
Abstract
We consider convex optimization problems with uncertain, probabilistically described, constraints. In this context, scenario optimization is a well recognized methodology where a sample of the constraints is used to describe uncertainty. One says that the scenario solution generalizes well, or has a high robustness level, if it satisfies most of the other constraints besides those in the sample. Over the past 10 years, the main theoretical investigations on the scenario approach have related the robustness level of the scenario solution to the number of optimization variables. This paper breaks into the new paradigm that the robustness level is a-posteriori evaluated after the solution is computed and the actual number of the so-called support constraints is assessed (wait-and-judge). A new theory is presented which shows that a-posteriori observing k support constraints in dimension \(d > k\) allows one to draw conclusions close to those obtainable when the problem is from the outset in dimension k. This new theory provides evaluations of the robustness that largely outperform those carried out based on the number of optimization variables.









Similar content being viewed by others

Notes
Measurability of \(V(x^*_N)\), as well as of other quantities, is taken for granted in this paper.
Computing the number of support constraints requires removing one by one the active constraints and verifying whether the solution changes, an operation that can be carried out at reasonably low computational cost.
Problem (10) can be equivalently written as the following optimal control problem, which may offer further insight in the usability of the approach.
Auxiliary dynamical system:
$$\begin{aligned} \left\{ \begin{array}{rcl} \frac{\mathrm {d}}{\mathrm {d}t}z_0(t) &{} = &{} z_1(t) \\ \frac{\mathrm {d}}{\mathrm {d}t}z_1(t) &{} = &{} 2 \; z_2(t) \\ &{} \vdots &{} \\ \frac{\mathrm {d}}{\mathrm {d}t}z_{d-2}(t) &{} = &{} (d-1) \; z_{d-1}(t) \\ \frac{\mathrm {d}}{\mathrm {d}t}z_{d-1}(t) &{} = &{} d \; u(t). \end{array} \right. \end{aligned}$$Auxiliary optimal control problem:
$$\begin{aligned} \gamma ^*= \inf _{z_0(0),\ldots ,z_{d-1}(0),u(\cdot ) \in \textsf {C}^0[0,1]}&z_0(1) \\ \text {subject to:}&z_k(t) \ge {N \atopwithdelims ()k} t^{N-k} \cdot \mathbf {1}_{[0,1-\epsilon (k))}(t), \quad t \in [0,1], \; k=0,1,\ldots ,d-1, \\&u(t) \ge {N \atopwithdelims ()d} t^{N-d} \cdot \mathbf {1}_{[0,1-\epsilon (d))}(t), \quad t \in [0,1]. \end{aligned}$$In the auxiliary optimal control problem, the optimization variables are the initial state and the input of the auxiliary dynamical system.
At the present state of knowledge, whether or not a valid \(\epsilon (k)\) exists such that \(\epsilon (k) < \epsilon \) for some k while \(\epsilon (k) \le \epsilon \) for any k is still an open problem.
Equation (18) can also be written in a more compact form using moment generating functions. Let \(\tilde{F}_k(t) := 1 - F_k(1 \! - \! t)\) and \(\tilde{M}_k(z)\) be the moment generating function of \(\tilde{F}_k(t)\). Multiplying the two sides of (18) by \(z^m/m!\) and summing up over m gives the equivalent characterization:
$$\begin{aligned} \sum _{k=0}^d \frac{z^k}{k!} \tilde{M}_k(z) = \exp (z), \end{aligned}$$which is explained as follows. The right-hand side is obtained because \(\sum _{m=0}^\infty z^m/m! = \exp (z)\), while in the left-hand side the kth term is calculated as follows, \(\sum _{m=k}^\infty z^m/m! {m \atopwithdelims ()k} \int _{[0,1]} t^{m-k} \mathrm {d}\tilde{F}_k(t) = z^k/k! \int _{[0,1]} \sum _{m=k}^\infty (zt)^{m-k}/(m \! - \! k)! \mathrm {d}\tilde{F}_k(t) = z^k/k! \int _{[0,1]} \exp (zt) \mathrm {d}\tilde{F}_k(t) = (z^k/k!) \tilde{M}_k(z)\).
References
Alamo, T., Tempo, R., Camacho, E.: Randomized strategies for probabilistic solutions of uncertain feasibility and optimization problems. IEEE Trans. Autom. Control 54(11), 2545–2559 (2009)
Alamo, T., Tempo, R., Luque, A., Ramirez, D.R.: Randomized methods for design of uncertain systems: sample complexity and sequential algorithms. Automatica 51, 160–172 (2015)
Anderson, E., Nash, P.: Linear programming in infinite-dimensional spaces: theory and applications. Wiley, New York (1987)
Ben-Tal, A., Nemirovski, A.: On safe tractable approximations of chance-constrained linear matrix inequalities. Math. Oper. Res. 34(1), 1–25 (2009)
Bertsimas, D., Thiele, A.: Robust and data-driven optimization: modern decision-making under uncertainty. In: Tutorials on Operations Research. INFORMS (2006)
Borwein, J., Lewis, A.: Convex analysis and nonlinear optimization. Springer, New York (2005)
Calafiore, G., Campi, M.: Uncertain convex programs: randomized solutions and confidence levels. Math. Program. 102(1), 25–46 (2005). doi:10.1007/s10107-003-0499-y
Calafiore, G., Campi, M.: The scenario approach to robust control design. IEEE Trans. Autom. Control 51(5), 742–753 (2006)
Campi, M.: Classification with guaranteed probability of error. Mach. Learn. 80, 63–84 (2010)
Campi, M., Calafiore, G., Garatti, S.: Interval predictor models: identification and reliability. Automatica 45(2), 382–392 (2009). doi:10.1016/j.automatica.2008.09.004
Campi, M., Carè, A.: Random convex programs with L1-regularization: sparsity and generalization. SIAM J. Control Optim. 51(5), 3532–3557 (2013)
Campi, M., Garatti, S.: The exact feasibility of randomized solutions of uncertain convex programs. SIAM J. Optim. 19(3), 1211–1230 (2008). doi:10.1137/07069821X
Campi, M., Garatti, S.: A sampling-and-discarding approach to chance-constrained optimization: feasibility and optimality. J. Optim. Theory Appl. 148(2), 257–280 (2011)
Campi, M., Garatti, S., Prandini, M.: The scenario approach for systems and control design. Annu. Rev. Control 33(2), 149–157 (2009). doi:10.1016/j.arcontrol.2009.07.001
Carè, A., Garatti, S., Campi, M.: FAST—fast algorithm for the scenario technique. Oper. Res. 62(3), 662–671 (2014)
Carè, A., Garatti, S., Campi, M.: Scenario min–max optimization and the risk of empirical costs. SIAM J. Optim. 25(4), 2061–2080 (2015)
Crespo, L., Giesy, D., Kenny, S.: Interval predictor models with a formal characterization of uncertainty and reliability. In: Proceedings of the 53rd IEEE Conference on Decision and Control (CDC), pp. 5991–5996. Los Angeles, CA, USA (2014)
Delage, E., Ye, Y.: Distributionally robust optimization under moment uncertainty with application to data-driven problems. Oper. Res. 58(3), 596–612 (2010)
Dentcheva, D.: Optimization models with probabilistic constraints. In: Calafiore, G., Dabbene, F. (eds.) Probabilistic and Randomized Methods for Design Under Uncertainty. Springer, London (2006)
Esfahani, P., Sutter, T., Lygeros, J.: Performance bounds for the scenario approach and an extension to a class of non-convex programs. IEEE Trans. Autom. Control 60(1), 46–58 (2015)
Farias, V., Jagabathula, S., Shah, D.: A nonparametric approach to modeling choice with limited data. Manag. Sci. 59(2), 305–322 (2013)
Garatti, S., Campi, M.: Modulating robustness in control design: principles and algorithms. IEEE Control Syst. Mag. 33(2), 36–51 (2013). doi:10.1109/MCS.2012.2234964
Grammatico, S., Zhang, X., Margellos, K., Goulart, P., Lygeros, J.: A scenario approach for non-convex control design. IEEE Trans. Autom. Control 61(2), 334–345 (2016)
Grant, M., Boyd, S.: CVX: Matlab Software for Disciplined Convex Programming, Version 2.1. http://cvxr.com/cvx (2014)
Hong, L., Hu, Z., Liu, G.: Monte Carlo methods for value-at-risk and conditional value-at-risk: a review. ACM Trans. Model. Comput. Simul. 24(4), 22:1–22:37 (2014)
Krishnamoorthy, K., Mathew, T.: Statistical Tolerance Regions. Wiley, Hoboken (2009)
Lasserre, J.: Moments, Positive Polynomials and Their Applications. Imperial College Press, London (2009)
Lei, J., Robins, J., Wasserman, L.: Distribution-free prediction sets. J. Am. Stat. Assoc. 108(501), 278–287 (2013)
Lofberg, J.: Yalmip: a toolbox for modeling and optimization in matlab. In: Proceedings of the CACSD Conference, pp. 284–289. Taipei, Taiwan (2004)
Lucchetti, R.: Convexity and Well-Posed Problems. Springer, New York (2006)
Luedtke, J., Ahmed, S.: A sample approximation approach for optimization with probabilistic constraints. SIAM J. Optim. 19, 674–699 (2008). doi:10.1137/070702928
Luedtke, J., Ahmed, S., Nemhauser, G.: An integer programming approach for linear programs with probabilistic constraints. Math. Program. 122(2), 247–272 (2010)
Luenberger, D.: Optimization by Vector Space Methods. Wiley, New York (1969)
Margellos, K., Goulart, P., Lygeros, J.: On the road between robust optimization and the scenario approach for chance constrained optimization problems. IEEE Trans. Autom. Control 59(8), 2258–2263 (2014)
Margellos, K., Prandini, M., Lygeros, J.: On the connection between compression learning and scenario based single-stage and cascading optimization problems. IEEE Trans. Autom. Control 60(10), 2716–2721 (2015)
de Mello, T.H., Bayraksan, G.: Monte Carlo sampling-based methods for stochastic optimization. Surv. Oper. Res. Manag. Sci. 19(1), 56–85 (2014)
Nemirovski, A.: On safe tractable approximations of chance constraints. Eur. J. Oper. Res. 219, 707–718 (2012)
Nemirovski, A., Shapiro, A.: Convex approximations of chance constrained programs. SIAM J. Optim. 17(4), 969–996 (2006). doi:10.1137/050622328
Nemirovski, A., Shapiro, A.: Scenario approximations of chance constraints. In: Calafiore, G., Dabbene, F. (eds.) Probabilistic and Randomized Methods for Design Under Uncertainty. Springer, London (2006)
Pagnoncelli, B., Ahmed, S., Shapiro, A.: Sample average approximation method for chance constrained programming: theory and applications. J. Optim. Theory Appl. 142(2), 399–416 (2009)
Pagnoncelli, B., Reich, D., Campi, M.: Risk-return trade-off with the scenario approach in practice: a case study in portfolio selection. J. Optim. Theory Appl. 155(2), 707–722 (2012)
Pagnoncelli, B., Vanduffel, S.: A provisioning problem with stochastic payments. Eur. J. Oper. Res. 221(2), 445–453 (2012)
Petersen, I.R., Tempo, R.: Robust control of uncertain systems: classical results and recent developments. Automatica 50, 1315–1335 (2014)
Prèkopa, A.: Stochastic Programming. Kluwer, Boston (1995)
Schildbach, G., Fagiano, L., Morari, M.: Randomized solutions to convex programs with multiple chance constraints. SIAM J. Optim. 23(4), 2479–2501 (2013)
Shapiro, A., Dentcheva, D., Ruszczyński, A.: Lectures on Stochastic Programming: Modeling and Theory. MPS-SIAM, Philadelphia (2009)
Shiryaev, A.: Probability. Springer, New York (1996)
Tempo, R., Calafiore, G., Dabbene, F.: Randomized Algorithms for Analysis and Control of Uncertain Systems, 2nd edn. Springer, London (2013)
Thiele, A.: Robust stochastic programming with uncertain probabilities. IMA J. Manag. Math. 19(3), 289–321 (2008). doi:10.1093/imaman/dpm011
Vayanos, P., Kuhn, D., Rustem, B.: A constraint sampling approach for multistage robust optimization. Automatica 48(3), 459–471 (2012)
Welsh, J., Kong, H.: Robust experiment design through randomisation with chance constraints. In: Proceedings of the 18th IFAC World Congress. Milan, Italy (2011)
Welsh, J., Rojas, C.: A scenario based approach to robust experiment design. In: Proceedings of the 15th IFAC Symposium on System Identification. Saint-Malo, France (2009)
Zhang, X., Grammatico, S., Schildbach, G., Goulart, P., Lygeros, J.: On the sample size of random convex programs with structured dependence on the uncertainty. Automatica 60, 182–188 (2015)
Zymler, S., Kuhn, D., Rustem, B.: Distributionally robust joint chance constraints with second-order moment information. Math. Program. 137(1–2), 167–198 (2013)
Author information
Authors and Affiliations
Corresponding author
Appendices
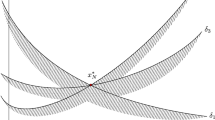
Appendix 1: The guarantee valid in dimension 1 is unattainable when 1 support constraint is seen in dimension 2
Consider the optimization problem illustrated in Fig. 9 where the probabilistic mass of the V-shaped constraints is p and that of the U-shaped constraints is \(1-p\). For a given \(\epsilon (1) < p\), the event \(\left\{ V(x^*_N) > \epsilon (1) \; \wedge \; s^*_N = 1 \right\} \) is met when all N constraints are U-shaped or when only 1 constraint is V-shaped. This event has probability \((1-p)^N + Np(1-p)^{N-1}\). The \(\sup \) of this probability over the p values that satisfy \(p > \epsilon (1)\) is \((1-\epsilon (1))^N + N\epsilon (1)(1-\epsilon (1))^{N-1}\). According to (3), this is the probability that \(V(x^*_N) > \epsilon (1)\) in a fully-supported problem in dimension 2. This probability is bigger than the probability \((1-\epsilon (1))^N\), let us call it \(\beta \), of \(V(x^*_N) > \epsilon (1)\) in a fully-supported problem in dimension 1. Hence, for the problem in dimension 2 given in Fig. 9 one has to increase \(\epsilon (1)\) to the value \(\epsilon '(1)\) such that \((1-\epsilon '(1))^N + N\epsilon '(1)(1-\epsilon '(1))^{N-1} = \beta \) to obtain that the probability of the event \(\left\{ V(x^*_N) > \epsilon '(1) \; \wedge \; s^*_N = 1 \right\} \) is bounded by \(\beta \).
Next we show that this example constitutes a counterexample to the validity of Eq. (7). To see this, take a generic \(\epsilon (1)\) and \(\epsilon (0) = \epsilon (2) = 1\). The right-hand side of (7) becomes \((1-\epsilon (1))^N\), which is smaller than
Since \(\mathbb P^N \left\{ V(x^*_N) > \epsilon (s^*_N) \right\} \) is the left-hand side of (7), this contradicts (7).
Appendix 2: MATLAB code
The following MATLAB code returns \(\epsilon (k) , k=0,1,\dots ,d\), for user assigned d , N, and \(\beta \).

Appendix 3: Examples of solutions of Eq. (18)
1.1 Fully-supported problems
One can easily verify that the following \(F_k\)’s satisfy Eq. (18):
These are the \(F_k\)’s of fully-supported problems. The fact that for fully-supported problems \(F_d(v)\) is as in (41) is proven in [12]. To show instead the validity of (40), argue as follows. For \(0 \le k < d\), relation
holds with probability one since, otherwise, complementing the set of k constraints with \(d-k+1\) other constraints that are satisfied by \(x^*_k\), which would be an event with nonzero probability, leads to a total set of \(d+1\) constraints among which fewer than d are of support, so contradicting the fully-supportedness assumption. Thus, the measures corresponding to \(F_k , k=0,1,\ldots ,d-1\), concentrate in 1. Further, (40) claims that the mass in 1 is equal to 1, which corresponds to say that the number of support constraints is equal to k with probability one. For \(k = 0\) this is obvious. For \(0< k < d\), this is also true because, if less than k constraints were of support, then at least one of the constraints would be satisfied by the solution generated when only the other constraints are in place, a fact that happens with probability zero since the violation of the solution generated when only the other constraints are in place is equal to 1 as shown in (42).
1.2 Two examples of problems in dimension \(d=2\)
Consider the problem
where \(\delta \) is uniform in [0, 1]. As it can be easily verified, this problem is fully-supported so that, according to (40),(41), its \(F_k\)’s are
Consider instead problem
where \(\delta _1\) takes value 1 or 2 with probability 0.5 each, and \(\delta _2\) is independent of \(\delta _1\) and is uniformly distributed on [0, 1]. This problem is not fully-supported and a simple calculation shows that
These \(F_k\)’s are another solution of Eq. (18).
Rights and permissions
About this article

Cite this article
Campi, M.C., Garatti, S. Wait-and-judge scenario optimization. Math. Program. 167, 155–189 (2018). https://doi.org/10.1007/s10107-016-1056-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10107-016-1056-9