
Abstract
Supplier selection in food supply chains (FSCs) is not much explored due to the inherent difficulties, complexities and nature of food industry. Food security and quality are top row topics in today’s world health scenario. During sudden food crisis, it needs extra attention where producers, suppliers, and stakeholders play the most vital roles. This paper puts forward a two-phase sustainable multi-tier supplier selection model for FSC based on an integrated decision analysis under multi-criteria perspectives considering sustainability criteria, suppliers and sub-suppliers. In the first phase, the model estimates supplier selection criteria weights using a combined version of step-wise weight assessment ratio analysis (SWARA) and level based weight assessment (LBWA) in conjunction with D-numbers. In the second phase, Measurement of Alternatives and Ranking according to the COmpromise Solution (MARCOS)-D method is applied to obtain a ranking pre-order of different tier suppliers. Moreover, several sensitivity analyses are carried out in order to examine model reliability. To check application practicability, the proposed model is implemented in a case study of WineSol Corporation in Spain. The proposed model is expected to serve as a kickoff point for develo** advanced decision-making models for effectually address multi-tier supplier selection problems under uncertain environment.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Global market and trade utterly need integrated supply chain management systems (SCMSs) to enable organizations to effectively react to increased customer satisfaction. SCM is interpreted as a process establishing network of firms, suppliers, transportation systems, logistics hubs and production units. The major concerns of any SCM is to coordinate and efficiently control material flow, information and finances in order to meet customer demands and overall business objectives (Meredith and Shafer 2019; Saberi et al. 2019). The main concern of SC managers is to ensure a harmonic balance among all elements in the SCM network. This harmony can be defined in terms of safety, security, stability, sustainability and cooperation between the elements during entire product life cycle. In many aspects, suppliers as the main operating engine can accelerate the system or negatively affect system efficiency.
Supplier relationship and development initiatives coupled with a capable and competent supplier network always play a decisive role for any enterprise in order to remain competitive in the worldwide market for drawing out maximum value through such relationships. Food SCM (FSCM) provides crucial support to any country’s socio-economic development and emphasize on precise development of producer–consumer relationships and transparency with regard to production practices. Nowadays, food and agricultural consumers are highly keen to be kept informed about the different processes which food products go through from farm level to market level. In other words, consumers are interested in being informed about the procurement quality, safety, production and packaging methods, hygiene and other related standards which strongly affect their willingness to buy products (Redmond and Griffith 2003). According to Wognum et al. (2011), food and agricultural organizations have to consider such parameters in their SC operations in order to meet consumer requirements and satisfaction. Apart from social considerations, an appropriately designed FSCM also requires efficient and effective SC operations in terms of economic and environmental considerations. For example, León-Bravo et al. (2019) investigated that there is a strong relationship between sustainability practices and its operational performances in an FSCM, especially, roles of multi-tier suppliers in food sector can not be neglected. In an FSCMS, multi-tier SC includes more than one level of manufacturers or suppliers to produce or supply products or services. There are numerous relationships happening between buyers and suppliers within the entire SC. In many real time situations, this process may involve number of different suppliers to bring products to customers. Wilhelm et al. (2016) believed that involvement of multi-tier suppliers is an essential requirement in achieving sustainability compliance in the entire SCMS, failing of which may put focal organizations at a risk of degraded brand value and unsolicited legal issues. Real time examples have already been observed for many well reputed supermarkets due to the delinquency of second and (1 + n)th-tier suppliers (Viswanadham and Samvedi 2013; Sawik 2020). These sub-suppliers are basically the extended parts of the SC and remain on the far side of direct control of the focal organizations. In spite of such incidents, most of the conventional approaches have disregarded organizational responsibilities for unfavorable consequences arising due to improper sub-level supplier selection including first phase of raw material extraction and environmental impacts in the SC. Moreover, past researchers have not paid much attention beyond the implied evaluation of straightforward first-tier suppliers. Dedicated studies in FSC are also limited in the literature due to its inherent complication and particularized nature of product characteristics. According to Rong et al. (2011), the most significant parameters in an FSC include product quality, security and safety. Global food industry currently struggles with multiple competitive primitivenesses along with new challenges of green production and safe delivery to end users. Even in pandemic crisis like COVID-19, the basic food supply system in many develo** countries have been severely interrupted due to lack of access to workers, failure of operating systems, supplier disruptions, transportation restrictions and production breakdown (WHO 2020). FSC industries usually face unexpected variations in operations, breakdowns, quality issues and other unpredicted events like supply disasters. A failure in supplier performance potentially liberates negative consequences for further upstream or downstream of FSC. One of the most promising elements in FSC is supplier performance, the potential interaction of which may totally collapse or enhance the overall efficiency (Diabat et al. 2012; Grimm et al. 2014; Pamucar 2020).
Suppliers are vital elements of any SCMS and their functional capacity and performance directly or indirectly affect the fluency of the system including manufacturing, service or food industries (Ahmed et al. 2020). Transportation companies, logistics services and raw material providers are parts of a SC network for any typical enterprise. Evaluating performance and quality of suppliers should be configured and programmed in long horizons. Development of such plans greatly reduces risk and vulnerability of SC and helps to progress toward a smoother production system (Tidy et al. 2016). Earlier studies have demonstrated the important role of supplier performance measurement on productivity of SCMSs (Narasimhan et al. 2008; Kim et al. 2018); healthcare centers (Liu et al. 2019); agriculture (Kamble et al. 2020); food industry (Govindan 2018; Yazdani et al. 2020) and logistics (Khan et al. 2019b; Khan et al. 2020a). Interested readers are referred to a comprehensive literature review on sustainable supply chain management recently published by Khan et al. (2021).
One of the important applications of SC operations is found in perishable products like food items. FSC is defined as an integrated operation starting from production farms to manufacturers to distribution centers which finally delivers agricultural products to the customers (Allaoui et al. 2018). In other words, FSC is a series of operations that has an important position in global SC networks with respect to the fact that food products are considered as the main demand of human beings. Furthermore, FSC is not only targeting to fulfill food demands of human beings, but also, it is one of the potential industries for job creation, economic growth, environmental and social effects (Vermeulen et al. 2012; Khan and Qianli 2017; Govindan 2018; Khan and Yu 2020; Khan et al. 2020b). Unlike other applications of SCM, the FSCM is always under surveillance of different environmental, social and economic organizations who support and propose consumption policies with respect to societal characteristics. Therefore, FSCM and its operational functions are very pragmatic and should deliberately be addressed in order to maximize customer satisfaction and organizational profits.
In one of the very first studies, Jedvall (1999) premeditated FSCM with respect to its effect on economy and environment in order to make SC operations more efficient and sustainable. Smith (2008) presented a framework to analyze the important factors for sustainable FSCs with a focus on suppliers, manufacturers, distributors, governmental and non-governmental organizations. Wognum et al. (2011) addressed FSCM using information systems in terms of transparency which has an important role in customer’s trust and brand loyalty. Cojocariu (2012) studied SCMS of modern agriculture and manufacturing technologies with emphasize on logistics considering green factors. Garnett (2013) studied FSCM policies and operations in terms of environmental aspects of production, consumption, and socio-economic challenges. Kaipa et al. (2013) presented a descriptive analysis of FSC for material and information flows in milk and fish companies. Li et al. (2014) presented a review for FSCM considering sustainable development goals in order to highlight the research gaps in applied methods. Govindan (2018) proposed a conceptual framework for sustainable production and consumption policies in FSC. This study presented a comprehensive literature review of sustainable SC and FSC. In this study, the author developed a framework for FSC by highlighting important indicators, drivers and barriers in FSC.
As discussed above, FSC is one of the significant SC networks which aims to deliver food products from farms to consumers before their expiration times. Thus, organizations are required to develop reliable and well-designed decision making models for facilitating the decision making process for different operations and functions. Decision making process in FSC has turned to be very difficult and at the same time, critical due to the presence of high number of decision factors and barriers. To overcome these, researchers have developed different decision making models using simulation, mathematical optimization, data mining, machine learning algorithms and multi-criteria decision making (MCDM) methods to address its complexities. Ting et al. (2014) proposed an association rule mining (ARM) and Dempster's rule of combination-based decision support system to increase the power of DMs in FSC to devise reliable plans for logistics section. The proposed decision support model was investigated for a real case study of wine industry in Hong Kong. Meneghetti and Monti (2015) developed an optimization model using constraint programming for sustainable network design of cold food products. In this model, they focused on important factors like facility location, storage temperature of warehouses, additional costs caused by temperature, energy use, and harmful greenhouse emissions. Bortolini et al. (2016) proposed a multi-objective optimization (MOO) model using mixed integer programming (MIP) for a FSC problem in multi-produce, multi-model, and multi-level distribution network environment. The proposed model was applied for an Italian fresh fruits and vegetable distribution network case study. In a similar study, Mohammed and Wang (2017) used a multi-objective mixed integer programming (MOMIP) model for a FSC problem considering green factors. In order to consider real life parametric changes, the proposed optimization model was implemented under fuzzy set theory (FST). The main focus of this study was to address facility location, transportation cost, CO2 emissions, and transportation time for a meat industry in the United Kingdom. Varsei and Polyakovskiy (2017) developed another MOMIP model to optimize facility location process, transportation costs, production costs, purchasing costs, CO2 emissions and social impact of wine SC network in Australia. Tabrizi et al. (2018) formulated a mathematical model for fish SC using a bi-level optimization model using Nash-Stackelberg equilibrium. A brief literature summary on decision-making models in FSC is tabulated Table 1.
2.2 MCDM methods for supplier selection
Supplier selection problem is one of the crucial processes in SC operations for any organization. Operational entities spend great amount of time and materials along with professionals to make SC operations more efficient. Supplier selection problem is performed in initial stages of SC operations where organizations are required to make one of the most important decisions through SC networks since supplier selection has a noticeable effect on the rest of operations. In order to make an appropriate decision and select best supplier among several suppliers, manufacturing centers come up with several comprehensive factors which highly contribute to DM’s opinion while assessing potential suppliers. Supplier selection factors differ broadly from an industry to another so that companies try to make more accurate definition on the factors that they define in order to evaluate all suppliers. Factors or criteria play a very crucial part in supplier selection problem. In other words, preferences of suppliers in supplier selection problem strongly rely on the criteria are introduced and defined. Sustainability has emerged as one of most important subjects that organizations aim to integrate within their policies and strategies. Under sustainability, along with technical criteria, economic, environmental and social criteria are also used to assess suppliers. Sustainability is now an integral part in most of the industries worldwide.
In supplier selection process, manufacturing industries aim to develop decision-making frameworks to compare potential candidate suppliers under several factors in order to identify the best alternative for yielding maximum benefits. However, supplier selection problem is a very complicated and difficult process and DMs require reliable methods in making appropriate assessments. MCDM methods are among such frequently adopted methods for supplier selection problems which can efficiently deal with multiple decision factors simultaneously. MCDM methods are used in two main ways to address supplier selection problem. First, methods such as best–worst method (BWM) (Rezaei 2015; Ecer and Pamucar 2020; Torkayesh et al. 2020a), step‐wise weight assessment ratio analysis (SWARA) (Zolfani et al. 2018), CRiteria Importance Through Intercriteria Correlation (CRITIC) (Diakoulaki et al. 1995; Ghorabaee et al. 2017), entropy (Lee and Chang 2018; Torkayesh et al. 2020b), analytic hierarchy process (AHP) (Yazdani et al. 2020; Sambasivam et al. 2020), analytic network process (ANP) (Asadabadi et al. 2019), quality function deployment (QFD) (Yazdani et al. 2017), data envelopment analysis (DEA) (Kumar et al. 2014; Chu et al. 2019), decision making trial and evaluation laboratory (DEMATEL) (Si et al. 2018) are used to obtain the importance of decision criteria or to find the relationship between them. On other hand, ranking MCDM methods such as ELimination Et Choix Traduisant la REalité (ELECTRE) (Govindan and Jepsen 2016), Viekriterijumsko Kompromisno Rangiranje (VIKOR) (Opricovic and Tzeng 2004), TODIM (an acronym in Portuguese of interactive and multi-criteria decision-making) (Bai et al. 2019), technique for order preference by similarity to ideal solution (TOPSIS) (Behzadian et al. 2012; Ramakrishnan and Chakraborty 2020), combined compromise solution (CoCoSo) (Yazdani et al. 2019a, b), measurement of alternatives and ranking according to compromise solution (MARCOS) (Stević et al. 2020; Chakraborty et al. 2020), Grey rational analysis (GRA) (Kuo and Liang 2011), preference ranking organization method for enrichment evaluations (PROMETHEE) (Brans and Smet 2016) are used to prioritize a set of suppliers based on defined decision criteria. In Table 2, MCDM methods for supplier selection problems in different industries are listed.
2.3 MCDM in food supplier selection
As discussed above, FSCM operations and functions are considered as important global concerns since they are dealing with fulfilling demands of human beings. Considering nutrition-based characteristics of food products, food manufacturing industries are dealing with an important challenge to select the most suitable supplier in order to get the best input raw materials that would benefit the consumers in several ways. However, the literature of food supplier selection problem is very limited and only a few studies have proposed a solution framework.
Grimm et al. (2014) addressed FSC problem by highlighting the significance of supplier management. They reviewed FSC studies to highlight the critical success factors for supplier management in terms of firm-related, relationship-related, partner-related, and context-related factors to integrate them with sustainable SC factors. Validi et al. (2014) developed a hybrid decision making model using genetic algorithm (GA) and TOPSIS method for selection of suitable distributor for diary production considering green factors. Banaeian et al. (2015) studied supplier selection problem in FSC under fuzzy environment. This study focused on identification of green factors in food supplier selection problem using Delphi, AHP, and Grey relational analysis (GRA) methods. Amorim et al. (2016) proposed a stochastic programming model for food supplier selection problem by considering the uncertainty in demand and supplier operation. Govindan et al. (2017) applied PROMETHEE method to address supplier selection problem for an Indian food industry considering green decision factors. Frej et al. (2017) utilized FI Trade off method for a Brazilian food supplier selection problem in terms of price, freight, accuracy, quality, flexibility, lead time, promptness factors. Miranda-Ackerman et al. (2017) proposed a hybrid decision making model by integrating life cycle analysis (LCA), TOPSIS, and MOO model for food supplier selection problem in an orange juice industry. Ma et al. (2017) studied food supplier selection in terms of safety risk factors using a MCDM-based interval intuitive fuzzy tool. Wang et al. (2018) developed a fuzzy AHP (FAHP) and fuzzy data envelopment analysis (FDEA) methods for supplier selection problem considering sustainable factors in an edible oil production industry. In this study, FAHP method was used to determine weights of supplier selection criteria, while FDEA was used to prioritize alternative suppliers. Allaoui et al. (2018) used AHP and ordered weighted averaging (OWA) methods to select the most suitable partner in food industry. Shi et al. (2018) developed an MCDM model using GRA and TOPSIS methods for food supplier selection problem considering green factors. The developed model was formulated under interval valued intuitionstic linguistic sets. Fu (2019) proposed a multi-choice goal programming model using AHP and additive ratio assessment (ARAS) methods for food supplier selection in catering industry. Lau et al. (2020) used a game theory based decision making model using fuzzy AHP, TOPSIS and ELECTRE methods for organic food supplier selection problem in Hong Kong. It considered different selection criteria like product quality, organic safety, monitoring cost, price, delivery, availability of services, commercial position, supplier relationship, risk factors and corporate social responsibility factors. It has been observed that none of the above studies have considered any combined weighting structure, nor used D-numbers. This paper takes an endeavour to structure a new decision making model to fill this gap. Table 3 lists MCDM methods for food supplier selection problems in a comprehensive way.
2.4 Research motivations, gaps, objectives and contributions
It is well know that multi-tier food supplier selection process in sustainable environment is highly influenced by the built-in uncertainties like lack of perfect information, incompatible historical data, adoption of advanced technologies, complex network relationship with customers, supply capacity contraints, supply quality, delivery issues, unavailability of items, logistics and transportation bottlenecks, social and cross-culturalism, virtuous compromise, demand unpredictability and information misinterpretation. Inaccuracis in data can directly influence system outcomes and misdirect DMs to incorrect strategic decisions regarding supplier selection. Therefore, development of such models which can support DMs while confronting ambiguous situations to overcome uncertainties becomes one of the frontier objectives and motivations for SC practitioners and researchers. The fundamental concept of overcoming uncertainties in decision making processes is to utilize fuzzy set (FS) approach. Several fuzzy-based decision making methods have been developed for supplier selection problems in the literuare. However, there exists a serious problem in resolving uncertain information using fuzzy logic. Unlike the fuzzy logic, D-numbers empower us to use linguistic variables without intersection with each other. Therefore, the assessment process for supplier selection problem could be performed in an efficient way as experts can express their judgments using D-number linguistic variables. As intersection between linguistc variables in reality is inevitable, D-numbers can be of high significance for supplier selection problem in such cases. On the other hand, SC of agricultural product such as wine industry are due to manifold risks and factors which make the assessment process very tough and difficult. However, applying D-number-based decision making model can overcome such issues.
Based on the above notions, this paper proposes a novel MCDM model which is based on the application of fuzzy linguistic variables and D-numbers to represent uncertainty. D-numbers basically represent a universal approach for intending uncertainty and imprecision in expert decisions. D-numbers can easily be combined with crisp numbers as well as with all so far known uncertainty theories like fuzzy numbers, Z-numbers (Zadeh 2011; Ghoushchi et al. 2020a, b; Reza et al. 2020), G-numbers (Ghoushchi and Khazaeili 2019) and R-numbers (Seiti et al. 2019a, b). Interval numbers which include fuzzy numbers, Z-numbers, G-numbers, R-numbers and grey numbers are used to express uncertainty based on predefined interval criteria values. Some of these approaches use one, two or more membership functions (MFs) to represent uncertainties. By introducing D-numbers, existing intervals of MFs are additionally corrected depending on the probability of choosing criterion value.
In the proposed model, criteria weights are defined by integrating LBWA (Zizovic and Pamucar 2019) and SWARA methods (Keršuliene et al. 2010). LBWA and SWARA methods are extended in D-number environment. Also, the obtained criteria weights are integrated through a function that enables variable integration of values while simultaneously exploiting advantages of both methods. Extensions of LBWA and SWARA methods using D-numbers (LBWA-D and SWARA-D) contribute to a more rational processing of expert preferences for defining criteria weights. Moreover, combination of two MCDM models for weight determination would definitely enhance reliability and robustness of the derived weights for decision factors. In the proposed multi-criteria model, evaluation and selection of alternatives are performed using MARCOS method (Stević et al. 2020). Extension of MARCOS method using linguistic variables and D-numbers enables a realistic recognition of existing uncertainties during expert evaluation of alternatives. The proposed model provides a new multi-criteria framework for supplier selection and processing of complex information in uncertain conditions. In addition, it enables reasoning and processing of uncertain information using D-numbers-based algorithm which contributes to rational decision making.
In order to illustrate the effectiveness of the proposed model, an empirical case study is presented in which application of the proposed model is presented. The set objectives are:
-
i.
Proposing a novel decision making model using D-numbers for a multi-tier supplier selection problem,
-
ii.
Enriching decision-making domain through model development to aid DMs in solving complex multi-tier supplier selection problems.
-
iii.
In order to illustrate the effectiveness of the proposed model, an empirical case study for a wine industry is presented in which application of the proposed model is presented.
-
iv.
Assessing suppliers (wine producers) under uncertainty and controlling quality and performance.
The proposed decision making model contributes to:
-
✔
A real case study of wine sector that operates in beverage market since many years,
-
✔
Establishing an efficient decision support model with participation of several experts that offers judgment of supplier performance under qualitative values. We offer a chance to experts to present their opinion by probability scale,
-
✔
The proposed model combining D-numbers, MARCOS and a new integrated weighting method (LBWA-SWARA) is applied for the first time,
-
✔
The model can easily be adopted with the relevant and few changes to other food supply sector including olive oil, fruits and vegetables, horticulture to name a few.
3 Preliminaries
3.1 D-numbers
Dempster-Shafer (DS) evidence theory (Dempster 1967; Shafer 1978) is a powerful method for processing uncertain information. As DS theory enables the development of algorithms for objective reasoning, so it has found wide applications in the field of artificial intelligence (AI). Deng (2012) introduced the concept of D-numbers in order to express uncertain information and judgments. Several MCDM models combined D-numbers in order to empower DM to express their opinions, information, and judgment not only by crisp numbers. Deng et al. (2014c) proposed an extended version of AHP method under D-numbers for supplier selection problem. Fan et al. (2016) integrated D-numbers with AHP method in order to determine weight of criteria in a curtain grouting efficiency evaluation problem. Mo and Deng (2018) developed an MCDM model for vehicle selection problems using D-numbers. In a similar study, ** a novel risk-based MCDM approach based on D-numbers and fuzzy information axiom and its applications in preventive maintenance planning. Appl Soft Comput 82:105559" href="/article/10.1007/s12063-021-00186-z#ref-CR107" id="ref-link-section-d240739926e2379">b) utilized fuzzy axiomatic design principles under D-numbers for preventive maintenance planning problem. Further, for eliminating the shortcomings of DS theory, Deng et al. (2014a, b) developed the concept of D-numbers. Deng et al. (2014a) singled out a key problem which is overcome by D-numbers through the elimination of exclusivity of elements in reasoning. Problem of exclusivity is explained in the appendix section through an example of medical diagnostics comprehensively. The basic characteristic of D-numbers is that it enables additional expression of the uncertainty that exists in expert preferences, which cannot be expressed by the existing uncertainty theories. D-numbers enable the fusion of expert decisions through a special reasoning algorithm, so their application in group decision-making is recommended. Based on the above properties, we can highlight the following advantages of D-numbers:
-
1
D-numbers represent a tool for additional expression of uncertainty in expert preferences, which is based on the introduction of the probability of choosing the appropriate criterion value;
-
2
D-numbers can be used to represent uncertainty in expert preferences whether the criterion values are expressed in crisp numbers or some other uncertainty theories (fuzzy numbers, Z-numbers, G-numbers, R-numbers and Grey numbers);
-
3
By applying a special algorithm for reasoning with D-numbers, the probability of expressing uncertainty of criterion value provides additional correction in interval value of fuzzy number, Z-number, G-number and other interval theories;
-
4
Through the algorithm of combining D-numbers, traditional theories for representing uncertainty are further strengthened, thus creating a powerful methodology that contributes to a more objective and rational decision-making in a dynamic environment;
-
5
D-numbers in relation to other popoular uncertainty theories have the ability to aggregate expert decisions based on combination and fusion algorithms of D-numbers.
-
6
On the other hand, existing uncertainty theories do not have any special algorithms for aggregation of expert decisions, but use other tools like mathematical operators for value aggregation.
-
7
Application of D-numbers eliminates the stated shortcomings of DS theory as the exclusive property of the elements in the frame of discernment is not required and completeness constraint is released if necessary. By eliminating this shortcoming using D-numbers, it is possible to apply DS theory to process uncertainty in an objective way. The basic mathematical concept of D-numbers is presented in the next section.

Proposed decision making model
Definition 1
Let Ω be a finite nonempty set, and a D-number is a map** that \(D:\Omega\rightarrow\left[0,1\right]\) , with
where Ø is an empty set and A is any subset of Ω. As emphasized within the advantages of D-numbers, D-number theory requires set of elements Ω to be mutually exclusive and completely constraint. Information is considered complete if it is\(\sum_{A\subseteq\Omega}D\left(A\right)=1\) , or if it is \(\sum_{A\subseteq\Omega}D\left(A\right)<1\) the information is incomplete.
Definition 2
(Deng and Jiang 2019). Let two D-numbers be given \(D_1=\{\left(b_1,\;v_1\right),...,\left(b_i,\;v_i\right),...,\left(b_n,\;v_n\right)\}\) and \(D_2=\{\left(b_n,\;v_n\right),...,\left(b_i,\;v_i\right),...,\left(b_1,\;v_1\right)\}\), then a combination of D-numbers D = D1ʘD2 can be defined as:
Equation (2) represents a generalization of DS rules. If complete information is presented through D-numbers (D1 and D2), that is, if \(Q_1=1\) and \(Q_2=1\) , then rule (2) is transformed into DS rule. Rule (2) is a basic tool for fusing uncertain information contained in D-numbers.
Property 1
(Permutation invariability). If there are two D-numbers that are represented as \(D_1=\left\{\left(b_1,\;v_1\right),...,\left(b_i,\;v_i\right),...,\left(b_n,\;v_n\right)\right\}\) and \(D_2=\left\{\left(b_n,\;v_n\right),...,\left(b_i,\;v_i\right),...,\left(b_1,\;v_1\right)\right\}\)\(\left(b_i,\;v_i\right)\;,\;\left(b_j,\;v_j\right)...\left(b_n,\;v_n\right)\}\), then we have \(D_1\Leftrightarrow D_2\) , where „⇔ “ means „equal to “.
Example 2
If there are two D-numbers that are represented as: \(D_1=\left\{\left(2,\;0.3\right),\left(5,\;0.35\right),\left(9,\;0.35\right)\right\}\) and \(D_2=\left\{\left(5,\;0.35\right),\left(2,\;0.3\right),\left(9,\;0.35\right)\right\}\), then we can say that it is \(D_1\Leftrightarrow D_2\).
Property 2
(Integration). For discrete D-number \(D=\left\{\left(b_1,v_1\right),\left(b_2,v_2\right)...\left(b_i,v_i\right),\left(b_j,v_j\right)...\left(b_n,v_n\right)\right\}\) we can define the integration operator as follows
where \(d_i\in R^+,v_i>0\) and \(\sum\nolimits_{i=1}^nv_i\leq1\).
Example 3
For discrete D-number \(D=\left\{\left(2,\;0.3\right),\;\left(5,\;0.35\right),\;\left(9,\;0.35\right)\right\}\), then we can define its integration operator as \(I\left(D\right)=2\cdot0.3\;+\;5\cdot0.35\;+\;9\cdot0.35=5.5\).
3.2 Transformation of the uncertain linguistic information to the trapezoidal fuzzy numbers
It is assumed that the DMs perform qualitative assessments of the alternatives using appropriate set of linguistic variables. Let \(S=\left\{\left.s_i\right|\;i=0,1,\dots,T-1\right\}\) represents a set of linguistic variables, where \(s_i\) represents a linguistic variable, while T represents odd D-numbers. Based on the settings shown, we can define the following linguistic examples:
Each linguistic variable \(s_i\) can be represented by triangular fuzzy numbers (TFN) \(A_i=\left(a_i^L,a_i^M,a_i^U\right),\;\left(a_i^L\leq a_i^M\leq a_i^U\right)\), which is further represented by the following membership function (MF) (Pamucar and Ecer 2020):
Transformation of linguistic variables into TFNs can be performed using Eq. (5)
Lets suppose there are \(A_i=\left(a_i^L,a_i^M,a_i^U\right)\) and \(B_i=\left(b_i^L,b_i^M,b_i^U\right)\) two TFNs, then we can define the following arithmetic rules for operations with TFNs.
Definition 3
Lets suppose there are \(A_i=\left(a_i^L,a_i^M,a_i^U\right)\) and \(B_i=\left(b_i^L,b_i^M,b_i^U\right)\) two TFNs, then we can compare them as follows:
-
i)
If \(a_i^L\geq b_i^L,\;a_i^M\geq b_i^M,\;a_i^U\geq b_i^U\) then \(A_i\geq B_i\).
-
ii)
If this three conditions \(a_i^L\geq b_i^L,\;a_i^M\geq b_i^M,\;a_i^U\geq b_i^U\) are not met, but \(\left(a_i^L+a_i^M+a_i^U\right)/3\geq\left(b_i^L+b_i^M+b_i^U\right)/3\) is met, then \(A_i\geq B_i\).
4 Proposed decision making model
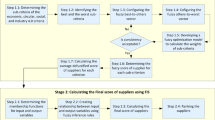
In this section, mathematical formulations of the proposed decision making model based on fuzzy linguistic descriptors and D-numbers are presented. The proposed model enables easy processing of uncertainties in expert preferences that are represented by linguistic variables and probabilities. Different phases of this model are shown in Fig. 1. In the first phase, criteria weights are determined using LBWA-D and SWARA-D methods, while in the second phase, alternative suppliers are evaluated using fuzzy linguistic MARCOS-D method.
This model is based on the integration of LBWA-D and SWARA-D methods which are used to determine criteria weights. The fuzzy linguistic MARCOS-D method is used in this model to evaluate alternative suppliers. Detail steps of the proposed model are presented in the next sections.
4.1 Phase- I: Determination of criteria weights
In the proposed model, criteria weights are determined by integration of LBWA and SWARA methods to overcome the limitations of unilateral application of these two methods to use the advantages of both weighting methods. Since either of these two methods has its inherent advantages and disadvantages, an integrated determination of criteria weights seems to be more pragmatic. The combinative weighting can conform to different situtaions where a group of experts are involved and have different knowledge and experince levels. One more advantage of integrated weights is that it not only benefits from the DMs’ expertise but also involves end users in the whole decision-making process more functionally. In addition, combined criteria weights also consider the influence of both LBWA and SWARA methods in ranking pre-orders of the considered alternatives. The motivation behind selecting LBWA and SWARA methods are presented below:
LBWA method requires smaller number of pairwise criteria comparisons and has a rational and logical mathematical algorithm (Zizovic and Pamucar 2019). From the group of subjective criteria weighting methods, LBWA stands out due to the following advantages (Bozanic et al. 2020): i) small number of comparisons; ii) algorithm does not become complicated with increase in number of criteria, thus making it suitable for complex MCDM problems; and iii) it allows DMs a logical algorithm to present their preferences while prioritizing criteria. This eliminates inconsistencies in expert preferences.
On the other hand, SWARA method stands out due to the following advantages: i) this method can be successfully used to coordinate and collect data from experts; ii) it has simple mathematics; iii) easily applicable in the case of larger group of criteria; iv) any suitable scale can be used to express expert preferences. These features give significant flexibility to SWARA method, making it an automatic choice for complex problems.
Kee** in mind all the above mentioned advantages of LBWA and SWARA methods and the fact that they have not still been explored in conjunction with DS theory, this paper aims to present extensions of LBWA and SWARA methods by applying D-numbers to address uncertainties, dilemmas and subjectivity for criteria comparisons.
a) LBWA-D method
Zizovic and Pamucar (2019) developed LBWA method for weight estimation in MCDM environment. This method empowers n optimal arrangement of experts’ judgement without increasing the complexity of the multiple criteria problem. The procedural steps of LBWA-D method are as follows:
Step 1: Determining the most important criterion from a set of criteria.
Suppose there is a group of k experts who are divided into two homogeneous groups. Also, suppose that the experts defined a set of \(C=\left\{C_1,\;C_2,\dots,\;C_n\right\}\) criteria, where n represents the total number of criteria. Experts decide on the selection of the most influential criterion from set C. Suppose that experts decide that \(C_1\)S is the most influential criterion from set C.
Step 2: Grou** criteria by levels of significance.
Experts group the criteria according to the levels of significance using the following rules:
Level \(S_1\) :
At the level of \(S_1\), group the criteria from the set S whose significance is equal to the significance of criterion \(C_1\) or is up to twice less than the significance of the criterion \(C_1\);
Level \(S_2\) :
At the level, group the criteria from the set whose significance is exactly twice less than the significance of the criterion \(C_1\) or up to three times less than the significance of the criterion \(C_1\);
Level \(S_3\) :
At the level S, group the criteria from the set whose significance is exactly k times less than the significance of the criteria \(C_1\) or is up to \(k+1\) times less than the significance of the criteria \(C_1\).
By applying the previously presented rules, experts establish a rough classification of the observed criteria, i.e. group the criteria according to the levels of significance. If the significance of a criterion \(C_j\) is denoted by \(s(C_j)\), where \(j\in\left\{1,2,\dots,n\right\}\), then we have \(S=S_1\cup S_2\cup\dots\cup S_k\), where for each level \(i\in\left\{1,2,\dots,k\right\}\), we have
Also, for each \(p,q\in\left\{1,2,\dots,k\right\}\) such that \(p\neq q\) holds \(S_p\cap S_q=\varnothing\).
Step 3: Comparison of criteria by significance. After grou** the criteria by their significance levels, it is necessary to compare them in pairs. The comparison in pairs is made in relation to the best criterion. Within the formed subsets (levels), each expert group compares the criteria according to their significance. Each criterion \(C_{i_p}\in S_i\) within a subset \(C_i=\left\{C_{i_1},C_{i_2,},\dots,C_{i_s}\right\}\) is assigned the value \(I_{i_p}=\left\{\left(b_{i_p(1)},v_{i_p(1)}\right),\dots,\left(b_{i_p(i)},v_{i_p(i)}\right),\dots,\left(b_{i_p(m)},v_{i_p(m)}\right)\right\}\),\(b_{i_p}\in\left[0,r\right],v_{i_p}\leq1\), so that the most important criterion \(C_1\) is assigned the value \(b_1=0\). Also, if \(C_{i_p}\) is more significant than \(C_{i_q}\) then \(b_p<b_q\), and if \(C_{i_p}\) is equivalent to \(C_{i_q}\) then \(b_p=b_q\). Maximum value of the scale for criteria comparison is defined by Eq. (12)
Since we have two homogeneous groups of experts, for each group of experts we get the values \(I_{i_p}\), i.e. we get \(I_{i_p}^1\) and \(I_{i_p}^2\). Thus, for each position \(I_{i_p}^1\) and \(I_{i_p}^2\), the D-number\(I_{i_p}=\left\{\left(b_{i_p(1)},v_{i_p(1)}\right),\dots,\left(b_{i_p(i)},v_{i_p(i)}\right),\dots,\left(b_{i_p(m)},v_{i_p(m)}\right)\right\}\) is defined. In order to obtain a unique value that compares the jth criterion with the most influential criterion (\(I_{i_p}\)), it is necessary to fuse the uncertainties presented in the initial expert preferences. Accordingly, by applying combination rule of D-numbers \(I_{i_p}=I_{i_p}^1\odot I_{i_p}^2\), analysis and fusion of uncertainties from D-numbers \(I_{i_p}^1=\left\{\left(b_{i_p(1)}^1,v_{i_p(1)}^1\right),\left(b_{i_p(2)}^1,v_{i_p(2)}^1\right),\dots,\left(b_{i_p(m)}^1,v_{i_p(m)}^1\right)\right\}\) and \(I_{i_p}^2=\left\{\left(b_{i_p(1)}^2,v_{i_p(1)}^2\right),\left(b_{i_p(2)}^2,v_{i_p(2)}^2\right),\dots,\left(b_{i_p(m)}^2,v_{i_p(m)}^2\right)\right\}\) are performed. After the fusion of uncertainty, the final values \(I_{i_p}=\left\{\left(b_{i_p(1)},v_{i_p(1)}\right),\left(b_{i_p(2)},v_{i_p(2)}\right),\dots,\left(b_{i_p(m)},v_{i_p(m)}\right)\right\}\) are defined. By applying integration operator of Eq. (3), the uncertainties represented by D-numbers are integrated into a unique value \({\overline I}_{i_p}\).
Step 4: Defining the coefficient of elasticity. In order to calculate the criterion influence function using Eq. (13), it is necessary to define the value of coefficient of elasticity (\(\varphi\)). Based on the defined maximum value of the scale for comparing criteria (r) using Eq. (12), the coefficient of elasticity \(\varphi\in N\) (where N represents a set of real numbers) should satisfy the condition \(\varphi>r\), where \(r=\text{max}\left\{\left|S_1\right|,\left|S_2\right|,\dots,\left|S_k\right|\right\}\).
Step 5. Calculation of the criterion influence function. The criterion influence function is used in Eq. (14) to calculate optimal values of criteria weights. The influence function \(f:S\rightarrow R\) is defined in the following way. For each criterion\(C_{i_p}\in C_i\), we can define influence function of the criterion as:
where i represents the number of levels/subsets where the criterion is classified, \(\varphi\) represents the coefficient of elasticity, while \({\overline I}_{i_p}\) represents the value assigned to the criterion \(C_{i_p}\) within the observed level.
Step 6. Calculation of optimal values of weight coefficients of criteria. Using Eq. (14), weight coefficient of the most influential criterion is calculated:
where \(\xi_1\) represents value of weight coefficient of the most influential criterion, while \(f\left(C_n\right)\) represents function of the influence of criterion defined in Step 5.
The values of the weighting coefficients of the remaining criteria are obtained by applying Eq. (15)
where \(j=2,3,\dots,n\), and n represents the total number of criteria.
b) SWARA-D method
Keršuliene et al. (2010) introduced SWARA method to determine criteria weights for MCDM problems. Since then this method has been applied for many real life solutions. Zolfani and Saparauskas (2013) used SWARA method for analyzing and assessing the sustainability factors of energy systems. Dehnavi et al. (2015) developed a decision making model using SWARA and adaptive neuro-fuzzy inference system for landslide hazard assessment for a case study in Iran. In this study, SWARA method was used to determine the importance of each landslide decision factors. Valipour et al. (2017) developed an integrated MCDM model based on SWARA and COPRAS methods for risk assessment of in foundation excavation projects. This study identified important decision factors for risk assessment in excavation industry and then determined the importance of the criteria via SWARA method. Zolfani et al. (2018) proposed a new version of SWARA method with a focus on improving criteria prioritization process which was achieved by integrating the reliability evaluation of expert judgments. Zolfani and Chatterjee (2019) constructed a decision making model using BWM and SWARA methods for sustainable design of household furnishing materials. Balki et al. (2020) combined SWARA and ARAS methods for an optimization problem of spark ignition (SI) engines where MCDM methods were supposed to select the best fuel alternative. SWARA was used to obtain the importance of energy criteria and then fuel alternatives were prioritized based on ARAS method. In a similar study, Ghenai et al. (2020) used SWARA and ARAS methods for prioritization of renewable energies such as wind, fuel cell and solar photo voltaic cell under sustainability factors. SWARA-D method has the following simple steps:
Step 1. Defining criteria significance. Suppose, there is a group of k experts who are divided into two homogeneous groups and the experts have defined a set of criteria \(C=\left\{C_1,C_2,\dots,C_n\right\}\), where n represents the total number of criteria. After that, an expert assessment is performed, i.e.comparative significance of the criteria is defined as \(s_j=\left\{\left(b_{j(1)},v_{j(1)}\right),\dots,\left(b_{j(i)},v_{j(i)}\right),\dots,\left(b_{j(m)},v_{j(m)}\right)\right\}\), \(b_j\in\left[0,e\right]\), \(v_j\leq1\), (where e represents the upper limit of the scale for comparing the criteria). In order to obtain a unique value of criteria significance \({\overline s}_j\) , it is necessary to perform fusion of the criteria significance, represented by D-numbers. By applying combination rule of D-numbers \({\overline s}_j=\overset1{s_j}\) ʘ \(\overset2{s_j}\), fusion of D-numbers is performed \(s_j^1=\left\{\left(b_{j(1)}^1,v_{j(1)}^1\right),\left(b_{j(2)}^1,v_{j(2)}^1\right),\dots,\left(b_{j(m)}^1,v_{j(m)}^1\right)\right\}\) and \(s_j^2=\left\{\left(b_{j(1)}^2,v_{j(1)}^2\right),\left(b_{j(2)}^2,v_{j(2)}^2\right),\dots,\left(b_{j(m)}^2,v_{j(m)}^2\right)\right\}\). By applying integration operator of Eq. (3), the uncertainties represented by D-numbers are integrated into a unique value \({\overline s}_j\).
Korak 2. Calculation of criteria weights. Criteria weights are obtained by using Eq. (16).
By applying Eq. (17), \(\zeta_j\) values are translated into the interval [0,1] so that they fulfill the condition \(\sum_{j=1}^n\zeta'_j=1\).
where \(\zeta'_j\) represents criterion weights, as obtained from SWARA-D method.
Finally, based on LBWA-D and SWARA-D criteria weights, aggregated weights are calculated using Eq. (18):
where \(w_j\) (\(j=1,2,\dots,n\)) represents final criteria weights, \(\xi_j\) represents criteria weights obtained using LBWA-D method, \(\zeta_j\) represents criteria weights obtained using SWARA-D method, while the coefficient \(\delta\in\left[0,1\right]\) defines the percentage share of weights.
It is recommended to use \(\delta=0.5\) value for initial ranking of alternatives, since both methods equally participate in this value while defining final criteria weights. For other values in the range of \(0.5<\delta\leq1\), LBWA-D method has advantage over SWARA-D, while SWARA-D method is favored for values \(0\leq\delta<0.5\) . It is also recommended that during the validation of final results, an analysis of impact of parameter \(\delta\) on final ranking should always be performed.
4.2 Phase- II: Fuzzy linguistic MARCOS-D method
Stević et al. (2020) introduced MARCOS method to prioritize alternatives with help of anti-ideal and idea solutions for supplier selection in a heathcare application. Other applications of this method include evaluation of human resources for transport company (Stević and Brković 2020), evaluation of project management software (Puška et al. 2020) and road traffic risk analysis (Stanković et al. 2020) to mention a few. The procedural steps of fuzzy linguistic MARCOS-D method are explained below:
Step 1. Forming an initial decision-making matrix . In the Y\(={\left[{\overline y}_{ij}\right]}_{b\times n}\)matrix, experts express their preferences using predefined fuzzy linguistic variables \(S=\left\{S_i\left|i=0,1,...,T-1\right.\right\}\). Expert evaluation of alternatives in relation to the criteria from the set \(C=\left\{C_1,C_2,\dots,C_n\right\}\) was performed using D-numbers and is presented as \(D_{y_{ij}}=\left\{\left(b_{y_{ij}}^1,v_{y_{ij}}^1\right),...,\left(b_{y_{ij}}^1,v_{y_{ij}}^1\right),\dots,\left(b_{y_{ij}}^m,v_{y_{ij}}^m\right)\right\}\), where \(b_{y_{ij}}^1\) represents the fuzzy linguistic variable (FLV) from the set S, and \(v_{y_{ij}}^1\) represents the probability of choosing FLV.
Since the experts are grouped into two homogeneous groups, each group of experts evaluates the alternatives. Thus, we get one initial decision matrix for each expert group, i.e. \(Y^1={\left[D_{y_{ij}(1)}\right]}_{b\times n}\) and \(Y^2={\left[D_{y_{ij}(2)}\right]}_{b\times n}\) where \(D_{y_{ij}(1)}=\left\{\left(b_{y_{ij}(1)}^1,v_{y_{ij}(1)}^1\right),...,\left(b_{y_{ij}(1)}^1,v_{y_{ij}(1)}^1\right),\dots,\left(b_{y_{ij}(1)}^m,v_{y_{ij}(1)}^m\right)\right\}\) and \(D_{y_{ij}(2)}=\left\{\left(b_{y_{ij}(1)}^1,v_{y_{ij}(2)}^1\right),...,\left(b_{y_{ij}(1)}^1,v_{y_{ij}(2)}^1\right),\dots,\left(b_{y_{ij}(1)}^m,v_{y_{ij}(2)}^m\right)\right\}\) represent the elements of the initial matrices \(Y^1\) and \(Y^2\) . In order to obtain a unique initial decision matrix Y, a fusion of the uncertainties represented by matrices \(Y^1\) and \(Y^2\) is performed by applying combination rule of D-numbers \(D_{y_{ij}=}D_{y_{ij}(1)\;}\odot D_{y_{ij}(2)}\) using Eq. (2). Since individual D-numbers represent uncertainties at the intersection of two FLVs (Fig. 6), FLV is transformed into fuzzy numbers using using Eq. (4).
Thus, the unique values of D-numbers are defined by applying Eqs. (19) and (20). FLV transformation is performed based on the ratio of the surfaces at the intersection \(s_{i,i+1}\) .
where \(s_{i,i+1}\) represents the intersection of linguistic variables \(s_i\) and \(s_{i+1}\) respectively, while \(s_i\) and \(s_{i+1}\) represent the area of the linguistic variable \(s_i\) and \(s_{i+1}\) , respectively.
By aggregating the unique values of D-numbers of Eq. (3), an aggregated initial initial decision matrix \(Y={\left[{\overline y}_{ij}\right]}_{b\times n}\) is obtained with transformed FLV into fuzzy numbers, where \(\;{\overline y}_{ij}\) represents fuzzy values.
Step 2: Formation of an extended initial fuzzy matrix. The extension of the initial fuzzy matrix is performed by defining the fuzzy ideal \(\widetilde A(ID)\) and fuzzy anti-ideal \(\widetilde A(AI)\) solution.
The fuzzy anti-ideal solution \(A(AI)\) is the worst alternative while the fuzzy ideal solution \(A(ID)\) is an alternative with the best characteristic. Depending on the nature of the criteria, \(A(AI)\) and \(A(ID)\) are defined by Eq. (22) as follows:
where B represents benefit criteria and C represents cost criteria.
Step 3: Creating a normalized fuzzy matrix. The elements of the normalized fuzzy matrix \(N={\left[{\widetilde n}_{ij}\right]}_{b\times n}\) are obtained by applying Eq. (23):
where elements \({\widetilde\chi}_{ij}=\left(\chi_{{}_{ij}}^l,\chi_{{}_{ij}}^m,\chi_{{}_{ij}}^u\right)\) and \({\widetilde\chi}_{idj}=\left(\chi_{{}_{idj}}^l,\chi_{{}_{idj}}^m,\chi_{{}_{idj}}^u\right)\) represent the elements of the matrix X.
Normalized fuzzy matrix is used in the next step to calculate the elements of the weighted fuzzy matrix.
Step 4: Determination of weighted fuzzy matrix \(V=\;{\left[{\widetilde v}_{ij}\right]}_{b\times n}\). The weighted matrix V is obtained by multiplying the normalized fuzzy matrix N with the fuzzy weight coefficients of the criterion \(w_j\), as shown in Eq. (24).
Weighted fuzzy matrix elements are used to calculate the \({\widetilde S}_i\) fuzzy matrix elements in Step 5.
Step 5: Calculation of \({\widetilde S}_i\) fuzzy matrix using the following expression:
where \({\widetilde S}_i\left(S_{{}_i}^l,S_{{}_i}^m,S_{{}_i}^u\right)\) represents the sum of the elements of the weighted fuzzy matrix \(V\) .
Elements of fuzzy matrix \({\widetilde S}_i\) are used to calculate the utility degree of alternatives, which is explained in the next step.
Step 6: Calculation of the utility degree of alternatives \({\widetilde K}_i\). By applying Eqs. (26) and (27), utility degrees of an alternative in relation to the anti-ideal and ideal solution are calculated.
In the next step, the utility degree of alternatives is used to calculate the utility functions \(f\left(\widetilde K_i^+\right)\) and \(f\left(\widetilde K_i^-\right)\).
Step 7. Determination of utility functions in relation to the ideal \(f\left(\widetilde K_i^+\right)\) and anti-ideal \(f\left(\widetilde K_i^-\right)\) solution. They are determined by applying Eqs. (28) and (29).
where \(d=\underset i{\text{max}}\left\{\sum_{i=1}^b\left(\widetilde K_i^-+\widetilde K_i^+\right)\right\}=\underset i{\text{max}}\left\{\sum_{i=1}^b\left(\widetilde K_i^{-u}+\widetilde K_i^{+u}\right)\right\}\).
Utility functions in relation to the ideal \(f\left(\widetilde K_i^+\right)\) and anti-ideal \(f\left(\widetilde K_i^-\right)\) solution are used in Eq. (30) to calculate the utility function of alternatives \(f\left(K_i\right)\) and final rank of alternatives.
Step 8: Determination of the utility function of alternatives \(f\left(K_i\right)\). Utility function is a compromised value of the observed alternative in relation to fuzzy ideal and fuzzy anti-ideal solutions. Utility functions of the alternatives are defined by Eq. (30).
where \(K_i^+\), \(K_i^-\), \(f\left(K_i^+\right)\) and \(f\left(K_i^-\right)\) represents defuzzified values of Eqs. (26)-(29). Defuzzified values are obtained by applying Eq. (31)
Step 9: Ranking the alternatives. Ranking of the alternatives is based on the final values of utility functions. It is desirable that an alternative has the highest possible value of the utility function.
5 Model implementation and results
5.1 Case study
In Spanish food and agriculture industry, one of the largest sectors is Winery units. In 2019 Spain has produced 12,333 tons of wine and olive oil. The quantity every year is increasing and many corporations are trying to join and bring high quality brands to the market. WineSol CorporationFootnote 1 is a cooperation company that distributes the ecological wine in Castilla-la-Mancha zone, one of the greatest wine region in whole Spain and Europe. It has more than 180 employees all around the country and drives transportation and distribution of wines in high volumes. The company is originated from a family business with years of experiences in wine production. The company has grown drastically and is trying to penetrate in new and emerging markets. Its global aim is to extend wine production fields and employ and educate people due to its traditional policy and social responsibility. They are currently directing a wine school in several cities tfor better promotion. The company mission is to gather best tasty and ecological wines for the loyalty of its clients. Long-term strategy is to keep competition of price in one side and constant relation to wine producers and control their products, performance and activities. WineSol is a known brand in the wine market which receives various types of bottled wines in a range of qualities. WineSol has a wide distribution system and network of sellers in Europe and Spain. Its major clients are supermarkets, restaurants, hotels, cruiser, and wine shops all over the country. Indeed, it has some first-tier suppliers that act as a bridge between WineSol (buyer) and upstream suppliers. The upstream suppliers can be farmers, focal and rural wine producers that directly provide wines in different factories. We study the performance of our “first-tier suppliers” that directly deliver WineSol the completed products packed for selling. The main task of WineSol is to contract with two or three of them as significant first-tier suppliers. This is an opportunity to enhance efficiency by controlling a wider group of products. Consequently, WineSol can vouch that ecological wines are going under a very strict control and the process assures no pesticides and chemicals ingredients being used.
In the company, one of the concerns of investors is to make wines from organic grapes. It has been decided to control and observe the performance of first-tier suppliers every six months and an initiative is also endeavored to provide a pre-approved list of sub-suppliers to its first-tier suppliers to understate sustainability hazards arising from the lower-level suppliers. WineSol collects ecological wine produced from five first-tier suppliers (S1,…S5) who further procure the bottles from three second-tier suppliers (SS1, SS2 and SS3). WineSol finally hack the blended brand, pack and distribute through its wide distribution channels. Couple of meetings and phone call conversation with company owners and experts resulted the characteristics that define the quality of a wine. Together with expert opinion and an exhaustive literature review, the following criteria are found predominant for sustainable and ecological wine production systems: 1. plant environment (C1) including climate and weather conditions (continental, maritime and mediterranean), temperature involving cool, mild, warm, hot, sunlight and soil condition; 2. quality and appropriateness of species and varieties that are originating from North America (C2); 3. viticulture practices, training and trellising, pruning, canopy management and harvest (mechanical or manual) (C3). It basically involves practices for soil preparation and tilling, growing and planting of varieties, trellising and pruning of vines, and combating diseases; 4. ecological practices (oxygen, sulfur dioxide and oak emission) (C4); 5. flexibility of delivery (C5); 6. offered price (C6); 7. environmental management system and pollution control (C7) and 8. social responsibility and sustainability of the suppliers (C8). Two groups of decision experts (D) are consulted to fill a set of questionnaire by them. They are responsible to visit wine providers’ sites, compare the importance of criteria and interpret the performance of suppliers. The experts are from chemical engineering backgrounds and have good experience and knowledge in wine sector. Group 1 (G1) is composed of 3 experts with more than 10 years of experiences in food and beverage sector, studied engineering in bachelor and master degree and consulting to several firms to keep quality standards. In other side, Group 2 (G2) is also having 3 SC executives with masters in environemmtal and agriculture and ecology sciences.
5.2 Application of the proposed model
5.2.1 First-tier supplier selection
The proposed model is now implemented for the first-tier supplier selection through the previously scripted two phases. The first phase involves determination of criteria weights using LBWA-D and SWARA-D methods. In the second phase, alternatives are evaluated using fuzzy linguistic MARCOS-D method, as already explained in Fig. 2.

Influence of varying weights in score functions of fuzzy linguistic MARCOS-D method
Phase I—Determination of criteria weights
a) Application of LBWA-D method
This section describes the detail procedure for defining criteria weights using LBWA-D method.
Step 1. Identification of the most important criterion from the set of given criteria \(S=\left\{C_1,C_2,\dots,C_8\right\}\). Expert groups defined criterion \(C_5\) as the most significant/influential criterion.
Step 2. Grou** criteria by levels of significance. In accordance with expert preferences, the criteria are grouped into the following levels:
Step 3. Based on Eq. (12), maximum value of criteria comparison scale is defined, as shown below:
Based on the maximum value of comparison scale, it can be concluded this scale ranges in the interval \(I_{i_p}\in\left[0,4\right]\). Comparisons of criteria performed by expert groups G1 and G2 are shown in Table 4.
In order to obtain unique comparisons of criteria by significance levels, a fusion of uncertainties is now performed. Using combination rule of D-numbers (Eq. (2)), unique D-numbers within the levels are obtained, as exhibited in Table 5.
By fusing the uncertainties obtained in Table 5, integrated values of preferences are obtained using Eq. (3):
Step 4. Based on r value and the condition that the coefficient of elasticity \(\varphi>r\), \(r=\text{max}\left\{\left|S_1\right|,\left|S_2\right|,\dots,\left|S_k\right|\right\}\), in this study, the value \(\varphi=5\) is taken as the coefficient of elasticity.
Step 5. Define influence function of the criteria. By applying Eq. (13), influence functions of the considered criteria are calculated as follows:
Thus, for criterion C1, we obtained a value \(f\left(C_j\right)=5/\left(2\cdot5+1.76\right)=0.43\) using Eq. (13). In a similar way, the remaining values of criteria influence functions are obtained.
Step 6. Calculation of optimal criteria weights.
Weight coefficient of the best criterion (C5) is obtained using Eq. (14), as shown below: \({\xi_{C5}} = \frac{1}{1 + 0.43 + 0.41 + 0.28 + ... + 0.45} = 0.198\)
Weights of remaining criteria are obtained using Eq. (15), as given below:
b) Application of SWARA-D method
This section presents application of the SWARA-D method for estimating criteria weights as follows:
Step 1. Define criteria significance.
The experts evaluated the criteria and defined comparative significance of the criteria, as shown in Table 6.
Based on the data presented in Table 6, it can be concluded that there is a dilemma when experts defined their preferences over the criteria. For example, for criterion C1, we noticed that experts in G1 have a dilemma between the values of 0.15, 0.2, and 0.25. Experts from G1 are 20% sure that the significance of criterion C1 is 0.15, so this dilemma is presented as (0.15, 0.2). Also, experts from the G1 group are 55% convinced that the significance of criterion C7 is 0.2, so this dilemma is presented as (0.2, 0.55). In addition to the above two dilemmas, G1 experts are 35% sure that the degree of significance is 0.25, so this dilemma is presented as (0.25, 0.35). Finally, all the uncertainties in G1 are represented with D-number D1 = {(0.5,0.3),(0.5; 1,0.35),(1.5,0.35)}. D-numbers for the remaining values shown in Table 5 are formed in the similar way.
In order to obtain a unique value of criteria significance \({\overline s}_j\), a fusion of the significance is performed by applying combination rules of D-numbers \({\overline s}_j=\overset1{s_j}\odot\overset2{s_j}\). After applying these rules and synthesis of uncertainties, the following unique D-numbers are obtained (Table 7).
.
Now, using integration operator of Eq. (3), uncertainties represented by D-numbers are integrated into a unique value \({\overline s}_j\):
Step 2. Criteria weight estimation.
Using Eq. (16), the estimated criteria significance values are given below.
For example, significance value of criterion C1 is estimated as follows: \(\zeta_{C1}=0.191/\left(0.151+1\right)=0.166\).
In a similar way we get the remaining values \(\zeta_j\). By normalizing these values using Eq. (17), final criteria weights are obtained as follows:
Based on the obtained weights according to LBWA-D and SWARA-D methods, aggregated criteria weights are finally computed using Eq. (17), as shown in Table 8.
To obtain aggregated values of weighting coefficients, a value \(\delta=0.5\) is considered here, in which both LBWA-D and SWARA-D methods equally participated in the weight calculation process.
Phase II—Evaluation of alternatives using fuzzy linguistic MARCOS-D method
After calculation of criteria weights, expert evaluation of the alternatives \(A_i=\left(i=1,2,\dots,5\right)\) is performed. Evaluation of alternatives \(A_i=\left(i=1,2,\dots,5\right)\) is performed on the basis of the eight considered criteria \(C_j\) \(\left(j=1,2,\dots,8\right)\).
Step 1. Construction of initial decision matrix (Y).
For the expert evaluation of alternatives, linguistic variables from the set \(S=\left\{\left.s_i\right|i=0,1,\dots,6\right\}\) are used, i.e.
Expert groups evaluated alternatives based on a set of linguistic variables, as shown in Table 13. In order to obtain a unique initial decision matrix Y, fusion of uncertainties is then performed by applying combination rules of D-numbers. Aggregated values of the linguistic variables after fusion are exhibited in Table 9. In D-numbers D = {(s3,0.1), (s3;s4,0.1)} and D = {(s3,0.5), (s3;s4,0.13), (s4,0.37)}, we did not obtain unique values of linguistic variables in all positions. In the first D-number, unique linguistic variable s3 is obtained in the first position, while in the second position, value between the linguistic variables s3 and s4, i.e. “s3;s4” is obtained. It is similar with the second D-number D = {(s3,0.5), (s3;s4,0.13), (s4,0.37)}. The unique linguistic variables s3 and s4 are obtained at the first and third positions, while the value between linguistic variables s3 and s4 is obtained at the second position. Now to determine a unique linguistic value, Eq. (5) is applied and the linguistic variables s3 and s4 are transformed into TFNs as follows: \(s_3=\left(0.333,0.500,0.667\right)\) and \(s_4=\left(0.500,0.667,0.833\right)\) . Unique values of D-numbers are then defined using Eqs. (19) and (20), as: C2-A2: D = {(s3,0.157),(s4,0.843)} and C2-A4: D = {(s3,0.572),(s4,0.428)}.
Now, by aggregating the unique values of D-numbers, an aggregated linguistic initial initial decision matrix is obtained, as shown below:
An aggregated value for position C1-A1 is thus obtained using Eq. (3), as follows: \(y_{11}=s_2\cdot0.17+s_3\cdot0.83=s_{2.83}\). In a similar way, remaining values from matrix \(\overline Y\) are calculated. Next, the linguistic variables from matrix \(\overline Y\) are transformed into triangular fuzzy numbers using Eq. (5), thus obtaining an aggregated initial initial decision matrix Y.
Step 2 and 3: Formation of extended initial fuzzy matrix (EIFM) and normalization of EIFM elements. The fuzzy matrix is extended and elements of this extended matrix are normalized using Eq. (22).
Step 4 and 5: Determination of weighted fuzzy matrix and calculation of \({\widetilde S}_i\) fuzzy matrix.
By multiplying criteria weights of Table 8 with the elements of matrix N, weighted fuzzy matrix is computed. Thereafter, elements of fuzzy matrix are obtained using Eq. (25), as follows:
Step 6: Calculation of utility degree of alternatives \({\widetilde K}_i\).
By applying Eqs. (26) and (27), utility degrees of the considered alternatives are calculated:
For example, \(\widetilde K_1^-\) and \(\widetilde K_1^-\) values of alternative A1, are obtained as follows:
Step 7. Determination of utility functions in relation to ideal \(f\left(\widetilde K_i^+\right)\) and anti-ideal \(f\left(\widetilde K_i^-\right)\) solutions. Using Eqs. (28) and (29), values of \(f\left(\widetilde K_i^+\right)\) and \(f\left(\widetilde K_i^-\right)\) are obtained.
For example, \(f\left(\widetilde K_i^+\right)\) and \(f\left(\widetilde K_i^-\right)\) values of alternative A1 are estimated as follows:
where \(d=\underset i{\text{max}}\left\{\sum_{i=1}^5\left(\widetilde K_i^-+\widetilde K_i^+\right)\right\}=\underset i{\text{max}}=\left\{1.312;2.492;5.399\right\}=5.399\).
Step 8: Determination of utility function of alternatives \(f\left(K_i\right)\) and subsequent ranking of the alternatives.
After defuzzification of \(\widetilde K_1^-\), \(\widetilde K_1^+\), \(f\left(\widetilde K_1^+\right)\) and \(f\left(\widetilde K_1^-\right)\) values, Eq. (30) is used to obtain utility functions of the alternatives, as shown in Table 10:
For example, utility function of alternative A1 is calculated as follows:
In the same way, \(f\left(K_i\right)\) values of the remaining alternatives are computed. The considered alternatives are ranked according to the descending values of the utility functions. From Table 10, it is clear that A4 is the best first-tier supplier, followed by A2, whereas A3 emerges out as the worst alternative supplier.
5.2.2 Second-tier supplier selection
In this section, the proposed model is now used for evaluation of the three second-tier suppliers (SS1, SS2 and SS3). Use of hazardous materials (SC1), green management and design (SC2), health and safety issues (SC3), manufacturing and technological capability (SC4) and social responsibility (SC5) are considered as the evaluating criteria. The second-tier suppliers are the one that produce bottle for wine producers. We have requested the same experts to visit the relevant suppliers and provide us their opinions. Similar to the previous stage of evaluating first-tier suppliers, criteria weights for second-tier supplier selection are calculated by both LBWA-D and SWARA-D methods and finally, the aggregated weights are estimated, as shown in Table 11. Health and safety (SC3) emerges to be the highest important criterion in the considered supplier evaluation process according to expert opinions.
The next step in finding the most suitable second-tier supplier is to develop the performance matrix using aggregated expert preferences, as adopted in Sect. 5.2.1. This matrix is shown in Table 14. Thereafter, by aggregating the unique values of D-numbers, an aggregated linguistic initial initial-decision matrix is obtained, as shown below:
Now, the utility functions and rank of the alternatives are obtained using Eqs. (19)-(31), as shown in Table 12. From this table, it is observed SS2 with highest utility score of 0.424 emerges out as the best alternative second-tier supplier for enhancing quality of the wine bottles regarding the pre-defined criteria.
6 Sensitivity analysis and discussion
Sensitivity analysis and validation of the results are now performed in three distinct phases. In the second phase of sensitivity analysis, influence of changes in parameter δ in criteria function values is analyzed. The third phase presents a comparison of ranking results between the fuzzy linguistic MARCOS-D method with three other D-number-based MCDM methods. Due to space limitations, sensitivity analyses for first-tier suppliers are shown here.
6.1 Changing the weights of the criteria
In the first phase, analysis of influence of changing criteria weights on ranking results is performed. Changes in criteria weights are considered in relation to the change in weight (w5) of the most influential criterion (C5). 50 scenarios are considered using Eq. (31) in which changes in w5 are simulated (Pamucar et al. 2017). At the same time, weights of other criteria are proportionally adjusted.
where \(\varpi_{n\beta}\) represents adjusted value of the criterion, \(\varpi_{n\alpha}\) represents reduced value of the best criterion (C5), \(w_\beta\) represents original value of the criterion and \(w_n\) represents original value of the best criterion (C5).
In the first scenario, value of criterion C5 is reduced by 1%, while the values of remaining criteria are proportionally adjusted using Eq. (31). In each subsequent scenarios, value of criterion C5 is changed by 2% while the values of remaining criteria are adjusted so as to satisfy the condition \({\textstyle\sum_{j=1}^8}w_j=1\). Changes in criteria weights for all the 50 scenarios are shown in Fig. 7.

Influence of parameter \(\delta\in\left[0,1\right]\) on alternative ranking
After the formation of new 50 weight vectors, score functions for all the alternatives are again estimated for fuzzy linguistic MARCOS-D method, as shown in Fig. 2.
From Fig. 2, it is observed that changes in weights of criterion C5 slightly affect criterion function values in fuzzy linguistic MARCOS-D method and thus, no changes in ranking of the alternatives are observed. Consequently, it can be concluded that the two alternatives {A4, A2} are indicated as good solutions, with the confirmed advantage of alternative A4 over A2.
6.2 Change of parameter δ in the function for aggregation of weight coefficients
As stated in Sect. 3.1, parameter δ affects the final values of criteria weights as it indicates the influence of LBWA-D and SWARA-D methods in the final weights. The initial ranks of the alternatives are derived at δ = 0.50 value. In this section, an analysis on the influence of varying δ values on criteria weights is performed to observe its effects on the final ranking results. Changes in δ values in the interval \(\delta\in\left[0,1\right]\) is simulated. The complete interval is divided into 100 equal sequences, i.e. 100 scenarios are formed. In the first scenario, δ is assumed to be of zero value, while for each subsequent scenario, value of δ is increased by 0.01. Thus, 100 new weight vectors are formed, through which the influence of these changes on final ranking are analyzed, as exhibited through Fig. 3.
From Fig. 3, it is distinctly noticed that changes in δ values in the interval \(\delta\in\left[0,1\right]\) affects criterion function values in fuzzy linguistic MARCOS-D method. However, despite such changes during the 100 scenarios, there is no change in the positions of the first three dominant alternatives {A4, A2, A1}. However, few minor changes are observed for alternatives A5 and A3 when δ > 0.15. From the presented analysis, it can be concluded that parameter δ has an impact on ranking of the alternatives, but these changes are insufficient to cause any major changes. However, it should be noted that such an analysis should always be performed as an indispensable step before making a final decision.
6.3 Comparison with fuzzy MCDM methodologies
Notes
The name of the company has changed due to anonymity and privacy.
References
Abdel-Baset M, Chang V, Gamal A, Smarandache F (2019) An integrated neutrosophic ANP and VIKOR method for achieving sustainable supplier selection: A case study in importing field. Comput Ind 106:94–110
Abdel-Basset M, Manogaran G, Gamal A, Smarandache F (2018) A hybrid approach of neutrosophic sets and DEMATEL method for develo** supplier selection criteria. Des Autom Embed Syst 22:257–278
Ahmed W, Ashraf MS, Khan SA, Sarpong SK, Arhin FK, Sarpong HK, Najmi A (2020) Analyzing the impact of environmental collaboration among supply chain stakeholders on a firm’s sustainable performance. Oper Manag Res 13:4–21
Alikhani R, Torabi SA, Altay N (2019) Strategic supplier selection under sustainability and risk criteria. Int J Prod Econ 208:69–82
Allaoui H, Guo Y, Choudhary A, Bloemhof J (2018) Sustainable agro-food supply chain design using two-stage hybrid multi-objective decision-making approach. Comput Oper Res 89:369–384
Amorim P, Curcio E, Almada-Lobo B, Barbosa-Póvoa AP, Grossmann IE (2016) Supplier selection in the processed food industry under uncertainty. Eur J Oper Res 252(3):801–814
Asadabadi MR, Chang E, Saberi M (2019) Are MCDM methods useful? A critical review of Analytic Hierarchy Process (AHP) and Analytic Network Process (ANP). Cogent Eng 6(1):1623153
Attari MYN, Torkayesh AE (2018) Develo** benders decomposition algorithm for a green supply chain network of mine industry: Case of Iranian mine industry. Oper Res Perspect 5:371–382
Awasthi A, Govindan K, Gold S (2018) Multi-tier sustainable global supplier selection using a fuzzy AHP-VIKOR based approach. Int J Prod Econ 195:106–117
Azimifard A, Moosavirad SH, Ariafar S (2018) Selecting sustainable supplier countries for Iran’s steel industry at three levels by using AHP and TOPSIS methods. Resour Policy 57:30–44
Bai C, Kusi-Sarpong S, Badri Ahmadi H, Sarkis J (2019) Social sustainable supplier evaluation and selection: a group decision-support approach. Int J Prod Res 57(22):7046–7067
Balki MK, Erdoğan S, Aydın S, Sayin C (2020) The optimization of engine operating parameters via SWARA and ARAS hybrid method in a small SI engine using alternative fuels. J Clean Prod 258:120685
Banaeian N, Mobli H, Nielsen IE, Omid M (2015) Criteria definition and approaches in green supplier selection–a case study for raw material and packaging of food industry. Prod Manuf Res 3(1):149–168
Banaeian N, Mobli H, Fahimnia B, Nielsen IE, Omid M (2018) Green supplier selection using fuzzy group decision making methods: A case study from the agri-food industry. Comput Oper Res 89:337–347
Behzadian M, Khanmohammadi Otaghsara S, Yazdani M, Ignatius J (2012) A state-of the-art survey of TOPSIS applications. Expert Syst App 39:13051-13069
Bortolini M, Faccio M, Ferrari E, Gamberi M, Pilati F (2016) Fresh food sustainable distribution: cost, delivery time and carbon footprint three-objective optimization. J Food Eng 174:56–67
Bozanic D, Jurisic D, Erkic D (2020) LBWA – Z-MAIRCA model supporting decision making in the army. Oper Res Eng Sci: Theory Appl 3(2):87–110
Brans JP, De Smet Y (2016) PROMETHEE methods. Multiple criteria decision analysis. Springer, NY, pp 187–219
Chakraborty S, Chattopadhyay R, Chakraborty S (2020) An integrated D-MARCOS method for supplier selection in an iron and steel industry. Decis Mak Appl Manag Eng 3(2):49–69
Chu J, Wu J, Chu C, Liu M (2019) A new DEA common-weight multi-criteria decision-making approach for technology selection. Int J Prod Res 58(12):3686–3700
Cojocariu CR (2012) A sustainable food supply chain: green logistics. Metal Int 17(3):205
Dehnavi A, Aghdam IN, Pradhan B, Varzandeh MHM (2015) A new hybrid model using step-wise weight assessment ratio analysis (SWARA) technique and adaptive neuro-fuzzy inference system (ANFIS) for regional landslide hazard assessment in Iran. CATENA 135:122–148
Dempster AP (1967) Upper and lower probabilities induced by a multivalued map**. Ann Math Stat 38(2):325–339
Deng X, Jiang W (2019) Evaluating green supply chain management practices under fuzzy environment: A novel method based on D-number theory. Int J Fuzzy Syst 21:1389–1402. https://doi.org/10.1007/s40815-019-00639-5
Deng X, Hu Y, Deng Y, Mahadevan S (2014a) Environmental impact assessment based on D-numbers. Expert Syst Appl 41(2):635–643
Deng X, Hu Y, Deng Y (2014b) Bridge condition assessment using D-numbers. Sci World J, Article ID 358057, 11 pages. https://doi.org/10.1155/2014/358057
Deng X, Hu Y, Deng Y, Mahadevan S (2014c) Supplier selection using AHP methodology extended by D-numbers. Expert Syst Appl 41(1):156–167
Deng Y (2012) D-numbers: theory and applications. Journal of Information & Computational Science 9(9):2421–2428
Diabat A, Govindan K, Panicker VV (2012) Supply chain risk management and its mitigation in a food industry. Int J Prod Res 50(11):3039–3050
Diakoulaki D, Mavrotas G, Papayannakis L (1995) Determining objective weights in multiple criteria problems: The critic method. Comput Oper Res 22(7):763–770
Durmic E, Stevic Z, Chatterjee P, Vasiljevic M, Tomasevic M (2020) Sustainable supplier selection using combined FUCOM – Rough SAW model. Rep Mech Eng 1(1):34–43
Ecer F, Pamucar D (2020) Sustainable supplier selection: A novel integrated fuzzy best worst method (F-BWM) and fuzzy CoCoSo with Bonferroni (CoCoSo’B) multi-criteria model. J Clean Prod 266:121981
Fallahpour A, Olugu EU, Musa SN, Wong KY, Noori S (2017) A decision support model for sustainable supplier selection in sustainable supply chain management. Comput Ind Eng 105:391–410
Fan G, Zhong D, Yan F, Yue P (2016) A hybrid fuzzy evaluation method for curtain grouting efficiency assessment based on an AHP method extended by D-numbers. Expert Syst Appl 44:289–303
Fathollahi-Fard AM, Govindan K, Hajiaghaei-Keshteli M, Ahmadi A (2019) A green home health care supply chain: New modified simulated annealing algorithms. J Clean Prod 240:118200
Fei L, Deng Y, Hu Y (2019) DS-VIKOR: A new multi-criteria decision-making method for supplier selection. Int J Fuzzy Syst 21(1):157–175
Fei L, Hu Y, **ao F, Chen L, Deng Y (2016) A Modified TOPSIS Method Based on D Numbers and Its Applications in Human Resources Selection. Math Probl Eng, Volume 2016, Article ID 6145196, 14 pages. https://dx.doi.org/10.1155/2016/6145196
Frej EA, Roselli LRP, Araújo de Almeida J, de Almeida AT (2017) A multicriteria decision model for supplier selection in a food industry based on FITradeoff method. Math Probl Eng, Volume 2017, Article ID 4541914, 9 pages. https://doi.org/10.1155/2017/4541914
Fu YK (2019) An integrated approach to catering supplier selection using AHP-ARAS-MCGP methodology. J Air Transp Manag 75:164–169
Garnett T (2013) Food sustainability: problems, perspectives and solutions. Proc Nutri Soc 72(1):29–39
Ghoushchi SJ, Khazaeili M (2019) G-Numbers: importance-necessity concept in uncertain environment. Int J Manag Fuzzy Syst 5(1):27–32
Ghoushchi SJ, Ab Rahman MN, Osgooei RD, E, Ghoushji MJ, (2020a) Integrated Decision-Making Approach Based on SWARA and GRA Methods for the Prioritization of Failures in Solar Panel Systems under Z-Information. Symmetry 12:310
Ghoushchi SJ, Gharibi K, Osgooei E, Ab Rahman MN, Khazaeili M (2020b) Risk Prioritization in Failure Mode and Effects Analysis with Extended SWARA and MOORA Methods Based on Z-Numbers Theory. Informatica, 1–27. https://doi.org/10.15388/20-INFOR439
Ghenai C, Albawab M, Bettayeb M (2020) Sustainability indicators for renewable energy systems using multi-criteria decision-making model and extended SWARA/ARAS hybrid method. Renew Energy 146:580–597
Girubha J, Vinodh S, Kek V (2016) Application of interpretative structural modelling integrated multi criteria decision making methods for sustainable supplier selection. J Model Manag 11(2):358–388
Govindan K (2018) Sustainable consumption and production in the food supply chain: A conceptual framework. Int J Prod Econ 195:419–431
Govindan K, Jepsen MB (2016) ELECTRE: A comprehensive literature review on methodologies and applications. Eur J Oper Res 250(1):1–29
Govindan K, Kadziński M, Sivakumar R (2017) Application of a novel PROMETHEE-based method for construction of a group compromise ranking to prioritization of green suppliers in food supply chain. Omega 71:129–145
Grimm JH, Hofstetter JS, Sarkis J (2014) Critical factors for sub-supplier management: A sustainable food supply chains perspective. Int J Prod Econ 152:159–173
Hwang CL, Yoon K (1981) Multiple attributes decision making methods and applications. Springer, Berlin
Jain N, Singh AR, Upadhyay RK (2020) Sustainable supplier selection under attractive criteria through FIS and integrated fuzzy MCDM techniques. Int J Sustain Eng, 1–22.
Jain V, Sangaiah AK, Sakhuja S, Thoduka N, Aggarwal R (2018) Supplier selection using fuzzy AHP and TOPSIS: a case study in the Indian automotive industry. Neural Comput Appl 29(7):555–564
Jedvall I (1999) A sustainable food supply chain. UNEP Industry and Environment April-September 1999:59–62
Kaipa R, Dukovska‐Popovska I, Loikkanen L (2013) Creating sustainable fresh food supply chains through waste reduction. Int J Phys Distrib Logist Manag 43(3), 262-276
Kamble SS, Gunasekaran A, Gawankar SA (2020) Achieving sustainable performance in a data-driven agriculture supply chain: A review for research and applications. Int J Prod Econ 219:179–194
Kaviani MA, Peykam A, Khan SA, Brahimi N, Niknam R (2020) A new weighted fuzzy programming model for supplier selection and order allocation in the food industry. J Model Manag 15(2):381–406
Khan SAR, Qianli D (2017) Impact of green supply chain management practices on firms’ performance: an empirical study from the perspective of Pakistan. Environ Sci Pollut Res 24(20):16829–16844
Khan SAR, Zhang Y, Anees M, Golpîra H, Lahmar A, Qianli D (2018) Green supply chain management, economic growth and environment: A GMM based evidence. J Clean Prod 185:588–599
Khan SAR, Jian C, Zhang Y, Golpîra H, Kumar A, Sharif A (2019a) Environmental, social and economic growth indicators spur logistics performance: from the perspective of South Asian Association for Regional Cooperation countries. J Clean Prod 214:1011–1023
Khan SAR, Sharif A, Golpîra H, Kumar A (2019b) A green ideology in Asian emerging economies: From environmental policy and sustainable development. Sustain Dev 27(6):1063–1075
Khan SAR, Yu Z (2020a) Assessing the eco-environmental performance: an PLS-SEM approach with practice-based view. Int J Logist Res Appl 1–19 https://doi.org/10.1080/13675567.2020.1754773
Khan SAR, Zhang Y, Kumar A, Zavadskas EK, Streimikiene D (2020a) Measuring the impact of renewable energy, public health expenditure, logistics, and environmental performance on sustainable economic growth. Sustain Dev 28(4):833–843
Khan SAR, Yu Z, Sharif A, Golpîra H (2020b) Determinants of economic growth and environmental sustainability in South Asian Association for Regional Cooperation: evidence from panel ARDL. Environ Sci Pollut Res, 1–13
Khan SAR, Yu Z, Golpîra H, Sharif A, Mardani A (2021) A state-of-the-art review and meta-analysis on sustainable supply chain management: Future research directions. J Clean Prod 278:123357
Keršuliene V, Zavadskas EK, Turskis Z (2010) Selection of rational dispute resolution method by applying new step-wise weight assessment ratio analysis (SWARA). J Bus Econ Manag 11(2):243–258
Ghorabaee MK, Amiri M, Zavadskas EK, Antuchevičienė J (2017) Assessment of third-party logistics providers using a CRITIC-WASPAS approach with interval type-2 fuzzy sets. Transport 32(1):66–78
Kim DY, Zhu P, **ao W, Lin YT (2020) Customer degree centrality and supplier performance: the moderating role of resource dependence. Oper Manag Res 1–17
Kumar S, Hong QS, Haggerty LN (2011) A global supplier selection process for food packaging. J Manuf Technol Manag 22(2):241-260
Kumar A, Jain V, Kumar S (2014) A comprehensive environment friendly approach for supplier selection. Omega 42(1):109–123
Kuo MS, Liang GS (2011) Combining VIKOR with GRA techniques to evaluate service quality of airports under fuzzy environment. Expert Syst Appl 38(3):1304–1312
Lau H, Shum PK, Nakandala D, Fan Y, Lee C (2020) A game theoretic decision model for organic food supplier evaluation in the global supply chains. J Clean Prod 242:118536
Lee HC, Chang CT (2018) Comparative analysis of MCDM methods for ranking renewable energy sources in Taiwan. Renew Sustain Energy Rev 92:883–896
León-Bravo V, Caniato F, Caridi M (2019) Sustainability in multiple stages of the food supply chain in Italy: practices, performance and reputation. Oper Manag Res 12(1–2):40–61
Lau H, Nakandala D, Shum PK (2018) A business process decision model for fresh-food supplier evaluation. Bus Process Manag J 24(3):716–744
Li D, Wang X, Chan HK, Manzini R (2014) Sustainable food supply chain management. Int J Prod Econ 152:1–8
Linnemann AR, Hendrix EM, Apaiah R, van Boekel TA (2015) Food chain design using multi criteria decision making, an approach to complex design issues. NJAS-Wagen J Life Sc 72:13–21
Liu CH, Tzeng GH, Lee MH, Lee PY (2013) Improving metro-airport connection service for tourism development: Using hybrid MCDM models. Tour Manag Perspect 6:95–107
Liu Y, Yang Y, Liu Y, Tzeng GH (2019) Improving sustainable mobile health care promotion: a novel hybrid MCDM method. Sustainability 11(3):752
Lu H, Jiang S, Song W, Ming X (2018) A Rough Multi-Criteria Decision-Making Approach for Sustainable Supplier Selection under Vague Environment. Sustainability 10(8):2622
Luthra S, Govindan K, Kannan D, Mangla SK, Garg CP (2017) An integrated framework for sustainable supplier selection and evaluation in supply chains. J Clean Prod 140:1686–1698
Ma L, Chen H, Yan H, Yang L, Wu L (2017) Multiple attribute decision making model and application to food safety risk evaluation. PLoS One 12(12):e0189835
Meneghetti A, Monti L (2015) Greening the food supply chain: an optimisation model for sustainable design of refrigerated automated warehouses. Int J Prod Res 53(21):6567–6587
Meredith JR, Shafer SM (2019) Operations and supply chain management for MBAs. Wiley
Miranda-Ackerman MA, Azzaro-Pantel C, Aguilar-Lasserre AA (2017) A green supply chain network design framework for the processed food industry: Application to the orange juice agrofood cluster. Comput Ind Eng 109:369–389
Mo H, Deng Y (2018) A New MADA Methodology Based on D-numbers 20:2458–2469. https://doi.org/10.1007/s40815-018-0514-3
Mohammed A, Wang Q (2017) The Fuzzy Multiobjective Distribution Planner for a Green Meat Supply Chain. Int J Prod Econ 184:47-58
Narasimhan R, Mahapatra S, Arlbjørn JS (2008) Impact of relational norms, supplier development and trust on supplier performance. Oper Manag Res 1(1):24–30
Opricovic S, Tzeng GH (2004) Compromise solution by MCDM methods: A comparative analysis of VIKOR and TOPSIS. Eur J Oper Res 156(2):445–455
Pamucar D (2020) Normalized weighted Geometric Dombi Bonferoni Mean Operator with interval grey numbers: Application in multicriteria decision making. Rep Mech Eng 1(1):44–52
Pamucar D, Ecer F (2020) Prioritizing the weights of the evaluation criteria under fuzziness: The fuzzy full consistency method - FUCOM-F. Facta Universitatis, Series: Mech Eng 18(3):419–437
Pamucar D, Mihajlović M, Obradović R, Atanasković P (2017) Novel approach to group multi-criteria decision making based on interval rough numbers: Hybrid DEMATEL-ANP-MAIRCA model. Expert Syst Appl 88:58-80
Petrovic I, Kankaras M (2020) A hybridized IT2FS-DEMATEL-AHP-TOPSIS multicriteria decision making approach: Case study of selection and evaluation of criteria for determination of air traffic control radar position. Decis Mak Appl Manag Eng 3(1):146–164
Puška A, Stojanović I, Maksimović A, Osmanović N (2020) Evaluation software of project management used measurement of alternatives and ranking according to compromise solution (MARCOS) method. Oper Res Eng Sci Theory Appl 3(1):89–102
Ramakrishnan KR, Chakraborty S (2020) A cloud TOPSIS model for green supplier selection. FU Mech Eng 18(3):375–397
Rashidi K, Cullinane K (2019) A comparison of fuzzy DEA and fuzzy TOPSIS in sustainable supplier selection: Implications for sourcing strategy. Expert Syst Appl 121:266–281
Redmond EC, Griffith CJ (2003) A comparison and evaluation of research methods used in consumer food safety studies. Int J Consum Stud 27(1):17-33
Rezaei J (2015) Best-worst multi-criteria decision making method. Omega 53:49-57
Rezaei J, Fahim PB, Tavasszy L (2014) Supplier selection in the airline retail industry using a funnel methodology: Conjunctive screening method and fuzzy AHP. Expert Syst Appl 41(18):8165–8179
Reza A, Rahim D, Ghoushchi SJ (2020) HSE risk prioritization of molybdenum operation process using extended FMEA approach based on Fuzzy BWM and Z-WASPAS. J Intell Fuzzy Syst 38(4):5157–5173
Rong A, Akkerman R, Grunow M (2011) An optimization approach for managing fresh food quality throughout the supply chain. Int J Prod Econ 131(1):421–429
Rouyendegh BD, Yildizbasi A, Üstünyer P (2020) Intuitionistic fuzzy TOPSIS method for green supplier selection problem. Soft Comput 24(3):2215–2228
Saberi S, Kouhizadeh M, Sarkis J, Shen L (2019) Blockchain technology and its relationships to sustainable supply chain management. Int J Prod Res 57(7):2117–2135
Sambasivam VP, Thiyagarajan G, Kabir G, Ali SM, Khan SAR, Yu Z (2020) Selection of Winter Season Crop Pattern for Environmental-Friendly Agricultural Practices in India. Sustainability 12(11):4562
Sang X, Liu X (2016) An interval type-2 fuzzy sets-based TODIM method and its application to green supplier selection. J Oper Res Soc 67(5):722–734
Sawik T (2020) On the Risk-Averse Selection of Resilient Multi-Tier Supply Portfolio. Omega. https://doi.org/10.1016/j.omega.2020.102267
Seiti H, Hafezalkotob A, Martínez L (2019a) R-numbers, a new risk modeling associated with fuzzy numbers and its application to decision making. Inf Sci 483:206–231
Seiti H, Hafezalkotob A, Najafi SE, Khalaj M (2019b) Develo** a novel risk-based MCDM approach based on D-numbers and fuzzy information axiom and its applications in preventive maintenance planning. Appl Soft Comput 82:105559
Shabanpour H, Yousefi S, Saen RF (2017) Future planning for benchmarking and ranking sustainable suppliers using goal programming and robust double frontiers DEA. Transp Res Part D: Transp Environ 50:129–143
Shafer G (1978) A mathematical theory of evidence. Technometrics 20(1):242
Shi H, Quan MY, Liu HC, Duan CY (2018) A novel integrated approach for green supplier selection with interval-valued intuitionistic uncertain linguistic information: A case study in the agri-food industry. Sustainability 10(3):733
Si SL, You XY, Liu HC, Zhang P (2018) DEMATEL technique: A systematic review of the state-of-the-art literature on methodologies and applications. Math Probl Eng
Smith BG (2008) Develo** sustainable food supply chains. Philos Trans R Soc B Biol Sci 363(1492):849–861
Song W, Xu Z, Liu HC (2017) Develo** sustainable supplier selection criteria for solar air-conditioner manufacturer: An integrated approach. Renew Sustain Energy Rev 79:1461–1471
Song Y, Li G (2018) A large-scale group decision-making with incomplete multi-granular probabilistic linguistic term sets and its application in sustainable supplier selection. J Oper Res Soc 1–15
Stanković M, Stević Ž, Das DK, Subotić M, Pamučar D (2020) A new fuzzy MARCOS method for road traffic risk analysis. Mathematics 8(3):457
Stević Ž, Brković N (2020) A novel integrated FUCOM-MARCOS model for evaluation of human resources in a transport company. Logistics 4(1):4
Stević Z, Pamučar D, Puška A, Chaterjee P (2020) Sustainable supplier selection in healthcare industries using a new MCDM method: Measurement of Alternatives and Ranking according to COmpromise Solution (MARCOS). Comput Ind Eng 140:106231
Su CM, Horng DJ, Tseng ML, Chiu AS, Wu KJ, Chen HP (2016) Improving sustainable supply chain management using a novel hierarchical grey-DEMATEL approach. J Clean Prod 134:469–481
Tabrizi S, Ghodsypour SH, Ahmadi A (2018) Modelling three-echelon warm-water fish supply chain: A bi-level optimization approach under Nash-Cournot equilibrium. Appl Soft Comput 71:1035–1053
Tidy M, Wang X, Hall M (2016) The role of Supplier Relationship Management in reducing Greenhouse Gas emissions from food supply chains: supplier engagement in the UK supermarket sector. J Clean Prod 112:3294–3305
Ting SL, Tse YK, Ho GTS, Chung SH, Pang G (2014) Mining logistics data to assure the quality in a sustainable food supply chain: A case in the red wine industry. Int J Prod Econ 152:200–209
Torkayesh SE, Amiri A, Iranizad A, Torkayesh AE (2020) Entropy based EDAS decision making model for neighborhood selection: A case study in Istanbul. J Ind Eng Decis Mak 1(1):1–11
Torkayesh SE, Iranizad A, Torkayesh AE, Basit MN (2020) Application of BWM-WASPAS model for digital supplier selection problem: A case study in online retail shop**. J Ind Eng Decis Mak 1(1):12–23
Validi S, Bhattacharya A, Byrne PJ (2014) A case analysis of a sustainable food supply chain distribution system-A multi-objective approach. Int J Prod Econ 152:71–87
Valipour A, Yahaya N, Md Noor N, Antuchevičienė J, Tamošaitienė J (2017) Hybrid SWARA-COPRAS method for risk assessment in deep foundation excavation project: An Iranian case study. J Civ Eng Manag 23(4):524–532
Varsei M, Polyakovskiy S (2017) Sustainable supply chain network design: A case of the wine industry in Australia. Omega 66:236–247
Vermeulen SJ, Campbell BM, Ingram JS (2012) Climate change and food systems. Annu Rev Environ Reesour 37
Viswanadham N, Samvedi A (2013) Supplier selection based on supply chain ecosystem, performance and risk criteria. Int J Prod Res 51(21):6484–6498
Wang CN, Nguyen VT, Thai HTN, Tran NN, Tran TLA (2018) Sustainable supplier selection process in edible oil production by a hybrid fuzzy analytical hierarchy process and green data envelopment analysis for the SMEs food processing industry. Mathematics 6(12):302
Wen TC, Chang KH, Lai HH (2020) Integrating the 2-tuple linguistic representation and soft set to solve supplier selection problems with incomplete information. Eng Appl Artif Intell 87:103248
Wilhelm MM, Blome C, Bhakoo V, Paulraj A (2016) Sustainability in multi-tier supply chains: Understanding the double agency role of the first-tier supplier. J Oper Manag 41:42–60
Wognum PN, Bremmers H, Trienekens JH, van der Vorst JG, Bloemhof JM (2011) Systems for sustainability and transparency of food supply chains-Current status and challenges. Adv Eng Inform 25(1):65–76
World Health Organization (2020) COVID-19 and food fafety: guidance for food businesses: interim guidance, 07 April 2020 (No. WHO/2019-nCoV/Food_Safety/2020.1). World Health Organization
**ao F (2018) A novel multi-criteria decision making method for assessing health-care waste treatment technologies based on D-numbers. Eng Appl Artif Intell 71:216–225
**ao F (2019) A multiple-criteria decision-making method based on D-numbers and belief entropy. Int J Fuzzy Syst 21(4):1144–1153
Yazdani M, Chatterjee P, Torkayesh AE (2020) An Integrated AHP-QFD-Based Compromise Ranking Model for Sustainable Supplier Selection. In Handbook of Research on Interdisciplinary Approaches to Decision Making for Sustainable supply chains (pp. 32–54). IGI Global
Yazdani M, Chatterjee P, Zavadskas EK, Zolfani SH (2017) Integrated QFD-MCDM framework for green supplier selection. J Clean Prod 142:3728–3740
Yazdani M, Wen Z, Liao H, Banaitis A, Turskis Z (2019a) A grey combined compromise solution (COCOSO-G) method for supplier selection in construction management. J Civ Eng Manag 25(8):858–874
Yazdani M, Zarate P, Kazimieras Zavadskas E, Turskis Z (2019) A Combined Compromise Solution (CoCoSo) method for multi-criteria decision-making problems. Manag Decis 57(9):2501–2519. https://doi.org/10.1108/MD-05-2017-0458
Zadeh LA (2011) A note on Z-numbers. Inf Sci 181(14):2923–2932
Zizovic M, Pamucar D (2019) New model for determining criteria weights: Level Based Weight Assessment (LBWA) model. Decis Mak Appl Manag Eng 2(2):126–137
Zolfani SH, Chatterjee P (2019) Comparative evaluation of sustainable design based on Step-Wise Weight Assessment Ratio Analysis (SWARA) and Best Worst Method (BWM) methods: a perspective on household furnishing materials. Symmetry 11(1):74
Zolfani SH, Saparauskas J (2013) New application of SWARA method in prioritizing sustainability assessment indicators of energy system. Eng Econ 24(5):408–414
Zolfani SH, Yazdani M, Zavadskas EK (2018) An extended stepwise weight assessment ratio analysis (SWARA) method for improving criteria prioritization process. Soft Comput 22(22):7399–7405
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
1.1 Problem of exclusivity
Example: Suppose a patient has symptoms of fever, polypnea, and cough. Two doctors examined the patient and assumed that it was flu (F), bacterial or fungal pneumonia (B) or COVID-19 (C). The first doctor submitted a report stating that the 35% probability is that the patient has an F or B (m1{F,B} = 0.35), while the probability of 55% that the patient has C (m1{C} = 0.55), the remaining probability of 10% refers to the unknown. Another doctor stated in his report that he was 45% sure that the patient had F (m2{F} = 0.45) and that 45% was sure that the patient had C (m2{C} = 0.50), the other 10% were not sure which disease the patient had. The problem that doctors need to solve is to define exactly which disease the patient has. Using DS theory, the following results were obtained: m{F} = 0.340; m{C} = 0.584; m{F,B} = 0.059 and m{F,B,C} = 0.017. As can be seen from the results, a hypothesis emerges that covers all other diseases that cause the symptoms of fever, polypnea and cough. This hypothesis is presented as {F,B,C}. However, this hypothesis is not covered by the doctor's report. It is obvious that this hypothesis is not rational from the aspect of medical diagnostics. The appearance of the irrational hypothesis is a consequence of the problem of the exclusivity of the elements in DS theory (Fig. 5), in our case of diagnosed diseases. From this real world example we can conclude that this limitation of DS theory limits its application for solving certain real problems.

Frame of discernment in DS theory and domain in D-numbers

Fuzzy linguistic variables

Varying criteria weights through 50 scenarios
Rights and permissions
About this article

Cite this article
Yazdani, M., Pamucar, D., Chatterjee, P. et al. “A multi-tier sustainable food supplier selection model under uncertainty”. Oper Manag Res 15, 116–145 (2022). https://doi.org/10.1007/s12063-021-00186-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12063-021-00186-z