
Abstract
Power systems are pivotal in providing sustainable energy across various sectors. However, optimizing their performance to meet modern demands remains a significant challenge. This paper introduces an innovative strategy to improve the optimization of PID controllers within nonlinear oscillatory Automatic Generation Control (AGC) systems, essential for the stability of power systems. Our approach aims to reduce the integrated time squared error, the integrated time absolute error, and the rate of change in deviation, facilitating faster convergence, diminished overshoot, and decreased oscillations. By incorporating the spiral model from the Whale Optimization Algorithm (WOA) into the Multi-Objective Marine Predator Algorithm (MOMPA), our method effectively broadens the diversity of solution sets and finely tunes the balance between exploration and exploitation strategies. Furthermore, the QQSMOMPA framework integrates quasi-oppositional learning and Q-learning to overcome local optima, thereby generating optimal Pareto solutions. When applied to nonlinear AGC systems featuring governor dead zones, the PID controllers optimized by QQSMOMPA not only achieve 14\(\%\) reduction in the frequency settling time but also exhibit robustness against uncertainties in load disturbance inputs.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
As regional power grids become increasingly interconnected, the complexity of the power grid’s overall structure grows, accompanied by a wider array of disturbances [1]. Consequently, Automatic Generation Control (AGC) emerges as a paramount concern within interconnected power systems [2]. When a disturbance affects a segment of the interconnected power system, the resulting frequency deviation traverses tie lines, potentially impacting power flow between regional grids [3]. In power systems, AGC plays a pivotal role in restoring unit frequency and inter-regional tie line power to predefined permissible ranges during regular operation or minor disruptions [12, 13]. Additionally, advanced controllers such as sliding mode controllers [14] and robust controllers [15] have been proposed to enhance AGC. However, these methods often entail high complexity and computational burdens, fostering the application of Proportional-Integral-Derivative (PID) controllers [16]. PID controllers are commonly preferred in educational and engineering contexts due to their simplicity, cost-effectiveness, and robustness against diverse disturbances [17].
Nevertheless, the performance of PID controllers hinges on their settings [18, 19], underscoring the importance of efficient optimization models [20]. The researchers improved the Bacterial Foraging Optimization Approach (BFOA) by reducing a time-domain objective function to develop PID controllers [21]. The researchers presented a novel approach called Teaching Learning-Based Optimization (TLBO) to optimize the parameters of PID controllers in a two-region thermal system [22]. Kumar et al. [23] compared two search algorithms for PID controller design, utilizing the Imperialist Competitive Algorithm (ICA) to determine ideal parameters. Gheisarnejad [24] devised a hybrid algorithm by combining the harmony search algorithm (HSCOA) and Cuckoo Optimization Algorithm (COA) mechanisms to tune PID gains. He et al. [25] presented the Wind-Driven Butterfly Optimization Algorithm (WDBOA), which effectively balances exploration and exploitation capabilities and demonstrates superior performance in PID controller parameter optimization.
Despite scholars optimizing auxiliary controller parameters, their research typically focuses on a single objective that aligns with specific control requirements and can be addressed by a single-objective optimization algorithm. Shiva and Mukherjee [26] used Integral Squared Error (ISE) as the objective function to design a PID controller. Meanwhile, Singh et al. [5] took into account a range of performance indicators. The performance measurements were consolidated into a singular target through the utilization of the analytical hierarchy process (AHP). The inherent contradiction between these objectives presents a challenge in determining an optimal scheme for a multi-objective model that effectively addresses the trade-offs between speed, economy, and safety.
The performance of AGC primarily hinges on three factors: (a) controller structure; (b) algorithm for optimizing controller parameters; and (c) loss function performance. Facing the challenge of balancing multiple, often conflicting, control optimization objectives in nonlinear and oscillatory AGC systems, the Multi-Objective Marine Predators Algorithm (MOMPA) [27] offers an innovative solution. Inspired by the foraging behavior of marine predators, this algorithm adopts their dynamic strategies to effectively tackle multi-objective optimization problems. MOMPA is specifically designed to explore and exploit the solution space, identifying solutions that balance various objectives across the complex Pareto front [28]. Despite MOMPA’s capability in navigating complex Pareto fronts, it faces challenges in highly multi-modal environments with numerous local optima, necessitating refined exploration and exploitation strategies to prevent premature convergence on suboptimal solutions [29].
The purpose of this paper is to provide a multi-objective approach that can effectively tune PID controllers with simple designs. We construct a multi-objective model featuring the Integrated Time Squared Error (ITSE), the Integrated Time Absolute Error (ITAE), and the rate of change in deviation as objectives, comprehensively addressing convergence rate, overshoot, and system oscillation. Our approach utilizes the efficient MOMPA integrating spiral mode, Quasi-Oppositional Learning (QOL), and Q-learning (QQSMOMPA) to optimize PID controller parameters for three real-world AGC systems. The inherent variability and uncertainty present in AGC systems, including load fluctuations and parameter shifts, necessitate optimization algorithms to possess a high degree of adaptability. The augmented diversity within the QQSMOMPA guarantees that the algorithm can adjust to these fluctuations, thereby sustaining optimal or near-optimal performance across more conditions. The contributions of this paper are summarized as follows:
-
(1)
Introduce a novel multi-objective optimization methodology aimed at augmenting PID controller performance in nonlinear and oscillatory AGC. This methodology stands out by concurrently minimizing ITSE, ITAE, and the deviation rate of change, thereby balancing the convergence rate, overshoot, and system oscillation.
-
(2)
Integration of advanced optimization techniques, including spiral model and Q-learning framework, to efficiently diversify solution sets and effectively balance exploration and exploitation strategies, resulting in superior Pareto solutions for AGC systems.
-
(3)
Demonstration of QQSMOMPA’s efficacy through experiments, showcasing superior performance and robustness in optimizing PID controllers for AGC under various conditions. When applied to nonlinear AGC systems featuring governor dead zones, the PID controllers optimized by QQSMOMPA not only achieve 14\(\%\) reduction in the frequency settling time but also exhibit robustness against uncertainties in load disturbance inputs.
The following sections are organized in the following manner: Sect. 2 provides an overview of the AGC problem and presents a multi-objective optimization model. Section 3 elaborates on MOMPA and the proposed SMOMPA and QQSMOMPA. In Sect. 4, we employ QQSMOMPA to resolve three real-world AGC scenarios. The paper concludes in Sect. 5.
2 The Description and Solution of the Problem of AGC
2.1 The Description of AGC
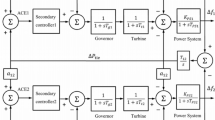
This section introduces the fundamental transfer function model of the AGC. The examination of AGC often utilizes a thermal power system with two regions and no reheat, as seen in Fig. 1, which serves as a widely adopted framework for AGC investigations. The interconnected grid system primarily consists of governors, turbines, and power systems. The inputs to the system consist of the control system signal \(\Delta P_{ref}\), changes in demand for energy \(\Delta P_{L}\), and deviations in tie-line power \(\Delta P_{tie}\). In addition, the outputs of the system encompass the frequency deviation \(\Delta f\) and the area control error (ACE), which are precisely specified by:
The symbol B is used to denote the frequency deviation parameter. To achieve desired goals, the control system adjusts the reference power setting of the generator set, thereby balancing the power generation and load in each region.
In previous studies [3, 30], the parameters for test system-1 were uniformly set. The parameters include \(T_{\textrm{g}}\) for the governor’s time constant, \(T_{t}\) for the non-reheat steam turbine’s time constant, B for the frequency deviation, \(T_{12}\) for the synchronous torque coefficient, \(\Delta P_{ref}\) for the reference power setting, \(\Delta P_{\textrm{g}}\) for the governor valve’s positional adjustment, \(\Delta P_{t}\) for changes in steam turbine power output, \(\Delta P_{L}\) for load demand changes, \(\Delta f\) for frequency variation, and \(\Delta P_{tie}\) for tie-line power discrepancies between regions. Per-unit values are provided for system variables: \(f=60\) Hz, \(B=0.425\) p.u MW/Hz, \(R=2.4\) Hz/p.u, \(T_{\textrm{g}}=0.03\) s, \(T_{t}=0.3\) s, \(K_{ps}=120\) Hz/p.u, \(T_{ps}=20\) s, and \(T_{12}=0.545\) p.u MW/rad.

Transfer function model of test system-1
When affected by load changes, the frequency can still be maintained near the stable point. Therefore, each link can be approximated using a low-order transfer function, as detailed in Elgerd [31].
The transfer functions of the governor, non-reheat turbine, and power system are given by:
and
The controller functions as a supplement to the AGC system. Despite significant advancements in advanced controllers, the traditional PID controller and its variations remain preferred due to its simple structure, high reliability, and excellent control performance. Furthermore, their ease of dynamic modeling and cost-effectiveness contribute to their effectiveness in engineering practice.
Assuming that in Fig. 1, the PID controller acts as an additional control element, the reference power settings \(\Delta P_{ref1}\) and \(\Delta P_{ref2}\) are given by:
where \(K_p\), \(K_i\), and \(K_d\) represent the gains of the PID controller. This paper assumes that the gains of all region controllers are the same, namely \(K_{p1} = K_{p2} = K_{p}\), \(K_{i1} = K_{i2} = K_{i}\), and \(K_{d1} = K_{d2} = K_{d}\). To achieve the control objectives, these gains must be accurately optimized, which is the motivation behind this paper.
2.2 The Construction of Multi-objective Optimization Model
As mentioned earlier, an effective AGC system for an interconnected grid aims to minimize frequency and power overshoots, guiding them to converge rapidly to zero. To achieve this goal, it is imperative to adjust the gains of the PID controller, a task that may be conceptualized as a multi-objective optimization problem (MOP). The general mathematical formulation for MOP is presented as follows:
where X represents the candidate solution, F(X) is employed to represent the goal function, while g(X) and h(X) are utilized to express unequal and equal limitations, respectively. M represents the count of goal functions, while a and b stand for the quantities of inequality and equality constraints correspondingly.
Dominance is a notion that describes the optimality of MOP. If \(X_1\) and \(X_2\) satisfy:
then consider that \(X_1\) dominates \(X_2\), denoted by \(X_{1} \prec X_{2}\).
According to the retrospective research [3, 5], ITAE and ITSE are widely used in the tuning of PID controller parameters. Each of these functions has unique properties that contribute to improving the above specifications, and the formula is as follows:
and
When the error is big in the parameter optimization based on the ITSE, the gradient reduces quickly; when the error is small, the gradient declines slowly, which is beneficial for the convergence of the optimization. Compared with ITSE, ITAE is very effective in controlling the error amplitude, but the convergence speed is slower. Furthermore, to enhance the stability of the entire system, a third objective function given by
is proposed considering the rate of change of \(\Delta f_{1}\), \(\Delta f_{2}\) and \(\Delta P_{tie}\) which is easy to calculate.
While ITAE prioritizes long-term precision and stability, potentially resulting in slower response times, ITSE aggressively reduces large errors, favoring rapid response but risking overshoot and instability. On the other hand, the rate of change of deviation function aims to smooth system response by minimizing error fluctuations, which may hinder rapid adaptation. Due to the conflict between objective functions, this paper constructs a multi-objective optimization model to tune the PID controller parameters, which is as follows:
In this paper, all PID gain coefficients are in the range of [0.0, 2.0]. The objective of the optimization work is to identify the Pareto optimum set of parameters for the PID controller. To accomplish this objective, this paper employs an enhanced version of the multi-objective marine predator algorithm (MOMPA), which is expounded upon in the subsequent section.
3 The Proposed Strategy
3.1 The MOMPA
The MOMPA, introduced by Chen et al. [27], stands out in the realm of multi-objective optimization for its innovative integration of dominance-based evolutionary strategies and its adeptness at balancing diversity and convergence in the Pareto frontier. Distinctively, MOMPA combines non-dominated sorting with a reference point strategy, a methodological choice that facilitates the identification and preservation of outstanding solutions, thereby ensuring a diverse set of Pareto-optimal solutions [32]. Unique to MOMPA is its adoption of a Gaussian perturbation technique, designed to enhance population diversity and bolster its global search efficacy [33].
The evolutionary strategies of MOMPA include high velocity, same velocity, and low velocity. During each phase, the updating process involves two matrices from the following options:
and
where \(\textit{N}\) represents the number of preys and \(\textit{d}\) denotes the number of dimensions. In MOMPA, \(\varvec{Elite}\) is randomly constructed from each generation of \(\varvec{Prey}\).
The strategies used in the high-velocity phase are as follows:
and
where the vector \(\varvec{{R_B}}\) consists of random numbers generated from a normal distribution. The variable \(\textit{N}\) represents the number of search agents, whereas \(\varvec{{R}}\) is a vector comprising random numbers generated from a uniform distribution within the range of 0 to 1. Moreover, the symbol \(\otimes\) denotes element-wise multiplications. The value of P is set to 0.5.
The strategies used in the same velocity phase are as follows:
and
where \(\varvec{{R_L}}\) is a vector of random numbers based on Lévy distribution. The remaining half of the prey is intended for exploitation, which is indicated by:
and
where \(CF = \left( 1-\frac{\textit{Iter}}{\textit{Iter}_{max}}\right) ^{\frac{2\textit{Iter}}{\textit{Iter}_{max}}}\) is made to regulate the \(\varvec{{stepsize}}\).
The strategies used in the low-velocity phase are as follows:
and
Another significant issue, such as the effects of fish aggregating devices (FADs), has the potential to alter the behavior of marine predators. The FADs are thought of as local optimums, and their results in the search space are the discovery of these spots.
When \(\textit{r} < FADs\), the strategy is as follows:
When \(\textit{r} \ge FADs\),
where the probability of the FADs effect is 0.2. The lower and upper bounds of the predators’ positions are \(\varvec{{lb}}\) and \(\varvec{{ub}}\), and \(\textit{r}\) is a uniform random value in the range of [0, 1]. The binary vector \(\varvec{U}\) is created by initializing a random vector in the range [0, 1] and setting its arrays to 0 if the value is less than 0.2 and 1 otherwise. Integers \(\textit{r}_1\) and \(\textit{r}_2\) are chosen at random from 1 to \(\textit{N}\).
Moreover, the MOMPA employs a Gaussian perturbation technique to enhance the diversity of the population and enhance its ability to explore the global search space. The equations of the Gaussian perturbation technique are as follows:
where G follows a normal distribution and \(i=1, \ldots , \textit{N}\).
It is worth noting that MOMPA utilizes a hybrid approach that combines the non-dominated sorting technique [34] with reference point strategy [35] to accurately and efficiently find preys of superior quality. The aforementioned procedure not only serves to improve the identification of solutions of superior quality but also plays a pivotal role in preserving the diversity present within the sets of Pareto optimal solutions. Despite the MOMPA’s efficacy in a broad spectrum of optimization scenarios, it encounters inherent limitations regarding search space complexity and susceptibility to local optima entrapment. This observation necessitates an evolution towards a more sophisticated solution, hence the development of the QQSMOMPA technique, aimed at ameliorating these constraints and augmenting the algorithm’s overall optimization capability.
3.2 The First Improvement: SMOMPA
To balance exploration and exploitation strategies and diversify the solution set, this paper integrates the spiral model from the whale optimization algorithm (WOA) into the MOMPA, thus develo** SMOMPA. The incorporation of the spiral model, initially proposed by Chen et al. [36] and based on the behavior of whales creating air bubbles to herd prey as elucidated by Gharehchopogh and Gholizadeh [37], serves as a strategic improvement. The selection of the spiral model for enhancement is motivated by its proven effectiveness in achieving a balanced interplay between the exploration and exploitation phases throughout the optimization process. Notably, the spiral model replicates the spiral bubble-net feeding strategy, which achieves a harmonious balance between encircling the prey and initiating a spiraling approach [38, 39]. This approach is akin to efficiently contracting the search area in optimization challenges while ensuring exhaustive exploration, thereby offering an effective method to navigate the delicate equilibrium between extensive global search and focused exploitation [40].
The strategy for updating the solution via the spiral model in SMOMPA is as follows:
where \(\textit{l}\) is a constant parameter that modifies the form of the spiral. By default, its value is set to 1. On the other hand, \(\alpha\) is a numerical value selected randomly from the interval \([-1,1]\) in each iteration.
3.3 The Second Improvement: QQSMOMPA
3.3.1 The QOL
QOL is an innovative optimization technique that draws inspiration from opposition-based learning (OBL) [41]. QOL entails evaluating potential solutions in conjunction with their quasi-opposite counterparts, which are not precise opposites but are deliberately selected to be more closely aligned with the original answers. The objective of this strategy is to improve the search for the best possible solutions within given numerical ranges. This approach aims to broaden the search scope within the solution space and facilitate the evasion of local optima [42, 43].
The quasi-opposite solution can be defined in \(\textit{d}\)-dimension as follows:

3.3.2 The Q-learning
To adaptively select among numerous strategies, this paper aims to utilize Q-learning for improvement. Q-learning is a renowned algorithm in the field of Reinforcement Learning (RL) and it plays a crucial part in the methodology suggested in this work. The Q-learning method employs a reward table to provide incentives and consequences to an agent based on its behavior in various states. The \(\varvec{Q-table}\) serves as an agent’s collection of experiences, as elucidated by Zamfirache et al. [44]. The primary objective of the agent is to make well-informed judgments by consistently updating its current state, taking into account the corresponding Q-value from the \(\varvec{Q-table}\), and evaluating all possible actions. The learning process occurs through a sequence of iterations, known as iterations (referred to as Iter), where agents gain knowledge by exploring their surroundings and updating their \(Q-table\) using the Bellman equation:
where \(\lambda\) is the learning rate value and \(\gamma\) is the discount factor between 0 and 1. \(r_{\text{ Iter } }\) is the immediate reward calculated by s and a. The Algorithm 1 demonstrates the sequential process of Q-learning.
3.3.3 The QQSMOMPA
Our enhancement strategy introduces the SMOMPA algorithm and its advanced iteration, QQSMOMPA, which integrates Q-learning to refine the exploration and exploitation phases of MOMPA. This combination enhances the algorithm’s ability to remember and utilize information about the search space across iterations, effectively hel** to escape local optima and improving search efficiency.
Q-learning is a crucial component in the process of making intelligent decisions. It dynamically chooses between the fish aggregating devices and the QOL strategy, depending on the rewards obtained. The incorporation of Q-learning, QOL, and FADs provides numerous benefits. It facilitates the dynamic selection of strategies, enabling the system to modify its approach flexibly based on the present condition and past knowledge. The overarching goal of Q-learning, which is to maximize long-term rewards, is applied to the choice of position update strategy, ultimately leading to the discovery of improved solutions [45, 46].
According to our proposed QQSMOMPA, the prey assumes the function of the agent. The states represent the continuous actions of each prey, whereas action indicates the movement of each agent from one state to another. The \(\varvec{Q-table}\) contains the historical performance of the Q-learning agent in previous episodes. This information is crucial for determining the most appropriate option during the three stages. QQSMOMPA regulates the determination of the suitable phases for each agent (\(i=1, \ldots , N\)) according to a particular criterion or parameter referred to as
With Q-learning assistance, the selection of actions for each prey becomes adaptive. The primary interaction between Q-learning and the three potential operations can be condensed into four steps, as outlined below:
-
1.
Initialize the \(\varvec{Q-table}\) as a \(3 \times 3\) zero matrix and \(\varvec{Reward}\) is given as: \(\left[ \begin{array}{ccc}-1 &{} 1 &{} 1 \\ 1 &{} 1 &{} 1 \\ 1 &{} 1 &{} 1\end{array}\right] .\)
-
2.
Obtain the best strategy for the current iteration to be executed based on the values contained in the \(\varvec{Q-table}\) for the current state shown in Eq. (28).
-
3.
Execute the selected action and calculate the number of selected preys in \(\varvec{Prey}\) by implementing non-dominant sorting and reference point. The immediate reward is updated as follows:
$$\begin{aligned} \varvec{Reward_{m,n}} = number \end{aligned}$$(29) -
4.
Update the \(\varvec{Q-table}\) using Algorithm 1.
An outstanding characteristic of the suggested method QQSMOMPA is its capacity to transition between various phases as required. Due to this particular characteristic, it can efficiently investigate both global and local optimal solutions. The Algorithm 2 demonstrates the sequential process of the proposed QQSMOMPA. Additionally, the proposed QQSMOMPA’s effectiveness is verified through its application to benchmark functions, as detailed in Supplementary Materials.
3.4 The Fuzzy Decision
After obtaining the Pareto optimal set of PID controller parameters, selecting a compromise solution becomes essential. The paper employs fuzzy set theory for a final evaluation of solutions in the Pareto optimal set. The fuzzy utility value \(\mu _{i}\) for the ith solution is determined by:
where the variable M denotes the quantity of goal functions, whereas the variable N denotes the quantity of solutions. The formula for \(\mu _{i, j}\) is as follows:
where \(f_{j}^{\max }\) represents the highest value of the jth goal function within the population, whereas \(f_{j}^{\min }\) represents the smallest value. It is noteworthy to mention that this research selects the option with the highest \(\mu\) value as the ideal compromise solution.

4 Practical AGC Problem
The proposed QQSMOMPA tuning PID controller’s gains to the AGC is shown in this section using three test systems. The obtained results are contrasted with the subsequent strategy: (1) BFOA: PI [21], (2) HBFOA:PI [47], (3) TLBO: PID [22], (4) ISFS: PID [3], (5) DE: PID [48]. The tests are conducted within the Matlab R2017a environment, utilizing a computing system equipped with an i7-8750 H CPU and 8 GB RAM.
4.1 Test System-1
The design of test system-1 is depicted in Fig. 1, where Table 1 lists the ideal controller parameters, peak values (p), and settling times (\(T_{s}\)). Utilizing the QQSMOMPA-tuned PID controller when introducing a 0.1 Step Load Disturbance (SLD) into region-1 at \(t = 0\) s, the peak of \(\Delta f_1\) is recorded at \(p=0.0651\) Hz (see Table 1), which is lower than the peak achieved with the ISFS-tuned PID controller (\(p=0.1226\) Hz) but slightly higher than that of the TLBO-tuned PID controller (\(p=0.0587\) Hz). In contrast, the QQSMOMPA-tuned PID controller achieves the smallest peak for \(\Delta f_2\) at \(p=0.0321\) Hz, outperforming the TLBO-tuned PID controller (\(p=0.0355\) Hz) and significantly the ISFS-tuned PID controller (\(p=0.1746\) Hz). Regarding \(\Delta P_{tie}\)’s peak value, the QQSMOMPA-tuned PID controller records the lowest at \(p=0.0123\) p.u, surpassing both the TLBO-tuned PID controller (\(p=0.0143\) p.u) and the ISFS-tuned PID controller (\(p=0.0155\) p.u). These results underline the effectiveness of our proposed method in minimizing system overshoot. Table 3 demonstrates how the QQSMOMPA framework, through the incorporation of QOL and Q-learning, adeptly balances exploration and exploitation to optimize PID controllers within nonlinear oscillatory AGC systems, yielding a diverse set of superior Pareto-optimal solutions. This balance is manifested in a spectrum of optimized PID controller gains, as evidenced by the objective function metrics, which unequivocally indicate an enhancement in performance via a comprehensive array of superior Pareto-optimal solutions.
When introducing a 0.1 SLD into region-1 at \(t = 0\) s, the resulting time-domain responses are showcased in Fig. 4. The QQSMOMPA-tuned PID controller’s responses are notably smoother, attributed to the formulation of the goal function J. Moreover, this method exhibits quicker convergence to zero for frequency deviations and tie-line power, alongside diminished peak magnitudes.
The PID controller settings, as detailed in Table 1, are kept constant to assess the controller’s stability across different operational scenarios. Furthermore, an analysis involving a concurrent 0.1 SLD in region-1 and a 0.2 SLD in region-2 has been conducted. The results for each region are depicted in Fig. 5. All evaluated strategies display adaptability to changes in the location and magnitude of load disturbances, effectively minimizing their regional discrepancies to zero. Notably, in these tests, our methodology exhibits enhanced transient response characteristics.

Transfer function model of test system-2
4.2 Test System-2
To better align AGC with real-world conditions, we incorporate governor dead band (GDB) into a two-area no-reheat thermal power generation system, as illustrated in Fig. 2. The presence of GDB introduces system oscillations at a natural frequency of approximately 0.5 Hz. The revised governor transfer function model is presented as follows:
The per-unit values are defined as \(f=60 {\rm Hz}, B=0.425 {\rm p.u MW/Hz}, R=2.4 {\rm Hz/p.u}, T_{{\rm g}}=0.2 {\rm s}, T_{t}=0.3 {\rm s}, K_{p s}=120 {\rm Hz/p.u}, T_{p s}=20 {\rm s}, T_{12}=0.444 {\rm p.u MW/rad}\). A 0.01 SLD is introduced to region-1 at \(t = 0\) s. According to Table 2, the \(T_s\) for \(\Delta f_2\) achieved by the QQSMOMPA-tuned PID controller is \(T_s=5.56 \text { s}\), demonstrating efficiency over the DE-tuned PID controller (\(T_s=6.89 \text { s}\)) and the ISFS-tuned PID controller (\(T_s=6.48 \text { s}\)). Likewise, the peak value of \(\Delta f_1\) is lowest when using the QQSMOMPA-tuned PID controller (\(p=0.0172 \text { Hz}\)) compared to the DE-tuned PID controller (\(p=0.0196 \text { Hz}\)) and the ISFS-tuned PID controller (\(p=0.0173 \text { Hz}\)).

Random load
The time-domain responses, derived from the gains listed in Table 2, are illustrated in Fig. 6. Characteristics such as improved responsiveness, reduced dam** oscillations, faster settling times, and decreased peak values distinguish the performance of QQSMOMPA-tuned PID controllers, enabling a swift return to equilibrium. Notably, while the ISFS-tuned PID controller emerges as a primary contender, it overlooks certain objective functions, limiting its ability to provide more feasible solutions.
Additionally, a simultaneous consideration of a 0.01 SLD in region-1 and a 0.03 SLD in region-2 is examined, to assess the resilience of each method in complex instances. The controller’s settings match those in Table 2. Figure 7 displays the matching system response. Each control scheme’s system frequency change is stable, showing the robustness of the system. In contrast, the present investigation demonstrates that the QQSMOMPA tuning PID controller exhibits enhanced anti-interference capabilities, as seen by the faster load interference suppression observed in the red track compared to previous experiments.
To verify the robustness of our proposed strategy against random disturbances under more complex conditions, a loading scenario is implemented on region-1 as depicted in Fig. 2. The loading scenario is random in duration and amplitude, and its amplitude range is \([-\,0.005,0.01]\) shown in Fig. 3.
Remaining the controller parameters unchanged, the same as Table 2, Fig. 8 shows the dynamic response of test system-2 when such a load disturbance occurs. Compared with DE: PID, QQSMOMPA has an excellent performance in optimizing PID controller parameters. From the superposition response, our scheme has better system robustness than other controllers in terms of the uncertainty of load disturbance input.

Test system-1’s time-domain responses to a 0.1 SLD in region-1

Test system-1’s time-domain responses to a 0.1 SLD in region-1 and 0.2 SLD in region-2

Test system-2’s time-domain responses to a 0.01 SLD in region-1

Test system-2’s time-domain responses to a 0.01 SLD in region-1 and a 0.03 SLD in region-2

Test system-2’s comparative time-domain responses to random load disturbance

Transfer function model of test system-3
4.3 Test System-3
We employ a three-region hydroelectric power system (test system-3) to evaluate the applicability of the QQSMOMPA-tuned PID controller for managing multiple generating units. The terminology used to describe this system is consistent with that of the previously mentioned test system-1 and test system-2. In test system-3, the scheduled tie-line power transmission between two adjacent regions may have indirect connections to tie lines in regions beyond the two adjacent regions it is originally scheduled to connect. The transfer function model of test system-3 is depicted in Fig. 9, and the relevant parameters are \(f=60 \mathrm {~Hz}, B=0.425\, \mathrm {p.u} \textrm{MW} / \textrm{Hz}, R=2.4 \mathrm {~Hz} / \textrm{p}. \textrm{u}, T_{\textrm{g}}=0.08 \mathrm {~s}, K_{r}=0.5 \mathrm {~s}, T_{r}=10 \mathrm {~s}\) \(T_{t}=0.3 \mathrm {~s}, K_{ep}=1.0, K_{ed}=4.0, K_{ei}=5.0, T_{w}=1 \mathrm {~s}, K_{p s}=120 \mathrm {~Hz} / \mathrm {p.u}, T_{p s}=20 \mathrm {~s}\) \(T_{12}=T_{23}=T_{13}=0.086 \, \mathrm {p.u} \textrm{MW} / \textrm{Hz}.\) The thermal systems in region-1 and region-2 make use of single-stage reheat turbines, whereas region-3 utilizes a contemporary hydraulic system that incorporates an electronic governor in place of a traditional mechanical governor.
The same optimization procedure employed in the previous test system is used to determine the optimal controller parameters for the test system-3 with Generation Rate Constraints (GRC).
The PID controller refined through the QQSMOMPA process demonstrates improved step responses in each region. It rapidly enters the specified frequency range, reducing overshoot caused by this adjustment compared to ISFS: PID, and efficiently dampens oscillations, resulting in a smoother convergence curve. Nevertheless, our algorithm is not flawless either. When comparing stability time, QQSMOMPA:PID is slightly longer than ISFS:PID, but still falls within an acceptable range. These enhancements are depicted in Figs. 10 and 11.

Test system-3’s time-domain responses to a 0.01 SLD in all regions

Test system-3’s time-domain responses to a 0.01 SLD in all regions
5 Conclusions
This paper delineates a novel framework for the optimization of PID controller gains within AGC systems for interconnected power grids, employing the QQSMOMPA algorithm. This methodology, grounded in the integration of ITAE, ITSE, and the deviation rate of change as optimization objectives, advances the state of controller tuning in AGC systems. The efficacy of this approach is substantiated through simulation analyses, evidencing the potential for improved robustness and control in AGC (Table 4).
Crucially, the auxiliary controller’s significant impact on enhancing control effectiveness highlights the imperative for continued refinement of controller structures. This underscores an emergent research trajectory that necessitates the exploration of advanced control strategies. Among these, reinforcement learning (RL) and model predictive control (MPC) stand out as pivotal areas for future investigation. RL’s adaptability and ability to optimize decision-making processes in real-time environments suggest a promising avenue for develo** dynamic control strategies that can autonomously adjust to fluctuating system dynamics. Concurrently, MPC’s foresight in anticipating system disturbances provides a compelling case for its application in preempting and mitigating control challenges. Additionally, we also notice the promising prospects of utilizing dendritic neuron models as controllers, offering another broad avenue for innovative control.
Data Availability Statement
Data will be available with a reasonable request.
References
Krim, Y., Abbes, D., Krim, S., & Mimouni, M. F. (2018). Intelligent droop control and power management of active generator for ancillary services under grid instability using fuzzy logic technology. Control Engineering Practice, 81, 215–230.
Han, W., Wang, G., & Stankovic, A. M. (2019). Active disturbance rejection control in fully distributed automatic generation control with co-simulation of communication delay. Control Engineering Practice, 85, 225–234.
Çelik, E. (2020). Improved stochastic fractal search algorithm and modified cost function for automatic generation control of interconnected electric power systems. Engineering Applications of Artificial Intelligence, 88, 103407.
Chen, G., Fan, C., Zhu, T., Teng, Y., Shi, H., & **ao, X. (2022). Study on AGC strategy involving the frequency control of HVDC power regulation. Energy Reports, 8, 498–505.
Singh, S. P., Prakash, T., Singh, V. P., & Babu, M. G. (2017). Analytic hierarchy process based automatic generation control of multi-area interconnected power system using Jaya algorithm. Engineering Applications of Artificial Intelligence, 60, 35–44.
Ding, S. X., & Li, L. (2021). Control performance monitoring and degradation recovery in automatic control systems: A review, some new results, and future perspectives. Control Engineering Practice, 111, 104790.
Sahoo, S. K., & Saha, A. K. (2022). A hybrid moth flame optimization algorithm for global optimization. Journal of Bionic Engineering, 19(5), 1522–1543.
Özbay, E., Özbay, F. A., & Gharehchopogh, F. S. (2023). Peripheral blood smear images classification for acute lymphoblastic leukemia diagnosis with an improved convolutional neural network. Journal of Bionic Engineering. https://doi.org/10.1007/s42235-023-00441-y. (Early Access)
Gao, S., Zhou, M., Wang, Y., Cheng, J., Yachi, H., & Wang, J. (2019). Dendritic neural model with effective learning algorithms for classification, approximation, and prediction. IEEE Transactions on Neural Networks and Learning Systems, 30(2), 601–604.
Li, J., Yu, T., & Zhang, X. (2021). Emergency fault affected wide-area automatic generation control via large-scale deep reinforcement learning. Engineering Applications of Artificial Intelligence, 106, 104500.
Khuntia, S. R., & Panda, S. (2012). Simulation study for automatic generation control of a multi-area power system by ANFIS approach. Applied Soft Computing, 12(1), 333–341.
Chen, K., Lin, J., Qiu, Y., Liu, F., & Song, Y. (2021). Deep learning-aided model predictive control of wind farms for AGC considering the dynamic wake effect. Control Engineering Practice, 116, 104925.
Gao, S., Zhou, M., Wang, Z., Sugiyama, D., Cheng, J., Wang, J., & Todo, Y. (2023). Fully complex-valued dendritic neuron model. IEEE Transactions on Neural Networks and Learning Systems, 34(4), 2105–2118.
Al-Hamouz, Z., Al-Duwaish, H., & Al-Musabi, N. (2011). Optimal design of a sliding mode AGC controller: Application to a nonlinear interconnected model. Electric Power Systems Research, 81(7), 1403–1409.
Hasan, N., Alsaidan, I., Sajid, M., Khatoon, S., & Farooq, S. (2022). Robust self tuned AGC controller for wind energy penetrated power system. Ain Shams Engineering Journal, 13(4), 101663.
Bisoffi, A., Beerens, R., Heemels, W. P. M. H., Nijmeijer, H., van de Wouw, N., & Zaccarian, L. (2020). To stick or to slip: A reset PID control perspective on positioning systems with friction. Annual Reviews in Control, 49, 37–63.
Arya, Y. (2017). AGC performance enrichment of multi-source hydrothermal gas power systems using new optimized FOFPID controller and redox flow batteries. Energy, 127, 704–715.
Somefun, O. A., Akingbade, K., & Dahunsi, F. (2021). The dilemma of PID tuning. Annual Reviews in Control, 52, 65–74.
Shi, L., Hu, Y., Su, S., Guo, S., **ng, H., Hou, X., Liu, Y., Chen, Z., Li, Z., & **a, D. (2020). A fuzzy PID algorithm for a novel miniature spherical robots with three-dimensional underwater motion control. Journal of Bionic Engineering, 17, 959–969.
Gao, S., Yu, Y., Wang, Y., Wang, J., Cheng, J., & Zhou, M. (2021). Chaotic local search-based differential evolution algorithms for optimization. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 51(6), 3954–3967.
Ali, E. S., & Abd-Elazim, S. M. (2011). Bacteria foraging optimization algorithm based load frequency controller for interconnected power system. International Journal of Electrical Power and Energy Systems, 33(3), 633–638.
Sahu, R. K., Panda, S., Rout, U. K., & Sahoo, D. K. (2016). Teaching learning based optimization algorithm for automatic generation control of power system using 2-DOF PID controller. International Journal of Electrical Power and Energy Systems, 77, 287–301.
Kumar, N., Kumar, V., & Tyagi, B. (2016). Multi area AGC scheme using imperialist competition algorithm in restructured power system. Applied Soft Computing, 48, 160–168.
Gheisarnejad, M. (2018). An effective hybrid harmony search and cuckoo optimization algorithm based fuzzy PID controller for load frequency control. Applied Soft Computing, 65, 121–138.
He, Y., Zhou, Y., Wei, Y., Luo, Q., & Deng, W. (2023). Wind driven butterfly optimization algorithm with hybrid mechanism avoiding natural enemies for global optimization and PID controller design. Journal of Bionic Engineering, 20(6), 2935–2972.
Shiva, C. K., & Mukherjee, V. (2015). A novel quasi-oppositional harmony search algorithm for automatic generation control of power system. Applied Soft Computing, 35, 749–765.
Chen, L., Cai, X., **, K., & Tang, Z. (2021). MOMPA: A high performance multi-objective optimizer based on marine predator algorithm. In Proceedings of the Genetic and Evolutionary Computation Conference Companion, Lille, France (pp. 177–178).
Faramarzi, A., Heidarinejad, M., Mirjalili, S., & Gandomi, A. H. (2020). Marine predators algorithm: A nature-inspired metaheuristic. Expert Systems with Applications, 152, 113377.
Ramezani, M., Bahmanyar, D., & Razmjooy, N. (2021). A new improved model of marine predator algorithm for optimization problems. Arabian Journal for Science and Engineering, 46(9), 8803–8826.
Guha, D., Roy, P. K., & Banerjee, S. (2018). Application of backtracking search algorithm in load frequency control of multi-area interconnected power system. Ain Shams Engineering Journal, 9(2), 257–276.
Elgerd, O. I. (1982). Electric energy systems theory: An introduction. New York: McGraw-Hill Book Company.
Long, Q., Wu, X., & Wu, C. (2021). Non-dominated sorting methods for multi-objective optimization: Review and numerical comparison. Journal of Industrial and Management Optimization, 17(2), 1001–1023.
**ao, S., Wang, H., Wang, W., Huang, Z., Zhou, X., & Xu, M. (2021). Artificial bee colony algorithm based on adaptive neighborhood search and Gaussian perturbation. Applied Soft Computing, 100, 106955.
Deb, K., Pratap, A., Agarwal, S., & Meyarivan, T. A. M. T. (2002). A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Transactions on Evolutionary Computation, 6(2), 182–197.
Deb, K., & Jain, H. (2013). An evolutionary many-objective optimization algorithm using reference-point-based nondominated sorting approach, part I: Solving problems with box constraints. IEEE Transactions on Evolutionary Computation, 18(4), 577–601.
Chen, H., Li, W., & Yang, X. (2020). A whale optimization algorithm with chaos mechanism based on quasi-opposition for global optimization problems. Expert Systems with Applications, 158, 113612.
Gharehchopogh, F. S., & Gholizadeh, H. (2019). A comprehensive survey: Whale optimization algorithm and its applications. Swarm and Evolutionary Computation, 48, 1–24.
Tang, J., & Wang, L. (2024). A whale optimization algorithm based on atom-like structure differential evolution for solving engineering design problems. Scientific Reports, 14(1), 795.
Zou, D., Li, M., & Ouyang, H. (2023). A MOEA/D approach using two crossover strategies for the optimal dispatches of the combined cooling, heating, and power systems. Applied Energy, 347, 121498.
Liu, X., Li, G., Yang, H., Zhang, N., Wang, L., & Shao, P. (2023). Agricultural UAV trajectory planning by incorporating multi-mechanism improved grey wolf optimization algorithm. Expert Systems with Applications, 233, 120946.
Tizhoosh, H. R. (2005). Opposition-based learning: A new scheme for machine intelligence. In Proceedings of the International Conference on Computational Intelligence for Modelling, Control and Automation and International Conference on Intelligent Agents, Web Technologies and Internet Commerce (CIMCA-IAWTIC’06), Vienna, Austria (Vol. 1, pp. 695–701).
Kumar, Y., & Sahoo, G. (2017). An improved cat swarm optimization algorithm based on opposition-based learning and Cauchy operator for clustering. Journal of Information Processing Systems, 13(4), 1000–1013.
Zhao, S., Wu, Y., Tan, S., Wu, J., Cui, Z., & Wang, Y.-G. (2023). QQLMPA: A quasi-opposition learning and Q-learning based marine predators algorithm. Expert Systems with Applications, 213, 119246.
Zamfirache, I. A., Precup, R. E., Roman, R. C., & Petriu, E. M. (2022). Reinforcement learning-based control using Q-learning and gravitational search algorithm with experimental validation on a nonlinear servo system. Information Sciences, 583, 99–120.
Wang, L., Gao, K., Lin, Z., Huang, W., & Suganthan, P. N. (2023). Problem feature based meta-heuristics with Q-learning for solving urban traffic light scheduling problems. Applied Soft Computing, 147, 110714.
Huynh, T. N., Do, D. T., & Lee, J. (2021). Q-learning-based parameter control in differential evolution for structural optimization. Applied Soft Computing, 107, 107464.
Panda, S., Mohanty, B., & Hota, P. K. (2013). Hybrid BFOA-PSO algorithm for automatic generation control of linear and nonlinear interconnected power systems. Applied Soft Computing, 13(12), 4718–4730.
Mohanty, B., Panda, S., & Hota, P. (2014). Differential evolution algorithm based automatic generation control for interconnected power systems with non-linearity. Alexandria Engineering Journal, 53(3), 537–552.
Gozde, H., & Taplamacioglu, M. C. (2011). Automatic generation control application with craziness based particle swarm optimization in a thermal power system. International Journal of Electrical Power and Energy Systems, 33(1), 8–16.
Acknowledgments
This work was supported in part by the National Natural Science Foundation of China under Grant 61873130; in part by the Chunhui Program Collaborative Scientific Research Project under Grant 202202004; in part by the Foundation of the Key Laboratory of Industrial Internet of Things and Networked Control of the Ministry of Education of China under Grant 2021FF01; in part by the Natural Science Foundation of Nan**g University of Posts and Telecommunications under Grant NY221082, Grant NY222144, and Grant NY223075; in part by the Huali Program for Excellent Talents in Nan**g University of Posts and Telecommunications; in part by the Postgraduate Research and Practice Innovation Program of Jiangsu Province under Grant; and in part by the Fundamental Research Funds for the Central Universities under WUT: 104972024KFYjc0072.
Funding
Open Access funding enabled and organized by CAUL and its Member Institutions.
Author information
Authors and Affiliations
Contributions
Yang Yang: writing—review and editing, funding acquisition. Yuchao Gao: writing-original draft. **ran Wu: supervision. Zhe Ding: writing-review and editing. Shangrui Zhao: writing-review and editing.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yang, Y., Gao, Y., Wu, J. et al. Improving PID Controller Performance in Nonlinear Oscillatory Automatic Generation Control Systems Using a Multi-objective Marine Predator Algorithm with Enhanced Diversity. J Bionic Eng (2024). https://doi.org/10.1007/s42235-024-00548-w
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42235-024-00548-w