
Abstract
Experimental and modeling studies have been conducted to develop an approach for self-cleansing rigid boundary open channel design such as drainage and sewer systems. Self-cleansing experiments in the literature are mostly performed on circular channel cross-section, while a few studies considered self-cleansing sediment transport in small rectangular channels. Experiments in this study were carried out in a rectangular channel with a length of 12.5 m, a width of 0.6 m, a depth of 0.7 m and having an automatic control system for regulating channel slope, discharge and sediment rate. Behind utilizing collected experimental data in this study, existing data in the literature for rectangular channels are used to develop self-cleansing models applicable for channel design. Through the modeling procedure, this study recommends Lq-norm multiple kernel fusion regression (LMKFR) techniques for self-cleansing sediment transport. The LMKFR is a regression technique based on the regularized kernel regression method which benefits from the combination of multiple information sources to improve the performance using the Lq-norm multiple kernel learning framework. The results obtained by LMKFR are compared to support vector regression benchmark and existing conventional regression self-cleansing sediment transport models in the literature for rectangular channels. The superiority of LMKFR is illustrated in an accurate modeling as compared with its alternatives in terms of various statistical error measurement criteria. The encouraging results of LMKFR can be linked to utilization of several kernels which are fused effectively using an Lq-norm prior that captures the intrinsic sparsity of the problem at hand. Promising performance of LMKFR technique in this study suggests it as an effective technique to be examined in similar environmental, hydrological and hydraulic problems.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In the design of rigid boundary channels such as urban drainage and sewer systems, the concept of self-cleansing is used to prevent or at least reduce continuous sedimentation. Self-cleansing refers to a state in which solid particles have no settle (non-deposition) or deposited particles in stream beds begin to move (bed sediment motion). Non-deposition design methods are mostly used for channel design due to its greater conservativeness compared to the bed motion methods (Safari et al. 2018).
Historically, the design of channels according to the non-deposition with clean bed (NCB) condition of sediment transport was based on experiences which concentrated on singular parameters such as velocity and shear stress. The tractive force method (Raths and McCauley 1962) where design shear stress is determined based on sediment size recommended by Merritt (2009) was also used. However, these methodologies frequently neglected pivotal elements concerning sediment transport hydraulics, notably sediment volumetric concentration, and channel-specific characteristics, as highlighted by Ota and Perrusquia (2013). However, in recent decades, there has been a concentrated effort to develop self-cleaning models that incorporate these key variables, resulting in more accurate and effective channel designs (May et al. 1996; Butler et al. 2003; Ota and Nalluri 2003; Vongvisessomjai et al. 2010; Montes et al. 2020; Safari et al. 2017; Safari and Aksoy 2021). Due to an easier construction process of circular channels, generally drainage and sewer pipes have circular cross-section shape and therefore, most of the studies were performed in circular cross-section channels (Safari et al. 2018) while a few studies considered self-cleansing sediment transport in rectangular channels such as Mayerle (1988) and Safari (2016). Utilizing Safari (2016) data, Safari and Aksoy (2021) showed that rectangular channel is more efficient than trapezoidal, circular, U-shape and V-bottom cross-sections where a lower velocity and shear stress are needed to keep sediment particles in motion which means less flow discharge and accordingly bed slope are needed for self-cleansing rectangular channel design. It makes rectangular channel more economical in contrast to the circular channel. However, existing rectangular cross-section data in the literature were performed in small cross-section channels having 311 mm and 462 mm for Mayerle (1988) and, 300 mm for Safari (2016) data. Therefore, a significant research gap exists for the lack of data for larger self-cleansing rectangular channels.
The majority of models in the literature were developed utilizing conventional regression technique. While these studies are useful in comprehending the influential factors of sediment transport in NCB conditions from a hydraulic perspective, they do not match the accuracy achieved by machine learning (ML) techniques. Consequently, in recent decade keen interests have been attracted in utilizing ML and numerical techniques to develop more robust models that offer greater precision for sediment transport studies (Danandeh Mehr and Safari 2020; Shankar et al. 2021; Shivashankar et al. 2022, 2023). For example, generalized structure group method of data handling (GS-GMDH), extreme learning machine (ELM), random forest (RF), adaptive neuro-fuzzy inference systems-butterfly optimization algorithm (ANFIS-BOA), weighted instances handler wrapper-RF (WIHW-RF), kernel ridge regression (KRR) and sparse kernel regression (SKR), M5 regression tree (M5RGT), ExtraTreesRegressor and AdaboostRegressor, outlier robust-ELM (OR-ELM) and generalized regularized extreme learning machine-gradient-based optimizer (GRELM-GBO) have been applied for self-cleansing sediment transport modeling respectively by Safari et al. (2019), Ebtehaj et al. (2020), Montes et al. (2021), Zounemat-Kermani et al. (2021), Kargar et al. (2021), Safari and Rahimzadeh Arashloo (2021a, b), Gul et al. (2021), Shakya et al. (2022a, b), Kouzehkalani Sales et al. (2023) and Gul and Safari (2023). The existing ML models for NCB were primarily developed based on data collected from circular channels, however, other studies, such as Safari and Rahimzadeh Arashloo (2021b) and, Gul and Safari (2023) developed self-cleansing models utilizing data of different cross-section channels. Consequently, a research gap exists in the literature for develo** robust ML self-cleansing sediment transport model for rectangular cross-section channels.
Among large number of existing ML models in the literature, this study developed Lq-norm multiple kernel fusion regression (LMKFR) self-cleansing model. The main reasons for implementation of LMKFR are that the common practice in the literature in the context of the similar problems is to consider all the input measurements as the components of a single vector which is subsequently fed to the commonly used Gaussian kernel function to construct the kernel matrix. A successful line of research in develo** self-cleansing channel models focuses on utilizing regression, and in particular, kernel regression methods. Although promising results have been obtained using such techniques, they suffer from a number of limitations. First, only focusing on a single kernel function may limit the modelling capacity of the algorithm. On the other hand, examining various plausible kernel functions and choosing the best one, while being time-consuming and inefficient, may not guarantee an optimal performance. A better approach would be to benefit from multiple kernel functions at the same time for an improved performance. Second, assuming all the input measurements as the elements of a single vector on top of which the kernel function is applied is a critical design decision since each single input measurement may have a different contribution to the output which may not be captured by using a single vector representation. Both of the aforementioned limitations are addressed via a multiple kernel learning approach (Rahimazdeh Arashloo, 2023) in this study. This is realized by considering each single input measurement to construct a separate kernel. Moreover, instead of using only a single kernel function, multiple kernel functions including the Gaussian, linear, and a polynomial kernel are utilized to construct several kernel matrices. Each of the constructed kernel matrices is expected to capture a different view of the problem. Fusing all the available information sources summarized as different kernel matrices is eventually realized via a multiple kernel learning formalism where a convex combination of all kernels is utilized. The fusion weights, reflecting the importance of each individual kernel matrix are learned automatically from the training data subject to an Lq-norm regularization which is also able to capture the underlying sparsity of the problem.
The main novelties and contributions of this study are as follows:
-
I)
While existing self-cleansing sediment transport data were collected for circular and a few data sets for small rectangular channels, this study provides data for a large rectangular channel.
-
II)
Ranges of experimental data is a crucial factor for reliability of the developed self-cleansing models. Together with utilizing experimental data collected in this study, further data sets taken from the literature are used to develop self-cleansing sediment transport models having rectangular channel width form 300 mm – 600 mm.
-
III)
This study recommends a robust ML technique for modeling environmental and hydrological problems as Lq-norm multiple kernel fusion regression (LMKFR) for the first time in the literature. In particular, the Lq-norm multiple kernel fusion regression approach addresses the limitations of the current techniques in capturing data similarities in terms of kernel functions and modelling the contribution of each input measure on the output using a multiple kernel learning approach subject to Lq-norm regularization.
2 Materials and methods
2.1 Experiments
Experiments were carried out in the Hydraulic Laboratory of Yaşar University, Izmir, Turkey. The rectangular flume used in the experiments had glass walls and an aluminum smooth bed, with a length of 12.5 m, a width of 0.6 m, and a depth of 0.7 m (Fig. 1). An automatic control system (ACS) for regulating channel slope, discharge and sediment discharge was used which made it possible to prepare different hydraulic conditions and record data. The slope of the bed was adjustable from small values to large slopes. A honeycomb system was used at the entrance of the flume in order to lower the disturbances and produce smooth conditions of the flow at the inlet. Two pumps were installed in the inflow and outflow of the flume. The flow was directed to the downstream edge of a stilling basin, where the experimental sand particles were collected and removed from the water surface by means of a metal grid. To obtain uniform flow conditions, the tailgate at the channel downstream was used. The water level was measured using five ultrasonic sensors, placed one meter from each other along the centerline of the channel. Three uniform sand particles were used having 1.18 mm, 2.05 mm and 3.34 mm sizes. A vibrant sediment feeder was used which had soil depth sensor at its tank to provide constant sediment discharge. Water velocity was measured using an acoustic Doppler velocimeter (ADV), a Nortek Victorino Profiler with downward transducers, placed at the channel centerline.

Experimental rigs: a 12.5 m-flume, b automatic control system (ACS) panel, c ultrasonic flow depth measurement device, d sediment feeder e Vectrino profiler ADV
Experiments were conducted to measure the hydraulic characteristics at non-deposition with clean bed (NCB) mode of sediment transport. To this end, first channel bed slope was adjusted and specific sediment size was selected. Flow discharge at the beginning of the experiments must be high enough to satisfy the non-deposition condition of sediment transport. A high flow discharge (60 l/s) was adjusted to keep sediment particles in motion and clean channel bed. Regulating the vibrant sediment feeder speed via ACS a specific sediment discharge was provided. In order to find the minimum flow discharge and accordingly flow velocity for NCB condition, adjusted high discharge was gradually decreased with 0.1 l/s intervals. During the experiments sediment particles motion were visually detected until to see that sediment particles start to cluster at observation section of the channel. Once the incipient deposition condition was achieved where sediment particles start to deposit at isolated parts of channel, the point above incipient deposition was considered as minimum flow condition of NCB for selected sediment size and channel bed slop. A similar procedure shown in Fig. 2 was repeated for different sediment sizes and channel bed slopes. Experimental data collected in this study are given in Table 1.

Experiment flowchart
d sediment median size, s sediment relative specific mass, S channel bed slope, Cv volumetric sediment concentration, Y flow depth, V flow mean velocity
2.2 Conventional regression models of NCB
The NCB condition refers to a flow state where sediments are transported without deposition and the bed remains clean. This flow condition is characterized by adequate velocity and shear stress, which keeps sediment particles in motion, and helps preserve the channel from sedimentation. This has been reviewed in detail by Safari et al. (2018). The majority of studies in the literature were conducted to develop conventional regression self-cleansing sediment transport models, while a few studies considered rectangular channel cross-section. Herein, existing conventional regression self-cleansing formulae for rectangular channels are given.
Mayerle (1988) performed experiments in rectangular and circular channels and subsequently, Mayerle et al. (1991) developed following equation for rectangular channels.
where g is gravitational acceleration, R hydraulic radius and Dgr grain size dimensionless parameter given as
where ν is kinematic viscosity of water. Ab Ghani (1993) utilized data collected from circular and rectangular channel cross-sections to develop
where \(\lambda\) is channel friction factor. To account for flow resistance, Safari et al. (2017) expanded upon previous researches by incorporating a shape factor. As a result, they suggested the following parameter as a shape factor (β):
where P is wetted perimeter, B water surface width and Dh hydraulic depth. Safari et al. (2017) proposed Eq. (5) applicable for all cross-section channels based on their own experimental data from a trapezoidal channel, as well as data collected from the literature from rectangular, circular and U-shape channels.
It is worth noting that the experimental data used to develop Eq. (5) came from channels of varying sizes. In a subsequent study, Safari (2016) conducted experiments in five channels with similar sizes: circular, rectangular, trapezoidal, U-shape, and V-bottom. Utilizing Safari (2016) data, Safari and Aksoy (2021) recommended
for rectangular cross-section channels. Safari and Aksoy (2021) simplified the shape factor β to P/B and recommended following equation which outperformed existing models in the literature.
It can be seen that the structure of the above equations are similar. Experimental data can be used to determine the constant values in Eq. (7), where the left-hand side represents the particle Froude number \(\left({F}_{p}= V/\sqrt{gd\left(s-1\right)}\right)\). It is worth noting that in aforementioned studies, Fp is treated as the dependent variable, while sediment volumetric concentration (Cv) and relative particle size (d/R) are the independent variables mostly used. The variations in the constant values in formulae given above can be attributed to the differences in the ranges of experimental data and channel size used in the various studies.
2.3 Data and model parameters
Together with experimental data collected in this study (Table 1), two data sets taken form Mayerle (1988) and Safari (2016) for rectangular cross-channels are further used for modeling (Safari et al. 2018). These studies performed experiments to determine NCB self-cleansing sediment transport condition. Mayerle (1988) performed experiments in two rectangular channels with 311 mm and 462 mm having 12.2 m and 7.2 m length, respectively. Mayerle (1988) utilized sediment sizes with range of 0.5 mm to 8.74 mm. Safari (2016) conducted experiments in a rectangular channel with 300 m width and 12 m length utilizing sediments having 0.15 mm to 1.52 mm sizes.
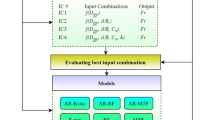
The basic structure of the NCB sediment transport formula is recommended by Mayerle et al. (1991) as Eq. (1) and its revised version by Safari and Aksoy (2021) as Eq. (7). The main difference between those equations is that, while in Eq. (1) sediment, flow and fluid characteristics are used in the model structure, Eq. (7) incorporates P/B as a cross-section shape factor based on Kazemipour and Apelt (1982) and Nalluri and Adepoju (1985) results to better illustrate the channel characteristics. To this end, two different scenarios are considered in this study for modeling as follows:
Consequently, particle Froude number (Fp) as given in left hand side of Eqs. (8, 9) is considered as model output and dimensionless parameters at right hand side of Eqs. (8, 9) are chosen as model inputs. Among 162 data, 122 data (75%) are used for training the models and rest of the data (25%) are considered to test the developed models (Table 2).
2.4 Lq-norm multiple kernel fusion regression (LMKFR)
The kernel regression optimization problem subject to a Tikhonov regularization in the primal space is expressed as
where \(\phi \left(.\right)\) denotes projection onto the feature space, \(n\) stands for the number of training samples, \(c\) is a trade-off parameter, and \(\mathbf{y}\) stands for the expected responses while \({.}^{\mathrm{\top }}\) denotes vector transpose. The kernel regression problem is typically considered in the dual space. It is known that the dual of the problem above is
where \(\mathbf{K}\) denotes the kernel matrix and \(\gamma =n/c\) and \({\varvec{\upomega}}\) is the parameter vector of the model. In a multiple kernel fusion scenario, there exist multiple sources of information for the problem at hand which are to be combined. In a kernel-based method, considering the combined kernel as a linear combination of multiple base kernels, the problem then becomes one of determining the optimal kernel fusion weights. The work in Rahimzadeh Arashloo (2023) considers the composite kernel as a linear fusion of non-negatively weighted kernels, in the presence of an \({\mathcal{l}}_{q}\)-norm constraint where for \(L\) kernels to be fused, the kernel matrix \(\mathbf{K}\) shall be replaced as \(\sum_{l=1}^{L}{\theta }_{l}{\mathbf{K}}_{l}\) where \({\theta }_{l}\)’s denote the non-negative fusion weights. The Lq-norm of an L-dimensional vector \({\varvec{\uptheta}}\) is defined as \(\left\| {{\varvec{\uptheta}}} \right\|_{q}^{q} = \left( {\left| {{{\varvec{\uptheta}}}_{1} } \right|^{q} + \left| {{{\varvec{\uptheta}}}_{2} } \right|^{q} + \cdots + \left| {{{\varvec{\uptheta}}}_{L} } \right|^{q} } \right)\) where \({\varvec{\uptheta}}{\text{l}}\) denotes the \({l}^{th}\) element of the parameter vector \({\varvec{\uptheta}}\). Once \(\mathbf{K}\) is replaced by \(\sum_{l=1}^{L}{\theta }_{l}{\mathbf{K}}_{l}\), the optimisation problem is derived as
where \({\varvec{\uptheta}}\ge 0\) is applied in an element-wise fashion. The \({\mathcal{l}}_{q}\)-norm constraint enables the model to tune into the intrinsic sparsity of the problem. In order to solve the optimisation problem above, the work in Rahimzadeh Arashloo (2023) constructs the Lagrangian dual optimization problem using which \({\varvec{\uptheta}}\) is derived as
After determining \({\varvec{\uptheta}}\), the objective is maximised w.r.t. \({\varvec{\upomega}}\). Requiring the partial derivative of the objective function with respect to \({\varvec{\upomega}}\) to vanish yields:
As the two sets of parameters above (i.e. \({\varvec{\uptheta}}\) and \({\varvec{\upomega}}\)) depend on each other, the work in Rahimzadeh Arashloo (2023) advocates an iterative method for optimisation where the two steps above are iterated in a loop till convergence. The method is summarized in the Algorithm below where \({\varvec{\upomega}}\) is initially set to a uniform \({\varvec{\uptheta}}\) that has a \(q\)-norm equal to \(1\). In this study, we consider \(13\) different kernels which are fused together. The kernels are obtained by using three different kernel functions of Gaussian, linear and second-degree polynomial operating on each of the four input measurements in addition to a Gaussian kernel applied to the vector collection of the input features.

Algorithm: ℓq -Norm multiple kernel fusion regression (LMKFR)
2.5 Support vector regression
The support vector regression (SVR) approach (Drucker et al. 1997) is a commonly deployed technique in regression analysis. As a supervised learning method, the SVR approach is based on similar principles as those deployed by the SVM classification method. The objective in the SVR method is to determine the best line fitting to the data. Nevertheless, different from other methods that try to minimize the error between the real and the predicted responses, SVR tries to find the best fitted line within a certain error threshold. As in the SVM classification approach where the separating hyper-plane is determined based on only a subset of training samples called support vectors, in the SVR method, the model is shaped by a subset of training objects. The optimization task for the support vector regression method is expressed as
where xi stands for a training object and yi is the desired corresponding target response while \(\epsilon\) is the threshold parameter. When operating in a kernel space, the training data xi in the equation above is replaced by the corresponding projection in the kernel space, i.e. \(\phi ({\mathbf{x}}_{i})\).
2.6 Performance criteria
In order to evaluate the models’ performances, three statistical indices of root mean square error (RMSE), coefficient of determination (R2) and discrepancy ratio (DR) are used in this study. RMSE is used to calculate the model error quantity, R2 for determination of correlation between measured and calculated values and DR for examination of model soundness to understand overestimation and underestimation behavior of a model. The perfect values of RMSE is zero while for both R2 and DR are unity. RMSE, R2 and DR can be written respectively as follows
where \({F}_{p}^{m}\) and \({F}_{p}^{c}\) are measured and calculated Fp respectively, n number of the data and, \(\overline{{F }_{p}^{m}}\) and \(\overline{{F }_{p}^{c}}\) are average values of \({F}_{p}^{m}\) and\({F}_{p}^{c}\), respectively. The DR is classified in three groups of \(0.90 \le DR \le 1.10\), \(0.75 \le DR \le 1.25\) and \(0.50 \le DR \le 1.50\) to show the soundness of the model with 10%, 25% and 50% errors, respectively.
3 Results
For the sake of analyzing the accuracy of LMKFR model at NCB self-cleansing sediment transport, its performance is compared to SVR benchmark and four conventional regression equations of Mayerle et al. (1991) as Eq. (1), Ab Ghani (1993) as Eq. (3) and Safari and Aksoy (2021) as Eqs. (6, 7). The comparisons are given in terms of mathematical and visual statistical performance criteria of RMSR, R2, DR, scatter plots and graphs showing the calculated Fp in contrast to its measured counterparts. As described before, two different scenarios are considered for modeling. Accordingly, LMKFR and SVR for scenarios 1 and 2 are given as LMKFR-S1, LMKFR-S2, SVR-S1 and SVR-S2.
Statistical model performance outcomes given in Table 3 based on RMSE and R2 illustrates that LMKFR models for both scenarios give much better results than SVR-based models and also conventional regression models. The performance of LMKFR technique for both scenarios is quite similar however, LMKFR-S1 with RMSE and R2 of 0.316 and 0.952, respectively, slightly generates better performance than LMKFR-S2 with RMSE and R2 of 0.350 and 0.938, respectively. Although SVR’s models results for both scenarios are not as high as LMKFR models’ accuracy, they provide much better results than conventional regression equations of Mayerle et al. (1991), Ab Ghani (1993) and Safari and Aksoy (2021), Eq. (7). Among conventional regression models, Ab Ghani (1993) equation gives less accurate results which can be linked to the fact that, it is based on different cross-section channels data including circular and rectangular cross-sections. The better performance of Safari and Aksoy (2021), Eq. (6) in comparison to the other conventional regression equations can justified by knowing that, it was developed solely on rectangular channel data. It must be emphasized that Ab Ghani (1993) and Safari and Aksoy (2021), Eq. (7) utilized different cross-section channel data for model development however, Safari and Aksoy (2021), Eq. (7) outperforms Ab Ghani (1993) model, due to it incorporates cross-section shape factor at its model structure which makes such an equation applicable for all channel cross-sections. The specific cross-section channel model gives better performance than generalized models on a specific cross-section channel data, however a cross-section specific model will provide poor results in other cross-section channels while generalized models are universal tool applicable for all cross-section channels.
The developed models’ performance and their comparison with conventional regression equations are given in Table 4 in terms of DR. Performance of the models is examined within the DR ranges of 0.90–1.10, 0.75–1.25 and 0.50–1.50 which shows the model soundness with 10%, 25% and 50% accuracies, respectively. It is seen from Table 4 that LMKFR models’ outcomes have more than 80% data in range of 0.90–1.10 DR. It shows that more than 80% of LMKFR’ calculated values have less than 10% error. Among conventional regression equations, Safari and Aksoy (2021), Eq. (6) has better DR for 0.90–1.10 range where 67.50% of model’s outcomes have less than 10% error. A better performance of LMKFR and SVR models can be noticed in contrast to the conventional regression equations.
The measured and calculated Fp for self-cleansing sediment transport at NCB condition for LMKFR-S1, LMKFR-S2, SVR- S1, SVR- S2, Mayerle et al. (1991), Ab Ghani (1993) and Safari and Aksoy (2021), Eqs. (6, 7) are shown in Fig. 3. It can be found from Fig. 3 that, while LMKFR-S1 and LMKFR-S2 results are almost matched to the measured counterparts, SVR- S1 and SVR- S2 models tend to overestimate the Fp. Except Safari and Aksoy (2021), Eq. (6), other conventional regression equations significantly overestimate the Fp values. As it is seen in Fig. 3, most of the conventional regression equations couldn’t detect the maximum Fp, however LMKFR almost perfectly capture the maximum Fp values. Ab Ghani (1993) overestimates Fp which is cause of utilizing higher number of circular cross-section data and a fewer number of rectangular channel data during the model development. From a general point of view, conventional regression models overestimate Fp values. It can be linked to the fact that; conventional regression models are overfitted to the entire data which causes to generate less accurate outcomes on unseen data sets. More importantly, existing data for rectangular channels in the literature were performed in small rectangular channels while in this study self-cleansing data for a large rectangular channel have been produced. The conventional regression models developed for small rectangular channels overestimate Fp values for large rectangular channel data.


Comparison of calculated and measured Fp for different models
In order to examine the models’ performance based on error measurement, the error quantities calculated as difference among the calculated and measured values (C–M) are shown in Fig. 4. The error curve as C–M is drawn to compare with zero error line (perfect line) in Fig. 4. It is useful to understand the model error and its over/underestimation behaviors. While C–M curve is matched to the zero error line, it can be said that model performance is perfect. Any fluctuation in C–M is an evidence for over/underestimation of the model. The positive and negative fluctuations show overestimation and underestimation of the model, respectively. It is found in Fig. 4 that LMKFR-S1 model tends to perfectly fit the zero error line. The LMKFR-S2, SVR-S1 and SVR- S2 models have a few slight positive and negative fluctuations. Mayerle et al. (1991) and Ab Ghani (1993) models generate considerable positive fluctuations which show their overestimation behaviors. Safari and Aksoy (2021), Eqs. (6, 7) give better results in comparison to other conventional regression equations, however slight overestimations are seen for Safari and Aksoy (2021), Eq. (7).

Comparison of models in terms of error
4 Discussion
The self-cleansing sediment transport models are of importance to reduce the amount of sediment deposition at drainage and sewer channels. An accurate self-cleansing model developed based on NCB design criterion could retain channel bottom clean form solid particles. The main research gaps in the literature regarding the NCB models are the lack of experimental data for large rectangular channel and application of robust ML model for rectangular channel design. This study overcomes to aforementioned deficiencies through conducting new set of experiments in a large rectangular channel and developed a novel and robust ML model as LMKFR for the first time in literature.
It is already found in the literature that rectangular cross-section requires less design velocity in comparison to other cross-section channels such as circular and trapezoidal cross-section channels (Safari et al. 2018; Safari and Aksoy 2021). However, most of the studies in the literature focused only on circular channels and there are a few studies that considered rectangular cross-section channels (Mayerle et al., 1991, Ota and Nalluri 2003; Vongvisessomjai, 2010, Safari 2016). This study provides novel experimental data to enhance the ranges of data in the literature to develop more reliable NCB model for self-cleansing design of drainage and sewer channels. The acquisition of novel experimental data for a large rectangular channel is imperative, especially given the limited data available in existing literature, which predominantly focuses on small rectangular channels (Mayerle 1988; Safari 2016). This novel dataset offers significant potential to gain enhanced insights into the phenomenon. Employing the same experimental procedures as those outlined in earlier studies such as Mayerle (1988) and Ab Ghani (1993) lends robustness to this investigation. This consistency ensures the acquisition of reliable data based on fundamental variables, thereby enhancing measurement precision. Consequently, it contributes to a deeper comprehension of sediment transport within large rectangular channels. Experimental studies serve as the bedrock of sediment transport research, revealing the intricacies of the problem by unveiling fundamental mechanisms. The data collected in this study exhibit a strong correlation with the findings of Mayerle (1988), showcasing similar trends. This consistency in trends underscores the reliability and consistency of the new dataset, empowering researchers to discern actual patterns from random occurrences within sediment transport mechanisms. While previous studies in the literature have often overlooked channel characteristics in their model structures, this study fills a critical gap by integrating the channel shape factor. This inclusion enables to gain a deeper understanding of how the channel’s cross-section shape impacts sewer channel design, a fact that has been frequently neglected in prior investigations.
The self-cleansing models’ performance is greatly affected on range of data and cross-section shape. For instance, cross-section specific models developed for rectangular channels have better performance than generalized formulae. It is due to the fact that, in generalized formulae (Ab Ghani 1993) data comprised from different cross-section channels were used while in cross-section specific models developed for rectangular channels only data collected from rectangular channel were used. Safari and Aksoy (2021) generalized equation performed satisfactory as well. The reason for a better performance of Safari and Aksoy (2021) is that, a cross-section shape factor is embodied in the model structure that makes it applicable for all cross-section channels.
Conventional regression equations are useful to better understand the hydraulic of sediment transport however, their computation ability is not superior on unseen data sets. Results obtained in this study show the less accurate results of conventional regression models which agrees with results reported in De Sutter et al. (2003) who evaluated the performance of Ackers (1984) and May (1993) models on several experimental data sets. It was found that both models performed poor while May (1993) outperformed Ackers (1984) model. It is cause of over-fitting problems where in conventional regression equations the entire data are utilized to find the coefficients and exponents in the equations (Kargar et al. 2021; Gul et al., 2023). This study developed robust ML models for NCB condition using LMKFR. The best LMKFR model in this study gives RMSE of 0.316 and R2 of 0.952 which is much better than its counterpart in the literature such as GS-GMDH model for Safari et al. (2019) with R2 of 0.86; ELM model for Ebtehaj et al. (2020) with RMSE of 1.05; RF model of Montes et al. (2021) with R2 of 0.91 and RMSE of 0.73; WIHW-RF model of Kargar et al. (2021) with RMSE of 0.64; KRR model of Safari and Rahimzadeh Arashloo (2021a) with RMSE 0.67; M5RGT model of Gul et al. (2021) with RMSE of 0.52 and, GRELM-GBO model of Gul and Safari (2023) with R2 of 0.84 and RMSE of 1.06. The superior generalization capability of the LMKFR for modeling self-cleansing sediment transport can be attributed to an optimal fusion of multiple sources of information in the kernel space while taking into account the inherence sparsity within the problem. This is achieved via an optimal fusion of multiple base kernels, each capturing a distinct view of the problem. The combination weights corresponding to different kernels are derived as the solution of a convex optimization task for which the optimum can be effectively achieved. The kernel-based approaches offer the favorable property of requiring much less training samples and provide highly competitive results in different learning tasks. Furthermore, the optimization problem associated with the consider approach is convex and can be effectively optimized. Last but not the least, we determine the parameters of the proposed approach via cross-validation on the training set and then evaluate the model on the unseen new test samples. As illustrated in the experiments, the proposed approach, thanks to a kernel fusion-based formulation, performs better than other approaches verifying its merits.
The LMKFR model developed in this study can be used in practice for drainage channel design. For this purpose, the design guideline recommended by Butler et al. (2003) can be implemented. Within the several design steps, in “bed load sediment transport” criterion, the developed LMKFR can be applied. It is pertinent to note that the experimental data utilized in formulating bed load sediment transport models were gathered under idealized conditions, specifically uniform and steady flow conditions. Nevertheless, as highlighted by Davies et al. (1996) and Butler et al. (2018), when addressing sediment transport modeling within scenarios of unsteady and non-uniform flow, the relationship between flow mean velocity and sediment particle velocity might be assumed to be analogous to that in steady and uniform flow conditions. Consequently, the application of bed load sediment transport models derived from experimental data obtained under idealized flow conditions can be considered in practical applications. However, as emphasized by Butler et al. (1996), it is imperative to exercise caution and employ these models in a conservative manner due to the variations inherent in unsteady and non-uniform flow conditions.
Including this study experimental data for NCB self-cleansing sediment transport condition, there are a few studies in the literature for rectangular cross-section channels. The main limitation of this study is the range of experimental data used for the model development. Conducting new experiments considering wide ranges of sediment sizes, channel bed slopes and develo** models established on in-sewer sediment are recommended as future research directions.
5 Conclusions
Experimental and modeling studies have been conducted to investigate the self-cleansing sediment transport in drainage and sewer channels at NCB condition. Experiments were conducted in a large rectangular channel in comparison to the existing rectangular channel experiments for NCB condition in the literature. Provided data in this study extends the ranges of data in the literature for rectangular cross-section channels to establish more reliable self-cleansing design model. Through the modeling stage, this study recommends Lq-norm multiple kernel fusion regression (LMKFR) techniques for NCB self-cleansing sediment transport modeling for the first time. The developed LMKFR model gives better performance than SVR benchmark and also conventional regression models based on mathematical and visual statistical performance indices. Most of conventional regression equations considerably overestimate particle Froude number while LMKFR outcomes are found close to the measured correspondences. By virtue of using a multiple kernel learning formalism that combines multiple kernels each of which captures a different view of the problem, LMKFR performs better than other approaches. A multiple kernel learning approach helps to enhance the model’s generalization capability. Furthermore, LMKFR takes into account the inherent sparsity of the task via an Lq-norm regularization constraint which is instrumental in preventing overfitting and improving the model’s accuracy. This study developed LMKFR for the first time in hydrological and environmental problems that may motivate its implementation and variety of similar problems. An essential pre-requisite for the considered multiple kernel fusion approach is the availability of multiple sources of information for the problem at hand. Furthermore, in order for the kernel fusion scheme to be effective different information sources need to be as independent as possible and provide complementary information so as the combined model becomes effective in improving the overall performance.
Data availability
The datasets used and/or analyzed during the current study are available given in the manuscript.
Code availability
None.
References
Ab Ghani A (1993). Sediment transport in sewers. PhD Thesis, University of Newcastle upon Tyne, UK
Ackers P (1984) Sediment transport in sewers and the design implications. In Proc., Int. Conf. on Planning, Construction, Maintenance, and Operation of Sewerage Systems, 215–230. Reading, UK: BHRA/WRc
Butler D, Digman CJ, Makropoulos C, Davies JW (2018) Urban drainage. Crc Press, Boca Raton
Butler D, May RWP, Ackers JC (1996) Sediment transport in sewers part 2: design. Proc Inst Civil Eng-Water Mari Energy 118(2):113–120
Butler D, May R, Ackers J (2003) Self-cleansing sewer design based on sediment transport principles. J Hydraul Eng 129(4):276–282
Danandeh Mehr A, Safari MJS (2020) Application of soft computing techniques for particle Froude number estimation in sewer pipes. J Pipeline Syst Eng Pract 11(2):04020002
Davies JW, Butler D, Xu YL (1996) Gross solids movement in sewers: laboratory studies as a basis for a model. J Inst Water Environ Manag 10(1):52–58
De Sutter R, Rushforth P, Tait S, Huygens M, Verhoeven R, Saul A (2003) Validation of existing bed load transport formulas using in-sewer sediment. J Hydraul Eng 129(4):325–333
Drucker H, Burges CJ, Kaufman L, Smola A, Vapnik V (1997) Support vector regression machines. Adv Neural Inf Process Syst 9:155–161
Ebtehaj I, Bonakdari H, Safari MJS, Gharabaghi B, Zaji AH, Madavar HR, Sheikh Khozani Z, Es-haghi MS, Shishegaran A, Danandeh Mehr A (2020) Combination of sensitivity and uncertainty analyses for sediment transport modeling in sewer pipes. Int J Sedim Res 35(2):157–170
Gul E, Safari MJS, Torabi Haghighi A, Danandeh Mehr A (2021) Sediment transport modeling in non-deposition with clean bed condition using different tree-based algorithms. PLoS ONE 16(10):e0258125
Gul E, Safari MJS (2023) Hybrid generalized regularized extreme learning machine through gradient-based optimizer model for self-cleansing non-deposition with clean bed mode of sediment transport. Big Data. https://doi.org/10.1089/big.2022.0120
Kargar K, Safari MJS, Khosravi K (2021) Weighted instances handler wrapper and rotation forest-based hybrid algorithms for sediment transport modeling. J Hydrol 598:126452
Kazemipour AK, Apelt CJ (1982) New data on shape effects in smooth rectangular channels. J Hydraul Res 20(3):225–233
Kouzehkalani Sales A, Gul E, Safari MJS (2023) Online sequential, outlier robust, and parallel layer perceptron extreme learning machine models for sediment transport in sewer pipes. Environ Sci Pollut Res. https://doi.org/10.1007/s11356-022-24989-0
May RWP (1993) Sediment transport in pipes and sewers with deposited beds. Rep. No. SR 320. Hydraulic Research Station, Wallingford
May RW, Ackers JC, Butler D, John S (1996) Development of design methodology for self-cleansing sewers. Water Sci Technol 33(9):195–205
Mayerle R (1988). Sediment transport in rigid boundary channels. PhD Thesis, University of Newcastle upon Tyne, UK
Mayerle R, Nalluri C, Novak P (1991) Sediment transport in rigid bed conveyances. J Hydraul Res 29(4):475–495.
Merritt LB (2009) Tractive force design for sanitary sewer self-cleansing. J Environ Eng 135(12):1338–1347
Montes C, Vanegas S, Kapelan Z, Berardi L, Saldarriaga J (2020) Non-deposition self-cleansing models for large sewer pipes. Water Sci Technol 81(3):606–621
Montes C, Kapelan Z, Saldarriaga J (2021) Predicting non-deposition sediment transport in sewer pipes using random forest. Water Res 189:116639
Nalluri C, Adepoju BA (1985) Shape effects on resistance to flow in smooth channels of circular cross-section. J Hydraul Res 23(1):37–46
Ota JJ, Nalluri C (2003) Urban storm sewer design: approach in consideration of sediments. J Hydraul Eng 129(4):291–297
Ota JJ, Perrusquia GS (2013) Particle velocity and sediment transport at the limit of deposition in sewers. Water Sci Technol 67(5):959–967
Rahimzadeh Arashloo S (2023) One-class classification using ℓp-norm multiple kernel fisher null approach. IEEE Trans Image Process 32:1843–1856
Raths CW, McCauley RR (1962) Deposition in a sanitary sewer. Water Sewage Works 109(5):192–197
Safari, M. J. S. (2016) Self-cleansing drainage system design by incipient motion and incipient deposition-based models. PhD Thesis, Istanbul Technical University, Turkey
Safari MJS, Aksoy H (2021) Experimental analysis for self-cleansing open channel design. J Hydraul Res 59(3):500–511
Safari MJS, Aksoy H, Unal NE, Mohammadi M (2017) Non-deposition self-cleansing design criteria for drainage systems. J Hydro-Environ Res 14:76–84
Safari MJS, Ebtehaj I, Bonakdari H, Es-haghi MS (2019) Sediment transport modeling in rigid boundary open channels using generalize structure of group method of data handling. J Hydrol 577:123951
Safari MJS, Mohammadi M, Ab Ghani A (2018) Experimental studies of self-cleansing drainage system design: a review. J Pipeline Syst Eng Pract 9(4):04018017
Safari MJS, Rahimzadeh Arashloo S (2021a) Kernel ridge regression model for sediment transport in open channel flow. Neural Comput Appl 33(17):11255–11271
Safari MJS, Arashloo SR (2021b) Sparse kernel regression technique for self-cleansing channel design. Adv Eng Inform 47:101230
Shakya D, Deshpande V, Agarwal M, Kumar B (2022a) Standalone and ensemble-based machine learning techniques for particle Froude number prediction in a sewer system. Neural Comput Appl 34(18):15481–15497
Shakya D, Agarwal M, Deshpande V, Kumar B (2022b) Estimating particle froude number of sewer pipes by boosting machine-learning models. J Pipeline Syst Eng Pract 13(2):04022012
Shankar MS, Pandey M, Shukla AK (2021) Analysis of existing equations for calculating the settling velocity. Water 13(14):1987
Shivashankar M, Pandey M, Zakwan M (2022) Estimation of settling velocity using generalized reduced gradient (GRG) and hybrid generalized reduced gradient–genetic algorithm (hybrid GRG-GA). Acta Geophys 70(5):2487–2497
Shivashankar M, Pandey M, Shukla AK (2023) Numerical investigation on the evaluation of the sediment retention efficiency of invert traps in an open rectangular combined sewer channel. J Hazard Toxic Radioact Waste 27(1):04022045
Vongvisessomjai N, Tingsanchali T, Babel MS (2010) Non-deposition design criteria for sewers with part-full flow. Urban Water J 7(1):61–77
Zounemat-Kermani M, Mahdavi-Meymand A, Hinkelmann R (2021) Nature-inspired algorithms in sanitary engineering: modelling sediment transport in sewer pipes. Soft Comput 25:6373–6390
Funding
This publication is supported as part of Project No. BAP085 entitled ‘“Experimental studies on sediment transport in open channel flow: drainage channel design consideration’’ has been approved by the Yaşar University Project Evaluation Commission (PEC) under the coordination of the first author (Safari, M.J.S.).
Author information
Authors and Affiliations
Contributions
Conceptualization: Mir Jafar Sadegh Safari and Shervin Rahimzadeh Arashloo, Data curation: Mir Jafar Sadegh Safari, Formal analysis: Mir Jafar Sadegh Safari and Shervin Rahimzadeh Arashloo, Mehrnoush Kohandel Gargari, Investigation: Mir Jafar Sadegh Safari and Shervin Rahimzadeh Arashloo, Mehrnoush Kohandel Gargari, Methodology: Mir Jafar Sadegh Safari and Shervin Rahimzadeh Arashloo, Resources: Mir Jafar Sadegh Safari and Shervin Rahimzadeh. Arashloo, Software Shervin: Rahimzadeh Arashloo, Supervision: Mir Jafar Sadegh Safari, Validation: Mir Jafar Sadegh Safari and Shervin Rahimzadeh Arashloo, Mehrnoush Kohandel Gargari, Visualization: Mir Jafar Sadegh Safari and Shervin Rahimzadeh Arashloo, Writing—original draft: Mir Jafar Sadegh Safari and Shervin Rahimzadeh Arashloo, Mehrnoush Kohandel Gargari, Writing—review and editing: Shervin Rahimzadeh Arashloo, Mehrnoush Kohandel Gargari.
Corresponding author
Ethics declarations
Conflicts of interest
The authors declare no conflicts of interest.
Ethical approval
Not applicable.
Consent to participate
Not applicable.
Consent for publication
All.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Safari, M.J.S., Rahimzadeh Arashloo, S. & Kohandel Gargari, M. Lq-norm multiple kernel fusion regression for self-cleansing sediment transport. Artif Intell Rev 57, 27 (2024). https://doi.org/10.1007/s10462-023-10673-3
Accepted:
Published:
DOI: https://doi.org/10.1007/s10462-023-10673-3