
Abstract
Food security is a crucial requirement in today’s world to meet the dietary needs of individuals. As the population continues to grow, the demand for food will increase by 70 to 100 percent by 2050. Therefore, there is an urgent need to develop an approach that can assist farmers in predicting crop yield accurately and in a timely manner before crop harvesting. In this direction, the present study proposed a nature-inspired optimized hybrid convolutional neural network with bidirectional long short-term memory to extract the nonlinear complex relationships among crop attributes. This hybrid deep learning model was optimized using a particle swarm optimization approach to automate the selection of appropriate hyperparameters for wheat yield prediction. The proposed model was developed to estimate wheat yield in a major wheat-producing state in India from 2000 to 2018 using the temporal and spatial characteristics of wheat crops. The experiment was conducted by integrating the historical yield, meteorological data, remote sensing-derived indices, and soil parameters from the October to April season. Furthermore, we also evaluated the performance of the proposed model in terms of the mean absolute error (MAE), root mean square error (RMSE), and mean squared error (MSE) with publicly available datasets such as Agro_data, Soybean_data, and FAO_data. The experimental results showed that the proposed PSO-CNN-Bi-LSTM method achieved an MAE of 0.39, MSE of 0.18, and RMSE of 0.42 (tonnes/ha) and outperformed existing CNN, LSTM, CNN-LSTM, CNN-Bi-LSTM, CNN-LSTM-PSO, CNN-Bi-LSTM-BO-GO, and neural network methods. Our findings demonstrated that the proposed methodology could be a promising alternative for predicting crop yield.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Agriculture plays a vital role in a country’s growth. Despite several initiatives launched by develo** nations to eradicate malnutrition and feed the growing population, the daily dietary needs of approximately 800 million people worldwide remain unmet due to insufficient access to food [1]. This concern is also reflected in the United Nations 2030 Agenda for Sustainable Development, which includes the zero hunger (SDG 2) and good health and well-being (SDG 3) goals aimed at addressing food security issues [2]. To overcome these issues, extensive research is required to develop intelligent farming paradigms incorporating remote sensing and IoT applications. Several statistical data models and machine learning-based methods have been deployed to predict crop yields across various countries [3]. This helps farmers take corrective action early to maintain their fields and plan their export–import policies.
In recent years, the application of artificial intelligence (AI) in agriculture has significantly benefited farmers. AI-based models have been developed to address various crop-related issues, reducing human intervention and enabling timely and accurate decision-making [2, 3]. Early crop yield prediction requires obtaining crops’ spatial-temporal attributes during ripening. The use of machine learning or deep learning models for prediction is becoming more prevalent because they can capture linear and nonlinear associations among the attributes, thereby enhancing the prediction accuracy of the network [4]. Although several statistical-based yield estimation models have been developed in the literature, they are often time-consuming and tedious, and their accuracy is mainly influenced by the weather and phenological attributes of a crop during its growth period [5]. In earlier studies, data mining and regression techniques were widely used to predict a crop based on production and climatic factors. Nevertheless, the main drawback of these methods is their inability to handle complex relationships among independent parameters [6, 7].
Machine learning methods often include irrelevant or duplicate features in the dataset to enhance a model’s accuracy. Therefore, feature selection is a crucial step in the preprocessing phase of a model [8]. Metaheuristic algorithms, such as particle swarm optimization, genetic algorithms, and ant colony optimization, are used to optimize the selection of optimal hyperparameters among a dataset’s attributes to find the best subset of features that can improve a model’s accuracy [6, 9]. In contrast, deep learning approaches have the advantage of feature learning over machine learning techniques because they can capture high-level features from the low-level features in a dataset [10]. While these techniques have gained popularity in various domains, their usage in agriculture research is still limited to a few cases.
Thus, the primary motivation of this work is to introduce an integrated model that overcomes the drawbacks of machine learning and linear models that can determine nonlinear relationships among the attributes of the wheat dataset. In this study, we have proposed a novel PSO-optimized Conv-1D and Bi-LSTM approach for wheat crop yield prediction in major wheat-producing states in India. The significant innovations and contributions of this work are summarized as follows:
-
Develop an optimized hybrid deep learning approach, namely, “PSO-CNN-Bi-LSTM,” for the optimal selection of hyperparameters for crop yield prediction based on spatial-temporal features, including the remote sensing-derived vegetation condition index, meteorological data, historical data, and soil factors.
-
Evaluate the performance of the proposed approach with publicly available large crop datasets in terms of the MAE, MSE, and RMSE to ensure its effectiveness and applicability compared with traditional approaches.
-
Perform a comparative analysis with baseline models and existing state-of-the-art hybrid models to demonstrate the credibility of the proposed approach.
The subsequent sections of this paper are arranged as follows. Section 2 discusses the existing related work. Section 3 explains the proposed methodology, study area, description of the dataset, and preprocessing steps. Section 4 illustrates the experimental outcomes, performance evaluation measures, and comparison with existing baseline methods. Section 5 describes the contributions and significance of the proposed work. Section 6 concludes the proposed study with the future direction and a discussion of the limitations of this work.
2 Related Work
This section provides an overview of the literature review related to crop yield prediction research. With advancements in artificial intelligence, deep learning (DL) and machine learning (ML) approaches have been increasingly utilized to overcome the limitations of traditional linear models in investigating agricultural issues. In the era of smart farming, several authors have employed deep learning-based LSTM networks to predict and forecast crop yields [10,11,12,13,14]. For instance, in a study [10], the authors proposed a recurrent neural network (RNN) to predict wheat yield in the Punjab province of India using historical and weather attributes of a particular region during the October to March season. The outcomes of the proposed technique were compared with random forest and regression methods, and the RMSE value was found to be 147.12. Similarly, in a study [11], the performance of the Kharif crop yield prediction was evaluated using a DNN-LSTM in the Rewari district of Haryana. The outcomes revealed that the proposed method achieved an RMSE value of 81.9 and was compared to traditional ARIMA and regression models. The results suggested that the model accuracy could be improved by expanding the dataset to train the network. However, the main drawback of the RNN-LSTM model is the vanishing gradient problem in predicting yield dependencies over time. Some authors have utilized regression and neural networks to analyze crop prediction. In a study [15], the authors performed a comparative analysis among random forest (RF), multiple linear regression (MLR), and an artificial neural network (ANN) to predict sugarcane yield using a publicly available CAN dataset. A global filtering method was used to overcome noise or outliers in the dataset. It was found that SFC was the most important essential attribute among the mentioned parameters in the data, and an RMSE value of 7.7 was obtained by using the random forest approach. Similarly, in a study [16], the authors evaluated the performance of random forest, polynomial regression, and SVR to predict potato and maize yields. They found that the random forest method performed best, with RMSE values of 510 and 129, respectively.
To address the limitations of individual methods, some researchers have combined multiple methods to develop hybrid architectures for improving the model accuracy. A PSO-based regression model architecture was employed in a study [6] to predict the yield of apricot and assess the essential attributes among the soil and irrigation samples of 110 GPS locations in central Iran. The authors used 61 variables to train the model with an 80% dataset and attained an RMSE value of 2.329. In another study [17], a hybrid approach of an ANN, a grey wolf optimizer (GWO), and an ICA was proposed to optimize the hyperparameters of data. The investigation was conducted on barley, wheat, potato, and sugar beet crops using agricultural statistical data with climatic factors. From the analysis, it was estimated that the RMSE value of the ANN-ICA approach was 3.20, which was slightly higher than the ANN-GWO value of 3.19. In a study [14], the authors utilized a GLCM with the LSTM method to capture the spatiotemporal features of a crop during the growing phase and obtained an RMSE value of 4.40. Similarly, to improve the performance of LSTM, an IOF-LSTM hybrid model was introduced in [18] to handle the underfitting and overfitting issues of LSTM and attained an RMSE value of 2.19. In a study [19], the authors proposed a hybrid method for predicting rice yield in the districts of West Bengal by combining the ARIMA model with an ANN. They overcame the limitations of the ARIMA model by using statistical data for experimentation over 20 years. The authors in [20] presented a generalized stacking model with LASSO regression for yield prediction based on 26 attributes related to the crop and climate of the study region in the US. The proposed ensemble model achieved 88.89% accuracy, surpassing traditional approaches. In a study [21], a hybrid MLP-ANN model was employed to predict maize yield and achieved an RMSE value of 71 kg/ha. The authors suggested that the model could be improved using a graph-based RNN structure to incorporate the spatial and temporal attributes of a crop. Numerous studies have demonstrated that optimization techniques enhance the accuracy of deep learning and machine learning models by selecting the appropriate hyperparameters [22, 23]. With the introduction of AI, various paradigms have been introduced to handle yield prediction in smart farming. However, researchers still need to improve the analysis of nonlinear crop-related datasets. The major shortcomings of the related work for crop yield prediction are as follows:
-
Most existing yield prediction models employ linear models or regression to achieve higher accuracy. Nevertheless, the major limitation is that these models cannot retrieve nonlinear characteristics and exhibit poor performance in long-term prediction.
-
Recently, RNNs and LSTM have gained popularity in processing long-term dependencies and forecasting production and yield. However, they have issues with vanishing gradients in long-term prediction. GRUs and Bi-LSTM models have been introduced to address this problem in the network.
-
Traditional crop yield prediction techniques employ SVM, ANN, MLP, or random forest approaches, which require longer training times in terms of processing large crop datasets because they include too many irrelevant parameters to achieve higher accuracy.
The challenges mentioned above demand a sophisticated crop yield prediction model. Therefore, we proposed a novel hybrid model to overcome the drawbacks of traditional approaches and leverage the advantages of deep learning methods for predicting wheat yield in significant wheat-producing regions. The proposed methodology and description of the dataset will be discussed in the next section.
3 Materials and Methods
3.1 Study Region
The present study focuses on India’s major wheat-producing states, which account for 13.5% of the world’s wheat production. In India, wheat crop cultivation is known as the “rabi season crop.” In this study, data from Haryana, Punjab, Rajasthan, Uttar Pradesh, Rajasthan, Bihar, and Gujarat were analyzed. Considering the latest statistics for 2021–22, Uttar Pradesh, Punjab, and Madhya Pradesh are India’s leading contributors to wheat production. Figure 1 presents the distribution of crop data in the dataset, revealing that Uttar Pradesh accounted for 21.8% and Madhya Pradesh for 16.9%, followed by Haryana and Punjab, according to statistical records.

Box plot representing the statewise data distribution in the dataset
3.2 Dataset and Preprocessing Steps
In this study, we gathered wheat crop-related temporal and spatial information, including meteorological and historical yield data from 2000 to 2018. All the relevant parameters were collected from the October–April crop season and combined in a CSV file containing 1,00,828 instances, with yield as the independent parameter and the 90 other parameters as dependent parameters, as illustrated in Table 1. The dataset includes various climatic factors, such as temperature, wind direction, maximum temperature, minimum temperature, surface pressure, wind speed, specific humidity, relative humidity, precipitation, soil moisture, dew point, and profile soil moisture, in addition to vegetation condition indices (VCIs), which were processed using the MOD13A2 NDVI product on the Google Earth engine for the study regions [24, 25]. The historical yield data was sourced from the Directorate of Economics and Statistics [16].
Approximately 5% of the data in the selected wheat dataset needed to be imputed. Some studies have suggested that the average imputation method performs well if there are less than 10% missing data [28, 29]. Therefore, we used the average imputation method to impute the missing data in the wheat dataset. Then, we performed feature engineering to standardize the data values using a standard scaler method, which distributes the data values within a specific range such that the mean is 0 and the standard deviation is 1. To implement this, we used the Feature Engine package in Python, which utilizes the scikit-learn fit and transform functions. After normalization, we used the drop-correlated library in Feature Engine and applied the Pearson correlation coefficient method with a 0.6 threshold to remove features that are less correlated with the yield attribute. This threshold limit was set to include features with significant correlations and exclude the remaining features for further analysis. We selected 33 features that correlated significantly with the independent variable. After choosing relevant components, we partitioned the dataset into a training and testing set with an 80:20 split to build and validate our proposed model.
3.3 Proposed Method (PSO-CNN-Bi-LSTM) for Yield Prediction
This section discusses the operation of the proposed methodology for yield prediction, and Fig. 2 shows the workflow of the proposed work, which will be discussed in detail in the subsequent section.

Methodology of the proposed PSO-CNN-Bi-LSTM method
In neural networks, hyperparameters are often a challenging aspect of the network performance. The stochastic gradient descent method is commonly used but requires extensive resources and manpower and does not always find the global optimal point. Therefore, the proposed methodology uses a nature-inspired technique named particle swarm optimization (PSO) to optimize the hyperparameters of a hybrid deep learning network. PSO effectively avoids local optimization issues during the training phase of the network. The PSO-optimized parameters of the CNN-Bi-LSTM model include the learning rate, number of hidden nodes, dropout rate, number of filters in Conv1D layers, and the number of neurons in the hidden layer. In the literature, many authors have illustrated the advantage of using CNNs for extracting relevant features from data. CNN applications are widely known in agriculture for seed classification, crop yield prediction, plant recognition, and fruit counting [12, 30,31,32,33]. At the same time, Bi-LSTM layers can capture long-term dependencies in both the forward and backward directions. The application of Bi-LSTM is widely used in smart farming for crop detection [34], intelligent irrigation systems [35], soil moisture forecasting in the field [36], etc. The CNN-Bi-LSTM model is also widely used for crop seed analysis [30], yield prediction [31], and crop prediction improvement [37]. The proposed method utilizes the advantages of both the CNN and the Bi-LSTM approaches.
-
Step 1. Data preprocessing and feature engineering of the original data. Initially, the original data are preprocessed to impute the values in the dataset, and after that, outliers are removed. Data scaling is performed using the standard scaler method represented by Eq. (1),
$$W=\frac{y-\gamma }{\sigma },$$(1)where “\(\gamma\)” is the mean and “σ” denotes the standard deviation of the sample “y”.
-
Step 2. Build the model and conduct the training process. After preprocessing, the CNN-Bi-LSTM network is represented by Eq. (2),
$$\mathrm{Z}\left(\mathrm{t}\right)=F \, (\mathrm{Y}(\mathrm{t}),\mathrm{ Z}(\mathrm{t}-1),\mathrm{ Z}(\mathrm{t}-2) \dots \dots .\mathrm{ Z}(\mathrm{t}-\mathrm{n})),$$(2)where \(\mathrm{Z}(\mathrm{t})\) is the predicted yield at a time and “\(t\)” and “\(F(t)\)” represent the proposed model’s function.
Then, the dataset is partitioned into 80% for training and 20% for testing and validating the results. Now, the model is trained with a 0.8 portion of the dataset. The hyperparameters of the network are optimized using the mechanism of PSO mentioned in Algorithm 2. The Conv1D and Bi-LSTM layers are fed with the optimal parameters to enhance the accuracy of the proposed model.
-
Step 3. Evaluate the model. The predicted values are compared with the actual values of the test set to determine the efficiency of the proposed model using the evaluation metric discussed in Eqs. (14) to (16). The description of these three steps is explained in the following section.
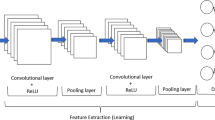
After preprocessing the original data, the convolution layer of the CNN network extracts meaningful information from the crop yield dataset. We have adopted the PSO method to continuously tune the hyperparameters of the CNN-Bi-LSTM network and encode them as “particles” using Eqs. (12) and (13). The fitness value of the parameters is automatically adjusted to obtain the optimal performance of the proposed approach. The structure of CNN includes an input layer, an output layer, a convolution layer, a pooling layer, and a fully connected layer, as represented in Fig. 3, and is a type of feedforward network [36]. The computations performed in the convolution layer are shown in Eq. (3),
where \(f\) is an activation function, \({v}_{ij}^{k}\) is the kernel of the \({i}^{th}\) activation map of the \(k-1\) layer and \({j}^{th}\) activation map of the \({k}^{th}\) layer, and \({d}_{j}\) is the collection of activation maps.

Convolution neural network (CNN)
In convolution layer processing, the activation map obtains the relevant features of the wheat dataset by extracting information from the lower layers to the higher layers of the input to create the linear model. The feature map of the convolutional layer becomes the input of the pooling layer, which captures the key points from the input to perform dimensionality reduction and discard the irrelevant features. The outcomes of these layers reduce the computational time overhead and improve the network’s speed. Then, the maximum pooling layer is utilized to enhance the proposed method’s robustness in terms of yield prediction. The outcomes of this layer are fed into Bi-LSTM layers that are processed through three gates to control the output (\({o}_{t}\)) and cell state (\({z}_{t}\)). The structure of the Bi-LSTM network includes two units of LSTM that receives input from both forward and backward directions, as represented in Fig. 4 [38, 39]. The roles of the Bi-LSTM method are that it can capture long-term dependencies bidirectionally and selectively retain and forget the information in the memory cells of the network [40]. Thereafter, a ReLU activation function is employed to distinguish the features of the respective classes and produce the desired prediction results. The processing of the hybrid proposed model includes data preprocessing and convolution, Bi-LSTM layer, fully connected layer, and particle swarm optimizer operations, which can be elaborated using Eqs. (4) to (11). The mathematical computation of the processing of LSTM is illustrated by Eqs. (4) to (8) and of Bi-LSTM by Eqs. (9) to (11). Let \({Y}_{t}=[{i}_{1},{i}_{2},{i}_{3}\dots {i}_{t}^{n}]\) represent the \({^\prime}\!n{^\prime}\) number of inputs, \({h}_{t}=[{h}_{1},{h}_{2},{h}_{3}\dots {h}_{t}^{k}]\) represent the hidden units in the network, and \({z}_{t}=[{z}_{1},{z}_{2},{z}_{3}\dots {z}_{t}^{k}]\) represent the cell state of LSTM at time \({^\prime}\!t{^\prime}\).

Bi-LSTM network
The LSTM architecture includes “\({f}_{t}\)” as a forget gate, “\({i}_{t}\)” as an input gate, and “\({o}_{t}\)” as an output gate [36]. Initially, the data passes through the forget gate “\({f}_{t}\)” and a determination is made on which data are discarded or processed from the cell state of the LSTM to retain in the memory using a sigmoid function, as computed in Eqs. (4) and (5) [41].
Here, \(\sigma\) represents the sigmoid function and \({W}_{f}\) and \({b}_{f}\) signify the weight and biases of the forget gate, respectively.
Now, the tanh function creates a vector state (\({v}_{t}\)) that determines the new information that can be added, as shown in Eq. (6).
The next step includes updating the state of a cell from \({z}_{t-1}\) to the new state \({z}_{t}\), as represented by Eq. (7).
The final step considers the computation of the output gate of the LSTM using Eq. (8).
Now, the hidden state is computed using the output tanh of the cell state (\(z\)),
The forward and backward states of the Bi-LSTM can be presented by Eqs. (9) to (11),
Here, \({h}_{t}\) represents the forward and backward LSTM outcomes in a combined manner to capture the temporal dependencies in the dataset. The proposed “PSO-CNN-Bi-LSTM” algorithm is represented in Algorithm 1.
Algorithm 1
Proposed PSO-CNN-Bi-LSTM network

PSO is a metaheuristic approach based on swarm intelligence that is utilized to ameliorate the ability of the CNN-Bi-LSTM network to repeatedly select the hyperparameters and overcome the need for manual adjustments [42]. In 1994, PSO was proposed by Kennedy et al., and it uses global and local data and fitness functions to search for the best solution for the particles [43]. Algorithm 2 illustrates the procedure of the PSO approach used in our work [44]. The basic concept of PSO includes the acceleration of each particle in achieving the particle best position \(({p}_{best})\) and global best position \({(g}_{best})\) with random weight adjustments at each time, where \({p}_{best}\) signifies the optimal solution attained by the particle and \({g}_{best}\) presents the best solution obtained by particles in the neighborhood of the particle. Each particle updates its position using Eqs. (12) and (13):
where \(\Theta {v}_{i-1}\) represents the inertia, \({co}_{1} ,{ro}_{1}\left[{p}_{best} -{x}_{i-1}\right]\) represents the cognitive (personal), and \({co}_{2},{ro}_{2}[{g}_{best}-x(i-1)]\) represents the social (global).
Algorithm 2
PSO technique

4 Results and Discussion
This section discusses the experimentation outcomes of the proposed framework, and a comparative analysis is presented in the subsequent section. The proposed methodology is implemented using the Python Jupyter Notebook on an i-7 processor with 16 GB RAM.
During the experiment, 80% of the data were utilized for training, and the remaining data were used to test the accuracy of the obtained results. We utilized four datasets: Dataset 1 includes wheat crop information, as discussed in Sect. 2, and the other three datasets are publicly available datasets collected from Kaggle, FAOSTAT, and GitHub to evaluate the proposed model performance. The Agro_data dataset (Dataset 2) was collected from Kaggle and consists of rice yield information from 2000 to 2015 [45]. A crop and livestock product dataset (Dataset 3) was collected from FAOSTAT [46]. The Soybean_data dataset (Dataset 4) consists of 25,345 instances with 395 attributes representing soybean yields in Iowa, Illinois, and Indiana [12]. The accuracy of the proposed model was evaluated with these datasets, and the subsequent section demonstrates that the proposed PSO-CNN-Bi-LSTM method obtained a higher prediction accuracy and reliability than those of the other existing approaches tested. The developed model incorporated temporal and phenological information to predict crop yield.
4.1 Evaluation Metrics
We used the following metrics to evaluate the performance of the proposed model: root mean square error (\(\mathrm{RMSE}\)), mean absolute error (\(\mathrm{MAE}\)), and mean squared error (\(\mathrm{MSE}\)). The root mean square error computes the quality of the prediction model by finding the difference between the true and predicted values based on the Euclidean distance. The mean absolute error distinguishes the true predicted labels from the actual ground truth data. The mean squared error measures the regression line fitness to the predicted data points. Their formulas are described by Eqs. (14) to (16):
where \(s\) = no. of dataset values, \(q\) = observed yield, and \({q}_{j}\) = mean yield value.
4.2 Experimental Analysis
Table 2 highlights the descriptive statistical results obtained for the yield attributes of Dataset 1, in which major wheat-producing state data were analyzed.
Table 2 represents the descriptive analysis of the wheat crop yield over the major states in India. The results illustrated that the highest mean values were observed in the Punjab and Haryana regions, with maximum wheat crop growth values of 5.8 and 5.56 tonnes/ha, respectively. Most of the districts in the Bihar region exhibited low wheat yields. The wheat crop data distribution appeared normal, as the kurtosis and skewness values were in the ranges of − 2 to + 2 and − 7 to + 7, respectively.
Figure 5 presents the analysis of wheat growth in the mentioned study sites from 2000 to 2018 and shows that the maximum growth values were observed in 2011 in the Panipat, Sirsa, and Fatehabad districts, with values of 5.56 tonnes/ha, 5.36 tonnes/ha, and 5.46 tonnes/ha, respectively. In contrast, the lowest growth value was observed in 2014, with 3.16 tons/ha in Gurgaon. The Sangrur district in Punjab exhibited maximum growth in 2018, with 5.8 tonnes/ha, whereas the lowest growth was observed in Gurdaspur in 2014, with 3.5 tonnes/ha. The annual variability of rainfall in the Rajasthan region influenced crop growth. In this region, the maximum yield was 4.48 tonnes/ha, and the lowest yield was 1.1 tonnes/ha in Bikaner. In the Uttar Pradesh region, the highest yield was 4.76 tonnes/ha and the lowest was 1.61 tonnes/ha in the Hapur and Moradabad districts, respectively. The Baruch district in Gujarat had the lowest wheat yield of 1.1 tonnes/ha in 2006, whereas the maximum yield of 4.56 tonnes/ha was observed in Junagadh. Among all the investigated districts, Sitamarhi had the lowest yield of 0.87 tonnes/ha.

Growth of the wheat crop in terms of yield (tonnes/ha)
Initially, feature engineering was performed to identify the correlation among features based on the Pearson correlation method with a threshold of 0.6 to the independent variable (yield) for all datasets, as presented in Fig. 6. Thereafter, noncorrelated features were removed and partitioned into the training and testing sets of the network. In the wheat dataset, the correlated features were found to be 33. For Dataset 2, 19 correlated features were fed into the training model, and for Dataset 3, this value was 7. For Dataset 4, based on the correlation analysis, the noncorrelated features were decreased to 196 features. The hyperparameters in the PSO-CNN-Bi-LSTM model are presented in Table 3.

Correlational analysis among dependent and independent attributes of wheat crop data
The framework of the proposed model includes one convolutional layer that has a 3*3 kernel size with 32 filters in a sequence and two bidirectional long short-term memory layers that have 32 neurons in one unit that control the overall capacity of a particular layer with a dropout rate of 0.2 and learning rate of 1e − 5 to train the network with the selected hyperparameters optimized using the PSO method. The model utilizes an optimizer that can update the weights and biases in the network, bridging the gaps between them and the loss function in the network.
4.3 Comparative Analysis
A comparative analysis was performed to confirm the credibility of the proposed PSO-CNN-Bi-LSTM method. This section highlights the obtained outcomes of the proposed model with existing baseline methods and existing recent studies in Sects. 4.3.1, 4.3.3, and 4.3.2. It also discusses the validation results of the actual and computed yields.
4.3.1 Comparison with Baseline Methods
This section highlights the comparison of the proposed method with existing machine learning, deep learning, and hybrid models, represented in Tables 4, 5, 6, and 7 for Dataset 1, Dataset 2, Dataset 3, and Dataset 4, respectively, in terms of the MSE, MAE, and RMSE.
For Dataset 1 (Table 4), we observe that the LSTM values for the evaluation metrics are 0.89, 0.78, and 0.94, and are relatively better in comparison to those of the neural network, with values of 10.1, 2.57, and 2.17, and CNN, with values of 6.8, 1.4, and 2.6, respectively. The CNN-Bi-LSTM model performs slightly better than the neural network, with values of 2.21, 1.17, and 1.48, respectively. The Bayesian optimized CNN-Bi-LSTM model is superior to existing approaches, with values of 0.97, 1.02, and 0.98, respectively. The CNN-LSTM-PSO model performs reasonably well, with values of 0.57, 0.57, and 0.75, respectively. The PSO-CNN-Bi-LSTM model demonstrates the best performance among the discussed experimental approaches, with values of 0.18, 0.39, and 0.42, respectively, the lowest values among those of the other baseline methods. Hyperparameter tuning using PSO improved the efficiency of the hybrid deep learning model. It is also observed that the mean square error is lowest with the proposed model and highest with the neural network.
For Dataset 2 (Table 5), we investigate that the hybrid deep learning model CNN-Bi-LSTM exhibits poor performance, with values of 1.96, 1.20, and 1.40. The performance improves significantly when optimizing the hyperparameters of the network using particle swarm optimization, and the attained values are 0.58, 0.55, and 0.76, respectively. Additionally, CNN-LSTM-BO performs slightly less than the CNN-LSTM PSO optimized model, with values of 0.72, 0.65, and 0.84, respectively. The proposed model results are closer to the CNN-LSTM sigmoid-based optimized model, with values of 0.59, 0.55, and 0.77, respectively. It is also observed that the CNN performance is lower with Dataset 2, whereas the neural network approach performs better than the CNN approach, with values of 0.62, 0.63, and 0.78, respectively.
Table 6 demonstrates the analysis for Dataset 3, in which the LSTM values for the performance metrics are 0.85, 0.48, and 0.92, respectively, whereas the CNN performance is lower than that of the LSTM approach, with values of 0.83, 0.39, and 0.91, respectively. The accuracies of the CNN-LSTM-PSO and CNN-LSTM-sigmoid models are similar in terms of the MSE and RMSE. The Bayesian–Gaussian optimized hybrid model performs better than CNN-Bi-LSTM, with values of 1.07, 0.80, and 1.03, respectively. The PSO-based optimized CNN-Bi-LSTM model has higher accuracy than the existing baseline models, with values of 0.82, 0.33, and 0.90, respectively.
For Dataset 4 (Table 7), we observe that LSTM performs poorly alone compared to the CNN method, with values of 115.6, 8.5, and 10.7, respectively. The accuracy of the CNN method is closer to that of the neural network, with values of 16.3, 3.90, and 4.03, respectively. The CNN-LSTM optimized network with PSO performs better than the CNN-LSTM optimized with the sigmoid function, with values of 40.6, 37.7, and 39.2, respectively. The performance of the CNN-Bi-LSTM model improves significantly due to the presence of bidirectional layers with convolutional layers to process the data, with results of 3.06, 3.52, and 1.74, respectively. The performance of the same model after PSO is improved by 0.02%, with values of 2.98, 3.45, and 1.72, respectively.
Figure 7 represents the overall performance of the baseline approaches in comparison to the proposed approach for Wheat_data (Dataset 1), Agro_data (dataset 2), Crop and livestock_FAO (Dataset 3), and Soybean_data (Dataset 4). The demonstrations show that the proposed model produces higher results than the benchmark models for the considered datasets. Hence, the hyperparameter tuning of the proposed model using particle swarm optimization increases the model accuracy, and its significance is observed in the analysis of all datasets.

Performance evaluation in terms of the a MSE, b MAE, and c RMSE
Figure 7a–c shows the performance of the baseline models in terms of the mean squared error, mean absolute error, and root mean squared error, and the lowest values are obtained using PSO-CNN-Bi-LSTM in comparison to all other techniques. This signifies the performance of the proposed model outcomes. Hence, hyperparameter tuning using a PSO-based hybrid deep learning model can lead to significant results compared to those of other existing methods.
4.3.2 Validation of the Model
The results were validated using the predicted values to the actual values of the original dataset with threefold cross-validation, represented graphically in Fig. 8. The computed results were evaluated based on the yield attribute using 500–600 epochs and a validation split of 0.05 in terms of the predict_test and Y_test data values for the abovementioned datasets. The actual value versus predicted yield value (in tonnes/ha) for Dataset 1 was in the range of 3.77–3.67 tonnes/ha and 4.68–4.63 tonnes/ha for the wheat crop data.

Validation results of the proposed model (PSO-CNN-Bi-LSTM) with the observed values for a Dataset 1, b Dataset 2, c Dataset 3, and d Dataset 4
For the wheat crop yield values in Dataset 1, differences of 0.1–1.6 were observed between the actual and predicted values, as shown in Fig. 8a. In contrast, for Dataset 2, a validation result for the rice yield that fell within a narrow range of 2734.2 to 2790.4 was observed, as shown in Fig. 8b. The accuracy of the validation results observed in Dataset 4, represented in Fig. 8d, was higher compared to that of the other publicly available datasets (Dataset 2 and Dataset 3), shown in Fig. 8b, c, respectively, due to the availability of a larger training dataset.
4.3.3 Comparison with Existing Hybrid Models
In this section, we have discussed the comparative analysis of the proposed method with existing approaches for crop yield prediction in Table 8. The proposed PSO-CNN-Bi-LSTM method achieved higher prediction accuracy and reliability than those of existing approaches.
Based on the experimental analysis and comparative analysis with existing studies, we have observed that the proposed PSO-CNN-Bi-LSTM performs best on all baseline models in the analysis of the four datasets. We have analyzed the performance of our approach with the studies [6, 10, 12, 14,15,16,17,18, 21]. Figure 9 presents the comparative analysis of the proposed model with existing baseline and state-of-the-art hybrid studies in terms of the RMSE. The graph shows that the proposed method outperforms the other methods. Among all these studies, we have investigated our results with the soybean crop dataset and found significant improvement by training the network with optimized hyperparameters fed to the convolutional and bidirectional hybrid model. The optimization of the network is performed using PSO to improve the efficiency of the model with Dataset 4, and a mean square error value of 2.98 is obtained. In contrast, the mentioned study achieved an RMSE value of 4.15–4.91 [12, 25].

Comparative performance of existing state-of-the-art models and the proposed PSO-CNN-Bi-LSTM models
5 Contribution and Significance
The experimental outcomes of this study illustrated the applicability of the PSO-CNN-Bi-LSTM model for estimating and predicting crop yield based on spatial, temporal, meteorological, and remote sensing-derived nonstationary and nonlinear characteristics of wheat crops. We improved the effectiveness of this hybrid deep neural network by optimizing the hybrid deep learning layers with particle swarm optimization to overcome the need to manually select the optimal hyperparameters in the network. The PSO-CNN-Bi-LSTM model improved the training time of the network by incorporating only relevant dataset characteristics and overcoming the limitations of traditional approaches [10, 16, 19, 47,48,49]. The convolutional neural network, neural network, and CNN-Bi-LSTM performed poorly compared to the proposed method, with root mean squared errors of 2.6, 3.1, and 1.48, respectively. In contrast, the optimized CNN-LSTM network with PSO result was close to the proposed approach, with a value of 0.57 tonnes/ha. We evaluated the yield estimates with publicly available large datasets to ensure their applicability to improve the training time and enhance the results, with an RMSE value of 1.72 [12]. The results were evaluated from district- to state-level yield estimates for wheat crops. We also investigated the vegetation cover using remote sensing-derived MOD13A2-based vegetation indices during the wheat crop-growing season in major wheat-producing states in India and found that the NDVI peaked during mid-March to mid-April, with a values in the range of 0.4–0.6, whereas the average VCI value ranged from 40.8 to 58.6.
The correlation between the actual and predicted yields demonstrated that the proposed approach could estimate the yield in a wheat dataset with 3.77 tonnes/ha to 3.67 tonnes/ha. In contrast, the Dataset 4 results signified the lowest difference between the observed and predicted values due to large data availability. The proposed model overcomes the limitation of the overfitting issue in a hybrid deep neural network by including a nature-inspired optimization approach that fits the function appropriately in terms of the training data, thereby reducing the training time required by the network and overcoming the trial-and-error method implemented by the network to find the optimal set of hyperparameters.
The primary technical challenge of the proposed work includes the data-intensive nature of deep learning methods, as they cannot be utilized well for problems with data scarcity. The accuracy of the proposed model can be further enhanced by incorporating daily sensor-based captured characteristics of crops to provide more training samples to a comprehensive prediction model. In our study, we have investigated wheat crops. Therefore, to generalize the applicability of the proposed model, this study can be extended to diverse season time series data to evaluate the forecasting and growth of crops. In the future, advanced analytical tools can be considered to address the black-box nature of the hybrid deep model and build an inherently interpretable framework.
6 Conclusion
In this study, we performed yield prediction using an optimized hybrid deep learning model named PSO-CNN-Bi-LSTM and compared the proposed model with existing baseline models with three publicly available datasets. In the proposed approach, the advantages of convolutional and Bi-LSTM layers are utilized to capture the relevant features and to obtain the long-term dependencies bidirectionally for yield prediction. Subsequently, the proposed model was validated by comparing the predicted yield with the observed yield. Finally, the performance of the proposed model was evaluated using the MSE, MAE, and RMSE, and their results were found to be lower than those of the baseline models for all four datasets. The evaluation metric results of the PSO-CNN-Bi-LSTM model for Dataset 1, Dataset 2, Dataset 3, and Dataset 4 demonstrate the good performance of the model, with values of 0.18, 0.39, and 0.42; 0.58, 0.55, and 0.76; 0.82, 0.33, and 0.90; and 2.98, 3.45, and 1.72, respectively.
The results have shown that the proposed model performed better than the existing models for the training and testing data. Despite our model’s promising results, the proposed work has some limitations. The first limitation of Dataset 1 includes the total number of entries. The total number of entries can be improved in the near future by introducing more training data into the dataset by considering a more significant number of state data instead of only data from major wheat producer states. Introducing more training data can further enhance the efficiency of the model. The second limitation is the training time required by the proposed model for Dataset 3. To ameliorate the training time of the proposed model for Dataset 3, appropriate features for experiment can be selected from the dataset. In the future, a more robust approach can be proposed to overcome the limitations that can deliver better performance in terms of the evaluation metrics.
Availability of Data and Materials
The data sources used in this study are mentioned in the references, and the publicly available datasets analyzed in the study can be found here: [https://www.fao.org/faostat/en/#data, https://www.kaggle.com/datasets/harshpatel66/agro-data].
References
Lal, R. (2016). Feeding 11 billion on 0.5 billion hectare of area under cereal crops. Food and Energy Security, 5(4), 239–251. https://doi.org/10.1002/fes3.99 .
UN Resolution adopted by the General Assembly on 25 September 2015: Transforming our world: the 2030 agenda for sustainable development. Retrieved January 5, 2023, from https://documents-dds-ny.un.org/doc/UNDOC/GEN/N15/291/89/PDF/N1529189.pdf?OpenElement
Srivastava, A. K., Safaei, N., Khaki, S., Lopez, G., Zeng, W., Ewert, F., Gaiser, T., & Rahimi, J. (2022). Winter wheat yield prediction using convolutional neural networks from environmental and phenological data. Scientific Reports, 12, 3215. https://doi.org/10.1038/s41598-022-06249-w
Chlingaryan, A., Sukkarieh, S., & Whelan, B. (2018). Machine learning approaches for crop yield prediction and nitrogen status estimation in precision agriculture: A review. Computer and Electronics in Agriculture, 151, 61–69. https://doi.org/10.1016/j.compag.2018.05.012
Oikonomidis, A., Catal, C., & Kassahun, A. (2022). Hybrid deep learning-based models for crop yield prediction. Applied Artificial Intelligence, 36, 1. https://doi.org/10.1080/08839514.2022.2031823
Esfandiarpour, I., Karimi, E., Shirani, H., & Esmaeilizadeh, M. (2019). Yield prediction of apricot using a hybrid particle swarm optimization-imperialist competitive algorithm- support vector regression (PSO-ICA-SVR) method. Scientia Horticulturae, 257, 108756. https://doi.org/10.1016/j.scienta.2019.108756
Ahamed, A. T. M. S., Mahmood, N. T., Hossain, N., Kabir, M. T., Das, K., Rahman, F., & Rahman, R. M. (2015). Applying data mining techniques to predict annual yield of major crops and recommend planting different crops in different districts in Bangladesh. IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing, 1–6. https://doi.org/10.1109/SNPD.2015.7176185
Oikonomidis, A., Catal, C., & Kassahun, A. (2023) Deep learning for crop yield prediction: a systematic literature review. New Zealand Journal of Crop and Horticultural Science, 51(1), 1–26. https://doi.org/10.1080/01140671.2022.2032213
Sinha, J., Kant, S., & Saini, M. (2023). Modelling big data analysis approach with multi-agent system for crop-yield prediction. International Journal of Information and Decision Sciences (IJIDS), 15(1). https://doi.org/10.1504/IJIDS.2023.129657
Bali, N., & Singla, A. (2021). Deep learning based wheat crop yield prediction model in Punjab region of north India. Applied Artificial Intelligence, 35(15), 1304–1328. https://doi.org/10.1080/08839514.2021.1976091
Saini, P., & Nagpal, B. (2022). Efficient crop yield prediction of kharif crop using deep neural network. IEEE International Conference on Computational Intelligence and Sustainable Engineering Solutions (CISES), 376–380. https://doi.org/10.1109/CISES54857.2022.9844369
Khaki, S., Wang, L., & Archontoulis, S. V. (2020). A CNN-RNN framework for crop yield prediction. Frontiers in Plant Science, 11, 1750. https://doi.org/10.3389/fpls.2019.01750
Kosaraju, C., Nama, C., Deepthi, Y., Ramanjamma, C., & Chandrakala, P. (2023). Mirchi crop yield prediction based on soil and environmental characteristics using modified RNN. IEEE International Students' Conference on Electrical, Electronics and Computer Science (SCEECS), 1–5. https://doi.org/10.1109/SCEECS57921.2023.10063004
Zhu, Y., Wu, S., Qin, M., Fu, Z., Gao, Y., Wang, Y., & Du, Z. (2022). A deep learning crop model for adaptive yield estimation in large areas. International Journal of Applied Earth Observation and Geoinformation, 110(102828), 1569–8432. https://doi.org/10.1016/j.jag.2022.102828
Maldaner, L. F., Corrêdo, L. D. P., Canata, T. F., & Molin, J. P. (2021). Predicting the sugarcane yield in real-time by harvester engine parameters and machine learning approaches. Computers and Electronics in Agriculture, 181, 0168–1699. https://doi.org/10.1016/j.compag.2020.105945
Kuradusenge, M., Hitimana, E., Hanyurwimfura, D., Rukundo, P., Mtonga, K., Mukasine, A., Uwitonze, C., Ngabonziza, J., & Uwamahoro, A. (2023). Crop yield prediction using machine learning models: Case of Irish potato and maize. Agriculture, 13(1), 225. https://doi.org/10.3390/agriculture13010225
Nosratabadi, S., Imre, F., Szell, K., Ardabili, S., Beszedes, B., & Mosav, A. (2020). Hybrid machine learning models for crop yield prediction. Neural and Evolutionary Computing. https://doi.org/10.48550/ar**v.2005.04155
Bhimavarapu, U., Battineni, G., & Chintalapudi, N. (2023). Improved optimization algorithm in LSTM to predict crop yield. Computers, 12, 10. https://doi.org/10.3390/computers12010010
Banik, A., Raju, G., Shukla, S., & Samiksha. (2021). Rice yield forecasting in West Bengal using hybrid model. Data Science and Security, 222–231. https://doi.org/10.1007/978-981-16-4486-3_24
Anbananthen, K. S. M., Subbiah, S., Chelliah, D., Sivakumar, P., Somasundaram, V., Velshankar, K. H., & Khan, M. K. A. A. (2021). An intelligent decision support system for crop yield prediction using hybrid machine learning algorithms. F1000Res, 11, 1143. https://doi.org/10.12688/f1000research.73009.1 .
Duarte de Souza, P. V., Pereira de Rezende, L., Pereira Duarte, A., & Miranda, G. V. (2023). Maize yield prediction using artificial neural networks based on a trial network dataset. Engineering, Technology & Applied Science Research, 13(2), 10338–10346. https://doi.org/10.48084/etasr.5664
Bazrafshan, O., Ehteram, M., Latif, S. D., Huang, Y. F., Teo, F. Y., Ahmed, A. N., & El-Shafie, A. (2022). Predicting crop yields using a new robust Bayesian averaging model based on multiple hybrid ANFIS and MLP models. Ain Shams Engineering Journal, 13, 2090–4479. https://doi.org/10.1016/j.asej.2022.101724
Gupta, S., Geetha, A., Sankaran, K. S., Sarwar Zamani, A., Ritonga, M., Raj, R., Ray, S., & Sobahi Mohammed, H. (2022). Machine learning- and feature selection-enabled framework for accurate crop yield prediction. Journal of Food Quality, 7, 6293985. https://doi.org/10.1155/2022/6293985
Crop production statistics. Retrieved January 5, 2023, from https://eands.dacnet.nic.in/
Yang, L., & Shami, A. (2020). On hyperparameter optimization of machine learning algorithms: Theory and practice. Neurocomputing, 415, 295–316. https://doi.org/10.1016/j.neucom.2020.07.061
Climate data. Retrieved January 10, 2023, from https://power.larc.nasa.gov
MODIS NDVI. Retrieved January 5, 2023, from https://developers.google.com/earth-engine/datasets/catalog/MODIS_MOD09GA_006_NDVI
Raymond, M. R. (1986). Missing data in evaluation research. Evaluation & the Health Professions, 9(4), 395–420. https://doi.org/10.1177/016327878600900401
Tsikriktsis, N. (2005). A review of techniques for treating missing data in OM survey research. Journal of Operations Management, 24(1), 53–62. https://doi.org/10.1016/j.jom.2005.03.001
Sabanci, K. (2023). Benchmarking of CNN models and MobileNet-BiLSTM approach to classification of tomato seed cultivars. Sustainability, 15(5), 4443. https://doi.org/10.3390/su15054443
Varghese, L. R., & Kandasamy, V. (2021). Convolution and recurrent hybrid neural network for hevea yield prediction. Journal of ICT Research and Applications, 15(2), 188–203. https://doi.org/10.5614/itbj.ict.res.appl.2021.15.2.6
Lecun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. IEEE, 11, 2278–2324. https://doi.org/10.1109/5.726791
Kim, B. S., & Kim, T. G. (2019). Cooperation of simulation and data model for performance analysis of complex systems. International Journal of Simulation Modelling, 18, 608–619.
de Castro, C., Filho, H., de Carvalho, A., Júnior, O., Ferreira de Carvalho, O. L., Pozzobon de Bem, P., & dos Santos de Moura, R., Olino de Albuquerque, A., Rosa Silva, C., Guimarães Ferreira, P.H., Fontes Guimarães, R., Trancoso Gomes, R.A. (2020). Rice crop detection using LSTM, Bi-LSTM, and machine learning models from Sentinel-1 time series. Remote Sensing, 12(16), 2655. https://doi.org/10.3390/rs12162655
Cordeiro, M., Markert, C., Araújo, S. S., Campos, N. G. S., Gondim, R. S., Coelho da Silva, T. L., & da Rocha, A. R. (2022). Towards smart farming: Fog-enabled intelligent irrigation system using deep neural networks. Future Generation Computer Systems, 129(115–124), 0167-739X. https://doi.org/10.1016/j.future.2021.11.013
Suebsombut, P., Sekhari, A., Sureephong, P., Belhi, A., & Bouras, A. (2021). Field data forecasting using LSTM and Bi-LSTM approaches. Applied Sciences, 11(24), 11820. https://doi.org/10.3390/app112411820
Olofintuyi, S. S., Olajubu, E. A., & Olanike, D. (2023). An ensemble deep learning approach for predicting cocoa yield. Heliyon, 9(4), e15245,2405–8440. https://doi.org/10.1016/j.heliyon.2023.e15245
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural. Computing, 9, 1735–1780.
Schuster, M., & Paliwal, K. K. (1997). Bidirectional recurrent neural networks. IEEE Transactions on Signal Processing, 45, 2673–2681.
Rhanoui, M., Mikram, M., Yousfi, S., & Barzali, S. (2019). A CNN-BiLSTM model for document-level sentiment analysis. Machine Learning and Knowledge Extraction, 1(3), 832–847. https://doi.org/10.3390/make1030048
Gers, F. (2001). Long short-term memory in recurrent neural networks. Ph.D. Thesis, Leibniz Universitat Hannover, Hannover, Germany.
Jang, J., Sun, C., & Mizutani, E. (1997). Neuro-fuzzy and soft computing: A computational approach to learning and machine intelligence. Prentice-Hall.
Kennedy, J., & Eberhart, R. C. (1995). Particle swarm optimization. IEEE International Conference on Neural Networks IV, 1942–1948.
Almeida, B. S. G. D., & Liete, V. C. (2019). Swarm intelligence - recent advances, new perspectives and applications. IntechOpen. https://doi.org/10.5772/intechopen.89633
Agro_data. Kaggle. Retrieved January 20, 2023, from https://www.kaggle.com/datasets/harshpatel66/agro-data
Crops and livestock products. FAOSTAT. Retrieved January 20, 2023 https://www.fao.org/faostat/en/#data
Divya, B., & Dash, A. (2022). Using ARIMA Model to forecast the area, yield and production of arhar in Odisha. Biological Forum – An International Journal, 14(3), 1179–1185.
Mishra, P., Yonar, A., Yonar, H., Kumari, B., Abotaleb, M., Das, S. S., & Patil, S. G. (2021). State of the art in total pulse production in major states of India using ARIMA techniques. Current Research in Food Science, 4, 800–806. https://doi.org/10.1016/j.crfs.2021.10.009
Suresh, K. K., & Krishna Priya, S. R. (2011). Forecasting sugarcane yield of Tamilnadu using ARIMA models. Sugar Tech, 13, 23–26 .https://doi.org/10.1007/s12355-011-0071-7 .
Acknowledgements
The authors are grateful to the Directorate of Economics and Statistics, Department of Agriculture, Cooperation, and Farmers Welfare, for making data available.
Author information
Authors and Affiliations
Contributions
Preeti Saini: conceptualization, data curation, formal analysis, investigation, methodology, resources, software, writing—original draft, and writing—review and editing. Bharti Nagpal: supervision, project administration, validation, and visualization.
Corresponding author
Ethics declarations
Ethical Approval
Not applicable.
Competing Interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Saini, P., Nagpal, B. PSO-CNN-Bi-LSTM: A Hybrid Optimization-Enabled Deep Learning Model for Smart Farming. Environ Model Assess 29, 517–534 (2024). https://doi.org/10.1007/s10666-023-09920-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10666-023-09920-2