
Abstract
An interval type-2 (IT2) mutual subsethood Cauchy fuzzy neural inference system has been proposed in this paper. The network architecture consists of 3-layers with all connection weights being IT2 Cauchy fuzzy membership functions (CMFs). The crisp inputs to the system are fuzzified into IT2CMFs with fixed centers and uncertain spreads. The hidden layer represents the rule-based knowledge. The firing degree of the antecedent part of each rule at the hidden layer is computed by aggregating the product of the mutual subsethood similarity measures between the inputs and the connection weights. A volume defuzzification is used to compute the numeric output. A gradient descent back-propagation algorithm is used to train the model. The novelty of the proposed model is threefold. First, is enriching the theory of the mutual subsethood fuzzy neural models by adopting the Cauchy membership function (CMF) as another powerful fuzzy basis function (FBF) rather than the classical choice of Gaussian fuzzy membership functions (GMFs). Second, is the success of computing the mutual subsethood similarity measure between the IT2CMFs and all the model parameters’ updating equations in analytic closed-form formulas, not numerically or approximately. Third, is the ability to extract the type-1 (T1) mutual subsethood Cauchy fuzzy neural inference system (T1MSCFuNIS) with all its analytic closed-form formulas directly as a special case from the general formulas of IT2MSCFuNIS model. Such a novelty makes the proposed model a concrete and effective development of the theory of mutual subsethood fuzzy neural models. Both IT2MSCFuNIS and T1MSCFuNIS models have been tested using different examples from the domains of function approximation, classification, and prediction. The results ensure the efficacy of both models compared with other models reported in the literature.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Fuzzy logic has been successfully used in a wide range of real-world applications. There are mainly two different approaches for designing a Fuzzy Logic System (FLS), namely: type-1 FLS (T1FLS) and type-2 FLS (T2FLS). The primary distinction between the two types is that grades of membership functions (MFs) in T1FLS are certain, whereas they are fuzzy in T2FLS [1].
Although T1FLSs have been used in a variety of nonlinear application problems, they still cannot handle high uncertainties, which affect the accuracy and performance of the systems. Such uncertainties stem from a variety of sources, including differences in the expert estimation of the MFs of the same linguistic values, different answers to the same question, noise in measurements, and noisy data [2, 3].
On the other hand, since MFs in T2FLSs are themselves fuzzy, they can handle uncertainties better than their type-1 counterparts.
The fact that the Footprint of Uncertainty (FOU) of a type-2 fuzzy MF (T2FMF) contains arbitrary forms of type-1 fuzzy MF (T1FMF) allows handling higher levels of uncertainty, particularly in noisy environments and environments with incomplete data [4]. However, despite such a powerful capability of T2FLSs, they are highly computationally expensive and time-consuming [5]. Therefore, interval type-2 fuzzy logic system (IT2FLs) has been proposed as a simplified less computational complexity form of the general T2FLs [6, 7].
IT2 fuzzy sets (IT2FSs) have been used in a wide range of applications. In [8], Liu, and Mendel presented a practical type-2 fuzzistics methodology for obtaining IT2FS models for words. In [9], Castro et al. presented a novel homogeneous integration strategy for an IT2 fuzzy inference system and applied it to forecasting the Mackey–Glass chaotic time series. In [10], Du et al. proposed an IT2 fuzzy control for nonlinear plants with parameter uncertainty. In [11], Chen and Barman proposed an adaptive weighted fuzzy interpolative reasoning method based on representative values and similarity measures of IT2 polygonal fuzzy sets to resolve contradictions in fuzzy rule-based systems. In [12], Li et al. applied Gaussian IT2FS theory to historical traffic volume data processing to obtain a high-precision 24-h prediction of traffic volume. In [31], in dynamic systems processing, e.g. [32, 33] and in time series prediction, e.g. [34, 35].
Earlier researches emphasized the direct effect of the shape of fuzzy sets adopted for the inputs of a fuzzy system on its approximation capability [36]. Therefore, more shapes of fuzzy membership functions (FMFs) should be investigated rather than being limited to a few traditional forms [37].
Motivated by this idea, this paper presents an enhancement to the theory of MSFuNIS models by develo** a more advanced concise model. The proposed model is called: Interval type-2 Mutual Subsethood Cauchy Fuzzy Neural Inference system (IT2MSCFuNIS). For more than two decades, Gaussian fuzzy membership functions (GFMFs) were the standard selection as a FBF for develo** most FNN models, and in particular for develo** MSFuNIS models [38]. This paper has three contributions. The first is the adoption of the Cauchy fuzzy membership function (CFMF) as a new FBF for develo** an MSFuNIS model. The second is the success of computing fuzzy mutual subsethood similarity between two IT2CFMFS and all updating equations of the network parameters in analytic closed-form formulas without any need to perform several mathematical integration operations, or to make an approximation of the membership function, or to employ numeric computations as found in all previous works that adopted GFMFs. Third, is the success of extracting the type-1 mutual subsethood Cauchy fuzzy neural inference system (T1MSCFuNIS) model with all its analytic closed-form formulas directly from the general case of IT2.
The remainder of this paper is organized as follows. Section 2 presents some basic concepts of T1FSs and T2FSs. Section 3 presents a basic mathematical background of IT2 Cauchy fuzzy sets. It also presents the proposed closed-form analytic formula of mutual subsethood similarity between two Cauchy IT2MFs. Section 4 describes the architecture of the proposed model and the closed-form formulas of all updating equations of the learning parameters. Section 5 outlines the simulation results. Section 6 presents more discussions with further extensions of this work. Section 7 concludes the paper.
2 Basic Concepts
2.1 Types of Fuzzy Sets
Types of fuzzy sets are briefly defined as follows [5, 39, 40]:
Definition 1
T1FS \(\widetilde{A}\) can be defined as:
where x is a variable with the domain X and the membership \({\mu }_{\widetilde{A}}\left(x\right)\in \left[\mathrm{0,1}\right]\).
Definition 2
The general T2FS \(\widetilde{A}\) can be defined as:
where x is the primary variable with the domain X, \(u\in \left[\mathrm{0,1}\right]\) is the primary membership, and \({\mu }_{\widetilde{A}}\left(x,u\right)\) is the secondary membership and \({\mu }_{\widetilde{A}}\left(x,u\right)\in \left[\mathrm{0,1}\right]\).
Definition 3
The IT2FS \(\widetilde{A}\) is a special case of the general T2FS wherein it always has \({\mu }_{\widetilde{A}}\left(x,u\right)=1\), can be defined as:
where x is the primary variable with the domain X and \(u\in \left[\mathrm{0,1}\right]\) is the primary membership.
2.2 Cauchy Fuzzy Sets
A Cauchy fuzzy set is a special case of Bell-shaped fuzzy sets. The membership function of T1 Cauchy FS is as follows:
The membership function of the IT2 Cauchy FS has two forms. The first form is given as:
where a is a fixed center and b is an uncertain spread.
The second form is:
where a is an uncertain center and b is a fixed spread.
In this paper, we will adopt the first form of the IT2 Cauchy FS where the FOU is bounded by the lower MF with lower spread bl, and the upper MF is bounded by the upper spread bu as shown in Fig. 1.

IT2 Cauchy fuzzy MF with fixed center and uncertain spread
3 The Basic Mathematical Background of IT2 Cauchy Fuzzy Sets
Let \(\widetilde{A}\) and \(\widetilde{B}\) be two IT2 Cauchy FSs of the first form. Each of the membership functions \({\mu }_{\widetilde{A}}(x)\) and \({\mu }_{\widetilde{B}}(x)\) are formed of upper and lower membership functions. Then the upper and lower membership functions of \(\widetilde{A}\) are:
Similarly, the upper and lower membership functions of \(\widetilde{B}\)
3.1 Points of Intersection
Assuming that \({\underline{x}}_{int}\) and \({\underline{x}}_{ext }\) are the internal and external points of intersection of \({\underline{\mu }}_{\widetilde{A}}\, and\, {\underline{\mu }}_{\widetilde{B}}\), then based on [40]:
Assuming that \({\overline{x}}_{int}\) and \({\overline{x}}_{ext }\) are the internal and external points of intersection of \({\overline{\mu }}_{\widetilde{A}} \,and\, {\overline{\mu }}_{\widetilde{B}}\), respectively
Additionally, the following set of useful relations can be obtained from (7)–(10) as follows:
denoting the membership degrees at \({\underline{x}}_{int }, {\underline{x}}_{ext }{\overline{x}}_{int },\,and\, {\overline{x}}_{ext}\) as\(\underline{v } ,\underline{w}, \overline{ v}, and \overline{w} {\text{respectively}}\), then from (11)–(14) we have
Because of the convexity of the Cauchy fuzzy set, see Fig. 2, it is obvious from (15)–(18) that \(\underline{v }\) is always greater than or equal to \(\underline{w}\) and \(\overline{v}\) is always greater than or equal to \(\overline{w}\), i.e., \(\underline{v } \ge \underline{w}\, and\, \overline{v} \ge \overline{w}\).

The intersection points of two IT2 Cauchy fuzzy sets
3.2 The Similarity Measure of Two IT2 Cauchy Fuzzy Sets
Wu and Mendel proposed a similarity measure for type-2 fuzzy sets that is an extension of Jaccard's similarity measure. The new similarity measure is defined as [41]:
where: \(\widetilde{A},\widetilde{B}\) are two IT2 Cauchy FSs, \(\cap \) is the fuzzy intersection operation, and \(\cup \) is the fuzzy union operation. Based on our analytic closed-form formula of mutual subsethood similarity measure between two type-1 Cauchy fuzzy sets [42], we have the following generalized proposition; see the proof in Appendix A.
Proposition 1
The similarity measure of two IT2 Cauchy FSs
where,
Corollary 1
The following three special cases can be obtained directly:
where
4 Architecture and Operational Details of the Proposed IT2MSCFuNIS Model
The proposed fuzzy neural model is a Mamdani-type model that represents fuzzy rules in the following form:
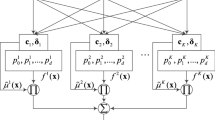
Where xj, i = 1,…,n are the inputs, \({\widetilde{A}}_{i}^{j}\) j = 1,…, m are T2 Cauchy FSs that are defined on the input universes of discourses (UODs) to represent input linguistic values, yk, k = 1,…, p are the outputs, and \({\widetilde{B}}_{k}^{j}\) are T2 Cauchy FSs defined on the output UODs to represent output linguistic values. Figure 3 shows the proposed architecture of a subsethood based Fuzzy neural network where x1 to \({x}_{m}\) and \({x}_{m+1}\) to \({x}_{n}\) are linguistic and numeric inputs respectively. Domain variables or features are represented by input nodes and target variables or classes are represented by output nodes. Each hidden node represents a fuzzy rule, and connections between hidden nodes and input nodes represent fuzzy rule antecedents. Each hidden-output node connection is a result of a fuzzy rule. Fuzzy sets which correspond to linguistic labels of fuzzy if–then rules (such as SHORT, MEDIUM, and TALL), are defined on input and output UODs and represented by IT2 Cauchy MFs with a center, lower spread, and upper spread. Thus, fuzzy link weight \({w}_{ji}\) from input nodes i to rule nodes j is thus modeled by the center \({w}_{ji}^{a}\), lower spread, and upper spread \({w}_{ji}^{b}\) of a Cauchy FS and denoted by \({w}_{ji}=\left({w}_{ji}^{a},{w}_{ji}^{\underline{b}},{w}_{ji}^{\overline{b}}\right).\) In the same way, the consequent fuzzy link weight from rule node j to output node k is denoted by \({w}_{kj}=\left({w}_{kj}^{a},{w}_{kj}^{\underline{b}},{w}_{kj}^{\overline{b}}\right).\)

The architecture of the fuzzy neural model
This proposed model can accept both numeric and fuzzy inputs simultaneously. Numeric inputs are first fuzzified, thus all network inputs are fuzzy. Since antecedent weights are also fuzzy, a method for transmitting a fuzzy signal along with a fuzzy weight is required. In this proposed model, along with the fuzzy weight, fuzzy mutual subsethood is used to handle a signal transmission. The strength of firing at the rule node is computed by a product aggregation operator. At the output layer, the signal computation is conducted via volume defuzzification to generate numeric outputs y1, y2, … yp. With the help of numerical training data, a gradient descent learning technique allows the model to fine-tune rules. Figure 3 shows the 3-layers architecture of the proposed fuzzy neural model where,
\({x}_{i}\): the crisp input (numeric or linguistic) i = 1, 2,.., n
\({\widetilde{x}}_{i}\): the fuzzified form of the crisp input \({x}_{i}\)
Thus, we have \({\widetilde{x}}_{i}=\left({x}_{i},{\underline{b}}_{xi},{\overline{b}}_{xi}\right)\) expressed as follows:
The link weight \({\widetilde{{\text{w}}}}_{ji}=\left({a}_{ji},{\underline{b}}_{ji},{\overline{b}}_{ji}\right)\) between node j in the hidden layer and input i where j = 1,2, … m is expressed as follows:
Similarly, the link weight \({\widetilde{w}}_{kj}=\left({a}_{kj},{\underline{b}}_{kj},\,{\overline{b}}_{kj}\right)\) between node k in the output layer and node j in the hidden layer, k = 1, 2, 3, …, p, is expressed as:
where
where \({S}_{ji}\) is the set-theoretic similarity measure between \({\widetilde{x}}_{i}\) and \({w}_{ji}\), \({z}_{j}\) is considered as the firing degree of the rule # j.
(i.e., hidden node #j) of the fuzzy neural model.
The model output at node k is yk, k = 1, 2, 3, …, p, where
where \(\lambda \) is the weighing constant, which is set within the range [0, 0.5].
In our case, the volume \({\overline{V}}_{kj}\) is simply the area of consequent weight fuzzy sets represented by IT2 Cauchy membership functions. Thus, \({\overline{V}}_{kj}\) is \({\overline{b}}_{kj}\pi \), and \({\underline{V}}_{ kj}\) is \({\underline{b}}_{kj}\pi \), then we have
Thus, from (45) to (43), then we have
4.1 Iterative Update Equations
Based on the training data, a supervised learning approach based on a gradient descent method is used for updating the model’s parameters. The training performance criterion is taken as a squared error function:
where E(t) is the error at iteration t, dk(t) is the desired output at output node k, yk(t) is the actual output at node k, and p is the number of nodes in the output layer. The model requires all link weights \({w}_{kj}=\left({w}_{kj}^{a},{w}_{kj}^{\underline{b}},{w}_{kj}^{\overline{b}}\right)\) at the output layer, and all link weights at the hidden layer \({w}_{ji}=\left({w}_{ji}^{a},{w}_{ji}^{\underline{b}},{w}_{ji}^{\overline{b}}\right)\) layers of the network to be IT2 Cauchy fuzzy sets. The basic update equations starting from the output layer and then the hidden layers are as follows:
where \(\eta \) is the learning rate, and \(\alpha \) is the momentum parameter.
4.2 Evaluation of Partial Derivatives
The following are the exact closed-form formulas for the partial derivatives needed for the iterative updates in the output and the hidden layers. The proof of all formulas is given in Appendix B.
4.2.1 At the Output Layer
The exact formulas of the partial derivatives of the updating parameters at this layer are as follows:
4.2.2 At the Hidden Layer
The exact formulas of the partial derivatives of the updating parameters at this layer are as follows:
where
It is worth mentioning that a major strength of the proposed mutual subsethood similarity measure \({\varepsilon }_{ji}\) as given in (36) is that it provides high flexibility in the derivation of the required parameters’ updating formulas as follows:
-
The updating formulas of \({a}_{ji min}\) and \({a}_{ji max}\) implicitly cover the needed updates formula for aji in (51) based on (39).
-
The updating formulas of \({\underline{b}}_{ji min}\) and \({\underline{b}}_{ji max}\) implicitly cover the needed updates formulas for \({\underline{b}}_{ji}\) and \(\underline{b}{x}_{i}\) in (52) and (54) based on (40).
-
The updating formulas for \({\overline{b}}_{ji min}\) and \({\overline{b}}_{ji max}\) implicitly cover the needed updates formulas for \({\overline{b}}_{ji}\) and \(\overline{b}{x}_{i}\) in (53) and (55) based on (41).
Another major strength of the exact parameters updating formulas (64)–(77) is that they can be used to directly derive the exact formula for the case Cauchy Type-1 MSuFNIS (T1MSCFuNIS) as given in Appendix C.
5 Tests and Results
The proposed model is tested using four benchmark problems in the domains of function approximation, pattern classification, and prediction as follows.
5.1 Example 1: Function Approximation
In this example, the proposed model is employed to approximate the Narazaki-Ralescu function [43]:
21 points are generated for training at an interval of 0.05 and 101 points are generated as test data at an interval of 0.01 within the range [0, 1]. To train the network, the centers of the fuzzy weights between the input layer and hidden layer, and between the hidden layer and output layer are randomly initialized in the range [0, 1.5]. Lower spreads and upper spreads of fuzzy weights between the input layer and hidden layer are randomly initialized in the ranges [0.00001, 0.9] and [0.00001, 1.0] respectively. Lower and upper spreads of fuzzy weights between the hidden layer and the output layer are randomly initialized in the range [0, 1.5]. The model is examined to be trained for three rules, and five rules respectively. The learning rate is taken at 0.05, momentum is 0.05, and weighing constant λ is 0.5. The model’s performance is assessed using \({{\text{J}}}_{1}\mathrm{\, and\, }{{\text{J}}}_{2}\) as the following:
where \({{\text{y}}}_{{\text{p}}}^{\mathrm{^{\prime}}}\) is the desired output and \({{\text{y}}}_{{\text{p}}}\) is the actual output. The experiments are repeated 15 times with random initialization of the parameters each time, and the average of J1 and J2 is computed over 15 times. For the proposed T1MSCFuNIS model with three rules; i.e. network structure 1–3–1, J1 = 0.039 and J2 = 0.032, and with five rules, i.e. network structure 1–5–1, J1 = 0.0252 and J2 = 0.0247. For the proposed IT2MSCFuNIS model with three rules J1 = 0.0189 and J2 = 0.014, and with five rules J1 = 0.0182 and J2 = 0.0133. Figure 4 shows the actual Narzaki & Ralescu function and the simulated one using the proposed IT2MSCFuNIS model with 3 rules.

Narzaki & Ralescu function approximation using three rules network of the IT2MSCFuNIS proposed model
Table 1 shows the Efficient approximation performance of the proposed models.
The model SuPFuNIS in [38] is a three-layer T1 Mamdani FNN that uses symmetric T1GMFs. It is the first standard model for mutual subsethood fuzzy inference systems that appeared in 2002. The mutual subsethood similarity between two GMFs is calculated accurately, but the calculations are based on several case-wise integration operations according to the possible forms of overlap** between the two GMFs. The model uses the gradient-descent (GD) method for adjusting the network parameters. The model ASuPFuNIS in [47] is the same as [38] but with asymmetric GMFs. The model in [49] is the same as [47] but with the adoption of a Differential Evolution (DE) optimization strategy for searching for a proper number of nodes in the hidden layer as well as the network parameters.
The model ASNF in [48] is a five-layer T1 Mamdani neural fuzzy network (T1NFN) that uses asymmetric GMFs. To avoid calculating accurate mutual subsethood similarity between two T1GMFs, a triangle approximation of the MFs is employed.
The model IT2MSFuNIS in [4] is a three-layer IT2 Mamdani FNN that uses symmetric IT2GMFs with uncertain spreads. The mutual subsethood similarity between two IT2GMFs is calculated by following the same idea of the standard model in [38], having the same drawback of the complexity of calculations. To avoid more complications when develo** the parameters’ updating formulas of the network, the authors in [4] simplified their model by making a type-reduction operation at the third layer to deal with T1GMFs rather than IT2GMFs. The model adjusts the network parameters through two stages. The first is an initial adjustment using DE as a global exploration mechanism. Then, a GD is adopted as a local exploitation of the solution space. The model in [50] is the same model of [4] but the authors adopt parallel DE over 24 compute nodes to adjust all the network parameters to overcome the computationally intense calculations of the mutual subsethood similarity of IT2GMFs for each training sample in every iteration. The model in [43] is a multilayer NN with special types of neurons that perform logical operations based on different forms of activation functions. The model in [44] is a four-layer T1 Mamdani NFIS that is inappropriately denoted as FNN. The model adopts different forms of FBFs including GMF. The model in [45] is a hybrid model that mixes the techniques of Genetic Algorithms (GAs), FL, and NNs. The model uses GAs to extract fuzzy rules as a fuzzy supervised learning approach. Then, a fine-tuning stage using a hill-climbing approach via neuro-fuzzy network architecture is used. The model is a four-layer T1 Mamdani NFIS that is inappropriately called FNN. The model in [46] is similar to that in [45] with some enhancements.
It is clear from the results shown in Table 1, that the proposed model T1MSFuNIS achieves better performance than all other compared models except the model IT2MSFuNIS [4]. On the other hand, the proposed model IT2MSCFuNIS outperforms all other models.
Due to the volume of data obtained as a result of the experiments conducted on the various examples mentioned in this paper, a comprehensive and detailed presentation will be presented of the results obtained for this example only, noting that all the following examples have the same manner of detailed results.
Figure 5 shows the decaying behavior of the J2% for the case of 5-rules using the proposed model T1MSCFuNIS. The computed average values and standard deviation of the updated weights over the 15 runs are shown in Tables 2, and 3.

J2% decaying behavior Example 1 using T1MSCFuNIS with 5-rules
Figure 6 shows the decaying behavior of the J2% for the case of 3-rules using the proposed model IT2MSCFuNIS. The computed average values and standard deviation of the updated weights over the 15 runs are shown in Tables 4, and 5.

J2% decaying behavior Example 1 using IT2MSCFuNIS with 3-rules
5.2 Example 2: Iris Dataset Classification
Iris data involves the classification of three subspecies of the Iris flower, namely Iris sestosa, Iris versicolor, and Iris virginica based on four feature measurements of the Iris flower which are Sepal length, Sepal width, Petal length, and Petal width [51]. There are 50 patterns (of four features) for each of the three subspecies of the Iris flower. The input pattern set thus comprises 150 four-dimensional patterns. To train the network of the proposed IT2MSCFuNIS model, the centers of the fuzzy weights between the input layer and hidden layer are randomly initialized in the range of the minimum and maximum values of respective input features of Iris data, these ranges are [4.3, 7.9], [2.0, 4.4], [1.0, 6.9], and [0.1, 2.5]. The centers of fuzzy weights between the hidden layer and output layer are randomly initialized in the range [0, 1]. Lower and upper spreads of fuzzy weights between the input layer and hidden layer are randomly initialized in the ranges [0.0001, 1.0] and [0.0001, 1.1] respectively. Lower and upper spreads of fuzzy weights between the hidden layer and the output layer are randomly initialized in the range [0, 1.0]. All the 150 patterns of the Iris data are presented sequentially to the input layer of the network for training. The learning rate is taken at 0.07, momentum is 0.07, and the weighing constant is 0.5.
Once the network is trained, the test patterns (which again comprised all 150 patterns of Iris data) are presented to the trained network, and the re-substitution error is computed. The experiments are repeated 15 times with different random initializations for the parameters each time.
Table 6 compares the performance of the proposed T1MSCFuNIS and IT2MSCFuNIS models with other soft computing models in terms of the number of rules and the percentage of re-substitution accuracy. Both of the proposed models are tested using 3-rules, i.e. network structure 4–3–3, and 5-rules, i.e. network structure 4–5–3. The results show that both models can strongly classify Iris data with 100% re-substitution accuracy with either three or five rules.
The model in [52] provides an algorithm for extracting fuzzy rules from a given neural-based fuzzy network. The model is a five-layer T1NFIS that uses different forms of FMFs including GMFs. The model is inappropriately denoted as FNN. The model in [53] is the same as in [52] but with an evolving capability that allows rule extraction and insertion. The model in [54] is a four-layer T1NFIS that can extract good features from the data set as well as extract a small but adequate number of classification rules. The model in [55] is a special form of multilayer perceptron network that implements Fuzzy systems. The network uses sigmoid activation functions to generate bell-shaped linguistic values. The model is considered a multi-layer T1 Mamdani NFIS that is inappropriately denoted as FNN. The model in [56] is a special form of T1 Mamdani multi-layer NFIS that uses triangular FMFs.
It is clear from the results shown in Table 6, that both proposed models T1MSFuNIS and IT2MSCFuNIS achieve better performance than most of the compared models except the model in [4]. The proposed models achieve the same performance as the models in [47] and [49].
5.3 Example 3: Miles per Gallon Prediction
This problem aims to estimate the city cycle fuel consumption in miles per gallon (MPG) [57]. There are 392 samples, 272 are randomly chosen for training and 120 for testing. The input layer of our model consists of three features which are weight, acceleration, and model year. The output layer represents the fuel consumption in MPG. To train the network, the centers of the fuzzy weights are randomly initialized in the range \([0, 1]\), and the upper spreads and the lower spreads are randomly initialized in the range [0.2, 0.9]. The model is trained for three rules and four rules. We keep the learning rate, momentum, and weighing constant \(\lambda \) at 0.01 0.01, and 0.5 respectively throughout all the experiments. The model’s performance is assessed using the root mean square error as follows:
The experiments are repeated 15 times with different random initializations for the parameters each time. Table 7 shows the performance of the proposed models compared with other methods.
For the proposed T1MSCFuNIS model with three rules; i.e. network structure 3–3–1, the average RMSEtrain is 0.1795 and the average RMSEtest 0.1705, while in the case of four rules, i.e. network structure 3–4–1 the average RMSEtrain is 0.1632 and the average RMSEtest is 0.1594. On the other hand, for the case of the IT2MSCFuNIS proposed model with three rules, the average RMSEtrain is 0.1509 and the average RMSEtest 0.1456, while while in the case of four rules RMSEtrain is 0.1404, and the average RMSEtest 0.1386.
The model SEIT2FNN is provided in [58] and tested for MPG in [59]. The model is a six-layer IT2 TSK-type self-organized NFIS that uses IT2GMF with an uncertain mean. The model is inappropriately denoted as IT2FNN. The model RIT2NFS-WB [59] is a reduced TSK-type IT2NFS that uses IT2GMFs with uncertain mean and is suitable for hardware implementation. Both models McIT2FIS-UM and McIT2FIS-US [60] are TSK-type IT2NFIS that are implemented as a five-layered network. The models adopt IT2GMF with uncertain mean and uncertain width respectively. The model eIT2FNN-LSTM in [29] is a self-evolving six-layer IT2FNIS for the synchronization and identification of nonlinear dynamics. The model uses a fuzzy LSTM neural network that can effectively deal with long-term dependence problems. eIT2FNN-LSTM uses IT2GMFs with uncertain mean.
The results given in Table 7 indicate that both proposed models T1MSFuNIS and IT2MSCFuNIS achieve better performance than all other compared models.
5.4 Example 4: Abalone Age Prediction
In this example, the abalone’s age is predicted based on its physical characteristics. The dataset is collected from the UCI machine learning repository [61]. The dataset includes 4177 samples, out of which, 3342 samples are used for training and the remaining 835 samples are used for testing. The input layer of our model consists of seven features which are Length, diameter, height, whole weight, shucked weight, viscera weight, and shell weight, the output represents the number of rings. To train the network, the centers of the fuzzy weights are randomly initialized in the range \([\mathrm{0,1}]\), and the upper spreads and the lower spreads are randomly initialized in the range [0.2, 0.9]. The model is trained for three rules and five rules we keep the learning rate to 0.01, momentum to 0.01, and weighing constant \(\lambda \) to 0.5, throughout all the experiments. The model’s performance is assessed using the root mean square, the experiments are repeated 15 times with different random initialization for the parameters each time, and the average of \(R{MSE}_{test}\) and \(R{MSE}_{train}\) are computed for the 15 times. Table 8 shows the performance of the proposed models compared with other methods.
For the proposed T1MSCFuNIS model with three rules, i.e. network structure 7–3–1, the average of RMSEtrain for the training set is 0.1047 and the average RMSEtest 0.1346, while in the case of five rules, i.e. network structure 7–5–1 the average RMSEtrain is 0.1010 and the average RMSEtest is 0.1315. On the otherhand, for the case of the IT2MSCFuNIS proposed model with three rules the average RMSEtrain is 0.1007 and the average RMSEtest 0.1078, while while in the case of five rules RMSEtrain is 0.0962 and the average RMSEtest 0.0951.
It is clear from the results shown in Table 8 that both proposed models T1MSFuNIS and IT2MSCFuNIS outperform all other compared models.
5.5 Example 5: Corona Virus Diagnosis
In this example, a rapid diagnosis of corona virus is based on Routine Blood Tests [62]. The source of the dataset is taken from the Kaggle dataset Diagnosis of COVID-19 and its clinical spectrum created by the Hospital Israelita Albert Einstein in São Paulo, Brazil [63]. The dataset is filtered and the features were selected as mentioned in [62]. Also, the dataset is split into 80% as the training set, and 20% as the testing set. The input layer of our model consists of 16 features including WBC count, Platelet Count, Patient age, HCT, Hgb, MPV, RBC Count, Basophils count, Absolute Eosinophil Count, Lymphocyte Count, MCHC, MCH, MCV, Absolute Monocyte Count, RDW and the presence of chronic disease. The output layer consists of two nodes that represent the diagnosis state of the patient being classified as positive or negative corona virus. The centers of the fuzzy weights are randomly initialized in the range [0, 1] and both the lower spreads and the upper spreads are randomly initialized in the range [0.2, 0.9]. The model is trained for three and five rules, i.e. for network structures 16–3–2 and 16–5–2 respectively. We keep the learning rate, momentum, and weighing constant \(\lambda \) at 0.7, 0.7, and 0.5 respectively throughout all the experiments. The model’s performance is assessed using the following three performance metrics:
where (TP) is the number of instances that are correctly classified as positive, (FP) is the number of instances that are incorrectly classified as positive, (TN) is the number of instances that are correctly classified as negative, and (FN) is the number of incorrectly classified instances as negative. The experiments are repeated 15 times with random initialization of the parameters each time, and the averages of sensitivity, specificity, and accuracy are computed. Table 9 shows the performance comparison of the proposed model with the models given in [62].
The models k-nearest Neighbor (KNN) and Random Forest (RF) are classical machine learning classifiers. ANFIS is a popular five-layer T1FNIS [64]. It is clear from Table 9, that the proposed model IT2MSCFuNIS outperforms the three compared models. On the other hand, the proposed model T1MSCFuNIS outperforms the compared models in Accuracy and Specificity metrics and behaves very competitively with KNN in Sensitivity metrics.
6 Discussions and Further Extensions
This section presents three issues that represent potential extensions of the proposed IT2MSuFNIS model in fairly detailed discussions. The first issue deals with the candidate FBFs that can be adopted in the proposed model and the controversy surrounding the trade-off between CMF and GMF. The second issue deals with the robustness of the performance of the proposed model. The third issue discusses the applicability of IT2MSuFNIS to various domains and the possibility of integration with other models, in particular the deep learning models.
6.1 Candidate FMFs for IT2MSCFuNIS
Both Gaussian and Cauchy functions are considered well-known types of Radial Basis Functions (RBFs). Cauchy function is also called “Inverse Quadratic Function” (IQ) and is considered a special case of the family of “Bell-Shaped Functions” (BSFs) [65, 66]. As an FMF, CFMF has some interesting properties that have been observed by researchers in a number of published papers.
The computational capabilities of the Cauchy function have been addressed in previously published papers. In [67], Chandra P. et al. and in [68], Ghose U. et al. showed that Cauchy activation functions have good statistical performance better than the traditional logistic activation functions when solving regression problems using feedforward artificial neural networks. They also emphasized the fact that the Cauchy function has less computational cost as it does not involve the calculation of exponential terms.
On the other hand, when compared with GFMF, CFMF has some interesting properties that have been observed by researchers in a number of published papers. In [69, 70], Abdelbar A.M., et al. proposed a fuzzy generalization of “Particle Swarm Optimization” (PSO) called FPSO that differs from standard PSO by assigning a charisma property to some particles in the population in order to influence other particles in the neighborhood. Such a charisma property is represented by an FMF. It is found that the performance of FPSO using CFMFs outperforms the performance in the case of GFMFs. Such a difference in performance is attributed to the fact that CFMF with a certain center and a certain spread covers a wider span than GFMF with the same values of center and spread. Such a “wider-tail” property of CFMFs allows better exploration of the search space by promoting diversity.
Also, in [71], Huang W. and Li Y. showed that a probabilistic FLS gives better performance when adopting probabilistic CFMFs rather than probabilistic GFMFs.
In [42], Amer N.S. and Hefny H.A. compared the similarity/possibility monotonic characteristic of the mutual subsethood similarity between two CFMFs with that of GFMFs. They found that CFMFs are featured by preserving higher values for the monotonicity relationship between similarity and possibility which has a significant impact on better interpretability properties when adopting CFMFs rather than GFMFs when building FLS. Therefore, it is clear from the above discussion that the interest in studying CFMFs is justified and objective.
As a possible challenging extension of our proposed IT2MSuFNIS model, other forms of RBFs may be investigated by following the same style of derivations to get a closed-form analytical formula of the model parameters.
6.2 Robustness of IT2MSCFuNIS
IT2MSCFuNIS is a highly efficient modeling technique for handling vague uncertainty in the input data. The model can handle imprecision in input data in two ways. First, it can accept and learn from fuzzy data. Second, it manipulates such imprecise data using IT2FMF. Achieving excellent experimental results with minimum error, minimum standard deviation, and a high level of generalization capabilities across different benchmark datasets is a positive indication of the robustness of the model. However, this is just one aspect of robustness. Robustness is mainly concerned with maintaining good performance under probabilistic uncertainty that causes external disturbances due to noisy data.
Therefore, other factors need to be addressed to test the overall robustness of the model such as injecting random noise with arbitrary distributions to the input data before training and adopting some robust optimization algorithms to perform better in the presence of outliers or noisy data points. Also, studying the performance of the FLS with probabilistic FMFs. Several approaches are found in the literature for achieving robustness of FNN models, e.g. [71,72,73,74,75,76,77,78,79,80,81].
Based on the above discussion, enhancing the robustness of our proposed IT2MSCFuNIS model is a possible extension for future work.
6.3 Applicability of IT2MSCFuNIS
The proposed IT2MSCFuNIS is a general-purpose modeling technique that provides better handling of uncertainties in quite concise analytical formulas. Therefore, it can be applied to various practical problems in different domains as presented in this paper. However, in some situations, further research may be needed to show how it can be integrated with other practical models. In this respect, we are interested in discussing how to integrate IT2MSCFuNIS with Deep Neural Networks (DNNs) models.
The main objective of integrating fuzzy logic models with DNNs models is to allow an explanation of the generated outputs and increase the interpretability of the DNN model [82]. Recently, various forms of integrating fuzzy logic models with DL architectures’ models have appeared in the literature [83]. The commonly used approach is to inject a fuzzy layer into the DL architecture. As for examples, in [84], Yeganejou and Dick proposed a Fuzzy Deep Learning Network (FDLN) by introducing a fuzzy c-means clustering layer after the traditional convolutional neural network (CNN) layers to improve the classification of large-size data sets of hand-written digits by generating reasonably-interpretable clusters in the derived feature space of the adopted CNN. In [85], ** and Panoutsos proposed an FDLN by replacing the second fully connected dense layer in the traditional CNN with a Fuzzy Radial Basis Function Network (FRBFN). Their approach is found to maintain a high level of accuracy similar to CNN while providing linguistic interpretability to the classification layer. In [86], Sharma et al. proposed a Deep Neuro-Fuzzy approach for the healthcare recommendation system. Their approach is mainly a multilevel decision making for predicting the risk and severity of the patient diseases. They used a traditional CNN that properly classifies Heart, Liver, and Kidney diseases, and then the classified outputs of the CNN are fed into a type-2 FLS to generate the risk level linguistically. In [87], Lin et al. a novel CNN model called “Vector Deep Fuzzy Neural Network” (VDFNN) is adopted for effective automatic classification of breast cancer based on histopathological images. Their proposed VDFNN is composed of a vector convolutional layer, a pooling layer, a feature fusion layer, and an FNN layer. A global average pooling method is applied in the feature fusion layer to reduce the dimension of features. Then, the features are fed to the FNN layer instead of the traditional fully connected network.
Based on the above brief presentation of previously published approaches of DFNN, it becomes clear that our proposed IT2MSuFNIS model has promising opportunities to be adopted in various DFNN applications, e.g. [86,87,88,89]. A favorable idea in this respect is to inject the IT2MSuFNIS model as a classification layer that is proceeded by a feature fusion layer in a similar manner to [87].
7 Conclusion
This paper presents a novel model for IT2MSuFNIS. The proposed model represents a further development step of the theory of the MSuFNIS model in terms of three contributions. The first is the adoption of another bell-shaped FBF rather than the traditional choice of Gaussian MF. The second is the success of computing fuzzy mutual subsethood similarity between two IT2 Cauchy MFs as well as all weights’ updating equations of the network parameters in analytic closed-form formulas without any need to perform several mathematical integration operations, or to make an approximation of the membership function, or to employ numeric computations. The third is the success of extracting a type-1 model of the proposed IT2MSuFNIS, called T1MSuFNIS, which is an accurate and concise model with closed-form parameter updating formulas. The performance of the proposed model is tested on four benchmark problems from the domains of classification, prediction, and function approximation. Simulation experiments have shown the superiority of both the proposed IT2MSuFNIS and T1MSuFNIS when compared with other models in terms of accuracy and number of rules. As a future work, we have three directions. First, is widening the scope of the applications to other real-world problems. Second, is the development of a TSK-type version of our proposed model. Third, which is quite challenging, is to investigate other forms of FBFs to enrich the theory of the MSuFNIS model.
References
Kayacan, E., Kayacan, E., Khanesar, M.A.: Identification of nonlinear dynamic systems using Type-2 fuzzy neural networks: a novel learning algorithm and a comparative study. IEEE Trans. Ind. Electron. 62(3), 1716–1724 (2015)
Abiyev, R.H., Kaynak, O., Alshanableh, T., Mamedov, F.: A type-2 neuro-fuzzy system based on clustering and gradient techniques applied to system identification and channel equalization. Appl. Soft Comput. 11(1), 1396–1406 (2011)
Abiyev, R.H.: Credit rating type-2 fuzzy neural networks. Math. Probl. Eng. 2014, 1–8 (2014)
Sumati, V., Patvardhan, C.: Interval type-2 mutual subsethood fuzzy neural inference system (IT2MSFuNIS). IEEE Trans. Fuzzy Syst. 26(1), 203–215 (2018)
Yeh, C.Y., Jeng, W.H.R., Lee, S.J.: Data-based system modeling using a type-2 fuzzy neural network with a hybrid learning algorithm. IEEE Trans. Neural Netw. 22(12), 2296–2309 (2011)
Lin, Y.-Y., Chang, J.-Y., Lin, C.-T.: A TSK type-based self-evolving compensatory interval type-2 fuzzy neural network (TSCITFNN) and its applications. IEEE Trans. Ind. Electron. 61(1), 447–459 (2014)
Wu, D., Mendel, J.M.: Similarity measures for closed general type-2 fuzzy sets: overview, comparisons, and a geometric approach. IEEE Trans. Fuzzy Syst. 27(3), 515–526 (2019)
Liu, F., Mendel, J.M.: Encoding words into interval type-2 fuzzy sets using an interval approach. IEEE Trans. Fuzzy Syst. 16(6), 1503–1521 (2008)
Castro, J.R., Castillo, O., Melin, P., Mendoza, O., Rodríguez-Díaz, A.: An interval type-2 fuzzy neural network for chaotic time series prediction with cross-validation and akaike test. Stud. Comput. Intell. 318, 269–285 (2010)
Du, Z., Yan, Z., Zhao, Z.: Interval type-2 fuzzy tracking control for nonlinear systems via sampled-data controller. Fuzzy Sets Syst. 356, 92–112 (2019)
Chen, S.-M., Barman, D.: Adaptive weighted fuzzy interpolative reasoning based on representative values and similarity measures of interval type-2 fuzzy sets. Inf. Sci. 478, 167–185 (2019)
Huang, R., Li, Y., Wang, J.: Long-term traffic volume prediction based on K-means Gaussian interval type-2 fuzzy sets. IEEE/CAA J. Autom. Sin. 6(6), 1344–1351 (2019)
Li, X.-Y., **ong, Y., Duan, C.-Y., Liu, H.-C.: Failure mode and effect analysis using interval type-2 fuzzy sets and fuzzy Petri nets. J. Intell. Fuzzy Syst. 37(1), 693–709 (2019)
Iordache, M., Schitea, D., Deveci, M., Akyurt, İZ., Iordache, I.: An integrated ARAS and interval type-2 hesitant fuzzy sets method for underground site selection: seasonal hydrogen storage in salt caverns. J. Petrol. Sci. Eng. 175, 1088–1098 (2019)
Nagarajan, D., Lathamaheswari, M., Broumi, S., Kavikumar, J.: A new perspective on traffic control management using triangular interval type-2 fuzzy sets and interval neutrosophic sets. Oper. Res. Perspect. 6, 1–13 (2019)
Wang, H., Yao, J., Zhang, X., Zhang, Y.: An area similarity measure for trapezoidal interval type-2 fuzzy sets and its application to service quality evaluation. Int. J. Fuzzy Syst. 23, 2252–2269 (2021)
Deveci, M., Cali, U., Kucuksari, S., Erdogan, N.: Interval type-2 fuzzy sets based multi-criteria decision-making model for offshore wind farm development in Ireland. Energy 198, 1–15 (2020)
Wang, H., Pan, X., Yan, J., Yao, J., He, S.: A projection-based regret theory method for multi-attribute decision making under interval type-2 fuzzy sets environment. Inf. Sci. 512, 108–122 (2020)
Lathamaheswari, M., Nagarajan, D., Kavikumar, J., Broumi, S.: Triangular interval type-2 fuzzy soft set and its application. Complex Intell. Syst. 6(3), 531–544 (2020)
Abiyev, R.H., Kaynak, O.: Type-2 fuzzy neural structure for identification and control of time-varying plants. IEEE Trans. Ind. Electron. 57(12), 4147–4159 (2010)
De Campos, S.P.V.: Fuzzy neural networks and neuro-fuzzy networks: a review of the main technique and applications used in literature. Appl. Soft Comput. J. 92(106275), 1–26 (2020)
Lin, C.-T., Pal, N.R., Wu, S.-L., Liu, Y.-T., Lin, Y.-Y.: An interval type-2 neural fuzzy system for online systems identification and feature elimination. IEEE Trans. Neural Netw. Learn. Syst. 26(7), 1442–1455 (2015)
Lin, Y.-Y., Liao, S.-H., Chang, J.-Y., Lin, C.-T.: Simplified interval type-2 fuzzy neural networks. IEEE Trans. Neural Netw. Learn. Syst. 25(5), 959–969 (2014)
Han, H.-G., Liu, H.-X., Liu, Z., Qiao, J.-F.: Fault detection of sludge bulking using a self-organizing type-2 fuzzy neural network. Control. Eng. Pract. 90, 27–37 (2019)
Wang, J., Kumbasar, T.: Parameter optimization of interval type-2 fuzzy neural networks based on PSO and BBBC methods. IEEE/CAA J. Autom. Sin. 6(1), 247–257 (2019)
Juang, C.-F., Huang, R.-B., Cheng, W.-Y.: An interval type-2 fuzzy neural network with support-vector regression for noisy regression problems. IEEE Trans. Fuzzy Syst. 18(4), 686–699 (2010)
Sumati, V., Patvardhan, C., Swarup, V.M.: Application of interval type-2 subsethood neural fuzzy inference system in classification. In: IEEE Region 10 Humanitarian Technology Conference, 2016, pp. 1–6 (2016)
Wang, C.-H., Cheng, C.-S., Lee, T.-T.: Dynamical optimal training for interval type-2 fuzzy neural network (T2FNN). IEEE Trans. Syst. Man Cybern. Part B Cybern. 34(3), 1462–1477 (2004)
Wang, H., Lue, C., Wang, X.: Synchronization and identification of nonlinear systems by using a novel self-evolving interval type-2 fuzzy LSTM neural network. Eng. Appl. Artif. Intell. 81, 79–93 (2019)
Kebria, P.M., Khosravi, A., Nahavandi, S., Wu, D., Bello, F.: Adaptive type-2 fuzzy neural network control for teleoperation systems with delay and uncertainties. IEEE Trans. Fuzzy Syst. 28(10), 2543–2554 (2020)
Dian, S., Hu, Y., Zhao, T., Han, J.: Adaptive backstep** control for flexible-joint manipulator using interval type-2 fuzzy neural network approximator. Nonlinear Dyn. 97(2), 1567–1580 (2019)
Juang, C.-F., Huang, R.-B., Lin, Y.-Y.: A recurrent self-evolving interval type-2 fuzzy neural network for dynamic system processing. IEEE Trans. Fuzzy Syst. 17(5), 1092–1105 (2009)
Han, H.-G., Li, J.-M., Wu, X.-L., Qiao, J.-F.: Cooperative strategy for constructing interval type-2 fuzzy neural network. Neurocomputing 365, 249–260 (2019)
Castillo, O., Castro, J.R., Melin, P., Diaz, A.R.: Application of interval type-2 fuzzy neural networks in non-linear identification and time series prediction. Soft. Comput. 18(6), 1213–1224 (2014)
Luo, C., Tan, C., Wang, X., Zheng, Y.: An evolving recurrent interval type-2 intuitionistic fuzzy neural network for online learning and time series prediction. Appl. Soft Comput. 78, 150–163 (2019)
Wang, L.X.: Fuzzy systems are universal approximators. In: IEEE international Conference on Fuzzy Systems, pp. 1163–1170 (1992)
Luo, Q., Yang, W.: Kernel shapes of fuzzy sets in fuzzy systems for function approximation. Inf. Sci. 178, 836–875 (2008)
Paul, S., Kumar, S.: Subsethood-product fuzzy neural inference system (SuPFuNIS). IEEE Trans. on Neural Netw. 13(3), 578–599 (2002)
Kayacan, E., Khanesar, M.A.: Fuzzy Neural Networks for Real-Time Control Applications: Concepts, Modeling, and algorithms for Fast Learning. Elsevier (2016)
Shukla, A.K., Yadav, M., Kumar, S., Muhuri, P.K.: Veracity handling and instance reduction in big data using interval type-2 fuzzy sets. Eng. Appl. Artif. Intell. 88, 1–16 (2020)
Wu, D., Mendel, J.M.: A comparative study of ranking methods, similarity measures and uncertainty measures for interval type-2 fuzzy sets. Inf. Sci. 179, 1169–1192 (2009)
Amer, N.S, Hefny, H.A.: Analytical formulas for similarity, possibility and distinguishability measures of Cauchy type fuzzy sets with comparison to Gaussian fuzzy set. In: IEEE Seventh International Conference on Intelligent Computing and Information Systems (ICICIS), pp. 21–26 (2015)
Narazaki, H., Ralescu, A.L.: An improved synthesis method for multilayered neural networks using qualitative knowledge. IEEE Trans. Fuzzy Syst. 1(2), 125–137 (1993)
Lin, Y., Cunningham, G.A.: A new approach to fuzzy-neural system modeling. IEEE Trans. Fuzzy Syst. 3(2), 190–198 (1995)
Russo, M.: FuGeNeSys a fuzzy genetic neural system for fuzzy modeling. IEEE Trans. Fuzzy Syst. 6(3), 373–388 (1998)
Russo, M.: Genetic fuzzy learning. IEEE Trans. Evol. Comput. 4(3), 259–273 (2000)
Velayutham, C.S., Kumar, S.: Asymmetric subsethood-product fuzzy neural inference system (ASuPFuNIS). IEEE Trans. Neural Netw. 16(1), 160–174 (2005)
Lin, C.J., Lin, T.C., Lee, C.Y.: An asymetry subsethood-based neural fuzzy network. Asian J. Control 10(1), 96–106 (2008)
Singh, L., Kumar, S., Paul, S.: Automatic simultaneous architecture and parameter search in fuzzy neural network learning using novel variable length crossover differential evolution. IEEE International Conference on Fuzzy Systems. In: IEEE World Congress on Computational Intelligence), pp. 1795–1802 (2008)
Sumati, V., Chellapilla, P., Paul, S., Singh, L.: Parallel interval type-2 subsethood neural fuzzy inference system. Expert Syst. Appl. 60, 156–168 (2016)
UCI Machine Learning Repository. Available at: https://archive.ics.uci.edu/~mlearn/MLRepository.html
Kasabov, N.K.: Learning fuzzy rules and approximate reasoning in fuzzy neural networks and hybrid systems. Fuzzy Sets and Syst. 82(2), 135–149 (1996)
Kasabov, N., Woodford, B.: Rule insertion and rule extraction from evolving fuzzy neural networks: algorithms and applications for building adaptive, intelligent expert systems. Proceeding of IEEE International Fuzzy Systems Conference, vol. 3. Seoul, Korea, pp. 1406–1411 (1999)
Chakraborty, D., Pal, N.R.: A neuro-fuzzy scheme for simultaneous feature selection and fuzzy rule-based classification. IEEE Trans. Neural Netw. 15(1), 110–123 (2004)
Halgamuge, S., Glesner, M.: Neural networks in designing fuzzy systems for real world applications. Fuzzy Sets Syst. 65, 1–12 (1994)
Nauk, D., Kruse, R.: A neuro-fuzzy method to learn fuzzy classification rules from data. Fuzzy Sets Syst. 89, 277–288 (1997)
UCI Machine Learning Repository. Available at: https://archive.ics.uci.edu/ml/datasetslauto+mpg
Juang, C.F., Tsao, Y.W.: A self-evolving interval type-2 fuzzy neural network with online structure and parameter learning. IEEE Trans. Fuzzy Syst. 16(6), 1411–1424 (2008)
Juang, C.F., Juang, K.J.: Reduced interval type-2 neural fuzzy system using weighted bound-set boundary operation for computation speedup and chip implementation. IEEE Trans. Fuzzy Syst. 21(3), 477–491 (2013)
Das, A.K., Subramanian, K., Sundaram, S.: An evolving interval type-2 neuro fuzzy inference system and is metacognitive sequential learning algorithm. IEEE Trans. Fuzzy Syst. 23(6), 2080–2093 (2015)
UCI Machine Learning Repository. Available at: https://archive.ics.uci.edu/ml/machine-learning-databases/abalone/
Deif, M., Hammam, R., Solyman, A.: Adaptive neuro-fuzzy inference system (ANFIS) for rapid diagnosis of COVID-19 cases based on routine blood tests. Int. J. Intell. Eng. Syst. 14, 178–189 (2021)
Kaagle datasets, COVID-19. Available at: https://www.kaggle.com/datasets/einsteindata4u/covid19?resource=download
Jang, J.-S.R.: ANFIS: adaptive-network-based fuzzy inference system. IEEE Trans. Syst. Man Cybern. 23(3), 665–685 (1993)
Duch, W., Janowski, N.: Survey of neural transfer functions. Neural Comput. Surv. 2, 163–212 (1999)
Duch, W., Janowski, N.: Transfer functions: hidden possibilities for better neural networks. In: Proceedings - European Symposium on Artificial Neural Networks (ESANN'2001), pp. 81–94 (2001)
Chandra, P., Ghose, U., Sood, A.: A non-sigmoidal activation function for feedforward artificial neural networks. In: International Joint Conference on Neural Networks (IJCNN). pp. 1–8 (2015)
Ghose, U., Chandra, P., Sood, A.: On the feasibility of solving regression learning tasks with FFANN using non-sigmoidal activation functions. In: International Conference on Applied and Theoretical Computing and Communication Technology (iCATccT). pp. 495–500 (2015)
Abdelbar A.M., Abdelshahid S., Wunsch D.C.: Fuzzy PSO: a generalization of particle swarm optimization. In: Proceeding of IEEE International Joint Conference on Neural Networks (IJCNN), vol. 2. pp. 1086–1091 (2205)
Abdelbar A.M., Abdelshahid S., Wunsch D.C.: Gaussian versus Cauchy membership functions in fuzzy PSO. In: International Joint Conference on Neural Networks (IJCNN). pp. 2902–2907 (2007)
Huang, W., Li, Y.: Bell-shaped probabilistic fuzzy set for uncertainties modeling. J. Theor. Appl. Inf. Technol. 46(2), 875–882 (2012)
Liu, Z., Li, H.X.: A probabilistic fuzzy logic system for uncertainty modeling. In: IEEE International Conference on Systems, Man, and Cybernetics (ICSMC), vol. 4. pp. 3853–3858 (2005)
Liu, Z., Li, H.X.: A probabilistic fuzzy logic system for modeling and control. IEEE Trans. Fuzzy Syst. 13(6), 848–859 (2005)
Li, H.X., Liu, Z.: A probabilistic neural-fuzzy learning system for stochastic modeling. IEEE Trans. Fuzzy Syst. 16(4), 898–908 (2008)
Garibaldi, J.M., Jaroszewski, M., Musikasuwan, S.: Nonstationary fuzzy sets. IEEE Trans. Fuzzy Syst. 16(4), 1072–1086 (2008)
Zhang, G., Li, H.X.: An efficient configuration for probabilistic fuzzy logic system. IEEE Trans. Fuzzy Syst. 20(5), 898–909 (2012)
Wang, Y.: Type-2 fuzzy probabilistic system. In: 9th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD). pp. 482–486 (2012)
Liy, Y., Wu, W., Fan, Q., Yang, D., Wang, J.: A modified learning algorithm with smoothing L1/2 regularization for Takagi-Sugeno fuzzy model. Neurocomputing 138, 229–237 (2014)
Li, H.X., Wang, Y., Zhang, G.: Probabilistic fuzzy classification for stochastic data. IEEE Trans. Fuzzy Syst. 25(6), 1391–1402 (2017)
Fang, W., **e, T.: Robustness analysis of stability of Takagi-Sugeno type fuzzy neural network. AIMS Math. 8(12), 31118–31140 (2023)
Zhang, L., Shi, Y., Chang, Y.C., Lin, C.T.: Robust fuzzy neural network with an adaptive inference engine. IEEE Trans. Cybern. (2023). https://doi.org/10.1109/TCYB.2023.3241170
Somani, A., Horsch, A., Prasad, D.K.: Interpretability in Deep Learning. Springer (2023)
Das, R., Sen, S., Maulik, U.: A survey on fuzzy deep neural networks. ACM Comput. Surv. 53(3), 1–25 (2020)
Yeganejou, M., Dick, A.: Classification via deep fuzzy c-means clustering. In: IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), pp. 1–6 (2018)
**, Z., Panoutsos, G.: Interpretable machine learning: convolutional neural networks with RBF fuzzy logic classification rules. In: International Conference on Intelligent Systems (IS), pp. 448–454 (2018)
Sharma, D., Aujla, G.S., Bajaj, R.: Deep neuro-fuzzy approach for risk and severity prediction using recommendation systems in connected health care. Trans. Emerg. Telecommun. Technol. 32(7), 1–18 (2020)
Lin, C.J., Wu, M.Y., Chuang, Y.H., Lee, C.L.: Vector deep fuzzy neural network for breast cancer classification. Sens. Mater. 35(3), 795–811 (2023)
Liu, M., Shi, J., Li, Z., Li, C., Zhu, J., Liu, S.: Towards better analysis of deep convolutional neural networks. IEEE Trans. Vis. Comput. Graph. 23(1), 91–100 (2017)
Bhatti, U.A., Yu, Z., Chanussot, J., Zeeshan, Z., Yuan, L., Luo, W., Nawaz, S.A., Bhatti, M.A., Ain, Q.U., Mehmood, A.: Local similarity-based spatial-spectral fusion hyperspectral image classification with deep CNN and Gabor filtering. IEEE Trans. Geosci. Remote Sens. 60, 1–15 (2022)
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB). Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB). This research received no external funding.
Author information
Authors and Affiliations
Contributions
Both authors contribute equally to this manuscript.
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare that they have no conflict of interests to this work.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A
Proof of Proposition 1
According to [42], the cardinality of T1 Cauchy fuzzy set A is
And, the cardinality of the intersection of two T1 Cauchy fuzzy sets, A and B with centers a1, a2 spreads b1 and b2. Taking \(\cap \) the minimum and \(\cup \) the maximum, then we have
where,
Then, the generalized formula for mutual subsethood similarity between two T1 Cauchy fuzzy sets A and B is [42]:
Now, for the case of IT2 Cauchy fuzzy sets, the similarity formula is a generalization of (90) as given in (19), see [41], then we have
For the case of two IT2 Cauchy fuzzy sets A and B, then
from (86), we have
Similarly,
Thus,
From (85), we have
Since \({\overline{b}}_{min}=\mathit{min}({\overline{b}}_{1}\),\({\overline{b}}_{2})\), then
Similarly,
Thus
From (96) and (102) in (91), we get the formula (20). ■
Appendix B
2.1 Evaluation of Partial Derivatives
2.1.1 At the Output Layer
Derivation of \(\left(\frac{\partial {\varvec{E}}}{\partial {{\varvec{a}}}_{{\varvec{k}}{\varvec{j}}}}\right)\):
From (104) and (105) in (103), we get the formula (64). ■
Derivation of \(\left(\frac{\partial {\varvec{E}}}{\partial {\underline{{\varvec{b}}}}_{{\varvec{k}}{\varvec{j}}}}\right)\):
From (43) and (45) with simplification, we have
From (104), (107), and (108) in (106), we get the formula (65) ■
Derivation of \(\left(\frac{\partial {\varvec{E}}}{\partial {\overline{{\varvec{b}}}}_{{\varvec{k}}{\varvec{j}}}}\right)\):
Similar to the derivation of \(\left(\frac{\partial E}{\partial {\underline{b}}_{kj}}\right)\) we have
From (104), (110), and (111) in (109), we get the formula (66) ■
2.1.2 At the Hidden Layer
Derivation of \(\left(\frac{\partial {\varvec{E}}}{\partial {{\varvec{a}}}_{{\varvec{j}}{\varvec{i}} {\varvec{m}}{\varvec{i}}{\varvec{n}}}}\right)\):
From (46) with simplification, we have
From (65) and (66) in (113), then we have
From (42), then
From (36) by differentiation and simplification, then
From (37), by differentiation, simplification, and using (15) and (16), then
From (38), by differentiation, simplification, and using (17) and (18), then
From (117) & (118) in (116) with simplification then
By substituting (114), (115), and (119) in (112), we get the formula (67). ■
Derivation of \(\frac{\partial {\varvec{E}}}{\partial {{\varvec{a}}}_{{\varvec{j}}{\varvec{i}} {\varvec{m}}{\varvec{a}}{\varvec{x}}}}\):
Following a similar derivation starting from (112) up to (118), we have
From (37) by differentiation and using (15) and (16), then
Also, from (38) by differentiation and using (17) and (18)
Thus, (122) and (123) in (121), then we have
From (124) in (120), we get the formula (68). ■
Derivation of \(\left(\frac{\partial {\varvec{E}}}{\partial {\underline{{\varvec{b}}}}_{{\varvec{j}}{\varvec{i}} {\varvec{m}}{\varvec{i}}{\varvec{n}}}}\right)\):
From (36) by differentiation and simplification
From (37) by differentiation with simplification and using (15) and (16), then
It is suitable to rewrite (127) using the notation
where, \(\underline{\tau }\) and \(\underline{\rho }\) are defined in (73) and (75).
Substituting (128) in (126), then we have
From (112) and (125), it is clear that
From (119) and (129) in (130), we have the formula (69).■
Derivation of \(\left(\frac{\partial {\varvec{E}}}{\partial {\overline{{\varvec{b}}}}_{{\varvec{j}}{\varvec{i}} {\varvec{m}}{\varvec{i}}{\varvec{n}}}}\right)\):
Similar to the derivation of \(\left(\frac{\partial E}{\partial {\underline{b}}_{ji min}}\right)\), we have
where,
It is suitable to rewrite (133) using the following notation
where \(\overline{\tau }\) and \(\overline{\rho }\) are defined in (74) and (76).
Substituting (134) in (132), then we have
From (112) and (131), it is clear that
From (119) and (135) in (136) then
Although formula (137) is a good closed formula, it is more suitable to get \(\left(\frac{\partial E}{\partial {\overline{b}}_{ji min}}\right)\) in terms of \(\left(\frac{\partial E}{\partial {\underline{b}}_{ji min}}\right)\) by dividing (137) by (69) to get the formula (70).■
Derivation of \(\left(\frac{\partial {\varvec{E}}}{\partial {\underline{{\varvec{b}}}}_{{\varvec{j}}{\varvec{i}} {\varvec{m}}{\varvec{a}}{\varvec{x}}}}\right)\):
From (36) by differentiation and simplification
From (37), by differentiation and simplification using (15) and (16), then
It is suitable to rewrite (140) using the following notation
where \(\underline{\uptau }\) and \(\underline{\uprho }\) are defined in (73) and (75).
Substituting (141) in (139), then we have
From (112) and (138), it is clear that
From (119) and (142) in (143), we get the formula (71).■
Derivation of \(\left(\frac{\partial {\varvec{E}}}{\partial {\overline{{\varvec{b}}}}_{{\varvec{j}}{\varvec{i}} {\varvec{m}}{\varvec{a}}{\varvec{x}}}}\right)\):
Similar to the derivation of \(\left(\frac{\partial E}{\partial {\underline{b}}_{ji max}}\right)\), we have
From (36) by differentiation, and simplification
From (38) by differentiation and simplification using (17) and (18)
Rewriting (146) in our new notation, then
Substituting (147) in (145), then we have
From (112) and (144), it is clear that
From (119) and (148) in (149) then
Although formula (150) is a good closed formula, it is more suitable to get \(\left(\frac{\partial E}{\partial {\overline{b}}_{ji max}}\right)\) in terms of \(\left(\frac{\partial E}{\partial {\underline{b}}_{ji max}}\right)\) by dividing (150) by (71) to get the formula (72).■
Appendix C
3.1 Derivation of Cauchy Type-1 MSuFNIS (T1MSCFuNIS)
3.1.1 At the Output Layer
The new settings of the parameters in the output layer when all IT2 Cauchy fuzzy sets are reduced to T1 are as follows:
Then, the general partial derivatives of the parameters given in (64)–(66) are reduced to the following forms:
3.1.2 At the Hidden Layer
The new settings of the parameters in the hidden layer when all IT2 Cauchy fuzzy sets are reduced to T1 are as follows:
Then, the general partial derivatives of the parameters given in (67)–(72) are reduced to the following forms:
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hefny, H.A., Amer, N.S. Interval Type-2 Mutual Subsethood Cauchy Fuzzy Neural Inference System (IT2MSCFuNIS). Int J Comput Intell Syst 17, 28 (2024). https://doi.org/10.1007/s44196-024-00405-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-024-00405-y