
Abstract
Background
In many countries, the prevalence of non-communicable diseases risk factors is commonly assessed through self-reported information from health interview surveys. It has been shown, however, that self-reported instead of objective data lead to an underestimation of the prevalence of obesity, hypertension and hypercholesterolemia. This study aimed to assess the agreement between self-reported and measured height, weight, hypertension and hypercholesterolemia and to identify an adequate approach for valid measurement error correction.
Methods
Nine thousand four hundred thirty-nine participants of the 2018 Belgian health interview survey (BHIS) older than 18 years, of which 1184 participated in the 2018 Belgian health examination survey (BELHES), were included in the analysis. Regression calibration was compared with multiple imputation by chained equations based on parametric and non-parametric techniques.
Results
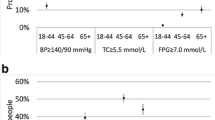
This study confirmed the underestimation of risk factor prevalence based on self-reported data. With both regression calibration and multiple imputation, adjusted estimation of these variables in the BHIS allowed to generate national prevalence estimates that were closer to their BELHES clinical counterparts. For overweight, obesity and hypertension, all methods provided smaller standard errors than those obtained with clinical data. However, for hypercholesterolemia, for which the regression model’s accuracy was poor, multiple imputation was the only approach which provided smaller standard errors than those based on clinical data.
Conclusions
The random-forest multiple imputation proves to be the method of choice to correct the bias related to self-reported data in the BHIS. This method is particularly useful to enable improved secondary analysis of self-reported data by using information included in the BELHES. Whenever feasible, combined information from HIS and objective measurements should be used in risk factor monitoring.
Similar content being viewed by others


Background
Worldwide, 63% of deaths are caused by non-communicable diseases (NCDs). A high proportion of NCDs are preventable by addressing their main physiological risk factors, such as high blood pressure, obesity and hypercholesterolemia [1]. Accurate data on the prevalence of these risk factors is therefore essential to build evidence-based prevention programs and policies [2]. In many countries, the prevalence of NCDs risk factors is commonly assessed through self-reported information from health interview surveys. It has been shown, however, that relying on self-reported data lead to an underestimation of the prevalence of overweight and obesity [3,4,5,6], hypertension [7,8,9,10] and hypercholesterolemia [11,12,13,14,15,16]. Social desirability or lack of knowledge may explain the overall validity problem. In addition to biased prevalence estimates, the measurement error related to self-reported data can also bias the estimated association between exposure and disease [17, Obesity, hypertension and hypercholesterolemia are leading biomedical risk factors of NCDs with surveillance often based on self-reported data. With a general increase in these risk factors rates in Belgium it is of paramount importance to obtain accurate prevalence data to correctly assess the effectiveness of NCD prevention programs. Results of this study confirm that using self-reported data alone leads to a severe underestimation of the prevalence of obesity, hypertension and hypercholesterolemia in Belgium. By exploring different approaches to correct for measurement error, this study shows how information from the BHIS and BELHES 2018 can be combined to provide a valid correction of those risk factors. Both regression calibration and MIME techniques generate accurate national prevalence rates of these risk factors, that could in turn be used by decision makers to allocate resources and set priorities in health. Our results suggest however that the random-forest multiple imputation is the most appropriate choice to correct the measurement error related to self-reported data in health interview surveys. Besides its ability to handle data with complex interaction or non-linearity, the technique has the advantage that it does not require to specify an imputation model which is particularly useful to allow secondary analysts to improve their analysis of self-reported data by using information included in the BELHES. Whenever feasible, combined information from health interview survey and measurements should be used in risk factor monitoring.Conclusions
Availability of data and materials
The data that support the findings of this study are not publicly available. Data are however available from the authors upon reasonable request and with specific permission (https://www.sciensano.be/en/node/55737/health-interview-survey-microdata-request-procedure). Legal restrictions make that BHIS and BHES data can only be communicated to other parties if an authorization is obtained from the sectoral committee social security and health of the Belgian data protection authority.
References
WHO. Noncommunicable diseases: Risk factors. World Health Organization. Available from: https://www.who.int/data/gho/data/themes/topics/topic-details/GHO/ncd-risk-factors. [Cited 2022 Mar 28].
World Health Organization. Noncommunicable diseases report 2018. World Health Organ. Geneva: World Health Organization; 2018. p. 223.
Maukonen M, Männistö S, Tolonen H. A comparison of measured versus self-reported anthropometrics for assessing obesity in adults: a literature review. Scand J Public Health. 2018;46: 565–79.
Flegal KM, Graubard B, Ioannidis JPA. Use and reporting of Bland-Altman analyses in studies of self-reported versus measured weight and height. Int J Obes (Lond). 2020;44(6):1311–8.
Tolonen H, Koponen P, Mindell JS, Männistö S, Giampaoli S, Dias CM, et al. Under-estimation of obesity, hypertension and high cholesterol by self-reported data: comparison of self-reported information and objective measures from health examination surveys. Eur J Public Health. 2014;24(6):941–8.
Gorber SC, Tremblay M, Moher D, Gorber B. A comparison of direct vs. self-report measures for assessing height, weight and body mass index: a systematic review. Obesity Reviews. 2007;8(4):307–26.
Gonçalves VSS, Andrade KRC, Carvalho KMB, Silva MT, Pereira MG, Galvao TF. Accuracy of self-reported hypertension: a systematic review and meta-analysis. J Hypertens. 2018;36(5):970–8.
Sarah CG, Mark T, Norm C, Jill H. The Accuracy of Self-Reported Hypertension: A Systematic Review and Meta-Analysis. Curr Hypertens Rev. 2008;4(1):36–62.
Atwood KM, Robitaille CJ, Reimer K, Dai S, Johansen HL, Smith MJ. Comparison of diagnosed, self-reported, and physically-measured hypertension in Canada. Can J Cardiol. 2013;29(5):606–12.
Ning M, Zhang Q, Yang M. Comparison of self-reported and biomedical data on hypertension and diabetes: findings from the China Health and Retirement Longitudinal Study (CHARLS). BMJ Open. 2016;6(1): e009836.
Huerta JM, Tormo MJ, Egea-Caparrós JM, Ortolá-Devesa JB, Navarro C. Accuracy of Self-Reported Diabetes, Hypertension and Hyperlipidemia in the Adult Spanish Population. DINO Study Findings Rev Esp Cardiol. 2009;62(2):143–52.
Fontanelli M de M, Nogueira LR, Garcez MR, Sales CH, Corrente JE, César CLG, et al. [Validity of self-reported high cholesterol in the city of São Paulo, Brazil, and factors associated with this information’s sensitivity]. Cad Saude Publica. 2018;34(12):e00034718.
Paalanen L, Koponen P, Laatikainen T, Tolonen H. Public health monitoring of hypertension, diabetes and elevated cholesterol: comparison of different data sources. Eur J Public Health. 2018;28(4):754–65.
Natarajan S, Lipsitz SR, Nietert PJ. Self-report of high cholesterol: determinants of validity in U.S. adults. Am J Prev Med. 2002;23(1):13–21.
Taylor A, Dal Grande E, Gill T, Pickering S, Grant J, Adams R, et al. Comparing self-reported and measured high blood pressure and high cholesterol status using data from a large representative cohort study. Aust N Z J Public Health. 2010;34(4):394–400.
Chun H, Kim IH, Min KD. Accuracy of self-reported hypertension, diabetes, and hypercholesterolemia: analysis of a representative sample of Korean older adults. Osong Public Health Res Perspect. 2016;7(2):108–15.
Carroll RJ, Ruppert D, Stefanski LA. Measurement error in nonlinear models. London; New York: Chapman & Hall; 1995.
Keogh RH, Bartlett JW. Measurement error as a missing data problem. ar**v:191006443 [stat]. 2019. Available from: http://arxiv.org/abs/1910.06443. [Cited 2022 Feb 21].
Prentice RL. Measurement error and results from analytic epidemiology: dietary fat and breast cancer. J Natl Cancer Inst. 1996;88(23):1738–47.
Rosella LC, Corey P, Stukel TA, Mustard C, Hux J, Manuel DG. The influence of measurement error on calibration, discrimination, and overall estimation of a risk prediction model. Popul Health Metr. 2012;10(1):20.
Jurek AM, Maldonado G, Greenland S, Church TR. Exposure-measurement error is frequently ignored when interpreting epidemiologic study results. Eur J Epidemiol. 2006;21(12):871–6.
Shaw PA, Deffner V, Keogh RH, Tooze JA, Dodd KW, Küchenhoff H, et al. Epidemiologic analyses with error-prone exposures: review of current practice and recommendations. Ann Epidemiol. 2018;28(11):821–8.
Cole SR, Chu H, Greenland S. Multiple-imputation for measurement-error correction. Int J Epidemiol. 2006;35(4):1074–81.
Visscher TLS, Viet AL, Kroesbergen IHT, Seidell JC. Underreporting of BMI in adults and its effect on obesity prevalence estimations in the period 1998 to 2001. Obesity (Silver Spring). 2006;14(11):2054–63.
Van Buuren S. Flexible imputation for missing data. Chapman & Hall/CRC. 2018. https://stefvanbuuren.name/fimd/.
Plankey MW, Stevens J, Fiegal KM, Rust PF. Prediction equations do not eliminate systematic error in self-reported body mass index. Obes Res. 1997;5(4):308–14.
Dutton DJ, McLaren L. The usefulness of “corrected” body mass index vs. self-reported body mass index: comparing the population distributions, sensitivity, specificity, and predictive utility of three correction equations using Canadian population-based data. BMC Public Health. 2014;14:430.
Edwards JK, Cole SR, Westreich D, Crane H, Eron JJ, Mathews WC, et al. Multiple Imputation to Account for Measurement Error in Marginal Structural Models. Epidemiology. 2015;26(5):645–52.
Blackwell M, Honaker J, King G. A Unified Approach to Measurement Error and Missing Data: Overview and Applications. Sociological Methods and Research. 2017;46(3):303–41.
Shaw PA, Gustafson P, Carroll RJ, Deffner V, Dodd KW, Keogh RH, et al. STRATOS guidance document on measurement error and misclassification of variables in observational epidemiology: Part 2-More complex methods of adjustment and advanced topics. Stat Med. 2020;39(16):2232–63.
Campion WM, Rubin D. Multiple Imputation for Nonresponse in Surveys. 1989.
Slade E, Naylor MG. A fair comparison of tree-based and parametric methods in multiple imputation by chained equations. Stat Med. 2020;39(8):1156–66.
Strobl C, Malley J, Tutz G. An Introduction to Recursive Partitioning: Rationale, Application and Characteristics of Classification and Regression Trees. Bagging and Random Forests Psychol Methods. 2009;14(4):323–48.
Burgette LF, Reiter JP. Multiple Imputation for Missing Data via Sequential Regression Trees. Am J Epidemiol. 2010;172(9):1070–6.
Laqueur HS, Shev AB, Kagawa RMC. SuperMICE: An Ensemble Machine Learning Approach to Multiple Imputation by Chained Equations. Am J Epidemiol. 2022;191(3):516–25.
Shah AD, Bartlett JW, Carpenter J, Nicholas O, Hemingway H. Comparison of random forest and parametric imputation models for imputing missing data using MICE: a CALIBER study. Am J Epidemiol. 2014;179(6):764–74.
Doove L, Buuren S, Dusseldorp E. Recursive partitioning for missing data imputation in the presence of interaction effects. Comput Stat Data Anal. 2014;72:92–104.
Demarest S, Van der Heyden J, Charafeddine R, Drieskens S, Gisle L, Tafforeau J. Methodological basics and evolution of the Belgian health interview survey 1997–2008. Arch Public Health. 2013;71(1):24.
Bel S, Van den Abeele S, Lebacq T, Ost C, Brocatus L, Stiévenart C, et al. Protocol of the Belgian food consumption survey 2014: objectives, design and methods. Arch Public Health. 2016;74(1):20.
Nguyen D, Hautekiet P, Berete F, Braekman E, Charafeddine R, Demarest S, et al. The Belgian health examination survey: objectives, design and methods. Archives of Public Health. 2020;78(1):50.
Health Interview Survey protocol. Available from: https://his.wiv-isp.be/SitePages/Protocol.aspx. [Cited 2021 May 6].
Tolonen H, Koponen P, Al-Kerwi A, Capkova N, Giampaoli S, Mindell J, et al. European health examination surveys - a tool for collecting objective information about the health of the population. Arch Public Health. 2018;76:38.
Bland JM, Altman DG. Statistical methods for assessing agreement between two methods of clinical measurement. Lancet. 1986;1(8476):307–10.
R Core Team. R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. 2021. Available from: https://www.R-project.org/.
van Buuren S, Groothuis-Oudshoorn K. mice: Multivariate Imputation by Chained Equations in R. J Stat Softw. 2011;45(3):1–67. https://doi.org/10.18637/jss.v045.i03.
Drieskens S, Demarest S, Bel S, De Ridder K, Tafforeau J. Correction of self-reported BMI based on objective measurements: a Belgian experience. Archives of Public Health. 2018;76(1):10.
Brettschneider AK, Rosario AS, Ellert U. Validity and predictors of BMI derived from self-reported height and weight among 11- to 17-year-old German adolescents from the KiGGS study. BMC Res Notes. 2011;4:414.
Großschädl F, Haditsch B, Stronegger WJ. Validity of self-reported weight and height in Austrian adults: sociodemographic determinants and consequences for the classification of BMI categories. Public Health Nutr. 2012;15(1):20–7.
De Vriendt T, Huybrechts I, Ottevaere C, Van Trimpont I, De Henauw S. Validity of self-reported weight and height of adolescents, its impact on classification into BMI-categories and the association with weighing behaviour. Int J Environ Res Public Health. 2009;6(10):2696–711.
Gugushvili A, Jarosz E. Inequality, validity of self-reported height, and its implications for BMI estimates: An analysis of randomly selected primary sampling units’ data. Prev Med Rep. 2019;16:100974.
Ng SP, Korda R, Clements M, Latz I, Bauman A, Bambrick H, et al. Validity of self-reported height and weight and derived body mass index in middle-aged and elderly individuals in Australia. Aust N Z J Public Health. 2011;35(6):557–63.
Lu S, Su J, **ang Q, Zhou J, Wu M. Accuracy of self-reported height, weight, and waist circumference in a general adult Chinese population. Popul Health Metrics. 2016;14(1):30.
Celis-Morales C, Livingstone KM, Woolhead C, Forster H, O’Donovan CB, Macready AL, et al. How reliable is internet-based self-reported identity, socio-demographic and obesity measures in European adults? Genes Nutr. 2015;10(5):28.
Pursey K, Burrows TL, Stanwell P, Collins CE. How accurate is web-based self-reported height, weight, and body mass index in young adults? J Med Internet Res. 2014;16(1):e4.
Stommel M, Schoenborn CA. Accuracy and usefulness of BMI measures based on self-reported weight and height: findings from the NHANES & NHIS 2001–2006. BMC Public Health. 2009;9:421.
McAdams MA, Van Dam RM, Hu FB. Comparison of self-reported and measured BMI as correlates of disease markers in US adults. Obesity (Silver Spring). 2007;15(1):188–96.
Madrigal H, Sánchez-Villegas A, Martínez-González MA, Kearney J, Gibney MJ, Irala J, et al. Underestimation of body mass index through perceived body image as compared to self-reported body mass index in the European Union. Public Health. 2000;114(6):468–73.
World Health Organization. Global action plan for the prevention and control of noncommunicable diseases. Geneva: 2013. https://www.who.int/publications/i/item/9789241506236.
White IR. Commentary: dealing with measurement error: multiple imputation or regression calibration? Int J Epidemiol. 2006;35(4):1081–2.
Acknowledgements
Not applicable.
Funding
This work was conducted as part of the WaIST project (Contribution of excess weight status to the societal impact of non-communicable diseases, multimorbidity and disability in Belgium: past, present, and future) supported by Sciensano, the Belgian institute for health.
Author information
Authors and Affiliations
Contributions
IP performed the analysis and wrote the manuscript. BD, JVH, EDC, SV were involved in the conception of the study. SV, JVH advised and helped the interpretation of data. BD, EDC, SV, SV, VG, JVDH provided critical revision of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
The study was approved by Ethics committee of Ghent University Hospital and a positive advice was obtained (advice with registration number B670201734213 and advice with registration number B670201834895). An informed consent was obtained for every BHIS and BHES participant.
All methods were carried out in accordance with relevant guidelines and regulations.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1.
Missing data pattern of the merged Belgian health interview survey/Belgian health examination survey 2018 dataset.
Additional file 2.
List of variables from the wider set of variables included in the imputation model.
Additional file 3.
Description of the population.
Additional file 4.
Bland-Altman plot for analysis of agreement between self-reported and measured height (by gender).
Additional file 5.
Bland-Altman plot for analysis of agreement between self-reported and measured height (by age category).
Additional file 6.
Bland-Altman plot for analysis of agreement between self-reported and measured height (by education level).
Additional file 7.
Bland-Altman plot for analysis of agreement between self-reported and measured weight (by gender).
Additional file 8.
Bland-Altman plot for analysis of agreement between self-reported and measured weight (by age category).
Additional file 9.
Bland-Altman plot for analysis of agreement between self-reported and measured weight (by education level).
Additional file 10.
Bland-Altman plot for analysis of agreement between self-reported and measured BMI (by age category).
Additional file 11.
Bland-Altman plot for analysis of agreement between self-reported and measured BMI (by education level).
Additional file 12.
Prevalence of overweight, obesity, hypertension and hypercholesterolemia using self-reported and measured data (by age).
Additional file 13.
Prevalence of overweight, obesity, hypertension and hypercholesterolemia using self-reported and measured data (by education level).
Additional file 14.
Confusion matrix comparing self-reported and measured high blood pressure (by age category).
Additional file 15.
Confusion matrix comparing self-reported and measured high blood pressure (by education level).
Additional file 16.
Confusion matrix comparing self-reported and measured hypercholesterolemia (by age category).
Additional file 17.
Confusion matrix comparing self-reported and measured hypercholesterolemia (by education level).
Additional file 18.
Estimates of the regression models for height, weight, hypertension and hypercholesterolemia.
Additional file 19.
Mean and standard deviation of the synthetic values plotted against iteration number for the classic and Random-forest multiply imputed 2018 BHIS data.
Additional file 20.
Prevalence estimates of overweight, obesity, hypertension and hypercholesterolemia in Belgium using self-reported, measured and adjusted BHIS data for 2008, 2013, and 2018.
Additional file 21.
Ratio of estimated standard errors: BELHES 2018 clinical/adjusted BHIS 2008-2013-2018.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Pelgrims, I., Devleesschauwer, B., Vandevijvere, S. et al. Using random-forest multiple imputation to address bias of self-reported anthropometric measures, hypertension and hypercholesterolemia in the Belgian health interview survey. BMC Med Res Methodol 23, 69 (2023). https://doi.org/10.1186/s12874-023-01892-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12874-023-01892-x