
Abstract
Information hiding technology has always been a hot research field in the field of information security. How to hide information in images is also a major research field of image transformation. Today’s information hiding technology has the problems of complicated encryption technology and large amount of information. Based on the genetic algorithm, this paper studies the image information hiding technology based on genetic algorithm, performs image simulation on different types of mothers, and displays the results. For the images that need to be hidden, no matter how the size changes, the mother image can achieve good information hiding. The change of the parent image is not large. Compared with the Least Significant Bit (LSB) technique, this method has a larger peak signal-to-noise.
Similar content being viewed by others
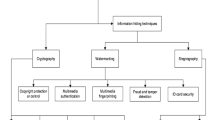

1 Introduction
With the increasing popularity of computer network applications, information security has become a hot area, and information hiding technology has become the focus of information security technology. Information hiding hides information such as plain text and password images in multimedia information, like images, videos, and audio. Since the information hiding technology mainly hides the existence of information, it is not easy to attract the attention of the attacker, and only the authorized legal users can use the corresponding method to accurately extract the secret information from the carrier information. It is precisely because of this information hiding technology that shows its strong advantages and development potential in the field of information security.
Information hiding technology is a cross-discipline. It involves mathematics, cryptography, information theory, computer vision, and other computer application technologies. It is a hot topic that researchers in various countries pay attention to and study. In the research of information hiding, the research results of information hiding carriers are rich now. The principle is to use the redundant information existing in the image to hide the secret object in order to achieve digital signature and authentication or achieve secure communication. At present, it is easier to attack and intercept data transmitted over the Internet through the Internet. If some important secret information is maliciously destroyed or eavesdropped during transmission, it will cause incalculable losses to users. How to provide a secure transmission method for users, that is, to transmit information in a secret manner and avoid the perception of third-party recipients, has become an urgent problem that needs to be solved and thus has led to the rapid development of information hiding technology. After years of research, information hiding technology has developed rapidly, and many information hiding algorithms have also been proposed [1,2,3,4]. Although in some respects it has been relatively mature, there are still a large number of practical problems to be solved such as information hiding capacity, anti-attack, and anti-statistical analysis. Therefore, there are many places where information hiding technology is worth for further research to better apply to the field of information security.
The basic idea of information hiding is to embed secret information into a carrier signal through an embedded algorithm in the process of hiding information to generate a hidden carrier that is not easily perceived. Secret information is released through the transmission of hidden carriers. It is difficult for a person trying to illegally steal information to visually distinguish whether other seemingly unknown secret information is concealed in this seemingly ordinary carrier signal. Even if hidden information is found in the transmitted information, such information is difficult to extract and delete, so that information encryption transmission can be realized in this way. Information hiding technology plays an important role in protecting important information from being destroyed or stolen. Therefore, compared with traditional cryptography, information hiding technology addresses information security issues from different perspectives. Traditional cryptography [5,6,7,8] favors protecting the information content itself. After being encrypted, the secret information becomes a garbled code, making it difficult to understand, but it is also very obvious that this garbled is telling others that the information is very important. It is easy to attract the attention of the attackers, stimulate the motivation of illegal interceptors to crack confidential information, and increase the risk of this information being intercepted and attacked. Information hiding technology can greatly reduce the probability that information is intercepted and attacked. However, this does not mean that information hiding technology can replace encryption technology because both research have different aspects of protected information. It is to strengthen the security of information from different perspectives. First of all, the encryption technology mainly covers information by masking the information content, while the information hiding technology is realized by covering the existence of information. Encryption process is equivalent to adding a lock on the content of information without being cracked. Information hiding technology is to disguise the content of information through another carrier and not be discovered by others. Therefore, the two are not only inconsistent but also complementary. If we can combine the two, we can better protect secret information.
Genetic algorithm [9,10,11] is a computational model designed by simulating Darwin’s genetic selection and biological evolution. The most important idea of Darwin’s genetic selection evolution is the survival principle of the fittest, which means that when the environment changes, only Individuals who can adapt to the environment can survive. In the evolutionary process, individuals with good quality are mainly preserved and combined through genetic manipulation, so that new individuals are continuously produced. Each individual will inherit the basic characteristics of the father but will produce new changes that are different from the parent, so that the population will evolve forward and continue to approach or obtain the optimal solution. Genetic algorithms have a good ability to solve complex system optimization problems, especially some combinatorial optimization problems, and have been solved in complex problems [12], image processing [13, 14], image partitioning [15, 16], machine learning [17, 18], and artificial life [19, 20]; and other fields have been successfully applied and show good performance.
At present, the main contents of information hiding algorithm research include the relationship between the embedded strength of information [21, 22], hidden capacity [
2.1.2 Initial population
In genetic algorithms, after the coding design, the initial population needs to be set, and the iterative operation is started from the initial population until it terminates the iteration according to a certain termination criterion. The larger the initial population size, the wider the search range and the longer the genetic manipulation per generation. In contrast, the smaller the initial population setting, the smaller the corresponding search range and the shorter the genetic manipulation time per generation. One of the most commonly used initialization population methods is the unsupervised random initialization method. There are 2k! kinds of possible occurrences of Sk. When the value is large, calculation is required for each case, the calculation difficulty will be quite large, and the operation efficiency will be very low. Therefore, one of the 2k! species sequences was randomly selected as the initial population.
2.1.3 Fitness function
The composition of the adaptation function is closely related to the objective function, which is often changed by the objective function. It is very important to choose the correct and reliable fitness function, because it will directly affect the convergence speed of the genetic algorithm and whether it can find the optimal solution. In order to be able to directly relate the fitness function to the individual quality of the population in the genetic algorithm, it is specified that the fitness value is always non-negative, and in any case, the larger the fitness value is, the better. The fitness scale transformations currently used are mainly linear scale transformations, power-scale transformations, and exponential scaling transformations. In this paper, peak signal-to-noise ratio (PSNR) is used as an index of image quality evaluation, and performance comparison between various algorithms can be performed conveniently. The peak signal-to-noise ratio of the mother image C and the secret image F is
The specific fitness function used in this algorithm can be defined as:
w is the scale-up factor used to amplify the differences between individuals in order to select individual performance evaluations. c is a constant, it can make some individuals with lower fitness also have the opportunity to enter the next generation, in order to maintain the diversity of the individual.
2.1.4 Operator
Selection: Selection is to select individuals with large values in the population to generate new populations, so that the individual values in the population continue to converge toward the optimal solution. The genetic algorithm uses a selection operator to select individuals. The operation process is a process in which the survival of the fittest takes place. Through this approach, the individual’s overall quality in a group is improved. The selection operator can select algorithms such as roulette selection, random traversal sampling, local selection, truncated selection, and tournaments. The first step in the selection process is to calculate the fitness. The fitness can be calculated according to the proportion, or the fitness can be calculated according to the sorting method. After calculating the fitness, the tall individuals who have selected the applicable values in the parent group according to the fitness enter the next generation group.
Crossover: Crossover is the process of selecting two individuals from the population and exchanging parts of the two individuals. This is the core of the genetic algorithm. When there are many identical chromosomes in the population or the chromosomes of the offspring are not much different from the previous generation, a new generation of chromosomes can be generated by chromosome crossing. When using crossover operations in a genetic algorithm, first randomly select two individuals to be mated in the new population, set the length of the selected individual bit string to k, and randomly select one or more integer points n in [1, k-1] as a cross position. Then, the crossover operation is performed according to the crossover probability P. The selected two individuals exchange their respective partial data according to the set requirements at the cross position to obtain two new individuals. Crossover operators commonly used by genetic algorithms have a little bit of crossover and multi-point intersections. This article chooses a single-point crossover operator.
Variation: The variation is that the offspring change the value of a position in the string by a small probability. In binary coding, it changes 1 to 0 and 0 to 1. Mutation operators provide new information for the population to maintain the diversity of the population’s chromosomes. The use of mutation in genetic algorithms is based on the set mutation probability P to change the value of the gene at the relevant gene position. The mutation operator in this paper uses a multi-point mutation operator for all gene segments. Firstly, determine whether each gene is mutated. If it is mutated, then a random number is generated between [0 2k-1], which is to transform the position of some hidden information. However, the newly generated random number cannot be equal to or adjacent to the current chromosome’s genetic value, that is, the newly generated value of the mutation cannot be duplicated or adjacent to the current chromosome’s contained gene value, so as to ensure that the replaced gene value does not conflict with the current gene value.
2.1.5 Control parameters
The control parameters mainly include population size, code length, number of iterations, mutation probability, and crossover probability. These parameters are all set to fixed values in the basic genetic algorithm. In addition, when selecting a specific operator, parameters related to the operator are also selected. The proper choice of genetic algorithm parameters directly relates to the convergence speed and accuracy of the algorithm. However, because there are many factors influencing the parameter selection, it is necessary to combine the characteristics of the problem itself to make a corresponding transformation, so that the genetic algorithm has the ability to solve and optimize different types of problems and powerful global search capabilities.
2.1.6 The choice of evolutionary termination criteria
There are two termination conditions of the loop, one is to set the maximum termination algebra, and the other is to terminate the loop when the conditions are met. The other is when the variance between the individual fitness in the population is less than a certain set value, the loop is terminated. In this paper, the algorithm is terminated if it meets the condition that the upper bound reached by the evolution algebra is 200 or the fourth consecutive generation has no change condition. After the individual with the highest fitness value finally decodes according to the encoding rules, it becomes the information hiding optimal distribution scheme.
2.2 Information hiding and extraction
Information hiding steps:
-
1)
Encrypt the image
-
2)
Select the mother image
-
3)
Optimize embedding according to the genetic algorithm
-
4)
Calculate the optimal solution and hide the image.
Image extraction steps:
-
1)
Extract embedded information
-
2)
According to the value of the genetic algorithm parameters do the appropriate operation to restore the secret information before embedding
-
3)
The secret information is restored to the original image based on the scramble key and the seed.
2.3 Arnold transform
The Arnold transform is a transformation proposed by the Russian mathematician Vladimir I. Arnold, a 2D Arnold of N × N digital images.
Transform is defined as:
x, y are the pixel coordinates of the original image, and x’, y’ are the transformed pixel coordinates. Guarantee |ad-bc| = 1.
3 Experimental results
3.1 Picture attribute
In order to verify the feasibility and effectiveness of the algorithm, we chose four images as masters respectively. As shown in Fig. 4, the encrypted image has a size of 512 × 256. Four master images contain one shot with a phone named MI 4. Life photos, three pictures from the Internet, two of them are color pictures, 1 is a black and white picture, this article was sequentially encoded as 1 (life photos), 2 (Internet color pictures), 3 (Internet color pictures), and 4 (Internet black and white). Encrypted pictures come from the Internet.
3.2 Simulation environment
The data processing in this paper is based on the MATLAB R2014b 8.4 software environment operating system for Windows 7 Ultimate Edition 64-bit SP1.
3.3 Genetic algorithm parameters
In this paper, the genetic algorithm environment is set to population size = 30, crossover probability = 0.5, mutation probability = 0.02, and to find the optimal solution iterations = 200.
4 Discussion
For image hiding technology, first of all, transform the image you want to hide and scramble the original image according to a certain coding method to form the key form. For a RGB image, original image, R layer, G layer, and B layer images, such as Fig. 2 are shown.

Comparison of different layers (the upper left is the original image, the upper right is the R layer image, the lower left is the G layer image, and the lower right is the B layer image)
The scrambling of the different layers in Fig. 2 is as shown in Fig. 3.

Scrambling effect (the upper left R layer is encrypted, the upper right G layer is encrypted, the lower left B layer is encrypted, and the lower right is the three-layer encrypted image)
It can be seen from the results of Fig. 3 that the scrambling display effects of different layers are different. For example, the information of the R layer and the B layer is scrambled and the background is black, and there is a certain similarity between the two, but the scrambling result of the G layer is similar to the three-layer encrypted image, the only difference is the color. To display the original image, you need to reverse the settings. This can achieve the effect of image encryption.
Four parent maps and images that need to be embedded are shown in Fig. 4.

Mother map and embedded map (the first row is the embedded map, the second and third rows are the mother map)
In order to be able to compare the effect of the encrypted image embedded in the mother map, this article changes the photos that need to be encrypted into different sizes for testing. The sizes are 512 × 256, 384 × 256, 256 × 256, and 128 × 256. After embedding the four parent images, the effect is as shown in Fig. 5.

The effect of after embedding parent image
Figure 5 shows the results of hidden pictures after they are coded by this method and hidden behind the parent figure. From the display results of the parent figure, the hidden method of this article can maintain good visual effects of the parent figure.
LSB algorithm is a commonly used information hiding algorithm. Peak signal-to-noise ratio represents the merits of the algorithm. Compared with LSB algorithm, the signal-to-noise ratio of this method is obviously higher. The result is shown in Fig. 6. The embedding effect is shown in Fig. 7. The result of Fig. 7 shows that the hidden effect of LSB is obviously worse than the method of this paper (Table 1).

Comparison of two methods

LSB embedding effect
5 Conclusions
The hiding capacity of the algorithm proposed in this paper can be adjusted according to specific conditions, and the amount of information per bit embedded in the image can be reached at most. Using the idea of genetic algorithm to get the most embedding effect, it can be seen from the experimental results that the effect of the vector image embedded in the information is basically consistent with that of the original image. The algorithm also has poor robustness and is easy to be attacked. It is also a common problem of using the airspace to hide information. As a non-deterministic quasi natural algorithm, genetic algorithm provides a new method for the optimization of complex systems and has proved to be effective. Although the genetic algorithm has a wide range of application value in many fields, it still has some problems. The scholars in various countries have been exploring the improvement of the genetic algorithm so that the genetic algorithm has a wider range of applications.
