Search
Search Results
-
Investigating interoperable event corpora: limitations of reusability of resources and portability of models
Studies on the applicability of heterogeneous semantically interoperable corpora are rare. We investigate to what extent reusability (both of systems...

-
Multiple annotation for biodiversity: develo** an annotation framework among biology, linguistics and text technology
Biodiversity information is contained in countless digitized and unprocessed scholarly texts. Although automated extraction of these data has been...

-
The CLARIN infrastructure as an interoperable language technology platform for SSH and beyond
CLARIN is a European Research Infrastructure Consortium develo** and providing a federated and interoperable platform to support scientists in the...

-
Beyond lexical frequencies: using R for text analysis in the digital humanities
This paper presents a combination of R packages—user contributed toolkits written in a common core programming language—to facilitate the humanistic...
-
TEI-friendly annotation scheme for medieval named entities: a case on a Spanish medieval corpus
Medieval documents are a rich source of historical data. Performing named-entity recognition (NER) on this genre of texts can provide us with...

-
From Original Sources to Linguistic Analysis: Tools and Datasets for the Investigation of Multilingualism in Medieval English
This chapter presents an outline of some of the different types of digital datasets and tools that are currently available to help researchers in the...
-
Entity normalization in a Spanish medical corpus using a UMLS-based lexicon: findings and limitations
Entity normalization is a common strategy to resolve ambiguities by map** all the synonym mentions to a single concept identifier in standard...

-
A flexible tool for a qualia-enriched FrameNet: the FrameNet Brasil WebTool
In this paper we present a database management and annotation tool for running an enriched FrameNet database, the FrameNet Brasil WebTool. We...
-
Evaluating the FAIRness of Scientific Data Repositories
Evaluation of FAIRness of scientific data repositories is a growing concern. FAIRness means making data compatible with FAIR data principles (M. D....
-
Conducting a Multivocal Systematic Literature Review About Compliance with the Brazilian Law for General Data Protection
A Multivocal Systematic Literature Review (MSLR) is a form of Systematic Literature Review (SLR) that includes gray literature in addition to formal...
-
Chinese Language Resources Through One-Third of a Century
This chapter provides a comprehensive overview of the co-development of Chinese language resources and Chinese language processing in the past three...
-
Treebanking user-generated content: a UD based overview of guidelines, corpora and unified recommendations
This article presents a discussion on the main linguistic phenomena which cause difficulties in the analysis of user-generated texts found on the web...

-
Multi-layered semantic annotation and the formalisation of annotation schemas for the investigation of modality in a Latin corpus
This paper stems from the project A World of Possibilities. Modal pathways over an extra-long period of time: the diachrony of modality in the Latin...

-
The ParlaMint corpora of parliamentary proceedings
This paper presents the ParlaMint corpora containing transcriptions of the sessions of the 17 European national parliaments with half a billion...

-
A multilingual, multimodal dataset of aggression and bias: the ComMA dataset
In this paper, we discuss the development of a multilingual dataset annotated with a hierarchical, fine-grained tagset marking different types of...

-
LexO: an open-source system for managing OntoLex-Lemon resources
The adoption of Semantic Web technologies and the Linked Data paradigm has been driven by the need to ensure the construction of resources that are...

-
Using a Moodle-Based Digital Escape Room to Train Competent EMI Lecturers and Instructors in a Multilingual Environment
Professional development for teachers in English medium instruction (EMI) universities is challenging in a multilingual and multicultural...
-
Finnish parliament ASR corpus
Public sources like parliament meeting recordings and transcripts provide ever-growing material for the training and evaluation of automatic speech...

-
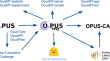
Democratizing neural machine translation with OPUS-MT
This paper presents the OPUS ecosystem with a focus on the development of open machine translation models and tools, and their integration into...
-
Syntactic annotation for Portuguese corpora: standards, parsers, and search interfaces
In the last two decades, four Portuguese syntactically annotated corpora were built along the lines initially defined for the Penn Parsed Historical...
