Search
Search Results
-
Speech-to-SQL: toward speech-driven SQL query generation from natural language question
Speech-based inputs have been gaining significant momentum with the popularity of smartphones and tablets in our daily lives, since voice is the most...

-
Diversity subspace generation based on feature selection for speech emotion recognition
Automatic emotion recognition from speech signals is an important research area. Many speech emotion recognition (SER) methods have been proposed,...

-
Fusion-s2igan: an efficient and effective single-stage framework for speech-to-image generation
The goal of a speech-to-image transform is to produce a photo-realistic picture directly from a speech signal. Current approaches are based on a...
-
Co-speech Gesture Generation with Variational Auto Encoder
The research field of generating natural gestures from speech input is called co-speech gesture generation. Co-speech generation methods should...
-
Shallow Diffusion Motion Model for Talking Face Generation from Speech
Talking face generation is synthesizing a lip synchronized talking face video by inputting an arbitrary face image and audio clips. People naturally...
-
Gammatonegram representation for end-to-end dysarthric speech processing tasks: speech recognition, speaker identification, and intelligibility assessment
Dysarthria is a disability that causes a disturbance in the human speech system and reduces the quality and intelligibility of a person’s speech....

-
Improvement of automatic speech recognition systems utilizing 2D adaptive wavelet transformation applied to recurrence plot of speech trajectories
Spectral-based features, typically used in ASR systems, do not capture the phase information of speech signals. Thus, exploiting new features that do...

-
CommanderUAP: a practical and transferable universal adversarial attacks on speech recognition models
Most of the adversarial attacks against speech recognition systems focus on specific adversarial perturbations, which are generated by adversaries...

-
Speech waveform reconstruction from speech parameters for an effective text to speech synthesis system using minimum phase harmonic sinusoidal model for Punjabi
Speech processing plays a vital role in current speech communication applications. The major objective of digital speech is transmission of messages...

-
Speech Enhancement with Generative Diffusion Models
AbstractAn alternative approach to speech denoising using generative diffusion models that model the distribution of training data is proposed. In...

-
A multitask co-training framework for improving speech translation by leveraging speech recognition and machine translation tasks
End-to-end speech translation (ST) has attracted substantial attention due to its less error accumulation and lower latency. Based on triplet ST data
... 
-
Design and Implementation of Speech Generation and Demonstration Research Based on Deep Learning
Aiming at complex and changeable factors such as speech theme and environment, which make it difficult for a speaker to prepare the speech text in a...
-
Audio-guided self-supervised learning for disentangled visual speech representations
In this paper, we propose a novel two-branch framework to learn the disentangled visual speech representations based on two particular observations....
-
Deep Learning-Based Acoustic Feature Representations for Dysarthric Speech Recognition
Dysarthria is a motor speech disorder and the most common neurodegenerative disease characterized by low volume in precise articulation, poor...

-
Detecting Speech Disorders Using A Machine-Learning Guided Method in Spontaneous Tunisian Dialect Speech
This work investigates the disfluencies processing task within the natural spoken language comprehension field. We present a transcription-based...

-
Speech based emotion recognition by using a faster region-based convolutional neural network
Automatic emotion identification from speech is a difficult problem that significantly depends on the accuracy of the speech characteristics employed...

-
WaveVC: Speech and Fundamental Frequency Consistent Raw Audio Voice Conversion
Voice conversion (VC) is a task for changing the speech of a source speaker to the target voice while preserving linguistic information of the source...

-
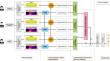
A novel conversational hierarchical attention network for speech emotion recognition in dyadic conversation
Speech is one of the most fundamental mediums for human-to-human interaction, thereby playing a pivotal role in sha** the landscape of...
-
Short Speech Key Generation Technology Based on Deep Learning
With the increasing popularity of biometric identity authentication in important key authentication applications, biometric key generation technology...
-
Robust Automatic Speech Recognition Using Wavelet-Based Adaptive Wavelet Thresholding: A Review
Automatic speech recognition (ASR) is one of the most fascinating fields of research and the performance of ASR systems is most promising in a closed...
