
Abstract
Referring image segmentation aims to segment object in an image based on a referring expression. Its difficulty lies in aligning expression semantics with visual instances. The existing methods based on semantic reasoning are limited by the performance of external syntax parser and do not explicitly explore the relationships between visual instances. This article proposes an end-to-end method for referring image segmentation by aligning ’linguistic relationship’ with ’visual relationships’. This method does not rely on external syntax parser for expression parsing. In this paper, the expression is adaptively and structurally parsed into three components: ’subject’, ’object’, and ’linguistic relationship’ by the Semantic Component Parser (SCP) in a learnable manner. Instances Activation Map Module (IAM) locates multiple visual instances based on the subject and object. In addition, the Relationship Based Visual Localization Module (RBVL) firstly enables each instance of the image to learn global knowledge, then decodes the visual relationships between these visual instances, and finally aligns the visual relationships with the linguistic relationships to further accurately locate the target object. The experimental results show that the proposed method improves performance by 4– 9% compared with baseline method on multiple referring image segmentation datasets.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Due to the rapid improvement of computer computing power, the applications of artificial intelligence (AI) are also increasing. However, the prerequisite for AI to serve humanity well is that AI can receive sufficient information provided by humans. Therefore, multi-modal interaction has become a hot topic in deep learning in recent years. As a popular multi-modal task, referring image segmentation aims to segment an object in an image according to the given descriptive text and picture, which has important application value for various applications such as language based human-computer interaction [1] and image editing [2]. The difficulty lies in the alignment between text semantics and visual instances. For example, the computer needs to segment the target mask from a picture (which includes people wearing green clothes, people wearing yellow clothes, etc.) based on an expression ’a person wearing green clothes’. The key to obtaining accurate segmentation results is that the model can correctly understand the expression ’a person wearing green clothes’ and locate the object.

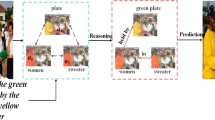
Motivation of our method. a The existing methods rely on external and inadaptive syntax parsing trees to propagate features, and do not consider the alignment between visual relationships and linguistic relationships. b Our proposed method can self-parse semantic components, then gradually and accurately locate the final target based on relationship alignment. Specificly, a sentence is divided into subject(in red), object(in green), and relationship component(in orange). Then, perceiving the instance through the ’a black dog’ and ’frisbee’ and decoding the visual relationship between instances. Finally, by aligning visual and linguistic relationships, locating the object indicated by the expression
In order to accurately infer the object described by the expression, researchers have proposed many methods based on semantic reasoning. The inherent structural information of a sentence is crucial for understanding its semantics. To explore and utilize the structured information of a sentence, [3,4,5,10] has brought great performance improvement in the field of Natural Language Processing(NLP). Some work [11, 2.2 Referring Image Segmentation Once Referring Image Segmentation(RIS) was proposed, it has aroused widespread interest among researchers and become a popular multi-modal task. The early methods [19, 20] use Convolutional Neural Network(CNN) and Recurrent Neural Network(RNN) to extract the features of vision and text respectively, and then directly concatenate the features of the two modalities. These methods deal with too much redundant information. Shi et al. [21], Ye et al. [22] and Jain and Gandhi [23] apply self-attention between text, vision, and cross-attention between text and vision, modeling single linguistic feature, single visual feature, and text-visual multi-modal features more accurately. These methods adopt the late fusion strategy and do not mine the interaction information between the two modalities in the early stage. Feng et al. [24] adopts an early fusion strategy, which explicitly incorporates text features when encoding image features, transforming the image encoder into a multi-modal feature encoder, resulting in more accurate representation of multi-modal features. Multi-scale features are very important in image segmentation tasks. High-scale features have more semantic information, while low-scale features have more detailed information. Li et al. [25], Margffoy-Tuay [26] and Ye et al. [27] iteratively model the multi-scale information of the image, adding low-level image features in each iteration process to gradually capture information at different scales of the image, improving the details of the segmentation results. In order to facilitate the model to better understand the semantics, [28, 29] integrate citation expression generation into expression understanding, utilize expression generation to promote understanding of expressions, and improve segmentation results. There are some methods that try to solve the problem of RIS from a novel perspective. Wang et al. [30] and Kim et al. citeKim2023RISCLIPRI use a large-scale pretrained multi-modal model CLIP [32] to learn text object matching relationships. Qiu et al. [33] learns the distribution similarity between predicted results and true values through generative adversarial learning. Liu et al. [34] represents each visual instance with instance specific features (ISFs) through grid-based methods, allowing the obtained ISFs to propagate through the spatial grid, enabling each ISF to learn global features and ultimately align with the target object. Jiao et al. [35] retrieves the most relevant images according to visual and textual similarity from external data pools, and then uses the retrieved images to enrich the visual information of small target objects for better multi-modal feature learning. Unlike these methods, the proposed method is based on semantic reasoning. It gradually perceives visual objects by analyzing the components of the text. Then, by decoding the relationships between visual objects and aligning them with textual relationships, the final target object is accurately located. This also conforms to the way humans think when facing complex referring image segmentation scenes. Referring Video Object Segmentation(RVOS) is a novel task. It requires the model to locate and segment a target object in a video sequence based on a sentence describing the object and its actions. The difficulty of this task lies in integrating multi-modal information and sequential information for pixel-level segmentation. Liang et al. [36] designs a memory module containing two parts, one for persistently storing global video content and the other for dynamically collecting local temporal context and segmentation history. The memory module can capture long-term dependencies and cross-modal interactions in videos with linear time complexity and constant space consumption. This achieves the goal of efficiently querying the entire video with a linguistic expression. Zhao et al. [37] designs a transformer-based model to fuse and align appearance, motion and language features. It includes Multi-Modal Video Transformer (MMVT) and Language Guided Feature Fusion Module (LGFF). MMVT can fuse and aggregate multi-modal and temporal features between different frames, and LGFF can fuse multi-modal features layer by layer and use language features to emphasize target areas. In addition, a multi-modal alignment loss (MMAL) is designed to explicitly align features of different modalities in the embedding space to reduce semantic gaps. Wu et al. [38] exploits the intrinsic structure of video content to provide a set of discriminative visual embeddings, which helps achieve more effective visual-verbal semantic alignment. It also proposes a boundary-aware segmentation method that combines object-aware features and boundary information to guide accurate video object segmentation. These methods have some relevance to our work. They are all solving the problem of knowledge alignment between multiple modalities.2.3 Referring Video Object Segmentation
3 Our Method
We propose a novel referring image segmentation method that utilizes progressive semantic reasoning. For each sentence, we first parse it into three independent semantic components, including subject component, object component, and linguistic relationship component. The model firstly locates the approximate visual region (including multiple instances) based on the subject and object components, and then accurately segments the target object by aligning the relationship between visual instances with linguistic relationship. An overview of our method is shown in Fig. 2. The input of this network consists of an image \(\textit{I} \in {\mathbb {R}}^{H\times W\times 3}\) and a referring text \(\textit{T} = \{w_i\}_{i=1...t}\) where t is the length of text.

Overview of the proposed framework. The framework contains five main components: Backbone to extract visual and linguistic features and add coordinate feature; Semantic component parser (SCP) parses the linguistic feature into three independent components; instance activate map (IAM) according to subject and components activating the response map of instances; relationship-based visual localization (RBVL) decodes the visual relationships between instances and then align the visual relationship and linguistic relationship to localize the ultimate target object; ConvLSTM module fuses features from multiple scales to improve the details of segmentation masks. Note that the meaning of the black dashed line is to perform the same operation as the black solid line simultaneously
3.1 Backbone
The backbone includes a visual feature extractor and a linguistic feature extractor, which extracts features from image I and text T. Follow previous works [4, 9, 20, 25], we use 8-D spatial coordinate feature \(\textit{SP} \in {\mathbb {R}}^{h\times w\times 8}\) to incorporate spatial information, where h and w is the height and width of visual feature map.
3.1.1 Visual Feature
Multi-scale features have been proven useful in other visual tasks. In the referring image segmentation task, advanced features can enhance the semantics of segmentation results, while low-level features can improve the details of segmentation results. Follow [25], we utilize output from three layers of the ResNet [39] and denote them from high-level to low-level, as: \(\textit{V}{_3}, \textit{V}{_4}, \textit{V}{_5}\) with dimension of \(\textit{h}{_3}\times \textit{w}{_3}\times \textit{c}{_3}\), \(\textit{h}{_4}\times \textit{w}{_4}\times \textit{c}{_4}\), \(\textit{h}{_5}\times \textit{w}{_5}\times \textit{c}{_5}\), respectively. c is the number of visual feature channels. Due to the fact that \(\textit{V}{_3}, \textit{V}{_4}, \textit{V}{_5}\) have the same operation in the subsequent process, for ease of description, we use \(\textit{V}\) instead of them. Then concatenates it with spatial coordinate feature and denotes as \({\tilde{V}}\in {\mathbb {R}}^{h \times w \times c_v}\).
3.1.2 Linguistic Feature
We use the pre-trained ELMo [40] to obtain a vector of word embedding representations of the text T. In order to enable each word in a sentence to learn contextual knowledge, we use bi-directional LSTM [41] to extract linguistic features. So, the linguistic feature Q of text is calculated as follow:
where \(\textit{Q} \in {\mathbb {R}}^{t\times \textit{c}{_w}}\).
3.2 Semantic Component Parser
The sentence is structurally parsed into subject, object, and linguistic relationship components. This process can help the model to better understand the semantics of the sentence. The target object indicated by an expression is usually contained within the semantics of the subject component. In this article, we design two semantic component parsers, and compare the performance of these two methods in Sect. 4.
3.2.1 Semantic Extraction Parser
Inspired by Mikolov et al. [42], in a semantic embedding space, vectors can capture linear relationships in semantics with a certain degree of accuracy, such as \(\textit{king}-\textit{man}+\textit{women}\approx \textit{queen}\). We design the Semantic extraction parser(SEP), as shown in part a of Fig. 3. The module consists of two steps. Firstly, the linguistic feature \(\textit{Q}\) is projected into a semantic embedding space. The semantic embedding vector \(\textit{s}\) can be calculated as follow:
where \(\textit{W}_{1} \in {\mathbb {R}}^{\textit{c}{_w}\times \textit{c}{_s}}\), \(\textit{s}\in {\mathbb {R}}^{1\times \textit{c}{_s}}\), Tanh(\(\cdot \)) is activation function, and \(\sum X[1]\) denotes the summation of the tensor X in the first channel. Then, the subject component \(S_S\), object component \(S_O\), and linguistic relationship \(S_R\) can be calculated as follows:
where \(\textit{P}_{i}(\cdot )\) has the same structure as P in Fig. 3a. In P, \(W_{p_{1}}\) and \(W_{p_{1}}\) mean the convolution operations, \(ReLU(\cdot )\) is activation function, \(L_2(\cdot )\) denotes L2-normalization, and \( \textit{S}{_i}\in {\mathbb {R}}^{1\times \textit{c}{_s}}\). Finally, \(S_{S}\), \(S_{O}\), \(S_{R}\) are concatenated to form the parsed semantic embedding vector \( S\in {\mathbb {R}}^{3\times \textit{c}{_s}}\).

Two Semantic Component Parsers. We use red, green, orange denotes subject component, object component, linguistic relationship component, respectively. In a Parser \(\textit{P}_{i=S, O, R}\) has the same architecture with \(\textit{P}\). In b the depth of the color reflects the likelihood of a word belonging to the corresponding component. The darker the color, the greater the probability. The Reduce_sum block denotes dimension reduction through summation
3.2.2 Component Prediction Parser
Inspired by Liu et al. [9], we consider the probability that each word belongs to one of the three components: subject, object, and linguistic relationship, as shown in Fig. 3b. This probability matrix A is calculated as follows:
where \(\textit{W}_{2} \in {\mathbb {R}}^{\textit{c}{_w}\times \textit{3}}\), \(\textit{A} \in {\mathbb {R}}^{\textit{3}\times \textit{t}}\). Finally, the parsed semantic embedding vector S is calculated as follow:
where \(*\) denotes matrix multiplication, and \(S\in {\mathbb {R}}^{3\times \textit{c}{_s}}\).

Architecture of Instance Activation Map. The gray cube represents the representation of subject or object components. The output of this module is the visual instance response of the subject components
3.3 Instance Activation Map
Based on the subject, object components and visual feature, we can activate their visual response of corresponding instances, as shown in Fig. 4. In this process, the weight is shared between activating subject and object instances. Taking the subject component \(S_S\) as an example, the calculation process of the instance activation map is as follows:
where \(\textit{W}_3 \in {\mathbb {R}}^{\textit{c}_{v} \times \textit{c}_{s}}\), \(\textit{W}_4 \in {\mathbb {R}}^{\textit{c}_{s} \times hw}\), \(\textit{W}_5 \in {\mathbb {R}}^{\textit{c}_{s} \times 1}\). \(\odot \) denotes element-wise multiplication. \(M_S\) is the instance activation map of the subject component. Similarly, we can calculate the instance activation map of the object component and denote it as \(M_O\).

Architecture of Relationship-Based Visual Localization. The Vis-trans block enables the learning of global contextual features at each position of the initial feature map. The Cosin block denotes calculating consine similarity between visual relationship representation and linguistic relationship representation
3.4 Relationship-Based Visual Localization
Based on the instance activation map \(M_S\), \(M_O\), and the linguistic relationship vector \(S_R\), we can locate the final target object, as shown in Fig. 5. Specifically, firstly, we perform global contextual feature encoding on feature map \(\tilde{V}\), so that every position on the feature map could learn global features, which can be described as follow:
where \(W_q, W_k, W_v \in {\mathbb {R}}^{c_v \times c_v}\). After this process, associations are established between positions that is equivalent to encoding the relationships between each other.
Secondly, the instance activation map \(M_S\) and \(M_O\) are dot multiplied with the feature map B to obtain the global context features of the corresponding instance, which is denoted as \(B_S\) and \(B_O\). Thirdly, we decode the visual relationship between the \(B_S\) and \(B_O\). Then, we project the visual relationship and the linguistic relationship into a relationship embedding space. The above operations are as follows:
where \(W_6 \in {\mathbb {R}}^{c_v \times c_r}\), \(W_7 \in {\mathbb {R}}^{c_s \times c_r}\), \(R_L \in {\mathbb {R}}^{1 \times c_r}\), \(R_V \in {\mathbb {R}}^{hw \times hw \times c_r}\) contains the visual relationships between all subject and object instances. \(R_V\) and \(R_L\) is the representation in relationship embedding space of vision and language, respectively.
The similarity between vectors in the common space can be measured by comparing their cosine similarity. Therefore, we can align visual with linguistic relationships in this relationship embedding space. Moreover, since the expression must accurately describe the object in the image, this alignment must exist and be unique. This process can be described as follow:
where \(H\in {\mathbb {R}}^{hw \times 1}\) reflects the similarity between the visual and linguistic relationships. The higher similarity score at a certain position in H, the more likely it is that this position belongs to the target region.
Finally, we use H to enhance the original feature \(\tilde{V}\), the enhanced feature denoted as \(\tilde{Y}\).
3.5 Convolutional LSTM
As mentioned in section 3.1.1, multilevel visual features are used. We concatenate S, \(\tilde{Y_i}\) as the input of Convolution LSTM block, and denote it as \(F_i\), where \(i=5,4,3\) represents multilevel visual features. Follow [25], we input the multi-modal feature \(F_i\) into the ConvLSTM block in the order of \(\{F_5, F_4, F_3\}\). The ultimate prediction P can be calculated as follow:
where \(MLP(\cdot )\) denotes Multi-layer Perceptron, \(BiInt(\cdot )\) denotes Bilinear interpolation which resizes the result the result to the original image size.
3.6 Loss Function
The prediction binary cross-entropy loss with the ground truth G can be calculated as follow:
where \(g_{jk}\) denotes the label on the position (j, k) of G, and \(p_{jk}\) denotes the prediction score on the position (j, k) of P.
In order to supervise the network in depth, we enlarge \(H_{i=5,4,3}\) to the same size as the original image, and then calculate its binary cross-entropy loss with ground truth G to obtain the location loss. Furthermore, we calculated localization losses on multiple scales as follow:
where \(x_{ijk}\) denotes the score on the position (j, k) of \(X_i\).
So, the final train loss is defined as follow:
where \(\alpha \) is a hyper-parameter to control the impact of \(L_l\).
4 Experiments
4.1 Experimental Settings
4.1.1 Datasets
To verify the effectiveness of the proposed method, we conducted extensive experiments on three widely used referring image segmentation datasets, which are UNC [43], UNC+ [43], and Google-Ref [44].
UNC: It contains 19,994 images with 142,209 referring expressions(contains 3.5 words on average) for 50,000 masks of referring objects, in which 120,624, 10,834, 5657, and 5095 examples are split by train, val, testA, and testB, respectively. These data are selected from the MSCOCO dataset by a two-player game [45]. Each image has multiple referring expressions that match it.
UNC+: It is also extracted from MSCOCO, and contains 141,564 referring expressions(contains 3.5 words on average) for 49,856 masks of referring objects in 19,992 images, in which 120,191, 10,758, 5726, 4889 examples are split by train, val, testA, and testB, respectively. However, the referring expression does not contain any positional information.
Google-Ref: It contains 104,560 referring expressions(contains 8.4 words on average) for 54,822 masks of referring objects in 26,711 images. The annotations are based on Mechanical Turk instead of using a two-player game.
4.1.2 Evaluation Metrics
Follow previous works, we use Overall Intersection-over-Union(Overall IoU) and Prec@X to evaluate the accuracy of segmentation. The Overall IoU metric represents the ratio of the total intersection area and the total joint area between the predicted mask of all test samples and the ground truth. Prec@X The percentage of IoU scores exceeding the threshold X in the predicted mask in the measurement calculation test set, where \(X \in \{0.5, 0.6, 0.7, 0.8, 0.9\}\).
4.1.3 Implementation Details
The proposed network is built on the public tensorflow-gpu toolbox and is trained on Nvidia RTX 2080Ti GRU that has 11GB memory with batch size is equal to 1. Follow previous works, we adopt Deeplab-ResNet101 [46] that is pretrained on the PASCAL-VOC dataset [47] and frozen as the CNN backbone to extract original visual feature from the input images. The input images are resized to 320\(\times \)320, and the length of referring expressions are sliced to 20. As for the size of the parameters, we set \(c_w=c_s=c_v=c_r=1000\). \(\alpha =0.3\) in our model. The network is trained using Adam optimizer [48] with an initial learning rate of \(2.5e^{-4}\) and a weight decay of \(5e^{-4}\). We stop training after 800K iterations.
4.2 Comparison with State-of-the-Art
4.2.1 Comparison of Overall Performance
We compare our proposed method with ten existing state of the art bottom-up methods, including RMI [20], KWA [21], DMN [26], RRN [25], CMSA [22], CGAN [33], QRN [29], SANet [7], EFN [24], CMPC [9]. Besides, we also compare our proposed methods with three existing state of the art top-down methods, including MAttNet [49], NMTree [3], CAC [28]. CPP and SEP respectively represent semantic component parser used in the proposed network. In Table 1, the word embedding vector is obtained from a randomly initialized matrix, +ELMo represents that we replace the randomly initialized matrix with pre-trained ELMo [40] to get the words embedding of text. +GLOVE represents that we replace the randomly initialized matrix with pre-trained GLOVE [52] to get the words embedding of text. The “TD” method obtains multiple proposals from pretrained target detectors, calculates the highest proposal score, and then segments the mask of the object in the proposal. Therefore, they typically have high performance. The “BU” method directly predicts the probability that each position in the image belongs to the segmented foreground. Due to the absence of a proposal, it is often difficult to accurately locate the complete region of the object. We use DCRF [53] to post-process the predicted results. From Table 1, it can be seen that compared to these state of the art methods, we achieved the best results on multiple data points. Compared to “BU” methods, we achieved the best results on all data items. In unc split by testB, compared with “TD” methods, it exceeded their best method by 7.71%; Compared to “BU” methods, it exceeds their best method 0.7%. Especially in unc+ split by testB, compared with the “BU” method, it exceeds their best method by 1.87%. We test using GLOVE as the initial word embedding model and the results shows that it slightly improves the performance of our method on UNC+ and G-ref datasets. We also test using ELMo as the initial word embedding model. Experimental results show that our method achieves optimal results when using EMLo as a word embedding model, and is better than some state-of-the-art methods (without using bert and swin-transformer) in recent years on multiple datasets. The reason for this difference is that GLOVE is static. It does not take into account the context within the text. The embedding of a word is same in different texts. In contrast, ELMo is dynamic. It takes into account contextual information. A word can have different embeddings in different contexts.
4.2.2 Comparison of Performance Improvement Brought by Explainable Reasoning Methods
We compared the performance improvement brought by explainable reasoning methods with existing state of the art based on explainable reasoning,including NMTree, LSCM [4], CMPC [9], SANet [7], BUSNet [6], on multiple datasets, as shown in Table 2. Due to the different performance of the baseline in different methods, the improvement of performance by the inference module will be affected by the performance of the baseline. For fairness, when comparing the performance of explainable inference blocks for each method, we use a setting that is close to our baseline performance as its own baseline. From Table 2, it can be seen that our proposed inference module has achieved the highest performance improvement in all dataset partitions. Especially in UNC+ and Gref, the improvement exceeded 7%, which is presented in detail in Table 3. We argue that is because the expression for UNC+ does not contain positional information, and Gref’s expression is longer. Therefore, it is necessary to have a more structured understanding of the meaning of expressions and gradually infer visual objects.
4.2.3 Model Complexity
We show the complexity of the model in Table 4. All data are obtained with RTX 2080Ti GPU as the computing device when testing the testB split of the UNC dataset. The index of inference time costs represents the average time taken per-batch when testing the testB split of the UNC dataset.
4.3 Ablation Studies
Our baseline method is RRN, but we replace the RNN blocks with BiLSTM. We conduct ablation experiments on each dataset partition for the Instance Activation Map (IAM), Component Prediction Parser (CPP), and Semantic Extraction Parser (SEP) blocks we proposed, and record the performance of adding the blocks, the results are shown in Table 3. We also record the ablation experimental results on the val set of UNC+ dataset with @ X as the evaluation and overall IoU metric.
From the third row of Table 3 and the third row of Table 5, it can be seen that our proposed IAM module has improved performance by almost 1–1.3% compared to the baseline. From the fourth and fifth rows of Table 3, it can be seen that our proposed CPP and SEP blocks have improved baseline performance by 3–7%. Moreover, the improvement of SEP blocks is greater than that of CPP blocks. From the fourth and fifth rows of Table 4, it can be seen that our proposed CPP and SEP have significant improvements for @ 0.5, @ 0.6, and @ 0.7, and reach their peak at @ 0.5 of 5.51%, while the improvements for @ 0.8 and @ 0.9 are relatively small.
This is in line with our expectations. The focus of our proposed method is to better locate the approximate area of the object, rather than the more refined segmentation of the object’s mask.

Qualitative analysis of our proposed RBVL and IAM methods. The second, third, and fourth columns demonstrate the significant improvement of our proposed method on segmentation results
4.4 Qualitative Analysis
4.4.1 Qualitative Analysis of Blocks
Figure 6 shows the optimization process of our proposed RBVL block and IAM block for segmentation results. In Fig. 6a, the baseline (second column) locates the two objects of “man”. After adding our proposed RBVL method (third column), we accurately located the approximate area of the target object, which is the “man wearing a jacket” on the right, rather than the “male athlete”. After further adding IAM blocks (fourth column), the segmentation results are further refined, which is already quite close to the ground truth. Similarly, in Fig. 6b, the baseline method locates both “child” and “woman” simultaneously. After adding RBVL, the model accurately located the ’child’. After further increasing IAM, the segmentation results are close to the ground truth. From Fig. 6, it can be seen that our proposed RBVL method can accurately locate the approximate area of the target object
4.4.2 Qualitative Analysis of Proposed SCP
After parsing the sentence through SCP, the obtained subject component and object component will be input to the IAM module to generate the corresponding heatmap. In Fig. 7a, the heatmap of the subject component includes children and adults in the picture, because they are more consistent with the semantics of "boy". At the same time, the heatmap of the object component has a high response in the area where the "striped shirt" appears in the picture. In Fig. 7b, the heatmap of the subject component locates three adults in the picture, because they are more consistent with the semantics of "guy". The heatmap of the object component has a high response in the area where the "white hat" appears in the picture. In Fig. 7c the heatmap of the subject component has a high response in the position where two athletes appear in the picture, because they are consistent with the semantics of subject component "player". Moreover, the heatmap of the object component has a high response at the position where the number 8 appears. These cases can illustrate that the proposed SCP module can learn subject components and object components well.

Qualitative analysis of our proposed SCP methods. The second column and third column demonstrates the activation map of subject and object component
4.4.3 Success cases
In Fig. 8, we present some success cases of our proposed method. It demonstrates the excellent performance of our method when faced with simple problems (expressions are easy to understand and visual objects are few) and hard problem of consciousness (subject and object components have multiple corresponding objects in the visual domain). In Fig. 8b, although there are two pizzas in the image, our proposed method can still accurately locate the target object through object “candle” and relationship “on the left”. Similarly, in Fig. 8c, although there are many “Broccoli” in the image, our method can also accurately locate the final Broccoli according to object “chopsticks” and relationship “on”.

Some successful cases of our proposed method

Some failure cases of our proposed method
4.4.4 Failure Case
In Fig. 9, we present some failure cases of our proposed method. As shown in Fig. 9a, our model locates two people in the image based on the expression “110”. However, the correct result would be the woman in the picture with the “110” number plate. This is due to the fact that the advantage of our method is to mine the structural information of the sentence, so as to obtain the subject, object and language relation components. Then by aligning the linguistic relationship with the visual relationship, our model can accurately segment the target. However, our model is not accurate enough to encode complex numbers like “110”. This ultimately lead itself to locate both the numbers “110” and “160” (which both contain the numbers “1” and “0”). In Fig. 9b, our model locates two people in the picture based on the expression “blue shirt”. It is true that both men are wearing blue shirts. At this point, the target is more likely to be the one on the right. Unfortunately, our model cannot accurately localize the target. This is due to the lack of more discriminative information in the expression. In Fig. 9c, there are multiple people who overlap with the “center person”. Due to the lack of image coding ability, our method can not obtain accurate segmentation results when multiple objects overlap.
5 Conclusion
In this paper, we use the alignment of language relationships in natural language expressions and visual relationships between visual objects to solve the problem of reference image segmentation. Our method mainly consists of SEP module and RBVL module. The SEP module parses the semantics of expressions into subject components, object components, and language relationship components. The RBVL module decodes the visual relationships between the subject and object components based on their corresponding visual regions, and then aligns the visual and linguistic relationships to enhance the response of the target object in the subject visual region. Our proposed method brings performance improvements on three benchmark datasets, surpassing existing methods based on explainable reasoning. Numerous ablation experiments have also demonstrated the effectiveness of our proposed method.
References
Khan E (2012) Natural language based human computer interaction : a necessity for mobile devices. https://api.semanticscholar.org/CorpusID:15641099
Chen J, Shen Y, Gao J, Liu J, Liu X (2017) Language-based image editing with recurrent attentive models. In: 2018 IEEE/CVF conference on computer vision and pattern recognition, pp 8721–8729
Liu D, Zhang H, Zha Z, Wu F (2018) Learning to assemble neural module tree networks for visual grounding. In: 2019 IEEE/CVF international conference on computer vision (ICCV), pp 4672–4681
Hui T, Liu S, Huang S, Li G, Yu S, Zhang F, Han J (2020) Linguistic structure guided context modeling for referring image segmentation. In: European conference on computer vision
Luo G, Zhou Y, Sun X, Cao L, Wu C, Deng C, Ji R (2020) Multi-task collaborative network for joint referring expression comprehension and segmentation. In: 2020 IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 10031–10040
Yang S, **a M, Li G, Zhou H-Y, Yu Y (2021) Bottom-up shift and reasoning for referring image segmentation. 2021 IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 11261–11270
Lin L, Yan P, Xu X, Yang S, Zeng K, Li G (2022) Structured attention network for referring image segmentation. IEEE Trans Multimed 24:1922–1932
Manning CD, Surdeanu M, Bauer J, Finkel JR, Bethard S, McClosky D (2014) The stanford corenlp natural language processing toolkit. In: Annual meeting of the association for computational linguistics
Liu S, Hui T, Huang S, Wei Y, Li B, Li G (2021) Cross-modal progressive comprehension for referring segmentation. IEEE Trans Pattern Anal Mach Intell 44:4761–4775
Vaswani A, Shazeer NM, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser L, Polosukhin I (2017) Attention is all you need. In: NIPS
Liu Z, Lin Y, Cao Y, Hu H, Wei Y, Zhang Z, Lin S, Guo B (2021) Swin transformer: Hierarchical vision transformer using shifted windows. In: 2021 IEEE/CVF international conference on computer vision (ICCV), pp 9992–10002
Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, Dehghani M, Minderer M, Heigold G, Gelly S, Uszkoreit J, Houlsby N (2020) An image is worth 16x16 words: transformers for image recognition at scale. ar**v:2010.11929
Ding H, Liu C, Wang S, Jiang X (2021) Vision-language transformer and query generation for referring segmentation. In: 2021 IEEE/CVF international conference on computer vision (ICCV), pp 16301–16310
Kim NH, Kim D, Lan C, Zeng W, Kwak S (2022) Restr: Convolution-free referring image segmentation using transformers. In: 2022 IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 18124–18133
Yang Z, Wang J, Tang Y, Chen K, Zhao H, Torr PHS (2021) Lavt: Language-aware vision transformer for referring image segmentation. In: 2022 IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 18134–18144
Wang W, Zhou T, Yu F, Dai J, Konukoglu E, Gool LV (2021) Exploring cross-image pixel contrast for semantic segmentation. In: 2021 IEEE/CVF international conference on computer vision (ICCV), pp 7283–7293
Li B, Weinberger KQ, Belongie SJ, Koltun V, Ranftl R (2022) Language-driven semantic segmentation. abs/2201.03546
Zhou T, Wang W, Konukoglu E, Gool LV (2022) Rethinking semantic segmentation: a prototype view. In: 2022 IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 2572–2583
Hu R, Rohrbach M, Darrell T (2016) Segmentation from natural language expressions. ar**v:1603.06180
Liu C, Lin ZL, Shen X, Yang J, Lu X, Yuille AL (2017) Recurrent multimodal interaction for referring image segmentation. In: 2017 IEEE international conference on computer vision (ICCV), pp 1280–1289
Shi H, Li H, Meng F, Wu Q (2018) Key-word-aware network for referring expression image segmentation. In: European conference on computer vision
Ye L, Rochan M, Liu Z, Wang Y (2019) Cross-modal self-attention network for referring image segmentation. In: 2019 IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 10494–10503
Jain K, Gandhi V (2021) Comprehensive multi-modal interactions for referring image segmentation. ar**v:2104.10412
Feng G, Hu Z, Zhang L, Lu H (2021) Encoder fusion network with co-attention embedding for referring image segmentation. In: 2021 IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 15501–15510
Li R, Li K, Kuo Y-C, Shu M, Qi X, Shen X, Jia J (2018) Referring image segmentation via recurrent refinement networks. In: 2018 IEEE/CVF conference on computer vision and pattern recognition, pp 5745–5753
Margffoy-Tuay E, Pérez J, Botero E, Arbeláez P (2018) Dynamic multimodal instance segmentation guided by natural language queries. ar**v:1807.02257
Ye L, Liu Z, Wang Y (2020) Dual convolutional LSTM network for referring image segmentation. IEEE Trans Multimed 22:3224–3235
Chen Y-W, Tsai Y-H, Wang T, Lin Y-Y, Yang M-H (2019) Referring expression object segmentation with caption-aware consistency. ar**v:1910.04748
Shi H, Li H, Wu Q, Ngan KN (2021) Query reconstruction network for referring expression image segmentation. IEEE Trans Multimed 23:995–1007
Wang Z, Lu Y, Li Q, Tao X, Guo Y, Gong M, Liu T (2021) CRIS: Clip-driven referring image segmentation. In: 2022 IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 11676–11685
Kim S, Kang M, Park J (2023) Risclip: Referring image segmentation framework using clip. ar**v:2306.08498
Radford A, Kim JW, Hallacy C, Ramesh A, Goh G, Agarwal S, Sastry G, Askell A, Mishkin P, Clark J, Krueger G, Sutskever I (2021) Learning transferable visual models from natural language supervision. In: International conference on machine learning
Qiu S, Zhao Y, Jiao J, Wei Y, Wei S (2020) Referring image segmentation by generative adversarial learning. IEEE Trans Multimed 22:1333–1344
Liu C, Jiang X, Ding H (2022) Instance-specific feature propagation for referring segmentation. ar**v:2204.12109
Jiao Y, Jie Z, Luo W, Chen J, Jiang Y-G, Wei X, Ma L (2021) Two-stage visual cues enhancement network for referring image segmentation. In: Proceedings of the 29th ACM international conference on multimedia
Liang C, Wang W, Zhou T, Miao J, Luo Y, Yang Y (2022) Local-global context aware transformer for language-guided video segmentation. IEEE Trans Pattern Anal Mach Intell 45:10055–10069
Zhao W, Wang K, Chu X, Xue F, Wang X, You Y (2022) Modeling motion with multi-modal features for text-based video segmentation. 2022 IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 11727–11736
Wu D, Dong X, Shao L, Shen J (2022) Multi-level representation learning with semantic alignment for referring video object segmentation. 2022 IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 4986–4995
He K, Zhang X, Ren S, Sun J (2015) Deep residual learning for image recognition. In: 2016 IEEE conference on computer vision and pattern recognition (CVPR), pp 770–778
Peters ME, Neumann M, Iyyer M, Gardner M, Clark C, Lee K, Zettlemoyer L (2018) Deep contextualized word representations. ar**v:1802.05365
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9:1735–1780
Mikolov T, Yih W-t, Zweig G (2013) Linguistic regularities in continuous space word representations. In: North American chapter of the association for computational linguistics
Yu L, Poirson P, Yang S, Berg AC, Berg TL (2016) Modeling context in referring expressions. ar**v:1608.00272
Mao J, Huang J, Toshev A, Camburu O-M, Yuille AL, Murphy KP (2015) Generation and comprehension of unambiguous object descriptions. 2016 IEEE conference on computer vision and pattern recognition (CVPR), pp 11–20
Kazemzadeh S, Ordonez V, Matten M, Berg TL (2014) Referitgame: referring to objects in photographs of natural scenes. In: Conference on empirical methods in natural language processing
Chen L-C, Papandreou G, Kokkinos I, Murphy KP, Yuille AL (2016) Deeplab: Semantic image segmentation with deep convolutional nets, Atrous convolution, and fully connected CRFS. IEEE Trans Pattern Anal Mach Intell 40:834–848
Everingham M, Gool LV, Williams CKI, Winn JM, Zisserman A (2010) The pascal visual object classes (VOC) challenge. Int J Comput Vision 88:303–338
Kingma DP, Ba J (2014) Adam: a method for stochastic optimization. CoRR ar**v:1412.6980
Yu L, Lin ZL, Shen X, Yang J, Lu X, Bansal M, Berg TL (2018) Mattnet: modular attention network for referring expression comprehension. In: 2018 IEEE/CVF conference on computer vision and pattern recognition, pp 1307–1315
He K, Gkioxari G, Dollár P, Girshick RB (2017) Mask r-CNN. IEEE Trans Pattern Anal Mach Intell 42:386–397
Chen Y, Li J, **ao H, ** X, Yan S, Feng J (2017) Dual path networks. In: NIPS. https://api.semanticscholar.org/CorpusID:35602767
Pennington J, Socher R, Manning CD (2014) Glove: global vectors for word representation. In: Conference on empirical methods in natural language processing. https://api.semanticscholar.org/CorpusID:1957433
Krähenbühl P, Koltun V (2011) Efficient inference in fully connected CRFS with gaussian edge potentials. In: NIPS. https://api.semanticscholar.org/CorpusID:5574079
Acknowledgements
This work is supported by National Natural Science Foundation of China (No. 61801398), Open project of Sichuan Provincial Key Laboratory of Intelligent Police, China, ZNJW2022KFQN002.
Author information
Authors and Affiliations
Contributions
MP completed the experiment and writing; BL provides guidance on innovation and methods, and modifies papers; CZ provided guidance on methods and revised the paper; LX completed the formalization of the formula; FX and MK supplemented and improved the experiment. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Pu, M., Luo, B., Zhang, C. et al. Text-Vision Relationship Alignment for Referring Image Segmentation. Neural Process Lett 56, 64 (2024). https://doi.org/10.1007/s11063-024-11487-2
Accepted:
Published:
DOI: https://doi.org/10.1007/s11063-024-11487-2