
Abstract
Sentiment Analysis is a method to identify, extract, and quantify people’s feelings, opinions, or attitudes. The wealth of online data motivates organizations to keep tabs on customers’ opinions and feelings by turning to sentiment analysis tasks. Along with the sentiment analysis, the emotion analysis of written reviews is also essential to improve customer satisfaction with restaurant service. Due to the availability of massive online data, various computerized methods are proposed in the literature to decipher text sentiments. The majority of current methods rely on machine learning, which necessitates the pre-training of large datasets and incurs substantial space and time complexity. To address this issue, we propose a novel unsupervised sentiment classification model. This study presents an unsupervised mathematical optimization framework to perform sentiment and emotion analysis of reviews. The proposed model performs two tasks. First, it identifies a review’s positive and negative sentiment polarities, and second, it determines customer satisfaction as either satisfactory or unsatisfactory based on a review. The framework consists of two stages. In the first stage, each review’s context, rating, and emotion scores are combined to generate performance scores. In the second stage, we apply a non-cooperative game on performance scores and achieve Nash Equilibrium. The output from this step is the deduced sentiment of the review and the customer’s satisfaction feedback. The experiments were performed on two restaurant review datasets and achieved state-of-the-art results. We validated and established the significance of the results through statistical analysis. The proposed model is domain and language-independent. The proposed model ensures rational and consistent results.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Sentiment analysis is a subfield of Natural Language Processing (NLP) that focuses on the automated analysis of human sentiments [1]. It is possible to examine and categorize a person’s emotions using sentiment analysis. We can learn about people’s feelings by analyzing their comments, criticism, and reviews. These feelings or opinions can be classified as positive, negative, or neutral. In recent years, there has been a significant increase in sentiment analysis and opinion mining research, making this a highly researched area [2]. Analyzing sentiments can prove helpful in social media monitoring, brand tracking, help desk software, and feedback analysis. Today’s businesses use data analysis to enhance the performance and quality of their products and, as a result, to compete in a crowded market. Sentiment Analysis is a method to get insight into a customer’s positive or negative reaction to a product, service, or support interaction. Automatically analyzing customer sentiments from social media, reviews, and surveys can help companies refine their offerings and make smarter business decisions. Similarly, sociologists, psychologists, and politicians use sentiment analysis to learn more about societal movements, attitudes, and ideological biases, as well as to predict public opinion and evaluate public support. Thus, sentiment analysis is an indispensable step toward data analysis.
1.1 Need for sentiment analysis
The vast volume of content published daily on several social networking sites necessitates automated solutions for managing and identifying opinions. Manually analyzing the sentiments can be highly tedious and sometimes impossible due to the sheer volume of data [3]. As a result, various sentiment analysis algorithms and techniques have been developed. Sentiment analysis is a powerful marketing technique since it helps businesses learn more about their customers’ feelings about their products and services. Brand recognition, consumer satisfaction, the effectiveness of marketing, and general product acceptance are all positively impacted by it. Improving product and brand recognition can also be accomplished by studying consumer psychology. However, good customer service can also convince customers to purchase products from a company, even if they are experiencing product downtime or other issues. Knowing that sentiments drive customer decision-making and that emotions help product managers to improve their customer service strategies. Numerous opinion mining researches examined unstructured text data, including customer reviews, blogs, tweets, news, and online reviews [4].
Nevertheless, there are still issues to be resolved. There has been comparatively limited study of the emotional resonance of customers’ written comments. Emotion detection can pick up moods like happiness, regret, anger, and sadness. Understanding a consumer’s feelings about a situation is essential to provide commendable service.
Therefore, examining the reviews’ emotions is equally crucial as analyzing their sentiment orientations. In the proposed work, we comprehend the textual feedback and tag sentiments as positive or negative. We also gauge emotions behind a review and classify whether the customers are satisfied with the service of the restaurant or not. Interested customers can use this decision assistance system to analyze online product comments and choose the most practical and reliable alternative. Companies can use the proposed system to analyze consumer satisfaction with their products and services and modify their manufacturing processes, operational activities, or marketing plans accordingly. Therefore, there is an urgency to perform sentiment analysis.
1.2 Leveraging e-commerce statistics to gauge public sentiment
During the Covid-19 pandemic, online purchasing grew dramatically with increased internet usage [5]. As per a recent survey,Footnote 114% of consumers altered their buying habits by increasing their online spending. Also, 56% of consumers boosted their online expenditures (Fig. 1). Figure 2Footnote 2 shows the different categories of products in which online shop** was enhanced. Extensive shop** was done in the domain of clothing, food & drinks.

Trend in online shop** by consumers during the Coronavirus epidemic

Product type that consumers bought online during an outbreak
As online shop** increased in the past decade, the same trend also followed in online food ordering. Figure 3 illustrates the upward trend in restaurant delivery and online takeaways over the last seven years. Another factor for this exponential increment is that the online system made customers’ lives easier. It is observed that around 82% of food delivery orders were placed from home, and 16% of orders were placed from the workplace. In the proposed work, we analyze the restaurant reviews and categorize them as either positive or negative sentiments. Most online shoppers examine product reviews before making a purchase decision. The most common questions shoppers seek are which products are popular, which features are high quality, etc. So, customer satisfaction is essential for a company to boost its sale. Customer satisfaction is a consumer’s view or sentiment about the gap between expectations and reality. Many customers express their opinion in online reviews such as TripAdvisor, Yelp, etc. Only a few restaurants use customer satisfaction analysis. Product, nutrition, and food preparation information are typically used to gauge restaurant customer satisfaction [6, 7]. Customer satisfaction surveys in restaurants are still comparatively less. In the proposed work, we classify the service of a restaurant as satisfactory or unsatisfactory based on reviews.

Online takeaway and restaurant delivery trends in the last 7 years
This paper proposes a game theory and MCDM-based optimization approach to maximize the accuracy and efficiency of sentiment analysis of subjective context. We created a novel decision-making system that labels each review with a sentiment polarity based on written reviews and classifies customer satisfaction. To the best of our knowledge, this is the first attempt to employ an optimization approach to tackle research in sentiment analysis.
1.3 Research problem
This study intends to create a framework that accomplishes two tasks. First, to improve the accuracy of assessing sentiment orientation of feedback. Second, perform an emotional analysis of a review to examine customer satisfaction with the restaurant’s services. To work on the mentioned research problem, we laid down the following objectives:
-
1)
To propose an unsupervised sentiment analysis system that makes it easier for customers to make purchasing decisions in critical situations without prior training.
-
2)
To enhance the accuracy of the sentiment tagging algorithm for sentiment identification.
-
3)
To propose a model that is language and domain independent.
-
4)
To propose an efficient system in terms of space and time complexity.
1.4 Contributions
The contributions and novelties of the study are given below:
-
1)
To the best of our knowledge, this is the first study to perform sentiment classification of restaurant reviews by combining MCDM and game theory. This research assesses the suitability of coupled MCDM and game models for NLP applications like sentiment analysis of English text.
-
2)
We propose a sentiment tagger that assigns an appropriate sentiment tag to each review. We also emotionally tag customer satisfaction for a review by analyzing textual feedback. We use star ratings and reviews’ textual feedback to classify sentiment into two classes on English review datasets.
-
3)
The proposed model employs optimization techniques for sentiment analysis of English text to maximize accuracy while minimizing time and space complexity. Since the proposed model is unsupervised, it is domain and language-independent and can be applied to any low-resource language dataset with minimal adjustments.
-
4)
We also examined and established the statistical significance of the proposed framework. Statistical performance indicators are studied and applied to the proposed model to determine its effectiveness and provide state-of-the-art performance.
1.5 Organization
The structure of a paper can be summarised as follows: We go over the fundamentals of sentiment analysis, MCDM, and game theory in Section 1. Section 2 summarises previous research in sentiment analysis and game theory. Section 3 discusses the preliminaries related to the proposed algorithm. Section 4 contains the proposed algorithm for sentiment analysis. We evaluate the proposed model against competing methods on two restaurant review datasets in Section 5. We also validated results using statistical significance. In Section 6, we discuss the advantages and disadvantages of the proposed algorithm. In Section 7, we summarise key findings and recommend future directions.
2 Literature review
This section discusses prior sentiment analysis work in chronological order. García-Pablos et al. [8] created unsupervised W2VLDA, which is based on topic modeling and can classify the polarity of people’s opinions. Donadi [9] introduced tensor-based sentiment analysis for the German language. Vashishtha & Susan [10] introduced a fuzzy-based approach for sentiment analysis that incorporates Natural Language Processing (NLP) and Word Sense Disambiguation (WSD). For aspect-level sentiment analysis, Song et al. [11] developed an attention-based extended short-term memory network that incorporates sentiment lexicon embeddings into its architecture. Attention-based Point Network (AttPNet) is a revolutionary sentiment analysis model suggested by Yang et al. [12].
Rani and Lobiyal [13] found sentiment polarity and advised statistical and knowledge-based ways to develop Hindi stop word lists. An attention-based approach was created by Pandesenda et al. [14] to address the issue of using NLP for online reviews. Recurrent Memory Neural Network (ReMemNN) was implemented by Liu et al. in 2020 [15] and evaluated on various datasets, including three English and four Chinese datasets from various sources. Basiri et al. [16] suggested a bidirectional neural network design to address the drawbacks of LSTMs and gated recurrent units (GRUs) for sentiment analysis. A knowledge-enabled BERT model for aspect-based sentiment analysis was created by [17]. The Game theory-based opinion leader detection (GOLD) approach for coalitions of opinion leaders was proposed by L. Jain et al. [18]. Regression analysis and sentiment analysis, specifically Term Frequency-Inverse Document Frequency (TF-IDF), were utilized by Mee et al. [19] for sentiment analysis. An integrated framework that integrates sentiment analysis and multi-criteria decision-making methods was employed by Heidary Dahooie [20]. The performance of attention-based models based on RNNs in various sentiment analysis situations was examined by Perikos et al. [21]. Ileri and Turan [22] used a neural network for sentiment analysis, and the model’s accuracy was roughly 85%. To capture the critical features of the dataset in the word embedding layer of sentiment classification deep learning algorithms, Duy Ngoc a Nguyen et al. [23] advocated embedding information in the ontology.
To forecast sentiment analysis using deep learning, De Oliveira Carosia et al. [24] applied investment methods to the Brazilian stock To forecast sentiment analysis using deep learning. For Twitter accounts, unsupervised sentiment analysis techniques were developed [25]. Aspect-based sentiment analysis was performed using Latent Dirichlet Allocation (LDA) techniques [26]. Zhang et al. [27] proposes a modal that analyses sentences syntactically and semantically on SemEval 2014 dataset. Jain et al. [3] presents machine learning techniques for consumer sentiment analysis on tourism datasets. A convolutional graph network based on SenticNet that took advantage of the emotional dependencies of the sentence depending on the particular aspect was developed by Liang et al. in 2022 [28].
Peng et al. [29] introduced BERT Post Training (BERT-PT) to fine-tune the CGBN model for sentiment analysis based on aspects. Zhang et al. [30] proposed ICDN multimodal for sentiment analysis. Gu et al. [31] proposed the IA-HiNET network for sentence-level sentiment analysis. Chiha et al. [32] presented framework for aspect and sentence level sentiment classification using techniques involving deep learning and fuzzy logic. Swathi et al. [33] presented TLBO and LSTM models for stock price prediction using the Twitter dataset. Wu et al. [1] proposed the DVA-BERT model for sentiment analysis which outperforms the BERT model. Wu et al. [34] proposed a framework for hotel selection based on the OVO-SVM algorithm and Word2Vec. Li et al. [35] conducted sentiment analysis on MOOCs platforms.
This paper introduces an innovative implementation of an unsupervised method based on optimization techniques. The integrated MCDM and non-cooperative game model are used to evaluate text sentiment.
2.1 Research gap
Previous researches demonstrate supervised, semi-supervised and unsupervised approaches for sentiment analysis. However, they have their limitations, as given below:
Machine learning (ML) techniques offer superior classification precision and accuracy. However, they also have significant limitations, such as they are time-consuming, domain-dependent, and requiring human intervention and information labeling. ML approaches like SVM and ANN are also used for sentiment classification. SVM performs poorly when there are more characteristics than samples and fails to work when there is no probabilistic reason for the classification. On the contrary, ANN requires a lot of training time and a massive dataset. Deep learning algorithms for sentiment analysis, including DNN, CNN, and RNN, are more straightforward than other models. However, they take longer to train because of their sophisticated design, high computational cost, and overfitting issues [16, 36–39].
Semi-supervised methods like generative, co-training, and graph-based methods are also used for sentiment analysis. However, classification problems do not work well with generative approaches. Co-training methods are unsuitable for datasets with only one feature sensitive to noise. Graph-based approaches depend on the structure and weights of edges and do not work well if the graph does not fit the task. Hybrid methods require less time but lack reliability and precision [36, 37, 40, 41].
Unsupervised approaches for sentiment analysis include hierarchical and partition methods. Due to the high computation cost, hierarchical algorithms are not ideal for massive datasets [74,75,76,77,78,79]. Partition methods are relatively scalable and straightforward but have poor accuracy and stability and are sensitive to noisy data. The lexicon-based approaches do not need information labeling but depend upon the domain, need powerful linguistic resources, and have low precision [36, 37]. Various studies used MCDM and game theoretic models to propose recommender systems [42, 80]. But till now, none of the studies employ the application of a mathematical optimization model to perform sentiment analysis of reviews.
2.2 How the proposed model is different from others?
In the proposed work, we designed an unsupervised mathematical framework to identify the sentiment of a review. We also compute the emotion score of a review and examine customer satisfaction feedback. In the proposed work, we comprehend the implicit information from textual feedback of reviews and convert them into numerical values called context scores. We use ratings, context scores, and emotional scores of written feedbacks for further processing. MCDM proved beneficial in combining context, rating, and emotions scores to calculate performance scores of reviews. Games are played on performance scores of reviews to assign the sentiment tag to a given review. The proposed model produced state-of-the-art results. Unlike supervised methods, the proposed model abstains from training massive datasets and thus is faster and domain independent. In the proposed model, we convert textual comments to context scores, thus eliminating the dependency on the language of the reviews. The model can perform sentiment analysis of reviews in any language with minimal alterations. Preliminaries of MCDM and Game Theory are discussed in Section 3. The proposed work is discussed in detail in Section 4.
3 Preliminaries
3.1 Game theory
Von Neumann and Morgenstern (2007) introduced game theory to build a mathematical framework capable of simulating decision-making fundamentals in interactive scenarios [43, 44]. Game theory is described as a set of situations in which each player must consider the actions of other players to make sensible judgments [45]. All players are assumed to be rational. The action is determined by other players’ actions [43]. In interactive decision situations, game theory provides predictive power. We create and evaluate complicated interactions involving decision-makers,Footnote 3 such as financial market investors, supply-chain businesses, and governments with competing interests [43, 46].
τ = < N, (S), (u)>, A game is represented as Γ = 〈N, (Si), (ui)〉, where N = Number of players, (Si) = Set of strategies, and (ui) = Payoffs. A game has the following components:
-
Players: Participants in a game who aim to maximize their payoffs.
-
Strategy profile: A set of players’ actions is known as a strategy profile. The game’s strategy profiles of players are displayed simultaneously by \({m}^{\ast }=\left\{{m}_1^{\ast },{m}_2^{\ast },..\dots \dots \dots \dots \dots, {m}_i^{*}\right\}\)the action sets for ith player’s plays in the game. The strategy profile of opponent players is \({m}_{-i}^{\ast }=\left\{{\mathrm{m}}_1^{\ast },{m}_2^{\ast },\dots \dots {m}_{i-1}^{*}\dots \dots {\mathrm{m}}_i^{*}\right\}\).
-
Payoff: The payoff of player receives after arriving at a particular outcome. The payoff can be in any quantifiable form.
-
Outcome: The participants determine an ideal approach for each action.
-
Best Response: The best response function (br) of each player is the best reaction he can make to a specific action: \({br}_i\left({\mathrm{m}}_{-i}\right)=\left\{{\mathrm{m}}_i\in {A}_i:{u}_i\left({\mathrm{m}}_i,{\mathrm{m}}_{-i}\right)\ge {u}_i\left({\mathrm{m}}_i^k,{\mathrm{m}}_{-i}\right);\forall {m}_i^k\in {A}_i\right\}\)
-
Nash Equilibrium: The Nash equilibrium is a decision-making principle that states players can achieve the desired outcome by not deviating from their initial strategy. It is one of the game’s best responses. i.e., if m∗ is a Nash equilibrium⇒mi∗ ∈ bri(m−i∗).
Alternatively, Nash equilibrium⇒Intersection of the best responses of players. Along with the above components, some strategies are essential to solve any game under game theory.
Strongly dominated strategy
A dominant strategy is a strategy that consistently generates the best outcome for a player regardless of what other players are doing. Every strongly dominant strategy implies Nash equilibrium and thus the best response. In a two-player game, (A, B) ∈ Rm × n a strategy s∗strongly dominates s if for all strategies of the other player t given by Eq. (1).
Weakly dominant strategy
In a two-player game, (A, B) ∈ Rm × n a strategy s is weakly dominated by s∗if for all strategies of the other player t given by Eq. (2).
3.2 Non-cooperative game
A non-cooperative game is a method for modelling and evaluating scenarios in which each player’s best choices rely on their beliefs or expectations about their opponents’ behaviour.
Non-cooperative games are generally analyzed through the game theory model, which tries to predict players’ strategies and payoffs and find Nash equilibria. Non-cooperative models assume that players do not have a cooperation mechanism (to make binding commitments) outside the specified rule of the game. A sample of non-cooperative game theory is presented below.
Example: Prisoner’s dilemma problem
Two suspects are apprehended for a crime in separate rooms in a police station, with no means of communicating. The prosecutor has separately told that they have two options either to confess (C) or not to confess (NC). A matrix represents the game. A row represents strategies for the first player. The column represents the strategies of the second player. Each matrix entry contains a tuple of values (x,y) where x is the payoff of the first player and y is the payoff of the second player.
Let N be the no. of players, with each player having a set of strategies. In the given example,
N = 2{Two Players: Player 1, Player 2}. Each player has 2 strategies confess or not confess S1 = S2 = {C, NC}. Each cell represents the payoffs of players for choosing a specific strategy. For example, if both players choose NC, NC, their respective payoffs are (−2, −2). The complete payoff matrix is shown in Table 1.
Strategy C is a strongly dominating strategy for player one because the payoff values (ui) of the C strategy are more significant than the NC strategy given by Eq. (3).
Similarly, for player 2, strategy C strongly dominates strategy since the payoff values of the C strategy are more significant than the NC strategy given by Eq. (4).
Thus, C is the strongly dominant strategy for both player 1 and player 2. Thus (C, C) is a strongly dominant strategy, Nash Equilibrium, and the players’ best response in this prisoner’s dilemma problem. The game theory encompasses a wide range of models. In this work, we used the Bayesian game theory model to analyze the sentiments of reviews.
3.3 MCDM
MCDM is a process that combines the performance of various alternatives based on a variety of qualitative and quantitative criteria to arrive at a solution that can be agreed upon by all alternatives involved [47]. There are two types of criteria in an MCDM problem. The benefit criteria are those that should be maximized. Cost criteria, on the other hand, are those that must be reduced to the minimum level. A typical MCDM problem with m alternatives (A1, A2,……… Am) and n criteria (C1, C2,..., Cn) can be presented in the following form.
There are four components to Eq. (5). M stands for the decision matrix, mij stands for the ith alternative’s performance concerning the jth criterion, and W stands for the weight vector, wj denotes the weight of the jth criterion. Typically, the original decision matrix M is incomparable because multiple units of measure are used to convey various criteria. Since the 1960s, numerous MCDM techniques and approaches have been created, suggested, and effectively applied in various areas [48, 49]. MCDM’s objective is to help decision-makers choose an alternative that satisfies their needs and is consistent with their preferences, not just to recommend the best alternative. A thorough understanding of MCDM approaches and the participants’ views is essential for efficient and successful decision-making in the early phases of the process. [50].
3.4 MCDM as a game of strategy
An MCDM problem with m alternatives and n criteria is typically defined in cardinal form, [51] shown by Eq. (6) represents performance-based MCDM.
where πij is the performance of the ith alternative under the jth criterion for i = 1,2...m and j = 1, 2,...n.
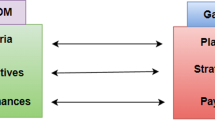
Madani et al. [52] established the relationship between MCDM and Game theory. Various studies used this combination to solve different problems in different fields [42, 53–56]. The essential components of MCDM, viz. criteria, alternatives, and alternative performance for each criterion, have a one-to-one correspondence with the basic components of the game, viz. player, strategies, and payoff, respectively. The correspondence is due to the similar nature shown by these parameters. Criteria in MCDM and players in a game are the initiators that follow specific alternatives and strategies, respectively; similarly, the performance score of each alternative under certain criteria corresponds to the payoff of the player having specific strategies. Figure 4 shows the relationship between MCDM and game theory.

MCDM-Game Relationship
4 Proposed work
A review has two components - written comment (qualitative) and rating (quantitive). We calculate the context score and emotion score from the written review comment. Context scores are numerical values of a review of positive and negative sentiment. We calculate the scores for the five emotions of a given review: happy, sad, surprise, angry, and fear. We use SentiWordnet to calculate context and emotion scores using python-based libraries. The combination of context, emotion, and rating enhances the performance of the proposed model. The proposed algorithm’s implementation flow chart is illustrated in Fig. 5. The notations used in this study are listed in Table 2.

Flowchart of the implementation of the proposed model
Step 1: Determine context scores of a review comment using SentiWordNet
In this step, we determine the context scores of textual comments using SentiWordNet. SentiWordNet contains a list of words with respective positive and negative polarities values. We take POS-tagged content words of a review comment. For each word, we extract the respective positive and negative polarity values from SentiWordNet to calculate the context scores of the comments. Thus, the context score values are between 0 and 1. Context has two polarities, positive and negative, named Positive context (CP) and Negative context (CN); values of CP and CN are evaluated using SentiWordNet. Figure 6 shows an excerpt of SentiWordNet. We follow Algorithm 1 to generate a context score.

Calculate context scores of reviews

SentiWordNet’s lexicon fragment
Step 2: Evaluate rating scores
The rating of a review is between 1 and 5. We calculate two rating scores, named Positive rating (RP) and Negative rating (RN). RP is equal to the rating given with a review, and RN is (5 - RP). RP ranges between 1 and 5, and RN is between 0 and 4.
Step 3: Determine the service feedback of the review comment
The restaurant’s service feedback can be either satisfactory (S) or unsatisfactory (U). We evaluate service feedback from the emotions in the review comments. We evaluate emotion scores using the text2emotionFootnote 4 library. Emotions are classified as Happy, angry, surprise, sad, or fear. Satisfactory service feedback includes happy and surprising emotions, and unsatisfactory service feedback includes anger, surprise, sadness, and fear. After step 3, we have six scores, viz. positive context (CP), negative context (CN), positive rating (RP), negative rating (RN), Satisfactory feedback (S), and unsatisfactory feedback (U). The values of these six scores have different ranges. In the next step, we pass these scores to the TOPSIS model and receive performance scores.
Step 4: Calculate the performance score of each parameter of service feedback and polarity scores by applying TOPSIS
Each review has two strategies - polarity and service feedback. Polarity can be positive (P) or negative (N) and is calculated as P = RP + CP and N = RN + CN. Similarly, service feedback can be satisfactory or unsatisfactory, calculated as S=H + SP, U=Sp + F + A + S. The possible combinations of strategies between polarity and service feedback are PS, PU, NS, and NU. Thus, each review has four possible strategies mentioned in Table 3.
Table 4 represents the numeric values corresponding to four strategies, PS, PU, NS, and NU, for review Ri. Here αi and βi represent numeric values for the positive and negative polarities of Ri, respectively. Similarly, γi and δi depict the numeric values of satisfactory and unsatisfactory service feedback of Ri, respectively. The matrix formed from the various combinations of all these values (αi, βi, γi, δi) is shown in Table 4.
Next, we apply the TOPSIS algorithm to evaluate the performance scores (λ1, λ2, λ3, λ4) of all the strategies of a review. Table 5 shows the performance scores for all the strategies of review Ri. Algorithm 2 depicts the TOPSIS method to calculate the performance scores.

Calculate the Performance Score (Pi)
Step 5: Play non-cooperative games among the reviews
In this final step, we take two players (say, Ri and Rj) and the four strategies (PS, PU, NS, NU) corresponding to each review. Then, we play a non-cooperative game between them. The performance scores calculated in the previous step are treated as payoff values for the players. The performance scores of players Ri and Rj are depicted in Table 6.
Table 7 represents a matrix of non-cooperative game. It shows the payoff values of the two players. A row represents the payoff for the first player for a given strategy. The column represents the payoff of the second player for a specific strategy. The dominant strategies of both players are derived using Eq. (1) and Eq. (2). The intersection of the dominant strategies of both players is known as Nash Equilibrium. We evaluate the Nash equilibrium and deduce a sentiment tag for a review. Algorithm 3 shows the methodology used to deduce sentiment tags for reviews by playing games amongst them.

Deduce sentiment tag for review.
4.1 Illustrative example: Let us consider two reviews R 1 and R 2
R 1 (4 Star): “Came here for lunch, and the food was good and tasty. We tried buffet and all the items in veg and non-veg were tasty.” R 2 (2 Star): “Food quality and taste is not good. Super slow service. Nice ambience but very poor in customer handling. Lot of items not available even if in the menu.” |
First, we calculate the context scores of the written review comment using Algorithm 1. Next, we calculate emotion scores for happy, sad, surprise, fear, and anger to evaluate service feedback. Using these emotion scores, we classify reviews under two service feedback categories - satisfactory (S) and unsatisfactory (U). Table 8 shows the numeric scores pertaining to the six parameters - CP, CN, RP, RN, S, and U, and the four strategies for reviews R1 and R2.
Next, we apply the TOPSIS model as given in Algorithm 2. We get the single score for each strategy of the two players, known as the performance scores. The calculated performance scores for R1 and R2 are given in Table 9.
Now, we play a non-cooperative game between players R1 and R2 with four strategies. Figure 7 shows the extensive form representation of the game played between R1 and R2.

Extensive Form Representation of game played between R1 and R2
In Table 10 for player R1, the first-row payoff values dominate the payoffs in other rows. The strategy corresponding to this first row of R1 is PS. Similarly, for R2, the payoff corresponding to the third column dominates other columns, and the strategy of that column is NU. The intersection of the PS strategy of R1 and the NU strategy of R2 gives the Nash equilibrium. Thus, the deduced strategies for R1 and R2 are PS, and NU, respectively. PS tag for R1 helps us to infer that the review has positive polarity (P) and satisfactory service feedback (S). The NU tag shows that R2 has negative polarity (N) and unsatisfactory service feedback (U). Figure 8 shows the Nash equilibrium of R1 and R2 and the interpretation of the tags.

Nash Equilibrium of R1 and R2
5 Experiments and results
In this section, we first introduce the datasets used for experimentation. In subsection 5.2, we give brief definitions of the evaluation metrics used to compare the performance of the proposed model. We compare the proposed model’s efficiency with other approaches on the TripAdvisor dataset and Yelp dataset in subsection 5.2 and subsection 5.4, respectively. We generalize the performance values using macro and micro metrics in subsection 5.5. In subsection 5.6, we validate the performance of the proposed model using statistical validation methods.
5.1 Data collection
We collected two restaurant review datasets – one from TripAdvisorFootnote 5 and the other from YelpFootnote 6 [57]. Each dataset contains reviews and their respective ratings. The data statistics of both datasets are listed in Table 11. Figure 9 shows a snapshot of Yelp’s rating and comments on McDonald’s restaurants.

McDonald’s Restaurant rating and review snapshot from Yelp
5.2 Performance evaluation using evaluation metrics
The robustness of the proposed framework was gauged using various evaluation metrics. These include F1-measure, accuracy, precision, MCC, etc. It is crucial to analyze a model using a variety of measures because a model may perform well with one evaluation metric but poorly with another. Figure 10 depicts the performance of the proposed model on the two datasets in terms of various evaluation metrics. The metrics are defined below from Eq. (7) to Eq. (15).

Performance of evaluation metrics over the two datasets
Accuracy is the proportion of correctly identified samples to the total number of samples. The accuracy of the proposed model for TripAdvisor dataset is 0.90, and for the Yelp dataset is 0.89. Precision reveals how many of the accurately predicted instances turned out to be positive. The precision values over TripAdvisor and Yelp datasets are 0.895 and 0.97, respectively. Recall measures how many actual positive cases our model could predict accurately. We received a recall value of 0.97 for both datasets. The Harmonic Mean of recall and precision is the F1 Score. F1 Score has a range of [0, 1]. TripAdvisor’s and Yelp’s F1 scores are 0.935 and 0.932, respectively. MCC is used to evaluate models and is a chi-square statistic for a 2 × 2 contingency table compared to the difference between actual and predicted values [58]. It ranges in the interval [−1, +1], with extreme values −1 and + 1 representing perfect misclassification and classification, respectively. The MCC for the proposed model for the TripAdvisor dataset is 0.74 and 0.687 for Yelp. The values are close to 1 and are thus close to the perfect classification.
5.3 Evaluations on TripAdvisor dataset
We compared the proposed model’s performance with the existing models on the TripAdvisor dataset. We used the supervised models for comparison: PLSA [59], FK-NN [60], Decision Tree-J48, and deep learning-based models. Khotimah et al. [59] proposed a Probabilistic Latent Semantic Analysis (PLSA) model that analyzed word frequencies and document counts of customer reviews. PLSA categorized words as positive or negative by assigning meanings across multiple domains. Billiyan et al. [60] used the Fuzzy K-Nearest Neighbor (FK-NN) method for sentiment analysis that combines the Fuzzy and K-Nearest Neighbour approaches. This hybrid model classifies customer reviews with positive or negative sentiments. PLSA performed better than the FK-NN on this dataset. The accuracy of FK-NN is 0.72, and PLSA is 0.76. We also compare results with the performance of Decision Tree-J48 by Laksono et al. [61]. The study by Ma et al. [62] introduced a deep learning model for computer vision to understand the information value of online restaurant reviews on the TripAdvisor datasets. Figure 11 shows the graphical representation of the comparison. The proposed model outperforms all the supervised models. The superior performance of the proposed model over supervised models exposing supervised models to more realistic data requires intensive training to work well [63]. On the contrary, the proposed unsupervised model needs no training with massive datasets.

Comparison of the proposed model with Supervised approaches
Next, we compared the proposed model with five different unsupervised models. The first unsupervised approach is POST-VIA360 [50] recommender system. It performed sentiment analysis and used contextual information to suggest places of interest like eateries. Compared to POST-VIA360, the proposed approach is significantly more effective. Zuheros et al. [64] proposed more innovative decision aid using the SA-MpMcDM methodology model - DOC-ABSADeepL. It used expert evaluations based on natural language reviews and numerical ratings. The DOC-ABSADeepL is a multi-task deep learning model for sentiment analysis that can parse an expert review into its component categories and extract critical insights.
Afzaal et al. [65] proposed fuzzy logic models viz. FURIA, FLR, FNN, FRNN, and VQNN to classify user opinions, extracting various aspects and delivering promising results. Fuzzy Lattice Reasoning (FLR) has the highest accuracy among the five models. FLR consists of a set of fuzzy lattice rules. The performance of FLR is less than the proposed model. One possible reason behind the low performance is that Fuzzy Logic models are not used uniformly to address a problem. It is perplexing as there are multiple solutions to the same problem. It takes a lot of testing to validate and verify the systems [66, 67].
The proposed model outperforms Buon Appetito [68] in precision, recall, and f-measure. The proposed model successfully outperforms all the unsupervised models, as shown in Fig. 12. with an accuracy of 0.90. The improved performance of the proposed models is due to combining two mathematical optimization models that help the system to produce more accurate results.

Comparison of the proposed model with unsupervised approaches
5.4 Evaluations on yelp dataset
We compared the performance of the proposed model over the yelp dataset with various supervised and unsupervised models. Hemalatha & Ramathmika [69] implemented various machine learning algorithms. Out of all the models, Naïve Bayes gave the best results. Govindarajan [70] proposed a comparative study of the effectiveness of ensemble techniques for sentiment classification in which SVM and Genetic algorithm worked best. Nasim & Haider [71] presented the Aspect-Based Sentiment Analysis (ABSA) Toolkit to perform aspect-level sentiment analysis on customer reviews in which XGBoost has comparable accuracy. Luo et al. [72] proposed a classification algorithm based on the SVM and FDO algorithms. The study by Ma et al. [62] introduced a deep learning model for computer vision to understand the information value of online restaurant reviews on the yelp dataset. Table 12 shows the experimental results of the proposed model with an accuracy of 89%, which is higher than the other supervised algorithms.
Along with accuracy, we also utilize the inefficiency parameter as a second yardstick to compare the effectiveness of various models. Table 12 shows that the Genetic algorithm has minimal inefficiency among the other supervised models but is still more than the proposed model. The deep learning models have the highest inefficiency rate over the Yelp dataset. The proposed model surpasses the other models in terms of accuracy, as it does not necessitate intensive training and high memory storage capacity.
We next compared our findings with topic modeling and lexical-based techniques. These techniques are unsupervised and are independent of training. We compare our results with JST [41], ASUM [73], HASM [48], TSM [49], and ASUM+. We tested the proposed algorithm on a small sample of 500 reviews (all of which were given 1 or 5 stars) and a larger sample of 1000 reviews (all of which were given 2 or 4 stars). The performance of the proposed model on both small and large datasets outperforms the other unsupervised algorithms. Figure 13 displays the outcomes of comparing the proposed algorithm with other unsupervised models on the same dataset. Results for the proposed model are equivalent to the small dataset and enhanced for the large dataset. However, the proposed model shows the highest accuracy for both small and big datasets.

Comparison of the proposed model with topic modeling techniques
The proposed model outperforms both datasets’ supervised, unsupervised, and semi-supervised models. The integration of mathematical optimization methodologies contributes to the reliability of the proposed model. To offer the optimal approach, an optimization model takes into account the objective (Enhanced accuracy of sentiment classification), the variables (rating, context, and emotion), and the constraints (sentiment analysis difficulties, such as sarcasm and irony detections, special characters, etc.). The optimization model returns a best-case feasibly-optimal outcome.
5.5 Macro and Micro evaluation
We used macro and micro averages to estimate overall performance while dealing with different datasets. Macro-average computes metrics independently for each class and then takes the average (thus treating all classes equally). Micro-average calculates the mean metric by adding all the contributions from each class. It’s a metric that can be advantageous to know the performance when datasets fluctuate in size. The macro and micro-averaged accuracy, F-score, and recall across the n datasets are described in Eq. (16) to Eq. (21).
The overall performance of the proposed model is illustrated in Fig. 14. Over two datasets, the macro and micro precisions are 0.90 and 0.89, respectively. The macro and micro recall values are 0.97 and 0.76, respectively. And the macro and micro F1-score values are 0.94 and 0. 93. All three evaluation metrics produce nearly identical macro and micro scores. This verifies that the proposed model produces consistent results on both datasets.

Macro and Micro average performance of the proposed model
5.6 Statistical validation of results
We conducted the statistical z-test of two proportions to check the robustness of the proposed model. Two samples of different sample sizes were taken from the TripAdvisor reviews dataset. In Sample 1, we took 1000 reviews (n1). Out of 1000 reviews, 900 (x1) were correctly tagged. Thus, sample proportion (p1) =0.90. In Sample 2, we took 500 reviews. From 500 reviews, 452 (x2) were correctly tagged, so the sample proportion is 0.906. The sample statistics are summarized in Table 13.
We conducted the z-test for two population proportions (p1 and p2). For the population proportion, we investigated the following null and alternative hypotheses.
Null Hypothesis (Ho): p1 = p2 i.e., The proportion of correctly tagged reviews is the same in both samples.
Alternate hypothesis (Ha): p1 ≠ p2 i.e., The proportion of correctly tagged reviews is not same in both samples.
The value of the pooled proportion is computed using Eq. (22).
We employed the two-tailed test and used the z-test for two population proportions. Eq. (23) shows the calculation of the z-statistic.
Figure 15 shows a graphical representation of the critical region of the assumed hypothesis. From the calculations, we failed to reject the null hypothesis, Ho. Thus, we can say that there is insufficient evidence to assert that the population proportions p1 and p2 differ from each other at the 0.05 significance level. This implies that the proportion of correctly tagged reviews is consistent throughout different sample sizes of the same datasets. Hence the results produced by the proposed model are stable and unswerving.

Graphical representation of the critical region of the null hypothesis
6 Discussion
The proposed model is an initial demonstration of the applicability of integrated TOPSIS and non-cooperative games for sentiment analysis. In this study, we perform binary classification of sentiments - positive or negative, and service feedback - satisfactory or unsatisfactory. This section discusses the proposed methodology’s computational complexities, error rates, advantages, and limitations.
-
1)
Space and Time complexity: An algorithm’s time and space complexity are essential for assessing efficiency. The time complexity of an algorithm can be estimated by the number of operations it must perform to complete its task for a given input. An algorithm’s space complexity measures the amount of space it consumes during execution for varying input sizes. Table 14 shows the algorithm’s time and space complexities, where m is the number of alternatives and n is the number of criteria. The recorded complexity comes under the P-class problem solvable in polynomial time. It is also a deterministic algorithm which means the algorithm continuously computes the correct answer. The time and space complexity is reduced by half by the use of game theory. This is because we play games between two players (Ri and Rj), thus, halving the time required to tag two reviews.
Table 14 Complexities of the proposed model -
2)
Evaluation of error rates: Error rate (ERR), also known as misclassification rate, shows the number of incorrectly identified samples from the actual positive and negative classifications sample. It is evaluated using Eq. (24).
$$ERR=\frac{FP+ FN}{TP+ TN+ FN+ FP}\times 100$$(24)The error rate performance of several supervised and unsupervised algorithms for the TripAdvisor dataset are depicted in Fig. 16. The Tree-J48 model has the highest error rate, while PLSA and FK-NN have nearly equivalent error rates. Because the suggested model has the lowest error percentage, it is more reliable than existing algorithms for the TripAdvisor restaurant reviews dataset.
Fig. 16 
Comparison of error rates of the proposed model with existing approaches on the TripAdvisor dataset
The error rate of the various models for the Yelp dataset is visually represented in Fig. 17. TSM’s maximum error rate indicates that its results are less dependable than other unsupervised models such as ASUM, JST, and TSM ASUM+. SVM FDO and linear SVC have higher error rates than existing supervised models. The proposed unsupervised model has the lowest error rate, implying that the results are more reliable.
Fig. 17 
Comparison of error rates of the proposed model with existing approaches on the Yelp dataset
-
3)
Advantages of the Proposed Model: This paper introduces a mathematical optimization framework for sentiment analysis. One of the significant advantages of the proposed model is that it is unsupervised. It does not need training on a huge dataset. The proposed model employs unlabelled and unclassified data. The proposed model can be applied to perform sentiment analysis of reviews in several languages. The only prerequisite is having access to SentiWordNet, or any similar lexicon that should be available to compute context scores of reviews. The proposed work is a mathematical optimization model with minimal space and time complexity. Mathematical optimization solutions may readily adjust to changing conditions and give us the information and flexibility required to respond to disruptions effectively. The proposed work paves the way to utilize mathematical optimizations in diverse NLP tasks.
-
4)
Challenges or Disadvantages of the Proposed Model: One significant reason for the dwindled performance of the proposed algorithm is that the SentiWordNet is not exhaustive. The list of words is incomplete, and a few words are given incorrect sentiment scores. Another set of statements that the proposed system could not correctly analyze were those containing sarcasm or irony. The true meaning of a comment can be complex for sentiment analysis algorithms to decipher when people communicate negative thoughts by offering unintentional praises. Consumers sometimes write reviews that may contain emoticons and slang words. The proposed methodology is unable to categorize such constructs. Emojis are treated by the proposed methodology like particular characters and are removed from the data during text pre-processing. Similar to this, texts with negations do not envisage positive outcomes. In Table 15 we list a sample of examples that the proposed algorithm could not correctly classify on the two review datasets. However, these roadblocks can be tackled, and we intend to take these cases in our future work.
Table 15 Examples where the proposed model fails


7 Conclusion
This study introduced a novel unsupervised technique for sentiment tagging. We developed an MCDM and game theory-based mathematical framework to perform sentiment analysis and adjudge the service feedback of a restaurant based on reviews. We evaluated the effectiveness of our proposed model on two restaurant review datasets and compared it with other unsupervised and supervised approaches. The proposed model gave state-of-the-art results and outperformed other approaches. The proposed work demonstrates that mathematical optimization techniques, such as MCDM and game theory, can be used to perform various NLP tasks effectively and efficiently.
The advantage of utilizing the Mathematical optimization model is that a mathematical model of sentiment analysis and an algorithm-based solver generate solutions for even the most challenging sentiment analysis problems and thus empower us to make the best possible decisions. Mathematical optimization solutions can easily adapt to changing conditions and provide us with the insight and adaptability we need to respond to disruptions efficiently. The proposed system could serve as a springboard for other emerging applications of sentiment analysis, such as the use of social media for effective policing, governmental accountability, participation by the public in decision-making, etc. This is an explanatory effort toward sentiment tagging of reviews. We understand that there is enormous scope for improvement. There are various challenges faced by the proposed model, like negation handling, slang, irony, etc. We plan to work on these tasks in the future. We can also intend to expand the polarity classifications (strong positive, positive, weak, positive, neutral strong negative, negative, weak negative) in future work. The proposed model can be extended to classify sentiments in low-resource languages such as Hindi, Bengali, and Urdu with minor modifications. The proposed model paved the way for mathematical optimization techniques to be applied to various NLP applications like WSD, query expansion, etc.
Notes
References
Wu J-L, Chung W-Y (2022) Sentiment-based masked language modeling for improving sentence-level valence-arousal prediction. Appl Intell 52:16353–16369. https://doi.org/10.1007/s10489-022-03384-9
Han H, Zhang J, Yang J, Shen Y, Zhang Y (2018) Generate domain-specific sentiment lexicon for review sentiment analysis. Multimed Tools Appl 77:21265–21280. https://doi.org/10.1007/S11042-017-5529-5/TABLES/7
Jain PK, Pamula R, Srivastava G (2021) A systematic literature review on machine learning applications for consumer sentiment analysis using online reviews. Comput Sci Rev 41:100413. https://doi.org/10.1016/J.COSREV.2021.100413
Al-Mashhadany AK, Hamood DN, Sadiq Al-Obaidi AT, Al-Mashhadany WK (2021) Extracting numerical data from unstructured Arabic texts (ENAT). Indones J Electr Eng Comput Sci 21:1759–1770. https://doi.org/10.11591/IJEECS.V21.I3.PP1759-1770
Ray PP (2018) A survey on internet of things architectures. J King Saud Univ - Comput Inf Sci 30:291–319. https://doi.org/10.1016/j.jksuci.2016.10.003
Fikri M, Sarno R (2019) A comparative study of sentiment analysis using SVM and SentiWordNet. Indones J Electr Eng Comput Sci 13:902–909. https://doi.org/10.11591/IJEECS.V13.I3.PP902-909
Rintyarna BS, Sarno R, Fatichah C (2020) Enhancing the performance of sentiment analysis task on product reviews by handling both local and global context. Int J Inf Decis Sci 12:75–101. https://doi.org/10.1504/IJIDS.2020.104992
García-Pablos A, Cuadros M, Rigau G (2017) W2VLDA: almost unsupervised system for aspect based sentiment analysis. Expert Syst Appl 91:127–137. https://doi.org/10.1016/j.eswa.2017.08.049
Donadi M (2018) A system for sentiment analysis of online-media with TensorFlow. 1–44
Vashishtha S, Susan S (2021) Highlighting keyphrases using senti-scoring and fuzzy entropy for unsupervised sentiment analysis. Expert Syst Appl 169:114323
Song M, Park H, Shin K s (2019) Attention-based long short-term memory network using sentiment lexicon embedding for aspect-level sentiment analysis in Korean. Inf Process Manag 56:637–653. https://doi.org/10.1016/J.IPM.2018.12.005
Hu J, Zhang X, Yang Y, Liu Y, Chen X (2020) New doctors ranking system based on VIKOR method. Int Trans Oper Res 27:1236–1261. https://doi.org/10.1111/itor.12569
Rani R, DL-J of KSU-C, (2020) Undefined performance evaluation of text-mining models with Hindi stopwords lists. Elsevier
Pandesenda AI, Yana RR, Sukma EA et al (2020) Sentiment analysis of service quality of online healthcare platform using fast large-margin. Proceedings - 2nd international conference on informatics, multimedia, cyber, and information system, ICIMCIS 2020 121–125. https://doi.org/10.1109/ICIMCIS51567.2020.9354295
Liu N, Shen B (2020) ReMemNN: a novel memory neural network for powerful interaction in aspect-based sentiment analysis. Neurocomputing 395:66–77. https://doi.org/10.1016/j.neucom.2020.02.018
Basiri ME, Nemati S, Abdar M, Cambria E, Acharya UR (2021) ABCDM: an attention-based bidirectional CNN-RNN deep model for sentiment analysis. Futur Gener Comput Syst 115:279–294. https://doi.org/10.1016/J.FUTURE.2020.08.005
Zhao A, Yu Y (2021) Knowledge-enabled BERT for aspect-based sentiment analysis. Knowl-Based Syst 227:107220. https://doi.org/10.1016/J.KNOSYS.2021.107220
Jain L, Katarya R, Sachdeva S (2020) Recognition of opinion leaders coalitions in online social network using game theory. Knowl-Based Syst 203:106158. https://doi.org/10.1016/j.knosys.2020.106158
Mee A, Homapour E, Chiclana F, Engel O (2021) Sentiment analysis using TF–IDF weighting of UK MPs’ tweets on Brexit. Knowl-Based Syst 228:107238. https://doi.org/10.1016/J.KNOSYS.2021.107238
Heidary Dahooie J, Raafat R, Qorbani AR, Daim T (2021) An intuitionistic fuzzy data-driven product ranking model using sentiment analysis and multi-criteria decision-making. Technol Forecast Soc Chang 173:121158. https://doi.org/10.1016/j.techfore.2021.121158
Perikos I, Kardakis S, Hatzilygeroudis I (2021) Sentiment analysis using novel and interpretable architectures of hidden Markov models. Knowl-Based Syst 229:107332. https://doi.org/10.1016/J.KNOSYS.2021.107332
Ileri M, Turan M (2021) Sentiment analysis of meeting room. HORA 2021 - 3rd international congress on human-computer interaction, optimization and robotic applications, proceedings. https://doi.org/10.1109/HORA52670.2021.9461354
Nguyen DN, Phan TT, Do P (2021) Embedding knowledge on ontology into the corpus by topic to improve the performance of deep learning methods in sentiment analysis. Sci Rep 11:23541. https://doi.org/10.1038/s41598-021-03011-6
de Oliveira Carosia AE, Coelho GP, da Silva AEA (2021) Investment strategies applied to the Brazilian stock market: a methodology based on sentiment analysis with deep learning. Expert Syst Appl 184:115470
Fiok K, Karwowski W, Gutierrez E, Wilamowski M (2021) Analysis of sentiment in tweets addressed to a single domain-specific Twitter account: Comparison of model performance and explainability of predictions. Expert Syst Appl 186:115771
Ozyurt B, Akcayol MA (2021) A new topic modeling based approach for aspect extraction in aspect based sentiment analysis: SS-LDA. Expert Syst Appl 168:114231
Zhang D, Zhu Z, Kang S, Zhang G, Liu P (2021) Syntactic and semantic analysis network for aspect-level sentiment classification. Appl Intell 51:6136–6147. https://doi.org/10.1007/S10489-021-02189-6/FIGURES/9
Liang R, Wang J q (2019) A Linguistic Intuitionistic Cloud Decision Support Model with Sentiment Analysis for Product Selection in E-commerce. Int J Fuzzy Syst 21:963–977. https://doi.org/10.1007/S40815-019-00606-0
Peng Y, **ao T, Yuan H (2022) Cooperative gating network based on a single BERT encoder for aspect term sentiment analysis. Appl Intell 52:5867–5879. https://doi.org/10.1007/S10489-021-02724-5/TABLES/7
Zhang Q, Shi L, Liu P, Zhu Z, Xu L (2022) ICDN: integrating consistency and difference networks by transformer for multimodal sentiment analysis. Appl Intell 1–14. https://doi.org/10.1007/s10489-022-03343-4
Gu T, Zhao H, Li M (2022) Effective inter-aspect words modeling for aspect-based sentiment analysis. Appl Intell 1–14. https://doi.org/10.1007/S10489-022-03630-0/TABLES/6
Chiha R, Ayed MB, Pereira C d C (2022) A complete framework for aspect-level and sentence-level sentiment analysis. Appl Intell 1–19. https://doi.org/10.1007/S10489-022-03279-9/TABLES/11
Swathi T, Kasiviswanath N, Rao AA (2022) An optimal deep learning-based LSTM for stock price prediction using twitter sentiment analysis. Appl Intell 1–14 52:13675–13688. https://doi.org/10.1007/S10489-022-03175-2/FIGURES/10
Wu J, Ma X, Chiclana F, Liu Y, Wu Y (2022) A consensus group decision making method for hotel selection with online reviews by sentiment analysis. Appl Intell 52:10716–10740. https://doi.org/10.1007/S10489-021-02991-2/FIGURES/7
Li L, Johnson J, Aarhus W, Shah D (2022) Key factors in MOOC pedagogy based on NLP sentiment analysis of learner reviews: what makes a hit. Comput Educ 176:104354. https://doi.org/10.1016/J.COMPEDU.2021.104354
Birjali M, Kasri M, Beni-Hssane A (2021) A comprehensive survey on sentiment analysis: approaches, challenges and trends. Knowl-Based Syst 226:107134. https://doi.org/10.1016/J.KNOSYS.2021.107134
**dal K, Aron R (2021) A systematic study of sentiment analysis for social media data. Mater Today: Proc. https://doi.org/10.1016/J.MATPR.2021.01.048
Hossain N, Bhuiyan MR, Tumpa ZN, Hossain SA (2020) Sentiment analysis of restaurant reviews using combined CNN-LSTM. 2020 11th international conference on computing, communication and networking technologies, ICCCNT 2020. https://doi.org/10.1109/ICCCNT49239.2020.9225328
Li M, Chen L, Zhao J, Li Q (2021) Sentiment analysis of Chinese stock reviews based on BERT model. Appl Intell 51:5016–5024. https://doi.org/10.1007/S10489-020-02101-8/TABLES/5
Zhang Z, Singh MP (2014) ReNew: a semi-supervised framework for generating domain-specific lexicons and sentiment analysis. 52nd annual meeting of the Association for Computational Linguistics, ACL 2014 - proceedings of the conference 1:542–551. https://doi.org/10.3115/v1/p14-1051
Lin C, He Y, Everson R, Rüger S (2012) Weakly supervised joint sentiment-topic detection from text. IEEE Trans Knowl Data Eng 24:1134–1145. https://doi.org/10.1109/TKDE.2011.48
Almutairi K, Hosseini Dehshiri SJ, Hosseini Dehshiri SS, Mostafaeipour A, Hoa AX, Techato K (2022) Determination of optimal renewable energy growth strategies using SWOT analysis, hybrid MCDM methods, and game theory: a case study. Int J Energy Res 46:6766–6789. https://doi.org/10.1002/ER.7620
Vincent TL, Brown JS (2005) Evolutionary game theory, natural selection, and darwinian dynamics
Muthumanickam K, Ilavarasan E (2015) Optimization of rootkit revealing system resources - a game theoretic approach. J King Saud Univ - Comput Inf Sci 27:386–392. https://doi.org/10.1016/j.jksuci.2014.10.004
Biaou BOS, Oluwatope AO, Odukoya HO, Babalola A, Ojo OE, Sossou EH (2020) Ayo game approach to mitigate free riding in peer-to-peer networks. J King Saud Univ - Comput Inf Sci 34:2451–2460. https://doi.org/10.1016/j.jksuci.2020.09.015
von Neumann J, Morgenstern O (2007) Theory of games and economic behavior (60th anniversary commemorative edition). Theory of games and economic behavior (60th anniversary commemorative edition) 9781400829460:1–741. https://doi.org/10.1515/9781400829460/MACHINEREADABLECITATION/BIBTEX
Kolios A, Mytilinou V, Lozano-Minguez E, Salonitis K (2016) A comparative study of multiple-criteria decision-making methods under stochastic inputs. Energies 9. https://doi.org/10.3390/en9070566
Kim S, Zhang J, Chen Z et al (2013) A hierarchical aspect-sentiment model for online reviews. Proceedings of the 27th AAAI conference on artificial intelligence, AAAI 2013 526–533. https://doi.org/10.1609/aaai.v27i1.8700
Mei Q, Ling X, Wondra M et al (2007) Topic sentiment mixture: modeling facets and opinions in weblogs. 16th international world wide web conference, WWW2007 171–180. https://doi.org/10.1145/1242572.1242596
Colomo-Palacios R, García-Peñalvo FJ, Stantchev V, Misra S (2017) Towards a social and context-aware mobile recommendation system for tourism. Pervasive Mob Comput 38:505–515. https://doi.org/10.1016/J.PMCJ.2016.03.001
Madani K, Lund JR (2012) California’s Sacramento–san Joaquin Delta conflict: from cooperation to chicken. J Water Resour Plan Manag 138:90–99. https://doi.org/10.1061/(asce)wr.1943-5452.0000164
Madani K, Lund JR (2011) A Monte-Carlo game theoretic approach for multi-criteria decision making under uncertainty. Adv Water Resour 34:607–616. https://doi.org/10.1016/j.advwatres.2011.02.009
Liu T, Deng Y, Chan F (2017) Evidential supplier selection based on DEMATEL and game theory. Int J Fuzzy Syst 20:1321–1333. https://doi.org/10.1007/S40815-017-0400-4
Debnath A, Bandyopadhyay A, Roy J, Kar S (2018) Game theory based multi criteria decision making problem under uncertainty: a case study on Indian tea industry. J Bus Econ Manag 19:154–175. https://doi.org/10.3846/16111699.2017.1401553
Hashemkhani Zolfani S, Banihashemi SSA (2014) Personnel selection based on a novel model of game theory and Mcdm approaches. https://doi.org/10.3846/bm.2014.024
Collins BC, Kumral M (2022) Examining impact and benefit agreements in mineral extraction using game theory and multiple-criteria decision making. Extr Ind Soc 10:101094. https://doi.org/10.1016/J.EXIS.2022.101094
Zhang S, Ly L, Mach N, Amaya C (2022) Topic modeling and sentiment analysis of yelp restaurant reviews. Int J Inf Syst Serv Sect 14:1–16. https://doi.org/10.4018/ijisss.295872
Kaden M, Hermann W, Villmann T (2014) Optimization of general statistical accuracy measures for classification based on learning vector quantization. 22nd European symposium on artificial neural networks, computational intelligence and machine learning, ESANN 2014 - proceedings 47–52
Khotimah DAK, Sarno R (2018) Sentiment detection of comment titles in booking.com using probabilistic latent semantic analysis
Billyan B, Sarno R, Sungkono KR, Tangkawarow IRHT (2019) Fuzzy k-nearest neighbor for restaurants business sentiment analysis on tripadvisor. 2019 international conference on information and communications technology, ICOIACT 2019 543–548. https://doi.org/10.1109/ICOIACT46704.2019.8938564
Laksono RA, Sungkono KR, Sarno R, Wahyuni CS (2019) Sentiment analysis of restaurant customer reviews on tripadvisor using naïve bayes. Proceedings of 2019 international conference on information and communication technology and systems, ICTS 2019 49–54. https://doi.org/10.1109/ICTS.2019.8850982
Ma Y, **ang Z, Du Q, Fan W (2018) Effects of user-provided photos on hotel review helpfulness: an analytical approach with deep leaning. Int J Hosp Manag 71:120–131. https://doi.org/10.1016/J.IJHM.2017.12.008
Du C, Du C, He H (2021) Multimodal deep generative adversarial models for scalable doubly semi-supervised learning. Inf Fusion 68:118–130. https://doi.org/10.1016/j.inffus.2020.11.003
Zuheros C, Martínez-Cámara E, Herrera-Viedma E, Herrera F (2021) Sentiment analysis based multi-person multi-criteria decision making methodology using natural language processing and deep learning for smarter decision aid. Case study of restaurant choice using TripAdvisor reviews. Inf Fusion 68:22–36. https://doi.org/10.1016/J.INFFUS.2020.10.019
Afzaal M, Usman M, Fong ACM et al (2016) Fuzzy Aspect Based Opinion Classification System for Mining Tourist Reviews. Adv Fuzzy Syst 2016:1–14. https://doi.org/10.1155/2016/6965725
Jain G, Lobiyal DK (2022) Word sense disambiguation using cooperative game theory and fuzzy Hindi WordNet based on ConceptNet. Trans Asian Low-Resour Lang Inf Process 21:1–25. https://doi.org/10.1145/3502739
Roubens M (1997) Fuzzy sets and decision analysis. Fuzzy Sets Syst 90:199–206
Trevisiol M, Chiarandini L, Baeza-Yates R Buon Appetito-Recommending Personalized Menus *. https://doi.org/10.1145/2631775.2631784
Hemalatha S, Ramathmika R (2019) Sentiment analysis of yelp reviews by machine learning. 2019 international conference on intelligent computing and control systems, ICCS 2019 700–704. https://doi.org/10.1109/ICCS45141.2019.9065812
Govindarajan M (2014) Sentiment analysis of restaurant reviews using hybrid classification method. Chennai India ISBN:978–93
Nasim Z, Haider S (2017) ABSA toolkit: an open source tool for aspect based sentiment analysis. Int J Artif Intell Tools 26:1750023. https://doi.org/10.1142/S0218213017500233
Luo Y, Xu X (2019) Predicting the helpfulness of online restaurant reviews using different machine learning algorithms: a case study of yelp. Sustainability 11:5254. https://doi.org/10.3390/SU11195254
Jo Y, Oh A (2011) Aspect and sentiment unification model for online review analysis. Proceedings of the 4th ACM international conference on web search and data mining, WSDM 2011 815–824. https://doi.org/10.1145/1935826.1935932
Vashishtha S, Susan S (2019) Fuzzy rule based unsupervised sentiment analysis from social media posts. Expert Syst Appl 138:112834. https://doi.org/10.1016/j.eswa.2019.112834
Yang Y, Ma Y, Zhang J, Gao X, Xu M (2020) Attpnet: attention-based deep neural network for 3D point set analysis. Sensors (Switzerland) 20:1–20. https://doi.org/10.3390/s20195455
Rani R, Lobiyal DK (2020) Performance evaluation of text-mining models with Hindi stopwords lists. J King Saud Univ - Comput Inf Sci 34:2771–2786. https://doi.org/10.1016/j.jksuci.2020.03.003
Kardakis S, Perikos I, Grivokostopoulou F, Hatzilygeroudis I (2021) Examining attention mechanisms in deep learning models for sentiment analysis. Appl Sci 11:3883 mdpi.com. https://doi.org/10.3390/app11093883
Perikos I, Kardakis S, Hatzilygeroudis I (2021) Sentiment analysis using novel and interpretable architectures of hidden Markov models[formula presented]. Knowl-Based Syst 229:107332. https://doi.org/10.1016/j.knosys.2021.107332
Nguyen DN, Phan TT, Do P (2021) Embedding knowledge on ontology into the corpus by topic to improve the performance of deep learning methods in sentiment analysis. Sci Rep 11:23541
Punetha N, Jain G (2023) Bayesian game model based unsupervised sentiment analysis of product reviews. Expert Syst Appl 214:119128. https://doi.org/10.1016/j.eswa.2022.119128
Availability of data and materials
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Punetha, N., Jain, G. Game theory and MCDM-based unsupervised sentiment analysis of restaurant reviews. Appl Intell 53, 20152–20173 (2023). https://doi.org/10.1007/s10489-023-04471-1
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-023-04471-1