
Abstract
Social media data has a mix of high and low-quality content. One form of commonly studied low-quality content is spam. Most studies assume that spam is context-neutral. We show on different Twitter data sets that context-specific spam exists and is identifiable. We then compare multiple traditional machine learning models and a neural network model that uses a pre-trained BERT language model to capture contextual features for identifying spam, both traditional and context-specific, using only content-based features. The neural network model outperforms the traditional models with an F1 score of 0.91. Because spam training data sets are notoriously imbalanced, we also investigate the impact of this imbalance and show that simple Bag-of-Words models are best with extreme imbalance, but a neural model that fine-tunes using language models from other domains significantly improves the F1 score, but not to the levels of domain-specific neural models. This suggests that the strategy employed may vary depending upon the level of imbalance in the data set, the amount of data available in a low resource setting, and the prevalence of context-specific spam vs. traditional spam. Finally, we make our data sets available for use by the research community.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Spam and junk content have been a problem on the Internet for decades (Sahami et al., 1998; Kaur et al., 2016; Ferrara et al., 2016; Dou et al., 2020). With the proliferation of direct marketing online, these forms of pollution continue to increase rapidly. By definition (Wu et al., 2019, https://help.twitter.com/en/rules-and-policies/twitter-rules, Pedia 2020), spam is unsolicited and unsought information, including pornography, inappropriate or nonsensical content, and commercial advertisements. These different types of spam take on new meaning in the context of social media, particularly on platforms like Twitter. For example, not everyone would view advertising as spam. When conducting a content analysis on tweets about an election, advertising about diapers is irrelevant to the election discussion and would be viewed as spam. If instead, we are analyzing content about parenting, diaper advertisements would be relevant to the content analysis and may not be viewed as spam. Because of mismatches like this, we introduce the concept of context-specific spam and attempt to understand how to accurately identify posts containing this form of spam, as well as more traditional forms of spam on Twitter.
Figure 1 shows the different types of content as they relate to spam. Filtering out traditional spam is an insufficient way to remove all spam tweets since context-specific spam remains. Similarly, classical spam filtering that considers all advertisements as spam is inadequate because it classifies legitimate context-specific advertising as spam. To accurately detect spam pollution, contextual understanding is required. The goal of our paper is to identify spam on Twitter, both traditional and context-specific. Researchers have been working on spam and bot detection for decades and have proposed a number of supervised learning approaches (Sahami et al., 1998; Kaur et al., 2016; Chen et al., 2015; Cresci et al., 2018). The state-of-the-art approaches extract features from both content and user information. Yet, on some platforms, user information can be difficult to obtain, either because of privacy concerns or because of API limitations. Consider the case of identifying spam among a set of tweets about a particular hashtag stream or keyword search like #metoo or #trump. Getting the user information for every post is impractical for these frequently used hashtags that have thousands of posts daily. As such, we focus on building models that only use post content, not user information.

Different types of content
In this paper, our primary goal is to identify polluted information, specifically traditional spam and context-specific spam using content-based features extracted from posts. Overall, our core contributions are as follows: (i) we formally define different forms of conversation pollution on social media, building a useful taxonomy of poor quality information on social media; (ii) we present a neural network model that identifies traditional and context-specific spam in a low resource setting and show that using a language model within the neural network performs better than classic state-of-the-art machine learning models; (iii) we generate and make available three Mechanical Turk data sets in three different conversation domains (https://github.com/GU-DataLab/context-spam), show the existence of context-specific spam on Twitter, and how the proportion of spam varies across conversation domains; (iv) we demonstrate the performance impact of imbalanced training data on Twitter and show that using a neural network model is promising in this setting; and (v) we show that classic machine learning models are more robust to cross-domain learning when the training data are balanced, but when the training data are heavily imbalaced, a neural network with a cross-domain pre-trained language odel leads to better performance than classic models, but still not as strong performance as domain-specific training because of the presence of context-specific spam.
The remainder of this paper is organized as follows. We present our proposed conversation pollution taxonomy in Sect. 2. Next, we discuss the related work in Sect. 3. Section 4 describes our experiment design for the spam learning task. Our data sets and the labeling task are described in Sect. 5. Then, in Sect. 6, we present our empirical evaluation, followed by conclusions in Sect. 7.
2 Conversation pollution taxonomy
Researchers are investigating different types of conversation pollution. Kolari et al. create a taxonomy of spam across the Internet (Kolari et al., 2007). The focus of their taxonomy is on different ways to distribute spam, e.g. email, IM, blogs, etc. We present a taxonomy that groups different types of conversation pollution, where spam is one form of pollution. Figure 2 shows this taxonomy. There are three high level categories of conversation pollution: deceptive/misleading (false information), abusive/offensive (threat), and persuasive/enticing (spam). False information is a post containing inaccurate content, including different forms of misinformation and disinformation. Threat content is designed to be offensive and/or abusive (Wu et al., 2019). Finally, spam content attempts to persuade and entice people to click, share, or buy something. We divide spam into two categories, traditional spam and context-specific spam.

Different forms of conversation pollution
In this paper, we focus on spam-related pollution. Specifically, we introduce a new form of spam that we refer to as context-specific spam. Context-specific spam is any post that is undesirable given the context/theme of the discussion. This includes context-irrelevant posts like irrelevant advertising. For the purposes of this paper, we consider advertising to be posts that are intended to promote a product or service. Irrelevant advertising is advertising that is not related to the discussion domain.
More formally, let \(T = \{t_{1}, t_{2}, ..., t_{n}\}\) be a tweet database containing n tweets. Different subsets of tweets are related to different thematic domains, \(D^i\) and \(T = \{D^i \cup D^j\) \(\forall i, j\}\). Let S be a set of traditional spam tweets such that \(S \subset T\). While traditional spam is domain-independent, spam can be specific to a domain. We define context-specific spam \(C^i\) as spam that is specific to a thematic domain \(D^i\), (\(C^i \subset D^i\)). An example of \(C^i\) is irrelevant advertising.
To provide more insight, suppose that we are analyzing tweets about an election, i.e. the domain of conversation is elections (\(D^i = election\)). Table 1 shows hypothetical, example tweets. The green tweets are examples of domain-relevant tweets. Given the domain, an advertisement about diapers (row 2) is irrelevant and therefore context-specific spam (\(C^i\)). However, a tweet promoting a candidate’s campaign (row 3) is an advertisement relevant to the domain (\(\overline{C^i \cup S}\)) and therefore is not considered spam.
The goal of this paper is to provide researchers with automated approaches to remove irrelevant content from a particular domain of Twitter data. To that end, we propose and evaluate methods to identify \(S \cup C^i\) (all spam) for different domains \(D^i\) in a low resource setting, i.e. limited training data, and different levels of imbalanced training data. Both these constraints are important because of the cost associated with labeling training data and the imbalance of these training data sets with respect to spam. It is not unusual for less than 10% of the training data to be labeled as traditional spam or context-specific spam.
3 Related work
The definition of conversation pollution, especially on social media, is ambiguous at best. We divide this section into two subsections, focusing on different types of pollution detection. While methods for identifying content-based spam on Twitter are emerging, to the best of our knowledge, none of the state-of-the-art works include context-specific spam detection (Kaur et al., 2016; Wu et al., 2018).
3.1 Junk email detection
Early spam detection work focused on junk email detection (Sahami et al., 1998; Sasaki and Shinnou 2005; Wu 2009; Mantel and Jensen 2011; Cormack et al., 2007). One of the early and well-known approaches for filtering junk emails was a Bayesian model (Sahami et al., 1998) that used words, hand-crafted phrases, and the domains of senders as features. Unlike our study, these works use sender information, in addition to message content, to perform classification.
3.2 Spam detection on Twitter
Identifying poor quality content on social media is more challenging because the domain is broad and there are many different social media platforms with different types of posts. To further exacerbate the problem, the number of types of spam keeps increasing. Traditionally, most spammers were direct marketers trying to sell their products. More recently, researchers have identified spammers with a range of objectives (Ferrara et al., 2016; Jiang et al., 2016), including product marketing, sharing pornography, and influencing political views. These objectives vary across social media platforms. Since our work focuses on Twitter spam, we focus on literature related to spam detection on Twitter (Wu et al., 2018). We pause to mention that Twitter itself detects and blocks spam links by using Google SafeBrowsing (Chen et al., 2015), and more recently using both user and available content to identify those spreading disinformation (Safety 2020). This overall approach focuses on context-independent spam and is designed to be more global in nature. While an important step, for many public health and social science studies using Twitter data, not removing context specific spam may lead to skewed research results.
Most research focuses on detecting content polluters (Lee et al., 2011; Wu et al., 2017; El-Mawass and Alaboodi 2016; Park and Han 2016; Hu et al., 2014), i.e. individuals who are sharing poor quality content. Lee et al. (2011) studied content polluters using social honeypots and grouped content polluters into spammers and promoters. Wu et al. use discriminant analysis to identify the key post in order to identify content polluters (Wu et al., 2017). They define content polluters as fraudsters, scammers, and spammers who spread disinformation. (El-Mawass and Alaboodi (2016) used machine learning to predict Arabic content polluters on Twitter and showed that Random Forest had the highest F1-score. Our work differs from these works because we focus on the identification of pollution at the post level as opposed to polluters at the individual level. We are also interested in low resource settings where the amount of training data available is limited.
Studies focusing on spammer/bot detection tend to use both content-based and user-based information (Wu et al., 2018; Wang 2010; Mccord and Chuah 2011; Chen et al., 2015; Lin et al., 2017; Wei 2020; Hu et al., 2013; Brophy and Lowd 2020; Jeong and Kim 2018) and the best approaches achieve a precision of around 80% for training and testing on balanced datasets. Those approaches can be used when both content and user information are available. As mentioned in Sect. 1, there are scenarios where this is impractical. For example, hundreds of thousands or millions of users may post using a specific hashtag (#covid) or keyword (coronavirus), making it impractical for a researcher using those data streams to collect user information from the Twitter API. To further complicate the situation, spam is not only generated by bots. It is also produced by humans. People and companies can post advertisements or links to low-quality content. Therefore, focusing on a strategy centered on bot detection will miss some types of spam.
There are also studies on spam (as opposed to spammer) detection on Twitter (see (Kaur et al., 2016; Wu et al., 2018) for more detailed surveys). Wang proposes using a Naive Bayes model that detects spam with graph-based features (Wang 2010). The study shows that most spam tweets contain ‘@’ or mentions and links. Since that early work, multiple studies have shown that Random Forest is effective for building models for detecting spam (Mccord and Chuah 2011; Santos et al., 2014; Chen et al., 2015; Lin et al., 2017). Chen et al., compare six algorithms that use both content-based and user-based features (Chen et al., 2015). They found that Random Forest was their best classifier, even when the training data was imbalanced. Detecting spam based solely on content is more challenging because of the lack of user information (Wang 2010). Santos et al. use traditional classifiers with Bag-of-Words (BoW) feature to detect spam using only content-based information (Santos et al., 2014). They also found that the Random Forest model outperformed other classic models. Our work differs from all this previous work since we want to detect both traditional and context-specific spam. We are also comparing classic machine learning and neural network models, conducting our analysis on three different domains on Twitter, and considering the impact of limited, imbalanced training data.
4 Experiment design for spam learning task
Our goal is to build a generalizable model for detecting spam on Twitter. In doing so, we investigate the following questions: (1) What are the best classic machine learning models for identifying spam on Twitter? (2) Can neural networks that incorporate a language model perform better than classic machine learning models? (3) How much does training set imbalance affect performance? (4) Are models built using one domain of Twitter training data transferable to another Twitter domain without customization? The last question is particularly important in cases when there are a small number of labels pertaining to the spam category.
Toward that end, this section describes the experimental design for understanding how different classic machine learning (Sect. 4.1) and neural network (Sect. 4.2) models perform and how transferable the models are (Sect. 4.3).
4.1 Classic machine learning models
We first evaluate classic machine learning models for this task given past good performance on variants of this task (Kaur et al., 2016; Wu et al., 2018; Santos et al., 2014; Hu et al., 2013, 2014). We build traditional models for each domain of interest. Figure 3 shows the details of our experimental design for generating ground truth labeled data (discussed in detail in Sect. 5), preprocessing, feature extraction, modeling and evaluation. The labeled ground truth data are inputs into the process. The data are preprocessed using simple, well-established cleaning methods.
4.1.1 Feature extraction
We consider four different types of features that are widely used in spam detection research (Wu et al., 2018) including entity counts, bag-of-words (BoW), word embeddings, and TF-IDF score. Features are mixed and matched for different models (Fig. 3).

Classic machine learning models methodology overview
4.1.2 Entity count statistics
Previous spammer detection research has incorporated different entity counts statistics (Chen et al., 2015; Brophy and Lowd 2020) such as the number of retweets, the number of friends, etc. However, since our focus is content-based analysis, we build features using only the tweet content. Entity count statistics features we consider include text length, URL count, mention count, digit count, hashtag count, whether it is a retweet, and word count after URLs are removed.
4.1.3 Bag-of-Words (BoW)
Santos et al. (2014) show that Random Forest with BoW performed the best in content-based spam detection so we also use word frequency counts as features.
4.1.4 Word embeddings
There are several embedding techniques for word representation. We use GloVe (Pennington and Socher 2014)—the most widely-used pre-trained word2vec for Twitter—to represent each word and then concatenate them as a feature vector for each sentence in a tweet.
4.1.5 TF-IDF
A classic information retrieval technique for identifying important words is computing the term frequency-inverse document frequency (TF-IDF) scores. We consider a variant of the BoW model where we use the TF-IDF weight instead of the word frequency to represent the words in each tweet.
4.1.6 Machine learning algorithms
We build various classic machine learning models, including Naive Bayes (NB), k-Nearest Neighbors (kNN), Logistic Regression (LR), Support Vector Machine (SVM), Decision Tree (DT) and Random Forest (RF). Given the high dimensionality and sparse feature space, we also evaluate using Elastic Net (EN) since it has been shown to work well for spammer detection by making the sparse learning more stable (Hu et al., 2013, 2014). All the models are trained using different combinations of features described above. We build and test each model for each domain.
4.2 Exploiting neural language models
Given the success of many neural models for text classification tasks using Twitter, we propose using a classic neural model that incorporates domain specific knowledge through the use of a language model. We hypothesize that using a language model specific to a particular domain will improve the accuracy of our spam detection models in that domain, providing necessary context. Toward that end, we incorporate a well-known neural language model, BERT (Devlin et al., 2018) and fine-tune it for this task. BERT has been used successfully for other learning tasks, including sentiment analysis (Munikar et al., 2019), natural language inference (Hossain et al., 2020) and document summarization (Cachola et al., 2020).
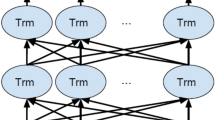
Our neural model begins by fine-tuning BERT to build a domain specific language model (LM) using unlabeled tweets from the domain. For example, if we are interested in gun violence, we would use a large number of tweets that discuss gun violence to fine-tune BERT. BERT uses a bidirectional transformer (Vaswani et al., 2017) and its representations are jointly conditioned on both the left and right context in all layers. The output from the language model is input into a single layer neural network for the classification task. The architecture of our neural model is shown in Fig. 4. We used the BERT tokenizer to tokenize a sentence into a list of tokens as input for BERT. After the multi-layer of transformers, we used a dropout rate of 0.1 in order to avoid over-fitting. We then fed the output vectors into a single-layer of neural network with softmax.

The structure of our neural network model
The classifier is a single layer neural network as shown in Eq. 1, where y represents the output vector from the classifier, W is a weight vector randomly initialized, x represents a contextual representation vector from BERT after the dropout layer (see Fig. 4), and b is a bias vector.
The weights of the classifier are updated using the cross-entropy loss function shown in Eq. 2. The class label C is obtained using the softmax function (see Eq. 3) to normalize the values of the output vector y from the classifier in order to obtain a probability score for each class. All BERT-based models are trained using the Adam optimizer (Kingma and Ba
4.3 Model transferability
One of our goals is to understand the strengths and limitations of our models for different domains on Twitter. For example, soccer is a different domain from politics. Toward that end, we design an experiment to measure how transferable each model built in one domain is to other domains. Figure 5 shows our experimental framework. First, we train and test models within the same domain independently. We also train models in one domain and then test them across other domains to determine cross-domain generalizability and transferability of spam detection models on Twitter. In the case of the neural network model, we use a language model built across all the domains to determine its effectiveness in settings where limited ground truth data exists and the labeled ground truth data are imbalanced. We surmise that cross-domain learning will be beneficial for identifying traditional spam, but not be as accurate for context-specific spam.

The high-level process to test model transferability
5 Labeling spam in multiple twitter domains
The need for ground truth data is two-fold. First, we need to determine whether or not context-specific spam is present and identifiable in tweets. Second, if it is present and identifiable, we need ground truth data to help build a reliable, predictive model. Since we are interested in comparing models on different domains of Twitter data, we also collected ground truth data on more than one domain. This section begins by describing the different data sets we use for our empirical evaluation (Sect. 5.1). We then explain how we generated the ground truth data (Sect. 5.2) and the characteristics of the spam in the ground truth data for each domain (Sect. 5.3).
5.1 Data description
We use three different domains of Twitter data for our empirical evaluation: meToo (a social movement focused on tackling issues related to sexual harassment and sexual assault of women), gun-violence, and parenting. The meToo data set was constructed by collecting tweets that include #meToo through the Twitter API. This data set contains over 12 million tweets from October 2018 to October 2019, the first year of the larger online movement. The gun-violence data set was collected using keywords and hashtags related to gun-violence through the Twitter API. Keywords used include guns, suicide, gun deaths, etc. We used data from 2017, approximately 22 million tweets. The parenting data set was constructed by collecting the tweets of 75 authorities who primarily post and discuss parenting topics and collecting tweets using parenting-related keywords and hashtags. Example authorities include parenting magazines and medical sites. For this data set, we collected over 200 million tweets in 2019. As is evident from the descriptions, these data sets cover a wide range of topics.
5.2 Ground truth data collection
We collected ground truth data by setting up multiple Amazon Mechanical Turk (MTurk) tasks, one for each domain of interest. MTurk is an established approach for labeling tasks (Buhrmester et al., 2011). We ask three raters to answer three questions per tweet:
-
Question 1: Is the tweet about domain \(D^i\)?
-
Question 2: Is the statement an advertisement?
-
Question 3: Is the statement spam?
For each question, we have definitions and examples to help raters answer the questions accurately. To make sure we separate advertising from traditional spam, in the definition of spam included for the workers, we explicitly state that advertising is not spam. We say that spam asks people for their personal information, contains harmful or inappropriate content/links including malware, phishing, or pornography, or is not understandable, e.g. not a complete sentence, not human language, etc. For this study, context-specific spam is limited to irrelevant advertising. Therefore, if Question 1 is false and Question 2 is true, we consider that context-specific spam. If Question 3 is true, we consider that traditional spam. Setting up the questions in this way allows us to see the prevalence of traditional and context-specific spam in the ground truth data sets.
From each of the data sets, we randomly sample 5000 English tweets, ensuring that there are no duplicates and that each tweet contains textual content after removing URLs. We also ensure that each tweet belongs to only one domain (either parenting, metoo or gun-violence). We recognize that tweets may belong to multiple domains. Here, we focus on single domain tweets and leave multi-domain posts for future work. Each tweet is labeled by three workers. We compute Krippendorff’s alpha scores (Krippendorff 2011) and conduct agreement analysis [1] to determine the quality of the labeling for the three different-domain tasks. We compute both task-based and worker-based agreement scores and average them among tasks and workers. The task-based score looks at every tweet and every rater who labeled it. The majority vote is determined and divided by the number of answers (this is the same as the number of raters in our study). The worker-based score is the total number of tasks a worker has a majority vote divided by the total number of tasks the worker completed. We exclude workers who complete only one task.
5.3 Data labeling results
Table 2 shows the scores for Krippendorff alpha, task agreement and worker agreement for each data set. By traditional standards, the alpha agreement is low (below 0.67) for five of the label categories. This results because Krippendorff’s alpha relies on vote proportions and some of the label categories are heavily imbalanced. For example, in the parenting data set, there are only 12 tweets that are labeled as traditional spam and 4988 are labeled as not traditional spam. In this domain, advertising is much more prevalent, i.e. context-specific spam. These types of large imbalances reduce the overall average. Analyzing the task-based scores, we find that they are higher than 0.85 for all the questions across all three data sets. The worker-based scores vary more from 0.79 to 0.99, but in general, have a high agreement. In the few places where there is higher disagreement, the text content is more ambiguous, and workers chose the “uncertain” option sometimes. Overall, the strong agreement across both the tasks and workers give us confidence using these data to build our models.
One interesting, but unexpected finding, is the difference in the fraction of spam across domains (see Fig. 6). The parenting-domain data set is the most balanced distribution between content-rich domain tweets and spam-related pollution tweets consisting of 2,485 spam tweets (12 traditional and 2,473 context-specific spam) and 2,515 domain tweets. While at first, this may seem surprising, because some of the authorities are also traditional magazines, e.g. Parents or Baby.com, they post about products – some of which are relevant to the parenting domain, e.g. diapers, and some of which are not, e.g. iPhones. For the meToo data set, the distribution is highly imbalanced between content-rich domain tweets and spam tweets, with only 281 spam tweets (118 traditional and 163 context-specific spam) and 4,719 domain tweets. The gun-violence data set is reasonably balanced between spam and non-spam content, consisting of 2,704 spam tweets (2,559 traditional and 145 context-specific spam) and 2,296 domain tweets. The high level of traditional spam results from the high level of abusive, vulgar/inappropriate language in this data stream.
Across these data sets, we have varying distributions of spam and a varying proportion of traditional spam and context-specific spam. The parenting domain has substantially more context-specific spam when compared to the other two domains. In contrast, gun-violence has significantly more traditional spam than context-specific spam. Finally, the meToo data set has a more even distribution of context-specific and traditional spam but has a much smaller percentage of spam overall. These stark differences highlight the importance of capturing these different forms of spam. Ignoring one of them may lead to a substantial loss of information about low-quality content.

The distribution of conversation pollution in our manually annotated data
6 Empirical evaluation
Our empirical evaluation is organized as follows. We begin by explaining the implementation details of experiments (Sect. 6.1). Next, we present an in-domain analysis (Sect. 6.2) where models trained on data from a given domain are used to predict spam in the same domain. We also consider different levels of imbalance in the training data to determine the smallest portion of the context-specific needed in order to train a reliable classifier. Next, we perform a cross-domain analysis (Sect. 6.3), where models trained on one domain are used to predict spam in other domains. These experiments are predicting spam (traditional and context-specific) vs. no spam. We then detect traditional and context-specific spam separately using the neural network model and show that we can effectively detect both types of spam (Sect. 6.4).
6.1 Implementation details
We now present our implementation details. All experiments were conducted using Python 3. To accelerate the preprocessing and feature extraction process, we used Apache Spark v2.4.0 (Spark 2018), taking advantage of multiple-core processing instead of using one single-core machine. The dimensions of features vary depending upon which features were extracted (Sect. 4.1) and the training data set (Sect. 5). The sample dimension numbersFootnote 1 include 7 for Entity Count Statistics, 7724 for Bag-of-Words, 1075 to 8600Footnote 2 for Word Embeddings and 5221 for TF-IDF. Processed features are then merged onto one single machine generating the final models. We use a single machine for the final model generation because some of the machine learning algorithms are not designed for a distributed environment and it is also easier for reproducibility to use a well-known package. Specifically, we use scikit-learn v0.22.1 (Pedregosa et al., 2011) for the modeling. For the neural language models (Sect. 4.2), we implemented both the language models and neural classifiers using PyTorch v1.4.0 (Paszke et al., 2019). All the language models and classifiers were trained using a Tesla T4 GPU.
For our different learning models, we conducted a sensitivity analysis using a grid-search on influential parameters. The best parameters varied by classifier, data set, and feature sets. They include \(k=\{5,7\}\) for kNN, \(C=\{1,10\}\) for LR and SVM, \(criterion=\{entropy,gini\}\) for DT, \(n\_estimators=\{50,100,200\}\) for RF, \(alpha=0.2\) and \(l1\_ratio=0.5\) for EN and \(hidden\_layer\_sizes=\{100,200\}\) for NN. The results presented in this paper use the optimized parameters for each model.
6.2 Within domain analysis
In this experiment, we compare classic machine learning models and a neural network model for predicting spam within a single domain, i.e. the training set and the test set are sampled from the same conversation domain. The gun-violence and parenting data sets are split into a 90/10 train/test split. Because the meToo data set only contains 281 spam tweets, we use 90% of the spam tweets in the training set (253 tweets) and have a small, balanced test set containing 28 spam and 28 domain tweets. Experiments were conducted and validated using 10-fold cross-validation on training sets and then evaluated on hold-out test sets. All baseline classifiers were constructed using different combinations of features as described in Sect. 4. The language model is pre-trained on 500,000 unlabeled domain-specific tweets.
Table 3 shows experimental results for both the training and testing data sets for detection of all spam - traditional and context-specific. Only the best classifier in each feature group is presented for ease of exposition. We also show the results of the vanilla neural network, i.e. a neural network without the pre-trained language model, to demonstrate the influence of the language model. We use the Counting+TF-IDF feature combination for the vanilla neural network since it tends to perform the best among four feature sets based on F1 (10-fold). The F1 scores are presented for both the training and test experiments. Accuracy, precision and recall are only shown for the test experiments. The best scores for each domain are highlighted in the table.
Focusing on the F1 scores from the 10-fold cross-validated training sets, the table shows that the neural network models with the pre-trained language models outperform all the baselines by a small amount, 1 to 2% for every domain. Similarly, focusing on the test F1 score, they outperform all the baselines by 2%, 5%, and 1% for the parenting, meToo, and gun-violence data sets, respectively. Random forest is the best classic machine learning model across domains. In general, for classic models, using the entity counting and TF-IDF weighted word features performs better than other feature combinations. In all cases, entity counting statistics plus word features perform better than entity counting features alone. These findings are consistent with previous research (Santos et al., 2014; Wu et al., The number of feature dimension is higher without preprocessing. GloVe embeddings include different dimension numbers from 25 dimensions to 200 dimensions. We conducted a sensitivity analysis and present the results using the best parameters. Amazon: Hit review policies. https://docs.aws.amazon.com/AWSMechTurk/latest/AWSMturkAPI/ApiReference_HITReviewPolicies.html (2011) Brophy, J., Lowd, D. (2020). Eggs: A flexible approach to relational modeling of social network spam. ar**v:2001.04909 Buhrmester, M., Kwang, T., & Gosling, S. D. (2011). Amazon’s mechanical turk: A new source of inexpensive, yet high-quality, data? Perspectives on Psychological Science, 6(1), 3–5. Cachola, I., Lo, K., Cohan, A., Weld, D.S. (2020). TLDR: Extreme summarization of scientific documents. In: Findings of the Association for Computational Linguistics: EMNLP. Chen, C., Zhang, J., Chen, X., **ang, Y., Zhou, W. (2015). 6 million spam tweets: A large ground truth for timely twitter spam detection. In: Proceedings of the IEEE international Conference on Communications (ICC). Cormack, G. V., Gómez Hidalgo, J. M., Sánz, E. P. (2007). Spam filtering for short messages. In: Proceedings of the ACM Conference on Conference on Information and Knowledge Management (CIKM). Cresci, S., Di Pietro, R., Petrocchi, M., Spognardi, A., & Tesconi, M. (2018). Social fingerprinting: Detection of spambot groups through dna-inspired behavioral modeling. IEEE Transactions on Dependable and Secure Computing, 15(4), 561–576. Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. preprint ar**v:1810.04805. Dou, Y., Ma, G., Yu, P. S., & **e, S. (2020). Robust spammer detection by nash reinforcement learning. In: Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD). El-Mawass, N., Alaboodi, S. (2016). Detecting arabic spammers and content polluters on twitter. In: Proceedings of the International Conference on Digital Information Processing and Communications (ICDIPC). Ferrara, E., Varol, O., Davis, C., Menczer, F., & Flammini, A. (2016). The rise of social bots. Communications of the ACM, 59(7), 96–104. Hossain, T., Logan IV, R. L., Ugarte, A., Matsubara, Y., Young, S., & Singh, S. (2020). Covidlies: Detecting covid-19 misinformation on social media. In: Proceedings of the Workshop on NLP for COVID-19 (Part 2) at EMNLP. Hu, X., Tang, J., & Liu, H. (2014). Online social spammer detection. In: Proceedings of the AAAI Conference on Artificial Intelligence (AAAI). Hu, X., Tang, J., Zhang, Y., & Liu, H. (2013). Social spammer detection in microblogging. In: Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI). Jeong, S., Kim, C. K. (2018). Online spammer detection using user-neighbor relationship. In: Proceedings of the IEEE International Conference on Big Data (Big Data). Jiang, M., Cui, P., & Faloutsos, C. (2016). Suspicious behavior detection: Current trends and future directions. IEEE Intelligent Systems, 31(1), 31–39. Kaur, P., Singhal, A., Kaur, J. (2016). Spam detection on twitter: A survey. In: Proceedings of the IEEE International Conference on Computing for Sustainable Global Development (INDIACom). Kingma, D. P., Ba, J. (2014). Adam: A method for stochastic optimization. ar**v preprint ar**v:1412.6980 Kolari, P., Java, A., Joshi, A., et al. (2007). Spam in blogs and social media, tutorial. In: Proceedings of the International AAAI Conference on Web and Social Media (ICWSM). Krippendorff, K. (2011). Computing krippendorff’s alpha-reliability. http://repository.upenn.edu/asc_papers/43. [Online; Retrieved 2/24/2021] Kumar, S., Shah, N. (2018). False information on web and social media: A survey. preprint ar**v:1804.08559 Lee, K., Eoff, B. D., Caverlee, J. (2011). Seven months with the devils: A long-term study of content polluters on twitter. In: Proceedings of the International AAAI Conference on Web and Social Media (ICWSM). Lin, G., Sun, N., Nepal, S., Zhang, J., **ang, Y., & Hassan, H. (2017). Statistical twitter spam detection demystified: Performance, stability and scalability. IEEE Access, 5, 11142–11154. Mantel, E., Jensen, S. (2011). Spam email detection based on n-grams with feature selection. US Patent 7,912,907. Mccord, M., Chuah, M. (2011). Spam detection on twitter using traditional classifiers. In: Proceedings of the International Conference on Autonomic and Trusted Computing. Munikar, M., Shakya, S., Shrestha, A. (2019). Fine-grained sentiment classification using bert. In: 2019 Artificial Intelligence for Transforming Business and Society (AITB), vol. 1, pp. 1–5. IEEE. Park, B. J., & Han, J. S. (2016). Efficient decision support for detecting content polluters on social networks: An approach based on automatic knowledge acquisition from behavioral patterns. Information Technology and Management, 17(1), 95–105. Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., et al. (2019). Pytorch: An imperative style, high-performance deep learning library. Advances in Neural Information Processing Systems (NeurIPS), 32, 8026–8037. Pedia, W.: Social Spam. (2020) https://en.wikipedia.org/wiki/Social_spam. [Online; Retrieved 2/11/20] Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., et al. (2011). Scikit-learn Machine learning in python. The Journal of Machine Learning Research (JMLR), 12, 2825–2830. Pennington, J., Socher, R., Manning, C.D. (2014). Glove: Global vectors for word representation. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP). Safety, T. Disclosing networks of state-linked information operations we’ve removed. https://blog.twitter.com/en_us/topics/company/2020/information-operations-june-2020.html (2020). [Online; Retrieved 8/7/2020]. Sahami, M., Dumais, S., Heckerman, D., Horvitz, E. (1998). A bayesian approach to filtering junk e-mail. In: Learning for Text Categorization: Papers from the 1998 workshop, vol. 62. Santos, I., Miñambres-Marcos, I., Laorden, C., Galán-García, P., Santamaría-Ibirika, A., Bringas, P. G. (2014). Twitter content-based spam filtering. In: International Joint Conference SOCO’13-CISIS’13-ICEUTE’13. Springer. Sasaki, M., Shinnou, H. (2005). Spam detection using text clustering. In: Proceedings of the IEEE International Conference on Cyberworlds. Spark, A. (2018). Apache spark. Retrieved January 17, 2018. Twitter: The Twitter Rules. https://help.twitter.com/en/rules-and-policies/twitter-rules/ (2020). [Online; Retrieved 2/11/2020]. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., Polosukhin, I. (2017). Attention is all you need. In: Advances in Neural Information Processing Systems (NeurIPS), pp. 5998–6008. Wang, A. H. (2010). Don’t follow me: Spam detection in twitter. In: Proceedings of the IEEE International Conference on Security and Cryptography (SECRYPT). Wei, F., Nguyen, U. T. (2020). Twitter bot detection using bidirectional long short-term memory neural networks and word embeddings. preprint ar**v:2002.01336. Wu, C. H. (2009). Behavior-based spam detection using a hybrid method of rule-based techniques and neural networks. Expert Systems with Applications, 36(3), 4321–4330. Wu, L., Hu, X., Morstatter, F., & Liu, H. (2017). Detecting camouflaged content polluters. In: Proceedings of the International AAAI Conference on Web and Social Media (ICWSM). Wu, L., Morstatter, F., Carley, K. M., & Liu, H. (2019). Misinformation in social media: Definition, manipulation, and detection. ACM SIGKDD Explorations Newsletter, 21(2), 80–90. Wu, T., Wen, S., **ang, Y., & Zhou, W. (2018). Twitter spam detection: Survey of new approaches and comparative study. Computers & Security, 76, 265–284. This research was funded by National Science Foundation awards \#1934925 and \#1934494, and the Massive Data Institute (MDI) at Georgetown University. We would like to thank our funders, the MDI staff, and the members of the Georgetown DataLab for their support. We would also like to thank the anonymous reviewers for the detailed and thoughtful reviews. Editors: João Gama, Alípio Jorge, Salvador García. Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations. Kawintiranon, K., Singh, L. & Budak, C. Traditional and context-specific spam detection in low resource settings.
Mach Learn 111, 2515–2536 (2022). https://doi.org/10.1007/s10994-022-06176-x Received: Revised: Accepted: Published: Issue Date: DOI: https://doi.org/10.1007/s10994-022-06176-xNotes
References
Acknowledgements
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Rights and permissions
About this article
Cite this article
Keywords
