
Abstract
Background
Currently, there is an urgent need for efficient tools to assess the diagnosis of COVID-19 patients. In this paper, we present feasible solutions for detecting and labeling infected tissues on CT lung images of such patients. Two structurally-different deep learning techniques, SegNet and U-NET, are investigated for semantically segmenting infected tissue regions in CT lung images.
Methods
We propose to use two known deep learning networks, SegNet and U-NET, for image tissue classification. SegNet is characterized as a scene segmentation network and U-NET as a medical segmentation tool. Both networks were exploited as binary segmentors to discriminate between infected and healthy lung tissue, also as multi-class segmentors to learn the infection type on the lung. Each network is trained using seventy-two data images, validated on ten images, and tested against the left eighteen images. Several statistical scores are calculated for the results and tabulated accordingly.
Results
The results show the superior ability of SegNet in classifying infected/non-infected tissues compared to the other methods (with 0.95 mean accuracy), while the U-NET shows better results as a multi-class segmentor (with 0.91 mean accuracy).
Conclusion
Semantically segmenting CT scan images of COVID-19 patients is a crucial goal because it would not only assist in disease diagnosis, also help in quantifying the severity of the illness, and hence, prioritize the population treatment accordingly. We propose computer-based techniques that prove to be reliable as detectors for infected tissue in lung CT scans. The availability of such a method in today’s pandemic would help automate, prioritize, fasten, and broaden the treatment of COVID-19 patients globally.
Similar content being viewed by others

Background
COVID-19 is a widespread disease causing thousands of deaths daily. Early diagnosis of this disease proved to be one of the most effective methods for infection tree pruning [1]. The large number of COVID-19 patients is rendering health care systems in many countries overwhelmed. Hence, a trusted automated technique for identifying and quantifying the infected lung regions would be quite advantageous.
Radiologists have identified three types of irregularities related to COVID-19 in Computed Tomography (CT) lung images: (1) Ground Glass Opacification (GGO), (2) Consolidation, and (3) pleural effusion [2, 3]. Develo** a tool for semantically segmenting medical lung images of COVID-19 patients would contribute and assess in quantifying those three irregularities. It would help the front-liners of the pandemic to better manage the situation of overloaded hospitals.
Deep learning (DL) has become a conventional method for constructing networks capable of successfully modeling higher-order systems to achieve human-like performance. Tumors have been direct targets for DL-assisted segmentation of medical images. In [28].
SegNet architecture
SegNet is a Deep Neural Network originally designed to model scene segmentors such as road image segmentation tool. This task requires the network to converge using highly imbalanced datasets since large areas of road images consist of classes such as road, sidewalk, sky. In the dataset section, we demonstrated numerically how the dataset used in this work exhibit disparity in class representation. As a consequence, SegNet was our first choice for this task.
SegNet is a DNN with an encoder-decoder depth of three. The encoder layers are identical to the convolutional layers of the VGG16 network. The decoder constructs the segmentation mask by utilizing pooling indices from the max-pooling of the corresponding encoder. The creators removed the fully connected layers to reduce complexity, which reduces the number of parameters of the encoder sector from \({1.34}{{\mathrm{e}}}{+8}\) to \({1.47}{{\mathrm{e}}}{+7}\). See [29].
Network training
Training the neural networks is done using the ADAM stochastic optimizer due to its fast convergence rate compared to other optimizers [30]. The input images are resized to \(256\times 256\) to reduce the training time and also for memory requirements. The one-hundred images dataset is divided into three sets for training, validation, and testing, with proportions of 0.72, 0.10, and 0.18 respectively. In spite of class imbalance discussed earlier, class weights are calculated using median frequency balancing and handed over to the pixel classification layer to formulated a weighted cross-entropy loss function [31]:
where K is the number of instances, N number of classes, \(l_k^n\) and \(p_k^n\) are label and prediction in class n in instance i, and \(w_i\) is the weight of class i.
Each network is trained nine times using different hyperparameters to find the best possible configuration. Table 2 lists these training hyperparameters. For the training performance, it was completed in 160 epochs for all the experiments. Training time variation was negligible among networks, with an average of 25 min. Figure 4 illustrates training performance and loss for the best binary segmentors (U-NET #4 and SegNet #4) and the best multi-class segmentors (U-NET #4 and SegNet #7). The criteria used to conclude the best experiments are discussed in the results section.
The training process was done using the Deep Learning Toolbox version 14.0 in MATLAB R2020a (9.8.0.1323502) in a Windows 10 version 10.0.18363.959 machine with an INTEL core-i5 9400F and an NVIDIA 1050ti 4GB VRAM GPU using CUDA 10.0.130. Usage of the GPU reduced training times by a factor of 35 on average.
Evaluation criteria and procedure
To fully quantify the performance of our models, we utilized five known classification criteria: sensitivity, specificity, G-mean, Sorensen-Dice (aka. F1), and F2 score. The following Eqs. (2)–(6) describe these criteria:
These criteria are selected because of the dataset imbalance nature discussed in the Materials and Methods section.
The evaluation was carried out as follows: the global accuracy of the classifier was calculated for each test image and averaged over all the images. Using the mean values of global accuracies, the best experiment of each network was chosen for a ”Class Level” assessment. Then, statistical scores (2)–(6) were calculated for each class and tabulated properly.
Results
Binary segmentation
Test images results
Table 3 shows results for both models of binary classifiers after evaluating every experiment of each network. We can see from the results that our networks achieve accuracy values larger than 0.90 in all cases, and 0.954 accuracy in the best case (experiment 4 of the network SegNet). The standard deviation of experiment 4 is 0.029. The second best network is experiment 4 of the U-NET architecture with an accuracy of 0.95 and a standard deviation of 0.043.
The best experiment of each architecture is selected for further performance investigation on the class level.
Class Level
Based on the criteria discussed in the “Methods” section, the best two networks found in the previous section are evaluated. We can see that the SegNet network surpasses U-NET with noticeable margins for all metrics except sensitivity and G-mean, where both networks produce similar results. See Table 4.
Multi class segmentation
Test images results
Similarly, we obtain the best experiment for each multi-classification network. The best experiment of the SegNet architecture is number 7, giving an accuracy of 0.907 with a standard deviation of 0.06. We also found that the overall best accuracy of 0.908 is achieved by the fourth experiment of U-NET network with a standard deviation of 0.065. All the experiments achieve higher accuracy than 0.8 except for the first three experiments of SegNet. Refer to Table 5.
Class level
In the same manner as the binary segmentation results section, the best experiment of each architecture is evaluated as presented in Table 6. Both networks struggled to recognize the C3 class. Nevertheless, they achieve good results for C1 and C2 . We also notice the high specificity rate regarding all the classes. The U-NET architecture recorded higher values for all parameters except the specificity.
Discussion
Binary classification problem
It can be referred from Table 5 that SegNet outperforms U-NET architecture by a noticeable margin. Both networks have an exceptionally high true positive count for the ”Not Infected” class. The results state in a quantifiable manner how reliable is the DNN models in distinguishing between the non-infected and infected classes, i.e. ill portions of the lungs. Further experiments involving a larger dataset is likely to confirm this. The high sensitivity (0.956) and specificity (0.945) of the best network (SegNet) indicate its goodness in modeling a trained radiologist for the task at hand.
Regarding the standard deviation of the results demonstrated in Table 3, the values ranged from 0.060 to 0.086. These low values indicate highly consistent accuracies in the test partition of the dataset.
The results of our SegNet show enhancements over Inf-Net and Semi-Inf-Net presented in [25] in terms of Dice, specificity, and sensitivity Metrics. As well, the U-NET outperforms them only in terms of sensitivity. Both works utilize the same dataset. As a binary segmentor, Inf-Net focuses on edge information and allocates a portion of computations to highlight it. This would remove focus from the important internal texture and allocate more weight to the fractal shaped edge, especially that no evidence of high contrast between the infection and lung tissue is found. Secondly, the parallel partial decoder used by the network gives less weights to low-level features which are considered a key for texture highlighting. Another reason might be that the SegNet was trained on dataset images that contain only lung areas.
SegNet outperforms the Semi-Inf-Net network, an architecture utilizes pseudo labeling to generate additional training data, by a small margin. This might be because the used pseudo-labeling technique generated 1600 labels from only 50 labeled images which were used to train the network.
SegNet also surpasses the COVID-SegNet architecture proposed in [22] in sensitivity and Dice metrics. This might be because, according to the authors, COVID-19 lesions were difficult to distinguish from the chest wall. COVID-SegNet was able to segment the lung region with close-to-perfect performance, yet was not able to match this accuracy in segmenting the infection regions that are close to the wall. A more detailed comparison, in which both architectures are trained and tested on the same dataset, might be necessary to further generalize this result.
It should be noted here that increasing the mini-batch size has a negative effect on the networks performance; further tests may lead to a generalized statement regarding this. A previous study investigated the mini-batch size role in the VGG16 network convergence. It concluded that smaller mini-batch sizes coupled with a low learning rate would yield a better training outcome [32]. Another study concluded that smaller mini-batch sizes tend to produce more stable training for ResNet networks by updating the gradient calculations more frequently [33].
Multi class problem
Table 6 shows how good the U-NET is in segmenting the Ground Glass Opacification and the Consolidation. The U-NET produced moderate results in segmenting the pleural effusion; a Dice of 0.23 and F2 score of 0.38 which downplays its role as a reliable tool for pleural effusion segmentation.
The C3 class, as discussed in the Dataset section, is the least represented class in the dataset. Therfore, such a result is expected from a multi-class segmentation model constructed using 72 image instances only.
The standard deviation values of the multiclass segmentors were, on average, a little higher than those of the binary segmentors. Yet, they still indicate that the networks are solid performers in terms of accuracy. The high specificity rates clearly state that the models are reliable in identifying non-infected tissue (class C0 ).
Five-fold cross validation
Due to the small size of images in the dataset, a five-fold cross-validation was performed as an overall assessment. The dataset images were first scrambled to form a newly randomized dataset. Then, for each iteration, images were divided into three sets: 70% for training, 10% for validation, and 20% for testing in a successive manner. The validation set was utilized for monitoring the network performance during training, and to keep the overall training data count as close as possible to the procedure performed in the Networks Training section.
Table 7 presents the statistical results using criteria described in the Evaluation Criteria and Procedure section. We notice low values of standard deviation for each score, except for the sensitivity of the \({\hbox {C}}_3\) class, with mean values close to the ones reported in Tables 4 and 6.
Network feature visualization
Deep Dream is a method used to visualize the features extracted by the network after the training process [34]. Since SegNet proved to be a reliable segmentor considering its high statistical scores, the generated Deep Dream image should lay out the key features distinguishing each class (non-infected, infected). We plotted the Deep Dream image in Fig. 5. We can apparently visualize a discerning pattern between the two classes in this image.
Conclusions
In this paper, the performance of two deep learning networks (SegNet & U-NET) was compared in their ability to detect diseased areas in medical images of the lungs of COVID-19 patients. The results demonstrated the ability of the SegNet network to distinguish between infected and healthy tissues in these images. A comparison of these two networks was also performed in a multiple classification procedure of infected areas in lung images. The results showed the U-NET network’s ability to distinguish between these areas. The results obtained in this paper represent promising prospects for the possibility of using deep learning to assist in an objective diagnosis of COVID-19 disease through CT images of the lung.

Dataset sample. CT scan (left), masked lungs (middle), and labeled classes (right), where black is class C0, dark gray is C1, light gray is C2, and white is C3.

Accumulation of the dataset’s labels. All the labels of the dataset were summed up to form a graphic that illustrates the regions of the lungs most prune to infection

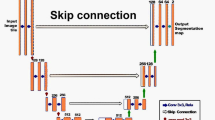
The DNN architectures The SegNet (top) where the encoder-decoder of the network are illustrated using the gray and white bubbles, and U-NET (bottom) where the contractive and expansive layer patches are encapsulated in blue and yellow bubbles

SegNet and U-NET binary and multi-class segmentors’ training accuracy and loss Four plots of training loss and accuracy for the best configuration of each segmentor

SegNet binary segmentor Deep Dream image Deep dream image laying out key features the network is using to segment the CT scans. infected tissue (right), non-infected (left)
Availability of data and materials
The data is openly accessible in [26], and the networks used in this work are freely available in https://github.com/adnan-saood/COVID19-DL.
Abbreviations
- NIFTI:
-
Neuroimaging informatics technology initiative
- COVID-19:
-
COrona VIrus Disease 2019
- CT:
-
Computed tomography
- GGO:
-
Ground glass opacification
- DL:
-
Deep learning
- GAN:
-
Generative adversarial networks
- CNN:
-
Convolutional neural networks
- ADAM:
-
Adaptive moment estimation
- DNN:
-
Deep neural network
References
Tan C, Zheng X, Huang Y, Liu J. Key to successful treatment of COVID-19: accurate identification of severe risks and early intervention of disease progression. 2020.
Shi H, Han X, Jiang N, Cao Y, Alwalid O, Gu J, et al. Radiological findings from 81 patients with COVID-19 pneumonia in Wuhan, China: a descriptive study. Lancet Infect Dis. 2020;20(4):425–34.
Ye Z, Zhang Y, Wang Y, Huang Z, Song B. Chest CT manifestations of new coronavirus disease 2019 (COVID-19): a pictorial review. Eur Radiol. 2020;30:4381–9.
Causey JL, Guan Y, Dong W, Walker K, Qualls JA, Prior F, et al. Lung cancer screening with low-dose CT scans using a deep learning approach. 2019. ar**v:1906.00240.
Daimary D, Bora MB, Amitab K, Kandar D. Brain tumor segmentation from MRI images using hybrid convolutional neural networks. Procedia Comput Sci. 2020;167:2419–28.
Singh VK, Rashwan HA, Romani S, Akram F, Pandey N, Sarker MMK, et al. Breast tumor segmentation and shape classification in mammograms using generative adversarial and convolutional neural network. Expert Syst Appl. 2020;139:112855.
Zhao W, Jiang D, Queralta JP, Westerlund T. MSS U-Net: 3D segmentation of kidneys and tumors from CT images with a multi-scale supervised U-Net. Inform Med Unlocked. 2020;19:100357.
Skourt BA, Hassani AE, Majda A. Lung CT image segmentation using deep neural networks. Procedia Comput Sci. 2018;127:109–13.
Huidrom R, Chanu YJ, Singh KM. Automated lung segmentation on computed tomography image for the diagnosis of lung cancer. CyS. 2018. https://doi.org/10.13053/cys-22-3-2526.
Almotairi S, Kareem G, Aouf M, Almutairi B, Salem MAM. Liver tumor segmentation in CT scans using modified SegNet. Sensors. 2020;20(5):1516.
Kumar P, Nagar P, Arora C, Gupta A. U-SegNet: fully convolutional neural network based automated brain tissue segmentation tool; 2018. ar**v:1806.04429.
Akkus Z, Kostandy P, Philbrick KA, Erickson BJ. Robust brain extraction tool for CT head images. Neurocomputing. 2020;6(392):189–95.
Li X, Gong Z, Yin H, Zhang H, Wang Z, Zhuo L. A 3D deep supervised densely network for small organs of human temporal bone segmentation in CT images. Neural Netw. 2020;4(124):75–85.
Yang J, Faraji M, Basu A. Robust segmentation of arterial walls in intravascular ultrasound images using Dual Path U-Net. Ultrasonics. 2019;7(96):24–33.
Ozturk T, Talo M, Yildirim EA, Baloglu UB, Yildirim O, Acharya UR. Automated detection of COVID-19 cases using deep neural networks with X-ray images. Comput Biol Med. 2020;6(121):103792.
Rahimzadeh M, Attar A. A modified deep convolutional neural network for detecting COVID-19 and pneumonia from chest X-ray images based on the concatenation of Xception and ResNet50V2. Inform Med Unlocked. 2020;19:100360.
Xu X, Jiang X, Ma C, Du P, Li X, Lv S, et al. A deep learning system to screen novel coronavirus disease 2019 pneumonia. Engineering. 2020.
Wang S, Kang B, Ma J, Zeng X, **ao M, Guo J, et al. A deep learning algorithm using CT images to screen for Corona Virus Disease (COVID-19). 2020.
Zheng C, Deng X, Fu Q, Zhou Q, Feng J, Ma H, et al. Deep learning-based detection for COVID-19 from chest CT using weak label. 2020.
Apostolopoulos ID, Mpesiana TA. Covid-19: automatic detection from X-ray images utilizing transfer learning with convolutional neural networks. Phys Eng Sci Med. 2020;43(2):635–40.
Narin A, Kata C, Pamuk Z. Automatic detection of coronavirus disease (COVID-19) using X-ray images and deep convolutional neural networks; 2020. ar**v:2003.10849.
Yan Q, Wang B, Gong D, Luo C, Zhao W, Shen J, et al. COVID-19 chest CT image segmentation: a deep convolutional neural network solution; 2020. ar**v:2004.10987.
Amyar A, Modzelewski R, Ruan S. Multi-task deep learning based CT imaging analysis for COVID-19: classification and segmentation. Computer Biol Med. 2020;21:104037.
Voulodimos A, Protopapadakis E, Katsamenis I, Doulamis A, Doulamis N. Deep learning models for COVID-19 infected area segmentation in CT images. Cold Spring Harbor Laboratory. 2020; 5.
Fan DP, Zhou T, Ji GP, Zhou Y, Chen G, Fu H, et al. Inf-Net: automatic COVID-19 lung infection segmentation from CT images. 2020.
COVID-19, Medical segmentation; 2020. http://medicalsegmentation.com/covid19/.
Hofmanninger J, Prayer F, Pan J, Röhrich S, Prosch H, Langs G. Automatic lung segmentation in routine imaging is primarily a data diversity problem, not a methodology problem. Eur Radiol Exp. 2020. https://doi.org/10.1186/s41747-020-00173-2.
Ronneberger O, Fischer P, Brox T. U-Net: convolutional networks for biomedical image segmentation. In: Lecture Notes in Computer Science. Springer, Berlin; 2015. p. 234–41.
Badrinarayanan V, Kendall A, Cipolla R. SegNet: a deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans Pattern Anal Mach Intell. 2017;39(12):2481–95.
Kingma DP, Ba J. Adam: a method for stochastic optimization; 2014. ar**v:1412.6980.
Phan TH, Yamamoto K. Resolving class imbalance in object detection with weighted cross entropy losses; 2020.
Kandel I, Castelli M. The effect of batch size on the generalizability of the convolutional neural networks on a histopathology dataset. ICT Express. 2020. https://doi.org/10.1016/j.icte.2020.04.010.
Masters D, Luschi C. Revisiting small batch training for deep neural networks; 2018.
Mordvintsev A, Olah C, Tyka M. Inceptionism: going deeper into neural networks. Google Research; 2015. Archived from the original on 2015-07-03.
Acknowledgements
Data for this study come from the Italian Society of Medical and Interventional Radiology [26].
Funding
This research did not require funding.
Author information
Authors and Affiliations
Contributions
IH proposed the research idea, the dataset, and the overall methodology. AS developed the methods and performed the experiments, collected the results, and drafted the paper. Both authors drew the conclusions. Both authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
The dataset used in this work is openly accessible and free to the public. No direct interaction with a human or animal entity was conducted in this work.
Consent for publication
Not applicable for this paper.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Saood, A., Hatem, I. COVID-19 lung CT image segmentation using deep learning methods: U-Net versus SegNet. BMC Med Imaging 21, 19 (2021). https://doi.org/10.1186/s12880-020-00529-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12880-020-00529-5