
Abstract
Introduction
The maculopathy in highly myopic eyes is complex. Its clinical diagnosis is a huge workload and subjective. To simply and quickly classify pathologic myopia (PM), a deep learning algorithm was developed and assessed to screen myopic maculopathy lesions based on color fundus photographs.
Methods
This study included 10,347 ocular fundus photographs from 7606 participants. Of these photographs, 8210 were used for training and validation, and 2137 for external testing. A deep learning algorithm was trained, validated, and externally tested to screen myopic maculopathy which was classified into four categories: normal or mild tessellated fundus, severe tessellated fundus, early-stage PM, and advanced-stage PM. The area under the precision–recall curve, the area under the receiver operating characteristic curve (AUC), sensitivity, specificity, accuracy, and Cohen’s kappa were calculated and compared with those of retina specialists.
Results
In the validation data set, the model detected normal or mild tessellated fundus, severe tessellated fundus, early-stage PM, and advanced-stage PM with AUCs of 0.98, 0.95, 0.99, and 1.00, respectively; while in the external-testing data set of 2137 photographs, the model had AUCs of 0.99, 0.96, 0.98, and 1.00, respectively.
Conclusions
We developed a deep learning model for detection and classification of myopic maculopathy based on fundus photographs. Our model achieved high sensitivities, specificities, and reliable Cohen’s kappa, compared with those of attending ophthalmologists.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
The maculopathy in highly myopic eyes is complex and its clinical diagnosis is a huge workload and subjective. |
We developed an accurate and reliable deep learning model based on color fundus images to screen myopic maculopathy. |
The artificial intelligence system could detect and classify normal or mild tessellated fundus, severe tessellated fundus, early pathologic myopia, and advance pathologic myopia. |
The model achieved high sensitivities, specificities, and reliable Cohen’s kappa compared with those of attending ophthalmologists. |
The artificial intelligence system was designed for easy integration into a clinical tool which could be applied in a large-scale myopia screening. |
Introduction
Pathologic myopia (PM) is a major cause of legal blindness worldwide and the prevalence of myopia-related complications is expected to continue increasing in the future, presenting a great challenge for ophthalmologists [1,2,3,4]. In East and Southeast Asia, the prevalence of myopia and high myopia in young adults is around 80–90% and 10–20%, respectively [5]. In China, the prevalence of myopia in 1995, 2000, 2005, 2010, and 2014 was 35.9%, 41.5%, 48.7%, 57.3%, and 57.1%, respectively, with a gradual upward trend [6]. According to the META-PM (meta analyses of pathologic myopia) classification system proposed by Ohno-Matsui et al., PM is defined as “eyes having equal to or more serious than diffuse choroidal atrophy” or “eyes having lacquer cracks, myopic choroidal neovascularization (CNV) or Fuchs spot” [7]. However, manual interpretation of fundus photographs is subject to clinician variability since clear definition of various morphological characteristics was lacking in the META-PM classification system.
Though tessellation is a common characteristic of myopia, it is occasionally an earlier sign of chorioretinal atrophy or staphyloma development as well [8]. The higher the degree of fundus tessellation was, the thinner the subfoveal choroidal thickness was [9,10,11]. Yan et al. reported that higher degree of fundus tessellation was significantly associated with longer axial length, more myopic refractive error, and best-corrected visual acuity (BCVA) [12]. These reports have indicated that severe fundus tessellation might be the first indicator of myopia-to-PM transition. And Foo et al. demonstrated that tessellated fundus had good predictive value for incident myopic macular degeneration [13]. Therefore, screening severe fundus tessellation which is defined as equal to or more serious than grade 2 proposed by Yan et al. is beneficial to detect people at high risk of PM [12]. When people present signs of PM, visual acuity might be gradually impaired. According to recent research, patients with severe PM which was defined as equal to or more serious than patchy chorioretinal atrophy or foveal detachment and/or active CNV presented significantly worse BCVA than those with common PM [14]. Whereas, diffuse atrophy and lacquer cracks (LCs) which cause mild vision impairment and progressed slowly were considered as early-stage PM [15, 16]. Considering the complex maculopathy in highly myopic eyes, a simplified PM classification model would facilitate early detection of population with high risks of PM and stratified management of PM. However, screening the large number of patients with myopia is a huge workload for ophthalmologists.
Fortunately, with the rapid development of artificial intelligence (AI) technologies, the application of AI could provide a potential solution for the increasing burden of myopia, attributed to its ability to analyze a tremendous amount of data. In the field of ophthalmology, the deep learning system has led to exciting prospects in the detection of papilledema, glaucomatous optic neuropathy, and diabetic retinopathy based on color fundus photographs [17,18,19,20]. As a result of the complexity of the classification and definition system of PM, the application of deep learning technology in PM lesion screening is still a challenge. As evidenced by Tan et al., Lu et al., Wu et al., the AI models based on fundus images have achieved good performance in diagnosing and classifying high myopia [21,22,23,Full size image
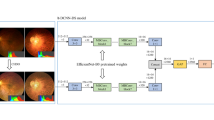
In the ROI interception module, we extracted the effective area by removing excessive black margins which may affect the identification of key feature information. Firstly, we converted the RGB images to grayscale images, in which the pixel value of background is equal to zero and the pixel value of effective area is greater than zero. Then, we used OpenCV tools to traverse the pixel information and get the location of effective area in grayscale images. Last, RGB images were cropped on the basis of the location of effective area.
In the data denoising module, an unsharp masking (USM) filter was applied to the cropped images to reduce noise interference during imaging according to the following formula [29]: \(I_{{\text{O}}} = a \cdot I_{{{\text{In}}}} + b \cdot G(\sigma )*I_{{{\text{In}}}} + c\), where \(I_{{{\text{I}}n}}\) represents the input image, \(I_{{\text{O}}}\) represents the standardized output image, \(G(\sigma )\) is a Gaussian filter with standard deviation s, and * represents the convolutional operator. Parameters a, b, c, and s were set to 4, 3.5, 128, and 30, respectively, on the basis of experience. The images were resampled to a resolution of 672 × 672 according to the code at Github (source code is at https://github.com/tensorflow/tpu/blob/master/models/official/efficientnet/efficientnet_builder.py).
In the data augmentation module, to increase the diversity of the data set and reduce the chance of overfitting [30], the horizontal and vertical flip**, rotation up to 60°, brightness shift within the range of 0.8–1.2, and contrast shift within the range of 0.9–1.1 were randomly applied to the images in the training data set, which increase its size to five times the original size.
In the data normalization module, the pixel values of images after augmentation were normalized within the range of 0–1. Then, z-score is used for standardization of the input image before deep learning.
Deep Learning Algorithm Development
Our training platform is implemented by PyTorch framework with Python3.6 and CUDA10.0. Training equipment comprised a 2.60 GHz Intel(R) CPU and a Tesla V100-SXM2 GPU. EfficientNet-B8 architecture, an excellent convolutional neural network suitable for large-size input image, was adopted [Statistical Analysis To determine the model performance, the receiver operating characteristic (ROC) curves were used and analyzed with Python software. According to the results of the classification model, the area under precision–recall (P–R) curve—the average precision value (AP), the area under ROC curve (AUC), sensitivity, specificity, and the overall accuracy were evaluated for the four groups.


