
Abstract
Remarkable advancements have been achieved in machine learning and computer vision through the utilization of deep neural networks. Among the most advantageous of these networks is the convolutional neural network (CNN). It has been used in pattern recognition, medical diagnosis, and signal processing, among other things. Actually, for these networks, the challenge of choosing hyperparameters is of utmost importance. The reason behind this is that as the number of layers rises, the search space grows exponentially. In addition, all known classical and evolutionary pruning algorithms require a trained or built architecture as input. During the design phase, none of them consider the process of pruning. In order to assess the effectiveness and efficiency of any architecture created, pruning of channels must be carried out before transmitting the dataset and computing classification errors. For instance, following pruning, an architecture of medium quality in terms of classification may transform into an architecture that is both highly light and accurate, and vice versa. There exist countless potential scenarios that could occur, which prompted us to develop a bi-level optimization approach for the entire process. The upper level involves generating the architecture while the lower level optimizes channel pruning. Evolutionary algorithms (EAs) have proven effective in bi-level optimization, leading us to adopt the co-evolutionary migration-based algorithm as a search engine for our bi-level architectural optimization problem in this research. Our proposed method, CNN-D-P (bi-level CNN design and pruning), was tested on the widely used image classification benchmark datasets, CIFAR-10, CIFAR-100 and ImageNet. Our suggested technique is validated by means of a set of comparison tests with regard to relevant state-of-the-art architectures.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In the realm of object recognition and computer vision, convolutional neural networks (CNNs) have garnered significant attention as a modeling technique [1, 2], as per a recent report [3]. The scientific community’s fascination with CNNs possessing numerous layers reached new heights in 2006, owing to the research conducted by a group of scholars [4, 5], and they have been increasingly employed for difficult classification problems or specific purposes requiring high accuracy. The design of CNNs is affected by a large number of hyperparameters [6, 7], which need to be fine-tuned for optimal performance [8]. Previously, studies have concentrated on refining architectures such as VGGNet [9] and ResNet [10], which are either manually crafted by experts or automatically generated through greedy induction methods [6, 11]. Despite the remarkable performance of CNN architectures [12, 13], specialists in machine learning and optimization propose that improved structures can be produced through automated methods. Researchers in the evolutionary computing domain recommend that this issue be modeled as an optimization problem and solved using an appropriate search algorithm [14]. The optimization of the number of blocks, nodes per block, and graph topology in each CNN block resembles the optimization of a vast search space. Evolutionary algorithms (EAs) are capable of approaching the global optimum and avoiding local optimal solutions (architectures), and thus, scholars have recently suggested utilizing such metaheuristic methods to tackle the issue of optimizing CNN architecture [15].
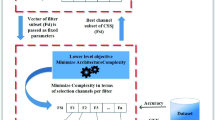
The VGG16 deep learning architecture [9] incurs a substantial storage expense for embedded systems, as it boasts more than 138 million parameters and demands in excess of 500MB of memory to recognize a \(224 \times 224\) image. A model of this size cannot be directly implemented into on-board hardware, which has limited storage and computation capabilities. The challenge of shrinking a deep learning model by consolidating and discarding redundant components can be tackled through pruning, which is considered a critical technique. Nevertheless, executing a pruning stage for deep models while avoiding a significant drop in accuracy presents a crucial challenge. CNN pruning approaches, such as neurons, filters, and channel pruning, have been proposed to save weight by eliminating unnecessary connections. These methods aim to preserve the accuracy of the model while reducing its size. However, currently, all existing work has focused on compressing manual designs, while automatic CNN architecture has no compression method. This is a significant challenge for the deep learning community, as the automatic generation of CNN architectures is becoming more popular due to its efficiency in terms of computational time and human effort (Fig. 1).

Illustration of the added value of the bi-level modeling
This study addresses the problem of channel pruning in deep neural networks. Channel pruning is a technique for removing redundant channels from a CNN architecture while preserving its accuracy. However, the vast number of options for channel pruning makes it infeasible to predict beforehand which channels should be deactivated. To solve this problem, we formulate the problem of “joint design and channel pruning” as a bi-level optimization problem. The upper-level objective is to find optimal architectures, while the lower-level objective is to apply channel pruning to the selected architecture. The evaluation of an upper-level architecture requires that it be sent to the lower level for channel pruning by deactivating certain channels. The task of channel pruning is conducted as an evolutionary optimization process at the upper level, resulting in the creation of a CNN architecture with the fewest channels and the best topology. We applied a solution to the challenge of channel pruning in deep neural networks by utilizing a method called co-evolutionary migration-based algorithm (CEMBA) to solve combinatorial bi-level optimization problems (BLOPs) [16]. CEMBA allows for a significant reduction in the number of evaluations conducted throughout the lower-level search process by having each population at the upper-level work with its corresponding population at the lower level. Our technique is the first to perform channel pruning on development structures during the evolution process, which implies that no other technique has ever performed channel pruning on development structures during the evolution process before. Our key contributions are:
-
This study presents the development of an evolutionary technique that integrates CNN architecture design with channel pruning in the optimization process. This is crucial because every newly created architecture needs to be pruned before its classification performance can be evaluated.
-
In this study, the integration of channel pruning within the CNN architecture design is modeled as a bi-level optimization problem. In this approach, architectures are automatically generated at the upper level through crossover and mutation with a predefined minimum number of blocks (NB) and number of nodes per block (NNB). Then, at the lower level, each architecture is pruned by removing redundant channels.
-
The proposed bi-level optimization model is solved by using a bi-level co-evolutionary method, which enables efficient collaboration between architecture creation (at the upper level) and channel pruning (at the lower level). This approach allows for the simultaneous optimization of both the architecture and the pruning process.
-
To evaluate the effectiveness of our proposed CNN-D-P, extensive tests are conducted using the CIFAR dataset, and the results are compared to a number of recent and notable peer research. Several metrics, such as the classification error, the number of GPUDays, and the number of parameters, are used to demonstrate the efficacy of our proposed approach.
2 Related work
Previous research has revealed that evolutionary algorithms (EAs) can be used as a technique for creating the structures of deep neural networks. A survey of evolutionary computing-based optimization of deep learning models was conducted by researchers in [15]. From this survey, the most relevant studies were chosen and presented in Table 1.
The provided Table 1 summarizes different research works in the field of evolutionary optimization of deep learning models for CNN design. The table contains information about the authors, year, and objectives of each work. A brief discussion and comparison of the listed works are presented below.
-
Cheung and Sable [17] proposed an evolutionary optimization approach based on the diagonal Levenberg–Marquardt method to improve the architectural hyperparameters of CNNs. They demonstrated that even basic evolutionary tactics can yield substantial benefits in terms of performance. They used their approach to optimize the performance of CNNs on the MNIST dataset.
-
Fu**o et al. [18] introduced an approach for exploring the evolution of hyperparameters in deep convolutional neural networks. They used evolutionary Deep Learning (evoDL) to improve the parameter tuning and activation functions of the CNNs. They presented AlexNet as the underlying framework for the CNNs.
-
**e et al. [19] proposed a method for expressing the network architecture of CNNs as a binary string to enhance the recognition accuracy. However, the high cost of computation meant that only small-scale datasets could be used for testing.
-
Real et al. [20] developed the structure of CNNs using the CIFAR-10 and CIFAR-100 datasets. They introduced a mutation operator to avoid locally optimal models and showed that neuro-evolution can be used to create highly accurate networks.
-
Alejandro et al. [21] created EvoDEEP to estimate the likelihood of layer transitions using the notion of finite state machines to improve network properties. Their objective was to reduce classification error rates while maintaining the layer sequence.
-
Mirjalili et al. [22] proposed NSGA-Net, which is an adaptation for solving multi-objective models. The results of their experiments on image classification and object alignment indicated that NSGA-Net can provide the user with less complex, accurate designs.
-
Sun et al. [23] proposed an evolutionary approach for enhancing the architecture of CNNs and initializing their weights for image classification applications. They accomplished this by providing a new way of initializing weights, a novel strategy for encoding variable-length chromosomes, a slack binary tournament selection mechanism, and an effective fitness assessment tool. Their experiments showed that the EvoCNN method is better than almost all other classification methods on almost all of the datasets that were studied.
-
**g et al. [24] proposed a comprehensive model for maximizing classification accuracy while minimizing tuning parameters. They used multi-objective particle swarm optimization with decomposition (MOPSO/D) to solve the suggested model based on a hybrid binary encoding defining component layers and network connections. In comparison with manually and automatically generated models, the results showed that their approach can achieve higher classification accuracy while using fewer tuning parameters.
-
Real et al. [25] enhanced a genetic algorithm (GA) with a tournament selection operator that takes into account the age of the chromosomes by choosing the youngest chromosomes. The designs were presented as small directed graphs, where edges and vertices represent common network operations and hidden states. To explore the entire search space, new mutation operators were developed to connect the edges’ origins to additional vertices and rename the edges randomly.
-
Lu et al. [26] presented the first multi-objective model for the problem of architectural search, minimizing two objectives that can be in conflict: the classification error rate and the computational complexity measured by the number of floating-point operations (FLOPS). The non-dominated sorting GA-II (NSGA-II) method was modified to adapt it to be used as a multi-objective evolutionary algorithm (EA).
In terms of comparison, all the works aim to optimize the performance of CNNs through evolutionary optimization. However, they differ in their specific objectives, such as improving architectural hyperparameters, exploring the evolution of hyperparameters, develo** the structure of CNNs, and maximizing classification accuracy while minimizing tuning parameters. Moreover, the proposed approaches and techniques used to achieve their objectives vary across the works, such as the use of mutation operator, finite state machines, and multi-objective optimization algorithms. Therefore, the results and performance of each work are unique and depend on the specific objectives and techniques used.
Deep network pruning is a widely recognized approach for reducing the size of a deep learning model by eliminating unnecessary components, such as layers, filters, channels, or neurons. A number of studies have focused on develo** new methods for reducing the computational complexity of CNNs. For example, Kamyab et al. [28] proposed an attention-based deep model for sentiment analysis that utilizes a two-channel CNN and a Bi-RNN model (ACR-SA). This model incorporates attention-based mechanisms with novel data processing techniques, word representation, and deep learning algorithms. Additionally, Lin et al. [29] proposed a method for filter pruning by examining the high rank of feature maps (HRank). Their approach is based on the observation that the average rank of many feature maps generated by a single filter remains constant regardless of the number of image batches received by the CNN. Guo et al. [30] proposed the multi-dimensional pruning (MDP) framework for compressing 2D CNNs along the channel and spatial dimensions and 3D CNNs along the channel, spatial, and temporal dimensions. Additionally, Lin et al. [31] suggested a novel 1N pruning strategy that maintains model accuracy while achieving significant CPU speedups. Yeoma et al. [32] also proposed a novel CNN pruning criterion inspired by the interpretability of neural networks. The most relevant units, such as weights or filters, are automatically identified based on their relevance ratings, which are derived from interpretable AI concepts. This allows for appropriate pruning of the neural networks based on specific requirements. Furthermore, these pruning techniques can be used to fine-tune neural networks for the final task or to apply more advanced pruning methods.
Recently, researchers in [15] have presented a comprehensive review of applications of evolutionary computing-based optimization of deep learning models. Based on this survey, channel pruning is one of the most popular pruning techniques for CNNs. Channel pruning aims to reduce the number of channels provided to the intermediate layers of CNNs as input. The input data to the CNN model are first channelized to provide an appropriate input, such as an image with three distinct channels (RGB). The CNN model’s output at each layer contains various and diverse channels. These channels enhance the model’s performance, but also raise storage and computing requirements. Thus, it is beneficial to eliminate channels considered unimportant in order to decrease computational and storage requirements. The most significant existing works on channel pruning include: He et al. [33] proposed a method called “channel pruning” that removes unimportant channels based on the statistics of the activation values, Li et al. [34] proposed a method called “structured channel pruning” that removes unimportant channels based on the correlation between channels and Lin et al. [34] proposed a method called “iterative channel pruning” that iteratively removes unimportant channels based on their importance scores. The following is a list of the most significant existing works on channel pruning:
-
He et al. [33] developed an approach based on the inference time that performs channel pruning via successfully eliminating the channels redundancy at CNN. Authors claim to have speed up deep CNN by using two steps: regression-based channel selection followed by an estimate of the least reconstruction error. Experiments with many datasets have revealed that the proposed technique accelerates deep CNN operations through a compact design. In the following, the formulation of the reconstruction error is detailed. The problem of minimization is designed as
$$\begin{aligned}&\text {arg} \ \min _{\delta , F} \frac{1}{N}\left\| O-\sum _{j=1}^{k} \delta _{j} F_{j}I_{j}\right\| ^{2}_{F'}\\ \nonumber&\text {Subject} \ \text {to},\left\| \delta \right\| _{0}\le k^{'} \end{aligned}$$(1)The number of channels in a feature map is represented by k, and the goal is to reduce it to \(k'\). The convolutional filter, F, of size \(o \times k \times f_h \times f_w\) is applied to input E of dimension \(N \times k \times f_h \times f_w\) to produce an output matrix, O. The number of samples in the dataset, D, is represented by N, and \(f_h\) and \(f_w\) represent the dimensions of the convolutional kernel. The problem of minimizing is formulated as minimizing the reconstruction error, subject to the constraint that the number of nonzero coefficients in the coefficient vector, \(\delta\), must be less than or equal to \(k'\). The Frobenius norm, represented by \(\left| . \right| _{F}\), is used in the optimization problem, \(I_j\) represents the input data fed to channel j, \(F_j\) is the j-th filter, and \(\delta _j\) is the j-th entry of the coefficient vector, \(\delta\).
-
Liu et al. [35] proposed an improved technique for the operation of pruning, in which, at the earliest stage, a threshold of pruning is established by investigating the connections of the network. In addition, connections and channels that fall below the trimming threshold will be deleted. The threshold estimate of this mechanism keeps the accuracy of the pruned network up to a certain point.
-
Chen et al. [36] considered the earlier hypothesis of neurons and independent channels in the deep neural network is mistaken. Authors insist that it exist dependencies between neurons and channels. They have designed a combinatorial optimization problem dedicated to network pruning. The problem is solved by a scalable algorithm. The proposed approach is called EvoNAS: Evolutionary Net Architecture Search.
-
Liu et al. [37] developed a new learning scheme for CNN. The authors reduces model size, computing operations, and execution memory. This decreases the size of the model, the number of computations, and the execution memory. They introduced low overhead when training the model of deep learning. The authors claimed their method as network slimming capable to compress a large model into a compact model while avoiding the compromising on higher precision. The most important aspect of this technique is determining a scale factor for each channel in the DNN. Then, the scale factor and the model will be jointly trained on the basis of sparseness regularization.
-
Yan et al. [38] developed a technique known as VarGNet. The authors reduces the operations of variable group convolution within the CNN model. The utilization of the variable group convolution resolves the problem of conflict between unbalanced computational intensity and low computational cost. In addition, they have improved the generated lightweight model performance by adopting angular distillation loss.
-
Howard et al. [39] proposed a DCNN compression approach based on the streamlined design. This approach leverages depth-wise separable convolutions. The authors called the technique MobileNets which estimates two hyperparameters, i.e. the resolution multiplier, and the width multiplier. Actually, the depth-wise convolution in this method applies a single filter to each input channel. In addition, a \(1 \times 1\) convolution is performed to consolidate the inputs inside another set of outputs. Faster inference is allowed by MobileNets via utilising the dataset sparsity (Fig. 2).

Channel pruning example scenario [40]
Despite the interesting and surprising results obtained from pruning in deep learning architecture optimization research, all previous studies have treated architecture optimization as a single-level problem. We demonstrated that CNN design can be improved by considering two optimization levels, each with its own search space. To our knowledge, this is the first study to present a bi-level model for the design and channel pruning problem (see Sect. 3).
2.1 Basics of bi-level optimization
Bi-level optimization refers to a mathematical problem in which an optimization problem contains another optimization problem as a constraint. These types of problems have attracted considerable attention from various research communities due to their practical applications and the potential of evolutionary algorithms to solve them. While most academic and real-world optimization problems involve a single level of optimization, there are cases where two levels are present, which is known as a BLOP [41]. In such scenarios, an optimization problem is nested inside external optimization constraints. The external optimization challenge is referred to as the upper-level problem or the leader problem. Meanwhile, the nested internal optimization issue is known as the lower level or the follower problem, resulting in a two-level problem known as a leader-follower problem or a Stackelberg game [42]. The follower problem is considered an upper-level constraint, and therefore only the optimal solution to the follower optimization problem can be considered a leader candidate.
Definition
Assuming \(\Re ^{n}\times \Re ^{n} \rightarrow \Re\) to be the leader problem and \(f:\Re ^{n}\times \Re ^{n} \rightarrow \Re\) to be the follower one, analytically, a BLOP could be stated as follows:
The formulation of this problem deals with two types of decision variables: (1) upper-level variables \(x_{u} \epsilon X_{U}\) and (2) lower-level variables \(x_{l} \epsilon X_{L}\). The optimization task for the follower problem is performed with respect to the variables \(x_{l}\), where the variables \(x_{u}\) act as parameters (as shown in Fig. 3). For each \(x_{u}\), a different follower problem exists, and its optimal solution needs to be determined. All variables (\(x_{u}, x_{l}\)) are considered in the leader problem, and optimization is expected to be performed with respect to both sets of variables. The upper-level constraint is denoted by the function \(G_{j}: X_{U} \times X_{L} \rightarrow \Re\), while the lower-level constraint is represented by \(g_{j}: X_{U} \times X_{L} \rightarrow \Re\). The difficulty in bi-level optimization arises because only lower-level optimal solutions can be considered feasible for the upper level after satisfying the upper-level constraints. For example, a member \(x^{l}=(x_{u}^{l}, x_{l}^{l})\) is considered feasible for the upper-level problem only if \(x^l\) satisfies the upper-level constraints and \(x_{l}^{l}\) is an optimal solution for the lower-level problem corresponding to \(x_{u}^{l}\).

An example of a BLOP with two levels is illustrated [43]
There are two main types of methods for solving BLOP: classical methods and evolutionary methods. Classical methods involve extreme point-based approaches, branch-and-bound, penalty function methods, complementary pivoting, and methods of trust region, among others. These methods have a major drawback of being highly reliant on the mathematical characteristics of the specific BLOP being solved. The second category of methods involves metaheuristic algorithms, which are generally evolutionary algorithms. In recent years, several evolutionary algorithms have demonstrated their effectiveness in solving BLOP due to their ability to handle large problem instances and their insensitivity to the mathematical features of the problem. Some notable works in this field include references [44, 45].
3 The proposed approach
3.1 CNN-D-P design and pruning overview
The two questions that drive our bi-level model are as follows:
-
How can we design a simpler architecture with minimal convolution blocks (NB) and nodes per block (NNB) while maintaining high performance, which is largely influenced by the graph topologies of the convolution blocks?
-
Given that all CNN architectures have multiple channels per layer, how can we determine the optimal number of channels per layer?

A bi-level model is used to design and channel prune
In order to tackle the two research questions, it is essential to utilize a bi-level model, as there are two primary justifications for this approach. Firstly, in order to optimize the hyperparameters for design and pruning, the high-level stage necessitates intelligent sampling across the entire search space. Secondly, to appraise the upper-level solution’s quality (NB, avgNNB, NC, Err), a fixed parameter vector (TOP, NC) must be fed to the lower level to identify the most optimal channel (NC) in the lower-level search space. Once the lower-level operation is completed, each architecture undergoes a 32-bit floating point data quantization into 5-bit integer levels to further minimize the storage size of the weight file. By examining each pair of hyperparameters separately, this approach resolves the issue as a bi-level optimization problem. This discovery exposes a significant flaw in current methods and represents the paper’s primary research gap. Figure 4 illustrates the bi-level model of the CNN architecture design and compression optimization issues, exemplifying the methodology.
The bi-level optimization process involves two phases that are distinct from each other. The first phase is the upper-level optimization process, which is focused on maximizing classification accuracy by optimizing (NB, NNB) and finding the optimal topology sequence. The second phase is the lower-level optimization process, which is dedicated to the pruning of CNN channels. The solutions that are obtained through bi-level optimization can be categorized into two types: upper-level solutions and lower-level solutions. The upper-level solution can be represented as a vector with two sub-vectors: The first sub-vector consists of integer values that indicate NB and NNB, while the second sub-vector is a binary sequence that represents the topology. This binary sequence is encoded using a scheme that is inspired by Genetic-CNN [46] and is designed to minimize the length of the upper-level chromosome. On the other hand, the lower-level solution comprises several sub-vectors, with each sub-vector representing the channel pruning decision for the corresponding convolution node filters. The goal is to develop a model for this bi-level problem that can identify simpler and more efficient structures. Figure 4 illustrates the bi-level optimization approach for CNN architecture design and compression optimization.
3.2 CNN-D-P: CEMBA’s adaptation to the bi-level model
To resolve the suggested bi-level optimization model using CEMBA’s adaptation, the following processes at the upper level must be specified:
3.2.1 Upper level
-
Upper-level solution encoding It is generated by concatenating the number of blocks NB, a series of integers representing the node numbers in each block, and the graph topology sequence of the convolution layer. This item signifies the potential for a directed graph.
-
Upper-level fitness function To assess a solution at a upper level, we must minimize the complexity of the CNN architecture by optimizing the (NB, NNB). In order to effectively achieve our objective, we propose the use of a fitness function that takes into account multiple factors that are critical to the performance of our CNN architecture. The fitness function is presented as follows:
The fitness function is composed of four terms, each of which represents a different aspect of the architecture. The first term \(({\text {NB/NBmax}})\) represents the number of blocks (NB) in the architecture, divided by the maximum number of blocks (NBmax) allowed. This term allows us to evaluate the size and complexity of the architecture, and whether it is appropriate for the problem at hand. The second term (AvgNNB/NNBmax) represents the average number of convolution nodes per block (AvgNNB), divided by the maximum number of convolution nodes per block (NNBmax) allowed. This term allows us to evaluate the complexity of each block in the architecture, and whether they are utilizing an appropriate number of nodes. The third term (NC/NCmax) represents the number of channels (NC) used in the architecture, divided by the maximum number of channels (NCmax) allowed. This term allows us to evaluate the amount of information that is being utilized in the architecture, and whether the architecture is over or under-utilizing the channels. The fourth and final term (ERR) represents the error of the architecture. This term allows us to evaluate the accuracy of the architecture in predicting the desired outcome. Overall, the use of this fitness function allows us to evaluate multiple aspects of the architecture in an objective manner. By considering these factors, we can make informed decisions on how to optimize and improve the architecture for better results. It is important to carefully consider all of these factors when designing a CNN architecture, as they can have a significant impact on the performance of the model.
At the upper level, the population has explored the uniform crossover operator [47], which allows for variation across all chromosome segments. To ensure diverse solutions, Gray encoding is used to convert each parent solution into a binary sequence. This encoding method is based on the observation that adjacent integer values differ by only one bit, unlike traditional binary encoding [48], and has been shown to prevent premature convergence at Hamming walls [26]. When an excessive number of mutations or crossover events are needed to produce a more advantageous variant, the uniform crossover technique randomly selects a recombination mask from a uniform distribution, which is a binary vector of 0 and 1. The first offspring is created by extracting bits from both parents when the corresponding mask bit is 0 and from both parents otherwise. The second offspring is generated using the inverse mask. The final step involves encoding each offspring as an integer vector and computing its fitness value. The binary chromosome’s length is a multiple of four since the suggested solution represents a vector of numbers, where each integer is encoded using four bits. If an offspring does not have a length that is a multiple of four, the final bits are removed to maintain a multiple of four length. It’s important to note that the NB value of a generated child may differ from the length of the NNB sequence, and the offspring solution is corrected by changing the sequence length value from NNB to NB. To improve accuracy, optimal topologies must be sought. The second modification is represented as a series of squared binary matrices, each for a possible directed network. Figure 5 depicts in X illustrates that a binary value of 1 denotes that the row node is the antecedent of the column node, whereas a binary value of 0 signifies the absence of a connection between the two nodes. As this study involves the CNN model, certain restrictions must be observed:

An instance of binary string encodings representing the topologies of five convolution blocks [3]
-
It’s necessary for each convolution node to have a predecessor, which can either be an earlier convolution node or the input convolution node.
-
All active convolutional nodes must have a successor node, which can be either a convolutional successor or the output successor.
-
Every active convolution node must have preceding nodes in the layers above it. For example, node 5 could be preceded by nodes 4, 3, 2, 1, and the input node.
-
The first convolutional node must be preceded by a single input node.
-
The output node of the last convolution node should have only one successor node.
To ensure diversity and enable exploration of unvisited areas of the search space, mutation is employed to rapidly introduce changes into a population. Various operators such as one-point mutation, random reset, and inversion mutation are used for this purpose. In our case, binary encoding is utilized for both levels (NB integer and NNB integer) and topology and filter activation decision vector, which enables us to gradually alter the topic solution using the one-point mutation operator. This ensures that variety is integrated gradually into the evolutionary process. Similar to the crossover operator, before performing the one-point mutation, the solution of the mutation operator is converted to a binary string using gray encoding. However, as the variance might affect the NB field, we use a repair method to ensure consistency. (assuming LNS = length (NNB sequence)). If NB is less than LNS, the last (LNS - (LNS - NB)) numbers in the chromosome are eliminated. On the other hand, if NB surpasses LNS, additional numbers (NB-LNS) are inserted at the end of the chromosome in a random manner. These two conditions ensure that NB and LNS remain equal.
According to prior investigations [3], we posit that NB ought to be situated in the spectrum of values ranging from 9 to 11, while NNB should fall within the confines of 32–49 in this particular examination. To gauge the accuracy, the holdout validation method [49] is employed, wherein 80% of data samples are randomly selected for training and the remaining 20% for testing.
3.2.2 Lower-level
-
Encoding the solution of the lower-level: The number of selected channels to be eliminated from the convolutional layer’s filter is akin to the NC. This subset of the channel is denoted by a binary vector with bits assigned the values of either 0 or 1. Figure 6 illustrates the encoding is binary, with a value of 1 indicating that a particular channel has been selected, and a value of 0 indicating that it has been pruned (removed from consideration).

The solution encoding of the lower level defining the binary vector of 1 selected, 0 pruned in terms of NCi
-
Fitness function of the lower level: To evaluate the lower-level solutions, the CNN architecture must be simplified by lowering the number of channels (NC) while maintaining or enhancing the high accuracy. In order to achieve our objective, we have developed a fitness function to assess the performance of our architecture. The function is presented as follows:
$$\begin{aligned} F({\text{NC}} ({\text{Arch}}))=({\text{NC/NC \,max}}) + ({\text{Err}}) \end{aligned}$$(4)
This fitness function is composed of two terms: the first term corresponds to the number of channels (NC) used in the architecture, divided by the maximum number of channels (NC max) allowed. The second term corresponds to the error (Err) of the architecture. The purpose of this fitness function is to evaluate the effectiveness and efficiency of our architecture. By considering the number of channels used in the architecture, we can determine whether the architecture is utilizing an appropriate number of channels, and whether there is room for optimization. Additionally, by considering the error of the architecture, we can determine whether the architecture is able to accurately predict the desired outcome. The use of a fitness function is a common practice in optimization problems and allows us to objectively measure the performance of our architecture. Through the evaluation of this fitness function, we can make informed decisions on how to improve and optimize our architecture for better results.
The proposed technique for performing deep pruning of convolutional neural networks (CNNs) at a lower level employs binary strings to represent the filters of the CNN model. It is crucial to note that the technique only prunes the convolution layers, which are stacked with pooling and fully connected layers to form a deep convolutional neural network (DCNN). The primary objective of this research paper is to automate the process of joint design and filter pruning of CNN architectures. As the channels are only present in the filter convolution layers, only these layers are pruned using the suggested method. Our approach involves treating each bit of the binary string as a separate channel, and for basic CNN model pruning, a single bit string suffices, where each bit corresponds to a model channel. The population is altered using the two-point crossover operator [47] since it enables the modification of chromosomal segments. In this process, each parent solution comprises a set of binary strings [50]. Once a pair of cutting points has been selected for each parent pair, the bits between the cuts are interchanged to produce two offspring solutions. In practice, the two-point crossover is utilized to allow for variation in all chromosomal regions. Utilizing the one-point crossover technique may leave the extreme regions (extreme genes) of the chromosomes unchanged, which can severely limit the crossover’s potential for exploitation and population diversity. To overcome this challenge, researchers have proposed using two cut-points rather than a single one to enable the variation of the entire chromosome.
The mutation operator generates a solution in the form of a binary string, which is then subjected to a random mutation of a single point. A crossing point on the chromosomes of both parents is randomly selected, and the bits at this point are exchanged between the two parental chromosomes. A 5-bit integer precision has been employed with the quantization technique to minimize the storage size of the weight file. The importance of using 5-bit integer precision lies in its ability to significantly reduce the storage space required while still maintaining reasonable accuracy levels. The quantization process is performed in a linear distribution between Wmin and Wmax to obtain more accurate results compared to density-based quantization. This approach ensures that even weights with low probabilities are accurately quantized, preserving their impact on the overall performance of the model. Therefore, the use of 5-bit integer precision quantization not only leads to efficient storage utilization but also maintains the model’s accuracy levels, making it a valuable optimization technique for large-scale deep learning models. This stage produces a sparsely compressed row comprising quantized weights. Additionally, due to the statistical characteristics of the quantization output, it is possible to apply Huffman compression to further compress the weights file. Nevertheless, this necessitates satisfying certain hardware requirements, including a Huffman decompressor and a converter to transform the compressed sparse row to weights matrix.
In order to calculate the test error, the holdout validation method [51] is employed, whereby 70% of the data records are randomly selected for training, and the remaining 30% for testing. To mitigate the issue of over-fitting, the training data are divided into fivefold, with 70% of the data assigned to each fold. During the training phase, five-fold cross-validation is employed, and the classification performance is averaged across the five folds of the training partitions. The validation technique employed in this study [52] is illustrated in Fig. 7. Finally, the classification error on the test data is reported in the experiments (30%).

Adopted nested validation strategy in our work
4 Experimental study
4.1 Benchmarks and research questions
CIFAR-10, CIFAR-100, and ImageNet are commonly used benchmark datasets in the field. The original dataset comprises of 60,000 RGB photos of size 32 × 32, divided into 10 groups of 6000 images each. The test set size is 10,000, while the training set size is 50,000. A similar dataset to CIFAR-10, CIFAR-100, has 100 classes with 600 images in each class. Both datasets pose significant challenges due to factors such as noise, image size, and rotation. To ensure fairness in comparisons, the images are augmented during the processing phase, with four zero pixels added to each picture, resulting in a modified 32x32 image. The cropped image is then randomly compressed with a probability of 0.50, inspired by reference [53]. Due to the high number of classes, most research does not use CIFAR-100 dataset for their experiments. To demonstrate the performance of our CNN-D-P, we conduct a series of experiments on CIFAR-10 and CIFAR-100 datasets. Finally, ImageNet is a dataset of 14,197,122 images annotated using the WordNet hierarchy. Since 2010, the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) has used this dataset as a standard for image classification and object recognition. The freely accessible dataset includes a collection of manually labeled training images and a set of test images without associated manual annotations. Our research focuses on the following key issues:
-
How do the CNN-D-P compare to prior CIFAR-10 image classification work?
-
Is it feasible for CNN-D-P to retain its effectiveness on CIFAR-100 if the number of classes is raised to 100?
-
Despite its high computational cost, is CNN-D-P capable of generating designs of good quality on ImageNet?
To address these research questions, we evaluate the optimal architecture generated by CNN-D-P and compare it to existing and contemporary architectures.
4.2 Performance indicators
The most common performance measures for image classification using DNN are the error rate and floating point operations.
The error rate, or test error, is calculated using Eq. (5), where FP and FN are false positives and false negatives, respectively, and NE is the total number of samples.
The number of parameters (Params) is the sum of the weights and biases in the convolution layer, as shown in Eq. (6), where Wc, Bc, pc, K are the weights, biases, parameters, and convolution layer size, respectively. N is the number of kernels, and C is the number of channels in the input [3].
Recall, precision, and F1-score are also commonly used to evaluate the performance of image classification models. Recall is the number of true positives divided by the sum of true positives and false negatives, as shown in Eq. (7). Precision is the number of true positives divided by the sum of true positives and false positives, as shown in Eq. (8). The F1-score is the harmonic mean of precision and recall, as shown in Eq. (9).
4.3 Peer algorithms and parameters setup
CNN-D-P is being evaluated against various evolutionary approaches-based works including Bi-CNN-D-C, BLOP-CNN, Genetic-CNN, LargeScale-Evo, AE-CNN, CNN-GA, and NSGA-Net. To ensure the most objective comparisons possible, the parameters of these algorithms are determined using the commonly used trial-and-error technique. The parameter settings employed in our research is divided into two categories: the upper-level search space and the lower-level search space. For the upper-level search space, the number of generations is set to 40, the population size is set to 30, the crossover probability is set to 0.9, the mutation probability is set to 0.1, the batch size is set to 128, and the number of epochs ranges from 50 to 300. The SGD learning rate is set to 0.1, the momentum is set to 0.9, and the number of generations and population size are set to 30 and 20, respectively. For the lower-level search space, the number of generations is set to 30, the population size is set to 30, the crossover probability is set to 0.9, the mutation probability is set to 0.1, the batch size is set to 128, and the number of epochs ranges from 50 to 350. The SGD learning rate is set to 0.1, the momentum is set to 0.9, and the number of generations and population size are set to 30 and 50, respectively. The implementation is done using the TensorFlow framework and Python version 3.5. We utilize eight Nvidia 2080Ti GPU cards for evaluating the CNN structures derived from the testing data.
4.4 Comparative results
4.4.1 Comparisons to evolutionary design methods
The comparative results obtained for the different CNN architectures developed by various CNN design approaches on the CIFAR-10, CIFAR-100, and ImageNet datasets are presented in Tables 2, 3, and 4. In the following sections, we provide detailed explanations of these outcomes for each category and statistic. Evolutionary algorithms possess global search capabilities that allow them to avoid local optima and explore the entire search space. By using the mating selection operator, they can also probabilistically adopt less efficient structures, enabling them to explore the entire search space. The accuracy of evolutionary algorithms ranges from 92.90 to 98.24 percent for CIFAR-10 and from 70.97 to 88.83 percent for CIFAR-100. BI-CNN-D-C exhibited the best performance, with an accuracy value of 98.24 percent for CIFAR-10 and 88.83 percent for CIFAR-100, while BLOP-CNN, Large-Scale-Evo, Genetic-CNN, CNN-GA, AE-CNN, NSGA-3 and -4, BLOP-CNN, have accuracy values ranging from 92.90 to 98.12 percent for CIFAR-10, 70.97 to 88.42 percent for CIFAR-100, and 91 to 93.34 percent for ImageNet. From Tables 2 and 3, we can see that the CNN-D-P method is the best, with a slight increase in accuracy value of 98.38 percent for CIFAR-10 and 88.96 percent for CIFAR-100.
In the realm of solution encoding approaches, Large-Scale-Evo faces several limitations due to a high number of constraints, unlike NSGA-Net, BLOP-CNN, Bi-CNN-D-C, and CNN-D-P. While this can narrow down the search space for Large-Scale-Evo, it can also negatively impact the diversity factor, which is a crucial element of EAs. On the other hand, NSGA-Net, BLOP-CNN, Bi-CNN-D-C, and CNN-D-P have demonstrated superior performance compared to Large-Scale-Evo on both the CIFAR-10 and CIFAR-100 datasets. It is worth noting that the NB and NNB values used in this research were manually predefined based on previous work.
This approach aids in constraining the exploration space by generating designs with varying block counts and sizes. In fact, this approach can generate a diverse set of designs with various topologies for each NB, NNB pair. This characteristic sets BLOP-CNN, Bi-CNN-D-C and CNN-D-P apart as the first algorithms to concurrently optimize and vary many components as a bi-level architecture. However, instead of focusing on accelerating the compression process, efficient model designs like BLOP-CNN prioritize enhancing convolution processes or network topologies. Therefore, we are prioritizing the research process for compression in a more effective and efficient manner. Next, we will examine the #Params metric. These metrics represent the number of parameters used in the model. Due to the reduction blocks and minimization of NB and NNB at the upper level, as well as the compression convolution layer hyperparameters (FSi, Nbits of quantized weights) at the lower level, the #Params of Bi-CNN-D-C is lower than that of NSGA-Net-4 and BLOP-CNN, as illustrated in Tables 2 and 3. It is worth noting that the CIFAR-10 and CIFAR-100 images have the same size. The only difference is the number of classes, which increases from ten (CIFAR-10) to one hundred (CIFAR-100). The final fully connected layer for CIFAR-100 takes longer to compute theoretically, but this is negligible because it is so small in comparison with the rest of the model (Fig. 8).

The ACC evolution of the optimal NB and NNB values discovered on the CIFAR-10 dataset
According to Fig. 7, the maximizing slope for the first 15 generations is steeper than the slope for the subsequent 15 generations. This might be explained by the fact that the search space of potential CNN architectures was exhaustively examined during the early phase of evolution. As a result, the population is scattered over the whole search space during the early phase. As a result, many low- and medium-quality designs are visited, and some are even regarded as the greatest architectural works known at the time. The evolutionary method was then able to concentrate the population in areas of the search space where the classification performance of the majority of designs was equivalent. This focus results in the algorithm sampling designs with equivalent classification accuracy, which explains the decrease in the maximizing slope. This phenomenon is also observable in several other uses of genetic algorithms. The maximizing slope for the first 15 generations is relatively steep compared to the subsequent 15 generations. This might be explained by the fact that the search space of potential CNN architectures was exhaustively examined during the early phase of evolution. At this stage, the vast search space contains low-, medium-, and high-quality architectural types. As a result, the population is scattered over the whole search space during the early phase. As a result, many low- and medium-quality designs are visited, and some are even regarded as the greatest architectural works known at the time. The evolutionary method was then able to concentrate the population in areas of the search space where the classification performance of the majority of designs was equivalent. This focus results in the algorithm sampling designs with equivalent classification accuracy, which explains the decrease in the maximizing slope. This phenomenon is also observable in several other uses of genetic algorithms [
The proposed algorithm will be expanded to prune other DCNN structures, and an algorithm for automatically finding neural network architectures will be developed and included with the proposed approach. This will result in the creation of an algorithm capable of discovering novel DCNN architectures with high performance and low computing complexity. The primary explanation for CNN-D-P outperformance relative to comparable efforts aligns with this work’s primary motivation. The superiority of CNN-D-P on CIFAR-10 and CIFAR-100 compared to other methods can be attributed to the main goal of this study. As mentioned in the beginning of this research, the primary drawback of current pruning techniques, including evolutionary algorithms, is that they rely on pre-existing architectures and then search for the optimal pruning strategy. This approach significantly restricts the efficacy of these methods, as they are confined to a particular point in the design search space. In contrast, our proposed approach adopts a metamorphic perspective that allows for a broader exploration of the search space, enabling greater flexibility and improved results. This fundamental difference in approach is likely a key factor in the superior performance of CNN-D-P.
The comparison between Bi-CNN-D-C and the proposed CNN-D-P method is an important aspect to consider in the evaluation of the paper. Bi-CNN-D-C is a method that allows joint design and filter pruning, but it has some limitations that are addressed by the proposed method. Firstly, filter pruning in Bi-CNN-D-C can lead to the removal of important channels, which may have a negative impact on the performance of the network. Additionally, filter pruning can result in the loss of interesting channels, which can decrease the overall effectiveness of the architecture. These issues are overcome by CNN-D-P, which embeds channel pruning within the CNN architecture and ensures that important channels are retained even if their filters have a large number of channels. The superior results of CNN-D-P compared to Bi-CNN-D-C are evident from Table 5. Furthermore, CNN-D-P is capable of moving from one design to another and optimizing the conservation of information while pruning each generated architecture more efficiently and effectively. This means that the algorithm is not restricted to a single point in the design space, and the approach has increased the search space. The combined interaction of the upper and lower optimization levels guarantees that the search process is narrowed down to high-performance designs with the fewest number of channels, as well as minimum NB and NNB. CNN-D-P is also the first evolutionary algorithm capable of autonomously compressing CNN topologies constructed with convolutional layers and offering bi-level interaction between convolutional layers and the hyperparameters of convolution filters. This allows for more comprehensive optimization of CNN architectures and hyperparameters. Therefore, while Bi-CNN-D-C and CNN-D-P share some similarities in terms of joint design and pruning, the proposed method addresses the limitations of Bi-CNN-D-C and offers a more effective and efficient approach to optimizing CNN architectures.
5 Conclusions and future work
Deep neural networks have demonstrated remarkable success in a variety of machine learning tasks, ranging from image classification to speech recognition. However, designing an optimal deep convolutional neural network (CNN) architecture remains a challenging and timely task. Recent research has explored methods for reducing the computational complexity of CNNs using evolutionary algorithms (EAs). These metaheuristic algorithms are capable of optimizing the CNN architecture for network compression and acceleration, which is particularly important for real-world applications where computational resources are limited. Despite the potential benefits of EAs in CNN architecture optimization, previous works have not considered the bi-level nature of neural architecture design and compression. In response, our research proposes a novel bi-level model of the CNN architecture design and pruning problem. Specifically, the upper level of our model aims to minimize network complexity in terms of the number of convolution nodes per block (NNB) and the average NNB with regard to block network topologies. On the other hand, the lower level of our model is concerned with simplifying the network in terms of the number of channels. To solve this bi-level model, we employ the Competitive Evolutionary Memetic Algorithm (CEMBA), which is a hybrid optimization algorithm that combines the benefits of both Evolutionary Algorithms and local search techniques. Our experimental results demonstrate the efficacy and superior performance of our proposed CNN-D-P approach on benchmark datasets such as CIFAR-10 and CIFAR-100. Our research contributes to the development of effective optimization techniques for CNN architecture design and pruning. By considering the bi-level nature of the problem, our approach is capable of achieving a more holistic optimization of CNN architectures, resulting in higher efficiency and accuracy. The proposed framework has significant potential for practical applications in various fields, including computer vision and natural language processing.
Looking towards the future, we anticipate exciting opportunities for further investigation. One potential avenue of exploration involves the development of an interaction model that facilitates user engagement with CNN-D-P via the evolutionary process. This would entail analyzing the generated architectures, identifying common patterns, and presenting recommendations in the form of soft or hard constraints to produce CNN architectures that align with expert knowledge and requirements. Another potential direction for our work is to expand into the domain of real-time federated learning, which involves collaboration among multiple local devices to train a unified global model while kee** training data on edge devices. This approach may help address critical concerns such as data privacy, security, access rights, and access to heterogeneous data in fields like telecommunications, the Internet of Things, the military, and pharmaceuticals.

