
Abstract
Background
Plant root research can provide a way to attain stress-tolerant crops that produce greater yield in a diverse array of conditions. Phenoty** roots in soil is often challenging due to the roots being difficult to access and the use of time consuming manual methods. Rhizotrons allow visual inspection of root growth through transparent surfaces. Agronomists currently manually label photographs of roots obtained from rhizotrons using a line-intersect method to obtain root length density and rooting depth measurements which are essential for their experiments. We investigate the effectiveness of an automated image segmentation method based on the U-Net Convolutional Neural Network (CNN) architecture to enable such measurements. We design a data-set of 50 annotated chicory (Cichorium intybus L.) root images which we use to train, validate and test the system and compare against a baseline built using the Frangi vesselness filter. We obtain metrics using manual annotations and line-intersect counts.
Results
Our results on the held out data show our proposed automated segmentation system to be a viable solution for detecting and quantifying roots. We evaluate our system using 867 images for which we have obtained line-intersect counts, attaining a Spearman rank correlation of 0.9748 and an \(r^2\) of 0.9217. We also achieve an \(F_1\) of 0.7 when comparing the automated segmentation to the manual annotations, with our automated segmentation system producing segmentations with higher quality than the manual annotations for large portions of the image.
Conclusion
We have demonstrated the feasibility of a U-Net based CNN system for segmenting images of roots in soil and for replacing the manual line-intersect method. The success of our approach is also a demonstration of the feasibility of deep learning in practice for small research groups needing to create their own custom labelled dataset from scratch.
Similar content being viewed by others

Background
High-throughput phenoty** of roots in soil has been a long-wished-for goal for various research purposes [1,2,3,4]. The challenge of exposing the architecture of roots hidden in soil has promoted studies of roots in artificial growth media [5]. However, root growth is highly influenced by physical constraints [6] and such studies have shown to be unrepresentative of roots in soil [7, 8].
Traditionally studies of roots in soil have relied on destructive and laborious methods such as trenches in the field and soil coring followed by root washing [9]. Recently 3D methods such as X-ray computed tomography [10] and magnetic resonance imaging [11] have been introduced, but these methods require expensive equipment and only allow small samples.
Since the 1990, rhizotrons [12,13,14] and minirhizotrons [15, 16] which allow non-invasive monitoring of spatial and temporal variations in root growth in soil, have gained popularity. Minirhizotrons facilitate the repeated observation and photographing of roots through the transparent surfaces of below ground observation tubes [17].
A major bottleneck when using rhizotron methods is the extraction of relevant information from the captured images. Images have traditionally been annotated manually using the line-intersect method where the number of roots crossing a line in a grid is counted and correlated to total root length [18, 19] or normalised to the total length of grid line [20]. The line-intersect method was originally developed for washed roots but is now also used in rhizotron studies where a grid is either directly superimposed on the soil-rhizotron interface [21, 22] or indirectly on recorded images [23, 24]. The technique is arduous and has been reported to take 20 min per metre of grid line in minirhizotron studies [25]. Line-intersect counts are not a direct measurement of root length and do not provide any information on architectural root traits such as branching, diameter, tip count, growth speed or growth angle of laterals.
To overcome these issues, several attempts have been made to automate the detection and measurement of roots, but all of them require manual supervision, such as mouse clicks to detect objects [26, 27].
The widely used “RootFly” software provides both manual annotation and automatic root detection functionality [28]. Although the automatic detection worked well on the initial three datasets the authors found it did not transfer well to new soil types (personal communication with Stan Birchfield, September 27, 2018).
Following the same manual annotation procedure as in RootFly, [29] calculated that it takes 1–1.5 h per 100 cm2 to annotate images of roots from minirhizotrons, adding up to thousands of hours for many minirhizotron experiments. Although existing software is capable of attaining much of the desired information, the annotation time required is prohibitive and severely limits the use of such tools.
Image segmentation is the splitting of an image into different meaningful parts. A fully automatic root segmentation system would not just save agronomists time but could also provide more localized information on which roots have grown and by how much as well as root width and architecture.
The low contrast between roots and soil has been a challenge in previous attempts to automate root detection. Often only young unpigmented roots can be detected [30] or roots in black peat soil [31]. To enable detection of roots of all ages in heterogeneous field soils, attempts have been made to increase the contrast between soil and roots using custom spectroscopy. UV light can cause some living roots to fluoresce and thereby stand out more clearly [3] and light in the near–infrared spectrum can increase the contrast between roots and soil [32].
Other custom spectroscopy approaches have shown the potential to distinguish between living and dead roots [33, 34] and roots from different species [35, 36]. A disadvantage of such approaches is that they require more complex hardware which is often customized to a specific experimental setup. A method which works with ordinary RGB photographs would be attractive as it would not require modifications to existing camera and lighting setups, making it more broadly applicable to the wider root research community. Thus in this work we focus on solving the problem of segmenting roots from soil using a software driven approach.
Prior work on segmenting roots from soil in photographs has used feature extraction combined with traditional machine learning methods [37, 38]. A feature extractor is a function which transforms raw data into a suitable internal representation from which a learning subsystem can detect or classify patterns [39]. The process of manually designing a feature extractor is known as feature engineering. Effective feature engineering for plant phenoty** requires a practitioner with a broad skill-set as they must have sufficient knowledge of both image analysis, machine learning and plant physiology [40]. Not only is it difficult to find the optimal description of the data but the features found may limit the performance of the system to specific datasets [41]. With feature engineering approaches, domain knowledge is expressed in the feature extraction code so further programming is required to re-purpose the system to new datasets.
Deep learning is a machine learning approach, conditioned on the training procedure, where a machine fed with raw data automatically discovers a hierarchy of representations that can be useful for detection or classification tasks [39]. Convolutional Neural Networks (CNNs) are a class of deep learning architectures where the feature extraction mechanism is encoded in the weights (parameters) of the network, which can be updated without the need for manual programming by changing or adding to the training data. Via the training process a CNN is able to learn from examples, to approximate the labels or annotations for a given input. This makes the effectiveness of CNNs highly dependent on the quality and quantity of the annotations provided.
Deep learning facilitates a decoupling of plant physiology domain knowledge and machine learning technical expertise. A deep learning practitioner can focus on the selection and optimisation of a general purpose neural network architecture whilst root experts encode their domain knowledge into annotated data-sets created using image editing software.
CNNs have now established their dominance on almost all recognition and detection tasks [42,43,44,45]. They have also been used to segment roots from soil in X-ray tomography [46] and to identify the tips of wheat roots grown in germination paper growth pouches [41]. CNNs have an ability to transfer well from one task to another, requiring less training data for new tasks [47]. This gives us confidence that knowledge attained from training on images of roots in soil in one specific setup can be transferred to a new setup with a different soil, plant species or lighting setup.
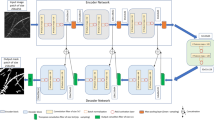
The aim of this study is to develop an effective root segmentation system using a CNN. For semantic segmentation tasks CNN architectures composed of encoders and decoders are often used. These so-called encoder-decoder architectures firstly transform the input using an encoder into a representation with reduced spatial dimensions which may be useful for classification tasks but will lack local detail, then a decoder will up-sample the representation given by the encoder to a similar resolution as the original input, potentially outputting a label for each pixel. Another encoder-decoder based CNN system for root image analysis is RootNav 2.0 [48] which is targeted more towards experimental setups with the entire root system visible, where it enables extraction of detailed root system architecture measurements. We use the U-Net CNN encoder-decoder architecture [49], which has proven to be especially useful in contexts where attaining large amounts of manually annotated data is challenging, which is the case in biomedical or biology experiments.
As a baseline machine learning approach we used the Frangi vessel enhancement filter [50], which was originally developed to enhance vessel structures on images of human vasculature. Frangi filtering represents a more traditional and simpler off-the-shelf approach which typically has lower minimum hardware requirements when compared to U-Net.
We hypothesize that (1) U-Net will be able to effectively discriminate between roots and soil in RGB photographs, demonstrated by a strong positive correlation between root length density obtained from U-Net segmentations and root intensity obtained from the manual line-intersect method. And (2) U-Net will outperform a traditional machine learning approach with larger amounts of agreement between the U-Net segmentation output and the test set annotations.
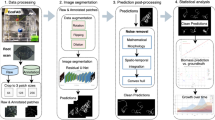
Methods
We used images of chicory (Cichorium intybus L.) taken during summer 2016 from a large 4 m deep rhizotron facility at University of Copenhagen, Taastrup, Denmark (Fig. 1). The images had been used in a previous study [51] where the analysis was performed using the manual line-intersect method. As we make no modifications to the hardware or photographic procedure, we are able to evaluate our method as a drop-in replacement to the manual line-intersect method.

Chicory (Cichorium intybus L.) growing in the rhizotron facility
The facility from which the images were captured consists of 12 rhizotrons. Each rhizotron is a soil filled rectangular box with 20 1.2 m wide vertically stacked transparent acrylic panels on two of its sides which are covered by 10 mm foamed PVC plates. These plates can be removed to allow inspection of root growth at the soil-rhizotron interface. There were a total of 3300 images which had been taken on 9 different dates during 2016. The photos were taken from depths between 0.3 and 4 m. Four photos were taken of each panel in order to cover its full width, with each individual image covering the full height and 1/4 of the width (For further details of the experiment and the facility see [51]). The image files were labelled according to the specific rhizotron, direction and panel they are taken from with the shallowest which is assigned the number 1 and the deepest panel being assigned the number 20.
Line-intersect counts were available for 892 images. They had been obtained using a version of the line-intersect method [18] which had been modified to use grid lines [19, 52] overlaid over an image to compute root intensity. Root intensity is the number of root intersections per metre of grid line in each panel [20].
In total four different grids were used. Coarser grids were used to save time when counting the upper panels with high root intensity and finer grids were used to ensure low variation in counts from the lower panels with low root intensity. The 4 grids used had squares of sizes 10, 20, 40 and 80 mm. The grid size for each depth was selected by the counter, aiming to have at least 50 intersections for all images obtained from that depth. For the deeper panels with less roots, it was not possible to obtain 50 intersections per panel so the finest grid (10 mm) was always used.
To enable comparison we only used photos that had been included in the analysis by the manual line-intersect method. Here photos containing large amounts of equipment were not deemed suitable for analysis. From the 3300 originals, images from panels 3, 6, 9, 12, 15 and 18 were excluded as they contained large amounts of equipment such as cables and ingrowth cores. Images from panel 1 were excluded as it was not fully covered with soil. Table 1 shows the number of images from each date, the number of images remaining after excluding panels unsuitable for analysis and if line-intersect counts were available.
Deeper panels were sometimes not photographed as when photographing the panels the photographer worked from the top to the bottom and stopped when it was clear that no deeper roots could be observed. We took the depth distribution of all images obtained from the rhizotrons in 2016 into account when selecting images for annotation in order to create a representative sample (Fig. 2). After calculating how many images to select from each depth the images were selected at random.

The number of images selected for annotation from each panel depth
The first 15 images were an exception to this. They had been selected by the annotator whilst aiming to include all depths. We kept these images but ensured they were not used in the final evaluation of model performance as we were uncertain as to what biases had led to their selection.
Annotation
We chose a total of 50 images for annotation. This number was based on the availability of our annotator and the time requirements for annotation.
To facilitate comparison with the available root intensity measurements by analysing the same region of the image as [51], the images were cropped from their original dimensions of \(4608\times 2592\) pixels to \(3991\times 1842\) pixels which corresponds to an area of approximately 300 \(\times\) 170 mm of the surface of the rhizotron. This was done by removing the right side of the image where an overlap between images is often present and the top and bottom which included the metal frame around the acrylic glass.
A detailed per-pixel annotation (Fig. 3) was then created as a separate layer in Photoshop by a trained agronomist with extensive experience using the line-intersect method. Annotation took approximately 30 min per image with the agronomist labelling all pixels which they perceived to be root.
The number of annotated root pixels ranged from 0 to 203533 (2.8%) per image.
Data split
During the typical training process of a neural network, the labelled or annotated data is split into a training, validation and test dataset. The training set is used to optimize a neural network using a process called Stochastic Gradient Descent (SGD) where the weights (parameters) are adjusted in such a way that segmentation performance improves. The validation set is used for giving an indication of system performance during the training procedure and tuning the so-called hyper-parameters, not optimised by SGD such as the learning rate. See the section U-Net Implementation for more details. The test set performance is only calculated once after the neural network training process is complete to ensure an unbiased indication of performance.
Firstly, we selected 10 images randomly for the test set. As the test set only contained 10 images, this meant the full range of panel heights could not be included. One image was selected from all panel heights except for 13, 17, 18 and 20. The test set was not viewed or used in the computation of any statistics during the model development process, which means it can be considered as unseen data when evaluating performance. Secondly, from the remaining 40 images we removed two images. One because it didn’t contain any roots and another because a sticker was present on the top of the acrylic. Thirdly, the remaining 38 images were split into split into training and validation datasets.
We used the root pixel count from the annotations to guide the split of the images into a train and validation data-set. The images were ordered by the number of root pixels in each image and then 9 evenly spaced images were selected for the validation set with the rest being assigned to the training set. This was to ensure a range of root intensities was present in both training and validation sets.
Metrics
To evaluate the performance of the model during development and testing we used \(F_1\). We selected \(F_1\) as a metric because we were interested in a system which would be just as likely to overestimate as it would underestimate the roots in a given photo. That meant precision and recall were valued equally. In this context precision is the ratio of correctly predicted root pixels to the number of pixels predicted to be root and recall is the ratio of correctly predicted root pixels to the number of actual root pixels in the image. Both recall and precision must be high for \(F_1\) to be high.
The \(F_1\) of the segmentation output was calculated using the training and validation sets during system development. The completed system was then evaluated using the test set in order to provide a measure of performance on unseen data. We also report accuracy, defined as the ratio of correctly predicted to total pixels in an image.
In order to facilitate comparison and correlation with line-intersect counts, we used an approach similar to [53] to convert a root segmentation to a length estimate. The scikit-image skeletonize function was used to first thin the segmentation and then the remaining pixels were counted. This approach was used for both the baseline and the U-Net segmentations.
For the test set we also measured correlation between the root length of the output segmentation and the manual root intensity given by the line-intersect method. We also measured correlation between the root length of our manual per-pixel annotations and the U-Net output segmentations for our held out test set. To further quantify the effectiveness of the system as a replacement for the line-intersect method, we obtained the coefficient of determination (\(r^2\)) for the root length given by our segmentations and root intensity given by the line-intersect method for 867 images. Although line-intersect counts were available for 892 images, 25 images were excluded from our correlation analysis as they had been used in the training dataset.
Frangi vesselness implementation
For our baseline method we built a system using the Frangi Vesselness enhancement filter [50]. We selected the Frangi filter based on the observation that the roots look similar in structure to blood vessels, for which the Frangi filter was originally designed. We implemented the system using the Python programming language (version 3.6.4), using the scikit-image [54] (version 0.14.0) version of Frangi. Vesselness refers to a measure of tubularity that is predicted by the Frangi filter for a given pixel in the image. To obtain a segmentation using the Frangi filter we thresholded the output so only regions of the image above a certain vesselness level would be classified as roots. To remove noise we further processed the segmentation output using connected component analysis to remove regions less than a threshold of connected pixels. To find optimal parameters for both the thresholds and the parameters for the Frangi filter we used the Covariance Matrix Adaptation Evolution Strategy (CMA-ES) [ U-Net receptive field input size (blue) and output size (green). The receptive field is the region of the input data which is provided to the neural network. The output size is the region of the original image which the output segmentation is for. The output is smaller than the input to ensure sufficient context for the classification of each pixel in the output
Preprocessing and augmentation
Each individual image tile was normalised to \([-0.5, +0.5]\) as centering inputs improves the convergence of networks trained with gradient descent [63]. Data augmentation is a way to artificially expand a dataset and has been found to improve the accuracy of CNNs for image classification [ a Elastic grid applied to an image tile and b corresponding annotation. A white grid is shown to better illustrate the elastic grid effect. A red rectangle illustrates the region which will be segmented. Augmentations such as elastic grid are designed to increase the likelihood that the network will work on similar data that is not included in the training set
Loss
Loss functions quantify our level of unhappiness with the network predictions on the training set [66]. During training the network outputs a predicted segmentation for each input image. The loss function provides a way to measure the difference between the segmentation output by the network and the manual annotations. The result of the loss function is then used to update the network weights in order to improve its performance on the training set. We used the Dice loss as implemented in V-Net [67]. Only 0.54% of the pixels in the training data were roots which represents a class imbalance. Training on imbalanced datasets is challenging because classifiers are typically designed to optimise overall accuracy which can cause minority classes to be ignored [68]. Experiments on CNNs in particular have shown the effect of class imbalance to be detrimental to performance [69] and can cause issues with convergence. The Dice loss is an effective way to handle class imbalanced datasets as errors for the minority class will be given more significance. For predictions p, ground truth annotation g, and number of pixels in an image N, Dice loss was computed as:
The Dice coefficient corresponds to \(F_1\) when there are only two classes and ranges from 0 to 1. It is higher for better segmentations. Thus it is subtracted from 1 to convert it to a loss function to be minimized. We combined the Dice loss with cross-entropy multiplied by 0.3, which was found using trial and error. This combination of loss functions was used because it provided better results than either loss function in isolation during our preliminary experiments.
Optimization
We used SGD with Nesterov momentum based on the formula from [70]. We used a value of 0.99 for momentum as this was used in the original U-Net implementation. We used an initial learning rate of 0.01 which was found by using trial and error whilst monitoring the validation and training \(F_1\). The learning rate alters the magnitude of the updates to the network weights during each iteration of the training procedure. We used weight decay with a value of \(1 \times 10^{-5}\). A learning rate schedule was used where the learning rate would be multiplied by 0.3 every 30 epochs. Adaptive optimization methods such as Adam [Full size table






