
Abstract
Background
Compared with other Populus species, Populus euphratica Oliv. exhibits better tolerance to abiotic stress, especially those involving extreme temperatures. However, little is known about gene regulation and signaling pathways involved in low temperature stress responses in this species. Recent development of Illumina/Solexa-based deep-sequencing technologies has accelerated the study of global transcription profiling under specific conditions. To understand the gene network controlling low temperature perception in P. euphratica, we performed transcriptome sequencing using Solexa sequence analysis to generate a leaf transcriptome at a depth of 10 gigabases for each sample.
Results
Using the Trinity method, 52,081,238 high-quality trimmed reads were assembled into a non-redundant set and 108,502 unigenes with an average length of 1,047 bp were generated. After performing functional annotations by aligning all-unigenes with public protein databases, 85,584 unigenes were annotated. Differentially expressed genes were investigated using the FPKM method by applying the Benjamini and Hochberg corrections. Overall, 2,858 transcripts were identified as differentially expressed unigenes in at least two samples and 131 were assigned as unigenes expressed differently in all three samples. In 4°C-treated sample and -4°C-treated sample, 1,661 and 866 differently expressed unigenes were detected at an estimated absolute log2-fold change of > 1, respectively. Among them, the respective number of up-regulated unigenes in C4 and F4 sample was 1,113 and 630, while the respective number of down-regulated ungenes is 548 and 236. To increase our understanding of these differentially expressed genes, we performed gene ontology enrichment and metabolic pathway enrichment analyses. A large number of early cold (below or above freezing temperature)-responsive genes were identified, suggesting that a multitude of transcriptional cascades function in cold perception. Analyses of multiple cold-responsive genes, transcription factors, and some key transduction components involved in ABA and calcium signaling revealed their potential function in low temperature responses in P. euphratica.
Conclusions
Our results provide a global transcriptome picture of P. euphratica under low temperature stress. The potential cold stress related transcripts identified in this study provide valuable information for further understanding the molecular mechanisms of low temperature perception in P. euphratica.
Similar content being viewed by others

Background
Low temperature has strong influence on the geographical distribution, growing season, quality and yield of plants. Previous reports have shown that plants may develop acquired freezing tolerance after exposure to non-freezing low temperatures [1, 2]. Plant cells cope with cold stress by regulating the expression of transcription factors and effectors during non-freezing low temperatures [3]. However, the transcriptome-level changes that underlie perception of temperatures below zero, which may be related to the ability to survive under extremely low temperatures [4], is poorly understood comparing that with cold sensing above freezing temperature.
A variety of cold-responsive (COR) genes that are under the control of some key transcription factors (TFs) are thought to be involved in cold sensing [5]. For example, the well characterized TF DREB1/CBF can regulate a subset of COR genes by binding the DRE/CRT cis-elements in promoter regions of COR genes [6–8]. By studying the DREB1/CBF network pathway, the roles of cellular or environmental factors, e.g. calcium, light, and circadian rhythm, are revealed in cold acclimation [1, 9]. The DREB1/CBF pathway in chilling response seemed well characterized in some plants, and its regulon has been identified in Brassica napus, rice, and poplar. However, the molecular mechanisms of cold-acclimation response are not well understood at the whole genome or transcriptome level since only 12% of cold responsive genes are members of the CBF regulon [10, 11]. It remains to be answered whether low temperature perception occurs below freezing temperature, and if so, whether it occurs by a similar molecular mechanism as above freezing temperature.
Populus euphratica Oliv. is naturally distributed in semiarid areas and plays an important role in maintaining local arid ecosystems [12]. They distinguish themselves considerably from other species by growing in deserts with extremely salty soil and wide environmental temperature ranges. Thus, P. euphratica has been widely considered as a model species for elucidating abiotic resistance mechanisms in trees [13–17]. Screening for cold responsive genes in P. euphratica can be a useful approach to understand the responses of woody plants to low temperatures and can also help elucidate the difference in cold perception between below- and above- freezing temperatures.
Recently, the development of Illumina/Solexa-based deep-sequencing technologies has made it possible to capture an unbiased view of the RNA transcript profile of a species under a given condition at the whole genome level [18]. Using this method, ESTs and numerous novel transcripts have been discovered in a tissue-specific manner [19, 20]. In the current study, we sought to identify genes linked to low temperature (below or above zero) perception and to explore the regulatory and sensory mechanisms involved in low temperature response processes by performing de novo assembly of the P. euphratica transcriptome using Solexa data. Two-year-old plants were subjected to temperatures of 4°C and a further drop to -4°C to conduct comprehensive analysis of transcriptional responses. The acquired information may facilitate attempts to elucidate response mechanisms of this species to chilling stress and will help in the development of strategies for improving of freezing tolerance in trees.
Results and discussion
Reads assembly and poplar databses alignment
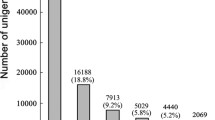
Three cDNA libraries were generated with mRNA from control (22°C), 4°C- or -4°C-treated P. euphratica plants and sequenced by Illumina deep-sequencing. After removing adapters, low-quality sequences, and ambiguous reads, a total of 132 million, 135 million, and 134 million clean reads with a mean length of 90 bp were generated in the control (CK), 4°C-treated sample (C4), and -4°C-treated sample (F4), respectively (Table 1). The raw data were deposited in the NCBI Sequence Read Archive (SRA) under the accession number SRP026075. The total length of the reads was >30 gigabases (Gb), equivalent to ~75-fold coverage of a P. trichocarpa genome. All trimmed reads were de novo assembled into contigs by the Trinity method [21]. The average contig size exceeded 320 bp in each of the three libraries (Figure 1A). Using paired-end information, the contigs were joined into assembled unigenes. Over 80% reads could be mapped back to the assembled transcripts, indicating a high quality of assembly (Additional file 1). Finally, 108,502 unigenes with an average length of 1,047 bp and N50 of 1,821 bp were assembled (Table 1). All unigenes were longer than 200 bp and 11.34% (12,309) of them were longer than 1,000 bp (Figure 1B).

Overview of assembly by Trinity. (A) Length frequency distribution of contigs obtained from de novo assembly of high-quality clean “reads”. (B) Length frequency distribution of unigenes produced by contig joining.
To estimate the representation of unigenes in the collection, all unique sequences generated from different assemblages were subjected to a BLAST comparison to compare EST collections from a variety of Populus species. The results indicated that our assemblages covered most P. euphratica transcripts (Additional file 2). By performing BLASTx against the Populus trichocarpa v3 dataset with an E-value of 1.0E-5 as threshold, 83,618 ESTs were assigned with an identity score ≥ 75%, covering 77.07% of assembled unigenes (Additional file 3). Of these unigenes, 79, 389 (97.3%) members shared >90% identity with their homologs from P. trichocarpa. Meanwhile, 3,6559 homologs (>80%) of P. trichocarpa v3 gene models have been sequenced. All these results indicate that our RNA-sequencing data has high contiguity, coverage, and could be used for further analyses.
Functional annotation and classification of the unigenes
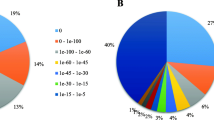
Using the best hits found by BLASTx or BLASTn with an E-value of < 1.0E-5, all of the unigenes were annotated according to the public databases including non-redundant protein (NR) database, non-redundant nucleotide (NT) database, SwissProt, Kyoto Encyclopedia of Genes and Genomes (KEGG) database and Clusters of Orthologous Groups (COG) database on the basis of similarities. The number of unigenes annotated with each database is summarized (Additional file 4). Of the 108,502 high-quality unique sequences, 85,584 (78.88%) unigenes had at least one significant match to an existing gene model in the BLAST searches (Additional file 4). By performing BLASTx against the NR database with an E-value cut-off of 1.0E-5, 71,428 BLASTx hits were obtained, covering 83.5% of the annotated unigenes. Within the P. euphratica unigene set, 49,291 (45.43%) unigenes were categorized (E-value < 1.0E-5) in 25 COG clusters (Figure 2). The five largest categories were: 1) general function predictions only (18.2%), 2) transcription (9.6%), 3) replication, recombination and repair (8.3%), 4) signal transduction mechanisms (7.3%) and 5) post-translational modification, protein turnover, chaperones (6.8%). Classification of Gene ontology (GO) terms was performed according to the NR annotation using the Blast2GO software [2]. In the category of biological process, the largest groups were cellular process, metabolic process, response to stimulus, and biological regulation (Figure 3). As for the molecular function category, unigenes with binding and catalytic activity formed the largest groups.

COG functional classification of the P. euphratica transcriptome. 49,291 unigenes with significant homologies in the COG database (E-value < 1.0 E-5) were classified into 25 COG categories. The capital letters in x-axis indicates the COG categories as listed on the right of the histogram, and the y-axis indicates the number of unigenes.

Function classifications of GO terms of all P. euphratica transcripts. Based on highscore BLASTx matches in the NR plant proteins database, P. euphratica unigenes were classified into three main GO categories and 31 sub-categories. The left y-axis indicates the percentage of a specific category of genes in each main category. The right y-axis indicates the number of genes in the same category.
To obtain a better understanding of the biological functions of the unigenes, a KEGG pathway-based analysis was also performed. Based on a comparison against the KEGG database using BLASTx with an E-value cutoff of <1.0E-5, 39,313 (36.23%) of the 108,502 unigenes had significant matches in the database and were assigned to 127 KEGG pathways. Of the 8,220 metabolism pathway unigenes, 2,726 were involved in plant hormone signal transduction pathways, including tryptophan metabolism, zeatin biosynthesis, diterpenoid biosynthesis, carotenoid biosynthesis, cysteine and methionine metabolism, brassinosteroid biosynthesis, α-Linolenic acid metabolism, and phenylalanine metabolism.
The three samples had 68 members in common when the 100 most abundant transcripts were compared (Additional file 5). The 23 unique members highly expressed in the control were involved in auxin signaling, cell division, and biogenesis. In contrast, the 19 unique members highly expressed in the C4 sample were stress (e.g., arginine decarboxylase, and dehydration) -induced genes. The 28 unique members highly expressed in the F4 sample were also stress-related genes, e.g., the glucanase, zinc finger protein, and E3 ubiquitin-protein ligase genes. These results indicate that our data are reliable.
Protein coding sequence prediction
Unigenes were aligned by BLASTx (E-value < 1.0E-5) against the NR, Swiss-Prot, KEGG, and COG protein databases in that order. Unigenes aligned to a high priority database were not aligned to databases of lower priority. The process ended when all alignments had been performed. The correct reading frame of the nucleotide sequences (5’-3’direction) of unigenes was defined by the highest rank in the BLAST results, and the corresponding protein sequences were obtained from the standard codon table. Unigenes that could not be aligned to any database were scanned with ESTScan [22] to produce the nucleotide and amino acid sequences of the predicted region. In total, 71,559 unigene coding sequences (CDSs) were generated by the BLASTx protein database searches described above. Of these unigenes with CDS sequences, the majority (44,005 members, occupied 61.5%) were over 500 bp and 23,479 were over 1, 000 bp in length (Figure 4A-B). Using the ESTscan program, we assigned another 489 unigene CDSs that could not be aligned to above databases (Figure 4C-D). The length frequency distributions of these unigene CDSs and their corresponding amino acid sequences are given (Figure 4).

Transcriptome coding sequence (CDS) predicted by BLASTx and ESTScan. (A) The length distribution of CDs using BLASTx. (B) The length distribution of proteins using BLASTx. (C) The length distribution of CDs using ESTscan. (D) The length distribution of proteins using ESTscan.
Differentially expressed gene among three samples
We measured gene expression levels based on fragments per kilobase of exon model per million mapped reads (FPKM). After applying the chi-square test and Benjamini-Hochberg multiple testing corrections using R program among three samples simultaneously, we identified 2,858 genes as reliable DEGs in at least two samples (assigned as either DEGs) regardless of fold change (Additional file 6). Of these DEGs, 131 were expressed differentially in all three samples (assigned as all-DEGs, Additional file 7). Given a standard at an estimated absolute log2-fold change of >1, the respective DEGs of CK vs. C4, CK vs. F4 and C4 vs. F4 were 1,661, 866, and 1,161 (Additional files 8, 9, 10). The number of up-regulated unigenes in C4 and F4 samples was 1,113 and 630, respectively.
To accurately identify DEGs, we selected the 50 most significantly up-regulated transcripts that could be well-annotated by poplar database or NR database. As a result, those coding for the chlorophyll a/b binding protein (e.g., Unigene50811, CL12828.Contig3, Unigene50363, and Unigene55266), rubisco activase (CL4046.Contig4, Unigene50527, and Unigene55538), AP2/ERF transcription factors (Unigene26311,Unigene22719, CL9386.Contig2, Unigene18453, and CL9876.Contig3), and some other transcription factors (CL1721.Contig8, and Unigene27837) were the most up-regulated interpretable transcripts in C4 sample (Additional file 11). As for the top 50 up-regulated transcripts in the F4 sample (Additional file 12), the annotated transcripts focused on transcription factors (DREB1 transcription factors e.g. unigene26567 and unigene26311; WRKY transcription factor Unigene18620) and xyloglucan endotransglycosylases (Unigene19292, Unigene14078 and CL29.Contig1).
Although Illumina sequencing is a highly efficient method for DEG screening, false positives still occur because of the sensitivity of this technology to templates present in DNA samples [23]. Thus, we validated the RNA sequencing data by performing qPCR analysis on 10 transcripts randomly selected from the up-regulated gene list. The qPCR results indicate that all of these DEGs exhibited similar expression kinetics to those obtained from the RNA sequencing analysis (Figure 5). These results support the validity of the method used for determining DEGs from the RNA sequencing analysis.

Expression analyses of 10 DEGs by qPCR. qPCR was performed on 10 members randomly selected from up-regulated gene lists of the C4 or F4 sample.
Gene ontology and pathway enrichment analyses of differentially expressed unigenes
All DEGs were mapped to each term of the Gene Ontology database (http://www.geneontology.org/, release data: Aug 1st, 2012) and the gene numbers were calculated from each GO term. Using a hypergeometric test, we identified the significantly enriched GO terms of DEGs compared to the genomic background (p ≤ 0.05, after Bonferroni correction). In the category of biological processes, three Go terms including “response to stress”, “response to stimulus” and “response to carbohydrate stimulus” are enriched (p ≤ 0.05, after bonferroni correction) after 4°C and -4°C treatments (Table 2), suggesting that genes in these processes may play important roles in low temperature perception. Additionally, “carbon fixation process”, “glucan metabolic process” and “macromolecule metabolic regulation processes” are also enriched for DEGs in C4 (Table 2), indicating that genes related to these processes may also participate in cold sensing. A close inspection referred to “response to stimulus” category indicated that “response to hormone stimulus” and “response to abiotic stimulus” were two over-presented subcategories (data not shown), suggesting our low temperature treatment may have caused an efficient abiotic stress and have activated some hormone response process. Furthermore, DEGs with “protein binding” and “protein modification” subcategories were also over-presented in both samples, indicating that comprehensive changes had taken place in cells in response to low temperature stress. We further performed Go enrichment analysis for genes that differentially expressed in all of three samples and the results indicated that those involved in gene expression regulation, macromolecule metabolic process regulation, and abiotic stimulus response were enriched. As for the category of “molecular function”, DEGs with “structural molecule activity” was the only common group that over-presented after 4°C and -4°C treatments (Table 2).
By performing the KEGG pathway analyses, we identified twelve pathways that changed significantly (q ≤ 0.05) under 4°C treatment, including the members involved in carbohydrate, energy, vitamin, hormone, and nitrogen metabolism (Additional file 13). “Plant pathogen interaction”, “hormone signal transduction”, and “biosynthesis of unsaturated fatty” pathways had the top three most differentially expressed unigene numbers and thus seem to play important roles in low temperature perception above freezing point. As for -4°C treatment, only 3 pathways changed significantly (Additional file 13). “Plant pathogen interaction” was assigned as a major pathway that changed significantly in both treated groups, indicating that low temperature stress response signal network may overlap with plant-pathogen interactions signals in P. euphratica. This is a notable finding considering that little is known about the overlap in signal transduction between abiotic and biotic stresses. Additionally, the transcripts of all of unsaturated fatty acid pathway genes increased significantly in the C4 sample. This result is in accordance with previous reports that plants undergoing low temperature stress preferentially accumulate poly-unsaturated and unsaturated fatty acids, which enhance low temperature tolerance under chilling conditions [24, 25].
Transcription factors responding to low temperature stress
Transcription factors play crucial roles in the regulation of target gene expression via specific binding to cis-acting elements in their promoters [26]. Many of the COR genes contain cis-elements, such as dehydration-responsive elements/C-repeat elements (DRE/CRT, A/GCCGAC) and myeloblastosis (MYB, C/TAACNA/G) [27, 28] in their promoters that can be regulated by DREB and MYB transcription factors. Analysis of these transcription factors could provide useful information on the complex regulatory networks involved in P. euphratica cold stress responses.
Changes in the expression of transcription factors occurred both after 4°C and -4°C treatments (Table 3). The AP2/ERF transcription factors were overrepresented ( log2-fold change > 1) in both treated samples. This family contains 24 and 22 up-regulated members in the C4 and F4 samples, respectively (Table 3), indicating its important role in low temperature stress responses. The AP2/ERF transcription factors have been subdivided into five subfamilies including AP2 subfamily, DREB subfamily, ERF subfamily, RAV subfamily and others. Some RAP homologs (e.g. unigene16978 and CL5587.contig2) and ERF homologs (e.g. unigene8840, CL4762.contig1, CL13298.contig1), which were seldom studied in cold sensing were up-regulated in both C4 and F4 samples, indicating the potential function of these subfamilies in cold response. As a group of DREB subfamily, CBF/DREB1 was found to be expressed specifically under cold stress but not under normal growth conditions. Here, several DREB1/CBF-like unigenes changed their expression significantly after low temperature treatments. The transcripts of two CBF4/DREB1D homologs, Unigene26311 and Unigene22719, both increased over 11-fold after both treatments (Additional files 11, 12). However, no Arabidopsis CBF2 homologs were found up-regulated in the P. euphratica transcriptome. Thus, our results not only indicate a key role of the CBF/DREB1 transcription factors in low temperature responses but also suggest that the CBF/DREB1 transcriptional activation mechanism of P. euphratica is not necessarily the same as that of Arabidopsis.
Previous studies have shown that not all cold-regulated gene expression is under the direct control of the CBF/DREB family [11, 29]. Besides the AP2/ERF family, it is likely that the WRKY and NAC transcription factors also play important roles in the transcriptional regulation of genes in early cold response in P. euphratica because they were overrepresented in the up-regulated gene list (log2-fold change > 1). In the WRKY family, 20 and 12 members were up-regulated in the C4 and F4 groups, respectively (Table 3). In comparison, none was found down-regulated in the respective groups. In the NAC transcription factor family, the transcripts of 9 and 5 members were up-regulated, while none was found down-regulated in both treated samples. Evidence that the WRKY and NAC transcription factor gene families may play important roles in the regulation of transcriptional reprogramming associated with cold stress responses is incremental [68]. The FPKM method formula was:
where C is the number of reads that uniquely aligned to one unigene; N is the total number of reads that uniquely aligned to all unigenes; L is the base number in the CDS of one unigene. The goal of this transformation is to normalize the counts in regard of the differing library sizes and the length of the transcripts [69].
We identified DEGs from different samples (CK, C4 and F4) using R program. The Pearson’s chi-square test was applied to assess the lane effect. For each gene, the P-value was computed. After that, Benjamini–Hochberg false discovery rate (FDR) was applied to correct the results for p value. FDR method is widely used in deep-sequencing studies because of its power in finding over-representative unigenes [70–73]. The transcripts that were induced or suppressed at an estimated absolute log2-fold change of >1 and FDR adjusted p-value ≤ 0.05 were considered to be differentially expressed [74].
GO and KEGG analyses for differentially expressed unigenes
In order to find the significantly enriched GO terms in DEGs against a genome background, the DEGs were annotated to GO database (http://www.geneontology.org/) using hypergeometric test for statistical analysis [25]. For p value correction, we used the rigorous Bonferroni correction method. The cutoff p value after correction was 0.05. GO terms fulfilling this condition were defined as being significantly enriched. The KEGG pathway enrichment analysis of DEGs was also performed with the whole genome background as a reference to find the main biochemical pathways and signal transduction pathways in which DEGs involved. After multiple testing corrections, we defined pathways with q-value ≤0.05 as being those significantly enriched in DEGs.
Quantitative PCR analysis
Quantitative PCR (qPCR) was performed to determine the expression level of selected unigenes. The qPCR was conducted using a power SYBR Green PCR Kit (ABI) in a MicroAmp™ 96-well plate with a StepOnePlus™ Real-Time PCR System (ABI). The relative expression value was calculated by the 2-ΔΔCt method using PeActin (GenBank accession number EF148840) as an internal control [75]. Gene-specific primers used in the qPCR analysis are listed in Additional file 14. RNA pools used in the qPCR analyses were extracted from three independent samples which were different from those used for RNA-seq. Three technical replicates were used for each sample.
Abbreviations
- COR:
-
Cold-responsive
- CBF:
-
CRT binding transcription factor
- RNA-seq:
-
RNA sequencing
- DEG:
-
Differentially expressed gene
- FDR:
-
False discovery rate
- FPKM:
-
Fragments per kilobase of exon region in a given gene per million mapped fragments
- GO:
-
Gene ontology
- KEGG:
-
Kyoto Encyclopedia of Genes and Genomes
- qPCR:
-
Quantitative real-time PCR
- TF:
-
Transcription factor.
References
Thomashow MF: Plant cold acclimation: freezing tolerance genes and regulatory mechanisms. Annu Rev Plant Physiol Plant Mol Biol. 1999, 50: 571-599. 10.1146/annurev.arplant.50.1.571.
Conesa A, Gotz S, Garcia-Gomez JM, Terol J, Talon M, Robles M: Blast2GO: a universal tool for annotation, visualization and analysis in functional genomics research. Bioinfo. 2005, 21 (18): 3674-3676. 10.1093/bioinformatics/bti610.
Korn M, Peterek S, Mock HP, Heyer AG, Hincha DK: Heterosis in the freezing tolerance, and sugar and flavonoid contents of crosses between Arabidopsis thaliana accessions of widely varying freezing tolerance. Plant Cell Environ. 2008, 31 (6): 813-827. 10.1111/j.1365-3040.2008.01800.x.
Hannah MA, Wiese D, Freund S, Fiehn O, Heyer AG, Hincha DK: Natural genetic variation of freezing tolerance in Arabidopsis. Plant Physiol. 2006, 142 (1): 98-112. 10.1104/pp.106.081141.
Viswanathan C, Zhu JK: Molecular genetic analysis of cold-regulated gene transcription. Philos Trans R Soc Lond B Biol Sci. 2002, 357 (1423): 877-886. 10.1098/rstb.2002.1076.
Carvallo MA, Pino MT, Jeknic Z, Zou C, Doherty CJ, Shiu SH, Chen TH, Thomashow MF: A comparison of the low temperature transcriptomes and CBF regulons of three plant species that differ in freezing tolerance: Solanum commersonii, Solanum tuberosum, and Arabidopsis thaliana. J Exp Bot. 2011, 62 (11): 3807-3819. 10.1093/jxb/err066.
Jaglo-Ottosen KR, Gilmour SJ, Zarka DG, Schabenberger O, Thomashow MF: Arabidopsis CBF1 overexpression induces COR genes and enhances freezing tolerance. Science. 1998, 280 (5360): 104-106. 10.1126/science.280.5360.104.
Hsieh TH, Lee JT, Yang PT, Chiu LH, Charng YY, Wang YC, Chan MT: Heterology expression of the Arabidopsis C-repeat/dehydration response element binding factor 1 gene confers elevated tolerance to chilling and oxidative stresses in transgenic tomato. Plant Physiol. 2002, 129 (3): 1086-1094. 10.1104/pp.003442.
Lee BH, Henderson DA, Zhu JK: The Arabidopsis cold-responsive transcriptome and its regulation by ICE1. Plant Cell. 2005, 17 (11): 3155-3175. 10.1105/tpc.105.035568.
Chinnusamy V, Zhu JK, Sunkar R: Gene regulation during cold stress acclimation in plants. Methods Mol Biol. 2010, 639: 39-55. 10.1007/978-1-60761-702-0_3.
Fowler S, Thomashow MF: Arabidopsis transcriptome profiling indicates that multiple regulatory pathways are activated during cold acclimation in addition to the CBF cold response pathway. Plant Cell. 2002, 14 (8): 1675-1690. 10.1105/tpc.003483.
Browicz K: Chorology of populus euphratica Olivier. Arboretum Kornickie. 1977, 22: 5-27.
Sun J, Wang MJ, Ding MQ, Deng SR, Liu MQ, Lu CF, Zhou XY, Shen X, Zheng XJ, Zhang ZK, Song J, Hu ZM, Xu Y, Chen SL: H2O2 and cytosolic Ca2+ signals triggered by the PM H+-coupled transport system mediate K+/Na+ homeostasis in NaCl-stressed Populus euphratica cells. Plant Cell Environ. 2010, 33 (6): 943-958. 10.1111/j.1365-3040.2010.02118.x.
Ye CY, Zhang HC, Chen JH, **a XL, Yin WL: Molecular characterization of putative vacuolar NHX-type Na+/H+ exchanger genes from the salt-resistant tree Populus euphratica. Physiol Plant. 2009, 137 (2): 166-174. 10.1111/j.1399-3054.2009.01269.x.
Wu Y, Ding N, Zhao X, Zhao M, Chang Z, Liu J, Zhang L: Molecular characterization of PeSOS1: the putative Na+/H+ antiporter of Populus euphratica. Plant Mol Biol. 2007, 65 (1–2): 1-11.
Ottow EA, Brinker M, Teichmann T, Fritz E, Kaiser W, Brosche M, Kangasjarvi J, Jiang X, Polle A: Populus euphratica displays apoplastic sodium accumulation, osmotic adjustment by decreases in calcium and soluble carbohydrates, and develops leaf succulence under salt stress. Plant Physiol. 2005, 139 (4): 1762-1772. 10.1104/pp.105.069971.
Gu R, Fonseca S, Puskas LG, Hackler L, Zvara A, Dudits D, Pais MS: Transcript identification and profiling during salt stress and recovery of Populus euphratica. Tree Physiol. 2004, 24 (3): 265-276. 10.1093/treephys/24.3.265.
Wilhelm BT, Marguerat S, Watt S, Schubert F, Wood V, Goodhead I, Penkett CJ, Rogers J, Bahler J: Dynamic repertoire of a eukaryotic transcriptome surveyed at single-nucleotide resolution. Nature. 2008, 453 (7199): 1239-1243. 10.1038/nature07002.
Wu T, Qin Z, Zhou X, Feng Z, Du Y: Transcriptome profile analysis of floral sex determination in cucumber. J Plant Physiol. 2010, 167 (11): 905-913. 10.1016/j.jplph.2010.02.004.
Wang XW, Luan JB, Li JM, Bao YY, Zhang CX, Liu SS: De novo characterization of a whitefly transcriptome and analysis of its gene expression during development. BMC Genomics. 2010, 11: 400-10.1186/1471-2164-11-400.
Grabherr MG, Haas BJ, Yassour M, Levin JZ, Thompson DA, Amit I, Adiconis X, Fan L, Raychowdhury R, Zeng Q, Chen ZH, Mauceli E, Hacohen N, Gnirke A, Rhind N, Palma FD, Birren BW, Nusbaum C, Lindblad-Toh K, Friedman N, Regev A: Full-length transcriptome assembly from RNA-Seq data without a reference genome. Nat Biotechnol. 2011, 29 (7): 644-652. 10.1038/nbt.1883.
Iseli C, Jongeneel CV, Bucher P: ESTScan: a program for detecting, evaluating, and reconstructing potential coding regions in EST sequences. Proc Int Conf Intell Syst Mol Biol. 1999, 7: 138-148.
Zhao Z, Tan L, Dang C, Zhang H, Wu Q, An L: Deep-sequencing transcriptome analysis of chilling tolerance mechanisms of a subnival alpine plant, Chorispora bungeana. BMC Plant Biol. 2012, 12: 222-10.1186/1471-2229-12-222.
Kodama H, Hamada T, Horiguchi G, Nishimura M, Iba K: Genetic enhancement of cold tolerance by expression of a gene for chloroplast [omega]-3 fatty acid desaturase in transgenic tobacco. Plant Physiol. 1994, 105 (2): 601-605.
Williams JP, Khan MU, Mitchell K, Johnson G: The effect of temperature on the level and biosynthesis of unsaturated fatty acids in diacylglycerols of Brassica napus leaves. Plant Physiol. 1988, 87 (4): 904-910. 10.1104/pp.87.4.904.
Yamaguchi-Shinozaki K, Shinozaki K: Transcriptional regulatory networks in cellular responses and tolerance to dehydration and cold stresses. Annu Rev Plant Biol. 2006, 57: 781-803. 10.1146/annurev.arplant.57.032905.105444.
Stockinger EJ, Gilmour SJ, Thomashow MF: Arabidopsis thaliana CBF1 encodes an AP2 domain-containing transcriptional activator that binds to the C-repeat/DRE, a cis-acting DNA regulatory element that stimulates transcription in response to low temperature and water deficit. Proc Natl Acad Sci U S A. 1997, 94 (3): 1035-1040. 10.1073/pnas.94.3.1035.
Yamaguchi-Shinozaki K, Shinozaki K: Organization of cis-acting regulatory elements in osmotic- and cold-stress-responsive promoters. Trends Plant Sci. 2005, 10 (2): 88-94. 10.1016/j.tplants.2004.12.012.
Kreps JA, Wu Y, Chang HS, Zhu T, Wang X, Harper JF: Transcriptome changes for Arabidopsis in response to salt, osmotic, and cold stress. Plant Physiol. 2002, 130 (4): 2129-2141. 10.1104/pp.008532.
Hu H, You J, Fang Y, Zhu X, Qi Z, **ong L: Characterization of transcription factor gene SNAC2 conferring cold and salt tolerance in rice. Plant Mol Biol. 2008, 67 (1–2): 169-181.
Şahin-Çevik M: A WRKY transcription factor gene isolated from Poncirus trifoliata shows differential responses to cold and drought stresses. Plant Omics J. 2012, 5 (438): 45-
Wang JY, Wang JP, He Y: A Populus euphratica NAC protein regulating Na(+)/K(+) homeostasis improves salt tolerance in Arabidopsis thaliana. Gene. 2013, 521 (2): 265-273. 10.1016/j.gene.2013.03.068.
Aslam M, Grover A, Sinha VB, Fakher B, Pande V, Yadav PV, Gupta SM, Anandhan S, Ahmed Z: Isolation and characterization of cold responsive NAC gene from Lepidium latifolium. Mol Biol Rep. 2012, 39 (10): 9629-9638. 10.1007/s11033-012-1828-0.
Marè C, Mazzucotelli E, Crosatti C, Francia E, Cattivelli L: HvWRKY38: a new transcription factor involved in cold-and drought-response in barley. Plant Mol Biol. 2004, 55 (3): 399-416. 10.1007/s11103-004-0906-7.
Zhou QY, Tian AG, Zou HF, **e ZM, Lei G, Huang J, Wang CM, Wang HW, Zhang JS, Chen SY: Soybean WRKY-type transcription factor genes, GmWRKY13, GmWRKY21, and GmWRKY54, confer differential tolerance to abiotic stresses in transgenic Arabidopsis plants. Plant Biotechnol J. 2008, 6 (5): 486-503. 10.1111/j.1467-7652.2008.00336.x.
Jiang Y, Deyholos MK: Functional characterization of Arabidopsis NaCl-inducible WRKY25 and WRKY33 transcription factors in abiotic stresses. Plant Mol Biol. 2009, 69 (1–2): 91-105.
Nogueira FT, Schlögl PS, Camargo SR, Fernandez JH: SsNAC23, a member of the NAC domain protein family, is associated with cold, herbivory and water stress in sugarcane. Plant Sci. 2005, 169 (1): 93-106. 10.1016/j.plantsci.2005.03.008.
Song SY, Chen Y, Chen J, Dai XY, Zhang WH: Physiological mechanisms underlying OsNAC5-dependent tolerance of rice plants to abiotic stress. Planta. 2011, 234 (2): 331-345. 10.1007/s00425-011-1403-2.
Hannah MA, Heyer AG, Hincha DK: A global survey of gene regulation during cold acclimation in Arabidopsis thaliana. PLoS Gen. 2005, 1 (2): e26-10.1371/journal.pgen.0010026.
Chinnusamy V, Ohta M, Kanrar S, Lee B-h, Hong X, Agarwal M, Zhu J-K: ICE1: a regulator of cold-induced transcriptome and freezing tolerance in Arabidopsis. Genes Dev. 2003, 17 (8): 1043-1054. 10.1101/gad.1077503.
Zhang S, Scheller HV: Photoinhibition of photosystem I at chilling temperature and subsequent recovery in Arabidopsis thaliana. Plant Cell Physiol. 2004, 45 (11): 1595-1602. 10.1093/pcp/pch180.
Ribas-Carbo M, Aroca R, Gonzalez-Meler MA, Irigoyen JJ, Sanchez-Diaz M: The electron partitioning between the cytochrome and alternative respiratory pathways during chilling recovery in two cultivars of maize differing in chilling sensitivity. Plant Physiol. 2000, 122 (1): 199-204. 10.1104/pp.122.1.199.
Pietrini F, Iannelli M, Battistelli A, Moscatello S, Loreto F, Massacci A: Effects on photosynthesis, carbohydrate accumulation and regrowth induced by temperature increase in maize genotypes with different sensitivity to low temperature. Funct Plant Biol. 1999, 26 (4): 367-373.
Aroca R, Irigoyen JJ, Sánchez-Dı́az M: Photosynthetic characteristics and protective mechanisms against oxidative stress during chilling and subsequent recovery in two maize varieties differing in chilling sensitivity. Plant Sci. 2001, 161 (4): 719-726. 10.1016/S0168-9452(01)00460-5.
Ellis RJ: The most abundant protein in the world. Trends Biochem Sci. 1979, 4: 241-244. 10.1016/0968-0004(79)90212-3.
Hola D, Kocova M, Rothova O, Wilhelmova N, Benesova M: Recovery of maize (Zea mays L.) inbreds and hybrids from chilling stress of various duration: photosynthesis and antioxidant enzymes. J Plant Physiol. 2007, 164 (7): 868-877. 10.1016/j.jplph.2006.04.016.
Fryer MJ, Oxborough K, Martin B, Ort DR, Baker NR: Factors associated with depression of photosynthetic quantum efficiency in Maize at low growth temperature. Plant Physiol. 1995, 108 (2): 761-767.
Kuk YI, Lee JH, Kim HY, Chung SJ, Chung GC, Guh JO, Lee HJ, Burgos NR: Relationships of cold acclimation and antioxidative enzymes with chilling tolerance in cucumber (Cucumis sativus L.). J Am Soc Hortic Sci. 2003, 128 (5): 661-666.
Chen HH, Li PH, Brenner ML: Involvement of abscisic Acid in potato cold acclimation. Plant Physiol. 1983, 71 (2): 362-365. 10.1104/pp.71.2.362.
Nitsch LM, Oplaat C, Feron R, Ma Q, Wolters-Arts M, Hedden P, Mariani C, Vriezen WH: Abscisic acid levels in tomato ovaries are regulated by LeNCED1 and SlCYP707A1. Planta. 2009, 229 (6): 1335-1346. 10.1007/s00425-009-0913-7.
Park HY, Seok HY, Park BK, Kim SH, Goh CH, Lee BH, Lee CH, Moon YH: Overexpression of Arabidopsis ZEP enhances tolerance to osmotic stress. Biochem Biophys Res Commun. 2008, 375 (1): 80-85. 10.1016/j.bbrc.2008.07.128.
Lang V, Mantyla E, Welin B, Sundberg B, Palva ET: Alterations in water status, endogenous abscisic acid content, and expression of rab18 Gene during the development of freezing tin Arabidopsis thaliana. Plant Physiol. 1994, 104 (4): 1341-1349.
Pandey S, Nelson DC, Assmann SM: Two novel GPCR-type G proteins are abscisic acid receptors in Arabidopsis. Cell. 2009, 136 (1): 136-148. 10.1016/j.cell.2008.12.026.
Ma Y, Szostkiewicz I, Korte A, Moes D, Yang Y, Christmann A, Grill E: Regulators of PP2C phosphatase activity function as abscisic acid sensors. Science. 2009, 324 (5930): 1064-1068.
Ye CY, Yang X, **a X, Yin W: Comparative analysis of cation/proton antiporter superfamily in plants. Gene. 2013, 521 (2): 245-251. 10.1016/j.gene.2013.03.104.
Monroy AF, Dhindsa RS: Low-temperature signal transduction: induction of cold acclimation-specific genes of alfalfa by calcium at 25 degrees C. Plant Cell. 1995, 7 (3): 321-331.
Gong D, Guo Y, Schumaker KS, Zhu J-K: The SOS3 family of calcium sensors and SOS2 family of protein kinases in Arabidopsis. Plant Physiol. 2004, 134 (3): 919-926. 10.1104/pp.103.037440.
Luan S: The CBL-CIPK network in plant calcium signaling. Trends Plant Sci. 2009, 14 (1): 37-42. 10.1016/j.tplants.2008.10.005.
Sheen J: Ca2+-dependent protein kinases and stress signal transduction in plants. Science. 1996, 274 (5294): 1900-1902. 10.1126/science.274.5294.1900.
Hrabak EM, Chan CW, Gribskov M, Harper JF, Choi JH, Halford N, Kudla J, Luan S, Nimmo HG, Sussman MR, Thomas M, Walker-Simmons K, Zhu JK, Harmon AC: The Arabidopsis CDPK-SnRK superfamily of protein kinases. Plant Physiol. 2003, 132 (2): 666-680. 10.1104/pp.102.011999.
Komatsu S, Yang G, Khan M, Onodera H, Toki S, Yamaguchi M: Over-expression of calcium-dependent protein kinase 13 and calreticulin interacting protein 1 confers cold tolerance on rice plants. Mol Genet Genomics. 2007, 277 (6): 713-723. 10.1007/s00438-007-0220-6.
Abbasi F, Onodera H, Toki S, Tanaka H, Komatsu S: OsCDPK13, a calcium-dependent protein kinase gene from rice, is induced by cold and gibberellin in rice leaf sheath. Plant Mol Biol. 2004, 55 (4): 541-552. 10.1007/s11103-004-1178-y.
Chen J, Xue B, **a X, Yin W: A novel calcium-dependent protein kinase gene from Populus euphratica. Biochem Biophys Res Commun. 2013, 441 (3): 630-636. 10.1016/j.bbrc.2013.10.103.
Chang S, Puryear J, Cairney J: A simple and efficient method for isolating RNA from pine trees. Plant Mol Biol Rep. 1993, 11 (2): 113-116. 10.1007/BF02670468.
Pertea G, Huang X, Liang F, Antonescu V, Sultana R, Karamycheva S, Lee Y, White J, Cheung F, Parvizi B, Tsai J, Quackenbush J: TIGR Gene Indices clustering tools (TGICL): a software system for fast clustering of large EST datasets. Bioinfo. 2003, 19 (5): 651-652. 10.1093/bioinformatics/btg034.
Kanehisa M, Araki M, Goto S, Hattori M, Hirakawa M, Itoh M, Katayama T, Kawashima S, Okuda S, Tokimatsu T, Yamanishi Y: KEGG for linking genomes to life and the environment. Nucleic Acids Res. 2008, 36 (Database issue): D480-D484.
Ye J, Fang L, Zheng H, Zhang Y, Chen J, Zhang Z, Wang J, Li S, Li R, Bolund L: WEGO: a web tool for plotting GO annotations. Nucleic Acids Res. 2006, 34 (Web Server issue): W293-W297.
Mortazavi A, Williams BA, McCue K, Schaeffer L, Wold B: Map** and quantifying mammalian transcriptomes by RNA-Seq. Nat Methods. 2008, 5 (7): 621-628. 10.1038/nmeth.1226.
Soneson C, Delorenzi M: A comparison of methods for differential expression analysis of RNA-seq data. BMC Bioinfo. 2013, 14: 91-10.1186/1471-2105-14-91.
Junttila S, Laiho A, Gyenesei A, Rudd S: Whole transcriptome characterization of the effects of dehydration and rehydration on Cladonia rangiferina, the grey reindeer lichen. BMC Genomics. 2013, 14: 870-10.1186/1471-2164-14-870.
Reiner A, Yekutieli D, Benjamini Y: Identifying differentially expressed genes using false discovery rate controlling procedures. Bioinfo. 2003, 19 (3): 368-375. 10.1093/bioinformatics/btf877.
Pang T, Ye C-Y, **a X, Yin W: De novo sequencing and transcriptome analysis of the desert shrub, Ammopiptanthus mongolicus, during cold acclimation using Illumina/Solexa. BMC Genomics. 2013, 14 (1): 488-10.1186/1471-2164-14-488.
Lu T, Lu G, Fan D, Zhu C, Li W, Zhao Q, Feng Q, Zhao Y, Guo Y, Li W: Function annotation of the rice transcriptome at single-nucleotide resolution by RNA-seq. Genome Res. 2010, 20 (9): 1238-1249. 10.1101/gr.106120.110.
Wu J, Zhang Y, Zhang H, Huang H, Folta KM, Lu J: Whole genome wide expression profiles of Vitis amurensis grape responding to downy mildew by using Solexa sequencing technology. BMC Plant Biol. 2010, 10: 234-10.1186/1471-2229-10-234.
Chen J, **a X, Yin W: A poplar DRE-binding protein gene, PeDREB2L, is involved in regulation of defense response against abiotic stress. Gene. 2011, 483 (1–2): 36-42.
Acknowledgements
We thank the technical assistance of Chu-Yu Ye, Chao Liu and Sha Tang from College of Biological Sciences and technology in Bei**g Forestry University. We also appreciate the assistance of Hongqing **e and Tong Xu from Bei**g Genomics Institute in data assessment. This work was supported by Bei**g Higher Education Young Elite Teacher Project (YETP0754), National Natural Science Foundation of China (31100492 and 31370597), Fundamental Research funds for the Central Universities (DT2012-01 and YX2011-22), National R&D Key Project of China (2011BAD38B01), and Research Fund for the Doctoral Program of Higher Education of China (20110014120002).
Author information
Authors and Affiliations
Corresponding authors
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
JHC designed the experiments, analyzed the data and drafted the manuscript. QQT and TP participated in plant material preparation and RNA preparation, LBJ and RLW applied FDR correction in determining differentially expressed genes, XLX and WLY conceived the study. All authors read and approved the final manuscript.
Electronic supplementary material
12864_2013_6038_MOESM2_ESM.xlsx
Additional file 2: Assessment of the unigene assembly based on comparison to poplar ESTs. All unique sequences generated from different assemblages were subjected to a BLAST comparison to compare EST collections from a variety of poplar species. (XLSX 11 KB)
12864_2013_6038_MOESM3_ESM.xlsx
Additional file 3: Alignment against the P. trichocarpa transcripts with an E-value threshold of 1.0E-5 and identity threshold of 75%.(XLSX 4 MB)
12864_2013_6038_MOESM4_ESM.docx
Additional file 4: Functional annotation summary. We aligned the unigene sequences to the Nr, Swiss-Prot, KEGG and COG databases by BLASTx (E-value < 0.00001) and to the nucleotide sequence database Nt (E-value < 0.00001) by BLASTn. We thus obtained proteins with the highest similarity to the given unigenes, as well as the functional annotations. (DOCX 16 KB)
12864_2013_6038_MOESM6_ESM.xlsx
Additional file 6: Differentially expressed genes among three samples. Unigenes that expressed differentially in at least two samples were list in this file. (XLSX 359 KB)
12864_2013_6038_MOESM7_ESM.xlsx
Additional file 7: Transcripts that differentially expressed in all three samples. Unigenes that expressed differentially in all three samples were list in this file. (XLSX 29 KB)
12864_2013_6038_MOESM11_ESM.xlsx
Additional file 11: Clustering of the top 50 well-annotated genes that are up-regulated in C4. All unigenes were annotated by NR or P. trichocarpa version 3 annotation dataset. (XLSX 33 KB)
12864_2013_6038_MOESM12_ESM.xlsx
Additional file 12: Clustering of the top 50 well-annotated genes that are up-regulated in F4. All unigenes were annotated by NR or P. trichocarpa version 3 annotation dataset. (XLSX 15 KB)
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
Open Access This article is published under license to BioMed Central Ltd. This is an Open Access article is distributed under the terms of the Creative Commons Attribution License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article

Cite this article
Chen, J., Tian, Q., Pang, T. et al. Deep-sequencing transcriptome analysis of low temperature perception in a desert tree, Populus euphratica. BMC Genomics 15, 326 (2014). https://doi.org/10.1186/1471-2164-15-326
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1471-2164-15-326