
Abstract
Over the last decade, deep neural networks have shown great success in the fields of machine learning and computer vision. Currently, the CNN (convolutional neural network) is one of the most successful networks, having been applied in a wide variety of application domains, including pattern recognition, medical diagnosis and signal processing. Despite CNNs’ impressive performance, their architectural design remains a significant challenge for researchers and practitioners. The problem of selecting hyperparameters is extremely important for these networks. The reason for this is that the search space grows exponentially in size as the number of layers increases. In fact, all existing classical and evolutionary pruning methods take as input an already pre-trained or designed architecture. None of them take pruning into account during the design process. However, to evaluate the quality and possible compactness of any generated architecture, filter pruning should be applied before the communication with the data set to compute the classification error. For instance, a medium-quality architecture in terms of classification could become a very light and accurate architecture after pruning, and vice versa. Many cases are possible, and the number of possibilities is huge. This motivated us to frame the whole process as a bi-level optimization problem where: (1) architecture generation is done at the upper level (with minimum NB and NNB) while (2) its filter pruning optimization is done at the lower level. Motivated by evolutionary algorithms’ (EAs) success in bi-level optimization, we use the newly suggested co-evolutionary migration-based algorithm (CEMBA) as a search engine in this research to address our bi-level architectural optimization problem. The performance of our suggested technique, called Bi-CNN-D-C (Bi-level convolution neural network design and compression), is evaluated using the widely used benchmark data sets for image classification, called CIFAR-10, CIFAR-100 and ImageNet. Our proposed approach is validated by means of a set of comparative experiments with respect to relevant state-of-the-art architectures.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
CNNs are currently among the most widely used machine learning models for object recognition and computer vision [1,2,3]. Despite the fact that CNN with several layers have been in use for a long time, they gained widespread interest in the scientific community in 2006 following the work of several researchers, such as Bengio et al. 2007 [4] and LeCun et al. 2015 [5]. In fact, when dealing with extremely complex classification problems or for specific purposes, CNN has become increasingly used, especially at a high level of precision. CNNs architecture is defined by a large number of hyperparameters, which should be fine-tuned to optimize the architecture. Previous works in the literature have been proposed with the goal of optimizing architectures such as ResNet [6] and VGGNet [7]. Unfortunately, the majority of these architectures are either defined manually by experts or automatically created using greedy induction techniques. Despite the impressive performance of the CNN design, experts in the disciplines of optimization and machine learning proposed that improved structures may be discovered using automated approaches. Evolutionary computation researchers proposed modeling this task as an optimization problem and then solving it with an appropriate search algorithm [8]. Indeed, selecting the blocks’ number, nodes per block and the graph’s topology within each CNN block is similar to solving a problem of optimization within a large search space. Due to the fact that EAs are capable of approximating the global optimum and thus avoiding local optimal solutions (architectures), authors in [9] proposed recently the use of such metaheuristic techniques to handle the challenge of optimizing the CNN architecture.

Bi-CNN-D-C scenario
Efficient model designs [10, 11] focus on acceleration over compression through the use of optimized convolutional operations or network architectures. Recently, as a means of improving accuracy, deepening on CNN models has become a popular trend, as demonstrated by ResNet [6], VGGNet [7] and Xception [12]. Indeed, it is challenging to deploy these deep models on low-resource devices such as smartphones and mobile robots. However, billions of network parameters represent a significant storage overhead for embedded devices, such as the VGG16 deep learning model, which has over 138 million parameters and requires over 500MB of memory space to classify a 224 224 image. Obviously, such a large model cannot be directly deployed in on-board devices. Deep compression process is a critical technique for resizing a deep learning model by consolidating and removing inadequate components. However, compressing deep models without significant loss of precision is a critical issue. Several techniques for CNN pruning have been presented, including neurons, filters and channel pruning approaches [13], which reduce model weight by removing unimportant connections.
Due to the fact that EAs are capable of approximating the global optimum and thus avoiding locally optimal solutions, recent works [9, 14, 15] recommend that similar metaheuristic algorithms be employed to address the CNN architectural optimization challenge in the field of network compression. To do so successfully, the solution encoding, the fitness function and the variation operators must all be defined. In fact, all previous work focuses on compressing manual architectures and their nonexistent compression for automated CNN architecture. We notice that in our previous works, the problematic of compression is not tackled.
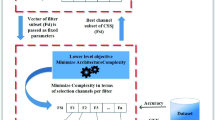
Motivated by recent survey papers [9, 14, 16] on deep neural networks pruning and the reported interesting results, we decided to tackle the problem of filter pruning. As any CNN architecture could be pruned in different ways, we framed the problem of “joint design and pruning” as a bi-level optimization problem. The upper-level goal is to search for good architectures, while the lower-level one is to apply filter pruning on the considered architecture. Indeed, the evaluation of an upper-level architecture requires sending this architecture to the lower level to execute the fitter pruning on it by deactivating some filters. The filters that should be deactivated could not be known before hand as the number of possibilities is huge and corresponds to a whole search space. For this reason, the filter pruning task is executed at the upper level as an evolutionary optimization (search) process. In this way, the fitness evaluation of each upper-level solution (architecture) requires the (near) optimal filter pruning decision (encoded as a binary vector where 0 means that the corresponding filter is deactivated) found at the lower level. By following such as a bi-level optimization process, the final output of our approach is an CNN architecture with minimum number of filters and optimized topology. Figure 1 illustrates an example of a Bi-CNN-D-C (bi-level convolution neural network design and compression) scenario. To our knowledge, this is the first study to model and solve the CNN architecture design and compression problem as bi-level method. Each upper-level solution necessitates solving a separate lower-level optimization problem; the computational cost intends to be prohibitively expensive. We address this issue by solving combinatorial BLOPs using CEMBA [17]. Indeed, each upper-level population collaborates with its corresponding lower-level population. This fact enables a significant reduction in the number of evaluations performed during the lower-level search process. The main contributions of our paper could be summarized as follows:
-
For the first time, an evolutionary method that combines CNN architecture generation with filter pruning within the optimization process is developed. This is motivated by the fact that any generated architecture should be first pruned before evaluating its classification performance.
-
The joint design and filter pruning is modeled as a bi-level optimization problem where architectures are generated through crossover and mutation at the upper level with minimum NB and NNB, while filter pruning of each architecture is applied at the lower level.
-
The bi-level optimization modeling is solved using a bi-level co-evolutionary algorithm to ensure the effective collaboration between the architecture generation (at the upper level) and the filter pruning at (the lower level).
-
Detailed experiments on CIFAR and ImageNet data sets in addition to a COVID-19 case study are conducted in comparison with several recent and prominent peer works. The merits of our proposed algorithm, Bi-CNN-D-C, are demonstrated based on several metrics including the classification error, the number of GPUDays and the number of parameters.
The rest of this paper is structured as follows. Section 2 summarizes the review of the literature on CNN pruning. Section 3 details our proposed approach. Section 4 details the experimental design and performance analysis results. Finally, in Sect. 5, the paper is concluded and some future research directions are suggested.
2 Related work
2.1 CNN design based on evolutionary optimization
Recently, some researchers have taken an interest in EAs as a means of evolving deep neural network architectures. A survey on applications of swarm intelligence and evolutionary computing based optimization of deep learning models has been published by Darwish et al. [9]. Based on this survey, we selected the most representative:
-
Cheung and Sable [18] optimized the architecture hyperparameters using a hybrid EA on the basis of the diagonal Levenberg Marquardt technique with rapid convergence and a low computing cost of fitness assessments number. They established the critical role of architectural choices in convolutional layer networks. Their findings demonstrate that even the simplest evolution strategies can yield significant gains. When variation effects are present, the employment of evolved parameters in combination with local contrast normalization preprocessing and absolute value across layers has proven a compulsive performance on the MNIST data sets [19].
-
Fu**o et al. [20] presented evolutionary Deep Learning, called evoDL, as a technique for discovering unique architectural designs. This technique is intended to be used to investigate the development of hyperparameters in deep convolutional neural networks, called DCNNs. Additionally, authors proposed AlexNet as a fundamental framework of the CNN and optimize both the parameters tuning and activation functions using evoDL.
-
Real et al. [21] used the CIFAR-10 and CIFAR-100 data sets to develop the CNN structure in order to identify the classification model. They presented a mutation operator that may be used to avoid locally optimum models. They demonstrated that neuro-evolution is capable of constructing highly accurate networks.
-
**e et al. [22] maximized the recognition accuracy by representing the network topology as a binary string. The primary constraint was the high computing cost, which compelled the authors to conduct the tests on small-scale data sets.
-
Mirjalili et al. [23] developed an adaption for solving bi-objective models, called NSGA-Net. The image classification and object alignment results obtained demonstrate that NSGA-Net is capable of providing the user with less than complicated correct designs.
-
Alejandro et al. [24] developed EvoDEEP to optimize network characteristics by calculating the probability of layer transitions based on the finite state machines concept. The goal was reducing classification error rates and preserving the layer sequence.
-
Real et al. [25] provided a GA with an updated tournament selection operator that takes into account the age of the chromosomes while selecting youngest chromosomes. The architectures are described as small directed graphs with edges and vertices representing common network actions and hidden states. They developed novel mutation operators connecting the edges’ origin to other vertices and rename the edges arbitrarily in order to cover the entire search space.
-
Sun et al. [26] developed an evolutionary technique for improving convolutional neural network designs and initializing their weights for image classification problems. This aim was realized by develo** a unique approach for initializing weight, a novel encoding variable-length chromosomes strategy, a slacked binary tournament selection methodology and an efficient fitness evaluation technique. Experiments indicated that the EvoCNN methodology surpasses clearly a wide number of existing approaches in terms of classification performance on practically all data sets investigated.
-
Lu et al. [26] established a multi-objective modeling of the architectural search problem for the first time by minimizing two potentially conflicting objectives: classification error rate and computational complexity, as measured by the number of floating point operations (FLOPS). In order to execute a multi-objective EA, they updated the non-dominated sorting GA-II (NSGA-II) algorithm.
-
**g et al. [27] developed a multi-objective model aiming to maximize classification accuracy while kee** the tuning parameters to a minimum. The proposed model was solved based on a hybrid binary encoding representing component layers and network connections using multi-objective particle swarm optimization with Decomposition, called MOPSO/D. The architectures discovered are considered to be exceptionally competitive when compared to models created manually and automatically.
2.2 CNN compression
Deep network compression is one of the most significant strategies for resizing a deep learning model by combining the removal of ineffective components [14]. However, compressing deep models without considerable loss of precision is a key challenge. Recently, many studies have been focused on discovering new techniques to minimize the computational complexity of CNNs based on EAs while retaining their performance [14]. We divide the network compression techniques into three categories depending on the existing work: filter pruning [29,30,31,32], quantization [33,34,35,36,37] and Huffman encoding [38,39,40].

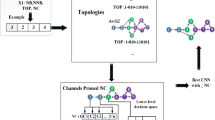
An illustration of how filter-level pruning works [28]
The convolutional operation in the CNN model integrates a large number of filters to improve its performance under various classification and prediction processes [41]. Recently, various pruning-based filter pruning techniques [29,30,31,32] have been suggested. The addition of filters enhances the defining features of the spatial characteristics generated by the CNN model [9, 42]. However, this increment results in a significant increase in the DNN model’s FLOPs. As a result, removing superfluous filters is critical for reducing the computational requirements of the DCNN model. Figure 2 illustrates a scenario using filter-level pruning. We summarize the most important works on filter pruning currently available:
-
Luo et al. [31] introduced an efficient framework named ThiNet for accelerating the operation of the CNN model through the use of compression during the training and testing phases. They implemented filter-level pruning, in which a filter that is no longer necessary is deleted based on statistical information generated from the following layer. The authors proposed pruning filters at the filter level as an optimization issue for determining which filters to prune. They solve the optimization problem with a greedy method which is defined as follows:
$$\begin{aligned} arg \min _{E} \sum _{N}^{i=1}\left(y_{i}-\sum _{j\epsilon E}X_{ij}\right)^{2} \nonumber \\ Subject \ to, \left| E \right| = k \times c_{rate} \nonumber \\ E \subset \begin{Bmatrix} 1,2,...,k \end{Bmatrix}, \end{aligned}$$(1)where N represents the training example number (\(X_{i}\),\(Y_{i}\)), \(\left| E \right|\) represents the subset element number, k represents the channel number within the CNN model and \(c_{rate}\) represents the channels number retrained after compression.
-
Bhattacharya and Lane [43] developed a technique for CNN compression that removes sparsification in convolutional filters and the fully connected layer. The primary goal was to minimize the amount of storage required by devices throughout the training and inference processes. By utilizing layer separation and convolutional filters, the computational and spatial complexity of the DCNN model can be significantly expanded.
-
Zhou et al. [44] suggested a multi-objective optimization problem for filter pruning, followed by a knee-guided approach. They proposed a trade-off between performance degradation and parameter count. The fundamental concept is to remove parameters that contribute to performance degradation. They used the performance loss criteria to determine the significance of a parameter. To produce a tiny compressed model, the number of filters should be limited to a minimum while yet achieving a high degree of precision. The challenge can be handled by identifying a compact binary representation capable of pruning the maximum number of filters while maintaining a reasonable level of performance. This work has the advantage of lowering the number of parameters and processing overhead.
-
Huynh et al. [45] presented the DeepMon approach for develo** deep learning inference on mobile devices. They assert that they can do inference in a short period of time and with minimal power consumption by using the graphics processing unit on the mobile device. They presented a method for convolutional processes on mobile graphics processing units to be optimized. The technique repurposes the results by utilizing CNN’s internal processing structure, which includes filters and a network of connections. Thus, deleting filters and superfluous connections demonstrates faster inference.
-
Denton et al. [32] significantly reduce the time required to evaluate a large CNN model developed for object recognition. The authors used insignificant convolutional filters to develop approximations that significantly minimize the necessary computation. They began by compressing each convolutional layer using an appropriate low-rank approximation and then fine-tuning until prediction performance was recovered.
Weight quantization decreases both the storage and computing requirements of the CNNs model [
where Eq. 2 denotes the quantization method with the parameters W and T. For instance, Q is set to 8 for 8-bit quantization. W is an arbitrary positive real number, and T has the same type as variable Q. The quantization strategy for compressing DNN models is explored in the current literature [33,34,35,36,37]. The strategies cover model reduction by arranging weight matrices optimally. However, the previous work does not address the negative repercussions of weight quantization or its estimation complexity.
A Huffman encode is a lossless data compression algorithm that is frequently used [46]. Schmidhuber et al. [39] utilized Huffman coding to compress text files generated by a neural prediction network. Han et al. [40] used a three-stage compression strategy to encode the quantized weights, which included pruning, quantization and finally Huffman coding [9]. Ge et al. [47] proposed a hybrid model compression technique based on Huffman coding to capture the sparse nature of trimmed weights. Huffman codes are superior to all other variable-length prefix codings. However, Elias and Golomb. 1975 encoding [48] can take advantage of various intriguing characteristics, such as the recurrence of specific sequences, to achieve greater average code lengths.
Despite the interesting findings of design and compression work on optimizing deep learning architectures, all researchers believed architecture optimization was a single-level problem. Therefore, We show that CNN design can be improved if two optimization levels are considered, where a search space is assigned to each level.
3 The proposed approach
3.1 Bi-CNN-efficient and compression overview
The two following questions motivate our bi-level model:
-
How can we design a less complex architecture with the minimum possible convolution blocks (NB) and convolution nodes per block (NNB) while achieving high performance, which is highly dependent on the topologies of the convolution blocks’ graphs?
-
For any CNN architecture, there are a large number of filters per layer; how could we determine the optimal number of filters per layer?

Design and prune the CNN architecture using a bi-level model
For the following reasons, a bi-level modeling of the design and compression architecture is necessary to solve these two research problems. On the one hand, optimizing the design and compression of hyperparameters requires intelligent sampling of the entire high-level search space. On the other hand, in order to assess the upper-level quality solution (NB, avgNNB, NF, Err), we must pass the vector (TOP, NF) to the lower level as a fixed parameter, with the intention of finding the best selected filters (NF) from the lower-level search space. Once the lower-level process is completed, each architecture is passed through the process of quantization of 32-bit floating point values into 5-bit integer levels. This process is used to further reduce the stored size of the weights file. These strategies approached the problem as a bi-level optimization problem, evaluating each pair of hyperparameters independently. This observation demonstrates a significant inconvenience of present approaches and is the paper’s key research gap. The bi-level modeling of the CNN architecture design and compression optimization problem illustrated in Fig. 3 demonstrates our approach.
In fact, the upper-level optimization process is concerned with optimizing the (NB, NNB) and determining the optimal topology sequence in terms of classification accuracy while the lower level focused on the CNN pruning filters. As we are in the case of bi-level optimization, we have two kinds of solutions: (1) an upper-level solution and (2) a lower-level one. Indeed, the upper-level solution is encoded as a vector containing two sub-vectors: (1) the first one contains integer values expressing the NB and the NNB and (2) the second one is a binary sequence expressing the topology (encoding adopted from Genetic-CNN [49]). This encoding is chosen to reduce as possible the chromosome length at the upper level. The lower-level is a sequence of sub-vectors each expressing the filter pruning decision of the corresponding convolution node. Modeling such a bi-level problem with the goal of finding better architectures with less complexity would be a better idea. It would be wiser to model such a bi-level problem with the goal of identifying more complex architectures.
3.2 Bi-CNN-D-C: adaptation of CEMBA to the bi-level model
To solve the proposed bi-level optimization model using CEMBA’s adaptation, the following upper-level processes should be detailed:
3.3 Upper level: CNN design
-
Upper-level solution encoding: It is constructed by concatenating the number of blocks NB with an integer sequence NNB representing the node numbers in every block and with a sequence of graph topology of the convolution layer. A possible directed graph is represented by this object.
-
Upper-level fitness function: Aim to evaluate an upper-level solution, we must reduce the complexity of the CNN architecture as much as possible by optimizing the (NB,NNB) while achieving high performance. In order to accomplish this, we propose the following fitness function:

Upper level: Crossover operator [4]
To differ the population at the upper level, the uniform crossover operator [50] has been considered, which allows for variation across all chromosomal segments. To guarantee the diversity of solution variation, every parent solution is converted into a binary sequence based on the Gray encoding [51]. This encoding technique is inspired by the fact that neighboring integer values vary by just one bit, which is not true for the conventional binary encoding [52]. This has been shown to help prevent premature convergence at so-called Hamming walls [53], where too many simultaneous mutations (or crossover events) are required to change the chromosome to a more advantageous solution. A uniform crossover procedure randomly selects a recombination mask from a uniform distribution. This mask represents a binary vector of 0 and 1. The first offspring is formed by extracting the bit from both parents in case that the corresponding mask bit is equal to 0 and from both parents if the corresponding mask bit is equal to 1. The second offspring is generated using the inverse mask. Finally, each offspring is encoded into an integer vector and the value of its fitness function is calculated. Due to the fact that the proposed solution represents a vector of integers, the length of the binary chromosome is a multiple of four (we mean that each integer is encoded using 4 bits). If this is not the case for a created offspring, the last bits are removed to maintain a multiple of four length. It is crucial to remember that the NB value of a created offspring may vary from the length of the NNB sequence. The offspring solution is rectified in this example by changing the sequence length value from NNB to NB. Then, in order to optimize accuracy, we must look for the optimum topologies. Then, in order to maximize accuracy, we must determine the optimal topologies. As seen in Fig. 4, the answer will be encoded as a squared binary matrices sequence, one for each conceivable directed network. A value of 1 indicates that the row node is the column node predecessor; a value of 0 indicates that there is no relationship between the two nodes. Due to the fact that this work is concerned with the CNN model, the following constraints must be respected:
-
Each active convolution node should have a predecessor node. The latter may be a previous convolution node or the convolution node at the input.
-
Each active convolution node should have a successor node. The latter may be a convolutional successor node or the output successor node.
-
Any active convolution node should have predecessors in its preceding layers. For instance, node 4 may have predecessors in the form of nodes 3, 2, 1 and the input node.
-
The initial convolutional node should have a single preceding node that acts as the input node.
-
The last convolution node’s output node should have only one successor node.
The goal of mutation is to inject abrupt changes within the population to ensure its diversity and thus its ability to explore other regions of the search space (e.g., non-visited ones so far). Among these operators, we cite one-point mutation, random reset, inversion mutation, just to name a few. As we adopted binary encoding as both levels (NB integer, NNB integer, topology, filter activation decision vector), the one-point mutation allowed us a progressive change of the subject solution. In this way, diversity is slightly incorporated within the evolutionary process. As with the crossover operator, the solution of mutation operator is converted to a binary string using Gray encoding before applying the one-point mutation. Due to the possibility that the variation will alter the NB field, the consistency is achieved by using the following repair technique. (assumes LNS = length (NNB sequence)).
-
If (NB< LNS), then delete the chromosome’s final (LNS-(LNS-NB)) integers.
-
If (NB > LNS), then at the end of the chromosome, add (NB-LNS) randomly generated integers. These two conditionals guarantee that NB will always equal LNS.
On the basis of prior work [1], we suppose that the quantity of NB must be in the interval [9, 11] while the quantity of NNB within the interval [32, 49] in this research. The Acc is computed using the holdout validation method [54] by 80% of data records are randomly selected for training and 20% for testing.
3.4 Lower level: CNN compression
-
Encoding the solution of the Upper level: It resembles the selected filters number (NF) to be pruned in the convolutional layer. The filter subset of the binary vector represented by a bit sequence of 0, 1.
-
Fitness function of the lower level : To assess the lower-level solutions, the complexity of the CNN architecture must be reduced by minimizing the NF while preserving or improving the high precision. To do so, we provide the following fitness function:
$$\begin{aligned} F(N F (Arch))=(N F/N F max) + (Err) \end{aligned}$$(3)
In the proposed lower-level deep pruning filters, a binary strings is adopted for representing the filters of a CNN model. It is essential to know that the suggested algorithm prunes convolution layers. DCNNs are constructed basically by stacking multiple convolution, pooling and fully connected layers. The goal of this paper is the automated joint design and filter pruning of CNN architectures. As filters are located only within convolution layers, only these latter are pruned. Our approach considers each bit as one single filter, e.g., if we are looking to represent two layers of convolution, 16 filters for one layer and 32 filters for the other one, we will require a string of 48-bit, while a bit with a zero assigned indicates the elimination of the corresponding filter. Furthermore, during pruning simple of CNN models, uniquely one bit string is needed, with every bit representing a model filter. Figure 5 shows the binary representation of a CNN before and after pruning. The two-point crossover operator is used to vary the population [50] since it enables chromosome parts to change. Each parent solution in this operation is a set of binary strings [51]. A couple of cutting points are chosen for each couple of parent in this process, after which the bits between the cuts will be exchanged to produce a couple of offspring solutions. In fact, the two-point crossover is adopted to allow the variation of all parts of the chromosomes. Indeed, if the one-point crossover is used, the extreme regions (extreme genes) of the chromosomes are likely to still unchanged. This could significantly reduce the exploitation ability of the crossover and the population diversity. To mitigate this issue, researchers proposed the use of two cut points instead of a single one to allow the variation of the entire chromosome.

CNN model’s binary representation before and after pruning half of the filters from every layer
Similar to crossover, the solution of mutation operator is encoded as a binary string, followed by a random mutation of one point. A point on the chromosomes of both parents is chosen at random and referred to as a “crossing point.” The bits to the right of this point are exchanged between the two parent chromosomes.
A quantization of 32-bit floating point values into 5-bit integer levels is used to further reduce the stored size of the weights file. The quantization part are spread linearly between Wmin and Wmax because it produces higher accuracy results than density-based quantization; thus, even if a weight occurs with a low probability, it may have a high value and therefore a high influence, and if quantized to be less than its real value. This stage produces a compressed sparse row of quantized weights.
Due to the statistical characteristics of the quantization output, Huffman compression might be used to further reduce the weights file. However, this adds the additional hardware needs of a Huffman decompressor and a compressed sparse row to weights matrix converter.
The test error is computed using the holdout validation technique [55], which randomly selects 70% of the data records for training and 30% for testing. To deal with this the over-fitting issue, the training data (70%) is divided into 5 folds, and thus, fivefold cross-validation is applied during training. The classification performance is averaged over the 5 folds of the training partitions. Figure 6 illustrates the adopted validation strategy in this work [56]. Eventually, in the experiments, we report the classification error on the test data (30%).

Adopted nested validation strategy in our work
4 Experimental study
4.1 Benchmarks and research questions
We compared the performance of the suggested strategy to earlier work using the two frequently used benchmark data sets: CIFAR-10, CIFAR-100 and ImageNet. The first batch of data contains 60,000 \(32\times 32\) RGB images that are grouped into ten groups of 6000 images each. Indeed, the test sample size is 10,000, but the training set sample size is 50,000. The other data set is similar to CIFAR-10, but differs in terms of class count; it comprises 100 classes and each class contains 600 images. Both data sets present significant challenges due to factors like as noise, image size and image rotation. The photographs are incremented during the processing stage to ensure that the comparisons are fair. Indeed, four zero pixels are added to each image, resulting in the modification of a \(32\times 32\) image. Following that, the clipped image is arbitrarily compressed with a probability of 0.5. This technique was influenced by [57]. Due to the enormous number of classes, the most of current studies do not conduct experiments using CIFAR 100 data sets. To demonstrate our Bi-CNN-D-C performance, we carry out a series of tests on CIFAR-10 and CIFAR-100. Finally, the ImageNet The third batch of collection contains 14,197,122 images that have been annotated using the WordNet hierarchy. Since 2010, the ImageNet Large-Scale Visual Recognition Challenge (ILSVRC) has used the data set as a benchmark for image classification and object recognition. The freely available data set provides a collection of training images that have been hand labeled. Additionally, a set of test images is released without the associated manual annotations. Our examination study will address the following main questions:
-
How do the architectures generated by Bi-CNN-D-C compare to previous work on CIFAR-10 image classification?
-
Is it possible for Bi-CNN-D-C to maintain its efficacy on CIFAR-100 and ImageNet, that is, when the number of classes is increased to 100?
-
Is Bi-CNN-D-C capable of producing high-quality designs in spite of its high computational cost?
To solve these RQs, we compare the best architecture developed by Bi-CNN-D-C to previously generated and current designs.
4.2 Performance indicators
According to previous work, the most used performance measures in image classification using DNN are error rate and floating point operations (FLOPs). Equation (8) gives the error rate (Test error), where FP stands for false positives, FN stands for false negatives and NE stands for the total number of samples.
#Params is the sum of the weights and biases in the convolution layer, and is given by Eq. (4), where Wc, Bc, pc and K are the weights, biases, parameters and the convolution layer size, respectively; N represents the kernels number; and C represents the channels number in the input image [1].
The GPUDays metric is the number of GPU day units where a unit means that the algorithm has performed one day on one GPU.
FLOPs represent the number of floating point operations per second, which is accredited as the computation speed, which is a measure of hardware performance, and is given by Eq. (7) where W, H and \(C_{in}\) represent, respectively, the width, height and number of channels of the input characteristics map. K is the core width, and \(C_{out}\) is the number of output channels.
Each method is executed 20 times, and then, the performance values of the best 20 outputted architectures of each method are averaged (for each metric).
4.3 Peer algorithms and parameters setup
The most representative previous studies from both categories of CNN generation methods are compared to our Bi-CNN-D-C methodology. From the evolutionary approach based on CNN Design, we selected BLOP-CNN, Genetic-CNN, LargeScale-Evo, AE-CNN, CNN-GA and NSGA-Net. From the pruning approaches, we selected DeepPruningES, Channel-Evo and Classical-Pruning [4.4.2 Evolution trajectory at the upper level When evolutionary algorithms are employed to solve real-world issues, we typically looking to realize whether or not they have converged. In this section, the evolutionary trajectories of the suggested method in terms of the benchmark data sets are studied. We analyze the convergence behavior of BLOP-CNN on CIFAR-10 Over the evolutionary search process, the NB quantity is decreased from 15 to 9. Additionally, the interval extent is minimized over generations, resulting in architectures with similar NB values at the conclusion of the optimization process. Due to the fact that NB and NNB are mutually exclusive objectives, minimizing the NNB is not easy. Indeed, the AVG NNB’s slope decrease is notably less than NB’s. This fact could be explicated by the fact that these two quantities may have a conflicting connection. Indeed, reducing the number of blocks NB may result in an increase in the number of nodes per block NNB, with the goal of maximizing or preserving the classification Acc. We believe that the EA at the top is attempting to strike a favorable trade-off between NB and NNB. Moreover, We find that the upper level is progressively maximized from generation to generation with a degree of convergence toward the maximum attained value. The quantity of Acc is increased from 40 to 98%. The first 15 generations have a rather steep maximization slope in comparison with the latter 15 generations. This could be explained by the fact that the search space of the possible CNN architecture is well explored during the first phase of the evolution process. During this phase, the huge search space contains low-, medium- and high-quality architectures. Thus, during the first phase the population is distributed over the entire search space. For this reason, a high number of low- and medium-quality architectures are visited and even designated as best found architectures at that stage so far. After that the evolutionary process was able to focus the population on the promising regions of the search space, where most architectures have similar respectful classification performance values. This focus makes the algorithm sampling well-performing architectures that are similar in terms of classification accuracy, which explains the alleviation of the maximization slope. This phenomenon could be observed also in many other applications of genetic algorithms [
4.4.3 Comparisons to pruning methods
The most representative previous studies compressed the already-existing CNN manual architecture. There is no existing work that compresses an architecture that is generated automatically. For this reason, Bi-CNN-D-C is the first work to compress an evolving CNN architecture automatically. Table 10 summarizes the CNN manual architectures that were used to compare the proposed approach. In fact, the results using the CIFAR-10 and CIFAR-100 data sets are presented in Tables 6 and 7, respectively. For each DCNN architecture, the best test error and number of FLOPs are shown. Based on Table 6, the average test error of the DeepPruningES algorithm is between 7.43 and 8.91%, where for the VGG16 and VGG19, they obtain similar results of 8.21% with a 32.01% and 32.56% diminution in the FLOPs number, and for ResNet56, ResNet110, DenseNet50 and DenseNet100, they obtain values lying between 7.43% and 8.91% with a 16.72% and 32.56% reduction in the FLOPs number. In Table 6, the average test error of the Channel-Evo algorithm is between 5.85 and 7.91%, with the VGG16 and VGG19 achieving similar results of 7.26% with a respective 52% and 53.05% reduction in the number of FLOPs, and the ResNet56, ResNet110, DenseNet5 and DenseNet100 values lying between [5.85 and 7.91%] and a [16.02% and 17.35%] reduction in the number of FLOPs. Always on Table 6, the average test error of the auto-balanced filter is between 8.27 and 9.32%, whereas the VGG16, VGG19, ResNet56, ResNet110, DenseNet50 and DenseNet110 obtain values between 8.27% and 9.32% and a [36.5% and 57%] reduction in FLOPs. The average test error of Classical-Pruning is laying between [6.46 and 9.09%]. In fact, the proposed Bi-CNN-D-C algorithm provide 1.98 \(\times\) 107 and \(2.21 \times 10^{7}\) of #Flops, with 32.5%, 28.9% pruned percentages. Bi-CNN-D-C is capable of reducing FLOPs while maintaining acceptable test errors.
4.4.4 Further analysis and discussion
The main reason that could explain the outperformance of Bi-CNN-D-C over considered peer works corresponds to the principal motivation of this work. From the start of this paper, we have mentioned that the main shortcoming of existing pruning methods including evolutionary ones consists in the fact that these methods take as input an existing (already designed) architecture, and then, the algorithm searches for the best possible pruning decision. This drastically limits the performance of such kind of methods. From a metamorphic vision, we could say that such an algorithm remains paralyzed in a single point of the architecture search space, which is not the case for our algorithm.
By allowing the joint design and pruning of architectures, our algorithm is able not only to move from an architecture to another but also to (near) optimally prune each generated architecture. In this way, our algorithm is not still paralyzed in a single point of the architecture space (i.e., it has the freedom search space sampling). Moreover, the collaborative interaction of the two optimization levels (upper and lower) ensures the narrowing of the search process toward high-performing architectures with minimum number filters (and also minimum NB and NNB). To the best of the authors’ knowledge, Bi-CNN-D-C is the first EA capable of compression automatically designing CNN architectures and providing bi-level interaction between convolutional layers and their hyperparameters.
4.5 Case study on COVID-19 diagnosis
4.5.1 Benchmarks
Chest X-ray and CT are two of the most commonly available radiological tests for the diagnosis of several lung diseases. Chest X-ray and CT are two of the most commonly available radiological tests for the diagnosis of several lung diseases. In our study, we acquired chest X-rays belonging to 50 COVID-19 patients from [61] by Dr. Joseph Cohen. In these data, a number of individuals having intense respiratory distress sickness, serious respiratory problem, pneumonia, COVID-19 have chest X-ray along with computed tomography images in this archive. We also choose normal chest X-ray photographs from the Kaggle library that have been labeled as chest X-ray images (pneumonia) https://www.kaggle.com/paultimothymooney/chest-xray-pneumonia. This study uses a chest X-ray images database divided into 2 separated groups: COVID-19 patient images and normal patient images. We scaled all images within the data set into 224 by 224 pixels. Then, the data set is randomly separated into 2 distinct data sets where 80% is considered for training and 20% for testing. Figures 8 and 9 show uninfected and infected people’s chest X-ray pictures, respectively.

Chest X-ray images appertaining to regular patients [1]

Chest X-ray images appertaining to patients having COVID-19 [1]
4.5.2 Existing works
Many computational intelligence strategies for COVID-19 detection using computed tomography (CT) and X-ray images have been proposed recently [62,63,64]. Fei et al. [74] and thus dynamic evolutionary algorithms could represent an interesting alternative to deal with such a challenge.



