
Abstract
This paper considers model uncertainty for multistage stochastic programs. The data and information structure of the baseline model is a tree, on which the decision problem is defined. We consider “ambiguity neighborhoods” around this tree as alternative models which are close to the baseline model. Closeness is defined in terms of a distance for probability trees, called the nested distance. This distance is appropriate for scenario models of multistage stochastic optimization problems as was demonstrated in Pflug and Pichler (SIAM J Optim 22:1–23, 2012). The ambiguity model is formulated as a minimax problem, where the the optimal decision is to be found, which minimizes the maximal objective function within the ambiguity set. We give a setup for studying saddle point properties of the minimax problem. Moreover, we present solution algorithms for finding the minimax decisions at least asymptotically. As an example, we consider a multiperiod stochastic production/inventory control problem with weekly ordering. The stochastic scenario process is given by the random demands for two products. We determine the minimax solution and identify the worst trees within the ambiguity set. It turns out that the probability weights of the worst case trees are concentrated on few very bad scenarios.








Similar content being viewed by others


Notes
Notation \(\text{ pred }_{s}(i)\) denoting the predecessor of \(i\) in \(\mathcal {N}_{s}\), with \(s<t\) might also be used. If \(s=t-1\) the notation is written as \(\text{ pred }_{t-1}(i)\) or \(i-\).
This quotient necessitates inclusion of constraint \(\sum _{i^{'},j^{'}}\pi (i^{'},j^{'})=1\), otherwise every multiplication of any feasible transportation plan \(\pi \), would be feasible.
Notice that even under strict convex-concavity and compactness of \(\mathcal {X}\) and \(\mathcal {Y}\) the convergence of \({\left\{ \begin{array}{ll} \begin{array}{l} x^{k+1}=\underset{}{\arg \min {}_{\mathrm {x}\in \mathcal {X}}f(x,y^{k})}\\ y^{k+1}=\arg \max _{y\in \mathbb {\mathcal {Y}}}f(x^{k+1},y) \end{array}\end{array}\right. }\) is not guaranteed.
The numerical example is taken from AIMMS optimization modeling [(Bisschop 2012), Chapter 17.]. However, all computational procedure, solution algorithms and results analysis are implemented in MATLAB R2012a.
References
Arrow KJ, Hurwicz L, Uzawa H (1958) Studies in linear and non-linear programming. Stanford University Press, CA
Birge JR, Louveaux F (1997) Introduction to stochastic programming. Springer, Berlin
Bisschop J (2012) AIMMS optimization modelling. Paragon Decision Technology, USA
Calafiore G (2007) Ambiguous risk measures and optimal robust portfolios. SIAM J Control Optim 18(3):853–877
Chen Z, Epstein L (2002) Ambiguity, risk and asset returns in continuous time. Econometrics 70(4):1403–1443
Danilin YM, Panin VM (1974) Methods for searching saddle points. Kibernetika 3:119–124
Delage E, Ye Y (2010) Distributionally robust optimization under moment uncertainty with application to data-driven problem. Oper Res 58:596–612
Demynov VF, Pevnyi AB (1972) Numerical methods for finding saddle points. USSR Comput Math Math Phys 12:1099–1127
Dupačová J (1980) On minimax decision rule in stochastic linear programing. Stud Math Program pp 47–60
Dupačová J (2001) Stochastic programming: Minimax approach. In: Floudas Ch. A, Pardalos PM (eds) Encyclopedia of Optimization, vol V, pp 327–330
Dupačová J (1987) The minimax approach to stochastic programming and an illustrative application. Stochastics 20:73–88
Dupačová J (2010) Uncertainties in minimax stochastic programs. Optimization 1:191–220
Fan K (1953) Minimax theorems. Proc Nat Acad Sci 39:42–47
Goh J, Sim M (2010) Distributionally robust optimization and its tractable approximations. Oper Res 58:902–917
Heitsch H, Römisch W, Strugarek C (2006) Stability of multistage stochastic programs. SIAM J Optim 17:511–525
Jagannathan R (1977) Minimax procedure for a class of linear programs under uncertainty. Oper Res 25:173–177
Pflug GCh, Römisch W (2007) Modelling, measuring and managing risk, 1st edn. World Scientific, Singapore
Pflug GCh, Wozabal D (2007) Ambiguity in portfolio selection. Quant Financ 7(4):435–442
Pflug GCh (2010) Version-independence and nested distributions in multistage stochastic optimization. SIAM J Optim 20(3):1406–1420
Pflug GCh, Pichler A (2012) A distance for multistage stochastic optimization models. SIAM J Optim 22(1):1–23
Qi L, Sun W (1995) An iterative method for the minimax problem. Minimax and Applications (Kluwer), art. Du and Pardalos
Rachev S, Römisch W (2002) Quantitative stability in stochastic programming: the method of probability metrics. Math Oper Res 27:798–818
Robinson W, Wets R (1987) Stability in two stage stochastic programming. SIAM J Control Optim 25:1409–1416
Römisch W, Schultz R (1991) Stability analysis for stochastic programs. Ann Oper Res 30:241–266
Rustem B, Howe M (2002) Algorithms for worst-case design and applications to risk management. princeton University Press, Princeton
Ruszczynski A, Shapiro A (2003) Stochastic Programming, 1st edn. ser. Handbooks in Operations Research and Management science, Amsterdam
Sasai H (1974) An interior penalty method for minimax for problems with constraints. SIAM J Control Optim 12:643–649
Scarf H (1958) Studies in the mathematical theory of an inventory problems. Stanford Univeristy Press, CA
Shapiro A, Kleywegt A (2002) Minimax analysis of stochastic problems. Optim Methods Softw 17:523–542
Shapiro A, Ahmed Sh (2004) On a class of minimax stochastic programs. SIAM J Optim 14:1237–1249
Sion M (1958) On general minimax theorems. Pac J Math 8:171–176
Thiele A (2008) Robust stochastic programming with uncertain probabilities. IMA J Manag Math 19:289–321
von Neumann J (1928) Zur Theorie der Gesellschaftsspiele. Math Ann 100:295–320
Wozabal D (2010) A framework for optimization under ambiguity. Ann Oper Res (online First)
Žácková a.k.a. Dupačová J (1966) On minimax solutions of stochastic linear programming problems. Casopis pro Pestovani Mathematiky 91:423–430
Author information
Authors and Affiliations
Corresponding author
Additional information
B. Analui was partially sponsored by WWTF project: Energy Policies and Risk Management for the 21st Century.
Appendix
Appendix
1.1 The proof of Theorem 1.
We fix a finite tree \(\mathbb {T}\) with a given structure and with the values of the scenario process sitting on its nodes. By determining the scenario probabilities \(P=(P_{i})_{i\in \mathcal {N}_{T}}\) the corresponding nested distribution \(\mathbb {P}(\mathbb {T},P)\) is formed. The alternative models are \(\mathbb {P}(\mathbb {T},\tilde{P})\) with a variant \(\tilde{P}\) of the scenario probabilities. The notion of compound can be generalized to infinitely many elements: Let \(\mathfrak {P}\) be the family of all probability measures on \(\mathcal {N}_{T}\), which is—since \(\mathcal {N}_{T}\) is a finite set—a simplex. Let \(\Lambda \) be a probability measure from \(\mathfrak {P}\). The compound \(\mathcal {C}(\mathbb {P}(\mathbb {T},\tilde{P}),\Lambda )\) is defined as
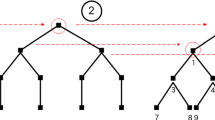
meaning that the compound is obtained by first sampling a distribution \(\tilde{P}\) according to \(\Lambda \) and then taking the model \(\mathbb {P}(\mathbb {T},\tilde{P})\). Refer to Fig. 9. in which \(\mathcal {C}(\mathbb {P}(\mathbb {T},\cdot ),\Lambda )\) is illustrated for probability measure \(\Lambda \) with finite support . If \(\Lambda \) sits on \(\tilde{P}^{(1)},\tilde{P}^{(2)},..,\tilde{P}^{(k)}\) with probabilities \(\lambda _{l}\) for \(1\le l\le k\), then compound model has \(k\) nodes at stage 1 and to the \(l\)th node of stage 1 the subtree \(\mathbb {P}(\mathbb {T},\tilde{P}^{(l)})\) is associated, i.e.
where the convex combination \(\sum _{l=1}^{k}\,\lambda _{l}\mathbb {P}(\mathbb {T},P^{(l)})\) is in the sense of compounding. Notice that the tree of \(\mathcal {C}(\mathbb {P}(\mathbb {T},\tilde{P}_{\lambda }),\Lambda )\) is of height \(T+1\). Thus original tree \(\mathbb {\mathbb {P}}(\mathbb {T},P)\) to be comparable with \(\mathcal {C}(\mathbb {P}(\mathbb {T},\tilde{P}_{\lambda }),\Lambda )\) , we assume that a further root (with probability one) is appended to the tree of \(\mathbb {\mathbb {P}}(\mathbb {T},P)\) and denote this extended tree by \(\mathbb {\mathbb {P}}_{+}(\mathbb {T},P)\). In the following, we write \(\mathbb {P}(\mathbb {T},\Lambda )\) for \(\mathcal {C}(\mathbb {P}(\mathbb {T},\cdot ),\Lambda )\).

The compound convex structure of trees \(\mathbb {P}(\mathbb {\mathbb {T}}, \tilde{P}^{(l)}\)) and augmented tree \(\mathbb {P}_{+}(\mathbb {\mathbb {T}},P\))
The convex hull of the set
with
is the set
The convexified problem (3.2) is rewritten to
Notice that in the formulation (7.2) the decision variables \(x\) must coincide in all randomly sampled subproblems, cf. Fig. 9. By safeguarding ourselves against any random selection of elements of \(\mathcal {B}_{\epsilon }\), we automatically safeguard ourselves against the worst case in \(\mathcal {B}_{\epsilon }\). The next step is to calculate the nested distance between two elements of \(\bar{\mathcal {P}}_{\epsilon }\). For two leaves \(i\) resp. \(j\) of the tree \(\mathbb {T}\) the distance is defined as the distance of the corresponding paths leading to \(i\) resp. \(j\), i.e.,
Assume that for all \(i\ne j\), there exist constants \(c\),\(\ C>0\) such that \(c\le \mathsf {d}(i,j)\le C.\) Let
It follows that
In order to show (7.3) notice that an optimal transportation plan can transport a mass of \(\min (P_{i},\tilde{P}_{i})\) from \(i\) to \(i\) with distance 0. Thus only the masses \(1-\sum _{i\in \mathcal {N}_{T}}\min (P_{i},\tilde{P}_{i})\) have to be transported, over distances which lie between \(c\) and \(C,\) whence the assertion follows. Notice well that the use of the distance \(\Vert P-\tilde{P}\Vert \) is only to demonstrate compactness. While the topologies generated by the two metrics \(\Vert P-\tilde{P}\Vert \) and \(\mathrm {dl}(\mathbb {P}(\mathbb {T},P),\mathbb {P}(\mathbb {T},\tilde{P}))\) are the same [due to relation (7.3)], balls are quite different in the two metrics and only the latter metric is appropriate for nested distributions. Next we see that \(\bar{\mathcal {P}}_{\epsilon }\) is compact, since it is the continuous image of the set of all probability measures on \(\mathcal {B}_{\epsilon }\), which is a compact set, since \(\mathcal {B}_{\epsilon }\) itself is compact. Thus all conditions for the validity of the basic von Neumann Minimax Theorem are fulfilled and a saddle point \((x^{*},\mathbb {P}(\mathbb {T},\Lambda ^{*}))\) must exist. Now we prove the equation
In order to see this, assume first that \(\Lambda \) is finite, say \(\mathbb {P}(\mathbb {\mathbb {T}},\Lambda )=\sum _{l=1}^{k}\,\lambda _{l}\mathbb {\mathbb {P}}(\mathbb {T},\tilde{P}^{(l)})\). Then:
If \(\Lambda \) is not finite, it can be approximated by finite measures and therefore the relation (7.4) holds in general. Finally, we show that the worse case model \(\mathbb {\tilde{\mathbb {P}}}^{*}\) happens at a single tree and not a mixture of trees: Let \(x^{*}\) be the minimax decision, i.e.
Let the saddle point model be \(\tilde{\mathbb {P}}^{*}=\mathbb {P}(\mathbb {T},\Lambda ^{*})\). The support of \(\Lambda ^{*}\) is closed (hence compact) and the continuous function \(\tilde{P}\mapsto \mathbb {E}_{\mathbb {P}(\mathbb {T},\tilde{P})}[H(x^{*},\xi )]\) takes its maximum at some distribution \(\tilde{P}^{*}\). Since \(\mathrm {dl}(\mathbb {P}(\mathbb {T},\tilde{P}^{*}),\mathbb {P}(\mathbb {T},P))\le \epsilon \) by construction, \(\mathbb {P}(\mathbb {T},\tilde{P}^{*})\in \mathcal {P}_{\epsilon }\) and therefore \(\mathbb {E}_{\mathbb {P}(\mathbb {T},\tilde{P}^{*})}[H(x^{*},\xi )]\le \mathbb {E}_{\tilde{\mathbb {P}}^{*}}[H(x^{*},\xi )]\). On the other hand,
Consequently, \(\mathbb {E}_{\mathbb {P}(\mathbb {T},\tilde{P}^{*})}[H(x^{*},\xi )]=\mathbb {E}_{\tilde{\mathbb {P}}^{*}}[H(x^{*},\xi )]\), which shows that the saddle point model can be chosen from \(\mathcal {P}_{\epsilon }\). This concludes the proof.
1.2 The proof of Proposition 1.
Here we prove the convergence of iterative procedure
Denote by \(F^{k}=\max _{1\le l\le k}F(x^{k+1},\mathbb {\, P}^{l})\), then \(F^{k+1}=\max _{1\le l\le k+1}F(x^{k+2},\mathbb {\,\tilde{P}}^{l})\) and by monotonicity \(F^{k+1}\ge F^{k}\). Since the function \(F\) is bounded, \(F^{k}\) converges to \(F^{*}{:=}\sup F^{k}.\) Moreover, by compactness, the sequence \(x^{k}\) has one or several cluster points. Let \(x^{*}\) such a cluster point. We show that \(F^{*}=\max _{\tilde{\mathbb {P}}\in \mathcal {P}_{\epsilon }}F(x^{*},\tilde{\,\mathbb {P}})\). Since always \(F^{*}\le \max _{\tilde{\mathbb {P}}\in \mathcal {P}_{\epsilon }}F(x^{*},\tilde{\mathbb {\, P}})\), suppose that \(F^{*}<\max _{\tilde{\mathbb {P}}\in \mathcal {P}_{\epsilon }}F(x^{*},\,\tilde{\mathbb {P}})\). Then there must exist a \(\tilde{\mathbb {P}}^{+}\) such that \(F(x^{*},\tilde{\,\mathbb {P}}^{+})>F^{*}.\) By continuity this inequality must then hold in a neighborhood of \(x^{*}\) and therefor there must exist a \(x^{k}\) for which the same inequality holds. However, this contradicts the construction of the iteration. Finally, we show that \(x^{*}\in \arg \min _{x\in \mathbb {X}}\max _{\tilde{\mathbb {P}}\in \mathcal {P}_{\epsilon }}F(x,\,\mathbb {\tilde{P}}).\) If not, there must exist a \(x^{+}\) such that \(\max _{\tilde{\mathbb {P}}\in \mathcal {P}_{\epsilon }}F(x^{+},\,\tilde{\mathbb {P}})<\max _{\tilde{\mathbb {P}}\in \mathcal {P}_{\epsilon }}F(x^{*},\tilde{\,\mathbb {P}}).\) Hence, by construction \(\underset{}{\max _{1\le l\le k}\ F(x^{+},\,\mathbb {\tilde{P}}^{l})\ge \max _{1\le l\le k}\ F(x^{k+1},\,\mathbb {\tilde{P}}^{l})=F^{k}}\) and letting \(k\) tend to infinity, one sees that \(\max _{\tilde{\mathbb {P}}\in \mathcal {P}_{\epsilon }}F(x^{+},\,\tilde{\mathbb {P}})\ge F^{*}=\max _{\tilde{\mathbb {P}}\in \mathcal {P}_{\epsilon }}F(x^{*},\tilde{\,\mathbb {P}})\) and this is a contradiction which shows that \(x^{*}\) is the cluster point and thus every cluster point is a solution of the minimax problem.
Rights and permissions
About this article

Cite this article
Analui, B., Pflug, G.C. On distributionally robust multiperiod stochastic optimization. Comput Manag Sci 11, 197–220 (2014). https://doi.org/10.1007/s10287-014-0213-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10287-014-0213-y