to optimize medical care for subgroups of patients based on genetic and/or molecular profiling1. A challenge in widespread adaptation of genetic profiling is the genome variability among different population groups2. One example is the identification of pathogenic variants in (Mendelian) single gene disorders (SGDs). While the same genes are responsible, there is considerable variability across populations in the specific causative pathogenic variants3. For example, while all pathogenic variants causing cystic fibrosis affect the CFTR gene, the common pathogenic variant observed in Puerto Rico4 is different from the variant observed in Qatar5 and both are different from the pathogenic variants common in European populations6. A recent analysis of ClinVar, the main NCBI database of pathogenic variants causative of SGDs, shows a significant bias towards pathogenic variants observed in European ancestry individuals2. As is the case for Hispanics, Blacks, and other non-European groups, SGD pathogenic variants found in Greater Middle Eastern populations are under-reported. Since screening technologies depend on public resources such as ClinVar7, OMIM8, and 1000 Genomes Project9 for source data, there are limited screening platforms to assess SGD pathogenic variants in the Greater Middle East10.
A striking example of this is the Qatari population11,12. The inhabitants of Qatar include approximately 300 thousand Qataris and 2.5 million expatriates13. The Qataris are comprised of distinct genetic subgroups11,14. The proportion of consanguineous marriage among Qataris is high15, leading to longer runs of homozygosity16. In addition, the tribal nature of marriages, where individuals select a mate from a limited gene pool that are members of the same tribe, contributes to higher chance of homozygosity for a pathogenic founder variant derived from a common ancestor, such as the well-known p.Arg366Cys CBS variant linked to homocystinuria17.
In prior studies, we and others have identified SGD pathogenic variants that are common in the Qatari population3 and in other Greater Middle East populations18, including many pathogenic variants that are only observed in Qatari genomes or are at an enriched (higher) risk allele frequency compared to populations outside of the Greater Middle East14. At present, there is a limited screening of the Qatari populations for inherited pathogenic variants19.
The focus of this study is to develop “QChip1,” a genoty** microarray designed as a research and screening tool capable of enabling precision medicine of Qataris. The aim for QChip1 was to enable accurate and comprehensive screening for SGD pathogenic variants in Qatari newborns, premarital couples and patients presenting to the clinic. First, we analyzed genetic data from 8445 Qataris, including whole-genome sequence (WGS), whole-exome sequence (WES), and clinical pathology case reports from affected families. Using these data, a Qatari Genome Knowledgebase was constructed, containing known and predicted pathogenic variants in SGDs. Second, with this knowledgebase, QChip1 was designed to assess the Qatari genome for SGD pathogenic variants in the knowledgebase. Third, QChip1 accuracy was confirmed by comparison of QChip1 genotypes to WGS data for a batch of Qatari genomes. Fourth, genomes from Qataris and residents of New York City (NYC), and Puerto Rico (PR) were genotyped on QChip1 to determine the prevalence of SGD pathogenic variants in Qataris and to compare this to other populations. The analysis demonstrated that QChip1 is highly accurate in identifying deleterious variants in Qataris, and that the majority of pathogenic variants among Qataris are Qatari-specific or Qatari-enriched. Overall, this study demonstrates the value of a custom genoty** array for precision medicine identification of pathogenic variants that cause single-gene disorders in human populations absent from or underrepresented by common knowledgebases used for pathogenic variant screening assay design7,8,9,20,21. In the interest of the advancement of science and open data sharing, a list of variants on the array, the genes and disorders with a known or potential link to the variants, and the prevalence of these variants in Qatar, Kuwait, NYC, and PR will be made available to the public through the QChip Browser (http://qchip.biohpc.cornell.edu), as well as through our 3rd party data sharing repositories at FigShare (https://figshare.com/projects/QChip1/120108) and NCBI BioProject (https://www.ncbi.nlm.nih.gov/bioproject/PRJNA774497).
Results
Construction of the Qatari Genome Knowledgebase
The Qatari Genome Knowledgebase of single gene coding sequence pathogenic and potentially pathogenic variants was based on sequence data from 8416 Qataris, including 6218 whole-genome sequence of Qataris recruited by the Qatar BioBank (QBB)22,23 and sequenced by the Qatar Genome Program (QGP)24,25, 180 whole-genome sequences12,26 and 1297 exome sequences11 of Qataris recruited by Weill Cornell Medicine Qatar and sequenced by Illumina, Bei**g Genomics Institute (BGI) or the New York Genome Center (NYGC), and 721 clinical reports from Hamad Medical Corporation (Supplementary Table 1). After filtering to remove variants observed in multiple cohorts, the analysis yielded 104,473,390 total variants in 20,069 genes in the Qatari population, including 87,813,560 single nucleotide variants (SNV) and 16,659,829 indels (Table 1); below we refer to this dataset as the Qatar Genome Knowlegebase (QGK). Assessment of QGK for ClinVar pathogenic variants and genes yielded a list of 10,490,820 variants in 3770 genes known to ClinVar. Parallel assessment of QGK for moderate or high impact variants in protein coding genes using SnpEff identified 805,649 variants in 19,770 genes (Table 1, Supplementary Table 2). The SnpEff list of moderate/high impact predicted variants was intersected with the ClinVar list of known variants and known genes to generate a final list of 207,370 pathogenic variants in 3770 genes, including 196,855 single nucleotide variants (SNVs) in 3769 genes and 10,515 indels in 1897 genes. This final list of variants included 13,891 (7%) predicted high impact (e.g., nonsense, frame shift and other loss of function) and 193,479 (93%) predicted moderate impact (e.g., missense variants).
Design of QChip1
For each variant in the Axiom QChip design, one or more probesets were added to the design, depending on the computationally predicted difficulty of obtaining a high-quality genotype, the priority of the variant, and available space on the array. QChip0 consisted of a total of 184,713 probes organized in 159,377 probesets for genoty** 91,942 variants in 3540 genes (Table 2). The additional probesets represent variants not previously genotyped by Thermo Fisher (formerly Affymetrix) arrays, for these novel variants (67,435 or 73.3% of 91,942) 2 or more probes were included in the probeset, while for known variants (24,507 or 26.7%) a single probe was included in the probeset.
QChip0 was then tested on 26 Qatari genomes for which WGS was available. Concordance was 99.7% ± 0.002 for n = 61,592 of n = 91,942 variant sites with non-missing genotypes in both WGS and QChip0 for all n = 26 samples. This high-confidence dataset consisted of 70,715 probes in 61,592 probesets for genoty** of 61,592 variants in 3438 genes (61,195 SNV probesets for 61,195 variants in 3476 genes, and 397 indel probesets for 397 variants in 300 genes), resulting in the final design of QChip1 (Table 2). Of these probes, 61,565 were autosomal and a small proportion (n = 27; 0.04%) non-autosomal (located in ChrX, ChrY, or MtDNA).
Testing of QChip1
The single nucleotide variants and indels represented on QChip1 were tested with an additional 473 Qatari genomes for which whole-genome sequencing was available24. After selection of the top performing probeset for each variant, probesets that were consistently top-performing across batches were compared to WGS genotypes. A total of 27,850 ± 0.75 variant sites where a high-confidence genotype was obtained for both QChip and WGS were compared, concordance was 99.1% ± 0.00034 (Table 3). Concordance was high for indels (92.4% ± 0.0057) and SNVs (99.2% ± 0.00034).
QChip1 was then used to determine the prevalence in the Qatari population and in non-Qatari populations for variants of interest for SGD pathogenicity research and screening in Qatar. Genoty** of n = 2708 Qatari, n = 226 European-American, South Asian American and African-American New York City (NYC) residents and n = 51 European and Afro-Caribbean Puerto Rico (PR) residents was conducted and analyzed as a single batch, including data from the first two (QChip0/QChip1) batches described above and a third batch with the rest of the samples. Probesets were again filtered based on performance, and variants were filtered based on missing genotype rate (<10%) low concordance with WGS in batches 1 or 2 (>90%) and minor allele frequency (<5%). The final set of variants for analysis included n = 32,674 SNVs. In order to assess the utility of QChip1 for use in other populations of the Greater Middle East (GME), the allele frequency of these variants was obtained for n = 540 Kuwaiti exomes and each variant was checked for presence in the Center for Arab Genetic Disorders (CAGS) database (http://cags.org.ae).
Use of QChip1
Among the 2,708 Qatari genomes tested, QChip1 identified a median of 2 homozygotes and 130 heterozygotes for SNVs of interest for SGD pathogenicity research and screening (Table 4). When assessed by Qatari subpopulations25, the highest median number (n = 205) of SNVs were identified in the Peninsular Arab subpopulation, 1.6-fold greater than the average median for the General Arab (109), Arabs of Western Eurasia and Persia (132), South Asian Arabs (137) and African Arab (129) subpopulations.
To help validate that QChip1 accurately detects known Qatari pathogenic variants, n = 140 variants identified as pathogenic either by the Hamad Medical Corporation (HMC) or by ClinVar were assessed in 2708 Qatari genomes by QChip1 (Table 5). There were n = 140 QChip1 pathogenic variants, including n = 140 (100%) present in ClinVar, n = 25 (18%) present in HMC, and n = 27 (19%) present in CAGS. Among these n = 140, n = 94 were only present in ClinVar, n = 19 were present in both HMC and ClinVar, n = 21 were present in ClinVar and CAGS but not HMC, and n = 6 present in all three pathogenic variant databases (ClinVar, HMC, CAGS). Among the n = 140 pathogenic variants, n = 3 were classified as “suspicious” based on high allele frequency (greater than 0.005)27. The three variants were previously reported in CAGS, HMC, or both, and appear to be truly pathogenic variants are enriched in the Qatari population due to founder effects, tribalism, consanguinity or a combination of these factors. One of these, NM_000071.2(CBS):c.1006C > T (p.Arg336Cys) linked to homocystinuria, is a well-documented founder variant in Qatar that was experimentally validated and is a priority for screening in the population17,28.
A major question for the future of QChip is the applicability of the variant list in other GME populations. In order to begin to answer this question, the QChip1 variant list was looked up in four datasets, including sequencing data from CAGS, Kuwait, Iran, and a collection across the GME (GME Variome)29,30,31,32. Out of the n = 140 pathogenic variants in Qatar genotyped by QChip1, 50%% (n = 70) were observed in one or more of the 4 GME datasets, including n = 28 (20%) in Kuwait, n = 32 (23%) in Iran, and n = 37 (26%) in the GME Variome. As expected, only n = 8 (6%) were observed in Puerto Rico and n = 16 (13%) were observed in NYC (Table 6). Based on these data, the utility of QChip1 was higher in GME than in the Americas; however, half the variants were unique to Qatar, and thus each GME nation (such as Kuwait and Iran) could benefit from a custom design.
All 140 of the pathogenic variants were accurately detected by QChip1 and were described in Table 5; for additional variants of interest for SGD research on QChip1 assessed on 2,708 Qatari genomes, see Supplementary Table 3. In Table 5 pathogenic variants were identified in CBS, a gene linked to homocystinuria (rs398123151 and rs121964972, 1 homozygote and 32 heterozygotes combined, 0.62% genomes), nemaline myopathy (rs886041851,16 heterozygotes, 0.3% genomes), and factor XI deficiency (rs121965063, 0.13% genomes). Relevant to these observations, all 2708 genomes tested were from the general medical clinic and general population, not from referrals to genetic disease clinics, and hence these data were interpreted as representative of the general population of Qatar.
Examination of the distribution of types of functional variants identified by QChip1 in the Qatari genome, the majority of variants of interest for research that were computationally predicted to have “high impact” were involved in structural interaction, which currently would be considered “benign” or “uncertain significance” by ACMG standards and ClinVar. The most common class of variants of interest for research that were computationally predicted “moderate” impact were missense variants (Supplementary Table 4). In some cases, the SnpEff annotation was different from the ClinVar annotation for a pathogenic variant, typically in situations where multiple transcripts lead to multiple alternative annotations for a varant and SnpEff is not aware of the “canonical” annotation in the literature, such as for NM_000071.2(CBS):c.1006C > T (p.Arg336Cys), which SnpEff correctly annotated on the transcript as c.1006C > T but did not provide the amino-acid change, but rather annotated it as “structural_interaction_variant”.
The applicability of the QChip1 was assessed across populations, including those directly genotyped using the array and others not genotyped in the array but of relevant Greater Middle Eastern ancestry. Of the 32,674 variants of interest for SGD research and screening were observed by QChip1 in at least 1 Qatari, 77% were at a frequency higher than any of the non-Qatari populations genotyped on the array (Fig. 1A). Among the Qatari genomes, the highest proportion of SGD risk alleles were in the Arabs of Western Eurasia and Persia, and African Arab subpopulations (Fig. 1A). As predicted, the majority (76%) of the Qatari genome pathogenic variants were not present in non-Qatari populations (Fig. 1B). QChip1 assessment of NYC and Puerto Rico residents demonstrated only rare detection of Qatari pathogenic variants in populations that included (based on genetic analysis of population clusters, Supplementary Fig. 1) European-American, South Asian-American, African-American populations (Table 5, Supplementary Table 3).

In order to demonstrate the population-specific value of QChip1, the risk alleles that were discovered by genome/exome sequencing, prioritized in the knowledgebase, included in the array design, successfully genotyped, and observed in array data for at least one of n = 2,708 Qataris are provided for download in Supplementary Table 1 and online at the Qatar Genome Browser (http://qchip.biohpc.cornell.edu). Shown is a summary of the population enrichment of these variants. A Enrichment of potentially pathogenic variants on QChip1 in Qatari subpopulations. In order to determine if Mendelian disease risk alleles were enriched in single Qatari subpopulations, a cross-population allele frequency comparison was conducted for five ancestries observed in Qatar (k1, QGP_PAR, Peninsular Arabs; k2, QGP_GAR, General Arabs; k4, QGP_WEP, Arabs of Western Eurasia and Persia; k5, QGP_SAS, South Asian Arabs, and k3, QGP_AFR, African Arabs). Not shown, QGP_ADM, Admixed Arabs. For each subpopulation, the risk allele frequency was compared to the maximum of the other four subpopulations. Shown is the proportion that was highest in the subpopulation for (left-to-right) QGP_PAR, QGP_GAR, QGP_WEP, QGP_SAS, and QGP_AFR. B Enrichment of potentially pathogenic variants on QChip1 in the Qatari genome relative to non-Qatari. The non-Qatari genomes were residents of New York City (total n = 226) and Puerto Rico (n = 51). The ancestry proportions of these 226 non-Qatari genomes in 5 clusters (k1 to k5) were calculated as described in Fig. 2 (combined analysis of non-Qataris and Qataris using ADMIXTURE68), the lowest cross-validation error was for k = 5, with the non-Qataris falling in 3 clusters (African-Americans from NYC, n = 60, k3; European-Americans from NYC, n = 153, k4; South Asian-Americans from NYC, n = 13, k5; Puerto Ricans of European Ancestry, k4; and Puerto Ricans of Afro-Caribbean Ancestry, k3). More details of the population structure were made available in Fig. 2 (Qataris) and Supplementary Fig. 1 (non-Qataris). Shown is the percentage of n = 32,674 potentially pathogenic variants in Mendelian (single gene) disorder genes that were observed in at least one Qatari and have a risk (minor) allele frequency in Qatar higher than in non-Qatari populations. The proportion of variants was calculated that were at elevated minor allele frequency (enriched) in the Qatari genome relative to the genomes of the 5 non-Qatari population clusters tested: USA African-American (k3), USA European-American (k4), USA South-Asian American (k5), PR Afro-Caribbean (k3), PR European (k4). Shown from left-to-right is the proportion that are enriched in Qatar relative to the maximum of all 5 populations, followed the proportion enriched relative to each individual population.
Within the subset of the variants that are known pathogenic and of interest for screening (n = 140), similar results were observed for Western populations, with only 6% of QChip1 pathogenic variants observed in Puerto Rico and only 13% found in NYC. Within Arab populations, the results were better but still not sufficient to justify the use of the array, with only 24% of QChip1 pathogenic variants observed in Kuwait and 15% reported in the Center for Arab Genetics Studies database.
Array performance
Using NGS data as the gold standard, the authors calculated the analytical sensitivity, specificity, accuracy, positive predictive value, and negative predictive value of QChip1. Using data from WGS and QChip1 for n = 140 (mostly rare) pathogenic variants in n = 472 Qatari, comparison was conducted for n = 66,220 genotypes. Of these, n = 39,286 could not be compared due to missing genotype in one of the two platforms, (99.8% were missing in WGS only), and among the remaining n = 26,934 there were n = 26,781 true negatives, n = 132 true positives, n = 21 false negatives, and n = 0 false positives. Based on these data, the sensitivity was 86.3%, the specificity was 100%, the accuracy was 99.9%, the positive predictive value was 100%, and the negative predictive value was 99.9%. This performance is very high relative to recently published evaluations of SNP chips performance on rare pathogenic variants33.
Discussion
This report described the design, testing, and application of QChip1, the first genoty** microarray specifically designed for precision medicine in the Greater Middle Eastern population. QChip was designed for and determined to be suitable for SGD research, clinical screening of newborns or couples planning children, and for genetic diagnosis of SGD patients in the country and in the region.
The main hypothesis of this project was confirmed, that variants of interest for SGD pathogenicity research and screening within known genes vary considerably across populations, as the majority of the QChip1 variants observed in Qatar were either Qatar-private or Qatar-enriched, and were absent from other GME populations and databases of SGD pathogenic variants specific to GME populations. In addition, the majority of QChip1 variants were absent from the Thermo Fisher database, one of the largest knowledgebases in the world of genetic disease variants used in clinical genetics and research genetics. Given the low cost (<$100 each array) and ease of use of the QChip1, it provides an accessible and sustainable alternative to extensive sequencing and interpretation of variants of unknown significance34 for the implementation of precision medicine in countries such as Qatar.
The development of QChip1 included the following steps: (1) assessment of the Qatari population to identify Qatari variants and genes of interest for SGD pathogenicity research and screening; (2) design and manufacture of genoty** probesets for inclusion in the QChip1 microarray; (3) refinement and testing of QChip1 by analysis of data from 469 Qataris also sequenced using WGS; and (4) use of the refined QChip1 for quantification of variants of interest for SGD pathogenicity research and screening in 2708 Qatari genomes, with a focus on (a) variants specific-to or enriched-in Qatar relative to non-Qatari DNA samples also genotyped using QChip1 and (b) variants known to be pathogenic.
The key findings of this study were that out of over 104 million variants in Qatar, extensive analysis both in silico and in vitro identified with over 99% accuracy over 32 thousand variants in the Qatari population that are known or predicted to alter the function of genes with a known role in SGDs. The majority of these 32 thousand variants were only observed in Qatar, including 103 of 140 (64%) known pathogenic variants previously observed in Qatari clinical case reports and in ClinVar. Of those variants also observed in Kuwait, the CAGS database of GME variants, NYC or Puerto Rico, the majority were enriched in Qatar, at a higher risk allele frequency. These observations confirm the hypothesis that a considerable proportion of SGD risk variants are population-private founder variants or population-enriched variants that drifted to elevated allele frequency in Qatar. Surprisingly, this hypothesis holds even when compared to neighboring GME populations. This observation justifies the effort invested this research team in develo** QChip1 and in producing a framework for the development of similar SGD clinical and research arrays for other understudied populations in the GME, the Americas, and beyond. The population genetic analysis presented here suggests that the high diversity of the Qatari population demonstrates the limited applicability of this array in the Greater Middle East region, which from a genetic perspective spans from Africa to Southern Europe, the Near East, Central Asia, and South Asia. The population-specificity of the variants on the array is a confirmation of the uniqueness and genetic isolation of the Qatari population as previously described by this research team.
The majority of genoty** arrays in use today were designed for coverage of the whole genome, and provide limited coverage of rare variants in genes known and potentially pathogenic in genetic disorders35. Screening arrays do exist, most designed for detection of cytogenetic defects in newborns36, arrays designed for pre-natal screening37, and exome arrays designed for exome-wide association studies (ExWAS)38. Exome sequencing is growing in popularity for the detection of risk variants, and a number of companies offer it as a service, including variant interpretation39. The challenge with exome sequencing is for clinical use is how to deal with the identification of variants of unknown significance40. In contrast, the concept of the QChip1 array is that all variants in the array were annotated prior to genoty**, hence circumventing the issue of variants of unknown significance issues while still covering rare variants. In this sense, the QChip1 knowledgebase is of great value, as it can be used to aid the interpretation of genetic data produced by targeted sequencing or genoty** of a panel of variants of interest for carrier screening, similar to the Plain Insight Panel41.
The challenge for array design is the selection of variants. There are over 7 million known missense and loss of function variants42, and no array can fit all. Unlike arrays designed for ExWAS, genome-wide association study (GWAS) and population genetics, limiting the array to common variants is not useful for screening for pathogenic variants, as common variants are less likely to be pathogenic, and rare variants are difficult to impute using reference panels and common variant genotype data43. In order to focus on pathogenic rare variants, arrays custom-tailored to a population are a better fit for individuals sampled from that population, as rare variants are more likely to be population-specific44.
This study provides advances in both knowledge and technology for the field of genomic medicine for a specific genetic population. On the knowledge front, it contains the largest knowledgebase of variants of interest for genetic disease research and screening in a Greater Middle Eastern population. While the consequences of many of the variants on QChip1 are unknown, the array provides a paradigm for clinical screening of this population and a platform for future genetic disease research in the Greater Middle Eastern populations. The variants included in the design and validated in a batch of n = 2708 Qatari were as rare as 1 in 5000 (minor allele frequency of 0.0002), and future whole-genome sequencing of Qataris are expected to yield thousands of additional variants of interest. A high confidence in the true existence of such rare SGD risk variants in the Qatari population was boosted by this study, as the variants were discovered by WGS and verified by QChip genoty**.
The QChip1 array did not include short tandem repeats, other repetitive variants, copy number variants, or structural variants. A small proportion of probes on QChip1 were designed for indel detection, but the concordance with whole-genome sequencing for the indels was inadequate. This may be due to inadequate probeset design and should be a focus for future QChip designs. The main limitation of arrays is the space for probes, and in this case the majority of variants were novel to the Axiom platform and hence required multiple probesets. In future iterations, the highest performing probesets identified in this study can be used, and poor performing probesets can be eliminated, thus making additional space on the array for additional variants. Thus, multiple iterations of QChip are needed to produce a high-quality design that genotypes a variety of variants. Another strategy that is frequently used by genoty** array manufacturers is to spread a design across multiple arrays that are genotyped together, i.e., the manufacturers can advertise an array with up to 5 million variants, in reality the “array” consists of 4 or more individual arrays45.
Another limitation of this study is cis/trans phase of variants, a challenge for exome sequencing. For example, multiple pathogenic variants in BTD can occur in the same genome, and hence screening for these variants includes a second step to determine phase46. In the case of this study, there were three pathogenic variants in BTD (rs397514369, rs13078881, rs138818907). Among those individuals with a BTD pathogenic variant, there were five heterozygotes for rs397514369, n = 4 homozygotes and n = 135 heterozygotes for rs13078881, and n = 5 heterozygotes for rs138818907. Zero individuals were positive for more than one BTD pathogenic variant, which rules out the possibility of two pathogenic variants in trans. However, were it the case that multiple BTD variants were observed in the same genome, follow-up validation of phase by Sanger sequencing would be needed. This is a disadvantage of exome sequencing and exome-focused array genoty**, as insufficient coverage of intergenic regions is available for phase inference. Follow-up sequencing is needed, until genome-wide technologies are widely available, such as WGS. Plans for QChip2 include broad coverage of sufficient variants for phase inference.
QChip1 was designed to be competitive relative to sequencing and existing arrays, hence there was a focus on achieving a platform that could provide data for under $100 per DNA sample, including reagents and labor. This is a price point that should remain competitive compared to alternative options for up to a decade, and remains the objective of major manufacturers of sequencing instruments47. A major saving is the small data footprint of the QChip1, relative to exome or genome sequencing, where orders of magnitude more data storage are needed. In particular, if the objective is to apply QChip1 on a national scale, the infrastructure investment is considerably more manageable for the prospect of running hundreds of thousands of arrays relative to sequencing hundreds of thousands of genomes or exomes. In perspective, the total Qatari population is approximately 300,000, so the entire Qatari population could be screened for all known and potentially pathogenic variants for approximately $30 million. As presented by the chair of the Qatar Foundation, HH Sheikha Moza bin Nassert at the WISH 2018 summit in Doha, such a precision medicine objective is under consideration for the next decade48.
Assessment of 2708 Qatari genomes shed novel insight into the Qatari population. As predicted from our prior assessments of the Qatari population3,11, the majority of the pathogenic and predicted pathogenic variants were Qatari-specific, underrepresented in non-Greater Middle Eastern genomes. The most commonly known and high predicted severity pathogenic variants were structural interaction variants and stop gain loss-of-function variants. The most pathogenic variants per genome were observed in the General Arab population, a finding that has implications for other Greater Middle East populations such as Kuwait, United Arab Emirates, and Saudi Arabia that share considerable ancestry with Qatar18,49,50,51. The median Qatari genome had 134 known or computationally predicted pathogenic alleles of interest for SGD research or screening. Of the known pathogenic alleles that were both previously observed in Qatar and known to the ClinVar database, the most common known pathogenic variants were causative of biotinidase deficiency, Stargardt disease, and homocystinuria. Among these 3 variants with risk allele frequency above 0.5% in Qatar, one was not previously known to the CAGS nor HMC databases NM_000060.2(BTD):c.[470G > A;1330G > C] linked to biotinidase deficiency. This is unusual, given the high frequency of the pathogenic variant at 0.0265, and could be an indication that either biotinidase deficiency is under-diagnosed in Qatar, or that the variant should be re-classified as “uncertain significance”. The other two variants with elevated risk allele frequency, one was reported in CAGS but not HMC database, NM_000350.2(ABCA4):c.[5512C > G;5882G > A] linked to Stargardt disease, risk allele frequency 0.0207. Again, it is unusual that the variant was not previously observed in the HMC database, although it is a known pathogenic variant in Arabs and quite possibly enriched in a subset of the Qatari population due to drift. The NM_000071.2(CBS):c.1006C > T (p.Arg336Cys) variant linked to homocystinuria is a well-known variant that is present in both the HMC and CAGS databases, and is known to be an enriched founder variant in the population. It was notable that this variant was incorrectly annotated by SnpEff as “structural interaction”, and only manual review based on the rsID identified the known function (Arg336Cys). This is an issue with annotation software that is not exclusive to SnpEff, where multiple transcripts overlap a variant (4 in the case of CBS), and the annotation for the “canonical” experimentally validated function of the variant in disease is buried among other annotations. This is a general problem in variant annotation, and computationally predicted annotations are to be considered an estimate that needs to be validated both by manual review of the literature and experimental validation in vitro. Other known pathogenic variants found using QChip1 included a Factor XI deficiency variant that was previously observed in both Arabs and in ancestral Jewish populations52.
QChip1 was designed to assess for pathogenic variants in SGDs, with the aim of genomic medicine for Qatari newborns, premarital couples and clinical genetics patients. A likely future strategy for QChip2 and beyond will be to produce multiple arrays for different purposes, including (1) genome-wide association array designed for genoty** of common variants and calculation of polygenic risk scores for multifactorial disorders53; (2) imputation of rare variants based on a Qatari genome imputation reference; (3) population-specific variants that influence drug kinetics and adverse effects; (4) structural variants and repeats; (5) expansion of the QChip1 SGD variants based on a larger sample of Qatari genomes; and (6) variants relevant to autoimmune disease and infectious disease in HLA54 and non-autosomal chromosomes, such as ChrX variants in the ACE2 receptor used by the SARS-Cov-2 virus to infect human cells55.
In addition to future versions of the array, the QChip knowledgebase and browser (Qatar Genome Browser) will continue to expand and be updated as more public data from Qatar and literature data on known SGD variants and genes become available. The knowledgebase, array, and browser produced by this project were intended as a first and enabling step towards advancing the state of the art of genomic medicine in Qatar and in populations that share ancestry with Qatar, as demonstrated in the population genetics analysis presented in this study. The intent is to demonstrate this approach as a framework for the development of precision medicine in populations of countries in continents such as Africa56, where a per-sample genome analysis cost beyond $100 is out of reach. Given the low cost of sequencing data production, the availability of cloud-based genome analysis infrastructure that does not require large capital investment, and the ease of rapid array design using the Axiom platform, a nation or population that currently has no prior knowledge of genetic variation could take the approach presented here and produce a genetic disease screening program in under a year, potentially saving thousands of lives at risk of unknowingly being affected by a genetic disorder.
The applicability of the QChip1 technology in the Qatari national population is clear, as all of the variants genotyped were previously observed in Qatari nationals, and we know from current and prior studies that the Qatari population sample used as the source of genetic variation for the QChip is also very diverse, with contributions of ancestry from Africa, Europe, and Asia11,12. The applicability to expatriates both living within Qatar and those outside of Qatar will depend on shared ancestry between the expatriate individual and the Qatari population. An expatriate coming from one of the populations that contribute to Qatari ancestry will be more likely to have one or more pathogenic variants in QChip. More distantly related individuals would see less benefit from QChip for screening. Confirming that hypothesis, only 6% of the known pathogenic variants were observed in Puerto Ricans, hence an expatriate from Puerto Rico in Qatar would not benefit as much from QChip1 screening as an expatriate from Kuwait, where 20% of QChip1 pathogenic variants were observed. Across the Greater Middle East region, a total of 50% of the QChip1 variants were observed. This study provides a strong argument for ancestry inference as a standard part of precision medicine, to determine the appropriate screening tool and allele frequency reference database for SGDs.
Methods
Subject recruitment and sample collection
All research participants were recruited using IRB-approved protocols and informed consent. Recruitment sites included Doha, Qatar (Weill Cornell Medicine – Qatar Institutional Review Board); New York, New York, USA (Weill Cornell Medicine Institutional Review Board); and Mayaguez, Puerto Rico, USA (Institutional Review Board, University of Puerto Rico at Mayagüez). Every research participant received and understood the accurate information in the consent document and other written information and (s)he released the permission to take part in the research by signing the informed consent. No plan was put in place for recontacting participants with information on actionable findings. DNA extracted from whole blood57 was tested for quality by RUCDR Infinite Biologics (Piscataway, New Jersey) to be of sufficient quality for array genoty**58.
Strategy to design and assess QChip1
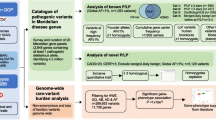
QChip1 was developed in steps (Fig. 2). Step 1. Pathogenic variants (known and predicted) in the coding regions of single genes in the Qatari genome were cataloged. Step 2. Using these data, QChip0 (the precursor of QChip1) was designed on the Axiom platform, tested using Qatari genomes and refined with optimal probes, variants and genes to create QChip1. Step 3. QChip1 was tested for concordance with whole-genome sequencing. Step 4. QChip1 was used to evaluate pathogenic variant Qatari prevalence and specificity by assessing genomes from Qataris and non-Qatari populations.

Step 1. Qatari Genome Knowledgebase. Identification of the single gene (Mendelian) pathogenic variants and genes in protein coding regions of the Qatari genome was generated using whole-genome sequencing, exome sequencing and clinical reports (see Table 1). After cataloging all variants and respective genes, the pathogenic variants and genes were identified using ClinVar and SnpEff. Step 2. Using this list, Qchip0 (the precursor of QChip1) was designed on the Axiom platform which was then tested with 25 Qatari DNA samples for which whole-genome sequencing was available. Step 3. Elimination of poor performance probes and variants led to the final design of QChip1, which was tested for concordance with genome sequencing using DNA samples from Qataris. Step 4. Use of QChip1 to assess the prevalence of pathogenic variants and genes among Qataris, New York City residents and Puerto Ricans.
Step 1: Identification of variants of interest for research or screening in the Qatari Genome
The knowledgebase of pathogenic variants in the Qatari genome was established from several sources, including (1) Qatar Genome Program whole-genome sequencing of 6218 Qatari genomes sequenced on the Illumina HiSeq (Illumina, San Diego, CA) at Sidra Medicine (Doha, Qatar); (2) Department of Genetic Medicine, Weill Cornell Medicine whole-genome sequencing of n = 180 Qatari genomes sequenced on the HiSeq at Illumina (n = 108)12 and the New York Genome Center (n = 72)26; (3) exome sequencing of n = 1297 Qatari genomes sequenced on the HiSeq at Bei**g Genomics Institute (n = 100)3 or New York Genome Center (n = 1197)11; and (4) n = 594 variants from n = 721 case reports of hereditary disorders identified by the Clinical Genetics Laboratory at Hamad Medical Corporation (HMC; Doha, Qatar; Supplementary Table 1). The HMC variants were collected in the period between 2002 and 2017, all probands were Qatari nationals. Details of the number of variants in each cohort were tabulated. The final knowledgebase without duplicates consisted of n = 104,473,390 variants, including single nucleotide variants (SNVs) and indels (short insertions and deletions; Table 1)
The identification of variants of interest for SGD research and screening in the Qatari genome was carried out in a 3 step process: (1) establishing a list of genes with a known link to Mendelian SGDs described in the ClinVar (version 7/21/20) database; (2) identification of Qatari variants computationally predicted to alter the function of SGD genes in a pathogenic maner, which are primarily of interest for SGD pathogenicity research, and (2) identification of Qatari variants known to be pathogenic in SGDs, based on being classified as such by the ClinVar database or by the HMC case reports.
Establishing a list of genes
A list of genes was compiled from ClinVar with the following criteria: (i) protein coding gene in human genome that (ii) has a known link to a SGD and (iii) contains one or more variants in ClinVar that are classified with a “clinical significance” value of “pathogenic” (Supplementary Table 2), recommended by American College of Medical Genetics (ACMG) for variants interpreted for Mendelian disorders59.
Identification of variants of interest for SGD pathogenicity research in Qataris
Single nucleotide variants (SNV) and indel variants in the Qatar Genome Knowledgebase were annotated using data from public and private sources. First, the allele frequency for each variant in Qataris and non-Qataris was calculated. Variants with a minor allele frequency above 5% in either Qataris or non-Qataris were excluded, per ACMG guidelines59. Second, variants were annotated with respect to impact on protein-coding genes in the ENSEMBL database60 using SnpEff61. Variants that did not affect the function of a SGD gene from ClinVar identified as described above were excluded. Third, variants that were predicted to produce missense or loss-of-function (LoF) variants were kept: these variants are classified by SnpEff as having “High” or “Moderate” potential impact on protein function. This collection of variants includes a variety of variants, including known pathogenic variants, variants of unknown significance, and benign variants.
Identification of pathogenic variants for SGD screening
Among the variants defined in step 1.2, a subset is known pathogenic variants, including those classified by ClinVar as pathogenic or those previously observed in HMC case reports of SGDs. These variants can be used for screening of Qataris in a Precision Medicine setting.
Step 2: Design of QChip1
The microarray platform for the QChip was based on the Axiom custom array platform capable of accommodating 1.3 × 106 probe features, each consisting of DNA probes covalently linked to a silicon wafer designed to hybridize DNA for the genomic sample. Multiple probes designed to hybridize to a genomic segment can be included in a single “probeset”, and one or more probesets designed to genotype a single variant can be included in the design, such that the performance of probes sets can be compared. The initial design was named “QChip0” and the final (post-quality-filtering) version as “QChip1”. The array design contained 693,652 probes in 597,049 probesets. A subset of n = 184,713 of the probes (27%), the focus of this report, were designed to assess variants of interest for SGD pathogenicity research and screening. These variants are computationally predicted or are known to affect the function of ClinVar SGD genes found in the variant knowledgebase. The remaining 73% of probes on QChip0, not the subject of this report, were designed for research purposes focused on population genetics, pharmacogenomics, and multifactorial disease research, and will be described in future publications based on future versions of QChip.
The probesets included probes complementary to reference and variant alleles, plus flanking sequence of 35 bases in both 5’ and 3’ directions. Note that this manuscript refers to reference GRCh38 and variant alleles from a genome sequencing perspective. However, in microarray genoty**, there is no “reference” allele, as both alleles are treated as equal by the technology, and hence potentially reducing false genotype calls attributable to reference bias62. Some variants were already present in the ThermoFisher (previously Affymetrix) knowledgebase, and thus previously validated to provide accurate genotypes for an SNV or indel, were assessed using a single probeset, while novel variants were assayed using two or more probesets.
Once the array was manufactured, it was tested on an initial batch of genomic DNA samples, including n = 26 Qataris from the Weill Cornell Medicine cohort WGS data. Genotypes were generated from the WGS data for these n = 26 using GATK Haplotype Caller 3.863,64, configured to output genotypes for all sites on the QChip list, including homozygous reference calls. Comparison of QChip and WGS genotypes was conducted for sites where both WGS and QChip produced a non-missing (sufficient quality) genotype.
In order to exclude poorly performing probesets, two rounds of filtering were applied, including a primary filter to select the highest performing probeset for each variant with multiple probesets, and a secondary filter to exclude variants with a high rate (>10%) of missing genotypes or high rate of discordant genotypes. Excluding poorly performing probes and variants led to the final design of QChip1 with 166,695 probes designed to detect 83,542 variants of 3438 genes. Concordance and filtering analysis were performed using Python65 scripts. The concordance analysis script takes as input two single-sample VCF files66 as input, including one with QChip1 genotypes and a second with WGS genotypes for all QChip1 sites (including reference and variant genotypes) by GATK 3.864.
Step 3: Test of QChip1
The concordance of genes and variants of QChip1 with whole-genome sequencing data was calculated for a second array genoty** batch of n = 443 Qatari genomic DNA samples previously sequenced using WGS by the Qatar Genome Program. Concordance was performed using the same method for the first batch of n = 26 as described above.
Step 4: Use of QChip1
QChip1 was then used to determine the prevalence of variants of interest for SGD research and screening in the Qatari population (n = 2708) compared to genomes for European-American, South Asian-American and African-American New York City (NYC) residents (n = 226) and European and Afro-Caribbean in Puerto Rico (PR) residents (n = 51). In addition to assessment of variant prevalence in Qataris as a single population, the population structure of Qataris was quantified as described previously67, and the prevalence of each variant was quantified for each known Qatari population cluster [Peninsular Arab (QGP_PAR), General Arab (QGP_GAR), Admixed Arab (QGP_ADM), Arabs of Western Eurasia and Persia (QGP_WEP), South Asian Arabs (QGP_SAS) and African Arabs (QGP_AFR); this nomenclature has replaced our prior nomenclature for these subgroups of Q1a, Q1b, Admixed, Q2a, Q2B and Q3, respectively, used in prior publications; Fig. 3]11. The population structure was quantified using ADMIXTURE68 for both Qataris and non-Qataris (Supplementary Fig. 1) using QChip1 data that was filtered to exclude indels, singletons, and variants in linkage disequilibrium (window 1000, step 25, maximum r2 0.1). Each genome was assigned to an inferred population cluster based on the k value with lowest cross-validation error (k = 5). Rather than classify individuals as admixed/non-admixed, each individual genome was assigned to the cluster (k) with the highest proportion of ancestry69. The results were visualized in a plot of principal components (PCs) calculated using PLINK70, with visualization in R71. Outliers were excluded based on over 2 standard deviations outside the median PC value for PCs 1 to 5. Each genome was color-coded by the inferred ancestry (1–5) and the country of origin (Qatar, US, PR).

Sites and samples that failed QC based on variant batch effects or PC outliers were excluded. After QC, ADMIXTURE analysis was conducted on the remaining n = 37,674 variants and n = 2985 samples of Qataris (n = 2708) and non-Qataris (n = 277) for a range of K from 3 to 12. The lowest cross-validation error was observed for k = 5 for the full dataset. After analysis, the Qatari and non-Qatari samples were plotted separately, the panels here show the Qatari samples from the joint analysis. A Admixture (k = 5) proportions. Shown is a plot of the admixture proportions (% k from 0 to 100%, y axis), with each column representing one genome, sorted from left-to-right by dominant (highest %) k, and decreasing % k1 to k5. Genomes are color-coded by the dominant (largest %) ancestry (QGP_PAR, Peninsular Arabs, red; QGP_GAR, General Arabs, orange; QGP_WEP, Arabs of West Eurasia and Persia, bright green; QGP_SAS, South Asian Arabs, olive green; and QGP_AFR, African Arabs, light blue). Samples from prior studies of Qatar population structure (Qatar Genome public samples from Fakhro et al.11 and Rodriguez-Flores et al.12 genotyped on QChip1 were included in the clustering analysis and were used to assign the clusters. B Principal components analysis of Qataris. Shown is a PC1 × PC2 plot of Qatari genomes in squares color-coded by cluster of largest proportion of inferred ancestry. Not shown, QGP_ADM, Admixed Arabs.
Data analysis
The final set of QChip1 data included SNV variants with high-quality genotypes and genomes with known ancestry that are of interest for research and screening of SGDs in Qataris. Analysis of these data included quantification and comparison across populations of the following parameters: (1) individual burden of variants; (2) prevalence of variants; (3) enrichment of variants among Qatari subpopulations; and (4) enrichment of variants in Qataris compared to non-Qatari populations.
Performance
Once a final set of pathogenic variants screened using QChip1 was identified, the performance of the array was quantified. Data for QChip1 and WGS was compared on n = 140 pathogenic variants for n = 472 genomes. Using WGS as a “gold standard”, the number of true negative (TN, both WGS and QChip1 call wild type genotype), true positive (TP, both WGS and QChip1 call heterozygote or homozygote for risk allele), false negative (FN, WGS calls positive but QChip1 calls negative), and false positive (FP, WGS calls negative and QChip1 calls positive). Based on these four numbers, the sensitivity [TP/(TP + FN)], specificity [TN/(TN + FP)], accuracy [TP/(TN + TP + FN + FP)], positive predictive value [TP/(TP + FP)], and negative predictive value [TN/(TN + FN)] was calculated.
Utility beyond Qatar
In order to assess the potential utility of QChip1 beyond Qatar, the number of QChip1 pathogenic variants was quantified in internal and external knowledgebases. The internal knowledgebases included the QChip1 data for Qatar, NYC, Puerto Rico, and the Hamad Medical Corporation (https://www.hamad.qa/EN/Pages/default.aspx) list of pathogenic variants. The external knowledgebases included ClinVar (https://www.ncbi.nlm.nih.gov/clinvar/), the Center for Arab Genetics Studies (https://www.cags.org.ae/en), the Iranome (http://www.iranome.ir/), the GME Variome (http://igm.ucsd.edu/gme/), and a set of exomes sequenced by the Dasman Diabetes Institute in Kuwait (https://www.dasmaninstitute.org/). Among the external databases, allele frequency was available for Iran (n = 800), GME (n = 886), and Kuwait (n = 540). The subset of variants present in one or more of the knowledgebases, as well as the subset present in one or more external knowledgebase focusing on the Greater Middle East region (CAGS, Iran, GME, Kuwait) was also quantified.
QChip genome browser
In order to provide researchers and clinicians access to annotation and allele frequency data in Qatar and USA for the QChip1 Qatar SGD pathogenicity research and screening variants and genes, a web browser was constructed. The Qatar Genome Browser architecture consisted of a searchable table with a user interface implemented in a Shiny RStudio72 application frontend, running within a Docker (docker.com) container instance installed on a Linux Centos (centos.org) server backend. The server was custom built by Red Barn (thinkredbarn.com) and configured by Cornell BioHPC73. In order to maintain security, the development version was accessible only within Cornell campus network or via Cornell VPN, with plans for a public release after publication of this report. Testing of the server was conducted to confirm that the url (http://qchip.biohpc.cornell.edu) was accessible from both Weill Cornell Medicine New York and Weill Cornell Medicine Qatar.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
Public datasets not produced by the authors and used in this study that describe disease genes, variants in disease genes, and their prevalence in Greater Middle East populations are available from ClinVar (https://www.ncbi.nlm.nih.gov/clinvar/), the Center for Arab Genetics Studies (https://www.cags.org.ae/en), the Iranome (http://www.iranome.ir/), the GME Variome (http://igm.ucsd.edu/gme/), and the Thanaraj Lab at the Dasman Diabetes Institute in Kuwait (https://research.dasmaninstitute.org/en/persons/alphonse-thangavel-thanaraj).
The data produced by the authors and used in this study can be divided into three categories: (1) sequence and genotype data used to produce the QChip knowledgebase of variants (2) QChip genotype data, and (3) summaries of variants in QChip. For the sake of scientific reproducibility, availability and access to these three categories of data is described here.
Category 1 data includes WGS data produced either by the Qatar Genome Program (QGP), Qatar BioBank (QBB) or by Weill Cornell Medicine, WES data produced by Weill Cornell Medicine (WCM), and a table of pathogenic variants previously observed at Hamad Medical Corporation (HMC). The QGP/QBB WGS data is described in Mbarek et al24, sharing of these data outside of Qatar is prohibited and is not consented by the IRB protocol. However, external access to QBB/QGP genotype and phenotype data can be obtained through an established ISO-certified process by submitting a project request at https://www.qatarbiobank.org.qa/research/how-apply which is subject to approval by the QBB IRB committee. A detailed description of the data management infrastructure for QBB was described previously22. The data and biosamples collected or generated by QBB are available to researchers at public and private institutions that conduct scientific research and that meet the requirements detailed in the Qatar Biobank Research Access policy. Approved Users are given access to QBB’s Research Data and/or Biosamples for the period agreed upon in the approved Access Agreement, with the possibility of subsequent renewal.” For more information on what meets the requirements, researchers can request the Qatar Biobank Research Access policy from qbbrpsupport@qf.org.qa. This policy has enabled data sharing and collaboration in multiple studies, including a population genetics analysis of over 6000 Qataris25 and the latest results of the COVID-19 Host Genetics Initiative74.
Category 1 data also includes WGS and WES data produced by Weill Cornell Medicine, these data are available for sharing with researchers. The majority of these data was described in prior publications and is available for download from NCBI SRA, see SRP060765 for published WGS data, SRP061943 and SRP061463 for published WES data. Unpublished WGS data from this study is accessible Unpublished WGS data from this study is accessible through NCBI BioProject PRJNA774497.
Category 1 data also includes an unpublished list of variants identified by HMC, these data are available from a FigShare repository created for this project (https://figshare.com/projects/QChip1/120108).
Category 2 data consists of QChip array genotypes for Qataris recruited by WCM, Qataris recruited by QBB, New Yorkers recruited by WCM, and Puerto Ricans recruited by UPRM. Consent for data sharing is not possible for Qataris recruited by QBB as well as for Puerto Ricans recruited by UPRM. QChip array genotypes for Qataris and New Yorkers recruited by WCM was deposited at NCBI (project accession PRJNA774497) and is included in the FigShare repository (https://figshare.com/projects/QChip1/120108).
Category 3 data consists of summaries of QChip variants, including annotation from Thermo Fisher (Affymetrix) on the QChip contents, annotation produced by the authors on QChip contents including allele frequency, a list of QChip variants of interest for SGD research, and a list of QChip variants of interest for SGD screening. All four datasets are available through the FigShare repository (https://figshare.com/projects/QChip1/120108). A browsable version of the list of variants with allele frequency data is in development and will be available at the project website (http://qchip.biohpc.cornell.edu). Variants of interest for screening in Qatar on QChip1 were deposited to dbSNP in a batch submission, are expected to be a part of dbSNP build 156, and were assigned the following accessions: ssID 2137544269 and ssIDs 5314393773 through 5314393911. The batch submission is available online at https://www.ncbi.nlm.nih.gov/SNP/snp_viewBatch.cgi?sbid=1063269.
Code availability
Software code consisting of Python, Bash, and R scripts used to produce and analyze the data presented in this manuscript are available through the GitHub https://github.com/juansearch/qchip1 and on the project website http://qchip.biohpc.cornell.edu.
References
Green, E. D. et al. Strategic vision for improving human health at The Forefront of Genomics. Nature 586, 683–92 (2020).
Popejoy, A. B. et al. The clinical imperative for inclusivity: race, ethnicity, and ancestry (REA) in genomics. Hum. Mutat. 39, 1713–20 (2018).
Rodriguez-Flores, J. L. et al. Exome sequencing identifies potential risk variants for Mendelian disorders at high prevalence in Qatar. Hum. Mutat. 35, 105–16 (2014).
Zeiger, A. M. et al. Identification of CFTR variants in Latino patients with cystic fibrosis from the Dominican Republic and Puerto Rico. Pediatr. Pulmonol. 55, 533–40 (2020).
Hammoudeh, S., Gadelhak, W., AbdulWahab, A., Al-Langawi, M. & Janahi, I. A. Approaching two decades of cystic fibrosis research in Qatar: a historical perspective and future directions. Multidiscip. Respiratory Med. 14, 29 (2019).
Terlizzi, V. et al. S737F is a new CFTR mutation typical of patients originally from the Tuscany region in Italy. Ital. J. Pediatrics 44, 2 (2018).
Landrum, M. J. et al. ClinVar: public archive of interpretations of clinically relevant variants. Nucleic Acids Res 44, D862–868 (2016).
Amberger, J. S., Bocchini, C. A., Schiettecatte, F., Scott, A. F. & Hamosh, A. OMIM.org: Online Mendelian Inheritance in Man (OMIM(R)), an online catalog of human genes and genetic disorders. Nucleic Acids Res. 43, D789–798 (2015).
Genomes Project, C. et al. A global reference for human genetic variation. Nature 526, 68–74 (2015).
Krstić, N. & Običan, S. G. Current landscape of prenatal genetic screening and testing. Birth Defects Res. 112, 321–31 (2020).
Fakhro, K. A. et al. The Qatar genome: a population-specific tool for precision medicine in the Middle East. Hum. Genome Var. 3, 16016 (2016).
Rodriguez-Flores, J. L. et al. Indigenous Arabs are descendants of the earliest split from ancient Eurasian populations. Genome Res. 26, 151–62 (2016).
Census 2010, Planning and Statistics Authority, https://www.psa.gov.qa/en/statistics1/StatisticsSite/Census/census2010/Pages/default.aspx [last accessed 12/13/21].
Rodriguez-Flores, J. L. et al. Exome sequencing of only seven Qataris identifies potentially deleterious variants in the Qatari population. PLoS ONE 7, e47614 (2012).
Bener, A. & Hussain, R. Consanguineous unions and child health in the State of Qatar. Paediatr. Perinat. Epidemiol. 20, 372–8 (2006).
Hunter-Zinck, H. et al. Population genetic structure of the people of Qatar. Am. J. Hum. Genet. 87, 17–25 (2010).
Zschocke, J. et al. Molecular neonatal screening for homocystinuria in the Qatari population. Hum. Mutat. 30, 1021–2 (2009).
Monies, D. et al. The landscape of genetic diseases in Saudi Arabia based on the first 1000 diagnostic panels and exomes. Hum. Genet. 136, 921–39 (2017).
El Shanti, H., Chouchane, L., Badii, R., Gallouzi, I. E. & Gasparini, P. Genetic testing and genomic analysis: a debate on ethical, social and legal issues in the Arab world with a focus on Qatar. J. Transl. Med. 13, 358 (2015).
Lek, M. et al. Analysis of protein-coding genetic variation in 60,706 humans. Nature 536, 285–91 (2016).
Stenson, P. D. et al. The Human Gene Mutation Database: towards a comprehensive repository of inherited mutation data for medical research, genetic diagnosis and next-generation sequencing studies. Hum. Genet. 136, 665–77 (2017).
Fthenou, E. et al. Conception, Implementation, and Integration of Heterogenous Information Technology Infrastructures in the Qatar Biobank. Biopreservation Biobanking 17, 494–505 (2019).
Al Thani, A. et al. Qatar Biobank Cohort Study: study design and first results. Am. J. Epidemiol. 188, 1420–33 (2019).
Mbarek, H. et al. Qatar Genome: insights on genomics from the Middle East. medRxiv https://doi.org/10.1101/2021.09.19.21263548 (2021).
Razali, R. M. et al. Thousands of Qatari genomes inform human migration history and improve imputation of Arab haplotypes. Nat. Commun. 12, 5929 (2021).
Rodriguez-Flores, J. L. et al. Bioinformatics workflow for whole genome sequence linkage analysis of multiplefamilies afflicted with rare disease of unknown heredity and penetrance. American Society of Human Genetics 66th Annual Meeting Vancouver, Canada, October 18–22, 2016.
Wright, C. F. et al. Evaluating variants classified as pathogenic in ClinVar in the DDD Study. Genet. Med. 23, 571–5 (2021).
El-Said, M. F. et al. A common mutation in the CBS gene explains a high incidence of homocystinuria in the Qatari population. Hum. Mutat. 27, 719 (2006).
Tadmouri, G. O., Al Ali, M. T., Al-Haj Ali, S. & Al Khaja, N. CTGA: the database for genetic disorders in Arab populations. Nucleic Acids Res. 34, D602–606 (2006).
Scott, E. M. et al. Characterization of Greater Middle Eastern genetic variation for enhanced disease gene discovery. Nat. Genet. 48, 1071–6 (2016).
John, S. E. et al. Genetic variants associated with warfarin dosage in Kuwaiti population. Pharmacogenomics 18, 757–64 (2017).
Fattahi, Z. et al. Iranome: a catalog of genomic variations in the Iranian population. Hum. Mutat. 40, 1968–84 (2019).
Weedon, M. N. et al. Use of SNP chips to detect rare pathogenic variants: retrospective, population based diagnostic evaluation. BMJ 372, n214 (2021).
Vears, D. F., Niemiec, E., Howard, H. C. & Borry, P. Analysis of VUS reporting, variant reinterpretation and recontact policies in clinical genomic sequencing consent forms. Eur. J. Hum. Genet. 26, 1743–51 (2018).
Thermo Fisher Scientific, Human Genoty**, Pharmacogenomics, and Microbiome Solutions with Microarrays, 2020, https://www.thermofisher.com/us/en/home/life-science/microarray-analysis/human-genoty**pharmacogenomic-microbiome-solutions-microarrays.html [last accessed 12/13/21].
Green, N. S. & Pass, K. A. Neonatal screening by DNA microarray: spots and chips. Nat. Rev. Genet. 6, 147–51 (2005).
Levy, B. & Wapner, R. Prenatal diagnosis by chromosomal microarray analysis. Fertil. Steril. 109, 201–12 (2018).
Guo, Y. et al. Illumina human exome genoty** array clustering and quality control. Nat. Protoc. 9, 2643–62 (2014).
Nykamp, K. et al. Sherloc: a comprehensive refinement of the ACMG-AMP variant classification criteria. Genet. Med. 19, 1105–17 (2017).
Petersen, B. S., Fredrich, B., Hoeppner, M. P., Ellinghaus, D. & Franke, A. Opportunities and challenges of whole-genome and -exome sequencing. BMC Genet. 18, 14 (2017).
Clinic for Special Children, Plain Insight Panel: Expanded Carrier Testing, 2019, https://clinicforspecialchildren.org/wp-content/uploads/2019/10/2019-Plain-Insight-Brochure.pdf [last accessed12/13/21].
Rodriguez-Flores, J. L. & Crystal, R. G. Computational variant impact prediction for gain-of-function somatic Missense SNVs. Eur. J. Hum. Genet. 27, 410 (2019).
Kowalski, M. H. et al. Use of >100,000 NHLBI Trans-Omics for Precision Medicine (TOPMed) Consortium whole genome sequences improves imputation quality and detection of rare variant associations in admixed African and Hispanic/Latino populations. PLoS Genet. 15, e1008500 (2019).
Abecasis, G. R. et al. An integrated map of genetic variation from 1,092 human genomes. Nature 491, 56–65 (2012).
illumina, Infinium Omni5-4 Kit, 2020, https://www.illumina.com/products/by-type/microarray-kits/infinium-omni5-quad.html [last accessed 12/13/21].
Borsatto, T. et al. Biotinidase deficiency: clinical and genetic studies of 38 Brazilian patients. BMC Med. Genet. 15, 96 (2014).
Bayley, H. Sequencing single molecules of DNA. Curr. Opin. Chem. Biol. 10, 628–37 (2006).
Ginsburg, G. S. et al. In World Innovation Summit for Health (https://www.wish.org.qa/wp-content/uploads/2018/01/IMPJ4495_WISH_Precision_Medicine_Report_WEB.pdf).
John, S. E. et al. Assessment of coding region variants in Kuwaiti population: implications for medical genetics and population genomics. Sci. Rep. 8, 16583 (2018).
AlSafar, H. S. et al. Introducing the first whole genomes of nationals from the United Arab Emirates. Sci. Rep. 9, 14725 (2019).
Fernandes, V. et al. Genome-wide characterization of Arabian Peninsula populations: shedding light on the history of a fundamental bridge between continents. Mol. Biol. Evol. 36, 575–86 (2019).
Peretz, H. et al. The two common mutations causing factor XI deficiency in Jews stem from distinct founders: one of ancient Middle Eastern origin and another of more recent European origin. Blood 90, 2654–9 (1997).
Khera, A. V. et al. Genome-wide polygenic scores for common diseases identify individuals with risk equivalent to monogenic mutations. Nat. Genet. 50, 1219–24 (2018).
Hosomichi, K., Shiina, T., Tajima, A. & Inoue, I. The impact of next-generation sequencing technologies on HLA research. J. Hum. Genet. 60, 665–73 (2015).
Shang, J. et al. Structural basis of receptor recognition by SARS-CoV-2. Nature 581, 221–4 (2020).
Bentley, A. R., Callier, S. & Rotimi, C. The emergence of genomic research in Africa and new frameworks for equity in biomedical research. Ethnicity Dis. 29, 179–86 (2019).
Lauro, F. M., Chastain, R. A., Blankenship, L. E., Yayanos, A. A. & Bartlett, D. H. The unique 16S rRNA genes of piezophiles reflect both phylogeny and adaptation. Appl. Environ. Microbiol. 73, 838–45 (2007).
Guha, P., Das, A., Dutta, S. & Chaudhuri, T. K. A rapid and efficient DNA extraction protocol from fresh and frozen humanblood samples. J. Clin. Laboratory Anal. 32, e22181 (2018).
Richards, S. et al. Standards and guidelines for the interpretation of sequence variants: a joint consensus recommendation of the American College of Medical Genetics and Genomics and the Association for Molecular Pathology. Genet. Med. 17, 405–24 (2015).
Zerbino, D. R. et al. Ensembl 2018. Nucleic Acids Res. 46, D754–d761 (2018).
Cingolani, P. et al. A program for annotating and predicting the effects of single nucleotide polymorphisms, SnpEff: SNPs in the genome of Drosophila melanogaster strain w1118; iso-2; iso-3. Fly 6, 80–92 (2012).
Martiniano, R., Garrison, E., Jones, E. R., Manica, A. & Durbin, R. Removing reference bias and improving indel calling in ancient DNA data analysis by map** to a sequence variation graph. Genome Biol. 21, 250 (2020).
McKenna, A. et al. The Genome Analysis Toolkit: a MapReduce framework for analyzing next-generation DNA sequencing data. Genome Res. 20, 1297–303 (2010).
Van der Auwera, G. A. et al. From FastQ data to high confidence variant calls: the Genome Analysis Toolkit best practices pipeline. Curr. Protoc. Bioinform. 43, 10.11–-11.10.33 (2013).
python.org, The Python Language Reference, 2020, https://docs.python.org/3/reference/ [last accessed 12/13/21].
Danecek, P. et al. The variant call format and VCFtools. Bioinformatics (Oxf., Engl.) 27, 2156–8 (2011).
O’Beirne, S. L. et al. Exome sequencing-based identification of novel type 2 diabetes risk allele loci in the Qatari population. PLoS ONE 13, e0199837 (2018).
Alexander, D. H., Novembre, J. & Lange, K. Fast model-based estimation of ancestry in unrelated individuals. Genome Res. 19, 1655–64 (2009).
O’Beirne, S. L. et al. Type 2 diabetes risk allele loci in the Qatari population. PLoS ONE 11, e0156834 (2016).
Chang, C. C. et al. Second-generation PLINK: rising to the challenge of larger and richer datasets. GigaScience 4, 7 (2015).
Ihaka, R. & Gentleman, R. R: a language for data analysis and graphics. J. Comput. Graph. Stat. 5, 299–314 (1996).
R Studio, Shiny from R Studio, 2020, https://shiny.rstudio.com/ [last accessed 12/13/21].
Cornell University, Institute of Biotechnology, Bioinformatics Internal Site Home, 2017, https://biohpc.cornell.edu/Default.aspx [last accessed 12/13/21].
COVID-19 Host Genetics Initiative. Map** the human genetic architecture of COVID-19. Nature (2021). https://doi.org/10.1038/s41586-021-03767-x [last accessed 12/13/21].
Acknowledgements
This is a collaborative work between Qatar Genome, Qatar Biobank, Weill Cornell (New York and Qatar), Hamad Medical Corporation and Sidra Medicine. We are thankful for everyone who contributed to this endeavor from all participating institutes. We would like to especially thank all participants in this study for their continuous support. We thank Dr. Fatemeh Abbaszadeh, for quality control and implementing QChip in the diagnostic services; N. Mohamed for editorial support, E. Betancourt for administrative support, E. Guzman for IT support, and J. Pillardy for high-performance computing support. J.R.F. also thanks Alan R. Shuldiner and Regeneron Genetics Center for supporting, J.R.F. to help complete this project. Special thanks to Alphonse Tharangeval at the Dasman Diabetes Institute in Kuwait for providing allele frequency lookups, and to the Center for Arab Genetic Studies in UAE, the GME Variome at University of California at San Diego and the Iranomefor providing public access to their databases. The authors are saddened by the passing of Andrew Brooks after the manuscript was submitted to the journal for review. This publication was made possible by The Qatar Foundation, the Weill Cornell Medical College in Qatar; NPRP 09-741-3 193, NPRP 5-436-3-116, NPRP 7-1425-3-370, NPRP 7-1301-3-336, and NPRP P8-1913-3-396 from the Qatar National Research Fund (a member of the Qatar Foundation). The findings achieved herein are solely the responsibility of the authors.
Author information
Authors and Affiliations
Contributions
J.R.F. helped conceptualize the project, chose and annotated the variants, contributed to array design and carried out all of the analyses relating to the QChip. R.T. and N.S. performed the quality control of the sequenced genomic data as well the joint variants calling and contributed in the design of the micro-array. A.R. led the Weill Cornell-Qatar aspect of the project. R.M.-B., Y.A., H.M., W.M., M.A. managed the sequencing project and provided assistance with particular tasks. Z.N., R.B., and A.A.N. contributed in the design of the microarray. M.M., E.K., F.Q., and N.A. contributed in the analytical validation of the micro-array. A.A.S. contributed to identification and phenoty** of subjects. J.M., K.A.F. contributed to the analysis of the Weill Cornell-Qatar subjects. K.M. helped conceptualize the project. A.B. contributed to the array design, quality control of sample, and overall management of the project. R.G.C., S.I.I. and A.A. designed and led the project.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Rodriguez-Flores, J.L., Messai-Badji, R., Robay, A. et al. The QChip1 knowledgebase and microarray for precision medicine in Qatar. npj Genom. Med. 7, 3 (2022). https://doi.org/10.1038/s41525-021-00270-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41525-021-00270-0
- Springer Nature Limited